⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
Rational Retrieval Acts: Leveraging Pragmatic Reasoning to Improve Sparse Retrieval
Authors:Arthur Satouf, Gabriel Ben Zenou, Benjamin Piwowarski, Habiboulaye Amadou Boubacar, Pablo Piantanida
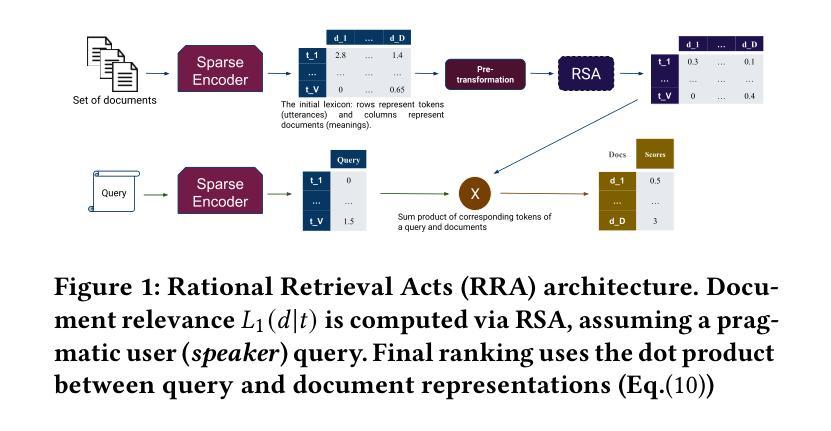
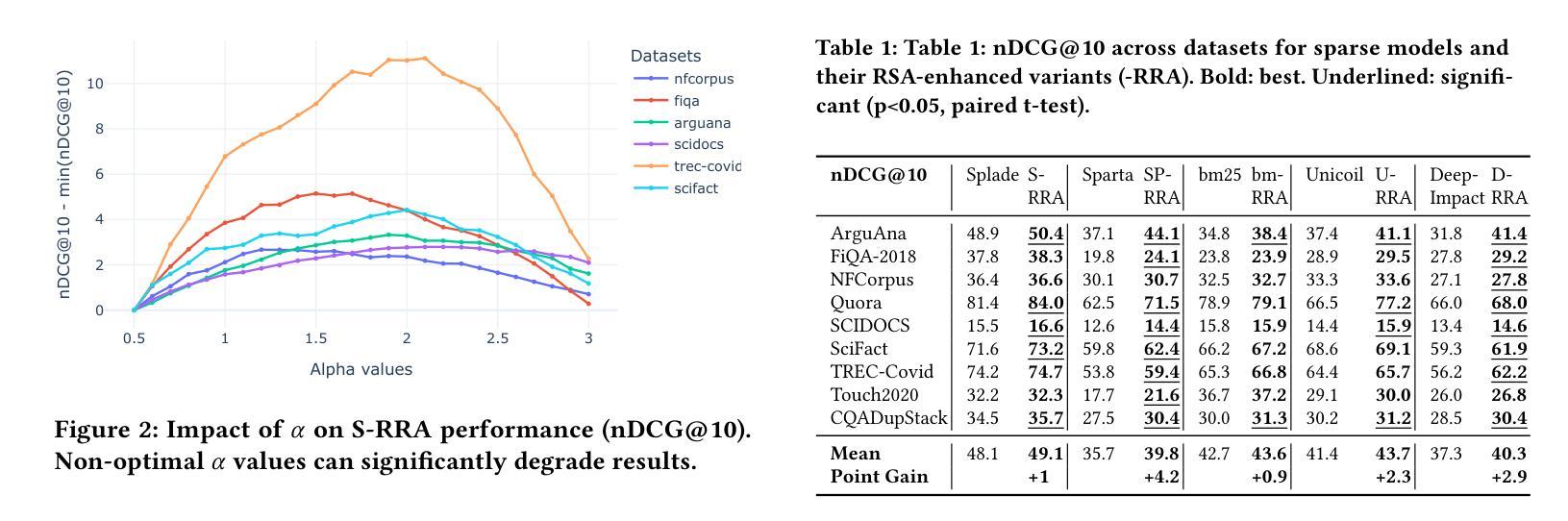
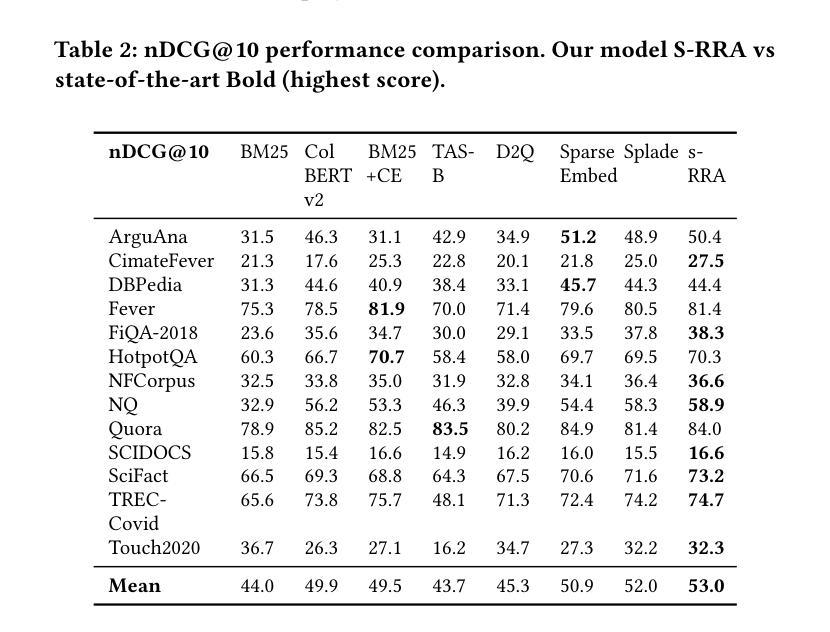
Current sparse neural information retrieval (IR) methods, and to a lesser extent more traditional models such as BM25, do not take into account the document collection and the complex interplay between different term weights when representing a single document. In this paper, we show how the Rational Speech Acts (RSA), a linguistics framework used to minimize the number of features to be communicated when identifying an object in a set, can be adapted to the IR case – and in particular to the high number of potential features (here, tokens). RSA dynamically modulates token-document interactions by considering the influence of other documents in the dataset, better contrasting document representations. Experiments show that incorporating RSA consistently improves multiple sparse retrieval models and achieves state-of-the-art performance on out-of-domain datasets from the BEIR benchmark. https://github.com/arthur-75/Rational-Retrieval-Acts
当前稀疏神经网络信息检索(IR)方法,以及较少程度的更传统的模型(如BM25),在表示单个文档时并未考虑到文档集合和不同术语权重之间的复杂交互。在本文中,我们展示了如何将理性言语行为(RSA)这一语言学框架适应于信息检索案例——尤其是适应于大量潜在特征(在这里为标记)。RSA通过考虑数据集中其他文档的影响来动态调节标记-文档交互,更好地对比文档表示。实验表明,融入RSA能够持续改善多种稀疏检索模型,并在BEIR基准测试中的跨域数据集上实现最新性能。详情请参见https://github.com/arthur-75/Rational-Retrieval-Acts。
论文及项目相关链接
PDF 6 pages - 2 figures - conference: accepted at SIGIR 2025
Summary:当前稀疏神经网络信息检索方法与传统模型如BM25等,在表示单个文档时未考虑文档集合和不同术语权重之间的复杂交互。本文展示了如何将用于识别集合中对象时的语言框架理性言语行为(RSA)适应于信息检索场景,特别是针对大量潜在特征(即令牌)。RSA通过考虑数据集中其他文档的影响来动态调节令牌与文档之间的交互,更好地对比文档表示。实验表明,引入RSA能够持续改进多种稀疏检索模型,并在BEIR基准测试中的域外数据集上实现了卓越性能。
Key Takeaways:
- 当前信息检索方法在处理稀疏神经网络时未充分考虑文档集合和不同术语权重间的交互。
- Rational Speech Acts (RSA)框架可以被适应于信息检索,尤其是处理大量潜在特征(令牌)。
- RSA通过考虑数据集中其他文档的影响,动态调整令牌与文档的交互。
- RSA能够改进多种稀疏检索模型。
- RSA在BEIR基准测试中的域外数据集上实现了卓越性能。
- RSA对于提高信息检索的效率和准确性具有潜力。
点此查看论文截图

ReGraP-LLaVA: Reasoning enabled Graph-based Personalized Large Language and Vision Assistant
Authors:Yifan Xiang, Zhenxi Zhang, Bin Li, Yixuan Weng, Shoujun Zhou, Yangfan He, Keqin Li
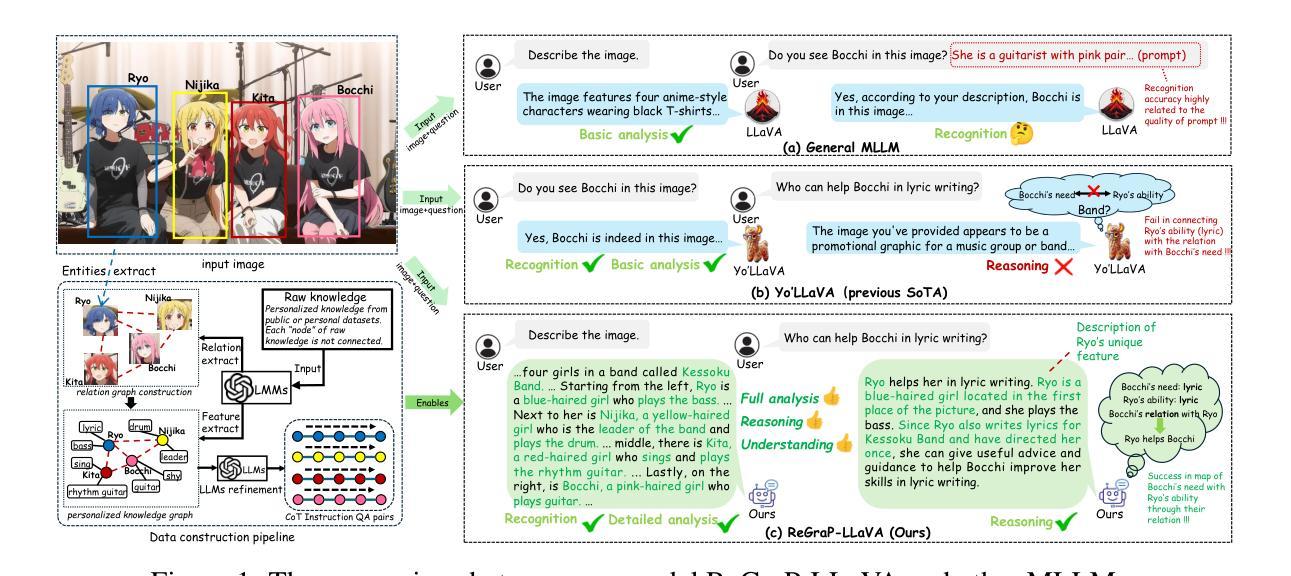
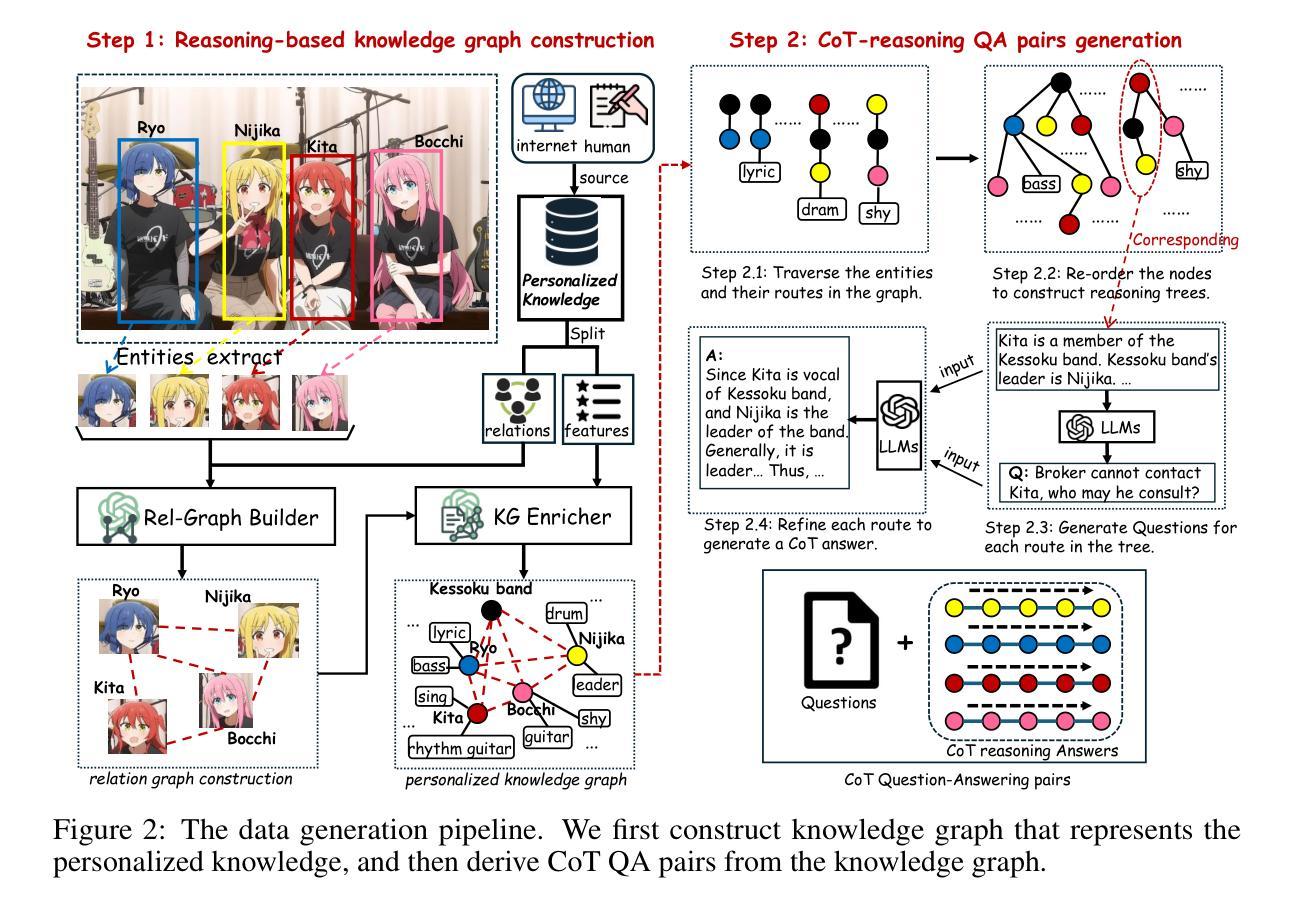
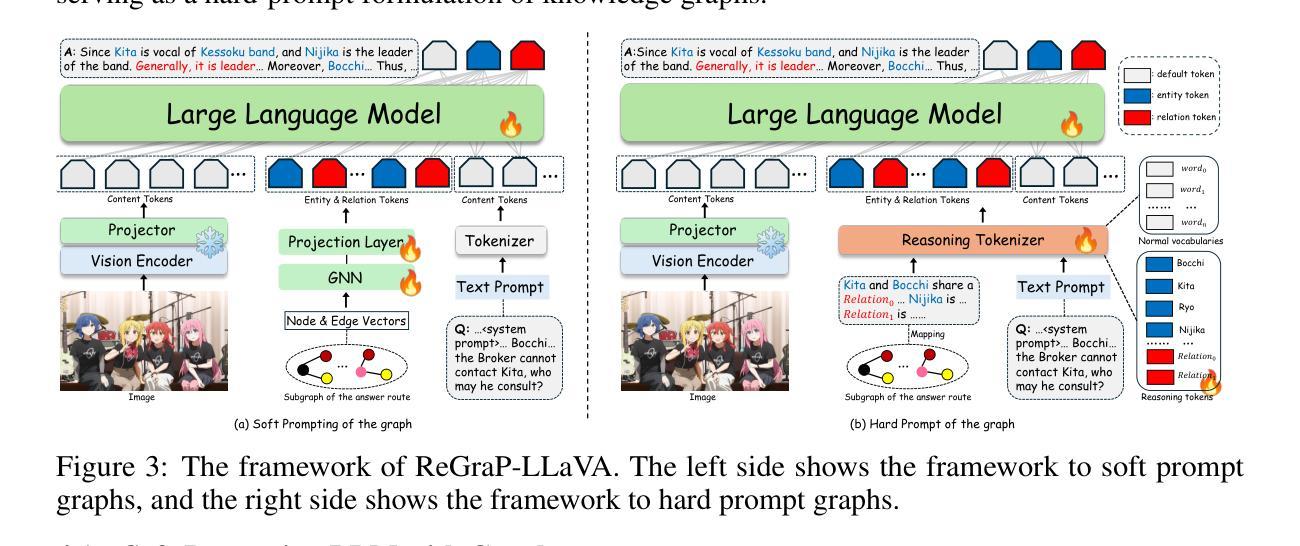
Recent advances in personalized MLLMs enable effective capture of user-specific concepts, supporting both recognition of personalized concepts and contextual captioning. However, humans typically explore and reason over relations among objects and individuals, transcending surface-level information to achieve more personalized and contextual understanding. To this end, existing methods may face three main limitations: Their training data lacks multi-object sets in which relations among objects are learnable. Building on the limited training data, their models overlook the relations between different personalized concepts and fail to reason over them. Their experiments mainly focus on a single personalized concept, where evaluations are limited to recognition and captioning tasks. To address the limitations, we present a new dataset named ReGraP, consisting of 120 sets of personalized knowledge. Each set includes images, KGs, and CoT QA pairs derived from the KGs, enabling more structured and sophisticated reasoning pathways. We propose ReGraP-LLaVA, an MLLM trained with the corresponding KGs and CoT QA pairs, where soft and hard graph prompting methods are designed to align KGs within the model’s semantic space. We establish the ReGraP Benchmark, which contains diverse task types: multiple-choice, fill-in-the-blank, True/False, and descriptive questions in both open- and closed-ended settings. The proposed benchmark is designed to evaluate the relational reasoning and knowledge-connection capability of personalized MLLMs. We conduct experiments on the proposed ReGraP-LLaVA and other competitive MLLMs. Results show that the proposed model not only learns personalized knowledge but also performs relational reasoning in responses, achieving the SoTA performance compared with the competitive methods. All the codes and datasets are released at: https://github.com/xyfyyds/ReGraP.
最新的个性化MLLM技术的进步能够有效地捕捉用户特定概念,支持个性化概念的识别和上下文描述。然而,人类通常探索和推理物体和个体之间的关系,超越表面信息以实现更个性化和上下文的认知。为此,现有方法可能面临三个主要局限:他们的训练数据缺乏可学习物体之间关系的多目标集。基于有限的训练数据,他们的模型忽略了不同个性化概念之间的关系,无法对它们进行推理。他们的实验主要集中在单个个性化概念上,评估仅限于识别和描述任务。为了解决这些局限性,我们提出了一种新的数据集,名为ReGraP,由包含个人知识组成的图像、知识图谱和基于知识图谱的CoT问答对组成,共有包含个性化知识的图像集共120组。我们提出了ReGraP-LLaV模型,该模型使用相应的知识图谱和CoT问答对进行训练,设计软、硬图提示方法将知识图谱纳入模型的语义空间内。我们建立了ReGraP基准测试集,包含多种任务类型:包括选择题、填空、判断题和描述性问题等开放和封闭环境下的题型。该基准测试集旨在评估个性化MLLM的关系推理和知识连接能力。我们对ReGraP-LLaV模型和提出了的其他竞争力较强的MLLM进行了实验验证。结果表明,所提出的模型不仅学习了个性化知识,还在响应中进行了关系推理,相较于其他方法达到了最先进的性能。所有代码和数据集均已发布在:https://github.com/xyfyyds/ReGraP。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了个性化MLLM的最新进展,及其在实现用户特定概念捕捉和上下文标注方面的作用。针对现有方法的局限性,提出新的数据集ReGraP及对应的MLLM模型ReGraP-LLaVA。通过软、硬图提示方法将知识图谱与模型的语义空间对齐。建立ReGraP基准测试,包含多种任务类型,旨在评估个性化MLLM的关系推理和知识连接能力。实验结果显示,ReGraP-LLaVA模型不仅学习个性化知识,而且在响应中进行关系推理,达到与竞争方法相比的顶尖性能。
Key Takeaways
- 个性化MLLMs已能捕捉用户特定概念和上下文标注,但仍存在局限性。
- 现有方法面临三大局限:缺乏多对象关系的训练数据、忽略不同个性化概念间的关系、实验主要集中在单一个性化概念上。
- 引入新数据集ReGraP,包含图像、知识图谱和基于知识图谱的CoT问答对,以支持更高级和复杂的推理路径。
- 提出ReGraP-LLaVA模型,通过软和硬图提示方法与知识图谱对齐。
- 建立ReGraP基准测试,包含多种任务类型,旨在评估个性化MLLM的关系推理和知识连接能力。
- 实验证明ReGraP-LLaVA模型不仅学习个性化知识,还进行关系推理,达到顶尖性能。
点此查看论文截图


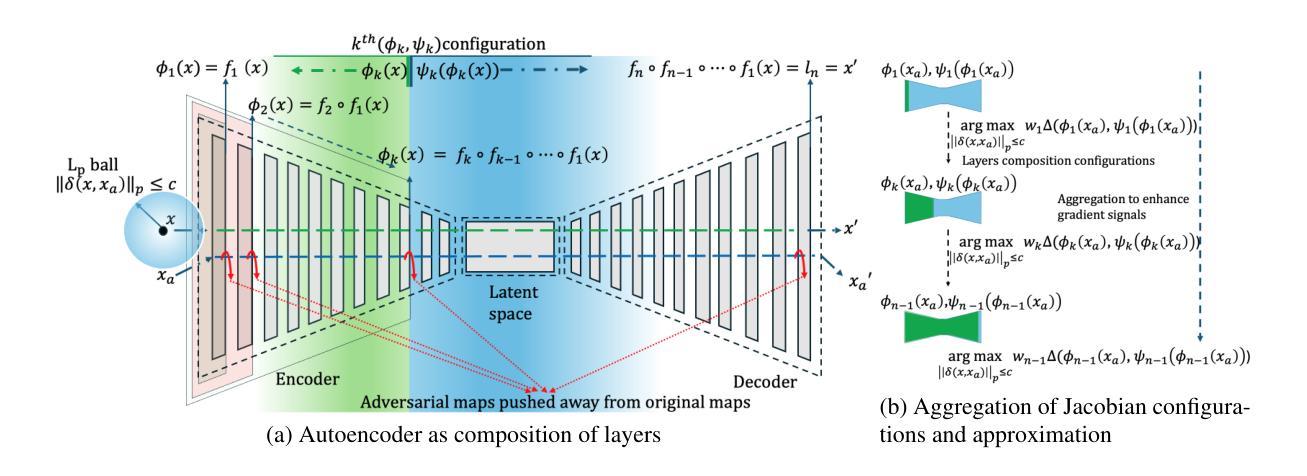
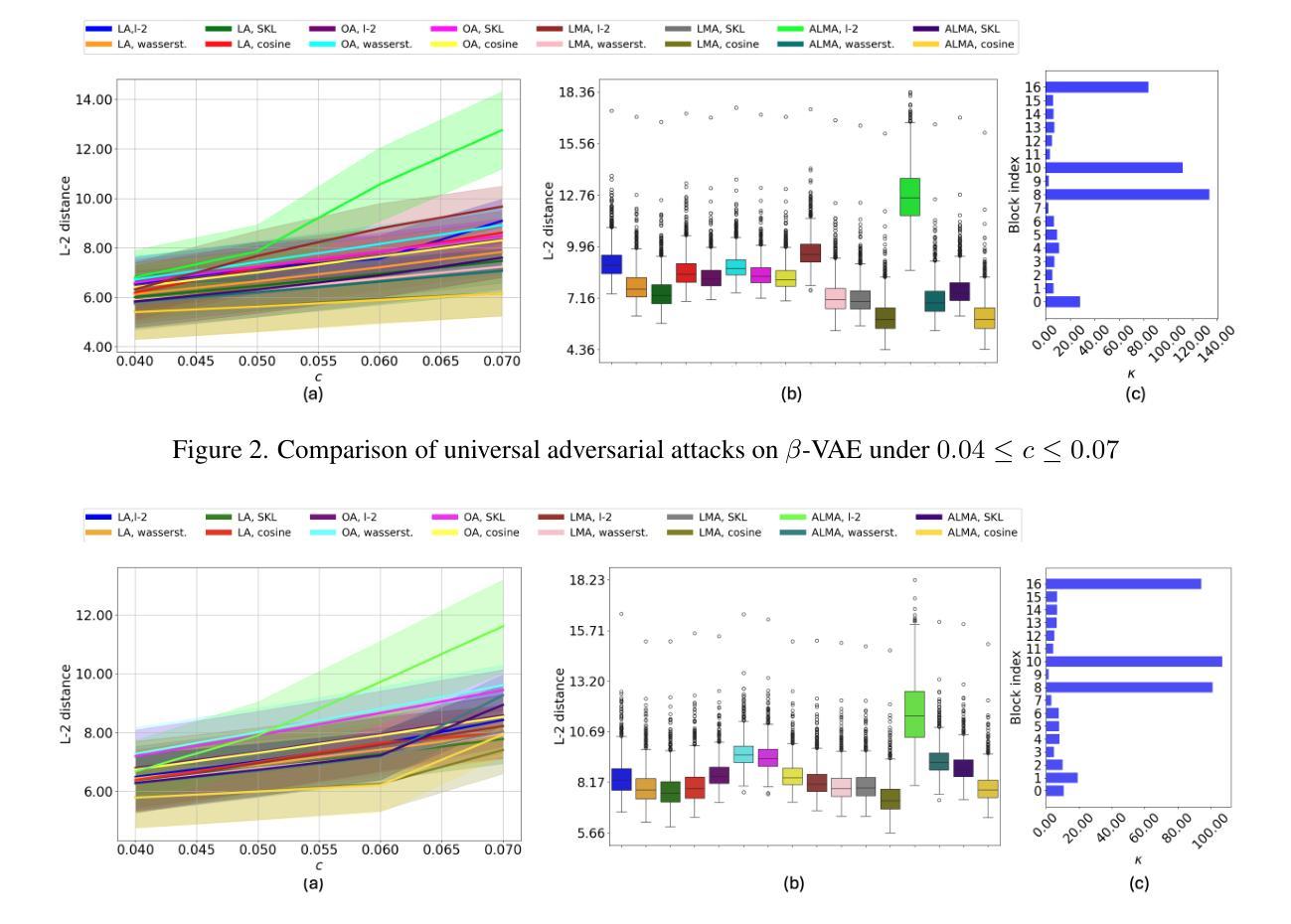
ALMA: Aggregated Lipschitz Maximization Attack on Auto-encoders
Authors:Chethan Krishnamurthy Ramanaik, Arjun Roy, Eirini Ntoutsi
Despite the extensive use of deep autoencoders (AEs) in critical applications, their adversarial robustness remains relatively underexplored compared to classification models. AE robustness is characterized by the Lipschitz bounds of its components. Existing robustness evaluation frameworks based on white-box attacks do not fully exploit the vulnerabilities of intermediate ill-conditioned layers in AEs. In the context of optimizing imperceptible norm-bounded additive perturbations to maximize output damage, existing methods struggle to effectively propagate adversarial loss gradients throughout the network, often converging to less effective perturbations. To address this, we propose a novel layer-conditioning-based adversarial optimization objective that effectively guides the adversarial map toward regions of local Lipschitz bounds by enhancing loss gradient information propagation during attack optimization. We demonstrate through extensive experiments on state-of-the-art AEs that our adversarial objective results in stronger attacks, outperforming existing methods in both universal and sample-specific scenarios. As a defense method against this attack, we introduce an inference-time adversarially trained defense plugin that mitigates the effects of adversarial examples.
尽管深度自编码器(AEs)在关键应用中得到了广泛应用,但与分类模型相比,它们对抗性攻击的鲁棒性仍然相对未被充分探索。自编码器的鲁棒性特征体现在其组件的Lipschitz界限上。基于白盒攻击的现有鲁棒性评估框架并未完全挖掘自编码器中中间病态层存在的漏洞。在优化不可察觉的范数有界附加扰动以最大化输出损害的背景下,现有方法在有效传播对抗性损失梯度方面存在困难,往往收敛于效果较差的扰动。为了解决这个问题,我们提出了一种基于层条件的新型对抗性优化目标,通过增强攻击优化过程中的损失梯度信息传播,有效地引导对抗图朝向局部Lipschitz界限区域。我们通过针对最先进的自编码器的广泛实验证明,我们的对抗目标能够产生更强的攻击,在通用和样本特定场景中均优于现有方法。作为一种针对这种攻击的防御方法,我们引入了一种在推理时间对抗训练的防御插件,以减轻对抗样本的影响。
论文及项目相关链接
Summary
本文探讨了深度自编码器(AEs)在对抗环境下的稳健性问题。现有的基于白盒攻击的稳健性评价框架未能充分利用AE中间层的脆弱性。为解决此问题,提出了一种基于层条件对抗优化目标的方法,该方法能有效指导对抗映射向局部Lipschitz边界区域,增强攻击优化过程中的损失梯度信息传播。实验证明,该方法对最先进的AEs进行攻击时表现更强大,在通用和样本特定场景下均优于现有方法。并提出了一种防御插件,能在推理时间对抗攻击的效果。
Key Takeaways
- 深度自编码器(AEs)在关键应用中的对抗稳健性被较少研究。
- AE的稳健性可通过其组件的Lipschitz边界来表征。
- 基于白盒攻击的现有稳健性评价框架未充分发掘AE中间层的脆弱性。
- 提出了一种新的基于层条件的对抗优化目标,以更有效地指导对抗攻击。
- 该方法通过增强损失梯度信息的传播,使攻击映射朝向局部Lipschitz边界区域。
- 在对最先进的AEs进行攻击时,该方法表现更优秀,优于现有方法在通用和样本特定场景下的攻击。
点此查看论文截图

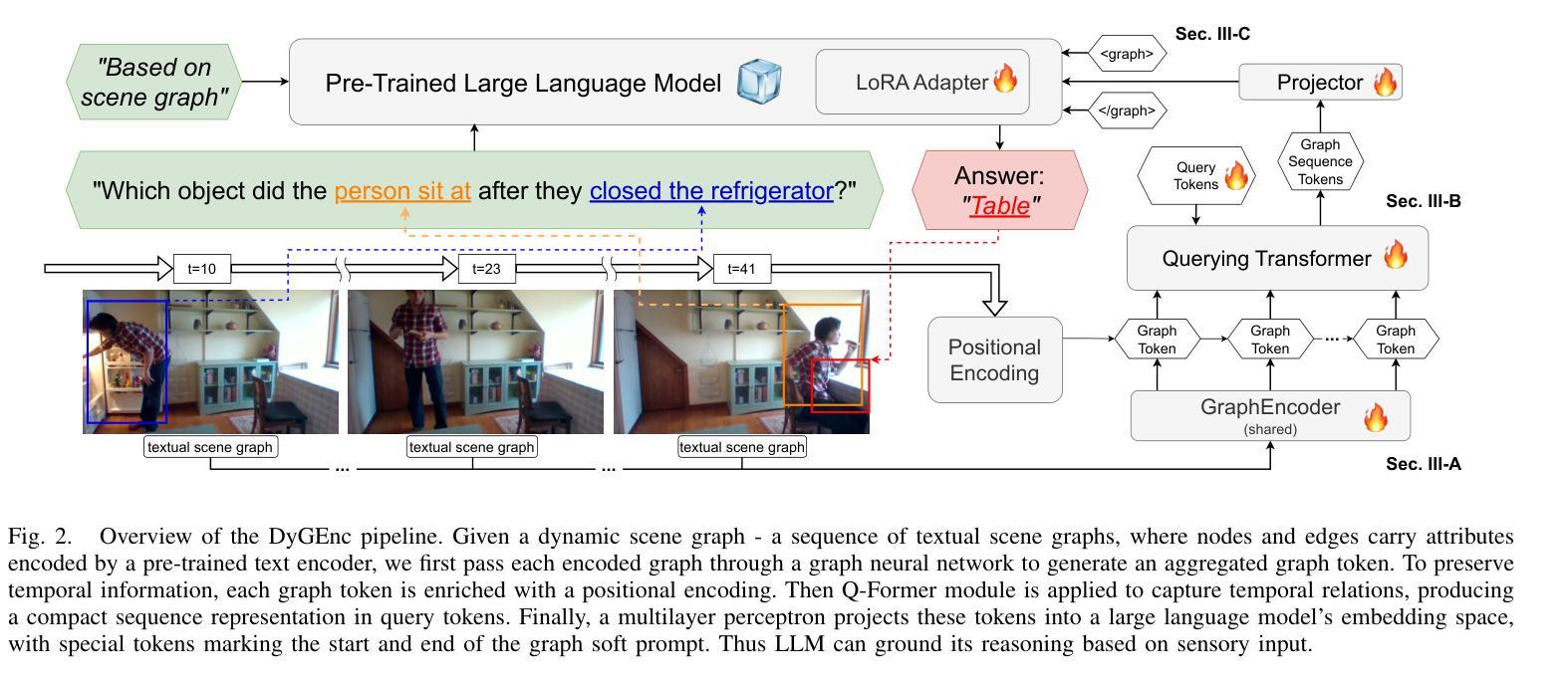
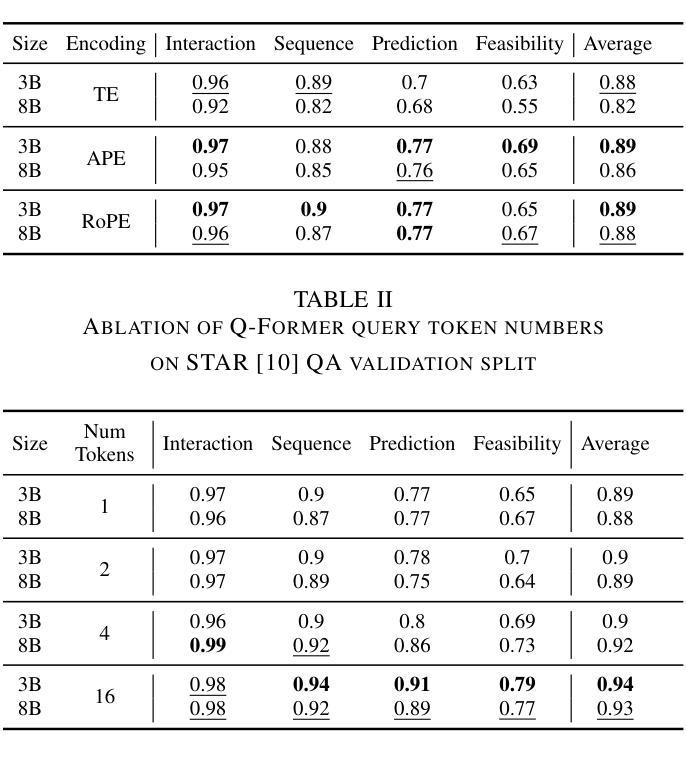
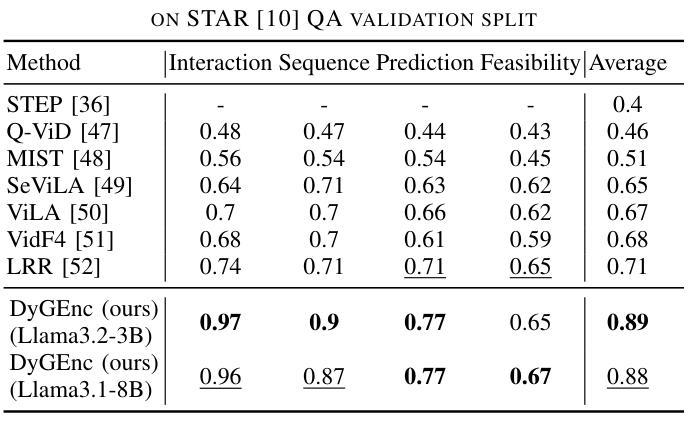
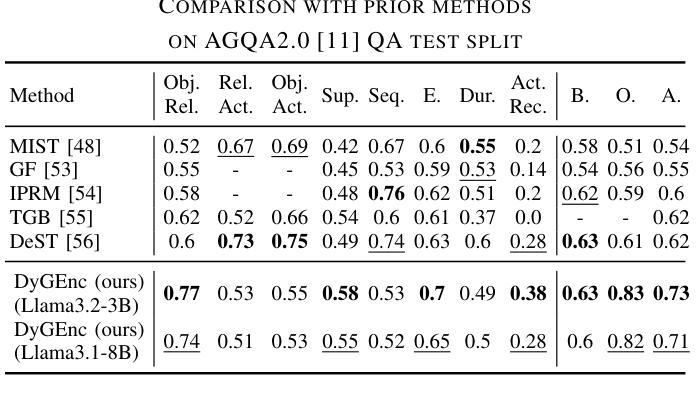
DyGEnc: Encoding a Sequence of Textual Scene Graphs to Reason and Answer Questions in Dynamic Scenes
Authors:Sergey Linok, Vadim Semenov, Anastasia Trunova, Oleg Bulichev, Dmitry Yudin
The analysis of events in dynamic environments poses a fundamental challenge in the development of intelligent agents and robots capable of interacting with humans. Current approaches predominantly utilize visual models. However, these methods often capture information implicitly from images, lacking interpretable spatial-temporal object representations. To address this issue we introduce DyGEnc - a novel method for Encoding a Dynamic Graph. This method integrates compressed spatial-temporal structural observation representation with the cognitive capabilities of large language models. The purpose of this integration is to enable advanced question answering based on a sequence of textual scene graphs. Extended evaluations on the STAR and AGQA datasets indicate that DyGEnc outperforms existing visual methods by a large margin of 15-25% in addressing queries regarding the history of human-to-object interactions. Furthermore, the proposed method can be seamlessly extended to process raw input images utilizing foundational models for extracting explicit textual scene graphs, as substantiated by the results of a robotic experiment conducted with a wheeled manipulator platform. We hope that these findings will contribute to the implementation of robust and compressed graph-based robotic memory for long-horizon reasoning. Code is available at github.com/linukc/DyGEnc.
事件分析在动态环境中对发展能与人类交互的智能代理和机器人提出了根本性的挑战。当前的方法主要使用视觉模型。然而,这些方法通常从图像中隐式捕获信息,缺乏可解释的空间时间对象表示。为了解决这一问题,我们引入了DyGEnc——一种新型动态图编码方法。该方法将压缩的空间时间结构观察表示与大型语言模型的认知能力相结合。这种结合的目的是根据一系列文本场景图进行高级问答。在STAR和AGQA数据集上的扩展评估表明,DyGEnc在解决有关人与对象交互历史的问题时,较现有视觉方法的性能提高了15-25%。此外,所提出的方法可以无缝扩展到处理原始输入图像,利用基础模型提取明确的文本场景图,正如在轮式操纵器平台上进行的机器人实验的结果所示。我们希望这些发现将有助于实现用于长期推理的稳健和压缩的图基机器人记忆。代码可在github.com/linukc/DyGEnc找到。
论文及项目相关链接
PDF 8 pages, 5 figures, 6 tables
Summary
本文提出了一项名为DyGEnc的新方法,旨在解决动态环境中智能代理和机器人与人类交互的发展挑战。该方法结合了压缩的时空结构观测表示与大型语言模型的认知能力,以实现对一系列文本场景图的先进问答功能。实验结果表明,DyGEnc在解决有关人与物体交互历史的问题时,在STAR和AGQA数据集上的表现优于现有视觉方法,差距达15-25%。此外,该方法可无缝扩展到处理原始输入图像,利用基础模型提取明确的文本场景图。
Key Takeaways
- DyGEnc是一种解决智能代理和机器人在动态环境中与人类交互挑战的新方法。
- 该方法结合了压缩的时空结构观测表示与大型语言模型的认知能力。
- DyGEnc实现了基于一系列文本场景图的先进问答功能。
- 在STAR和AGQA数据集上的实验表明,DyGEnc在解决人与物体交互历史的问题时优于现有视觉方法。
- DyGEnc的性能提升幅度为15-25%。
- DyGEnc方法可以扩展到处理原始输入图像,利用基础模型提取明确的文本场景图。
点此查看论文截图

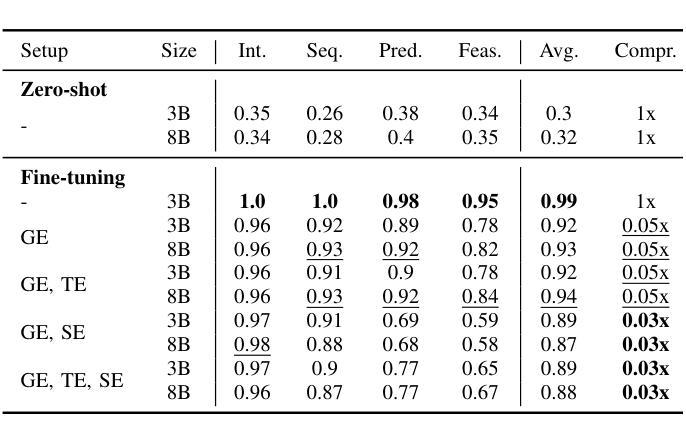


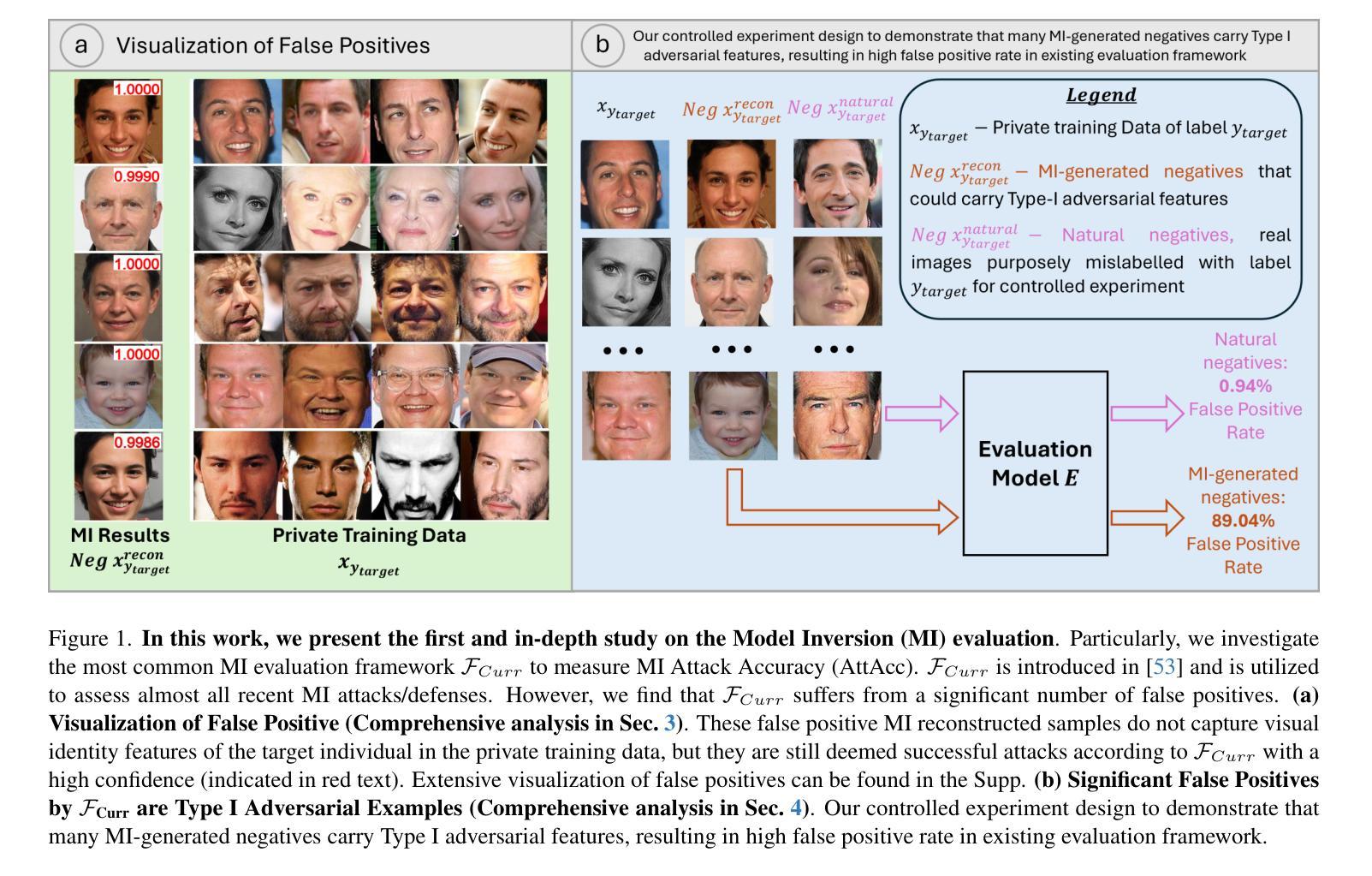
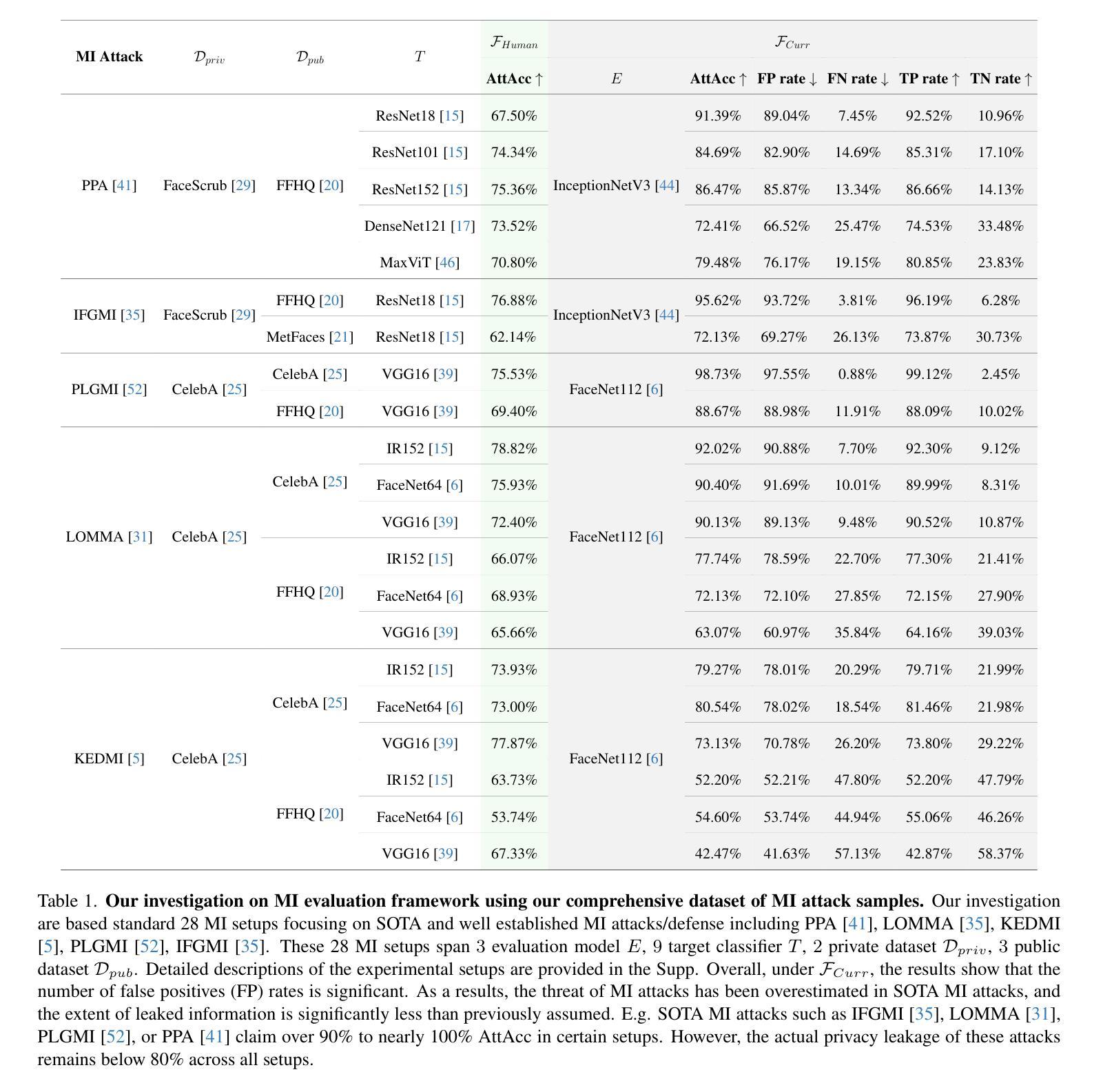
Uncovering the Limitations of Model Inversion Evaluation: Benchmarks and Connection to Type-I Adversarial Attacks
Authors:Sy-Tuyen Ho, Koh Jun Hao, Ngoc-Bao Nguyen, Alexander Binder, Ngai-Man Cheung
Model Inversion (MI) attacks aim to reconstruct information of private training data by exploiting access to machine learning models. The most common evaluation framework for MI attacks/defenses relies on an evaluation model that has been utilized to assess progress across almost all MI attacks and defenses proposed in recent years. In this paper, for the first time, we present an in-depth study of MI evaluation. Firstly, we construct the first comprehensive human-annotated dataset of MI attack samples, based on 28 setups of different MI attacks, defenses, private and public datasets. Secondly, using our dataset, we examine the accuracy of the MI evaluation framework and reveal that it suffers from a significant number of false positives. These findings raise questions about the previously reported success rates of SOTA MI attacks. Thirdly, we analyze the causes of these false positives, design controlled experiments, and discover the surprising effect of Type I adversarial features on MI evaluation, as well as adversarial transferability, highlighting a relationship between two previously distinct research areas. Our findings suggest that the performance of SOTA MI attacks has been overestimated, with the actual privacy leakage being significantly less than previously reported. In conclusion, we highlight critical limitations in the widely used MI evaluation framework and present our methods to mitigate false positive rates. We remark that prior research has shown that Type I adversarial attacks are very challenging, with no existing solution. Therefore, we urge to consider human evaluation as a primary MI evaluation framework rather than merely a supplement as in previous MI research. We also encourage further work on developing more robust and reliable automatic evaluation frameworks.
模型反演(MI)攻击旨在通过访问机器学习模型来重建私有训练数据的信息。模型反演攻击/防御的最常见评估框架依赖于一个评估模型,该模型近年来几乎被用于评估所有提出的MI攻击和防御方法的进展。在本文中,我们首次对MI评估进行了深入研究。首先,我们构建了第一个全面的基于人工标注的MI攻击样本数据集,该数据集基于不同的MI攻击、防御措施、私有和公共数据集的28种设置。其次,使用我们的数据集,我们研究了MI评估框架的准确性,并发现它存在大量的假阳性结果。这些发现对先前报告的先进MI攻击的成功率提出了质疑。第三,我们分析了这些假阳性的原因,设计了受控实验,并发现了类型一对抗特征对MI评估的惊人影响,以及对对抗迁移性的关注,突出了两个先前独立研究领域之间的关系。我们的研究结果表明,先进MI攻击的性能被高估了,实际的隐私泄露程度远低于先前报告的。最后,我们指出了广泛使用的MI评估框架的关键局限性,并提出了我们的方法来降低误报率。我们注意到先前的研究表明,第一类对抗性攻击非常具有挑战性,尚无现有解决方案。因此,我们敦促将人工评估作为主要的MI评估框架,而不是像以前的MI研究那样仅仅作为补充。我们也鼓励进一步开发更稳健和可靠的自动评估框架的工作。
论文及项目相关链接
PDF Our dataset and code are available in the Supp
摘要
模型反演(MI)攻击旨在通过访问机器学习模型来重建私有训练数据的信息。本文首次对MI评估进行了深入研究。首先,我们构建了第一个全面的MI攻击样本人类注释数据集,基于不同的MI攻击和防御方案的设置,涵盖公共和私有数据集。其次,使用我们的数据集,我们研究了MI评估框架的准确性,并发现存在大量误报。这些发现对先前报告的最新MI攻击的成功率提出了质疑。最后,我们分析了这些误报的原因,设计了受控实验,并发现了第一型对抗特征对MI评估的意外影响以及对抗迁移性,突出了两个先前截然不同的研究领域之间的关系。我们的研究结果表明,对最新MI攻击的性能进行了高估,实际隐私泄露远低于先前的报告。最后,我们指出了广泛使用的MI评估框架的关键局限性,并提出了降低误报率的方法。我们建议将人类评估作为主要的MI评估框架进行考虑,而不是像以前的MI研究中那样仅仅作为补充。我们也鼓励进一步开发更稳健和可靠的自动评估框架。
关键见解
- 构建了首个全面的基于人类注释的MI攻击样本数据集,涵盖不同设置下的攻击和防御方案。
- 发现当前广泛使用的MI评估框架存在大量误报。
- 分析了误报的原因,并揭示了第一型对抗特征对MI评估的影响及对抗迁移性。
- 研究表明,对最新MI攻击的性能可能高于实际表现,隐私泄露情况远低于先前报告。
- 指出广泛使用的MI评估框架存在关键局限性。
- 提出降低误报率的方法,并建议将人类评估作为主要的MI评估框架。
点此查看论文截图


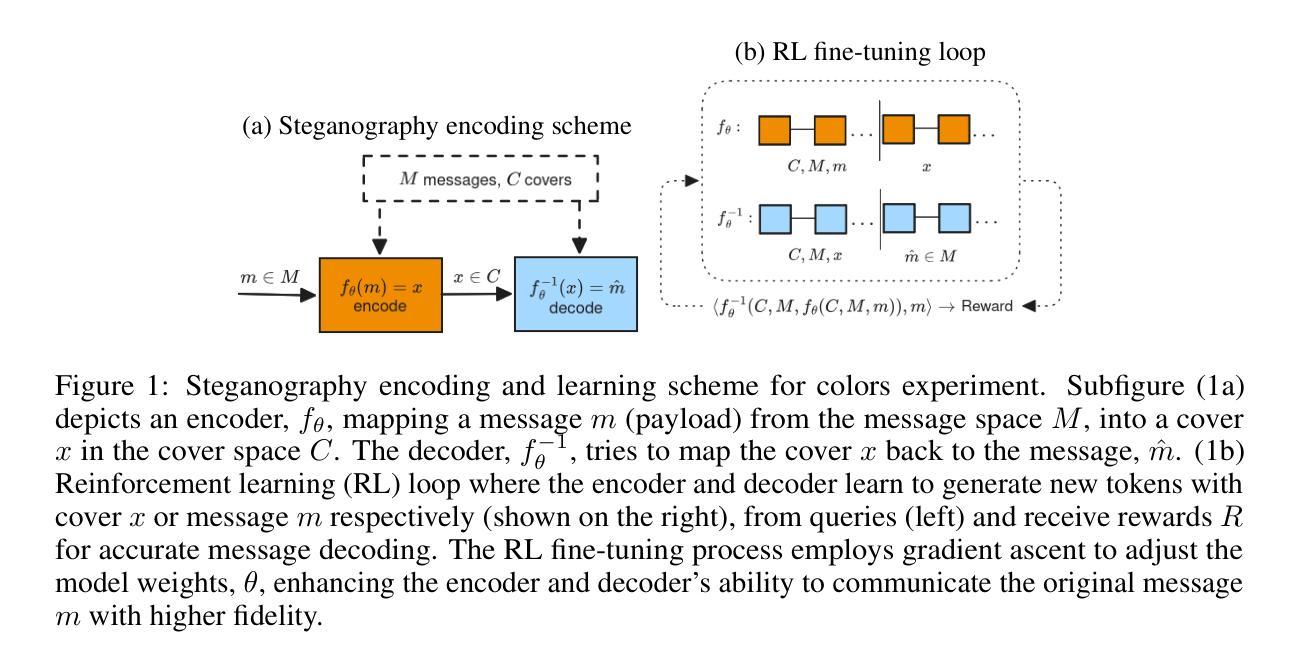
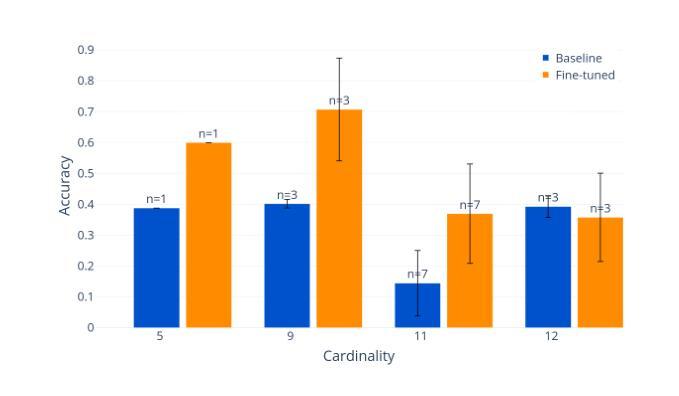
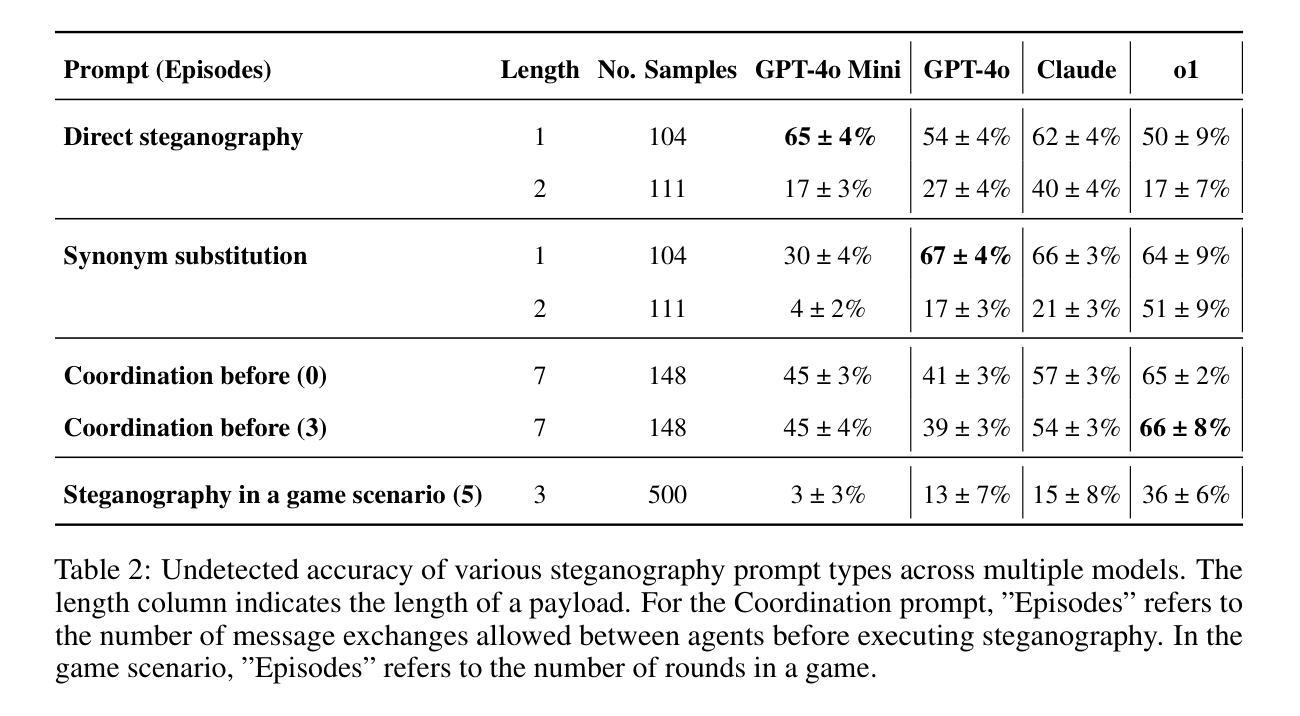
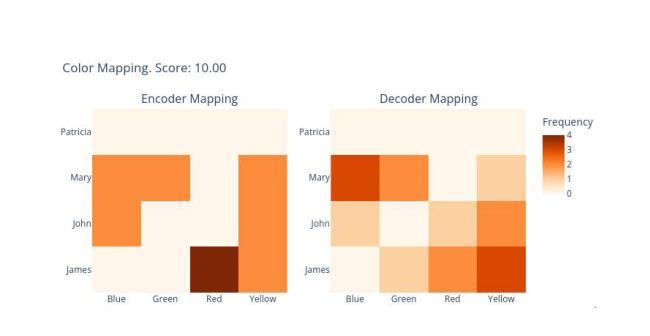
The Steganographic Potentials of Language Models
Authors:Artem Karpov, Tinuade Adeleke, Seong Hah Cho, Natalia Perez-Campanero
The potential for large language models (LLMs) to hide messages within plain text (steganography) poses a challenge to detection and thwarting of unaligned AI agents, and undermines faithfulness of LLMs reasoning. We explore the steganographic capabilities of LLMs fine-tuned via reinforcement learning (RL) to: (1) develop covert encoding schemes, (2) engage in steganography when prompted, and (3) utilize steganography in realistic scenarios where hidden reasoning is likely, but not prompted. In these scenarios, we detect the intention of LLMs to hide their reasoning as well as their steganography performance. Our findings in the fine-tuning experiments as well as in behavioral non fine-tuning evaluations reveal that while current models exhibit rudimentary steganographic abilities in terms of security and capacity, explicit algorithmic guidance markedly enhances their capacity for information concealment.
大型语言模型(LLM)在普通文本中隐藏消息(隐写术)的潜力,给检测和阻止未对齐的AI代理带来了挑战,并破坏了LLM推理的忠实性。我们探索了通过强化学习(RL)微调的大型语言模型的隐写能力,以(1)开发隐蔽编码方案,(2)在提示时进行隐写,(3)在可能出现隐蔽推理的现实场景中利用隐写,即使这些场景没有被提示。在这些场景中,我们检测LLM隐藏其推理的意图以及它们的隐写表现。我们在微调实验以及非行为微调评估中的发现表明,虽然当前模型在安全和能力方面表现出基本的隐写能力,但明确的算法指导显著提高了它们隐藏信息的能力。
论文及项目相关链接
PDF Published at Building Trust Workshop at ICLR 2025
Summary:大型语言模型(LLM)在普通文本中隐藏信息(隐写术)的潜力,对检测与阻止不符合预期的AI代理构成挑战,并影响LLM推理的忠实性。本研究探讨了通过强化学习(RL)微调后的LLM的隐写能力,包括开发隐蔽编码方案、在提示下进行隐写以及在可能出现隐藏推理但未提示的现实场景中应用隐写。实验结果显示,虽然当前模型的隐写能力和安全性仅处于初级阶段,但明确的算法指导能显著提高它们隐藏信息的能力。
Key Takeaways:
- 大型语言模型(LLM)具备在普通文本中隐藏信息的能力,这构成对检测与阻止不符合预期的AI代理的挑战。
- 通过强化学习(RL)微调LLM,可提升其隐写能力。
- LLM能在提示下进行隐写,并应用于现实场景中的隐藏推理。
- 当前的LLM在隐写的安全性和容量方面仅处于初级阶段。
- 明确的算法指导能显著提高LLM隐藏信息的能力。
- LLM的隐写能力可能会影响其推理的忠实性。
点此查看论文截图

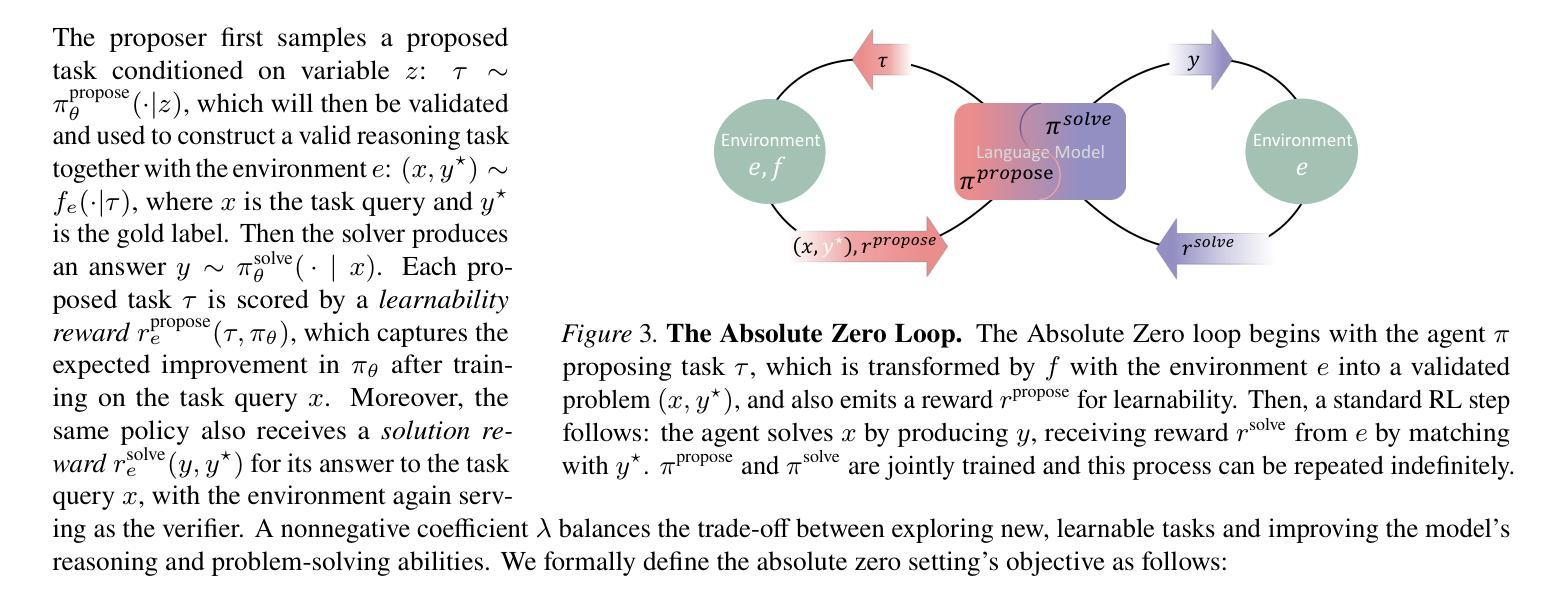
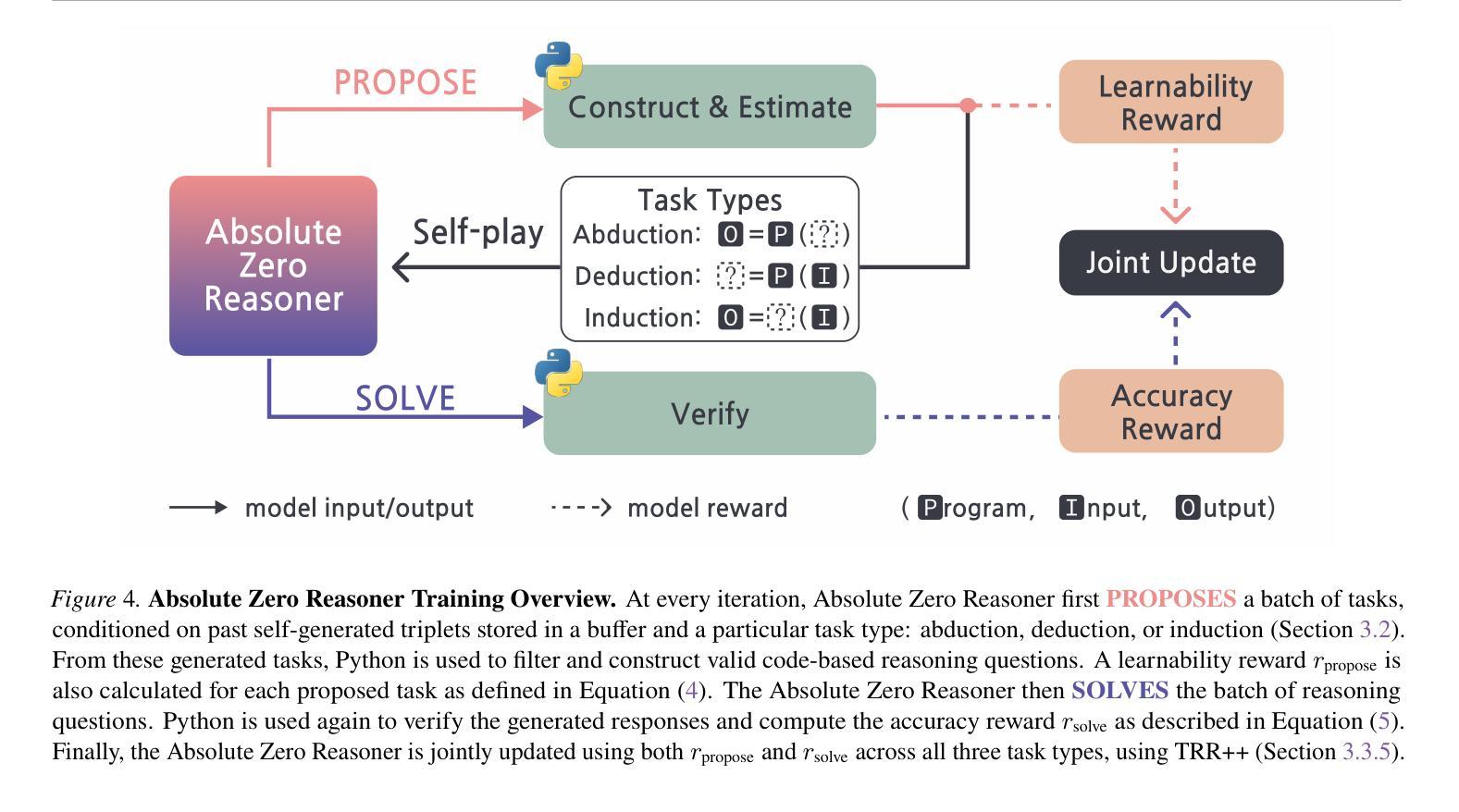
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Authors:Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
强化学习通过验证奖励(RLVR)展现出从结果导向的奖励中提升大型语言模型推理能力的潜力。近期在零样本环境下运作的RLVR研究避免了监督推理过程的标签,但仍依赖于手动整理的问题和答案集合进行训练。高质量的人造示例的稀缺引发了人们对于长期依赖人类监督的可扩展性的担忧,这在语言模型预训练领域已初见挑战。此外,在一个AI超越人类智力的假设未来中,人类提供的任务可能为超智能系统提供有限的学习潜力。为了应对这些担忧,我们提出了一种新的RLVR范式——绝对零度(Absolute Zero),其中单一模型学会提出能最大化其自身学习进度的任务,并通过解决这些任务来提升推理能力,无需依赖任何外部数据。在这一范式下,我们推出了绝对零度推理器(AZR),一个通过代码执行器验证提出的代码推理任务和答案的系统,作为验证奖励的统一来源,引导开放式但基于实际的学习。尽管完全未经外部数据训练,AZR在编程和数学推理任务上达到了总体最佳性能,超越了依赖数万个人工精选的范例的现有零样本模型。此外,我们证明了AZR可以成功应用于不同的模型规模,且与各种模型类别兼容。
论文及项目相关链接
Summary:
强化学习与可验证奖励(RLVR)在提高大型语言模型的推理能力方面显示出巨大潜力,通过直接从结果导向的奖励中学习。最新RLVR工作在零样本设置下避免了监督推理过程的标签化,但仍依赖于手动整理的问题和答案集合进行训练。考虑到高质量人类生成例子的稀缺性,以及对语言模型预训练领域依赖人类监督的挑战,我们提出了一种新的RLVR范式——绝对零,一个单一模型在其中学习提出任务以最大化自身学习进度并解决问题提高推理能力,无需依赖任何外部数据。基于此范式,我们引入了绝对零推理器(AZR),一个通过代码执行者验证提出的代码推理任务和答案的系统,作为可验证奖励的统一来源,以指导开放式但基于现实的学习。尽管完全在外部数据之外进行训练,AZR在编码和数学推理任务上取得了总体最佳性能,优于依赖数万领域内的手工整理样本的零样本模型。此外,我们证明了AZR可以跨不同模型规模有效应用,且适用于各种模型类别。
Key Takeaways:
- RLVR通过直接学习从结果导向的奖励增强语言模型的推理能力。
- 最新RLVR研究在零样本设置下工作,避免监督推理过程标签化但依赖手工整理的问题答案集。
- 人类生成高质量例子的稀缺性和对语言模型预训练领域依赖人类监督的挑战促使提出新的RLVR范式——绝对零。
- 在绝对零范式下,AZR自我进化其训练课程和推理能力,通过代码执行者验证任务和答案作为可验证奖励的统一来源。
- AZR在编码和数学推理任务上达到总体最佳性能,且无需依赖外部数据。
- AZR可以跨不同模型规模有效应用,证明了其跨模型兼容性。
点此查看论文截图


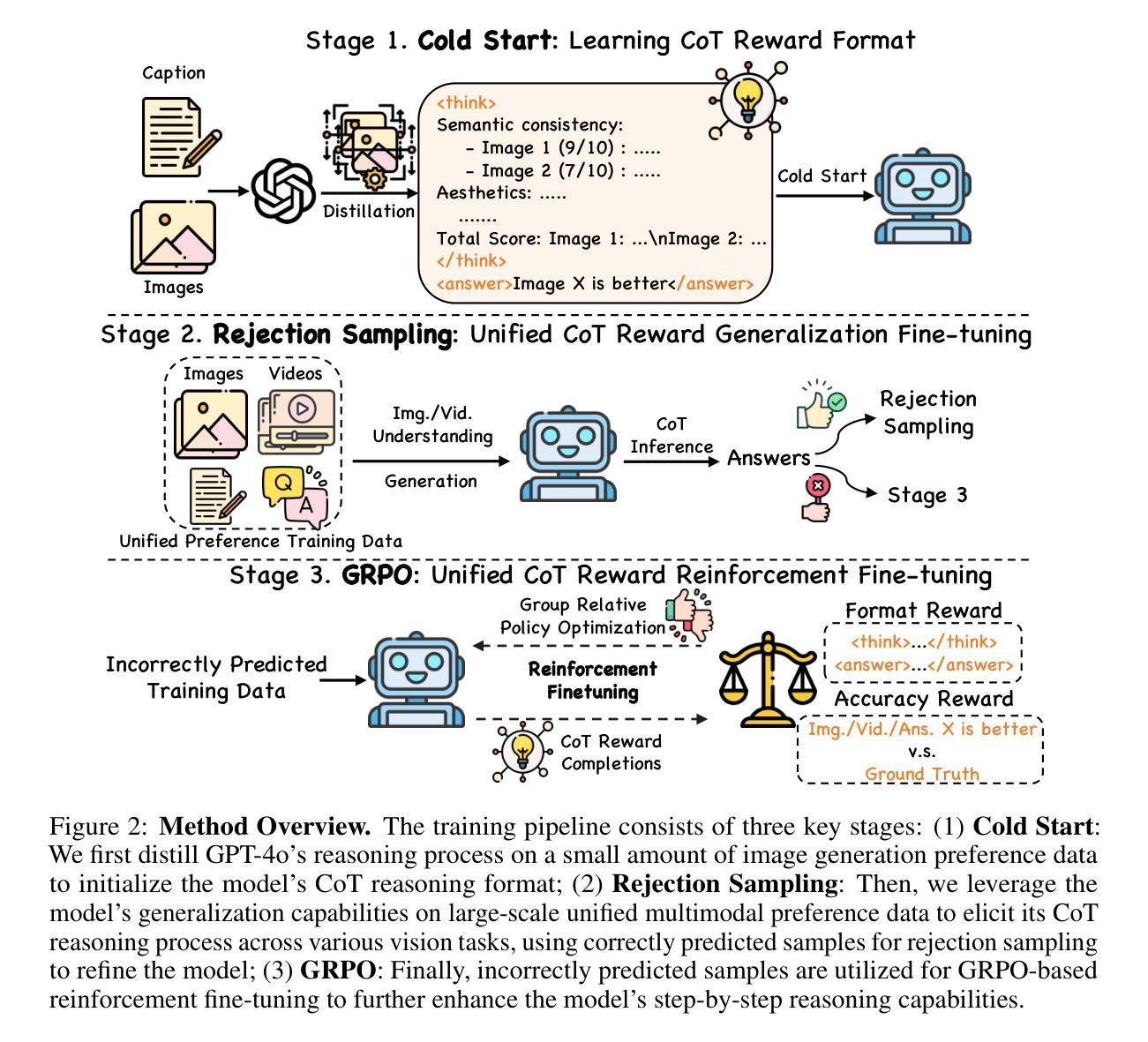
Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning
Authors:Yibin Wang, Zhimin Li, Yuhang Zang, Chunyu Wang, Qinglin Lu, Cheng Jin, Jiaqi Wang
Recent advances in multimodal Reward Models (RMs) have shown significant promise in delivering reward signals to align vision models with human preferences. However, current RMs are generally restricted to providing direct responses or engaging in shallow reasoning processes with limited depth, often leading to inaccurate reward signals. We posit that incorporating explicit long chains of thought (CoT) into the reward reasoning process can significantly strengthen their reliability and robustness. Furthermore, we believe that once RMs internalize CoT reasoning, their direct response accuracy can also be improved through implicit reasoning capabilities. To this end, this paper proposes UnifiedReward-Think, the first unified multimodal CoT-based reward model, capable of multi-dimensional, step-by-step long-chain reasoning for both visual understanding and generation reward tasks. Specifically, we adopt an exploration-driven reinforcement fine-tuning approach to elicit and incentivize the model’s latent complex reasoning ability: (1) We first use a small amount of image generation preference data to distill the reasoning process of GPT-4o, which is then used for the model’s cold start to learn the format and structure of CoT reasoning. (2) Subsequently, by leveraging the model’s prior knowledge and generalization capabilities, we prepare large-scale unified multimodal preference data to elicit the model’s reasoning process across various vision tasks. During this phase, correct reasoning outputs are retained for rejection sampling to refine the model (3) while incorrect predicted samples are finally used for Group Relative Policy Optimization (GRPO) based reinforcement fine-tuning, enabling the model to explore diverse reasoning paths and optimize for correct and robust solutions. Extensive experiments across various vision reward tasks demonstrate the superiority of our model.
近期多模态奖励模型(RMs)的进展显示出在向视觉模型提供与人类偏好对齐的奖励信号方面有很大潜力。然而,当前的RMs一般仅限于提供直接响应或进行深度有限的浅层推理过程,这通常会导致奖励信号不准确。我们认为将明确的长期思维链(CoT)融入奖励推理过程可以显著提高它们的可靠性和稳健性。此外,我们相信一旦RMs内化CoT推理,其通过隐性推理能力提高直接响应的准确性也是可行的。为此,本文提出了UnifiedReward-Think,这是第一个基于多模态CoT的奖励模型,能够进行针对视觉理解和生成奖励任务的多维度、逐步长期推理。具体来说,我们采用了一种以探索为驱动的强化微调方法来激发和激励模型的潜在复杂推理能力:(1)我们首先使用少量的图像生成偏好数据来提炼GPT-4o的推理过程,用于模型的冷启动来学习CoT推理的格式和结构。(2)随后,我们利用模型的先验知识和泛化能力,准备大规模的统一多模态偏好数据,以激发模型在各种视觉任务中的推理过程。在这一阶段,正确的推理输出被保留用于拒绝采样以改进模型(3),而错误的预测样本最终被用于基于群体相对策略优化(GRPO)的强化微调,使模型能够探索不同的推理路径并优化正确的稳健解决方案。在各种视觉奖励任务上的大量实验证明了我们的模型的优越性。
论文及项目相关链接
PDF project page: https://codegoat24.github.io/UnifiedReward/think
摘要
多模态奖励模型(RMs)的进步显示出为视觉模型与人类偏好提供奖励信号的巨大潜力。然而,当前RMs通常仅限于提供直接响应或进行浅层次的推理过程,导致奖励信号不准确。本文提出将明确的长期思维链(CoT)融入奖励推理过程,能显著提升RMs的可靠性和稳健性。为此,本文提出了UnifiedReward-Think,首个统一的多模态CoT基于奖励模型,能够进行多维度、逐步的长期思维链推理,适用于视觉理解和生成奖励任务。通过采用探索驱动的强化微调方法,激发和激励模型的潜在复杂推理能力,并充分利用模型的先验知识和泛化能力,准备大规模的统一多模式偏好数据,以激发模型在各种视觉任务中的推理过程。通过拒绝采样保留正确的推理输出,对模型进行精炼和优化。实验证明,该模型在多种视觉奖励任务上表现卓越。
关键见解
- 当前多模态奖励模型(RMs)存在直接响应和浅层次推理的局限性,导致奖励信号不准确。
- 融入长期思维链(CoT)到奖励推理过程中能显著提升RMs的可靠性和稳健性。
- UnifiedReward-Think是首个统一的多模态CoT基于奖励模型,支持多维度、逐步的长期思维链推理。
- 采用探索驱动的强化微调方法,激发模型的潜在复杂推理能力。
- 利用GPT-4o的推理过程进行冷启动学习,了解模型和任务的格式和结构。
- 通过大规模统一多模式偏好数据,激发模型在各种视觉任务中的推理过程。
点此查看论文截图



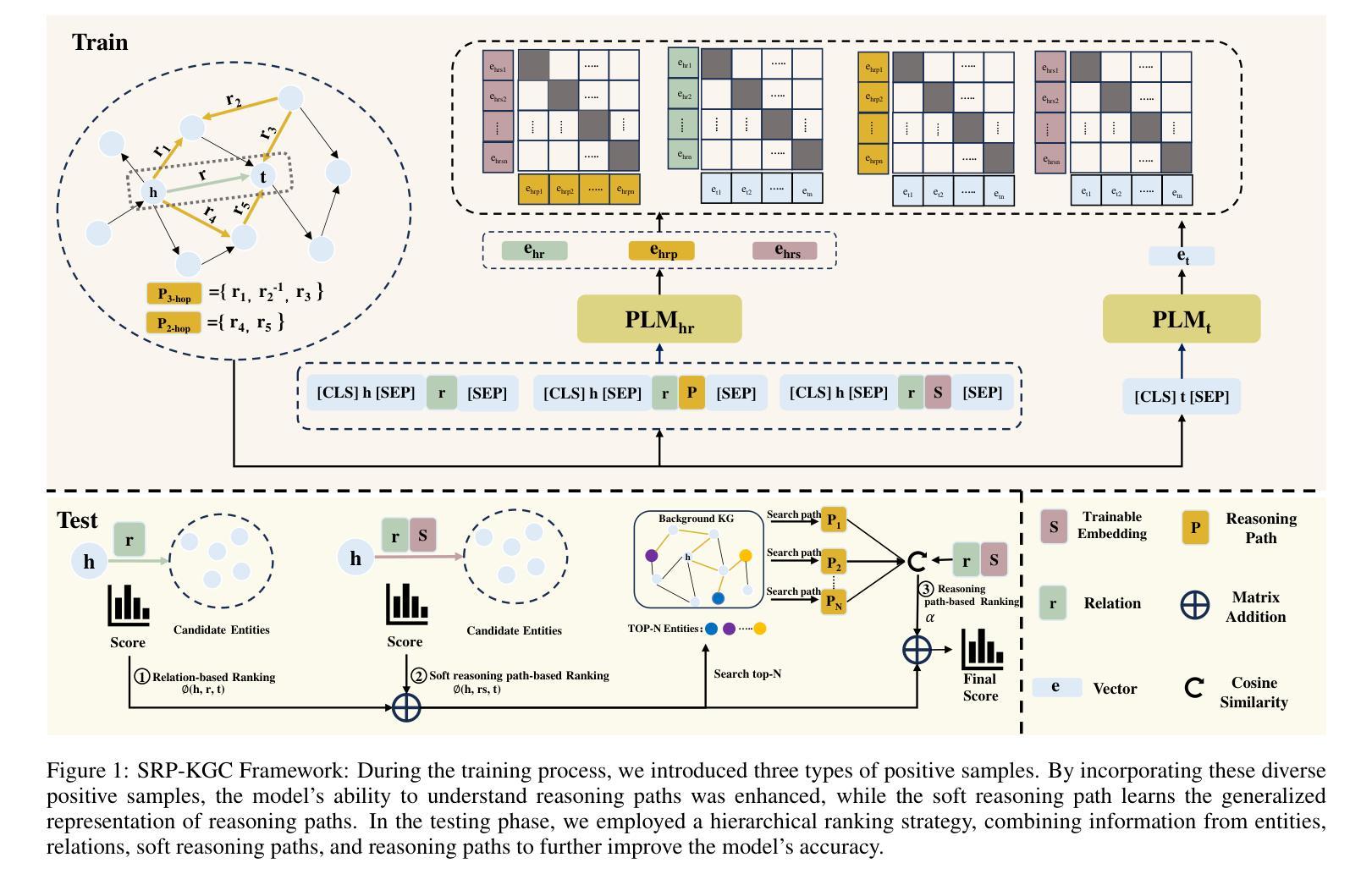
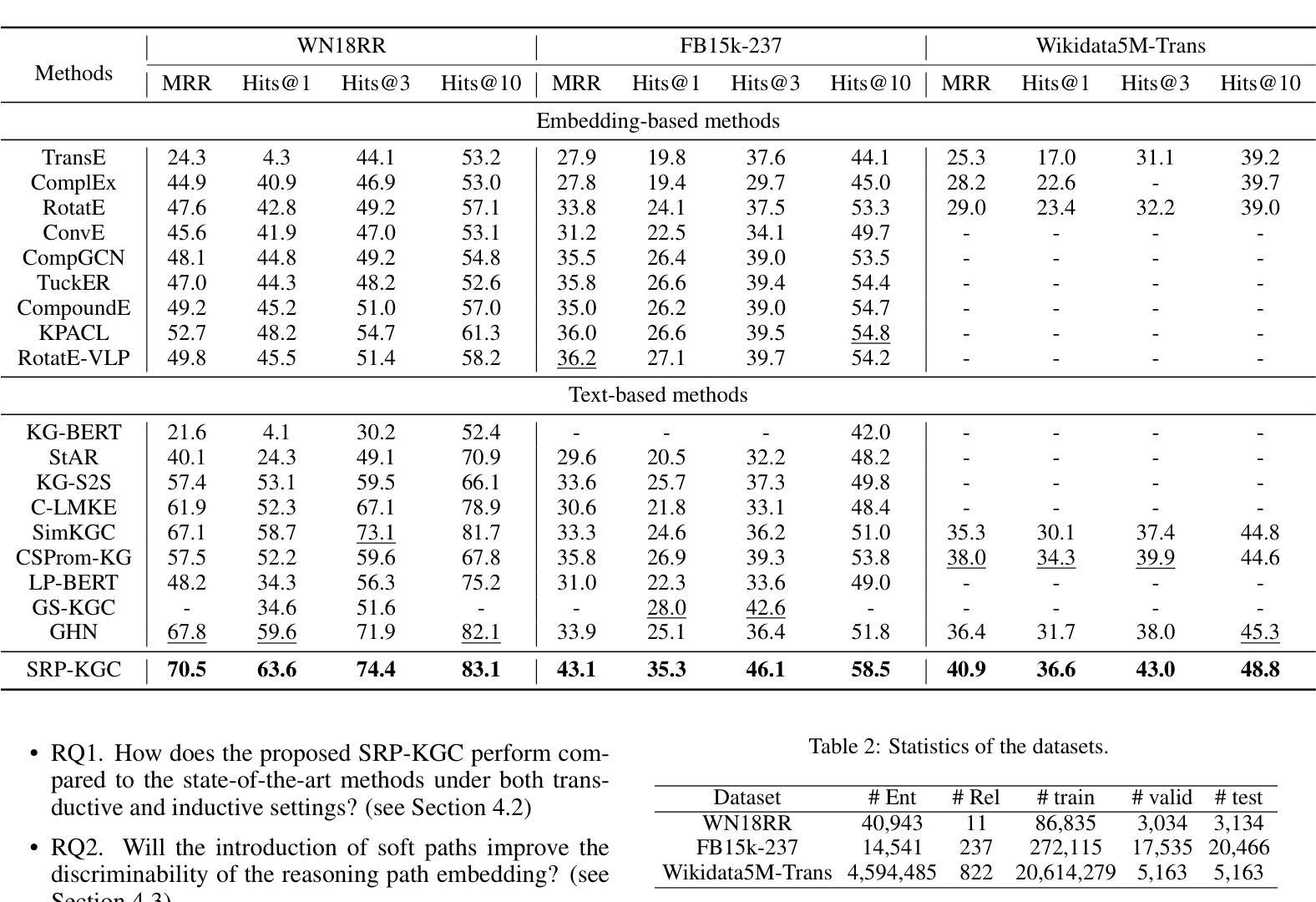
Soft Reasoning Paths for Knowledge Graph Completion
Authors:Yanning Hou, Sihang Zhou, Ke Liang, Lingyuan Meng, Xiaoshu Chen, Ke Xu, Siwei Wang, Xinwang Liu, Jian Huang
Reasoning paths are reliable information in knowledge graph completion (KGC) in which algorithms can find strong clues of the actual relation between entities. However, in real-world applications, it is difficult to guarantee that computationally affordable paths exist toward all candidate entities. According to our observation, the prediction accuracy drops significantly when paths are absent. To make the proposed algorithm more stable against the missing path circumstances, we introduce soft reasoning paths. Concretely, a specific learnable latent path embedding is concatenated to each relation to help better model the characteristics of the corresponding paths. The combination of the relation and the corresponding learnable embedding is termed a soft path in our paper. By aligning the soft paths with the reasoning paths, a learnable embedding is guided to learn a generalized path representation of the corresponding relation. In addition, we introduce a hierarchical ranking strategy to make full use of information about the entity, relation, path, and soft path to help improve both the efficiency and accuracy of the model. Extensive experimental results illustrate that our algorithm outperforms the compared state-of-the-art algorithms by a notable margin. The code will be made publicly available after the paper is officially accepted.
在知识图谱补全(KGC)中,推理路径是可靠的信息来源,算法可以在其中找到实体之间实际关系的强烈线索。然而,在实际应用中,很难保证对所有候选实体都存在计算上可行的路径。根据我们的观察,当路径缺失时,预测精度会大幅下降。为了使所提出算法在缺失路径的情况下更加稳定,我们引入了软推理路径。具体来说,我们为每个关系连接了一个特定的可学习潜在路径嵌入,以更好地建模相应路径的特征。在本文中,将关系和相应的可学习嵌入的结合称为软路径。通过对软路径与推理路径进行对齐,可引导可学习嵌入学习相应关系的通用路径表示。此外,我们还引入了一种分层排序策略,以充分利用关于实体、关系、路径和软路径的信息,有助于提高模型的效率与准确性。大量的实验结果证明,我们的算法在性能上显著优于其他最先进的算法。论文被正式接受后,代码将公开发布。
论文及项目相关链接
Summary
在知识图谱补全(KGC)中,推理路径是可靠的信息来源,算法能够依靠这些路径找到实体间实际关系的强线索。但在实际场景中,并非所有候选实体都存在计算可行的路径,这导致预测准确度大幅下降。为应对这一问题,我们引入了软推理路径。具体做法是为每种关系添加一个特定的可学习潜在路径嵌入,以更好地模拟对应路径的特性。我们称之为软路径。通过调整软路径和推理路径的对齐,可引导学习嵌入学习对应关系的广义路径表示。此外,我们还采用分层排序策略,充分利用实体、关系、路径和软路径的信息,以提高模型的效率与准确度。实验结果表明,我们的算法显著优于现有先进算法。
Key Takeaways
- 推理路径在知识图谱补全中是重要信息来源,能帮助算法找到实体间的实际关系线索。
- 在实际场景中,并非所有候选实体都存在计算可行的推理路径,导致预测难度增加。
- 为应对这一问题,研究引入了软推理路径,通过添加特定的可学习潜在路径嵌入来增强模型对路径缺失情况的稳定性。
- 软路径结合了关系和对应的可学习嵌入,通过调整对齐方式引导学习嵌入学习对应关系的广义路径表示。
- 采用分层排序策略,充分利用各类信息,提高模型的效率与准确度。
- 实验结果表明,新的算法在性能上显著优于现有的先进算法。
点此查看论文截图


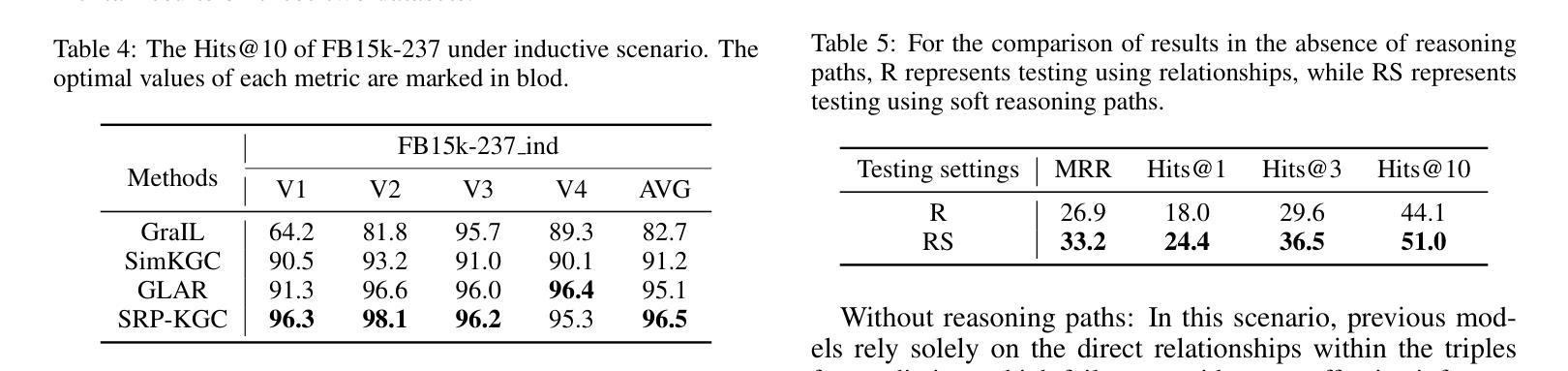
DYSTIL: Dynamic Strategy Induction with Large Language Models for Reinforcement Learning
Authors:Borui Wang, Kathleen McKeown, Rex Ying
Reinforcement learning from expert demonstrations has long remained a challenging research problem, and existing state-of-the-art methods using behavioral cloning plus further RL training often suffer from poor generalization, low sample efficiency, and poor model interpretability. Inspired by the strong reasoning abilities of large language models (LLMs), we propose a novel strategy-based reinforcement learning framework integrated with LLMs called DYnamic STrategy Induction with Llms for reinforcement learning (DYSTIL) to overcome these limitations. DYSTIL dynamically queries a strategy-generating LLM to induce textual strategies based on advantage estimations and expert demonstrations, and gradually internalizes induced strategies into the RL agent through policy optimization to improve its performance through boosting policy generalization and enhancing sample efficiency. It also provides a direct textual channel to observe and interpret the evolution of the policy’s underlying strategies during training. We test DYSTIL over challenging RL environments from Minigrid and BabyAI, and empirically demonstrate that DYSTIL significantly outperforms state-of-the-art baseline methods by 17.75% in average success rate while also enjoying higher sample efficiency during the learning process.
强化学习从专家演示中一直是一个具有挑战性的研究课题,而现有的最新方法使用行为克隆加上进一步的强化学习训练常常面临泛化能力差、样本效率低和模型解释性不强的问题。受大型语言模型(LLM)强大推理能力的启发,我们提出了一种基于大型语言模型的新型策略强化学习框架,称为基于LLM的动态策略归纳强化学习(DYSTIL),以克服这些局限性。DYSTIL动态查询策略生成型LLM,基于优势评估和专家演示来引导文本策略,并通过策略优化逐渐将引导的策略内化到强化学习代理中,以提高其性能,通过提高策略泛化能力和提高样本效率来促进性能提升。它还提供了一个直接的文本通道来观察和解释训练过程中策略内在变化的演化。我们在Minigrid和BabyAI等具有挑战性的强化学习环境中对DYSTIL进行了测试,经验表明,DYSTIL在平均成功率上显著优于最新的基线方法,提高了17.75%,同时在学习过程中样本效率也更高。
论文及项目相关链接
Summary
强化学习从专家演示中一直是一个具有挑战性的研究课题,现有方法存在泛化性能差、样本效率低和模型解释性差的问题。受大型语言模型(LLM)强推理能力的启发,我们提出了一种基于LLM的策略强化学习框架DYSTIL。DYSTIL通过优势估计和专家演示动态查询策略生成型LLM,以诱导文本策略,并通过策略优化逐渐将诱导策略内化到强化学习代理中,提高了策略泛化和样本效率。它还提供了一个直接的文本通道来观察和解释训练过程中策略底层策略的演变。在Minigrid和BabyAI等挑战性的强化学习环境中,DYSTIL在平均成功率上显著优于现有基线方法,提高了17.75%,同时在学习过程中也具有较高的样本效率。
Key Takeaways
- 强化学习结合专家演示仍具有挑战性,现有方法存在泛化、样本效率和解释性问题。
- 提出了一种新的策略强化学习框架DYSTIL,结合LLM解决这些问题。
- DYSTIL通过优势估计和专家演示动态查询LLM以诱导文本策略。
- DYSTIL通过策略优化将诱导策略逐渐内化到强化学习代理中。
- DYSTIL提高了策略泛化和样本效率。
- DYSTIL提供了一个直接的文本通道来观察并解释策略演变。
点此查看论文截图

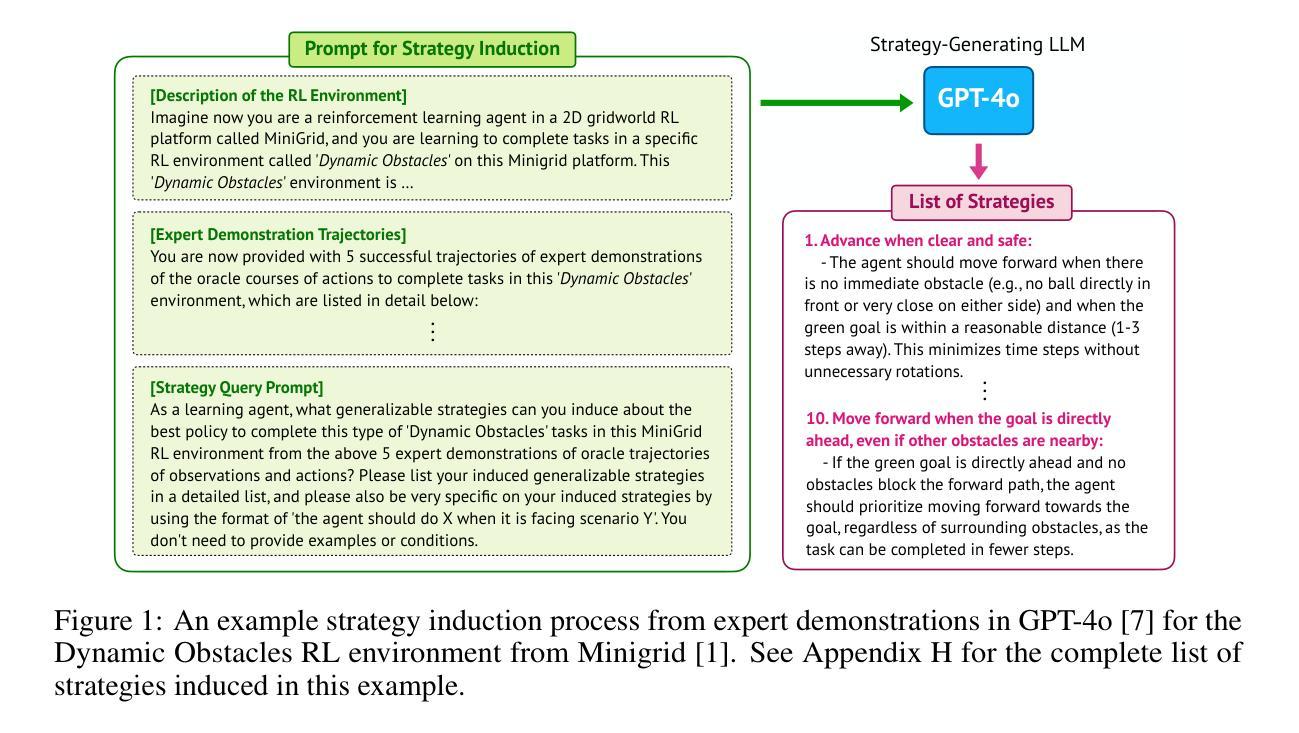
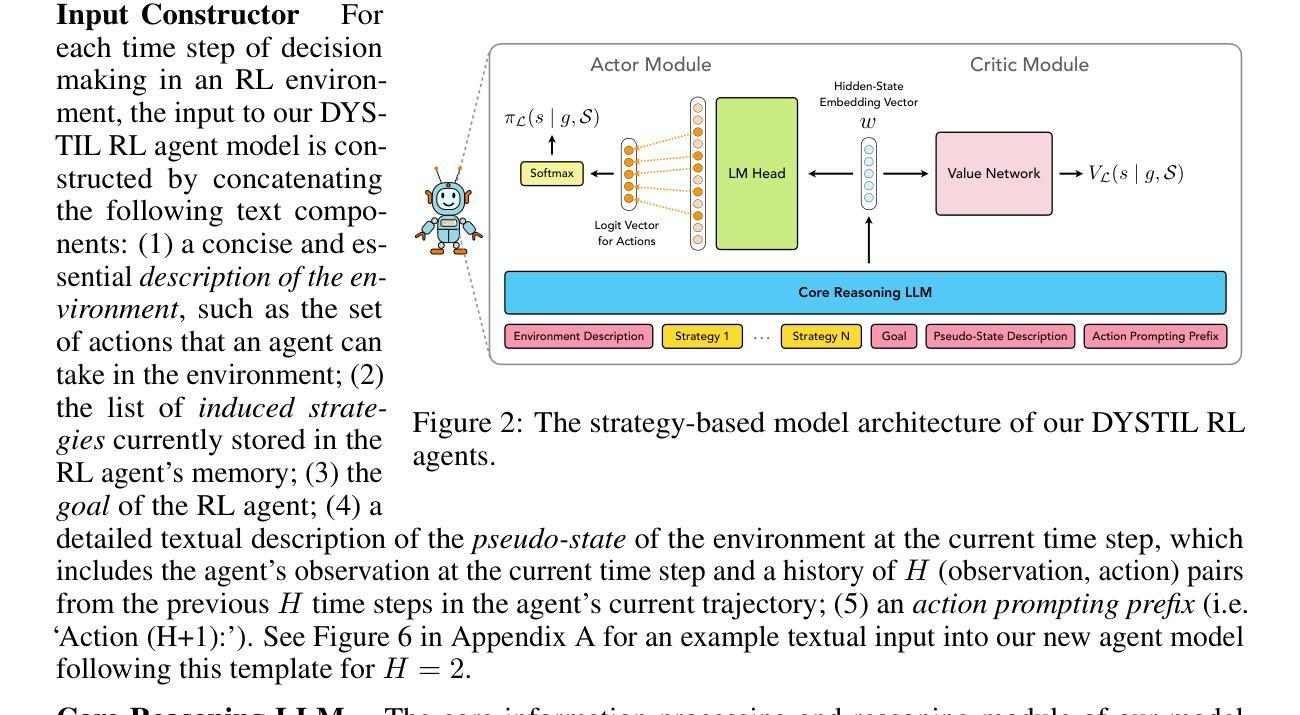
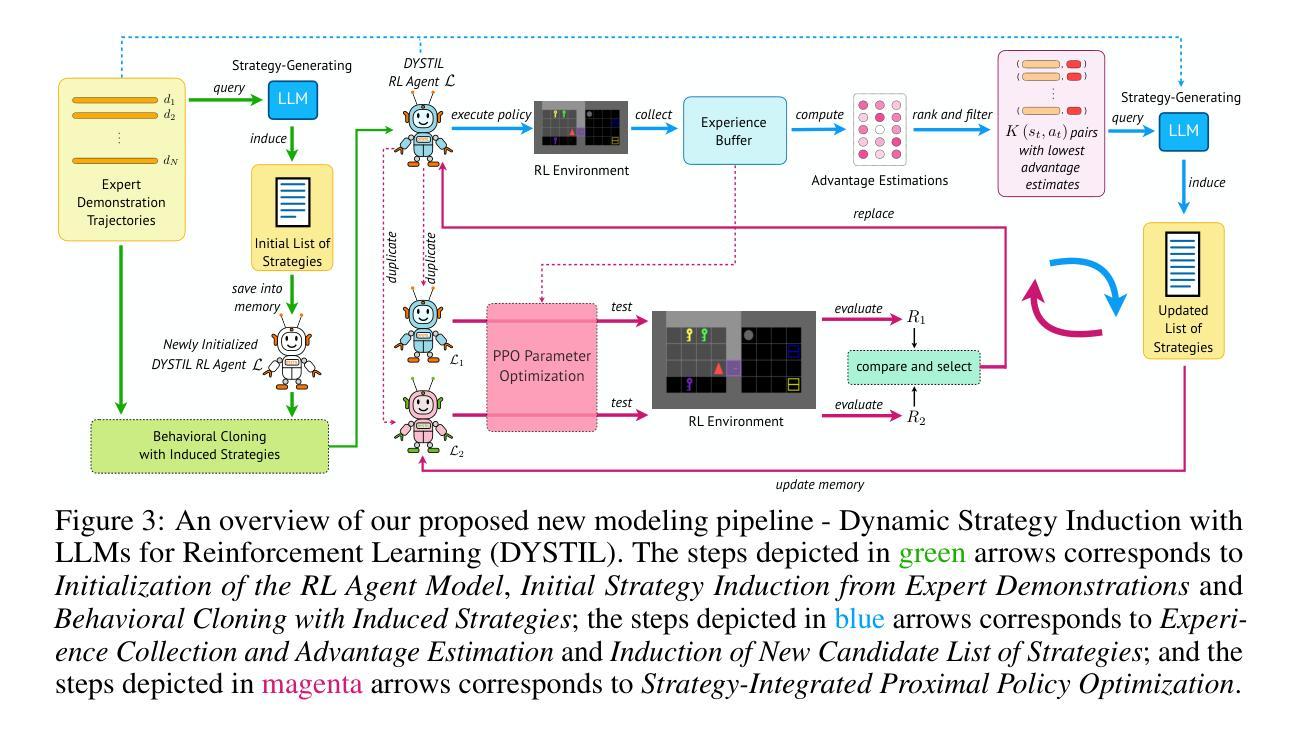
VLM Q-Learning: Aligning Vision-Language Models for Interactive Decision-Making
Authors:Jake Grigsby, Yuke Zhu, Michael Ryoo, Juan Carlos Niebles
Recent research looks to harness the general knowledge and reasoning of large language models (LLMs) into agents that accomplish user-specified goals in interactive environments. Vision-language models (VLMs) extend LLMs to multi-modal data and provide agents with the visual reasoning necessary for new applications in areas such as computer automation. However, agent tasks emphasize skills where accessible open-weight VLMs lag behind their LLM equivalents. For example, VLMs are less capable of following an environment’s strict output syntax requirements and are more focused on open-ended question answering. Overcoming these limitations requires supervised fine-tuning (SFT) on task-specific expert demonstrations. Our work approaches these challenges from an offline-to-online reinforcement learning (RL) perspective. RL lets us fine-tune VLMs to agent tasks while learning from the unsuccessful decisions of our own model or more capable (larger) models. We explore an off-policy RL solution that retains the stability and simplicity of the widely used SFT workflow while allowing our agent to self-improve and learn from low-quality datasets. We demonstrate this technique with two open-weight VLMs across three multi-modal agent domains.
最新的研究旨在将大型语言模型(LLM)的通用知识和推理能力转化为能够在交互式环境中完成用户指定目标的代理。视觉语言模型(VLM)将LLM扩展到多模态数据,并为代理提供视觉推理能力,对于计算机自动化等领域的新应用来说,这是必要的。然而,代理任务强调的是可用开放权重VLM落后于其LLM等效项的技能。例如,VLM在遵循环境的严格输出语法要求方面能力较差,更侧重于开放式问答。要克服这些限制,需要对特定任务的专家演示进行有监督的微调(SFT)。我们的工作从离线到在线强化学习(RL)的角度来应对这些挑战。强化学习让我们能够在遵循广泛使用的SFT工作流程的稳定性和简单性的同时,对VLM进行微调以执行代理任务,并从我们自己的模型或更强大的模型的失败决策中学习。我们探索了一种离线策略RL解决方案,允许我们的代理自我改进并从低质量数据集中学习。我们在三个多模态代理领域使用两个开放权重VLM对此技术进行了演示。
论文及项目相关链接
PDF SSI-FM Workshop ICLR 2025
Summary
大型语言模型(LLMs)的通用知识和推理能力被用于构建能在互动环境中完成用户指定任务的智能代理。视觉语言模型(VLMs)扩展了LLMs,使其能处理多模式数据,并为代理提供视觉推理能力,从而适用于计算机自动化等领域的新应用。然而,VLMs在某些技能方面落后于LLMs,如遵循环境的严格输出语法要求和处理开放式问答等。为了克服这些限制,需要在任务特定的专家演示上进行监督微调(SFT)。本研究从线下到线上的强化学习(RL)角度应对这些挑战。RL允许我们微调VLMs以完成代理任务,同时从我们自己模型的失败决策或更强大的模型中学习。我们探索了一种离策略RL解决方案,它保留了广泛使用的SFT工作流的稳定性和简单性,同时允许我们的代理自我改进并从低质量数据集中学习。我们在三个多模式代理领域使用两个开源VLMs演示了这项技术。
Key Takeaways
- 大型语言模型(LLMs)具备通用知识和推理能力,被用于构建智能代理以完成用户指定任务。
- 视觉语言模型(VLMs)扩展了LLMs,处理多模式数据并具备视觉推理能力,适用于新应用领域。
- VLMs在某些技能方面相对落后于LLMs,如严格输出语法要求的遵循和开放式问答处理。
- 为了克服VLMs的限制,需在任务特定的专家演示上进行监督微调(SFT)。
- 强化学习(RL)允许对VLMs进行微调,以完成代理任务,并从模型自身的失败决策或更强大的模型中学习。
- 提出的离策略RL解决方案保留了SFT的稳定性、简单性,并允许代理自我改进,从低质量数据集中学习。
点此查看论文截图


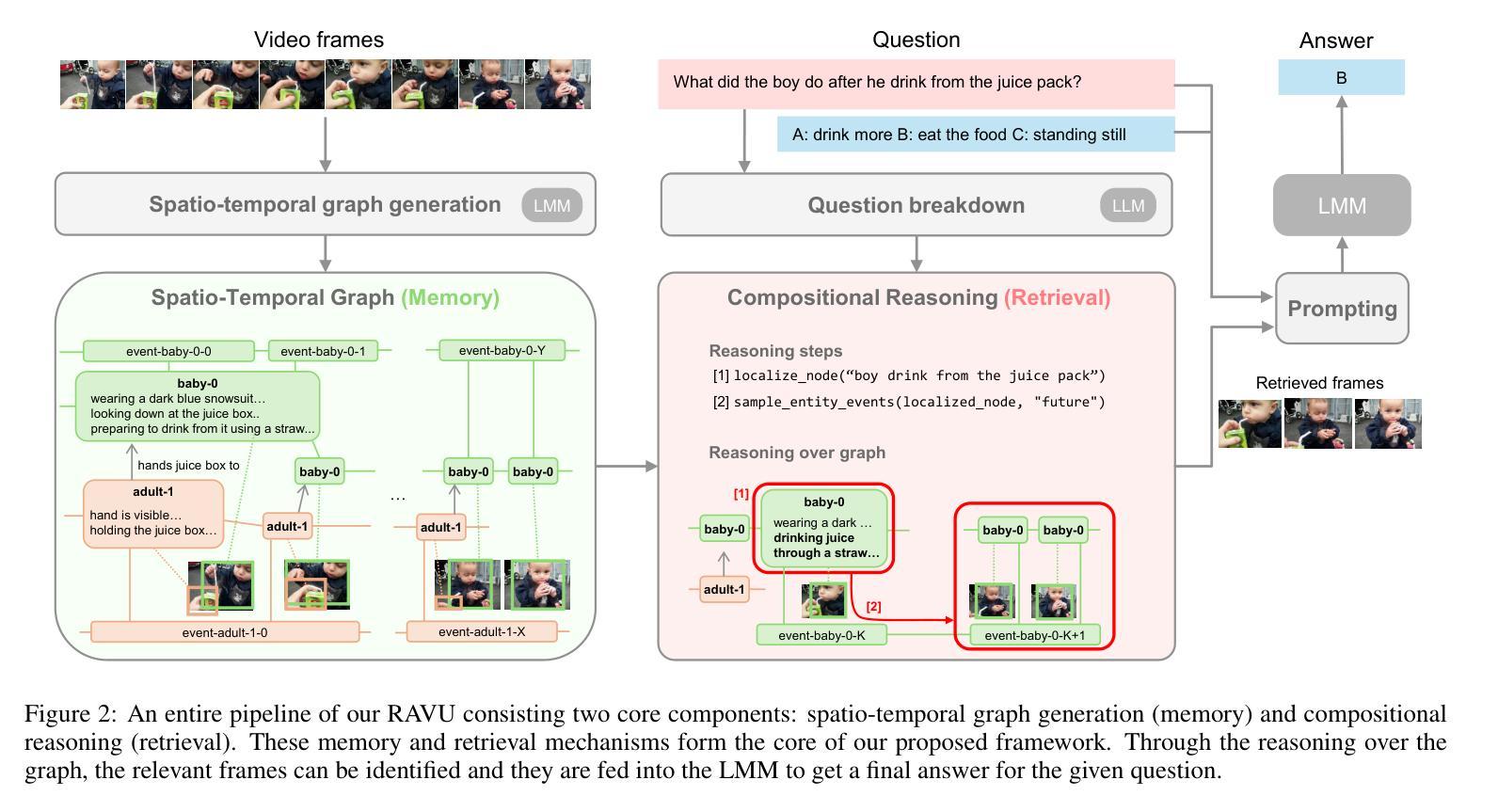
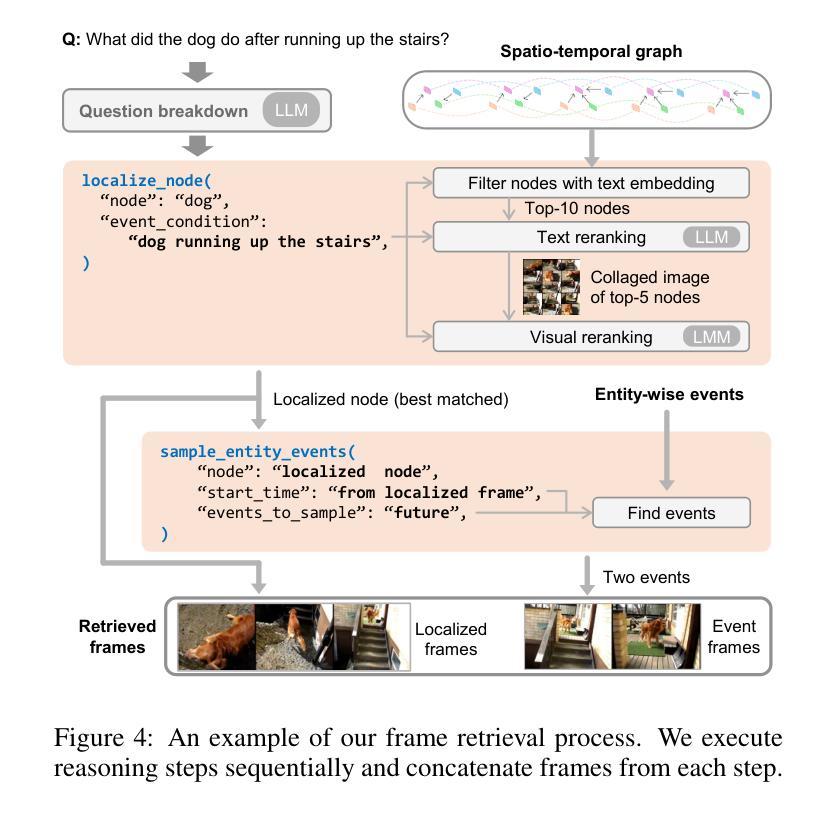
RAVU: Retrieval Augmented Video Understanding with Compositional Reasoning over Graph
Authors:Sameer Malik, Moyuru Yamada, Ayush Singh, Dishank Aggarwal
Comprehending long videos remains a significant challenge for Large Multi-modal Models (LMMs). Current LMMs struggle to process even minutes to hours videos due to their lack of explicit memory and retrieval mechanisms. To address this limitation, we propose RAVU (Retrieval Augmented Video Understanding), a novel framework for video understanding enhanced by retrieval with compositional reasoning over a spatio-temporal graph. We construct a graph representation of the video, capturing both spatial and temporal relationships between entities. This graph serves as a long-term memory, allowing us to track objects and their actions across time. To answer complex queries, we decompose the queries into a sequence of reasoning steps and execute these steps on the graph, retrieving relevant key information. Our approach enables more accurate understanding of long videos, particularly for queries that require multi-hop reasoning and tracking objects across frames. Our approach demonstrate superior performances with limited retrieved frames (5-10) compared with other SOTA methods and baselines on two major video QA datasets, NExT-QA and EgoSchema.
理解长视频对于大型多模态模型(LMMs)来说仍然是一个巨大的挑战。由于缺少明确的记忆和检索机制,当前的LMMs在处理长达数小时的视频时面临困难。为了解决这个问题,我们提出了RAVU(基于检索增强的视频理解),这是一个通过时空图上的组合推理进行检索增强视频理解的新型框架。我们构建了视频的图表示,捕捉实体之间的空间和时间关系。这个图作为一个长期记忆,允许我们跟踪物体及其随时间变化的行为。为了回答复杂的查询,我们将查询分解成一系列的推理步骤,并在图上执行这些步骤,检索相关的关键信息。我们的方法使得对长视频的准确理解更加可能,特别是对于需要多跳推理和跨帧跟踪物体的查询。在两个主要的视频问答数据集NExT-QA和EgoSchema上,我们的方法在有限的检索帧(5-10帧)内表现出了优于其他先进方法和基准线的性能。
论文及项目相关链接
Summary
本摘要以简洁明了的方式描述了解决大型多媒体模型(LMMs)在理解长视频时所面临的困境的最新进展。面对长视频的长时间处理挑战,提出了一种名为RAVU的新型框架,通过时空图上的组合推理增强检索能力。该框架构建视频的图表示,捕捉实体之间的空间和时间关系,作为长期记忆跟踪物体和动作。通过分解查询并执行图形上的推理步骤来回答复杂的查询,提高了对长视频的理解准确性,特别是在需要多跳推理和跨帧跟踪的查询上。在两个主要视频问答数据集上相比其他前沿方法和基线表现出卓越性能。摘要来源于上述文本并控制在了一百字以内。
Key Takeaways:从文本中抽取出的关键信息可以整理成以下几点:
点此查看论文截图


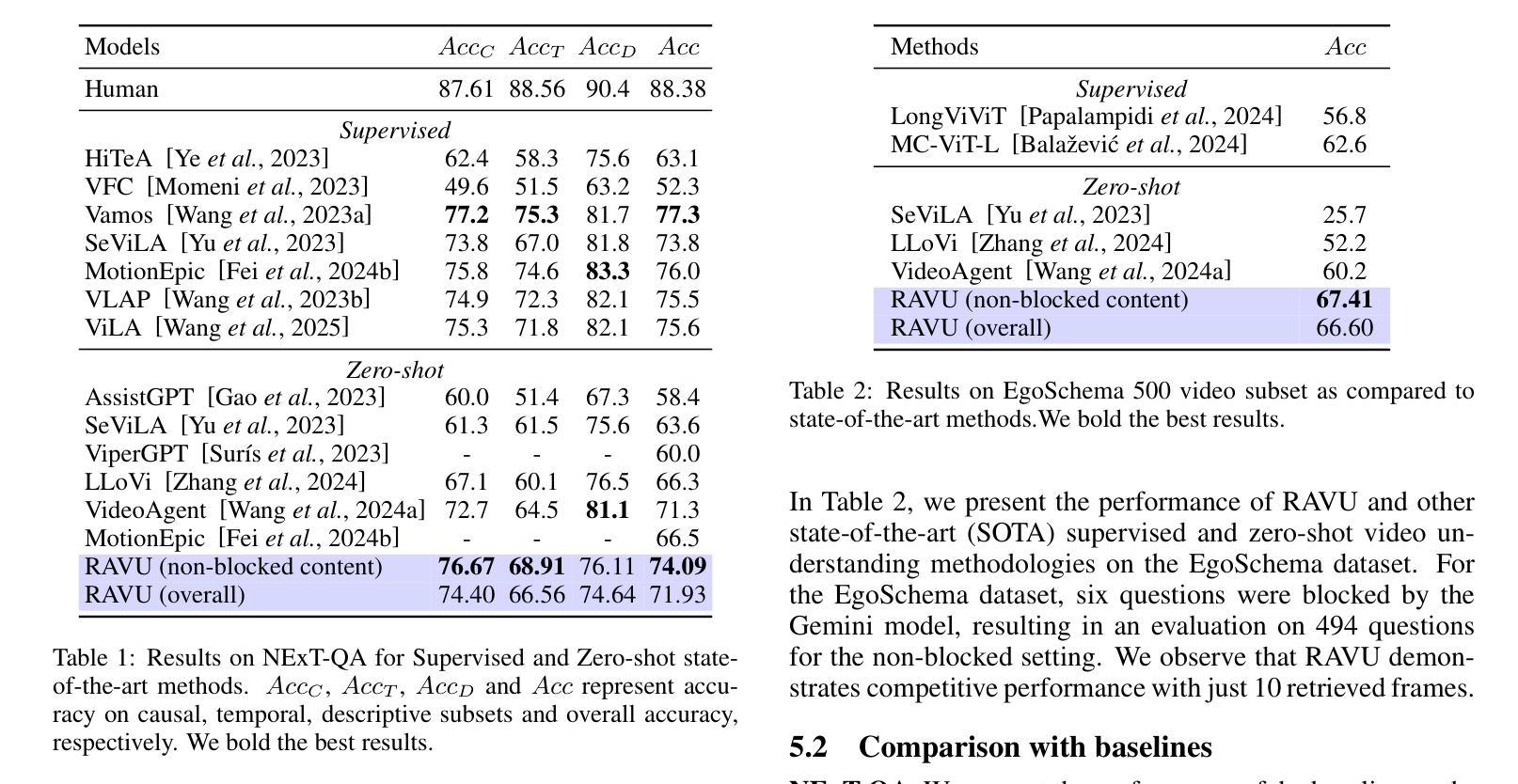
CombiBench: Benchmarking LLM Capability for Combinatorial Mathematics
Authors:Junqi Liu, Xiaohan Lin, Jonas Bayer, Yael Dillies, Weijie Jiang, Xiaodan Liang, Roman Soletskyi, Haiming Wang, Yunzhou Xie, Beibei Xiong, Zhengfeng Yang, Jujian Zhang, Lihong Zhi, Jia Li, Zhengying Liu
Neurosymbolic approaches integrating large language models with formal reasoning have recently achieved human-level performance on mathematics competition problems in algebra, geometry and number theory. In comparison, combinatorics remains a challenging domain, characterized by a lack of appropriate benchmarks and theorem libraries. To address this gap, we introduce CombiBench, a comprehensive benchmark comprising 100 combinatorial problems, each formalized in Lean~4 and paired with its corresponding informal statement. The problem set covers a wide spectrum of difficulty levels, ranging from middle school to IMO and university level, and span over ten combinatorial topics. CombiBench is suitable for testing IMO solving capabilities since it includes all IMO combinatorial problems since 2000 (except IMO 2004 P3 as its statement contain an images). Furthermore, we provide a comprehensive and standardized evaluation framework, dubbed Fine-Eval (for $\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation), for formal mathematics. It accommodates not only proof-based problems but also, for the first time, the evaluation of fill-in-the-blank questions. Using Fine-Eval as the evaluation method and Kimina Lean Server as the backend, we benchmark several LLMs on CombiBench and observe that their capabilities for formally solving combinatorial problems remain limited. Among all models tested (none of which has been trained for this particular task), Kimina-Prover attains the best results, solving 7 problems (out of 100) under both with solution'' and without solution’’ scenarios. We open source the benchmark dataset alongside with the code of the proposed evaluation method at https://github.com/MoonshotAI/CombiBench/.
将大型语言模型与形式推理相结合的神经营略方法,最近已在代数、几何和数论的数学竞赛问题上达到了人类水平的性能。相比之下,组合学仍然是一个具有挑战性的领域,其特点是缺乏适当的基准测试和定理库。为了弥补这一空白,我们引入了CombiBench,这是一个包含100个组合问题的全面基准测试集,每个问题都在Lean~4中形式化,并配有其相应的非正式陈述。该问题集涵盖了从中学到IMO和大学水平的广泛难度级别,并涵盖了十多个组合主题。CombiBench适合用于测试IMO解题能力,因为它包含了自2000年以来所有的IMO组合问题(除IMO 2004 P3因其陈述中包含图像而除外)。此外,我们还提供了一个全面且标准化的评估框架,称为Fine-Eval(用于$\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation),用于形式数学。它不仅适用于基于证明的问题,而且首次实现了填充空白问题的评估。我们使用Fine-Eval作为评估方法,Kiminna Lean Server作为后端,在CombiBench上对几个LLM进行了基准测试,并观察到它们在正式解决组合问题上能力有限。在测试的所有模型中(没有任何模型接受过此项特定任务的训练),Kiminna Prover取得了最好的结果,在“有解决方案”和“无解决方案”的场景下均解决了7个问题(总共100个问题)。我们在https://github.com/MoonshotAI/CombiBench/上公开基准测试数据集以及所提出评估方法的代码。
论文及项目相关链接
Summary
这篇文本介绍了针对组合数学领域的一个新基准测试套件CombiBench。该基准测试包含了多种难度级别的组合问题,并且采用了全新的评估框架Fine-Eval。文章指出尽管大型语言模型在某些数学竞赛问题上达到了人类水平的表现,但在组合数学领域的性能仍然有限。目前最好的模型Kiminar-Prover在基准测试中仅解决了其中的七个问题。相关资源已开源供公众使用。
Key Takeaways
- CombiBench是一个全面的组合数学基准测试套件,包含从中学至国际数学奥林匹克竞赛(IMO)及大学级别的广泛组合问题。
- Fine-Eval是一个全新的标准化评估框架,可用于形式数学的评估,支持证明题及填空题的评价。
- 大型语言模型(LLMs)在组合数学领域的性能仍然有限,即使在某些数学竞赛问题上表现出接近人类水平的能力。
- Kimina Lean Server作为后端工具,用于基准测试。
- CombiBench中最优秀的模型是Kiminar-Prover,在测试中解决了七个问题。
- CombiBench及相关资源已开源,可供公众使用和研究。
点此查看论文截图



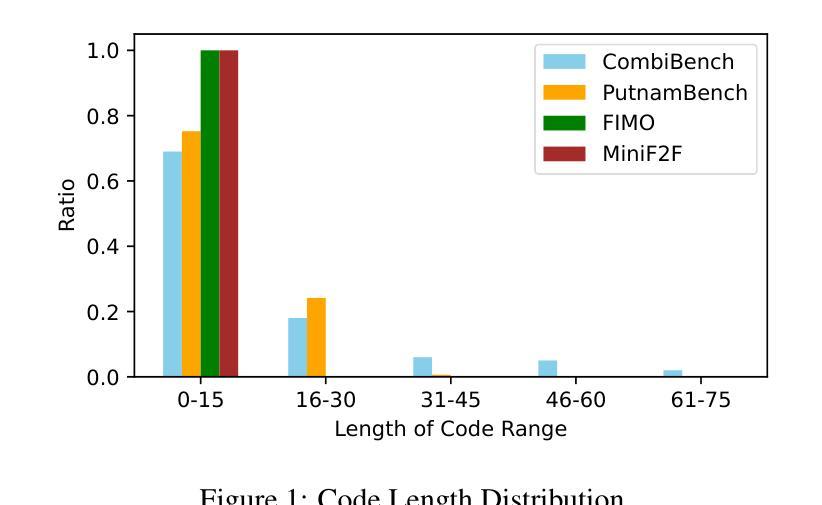
MORE: Mobile Manipulation Rearrangement Through Grounded Language Reasoning
Authors:Mohammad Mohammadi, Daniel Honerkamp, Martin Büchner, Matteo Cassinelli, Tim Welschehold, Fabien Despinoy, Igor Gilitschenski, Abhinav Valada
Autonomous long-horizon mobile manipulation encompasses a multitude of challenges, including scene dynamics, unexplored areas, and error recovery. Recent works have leveraged foundation models for scene-level robotic reasoning and planning. However, the performance of these methods degrades when dealing with a large number of objects and large-scale environments. To address these limitations, we propose MORE, a novel approach for enhancing the capabilities of language models to solve zero-shot mobile manipulation planning for rearrangement tasks. MORE leverages scene graphs to represent environments, incorporates instance differentiation, and introduces an active filtering scheme that extracts task-relevant subgraphs of object and region instances. These steps yield a bounded planning problem, effectively mitigating hallucinations and improving reliability. Additionally, we introduce several enhancements that enable planning across both indoor and outdoor environments. We evaluate MORE on 81 diverse rearrangement tasks from the BEHAVIOR-1K benchmark, where it becomes the first approach to successfully solve a significant share of the benchmark, outperforming recent foundation model-based approaches. Furthermore, we demonstrate the capabilities of our approach in several complex real-world tasks, mimicking everyday activities. We make the code publicly available at https://more-model.cs.uni-freiburg.de.
自主长期移动操作涵盖了众多挑战,包括场景动态变化、未知区域和错误恢复。近期的研究工作已经利用基础模型进行场景级别的机器人推理和规划。然而,当处理大量物体和大规模环境时,这些方法的性能会下降。为了解决这些局限性,我们提出了MORE,这是一种增强语言模型解决能力的新方法,用于解决零移动操作规划任务中的重组任务。MORE利用场景图来表示环境,结合实例差异,并引入主动过滤方案,提取任务相关的子图对象和区域实例。这些步骤产生了有界规划问题,有效地减轻了幻觉现象,提高了可靠性。此外,我们还引入了一些改进功能,使规划能够在室内和室外环境中进行。我们在BEHAVIOR-1K基准测试上的81项多样化的重组任务中评估了MORE的性能,它成为第一个成功解决该基准测试中大部分任务的方法,超越了近期基于基础模型的方法。此外,我们还展示了该方法在模仿日常活动的复杂现实任务中的能力。我们的代码公开在https://more-model.cs.uni-freiburg.de。
论文及项目相关链接
Summary
该文本介绍了自主长远视角移动操控的挑战,包括场景动态、未知区域和错误恢复等问题。为解决这些问题,提出了一种名为MORE的新方法,用于增强语言模型解决零移动操控规划任务的能力。MORE利用场景图表示环境,实现实例区分,并引入主动过滤方案,提取任务相关的子图。这些步骤解决了规划问题,提高了可靠性和可靠性。此外,还介绍了在室内和室外环境中进行规划的几项改进。在BEHAVIOR-1K基准测试中,MORE成功解决了大量任务,优于近期基于基础模型的方法。代码已公开在[链接地址]。
Key Takeaways
- 自主长远视角移动操控面临场景动态、未知区域和错误恢复等挑战。
- 近期方法利用基础模型进行场景级机器人推理和规划,但在处理大量物体和大规模环境时性能下降。
- MORE方法旨在增强语言模型解决零移动操控规划任务的能力。
- MORE利用场景图表示环境,实现实例区分和主动过滤方案提取任务相关子图。
- MORE方法有效解决了规划问题,提高了可靠性和效率。
- MORE方法在BEHAVIOR-1K基准测试中表现优异,成功解决大量任务,优于其他方法。
点此查看论文截图


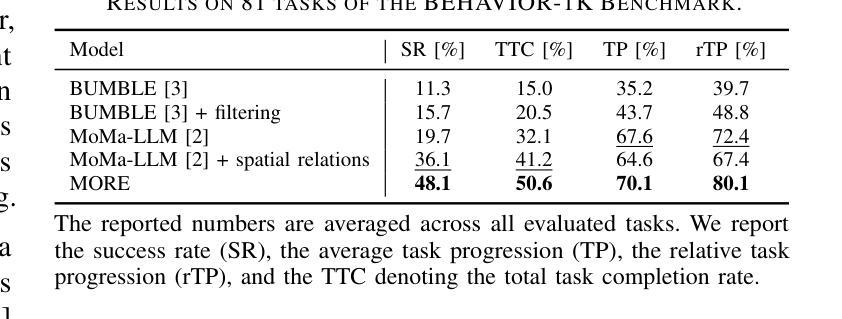

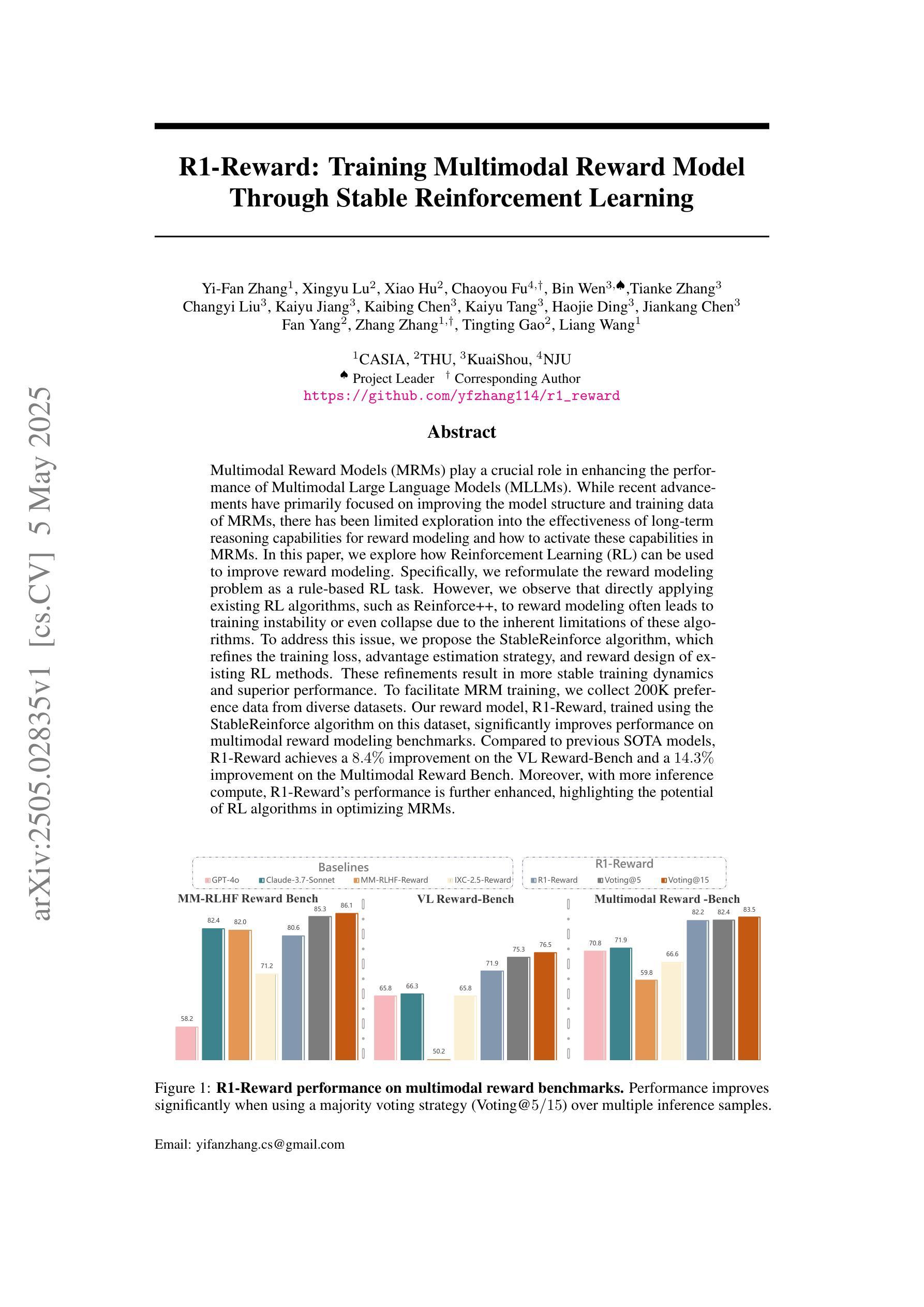
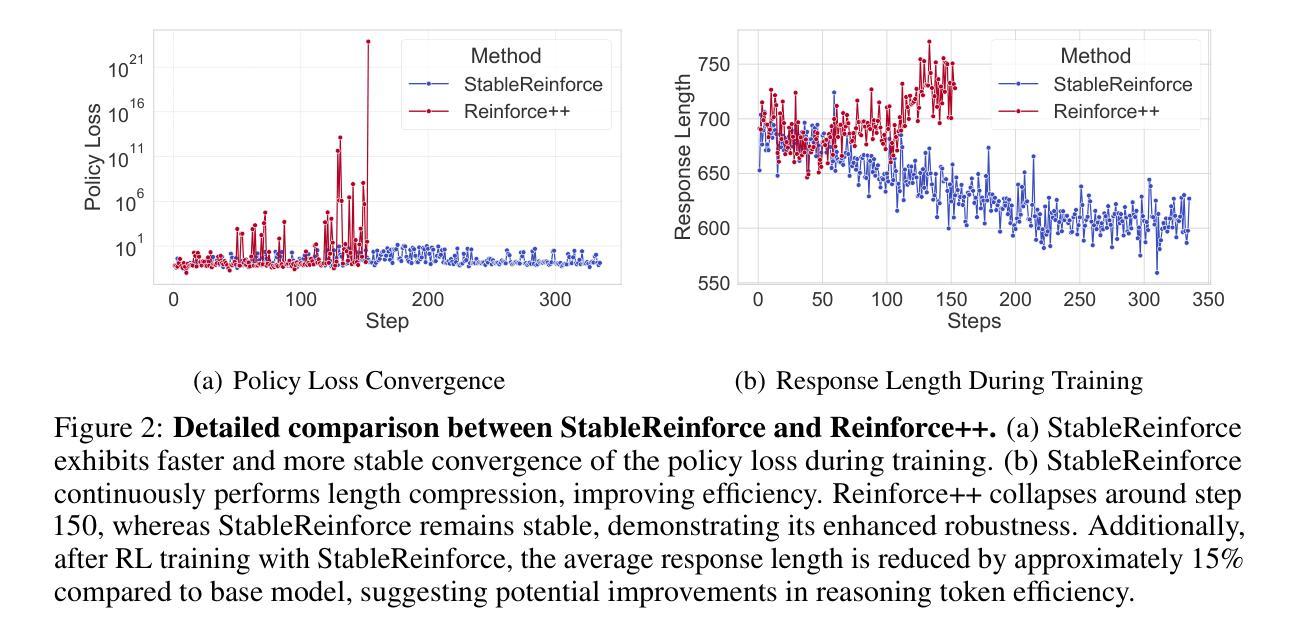
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
Authors:Yi-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, Haojie Ding, Jiankang Chen, Fan Yang, Zhang Zhang, Tingting Gao, Liang Wang
Multimodal Reward Models (MRMs) play a crucial role in enhancing the performance of Multimodal Large Language Models (MLLMs). While recent advancements have primarily focused on improving the model structure and training data of MRMs, there has been limited exploration into the effectiveness of long-term reasoning capabilities for reward modeling and how to activate these capabilities in MRMs. In this paper, we explore how Reinforcement Learning (RL) can be used to improve reward modeling. Specifically, we reformulate the reward modeling problem as a rule-based RL task. However, we observe that directly applying existing RL algorithms, such as Reinforce++, to reward modeling often leads to training instability or even collapse due to the inherent limitations of these algorithms. To address this issue, we propose the StableReinforce algorithm, which refines the training loss, advantage estimation strategy, and reward design of existing RL methods. These refinements result in more stable training dynamics and superior performance. To facilitate MRM training, we collect 200K preference data from diverse datasets. Our reward model, R1-Reward, trained using the StableReinforce algorithm on this dataset, significantly improves performance on multimodal reward modeling benchmarks. Compared to previous SOTA models, R1-Reward achieves a $8.4%$ improvement on the VL Reward-Bench and a $14.3%$ improvement on the Multimodal Reward Bench. Moreover, with more inference compute, R1-Reward’s performance is further enhanced, highlighting the potential of RL algorithms in optimizing MRMs.
多模态奖励模型(MRMs)在提高多模态大型语言模型(MLLMs)性能中起着至关重要的作用。虽然最近的进展主要集中在改进MRM的模型结构和训练数据上,但对于奖励模型的长远推理能力的有效性以及如何激活这些能力在MRM中的研究仍然有限。在本文中,我们探讨了强化学习(RL)如何用于提高奖励建模的效果。具体来说,我们将奖励建模问题重新制定为一个基于规则的强化学习任务。然而,我们观察到,直接应用现有的强化学习算法(如Reinforce++)进行奖励建模往往会导致训练不稳定甚至崩溃,这是由于这些算法本身的局限性所致。为了解决这一问题,我们提出了StableReinforce算法,该算法对现有的RL方法的训练损失、优势估计策略和奖励设计进行了改进。这些改进带来了更稳定的训练动力和更优越的性能。为了促进MRM的训练,我们从各种数据集中收集了20万条偏好数据。我们的奖励模型R1-Reward,使用StableReinforce算法在此数据集上进行训练,在多媒体奖励建模基准测试中显著提高了性能。与之前的最佳模型相比,R1-Reward在VL Reward-Bench上实现了8.4%的改进,在多媒体奖励基准测试上实现了14.3%的改进。此外,随着更多的推理计算,R1-Reward的性能得到了进一步提高,这突显了强化学习算法在优化MRM方面的潜力。
论文及项目相关链接
PDF Home page: https://github.com/yfzhang114/r1_reward
Summary
本文探讨了多模态奖励模型(MRMs)在多模态大语言模型(MLLMs)中的重要性及其优化方法。文章重点关注强化学习(RL)在奖励建模中的应用,并提出了StableReinforce算法来解决现有RL算法在奖励建模中的训练不稳定问题。通过改进训练损失、优势估计策略和奖励设计,StableReinforce算法使训练过程更加稳定,性能更加优越。此外,文章还介绍了基于该算法训练的R1-Reward模型在多模态奖励建模基准测试上的表现,相较于先前最先进模型有明显提升。
Key Takeaways
- 多模态奖励模型(MRMs)对增强多模态大语言模型(MLLMs)性能至关重要。
- 强化学习(RL)在奖励建模中的应用有望提升模型性能。
- StableReinforce算法解决了现有RL算法在奖励建模中的训练不稳定问题。
- R1-Reward模型通过改进训练损失、优势估计策略和奖励设计,表现出优越的性能。
- R1-Reward模型在多模态奖励建模基准测试上的表现优于先前最先进模型。
- R1-Reward模型在增加推理计算的情况下,性能进一步提升。
点此查看论文截图
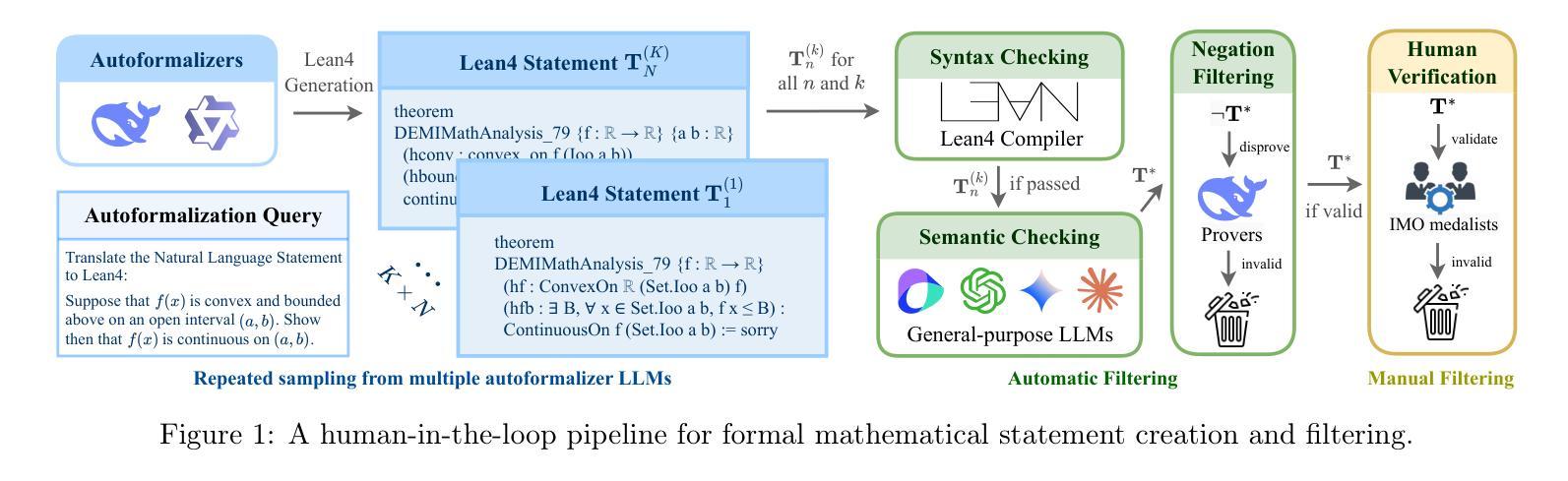
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
Authors:Zhouliang Yu, Ruotian Peng, Keyi Ding, Yizhe Li, Zhongyuan Peng, Minghao Liu, Yifan Zhang, Zheng Yuan, Huajian Xin, Wenhao Huang, Yandong Wen, Ge Zhang, Weiyang Liu
Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
数学逻辑推理仍是人工智能面临的一项关键挑战,现有基准测试的范围和规模存在局限性。为了解决这一问题,我们推出了FormalMATH,这是一个大规模Lean4基准测试,包含5560个经过正式验证的问题,涵盖从高中奥林匹克挑战到不同领域(如代数、应用数学、微积分、数论和离散数学)的本科定理。为了缓解手动形式化的低效性,我们引入了一种新型人机结合自动形式化管道,集成了:(1)用于语句自动形式化的专业大型语言模型(LLM),(2)多LLM语义验证,以及(3)使用现成的LLM证明书的否定证明过滤策略。这种方法通过保留72.09%的语句在手动验证之前确保了与原始自然语言问题的忠实度,降低了专家注释成本。我们对最新的基于LLM的定理证明器的评估表明存在显著局限性:即使在实用的采样预算下,最先进的模型成功率也只有16.46%,表现出明显的领域偏见(例如在代数方面表现出色,但在微积分方面失败)和对简化自动化策略的过度依赖。值得注意的是,我们发现自然语言解决方案指导与证明成功之间存在一种反直觉的逆向关系,这表明人类编写的非正式推理在正式推理场景中引入噪音而非清晰度。我们相信FormalMATH为基准测试数学逻辑推理提供了一个稳健的基准测试平台。
论文及项目相关链接
PDF Technical Report v1 (33 pages, 8 figures, project page: https://sphere-ai-lab.github.io/FormalMATH/)
Summary
基于人工智能在处理形式化数学推理时所面临的挑战,我们推出了FormalMATH这一大规模Lean4基准测试平台。该平台涵盖了从高中奥赛挑战到本科级别定理证明的正式验证问题共计5,560个。为了减轻手动形式化的效率问题,我们开发了一种新型人机结合自动形式化管道,集成了语言模型自动形式化声明、多语言模型语义验证以及基于否定的反证过滤策略。尽管有自动验证系统的辅助,专家标注成本仍然较高,但该系统确保了原始自然语言问题的忠实性。我们评估了目前最先进的语言模型定理证明器,发现它们存在显著局限性:即使是最强大的模型在实际采样预算下成功率也只有16.46%,显示出明显的领域偏见和过于依赖简化自动化战术的问题。研究还发现,在思维链推理场景中,自然语言指导的解答与证明成功之间存在一种反向关系。我们相信FormalMATH是一个用于评估数学形式推理能力的稳健基准测试平台。
Key Takeaways
- FormalMATH是一个大规模基准测试平台,包含涵盖多个领域的正式验证问题。
- 推出了人机结合自动形式化管道,以提高效率并减少人工标注成本。
- 自动验证系统确保了原始自然语言问题的忠实性。
- 最先进的语言模型定理证明器存在显著局限性,如低成功率和领域偏见问题。
- 自然语言指导的解答与证明成功之间存在一种反向关系。
- 语言模型在形式化推理中过于依赖简化自动化战术。
点此查看论文截图




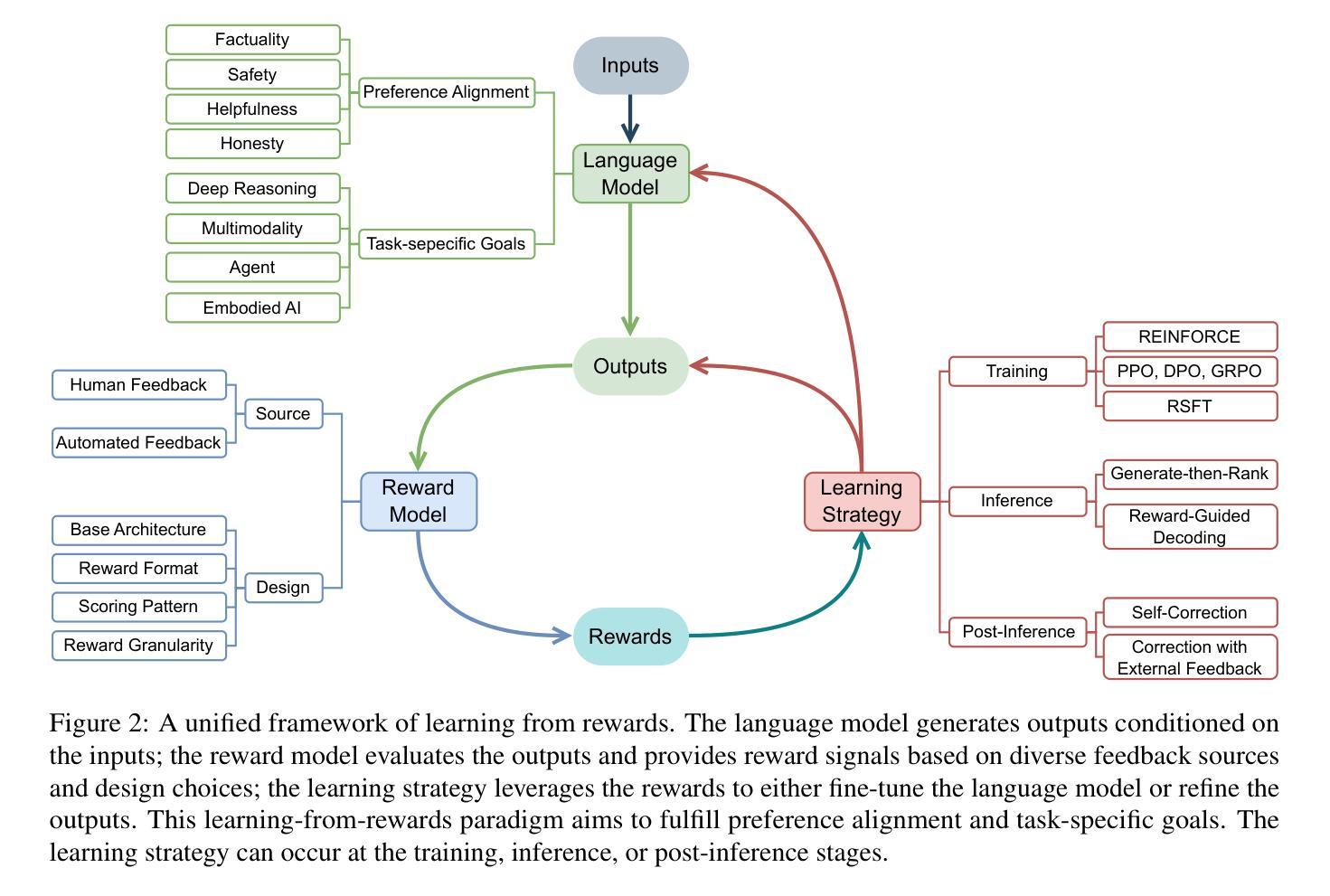
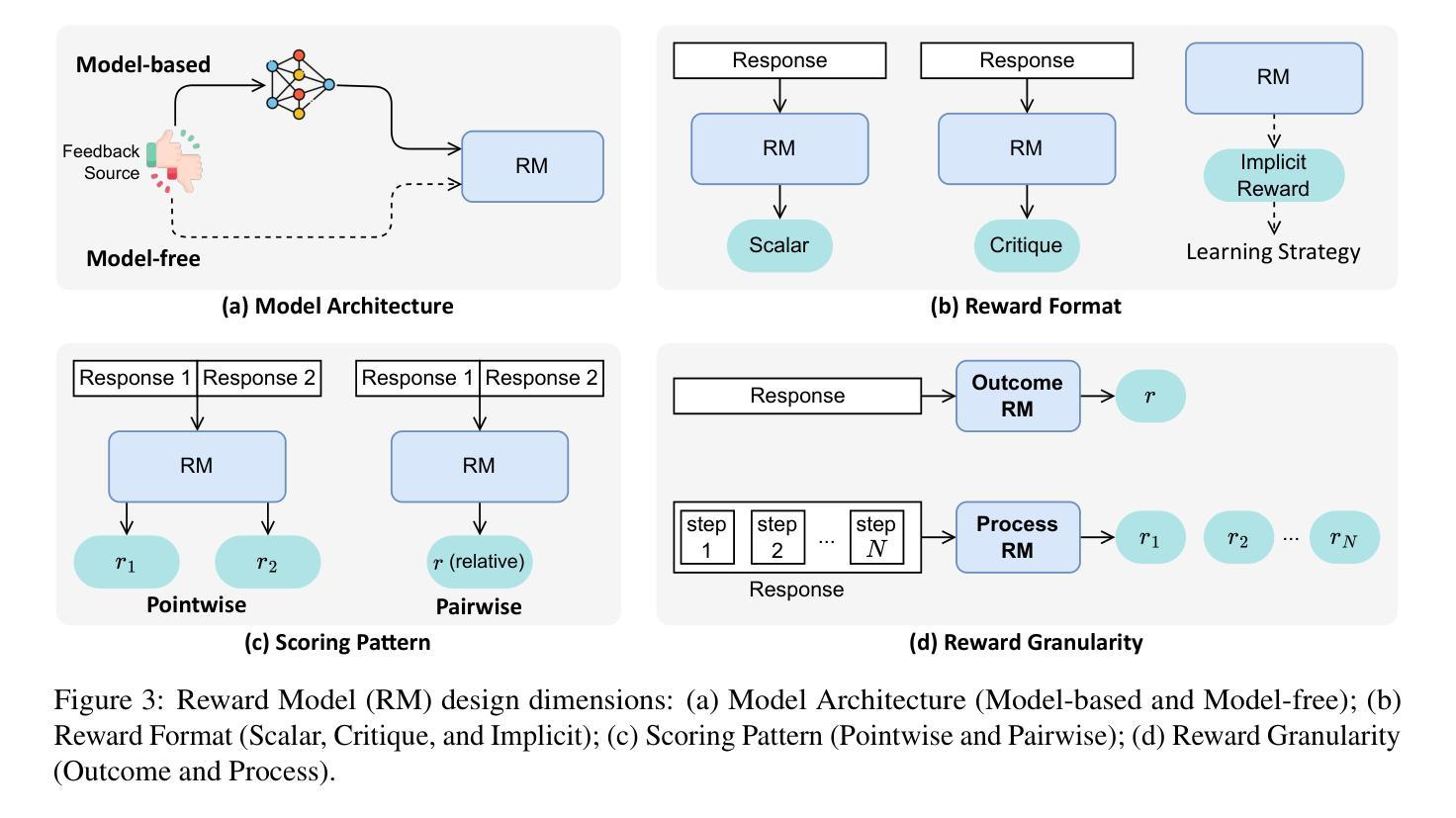
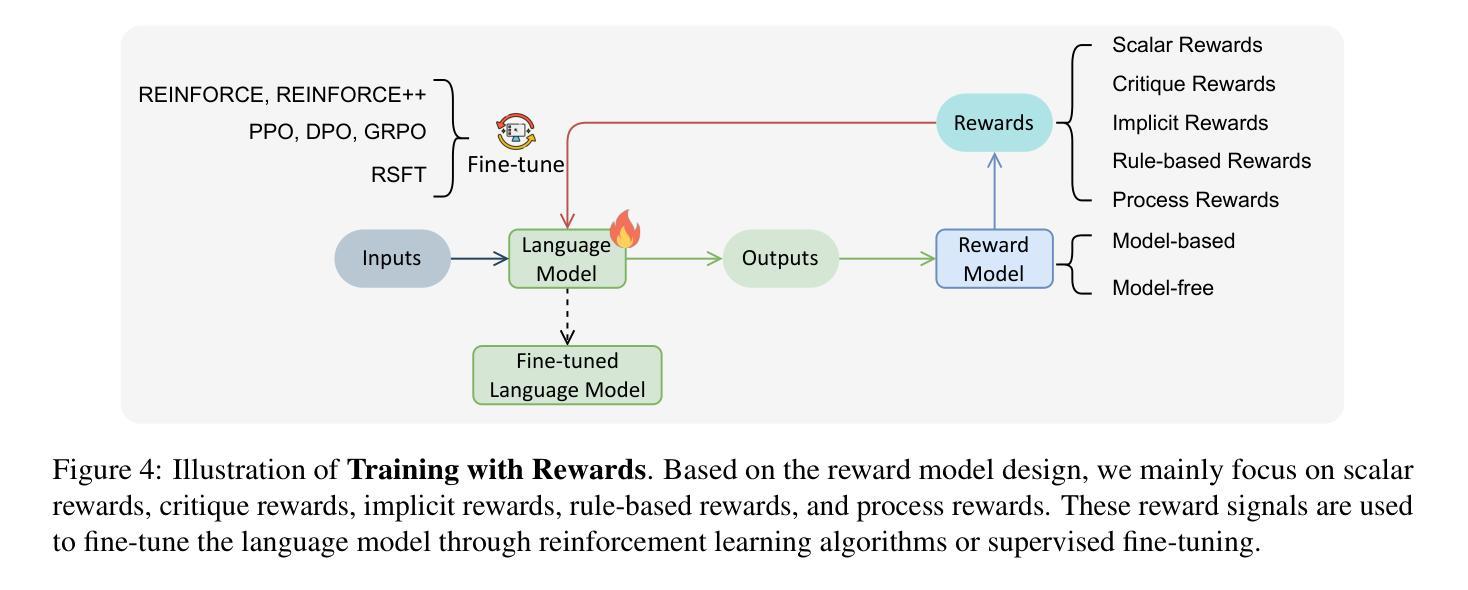
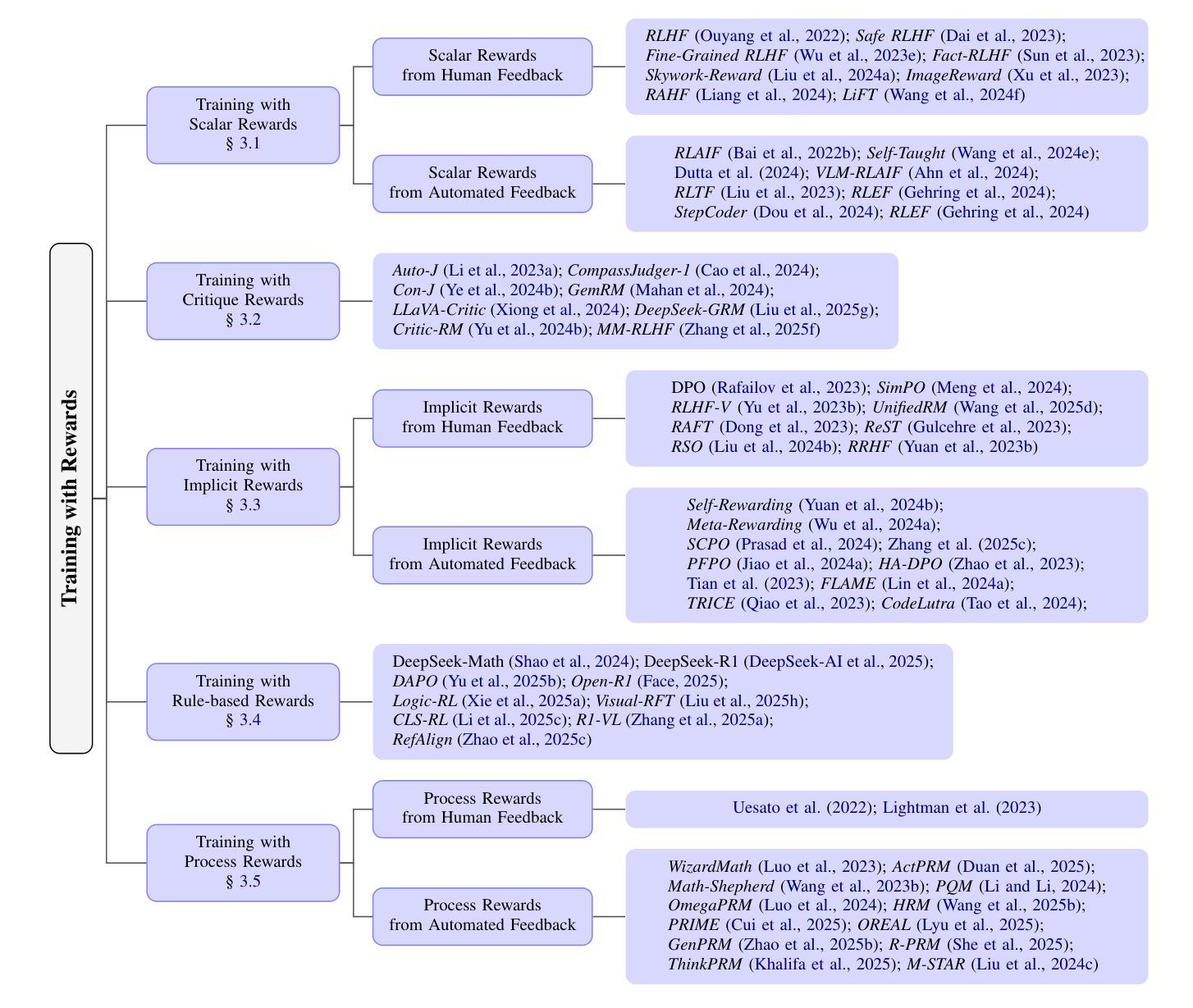
Sailing AI by the Stars: A Survey of Learning from Rewards in Post-Training and Test-Time Scaling of Large Language Models
Authors:Xiaobao Wu
Recent developments in Large Language Models (LLMs) have shifted from pre-training scaling to post-training and test-time scaling. Across these developments, a key unified paradigm has arisen: Learning from Rewards, where reward signals act as the guiding stars to steer LLM behavior. It has underpinned a wide range of prevalent techniques, such as reinforcement learning (in RLHF, DPO, and GRPO), reward-guided decoding, and post-hoc correction. Crucially, this paradigm enables the transition from passive learning from static data to active learning from dynamic feedback. This endows LLMs with aligned preferences and deep reasoning capabilities. In this survey, we present a comprehensive overview of the paradigm of learning from rewards. We categorize and analyze the strategies under this paradigm across training, inference, and post-inference stages. We further discuss the benchmarks for reward models and the primary applications. Finally we highlight the challenges and future directions. We maintain a paper collection at https://github.com/bobxwu/learning-from-rewards-llm-papers.
最近的大型语言模型(LLM)发展已经从预训练规模化转向后训练和测试时间规模化。在这些发展中,出现了一个关键的统一范式:从奖励中学习,其中奖励信号作为引导星来引导LLM的行为。它已经支撑了一系列流行的技术,如强化学习(在RLHF、DPO和GRPO中)、奖励引导解码和事后校正。关键的是,这一范式使LLM能够从被动学习静态数据过渡到主动学习动态反馈。这使得LLM具有一致的偏好和深厚的推理能力。在这篇综述中,我们对从奖励中学习的范式进行了全面的概述。我们按训练、推理和推理后阶段分类和分析该范式下的策略。我们还进一步讨论了奖励模型的基准测试和主要应用。最后,我们强调了挑战和未来方向。相关论文集合请见:https://github.com/bobxwu/learning-from-rewards-llm-papers。
论文及项目相关链接
PDF 35 Pages
Summary
近期大型语言模型(LLM)的发展已从预训练扩展转向后训练和测试时间扩展。在这些发展中,一个关键统一范式应运而生:从奖励中学习。奖励信号作为指导LLM行为的指南星。它已成为多种流行技术的基石,如强化学习(在RLHF、DPO和GRPO中)、奖励引导解码和事后校正。这个范式使LLM从被动学习静态数据转变为从动态反馈中学习,赋予LLM对齐的偏好和深度推理能力。本文全面概述了从奖励中学习的范式,分析和分类了该范式下的策略在训练、推理和推理后的阶段。我们进一步讨论了奖励模型的标准和主要应用,并强调了挑战和未来方向。我们提供论文集合链接:链接地址。
Key Takeaways
- 大型语言模型(LLM)的发展已从预训练扩展转向后训练和测试时间扩展。
- 从奖励中学习已成为LLM的一个重要发展范式,涵盖多种技术如强化学习、奖励引导解码和事后校正。
- 该范式使LLM从被动学习静态数据转变为从动态反馈中学习,增强了模型的适应性和灵活性。
- 从奖励中学习使LLM具备对齐的偏好和深度推理能力,提高了模型的智能水平。
- 该论文全面概述了从奖励中学习的策略在训练、推理和推理后的阶段,并提供了相关的论文集合链接。
点此查看论文截图

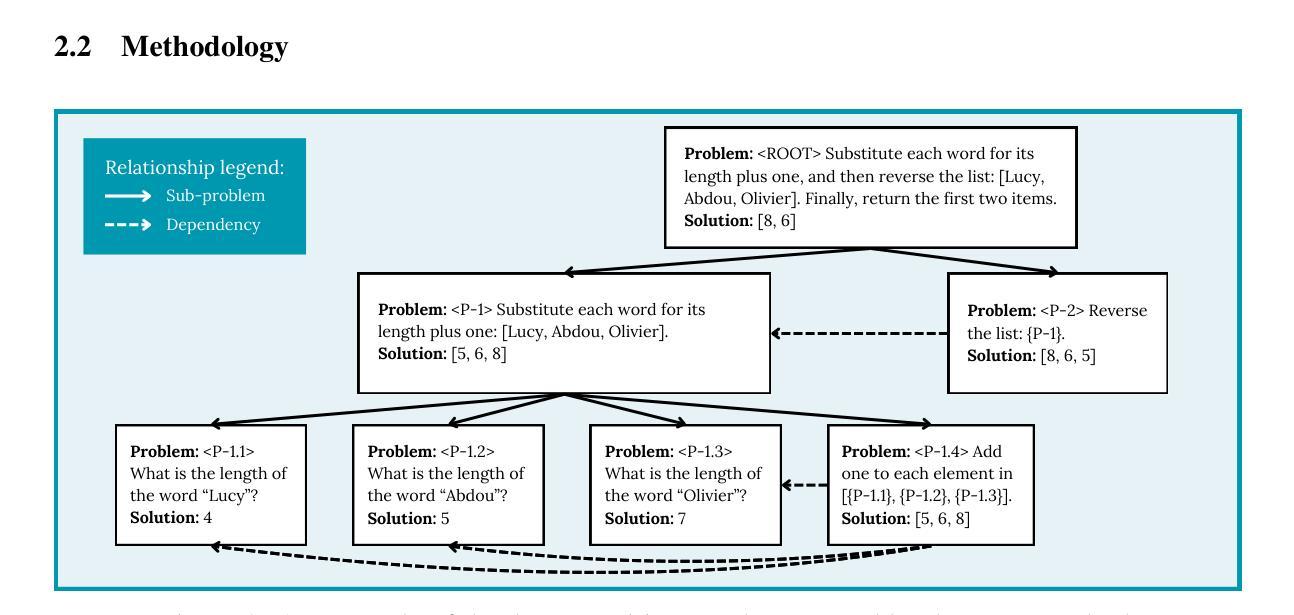
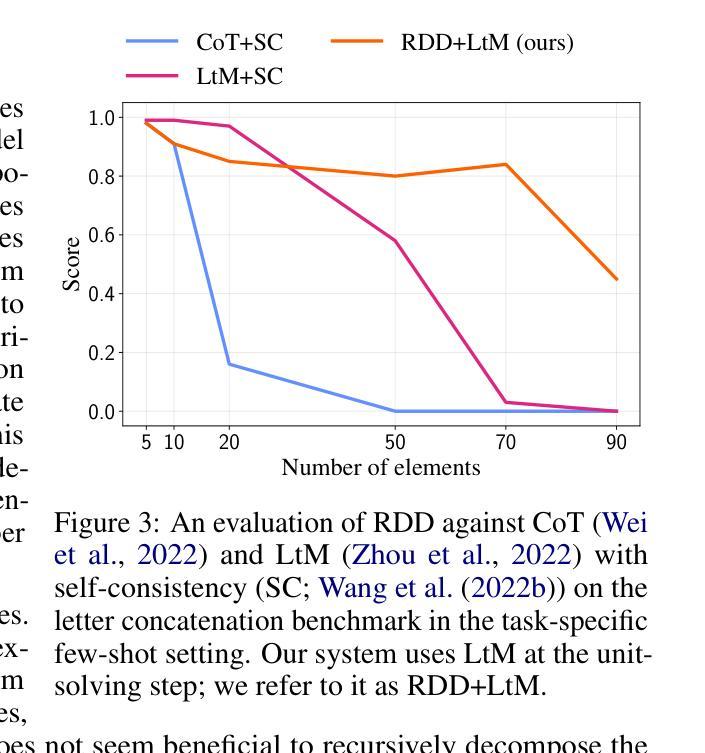
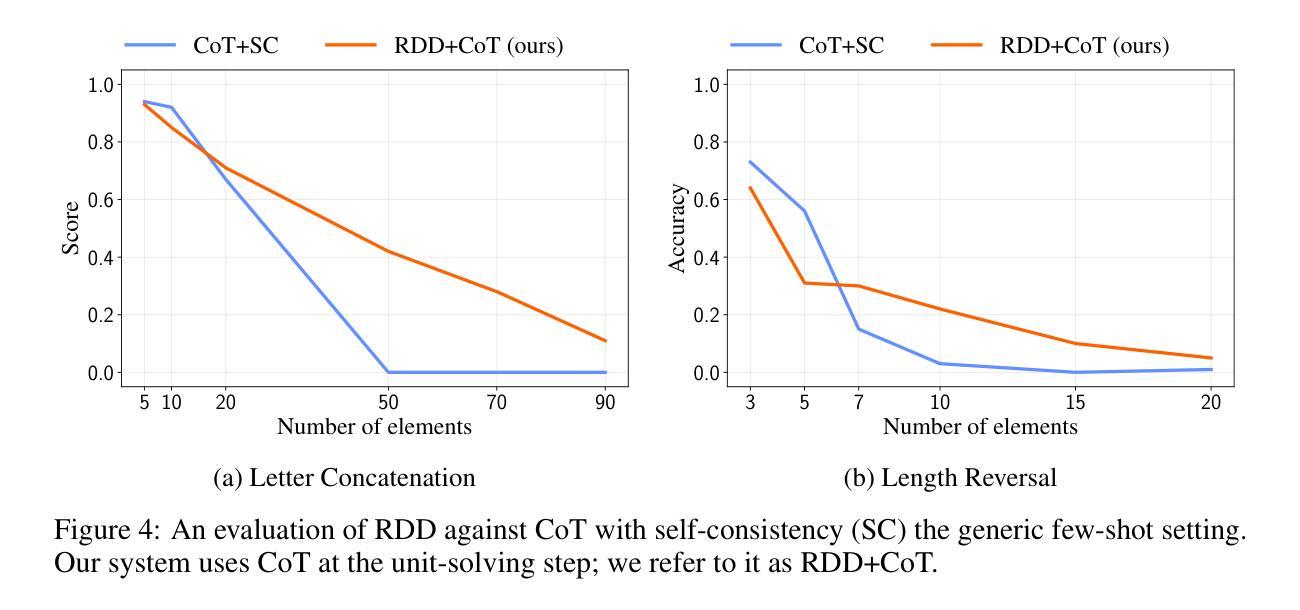
Recursive Decomposition with Dependencies for Generic Divide-and-Conquer Reasoning
Authors:Sergio Hernández-Gutiérrez, Minttu Alakuijala, Alexander V. Nikitin, Pekka Marttinen
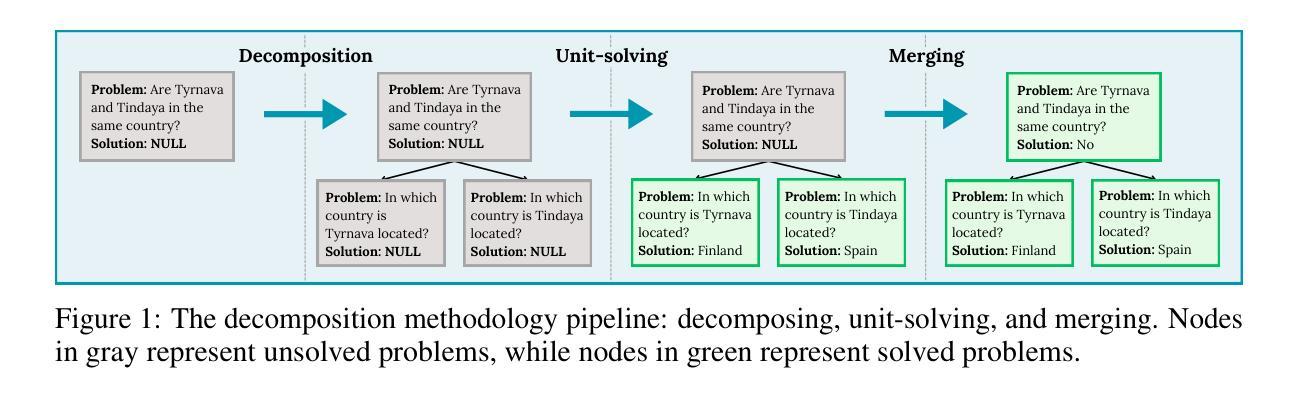
Reasoning tasks are crucial in many domains, especially in science and engineering. Although large language models (LLMs) have made progress in reasoning tasks using techniques such as chain-of-thought and least-to-most prompting, these approaches still do not effectively scale to complex problems in either their performance or execution time. Moreover, they often require additional supervision for each new task, such as in-context examples. In this work, we introduce Recursive Decomposition with Dependencies (RDD), a scalable divide-and-conquer method for solving reasoning problems that requires less supervision than prior approaches. Our method can be directly applied to a new problem class even in the absence of any task-specific guidance. Furthermore, RDD supports sub-task dependencies, allowing for ordered execution of sub-tasks, as well as an error recovery mechanism that can correct mistakes made in previous steps. We evaluate our approach on two benchmarks with six difficulty levels each and in two in-context settings: one with task-specific examples and one without. Our results demonstrate that RDD outperforms other methods in a compute-matched setting as task complexity increases, while also being more computationally efficient.
推理任务在许多领域都至关重要,特别是在科学和工业领域。尽管大型语言模型(LLM)在推理任务方面取得了进展,采用了如思维链和最少到最多的提示等技术,但这些方法仍无法在性能或执行时间上有效地扩展到复杂问题。此外,它们通常需要针对每个新任务进行额外的监督,例如上下文示例。在这项工作中,我们引入了基于依赖的递归分解(RDD),这是一种解决推理问题的可扩展的分而治之方法,它需要的监督比先前的方法少。我们的方法可以直接应用于新的问题类别,即使在没有任何特定任务指导的情况下也是如此。此外,RDD支持子任务依赖关系,允许按顺序执行子任务,以及一种错误恢复机制,可以纠正之前步骤中犯下的错误。我们在两个基准测试上对两种方法进行了评估,每个基准测试包括六个难度级别,并在两种上下文环境中进行了评估:一个有特定任务示例的上下文环境和一个没有特定任务示例的上下文环境。我们的结果表明,随着任务复杂性的增加,在算力匹配的环境中,RDD的表现优于其他方法,同时其计算效率也更高。
论文及项目相关链接
Summary:
在科技和工程等领域,推理任务至关重要。尽管大型语言模型(LLMs)在推理任务上有所进展,但它们对于复杂问题的性能和执行时间仍无法有效扩展。本研究提出了递归分解与依赖关系(RDD)方法,一种解决推理问题的可伸缩的分而治之方法,它减少了监督要求,能够直接应用于新问题类别而无需任何任务特定指导。RDD支持子任务依赖关系,允许子任务的顺序执行以及错误恢复机制。在基准测试中,随着任务复杂性的增加,RDD在环境匹配设置中表现出优于其他方法的表现,且计算效率更高。
Key Takeaways:
- 推理任务在许多领域,特别是科学和工程领域,具有关键作用。
- 大型语言模型(LLMs)在解决复杂推理问题时存在性能和执行时间的局限性。
- 递归分解与依赖关系(RDD)是一种新的解决推理问题的分而治之方法,具有可扩展性并减少了监督需求。
- RDD可直接应用于新问题类别,无需特定任务指导。
- RDD支持子任务依赖关系,允许有序执行和错误恢复机制。
- RDD在基准测试中表现出优异的性能,特别是在任务复杂性增加时。
点此查看论文截图

Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
Authors:Jiarui Yao, Yifan Hao, Hanning Zhang, Hanze Dong, Wei Xiong, Nan Jiang, Tong Zhang
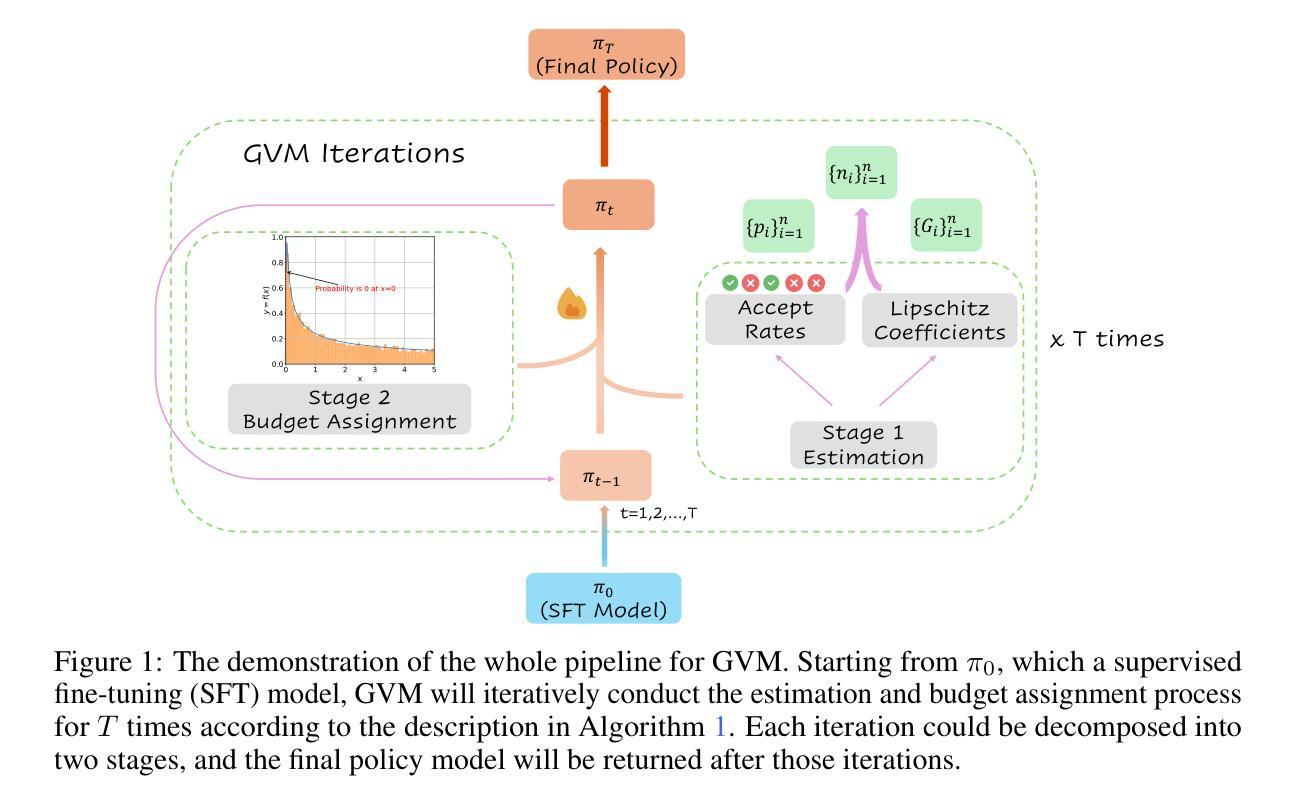
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.
大型语言模型中的思维链(CoT)推理可以被形式化为一个潜在变量问题,其中模型需要生成中间推理步骤。虽然先前的方法(如基于奖励排名的微调(RAFT))已经依赖于这种表述,但它们通常在提示之间应用统一推理预算,这忽略了不同难度和收敛行为的变化性。本研究确定了CoT训练中的主要瓶颈是由于静态采样策略导致的不高效的随机梯度估计。我们提出了GVM-RAFT,这是一种针对提示的特定动态样本分配策略,旨在在计算预算约束下最小化随机梯度方差。该方法通过监控提示接受率和随机梯度范数来动态分配计算资源,确保产生的梯度方差最小化。我们的理论分析表明,在合适的条件下,所提出的动态采样策略可以加速收敛保证。在数学推理方面的实验表明,相对于原始的RAFT,GVM-RAFT实现了2-4倍的速度提升和显著的准确性改进。所提出的动态采样策略是通用的,可以并入其他强化学习算法(如GRPO),在收敛性和测试精度上实现类似的改进。我们的代码在https://github.com/RLHFlow/GVM上提供。
论文及项目相关链接
Summary
大型语言模型的链式思维(CoT)推理可形式化为一个潜在变量问题,需要生成中间推理步骤。本文识别出CoT训练中的主要瓶颈在于由于静态采样策略导致的无效随机梯度估计。为解决这一问题,本文提出了一种基于提示的特定动态样本分配策略(GVM-RAFT),旨在减少计算预算约束下的随机梯度方差。通过监测提示接受率和随机梯度范数来动态分配计算资源,确保梯度方差最小化。理论分析和数学推理实验表明,所提出的动态采样策略在适当条件下可加速收敛,与标准RAFT相比,GVM-RAFT实现了2-4倍的速度提升和显著的性能改进。此外,该策略具有通用性,可应用于其他强化学习算法,如GRPO,以提高收敛性和测试精度。
Key Takeaways
- 链式思维(CoT)推理在大型语言模型中可形式化为潜在变量问题。
- 现有方法如RAFT在推理训练中应用统一推理预算,忽略了不同提示的难度和收敛行为的差异。
- 本文识别出CoT训练中的瓶颈在于静态采样策略导致的无效随机梯度估计。
- 提出了GVM-RAFT,一种基于提示的特定动态样本分配策略,以减少随机梯度方差。
- GVM-RAFT通过监测提示接受率和随机梯度范数来动态分配计算资源。
- 理论分析和实验表明,GVM-RAFT可加速收敛,并在数学推理任务中实现显著的性能提升。
- GVM-RAFT策略可应用于其他强化学习算法,以提高收敛性和测试精度。
点此查看论文截图

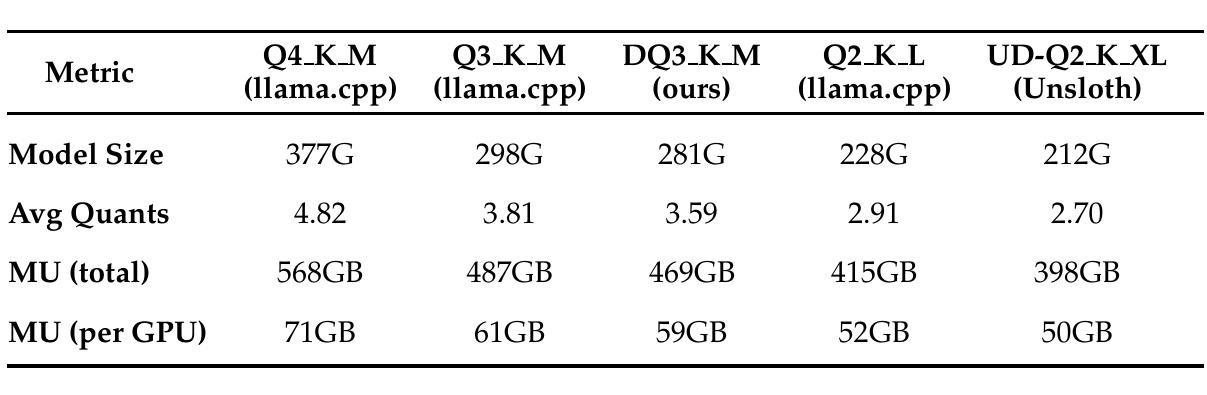
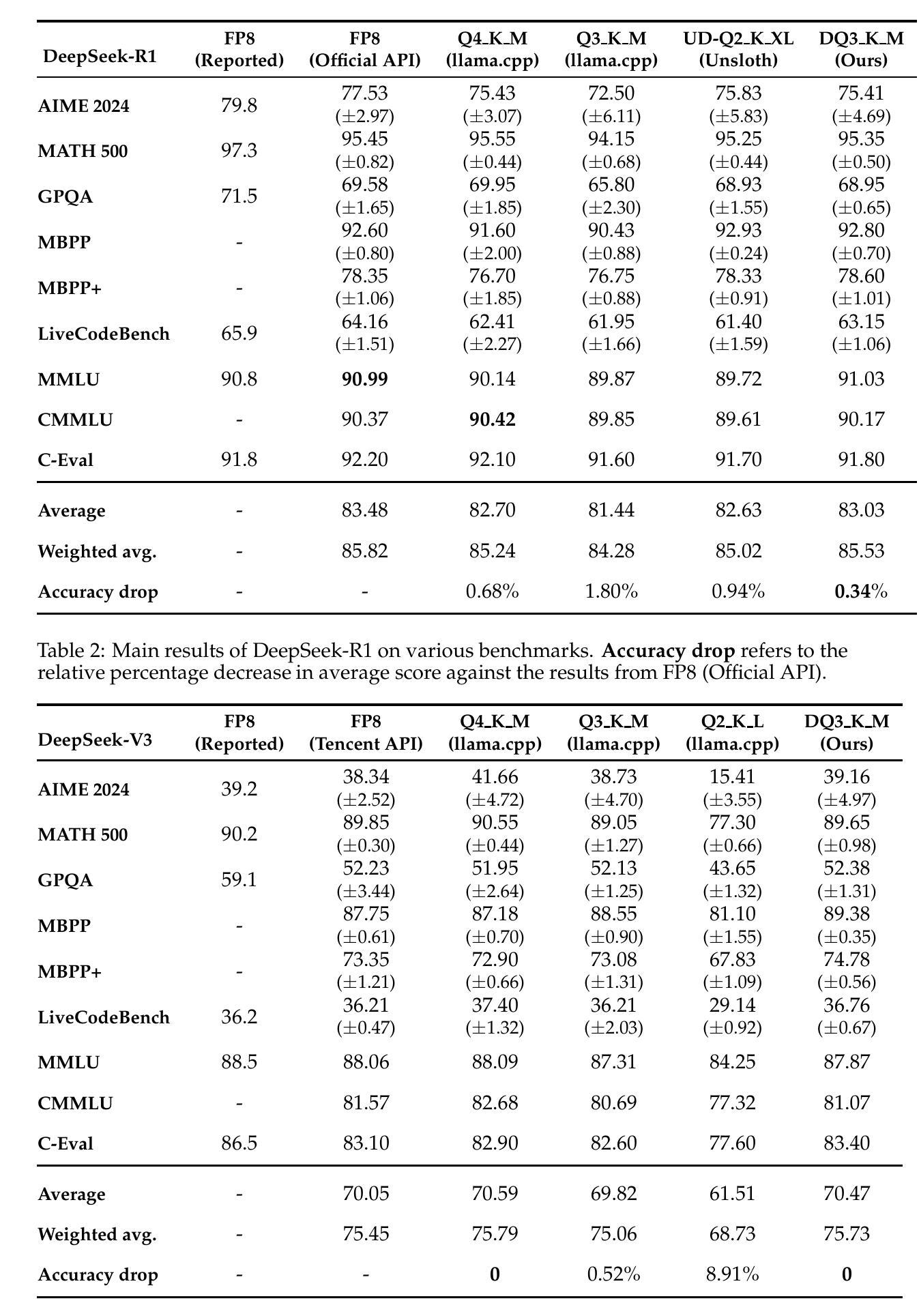
Quantitative Analysis of Performance Drop in DeepSeek Model Quantization
Authors:Enbo Zhao, Yi Shen, Shuming Shi, Jieyun Huang, Zhihao Chen, Ning Wang, Siqi Xiao, Jian Zhang, Kai Wang, Shiguo Lian
Recently, there is a high demand for deploying DeepSeek-R1 and V3 locally, possibly because the official service often suffers from being busy and some organizations have data privacy concerns. While single-machine deployment offers infrastructure simplicity, the models’ 671B FP8 parameter configuration exceeds the practical memory limits of a standard 8-GPU machine. Quantization is a widely used technique that helps reduce model memory consumption. However, it is unclear what the performance of DeepSeek-R1 and V3 will be after being quantized. This technical report presents the first quantitative evaluation of multi-bitwidth quantization across the complete DeepSeek model spectrum. Key findings reveal that 4-bit quantization maintains little performance degradation versus FP8 while enabling single-machine deployment on standard NVIDIA GPU devices. We further propose DQ3_K_M, a dynamic 3-bit quantization method that significantly outperforms traditional Q3_K_M variant on various benchmarks, which is also comparable with 4-bit quantization (Q4_K_M) approach in most tasks. Moreover, DQ3_K_M supports single-machine deployment configurations for both NVIDIA H100/A100 and Huawei 910B. Our implementation of DQ3_K_M is released at https://github.com/UnicomAI/DeepSeek-Eval, containing optimized 3-bit quantized variants of both DeepSeek-R1 and DeepSeek-V3.
最近,对DeepSeek-R1和V3的本地部署需求很高,可能是因为官方服务经常很繁忙,而且一些组织对数据隐私存在担忧。虽然单机部署可以提供基础设施的简单性,但模型的671B FP8参数配置超出了标准8 GPU机器的实际内存限制。量化是一种广泛使用的技术,有助于减少模型内存消耗。然而,量化后DeepSeek-R1和V3的性能尚不清楚。本技术报告首次对DeepSeek模型谱进行全面的多位宽量化定量评估。研究发现,与FP8相比,4位量化几乎没有性能下降,同时能够在标准NVIDIA GPU设备上实现单机部署。我们进一步提出了DQ3_K_M的动态3位量化方法,在各种基准测试中显著优于传统的Q3_K_M变体,并且在大多数任务中与4位量化(Q4_K_M)方法相当。此外,DQ3_K_M支持NVIDIA H100/A100和华为910B的单机部署配置。我们的DQ3_K_M实现已发布在https://github.com/UnicomAI/DeepSeek-Eval上,其中包括DeepSeek-R1和DeepSeek-V3的优化后的3位量化版本。
论文及项目相关链接
Summary
近期对DeepSeek-R1和V3的本地部署需求大增,因官方服务繁忙及组织对数据隐私的担忧。尽管单机部署可简化基础设施,但模型配置的参数超过标准8 GPU机器的实际内存限制。本报告首次对DeepSeek模型进行多位宽量化评估,发现4位量化与FP8相比性能损失极小,可实现标准NVIDIA GPU设备的单机部署。此外,提出了一种动态3位量化方法DQ3_K_M,在各种基准测试中显著优于传统Q3_K_M方法,且与大多数任务中的4位量化方法相近。DQ3_K_M支持NVIDIA H100/A100和华为910B的单机部署配置。
Key Takeaways
- DeepSeek-R1和V3的本地部署需求增加,因为官方服务繁忙及隐私担忧。
- 单机部署虽简化了基础设施,但模型参数超出了标准8 GPU机器的内存限制。
- 报告首次全面评估了DeepSeek模型的多位宽量化。
- 4位量化与FP8相比性能损失小,可实现标准NVIDIA GPU设备的单机部署。
- 提出的DQ3_K_M动态量化方法在多种基准测试中表现优异。
- DQ3_K_M与传统方法相比有显著改善,且在多数任务中表现接近4位量化方法。
点此查看论文截图