⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-06 更新
FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing
Authors:Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton van den Hengel, Yuankai Qi, Qingming Huang
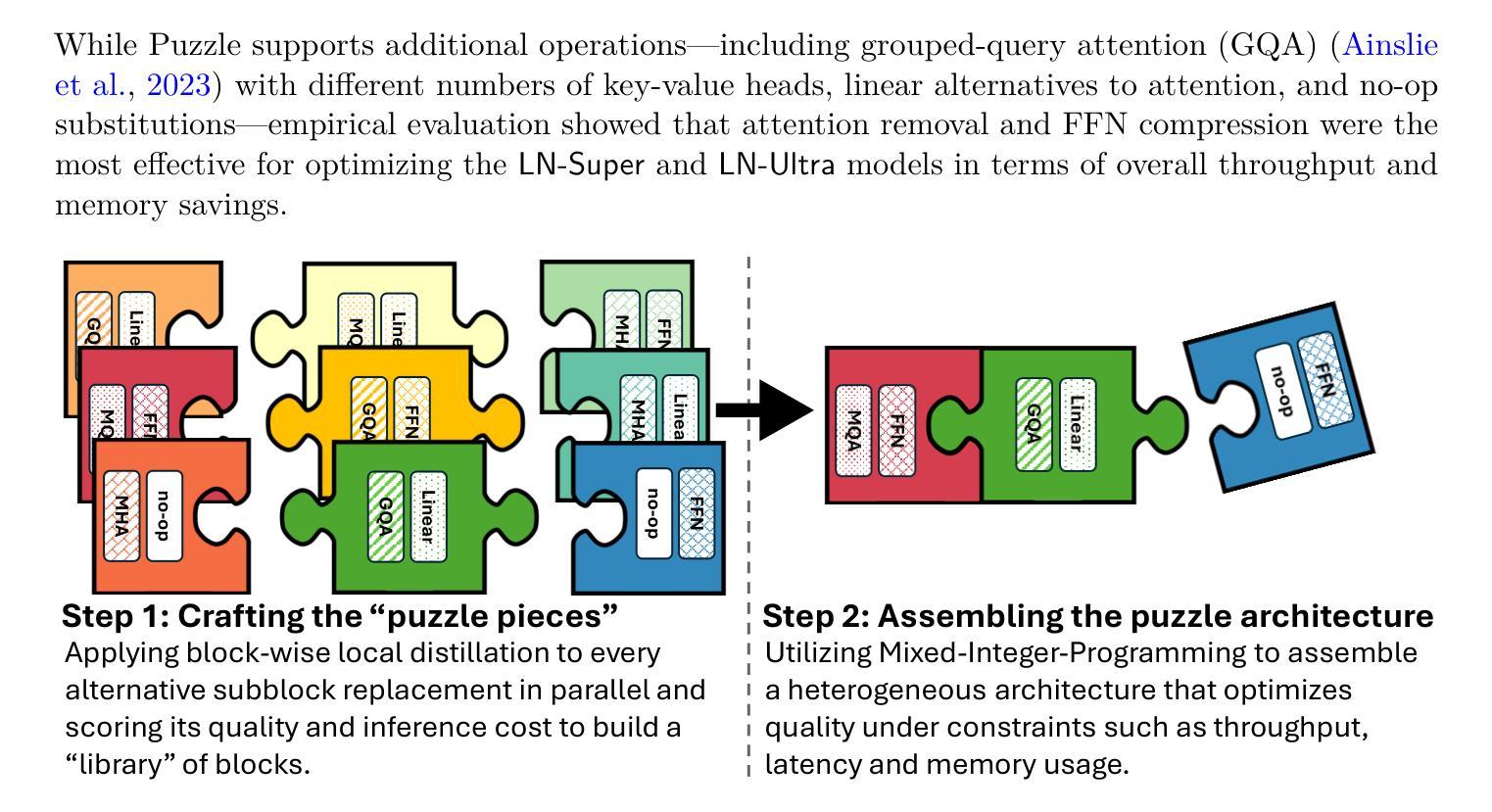
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of a given brief reference audio. Existing methods focus primarily on reducing the word error rate while ignoring the importance of lip-sync and acoustic quality. To address these issues, we propose a large language model (LLM) based flow matching architecture for dubbing, named FlowDubber, which achieves high-quality audio-visual sync and pronunciation by incorporating a large speech language model and dual contrastive aligning while achieving better acoustic quality via the proposed voice-enhanced flow matching than previous works. First, we introduce Qwen2.5 as the backbone of LLM to learn the in-context sequence from movie scripts and reference audio. Then, the proposed semantic-aware learning focuses on capturing LLM semantic knowledge at the phoneme level. Next, dual contrastive aligning (DCA) boosts mutual alignment with lip movement, reducing ambiguities where similar phonemes might be confused. Finally, the proposed Flow-based Voice Enhancing (FVE) improves acoustic quality in two aspects, which introduces an LLM-based acoustics flow matching guidance to strengthen clarity and uses affine style prior to enhance identity when recovering noise into mel-spectrograms via gradient vector field prediction. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks. The demos are available at {\href{https://galaxycong.github.io/LLM-Flow-Dubber/}{\textcolor{red}{https://galaxycong.github.io/LLM-Flow-Dubber/}}}.
电影配音旨在将剧本转换为与给定电影片段在时间和情感方面对齐的语音,同时保留给定简短参考音频的音色。现有方法主要专注于降低词错误率,而忽视唇形同步和音质的重要性。为了解决这些问题,我们提出了一种基于大语言模型(LLM)的配音流程匹配架构,名为FlowDubber。它通过结合大型语音语言模型和双对比对齐,实现了高质量的声音视觉同步和发音,并通过提出的声音增强流程匹配,实现了比以前工作更好的音质。首先,我们引入Qwen2.5作为LLM的骨干,从电影剧本和参考音频中学习上下文序列。然后,提出的语义感知学习侧重于在音素级别捕获LLM语义知识。接下来,双对比对齐(DCA)增强了与嘴唇运动的相互对齐,减少了相似音素可能产生的混淆。最后,提出的基于流的语音增强(FVE)从两个方面提高了音质:它引入了一种基于LLM的声学流程匹配指导,以增强清晰度,并使用仿射风格先验来增强身份,通过梯度矢量场预测恢复噪声时的梅尔频谱图。大量实验表明,我们的方法在两个主要基准上优于几种最新方法。相关演示可通过链接{\href{https://galaxycong.github.io/LLM-Flow-Dubber/}{\textcolor{red}{https://galaxycong.github.io/LLM-Flow-Dubber/}}}查看。
论文及项目相关链接
Summary
电影配音旨在将剧本转换为与给定电影片段在时间和情感方面对齐的演讲,同时保留简短参考音频的音色。现有方法主要关注降低词错误率,而忽视唇同步和音质的重要性。为解决这些问题,我们提出一种基于大语言模型(LLM)的流程匹配架构进行配音,名为FlowDubber,通过结合大型语音语言模型和双对比对齐,实现了高质量的声音同步和发音,同时提出的声音增强流程匹配获得了更好的音质。我们的方法通过引入Qwen2.5作为LLM的后端,学习电影剧本和参考音频的上下文序列,并关注捕捉LLM语义知识在音素层面。此外,双对比对齐提高了与唇部动作的相互对齐,减少了相似音素可能产生的混淆。最后,我们提出的基于流的语音增强(FVE)从两个方面提高了音质:引入LLM的声学流程匹配指导以增强清晰度,并使用仿射风格先验在通过梯度向量场预测恢复噪声时增强身份特征。大量实验表明,我们的方法在两个主要基准测试上优于几种最新方法。
Key Takeaways
- 电影配音需同步语音和影像,兼顾时间和情感方面。
- 现有方法主要关注词错误率,但忽视唇同步和音质。
- FlowDubber架构结合大语言模型(LLM)和流程匹配实现高质量音频-视觉同步和发音。
- Qwen2.5作为LLM后端,学习电影剧本和参考音频的上下文序列。
- 语义感知学习捕捉LLM在音素层面的语义知识。
- 双对比对齐(DCA)提高唇部动作相互对齐,减少音素混淆。
- 基于流的语音增强(FVE)提高音质,通过引入LLM的声学流程匹配指导和仿射风格先验增强清晰度和身份特征。
点此查看论文截图

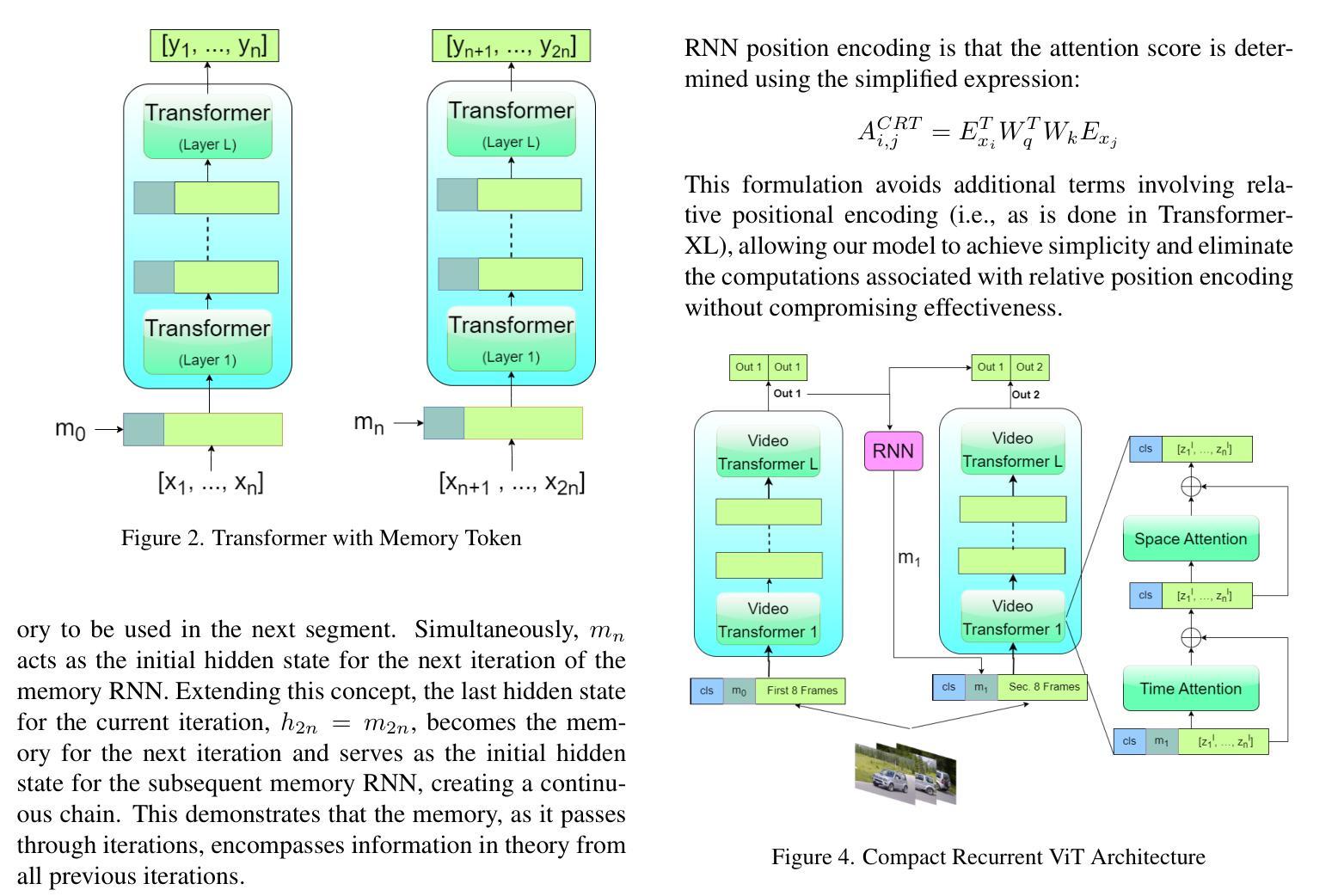
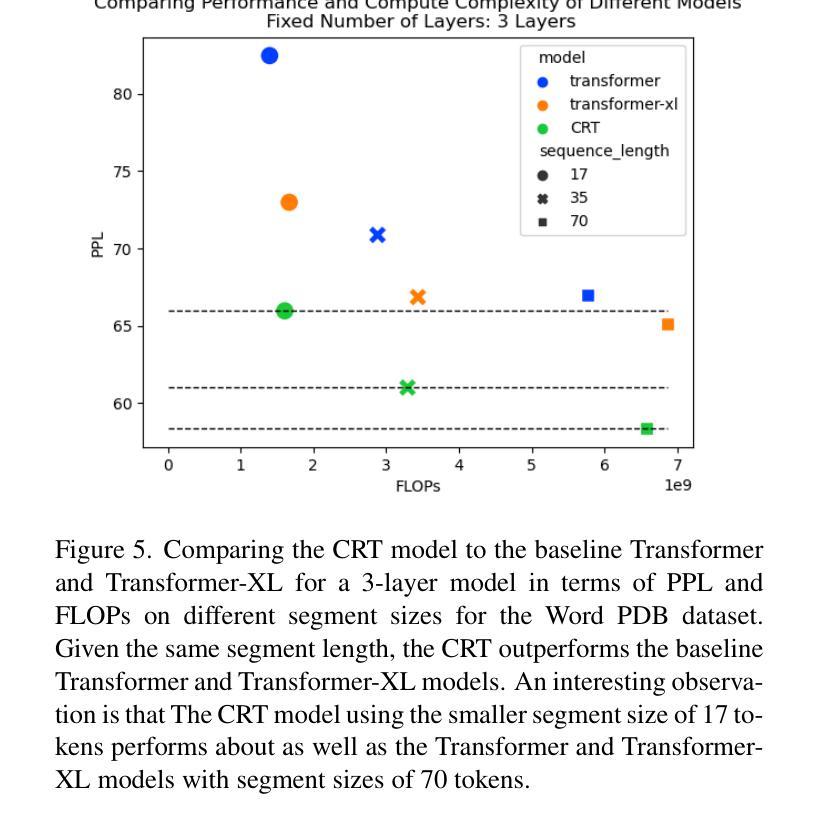
Compact Recurrent Transformer with Persistent Memory
Authors:Edison Mucllari, Zachary Daniels, David Zhang, Qiang Ye
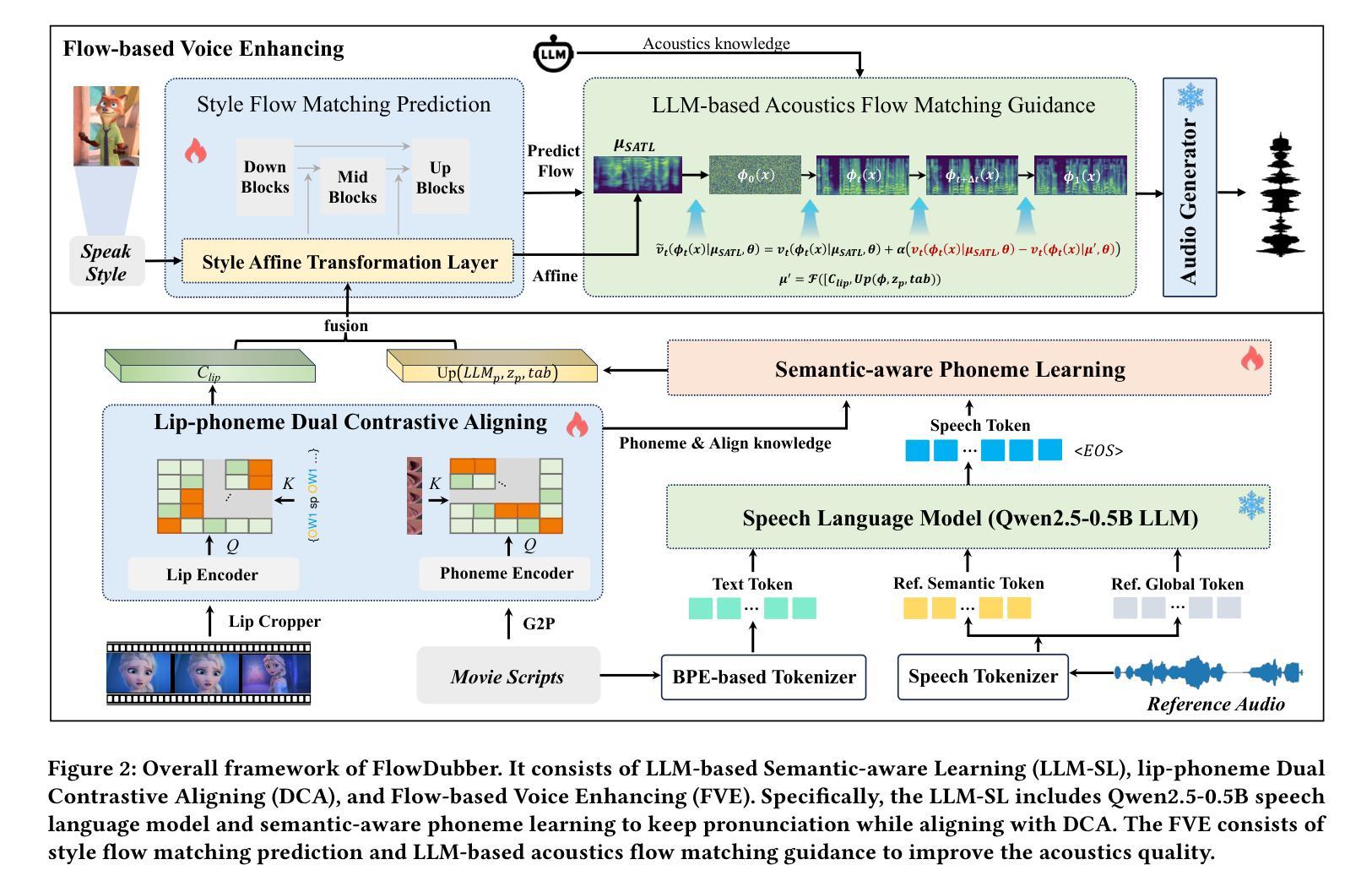
The Transformer architecture has shown significant success in many language processing and visual tasks. However, the method faces challenges in efficiently scaling to long sequences because the self-attention computation is quadratic with respect to the input length. To overcome this limitation, several approaches scale to longer sequences by breaking long sequences into a series of segments, restricting self-attention to local dependencies between tokens within each segment and using a memory mechanism to manage information flow between segments. However, these approached generally introduce additional compute overhead that restricts them from being used for applications where limited compute memory and power are of great concern (such as edge computing). We propose a novel and efficient Compact Recurrent Transformer (CRT), which combines shallow Transformer models that process short local segments with recurrent neural networks to compress and manage a single persistent memory vector that summarizes long-range global information between segments. We evaluate CRT on WordPTB and WikiText-103 for next-token-prediction tasks, as well as on the Toyota Smarthome video dataset for classification. CRT achieves comparable or superior prediction results to full-length Transformers in the language datasets while using significantly shorter segments (half or quarter size) and substantially reduced FLOPs. Our approach also demonstrates state-of-the-art performance on the Toyota Smarthome video dataset.
Transformer架构在许多语言处理和视觉任务中都取得了显著的成功。然而,该方法在扩展到长序列时面临挑战,因为自注意力计算与输入长度呈二次方关系。为了克服这一局限性,一些方法通过将长序列分解成一系列片段来适应更长的序列,限制自注意力在每个片段内标记之间的局部依赖关系,并使用记忆机制来管理片段之间的信息流。然而,这些方法通常引入了额外的计算开销,限制了它们在计算内存和功率受限的应用领域(如边缘计算)的使用。我们提出了一种新型高效的Compact Recurrent Transformer(CRT),它将浅层Transformer模型与递归神经网络相结合,处理和压缩一个持久记忆向量,该向量总结了片段之间的长距离全局信息。我们在WordPTB和WikiText-103数据集上评估CRT的下一个标记预测任务性能,以及在丰田智能家居视频数据集上进行分类任务评估。CRT在语言数据集中实现了与全长Transformer相当的预测结果,同时使用了较短的片段(一半或四分之一大小),并大幅减少了FLOPs。我们的方法在丰田智能家居视频数据集上也表现出了最先进的性能。
论文及项目相关链接
Summary
本文提出一种新型高效紧凑循环Transformer(CRT)模型,旨在解决现有Transformer在处理长序列时的局限性。CRT结合浅层Transformer模型和循环神经网络,对长序列进行分段处理,同时压缩和管理一个持久内存向量,以汇总分段间的长距离全局信息。在WordPTB和WikiText-103的下一个令牌预测任务以及Toyota Smarthome视频数据集上的分类任务中,CRT实现了与全长Transformer相当或更优的预测结果,同时使用了更短的序列分段并大幅减少了计算量。
Key Takeaways
- Transformer架构在处理长序列时面临挑战,自注意力计算是输入长度的二次方。
- 现有方法通过分段处理长序列来克服这一限制,但引入了额外的计算开销,不适用于计算内存和功率有限的场景。
- CRT模型结合了浅层Transformer模型和循环神经网络,处理短局部分段,同时压缩和管理一个持久内存向量来汇总分段间的全局信息。
- CRT在WordPTB和WikiText-103的下一个令牌预测任务中表现优秀。
- CRT在Toyota Smarthome视频数据集上的分类任务上达到了最先进的性能。
- CRT使用更短的序列分段并大幅减少了计算量。
点此查看论文截图

How Transformers Learn Regular Language Recognition: A Theoretical Study on Training Dynamics and Implicit Bias
Authors:Ruiquan Huang, Yingbin Liang, Jing Yang
Language recognition tasks are fundamental in natural language processing (NLP) and have been widely used to benchmark the performance of large language models (LLMs). These tasks also play a crucial role in explaining the working mechanisms of transformers. In this work, we focus on two representative tasks in the category of regular language recognition, known as even pairs' and parity check’, the aim of which is to determine whether the occurrences of certain subsequences in a given sequence are even. Our goal is to explore how a one-layer transformer, consisting of an attention layer followed by a linear layer, learns to solve these tasks by theoretically analyzing its training dynamics under gradient descent. While even pairs can be solved directly by a one-layer transformer, parity check need to be solved by integrating Chain-of-Thought (CoT), either into the inference stage of a transformer well-trained for the even pairs task, or into the training of a one-layer transformer. For both problems, our analysis shows that the joint training of attention and linear layers exhibits two distinct phases. In the first phase, the attention layer grows rapidly, mapping data sequences into separable vectors. In the second phase, the attention layer becomes stable, while the linear layer grows logarithmically and approaches in direction to a max-margin hyperplane that correctly separates the attention layer outputs into positive and negative samples, and the loss decreases at a rate of $O(1/t)$. Our experiments validate those theoretical results.
语言识别任务在自然语言处理(NLP)中是最基本的任务之一,并且已被广泛应用于评估大型语言模型(LLM)的性能。这些任务在解释变压器的工作原理方面也起着至关重要的作用。在这项工作中,我们专注于常规语言识别类别中的两个代表性任务,即“偶数对”和“奇偶校验”,这两个任务的目标是确定在给定的序列中某些子序列的出现是否为偶数。我们的目标是探索由注意力层和线性层组成的一层变压器如何学习解决这些任务,通过理论分析其在梯度下降下的训练动态。虽然“偶数对”可以直接由一层变压器解决,“奇偶校验”需要通过将思维链(CoT)集成到为“偶数对”任务训练良好的变压器的推理阶段或一层变压器的训练中来解决。对于这两个问题,我们的分析表明,注意力层和线性层的联合训练表现出两个明显的阶段。在第一阶段,注意力层迅速增长,将数据序列映射为可分立的向量。在第二阶段,注意力层变得稳定,而线性层的增长呈对数趋势,并朝向一个最大间隔超平面发展,该超平面能正确地将注意力层的输出分为正样本和负样本,损失以O(1/t)的速度减少。我们的实验验证了这些理论结果。
论文及项目相关链接
PDF accepted by ICML 2025
Summary
本论文研究了自然语言处理中的语言识别任务,特别是针对“even pairs”和“parity check”两个代表性任务。文章着重探讨了单层变压器模型如何学习解决这些任务,通过理论分析和实验验证,揭示了模型在训练过程中的两个明显阶段以及如何利用Chain-of-Thought(CoT)解决奇偶校验问题。
Key Takeaways
- 语言识别任务是评估大型语言模型性能的重要基准,也有助于解释变压器的工作原理。
- “even pairs”和“parity check”是语言识别中的代表性任务,旨在确定给定序列中某些子序列的出现是否为偶数。
- 单层变压器模型可以直接解决“even pairs”问题,但解决“parity check”问题需要集成Chain-of-Thought(CoT)。
- 单层变压器模型在解决这些问题的过程中展现出两个明显的训练阶段:第一阶段是注意力层的快速增长;第二阶段是注意力层的稳定以及线性层的对数增长。
- 线性层最终会朝向一个最大间隔超平面发展,正确地将注意力层的输出分为正负样本。
- 损失函数随时间呈O(1/t)速率下降。
点此查看论文截图

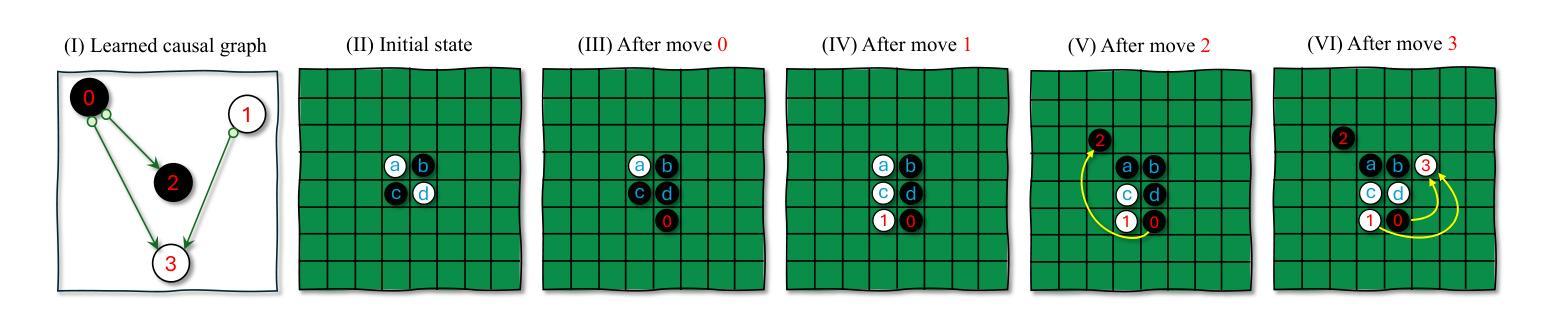
A Causal World Model Underlying Next Token Prediction: Exploring GPT in a Controlled Environment
Authors:Raanan Y. Rohekar, Yaniv Gurwicz, Sungduk Yu, Estelle Aflalo, Vasudev Lal
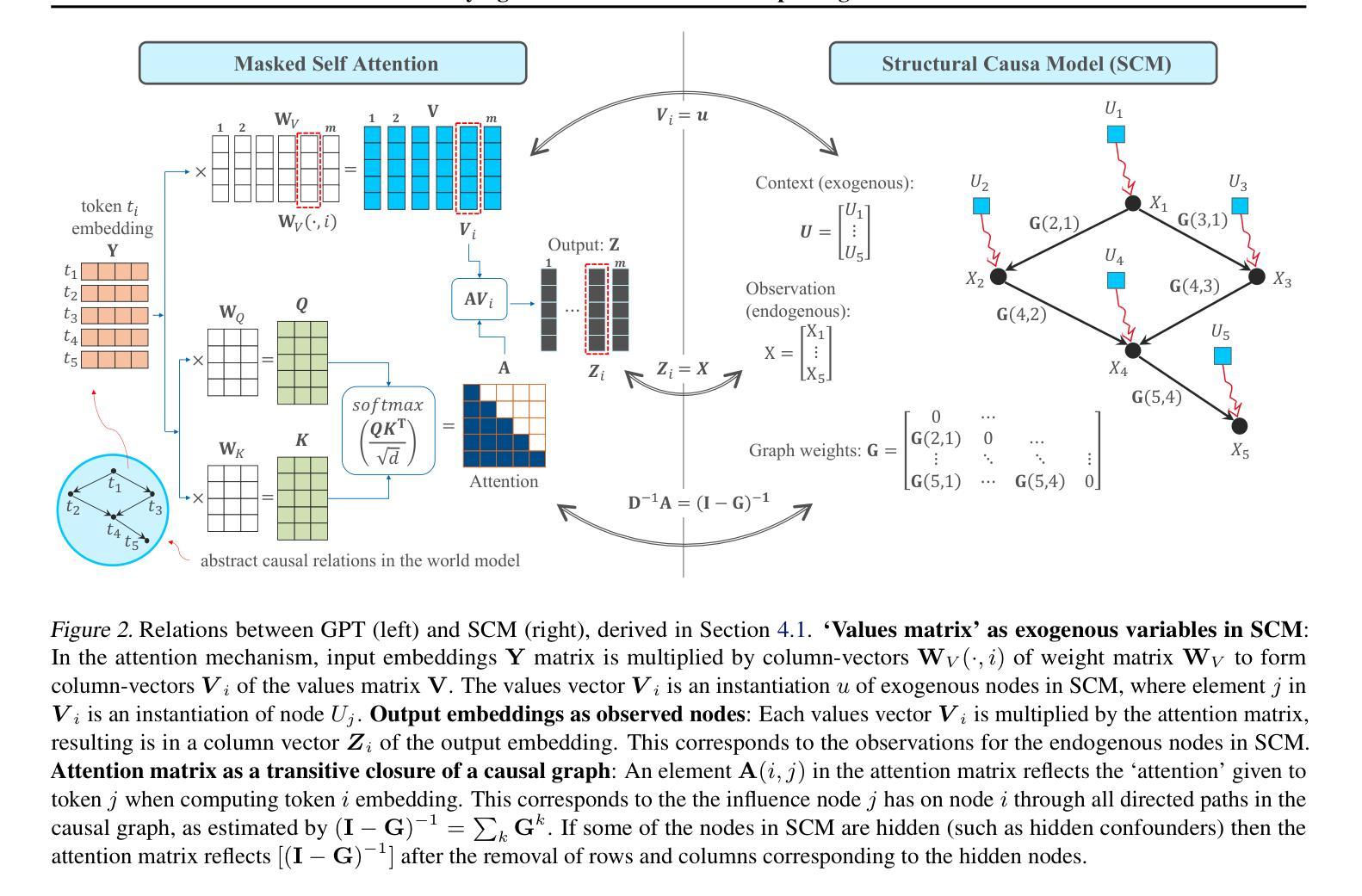
Do generative pre-trained transformer (GPT) models, trained only to predict the next token, implicitly learn a world model from which a sequence is generated one token at a time? We address this question by deriving a causal interpretation of the attention mechanism in GPT, and suggesting a causal world model that arises from this interpretation. Furthermore, we propose that GPT models, at inference time, can be utilized for zero-shot causal structure learning for input sequences and present a confidence score. Empirical evaluation is conducted in a controlled environment using the setup and rules of the Othello and Chess strategy games. A GPT, pre-trained on real-world games played with the intention of winning, is tested on out-of-distribution synthetic data consisting of sequences of random legal moves. We find that the GPT model is likely to generate legal next moves for out-of-distribution sequences for which a causal structure is encoded in the attention mechanism with high confidence. In cases for which the GPT model generates illegal moves it also fails to capture any causal structure.
使用仅用于预测下一个代币的生成式预训练转换器(GPT)模型,是否会隐式地学习一个世界模型,该模型能够逐个代币地生成一个序列?我们通过推导GPT中注意力机制的因果解释,以及由此产生的因果世界模型来回答这个问题。此外,我们提出,在推理阶段,GPT模型可用于输入序列的零样本因果结构学习,并呈现置信度得分。在Othello和象棋策略游戏的设置和规则控制的环境下进行实证研究。GPT在现实世界游戏中进行预训练,旨在赢得比赛,然后测试其在由随机合法动作序列组成的离群合成数据上的表现。我们发现,GPT模型很可能为离群序列生成合法的下一个动作,在这些动作中,注意力机制编码了因果关系结构并表现出高置信度。在GPT模型生成非法动作的情况下,它也无法捕捉到任何因果关系结构。
论文及项目相关链接
PDF International Conference on Machine Learning (ICML), 2025
Summary:GPT模型通过预测下一个词符进行训练,是否会从世界模型中生成序列的每一个词符?本文给出了一个对GPT中注意力机制的因果解释,并提出一个由此产生的因果世界模型。同时,我们提出GPT模型在推理时间可用于零步因果结构学习输入序列并呈现置信度评分。实验通过棋类游戏进行实证评估,结果表明GPT模型能够针对有注意力机制编码因果结构的非分布序列生成合法下一步,而对生成非法行为的序列则无法捕捉到因果结构。
Key Takeaways:
- GPT模型是否通过学习预测下一个词符来隐含地了解世界模型。
- 通过注意力机制的因果解释,提出了一个因果世界模型。
- GPT模型在推理时间可以用于零步因果结构学习输入序列。
- GPT模型能够根据注意力机制中的因果结构对输出序列的合法性进行自信度评估。
- 在棋类游戏的实证评估中,GPT模型能针对有编码因果结构的非分布序列生成合法下一步。
- GPT模型对生成非法行为的序列无法捕捉到因果结构。
点此查看论文截图


An Efficient Matrix Multiplication Algorithm for Accelerating Inference in Binary and Ternary Neural Networks
Authors:Mohsen Dehghankar, Mahdi Erfanian, Abolfazl Asudeh
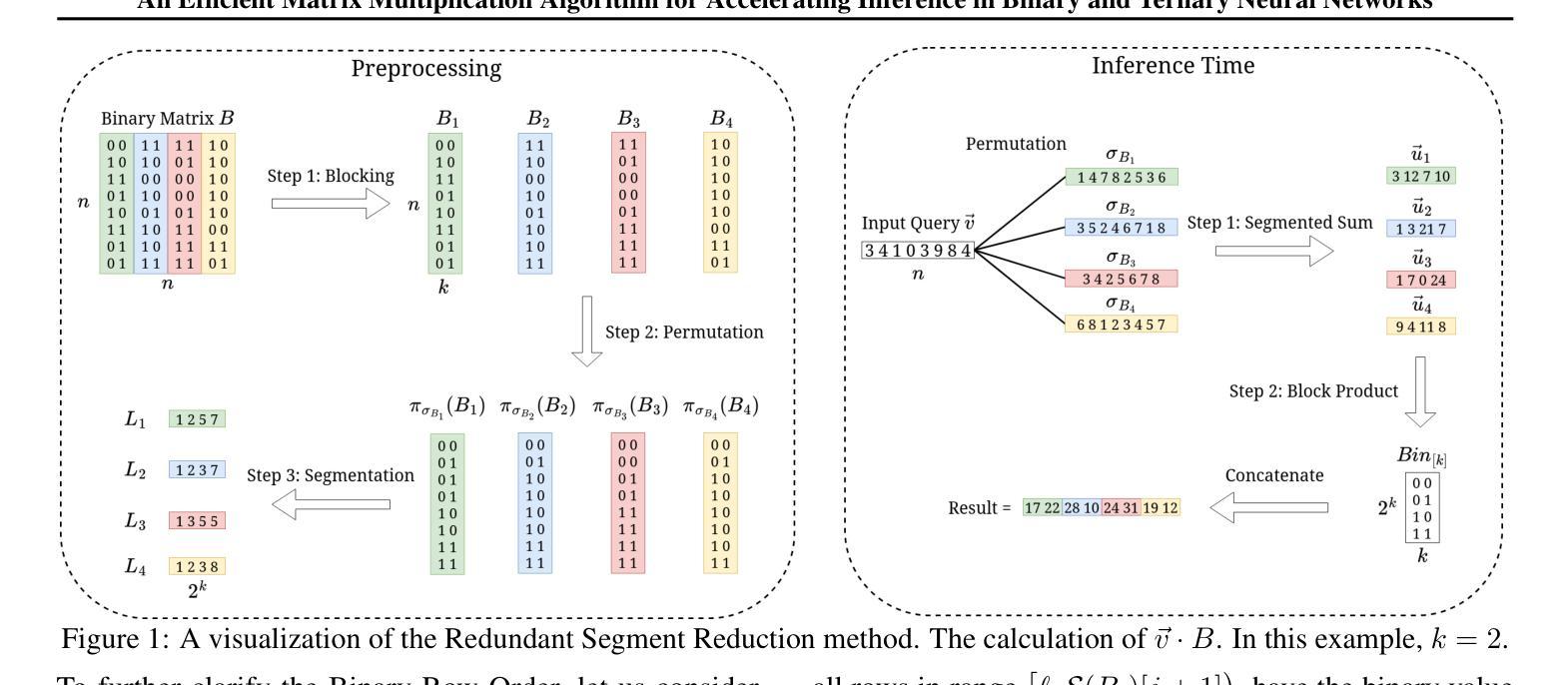
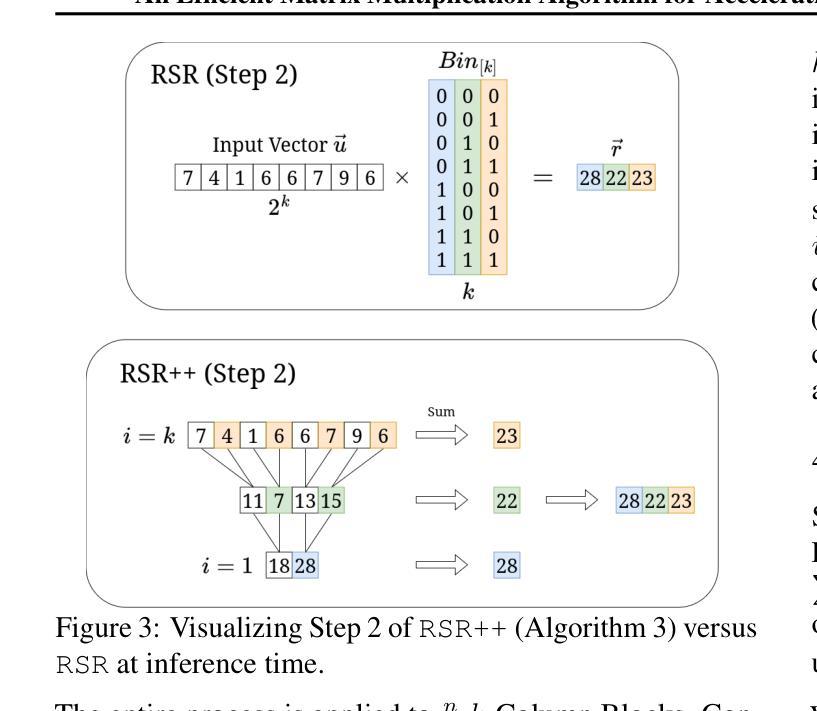
Despite their tremendous success and versatility, Deep Neural Networks (DNNs) such as Large Language Models (LLMs) suffer from inference inefficiency and rely on advanced computational infrastructure. To address these challenges and make these models more accessible and cost-effective, in this paper, we propose algorithms to improve the inference time and memory efficiency of DNNs with binary and ternary weight matrices. Particularly focusing on matrix multiplication as the bottleneck operation of inference, we observe that, once trained, the weight matrices of a model no longer change. This allows us to preprocess these matrices and create indices that help reduce the storage requirements by a logarithmic factor while enabling our efficient inference algorithms. Specifically, for a $n\times n$ weight matrix, our efficient algorithm guarantees a time complexity of $O(\frac{n^2}{\log n})$, a logarithmic factor improvement over the standard vector-matrix multiplication. Besides theoretical analysis, we conduct extensive experiments to evaluate the practical efficiency of our algorithms. Our results confirm the superiority of our approach both with respect to time and memory, as we observed a reduction in the multiplication time up to 29x and memory usage up to 6x. When applied to LLMs, our experiments show up to a 5.24x speedup in the inference time.
尽管深度神经网络(DNNs)如大型语言模型(LLM)取得了巨大的成功并具有极大的灵活性,但它们却面临着推理效率低下的问题,并依赖于先进的计算基础设施。为了应对这些挑战,使这些模型更加易于访问并具有成本效益,本文提出了改进DNN推理时间和内存效率的算法,特别是针对二元和三元权重矩阵。我们重点关注矩阵乘法作为推理过程中的瓶颈操作,观察到一旦训练完成,模型的权重矩阵就不再改变。这使我们能够对这些矩阵进行预处理并创建索引,有助于以对数因子减少存储要求,同时实现高效的推理算法。具体来说,对于$n\times n$的权重矩阵,我们的高效算法保证了时间复杂度为$O(\frac{n^2}{\log n})$,相对于标准向量-矩阵乘法有一个对数因子的改进。除了理论分析外,我们还进行了广泛的实验来评估算法的实际效率。结果证实了我们方法在时间和内存方面的优越性,我们观察到乘法时间减少了高达29倍,内存使用率减少了高达6倍。当应用于LLM时,我们的实验显示推理时间最多可加快5.24倍。
论文及项目相关链接
PDF Accepted at ICML 2025
Summary
该论文针对深度神经网络(DNNs)如大型语言模型(LLMs)的推理效率和内存使用问题,提出了改进算法。通过引入二进制和三元权重矩阵,优化矩阵乘法运算,降低存储需求并提高推理效率。理论分析和实验验证均证明,该方法在时间和内存上均表现出优越性,应用于LLMs时推理速度最快可提高5.24倍。
Key Takeaways
- 该论文关注深度神经网络(DNNs)如大型语言模型(LLMs)的推理效率和内存效率问题。
- 论文提出了使用二进制和三元权重矩阵的算法,以优化矩阵乘法运算,从而提高推理效率。
- 论文观察到训练后的权重矩阵不再改变,因此可以对其进行预处理并建立索引,以降低存储要求。
- 对于$n\times n$的权重矩阵,论文提出的算法保证时间复杂度为$O(\frac{n^2}{\log n})$,较标准向量矩阵乘法有对数级的改进。
- 实验结果表明,该算法在时间和内存上均表现出优越性,乘法时间最多可减少29倍,内存使用最多可减少6倍。
- 当应用于LLMs时,该算法可提高推理速度,最快可提高5.24倍。
- 该论文为DNNs的推理效率和内存使用问题提供了新的解决方案。
点此查看论文截图



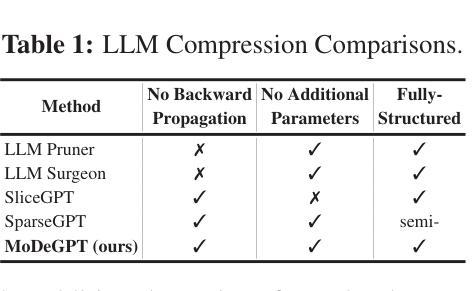
MoDeGPT: Modular Decomposition for Large Language Model Compression
Authors:Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu
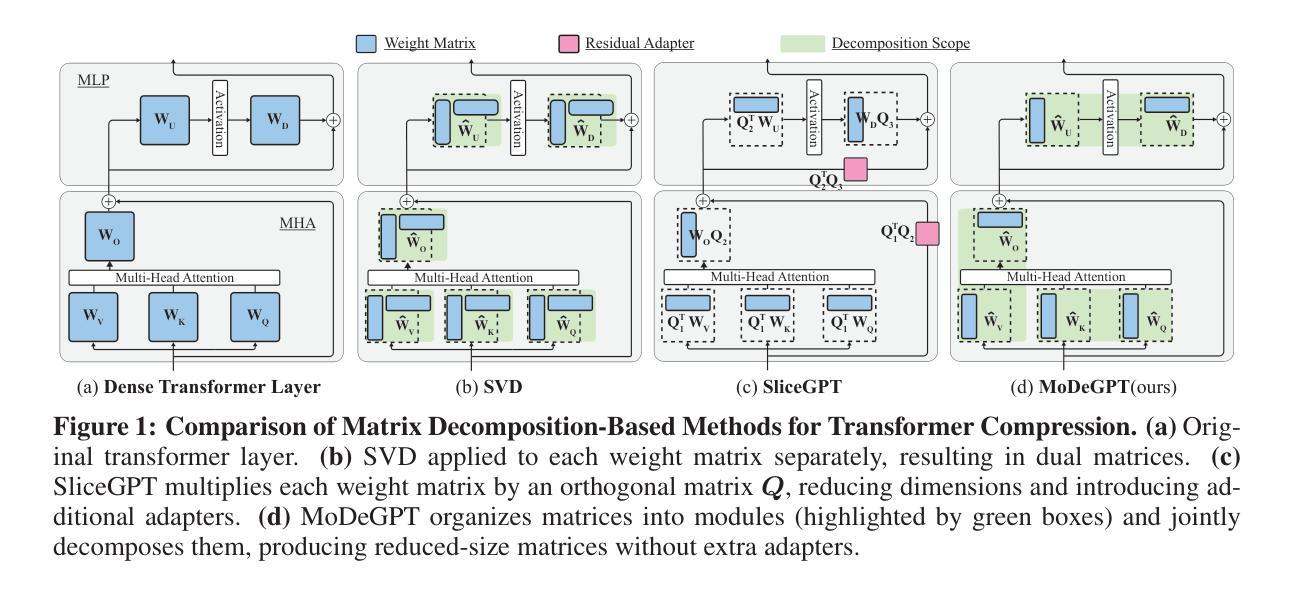
Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms – Nystr"om approximation, CR decomposition, and SVD – and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.
大型语言模型(LLM)在各项任务中表现出卓越的性能,从而改变了人工智能领域的格局。然而,由于其巨大的计算需求,在资源有限的设备上部署这些模型具有挑战性。最近,使用低秩矩阵技术的压缩方法显示出潜力,但这些方法往往会导致精度下降或在参数和推理延迟方面引入显著开销。本文介绍了MoDeGPT,这是一种新型结构化压缩框架,无需恢复微调即可解决上述缺点。MoDeGPT将Transformer块分区成由矩阵对组成的模块,并通过重建模块级输出降低隐藏维度。MoDeGPT是基于一个理论框架开发的,该框架利用三种成熟的矩阵分解算法——Nyström近似、CR分解和SVD——并将它们应用于我们重新定义的变压器模块。我们的综合实验表明,MoDeGPT无需反向传播即可匹配或超越依赖梯度信息的先前结构化压缩方法,并在压缩13B模型时节省了98%的计算成本。在\textsc{Llama}-2/3和OPT模型上,MoDeGPT在25-30%的压缩率下保持了90-95%的零样本性能。此外,压缩可以在单个GPU上于几小时内完成,并且最多可提高推理吞吐量达46%。
论文及项目相关链接
PDF ICLR 2025 Oral
Summary
LLM的性能令人瞩目,但其巨大的计算需求在资源有限的设备上部署是一大挑战。最近,低秩矩阵技术的压缩方法展现出潜力,但可能导致精度下降或增加参数和推理延迟。本文提出MoDeGPT,一种新型结构化压缩框架,无需恢复微调即可解决上述问题。MoDeGPT将Transformer块分区为模块,利用三种矩阵分解算法,实现模块级别的输出重建和隐藏维度的减少。实验显示,MoDeGPT在不进行反向传播的情况下,超越依赖梯度信息的传统压缩方法,在压缩13B模型时节省98%的计算成本。对于Llama-2/3和OPT模型,MoDeGPT在保持90-95%零样本性能的同时实现25-30%的压缩率,且压缩过程可在单个GPU上几小时内完成,提高推理速度达46%。
Key Takeaways
- LLM展现了强大的性能,但在资源受限设备上的部署存在挑战。
- 低秩矩阵技术的压缩方法虽然显示出潜力,但可能带来精度损失和额外的参数与推理延迟。
- MoDeGPT是一种新型结构化压缩框架,通过模块分解解决上述问题,无需恢复微调。
- MoDeGPT将Transformer块划分为模块并运用三种矩阵分解算法,实现模块级别的输出重建和隐藏维度减少。
- MoDeGPT在不进行反向传播的情况下超越传统压缩方法,大幅节省计算成本。
- MoDeGPT在保持高零样本性能的同时实现较高的压缩率。
点此查看论文截图



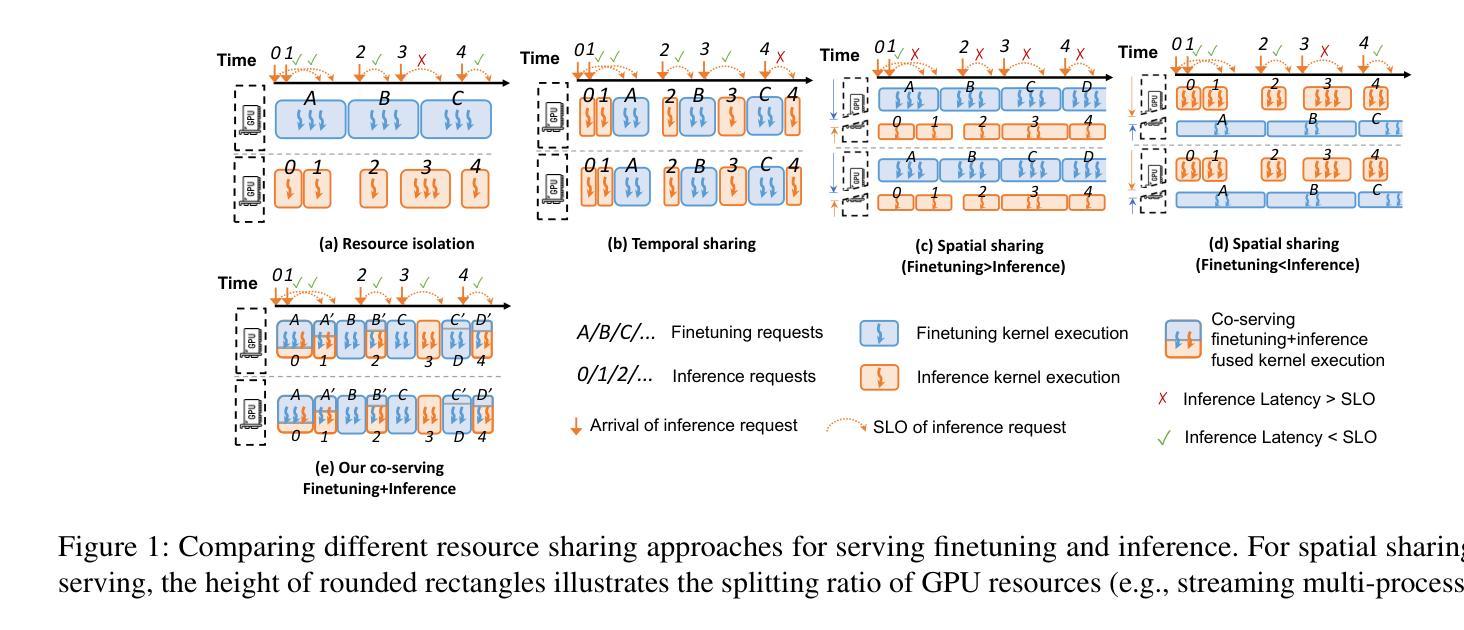
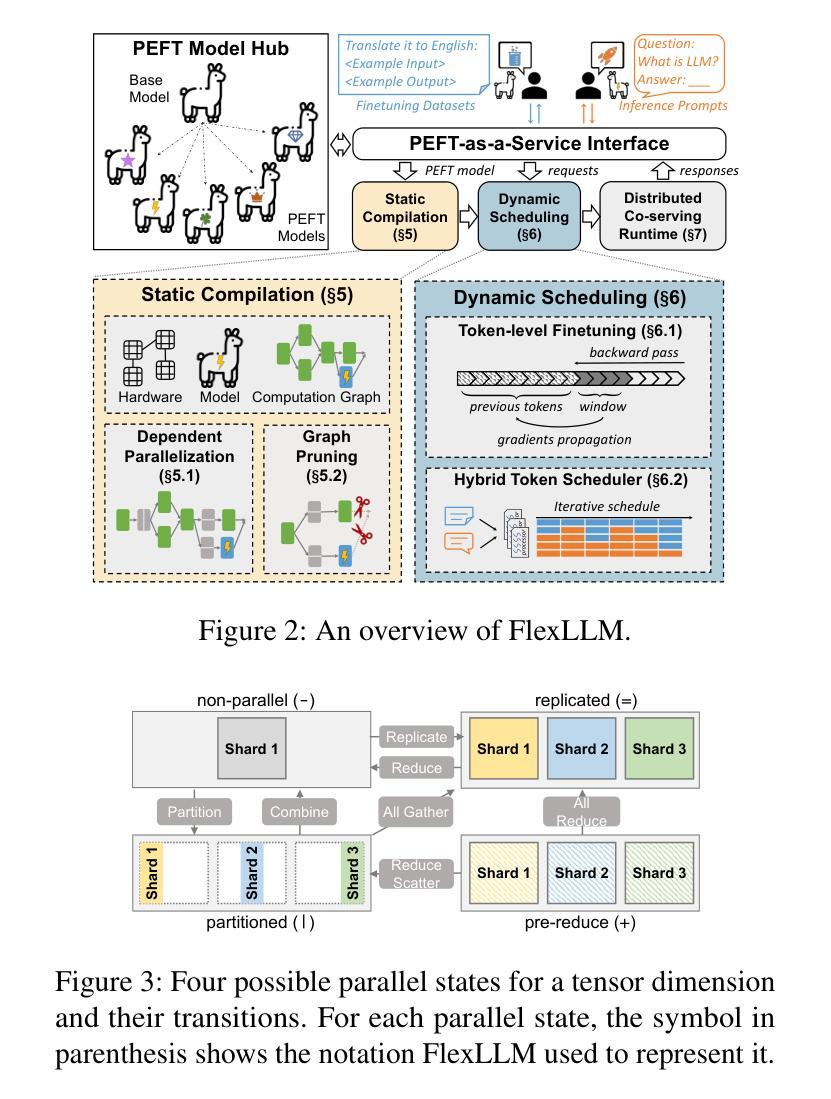
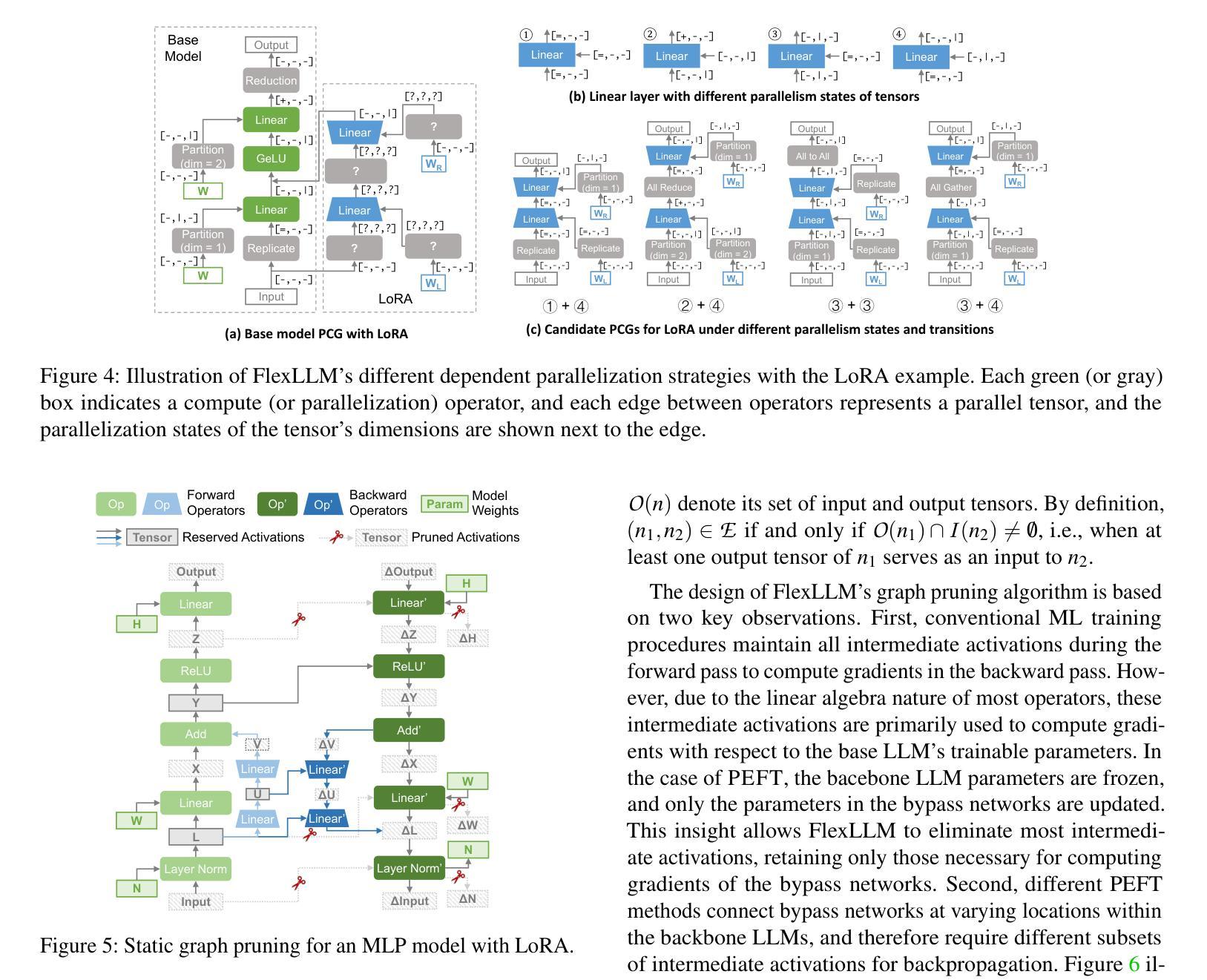
FlexLLM: A System for Co-Serving Large Language Model Inference and Parameter-Efficient Finetuning
Authors:Gabriele Oliaro, Xupeng Miao, Xinhao Cheng, Vineeth Kada, Ruohan Gao, Yingyi Huang, Remi Delacourt, April Yang, Yingcheng Wang, Mengdi Wu, Colin Unger, Zhihao Jia
Finetuning large language models (LLMs) is essential for task adaptation, yet serving stacks today isolate inference and finetuning on separate GPU clusters – wasting resources and under-utilizing hardware. We introduce FlexLLM, the first system to co-serve LLM inference and PEFT-based finetuning on shared GPUs by fusing computation at the token level. The static compilation optimizations in FlexLLM – dependent parallelization and graph pruning significantly shrink activation memory, leading to end-to-end GPU memory savings by up to 80%. At runtime, a novel token-level finetuning mechanism paired with a hybrid token scheduler dynamically interleaves inference and training tokens within each co-serving iteration, meeting strict latency SLOs while maximizing utilization. In end-to-end benchmarks on LLaMA-3.1-8B, Qwen-2.5-14B, and Qwen-2.5-32B, FlexLLM sustains the inference SLO requirements up to 20 req/s, and improves finetuning throughput by 1.9-4.8x under heavy inference workloads and 2.5-6.8x under light loads, preserving over 76% of peak finetuning progress even at peak demand. The source code of FlexLLM is publicly available at https://github.com/flexflow/FlexFlow/.
微调大型语言模型(LLM)对于任务适应至关重要,然而,当前的服务器堆栈将推理和微调隔离在不同的GPU集群上,这浪费了资源并未能充分利用硬件。我们推出了FlexLLM,这是第一个能够在共享GPU上共同提供LLM推理和基于PEFT的微调的系统,通过令牌级别的融合计算来实现。FlexLLM中的静态编译优化——依赖并行化和图修剪,极大地减少了激活内存,导致端到端GPU内存节省高达80%。运行时,一种新型令牌级微调机制与混合令牌调度程序相结合,在每个共同服务迭代中动态交错推理和训练令牌,满足严格的延迟SLO要求,同时最大限度地提高利用率。在LLaMA-3.1-8B、Qwen-2.5-14B和Qwen-2.5-32B的端到端基准测试中,FlexLLM维持了高达20 req/s的推理SLO要求,并在重推理工作负载下提高微调吞吐量1.9-4.8倍,在轻负载下提高2.5-6.8倍。即使在高峰需求时,也能保持超过76%的峰值微调进度。FlexLLM的源代码已在https://github.com/flexflow/FlexFlow/上公开可用。
论文及项目相关链接
Summary
大型语言模型(LLM)的微调对于任务适应至关重要,但目前的服务堆栈将推理和微调隔离在单独的GPU集群上,浪费资源且未能充分利用硬件。FlexLLM系统首次实现了在共享GPU上同时提供LLM推理和基于PEFT的微调服务,通过令牌级别的融合计算。FlexLLM的静态编译优化,如依赖并行化和图剪枝,显著减少了激活内存,实现了端到端GPU内存节省高达80%。运行时,一种新的令牌级微调机制与混合令牌调度器相结合,在每个协同服务迭代中动态交替推理和训练令牌,满足严格的延迟SLO要求,同时最大化利用率。在LLaMA-3.1-8B、Qwen-2.5-14B和Qwen-2.5-32B的端到端基准测试中,FlexLLM维持了推理SLO要求,并在重负载和轻负载下分别提高了微调吞吐量的1.9-4.8倍和2.5-6.8倍,即使在高峰需求时也能保持超过76%的峰值微调进度。
Key Takeaways
- FlexLLM系统允许在共享GPU上同时进行LLM推理和微调,提高了资源利用率。
- 通过令牌级别的融合计算,FlexLLM优化了计算过程。
- 静态编译优化(如依赖并行化和图剪枝)显著减少了激活内存使用。
- FlexLLM实现了高达80%的端到端GPU内存节省。
- 新的令牌级微调机制和混合令牌调度器动态交替推理和训练过程,满足延迟要求并最大化利用率。
- 在多种LLM基准测试中,FlexLLM维持了推理性能并显著提高了微调吞吐量。
点此查看论文截图