⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-06 更新
VIDSTAMP: A Temporally-Aware Watermark for Ownership and Integrity in Video Diffusion Models
Authors:Mohammadreza Teymoorianfard, Shiqing Ma, Amir Houmansadr
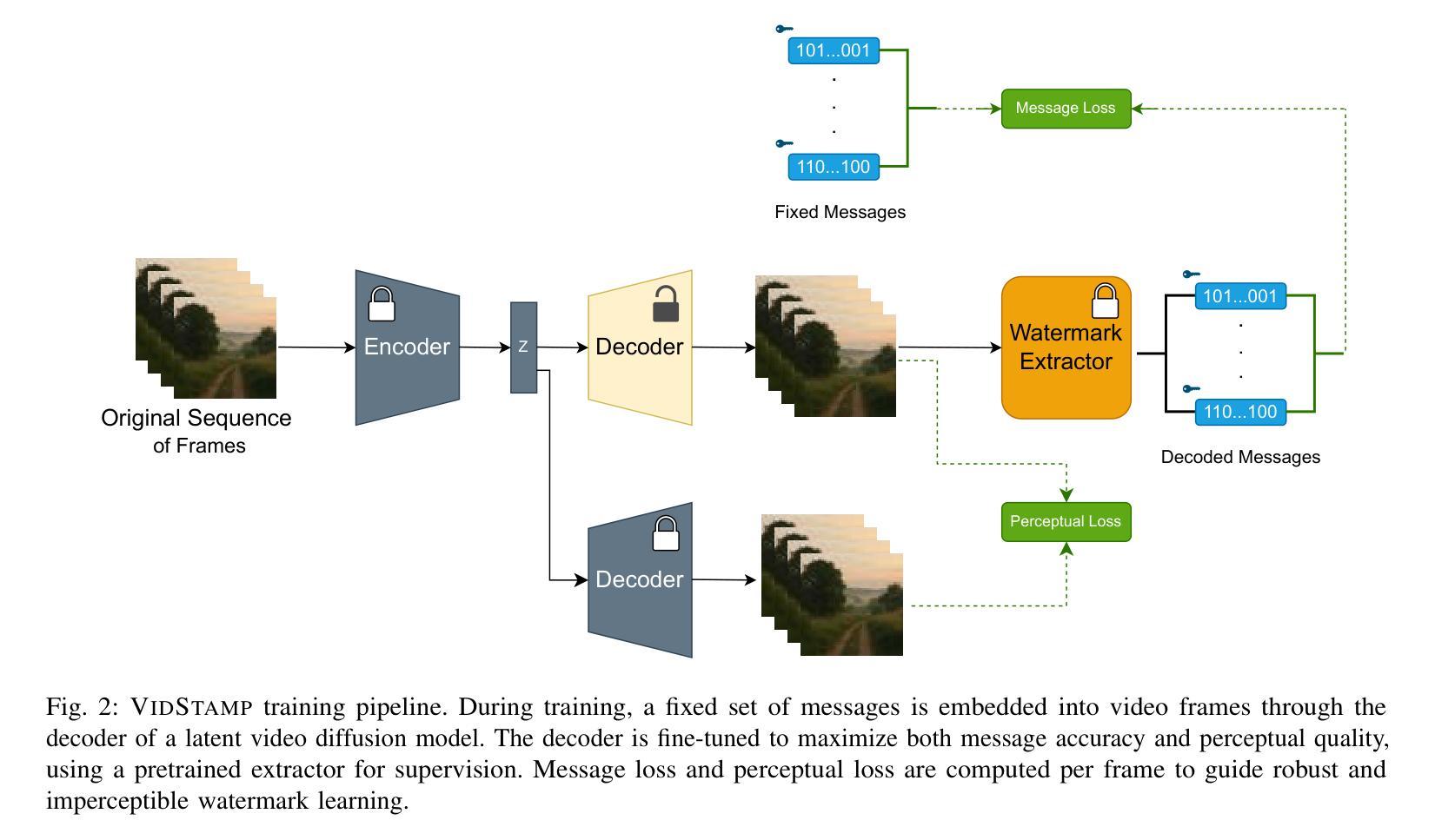
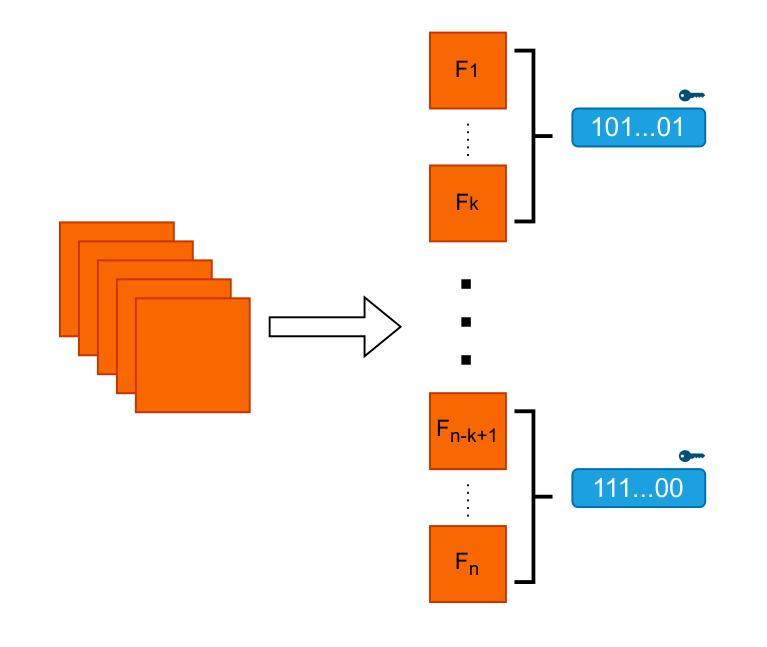
The rapid rise of video diffusion models has enabled the generation of highly realistic and temporally coherent videos, raising critical concerns about content authenticity, provenance, and misuse. Existing watermarking approaches, whether passive, post-hoc, or adapted from image-based techniques, often struggle to withstand video-specific manipulations such as frame insertion, dropping, or reordering, and typically degrade visual quality. In this work, we introduce VIDSTAMP, a watermarking framework that embeds per-frame or per-segment messages directly into the latent space of temporally-aware video diffusion models. By fine-tuning the model’s decoder through a two-stage pipeline, first on static image datasets to promote spatial message separation, and then on synthesized video sequences to restore temporal consistency, VIDSTAMP learns to embed high-capacity, flexible watermarks with minimal perceptual impact. Leveraging architectural components such as 3D convolutions and temporal attention, our method imposes no additional inference cost and offers better perceptual quality than prior methods, while maintaining comparable robustness against common distortions and tampering. VIDSTAMP embeds 768 bits per video (48 bits per frame) with a bit accuracy of 95.0%, achieves a log P-value of -166.65 (lower is better), and maintains a video quality score of 0.836, comparable to unwatermarked outputs (0.838) and surpassing prior methods in capacity-quality tradeoffs. Code: Code: \url{https://github.com/SPIN-UMass/VidStamp}
视频扩散模型的迅速崛起能够生成高度逼真和时序连贯的视频,这引发了人们对内容真实性、来源和误用的严重关注。现有的水印方法,无论是被动的、后处理的,还是从图像技术中改编的,通常都难以抵御针对视频的具体操作,如插入帧、删除帧或重新排序帧,并且通常会降低视觉质量。在这项工作中,我们引入了VIDSTAMP,这是一种水印框架,它将每帧或每段信息直接嵌入到具有时间感知的视频扩散模型的潜在空间中。通过两阶段管道对模型的解码器进行微调,首先是在静态图像数据集上促进空间消息分离,然后是在合成的视频序列上恢复时间一致性,VIDSTAMP学会了嵌入大容量、灵活的水印,同时最小化感知影响。利用3D卷积和时间注意力等组件,我们的方法不增加任何推理成本,并且比先前的方法提供更好的感知质量,同时保持对常见失真和篡改的相当稳健性。VIDSTAMP每个视频嵌入768位(每帧48位),位准确性为95.0%,对数P值为-166.65(越低越好),并且保持视频质量分数为0.836,与未加水印的输出(0.838)相当,并在容量与质量权衡方面超越了先前的方法。代码:\url{https://github.com/SPIN-UMass/VidStamp}。
论文及项目相关链接
摘要
视频扩散模型的迅速崛起可实现高度逼真且时间连贯的视频生成,引发了人们对内容真实性、来源和误用的关注。现有水印方法难以抵御视频特定操作如插帧、删帧或重新排序等,并且往往会降低视觉质量。本文介绍VIDSTAMP,一种嵌入视频扩散模型潜在空间的水印框架,该框架可直接在逐帧或逐段中嵌入信息。通过两阶段管道微调模型解码器,首先在静态图像数据集上促进空间信息分离,然后在合成视频序列上恢复时间连贯性,VIDSTAMP学会嵌入高容量、灵活的水印,对感知影响最小。利用三维卷积和时间注意力等架构组件,该方法不增加推理成本,感知质量优于先前方法,同时保持对常见失真和篡改的稳健性。VIDSTAMP嵌入每视频768位(每帧48位),位精度为95.0%,对数P值为-166.65(越低越好),并保持视频质量得分0.836,与未加水印的输出(0.838)相当,并且在容量与质量权衡方面优于先前方法。
关键见解
- 视频扩散模型的快速发展导致了对内容真实性、来源和误用的关注增加。
- 现有水印方法难以抵御视频特定操作,且会降低视觉质量。
- VIDSTAMP是一种新型水印框架,直接嵌入视频扩散模型的潜在空间。
- 通过两阶段微调解码器,VIDSTAMP能够在保持时间连贯性的同时嵌入高容量水印。
- 利用三维卷积和时间注意力机制,VIDSTAMP提高了水印的嵌入效率和视频质量。
- VIDSTAMP方法不增加推理成本,感知质量优于先前方法,且保持了良好的鲁棒性。
- VIDSTAMP实现了高容量的水印嵌入,同时保持了视频质量,并在容量与质量之间达到了较好的权衡。
点此查看论文截图


Where’s the liability in the Generative Era? Recovery-based Black-Box Detection of AI-Generated Content
Authors:Haoyue Bai, Yiyou Sun, Wei Cheng, Haifeng Chen
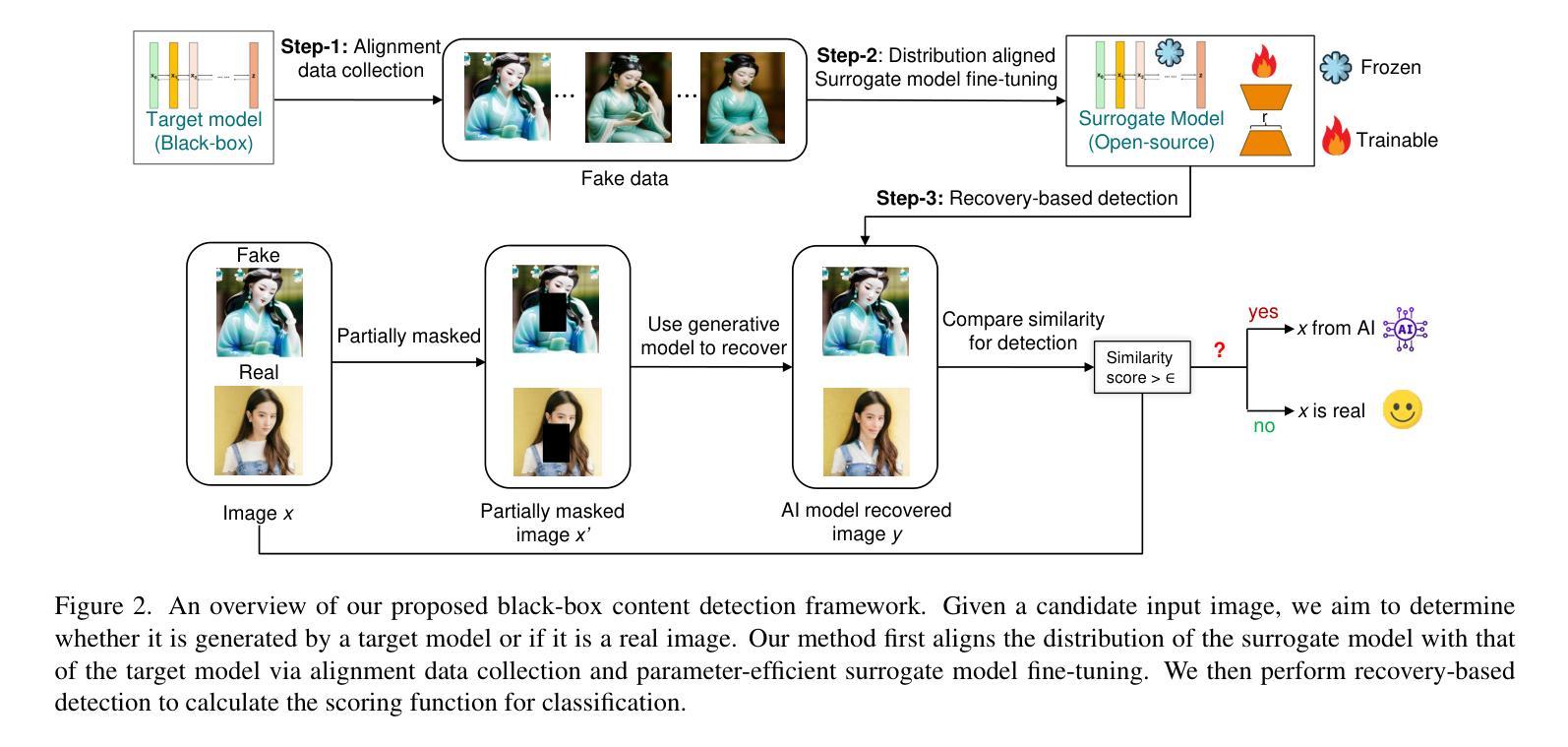
The recent proliferation of photorealistic images created by generative models has sparked both excitement and concern, as these images are increasingly indistinguishable from real ones to the human eye. While offering new creative and commercial possibilities, the potential for misuse, such as in misinformation and fraud, highlights the need for effective detection methods. Current detection approaches often rely on access to model weights or require extensive collections of real image datasets, limiting their scalability and practical application in real world scenarios. In this work, we introduce a novel black box detection framework that requires only API access, sidestepping the need for model weights or large auxiliary datasets. Our approach leverages a corrupt and recover strategy: by masking part of an image and assessing the model ability to reconstruct it, we measure the likelihood that the image was generated by the model itself. For black-box models that do not support masked image inputs, we incorporate a cost efficient surrogate model trained to align with the target model distribution, enhancing detection capability. Our framework demonstrates strong performance, outperforming baseline methods by 4.31% in mean average precision across eight diffusion model variant datasets.
最近由生成模型创造的逼真的图像大量涌现,引发了人们的兴奋和担忧。因为这些图像与人类眼睛所见的真实图像越来越难以区分。这些生成模型在提供新的创意和商业可能性的同时,误用这些模型所带来的潜在风险(如虚假信息和欺诈)也凸显了有效检测方法的必要性。当前大多数检测方法是依赖于模型权重访问或使用大量真实图像数据集,这限制了其在现实世界场景中的可扩展性和实际应用。在这项研究中,我们引入了一种新型的黑盒检测框架,只需API访问权限即可使用,无需依赖模型权重或大型辅助数据集。我们的方法采用了一种损坏和恢复策略:通过掩盖图像的一部分并评估模型重建它的能力,我们可以测量图像本身由模型生成的可能性。对于不支持掩码图像输入的黑盒模型,我们采用了一个成本效益高的替代模型进行训练并与目标模型分布对齐,从而提高检测能力。我们的框架表现出强大的性能,在八个扩散模型变体数据集上平均精度均值比基线方法高出4.31%。
论文及项目相关链接
PDF CVPR 2025
Summary
本文介绍了一种新型的黑盒检测框架,该框架仅需要API访问,无需模型权重或大型辅助数据集,便能检测出图像是否由生成模型生成,从而提高对抗虚假信息和欺诈等误用的能力。通过采用掩盖部分图像并评估模型重建能力的方法,该框架能有效衡量图像生成的可能性。对于不支持掩盖图像输入的黑盒模型,则引入成本效益高的代理模型进行训练,以与目标模型分布对齐,从而提升检测能力。该框架在八个扩散模型变体数据集上的平均精度高于基线方法4.31%。
Key Takeaways
- 生成模型的普及导致虚假图像的出现,对人类视觉难以区分,对创意和商业带来机会同时也存在潜在误用风险。
- 当前检测生成图像的方法存在局限性,通常需要模型权重或大量真实图像数据集,难以广泛应用。
- 引入新型黑盒检测框架,只需API访问即可进行检测,避免了依赖模型权重或大型辅助数据集的需要。
- 该框架利用掩盖并重建策略检测图像是否由模型生成。通过衡量模型重建被掩盖部分的能力评估图像生成可能性。
- 针对不支持掩盖图像输入的黑盒模型,使用成本效益高的代理模型训练来提升检测能力。
- 该框架在不同扩散模型数据集上实现了高检测精度,相对于基线方法提升平均精度达4.31%。
点此查看论文截图

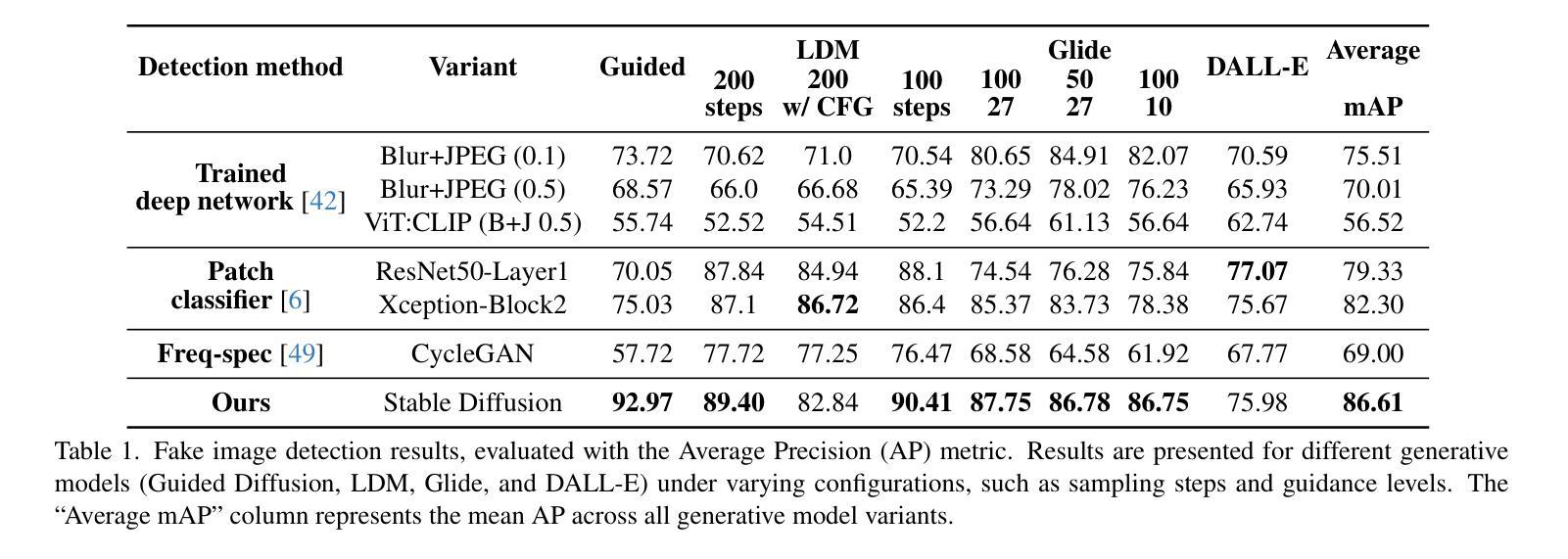
RestoreGrad: Signal Restoration Using Conditional Denoising Diffusion Models with Jointly Learned Prior
Authors:Ching-Hua Lee, Chouchang Yang, Jaejin Cho, Yashas Malur Saidutta, Rakshith Sharma Srinivasa, Yilin Shen, Hongxia Jin
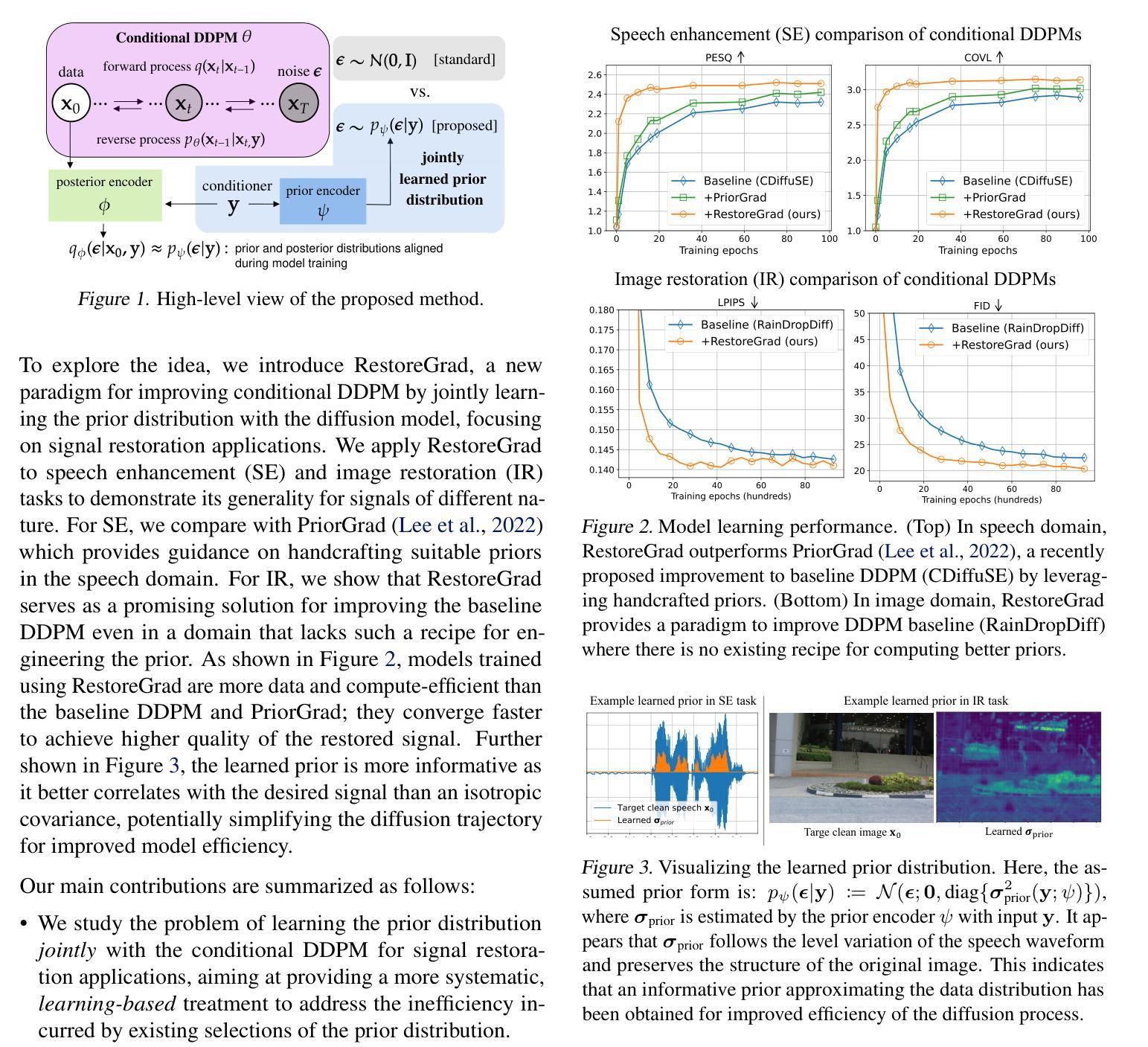
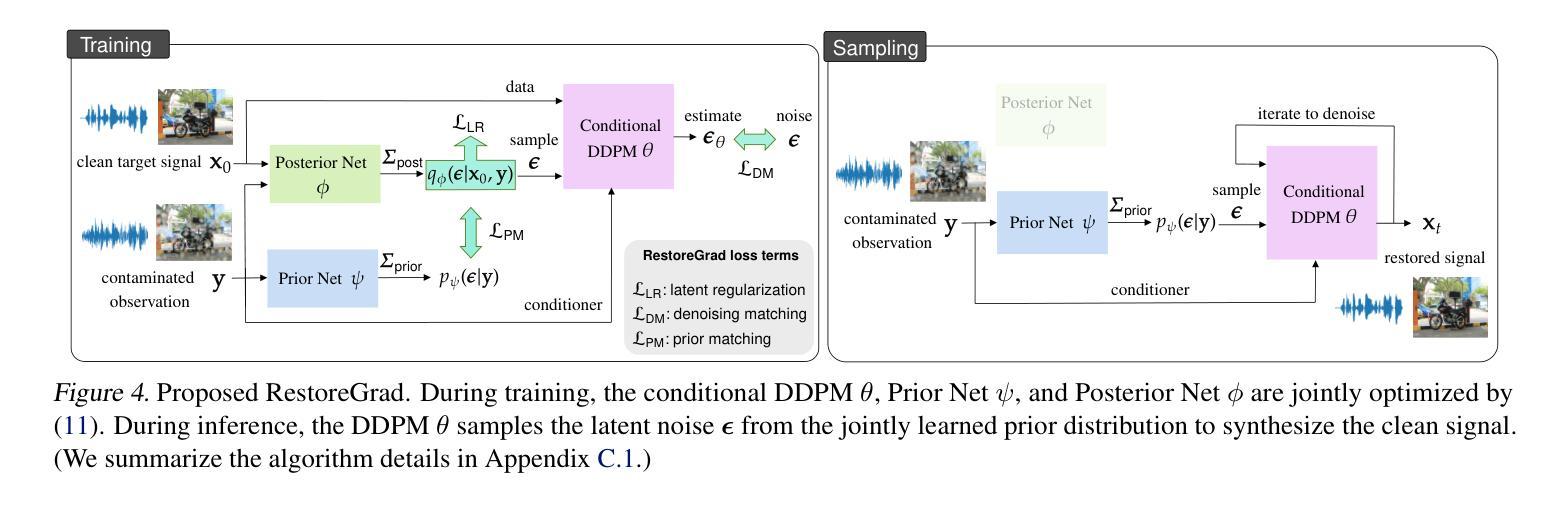
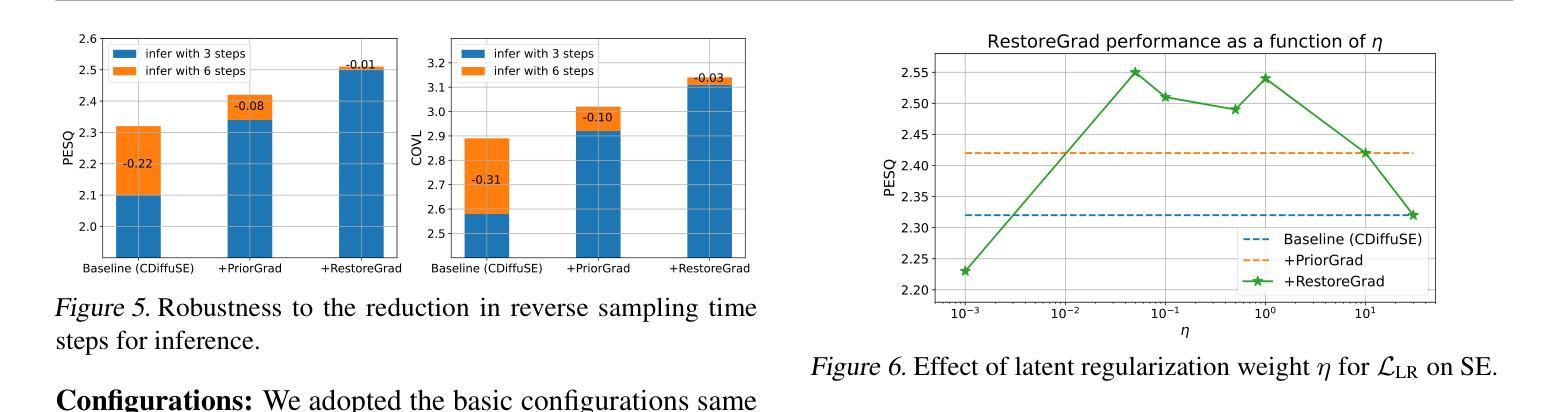
Denoising diffusion probabilistic models (DDPMs) can be utilized for recovering a clean signal from its degraded observation(s) by conditioning the model on the degraded signal. The degraded signals are themselves contaminated versions of the clean signals; due to this correlation, they may encompass certain useful information about the target clean data distribution. However, existing adoption of the standard Gaussian as the prior distribution in turn discards such information, resulting in sub-optimal performance. In this paper, we propose to improve conditional DDPMs for signal restoration by leveraging a more informative prior that is jointly learned with the diffusion model. The proposed framework, called RestoreGrad, seamlessly integrates DDPMs into the variational autoencoder framework and exploits the correlation between the degraded and clean signals to encode a better diffusion prior. On speech and image restoration tasks, we show that RestoreGrad demonstrates faster convergence (5-10 times fewer training steps) to achieve better quality of restored signals over existing DDPM baselines, and improved robustness to using fewer sampling steps in inference time (2-2.5 times fewer), advocating the advantages of leveraging jointly learned prior for efficiency improvements in the diffusion process.
降噪扩散概率模型(DDPMs)可以通过将模型设置为受干扰信号的方式,从退化的观测信号中恢复出干净信号。退化的信号本身是干净信号的污染版本;由于这种相关性,它们可能包含有关目标清洁数据分布的某些有用信息。然而,现有技术采用标准高斯作为先验分布,这反而丢弃了这些信息,导致性能不佳。在本文中,我们提出通过利用与扩散模型联合学习的更具信息量的先验分布,改进用于信号恢复的条件DDPMs。所提出的框架称为RestoreGrad,它无缝地将DDPM集成到变分自动编码器框架中,并利用退化信号和清洁信号之间的相关性来编码更好的扩散先验。在语音和图像恢复任务中,我们证明了RestoreGrad在达到现有DDPM基准的恢复信号质量时,收敛速度更快(训练步骤减少5-10倍),并且在推理时间使用较少的采样步骤(减少2-2.5倍)时表现出更强的稳健性,这证明了利用联合学习的先验进行效率改进的扩散过程的优点。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
本文介绍了如何通过利用更加信息丰富的先验来改进基于条件去噪扩散概率模型(DDPMs)的信号恢复。通过联合学习扩散模型的先验分布,提出了一种名为RestoreGrad的框架,该框架无缝集成DDPMs到变分自编码器框架中,并利用退化信号和清洁信号之间的相关性来编码更好的扩散先验。在语音和图像恢复任务上,RestoreGrad展示了更快的收敛速度(训练步骤减少5-10倍),能够在较少的采样步骤中实现更高质量的恢复信号,验证了联合学习先验以提高扩散过程效率的优势。
Key Takeaways
- DDPMs可用于从退化的观测中恢复清洁信号,通过以退化信号为条件来实现。
- 现有方法使用标准高斯作为先验分布,这可能会丢弃有关目标清洁数据分布的有用信息。
- RestoreGrad框架通过利用更加信息丰富的先验来改善基于条件的DDPMs在信号恢复方面的性能。
- RestoreGrad框架将DDPMs无缝集成到变分自编码器框架中。
- RestoreGrad能编码退化信号和清洁信号之间的相关性,以得到更好的扩散先验。
- RestoreGrad在语音和图像恢复任务上展示了更快的收敛速度和更高的恢复信号质量。
点此查看论文截图

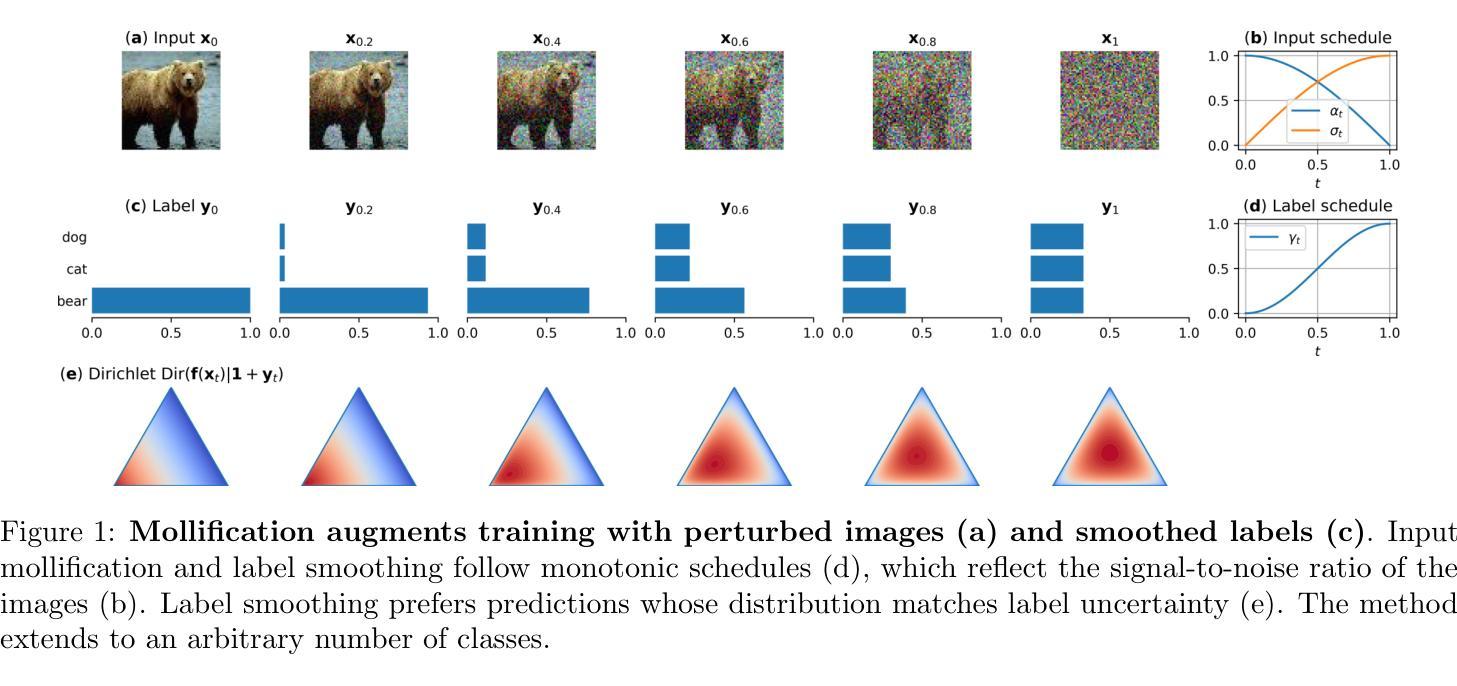
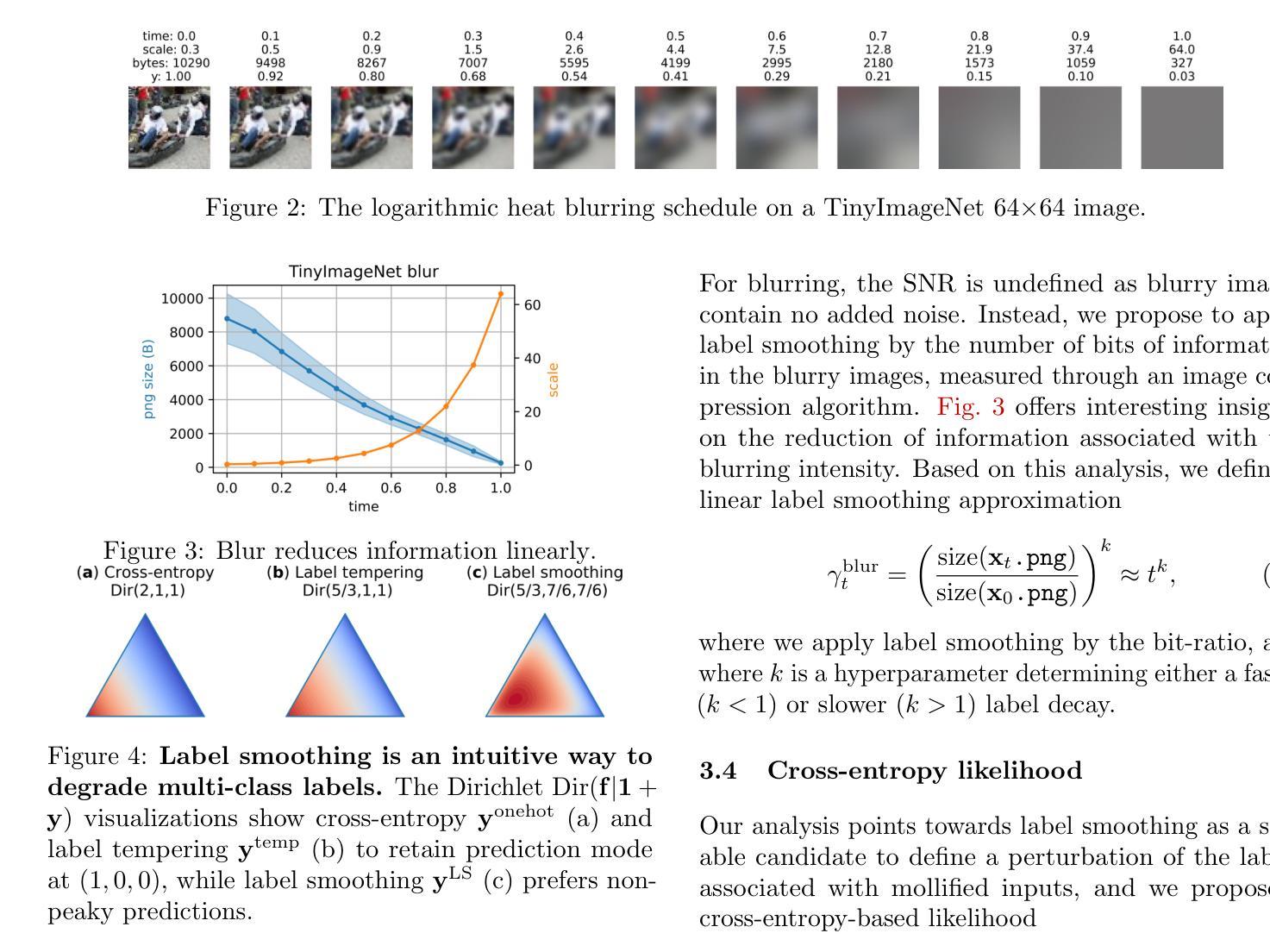
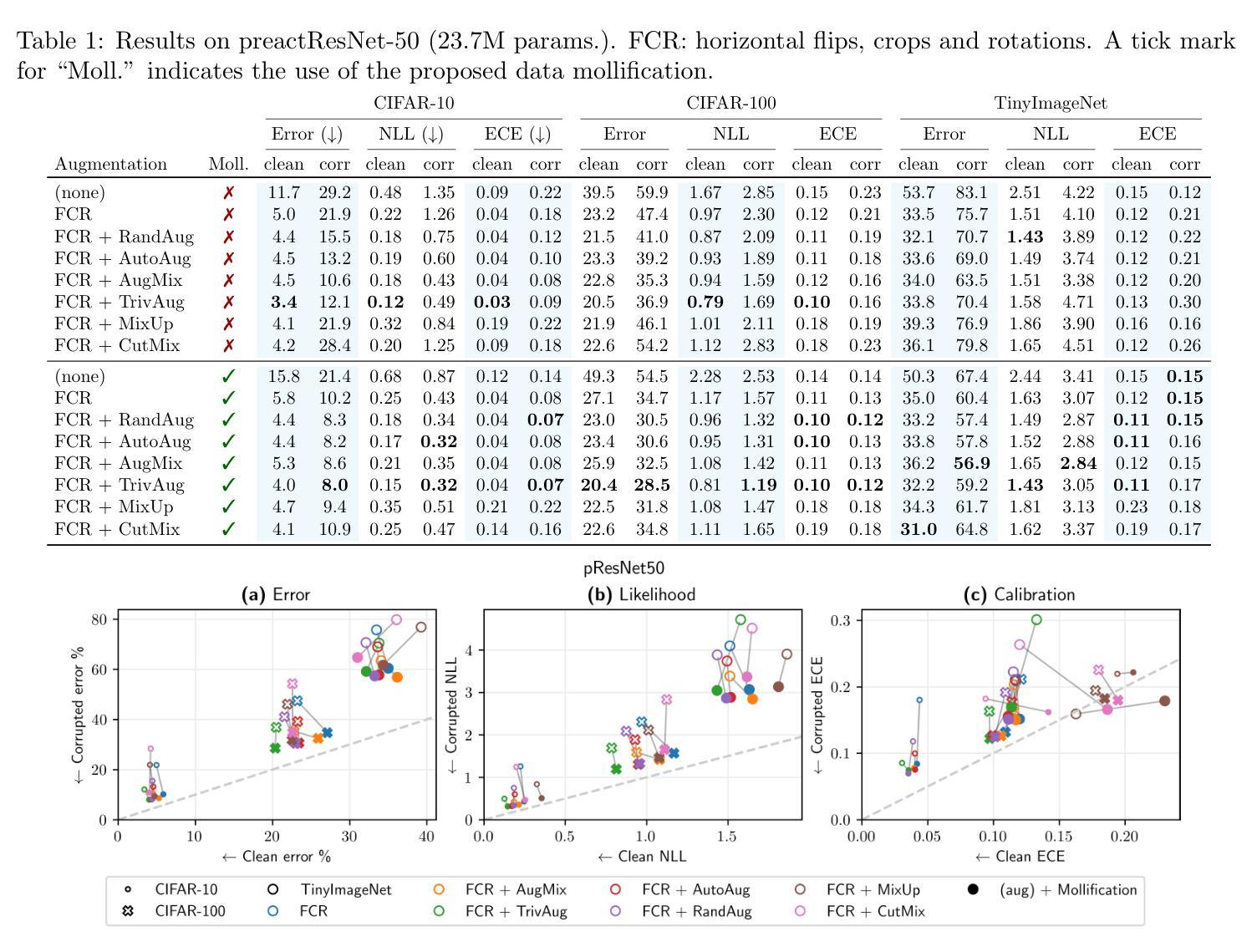
Robust Classification by Coupling Data Mollification with Label Smoothing
Authors:Markus Heinonen, Ba-Hien Tran, Michael Kampffmeyer, Maurizio Filippone
Introducing training-time augmentations is a key technique to enhance generalization and prepare deep neural networks against test-time corruptions. Inspired by the success of generative diffusion models, we propose a novel approach of coupling data mollification, in the form of image noising and blurring, with label smoothing to align predicted label confidences with image degradation. The method is simple to implement, introduces negligible overheads, and can be combined with existing augmentations. We demonstrate improved robustness and uncertainty quantification on the corrupted image benchmarks of CIFAR, TinyImageNet and ImageNet datasets.
引入训练时的数据增强是提高深度神经网络泛化能力并应对测试时腐蚀的关键技术。受生成扩散模型成功的启发,我们提出了一种新的方法,将图像噪声和模糊形式的数据模糊化与标签平滑相结合,以调整预测标签置信度与图像退化之间的匹配度。该方法易于实现,几乎不会增加开销,并且可以与现有的数据增强方法相结合。我们在CIFAR、TinyImageNet和ImageNet数据集的受腐蚀图像基准测试中,展现了提高的鲁棒性和不确定性量化能力。
论文及项目相关链接
PDF AISTATS 2025. Code: https://github.com/markusheinonen/supervised-mollification
Summary:
引入训练时数据增强是提高深度神经网络泛化能力并应对测试时腐蚀的关键技术。受生成扩散模型的启发,我们提出了一种新颖的方法,通过图像噪声和模糊等数据进行平滑处理,结合标签平滑,使预测标签置信度与图像退化相匹配。该方法实现简单,引入的额外开销小,可与现有的数据增强方法相结合。我们在CIFAR、TinyImageNet和ImageNet数据集的腐蚀图像基准测试中展示了其提高的鲁棒性和不确定性量化能力。
Key Takeaways:
- 引入训练时数据增强有助于提高深度神经网络的泛化能力。
- 提出了一种结合数据平滑处理和标签平滑的新方法,以应对图像噪声和模糊等问题。
- 该方法可实现简单,且引入的额外开销小。
- 新方法可与现有的数据增强方法相结合使用。
- 在多个数据集上的腐蚀图像基准测试中,该方法提高了模型的鲁棒性和不确定性量化能力。
- 该方法受到生成扩散模型的启发,利用扩散模型的优点来解决深度神经网络的问题。
点此查看论文截图