⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
Authors:Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, Haoqian Wang
Reconstructing a high-quality, animatable 3D human avatar with expressive facial and hand motions from a single image has gained significant attention due to its broad application potential. 3D human avatar reconstruction typically requires multi-view or monocular videos and training on individual IDs, which is both complex and time-consuming. Furthermore, limited by SMPLX’s expressiveness, these methods often focus on body motion but struggle with facial expressions. To address these challenges, we first introduce an expressive human model (EHM) to enhance facial expression capabilities and develop an accurate tracking method. Based on this template model, we propose GUAVA, the first framework for fast animatable upper-body 3D Gaussian avatar reconstruction. We leverage inverse texture mapping and projection sampling techniques to infer Ubody (upper-body) Gaussians from a single image. The rendered images are refined through a neural refiner. Experimental results demonstrate that GUAVA significantly outperforms previous methods in rendering quality and offers significant speed improvements, with reconstruction times in the sub-second range (0.1s), and supports real-time animation and rendering.
重建一个高质量、可动画化的3D人类化身,从单张图像中表现出具有表情的面部和手部动作,由于其广泛的应用潜力而备受关注。3D人类化身重建通常需要多视角或单目视频以及对个人ID的训练,这既复杂又耗时。此外,受限于SMPLX的表现力,这些方法往往侧重于身体动作,但在面部表情方面却表现挣扎。为了应对这些挑战,我们首先引入了一个表情丰富的人类模型(EHM)以增强面部表情能力,并开发了一种精确的跟踪方法。基于这个模板模型,我们提出了GUAVA,这是第一个用于快速可动画的3D高斯化身重建框架。我们利用逆向纹理映射和投影采样技术从单张图像推断出上半身的高斯分布。渲染的图像通过神经网络精炼器进行精炼。实验结果表明,GUAVA在渲染质量上显著优于以前的方法,并在速度上实现了显著的提升,重建时间在亚秒范围内(0.1秒),支持实时动画和渲染。
论文及项目相关链接
PDF Project page: https://eastbeanzhang.github.io/GUAVA/
Summary
这篇文本介绍了从单张图像重建高质量、可动画的3D人类角色模型的研究进展。该模型具有表达性面部和手部动作,并广泛应用于多个领域。为解决现有方法复杂度高、耗时较长且面部表情表达能力有限的问题,研究团队引入了表达性人类模型(EHM)以提高面部表情能力,并开发了精准追踪方法。基于该模板模型,提出了首个快速可动画的上半身3D高斯角色重建框架GUAVA。利用逆向纹理映射和投影采样技术从单张图像推断上半身高斯分布,并通过神经网络进行图像渲染优化。实验结果表明,GUAVA在渲染质量上显著优于先前方法,具有亚秒级的重建时间(0.1秒),并支持实时动画和渲染。
Key Takeaways
- 重建高质量、可动画的3D人类角色模型是研究的热点,具有广泛的应用前景。
- 现有方法复杂度高、耗时较长,且面部表情表达能力有限。
- 为解决上述问题,研究团队引入了表达性人类模型(EHM)。
- 基于EHM模板模型,提出了首个快速可动画的上半身3D高斯角色重建框架GUAVA。
- GUAVA利用逆向纹理映射和投影采样技术从单张图像推断上半身高斯分布。
- GUAVA通过神经网络优化图像渲染质量。
点此查看论文截图


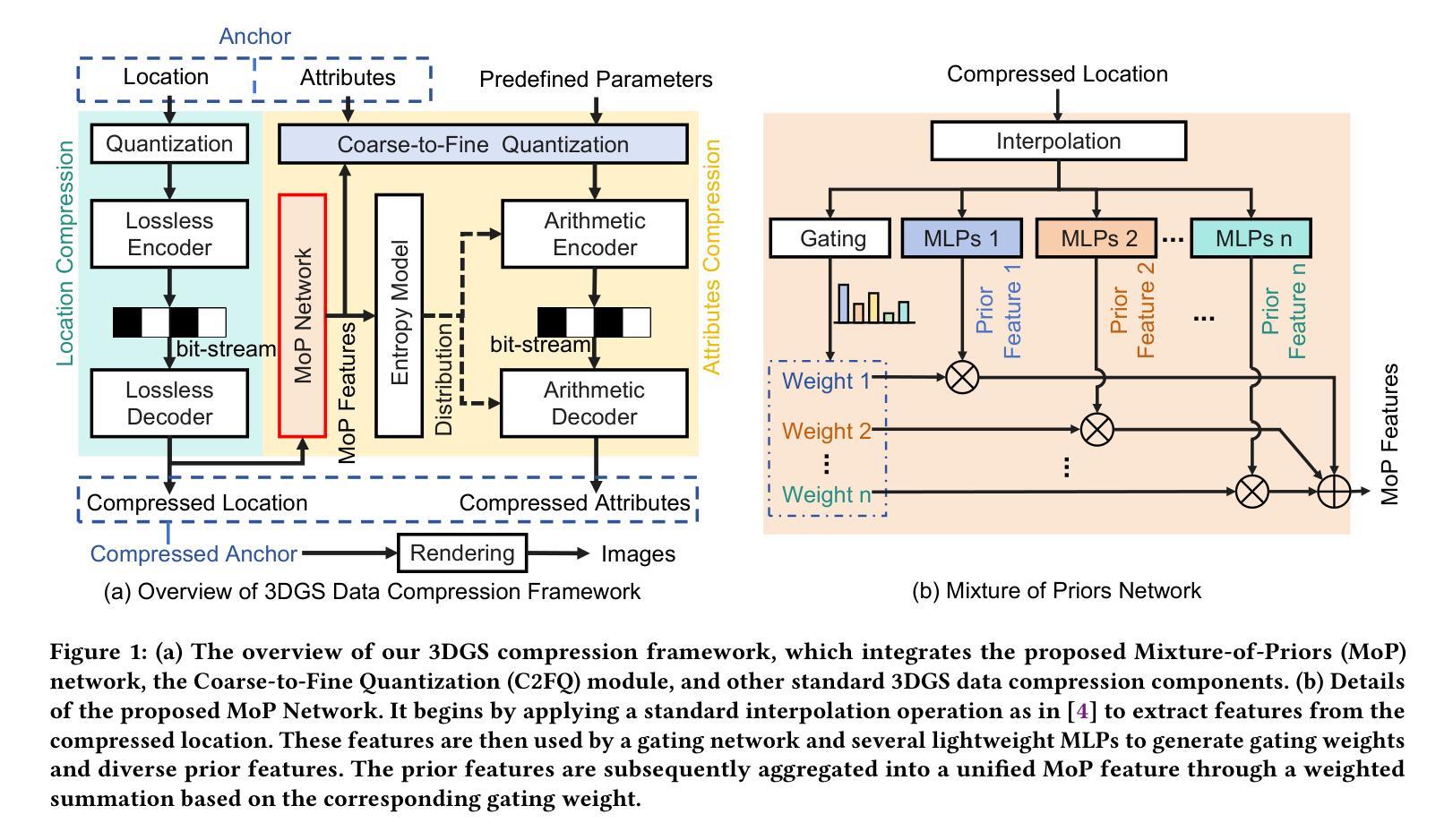
3D Gaussian Splatting Data Compression with Mixture of Priors
Authors:Lei Liu, Zhenghao Chen, Dong Xu
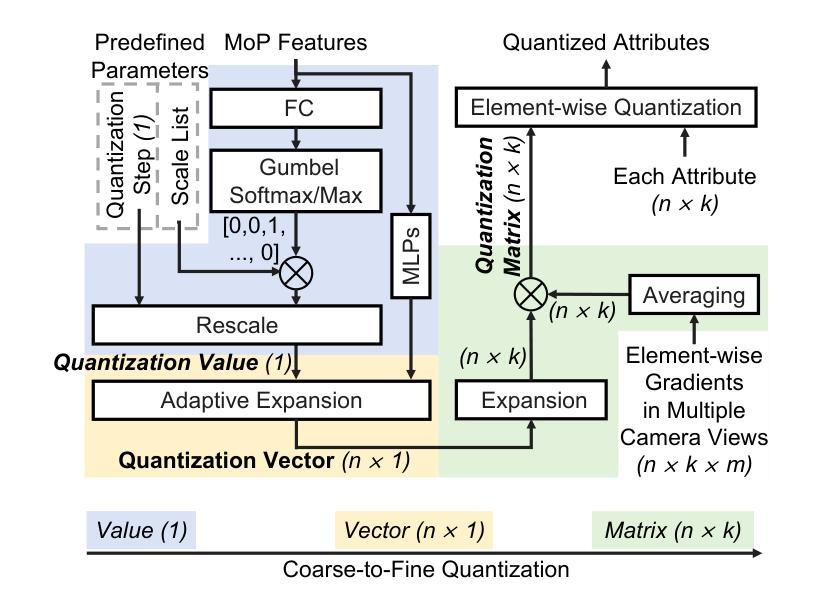
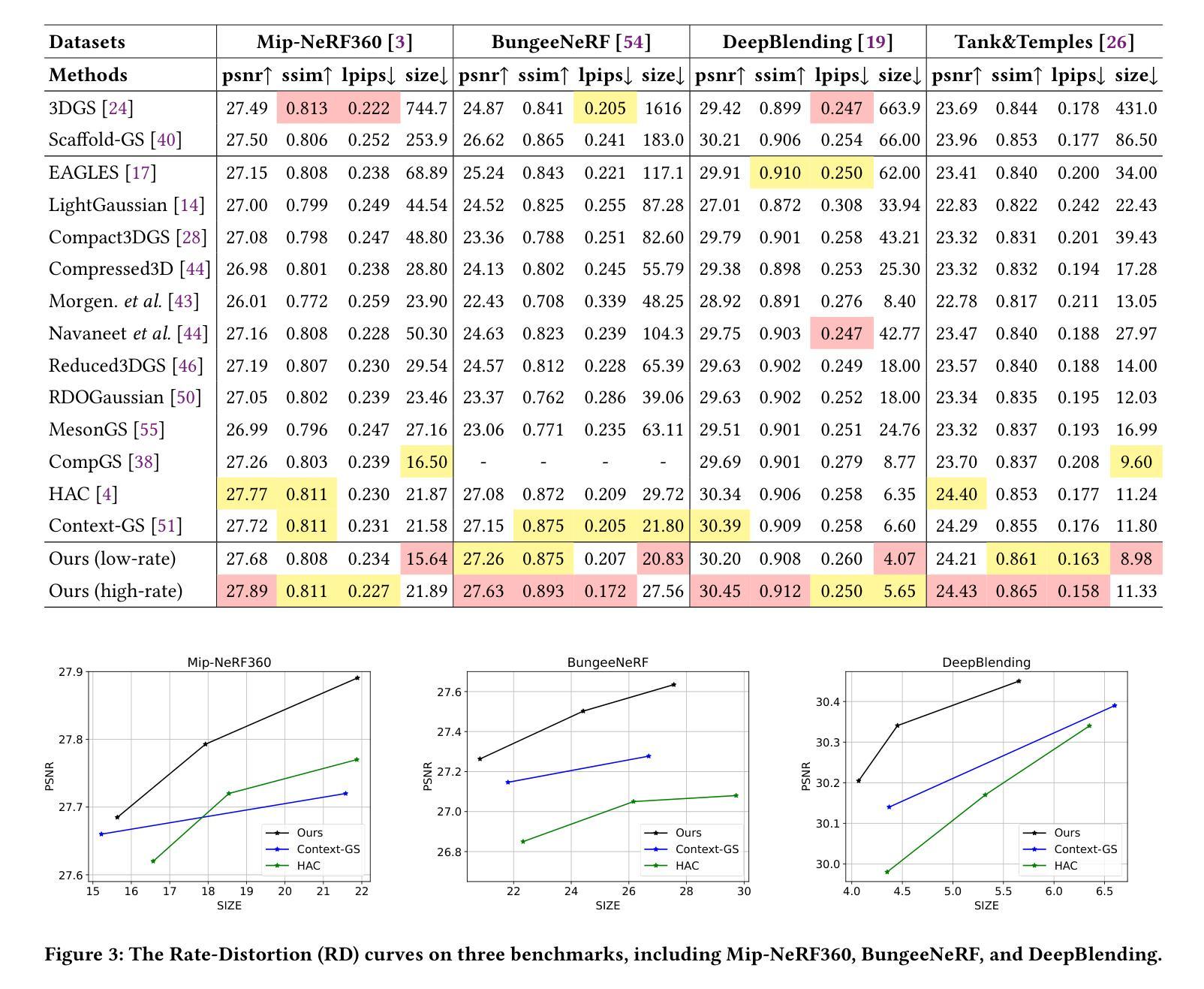
3D Gaussian Splatting (3DGS) data compression is crucial for enabling efficient storage and transmission in 3D scene modeling. However, its development remains limited due to inadequate entropy models and suboptimal quantization strategies for both lossless and lossy compression scenarios, where existing methods have yet to 1) fully leverage hyperprior information to construct robust conditional entropy models, and 2) apply fine-grained, element-wise quantization strategies for improved compression granularity. In this work, we propose a novel Mixture of Priors (MoP) strategy to simultaneously address these two challenges. Specifically, inspired by the Mixture-of-Experts (MoE) paradigm, our MoP approach processes hyperprior information through multiple lightweight MLPs to generate diverse prior features, which are subsequently integrated into the MoP feature via a gating mechanism. To enhance lossless compression, the resulting MoP feature is utilized as a hyperprior to improve conditional entropy modeling. Meanwhile, for lossy compression, we employ the MoP feature as guidance information in an element-wise quantization procedure, leveraging a prior-guided Coarse-to-Fine Quantization (C2FQ) strategy with a predefined quantization step value. Specifically, we expand the quantization step value into a matrix and adaptively refine it from coarse to fine granularity, guided by the MoP feature, thereby obtaining a quantization step matrix that facilitates element-wise quantization. Extensive experiments demonstrate that our proposed 3DGS data compression framework achieves state-of-the-art performance across multiple benchmarks, including Mip-NeRF360, BungeeNeRF, DeepBlending, and Tank&Temples.
3D高斯喷溅(3DGS)数据压缩对于实现三维场景建模中的高效存储和传输至关重要。然而,由于其熵模型不足以及针对无损和有损压缩场景的量化策略不佳,其开发仍受到限制。现有方法尚未1)充分利用超先验信息来构建稳健的条件熵模型,以及2)应用精细的、逐元素量化策略来提高压缩粒度。在这项工作中,我们提出了一种新颖的先验混合(MoP)策略,旨在同时解决这两个挑战。具体来说,受到专家混合(MoE)范式的启发,我们的MoP方法通过多个轻量级MLP处理超先验信息,以生成多种先验特征,然后通过这些特征通过门控机制集成到MoP特征中。为了增强无损压缩,使用MoP特征作为超先验信息来改善条件熵建模。而对于有损压缩,我们将MoP特征作为逐元素量化过程中的指导信息,采用先验引导的粗细量化(C2FQ)策略,并预设量化步长值。具体来说,我们将量化步长值扩展为矩阵,并在MoP特征的引导下从粗到细粒度进行自适应细化,从而获得促进逐元素量化的量化步长矩阵。大量实验表明,我们提出的3DGS数据压缩框架在多个基准测试上达到了最先进的性能,包括Mip-NeRF360、BungeeNeRF、DeepBlending和Tank&Temples。
论文及项目相关链接
Summary
本文介绍了基于混合先验(MoP)策略的改进型三维高斯斑点法(3DGS)数据压缩方法,以解决现有的压缩问题。此方法能同时处理两类问题:缺乏先验信息的充分利用和对无损和损失压缩场景中的次优量化策略。通过引入混合专家(MoE)范式,利用多个轻量级多层感知器(MLP)处理先验信息,生成多样化的先验特征,再通过门控机制集成到MoP特征中。对于无损压缩,使用MoP特征作为超先验信息提高条件熵建模;对于损失压缩,结合MoP特征进行逐元素量化过程,并采用先验引导的粗糙到精细量化(C2FQ)策略,根据预设的量化步长值进行调整优化。实验表明,该方法在多个基准测试集上取得了先进的表现。
Key Takeaways
- 当前在利用三维高斯斑点法(3DGS)进行场景建模时面临两大挑战:对超先验信息的不充分使用和量化策略的不足。
- 提出了一种基于混合先验(MoP)策略的改进方法,旨在同时解决这两个挑战。该方法利用了混合专家(MoE)框架的启发,并使用多个轻量级多层感知器处理超先验信息。
- MoP特征用于提高无损压缩的条件熵建模和损失压缩的逐元素量化过程。
点此查看论文截图

Sparfels: Fast Reconstruction from Sparse Unposed Imagery
Authors:Shubhendu Jena, Amine Ouasfi, Mae Younes, Adnane Boukhayma
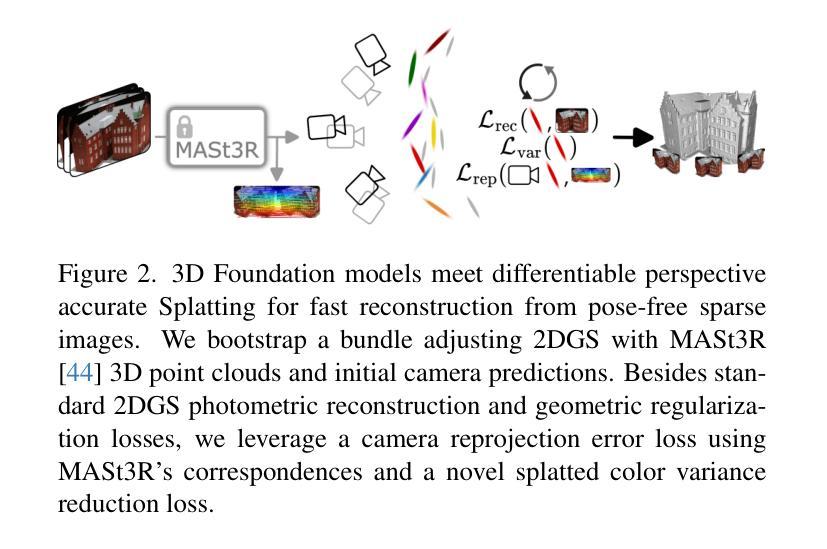
We present a method for Sparse view reconstruction with surface element splatting that runs within 3 minutes on a consumer grade GPU. While few methods address sparse radiance field learning from noisy or unposed sparse cameras, shape recovery remains relatively underexplored in this setting. Several radiance and shape learning test-time optimization methods address the sparse posed setting by learning data priors or using combinations of external monocular geometry priors. Differently, we propose an efficient and simple pipeline harnessing a single recent 3D foundation model. We leverage its various task heads, notably point maps and camera initializations to instantiate a bundle adjusting 2D Gaussian Splatting (2DGS) model, and image correspondences to guide camera optimization midst 2DGS training. Key to our contribution is a novel formulation of splatted color variance along rays, which can be computed efficiently. Reducing this moment in training leads to more accurate shape reconstructions. We demonstrate state-of-the-art performances in the sparse uncalibrated setting in reconstruction and novel view benchmarks based on established multi-view datasets.
我们提出了一种基于表面元素拼贴技术的稀疏视图重建方法,该方法在消费级GPU上运行时间不超过3分钟。尽管已有少数方法解决了从噪声或未校准的稀疏相机中学习稀疏辐射场的问题,但在这种情况下,形状恢复的探索仍然相对较少。一些辐射和形状学习测试时间优化方法通过学习数据先验或使用外部单眼几何先验的组合来解决稀疏定位设置问题。与之不同,我们提出了一种高效且简单的流程,利用了一个最新的单一3D基础模型。我们利用该模型的各种任务头,特别是点图和相机初始化来实例化一个调整束的二维高斯拼贴(2DGS)模型,并利用图像对应关系来指导在2DGS训练过程中的相机优化。我们贡献的关键在于沿光线拼贴颜色方差的新公式,该公式可以高效计算。在训练中减少这一时刻会导致更准确的形状重建。我们在稀疏未校准设置下的重建和基于多视图数据集的新视图基准测试中展示了最先进的性能。
论文及项目相关链接
PDF Project page : https://shubhendu-jena.github.io/Sparfels/
摘要
本文提出了一种基于表面元素拼贴技术的稀疏视角重建方法,该方法在消费级GPU上运行时间不超过3分钟。尽管已有一些方法解决了稀疏辐射场学习的问题,但在噪声或无姿态稀疏相机的情况下,形状恢复的探索相对较少。我们的方法不同于现有的测试时间优化方法,如学习数据先验或结合外部单眼几何先验技术来处理稀疏有姿态场景,而是使用单个最近的3D基础模型构建了一个高效且简单的管道。我们利用该模型的各种任务头,特别是点图和相机初始化来建立束调整二维高斯拼贴模型,并利用图像对应关系来指导相机优化在二维GS训练中的位置。本文的关键贡献是沿射线拼贴颜色方差的新公式,可以高效计算。减少训练中的这个矩会提高形状重建的准确性。在稀疏未校准情况下重建和新视角评估中,我们的方法在基于多视角数据集的实验中达到了领先水平。
要点总结
一、提出了一个高效、基于表面元素拼贴的稀疏视角重建方法,在消费者级别的GPU上运行时间为三分钟以内。
二、虽然其他方法解决了稀疏辐射场学习的问题,但在噪声或无姿态稀疏相机环境下的形状恢复仍然相对未被充分探索。
三、不同于现有的测试时间优化方法如学习数据先验等处理稀疏有姿态场景,采用单个近期的三维基础模型。提出了点图和相机初始化等任务头用于建立二维高斯拼贴模型(2DGS)。利用图像对应关系指导相机优化在二维GS训练中的位置。
点此查看论文截图


SparSplat: Fast Multi-View Reconstruction with Generalizable 2D Gaussian Splatting
Authors:Shubhendu Jena, Shishir Reddy Vutukur, Adnane Boukhayma
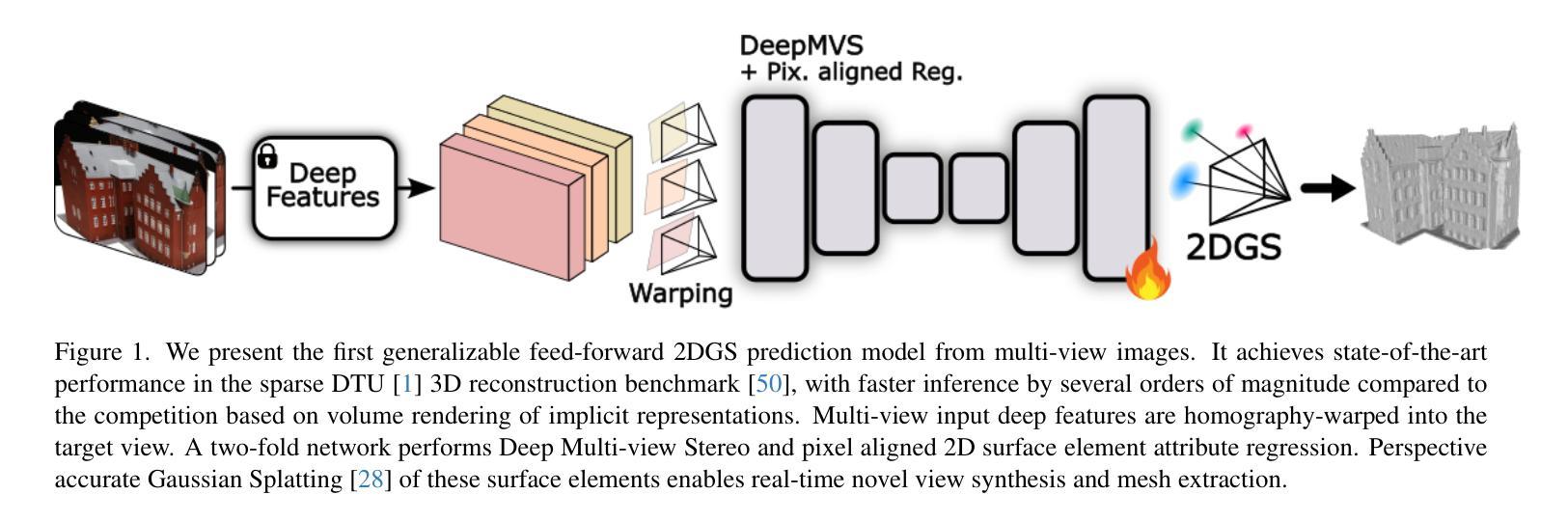
Recovering 3D information from scenes via multi-view stereo reconstruction (MVS) and novel view synthesis (NVS) is inherently challenging, particularly in scenarios involving sparse-view setups. The advent of 3D Gaussian Splatting (3DGS) enabled real-time, photorealistic NVS. Following this, 2D Gaussian Splatting (2DGS) leveraged perspective accurate 2D Gaussian primitive rasterization to achieve accurate geometry representation during rendering, improving 3D scene reconstruction while maintaining real-time performance. Recent approaches have tackled the problem of sparse real-time NVS using 3DGS within a generalizable, MVS-based learning framework to regress 3D Gaussian parameters. Our work extends this line of research by addressing the challenge of generalizable sparse 3D reconstruction and NVS jointly, and manages to perform successfully at both tasks. We propose an MVS-based learning pipeline that regresses 2DGS surface element parameters in a feed-forward fashion to perform 3D shape reconstruction and NVS from sparse-view images. We further show that our generalizable pipeline can benefit from preexisting foundational multi-view deep visual features. The resulting model attains the state-of-the-art results on the DTU sparse 3D reconstruction benchmark in terms of Chamfer distance to ground-truth, as-well as state-of-the-art NVS. It also demonstrates strong generalization on the BlendedMVS and Tanks and Temples datasets. We note that our model outperforms the prior state-of-the-art in feed-forward sparse view reconstruction based on volume rendering of implicit representations, while offering an almost 2 orders of magnitude higher inference speed.
从场景恢复三维信息,通过多视图立体重建(MVS)和新颖视图合成(NVS)本质上具有挑战性,特别是在涉及稀疏视图设置的情况下。三维高斯平铺(3DGS)的出现,实现了实时、逼真的NVS。之后,二维高斯平铺(2DGS)利用透视准确的二维高斯原始栅格化,在渲染过程中实现准确的三维几何表示,提高了三维场景重建的实时性能。最近的方法解决了稀疏实时NVS的问题,使用通用基于MVS的学习框架内的3DGS来回归三维高斯参数。我们的工作通过解决可泛化的稀疏三维重建和NVS联合挑战来扩展这一研究领域,并在两项任务中都取得了成功。我们提出了一种基于MVS的学习流水线,以前馈方式回归二维GS表面元素参数,从稀疏视图图像进行三维形状重建和NVS。我们进一步表明,我们的可泛化管道可以从现有的多视角深度视觉特征中受益。所得模型在DTU稀疏三维重建基准测试上达到了最先进的水平,表现在与真实值的Chamfer距离以及先进的NVS上。它在BlendedMVS和Tanks and Temples数据集上也表现出强大的泛化能力。我们注意到,我们的模型在基于隐式表示的体积渲染的前馈稀疏视图重建方面优于先前最先进的模型,同时推理速度提高了近两个数量级。
论文及项目相关链接
PDF Project page : https://shubhendu-jena.github.io/SparSplat/
摘要
利用基于多视图立体重建(MVS)和新颖视图合成(NVS)的3D高斯喷绘(3DGS)技术,实现稀疏视角下的实时、逼真的NVS。提出一种MVS学习管道,以回归2DGS表面元素参数的方式进行前馈,实现从稀疏视角图像进行3D形状重建和NVS。该管道能够成功应对通用稀疏3D重建和NVS的挑战,并从现有的多视角深度视觉特征中受益。在DTU稀疏3D重建基准测试、新颖视图合成以及BlendedMVS和Tanks and Temples数据集上表现出强大的泛化能力和最先进的结果。与基于体积渲染的隐式表示的前馈稀疏视图重建的现有最先进的模型相比,该模型的推理速度提高了近两个数量级。
关键见解
- 稀疏视角下的多视图立体重建和新颖视图合成具有挑战性。
- 3D高斯喷绘(3DGS)技术实现了实时、逼真的新颖视图合成。
- 提出一种基于MVS的学习管道,通过回归2DGS表面元素参数进行前馈,实现3D形状重建和NVS。
- 该管道能够成功应对通用稀疏3D重建和NVS的挑战。
- 现有多视角深度视觉特征可以受益于该学习管道。
- 在多个基准测试和数据集上,该模型表现出强大的泛化能力和最先进的结果。
- 与其他最先进模型相比,该模型的推理速度显著提高。
点此查看论文截图

SignSplat: Rendering Sign Language via Gaussian Splatting
Authors:Maksym Ivashechkin, Oscar Mendez, Richard Bowden
State-of-the-art approaches for conditional human body rendering via Gaussian splatting typically focus on simple body motions captured from many views. This is often in the context of dancing or walking. However, for more complex use cases, such as sign language, we care less about large body motion and more about subtle and complex motions of the hands and face. The problems of building high fidelity models are compounded by the complexity of capturing multi-view data of sign. The solution is to make better use of sequence data, ensuring that we can overcome the limited information from only a few views by exploiting temporal variability. Nevertheless, learning from sequence-level data requires extremely accurate and consistent model fitting to ensure that appearance is consistent across complex motions. We focus on how to achieve this, constraining mesh parameters to build an accurate Gaussian splatting framework from few views capable of modelling subtle human motion. We leverage regularization techniques on the Gaussian parameters to mitigate overfitting and rendering artifacts. Additionally, we propose a new adaptive control method to densify Gaussians and prune splat points on the mesh surface. To demonstrate the accuracy of our approach, we render novel sequences of sign language video, building on neural machine translation approaches to sign stitching. On benchmark datasets, our approach achieves state-of-the-art performance; and on highly articulated and complex sign language motion, we significantly outperform competing approaches.
目前最前沿的通过高斯平铺技术实现条件性人体渲染的方法主要关注从多个视角捕捉的简单身体动作,这常常在舞蹈或行走的情境中。然而,对于更复杂的用例,如手语,我们更关注手和脸部的细微和复杂动作,而非大动作。构建高保真模型的问题在于手语的多视角数据捕捉的复杂性。解决方案是更好地利用序列数据,确保我们能够利用时间变化性来克服仅来自少数视角的有限信息。然而,从序列级别的数据中学习需要极其精确和一致的模型拟合,以确保在复杂的动作中外观的一致性。我们专注于如何实现这一点,通过约束网格参数来构建一个准确的高斯平铺框架,该框架能够从有限的视角对微妙的人体运动进行建模。我们对高斯参数采用正则化技术来缓解过度拟合和渲染伪影。此外,我们提出了一种新的自适应控制方法来密集化高斯并精简网格表面的平铺点。为了证明我们的方法的准确性,我们在神经机器翻译方法的基础上,渲染了新的手语视频序列。在基准数据集上,我们的方法达到了最先进的性能;在高度精细且复杂的手语动作上,我们显著优于其他方法。
论文及项目相关链接
Summary
本文介绍了一种基于序列数据的条件人体渲染方法,针对复杂的手势和面部表情进行精细建模。通过利用高斯映射技术,从有限视角构建准确的模型,并采用正则化技术避免过拟合和渲染瑕疵。同时,提出了一种新的自适应控制方法,用于在网格表面细化高斯并删除溅点。在基准数据集上,该方法达到了最新技术水平,并在高度精细和复杂的标志语言运动中显著优于竞争对手。
Key Takeaways
- 本文关注复杂手势和面部表情的精细建模,如标志语言。
- 提出一种基于序列数据的条件人体渲染方法,克服有限视角信息的不足。
- 利用高斯映射技术构建准确模型,并采用正则化技术避免过拟合和渲染瑕疵。
- 引入新的自适应控制方法,用于细化高斯并在网格表面删除溅点。
- 方法在基准数据集上达到最新技术水平。
- 在高度精细和复杂的标志语言运动中显著优于其他方法。
点此查看论文截图

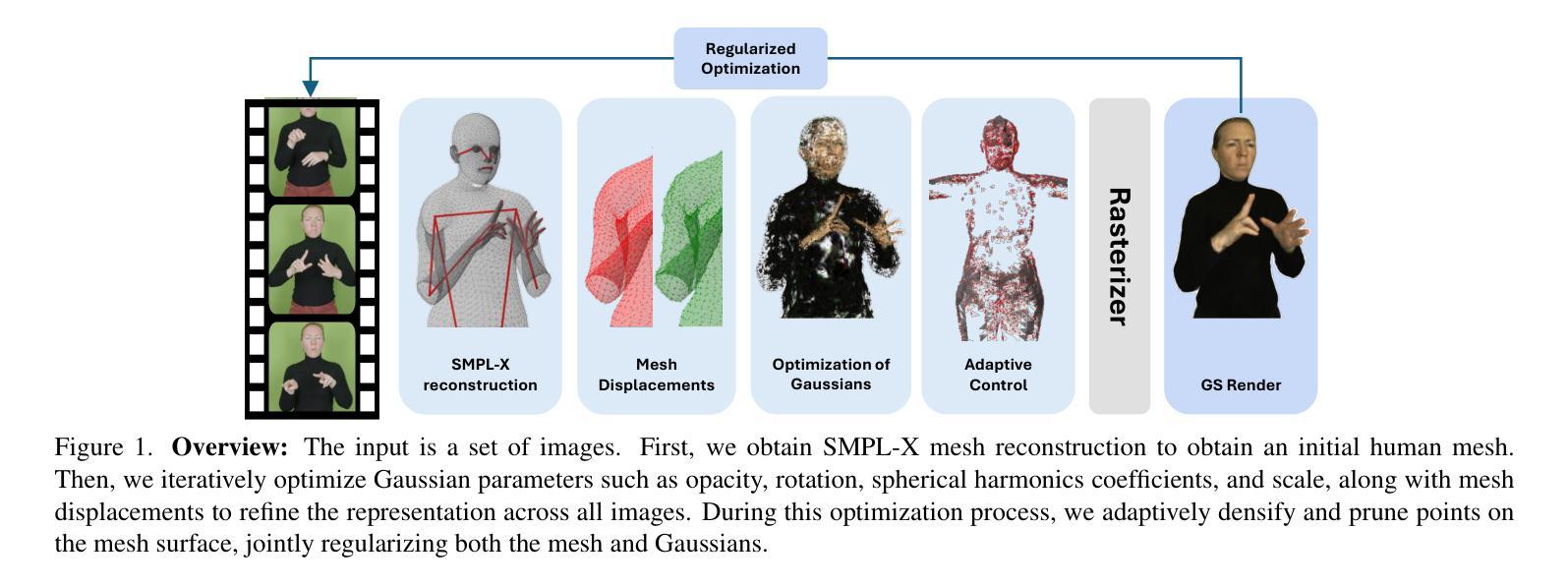
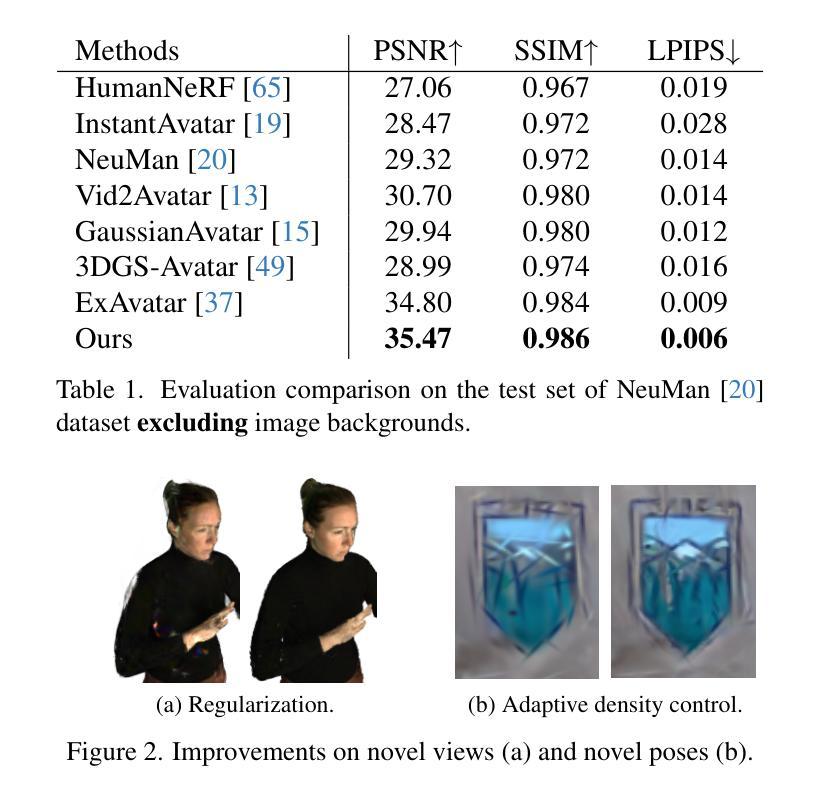
HybridGS: High-Efficiency Gaussian Splatting Data Compression using Dual-Channel Sparse Representation and Point Cloud Encoder
Authors:Qi Yang, Le Yang, Geert Van Der Auwera, Zhu Li
Most existing 3D Gaussian Splatting (3DGS) compression schemes focus on producing compact 3DGS representation via implicit data embedding. They have long coding times and highly customized data format, making it difficult for widespread deployment. This paper presents a new 3DGS compression framework called HybridGS, which takes advantage of both compact generation and standardized point cloud data encoding. HybridGS first generates compact and explicit 3DGS data. A dual-channel sparse representation is introduced to supervise the primitive position and feature bit depth. It then utilizes a canonical point cloud encoder to perform further data compression and form standard output bitstreams. A simple and effective rate control scheme is proposed to pivot the interpretable data compression scheme. At the current stage, HybridGS does not include any modules aimed at improving 3DGS quality during generation. But experiment results show that it still provides comparable reconstruction performance against state-of-the-art methods, with evidently higher encoding and decoding speed. The code is publicly available at https://github.com/Qi-Yangsjtu/HybridGS.
现有的大多数3D高斯展布(3DGS)压缩方案主要侧重于通过隐式数据嵌入生成紧凑的3DGS表示。它们具有较长的编码时间和高度定制的数据格式,使得难以广泛部署。本文提出了一种新的3DGS压缩框架,称为HybridGS,它结合了紧凑生成和标准化点云数据编码。HybridGS首先生成紧凑且显式的3DGS数据。引入双通道稀疏表示来监督原始位置和特征位深度。然后,它利用标准点云编码器执行进一步的数据压缩并形成标准输出比特流。提出了一种简单有效的速率控制方案,以调整可解释的数据压缩方案。目前阶段,HybridGS不包括任何旨在提高生成过程中的3DGS质量的模块。但实验结果表明,它仍然提供了与最新技术相当的重构性能,并且编码和解码速度明显更高。代码可在https://github.com/Qi-Yangsjtu/HybridGS获取。
论文及项目相关链接
PDF Accepted by ICML2025
Summary
本文提出了一种新的3DGS压缩框架HybridGS,结合了紧凑生成和标准化点云数据编码。该框架旨在解决现有压缩方案编码时间长、数据格式高度定制化的问题,使得部署困难。HybridGS通过引入双通道稀疏表示和速率控制方案,实现了快速且有效的数据压缩,同时在生成性能上与其他先进技术相比仍具有竞争力。
Key Takeaways
- HybridGS结合了紧凑生成和标准化点云数据编码,旨在解决现有3DGS压缩方案的缺陷。
- 引入双通道稀疏表示,用于监督原始数据的位深度。
- 利用标准点云编码器进行进一步的数据压缩,形成标准输出比特流。
- 提出简单有效的速率控制方案,以支持可解释的数据压缩。
- HybridGS目前不专注于提高生成阶段的3DGS质量。
- 实验结果表明,HybridGS在重建性能上与其他先进技术相当。
点此查看论文截图


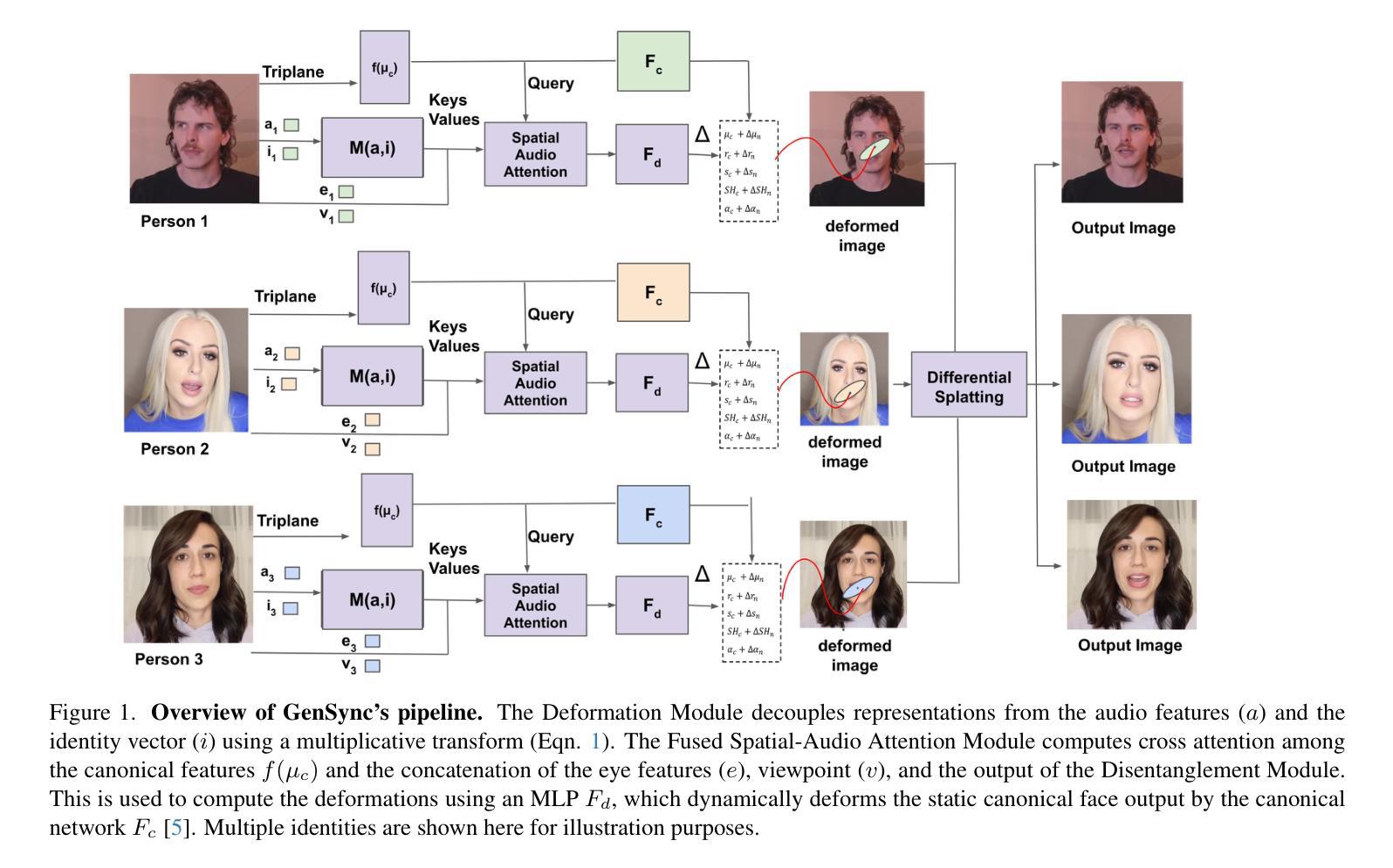
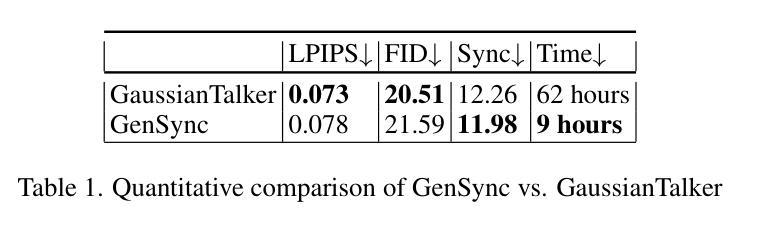
GenSync: A Generalized Talking Head Framework for Audio-driven Multi-Subject Lip-Sync using 3D Gaussian Splatting
Authors:Anushka Agarwal, Muhammad Yusuf Hassan, Talha Chafekar
We introduce GenSync, a novel framework for multi-identity lip-synced video synthesis using 3D Gaussian Splatting. Unlike most existing 3D methods that require training a new model for each identity , GenSync learns a unified network that synthesizes lip-synced videos for multiple speakers. By incorporating a Disentanglement Module, our approach separates identity-specific features from audio representations, enabling efficient multi-identity video synthesis. This design reduces computational overhead and achieves 6.8x faster training compared to state-of-the-art models, while maintaining high lip-sync accuracy and visual quality.
我们介绍了GenSync,这是一个使用3D高斯喷绘技术实现多身份唇同步视频合成的新型框架。与大多数现有3D方法需要为每个身份训练新模型不同,GenSync学习了一个统一网络,该网络可以为多个说话者合成唇同步视频。通过融入分离模块,我们的方法能够将身份特定特征从音频表示中分离出来,从而实现高效的多身份视频合成。这种设计减少了计算开销,与最先进模型相比实现了6.8倍的快速训练,同时保持了高唇同步精度和视觉质量。
论文及项目相关链接
Summary:
GenSync是一个基于3D高斯贴图的多身份唇同步视频合成新框架。与其他大多数需要为每个身份训练新模型的3D方法不同,GenSync学习一个统一网络,为多个说话者合成唇同步视频。通过融入分离模块,该方法能够从音频表示中分离出身份特定特征,从而实现高效的多身份视频合成。这种设计减少了计算开销,并且与最先进的模型相比,训练速度提高了6.8倍,同时保持了高唇同步精度和视觉质量。
Key Takeaways:
- GenSync是一个用于多身份唇同步视频合成的新框架。
- GenSync采用3D高斯贴图技术。
- GenSync学习一个统一网络来处理多个说话者的视频合成。
- 通过Disentanglement Module,GenSync能够从音频表示中分离身份特定特征。
- GenSync减少了计算开销,并且训练速度比现有技术快6.8倍。
- GenSync保持了高唇同步精度。
点此查看论文截图



Visual enhancement and 3D representation for underwater scenes: a review
Authors:Guoxi Huang, Haoran Wang, Brett Seymour, Evan Kovacs, John Ellerbrock, Dave Blackham, Nantheera Anantrasirichai
Underwater visual enhancement (UVE) and underwater 3D reconstruction pose significant challenges in computer vision and AI-based tasks due to complex imaging conditions in aquatic environments. Despite the development of numerous enhancement algorithms, a comprehensive and systematic review covering both UVE and underwater 3D reconstruction remains absent. To advance research in these areas, we present an in-depth review from multiple perspectives. First, we introduce the fundamental physical models, highlighting the peculiarities that challenge conventional techniques. We survey advanced methods for visual enhancement and 3D reconstruction specifically designed for underwater scenarios. The paper assesses various approaches from non-learning methods to advanced data-driven techniques, including Neural Radiance Fields and 3D Gaussian Splatting, discussing their effectiveness in handling underwater distortions. Finally, we conduct both quantitative and qualitative evaluations of state-of-the-art UVE and underwater 3D reconstruction algorithms across multiple benchmark datasets. Finally, we highlight key research directions for future advancements in underwater vision.
水下视觉增强(UVE)和水下3D重建在计算机视觉和基于人工智能的任务中构成了重大挑战,原因在于水生环境的复杂成像条件。尽管出现了许多增强算法,但涵盖UVE和水下3D重建的全面系统综述仍然缺失。为了推动这些领域的研究,我们从多个角度进行了深入的回顾。首先,我们介绍了基本的物理模型,并强调了挑战传统技术的特性。我们调查了专门为水下场景设计的视觉增强和3D重建的先进方法。本文评估了从非学习方法到先进的数据驱动技术(包括神经辐射场和3D高斯喷射)的各种方法,并讨论了它们在处理水下失真方面的有效性。最后,我们在多个基准数据集上进行了最新UVE和水下3D重建算法的量化和质性评估。最后,我们强调了水下视觉未来进步的关键研究方向。
论文及项目相关链接
Summary
本文深入回顾了水下视觉增强和3D重建的研究,介绍了其面临的基础物理模型挑战、先进的视觉增强和3D重建方法,并评估了非学习方法和先进的数据驱动技术的有效性,包括神经网络辐射场和3D高斯喷涂在处理水下失真方面的表现。同时,对最新的水下视觉增强和3D重建算法进行了多基准数据集的定量和定性评估,并指出了未来水下视觉研究的关键方向。
Key Takeaways
- 介绍了水下视觉增强(UVE)和3D重建在水下环境中的复杂成像条件所带来的挑战。
- 强调了现有的增强算法无法全面覆盖UVE和3D重建的问题,需要进行深入研究。
- 从多个角度进行了全面的文献综述,介绍了基础物理模型、先进的视觉增强和3D重建方法。
- 评估了多种方法在处理水下失真方面的有效性,包括非学习方法和数据驱动技术。
- 通过定量和定性评估,对比了当前先进的水下视觉增强和3D重建算法在多个基准数据集上的性能。
- 指出未来水下视觉研究的关键方向,包括更精确的模型、更高的效率、跨模态融合等。
点此查看论文截图




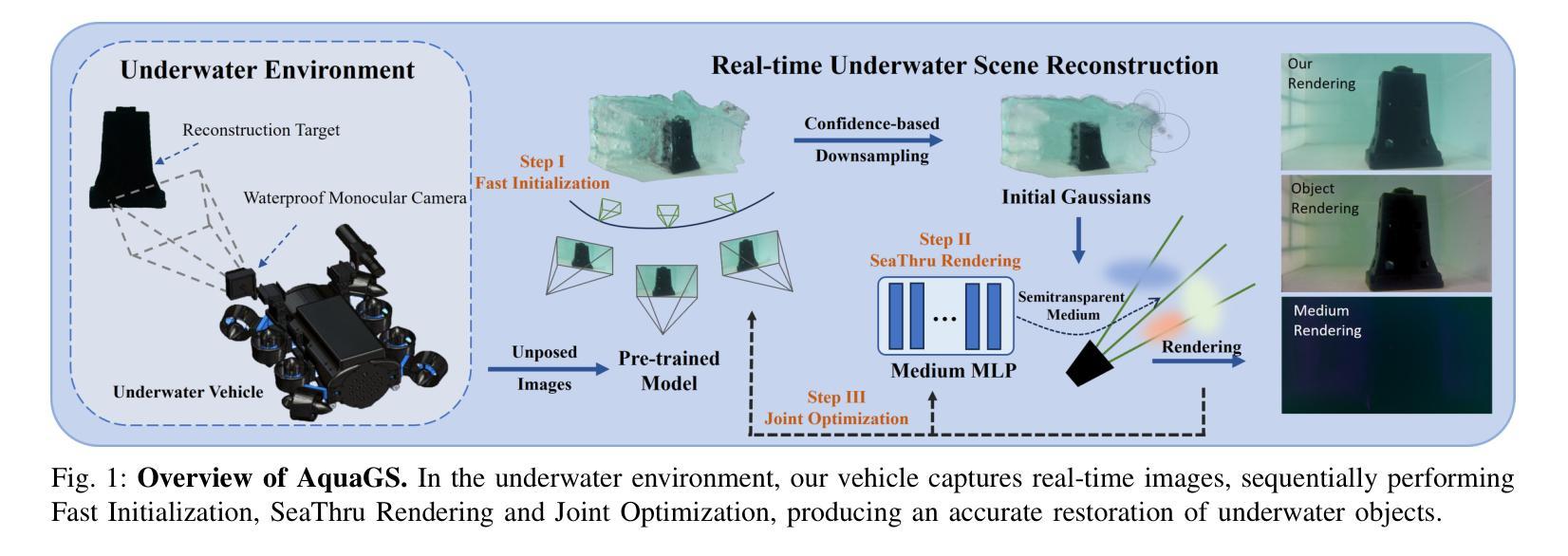
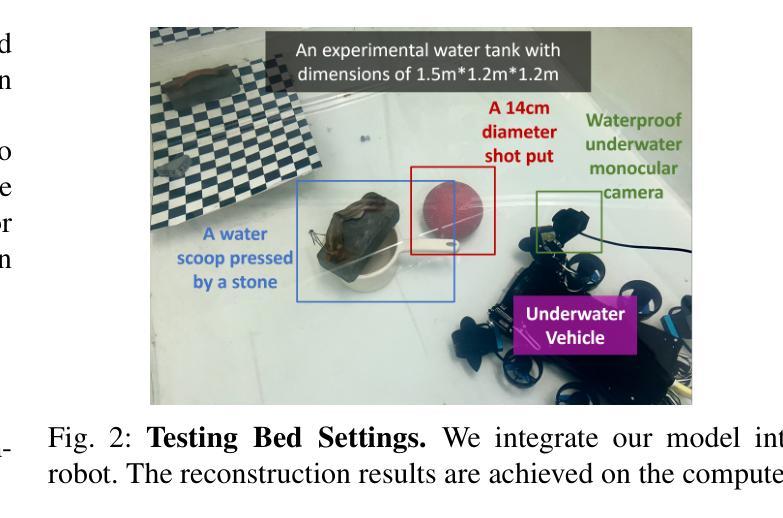
AquaGS: Fast Underwater Scene Reconstruction with SfM-Free Gaussian Splatting
Authors:Junhao Shi, Jisheng Xu, Jianping He, Zhiliang Lin
Underwater scene reconstruction is a critical tech-nology for underwater operations, enabling the generation of 3D models from images captured by underwater platforms. However, the quality of underwater images is often degraded due to medium interference, which limits the effectiveness of Structure-from-Motion (SfM) pose estimation, leading to subsequent reconstruction failures. Additionally, SfM methods typically operate at slower speeds, further hindering their applicability in real-time scenarios. In this paper, we introduce AquaGS, an SfM-free underwater scene reconstruction model based on the SeaThru algorithm, which facilitates rapid and accurate separation of scene details and medium features. Our approach initializes Gaussians by integrating state-of-the-art multi-view stereo (MVS) technology, employs implicit Neural Radiance Fields (NeRF) for rendering translucent media and utilizes the latest explicit 3D Gaussian Splatting (3DGS) technique to render object surfaces, which effectively addresses the limitations of traditional methods and accurately simulates underwater optical phenomena. Experimental results on the data set and the robot platform show that our model can complete high-precision reconstruction in 30 seconds with only 3 image inputs, significantly enhancing the practical application of the algorithm in robotic platforms.
水下场景重建是水下操作的关键技术,能够从水下平台捕获的图像生成3D模型。然而,由于介质干扰,水下图像的质量往往下降,这限制了从运动结构(SfM)姿态估计的有效性,导致随后的重建失败。此外,SfM方法通常运行较慢,进一步阻碍了它们在实时场景中的应用。在本文中,我们介绍了AquaGS,一种基于SeaThru算法的非SfM水下场景重建模型,它有助于快速准确地分离场景细节和介质特征。我们的方法通过集成最新的多视角立体(MVS)技术来初始化高斯分布,使用隐式神经辐射场(NeRF)呈现半透明介质,并利用最新的显式3D高斯展布(3DGS)技术呈现物体表面,这有效地解决了传统方法的局限性,并能准确地模拟水下光学现象。在数据集和机器人平台上的实验结果表明,我们的模型仅使用3个图像输入就能在30秒内完成高精度重建,这大大增强了算法在机器人平台上的实际应用。
论文及项目相关链接
摘要
水下场景重建是一项对水下操作至关重要的技术,能通过水下平台捕获的图像生成3D模型。但由于介质干扰,水下图像质量往往下降,影响从运动结构(SfM)姿态估计的效果,导致重建失败。此外,SfM方法通常运行较慢,进一步阻碍其在实时场景中的应用。本文介绍了AquaGS,一种基于SeaThru算法的非SfM水下场景重建模型,能够迅速准确地分离场景细节和介质特征。该方法通过集成最新多视角立体(MVS)技术初始化高斯分布,采用隐式神经辐射场(NeRF)呈现半透明介质,并利用最新的显式3D高斯拼贴(3DGS)技术呈现物体表面,有效解决传统方法的局限,准确模拟水下光学现象。在数据集和机器人平台上的实验表明,该模型仅需3张图像输入,就能在30秒内完成高精度重建,显著提高了算法在机器人平台上的实际应用性能。
要点掌握
- 水下场景重建是水下操作的关键技术,能够从水下平台拍摄的图片生成3D模型。
- 介质干扰导致水下图像质量下降,影响SfM姿态估计和后续重建。
- 提出的AquaGS模型基于SeaThru算法,无需SfM技术。
- AquaGS能迅速分离场景细节和介质特征。
- 该方法集成了多视角立体(MVS)技术、隐式神经辐射场(NeRF)和3D高斯拼贴(3DGS)技术。
- AquaGS能准确模拟水下光学现象,并有效解决传统方法的局限。
点此查看论文截图



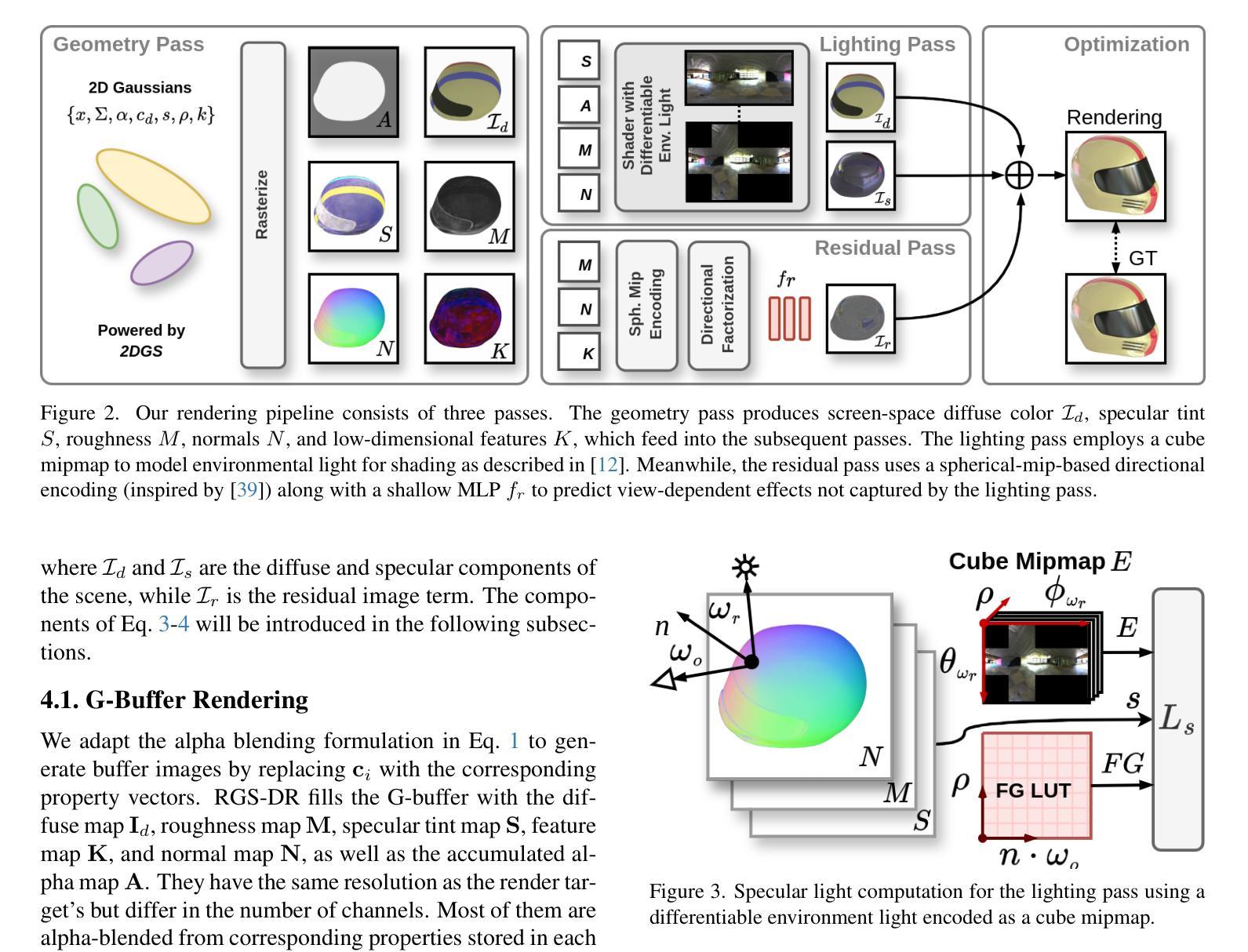
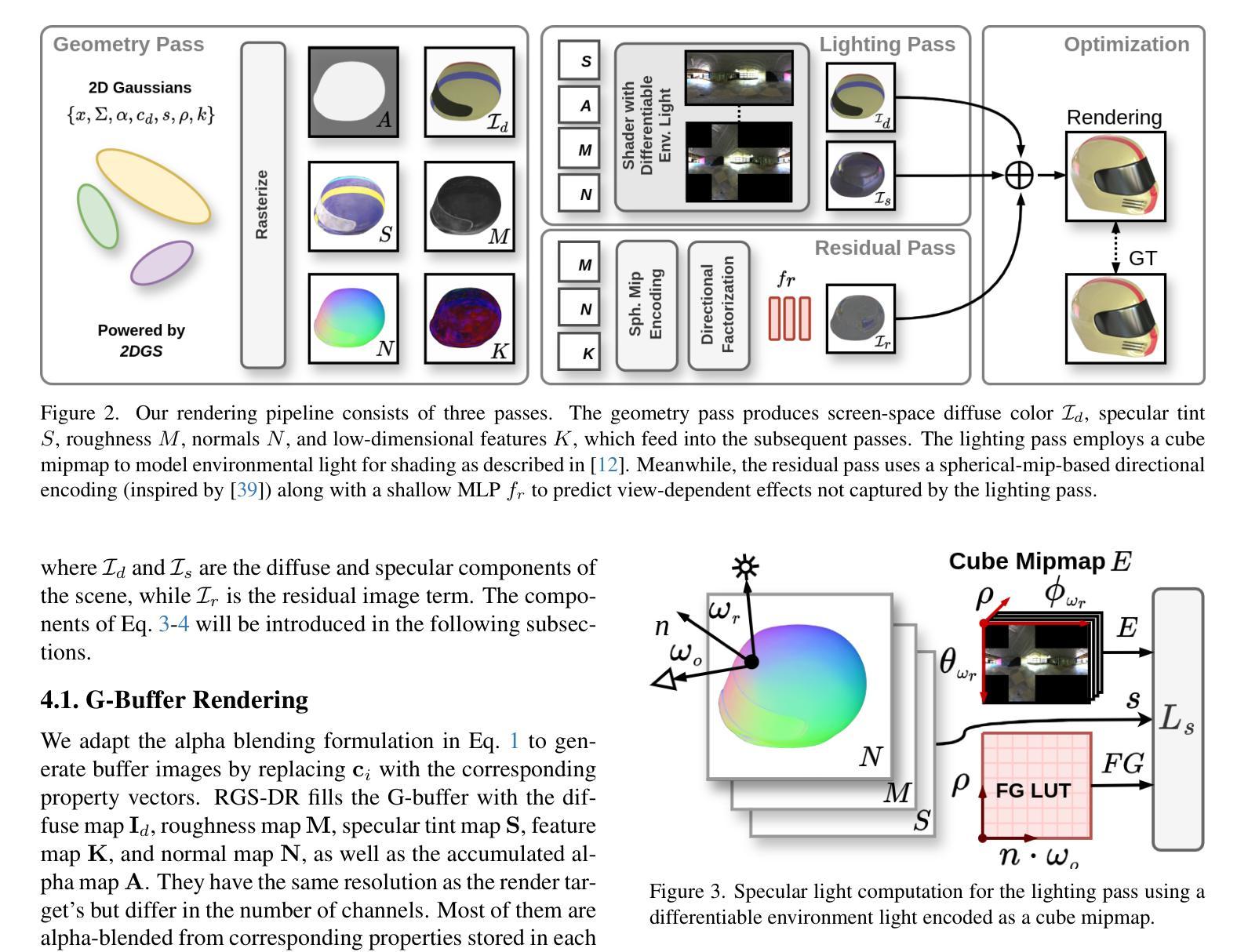
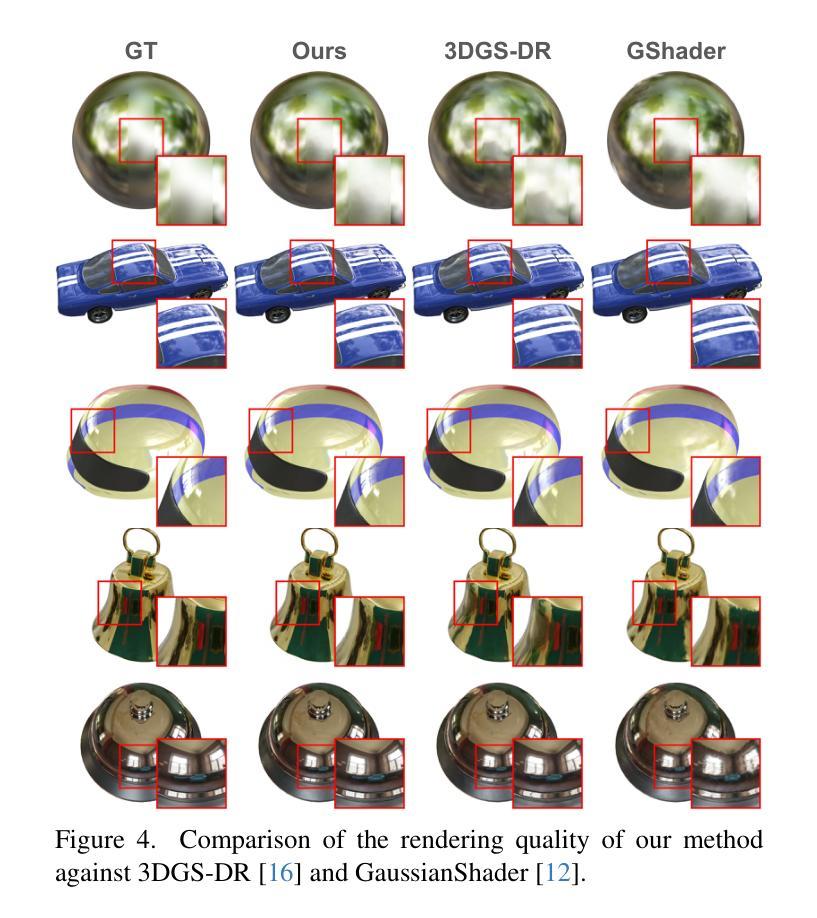
RGS-DR: Reflective Gaussian Surfels with Deferred Rendering for Shiny Objects
Authors:Georgios Kouros, Minye Wu, Tinne Tuytelaars
We introduce RGS-DR, a novel inverse rendering method for reconstructing and rendering glossy and reflective objects with support for flexible relighting and scene editing. Unlike existing methods (e.g., NeRF and 3D Gaussian Splatting), which struggle with view-dependent effects, RGS-DR utilizes a 2D Gaussian surfel representation to accurately estimate geometry and surface normals, an essential property for high-quality inverse rendering. Our approach explicitly models geometric and material properties through learnable primitives rasterized into a deferred shading pipeline, effectively reducing rendering artifacts and preserving sharp reflections. By employing a multi-level cube mipmap, RGS-DR accurately approximates environment lighting integrals, facilitating high-quality reconstruction and relighting. A residual pass with spherical-mipmap-based directional encoding further refines the appearance modeling. Experiments demonstrate that RGS-DR achieves high-quality reconstruction and rendering quality for shiny objects, often outperforming reconstruction-exclusive state-of-the-art methods incapable of relighting.
我们介绍了RGS-DR,这是一种新型逆向渲染方法,用于重建和渲染具有光泽和反射特性的物体,支持灵活的重新打光和场景编辑。与现有方法(例如NeRF和3D高斯拼贴)相比,它们在处理与视图相关的效果时遇到困难,而RGS-DR使用2D高斯surfel表示法来准确估计几何和表面法线,这是高质量逆向渲染的基本属性。我们的方法通过可学习的原始元素显式建模几何和材料属性,并将其渲染到延迟着色管道中,这有效地减少了渲染伪影并保持了锐利的反射。通过采用多层次立方体mipmap,RGS-DR能够准确近似环境光照积分,从而实现高质量的重建和重新打光。基于球形mipmap的方向编码的残差传递进一步改进了外观建模。实验表明,RGS-DR在重建和渲染光泽物体方面达到了高质量水平,往往超越了那些不能进行重新打光的仅重建的顶尖方法。
论文及项目相关链接
Summary
RGS-DR是一种新型逆向渲染方法,能重建和渲染具有光泽和反射特性的物体,支持灵活的重新照明和场景编辑。该方法采用2D高斯surfel表示法准确估计几何和表面法线,通过可学习的原始元素显式建模几何和材质属性,并渲染到延迟着色管道中,有效减少渲染伪影,保留锐利反射。通过采用多级立方体mipmap,RGS-DR准确近似环境照明积分,实现高质量重建和重新照明。使用基于球面mipmap的方向编码的残差传递进一步改进了外观建模。实验表明,RGS-DR在重建和渲染光泽物体方面具有高质量,经常超越无法重新照明的重建专用最先进方法。
Key Takeaways
- RGS-DR是一种用于重建和渲染具有光泽和反射特性的物体的新型逆向渲染方法。
- 该方法采用2D高斯surfel表示法来准确估计几何和表面法线,这是高质量逆向渲染的关键属性。
- RGS-DR通过可学习的原始元素显式建模几何和材质属性,并将其渲染到延迟着色管道中,以提高渲染质量并减少伪影。
- 采用多级立方体mipmap技术,RGS-DR能准确近似环境照明积分,实现高质量的重建和重新照明。
- 残差传递和基于球面mipmap的方向编码进一步改进了RGS-DR的外观建模。
- RGS-DR在重建和渲染光泽物体方面的性能超越了某些最先进的方法。
点此查看论文截图

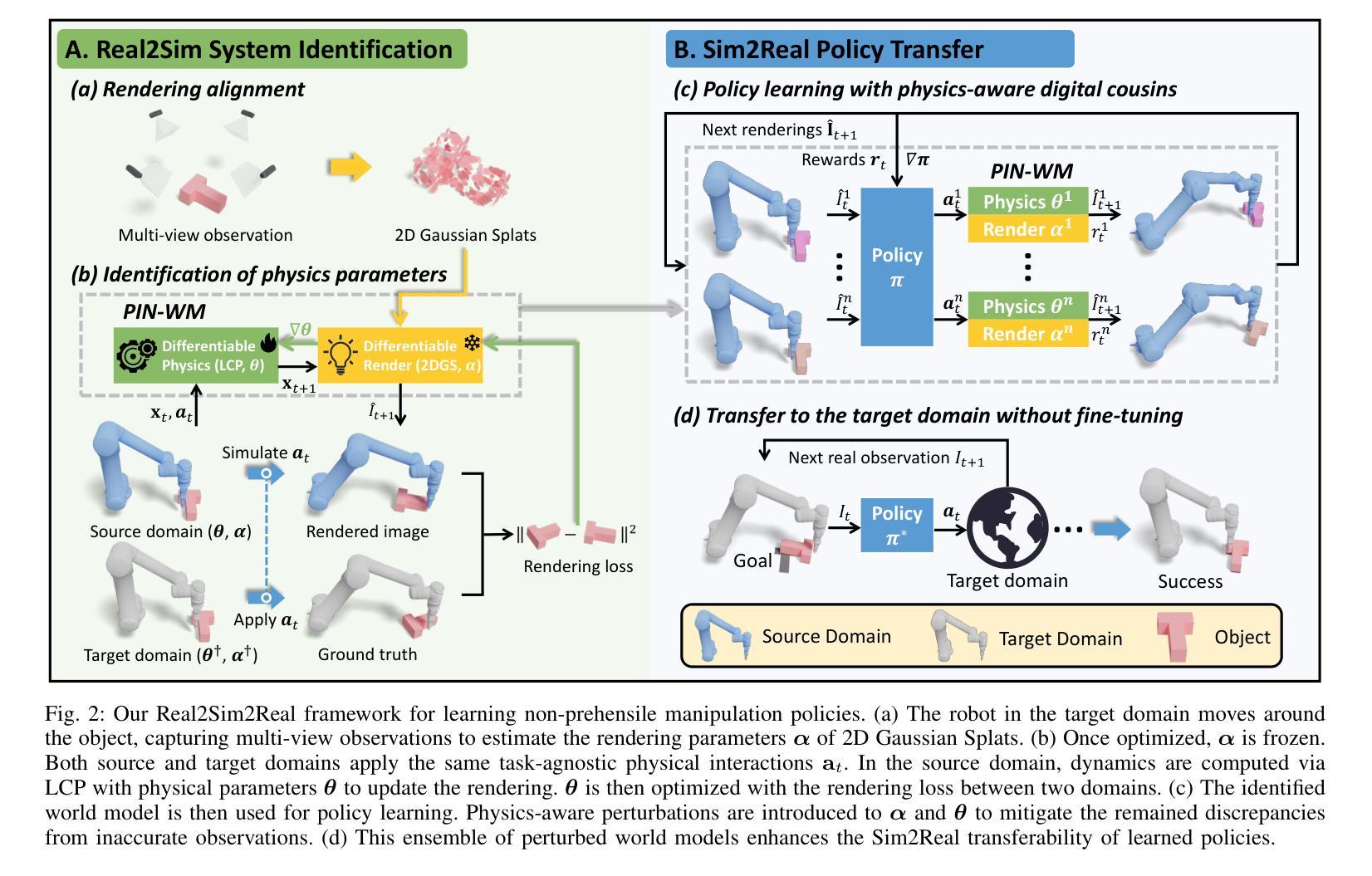
PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation
Authors:Wenxuan Li, Hang Zhao, Zhiyuan Yu, Yu Du, Qin Zou, Ruizhen Hu, Kai Xu
While non-prehensile manipulation (e.g., controlled pushing/poking) constitutes a foundational robotic skill, its learning remains challenging due to the high sensitivity to complex physical interactions involving friction and restitution. To achieve robust policy learning and generalization, we opt to learn a world model of the 3D rigid body dynamics involved in non-prehensile manipulations and use it for model-based reinforcement learning. We propose PIN-WM, a Physics-INformed World Model that enables efficient end-to-end identification of a 3D rigid body dynamical system from visual observations. Adopting differentiable physics simulation, PIN-WM can be learned with only few-shot and task-agnostic physical interaction trajectories. Further, PIN-WM is learned with observational loss induced by Gaussian Splatting without needing state estimation. To bridge Sim2Real gaps, we turn the learned PIN-WM into a group of Digital Cousins via physics-aware randomizations which perturb physics and rendering parameters to generate diverse and meaningful variations of the PIN-WM. Extensive evaluations on both simulation and real-world tests demonstrate that PIN-WM, enhanced with physics-aware digital cousins, facilitates learning robust non-prehensile manipulation skills with Sim2Real transfer, surpassing the Real2Sim2Real state-of-the-arts.
非预抓取操作(例如,受控推动/戳刺)构成了一项基础机器人技能,但由于其对涉及摩擦和恢复力的复杂物理交互的高度敏感性,其学习仍然具有挑战性。为了实现稳健的策略学习和泛化,我们选择学习涉及非预抓取操作的三维刚体动力学世界模型,并将其用于基于模型的强化学习。我们提出了PIN-WM,即物理信息世界模型,能够实现从视觉观察中高效端到端地识别三维刚体动态系统。通过采用可微分物理模拟,PIN-WM仅通过少量任务无关的物理解算轨迹即可学习。此外,PIN-WM通过高斯Splatting诱导的观察损失进行学习,无需进行状态估计。为了弥虚拟与现实之间的差距,我们通过物理感知随机化将学习到的PIN-WM转换为数字孪生群体,随机扰动物理和渲染参数来生成多样而有意义的PIN-WM变化。在模拟和真实世界测试上的广泛评估表明,通过增强物理感知的数字孪生群体,PIN-WM有助于学习具有从模拟到现实迁移能力的稳健的非预抓取操作技能,超越了最新的Real2Sim2Real技术。
论文及项目相关链接
PDF Robotics: Science and Systems 2025
Summary
针对非抓取操作(如控制推动/戳刺)的机器人技能学习,存在对复杂物理交互的高度敏感性,包括摩擦和恢复系数等挑战。为实现稳健的策略学习和泛化,我们选择了学习涉及非抓取操作的三维刚体动力学的世界模型,并用于基于模型强化学习。我们提出PIN-WM,一种基于物理信息的世界模型,能够高效端到端识别三维刚体动态系统,从视觉观察中学习。通过采用可微分物理仿真,PIN-WM仅通过少量、任务无关的物理解算轨迹即可学习。此外,通过高斯拼贴技术引入观测损失进行训练,无需状态估计。为解决模拟到现实的差距问题,我们将学到的PIN-WM转化为数字分身群体,通过物理感知随机化技术扰动物理和渲染参数,生成多样且意义深远的模型变体。在模拟和真实世界测试中的广泛评估表明,辅以物理感知的数字分身群体,PIN-WM能学习稳健的非抓取操作技能并实现模拟到现实的迁移学习性能超越现有的先进水平。
Key Takeaways
- 非抓取操作的机器人技能学习面临复杂物理交互的挑战。
- 提出PIN-WM模型:利用基于物理信息的世界模型学习三维刚体动力学。
- 采用可微分物理仿真进行高效端到端学习。
- 通过高斯拼贴技术引入观测损失进行训练,无需状态估计。
- 利用物理感知随机化技术将模型转化为数字分身群体以解决模拟到现实的差距问题。
点此查看论文截图

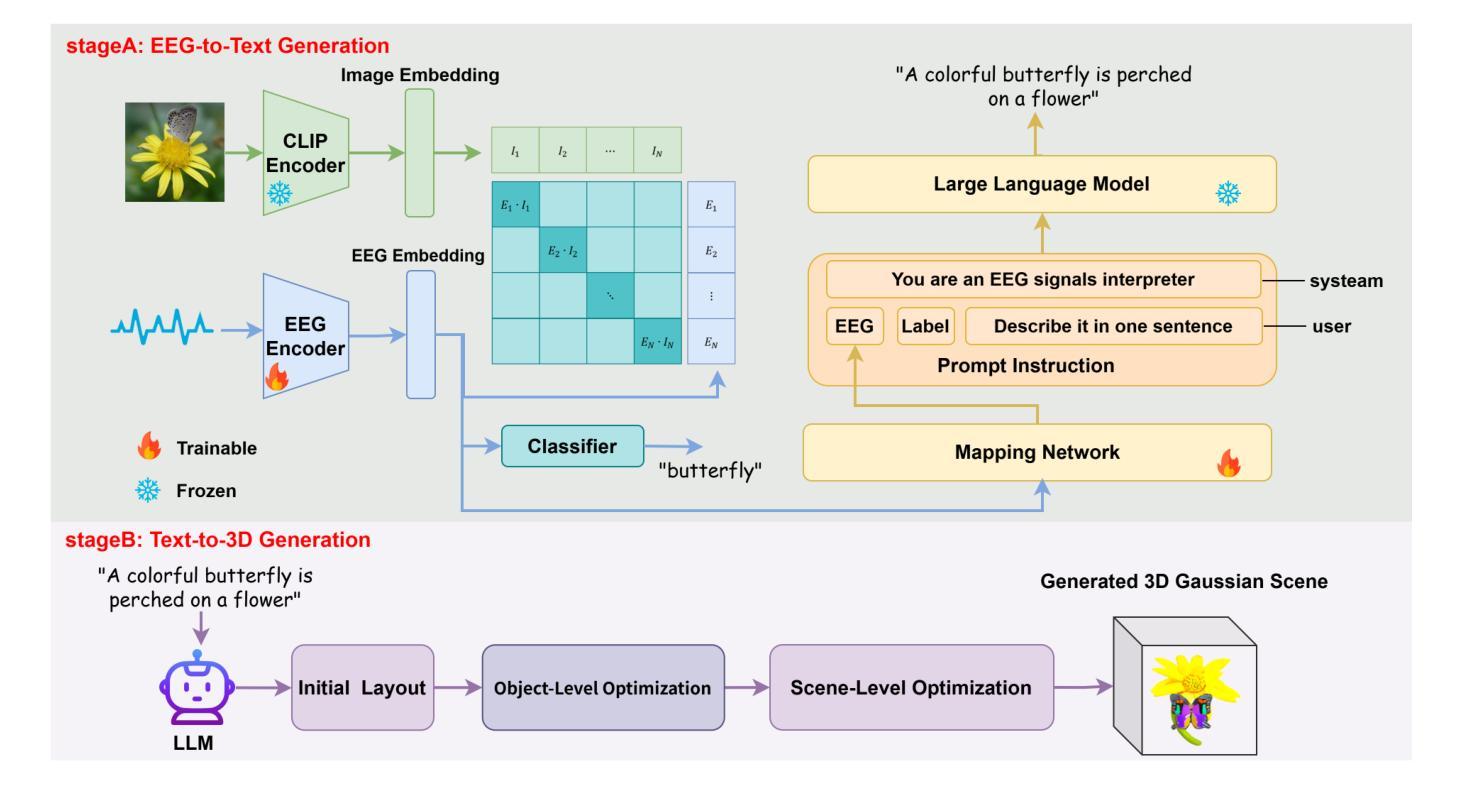
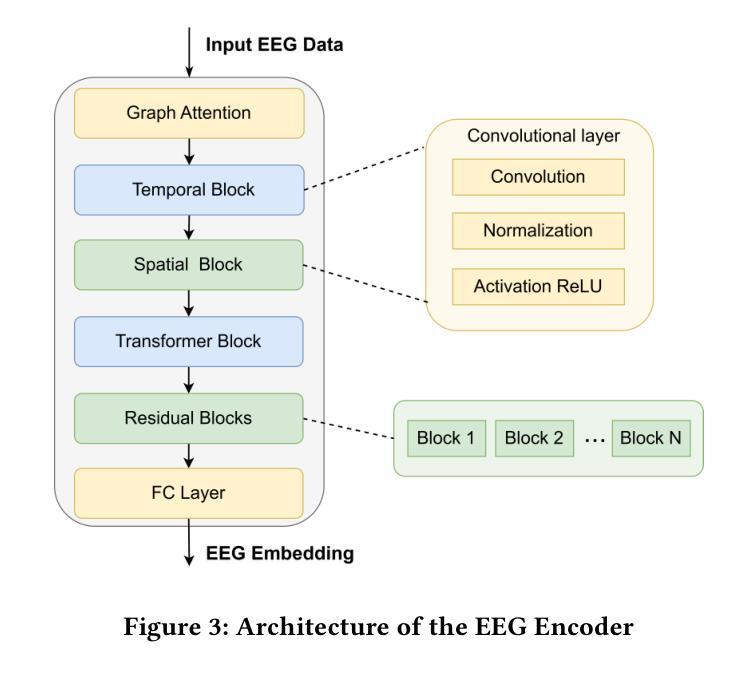
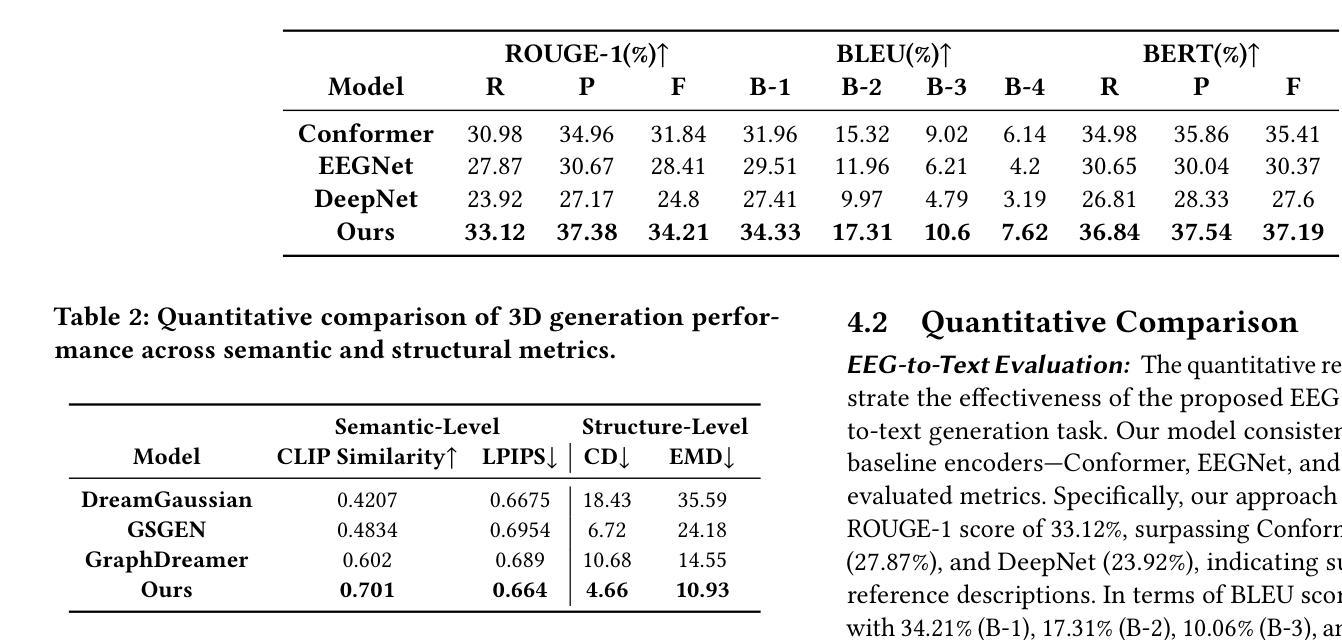
Mind2Matter: Creating 3D Models from EEG Signals
Authors:Xia Deng, Shen Chen, Jiale Zhou, Lei Li
The reconstruction of 3D objects from brain signals has gained significant attention in brain-computer interface (BCI) research. Current research predominantly utilizes functional magnetic resonance imaging (fMRI) for 3D reconstruction tasks due to its excellent spatial resolution. Nevertheless, the clinical utility of fMRI is limited by its prohibitive costs and inability to support real-time operations. In comparison, electroencephalography (EEG) presents distinct advantages as an affordable, non-invasive, and mobile solution for real-time brain-computer interaction systems. While recent advances in deep learning have enabled remarkable progress in image generation from neural data, decoding EEG signals into structured 3D representations remains largely unexplored. In this paper, we propose a novel framework that translates EEG recordings into 3D object reconstructions by leveraging neural decoding techniques and generative models. Our approach involves training an EEG encoder to extract spatiotemporal visual features, fine-tuning a large language model to interpret these features into descriptive multimodal outputs, and leveraging generative 3D Gaussians with layout-guided control to synthesize the final 3D structures. Experiments demonstrate that our model captures salient geometric and semantic features, paving the way for applications in brain-computer interfaces (BCIs), virtual reality, and neuroprosthetics. Our code is available in https://github.com/sddwwww/Mind2Matter.
从脑信号重建3D物体在脑机接口(BCI)研究中受到了广泛关注。目前的研究主要利用功能磁共振成像(fMRI)进行3D重建任务,因其具有出色的空间分辨率。然而,fMRI的临床应用受限于其高昂的成本和无法支持实时操作。相比之下,脑电图(EEG)作为经济实惠、非侵入式和移动式的实时脑机交互系统解决方案,具有明显优势。虽然深度学习领域的最新进展在神经数据生成图像方面取得了显著进步,但将EEG信号解码为结构化的3D表示仍然很少被探索。在本文中,我们提出了一种利用神经解码技术和生成模型将EEG记录转化为3D对象重建的新框架。我们的方法包括训练EEG编码器以提取时空视觉特征,微调大型语言模型以将这些特征解释为描述性的多模式输出,并利用带有布局指导控制的生成性3D高斯来合成最终的3D结构。实验表明,我们的模型捕捉了显著的几何和语义特征,为脑机接口(BCI)、虚拟现实和神经矫形器应用铺平了道路。我们的代码可在https://github.com/sddwwww/Mind2Matter中找到。
论文及项目相关链接
Summary
本文介绍了利用脑电波信号进行三维物体重建的研究。由于高昂的成本和无法支持实时操作,功能性磁共振成像(fMRI)在三维重建任务中的使用受到限制。研究提出了一种利用脑电图(EEG)信号进行三维物体重建的新框架,通过神经解码技术和生成模型将EEG信号转换为三维物体结构。该框架包括训练EEG编码器提取时空视觉特征、微调大型语言模型以解释这些特征并生成多模式输出,并利用布局控制的生成性三维高斯模型合成最终的三维结构。实验证明该模型能够捕捉关键的几何和语义特征,为脑机接口、虚拟现实和神经仿生等领域的应用开辟了道路。
Key Takeaways
- 利用脑电波信号进行三维物体重建是脑机接口研究领域的热点。
- 当前研究主要使用功能性磁共振成像(fMRI)进行三维重建,但其高昂成本和无法实时操作限制了应用。
- 脑电图(EEG)作为一种经济、非侵入式和可移动的技术,在实时脑机交互系统中具有优势。
- 深度学习在图像生成和神经数据解码方面取得了显著进展,但将EEG信号解码为结构化三维表示仍待探索。
- 研究提出了一种新的框架,利用神经解码技术和生成模型将EEG信号转换为三维物体结构。
- 该框架包括训练EEG编码器、微调大型语言模型和利用生成性三维高斯模型合成三维结构等步骤。
点此查看论文截图

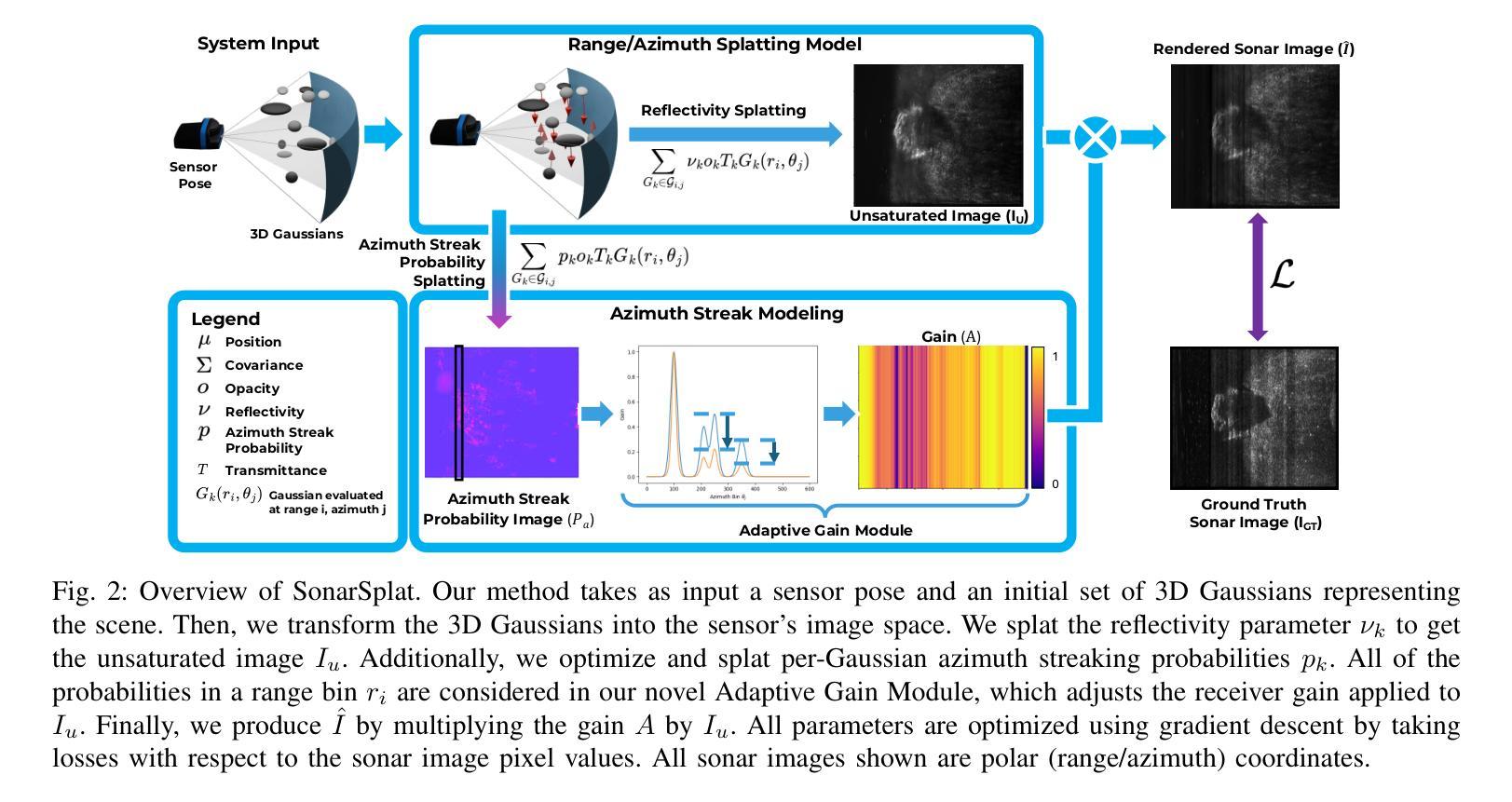
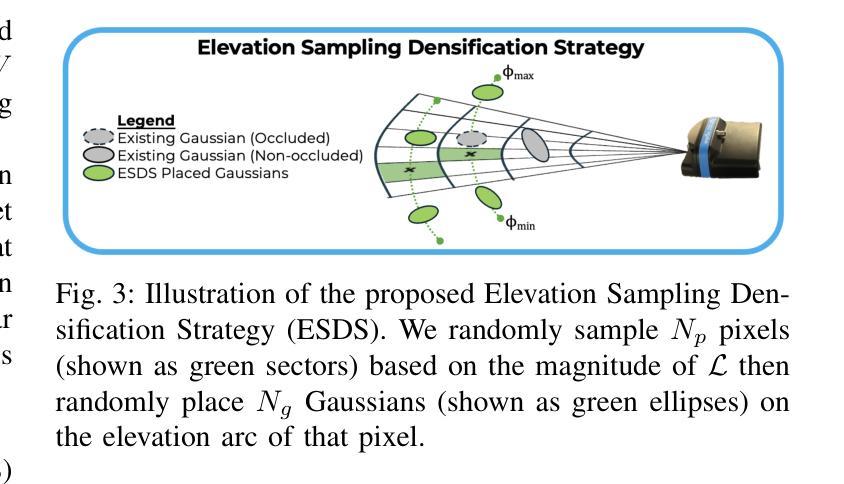
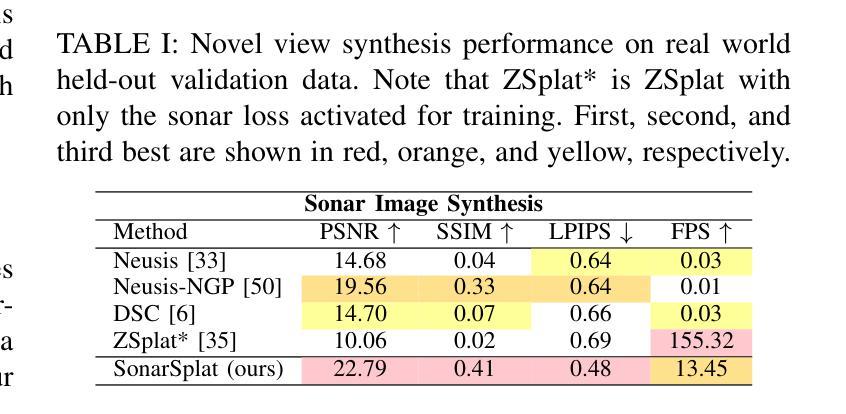
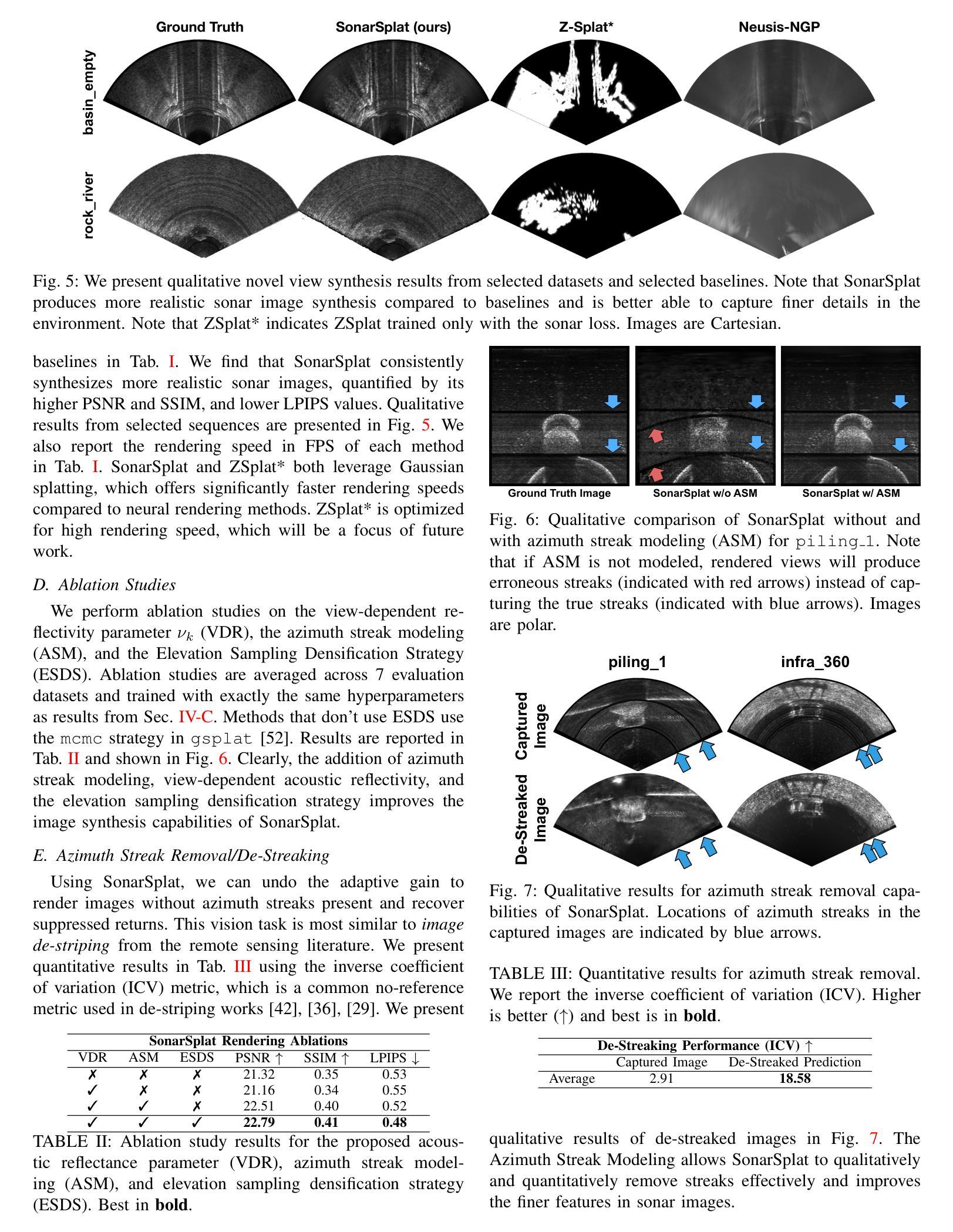
SonarSplat: Novel View Synthesis of Imaging Sonar via Gaussian Splatting
Authors:Advaith V. Sethuraman, Max Rucker, Onur Bagoren, Pou-Chun Kung, Nibarkavi N. B. Amutha, Katherine A. Skinner
In this paper, we present SonarSplat, a novel Gaussian splatting framework for imaging sonar that demonstrates realistic novel view synthesis and models acoustic streaking phenomena. Our method represents the scene as a set of 3D Gaussians with acoustic reflectance and saturation properties. We develop a novel method to efficiently rasterize Gaussians to produce a range/azimuth image that is faithful to the acoustic image formation model of imaging sonar. In particular, we develop a novel approach to model azimuth streaking in a Gaussian splatting framework. We evaluate SonarSplat using real-world datasets of sonar images collected from an underwater robotic platform in a controlled test tank and in a real-world river environment. Compared to the state-of-the-art, SonarSplat offers improved image synthesis capabilities (+3.2 dB PSNR) and more accurate 3D reconstruction (52% lower Chamfer Distance). We also demonstrate that SonarSplat can be leveraged for azimuth streak removal.
在这篇论文中,我们提出了SonarSplat,这是一种新型的用于成像声呐的高斯模糊框架,它展示了真实的新型视图合成,并模拟了声线拖尾现象。我们的方法将场景表示为具有声反射和饱和属性的3D高斯集合。我们开发了一种新方法,可以有效地将高斯量化为范围/方位图像,该图像忠实于成像声呐的声成像形成模型。特别是,我们在高斯模糊框架中开发了一种新型方法,用于模拟方位拖尾。我们使用真实世界的声呐图像数据集对SonarSplat进行了评估,这些数据集是从受控测试水箱和真实世界河流环境中水下机器人平台收集的。与最新技术相比,SonarSplat提供了更好的图像合成能力(+ 3.2分贝峰值信噪比),并且三维重建更准确(降低了52%的Chamfer距离)。我们还证明了SonarSplat可以用于消除方位拖尾。
论文及项目相关链接
Summary
本文介绍了SonarSplat,一种新颖的基于高斯点绘技术的成像声纳方法,可实现真实的新型视角合成,并模拟声波拖尾现象。该方法将场景表示为具有声学反射和饱和特性的三维高斯集合。通过高效的高斯栅格化技术,生成忠于声学成像声纳模型的方位图像。特别地,本文开发了一种在高斯点绘框架内模拟方位拖尾的新方法。通过实际水下机器人平台采集的声纳图像数据集进行验证,SonarSplat相较于现有技术,图像合成能力提升(+3.2 dB PSNR),三维重建更为精准(降低了52%的Chamfer距离)。此外,SonarSplat还可以用于去除方位拖影。
Key Takeaways
- SonarSplat是一种基于高斯点绘技术的成像声纳方法。
- 该方法实现了真实的新型视角合成,并模拟声波拖尾现象。
- SonarSplat将场景表示为具有声学反射和饱和特性的三维高斯集合。
- 通过高效的高斯栅格化技术,生成忠于声学成像声纳模型的方位图像。
- SonarSplat在模拟方位拖尾方面有所创新。
- 与现有技术相比,SonarSplat在图像合成和三维重建方面表现出优越性能。
点此查看论文截图


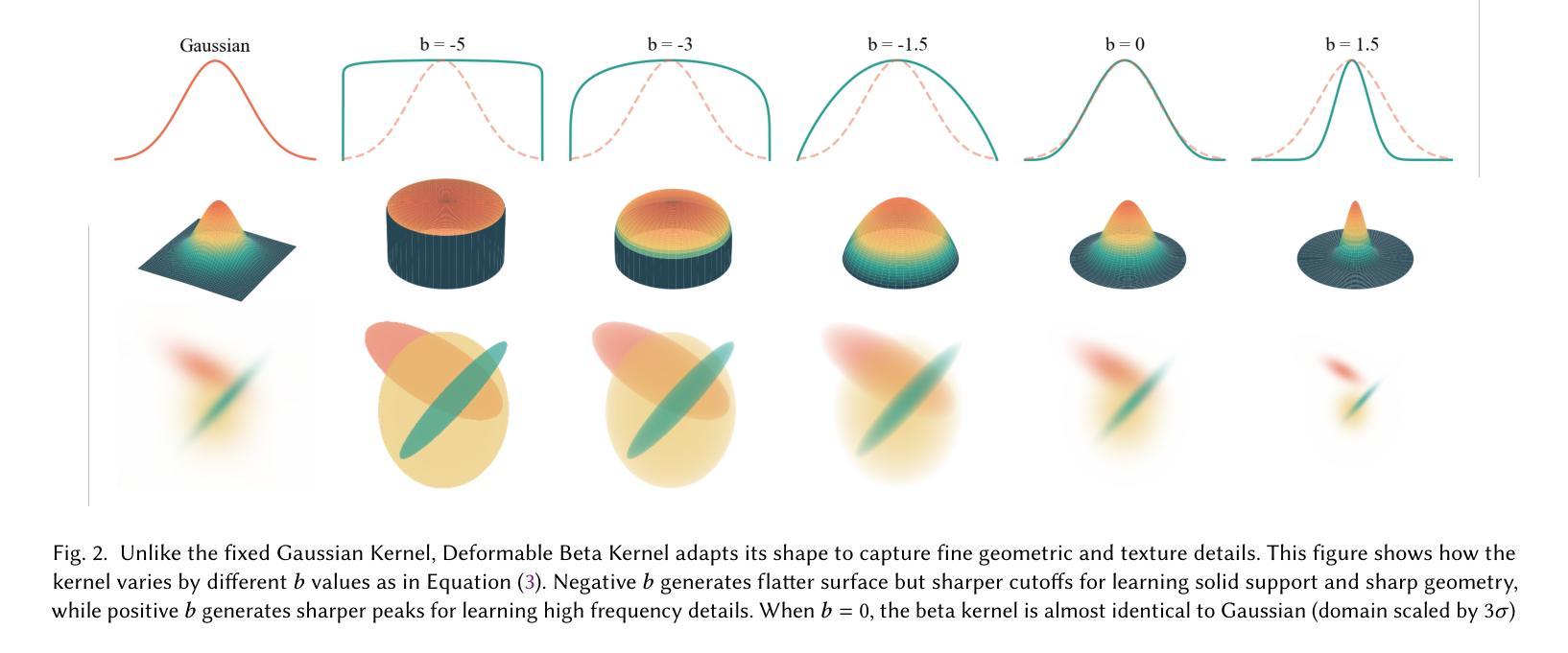
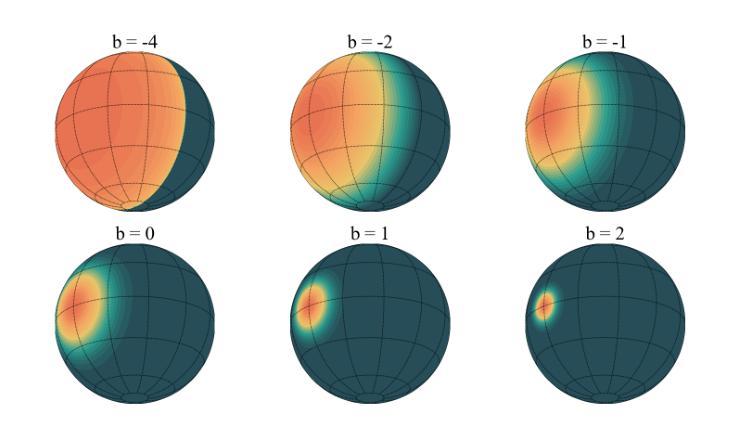
Deformable Beta Splatting
Authors:Rong Liu, Dylan Sun, Meida Chen, Yue Wang, Andrew Feng
3D Gaussian Splatting (3DGS) has advanced radiance field reconstruction by enabling real-time rendering. However, its reliance on Gaussian kernels for geometry and low-order Spherical Harmonics (SH) for color encoding limits its ability to capture complex geometries and diverse colors. We introduce Deformable Beta Splatting (DBS), a deformable and compact approach that enhances both geometry and color representation. DBS replaces Gaussian kernels with deformable Beta Kernels, which offer bounded support and adaptive frequency control to capture fine geometric details with higher fidelity while achieving better memory efficiency. In addition, we extended the Beta Kernel to color encoding, which facilitates improved representation of diffuse and specular components, yielding superior results compared to SH-based methods. Furthermore, Unlike prior densification techniques that depend on Gaussian properties, we mathematically prove that adjusting regularized opacity alone ensures distribution-preserved Markov chain Monte Carlo (MCMC), independent of the splatting kernel type. Experimental results demonstrate that DBS achieves state-of-the-art visual quality while utilizing only 45% of the parameters and rendering 1.5x faster than 3DGS-MCMC, highlighting the superior performance of DBS for real-time radiance field rendering. Interactive demonstrations and source code are available on our project website: https://rongliu-leo.github.io/beta-splatting/.
3D高斯贴图(3DGS)已经通过实现实时渲染推动了辐射场重建的发展。然而,它依赖于高斯核进行几何处理以及低阶球面谐波(SH)进行颜色编码,这限制了其捕捉复杂几何和多样色彩的能力。我们引入了可变形Beta贴图(DBS),这是一种可变形且紧凑的方法,可增强几何和颜色的表示。DBS用可变形的Beta核替换高斯核,提供有界支持和自适应频率控制,以更高的保真度捕捉精细的几何细节,同时实现更好的内存效率。此外,我们将Beta核扩展到颜色编码,这有助于改进漫反射和镜面成分的表示,与基于SH的方法相比产生更优越的结果。此外,不同于依赖高斯属性的先前稠密化技术,我们从数学上证明,仅调整正则化不透明度就可以确保与贴图核类型无关的分布保留马尔可夫链蒙特卡洛(MCMC)。实验结果表明,DBS实现了最先进的视觉质量,同时仅使用45%的参数并以比3DGS-MCMC快1.5倍的速度进行渲染,突显了DBS在实时辐射场渲染中的卓越性能。交互式演示和项目源代码可在我们的网站上找到:https://rongliu-leo.github.io/beta-splatting/。
论文及项目相关链接
PDF SIGGRAPH 2025
Summary
本文介绍了基于可变形Beta Splatting(DBS)技术的辐射场重建方法。该技术改进了3D Gaussian Splatting(3DGS)的几何和色彩表现能力,通过使用可变形Beta核来提高几何细节表现,同时扩展Beta核至色彩编码以提升色彩表现。此外,DBS优化了内存效率和渲染速度,实现了实时辐射场渲染的优异性能。
Key Takeaways
- 3DGS受限于高斯核和低阶球面谐波(SH)的色彩编码,难以捕捉复杂几何和多样色彩。
- DBS通过引入可变形Beta核,增强了几何表现能力,可实现更高精度的精细几何细节捕捉。
- Beta核扩展至色彩编码,提升了漫反射和镜面成分的表现,优于SH方法。
- 调整正则化不透明度可确保分布保留的Markov链蒙特卡洛(MCMC)方法,与splatting核类型无关。
- 实验结果表明,DBS实现了较高的视觉质量,同时使用的参数比3DGS-MCMC少45%,并且渲染速度提高了1.5倍。
点此查看论文截图


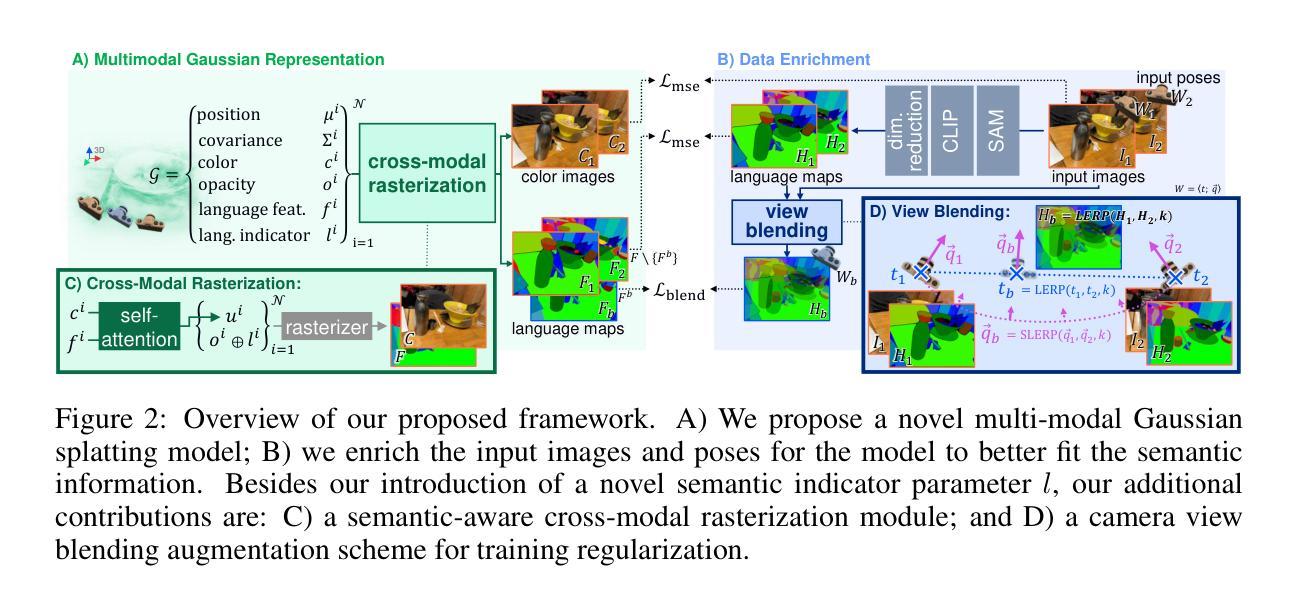
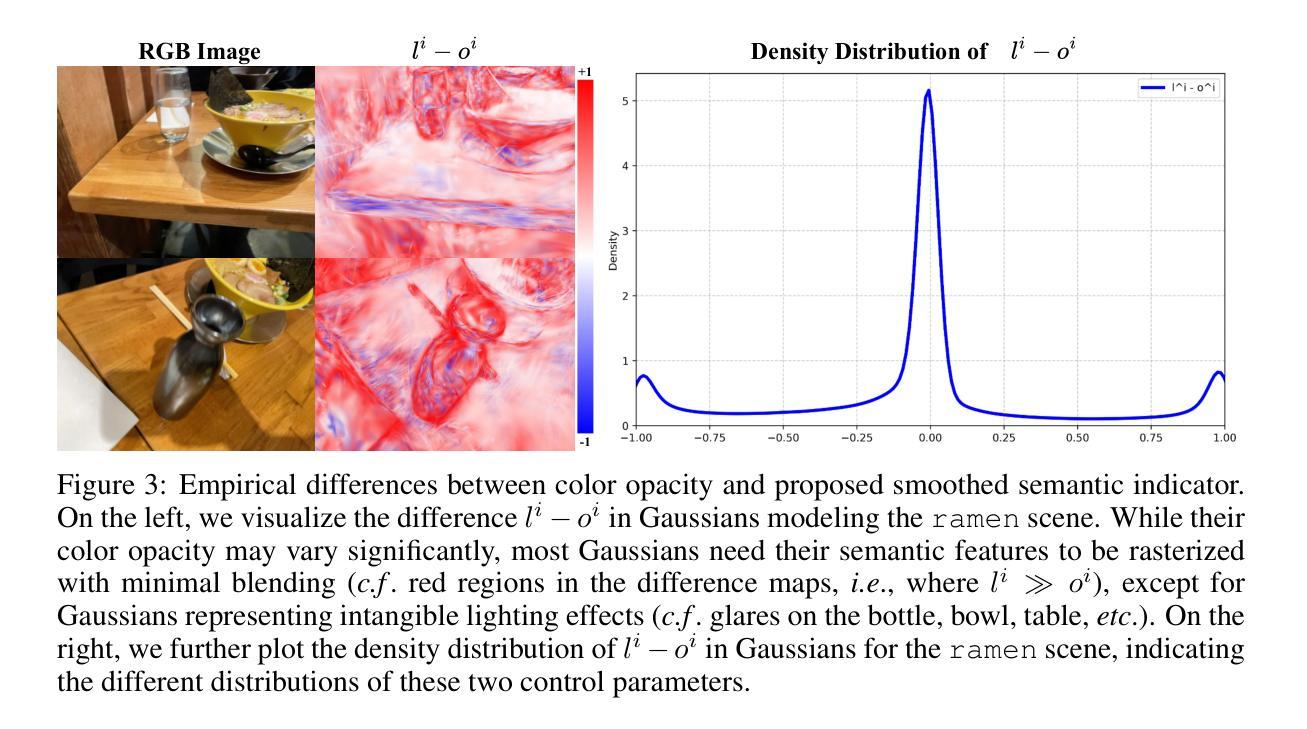
3D Vision-Language Gaussian Splatting
Authors:Qucheng Peng, Benjamin Planche, Zhongpai Gao, Meng Zheng, Anwesa Choudhuri, Terrence Chen, Chen Chen, Ziyan Wu
Recent advancements in 3D reconstruction methods and vision-language models have propelled the development of multi-modal 3D scene understanding, which has vital applications in robotics, autonomous driving, and virtual/augmented reality. However, current multi-modal scene understanding approaches have naively embedded semantic representations into 3D reconstruction methods without striking a balance between visual and language modalities, which leads to unsatisfying semantic rasterization of translucent or reflective objects, as well as over-fitting on color modality. To alleviate these limitations, we propose a solution that adequately handles the distinct visual and semantic modalities, i.e., a 3D vision-language Gaussian splatting model for scene understanding, to put emphasis on the representation learning of language modality. We propose a novel cross-modal rasterizer, using modality fusion along with a smoothed semantic indicator for enhancing semantic rasterization. We also employ a camera-view blending technique to improve semantic consistency between existing and synthesized views, thereby effectively mitigating over-fitting. Extensive experiments demonstrate that our method achieves state-of-the-art performance in open-vocabulary semantic segmentation, surpassing existing methods by a significant margin.
近期,三维重建方法和视觉语言模型的进步推动了多模态三维场景理解的发展,这在机器人技术、自动驾驶和虚拟/增强现实等领域有重要应用。然而,当前的多模态场景理解方法过于简单地将语义表示嵌入到三维重建方法中,而没有在视觉和语言模态之间取得平衡,这导致对半透明或反射物体的语义栅格化效果不佳,以及对颜色模态的过拟合问题。为了缓解这些局限性,我们提出了一种解决方案,该方案可以充分处理不同的视觉和语义模态,即一种用于场景理解的三维视觉语言高斯平铺模型,重点学习语言模态的表示。我们提出了一种新颖的跨模态栅格化器,使用模态融合以及平滑的语义指标来增强语义栅格化。我们还采用相机视角混合技术,以提高现有和合成视角之间的语义一致性,从而有效地减轻过拟合问题。大量实验表明,我们的方法在开放词汇语义分割上达到了最先进的性能,显著超越了现有方法。
论文及项目相关链接
PDF Accepted at ICLR 2025. Main paper + supplementary material
Summary
近期,随着三维重建方法和视觉语言模型的进步,多模态三维场景理解得到了极大的发展,广泛应用于机器人、自动驾驶、虚拟/增强现实等领域。然而,当前的多模态场景理解方法在处理半透明或反射物体时存在语义栅格化不佳的问题,并存在颜色模态的过拟合现象。针对此问题,我们提出了一个解决方案:一个专门处理视觉和语言模态的3D视觉语言高斯扩展模型。通过跨模态栅格化技术和平滑语义指标的运用,提高语义栅格化的质量。同时采用相机视角融合技术,提高了现有和合成视角之间的语义一致性,有效缓解了过拟合现象。实验证明,我们的方法在开放词汇语义分割任务上取得了显著优于现有方法的性能。
Key Takeaways
- 近期技术进步推动了多模态三维场景理解的发展,应用领域广泛。
- 当前方法在处理半透明或反射物体时存在语义栅格化问题。
- 提出了一种新的3D视觉语言高斯扩展模型,专门处理视觉和语言模态。
- 通过跨模态栅格化技术和平滑语义指标提升语义栅格化质量。
- 采用相机视角融合技术提高视角间语义一致性,缓解过拟合现象。
- 实验证明所提方法在开放词汇语义分割任务上表现优越。
点此查看论文截图


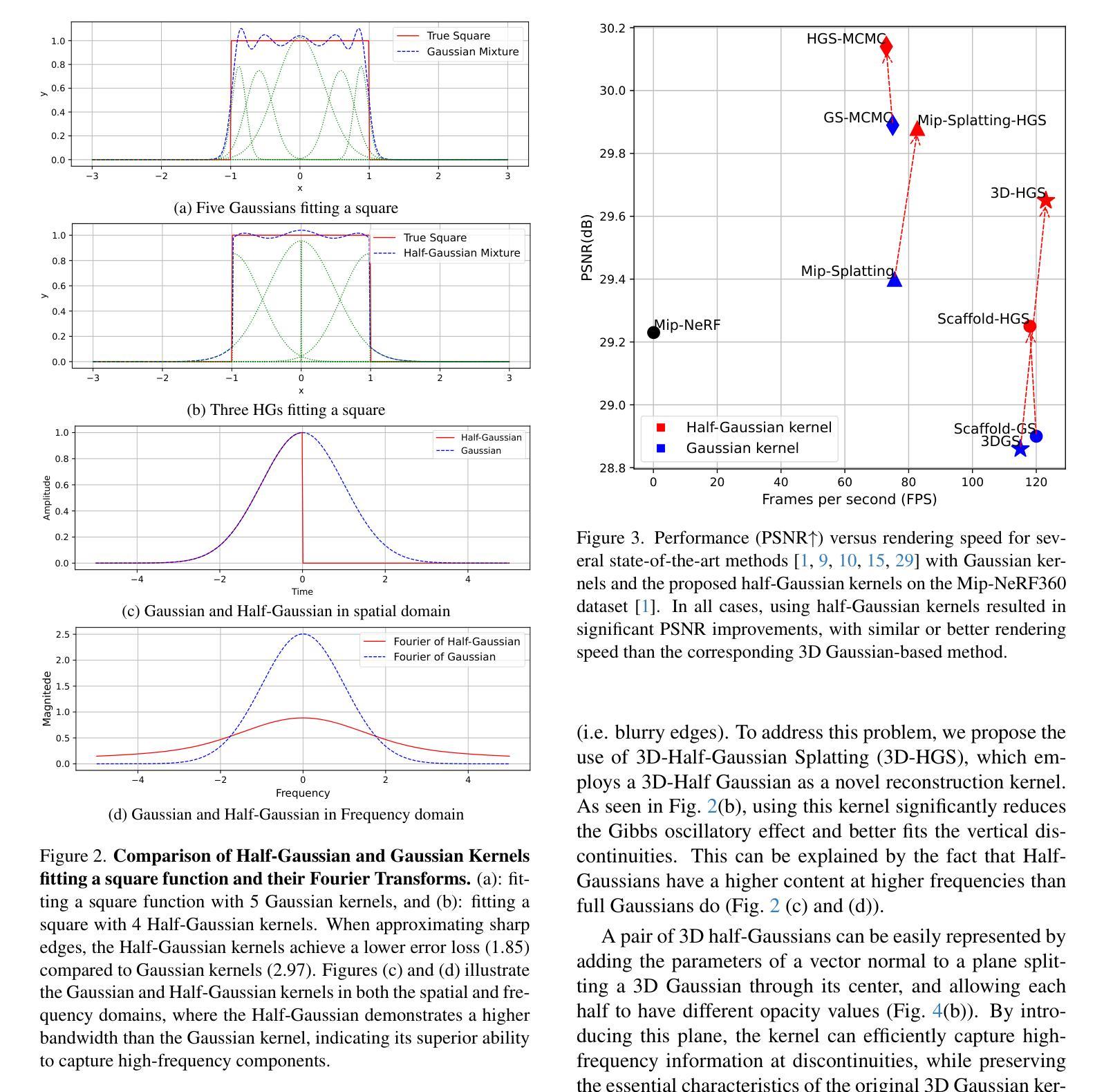
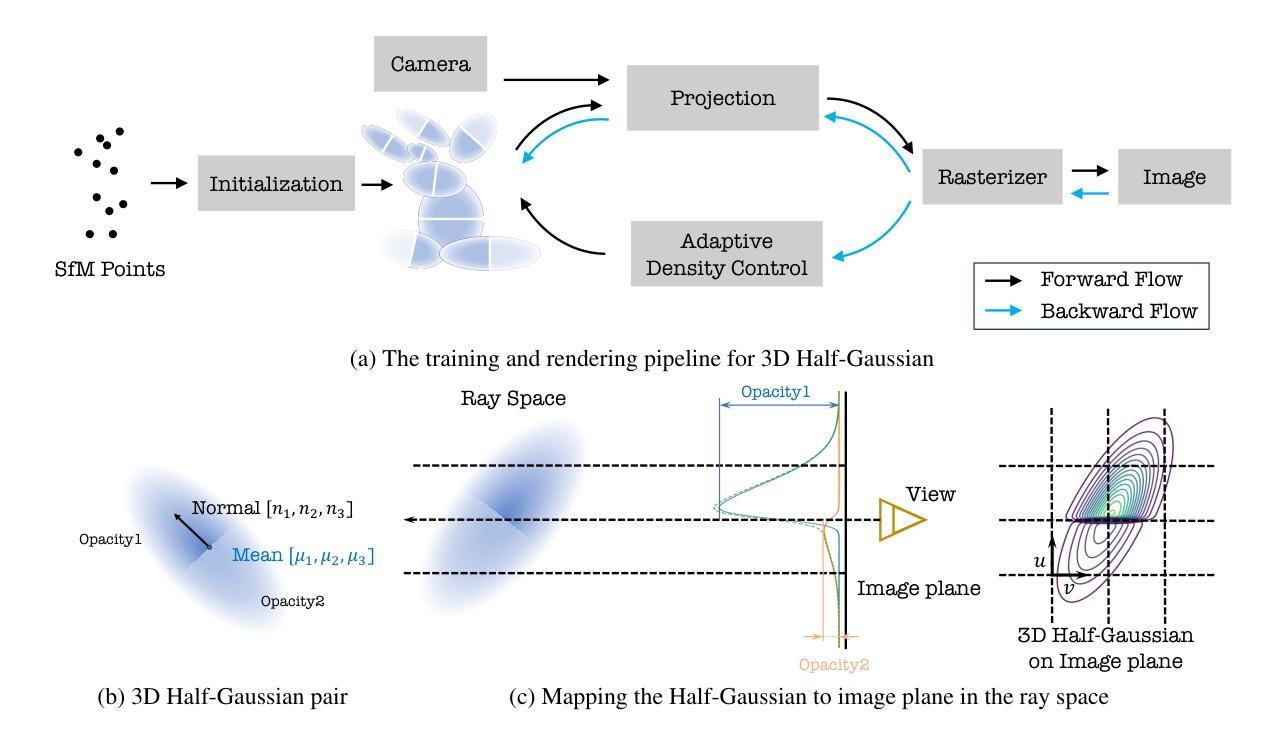
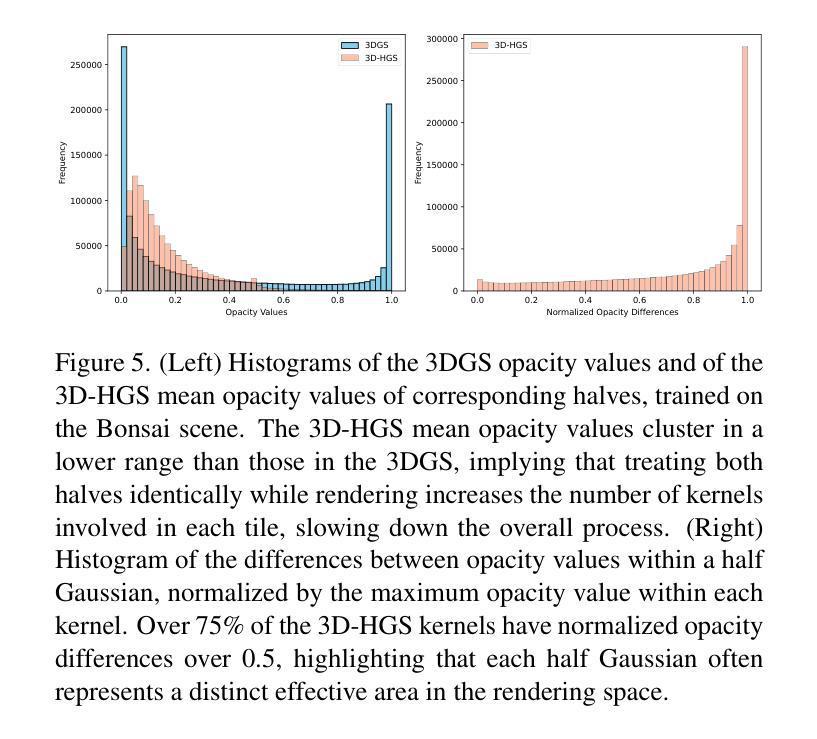
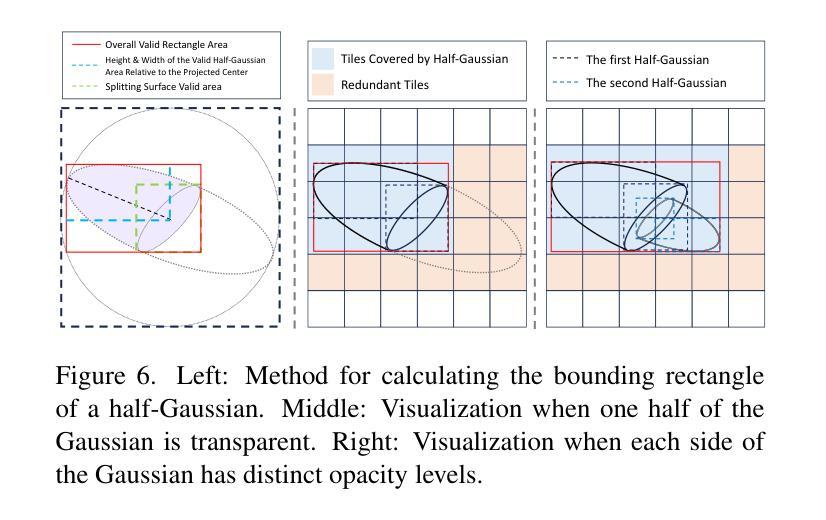
3D-HGS: 3D Half-Gaussian Splatting
Authors:Haolin Li, Jinyang Liu, Mario Sznaier, Octavia Camps
Photo-realistic image rendering from 3D scene reconstruction has advanced significantly with neural rendering techniques. Among these, 3D Gaussian Splatting (3D-GS) outperforms Neural Radiance Fields (NeRFs) in quality and speed but struggles with shape and color discontinuities. We propose 3D Half-Gaussian (3D-HGS) kernels as a plug-and-play solution to address these limitations. Our experiments show that 3D-HGS enhances existing 3D-GS methods, achieving state-of-the-art rendering quality without compromising speed.
基于神经渲染技术的3D场景重建的光照现实图像渲染技术已经取得了显著的进步。其中,3D高斯涂绘(3D-GS)在质量和速度方面优于神经辐射场(NeRFs),但在处理形状和颜色不连续方面存在困难。我们提出了3D半高斯(3D-HGS)核作为一种即插即用的解决方案来解决这些局限性。我们的实验表明,3D-HGS可以增强现有的3D-GS方法,在不牺牲速度的情况下实现最先进的渲染质量。
论文及项目相关链接
PDF 8 pages, 9 figures
Summary
基于神经渲染技术的三维场景重建的光照现实图像渲染取得了显著的进展。然而,现有的方法如Neural Radiance Fields (NeRFs)在某些情况下仍面临质量不高和速度缓慢的问题。针对这些问题,我们提出了一种新型的解决方案——使用三维半高斯(Half-Gaussian)核技术,它能在保证渲染速度的同时提高渲染质量。该技术作为一个插拨式的解决方案,能够有效地改善现有的技术,并实现目前最高水平的渲染质量。我们相信这一技术将在未来的图像渲染领域发挥重要作用。
Key Takeaways
- 神经渲染技术在三维场景重建的光照现实图像渲染方面取得了显著进展。
- 当前方法如NeRFs在质量和速度方面存在局限性。
- 三维半高斯核技术作为一种插拨式解决方案,旨在解决现有方法的局限。
- 三维半高斯核技术能够改善现有技术并提升渲染质量,同时不牺牲速度。
点此查看论文截图