⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-06 更新
TSTMotion: Training-free Scene-awarenText-to-motion Generation
Authors:Ziyan Guo, Haoxuan Qu, Hossein Rahmani, Dewen Soh, Ping Hu, Qiuhong Ke, Jun Liu
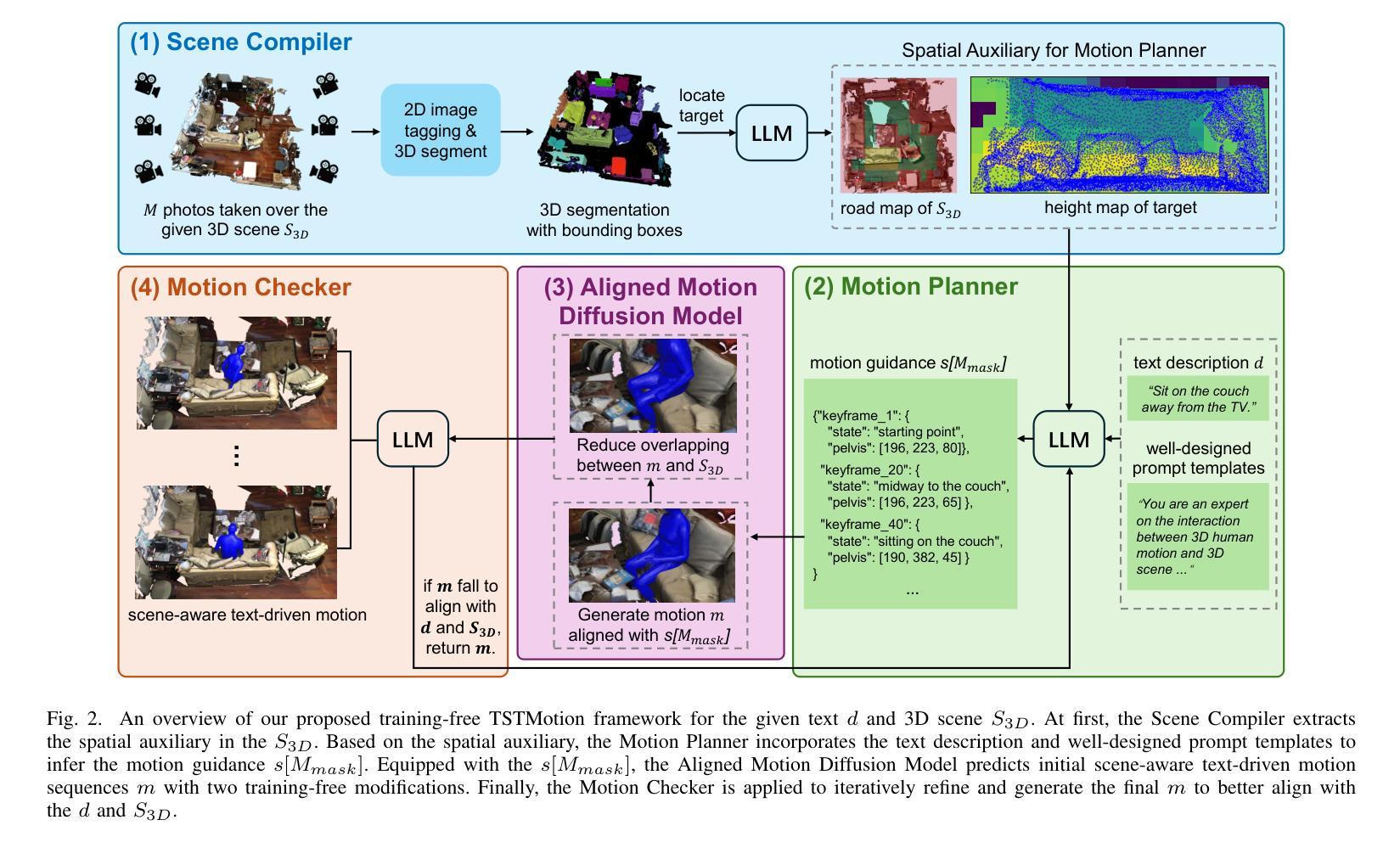
Text-to-motion generation has recently garnered significant research interest, primarily focusing on generating human motion sequences in blank backgrounds. However, human motions commonly occur within diverse 3D scenes, which has prompted exploration into scene-aware text-to-motion generation methods. Yet, existing scene-aware methods often rely on large-scale ground-truth motion sequences in diverse 3D scenes, which poses practical challenges due to the expensive cost. To mitigate this challenge, we are the first to propose a \textbf{T}raining-free \textbf{S}cene-aware \textbf{T}ext-to-\textbf{Motion} framework, dubbed as \textbf{TSTMotion}, that efficiently empowers pre-trained blank-background motion generators with the scene-aware capability. Specifically, conditioned on the given 3D scene and text description, we adopt foundation models together to reason, predict and validate a scene-aware motion guidance. Then, the motion guidance is incorporated into the blank-background motion generators with two modifications, resulting in scene-aware text-driven motion sequences. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework. We release our code in \href{https://tstmotion.github.io/}{Project Page}.
文本到动作生成近期引起了研究者的极大兴趣,主要集中于在空白背景下生成人类动作序列。然而,人类动作通常发生在多样的3D场景中,这促使人们探索场景感知的文本到动作生成方法。然而,现有的场景感知方法常常依赖于大规模真实场景的多样运动序列,这在实际应用中带来了高昂的成本挑战。为了缓解这一挑战,我们首次提出一个无需训练的场景感知文本到动作框架,称为“TSTMotion”,它能够有效地赋予预训练的空白背景动作生成器场景感知能力。具体而言,基于给定的3D场景和文本描述,我们采用基础模型进行推理、预测和验证场景感知动作指导。然后,将该动作指导融入空白背景动作生成器,并进行两次修改,从而生成场景感知的文本驱动动作序列。大量实验证明了我们提出的框架的有效性和泛化能力。我们已在项目页面(https://tstmotion.github.io/)发布我们的代码。
论文及项目相关链接
PDF Accepted by ICME2025
Summary
文本到动作生成技术近期受到研究关注,主要集中于在空白背景下生成人类动作序列。然而,人类动作通常发生在多样的3D场景中,这促使了场景感知文本到动作生成方法的探索。为缓解因大规模真实场景动作序列导致的成本高昂问题,我们首次提出无需训练的场景感知文本到动作生成框架TSTMotion,该框架使预训练空白背景动作生成器具备场景感知能力。通过给定的3D场景和文本描述,我们采用基础模型进行推理、预测和验证场景感知动作指导。然后,将此动作指导融入空白背景动作生成器,进行两次修改,从而生成场景感知文本驱动的动作序列。实验证明,该框架有效且通用性强。我们已在项目页面发布代码。
Key Takeaways
- 文本到动作生成技术受关注,特别是在生成人类动作序列方面。
- 人类动作常发生在多样的3D场景中,推动场景感知文本到动作生成方法的探索。
- 现有场景感知方法依赖大规模真实场景运动序列,导致高昂成本。
- 提出无需训练的场景感知文本到动作生成框架TSTMotion,使预训练模型具备场景感知能力。
- 利用基础模型进行推理、预测和验证场景感知动作指导。
- 将动作指导融入空白背景动作生成器,生成场景感知文本驱动的动作序列。
点此查看论文截图