⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-06 更新
Model See Model Do: Speech-Driven Facial Animation with Style Control
Authors:Yifang Pan, Karan Singh, Luiz Gustavo Hafemann
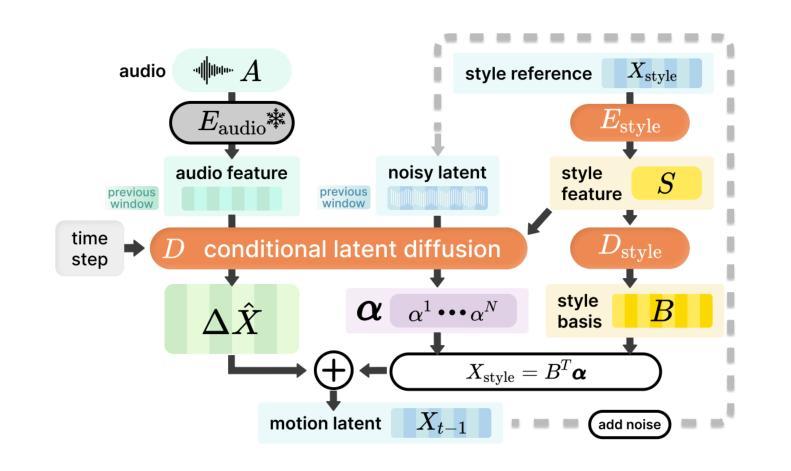
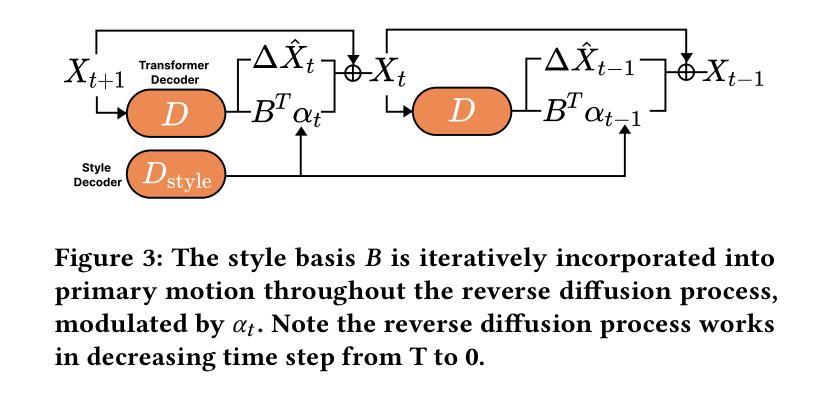
Speech-driven 3D facial animation plays a key role in applications such as virtual avatars, gaming, and digital content creation. While existing methods have made significant progress in achieving accurate lip synchronization and generating basic emotional expressions, they often struggle to capture and effectively transfer nuanced performance styles. We propose a novel example-based generation framework that conditions a latent diffusion model on a reference style clip to produce highly expressive and temporally coherent facial animations. To address the challenge of accurately adhering to the style reference, we introduce a novel conditioning mechanism called style basis, which extracts key poses from the reference and additively guides the diffusion generation process to fit the style without compromising lip synchronization quality. This approach enables the model to capture subtle stylistic cues while ensuring that the generated animations align closely with the input speech. Extensive qualitative, quantitative, and perceptual evaluations demonstrate the effectiveness of our method in faithfully reproducing the desired style while achieving superior lip synchronization across various speech scenarios.
语音驱动的3D面部动画在虚拟化身、游戏和数字内容创建等应用中扮演着关键角色。尽管现有方法在实现准确的唇部同步和生成基本情感表达方面取得了显著进展,但它们往往难以捕捉和有效转移细微的表现风格。我们提出了一种基于示例的生成框架,该框架以参考风格片段为条件,利用潜在扩散模型生成高度表达且时间连贯的面部动画。为解决准确遵循风格参考的挑战,我们引入了一种新的条件机制,称为风格基础,它从参考中提取关键姿势,并通过扩散生成过程进行加法指导,以适合风格而不损害唇部同步质量。这种方法使模型能够捕捉细微的风格线索,同时确保生成的动画与输入语音紧密对齐。广泛的定性、定量和感知评估表明,我们的方法在忠实再现所需风格的同时,在各种语音场景中实现了卓越的唇部同步效果。
论文及项目相关链接
PDF 10 pages, 7 figures, SIGGRAPH Conference Papers ‘25
Summary
本文介绍了基于语音驱动的3D面部动画技术,在虚拟角色、游戏和数字内容创作等领域有广泛应用。现有方法虽可实现准确的唇同步和基本情感表达,但在捕捉和转移微妙的表演风格上仍有困难。本文提出了一种新颖的基于实例的生成框架,通过条件扩散模型以参考风格片段为条件,生成高度表达和情感连贯的面部动画。为解决准确贴合风格参考的挑战,引入了一种名为“风格基础”的新条件机制,从参考中提取关键姿势,并增加性地引导扩散生成过程,以贴合风格而不影响唇同步质量。该方法既保证了动画与输入语音的紧密对齐,又能捕捉微妙的风格线索。
Key Takeaways
- 语音驱动的3D面部动画在虚拟角色、游戏和数字内容创作等领域有重要应用。
- 现有方法在捕捉和转移微妙的表演风格上遇到困难。
- 提出了一种基于实例的生成框架,通过条件扩散模型以参考风格片段为条件,生成高度表达和情感连贯的面部动画。
- 引入了“风格基础”机制,从参考中提取关键姿势,并引导扩散生成过程以贴合风格。
- 方法在保证唇同步质量的同时,能捕捉微妙的风格线索。
- 进行了多方面的评估,证明该方法在忠实复制期望的风格和实现优质唇同步方面效果显著。
点此查看论文截图

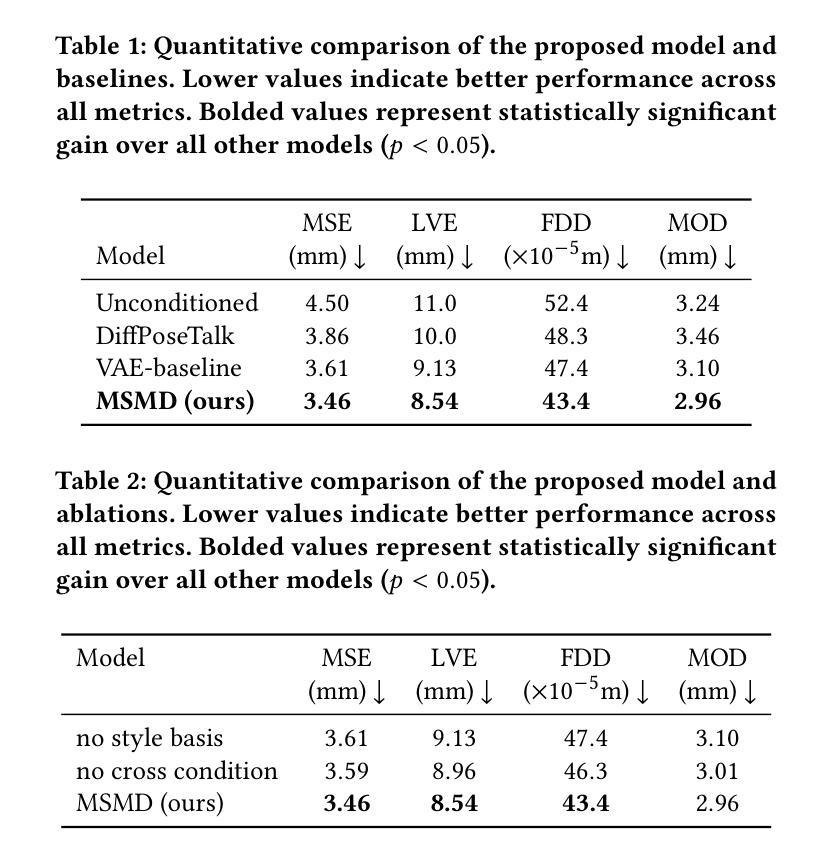
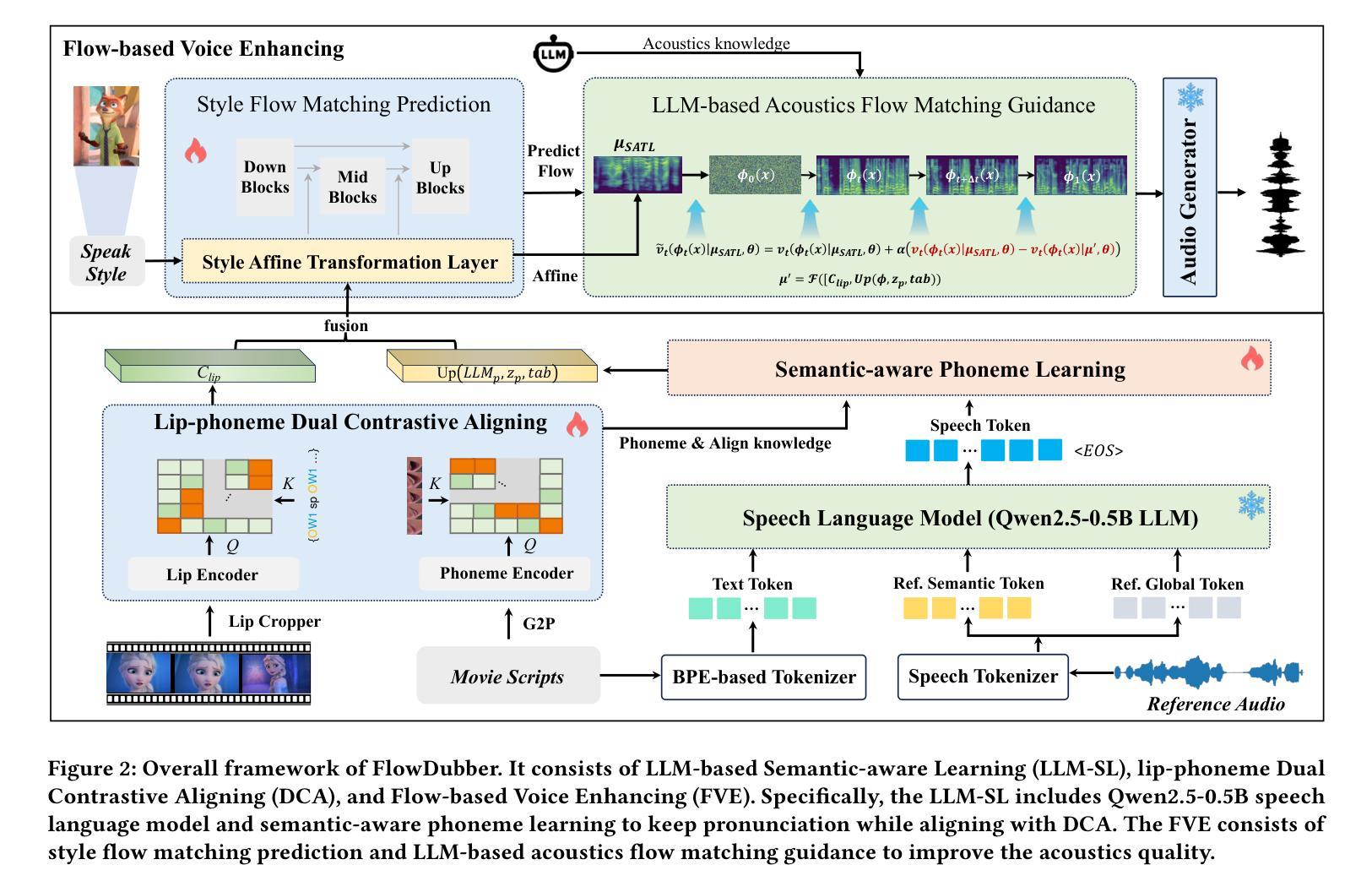
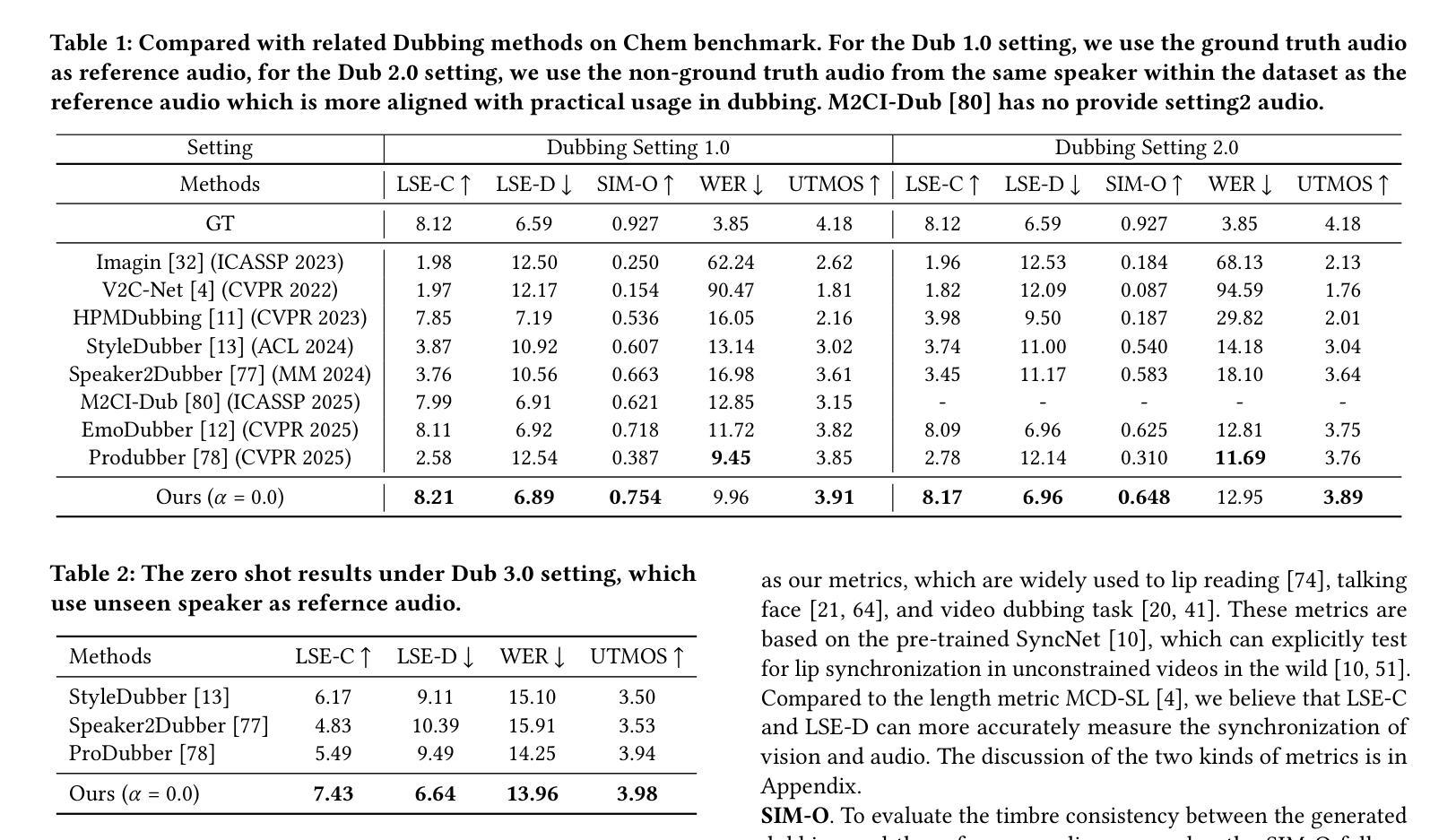
FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing
Authors:Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton van den Hengel, Yuankai Qi, Qingming Huang
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of a given brief reference audio. Existing methods focus primarily on reducing the word error rate while ignoring the importance of lip-sync and acoustic quality. To address these issues, we propose a large language model (LLM) based flow matching architecture for dubbing, named FlowDubber, which achieves high-quality audio-visual sync and pronunciation by incorporating a large speech language model and dual contrastive aligning while achieving better acoustic quality via the proposed voice-enhanced flow matching than previous works. First, we introduce Qwen2.5 as the backbone of LLM to learn the in-context sequence from movie scripts and reference audio. Then, the proposed semantic-aware learning focuses on capturing LLM semantic knowledge at the phoneme level. Next, dual contrastive aligning (DCA) boosts mutual alignment with lip movement, reducing ambiguities where similar phonemes might be confused. Finally, the proposed Flow-based Voice Enhancing (FVE) improves acoustic quality in two aspects, which introduces an LLM-based acoustics flow matching guidance to strengthen clarity and uses affine style prior to enhance identity when recovering noise into mel-spectrograms via gradient vector field prediction. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks. The demos are available at {\href{https://galaxycong.github.io/LLM-Flow-Dubber/}{\textcolor{red}{https://galaxycong.github.io/LLM-Flow-Dubber/}}}.
电影配音旨在将剧本转换为与给定电影片段在时间和情感方面都对齐的演讲,同时保留给定简短参考音频的音色。现有方法主要关注降低词错误率,而忽视唇同步和音质的重要性。为了解决这些问题,我们提出了一种基于大型语言模型(LLM)的配音流匹配架构,名为FlowDubber。它通过结合大型语音语言模型和双对比对齐,同时提出语音增强流匹配,实现了高质量的声音和视觉同步以及发音。首先,我们引入Qwen2.5作为LLM的骨干,从电影剧本和参考音频中学习上下文序列。然后,所提出的语义感知学习侧重于在音素级别捕获LLM语义知识。接下来,双对比对齐(DCA)通过唇部运动增强相互对齐,减少相似音素的混淆。最后,提出的基于流的语音增强(FVE)从两个方面提高了音质:它引入基于LLM的声学流匹配指导,以提高清晰度,并使用仿射风格先验来增强身份特征,通过梯度矢量场预测将噪声恢复为梅尔频谱。大量实验表明,我们的方法在两个主要基准测试上优于几种最新技术。演示视频可在{\href{https://galaxycong.github.io/LLM-Flow-Dubber/}{\textcolor{red}{https://galaxycong.github.io/LLM-Flow-Dubber/}}}查看。
论文及项目相关链接
Summary
本文介绍了针对电影配音的一种新方法——FlowDubber。该方法基于大型语言模型(LLM),实现了高质量的电影音频与视觉同步,通过引入Qwen2.5作为LLM的骨干,结合语义感知学习和双重对比对齐技术,提高了语音质量。此外,该方法还引入了基于流的语音增强技术,提高了声学质量。实验证明,该方法在主流基准测试中表现优于其他方法。
Key Takeaways
- FlowDubber是一种基于大型语言模型的电影配音方法,旨在实现高质量的电影音频与视觉同步。
- Qwen2.5作为LLM的骨干用于学习电影剧本和参考音频的上下文序列。
- 语义感知学习可以捕获LLM的语义知识,并用于提高语音质量。
- 双重对比对齐技术提高了语音与唇部动作的相互对齐精度。
- 基于流的语音增强技术提高了声学质量,通过LLM的声学流匹配指导增强了语音清晰度。
点此查看论文截图

EmoGene: Audio-Driven Emotional 3D Talking-Head Generation
Authors:Wenqing Wang, Yun Fu
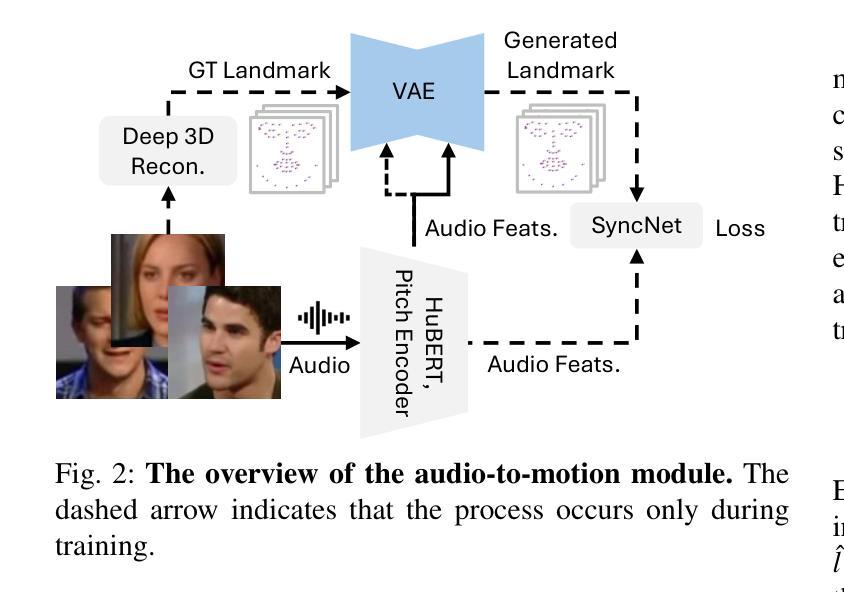
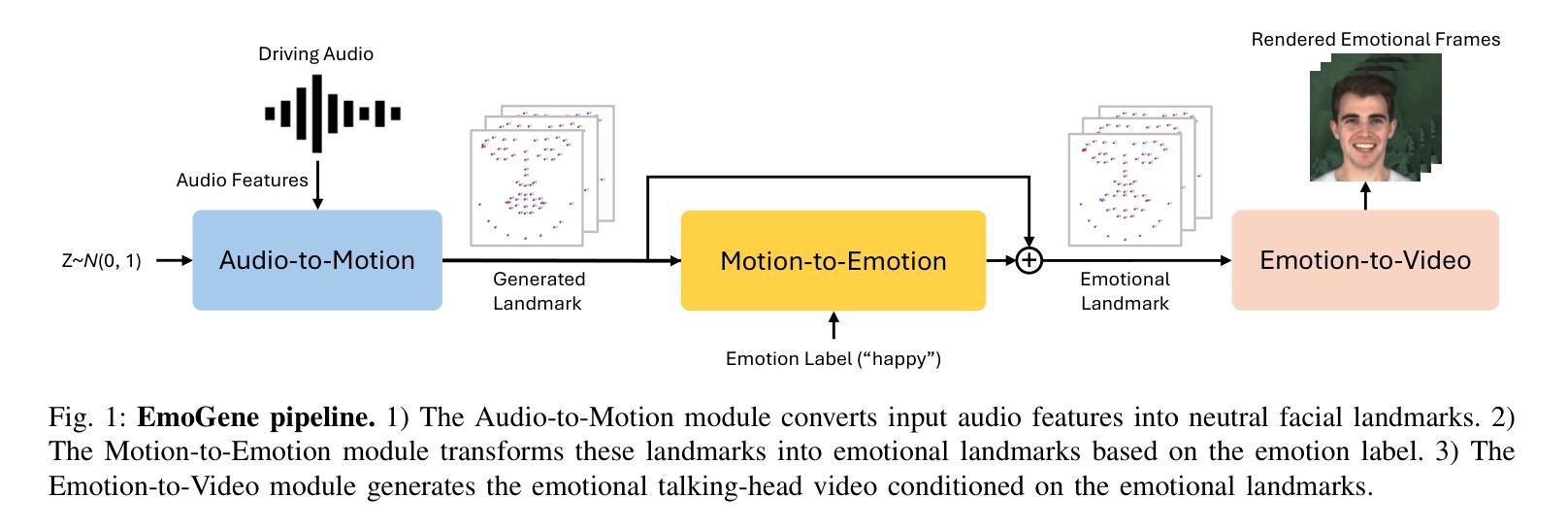
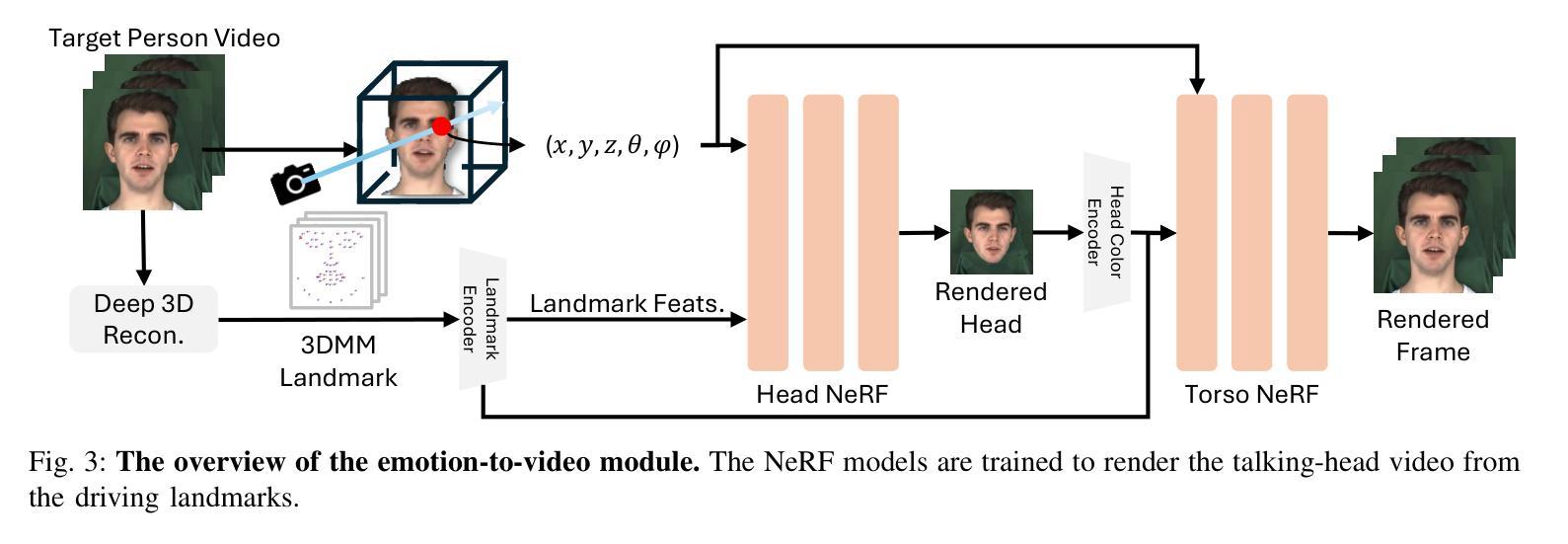
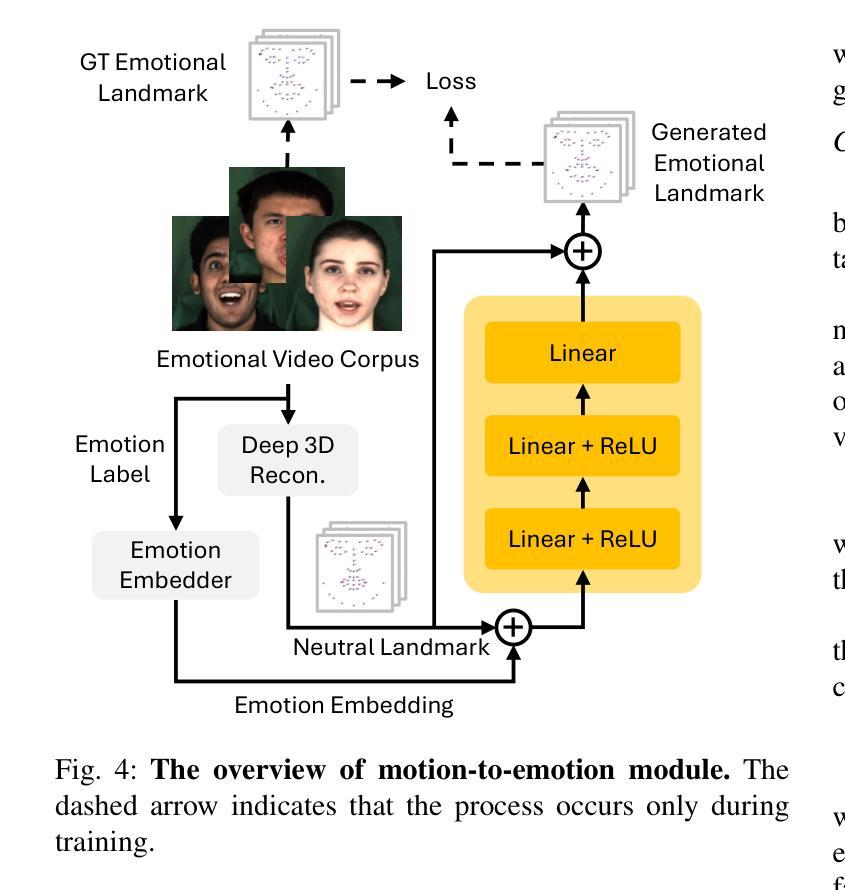
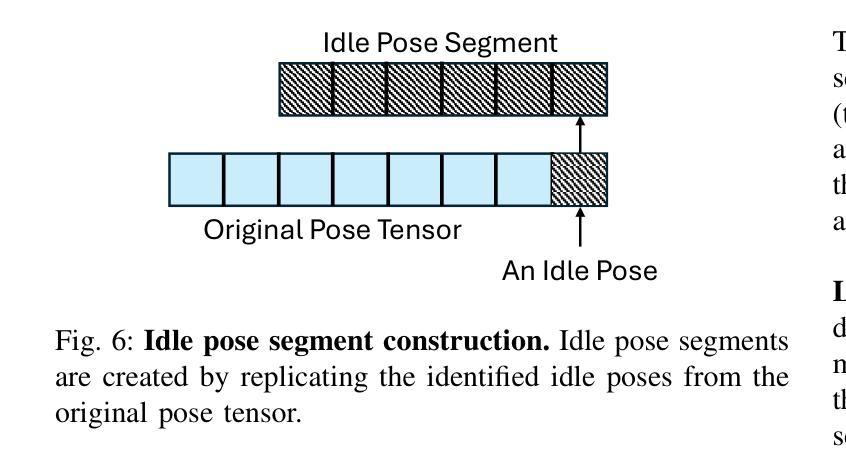
Audio-driven talking-head generation is a crucial and useful technology for virtual human interaction and film-making. While recent advances have focused on improving image fidelity and lip synchronization, generating accurate emotional expressions remains underexplored. In this paper, we introduce EmoGene, a novel framework for synthesizing high-fidelity, audio-driven video portraits with accurate emotional expressions. Our approach employs a variational autoencoder (VAE)-based audio-to-motion module to generate facial landmarks, which are concatenated with emotional embedding in a motion-to-emotion module to produce emotional landmarks. These landmarks drive a Neural Radiance Fields (NeRF)-based emotion-to-video module to render realistic emotional talking-head videos. Additionally, we propose a pose sampling method to generate natural idle-state (non-speaking) videos for silent audio inputs. Extensive experiments demonstrate that EmoGene outperforms previous methods in generating high-fidelity emotional talking-head videos.
音频驱动的说话人头部生成是虚拟人机交互和电影制作中一项至关重要的技术。虽然最近的进步主要集中在提高图像保真度和唇部同步方面,但生成准确的情绪表达仍然被较少研究。在本文中,我们介绍了EmoGene,这是一种合成高保真、音频驱动的带有准确情绪表达的视频肖像的新型框架。我们的方法采用基于变分自动编码器(VAE)的音频到动作模块来生成面部特征点,这些特征点与动作到情感模块中的情感嵌入进行组合,产生情感特征点。这些特征点驱动基于神经辐射场(NeRF)的情感到视频模块,以呈现逼真的情感化说话头部视频。此外,我们还提出了一种姿态采样方法,以生成用于静默音频输入的天然非讲话状态视频。大量实验表明,EmoGene在生成高保真情绪化谈话头部视频方面优于以前的方法。
论文及项目相关链接
PDF Accepted by the 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG)
Summary
本文介绍了一种名为EmoGene的新型框架,该框架用于合成高保真音频驱动的视频肖像,并具备准确的情感表达。它采用变分自编码器(VAE)基础的音频到运动模块来生成面部地标,与情感嵌入在运动到情感模块中结合,产生情感地标。这些地标驱动基于神经辐射场(NeRF)的情感到视频模块,以呈现真实的情感谈话头视频。此外,该研究还提出了一种姿态采样方法,用于生成针对无声音频输入的自然的静止状态视频。实验表明,EmoGene在生成高保真情感谈话头视频方面优于先前的方法。
Key Takeaways
- EmoGene是一个用于合成高保真音频驱动的视频肖像的框架,具备准确的情感表达功能。
- 该框架采用变分自编码器(VAE)基础的音频到运动模块生成面部地标。
- 运动到情感模块结合情感嵌入,产生情感地标,用于驱动视频渲染。
- 基于神经辐射场(NeRF)的情感到视频模块呈现真实的情感谈话头视频。
- EmoGene还具备生成针对无声音频输入的自然的静止状态视频的能力。
- 框架通过姿态采样方法实现更自然的视频生成。
点此查看论文截图