⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-06 更新
CDFormer: Cross-Domain Few-Shot Object Detection Transformer Against Feature Confusion
Authors:Boyuan Meng, Xiaohan Zhang, Peilin Li, Zhe Wu, Yiming Li, Wenkai Zhao, Beinan Yu, Hui-Liang Shen
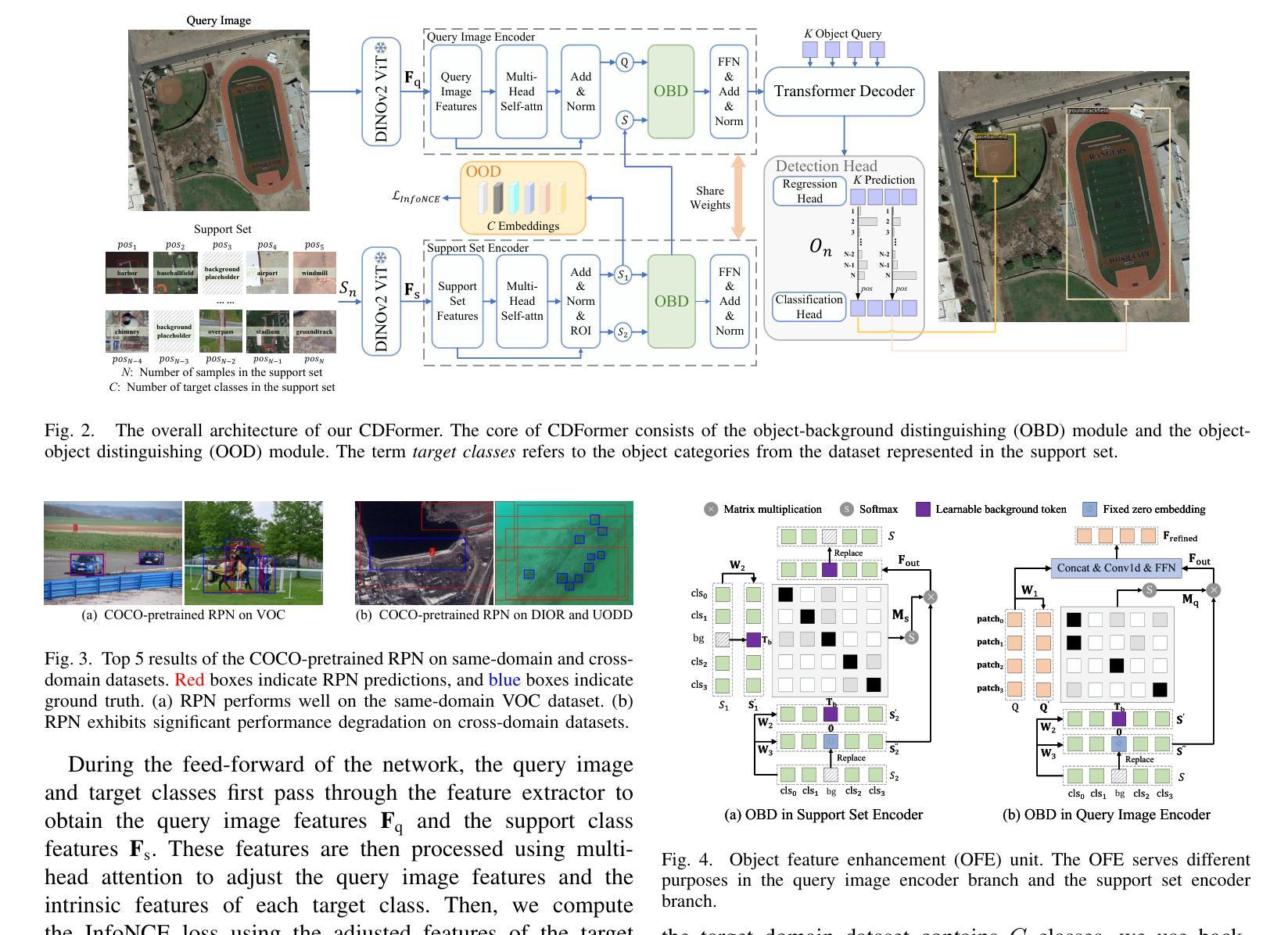
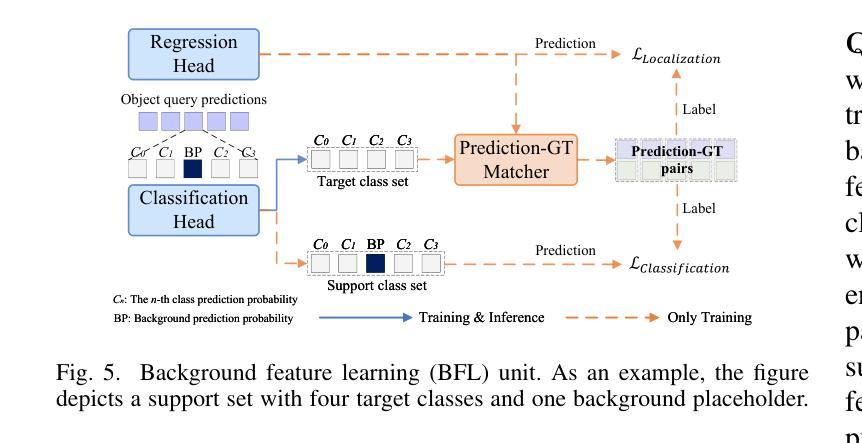
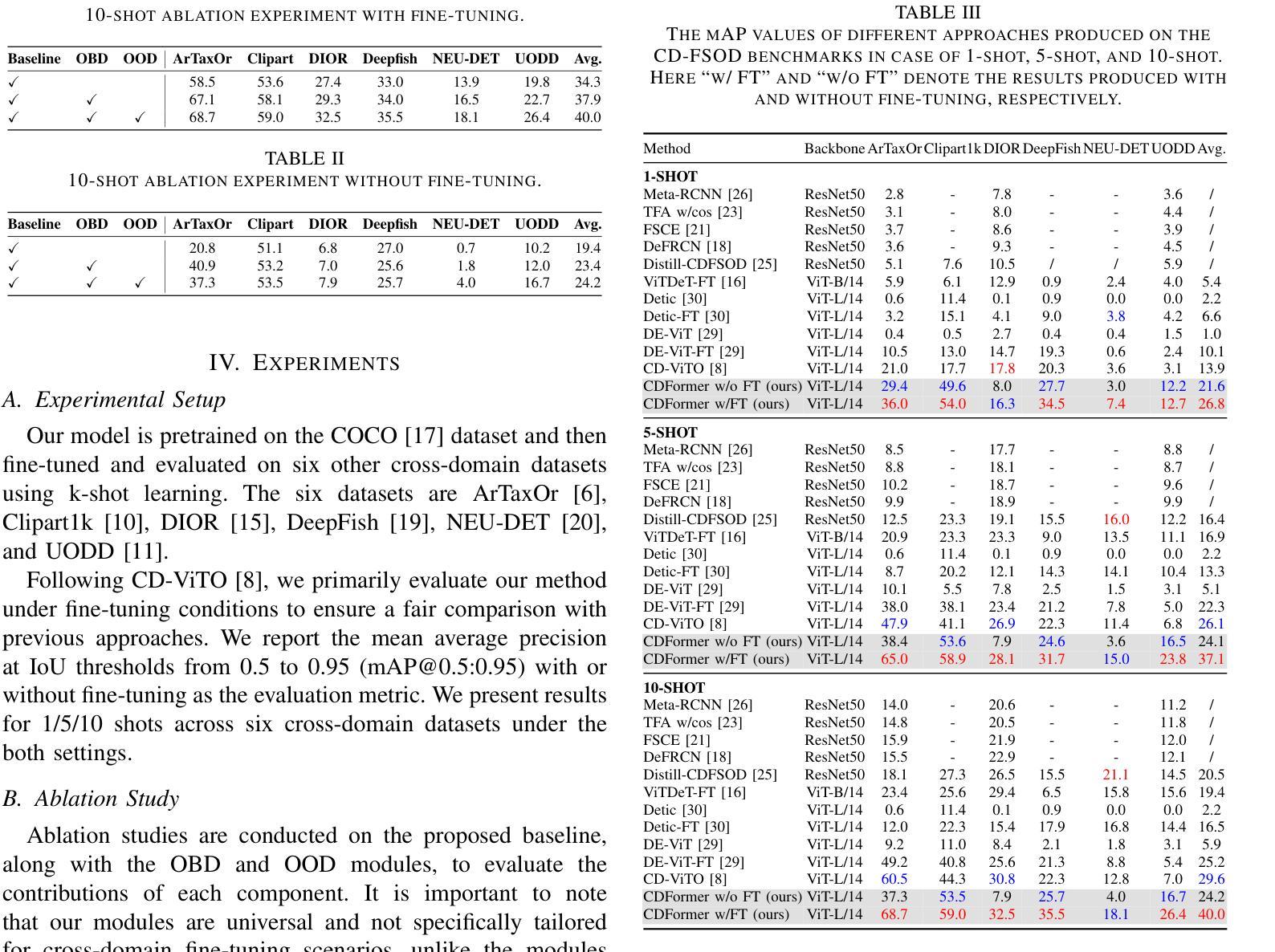
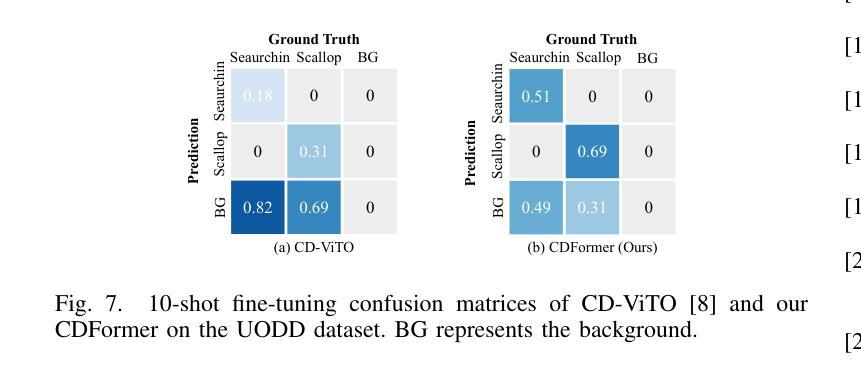
Cross-domain few-shot object detection (CD-FSOD) aims to detect novel objects across different domains with limited class instances. Feature confusion, including object-background confusion and object-object confusion, presents significant challenges in both cross-domain and few-shot settings. In this work, we introduce CDFormer, a cross-domain few-shot object detection transformer against feature confusion, to address these challenges. The method specifically tackles feature confusion through two key modules: object-background distinguishing (OBD) and object-object distinguishing (OOD). The OBD module leverages a learnable background token to differentiate between objects and background, while the OOD module enhances the distinction between objects of different classes. Experimental results demonstrate that CDFormer outperforms previous state-of-the-art approaches, achieving 12.9% mAP, 11.0% mAP, and 10.4% mAP improvements under the 1/5/10 shot settings, respectively, when fine-tuned.
跨域小样本目标检测(CD-FSOD)旨在使用有限的类别实例在不同的领域进行新型目标检测。特征混淆,包括目标背景混淆和目标间混淆,在跨域和小样本设置中都存在很大的挑战。在这项工作中,我们引入了CDFormer,这是一个对抗特征混淆的跨域小样本目标检测变压器,以解决这些挑战。该方法通过两个关键模块:目标背景区分(OBD)和目标区分(OOD),专门解决特征混淆问题。OBD模块利用可学习的背景令牌来区分目标和背景,而OOD模块增强了不同类别对象之间的区别。实验结果表明,经过微调后,CDFormer优于以前的最先进方法,在1/5/10射击条件下分别提高了12.9%、11.0%和10.4%的mAP。
论文及项目相关链接
Summary
CDFormer是一个针对跨域和少量样本情况下的特征混淆问题的对象检测模型。通过对象背景区分(OBD)和对象间区分(OOD)两个关键模块来解决这一问题,提高跨域少量样本下的对象检测性能。经过实验验证,CDFormer相较于之前的最优方法有着显著的性能提升。
Key Takeaways
- CDFormer是针对跨域和少量样本情况下的对象检测模型。
- 特征混淆是跨域和少量样本设置中的主要挑战。
- CDFormer通过对象背景区分(OBD)和对象间区分(OOD)两个模块来解决特征混淆问题。
- OBD模块利用可学习的背景令牌来区分对象和背景。
- OOD模块增强了不同类别对象之间的区分度。
- 实验结果显示,CDFormer在微调后,相较于之前的最优方法,在1/5/10个样本的情况下分别提高了12.9%、11.0%和10.4%的mAP。
- CDFormer能有效应对跨域场景下的新目标检测任务。
点此查看论文截图


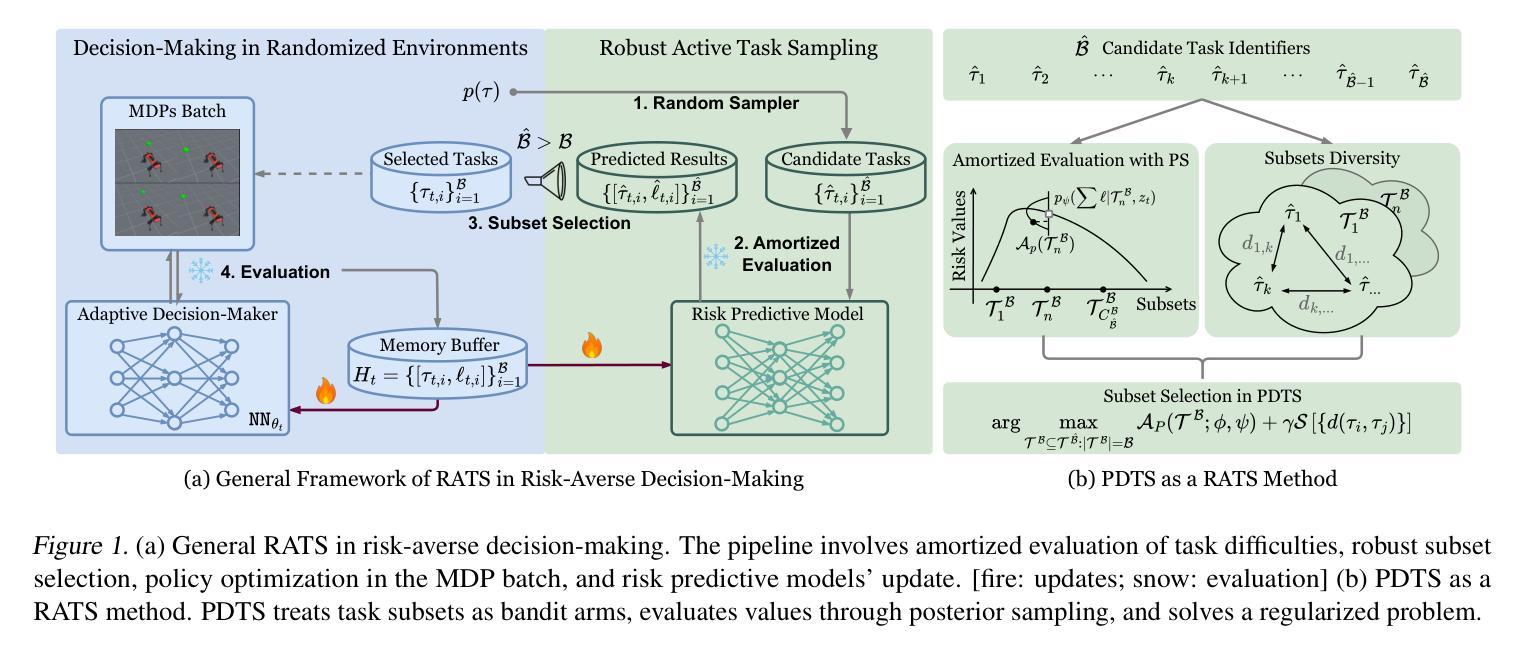
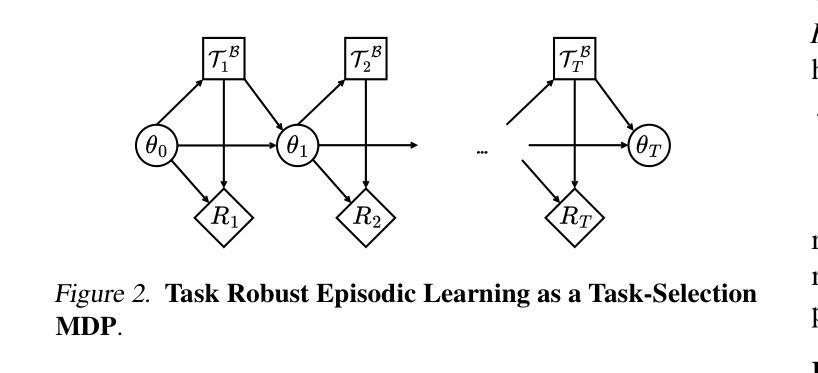
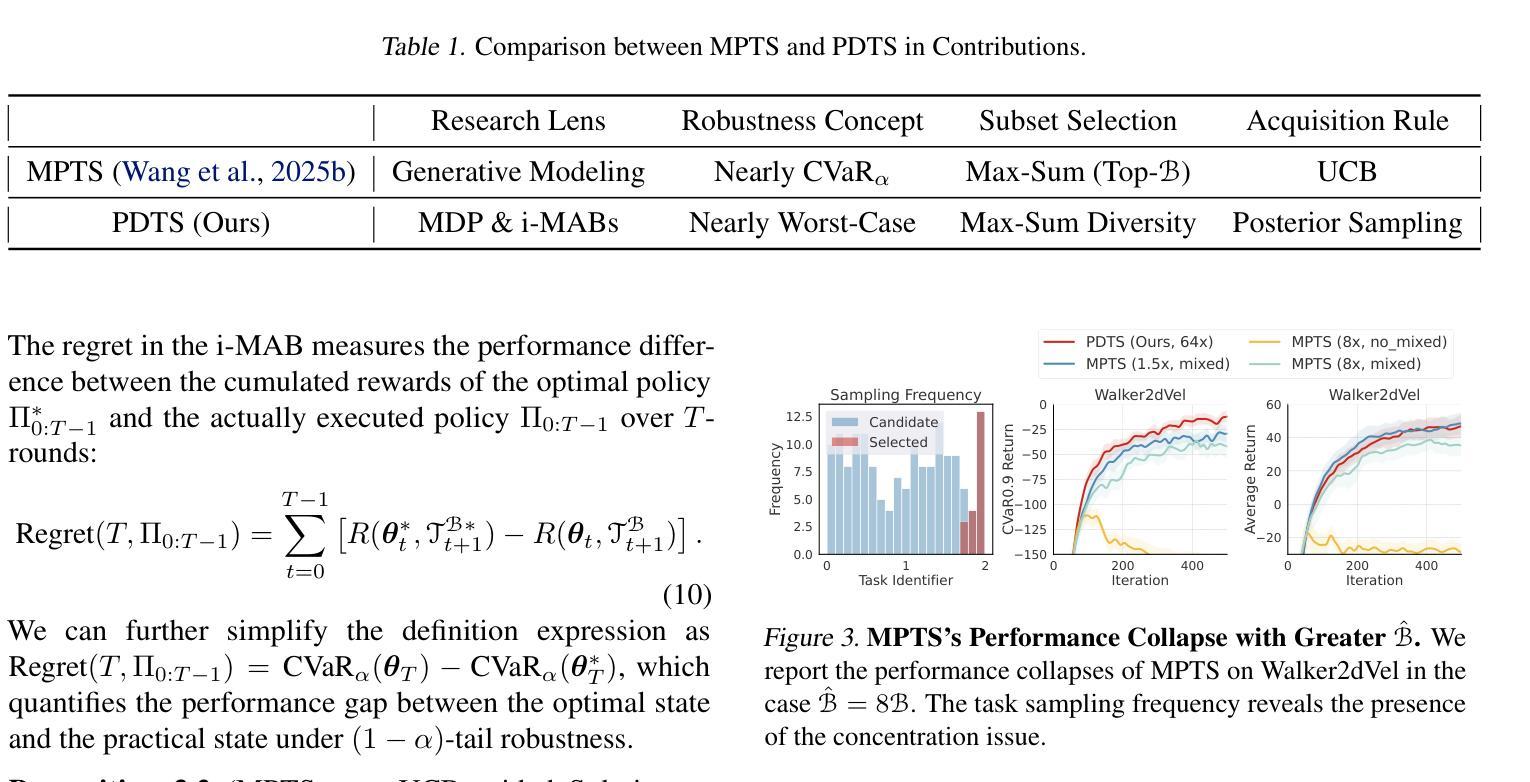
Fast and Robust: Task Sampling with Posterior and Diversity Synergies for Adaptive Decision-Makers in Randomized Environments
Authors:Yun Qu, Qi Cheems Wang, Yixiu Mao, Yiqin Lv, Xiangyang Ji
Task robust adaptation is a long-standing pursuit in sequential decision-making. Some risk-averse strategies, e.g., the conditional value-at-risk principle, are incorporated in domain randomization or meta reinforcement learning to prioritize difficult tasks in optimization, which demand costly intensive evaluations. The efficiency issue prompts the development of robust active task sampling to train adaptive policies, where risk-predictive models are used to surrogate policy evaluation. This work characterizes the optimization pipeline of robust active task sampling as a Markov decision process, posits theoretical and practical insights, and constitutes robustness concepts in risk-averse scenarios. Importantly, we propose an easy-to-implement method, referred to as Posterior and Diversity Synergized Task Sampling (PDTS), to accommodate fast and robust sequential decision-making. Extensive experiments show that PDTS unlocks the potential of robust active task sampling, significantly improves the zero-shot and few-shot adaptation robustness in challenging tasks, and even accelerates the learning process under certain scenarios. Our project website is at https://thu-rllab.github.io/PDTS_project_page.
任务鲁棒性适应是序列决策制定中的一个长期追求。一些风险规避策略,例如条件风险价值原则,被纳入领域随机化或元强化学习中,以优化中的优先困难任务为目标,这些任务需要大量的昂贵评估。效率问题促使了鲁棒性活动任务采样的开发,以训练自适应策略,其中风险预测模型用于替代策略评估。这项工作将鲁棒活动任务采样的优化管道特征化为马尔可夫决策过程,提供了理论和实践见解,并构成了风险规避场景中的稳健性概念。重要的是,我们提出了一种易于实施的方法,称为后验和多样性协同任务采样(PDTS),以实现快速和稳健的序列决策制定。大量实验表明,PDTS释放了鲁棒活动任务采样的潜力,在具有挑战性的任务中显著提高了零样本和少样本适应的稳健性,甚至在特定场景下加速了学习过程。我们的项目网站是https://thu-rllab.github.io/PDTS_project_page。
论文及项目相关链接
Summary
风险规避策略如条件风险价值原则被应用于领域随机化或元强化学习中,以优化优先处理困难任务。为提高效率,发展出稳健的活动任务采样法来训练自适应策略,利用风险预测模型代替策略评估。本文描述了稳健活动任务采样的优化流程为一个马尔可夫决策过程,提供了理论和实践见解,并构成风险规避场景中的稳健性概念。提出了一种简单实用的方法——后验与多样性协同任务采样(PDTS),以实现快速稳健的序列决策。大量实验表明,PDTS在挑战性任务中显著提高了零样本和少样本适应的稳健性,并在某些场景下加速了学习过程。
Key Takeaways
- 风险规避策略被用于领域随机化和元强化学习中,旨在优化处理困难任务。
- 稳健的活动任务采样法用于训练自适应策略,使用风险预测模型替代策略评估。
- PDTS方法被提出以简化序列决策过程,实现快速和稳健的适应。
- PDTS通过优化采样策略提高了零样本和少样本适应的稳健性。
- 该方法在某些场景下能够加速学习过程。
- 本文将优化流程描述为马尔可夫决策过程,并提供了理论和实践分析。
点此查看论文截图


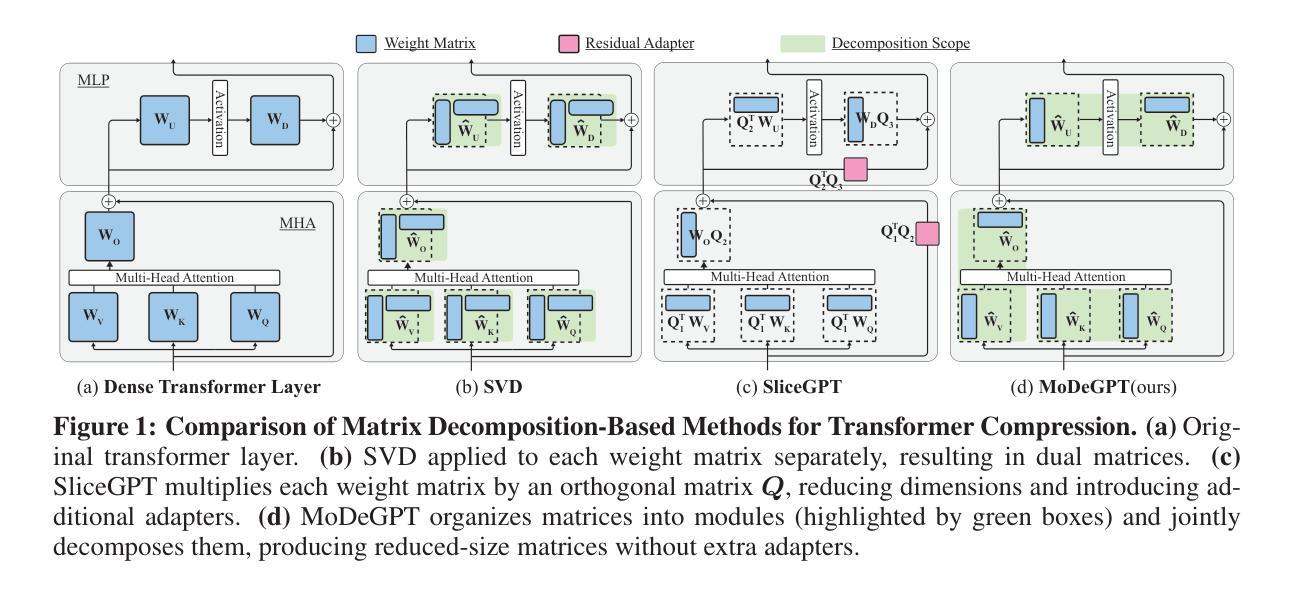
MoDeGPT: Modular Decomposition for Large Language Model Compression
Authors:Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu
Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms – Nystr"om approximation, CR decomposition, and SVD – and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.
大型语言模型(LLM)在各项任务中表现出卓越的性能,从而改变了人工智能领域的格局。然而,巨大的计算需求使得在资源有限的设备上部署它们具有挑战性。最近,使用低秩矩阵技术的压缩方法显示出潜力,但这些方法往往会导致精度下降或在参数和推理延迟方面引入显著开销。本文介绍了MoDeGPT,这是一种新型结构化压缩框架,无需进行恢复微调即可解决上述缺点。MoDeGPT将Transformer块分区成由矩阵对组成的模块,并通过重建模块级输出降低隐藏维度。MoDeGPT是基于一个理论框架开发的,该框架利用三种成熟的矩阵分解算法——Nyström近似、CR分解和SVD,并应用于我们重新定义的变压器模块。我们的综合实验表明,MoDeGPT无需反向传播即可匹配或超越以前依赖于梯度信息的结构化压缩方法,并在压缩13B模型时节省了98%的计算成本。在\textsc{Llama}-2/3和OPT模型上,MoDeGPT在25-30%的压缩率下保持90-95%的零样本性能。此外,压缩可以在单个GPU上于几小时内完成,并提高最多46%的推理吞吐量。
论文及项目相关链接
PDF ICLR 2025 Oral
Summary
大型语言模型(LLMs)在人工智能领域展现出卓越性能,但其巨大的计算需求使得在资源有限的设备上部署具有挑战性。本文提出一种新型结构化压缩框架MoDeGPT,它采用模块化分解技术,无需恢复微调即可解决上述问题。MoDeGPT将Transformer块分割成模块,通过重构模块级输出来减少隐藏维度。基于三种成熟的矩阵分解算法构建的理论框架,实验结果显示MoDeGPT无需反向传播就能匹配或超越依赖于梯度信息的先前结构化压缩方法,在压缩一个13B模型时节省98%的计算成本。同时,MoDeGPT能在单个GPU上完成压缩,并提升高达46%的推理吞吐量。它对LLM性能维护表现优异,压缩率高达90-95%,保证了高效性与易用性之间的平衡。总体而言,该模型将为减少资源限制和设备环境的大型语言模型部署提供了一种全新的方案。基于复杂环境下任务量调整适应性实现平衡利用,降低应用运行风险的同时确保业务逻辑完整性。文中方法具有较高的实用价值和广泛的应用前景。在面向大型语言模型的高效压缩与部署方面具有创新性和突破性进展。在未来的实际应用中将会带来革命性的变化和发展空间。MoDeGPT模型值得深入研究与应用探索之中带来显著的推动作用和影响力的优秀算法和方法论的深度融合尝试思路独具特色和创新性思维的力量核心解决多种困难问题与理论的应用兼容之中发挥巨大潜力价值,实现高效运行与应用的推广价值显著。具有里程碑意义的重要成果。通过简单、高效、可靠的技术手段实现了对大型语言模型的精确处理和提高。为中国新一代人工智能的高质量发展提供新动力和新策略性指导思想对面向海量信息计算和海量信息处理问题展示极其重要的指导意义成为未来人工智能领域的重要发展方向之一。本文提出的MoDeGPT模型将引领人工智能领域的新一轮研究热潮具有重要参考价值并在各领域中获得广泛的应用与实践推进经济社会发展贡献力量成就一代开创性工作成效体现国际化标准的高质量论文与研究具有深远的影响和重要的意义值得我们密切关注和研究进一步推广运用推动产业发展与进步共同助力人类社会的发展进步共同探索更多创新型的突破式方案创造美好未来。Key Takeaways:
- 大型语言模型(LLMs)的计算需求使其在某些设备上的部署具有挑战性。
- MoDeGPT是一种新型结构化压缩框架,解决了现有压缩方法的缺点,无需恢复微调。
- MoDeGPT通过模块化分解技术将Transformer块分割成模块,减少了隐藏维度。
- MoDeGPT基于三种成熟的矩阵分解算法构建,匹配或超越了先前的结构化压缩方法。
- MoDeGPT能显著降低计算成本,提高推理吞吐量,同时保持较高的性能维护率。
- MoDeGPT在LLM性能维护方面表现优异,压缩率高达90-95%。
点此查看论文截图