⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-03 更新
KeySync: A Robust Approach for Leakage-free Lip Synchronization in High Resolution
Authors:Antoni Bigata, Rodrigo Mira, Stella Bounareli, Michał Stypułkowski, Konstantinos Vougioukas, Stavros Petridis, Maja Pantic
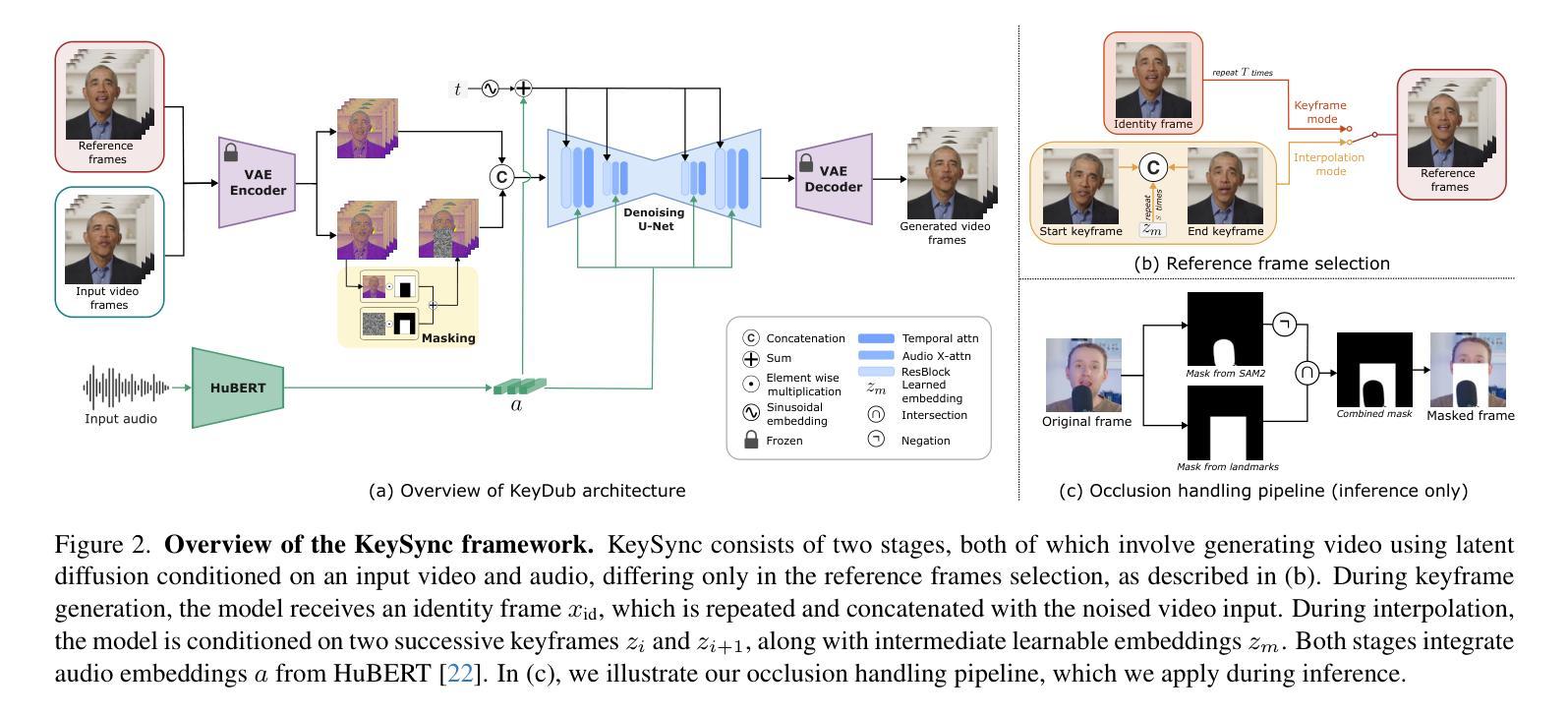
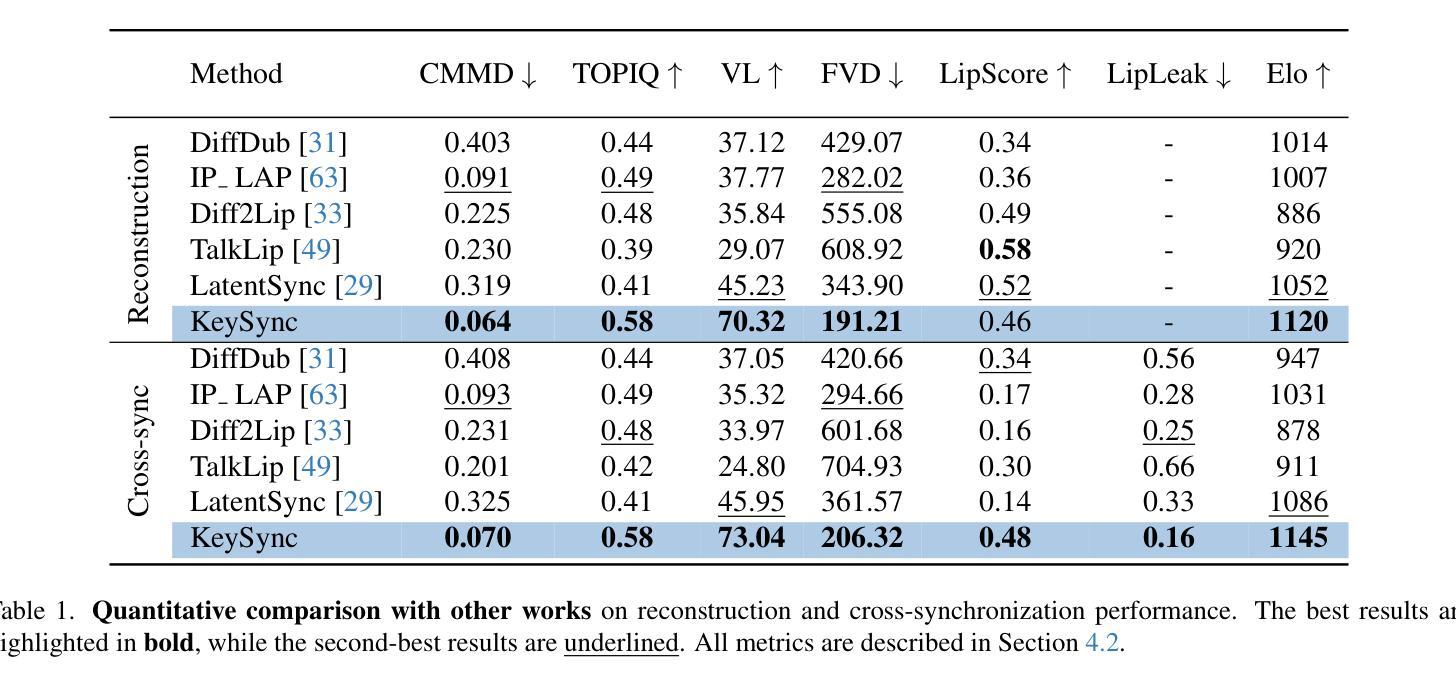
Lip synchronization, known as the task of aligning lip movements in an existing video with new input audio, is typically framed as a simpler variant of audio-driven facial animation. However, as well as suffering from the usual issues in talking head generation (e.g., temporal consistency), lip synchronization presents significant new challenges such as expression leakage from the input video and facial occlusions, which can severely impact real-world applications like automated dubbing, but are often neglected in existing works. To address these shortcomings, we present KeySync, a two-stage framework that succeeds in solving the issue of temporal consistency, while also incorporating solutions for leakage and occlusions using a carefully designed masking strategy. We show that KeySync achieves state-of-the-art results in lip reconstruction and cross-synchronization, improving visual quality and reducing expression leakage according to LipLeak, our novel leakage metric. Furthermore, we demonstrate the effectiveness of our new masking approach in handling occlusions and validate our architectural choices through several ablation studies. Code and model weights can be found at https://antonibigata.github.io/KeySync.
唇同步,也称为将现有视频中的唇部动作与新输入的音频对齐的任务,通常被构建为音频驱动的面部动画的简化版本。然而,除了遭受说话人头部生成中的常见问题(如时间一致性)之外,唇同步还面临着一些重要的新挑战,如输入视频中的表情泄露和面部遮挡等。这些问题会严重影响自动化配音等实际应用,但在现有工作中往往被忽视。为了解决这些不足,我们提出了KeySync,这是一个两阶段的框架,成功地解决了时间一致性的问题,同时采用精心设计的掩模策略解决了泄漏和遮挡问题。我们表明,KeySync在唇部重建和跨同步方面达到了最新水平,根据我们新型泄漏指标LipLeak,提高了视觉质量并减少了表达泄漏。此外,我们通过几项消融研究验证了处理遮挡的新掩模方法的有效性,并验证了我们的架构选择。代码和模型权重可在https://antonibigata.github.io/KeySync找到。
论文及项目相关链接
Summary
文本描述了同步说话头部的问题及其解决方案。文本同步通常被看作音频驱动面部动画的一个简单变体,但在现实应用中如自动化配音存在表达泄露和面部遮挡等严重问题。提出一种名为KeySync的两阶段框架,可以解决时间一致性问题,并通过精心设计的方法处理泄露和遮挡问题。实验表明,KeySync在唇部重建和跨同步方面取得了最新结果,并改进了视觉质量并减少了泄露。同时验证了新掩码处理遮挡的有效性。代码和模型权重可在网上找到。
Key Takeaways
- 文本同步是音频驱动面部动画的简化变体,面临时间一致性问题以及表达泄露和面部遮挡的挑战。
- KeySync框架成功解决时间一致性问题,并通过特定策略处理泄露和遮挡问题。
- KeySync通过精心设计的方法提高唇部重建的精度和跨同步效果。
- KeySync改进了视觉质量并减少了泄露,这一成果通过新设计的泄露度量指标得到验证。
- KeySync能有效处理面部遮挡问题,通过新掩码方法实现。
- 通过消融研究验证了KeySync架构选择的合理性。
点此查看论文截图