⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-03 更新
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
Authors:Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, Hongsheng Li
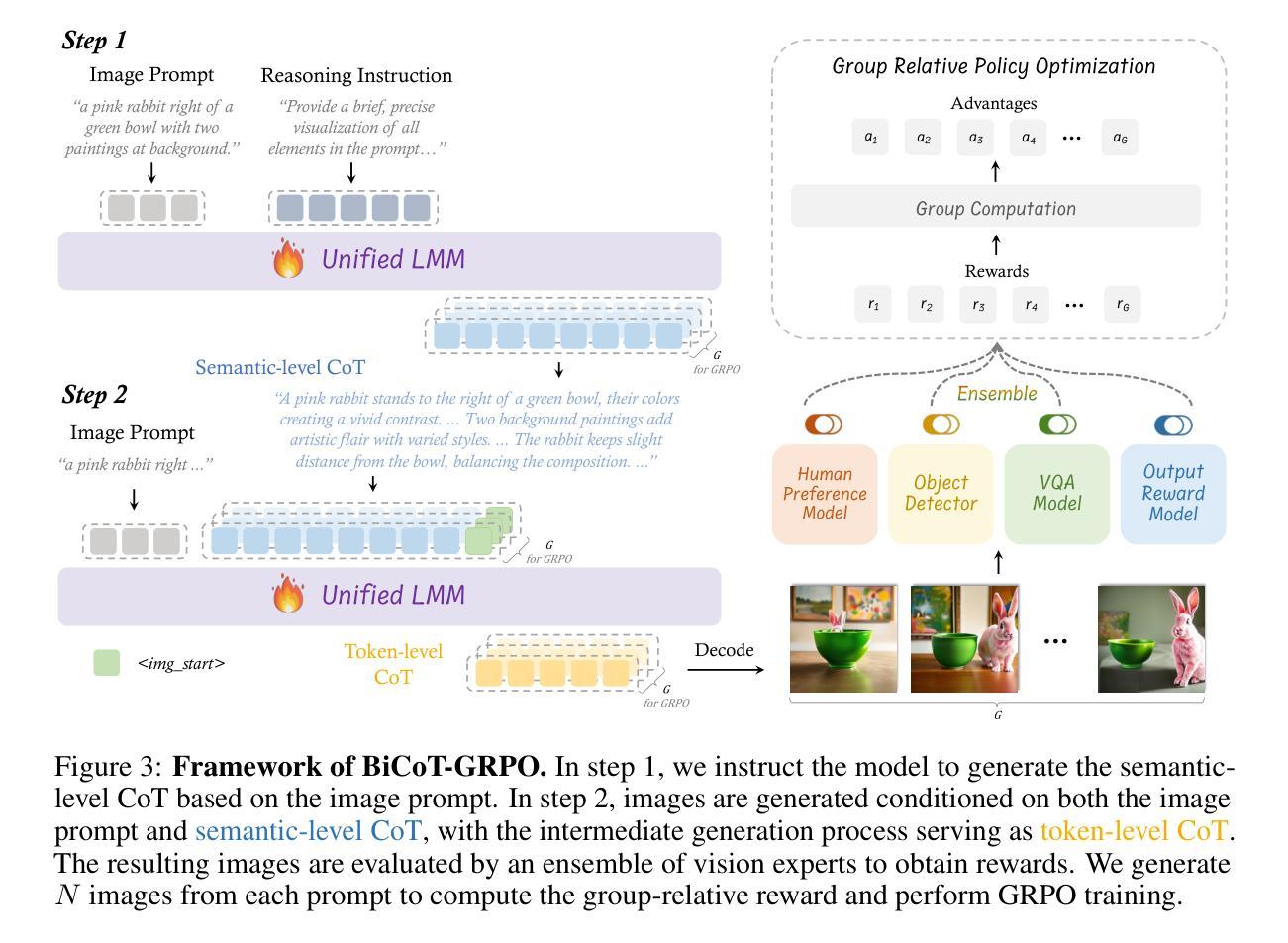
Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1
最近的大型语言模型进展展示了思维链(CoT)和强化学习(RL)如何提升性能。然而,将此类推理策略应用于视觉生成领域仍待大量探索。在本文中,我们提出了T2I-R1,这是一种新颖的推理增强文本到图像生成模型,通过双级CoT推理过程的强化学习驱动。具体来说,我们确定了两个级别的CoT,可以用来增强生成的不同阶段:(1)语义级的CoT用于提示的高级规划和(2)令牌级的CoT用于斑块对斑块生成过程中的低级像素处理。为了更好地协调这两个级别的CoT,我们引入了BiCoT-GRPO,采用生成奖励集合,可以在同一训练步骤中无缝优化两种生成CoT。通过将我们的推理策略应用于基线模型Janus-Pro,我们在T2I-CompBench上实现了13%的改进,在WISE基准测试上实现了19%的改进,甚至超越了最先进的模型FLUX.1。代码可在https://github.com/CaraJ7/T2I-R1找到。
论文及项目相关链接
PDF Project Page: https://github.com/CaraJ7/T2I-R1
Summary
本文介绍了一种新型结合强化学习与双重思维链(CoT)推理过程(语义级和token级)的文本到图像生成模型T2I-R1。通过引入BiCoT-GRPO来协调这两种层次的推理,实现在同一训练步骤中对两种推理的优化。将推理策略应用于基线模型Janus-Pro后,在T2I-CompBench和WISE基准测试中取得了显著的性能提升,超越了现有最佳模型FLUX。代码已公开在GitHub上。
Key Takeaways
- T2I-R1模型结合了强化学习(RL)与双重思维链(CoT)推理过程,用于文本到图像的生成任务。
- 模型包含两个层次的CoT推理:语义级CoT用于高级规划提示,token级CoT用于低级的像素处理。
- BiCoT-GRPO被引入以协调这两个层次的CoT推理,实现优化生成过程。
- T2I-R1模型在基线模型Janus-Pro的基础上应用推理策略,实现了显著的性能提升。
- 在T2I-CompBench和WISE基准测试中,T2I-R1模型超越了现有最佳模型FLUX。
- 模型性能的提升得益于强化学习和双重思维链推理的结合,这种结合有助于改进模型的决策过程。
点此查看论文截图



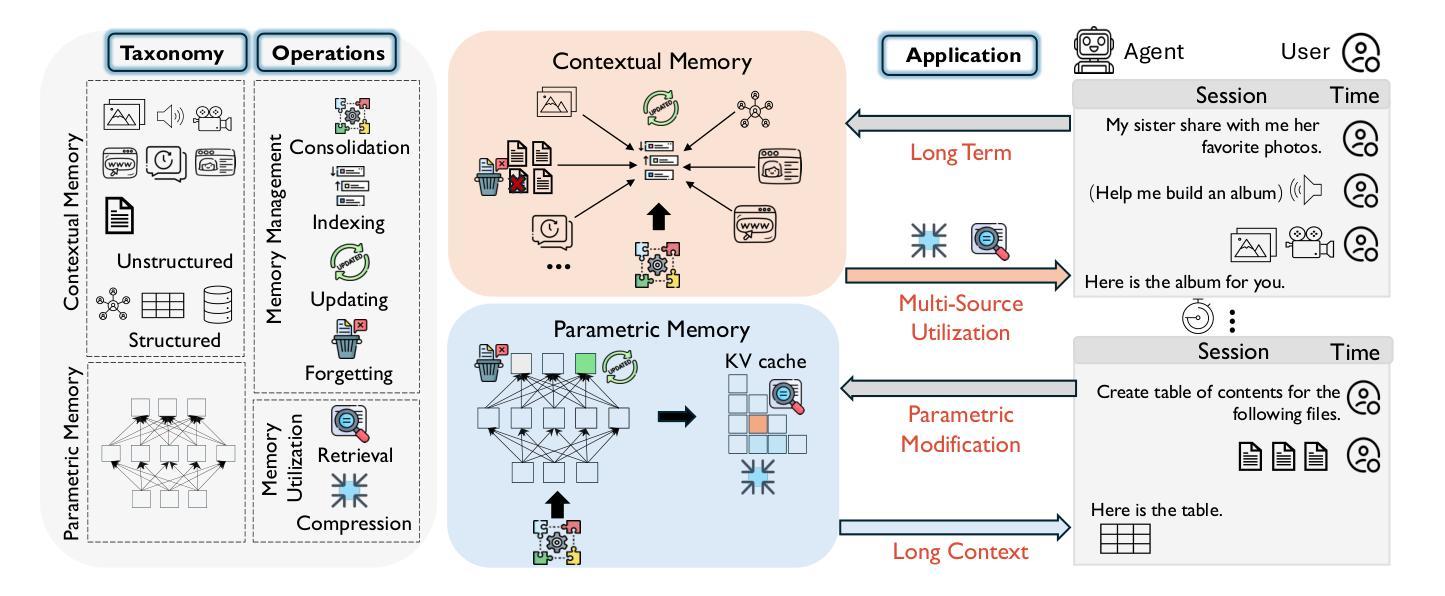
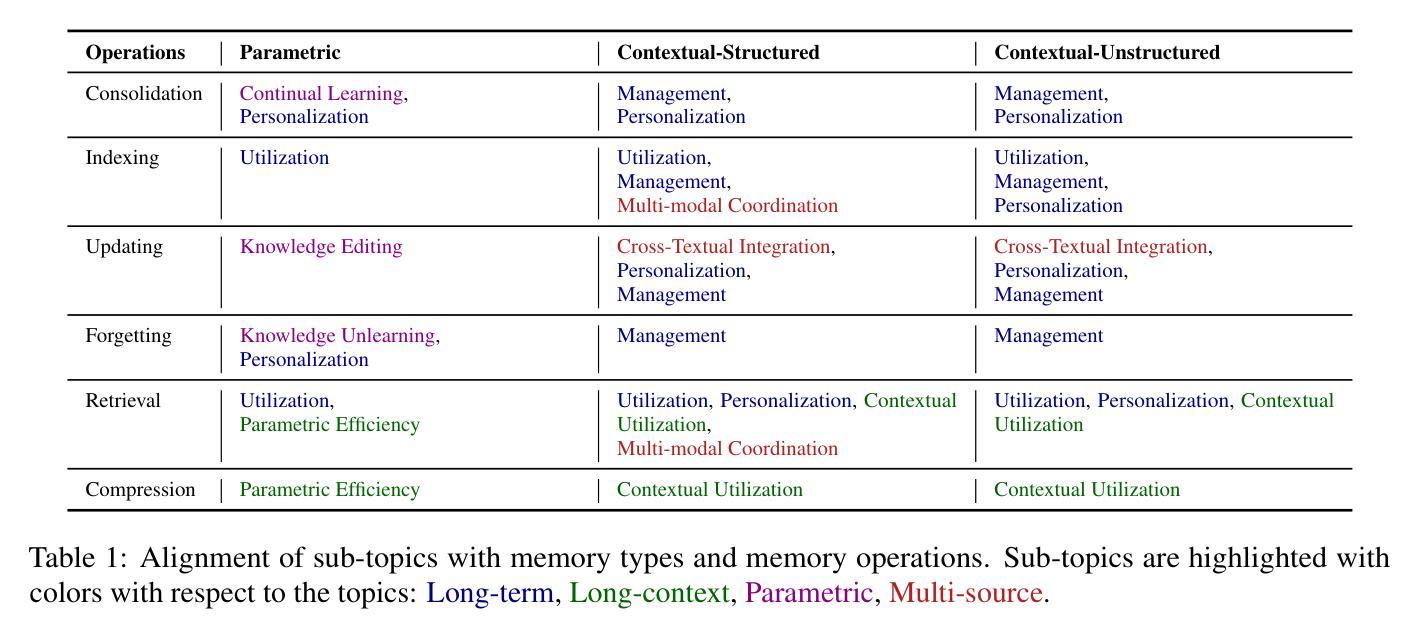
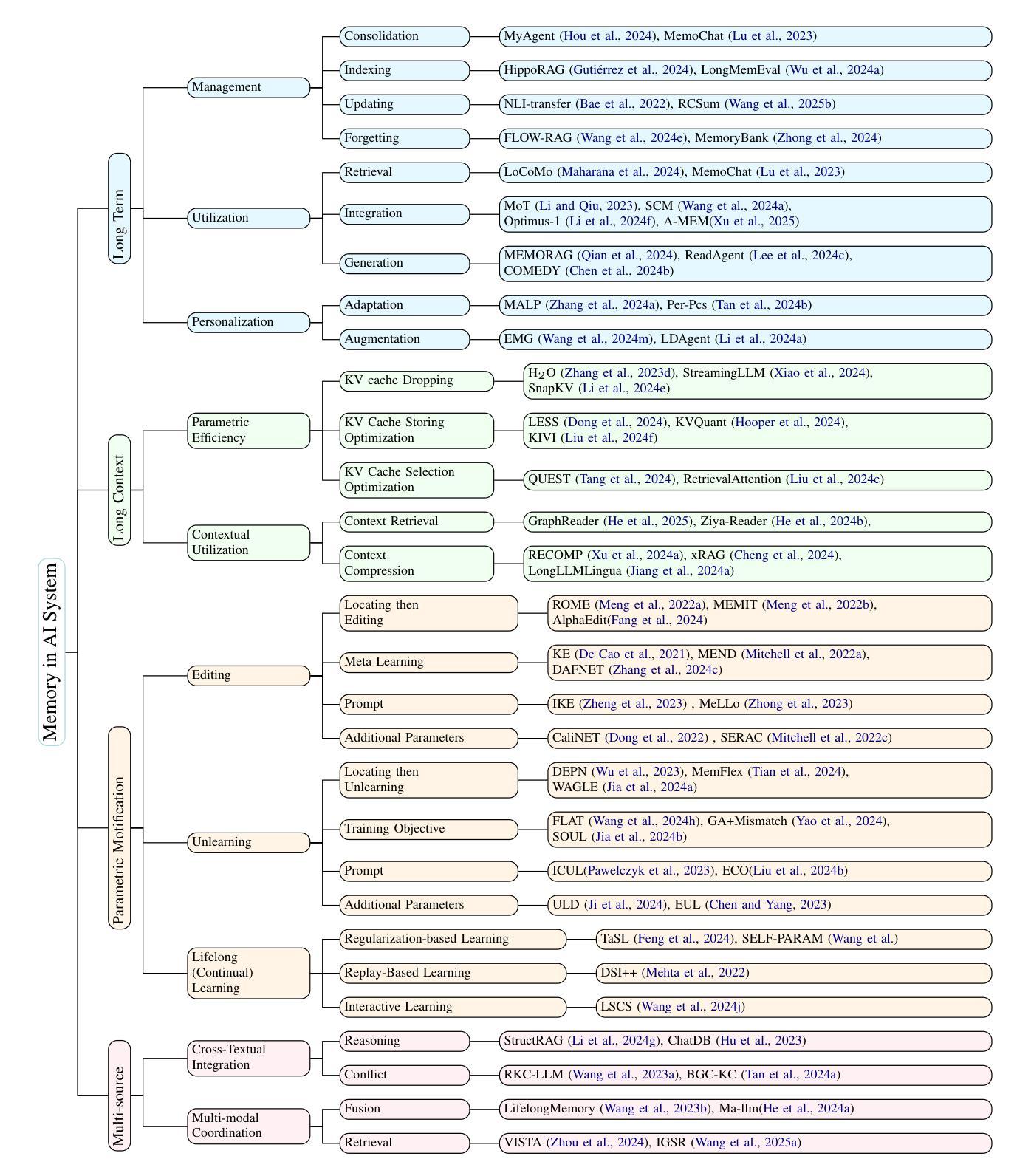
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
Authors:Yiming Du, Wenyu Huang, Danna Zheng, Zhaowei Wang, Sebastien Montella, Mirella Lapata, Kam-Fai Wong, Jeff Z. Pan
Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
记忆是人工智能系统的基础组成部分,支撑着基于大语言模型的智能体。尽管先前的调查主要关注大型语言模型中的记忆应用,但它们经常忽略底层内存动态的原子操作。在这项调查中,我们首先将内存表示分类为参数表示、上下文结构化表示和上下文非结构化表示,然后介绍了六种基本内存操作:整合、更新、索引、遗忘、检索和压缩。我们系统地将这些操作映射到长期记忆、长上下文环境、参数修改和多源记忆中最相关的主题。通过原子操作和表示类型的透镜重新审视内存系统,本调查为与人工智能相关的研究、基准数据集和工具提供了结构化和动态的视角,并阐明了基于大型语言模型的智能体中功能性交互的同时概述了未来研究的前景。\footnote{论文清单、数据集、方法和工具可访问链接:https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}。
论文及项目相关链接
Summary
LLMs基于代理的智能系统以记忆为关键要素。现有调查多关注LLM中的记忆应用,却忽略了支撑其功能的原子操作。本文通过分类记忆表征(参数型、上下文结构型和上下文非结构型)及介绍六种基本记忆操作(整合、更新、索引、遗忘、检索和压缩),将其与长期记忆、长语境、参数修改和多源记忆等相关研究主题相联系。本文重新构建AI中的记忆系统视角,以原子操作和表征类型作为观察视角,对与AI中的记忆相关的研究、基准数据集和工具进行结构化且动态的阐述,同时明确了LLMs代理的功能交互,并指出了未来研究的潜在方向。
Key Takeaways
- 论文调研了LLM智能系统中基于记忆的基本要素,聚焦于先前被忽视的记忆原子操作研究。
- 文章提出了三类记忆表征方式:参数型、上下文结构型和上下文非结构型。
- 文章详细介绍了六种关键记忆操作:整合、更新、索引、遗忘、检索和压缩。
- 文章首次系统性地将这些操作映射到相关的研究主题上,包括长期记忆和语境敏感性研究等。
- 该调查为读者提供了一个清晰框架来理解AI系统中的记忆结构,特别是在LLM背景下的记忆功能交互。
- 文章提供了相关领域的基准数据集和方法论工具,以帮助未来研究工作的开展。
点此查看论文截图

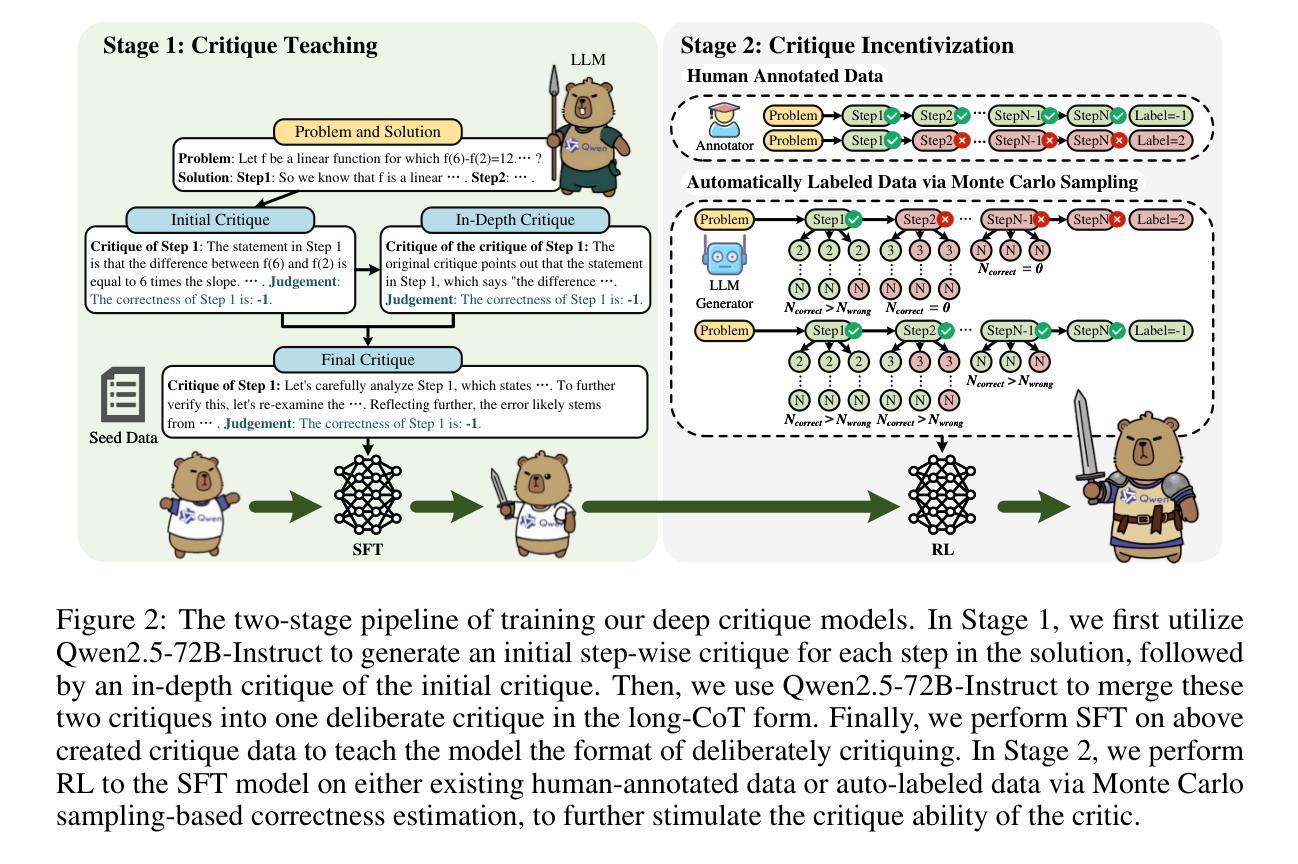
DeepCritic: Deliberate Critique with Large Language Models
Authors:Wenkai Yang, Jingwen Chen, Yankai Lin, Ji-Rong Wen
As Large Language Models (LLMs) are rapidly evolving, providing accurate feedback and scalable oversight on their outputs becomes an urgent and critical problem. Leveraging LLMs as critique models to achieve automated supervision is a promising solution. In this work, we focus on studying and enhancing the math critique ability of LLMs. Current LLM critics provide critiques that are too shallow and superficial on each step, leading to low judgment accuracy and struggling to offer sufficient feedback for the LLM generator to correct mistakes. To tackle this issue, we propose a novel and effective two-stage framework to develop LLM critics that are capable of deliberately critiquing on each reasoning step of math solutions. In the first stage, we utilize Qwen2.5-72B-Instruct to generate 4.5K long-form critiques as seed data for supervised fine-tuning. Each seed critique consists of deliberate step-wise critiques that includes multi-perspective verifications as well as in-depth critiques of initial critiques for each reasoning step. Then, we perform reinforcement learning on the fine-tuned model with either existing human-labeled data from PRM800K or our automatically annotated data obtained via Monte Carlo sampling-based correctness estimation, to further incentivize its critique ability. Our developed critique model built on Qwen2.5-7B-Instruct not only significantly outperforms existing LLM critics (including the same-sized DeepSeek-R1-distill models and GPT-4o) on various error identification benchmarks, but also more effectively helps the LLM generator refine erroneous steps through more detailed feedback.
随着大型语言模型(LLM)的快速发展,对其输出提供准确的反馈和可扩展的监督成为一个紧迫且关键的问题。利用LLM作为批评模型来实现自动化监督是一个有前景的解决方案。在这项工作中,我们专注于研究和提高LLM的数学批判能力。当前的LLM评论家对每一步的评论过于肤浅,导致判断准确性低,难以为LLM生成器提供足够的反馈来纠正错误。为了解决这一问题,我们提出了一种新颖有效的两阶段框架来开发能够有针对性地对数学解决方案的每一步推理进行批判的LLM评论家。在第一阶段,我们利用Qwen2.5-72B-Instruct生成4.5K长形式的评论作为监督微调种子数据。每条种子评论都包含有针对性的步骤批判,包括多视角验证以及每个推理步骤的初步评论的深入批判。然后,我们对微调后的模型使用PRM800K的现有手工标注数据或我们通过蒙特卡洛采样法估计的正确性自动标注的数据进行强化学习,以进一步激励其批判能力。我们基于Qwen2.5-7B-Instruct开发的批评模型不仅在各种错误识别基准测试中显著优于现有LLM评论家(包括相同规模的DeepSeek-R1-distill模型和GPT-4o),而且更有效地帮助LLM生成器通过更详细的反馈来修正错误步骤。
论文及项目相关链接
PDF Work in progress. Data and models are available at https://github.com/RUCBM/DeepCritic
Summary:随着大型语言模型(LLM)的快速发展,对其输出进行准确的反馈和可扩展的监督成为了一个紧迫且关键的问题。利用LLM作为批判模型以实现自动化监督是一个有前景的解决方案。本研究专注于研究和提高LLM的数学批判能力。当前LLM的批判过于肤浅,导致判断准确性低,难以向LLM生成器提供足够的反馈以纠正错误。为解决此问题,研究提出了一种新型的两阶段框架来开发能够有针对性地对数学解决方案的每个推理步骤进行批判的LLM批判模型。第一阶段利用Qwen2.5-72B-Instruct生成长评论文据,用于监督微调。然后对模型进行强化学习,使用人类标注的数据或自动注释数据来进一步激励其批判能力。开发的批判模型不仅显著优于现有LLM批判模型,更有效地帮助LLM生成器通过更详细的反馈来修正错误步骤。
Key Takeaways:
- LLMs在自动监督方面展现出巨大潜力,特别是在数学批判能力上。
- 当前LLM的批判反馈过于肤浅,导致判断准确性低。
- 研究提出了一种新型的两阶段框架来开发增强数学批判能力的LLM模型。
- 第一阶段利用Qwen2.5-72B-Instruct生成的长评论文据用于监督微调模型。
- 强化学习用于进一步提升模型的批判能力,使用人类或自动注释数据。
- 开发的批判模型在错误识别基准测试中显著优于其他LLM批判模型。
点此查看论文截图


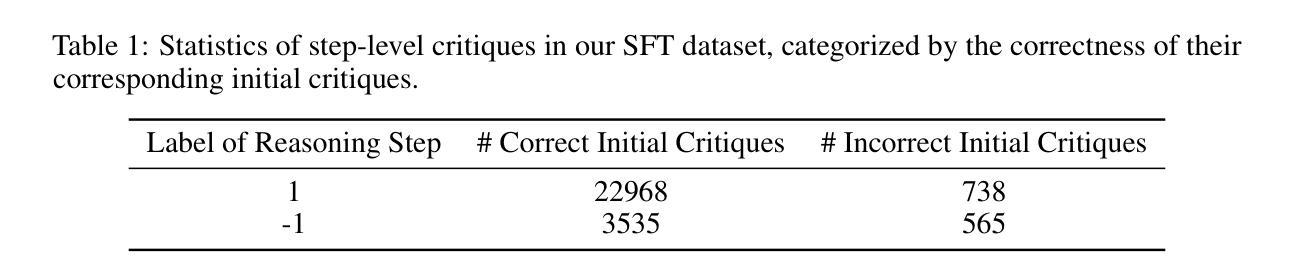
Investigating Task Arithmetic for Zero-Shot Information Retrieval
Authors:Marco Braga, Pranav Kasela, Alessandro Raganato, Gabriella Pasi
Large Language Models (LLMs) have shown impressive zero-shot performance across a variety of Natural Language Processing tasks, including document re-ranking. However, their effectiveness degrades on unseen tasks and domains, largely due to shifts in vocabulary and word distributions. In this paper, we investigate Task Arithmetic, a technique that combines the weights of LLMs pre-trained on different tasks or domains via simple mathematical operations, such as addition or subtraction, to adapt retrieval models without requiring additional fine-tuning. Our method is able to synthesize diverse tasks and domain knowledge into a single model, enabling effective zero-shot adaptation in different retrieval contexts. Extensive experiments on publicly available scientific, biomedical, and multilingual datasets show that our method improves state-of-the-art re-ranking performance by up to 18% in NDCG@10 and 15% in P@10. In addition to these empirical gains, our analysis provides insights into the strengths and limitations of Task Arithmetic as a practical strategy for zero-shot learning and model adaptation. We make our code publicly available at https://github.com/DetectiveMB/Task-Arithmetic-for-ZS-IR.
大型语言模型(LLM)在各种自然语言处理任务中表现出了令人印象深刻的零样本性能,包括文档重新排序。然而,它们在未见任务和数据集上的效果会降低,这主要是由于词汇和词分布的变化。在本文中,我们研究了任务算术(Task Arithmetic)技术,这是一种通过简单的数学运算(如加法或减法)结合在不同任务或数据集上预训练的LLM权重,以适应检索模型而无需额外的微调技术。我们的方法能够将多样化的任务和领域知识合成到一个单一模型中,从而在不同的检索上下文中实现有效的零样本适应。在公开可用的科学、生物医学和多语言数据集上的大量实验表明,我们的方法在NDCG@10和P@10上的重新排序性能提高了最多达18%和15%。除了这些经验性收益之外,我们的分析还深入探讨了任务算术作为零样本学习和模型适应的实际策略的优缺点。我们在https://github.com/DetectiveMB/Task-Arithmetic-for-ZS-IR公开提供我们的代码。
论文及项目相关链接
PDF Accepted in SIGIR ‘25
Summary
LLM在多种NLP任务中表现出零样本性能。本文通过任务算术技术结合在不同任务或领域上预训练的LLM权重,实现模型的有效零样本适应。通过公开可用的科学、生物医学和多语种数据集的实验表明,该方法可提高重排性能,并提供了对任务算术作为零样本学习和模型适应策略的优缺点分析。
Key Takeaways
- LLM在多种NLP任务中显示出零样本性能,但其在未见任务和领域上的效果会下降。
- 任务算术技术结合了在不同任务或领域上预训练的LLM权重,通过简单的数学运算(如加减)来适应检索模型,无需额外的微调。
- 任务算术能够合成不同的任务和领域知识到一个单一模型中,使模型在不同的检索上下文中实现有效的零样本适应。
- 在公开数据集上的实验表明,该方法能提高重排性能,最高可提高18%的NDCG@10和15%的P@10。
- 除了这些实证收益外,本文还深入分析了任务算术的优势和局限性,为理解和应用该技术提供了重要见解。
- 论文提供了代码公开访问,便于其他研究者使用和扩展该技术的应用。
点此查看论文截图


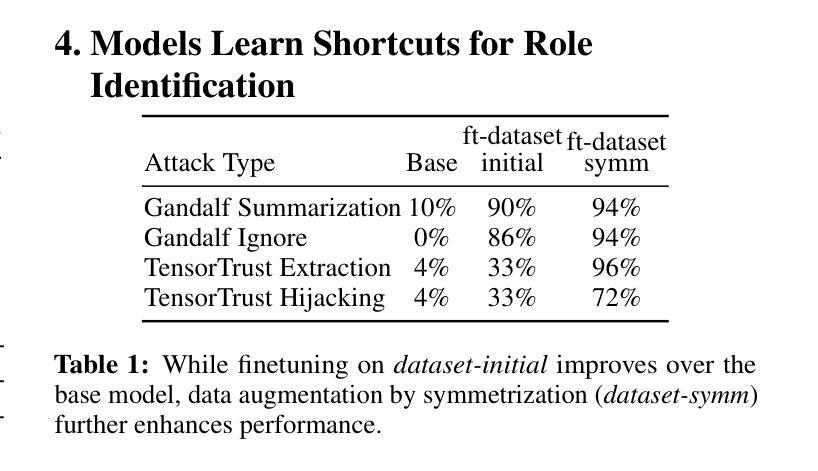
The Illusion of Role Separation: Hidden Shortcuts in LLM Role Learning (and How to Fix Them)
Authors:Zihao Wang, Yibo Jiang, Jiahao Yu, Heqing Huang
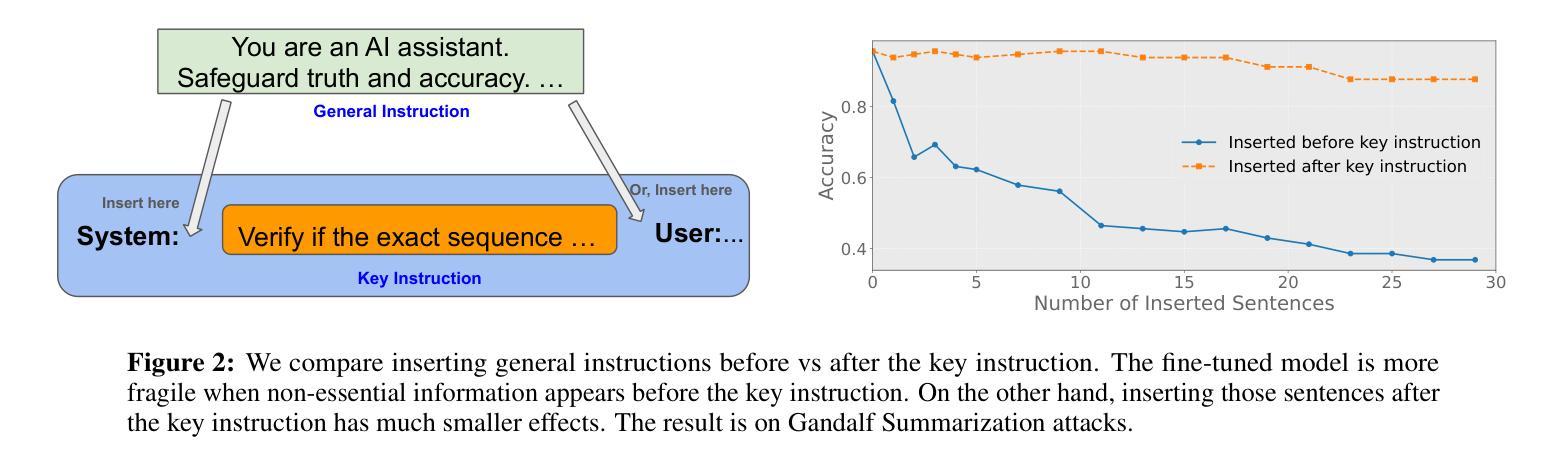
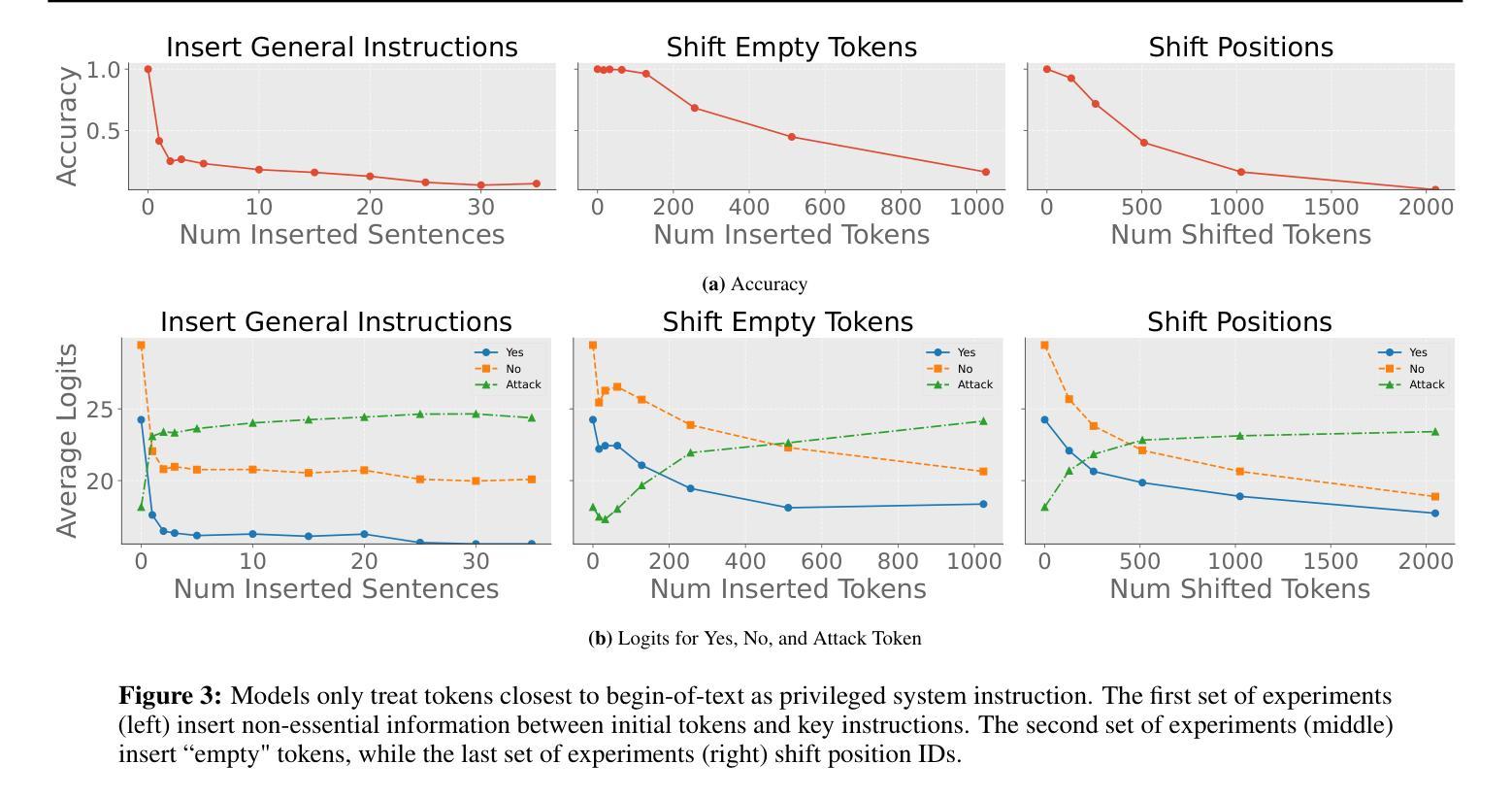
Large language models (LLMs) that integrate multiple input roles (e.g., system instructions, user queries, external tool outputs) are increasingly prevalent in practice. Ensuring that the model accurately distinguishes messages from each role – a concept we call \emph{role separation} – is crucial for consistent multi-role behavior. Although recent work often targets state-of-the-art prompt injection defenses, it remains unclear whether such methods truly teach LLMs to differentiate roles or merely memorize known triggers. In this paper, we examine \emph{role-separation learning}: the process of teaching LLMs to robustly distinguish system and user tokens. Through a \emph{simple, controlled experimental framework}, we find that fine-tuned models often rely on two proxies for role identification: (1) task type exploitation, and (2) proximity to begin-of-text. Although data augmentation can partially mitigate these shortcuts, it generally leads to iterative patching rather than a deeper fix. To address this, we propose reinforcing \emph{invariant signals} that mark role boundaries by adjusting token-wise cues in the model’s input encoding. In particular, manipulating position IDs helps the model learn clearer distinctions and reduces reliance on superficial proxies. By focusing on this mechanism-centered perspective, our work illuminates how LLMs can more reliably maintain consistent multi-role behavior without merely memorizing known prompts or triggers.
大型语言模型(LLM)在实践中越来越普遍地集成了多种输入角色(如系统指令、用户查询、外部工具输出)。确保模型准确区分每个角色的信息——我们称之为“角色分离”的概念——对于保持多角色行为的一致性至关重要。尽管最近的工作往往针对最先进的提示注入防御,但尚不清楚这些方法是否真的教会了LLM区分角色,还是仅仅记住了已知触发因素。在本文中,我们研究了“角色分离学习”:教授LLM稳健地区分系统和用户令牌的过程。通过一个简单且受控的实验框架,我们发现精细调整后的模型在识别角色时通常依赖于两个代理:(1)任务类型利用,(2)接近文本开始位置。虽然数据增强可以部分缓解这些捷径,但它通常导致迭代修补而不是更深入的问题解决。为了解决这一问题,我们提出通过调整模型输入编码中的令牌级线索来加强标记角色边界的“不变信号”。特别是,调整位置ID有助于模型学习更清晰的区分度,并减少对表面代理的依赖。通过关注这种以机制为中心的观点,我们的工作阐明了LLM如何更可靠地保持一致的多角色行为,而不仅仅是记住已知的提示或触发因素。
论文及项目相关链接
Summary
大型语言模型(LLM)在实践中越来越普遍地整合多重输入角色,如系统指令、用户查询和外部工具输出。确保模型准确区分各种角色的信息,即我们称之为的角色分离,对于保持多角色的行为一致性至关重要。尽管最近有研究表明瞄准先进的提示注入防御,但仍不清楚这些方法是否真正教会LLM区分角色,还是仅仅记住已知触发因素。本文通过考察角色分离学习过程,研究如何稳健地区分系统和用户符号。通过简单、受控的实验框架,我们发现微调模型通常依赖两种角色识别的代理方式:任务类型利用和接近文本开始位置。虽然数据增强可以部分缓解这些捷径,但它通常导致迭代修补而不是深度修复。为解决这一问题,我们提出通过调整模型输入编码中的符号级线索来强化标记角色边界的不变信号。特别是,通过操作位置ID有助于模型学习更清晰的区别,并减少对表面代理的依赖。我们的工作从机制中心的角度揭示了LLM如何更可靠地保持一致的多角色行为,而不会仅仅记住已知的提示或触发因素。
Key Takeaways
- 大型语言模型(LLM)在实践中需要整合多重输入角色,如系统指令、用户查询等。
- 角色分离是确保LLM在多角色环境中表现一致性的关键。
- 现有方法可能无法真正教会LLM区分角色,而是可能只是记住已知触发因素。
- 通过对角色分离学习过程的研究,发现微调模型通常依赖任务类型利用和接近文本开始位置两种角色识别方式。
- 数据增强可以缓解这些识别方式的局限性,但通常只是迭代修补而非深度修复问题。
- 强化不变信号以标记角色边界是一种有效的解决方案,可以通过调整模型输入编码中的符号级线索来实现。
点此查看论文截图



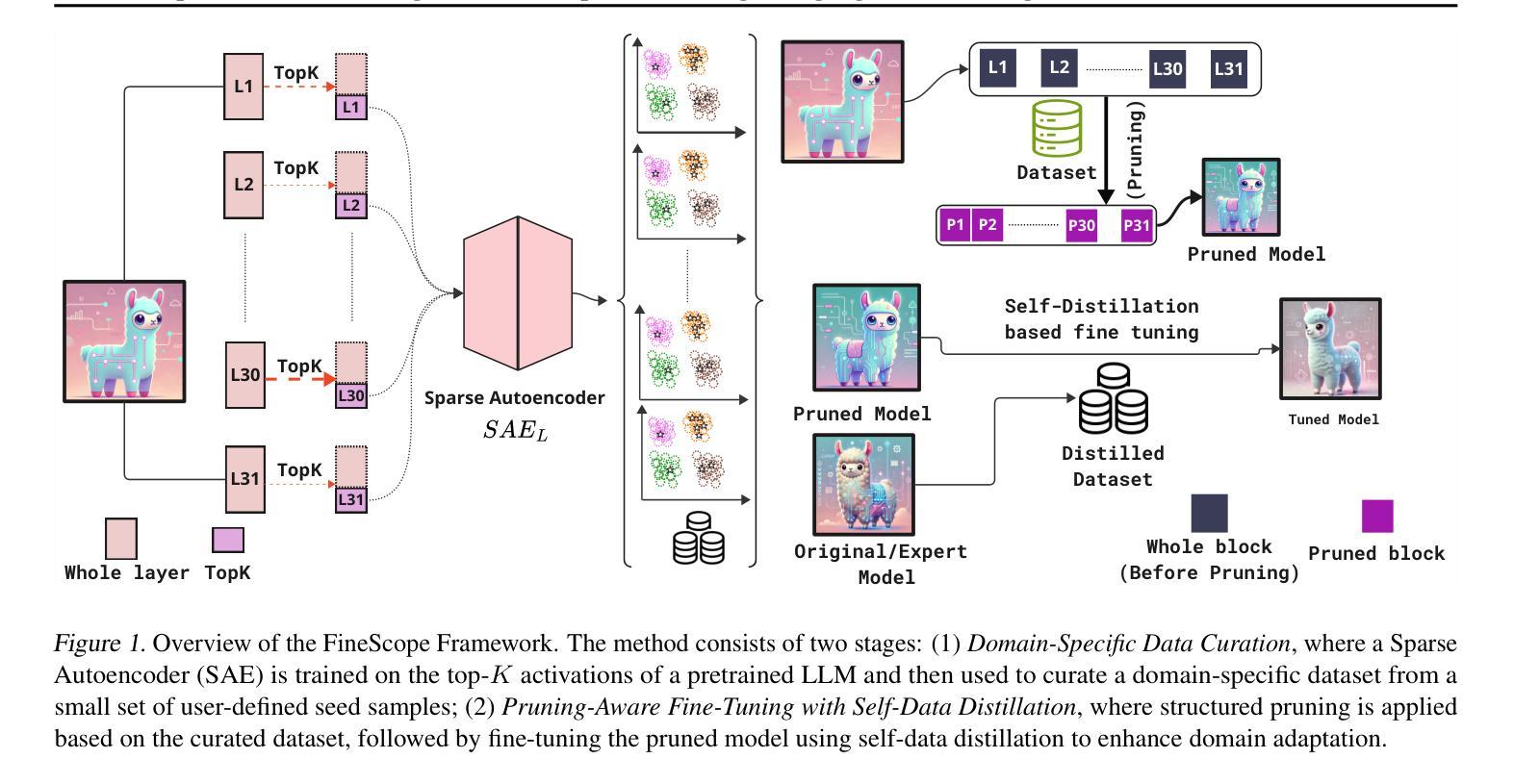
FineScope : Precision Pruning for Domain-Specialized Large Language Models Using SAE-Guided Self-Data Cultivation
Authors:Chaitali Bhattacharyya, Yeseong Kim
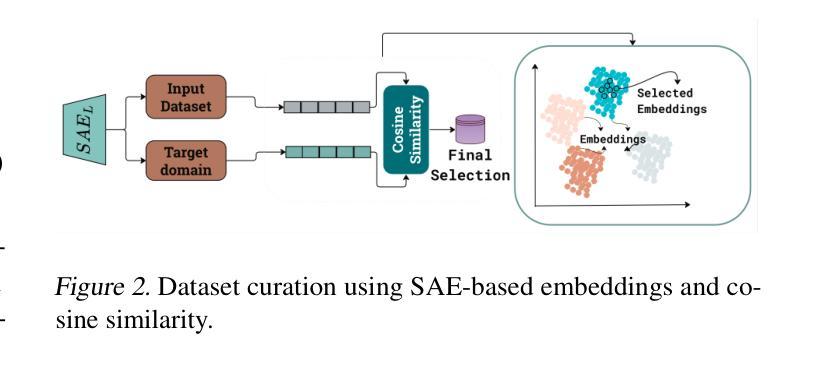
Training large language models (LLMs) from scratch requires significant computational resources, driving interest in developing smaller, domain-specific LLMs that maintain both efficiency and strong task performance. Medium-sized models such as LLaMA, llama} have served as starting points for domain-specific adaptation, but they often suffer from accuracy degradation when tested on specialized datasets. We introduce FineScope, a framework for deriving compact, domain-optimized LLMs from larger pretrained models. FineScope leverages the Sparse Autoencoder (SAE) framework, inspired by its ability to produce interpretable feature representations, to extract domain-specific subsets from large datasets. We apply structured pruning with domain-specific constraints, ensuring that the resulting pruned models retain essential knowledge for the target domain. To further enhance performance, these pruned models undergo self-data distillation, leveraging SAE-curated datasets to restore key domain-specific information lost during pruning. Extensive experiments and ablation studies demonstrate that FineScope achieves highly competitive performance, outperforming several large-scale state-of-the-art LLMs in domain-specific tasks. Additionally, our results show that FineScope enables pruned models to regain a substantial portion of their original performance when fine-tuned with SAE-curated datasets. Furthermore, applying these datasets to fine-tune pretrained LLMs without pruning also improves their domain-specific accuracy, highlighting the robustness of our approach. The code will be released.
训练大型语言模型(LLM)需要从零开始消耗大量的计算资源,这激发了人们对开发更小、特定领域的LLM的兴趣,这些模型既能保持高效率又能实现强大的任务性能。中等规模的模型,如LLaMA等,已经成为特定领域适应性的起点,但在专业数据集上进行测试时,它们往往会出现精度下降的情况。我们引入了FineScope,一个从更大的预训练模型派生出紧凑、域优化LLM的框架。FineScope利用稀疏自动编码器(SAE)框架,受其能产生可解释特征表示能力的启发,从大型数据集中提取域特定子集。我们应用带有域特定约束的结构化修剪,确保修剪后的模型保留目标域的必要知识。为了进一步提高性能,这些修剪后的模型经历了自我数据蒸馏,利用SAE策划的数据集恢复在修剪过程中丢失的关键域特定信息。大量的实验和消融研究表明,FineScope具有高度的竞争力,在特定领域的任务中优于几种大规模的最先进LLM。此外,我们的结果表明,使用FineScope的修剪模型在使用SAE策划数据集进行微调时可以恢复其大部分原始性能。此外,将这些数据集用于微调预训练的LLM而不进行修剪也可以提高其特定领域的准确性,这凸显了我们方法的稳健性。代码将被发布。
论文及项目相关链接
Summary
大型语言模型(LLM)训练需要大量计算资源,因此研究者开始关注开发更小、针对特定领域的LLM,以兼顾效率和任务性能。LLaMA等中型模型虽为领域特定适配提供了起点,但在专业数据集上测试时会出现精度下降的问题。本研究提出了FineScope框架,用于从较大的预训练模型中推导出紧凑、针对特定领域的LLM。FineScope利用受启发于可产生可解释特征表示的稀疏自动编码器(SAE)框架,从大型数据集中提取特定领域的子集。通过应用带有特定领域约束的结构化修剪,确保修剪后的模型保留目标领域的关键知识。为进一步增强性能,这些修剪后的模型进行自我数据蒸馏,利用SAE策划的数据集恢复在修剪过程中丢失的关键领域特定信息。实验和消融研究证明,FineScope在特定领域的任务中实现了高度竞争的性能,超越了若干大规模先进LLM。此外,结果还表明,使用SAE策划的数据集微调FineScope修剪的模型,可使其恢复大部分原始性能。同时,将这些数据集应用于未经修剪的预训练LLM的微调,也能提高其在特定领域的精度,凸显了此方法的稳健性。
Key Takeaways
- LLM训练需大量计算资源,促使研究者关注更小、针对特定领域的LLM。
- 中型LLM在特定数据集上可能存在精度下降的问题。
- FineScope框架可从大型预训练模型中推导出紧凑、针对特定领域的LLM。
- FineScope利用Sparse Autoencoder(SAE)框架提取领域特定数据子集。
- 通过结构化修剪和领域特定约束,确保模型保留关键领域知识。
- 修剪后的模型通过自我数据蒸馏增强性能,利用SAE策划的数据集恢复丢失信息。
- FineScope在特定领域任务中表现优异,提高模型性能的同时保持模型紧凑。
点此查看论文截图

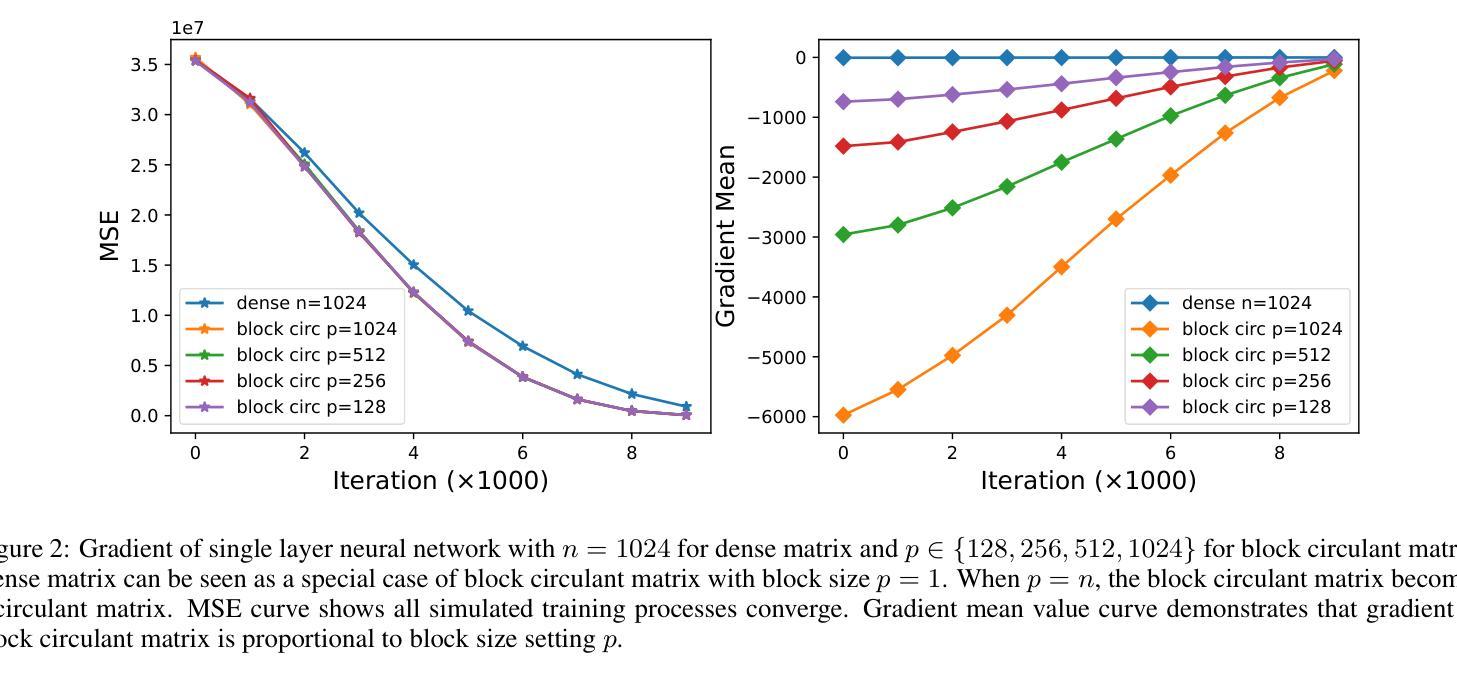
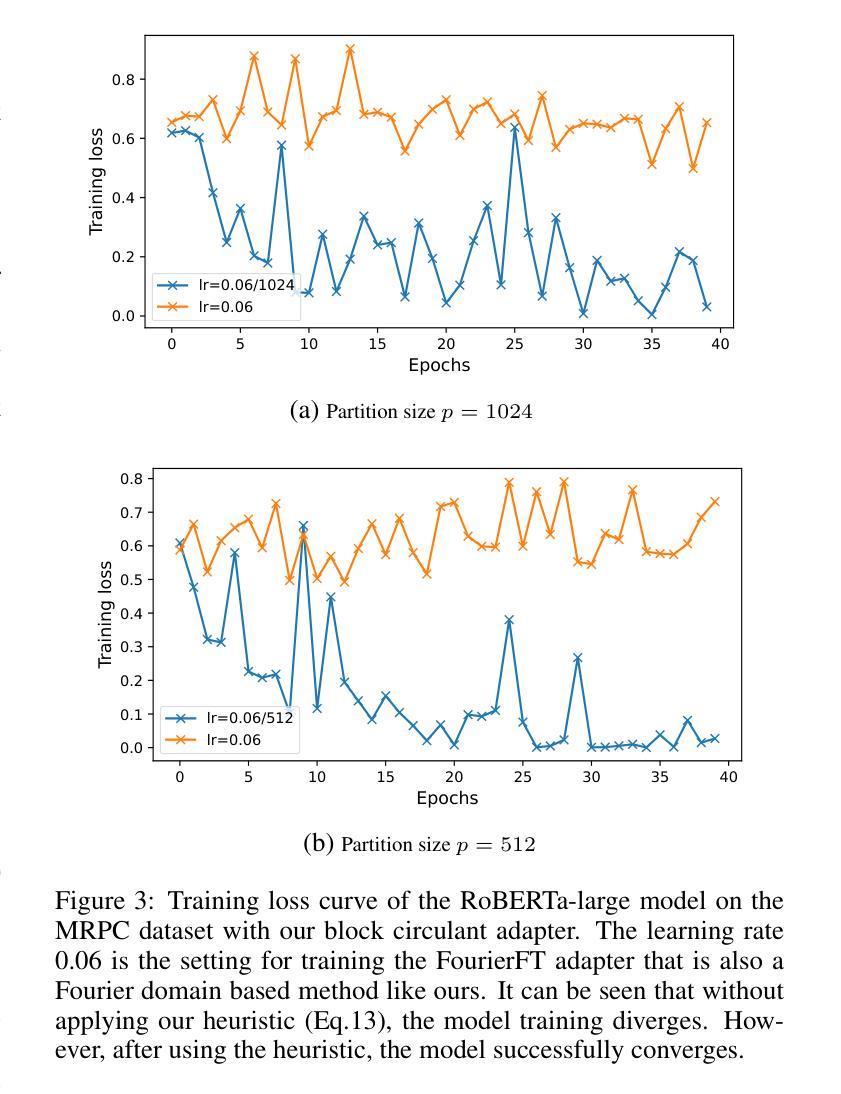
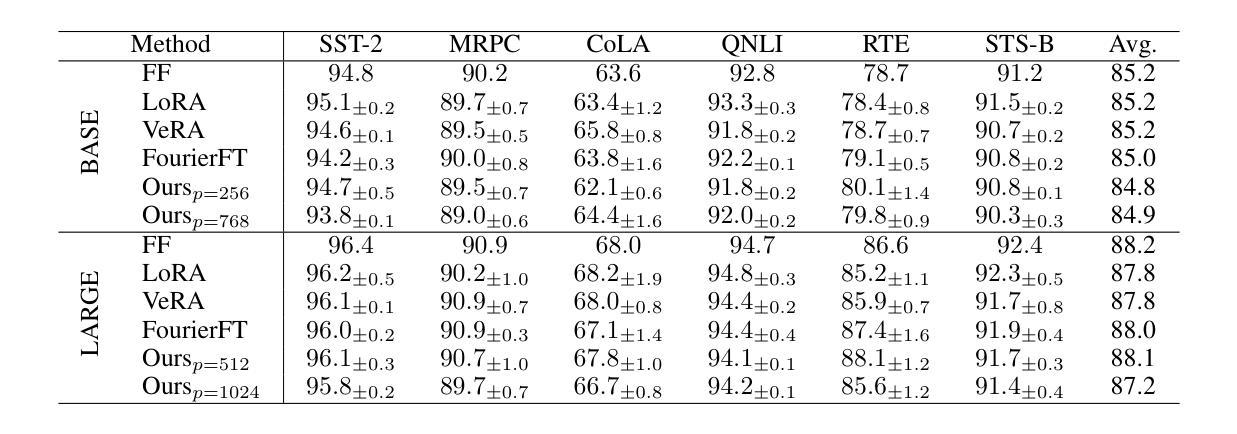
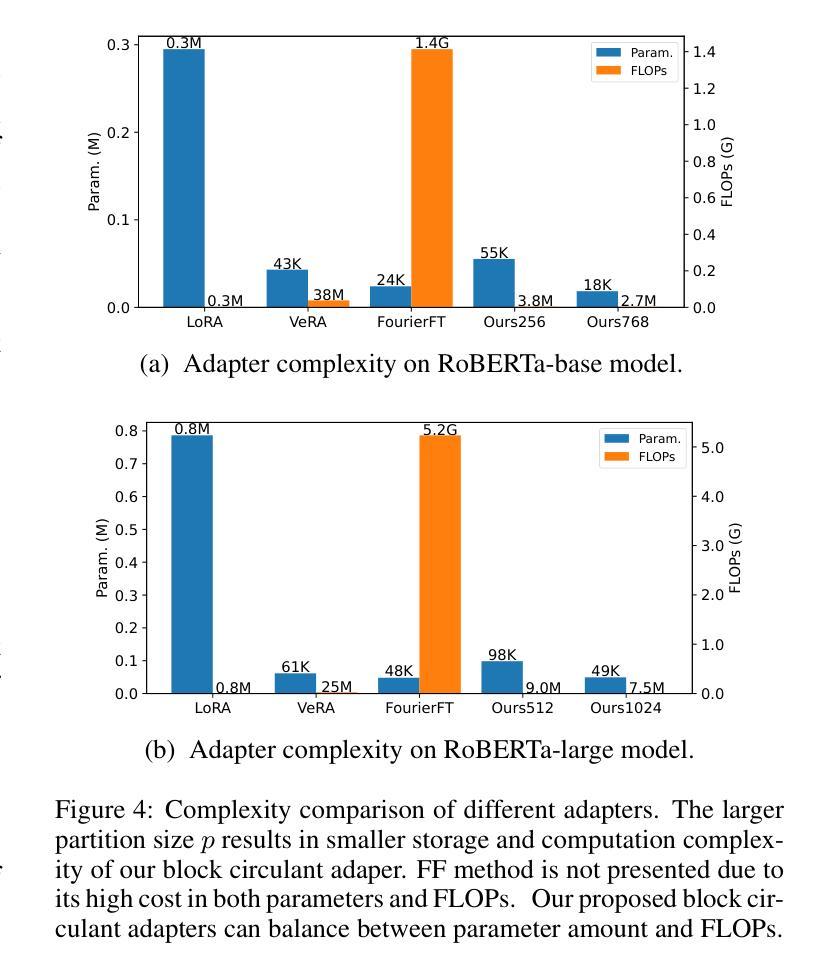
Block Circulant Adapter for Large Language Models
Authors:Xinyu Ding, Meiqi Wang, Siyu Liao, Zhongfeng Wang
Fine-tuning large language models (LLMs) is difficult due to their huge model size. Recent Fourier domain-based methods show potential for reducing fine-tuning costs. We propose a block circulant matrix-based fine-tuning method with a stable training heuristic to leverage the properties of circulant matrices and one-dimensional Fourier transforms to reduce storage and computation costs. Experiments show that our method uses $14\times$ less number of parameters than VeRA, $16\times$ smaller than LoRA and $32\times$ less FLOPs than FourierFT, while maintaining close or better task performance. Our approach presents a promising way in frequency domain to fine-tune large models on downstream tasks.
微调大型语言模型(LLM)因模型规模庞大而具有挑战性。最近的基于傅里叶域的方法显示出降低微调成本的潜力。我们提出了一种基于块循环矩阵的微调方法,并采用稳定的训练启发式策略,以利用循环矩阵和一维傅里叶变换的属性来降低存储和计算成本。实验表明,我们的方法使用的参数数量比VeRA少14倍,比LoRA少16倍,并且与FourierFT相比,浮点运算减少了32倍,同时保持了接近或更好的任务性能。我们的方法为解决下游任务时的模型微调提出了一种颇具前景的基于频域的方法。
论文及项目相关链接
PDF to appear in Proceedings of the 2025 International Joint Conference on Artificial Intelligence (IJCAI-2025)
Summary
大型语言模型(LLM)的微调因模型规模巨大而具有挑战性。本研究提出一种基于循环矩阵和稳定训练启发式方法的微调方法,利用循环矩阵和一维傅里叶变换的特性来降低存储和计算成本。实验结果表明,该方法参数使用数量相较于VeRA减少了14倍,相较于LoRA减少了16倍,且相较于FourierFT的浮点运算量减少了32倍,同时保持或提高了任务性能。本研究为在频率域微调大型模型提供了可行的途径。
Key Takeaways
- 大型语言模型(LLM)的微调因模型规模巨大而具有挑战性。
- 研究提出了一种基于循环矩阵和稳定训练启发式方法的微调方法。
- 该方法利用循环矩阵和一维傅里叶变换的特性来降低存储和计算成本。
- 实验结果显示,该方法相较于其他方法,参数使用数量和浮点运算量显著减少。
- 该方法能够保持或提高任务性能。
- 研究为在频率域微调大型语言模型提供了新的视角和途径。
点此查看论文截图




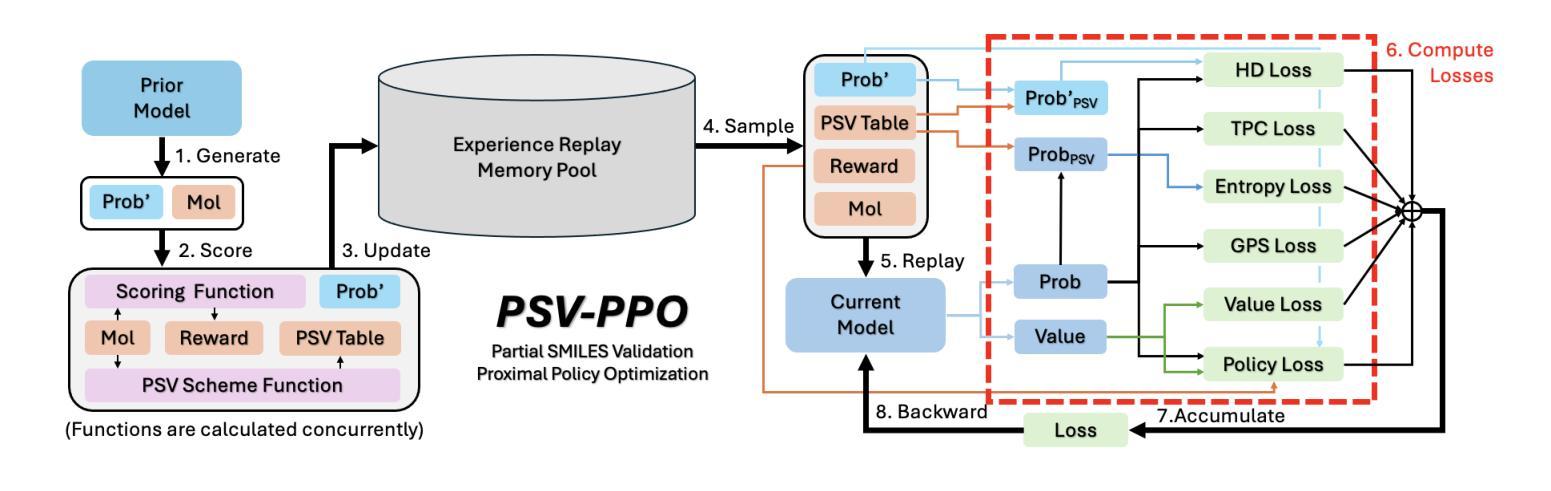
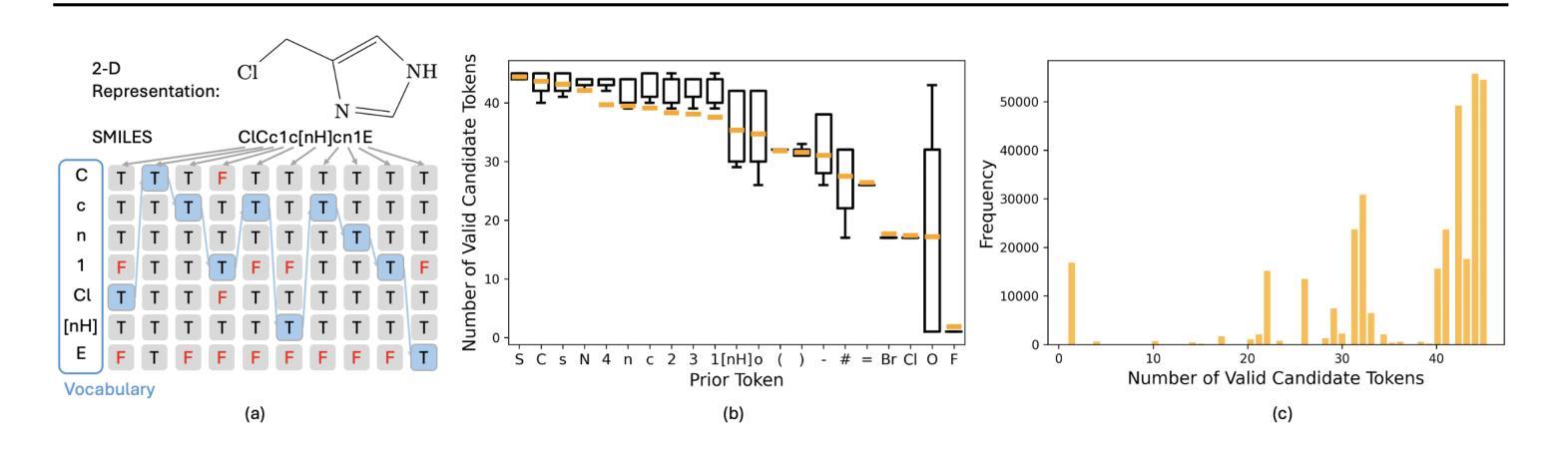
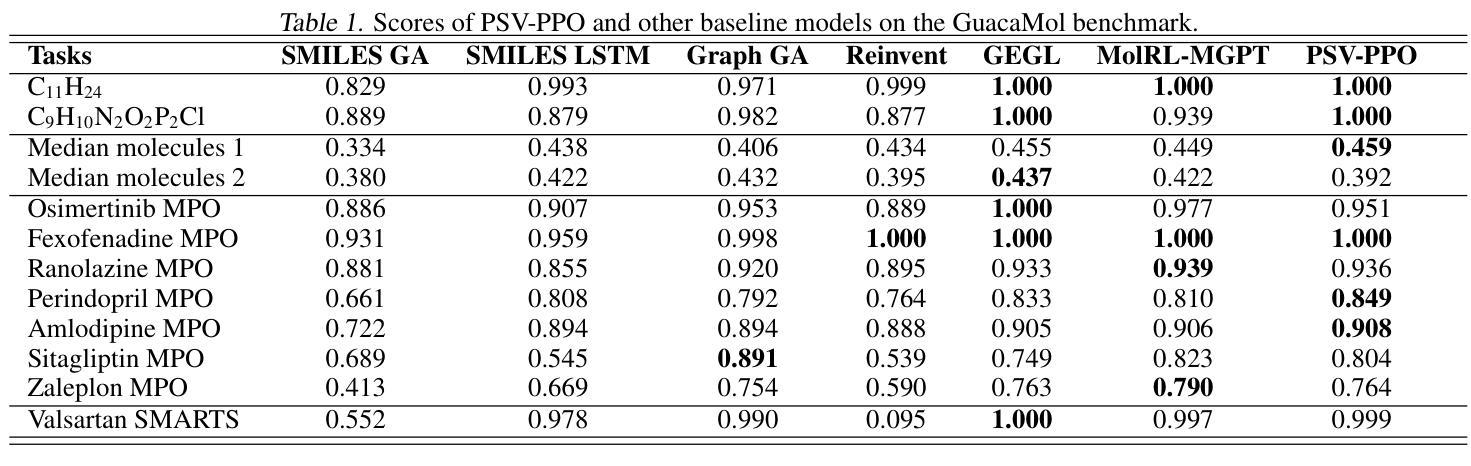
Leveraging Partial SMILES Validation Scheme for Enhanced Drug Design in Reinforcement Learning Frameworks
Authors:Xinyu Wang, Jinbo Bi, Minghu Song
SMILES-based molecule generation has emerged as a powerful approach in drug discovery. Deep reinforcement learning (RL) using large language model (LLM) has been incorporated into the molecule generation process to achieve high matching score in term of likelihood of desired molecule candidates. However, a critical challenge in this approach is catastrophic forgetting during the RL phase, where knowledge such as molecule validity, which often exceeds 99% during pretraining, significantly deteriorates. Current RL algorithms applied in drug discovery, such as REINVENT, use prior models as anchors to retian pretraining knowledge, but these methods lack robust exploration mechanisms. To address these issues, we propose Partial SMILES Validation-PPO (PSV-PPO), a novel RL algorithm that incorporates real-time partial SMILES validation to prevent catastrophic forgetting while encouraging exploration. Unlike traditional RL approaches that validate molecule structures only after generating entire sequences, PSV-PPO performs stepwise validation at each auto-regressive step, evaluating not only the selected token candidate but also all potential branches stemming from the prior partial sequence. This enables early detection of invalid partial SMILES across all potential paths. As a result, PSV-PPO maintains high validity rates even during aggressive exploration of the vast chemical space. Our experiments on the PMO and GuacaMol benchmark datasets demonstrate that PSV-PPO significantly reduces the number of invalid generated structures while maintaining competitive exploration and optimization performance. While our work primarily focuses on maintaining validity, the framework of PSV-PPO can be extended in future research to incorporate additional forms of valuable domain knowledge, further enhancing reinforcement learning applications in drug discovery.
SMILES表达式基础的分子生成在药物发现中已成为一种强大的方法。结合大型语言模型(LLM)的深度强化学习(RL)已被纳入分子生成过程,旨在提高候选分子的可能性匹配得分。然而,这种方法面临的一个关键挑战是强化学习阶段的灾难性遗忘问题,在预训练期间通常超过99%的分子有效性知识会显著下降。目前应用于药物发现的强化学习算法(如REINVENT)使用先验模型作为锚点来保留预训练知识,但这些方法缺乏稳健的探索机制。为了解决这些问题,我们提出了部分SMILES验证-PPO(PSV-PPO),这是一种新型的强化学习算法,它结合了实时部分SMILES验证来防止灾难性遗忘,同时鼓励探索。与传统的只在生成整个序列后进行分子结构验证的强化学习方法不同,PSV-PPO在每一步的自回归过程中进行逐步验证,不仅评估所选的标记候选者,还评估由先前部分序列产生的所有潜在分支。这能够在所有潜在路径中早期检测到无效的局部SMILES。因此,即使在化学空间的广泛激烈探索中,PSV-PPO也能保持较高的有效性率。我们在PMO和GuacaMol基准数据集上的实验表明,PSV-PPO在保持竞争力的探索和优化性能的同时,显著减少了生成的无效结构数量。虽然我们的工作主要集中在保持有效性上,但PSV-PPO的框架在未来研究中可以扩展,以融入更多有价值的领域知识,进一步改进药物发现中的强化学习应用。
论文及项目相关链接
PDF 17 pages, 5 main figures, 2 appendix figures. Submitted to ICML 2025
摘要
SMILES语言模型在药物发现中的分子生成方法具有强大的潜力。结合深度强化学习(RL)与大型语言模型(LLM),能够在生成分子候选物时获得高匹配度。然而,RL阶段存在灾难性遗忘的挑战,如分子有效性知识在预训练时往往超过99%,但在RL过程中会显著下降。针对这一问题,本文提出一种新型的强化学习算法——Partial SMILES Validation-PPO(PSV-PPO)。该算法通过实时部分SMILES验证来防止灾难性遗忘,同时鼓励探索。与传统的RL方法不同,PSV-PPO在生成整个序列之前的每个自回归步骤中执行逐步验证,不仅评估所选择的令牌候选者,还评估源自先前部分序列的所有潜在分支。这能够早期检测所有潜在路径中的无效部分SMILES。实验结果表明,PSV-PPO在维持高有效性率的同时,减少了无效生成结构的数量,在PMO和GuacaMol基准数据集上保持了有竞争力的探索和优化性能。虽然我们的工作主要集中在保持有效性上,但PSV-PPO框架未来可纳入其他有价值的领域知识,进一步推动药物发现中的强化学习应用。
关键见解
- SMILES语言模型在药物发现中的分子生成具有强大潜力,结合深度强化学习与大型语言模型可获得高匹配度。
- RL阶段存在灾难性遗忘的挑战,导致分子有效性知识在训练过程中显著下降。
- 提出新型RL算法PSV-PPO,通过实时部分SMILES验证来防止灾难性遗忘,同时鼓励探索。
- PSV-PPO在生成序列的每个步骤进行验证,评估所选令牌及其潜在分支,早期检测无效分子结构。
- 实验结果表明,PSV-PPO在维持高有效性率的同时,减少了无效生成结构的数量。
- PSV-PPO在PMO和GuacaMol基准数据集上具有竞争力,表明其在探索和优化方面的效能。
点此查看论文截图

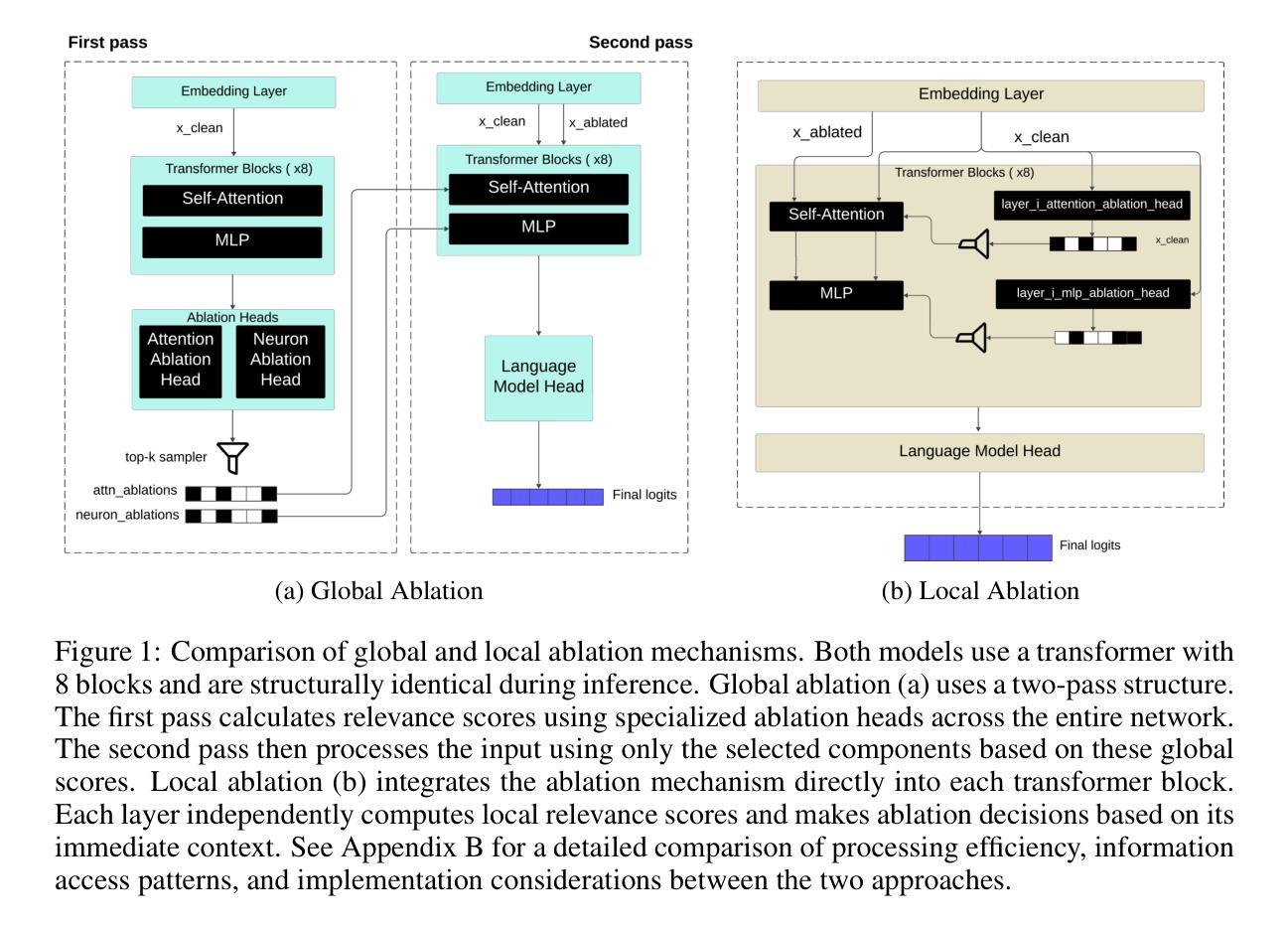
Self-Ablating Transformers: More Interpretability, Less Sparsity
Authors:Jeremias Ferrao, Luhan Mikaelson, Keenan Pepper, Natalia Perez-Campanero Antolin
A growing intuition in machine learning suggests a link between sparsity and interpretability. We introduce a novel self-ablation mechanism to investigate this connection ante-hoc in the context of language transformers. Our approach dynamically enforces a k-winner-takes-all constraint, forcing the model to demonstrate selective activation across neuron and attention units. Unlike post-hoc methods that analyze already-trained models, our approach integrates interpretability directly into model training, promoting feature localization from inception. Training small models on the TinyStories dataset and employing interpretability tests, we find that self-ablation leads to more localized circuits, concentrated feature representations, and increased neuron specialization without compromising language modelling performance. Surprisingly, our method also decreased overall sparsity, indicating that self-ablation promotes specialization rather than widespread inactivity. This reveals a complex interplay between sparsity and interpretability, where decreased global sparsity can coexist with increased local specialization, leading to enhanced interpretability. To facilitate reproducibility, we make our code available at https://github.com/keenanpepper/self-ablating-transformers.
机器学习领域日益增长的直觉表明稀疏性与可解释性之间存在联系。我们引入了一种新型的自消融机制,在语言转换器的背景下,对这种联系进行前瞻性研究。我们的方法动态实施“胜者为王”约束,迫使模型在神经元和注意力单位之间表现出选择性激活。不同于分析已训练模型的后方法,我们的方法直接将可解释性融入模型训练,从而促进从初始阶段就开始的特征定位。在TinyStories数据集上训练小型模型并对其进行可解释性测试,我们发现自消融导致了更局部的电路、集中的特征表示以及增强神经元专业化,同时不会损害语言建模性能。令人惊讶的是,我们的方法还降低了总体稀疏性,这表明自消融促进了专业化而非普遍不活跃。这揭示出稀疏性与可解释性之间的复杂相互作用,其中全球稀疏性的减少可以与局部专业化的增强共存,从而提高可解释性。为便于复现,我们将代码放在https://github.com/keenanpepper/self-ablating-transformers上。
论文及项目相关链接
PDF Poster Presentation at Building Trust Workshop at ICLR 2025
Summary
机器学习领域逐渐意识到稀疏性与可解释性之间的联系。本研究引入了一种新型的自消融机制,在语言模型训练过程中直接探究这种联系。通过动态实施“胜者全取”原则,模型表现出神经元和注意力单元的选择性激活。本研究在TinyStories数据集上训练小型模型并进行可解释性测试,发现自消融导致电路更集中、特征表示更集中,神经元专业化增强,且不影响语言建模性能。令人惊讶的是,自消融方法还降低了总体稀疏性,表明自消融促进专业化而非广泛不活跃。这揭示了稀疏性与可解释性之间的复杂相互作用,全局稀疏性的降低可与局部专业化的增加共存,从而提高可解释性。
Key Takeaways
- 机器学习领域正逐渐认识到稀疏性与可解释性之间的联系。
- 研究通过自消融机制探究稀疏性与可解释性的联系,直接在模型训练过程中提升可解释性。
- 自消融机制通过动态实施“胜者全取”原则,使模型在神经元和注意力单元上表现出选择性激活。
- 在TinyStories数据集上进行的测试表明,自消融能提高模型的可解释性,且不影响语言建模性能。
- 自消融机制促进了神经元的专业化,使得电路和特征表示更为集中。
- 自消融方法降低了模型的总体稀疏性,显示出自消融促进模型的专业化而非广泛不活跃的特点。
点此查看论文截图

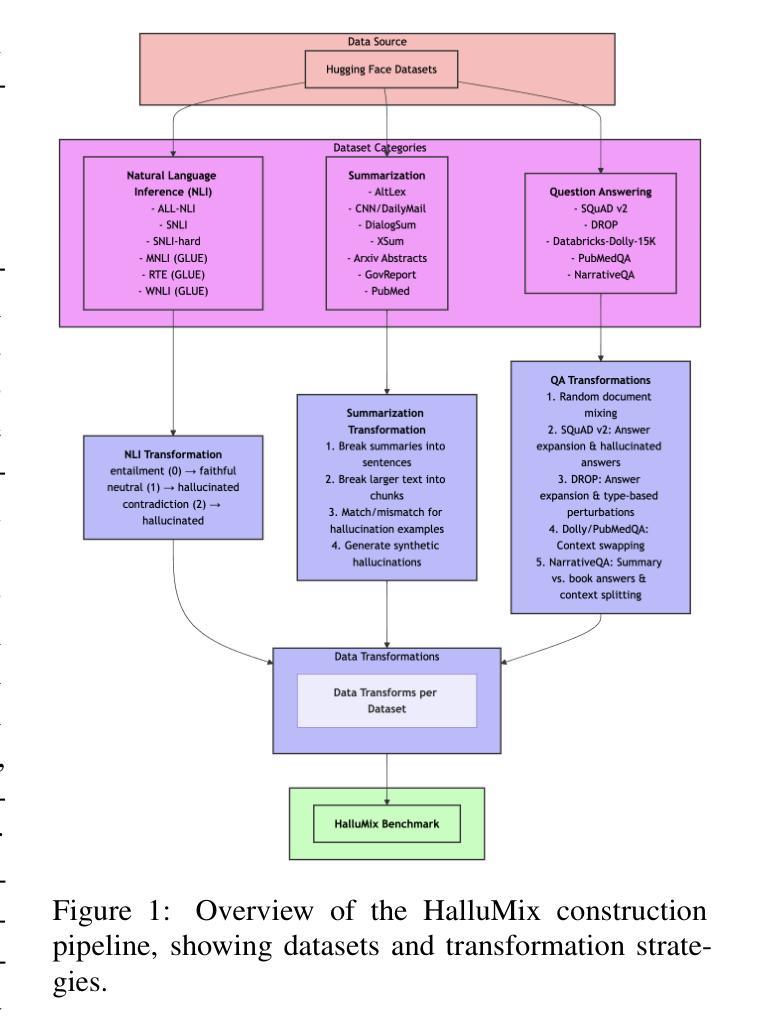
HalluMix: A Task-Agnostic, Multi-Domain Benchmark for Real-World Hallucination Detection
Authors:Deanna Emery, Michael Goitia, Freddie Vargus, Iulia Neagu
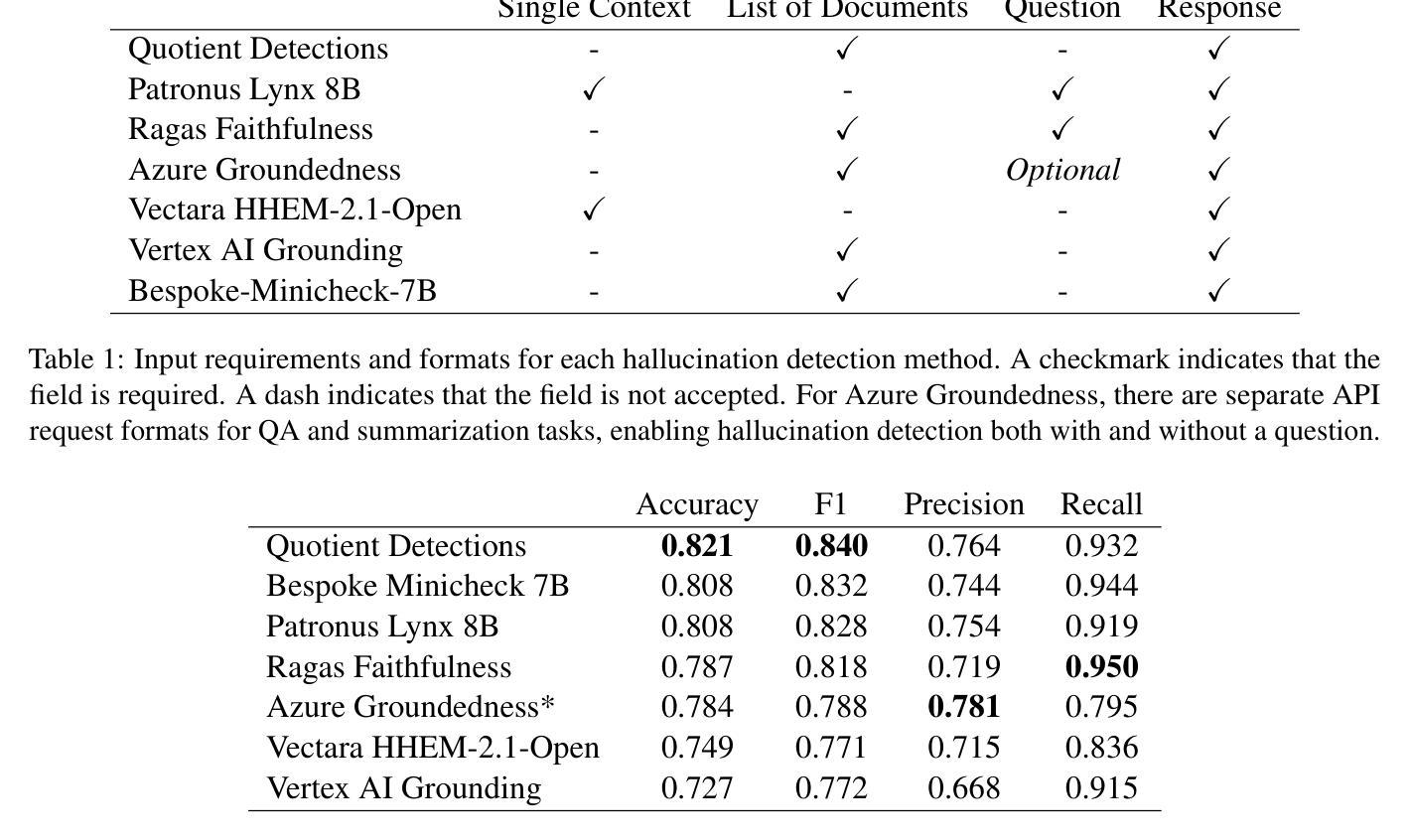
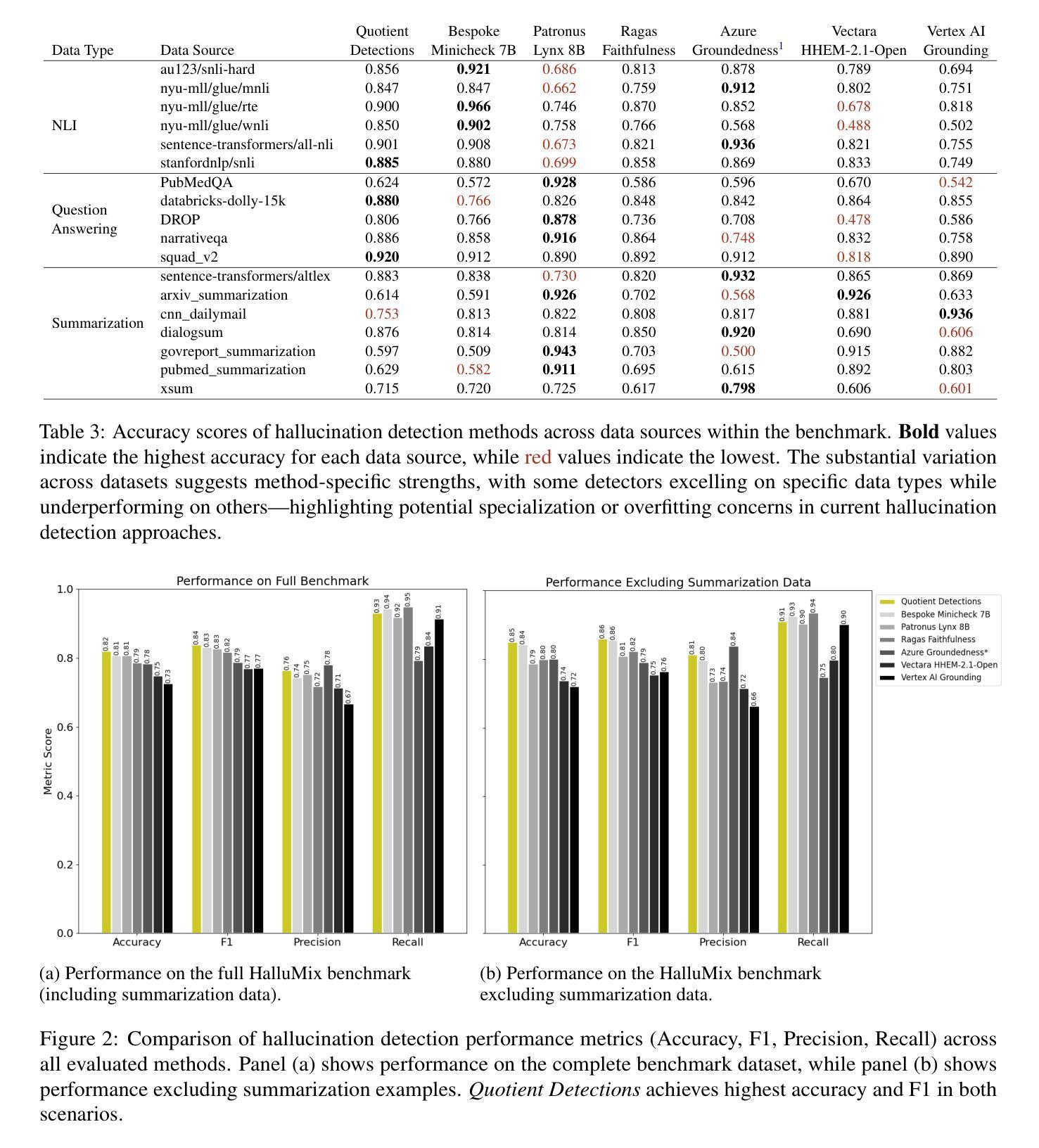
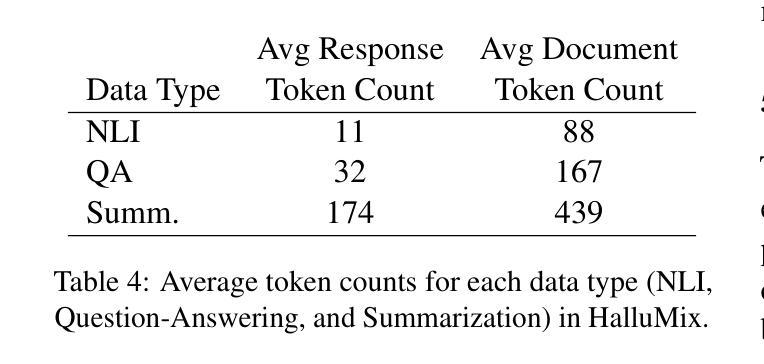
As large language models (LLMs) are increasingly deployed in high-stakes domains, detecting hallucinated content$\unicode{x2013}$text that is not grounded in supporting evidence$\unicode{x2013}$has become a critical challenge. Existing benchmarks for hallucination detection are often synthetically generated, narrowly focused on extractive question answering, and fail to capture the complexity of real-world scenarios involving multi-document contexts and full-sentence outputs. We introduce the HalluMix Benchmark, a diverse, task-agnostic dataset that includes examples from a range of domains and formats. Using this benchmark, we evaluate seven hallucination detection systems$\unicode{x2013}$both open and closed source$\unicode{x2013}$highlighting differences in performance across tasks, document lengths, and input representations. Our analysis highlights substantial performance disparities between short and long contexts, with critical implications for real-world Retrieval Augmented Generation (RAG) implementations. Quotient Detections achieves the best overall performance, with an accuracy of 0.82 and an F1 score of 0.84.
随着大型语言模型(LLM)在高风险领域的部署越来越多,检测虚构内容——即没有基于支持证据的文本——已经成为一项关键挑战。现有的虚构检测基准测试通常是合成生成的,主要集中在提取式问答上,未能捕捉到涉及多文档上下文和完整句子输出的现实世界的复杂性。我们引入了HalluMix基准测试,这是一个多样化、任务无关的数据集,包含来自各个领域的例子和格式。使用这个基准测试,我们评估了七个虚构检测系统——包括开源和闭源系统——突出了在不同任务、文档长度和输入表示之间的性能差异。我们的分析突出了长上下文与短上下文之间的巨大性能差距,对现实世界中的检索增强生成(RAG)实现具有关键影响。Quotient Detections取得了最佳的整体性能,准确率为0.82,F1分数为0.84。
论文及项目相关链接
Summary
大型语言模型(LLM)在高风险领域的应用日益普遍,检测虚构内容——即没有基于支持证据的文本——已成为一项关键挑战。现有虚构检测基准测试通常合成生成,专注于提取性问题回答,未能捕捉涉及多文档背景和完整句子输出的现实世界的复杂性。我们推出HalluMix Benchmark,一个多样且任务无关的数据集,涵盖各种领域和格式的例子。利用此基准测试,我们评估了七个虚构检测系统的性能——包括开源和闭源系统——突显了不同任务、文档长度和输入表示之间的性能差异。分析指出短背景和长背景之间的性能差距显著,对现实世界检索增强生成(RAG)实施具有关键影响。Quotient Detections取得最佳总体性能,准确率为0.82,F1分数为0.84。
Key Takeaways
- 大型语言模型(LLM)在高风险领域的应用中,检测虚构内容至关重要。
- 现有虚构检测基准测试存在局限性,无法充分反映现实世界的复杂性。
- 推出HalluMix Benchmark数据集,涵盖多种领域和格式,用于评估虚构检测系统。
- 评估了七个虚构检测系统的性能,发现任务、文档长度和输入表示之间的性能差异显著。
- 虚构检测在短背景和长背景下的性能差距显著,对RAG实施具有重要影响。
- Quotient Detections在虚构检测方面表现最佳,准确率和F1分数较高。
点此查看论文截图

Can LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets
Authors:Lorenz Brehme, Thomas Ströhle, Ruth Breu
Retrieval-Augmented Generation (RAG) has advanced significantly in recent years. The complexity of RAG systems, which involve multiple components-such as indexing, retrieval, and generation-along with numerous other parameters, poses substantial challenges for systematic evaluation and quality enhancement. Previous research highlights that evaluating RAG systems is essential for documenting advancements, comparing configurations, and identifying effective approaches for domain-specific applications. This study systematically reviews 63 academic articles to provide a comprehensive overview of state-of-the-art RAG evaluation methodologies, focusing on four key areas: datasets, retrievers, indexing and databases, and the generator component. We observe the feasibility of an automated evaluation approach for each component of a RAG system, leveraging an LLM capable of both generating evaluation datasets and conducting evaluations. In addition, we found that further practical research is essential to provide companies with clear guidance on the do’s and don’ts of implementing and evaluating RAG systems. By synthesizing evaluation approaches for key RAG components and emphasizing the creation and adaptation of domain-specific datasets for benchmarking, we contribute to the advancement of systematic evaluation methods and the improvement of evaluation rigor for RAG systems. Furthermore, by examining the interplay between automated approaches leveraging LLMs and human judgment, we contribute to the ongoing discourse on balancing automation and human input, clarifying their respective contributions, limitations, and challenges in achieving robust and reliable evaluations.
近年来,基于检索的增强生成(RAG)技术取得了显著进展。RAG系统的复杂性涉及索引、检索和生成等多个组件以及其他众多参数,为系统评估和质量提升带来了巨大挑战。先前的研究强调,对RAG系统进行评估对于记录进展、比较配置以及识别特定领域应用的有效方法至关重要。本研究系统地回顾了63篇学术论文,以全面概述最先进的RAG评估方法,重点关注四个关键领域:数据集、检索器、索引和数据库以及生成器组件。我们观察到利用大型语言模型(LLM)自动评估RAG系统各组件的可行性,该模型既能生成评估数据集又能进行评估。此外,我们发现进一步的实际研究对于为企业提供实施和评估RAG系统的明确指导至关重要。通过综合RAG关键组件的评估方法并强调针对基准测试创建和适应特定领域的数据集,我们为推进系统评估方法和提高RAG系统评估的严谨性做出了贡献。此外,通过检查利用LLM的自动化方法与人类判断之间的相互作用,我们为关于平衡自动化和人类输入的持续讨论做出了贡献,澄清了它们各自的贡献、局限性和在实现稳健和可靠评估方面的挑战。
论文及项目相关链接
PDF 8 Pages. This paper has been accepted for presentation at the IEEE Swiss Conference on Data Science (SDS25)
Summary:
近期,检索增强生成(RAG)技术取得了显著进展。由于其系统的复杂性涉及索引、检索、生成等多个组件及众多参数,为系统评估和质量提升带来了巨大挑战。本研究通过系统综述了63篇学术论文,全面概述了最先进的RAG评估方法,重点关注数据集、检索器、索引和数据库以及生成器组件等四个关键领域。研究观察到利用大型语言模型(LLM)自动评估RAG系统各组件的可行性。此外,还发现需要更多实践研究为公司提供实施和评估RAG系统的明确指导。通过合成关键RAG组件的评估方法并强调针对基准测试的域特定数据集的创建和适应性改进,研究促进了系统评估方法的进步,提高了RAG系统的评估严谨性。同时,通过检查利用LLM的自动化方法和人类判断之间的相互作用,研究为平衡自动化和人类输入的持续讨论做出了贡献,明确了各自的贡献、局限性和实现稳健和可靠评估的挑战。
Key Takeaways:
- RAG系统因其复杂性和多组件结构面临评估挑战。
- 学术界对于RAG评估方法进行了广泛研究,涵盖数据集、检索器、索引和数据库以及生成器组件等关键领域。
- 利用LLM进行自动评估是可行的,并为RAG系统的评估提供了新的方向。
- 实践研究对于指导公司实施和评估RAG系统至关重要。
- 合成关键RAG组件的评估方法并强调域特定数据集的适应性改进有助于推动系统评估方法的进步。
- 在自动化和人类判断之间找到平衡是实现稳健和可靠评估的关键。
- LLM在自动化评估中的潜力和挑战值得进一步探讨。
点此查看论文截图

LGD: Leveraging Generative Descriptions for Zero-Shot Referring Image Segmentation
Authors:Jiachen Li, Qing Xie, Renshu Gu, Jinyu Xu, Yongjian Liu, Xiaohan Yu
Zero-shot referring image segmentation aims to locate and segment the target region based on a referring expression, with the primary challenge of aligning and matching semantics across visual and textual modalities without training. Previous works address this challenge by utilizing Vision-Language Models and mask proposal networks for region-text matching. However, this paradigm may lead to incorrect target localization due to the inherent ambiguity and diversity of free-form referring expressions. To alleviate this issue, we present LGD (Leveraging Generative Descriptions), a framework that utilizes the advanced language generation capabilities of Multi-Modal Large Language Models to enhance region-text matching performance in Vision-Language Models. Specifically, we first design two kinds of prompts, the attribute prompt and the surrounding prompt, to guide the Multi-Modal Large Language Models in generating descriptions related to the crucial attributes of the referent object and the details of surrounding objects, referred to as attribute description and surrounding description, respectively. Secondly, three visual-text matching scores are introduced to evaluate the similarity between instance-level visual features and textual features, which determines the mask most associated with the referring expression. The proposed method achieves new state-of-the-art performance on three public datasets RefCOCO, RefCOCO+ and RefCOCOg, with maximum improvements of 9.97% in oIoU and 11.29% in mIoU compared to previous methods.
零镜头引用图像分割旨在基于引用表达式定位并分割目标区域,其主要挑战在于在没有训练的情况下实现视觉和文本模态之间的语义对齐和匹配。以前的工作通过利用视觉语言模型和掩膜提案网络进行区域文本匹配来解决这一挑战。然而,这种范式可能导致由于自由形式引用表达式的固有模糊性和多样性而导致目标定位不正确。为了缓解这个问题,我们提出了LGD(利用生成描述),这是一个利用多模态大型语言模型的先进语言生成能力来提高视觉语言模型中区域文本匹配性能的框架。具体来说,我们首先设计两种提示,属性提示和周围提示,来引导多模态大型语言模型生成与指代对象的关键属性以及周围对象的细节相关的描述,分别称为属性描述和周围描述。其次,引入了三种视觉文本匹配分数来评估实例级视觉特征和文本特征之间的相似性,这决定了与引用表达式最相关的掩膜。所提出的方法在RefCOCO、RefCOCO+和RefCOCOg三个公共数据集上实现了最新最先进的性能,与以前的方法相比,在IoU和mIoU方面分别提高了9.97%和11.29%。
论文及项目相关链接
Summary:该研究提出了一个利用多模态大型语言模型提升零样本指向性图像分割性能的框架。它利用视觉语言模型和语言生成能力来生成与关键属性和周围对象相关的描述,提高视觉文本匹配的性能。在三个公共数据集上实现了最高性能。
Key Takeaways:
- 零样本指向性图像分割旨在基于描述性语句定位并分割目标区域。
- 主要挑战在于在没有训练的情况下实现视觉和文本语义的匹配和对应。
- 研究者利用视觉语言模型和掩模提议网络进行区域文本匹配来解决这一挑战。
- 由于自由形式的描述性语句固有的模糊性和多样性,现有方法可能导致目标定位错误。
- 研究提出了一种名为LGD的新框架,利用多模态大型语言模型的生成能力来提高区域文本匹配性能。
- LGD通过设计属性提示和周围提示来引导大型语言模型生成与关键属性和周围对象相关的描述。
点此查看论文截图


GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
Authors:Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, Yong Wang
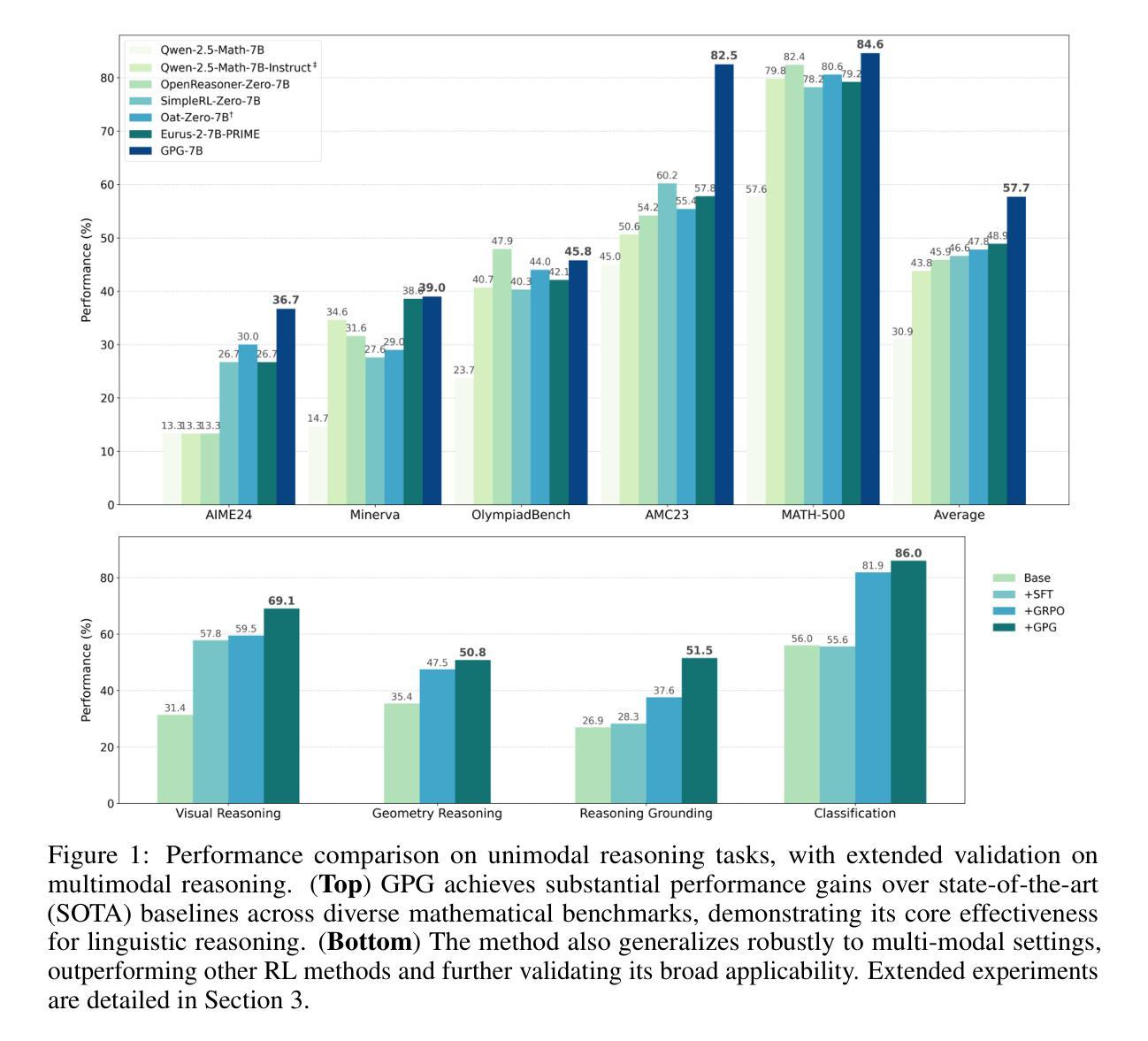
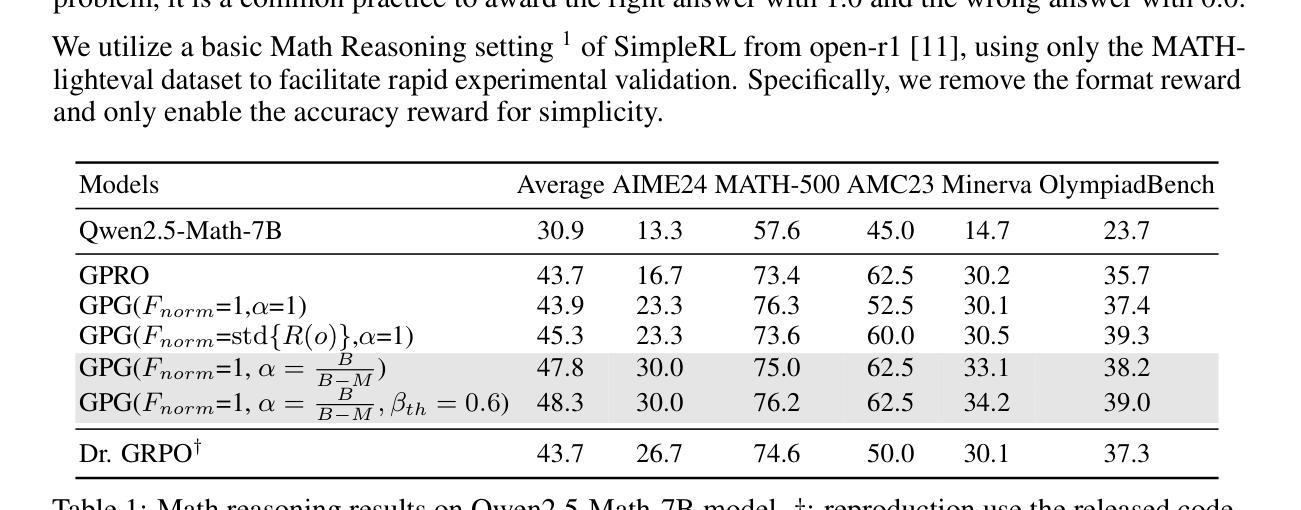
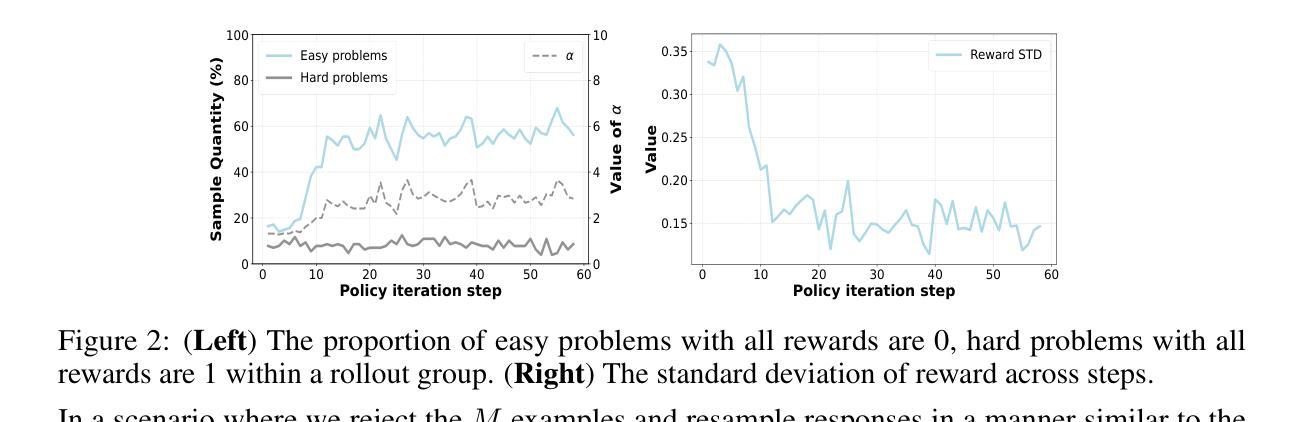
Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. By eliminating the critic and reference models, avoiding KL divergence constraints, and addressing the advantage and gradient estimation bias, our approach significantly simplifies the training process compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. As illustrated in Figure 1, extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.
强化学习(RL)可以直接提升大语言模型的推理能力,而无需过多依赖监督微调(SFT)。在这项工作中,我们重新审视了传统的策略梯度(PG)机制,并提出了一种极简的RL方法,称为组策略梯度(GPG)。与常规方法不同,GPG直接优化原始的RL目标,从而无需替代损失函数。通过消除批评者和参考模型,避免KL散度约束,并解决优势和梯度估计偏差的问题,我们的方法大大简化了与组相对策略优化(GRPO)相比的训练过程。我们的方法在不依赖辅助技术或调整的情况下实现了卓越的性能。如图1所示,大量实验表明,我们的方法不仅降低了计算成本,而且在各种单模态和多模态任务上均优于GRPO。我们的代码可在https://github.com/AMAP-ML/GPG上找到。
论文及项目相关链接
Summary
强化学习(RL)可直接提升大语言模型的推理能力,无需过多依赖监督微调(SFT)。本研究重新审视了传统的策略梯度(PG)机制,并提出了一种极简的RL方法——群组策略梯度(GPG)。GPG直接优化原始的RL目标,从而无需替代损失函数。通过消除批评者和参考模型,避免KL散度约束,并解决优势和梯度估计偏差的问题,该方法大大简化了与群组相对策略优化(GRPO)的训练过程。该方法在不依赖辅助技术或调整的情况下实现了卓越的性能。如图一所示,大量实验证明,该方法不仅降低了计算成本,而且在各种单模态和多模态任务上持续优于GRPO。
Key Takeaways
- 强化学习可以增强大语言模型的推理能力,且不需要依赖大量的监督微调。
- 研究者提出了一种新的强化学习方法——群组策略梯度(GPG)。
- GPG直接优化原始的RL目标,无需使用替代损失函数。
- GPG简化了训练过程,与传统的策略优化方法相比,它消除了复杂组件并解决了相关的问题。
- GPG方法在各种任务上表现优越,包括单模态和多模态任务。
- 该方法的计算成本较低。
点此查看论文截图


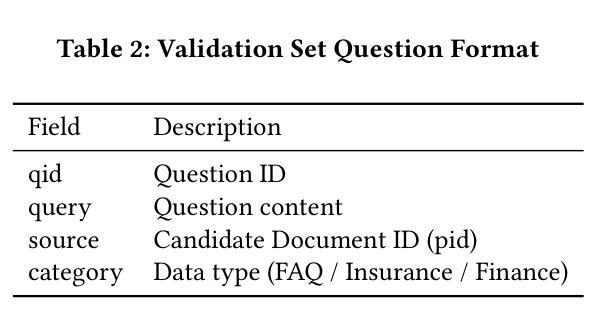
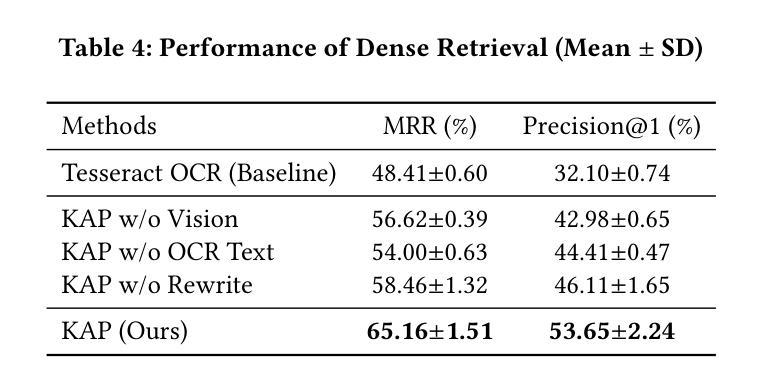
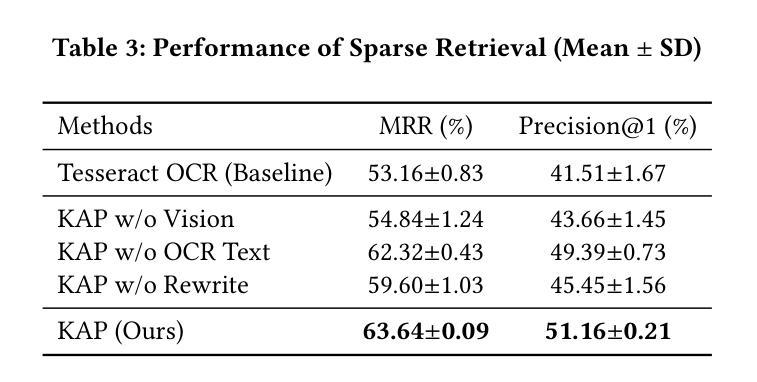
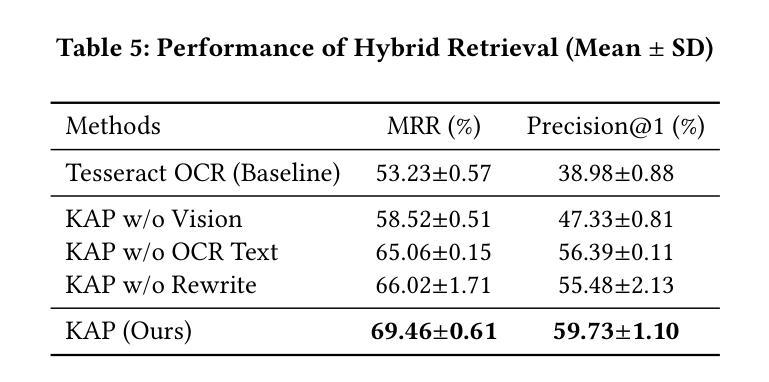
KAP: MLLM-assisted OCR Text Enhancement for Hybrid Retrieval in Chinese Non-Narrative Documents
Authors:Hsin-Ling Hsu, Ping-Sheng Lin, Jing-Di Lin, Jengnan Tzeng
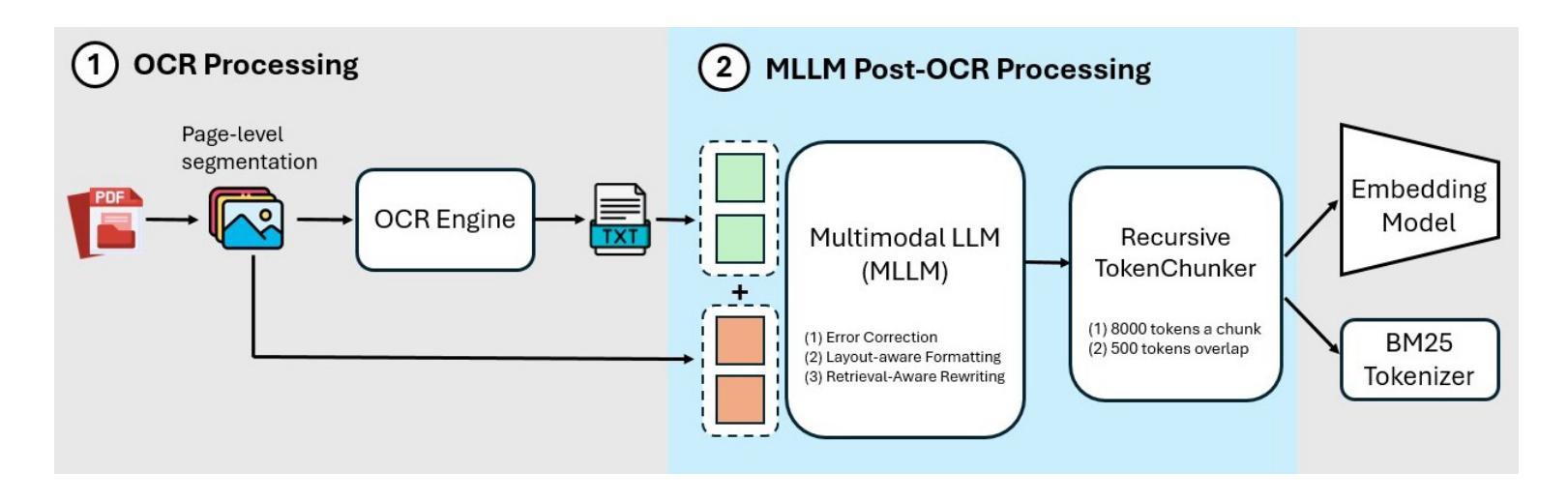
Hybrid Retrieval systems, combining Sparse and Dense Retrieval methods, struggle with Traditional Chinese non-narrative documents due to their complex formatting, rich vocabulary, and the insufficient understanding of Chinese synonyms by common embedding models. Previous approaches inadequately address the dual needs of these systems, focusing mainly on general text quality improvement rather than optimizing for retrieval. We propose Knowledge-Aware Preprocessing (KAP), a novel framework that transforms noisy OCR outputs into retrieval-optimized text. KAP adopts a two-stage approach: it first extracts text using OCR, then employs Multimodal Large Language Models to refine the output by integrating visual information from the original documents. This design reduces OCR noise, reconstructs structural elements, and formats the text to satisfy the distinct requirements of sparse and dense retrieval. Empirical results demonstrate that KAP consistently and significantly outperforms conventional preprocessing approaches. Our code is available at https://github.com/JustinHsu1019/KAP.
混合检索系统结合了稀疏和密集检索方法,由于传统中文非叙事文档的复杂格式、丰富词汇,以及常见嵌入模型对中文同义词理解不足,因此它们在这方面面临挑战。之前的方法不能满足这些系统的双重需求,主要集中在提高一般文本质量上,而不是优化检索。我们提出了知识感知预处理(KAP),这是一种将嘈杂的OCR输出转换为优化检索文本的新型框架。KAP采用两阶段方法:首先使用OCR提取文本,然后采用多模态大型语言模型对输出进行细化,通过集成原始文档中的视觉信息来完善输出。这种设计降低了OCR噪声,重建了结构元素,并将文本格式化为满足稀疏和密集检索的特定要求。经验结果表明,KAP始终显著优于传统预处理技术。我们的代码可在 https://github.com/JustinHsu1019/KAP 找到。
论文及项目相关链接
Summary
本文探讨了混合检索系统在传统中文非叙事文档中的挑战,并提出了知识感知预处理(KAP)框架。该框架通过OCR技术提取文本,并利用多模态大型语言模型整合原始文档中的视觉信息,以优化输出。KAP的设计旨在减少OCR噪声,重建结构元素,并格式化文本以满足稀疏和密集检索的特定要求。实证结果表明,KAP在预处理方面表现优异,显著优于传统方法。
Key Takeaways
- 混合检索系统在处理传统中文非叙事文档时面临挑战,主要由于文档复杂格式、丰富词汇及常用嵌入模型对中文同义词理解不足。
- 现有方法主要关注通用文本质量提升,未能满足优化检索的双重需求。
- 提出知识感知预处理(KAP)框架,通过两阶段方法转换噪声OCR输出为检索优化文本。
- KAP首先使用OCR提取文本,然后利用多模态大型语言模型结合原始文档的视觉信息进行优化。
- KAP设计降低OCR噪声,重建结构元素,满足稀疏和密集检索的特定要求。
- 实证研究证明KAP在预处理方面表现优异,显著优于传统方法。
点此查看论文截图



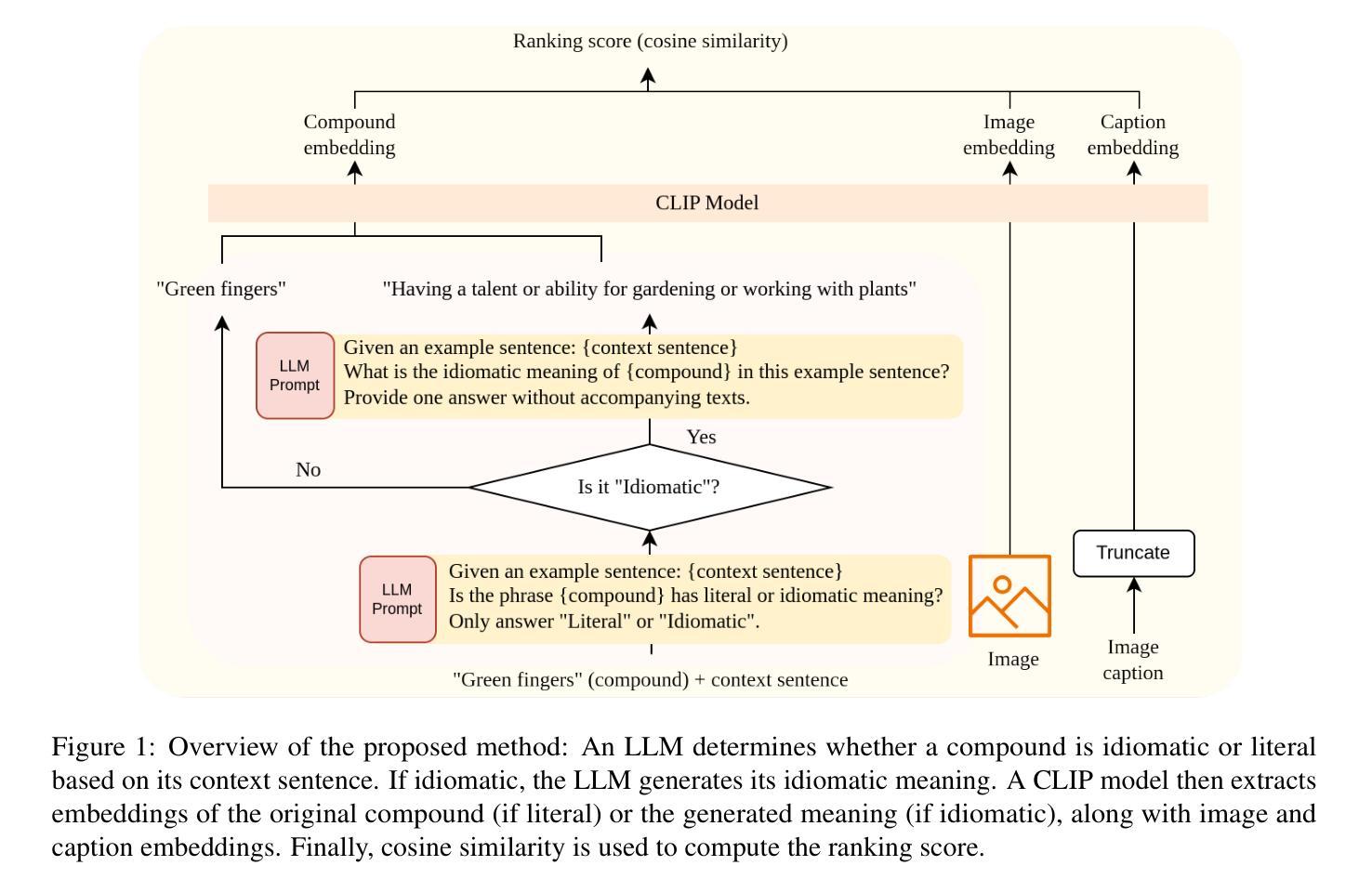
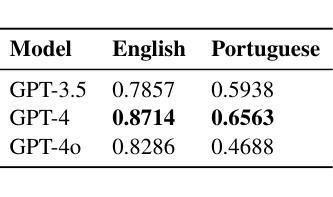
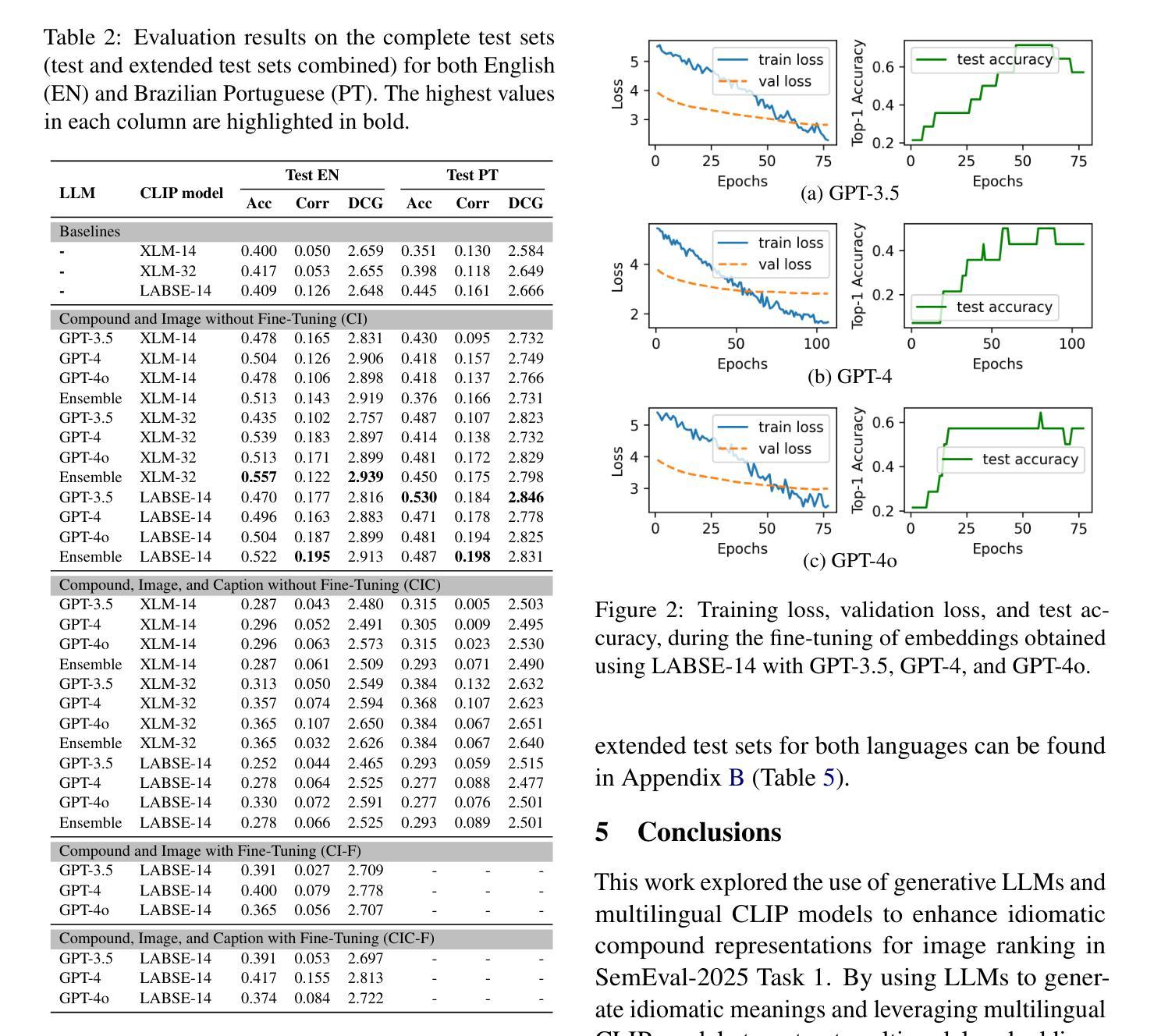
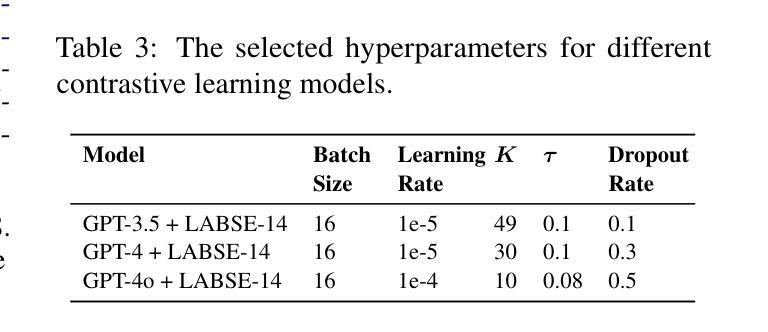
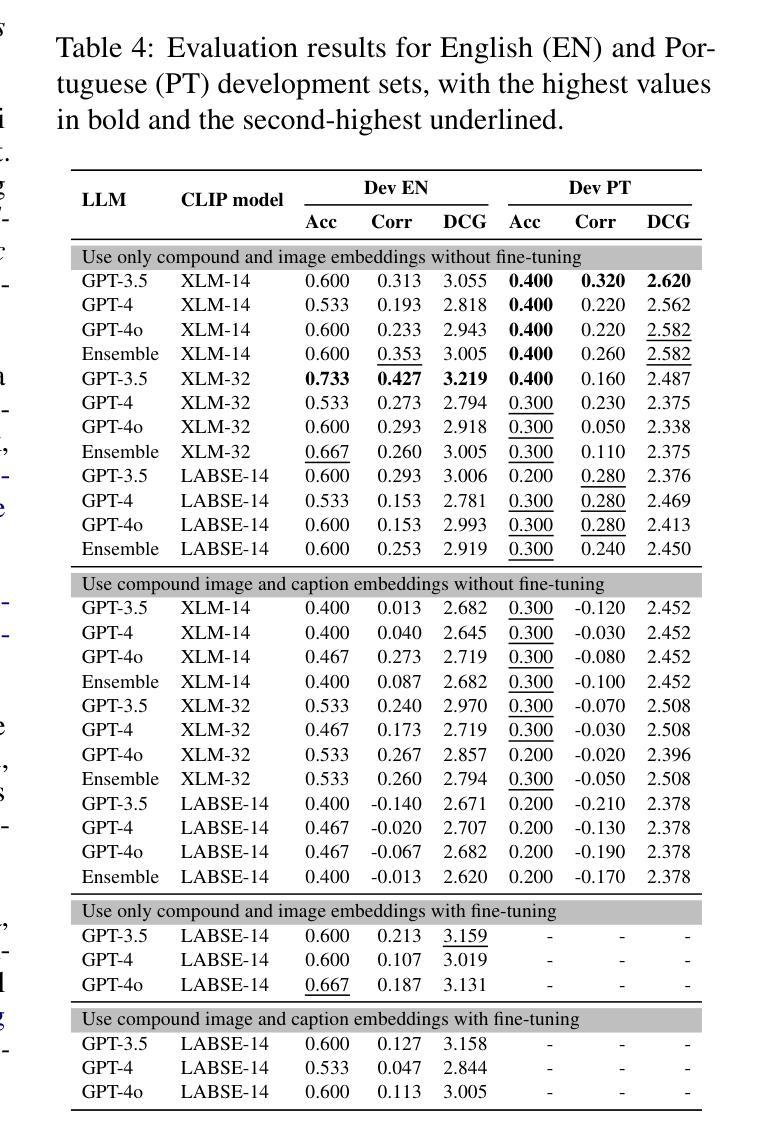
UoR-NCL at SemEval-2025 Task 1: Using Generative LLMs and CLIP Models for Multilingual Multimodal Idiomaticity Representation
Authors:Thanet Markchom, Tong Wu, Liting Huang, Huizhi Liang
SemEval-2025 Task 1 focuses on ranking images based on their alignment with a given nominal compound that may carry idiomatic meaning in both English and Brazilian Portuguese. To address this challenge, this work uses generative large language models (LLMs) and multilingual CLIP models to enhance idiomatic compound representations. LLMs generate idiomatic meanings for potentially idiomatic compounds, enriching their semantic interpretation. These meanings are then encoded using multilingual CLIP models, serving as representations for image ranking. Contrastive learning and data augmentation techniques are applied to fine-tune these embeddings for improved performance. Experimental results show that multimodal representations extracted through this method outperformed those based solely on the original nominal compounds. The fine-tuning approach shows promising outcomes but is less effective than using embeddings without fine-tuning. The source code used in this paper is available at https://github.com/tongwu17/SemEval-2025-Task1-UoR-NCL.
SemEval-2025 Task 1的重点是根据给定的具有英语和巴西葡萄牙语中习惯用法的复合名词来排列图像。为了应对这一挑战,这项工作使用生成式大型语言模型(LLM)和多语言CLIP模型,以增强习惯用法的复合名词表示。LLM为潜在的习惯用语复合词生成习惯用法意义,丰富了它们的语义解释。这些意义随后使用多语言CLIP模型进行编码,作为图像排序的表示。对比学习和数据增强技术被应用于微调这些嵌入,以提高性能。实验结果表明,通过这种方法提取的多模式表示优于仅基于原始名义复合词的表示。微调方法显示出有希望的成果,但不如不使用微调直接使用嵌入有效。本文使用的源代码可在https://github.com/tongwu17/SemEval-2025-Task1-UoR-NCL获得。
论文及项目相关链接
Summary
本文介绍了SemEval-2025任务1,该任务聚焦于根据含有英语和巴西葡萄牙语中习语含义的名词短语对图像进行排序。为解决这一挑战,该研究采用生成式大型语言模型(LLMs)和多语种CLIP模型,以增强习语短语的表现。LLMs为潜在习语生成含义,丰富了语义解释。随后使用多语种CLIP模型对这些含义进行编码,作为图像排序的代表。该研究还应用了对比学习和数据增强技术来微调这些嵌入,以提高性能。实验结果表明,通过该方法提取的多模式表示优于仅基于原始名词化合物的表示。微调方法显示出有希望的结果,但不如不使用微调的嵌入方法有效。本文使用的源代码可在链接找到。
Key Takeaways
- SemEval-2025 Task 1集中于根据含有习语含义的名词短语对图像进行排序。
- 研究使用生成式大型语言模型(LLMs)和多语种CLIP模型以增强习语表现。
- LLMs能够生成潜在习语的含义,丰富语义解释。
- 多语种CLIP模型用于编码这些含义,作为图像排序的代表。
- 对比学习和数据增强技术用于微调嵌入,以提高性能。
- 实验结果显示多模式表示方法优于仅基于原始名词化合物的表示。
点此查看论文截图

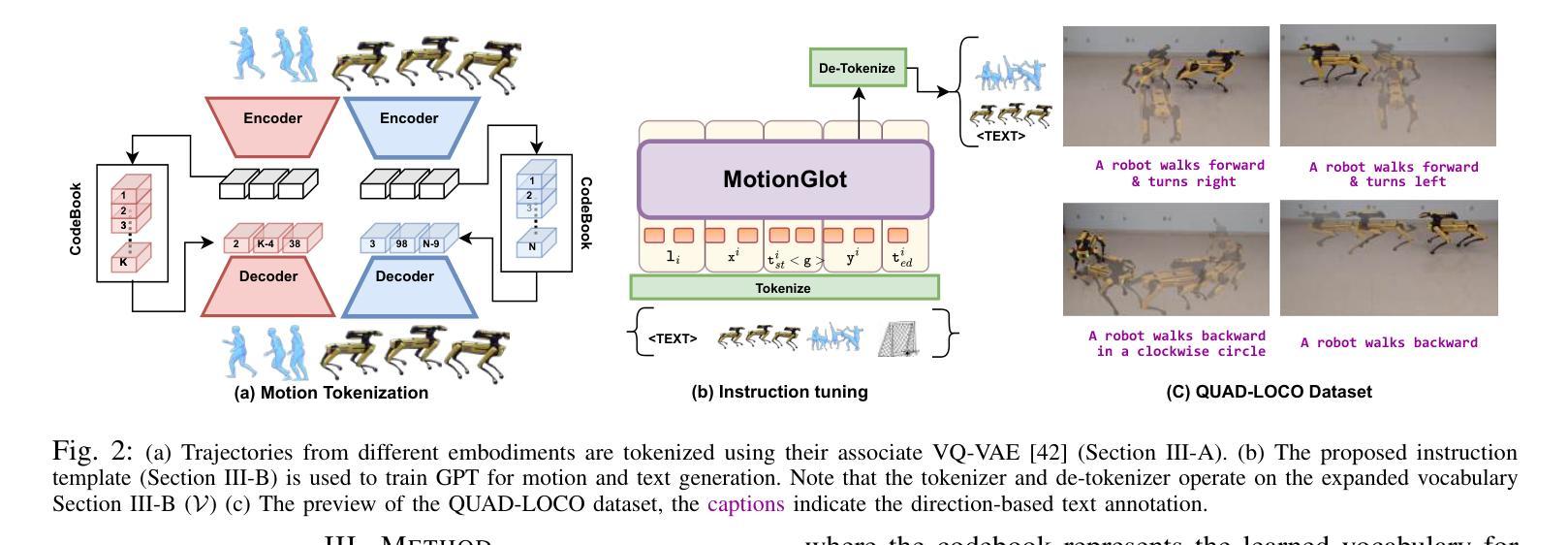
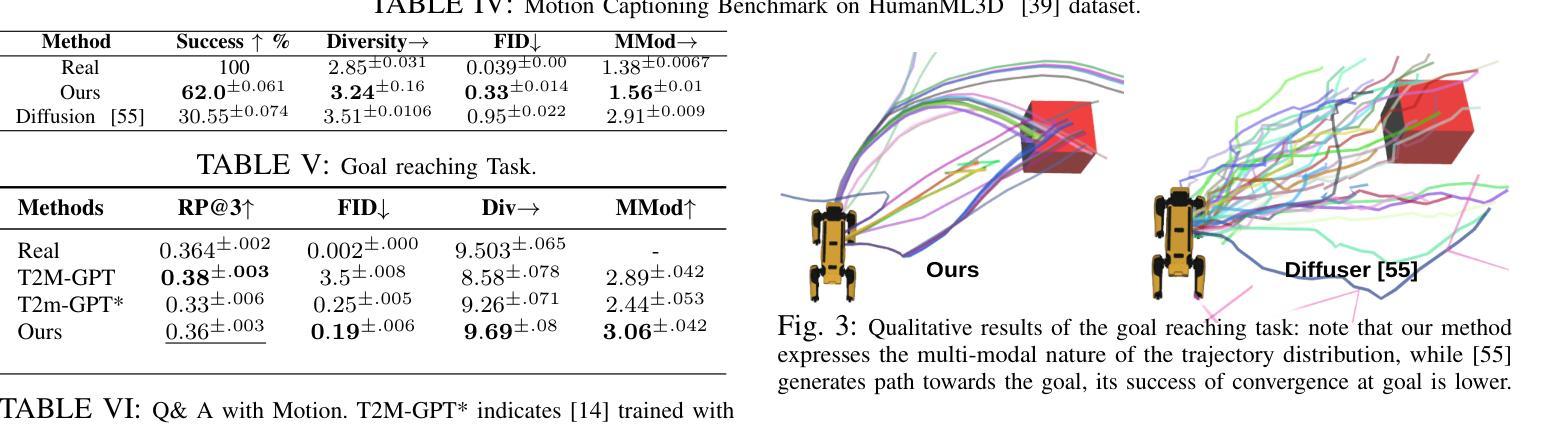
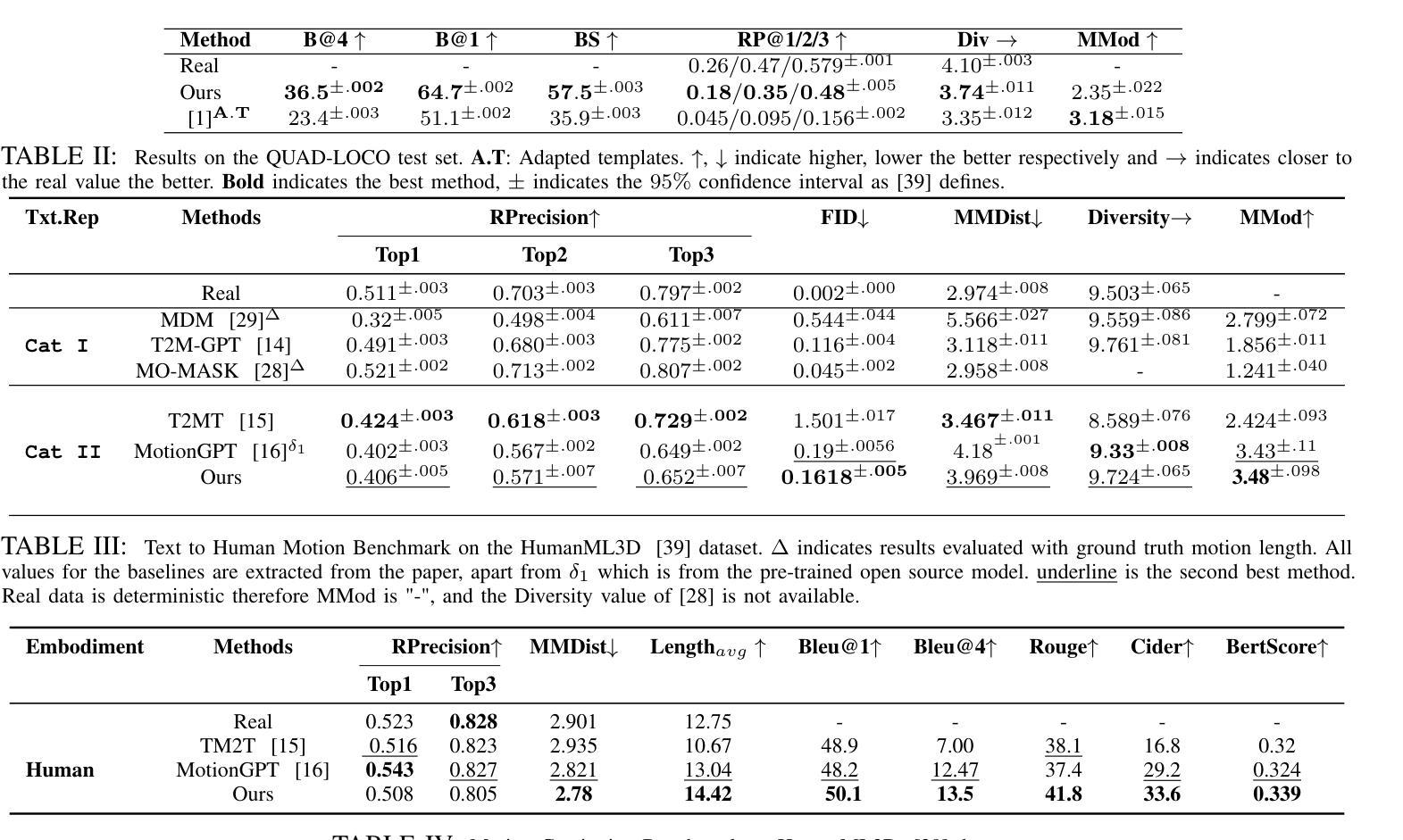
MotionGlot: A Multi-Embodied Motion Generation Model
Authors:Sudarshan Harithas, Srinath Sridhar
This paper introduces MotionGlot, a model that can generate motion across multiple embodiments with different action dimensions, such as quadruped robots and human bodies. By leveraging the well-established training procedures commonly used in large language models (LLMs), we introduce an instruction-tuning template specifically designed for motionrelated tasks. Our approach demonstrates that the principles underlying LLM training can be successfully adapted to learn a wide range of motion generation tasks across multiple embodiments with different action dimensions. We demonstrate the various abilities of MotionGlot on a set of 6 tasks and report an average improvement of 35.3% across tasks. Additionally, we contribute two new datasets: (1) a dataset of expert-controlled quadruped locomotion with approximately 48,000 trajectories paired with direction-based text annotations, and (2) a dataset of over 23,000 situational text prompts for human motion generation tasks. Finally, we conduct hardware experiments to validate the capabilities of our system in real-world applications.
本文介绍了MotionGlot模型,该模型能够在多种具有不同动作维度的载体上生成动作,如四足机器人和人体。通过借鉴大型语言模型(LLM)常用的训练流程,我们引入了专为运动相关任务设计的指令调整模板。我们的方法表明,LLM训练的基本原理可以成功适应不同载体和不同动作维度的广泛运动生成任务。我们在一组6个任务上展示了MotionGlot的各种功能,并报告了跨任务的平均改进率为35.3%。此外,我们还提供了两个新的数据集:(1)专家控制的四足运动数据集,包含大约48,000条带有方向性文本注释的轨迹;(2)包含超过23,000个情境文本提示的人类运动生成任务数据集。最后,我们通过硬件实验验证了我们的系统在现实世界应用中的能力。
论文及项目相关链接
Summary
MotionGlot模型可生成跨多种行动维度的不同实体的动作,如四足机器人和人体。该研究采用大型语言模型(LLM)的常见训练程序,并引入针对运动相关任务的指令调整模板。研究证明LLM训练原理可成功适应不同行动维度的多个实体的广泛运动生成任务。MotionGlot在6项任务上的平均改进率为35.3%。此外,研究还贡献了两个新数据集:包含约48000条与方向文本注释配对轨迹的专家控制四足行走数据集,以及包含超过23000条用于人体运动生成任务的情境文本提示数据集。最后,通过硬件实验验证了系统的现实应用能力。
Key Takeaways
- MotionGlot模型可以生成跨多种实体的动作,这些实体具有不同的行动维度,如四足机器人和人体。
- 该研究利用大型语言模型的训练程序,并引入指令调整模板,为运动相关任务提供定制解决方案。
- 研究证明了LLM训练原理可以成功适应多种运动生成任务,这些任务涉及不同行动维度的多个实体。
- MotionGlot在多个任务上的平均性能改进达到35.3%。
- 研究贡献了两个新数据集,包括专家控制的四足行走数据集和用于人体运动生成任务的情境文本提示数据集。
- 通过硬件实验验证了系统的现实应用能力。
点此查看论文截图


Reward-Augmented Data Enhances Direct Preference Alignment of LLMs
Authors:Shenao Zhang, Zhihan Liu, Boyi Liu, Yufeng Zhang, Yingxiang Yang, Yongfei Liu, Liyu Chen, Tao Sun, Zhaoran Wang
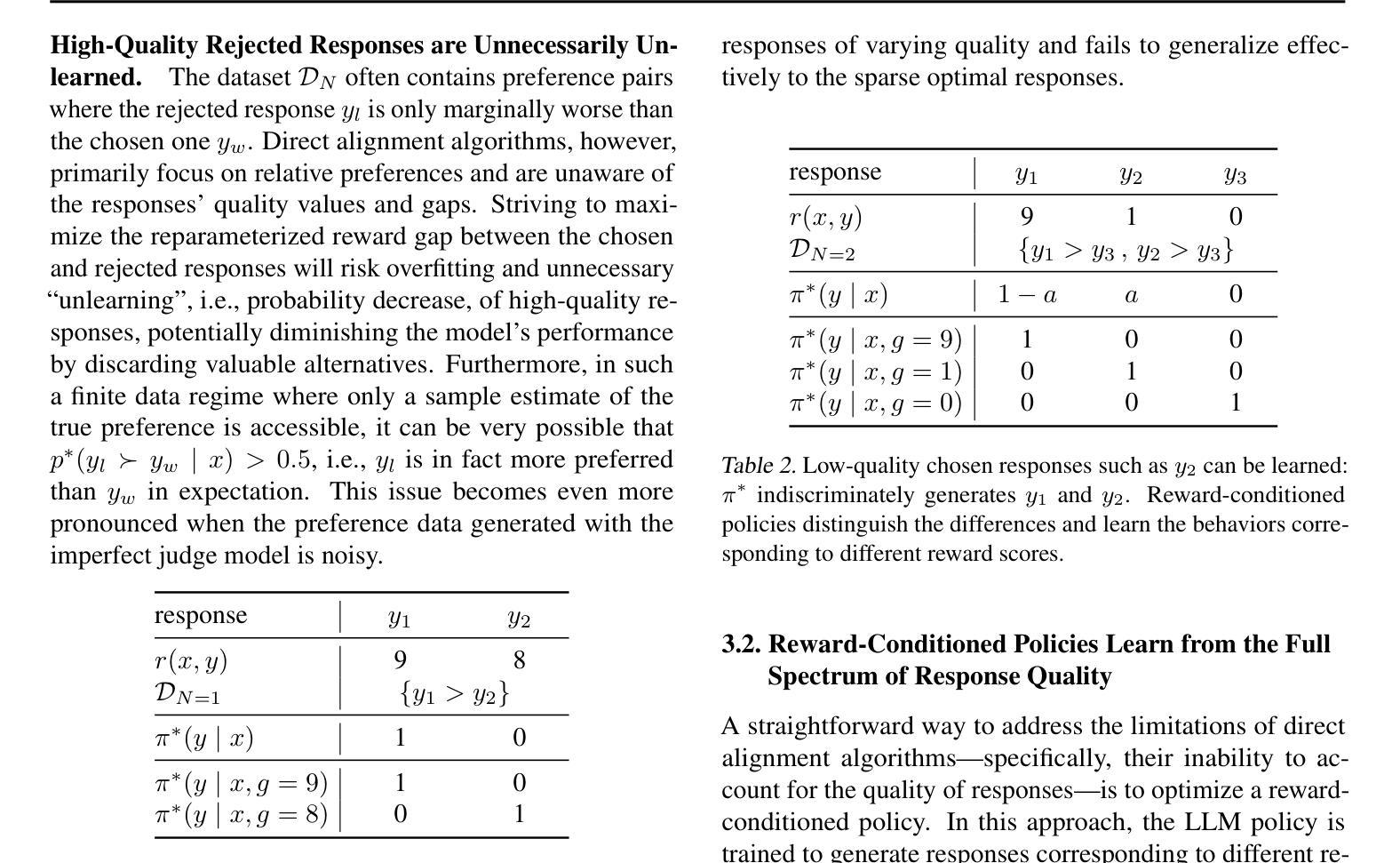
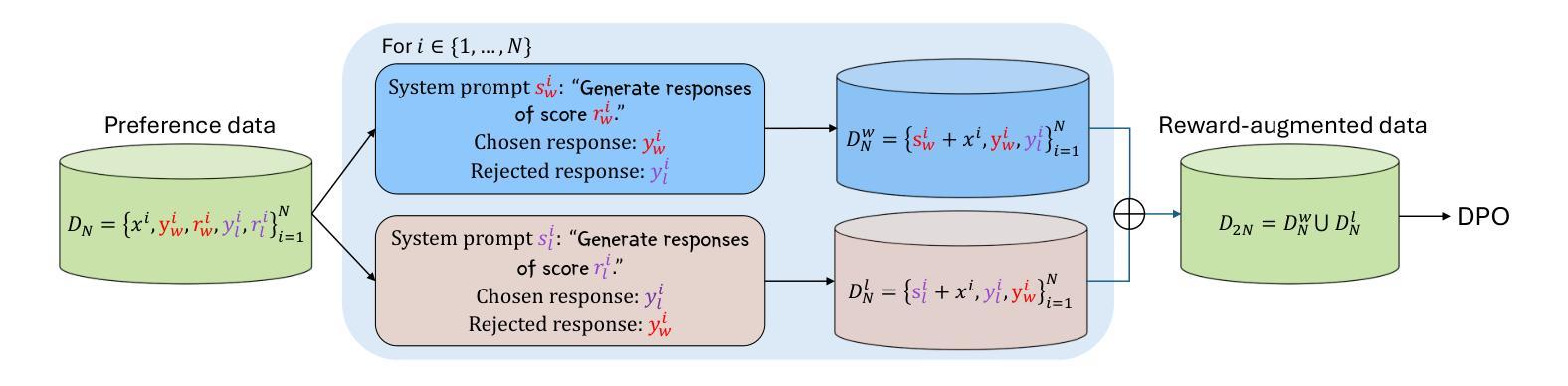
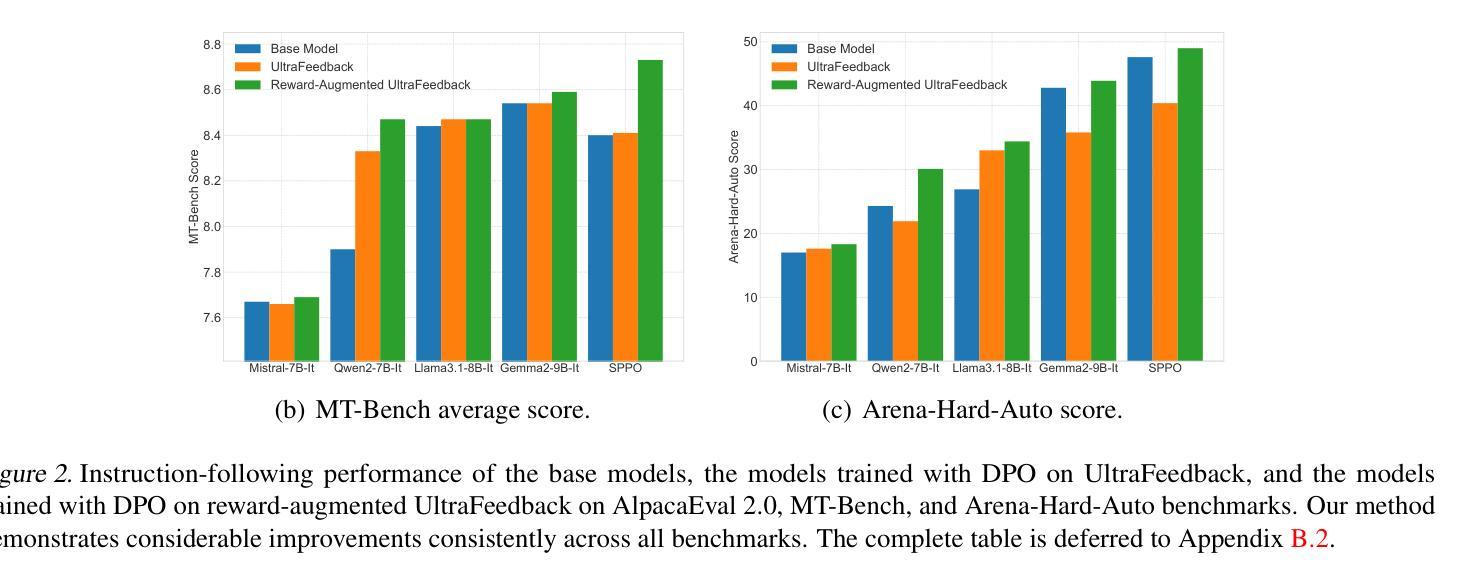
Preference alignment in Large Language Models (LLMs) has significantly improved their ability to adhere to human instructions and intentions. However, existing direct alignment algorithms primarily focus on relative preferences and often overlook the qualitative aspects of responses, despite having access to preference data that includes reward scores from judge models during AI feedback. Striving to maximize the implicit reward gap between the chosen and the slightly inferior rejected responses can cause overfitting and unnecessary unlearning of the high-quality rejected responses. The unawareness of the reward scores also drives the LLM to indiscriminately favor the low-quality chosen responses and fail to generalize to optimal responses that are sparse in data. To overcome these shortcomings, our study introduces reward-conditioned LLM policies that discern and learn from the entire spectrum of response quality within the dataset, helping extrapolate to more optimal regions. We propose an effective yet simple data relabeling method that conditions the preference pairs on quality scores to construct a reward-augmented dataset. The experiments across various benchmarks and diverse models demonstrate that our approach consistently boosts DPO by a considerable margin. Through comprehensive ablation studies, we demonstrate that our method not only maximizes the utility of preference data but also mitigates the issue of unlearning, demonstrating its broad effectiveness beyond mere data expansion. Our code is available at https://github.com/shenao-zhang/reward-augmented-preference.
偏好对齐在大语言模型(LLM)中的应用显著提高了它们遵循人类指令和意图的能力。然而,现有的直接对齐算法主要关注相对偏好,往往忽视响应的定性方面,尽管可以访问包含来自判断模型的奖励分数的AI反馈偏好数据。努力最大化所选和略为逊色的被拒绝响应之间的隐含奖励差距可能会导致过度拟合和不必要的对高质量被拒绝响应的遗忘。对奖励分数的无知也驱使LLM不加区别地偏爱低质量的选定响应,并无法推广到数据稀缺的最佳响应。为了克服这些缺点,我们的研究引入了奖励条件LLM策略,能够识别并从数据集内的整个响应质量谱中学习,有助于推断出更优化的区域。我们提出了一种有效而简单的数据重新标记方法,该方法根据质量分数对偏好对进行条件处理,以构建奖励增强数据集。在不同基准测试和多种模型上的实验表明,我们的方法始终如一地大幅提高了DPO。通过全面的消融研究,我们证明了我们的方法不仅最大限度地利用了偏好数据,而且缓解了遗忘问题,证明了其在单纯的数据扩展之外的广泛有效性。我们的代码可在https://github.com/shenao-zhang/reward-augmented-preference找到。
论文及项目相关链接
PDF Published at ICML 2025
Summary
大型语言模型(LLM)的偏好对齐显著提高了其遵循人类指令和意图的能力。然而,现有的直接对齐算法主要关注相对偏好,忽视响应的定性方面,尽管在AI反馈期间可以访问包含判断模型奖励分数的偏好数据。努力最大化所选和略为逊色的拒绝响应之间的隐性奖励差距可能导致过度拟合和不必要的对高质量拒绝响应的遗忘。忽视奖励分数还导致LLM不加区别地偏爱低质量的选定响应,并且无法概括数据稀缺的最佳响应。为了克服这些缺点,我们的研究引入了以奖励为条件的LLM策略,能够辨别并学习数据集内响应质量的全谱,有助于推断出更优化的区域。我们提出了一种有效而简单的数据重新标记方法,根据质量分数对偏好对进行条件处理,以构建奖励增强数据集。在不同基准测试和模型的实验表明,我们的方法持续且大幅提升了DPO。通过全面的消除研究,我们证明了我们的方法不仅最大限度地利用了偏好数据,还缓解了遗忘问题,这证明了其广泛的实用性超越了单纯的数据扩展。
Key Takeaways
- 偏好对齐在大型语言模型(LLM)中显著提高了遵循人类指令和意图的能力。
- 现有直接对齐算法主要关注相对偏好,但忽视响应的定性方面。
- 过度追求隐性奖励差距可能导致过度拟合和对高质量拒绝响应的遗忘。
- 忽视奖励分数会导致LLM不加区别地偏爱低质量响应,且无法概括最佳响应。
- 研究引入了奖励增强的大型语言模型策略,能学习响应质量的全谱并推断出更优化的区域。
- 提出了一种有效且简单的数据重新标记方法,构建了奖励增强数据集。
点此查看论文截图

Automated Review Generation Method Based on Large Language Models
Authors:Shican Wu, Xiao Ma, Dehui Luo, Lulu Li, Xiangcheng Shi, Xin Chang, Xiaoyun Lin, Ran Luo, Chunlei Pei, Changying Du, Zhi-Jian Zhao, Jinlong Gong
Literature research, vital for scientific work, faces the challenge of surging information volumes exceeding researchers’ processing capabilities. We present an automated review generation method based on large language models (LLMs) to overcome efficiency bottlenecks and reduce cognitive load. Our statistically validated evaluation framework demonstrates that the generated reviews match or exceed manual quality, offering broad applicability across research fields without requiring users’ domain knowledge. Applied to propane dehydrogenation (PDH) catalysts, our method swiftly analyzed 343 articles, averaging seconds per article per LLM account, producing comprehensive reviews spanning 35 topics, with extended analysis of 1041 articles providing insights into catalysts’ properties. Through multi-layered quality control, we effectively mitigated LLMs’ hallucinations, with expert verification confirming accuracy and citation integrity while demonstrating hallucination risks reduced to below 0.5% with 95% confidence. Released Windows application enables one-click review generation, enhancing research productivity and literature recommendation efficiency while setting the stage for broader scientific explorations.
文献研究对于科学工作至关重要,但随着信息量的激增,研究者面临处理信息的能力瓶颈挑战。我们提出了一种基于大型语言模型(LLM)的自动摘要生成方法,以提高效率,减轻认知负担。我们的统计验证评估框架显示,生成的摘要与人工摘要质量相当甚至更好,且广泛应用于各个领域,无需用户具备专业知识。在丙烷脱氢(PDH)催化剂的应用中,我们的方法迅速分析了343篇文章,平均每篇文章每个LLM账户只需几秒钟,生成了涵盖35个主题的全面摘要。通过对1041篇文章进行深入分析,为催化剂的性能提供了见解。通过多层次的质量控制,我们有效缓解了LLM的幻觉问题。专家验证确认了我们系统的准确性和引用完整性,同时表明幻觉风险已降低到低于0.5%,并具有95%的信心。发布的Windows应用程序可实现一键生成摘要,提高研究生产力和文献推荐效率,为更广泛的科学探索奠定了基础。
论文及项目相关链接
PDF Code: https://github.com/TJU-ECAT-AI/AutomaticReviewGeneration Data: https://github.com/TJU-ECAT-AI/AutomaticReviewGenerationData This research has been invited for a Short Oral presentation at the 18th ICC - International Congress on Catalysis, taking place in Lyon, France from July 14-19, 2024 Published at https://doi.org/10.1093/nsr/nwaf169 for newer edition
Summary
基于文献信息爆炸式增长所带来的挑战,研究者提出了一种基于大型语言模型(LLM)的自动化摘要生成方法,旨在提高研究效率并降低认知负荷。该方法在丙烷脱氢(PDH)催化剂研究中的应用,展示了其在快速分析大量文献中的效率和准确性。该方法能有效降低LLM产生的幻觉风险,同时提供专家验证确认其准确性和引文完整性。该方法的推广使用有望提高研究生产力和文献推荐效率。
Key Takeaways
- 大型语言模型(LLM)用于自动化摘要生成,解决文献信息量大带来的挑战。
- 该方法在丙烷脱氢催化剂研究中的应用展示了其高效性和准确性。
- 通过多层质量控制有效降低了LLM产生的幻觉风险。
- 专家验证确认了该方法的准确性和引文完整性。
- 该方法提高了研究生产力和文献推荐效率。
- 该方法具有广泛的应用性,适用于不同研究领域,无需用户具备特定领域知识。
点此查看论文截图

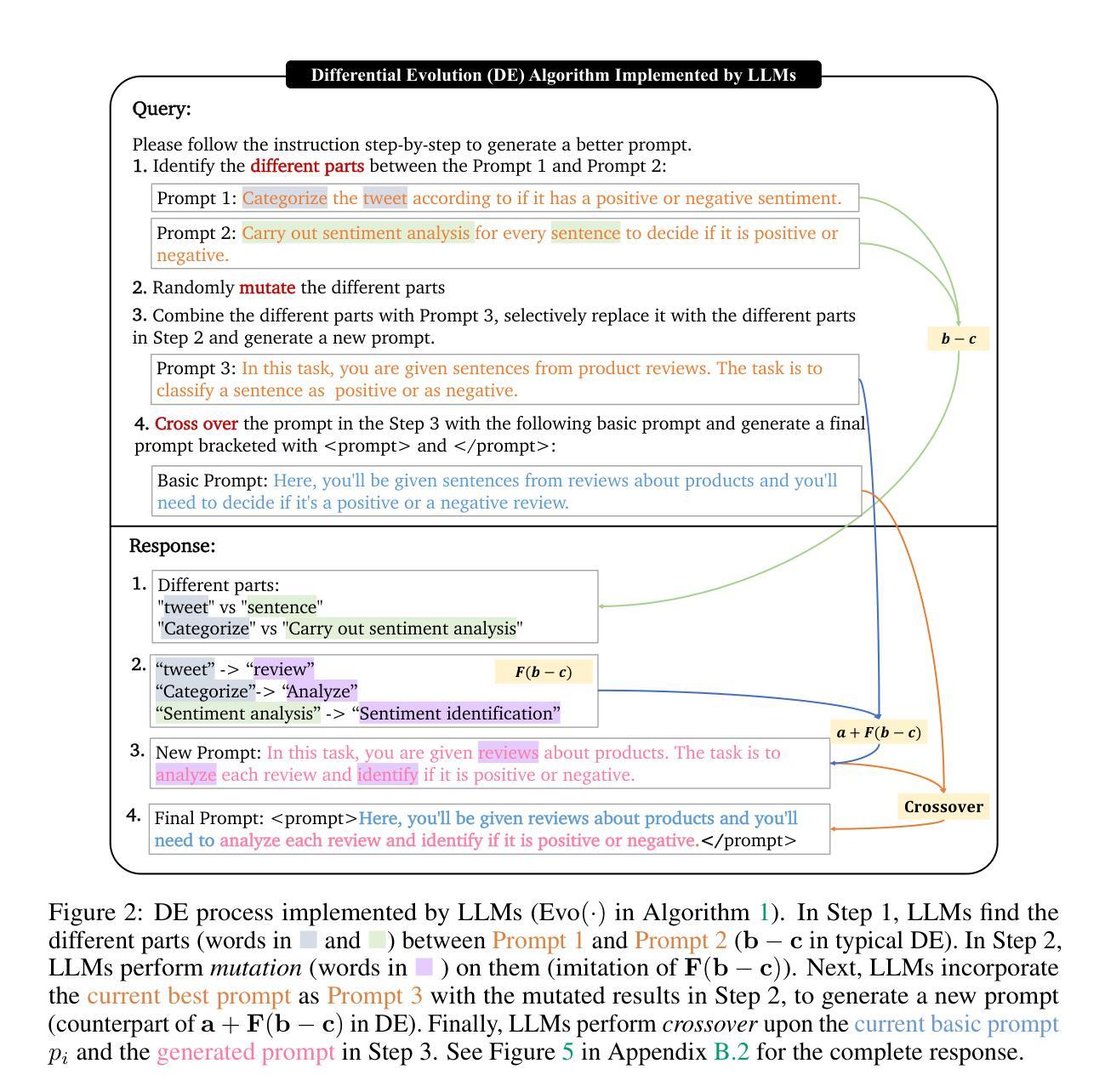
EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Authors:Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, Yujiu Yang
Large Language Models (LLMs) excel in various tasks, but they rely on carefully crafted prompts that often demand substantial human effort. To automate this process, in this paper, we propose a novel framework for discrete prompt optimization, called EvoPrompt, which borrows the idea of evolutionary algorithms (EAs) as they exhibit good performance and fast convergence. To enable EAs to work on discrete prompts, which are natural language expressions that need to be coherent and human-readable, we connect LLMs with EAs. This approach allows us to simultaneously leverage the powerful language processing capabilities of LLMs and the efficient optimization performance of EAs. Specifically, abstaining from any gradients or parameters, EvoPrompt starts from a population of prompts and iteratively generates new prompts with LLMs based on the evolutionary operators, improving the population based on the development set. We optimize prompts for both closed- and open-source LLMs including GPT-3.5 and Alpaca, on 31 datasets covering language understanding, generation tasks, as well as BIG-Bench Hard (BBH) tasks. EvoPrompt significantly outperforms human-engineered prompts and existing methods for automatic prompt generation (e.g., up to 25% on BBH). Furthermore, EvoPrompt demonstrates that connecting LLMs with EAs creates synergies, which could inspire further research on the combination of LLMs and conventional algorithms.
大型语言模型(LLM)在各种任务中表现出色,但它们依赖于精心设计的提示,通常需要大量的人工努力。为了自动化这个过程,本文提出了一种用于离散提示优化的新型框架,名为EvoPrompt,它借鉴了进化算法(EA)的思想,因为进化算法具有良好的性能和快速的收敛速度。为了使EA能够在离散提示上工作,这些离散提示是自然语言表达式,需要连贯且人类可读,我们将LLM与EA连接起来。这种方法使我们能够同时利用LLM的强大语言处理能力和EA的高效优化性能。具体来说,EvoPrompt不涉及任何梯度或参数,它从提示种群开始,基于进化算子使用LLM迭代生成新的提示,根据开发集改进种群。我们对封闭和开源的LLM进行了提示优化,包括GPT-3.5和Alpaca,在涵盖语言理解、生成任务以及BIG-Bench Hard(BBH)任务的31个数据集上进行优化。EvoPrompt显著优于人工设计的提示和现有的自动提示生成方法(例如在BBH上高达25%)。此外,EvoPrompt证明将LLM与EA连接会产生协同效应,这可能激发关于LLM和常规算法组合进一步研究。
论文及项目相关链接
PDF International Conference on Learning Representations (ICLR) 2024
Summary
大型语言模型(LLM)在各种任务中表现出色,但它们依赖于精心设计的提示,这需要大量人力。本文提出了一种用于离散提示优化的新型框架EvoPrompt,它借鉴了进化算法(EA)的思想,具有良好的性能和快速的收敛速度。通过将LLM与EA相结合,EvoPrompt能够同时利用LLM的强大语言处理能力和EA的高效优化性能。EvoPrompt在多个数据集上优化了闭源和开源LLM的提示,包括GPT-3.5和Alpaca等,涵盖了语言理解、生成任务以及BIG-Bench Hard(BBH)任务。相较于人工设计的提示和现有的自动提示生成方法,EvoPrompt表现出显著的优势(在BBH任务上提升了高达25%)。此外,EvoPrompt展示了连接LLM与EA的协同作用潜力,为未来研究结合LLM和常规算法提供了启示。
Key Takeaways
- 大型语言模型(LLM)依赖精心设计的人工提示。
- EvoPrompt是一种利用进化算法思想进行离散提示优化的新型框架。
- EvoPrompt结合了LLM的强大语言处理能力与进化算法的高效优化性能。
- EvoPrompt优化了包括GPT-3.5和Alpaca在内的多种LLM的提示。
- EvoPrompt在多种任务上表现优于人工设计的提示和其他自动提示生成方法。
- EvoPrompt显著提升了在BIG-Bench Hard(BBH)任务上的性能(提升了高达25%)。
点此查看论文截图