⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
Authors:Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, Haoqian Wang
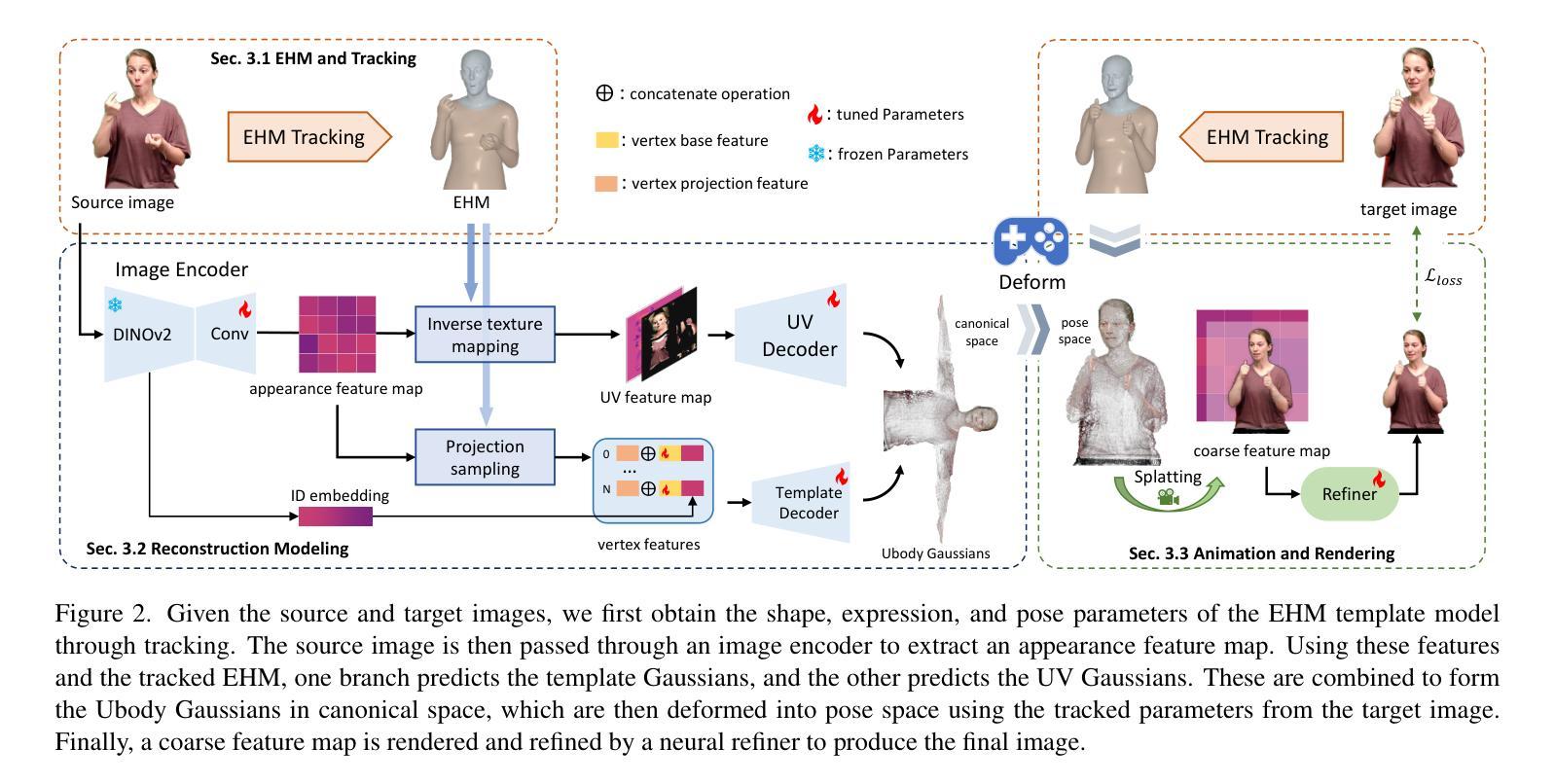
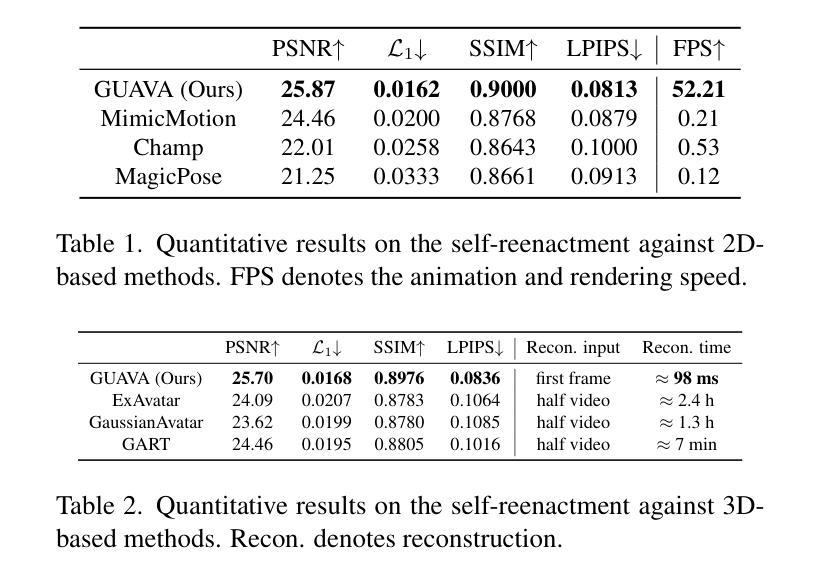
Reconstructing a high-quality, animatable 3D human avatar with expressive facial and hand motions from a single image has gained significant attention due to its broad application potential. 3D human avatar reconstruction typically requires multi-view or monocular videos and training on individual IDs, which is both complex and time-consuming. Furthermore, limited by SMPLX’s expressiveness, these methods often focus on body motion but struggle with facial expressions. To address these challenges, we first introduce an expressive human model (EHM) to enhance facial expression capabilities and develop an accurate tracking method. Based on this template model, we propose GUAVA, the first framework for fast animatable upper-body 3D Gaussian avatar reconstruction. We leverage inverse texture mapping and projection sampling techniques to infer Ubody (upper-body) Gaussians from a single image. The rendered images are refined through a neural refiner. Experimental results demonstrate that GUAVA significantly outperforms previous methods in rendering quality and offers significant speed improvements, with reconstruction times in the sub-second range (0.1s), and supports real-time animation and rendering.
从单幅图像重建高质量、可动画的3D人类角色化身,并赋予其表情丰富、动作自如的面部和手部动作,这一技术因其广泛的应用前景而受到广泛关注。3D人类角色化身的重建通常需要多视角或单眼视频以及针对个体ID进行训练,这一过程既复杂又耗时。此外,受限于SMPLX的表达能力,这些方法通常更侧重于身体动作,而在面部表情方面存在困难。为了应对这些挑战,我们首先引入了一个表现力丰富的人类模型(EHM)来提高面部表情能力,并开发了一种精确的跟踪方法。基于这个模板模型,我们提出了GUAVA,这是第一个用于快速可动画的上半身3D高斯化身重建框架。我们利用逆向纹理映射和投影采样技术,从单幅图像推断出上半身高斯模型(Ubody)。渲染图像通过神经网络优化器进行细化。实验结果表明,GUAVA在渲染质量上大大优于以前的方法,并在速度上实现了显著的提升,重建时间在亚秒范围内(0.1秒),支持实时动画和渲染。
论文及项目相关链接
PDF Project page: https://eastbeanzhang.github.io/GUAVA/
Summary
本文介绍了一种从单张图片重建高质量、可动画的3D人物角色的方法。针对传统方法面临的多视角或单眼视频需求、个体ID训练复杂耗时、以及SMPLX模型表情表现力有限等问题,本文引入了一个表现力更强的人类模型(EHM),并提出了一种基于模板模型的快速可动画化三维高斯体(GUAVA)重建框架。利用逆向纹理映射和投影采样技术,从单张图像中推断出上半身高斯体数据,并通过神经网络对渲染图像进行精炼。实验结果显示,GUAVA在渲染质量上显著优于之前的方法,具有亚秒级的重建时间(0.1秒),并支持实时动画和渲染。
Key Takeaways
- 引入了一种从单张图片重建高质量、可动画的3D人物角色的方法。
- 针对传统重建方法存在的问题,如复杂度和时间消耗大、受限于SMPLX模型的表情表现力不足等进行了改进。
- 引入了表现力更强的人类模型(EHM)以提升面部表达能力。
- 提出了基于模板模型的快速可动画化三维高斯体(GUAVA)重建框架。
- 利用逆向纹理映射和投影采样技术从单张图像推断上半身高斯体数据。
- 通过神经网络精炼渲染图像,提升渲染质量。
点此查看论文截图