⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-02 更新
Sadeed: Advancing Arabic Diacritization Through Small Language Model
Authors:Zeina Aldallal, Sara Chrouf, Khalil Hennara, Mohamed Motaism Hamed, Muhammad Hreden, Safwan AlModhayan
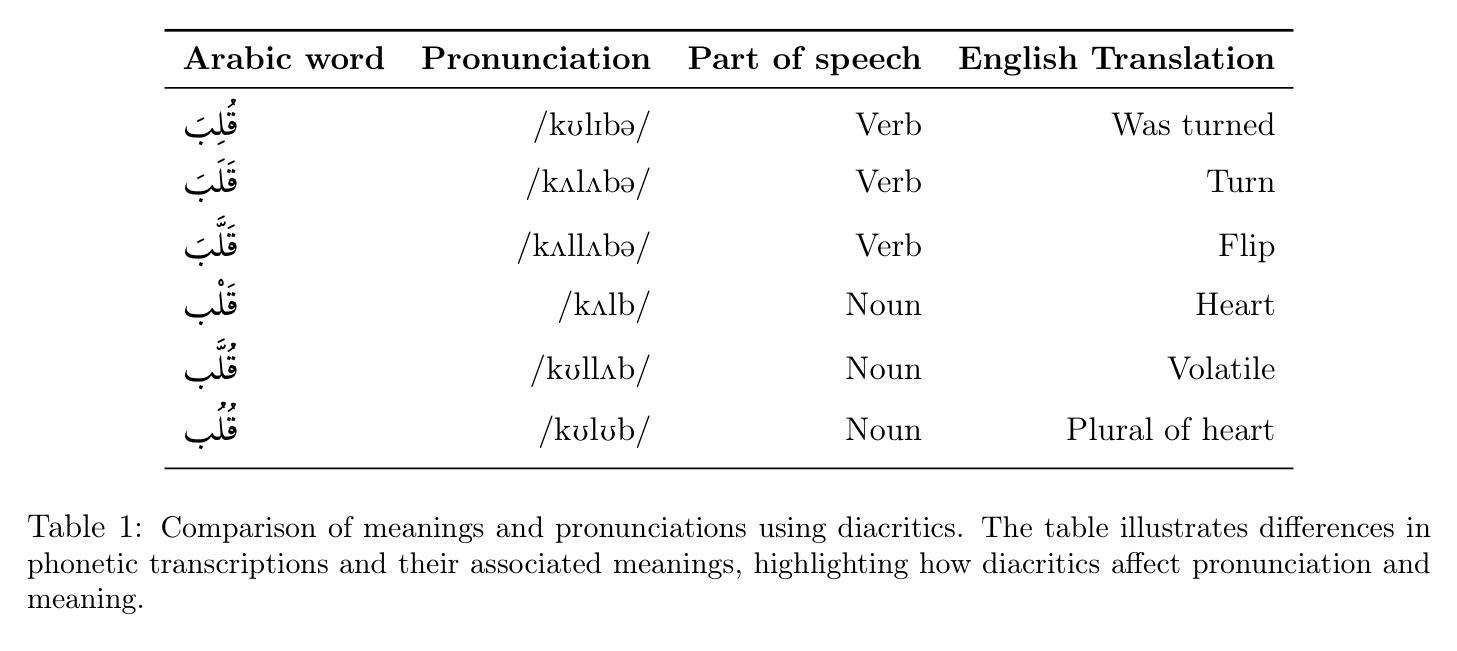
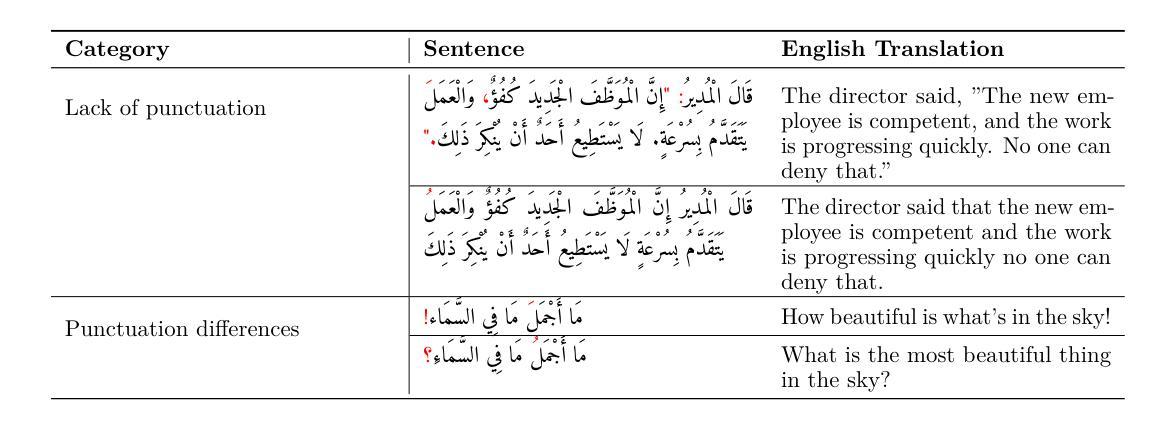
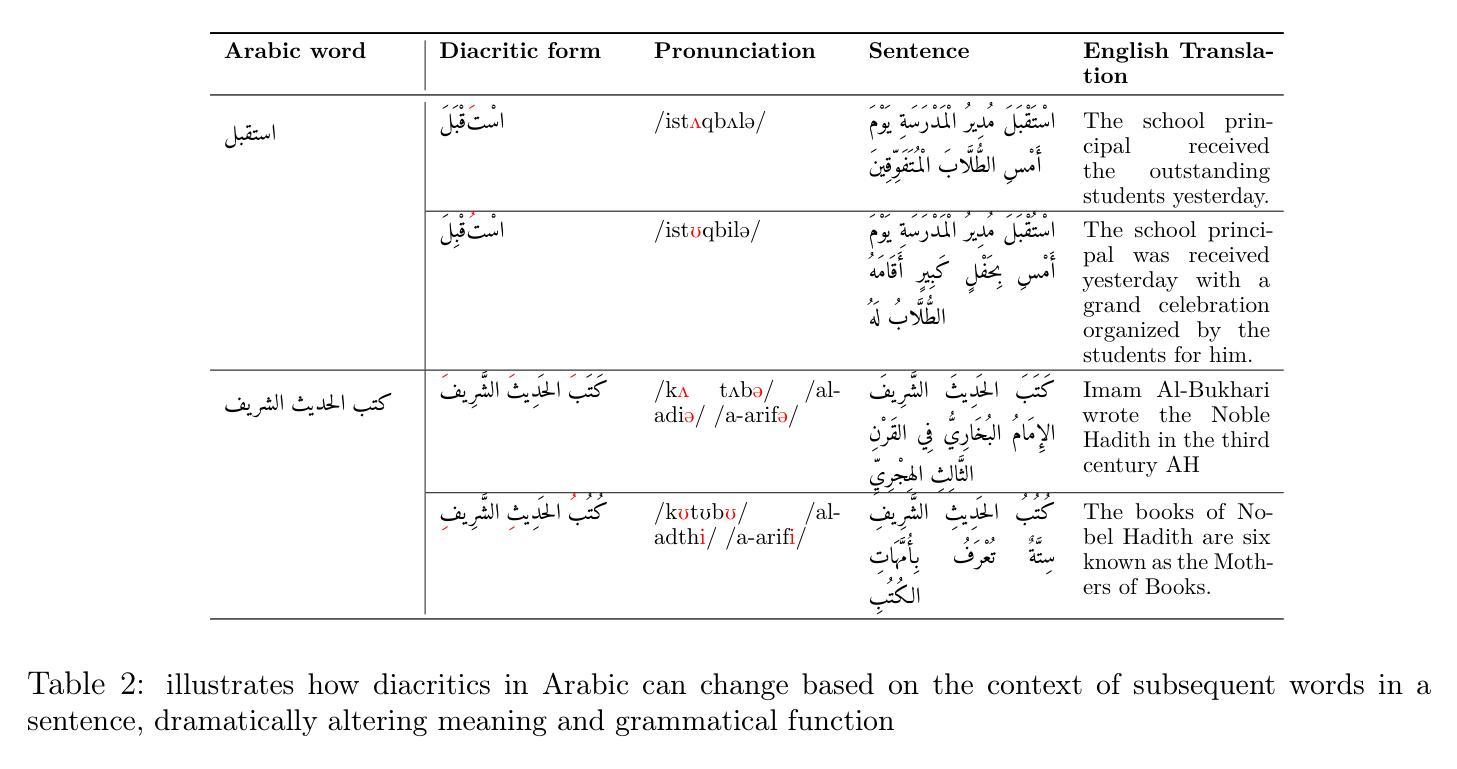
Arabic text diacritization remains a persistent challenge in natural language processing due to the language’s morphological richness. In this paper, we introduce Sadeed, a novel approach based on a fine-tuned decoder-only language model adapted from Kuwain 1.5B Hennara et al. [2025], a compact model originally trained on diverse Arabic corpora. Sadeed is fine-tuned on carefully curated, high-quality diacritized datasets, constructed through a rigorous data-cleaning and normalization pipeline. Despite utilizing modest computational resources, Sadeed achieves competitive results compared to proprietary large language models and outperforms traditional models trained on similar domains. Additionally, we highlight key limitations in current benchmarking practices for Arabic diacritization. To address these issues, we introduce SadeedDiac-25, a new benchmark designed to enable fairer and more comprehensive evaluation across diverse text genres and complexity levels. Together, Sadeed and SadeedDiac-25 provide a robust foundation for advancing Arabic NLP applications, including machine translation, text-to-speech, and language learning tools.
阿拉伯文本变音符标注(diacritization)在自然语言处理中仍然是一个持续存在的挑战,原因在于该语言的形态丰富性。在本文中,我们介绍了Sadeed,这是一种新型方法,基于精细调整仅解码的语言模型开发,该模型是由Kuwain团队开发的Hennara等人训练的有针对性的紧凑模型(版本号为2025)。Sadeed经过精心挑选的高质量变音符标注数据集进行微调,这些数据集是通过严格的数据清理和标准化管道构建的。尽管使用的计算资源相对有限,但Sadeed与专有大型语言模型相比仍具有竞争力,并且在类似领域训练的常规模型表现更出色。此外,我们强调了当前阿拉伯变音符标注基准测试实践中的关键局限性。为了解决这个问题,我们推出了SadeedDiac-25,新的基准测试旨在实现不同文本类别和复杂度级别的更公平和更全面的评估。总的来说,Sadeed和SadeedDiac-25为推进阿拉伯自然语言处理应用提供了坚实的基础,包括机器翻译、文本到语音转换和语言学习工具等。
论文及项目相关链接
Summary
本文介绍了Sadeed,一种基于Kuwain 1.5B Hennara等人在2025年提出的紧凑型阿拉伯语语料库训练的解码器语言模型,针对阿拉伯语文本发音符号问题进行了精细调整和优化。相较于其他大型专有语言模型和传统相似领域训练模型,Sadeed在高质量发音符号数据集上表现优异。此外,本文还指出了当前阿拉伯语发音符号评估方法的关键局限性,并引入了SadeedDiac-25新基准测试,以实现对不同文本类型和复杂度的更全面和公平的评估。总的来说,Sadeed和SadeedDiac-25为推进阿拉伯语NLP应用提供了坚实的基础。
Key Takeaways
- 阿拉伯语文本发音符号化是自然语言处理中的一个持续挑战。
- Sadeed是一种基于紧凑型阿拉伯语语料库训练的解码器语言模型,针对这一挑战进行了精细调整和优化。
- Sadeed在高质量发音符号数据集上的表现具有竞争力,并优于其他大型专有语言模型和传统相似领域训练模型。
- 当前阿拉伯语发音符号评估方法存在局限性。
- 引入了新的基准测试SadeedDiac-25,以更全面地评估不同文本类型和复杂度的阿拉伯语发音符号问题。
- Sadeed和SadeedDiac-25为推进阿拉伯语NLP应用(如机器翻译、文本转语音和语言学习工具)提供了坚实的基础。
- Sadeed的适用性和性能在多种阿拉伯语NLP应用中具有潜在价值。
点此查看论文截图

TT-LoRA MoE: Unifying Parameter-Efficient Fine-Tuning and Sparse Mixture-of-Experts
Authors:Pradip Kunwar, Minh N. Vu, Maanak Gupta, Mahmoud Abdelsalam, Manish Bhattarai
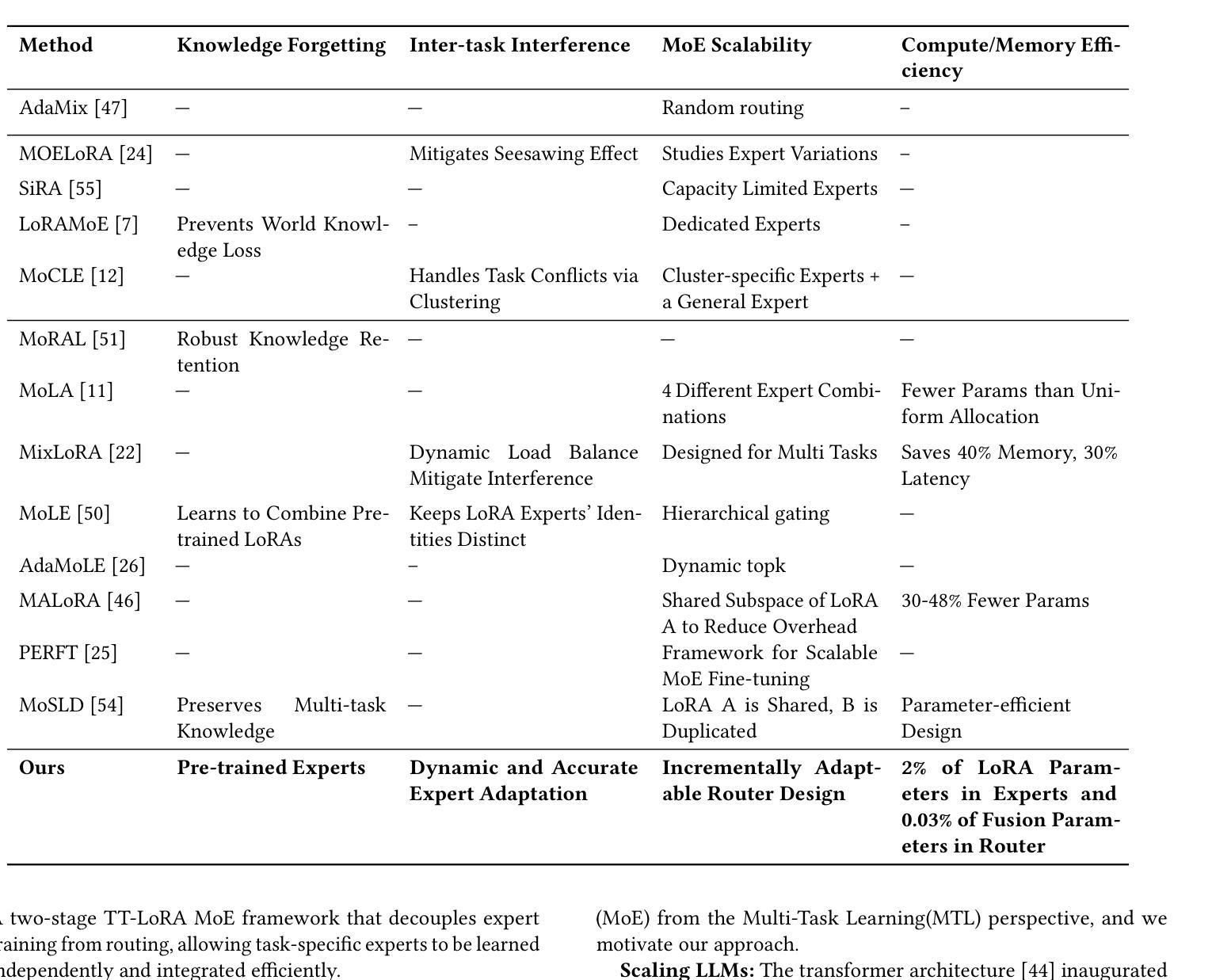
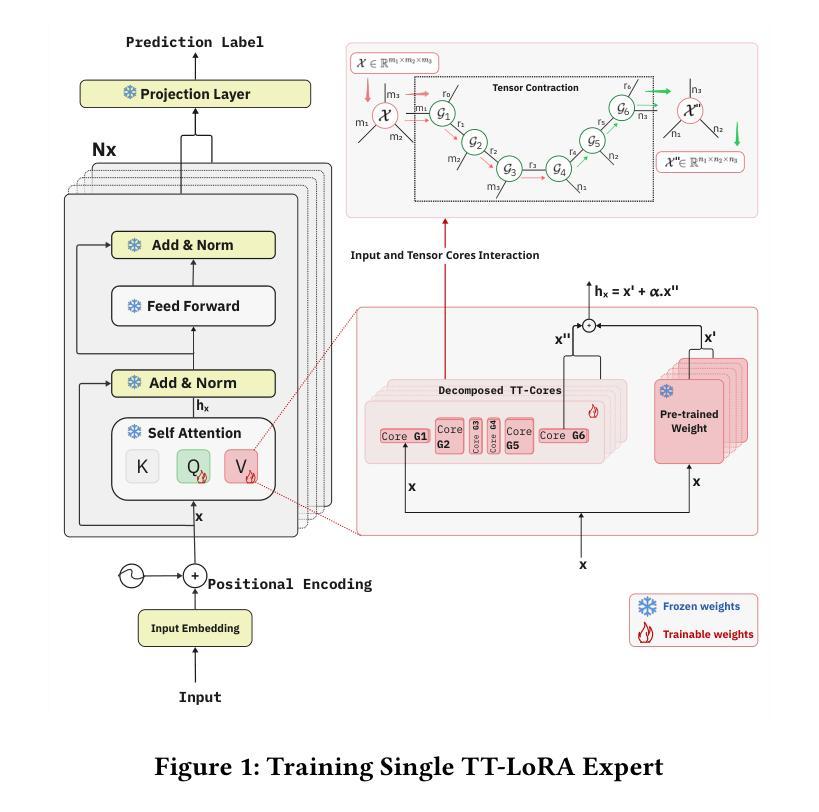
We propose Tensor-Trained Low-Rank Adaptation Mixture of Experts (TT-LoRA MoE), a novel computational framework integrating Parameter-Efficient Fine-Tuning (PEFT) with sparse MoE routing to address scalability challenges in large model deployments. Unlike traditional MoE approaches, which face substantial computational overhead as expert counts grow, TT-LoRA MoE decomposes training into two distinct, optimized stages. First, we independently train lightweight, tensorized low-rank adapters (TT-LoRA experts), each specialized for specific tasks. Subsequently, these expert adapters remain frozen, eliminating inter-task interference and catastrophic forgetting in multi-task setting. A sparse MoE router, trained separately, dynamically leverages base model representations to select exactly one specialized adapter per input at inference time, automating expert selection without explicit task specification. Comprehensive experiments confirm our architecture retains the memory efficiency of low-rank adapters, seamlessly scales to large expert pools, and achieves robust task-level optimization. This structured decoupling significantly enhances computational efficiency and flexibility: uses only 2% of LoRA, 0.3% of Adapters and 0.03% of AdapterFusion parameters and outperforms AdapterFusion by 4 value in multi-tasking, enabling practical and scalable multi-task inference deployments.
我们提出了Tensor-Trained Low-Rank Adaptation Mixture of Experts(TT-LoRA MoE)这一新型计算框架,它将参数高效微调(PEFT)与稀疏MoE路由相结合,以解决大型模型部署中的可扩展性挑战。与传统的MoE方法不同,随着专家数量的增长,它面临着巨大的计算开销。TT-LoRA MoE将训练过程分解为两个优化阶段。首先,我们独立地训练针对特定任务轻量级的张量化低秩适配器(TT-LoRA专家)。随后,这些专家适配器保持冻结状态,消除了多任务设置中的任务间干扰和灾难性遗忘。一个单独训练的稀疏MoE路由器在推理时动态利用基础模型表示,为每个输入选择恰好一个专业适配器,无需明确的任务指定即可自动选择专家。综合实验证实,我们的架构保留了低秩适配器的内存效率,能够无缝扩展到大型专家池,并实现稳健的任务级优化。这种结构化的解耦显著提高了计算效率和灵活性:仅使用LoRA的2%,适配器的0.3%,以及AdapterFusion的0.03%参数,并在多任务方面比AdapterFusion高出4个价值点,从而实现实用且可扩展的多任务推理部署。
论文及项目相关链接
Summary
TT-LoRA MoE是一个结合参数有效微调(PEFT)和稀疏MoE路由的计算框架,旨在解决大型模型部署中的可扩展性挑战。该框架通过独立训练专业任务专用的低秩适配器(TT-LoRA专家),然后利用稀疏MoE路由器动态选择输入所需的特定适配器,实现专家选择的自动化,从而提高计算效率和灵活性。
Key Takeaways
- TT-LoRA MoE结合了参数有效微调(PEFT)和稀疏MoE路由,旨在解决大型模型部署中的可扩展性问题。
- 该框架通过训练轻量级的、针对特定任务的低秩适配器(TT-LoRA专家),实现训练过程的优化。
- 适配器在训练后保持冻结,消除了多任务设置中的任务间干扰和灾难性遗忘。
- 稀疏MoE路由器动态选择特定适配器的输入,实现了专家选择的自动化,无需明确的任务指定。
- TT-LoRA MoE保留了低秩适配器的内存效率,可轻松扩展到大型专家池,并实现稳健的任务级别优化。
- 该框架的结构化解耦显著提高了计算效率和灵活性。
点此查看论文截图

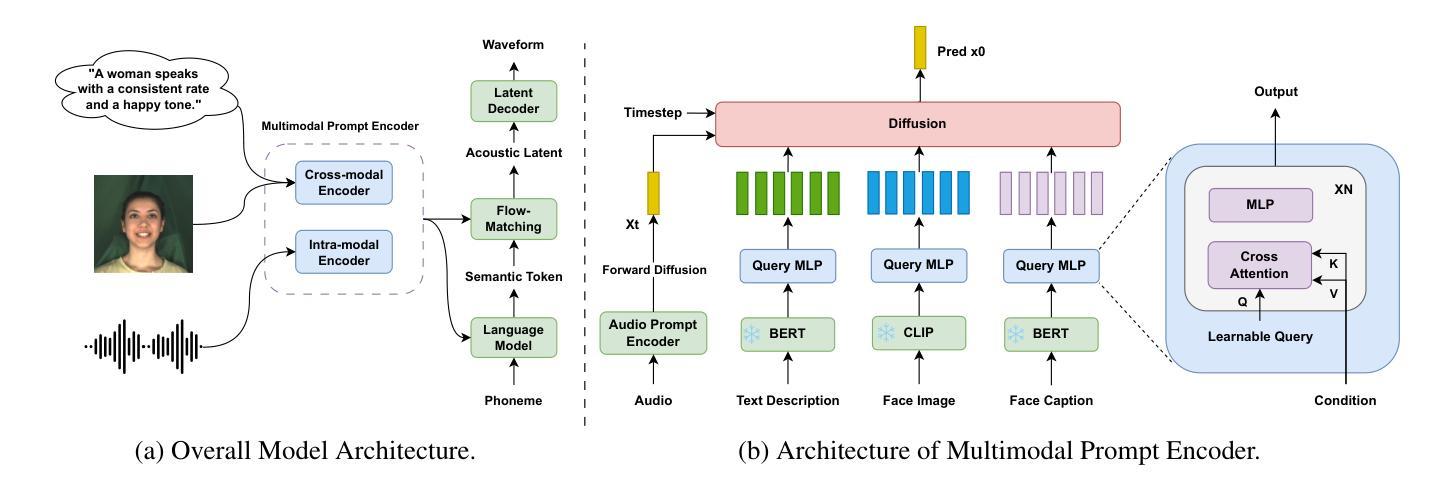
FleSpeech: Flexibly Controllable Speech Generation with Various Prompts
Authors:Hanzhao Li, Yuke Li, Xinsheng Wang, Jingbin Hu, Qicong Xie, Shan Yang, Lei Xie
Controllable speech generation methods typically rely on single or fixed prompts, hindering creativity and flexibility. These limitations make it difficult to meet specific user needs in certain scenarios, such as adjusting the style while preserving a selected speaker’s timbre, or choosing a style and generating a voice that matches a character’s visual appearance. To overcome these challenges, we propose \textit{FleSpeech}, a novel multi-stage speech generation framework that allows for more flexible manipulation of speech attributes by integrating various forms of control. FleSpeech employs a multimodal prompt encoder that processes and unifies different text, audio, and visual prompts into a cohesive representation. This approach enhances the adaptability of speech synthesis and supports creative and precise control over the generated speech. Additionally, we develop a data collection pipeline for multimodal datasets to facilitate further research and applications in this field. Comprehensive subjective and objective experiments demonstrate the effectiveness of FleSpeech. Audio samples are available at https://kkksuper.github.io/FleSpeech/
可控的语音生成方法通常依赖于单一或固定的提示,这限制了创造性和灵活性。这些局限使得在某些场景中难以满足特定用户的需求,例如在保持选定演讲者的音色同时调整风格,或者选择一种风格并生成与角色视觉外观相匹配的语音。为了克服这些挑战,我们提出了FleSpeech,这是一个新型的多阶段语音生成框架,通过整合各种控制形式,允许更灵活地操作语音属性。FleSpeech采用多模态提示编码器,处理和统一不同的文本、音频和视觉提示,形成一个连贯的表示。这种方法提高了语音合成的适应性,支持对生成的语音进行创造性和精确的控制。此外,我们还为多模态数据集开发了一个数据收集管道,以促进该领域的进一步研究和应用。综合的主观和客观实验证明了FleSpeech的有效性。音频样本可在https://kkksuper.github.io/FleSpeech/找到。
论文及项目相关链接
PDF 14 pages, 3 figures
总结
本文提出了一个名为FleSpeech的新型多阶段语音生成框架,旨在解决现有可控语音生成方法在创造性和灵活性方面的局限性。FleSpeech通过整合各种形式的控制,允许更灵活地操作语音属性。它采用多模态提示编码器,处理和统一不同的文本、音频和视觉提示,形成一个连贯的表示,从而提高语音合成的适应性并支持对生成语音的创造性精确控制。此外,还开发了一个用于多模态数据集的数据收集管道,以促进该领域的进一步研究和应用。实验证明FleSpeech的有效性。
关键见解
- FleSpeech是一个新型的多阶段语音生成框架,旨在解决现有方法的创造性和灵活性不足的问题。
- 通过整合各种形式的控制,FleSpeech允许更灵活地操作语音属性。
- FleSpeech采用多模态提示编码器,能够处理和统一不同的文本、音频和视觉提示。
- 该框架提高了语音合成的适应性,并支持对生成语音的创造性精确控制。
- FleSpeech还开发了一个用于收集多模态数据集的数据管道。
- 实验结果证明FleSpeech的有效性。
点此查看论文截图