⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
RAVU: Retrieval Augmented Video Understanding with Compositional Reasoning over Graph
Authors:Sameer Malik, Moyuru Yamada, Ayush Singh, Dishank Aggarwal
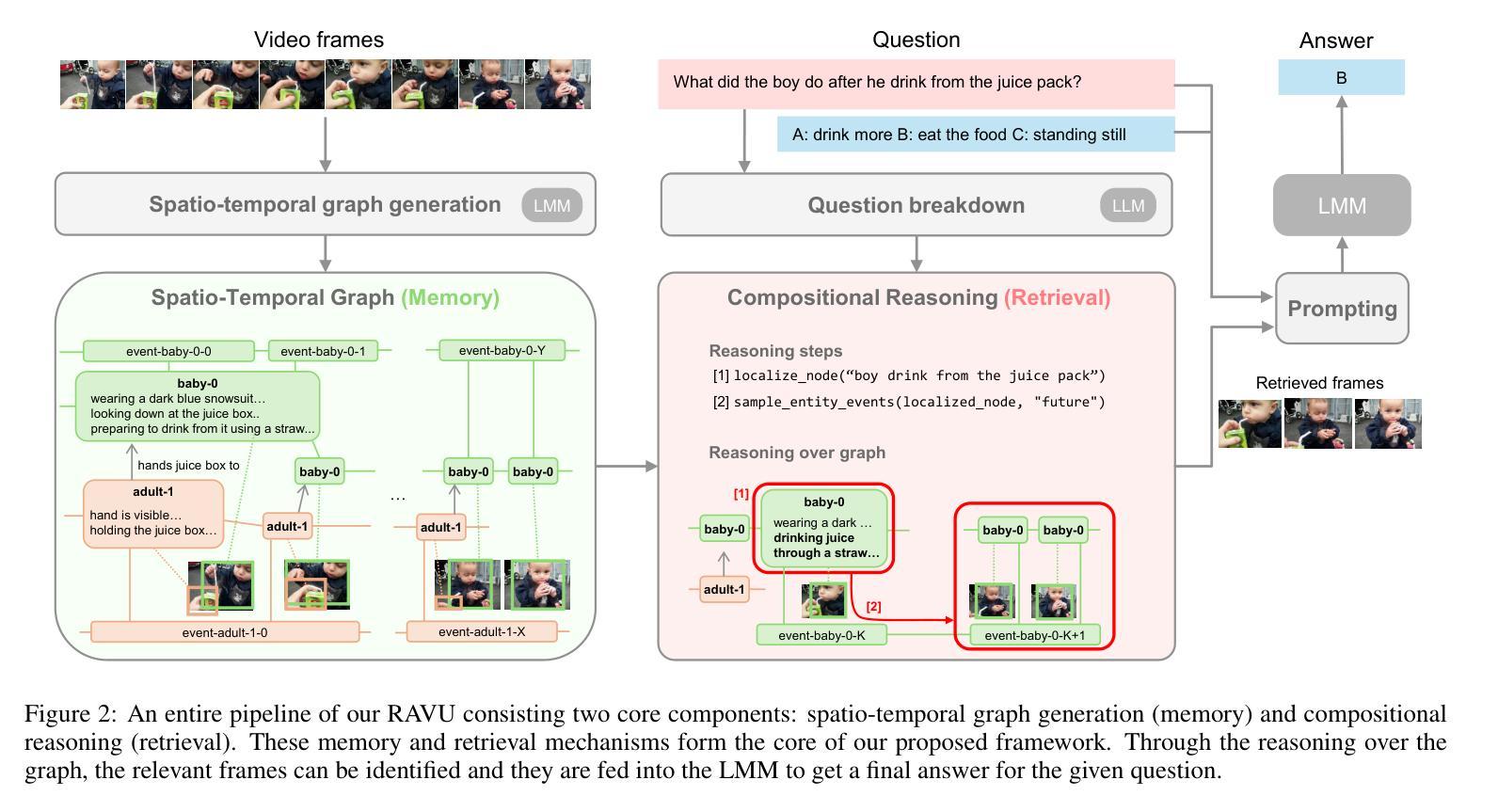
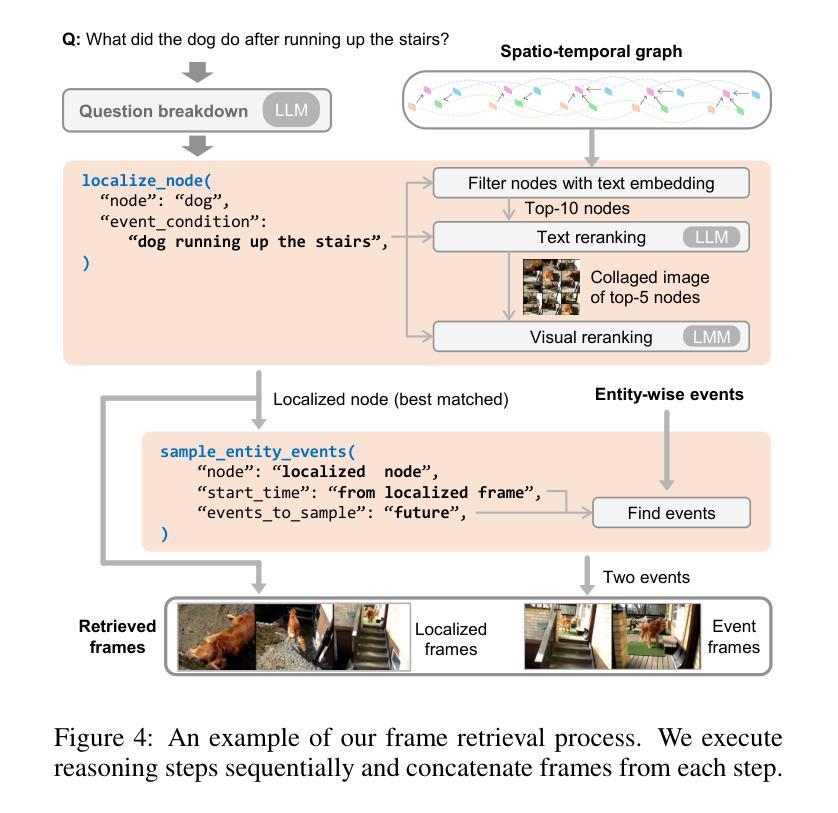
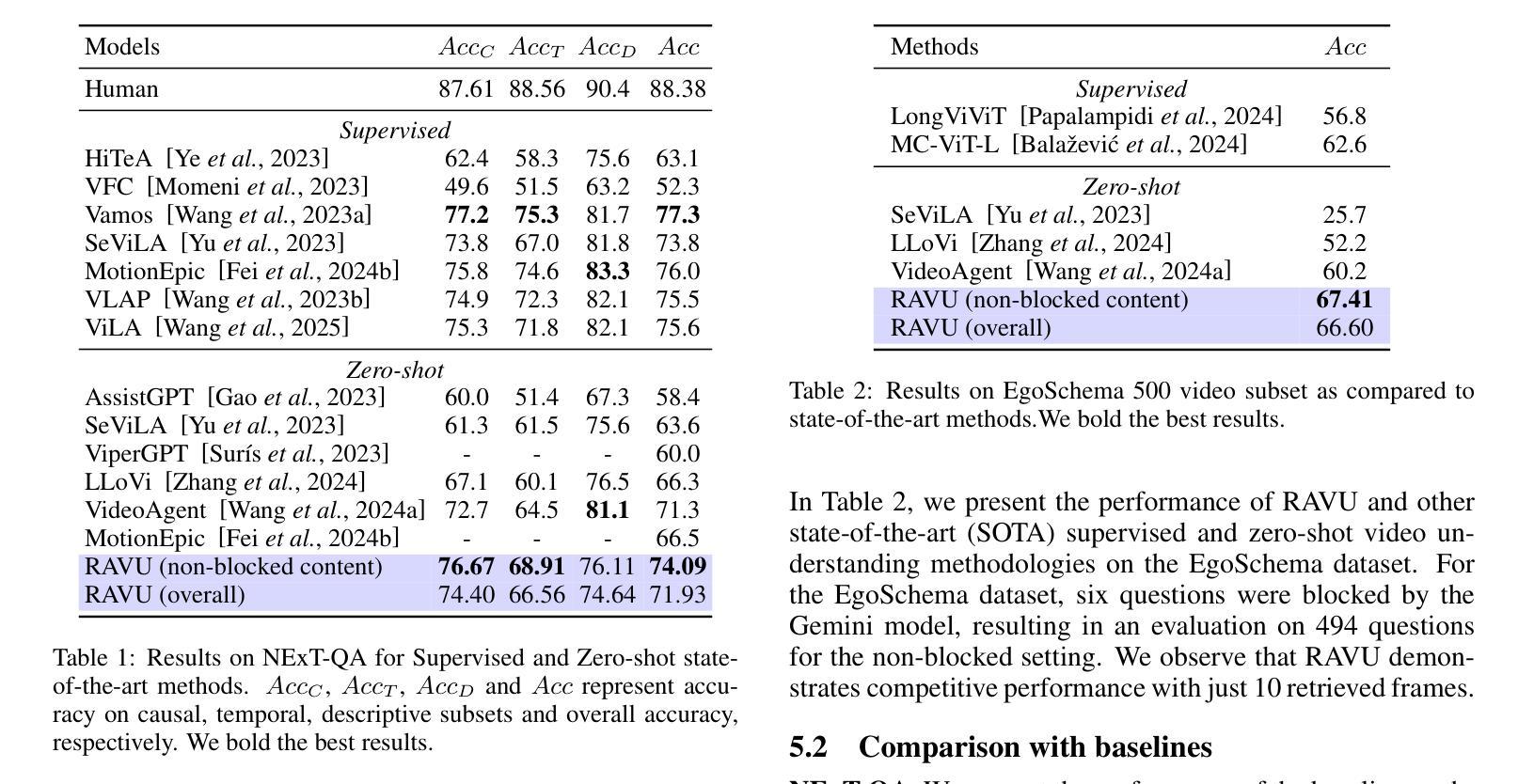
Comprehending long videos remains a significant challenge for Large Multi-modal Models (LMMs). Current LMMs struggle to process even minutes to hours videos due to their lack of explicit memory and retrieval mechanisms. To address this limitation, we propose RAVU (Retrieval Augmented Video Understanding), a novel framework for video understanding enhanced by retrieval with compositional reasoning over a spatio-temporal graph. We construct a graph representation of the video, capturing both spatial and temporal relationships between entities. This graph serves as a long-term memory, allowing us to track objects and their actions across time. To answer complex queries, we decompose the queries into a sequence of reasoning steps and execute these steps on the graph, retrieving relevant key information. Our approach enables more accurate understanding of long videos, particularly for queries that require multi-hop reasoning and tracking objects across frames. Our approach demonstrate superior performances with limited retrieved frames (5-10) compared with other SOTA methods and baselines on two major video QA datasets, NExT-QA and EgoSchema.
理解长视频对于大型多模态模型(LMMs)来说仍然是一个巨大的挑战。由于当前LMM缺乏明确的记忆和检索机制,它们难以处理甚至长达数小时的视频。为了解决这个问题,我们提出了RAVU(基于检索辅助的视频理解),这是一种通过时空图上的组合推理增强视频理解的新型框架。我们构建了视频的图表示,捕捉实体之间的空间和时间关系。该图作为长期记忆,使我们能够跟踪跨越时间的对象和它们的动作。为了回答复杂的查询,我们将查询分解成一系列的推理步骤并在图上执行这些步骤,检索相关的关键信息。我们的方法使我们对长视频有更准确的了解,特别是对于需要多跳推理和跨帧跟踪对象的查询。与其他SOTA方法和基线相比,我们的方法在两大视频QA数据集NExT-QA和EgoSchema上展示了优越的性能,即使只检索了有限的帧数(5-10)。
论文及项目相关链接
Summary
RAVU(Retrieval Augmented Video Understanding)是一种新型的视频理解框架,它通过构建时空图来解决大型多模态模型处理长时间视频时的记忆和检索机制不足的问题。该框架将视频表示为图形,捕捉实体之间的空间和时间关系,作为长期记忆来跟踪物体和它们在时间上的行为。对于复杂的查询,RAVU将其分解为一系列的推理步骤并在图形上执行这些步骤以检索相关信息。此方法提高了对长时间视频的准确理解能力,特别是在需要多跳推理和跨帧跟踪对象的查询方面。在主要的视频问答数据集NExT-QA和EgoSchema上,相较于其他前沿方法和基线,该方法在有限的检索帧(5-10帧)内表现出卓越的性能。
Key Takeaways
- RAVU是一种新型视频理解框架,旨在解决大型多模态模型处理长时间视频的难题。
- 该框架通过构建时空图来捕捉视频中的空间和时间关系。
- RAVU利用图形作为长期记忆,以便跟踪物体和它们在时间上的行为。
- 对于复杂的查询,RAVU将其分解为推理步骤并在图形上执行以检索信息。
- 该方法提高了对长时间视频的准确理解能力,特别是在需要多跳推理和跨帧跟踪对象的查询方面。
- 在主要的视频问答数据集上,RAVU相较于其他方法表现出卓越的性能。
点此查看论文截图


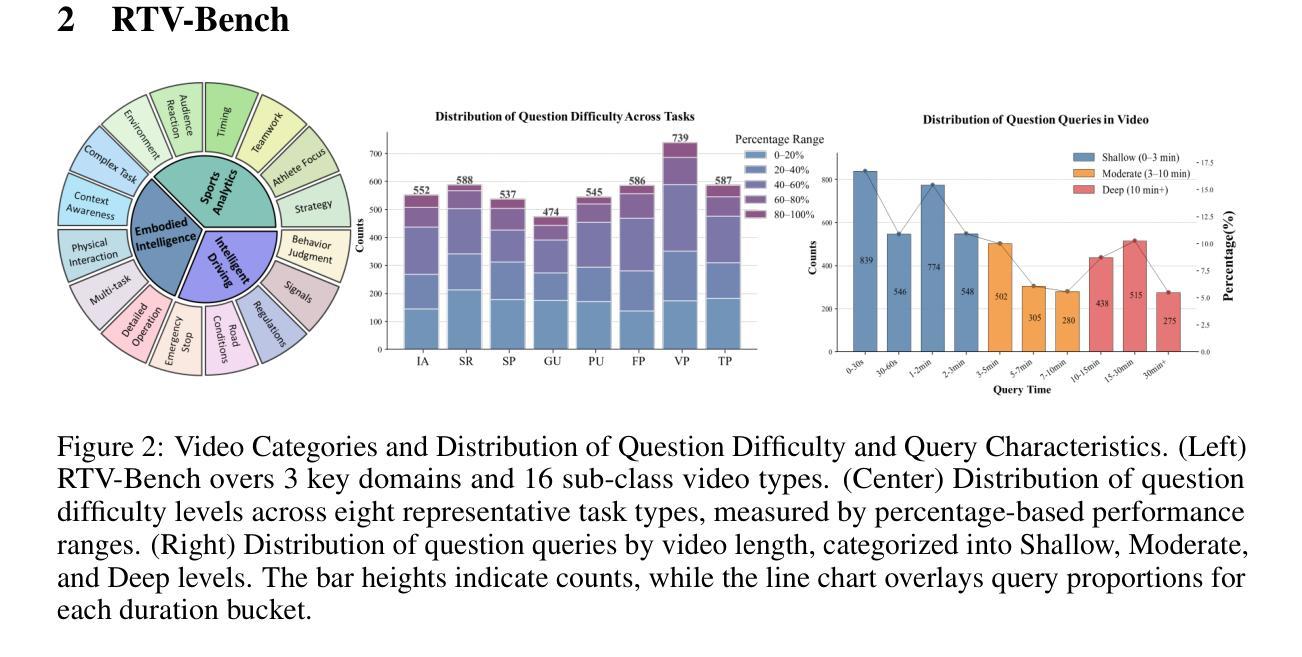
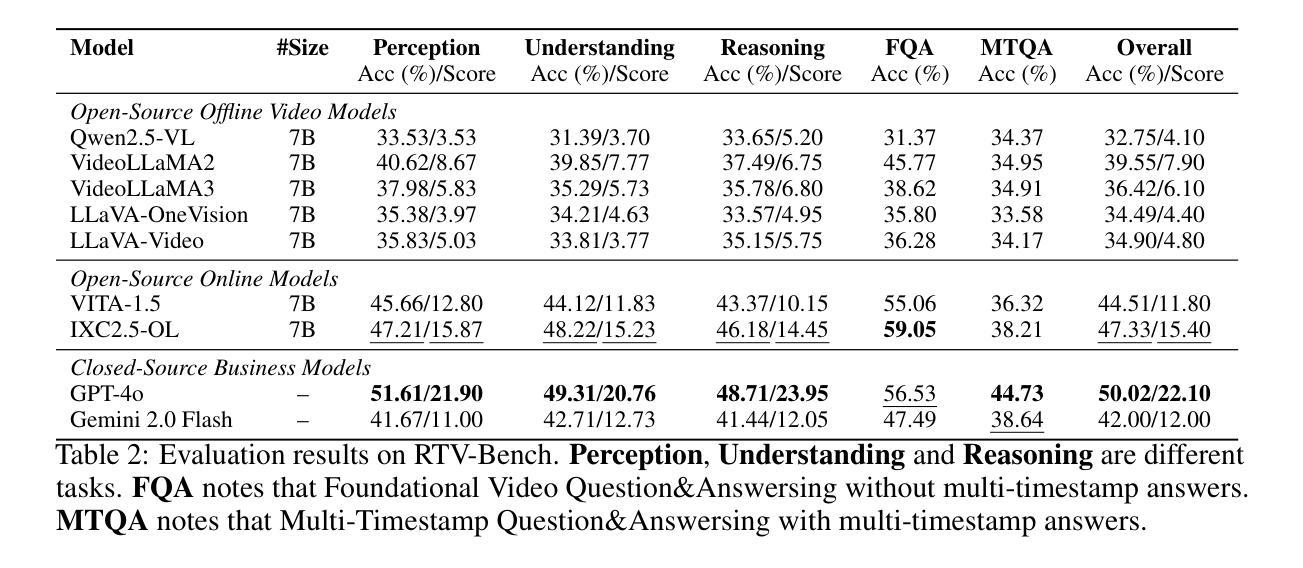
RTV-Bench: Benchmarking MLLM Continuous Perception, Understanding and Reasoning through Real-Time Video
Authors:Shuhang Xun, Sicheng Tao, Jungang Li, Yibo Shi, Zhixin Lin, Zhanhui Zhu, Yibo Yan, Hanqian Li, Linghao Zhang, Shikang Wang, Yixin Liu, Hanbo Zhang, Ying Ma, Xuming Hu
Multimodal Large Language Models (MLLMs) increasingly excel at perception, understanding, and reasoning. However, current benchmarks inadequately evaluate their ability to perform these tasks continuously in dynamic, real-world environments. To bridge this gap, we introduce RTV-Bench, a fine-grained benchmark for MLLM real-time video analysis. RTV-Bench uses three key principles: (1) Multi-Timestamp Question Answering (MTQA), where answers evolve with scene changes; (2) Hierarchical Question Structure, combining basic and advanced queries; and (3) Multi-dimensional Evaluation, assessing the ability of continuous perception, understanding, and reasoning. RTV-Bench contains 552 diverse videos (167.2 hours) and 4,631 high-quality QA pairs. We evaluated leading MLLMs, including proprietary (GPT-4o, Gemini 2.0), open-source offline (Qwen2.5-VL, VideoLLaMA3), and open-source real-time (VITA-1.5, InternLM-XComposer2.5-OmniLive) models. Experiment results show open-source real-time models largely outperform offline ones but still trail top proprietary models. Our analysis also reveals that larger model size or higher frame sampling rates do not significantly boost RTV-Bench performance, sometimes causing slight decreases. This underscores the need for better model architectures optimized for video stream processing and long sequences to advance real-time video analysis with MLLMs. Our benchmark toolkit is available at: https://github.com/LJungang/RTV-Bench.
多模态大型语言模型(MLLMs)在感知、理解和推理方面越来越出色。然而,当前的基准测试不足以评估它们在动态、现实环境中连续执行这些任务的能力。为了弥补这一空白,我们引入了RTV-Bench,这是一个用于MLLM实时视频分析的精细基准测试。RTV-Bench采用三个关键原则:(1)多时间戳问答(MTQA),答案随场景变化而演变;(2)分层问题结构,结合基本和高级查询;(3)多维评估,评估连续感知、理解和推理的能力。RTV-Bench包含552个多样化的视频(167.2小时)和4631个高质量的问答对。我们评估了领先的多模态大型语言模型,包括专有模型(GPT-4o、Gemini 2.0)、开源离线模型(Qwen2.5-VL、VideoLLaMA3)和开源实时模型(VITA-1.5、InternLM-XComposer2.5-OmniLive)。实验结果表明,开源实时模型大多优于离线模型,但仍落后于顶级专有模型。我们的分析还表明,更大的模型规模或更高的帧采样率并不会显著提高RTV-Bench的性能,有时甚至会导致轻微下降。这强调了在视频流处理和长序列优化方面需要更好的模型架构,以推动多模态大型语言模型的实时视频分析。我们的基准测试工具包可在:https://github.com/LJungang/RTV-Bench 找到。
论文及项目相关链接
PDF 13 pages, 4 figures, 5 tables
摘要
多模态大型语言模型(MLLMs)在感知、理解和推理方面表现出色。然而,当前的评价基准未能充分评估模型在动态、真实环境中的持续任务执行能力。为解决此差距,我们推出RTV-Bench,一个针对MLLM实时视频分析的精细基准。RTV-Bench采用三个关键原则:一是多时间戳问答(MTQA),答案随场景变化而演变;二是层次化问题结构,结合基本和高级查询;三是多维度评估,评估持续感知、理解和推理的能力。RTV-Bench包含552个多样化视频(167.2小时)和4631组高质量问答对。我们评估了领先的多模态大型语言模型,包括专有模型(GPT-4o、Gemini 2.0)、开源离线模型(Qwen2.5-VL、VideoLLaMA3)和开源实时模型(VITA-1.5、InternLM-XComposer2.5-OmniLive)。实验结果表明,开源实时模型大多优于离线模型,但仍落后于顶级专有模型。分析还显示,模型规模增大或帧采样率提高并不显著提升RTV-Bench性能,有时甚至会导致轻微下降。这突显出需要更好的模型架构来优化视频流处理和长序列,以推动多模态大型语言模型在实时视频分析方面的应用。我们的基准测试工具可在:https://github.com/LJungang/RTV-Bench获取。
关键见解
- 多模态大型语言模型在感知、理解和推理方面表现出色,但当前评估基准不足以反映它们在动态、真实环境中的持续性能。
- RTV-Bench是一个新的基准测试,旨在填补这一空白,通过三个关键原则评估模型的实时视频分析能力。
- 实验结果显示,开源实时模型性能优于离线模型,但仍落后于某些专有模型。
- 模型规模增大或帧采样率提高并不总是提升性能,这提示需要针对视频流处理和长序列优化的新模型架构。
- 实时视频分析需要更好的模型来应对视频流的连续性和实时性挑战。
- RTV-Bench包含多样化的视频和高质量问答对,为评估模型提供了丰富的数据集。
点此查看论文截图