⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
Authors:Zuwei Long, Yunhang Shen, Chaoyou Fu, Heting Gao, Lijiang Li, Peixian Chen, Mengdan Zhang, Hang Shao, Jian Li, Jinlong Peng, Haoyu Cao, Ke Li, Rongrong Ji, Xing Sun
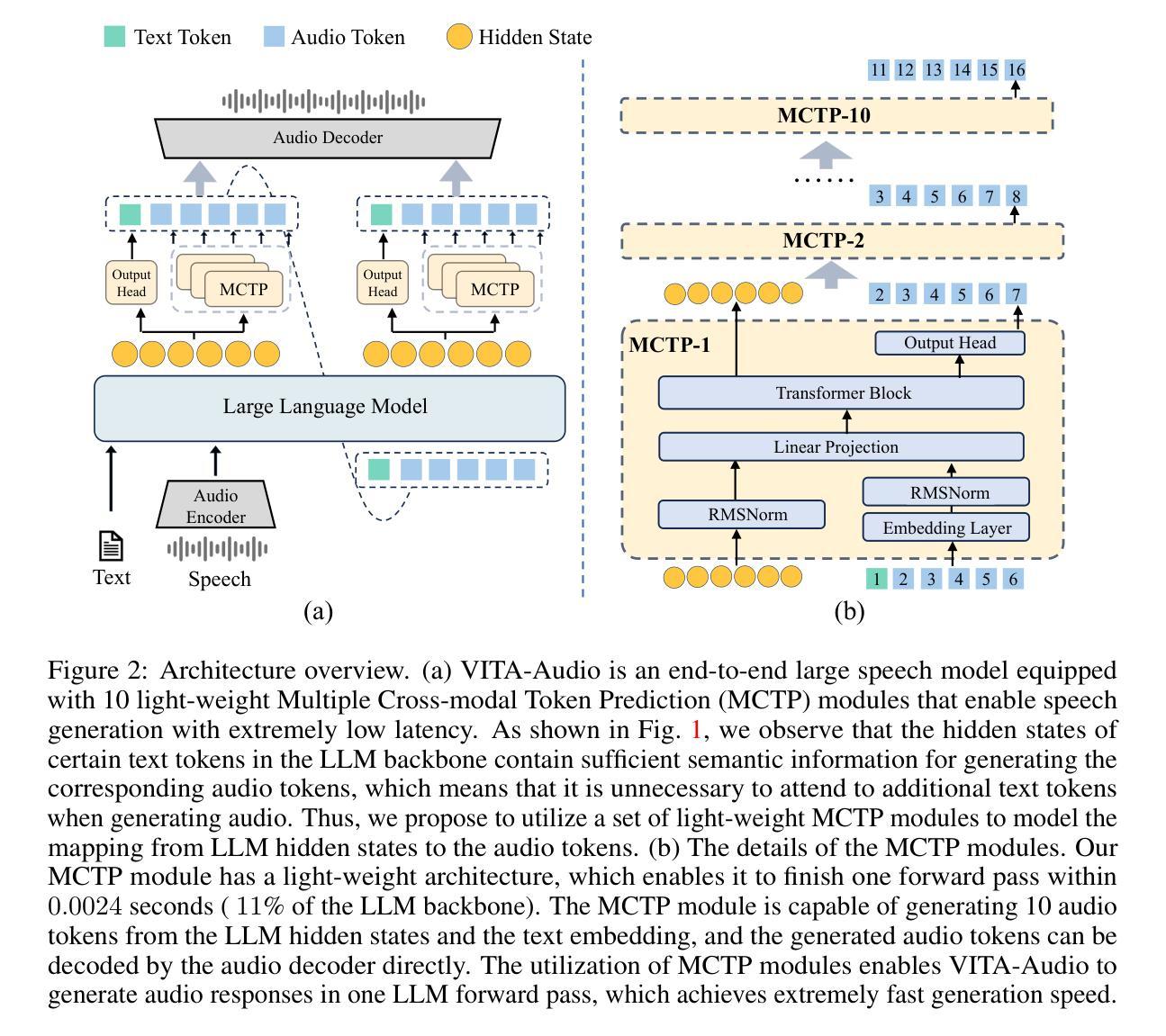
With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
随着自然人机交互需求的不断增长,基于语音的系统越来越受到关注,因为语音是日常沟通中最常见的形式之一。然而,现有的语音模型在流模式下生成第一个音频令牌时仍然面临较高的延迟,这为其部署带来了显著的瓶颈。为了解决这一问题,我们提出了VITA-Audio,这是一个端到端的大型语音模型,具有快速的音频文本令牌生成能力。具体来说,我们引入了一个轻量级的跨模态令牌预测(MCTP)模块,该模块可以在单个模型前向传递过程中有效地生成多个音频令牌,这不仅可以加速推理,而且可以显著降低流场景中生成第一个音频的延迟。此外,还探索了一种四阶段渐进式训练策略,以在尽可能不损失语音质量的情况下实现模型加速。据我们所知,VITA-Audio是有能力在第一次前向传递过程中生成音频输出的首个多模态大型语言模型,可实现实时的低延迟对话功能。VITA-Audio完全可复现,仅使用开源数据进行训练。实验结果表明,我们的模型在7B参数规模上实现了3~5倍的推理速度提升,并且在多个自动语音识别(ASR)、文本到语音(TTS)和语音问答(SQA)任务的基准测试中显著优于类似规模的开源模型。
论文及项目相关链接
PDF Training and Inference Codes: https://github.com/VITA-MLLM/VITA-Audio
Summary
随着人类对自然人机交互的需求不断增长,语音作为日常沟通的最常见形式之一,基于语音的系统受到了越来越多的关注。针对现有语音模型在流式传输过程中生成首个音频令牌时存在的高延迟问题,本文提出了VITA-Audio,一个端到端的大型语音模型,具有快速音频文本令牌生成能力。通过引入轻量级的跨模态令牌预测模块和采用四阶段渐进训练策略,VITA-Audio不仅加速了推理,而且显著降低了生成首个音频时的延迟。此外,VITA-Audio是首个能够在首次前向传递中产生音频输出的多模态大型语言模型,具有实时对话能力且延迟极低。实验结果表明,该模型在7B参数规模上实现了3~5倍的推理速度提升,并且在自动语音识别、文本到语音和语音问答任务上显著优于同类规模的开源模型。
Key Takeaways
- VITA-Audio是一个针对语音模型的优化方案,旨在解决现有模型在流式传输过程中生成首个音频令牌时的高延迟问题。
- VITA-Audio通过引入MCTP模块实现快速音频文本令牌生成,降低生成首个音频时的延迟。
- VITA-Audio采用四阶段渐进训练策略,实现模型加速并最小化语音质量的损失。
- VITA-Audio是首个能够在首次前向传递中产生音频输出的多模态大型语言模型,具备实时对话能力。
- 实验结果表明,VITA-Audio在推理速度上有显著提升,并且在多个语音任务上表现优异。
- VITA-Audio模型可完全复现,并且仅使用开源数据进行训练。
- VITA-Audio的提出进一步推动了自然人机交互领域的发展。
点此查看论文截图



PAHA: Parts-Aware Audio-Driven Human Animation with Diffusion Model
Authors:Y. B. Wang, S. Z. Zhou, J. F. Wu, T. Hu, J. N. Zhang, Y. Liu
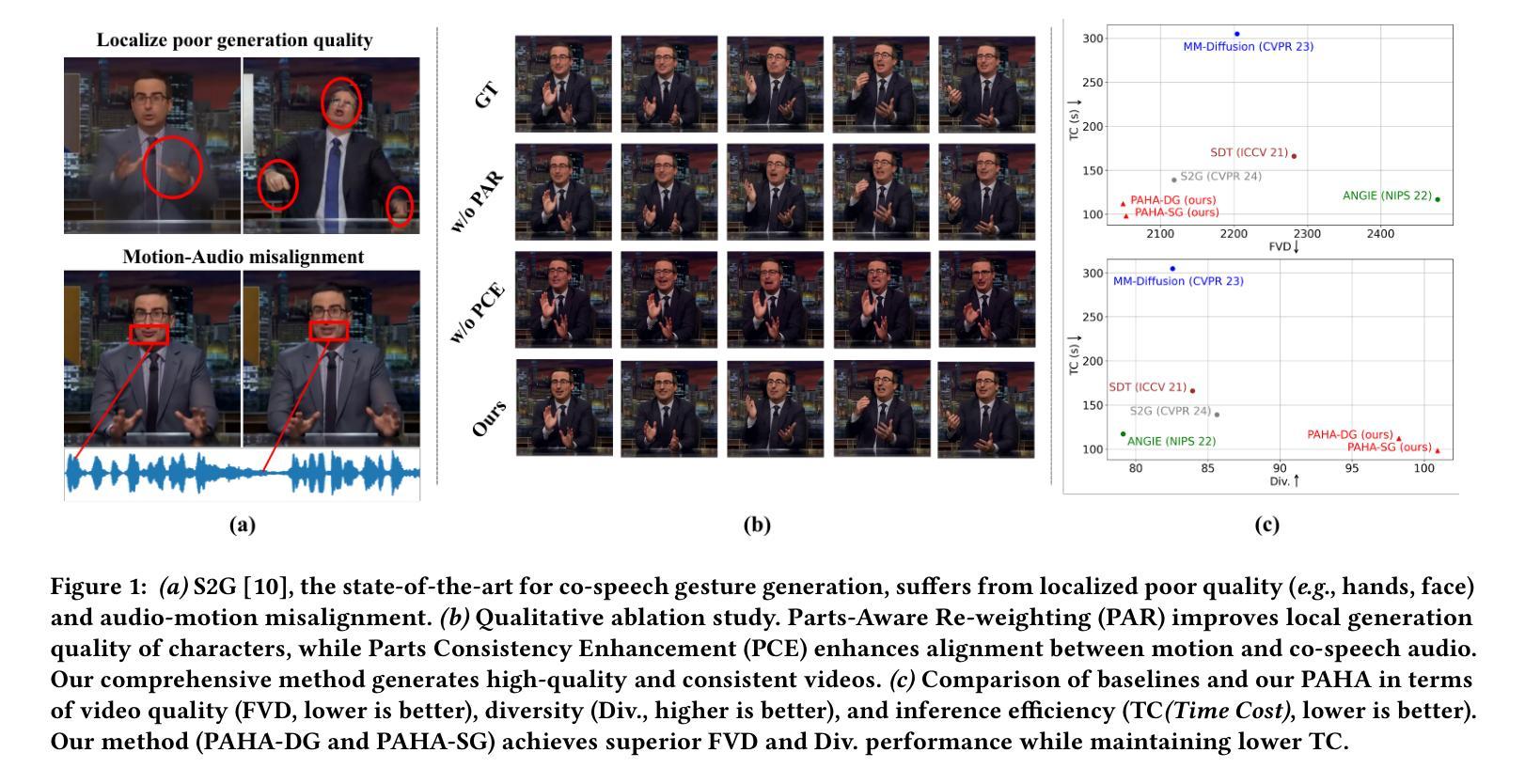
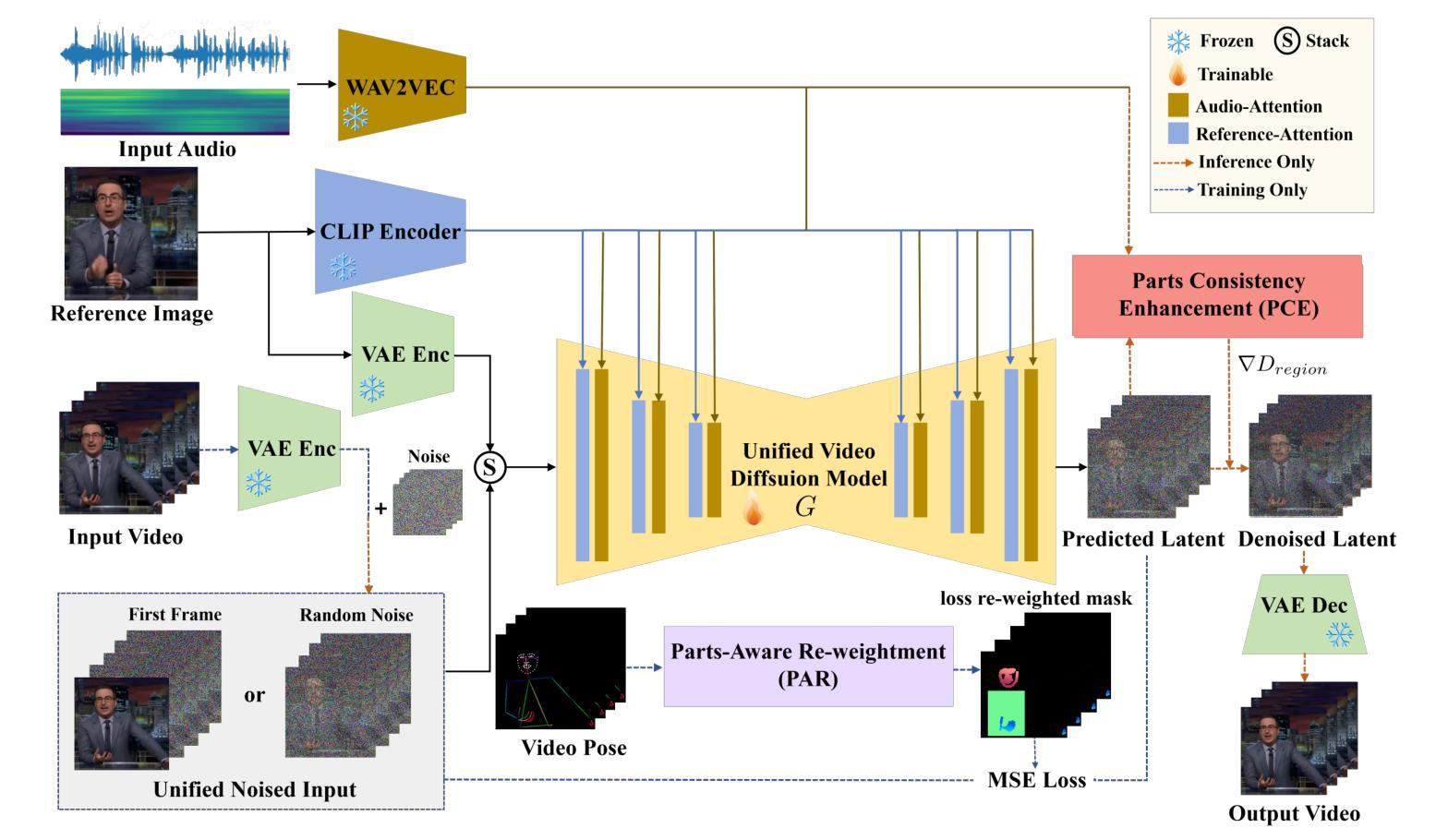
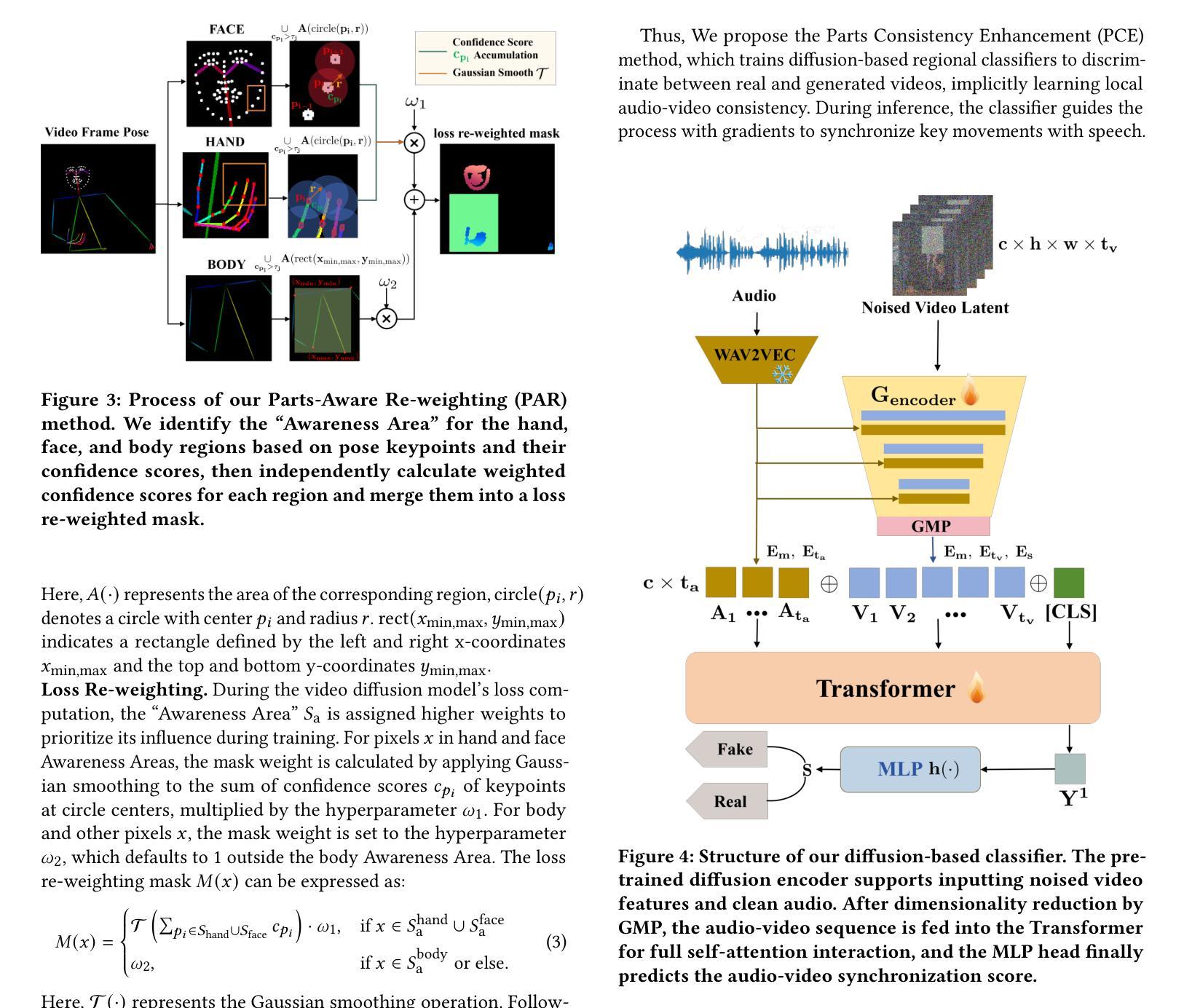
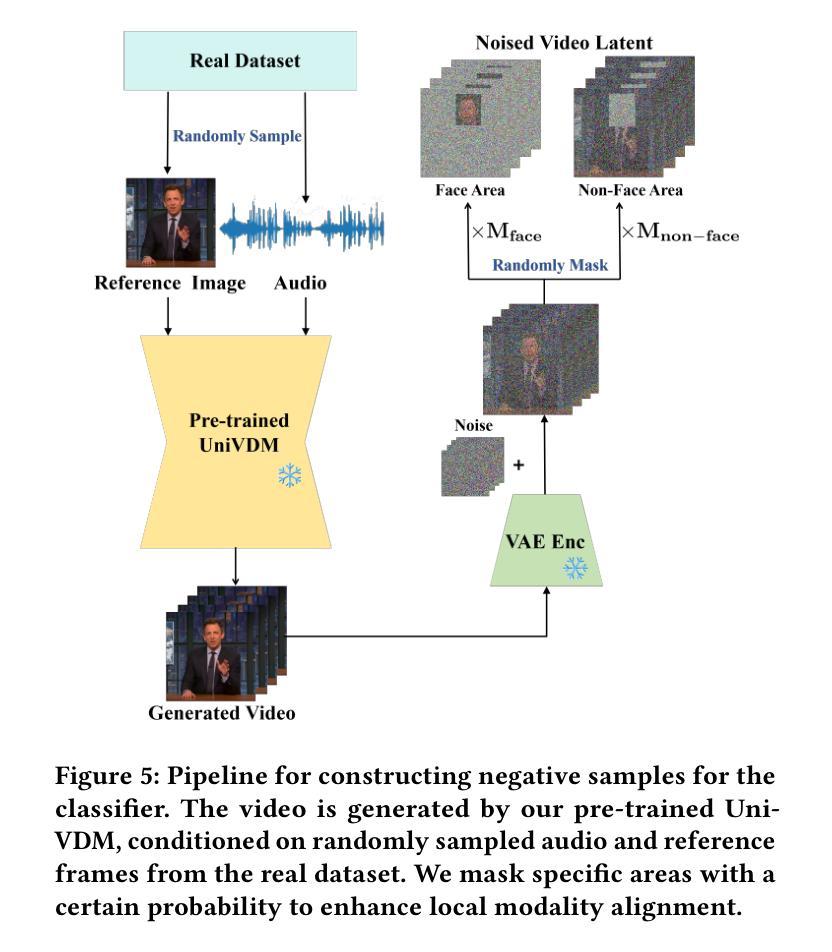
Audio-driven human animation technology is widely used in human-computer interaction, and the emergence of diffusion models has further advanced its development. Currently, most methods rely on multi-stage generation and intermediate representations, resulting in long inference time and issues with generation quality in specific foreground regions and audio-motion consistency. These shortcomings are primarily due to the lack of localized fine-grained supervised guidance. To address above challenges, we propose PAHA, an end-to-end audio-driven upper-body human animation framework with diffusion model. We introduce two key methods: Parts-Aware Re-weighting (PAR) and Parts Consistency Enhancement (PCE). PAR dynamically adjusts regional training loss weights based on pose confidence scores, effectively improving visual quality. PCE constructs and trains diffusion-based regional audio-visual classifiers to improve the consistency of motion and co-speech audio. Afterwards, we design two novel inference guidance methods for the foregoing classifiers, Sequential Guidance (SG) and Differential Guidance (DG), to balance efficiency and quality respectively. Additionally, we build CNAS, the first public Chinese News Anchor Speech dataset, to advance research and validation in this field. Extensive experimental results and user studies demonstrate that PAHA significantly outperforms existing methods in audio-motion alignment and video-related evaluations. The codes and CNAS dataset will be released upon acceptance.
音频驱动的人形动画技术广泛应用于人机交互领域,扩散模型的兴起进一步推动了其发展。目前,大多数方法依赖于多阶段生成和中间表示,导致推理时间长,特定前景区域生成质量和音频运动一致性存在问题。这些缺点主要是由于缺乏局部精细监督指导。为了解决上述挑战,我们提出了PAHA,这是一个基于扩散模型的端到端音频驱动人体上半身动画框架。我们介绍了两种关键方法:部件感知重加权(PAR)和部件一致性增强(PCE)。PAR根据姿态置信度分数动态调整区域训练损失权重,有效提高视觉效果。PCE构建并训练基于扩散的区域音频视觉分类器,提高运动一致性和语音同步性。随后,我们为上述分类器设计了两种新颖推理指导方法:序列指导(SG)和差分指导(DG),以平衡效率和质量。此外,我们构建了CNAS,首个公开的中文新闻主播语音数据集,以推动该领域的研究和验证。大量的实验和用户研究结果表明,PAHA在音频运动对齐和视频相关评估方面显著优于现有方法。代码和CNAS数据集将在接受后发布。
论文及项目相关链接
Summary
基于扩散模型的音频驱动人体动画技术取得新进展。针对当前方法存在的多阶段生成、推理时间长以及特定前景区域生成质量和音频运动一致性等问题,提出PAHA框架及PAR和PCE两大方法。PAR通过姿态置信度分数动态调整区域训练损失权重,提升视觉效果;PCE构建基于扩散模型的区域音频视觉分类器,增强运动一致性。设计两种新型推理引导方法SG和DG,实现效率和质量的平衡。同时,建立首个中文新闻主播语音数据集CNAS,推动相关领域研究验证。实验和用户研究证明PAHA在音频运动对齐和视频相关评估上显著优于现有方法。
Key Takeaways
- 音频驱动人体动画技术在人机交互中广泛应用,扩散模型的出现进一步推动了其发展。
- 当前方法存在多阶段生成、推理时间长的问题。
- 存在特定前景区域生成质量和音频运动一致性问题,主要由于缺乏局部精细监督指导。
- PAHA框架通过PAR和PCE两大方法解决上述问题,提高视觉效果和运动一致性。
- PAR方法通过姿态置信度分数动态调整区域训练损失权重。
- PCE构建基于扩散模型的区域音频视觉分类器。
点此查看论文截图

SepALM: Audio Language Models Are Error Correctors for Robust Speech Separation
Authors:Zhaoxi Mu, Xinyu Yang, Gang Wang
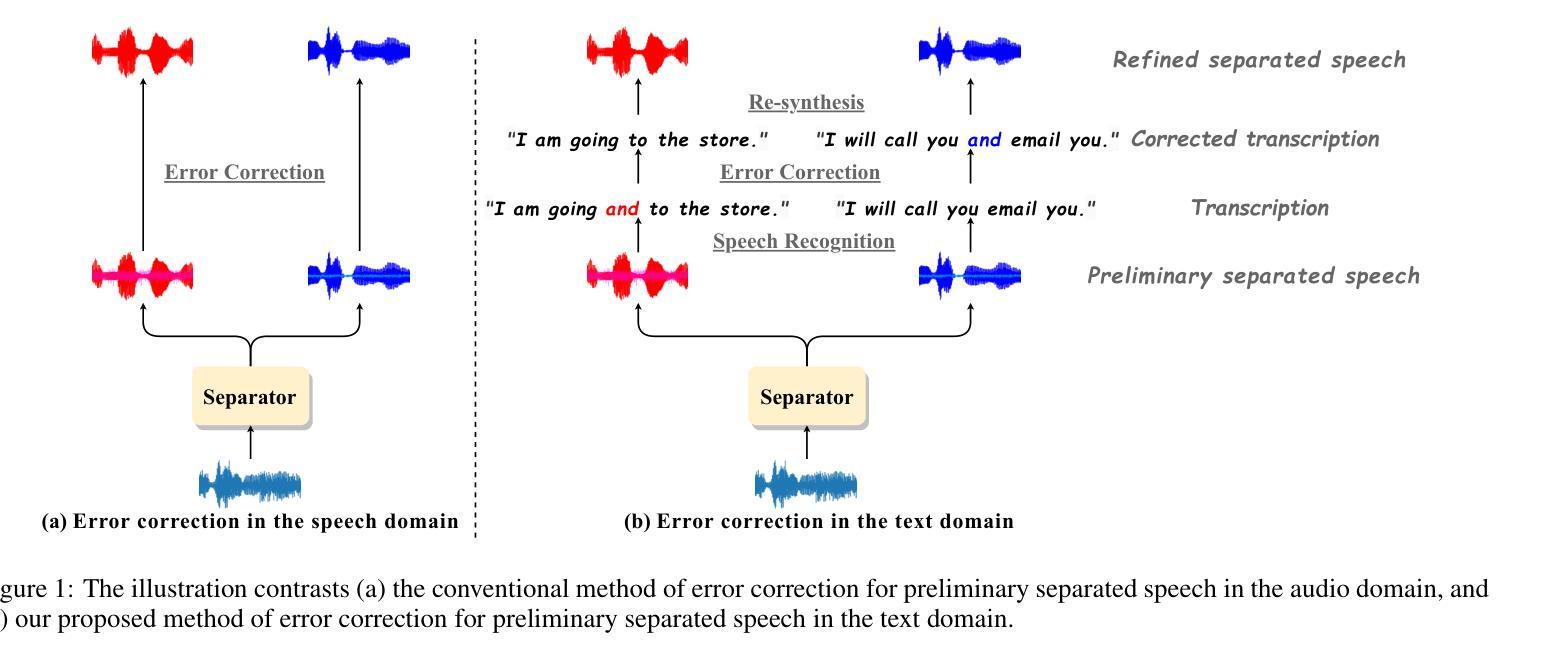
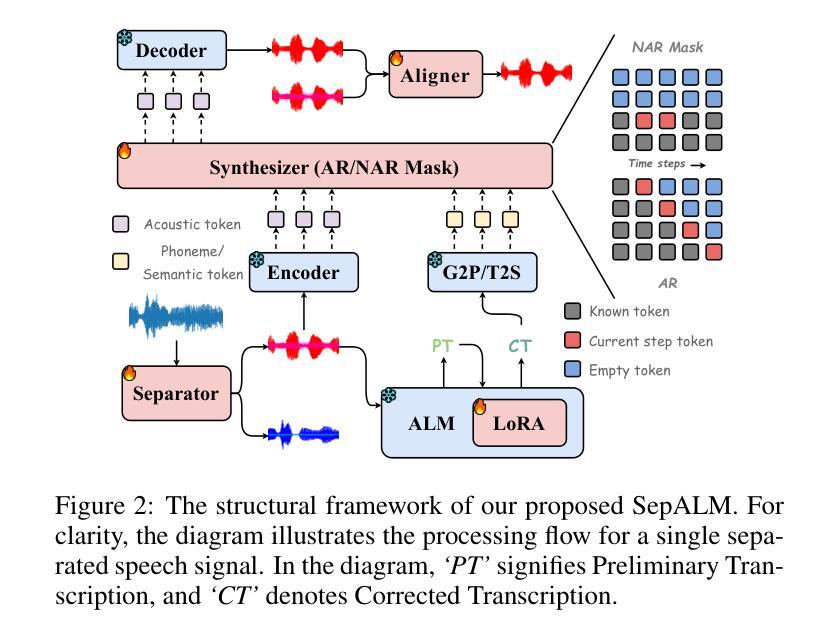
While contemporary speech separation technologies adeptly process lengthy mixed audio waveforms, they are frequently challenged by the intricacies of real-world environments, including noisy and reverberant settings, which can result in artifacts or distortions in the separated speech. To overcome these limitations, we introduce SepALM, a pioneering approach that employs audio language models (ALMs) to rectify and re-synthesize speech within the text domain following preliminary separation. SepALM comprises four core components: a separator, a corrector, a synthesizer, and an aligner. By integrating an ALM-based end-to-end error correction mechanism, we mitigate the risk of error accumulation and circumvent the optimization hurdles typically encountered in conventional methods that amalgamate automatic speech recognition (ASR) with large language models (LLMs). Additionally, we have developed Chain-of-Thought (CoT) prompting and knowledge distillation techniques to facilitate the reasoning and training processes of the ALM. Our experiments substantiate that SepALM not only elevates the precision of speech separation but also markedly bolsters adaptability in novel acoustic environments.
虽然目前的语音分离技术在处理冗长的混合音频波形方面表现出色,但它们在实际环境中的复杂性方面经常面临挑战,包括嘈杂和回声环境,这可能导致分离后的语音出现伪像或失真。为了克服这些限制,我们引入了SepALM,这是一种采用音频语言模型(ALM)在初步分离后纠正和重新合成文本域内的语音的开创性方法。SepALM包含四个核心组件:分离器、校正器、合成器和对齐器。通过集成基于ALM的端到端错误校正机制,我们降低了误差积累的风险,并绕过了传统方法中遇到的优化障碍,这些方法将自动语音识别(ASR)与大型语言模型(LLM)相结合。此外,我们还开发了链思维(CoT)提示和知识蒸馏技术,以促进ALM的推理和训练过程。我们的实验证实,SepALM不仅提高了语音分离的精度,还显著提高了对新环境的适应能力。
论文及项目相关链接
PDF Appears in IJCAI 2025
Summary:针对现有语音分离技术在处理复杂现实环境(如噪声和回声环境)时面临的挑战,提出了一种名为SepALM的创新方法。该方法采用音频语言模型(ALM)在文本域内对初步分离的语音进行修正和重新合成。通过整合ALM端到端的错误修正机制,该方法避免了传统方法中语音识别与大型语言模型结合时的优化难题,提高了语音分离的准确性和适应性。通过引入链式思维(CoT)提示和知识蒸馏技术,进一步促进了模型的推理和训练过程。
Key Takeaways:
- SepALM旨在解决现有语音分离技术在现实环境中的挑战。
- 它通过音频语言模型(ALM)在文本域内进行语音修正和重新合成。
- SepALM通过整合端到端的错误修正机制,减少了错误累积的风险。
- 该方法避免了传统方法结合语音识别与大型语言模型时的优化难题。
- SepALM提高了语音分离的精确度并增强了在新声环境中的适应性。
- 通过引入链式思维(CoT)提示,促进了模型的推理过程。
点此查看论文截图

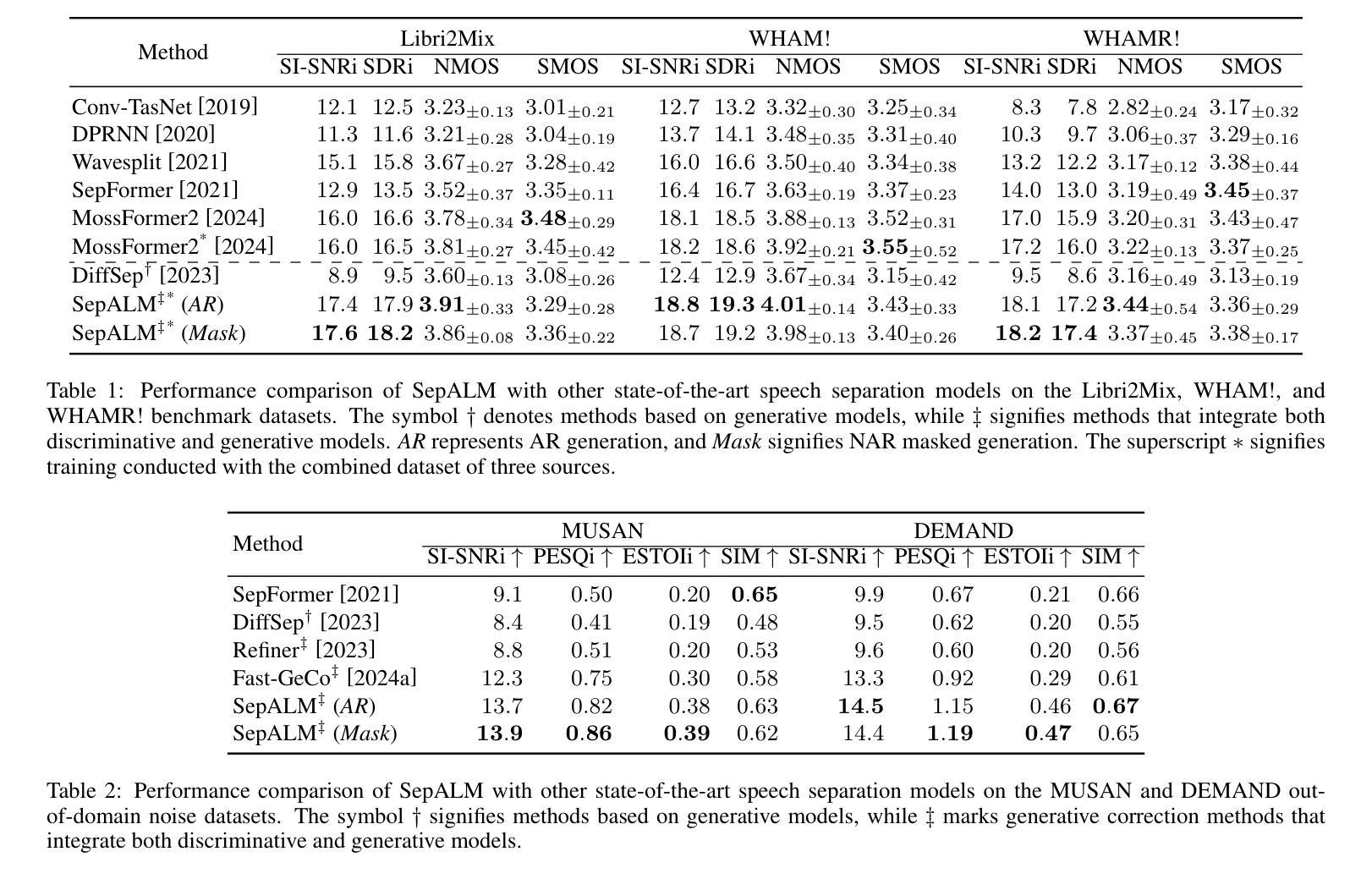
CoGenAV: Versatile Audio-Visual Representation Learning via Contrastive-Generative Synchronization
Authors:Detao Bai, Zhiheng Ma, Xihan Wei, Liefeng Bo
The inherent synchronization between a speaker’s lip movements, voice, and the underlying linguistic content offers a rich source of information for improving speech processing tasks, especially in challenging conditions where traditional audio-only systems falter. We introduce CoGenAV, a powerful and data-efficient model designed to learn versatile audio-visual representations applicable across a wide range of speech and audio-visual tasks. CoGenAV is trained by optimizing a dual objective derived from natural audio-visual synchrony, contrastive feature alignment and generative text prediction, using only 223 hours of labeled data from the LRS2 dataset. This contrastive-generative synchronization strategy effectively captures fundamental cross-modal correlations. We showcase the effectiveness and versatility of the learned CoGenAV representations on multiple benchmarks. When utilized for Audio-Visual Speech Recognition (AVSR) on LRS2, these representations contribute to achieving a state-of-the-art Word Error Rate (WER) of 1.27. They also enable strong performance in Visual Speech Recognition (VSR) with a WER of 22.0 on LRS2, and significantly improve performance in noisy environments by over 70%. Furthermore, CoGenAV representations benefit speech reconstruction tasks, boosting performance in Speech Enhancement and Separation, and achieve competitive results in audio-visual synchronization tasks like Active Speaker Detection (ASD). Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
说话者的嘴唇动作、声音和底层语言内容之间的固有同步性,为改进语音识别任务提供了丰富的信息来源,特别是在传统仅依赖音频的系统表现不佳的困难条件下。我们推出了CoGenAV,这是一个强大且数据高效模型,旨在学习适用于广泛语音和视听任务的通用视听表示。CoGenAV通过优化从自然视听同步中得出的双重目标、对比特征对齐和文本生成预测来进行训练,仅使用LRS2数据集的223小时标记数据进行训练。这种对比生成同步策略有效地捕捉了跨模态的基本相关性。我们在多个基准测试上展示了学习到的CoGenAV表示的有效性和通用性。在LRS2上的视听语音识别(AVSR)中利用这些表示,实现了词错误率(WER)达到先进水平的1.27%。它们还在LRS2上的视觉语音识别(VSR)中实现了强大的性能,词错误率为22.0,并且在噪声环境中的性能提高了70%以上。此外,CoGenAV表示还受益于语音重建任务,提高了语音增强和分离的性能,并在如主动说话人检测(ASD)等视听同步任务中取得了具有竞争力的结果。我们的模型将开源,以促进学术界和工业界的进一步发展和合作。
论文及项目相关链接
Summary
本文介绍了CoGenAV模型,该模型通过优化自然视听同步、对比特征对齐和生成文本预测的双目标,利用LRS2数据集仅223小时的标签数据进行训练。该模型的对比生成同步策略有效地捕捉了跨模态的基本关联。在多个基准测试中,CoGenAV表示的有效性及通用性得到了展示。在LRS2上的音频视觉语音识别(AVSR)中,它达到了先进的词错误率(WER)1.27。在LRS2上的视觉语音识别(VSR)中,它的性能也很强,WER为22.0。此外,CoGenAV表示还能提高语音重建任务的性能,并在有噪音的环境中提高70%以上的性能。该模型还将公开源代码,以便学术界和工业界的进一步开发和协作。
Key Takeaways
- CoGenAV模型结合了说话者的嘴唇动作、声音和底层语言内容,为改进语音处理任务提供了丰富信息。
- 该模型通过优化自然视听同步、对比特征对齐和生成文本预测的双目标进行设计。
- 使用仅223小时的LRS2数据集标签数据进行训练,显示出数据效率。
- 对比生成同步策略有效捕捉跨模态关联。
- CoGenAV在多个基准测试中表现优异,如音频视觉语音识别(AVSR)的词错误率达到1.27。
- 模型在视觉语音识别(VSR)方面也表现出色,并在嘈杂环境中性能显著提升超过70%。
点此查看论文截图

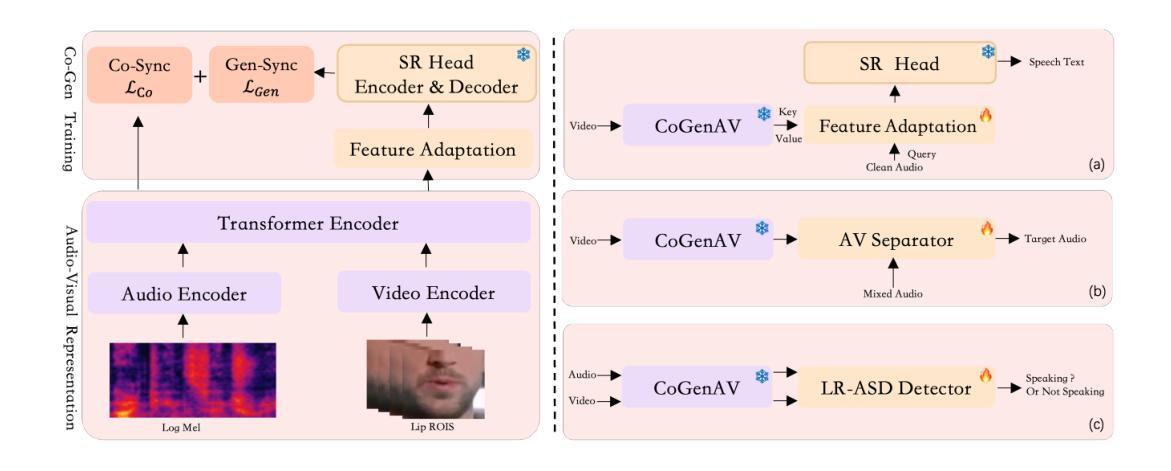
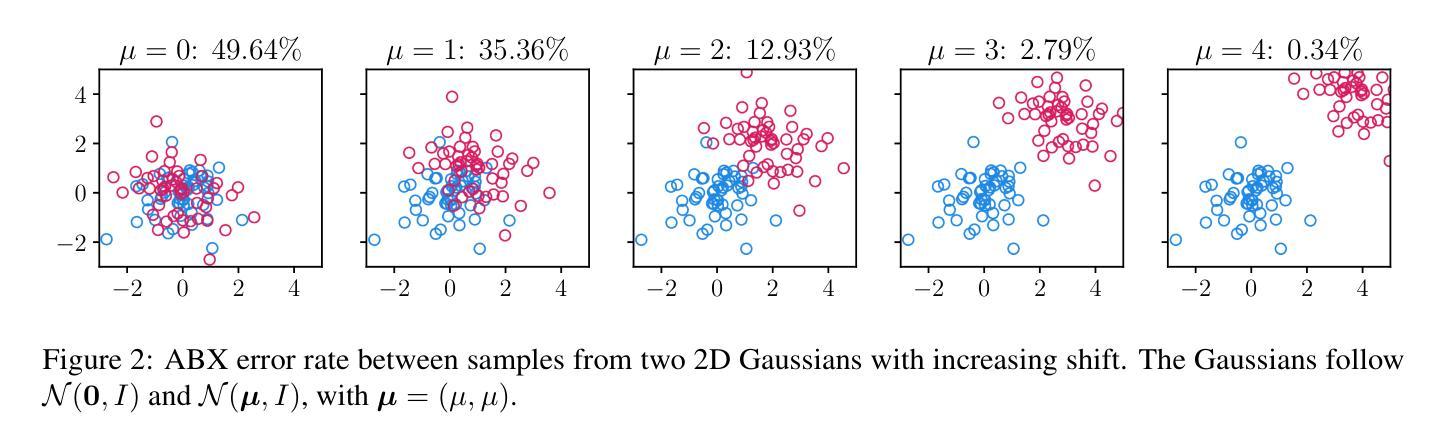
fastabx: A library for efficient computation of ABX discriminability
Authors:Maxime Poli, Emmanuel Chemla, Emmanuel Dupoux
We introduce fastabx, a high-performance Python library for building ABX discrimination tasks. ABX is a measure of the separation between generic categories of interest. It has been used extensively to evaluate phonetic discriminability in self-supervised speech representations. However, its broader adoption has been limited by the absence of adequate tools. fastabx addresses this gap by providing a framework capable of constructing any type of ABX task while delivering the efficiency necessary for rapid development cycles, both in task creation and in calculating distances between representations. We believe that fastabx will serve as a valuable resource for the broader representation learning community, enabling researchers to systematically investigate what information can be directly extracted from learned representations across several domains beyond speech processing. The source code is available at https://github.com/bootphon/fastabx.
我们介绍fastabx,这是一个用于构建ABX辨别任务的高性能Python库。ABX是衡量通用类别之间差异的一种度量。它已被广泛用于评估自监督语音表示中的语音辨别力。然而,由于缺乏足够的工具,其更广泛的应用受到了限制。fastabx通过提供一个能够构建任何类型的ABX任务同时提供快速开发周期所需的效率的框架来解决这一差距,无论是在任务创建还是在计算表示之间的距离方面。我们相信fastabx将为更广泛的表示学习社区提供宝贵的资源,使研究人员能够系统地研究从多个领域(包括语音处理领域之外)的已学习表示中可以直接提取哪些信息。源代码可在https://github.com/bootphon/fastabx找到。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
fastabx是一个高性能的Python库,用于构建ABX辨别任务。它旨在解决在自我监督的语音表示中评估音位区分能力的问题。该库提供了广泛的框架,能构建各种类型的ABX任务并在任务创建和计算表示之间的距离时实现高效率,满足快速开发周期的需求。fastabx将服务于更广泛的表示学习社区,使研究人员能够系统地研究从多个领域(包括语音处理领域)的已学表示中直接提取的信息。
Key Takeaways
- fastabx是一个用于构建ABX辨别任务的Python库。
- ABX用于评估音位区分能力的问题,特别是在自我监督的语音表示中。
- fastabx提供了构建各种ABX任务的框架。
- fastabx实现了高效的任务创建和计算表示之间的距离。
- fastabx填补了现有工具的空白,支持快速开发周期。
- fastabx对更广泛的表示学习社区有价值,因为它能系统地研究从多个领域的已学表示中提取的信息。
点此查看论文截图


Co$^{3}$Gesture: Towards Coherent Concurrent Co-speech 3D Gesture Generation with Interactive Diffusion
Authors:Xingqun Qi, Yatian Wang, Hengyuan Zhang, Jiahao Pan, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
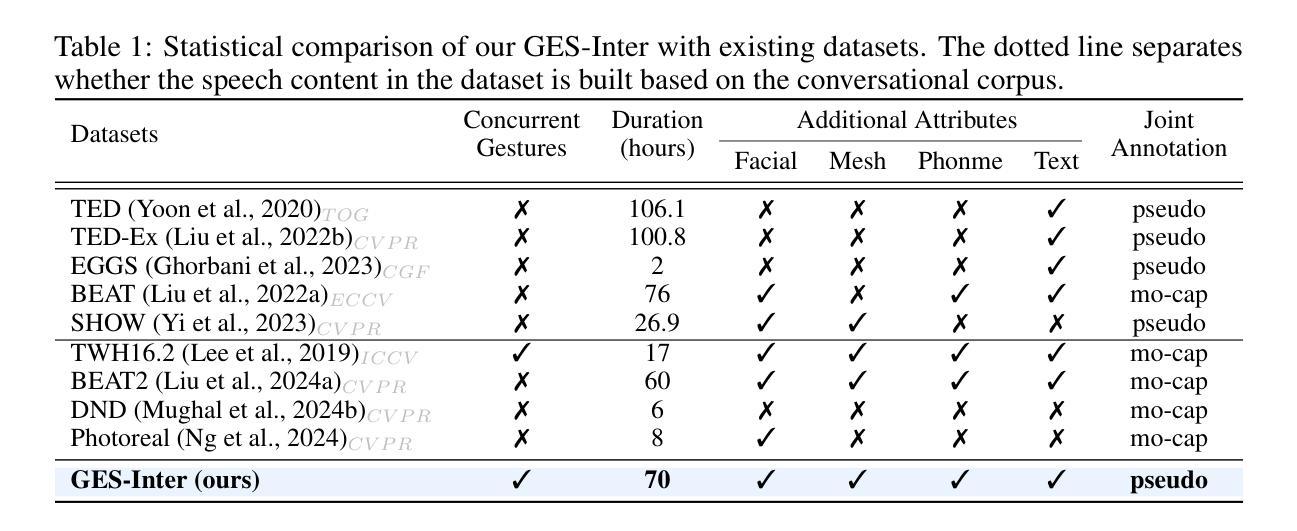
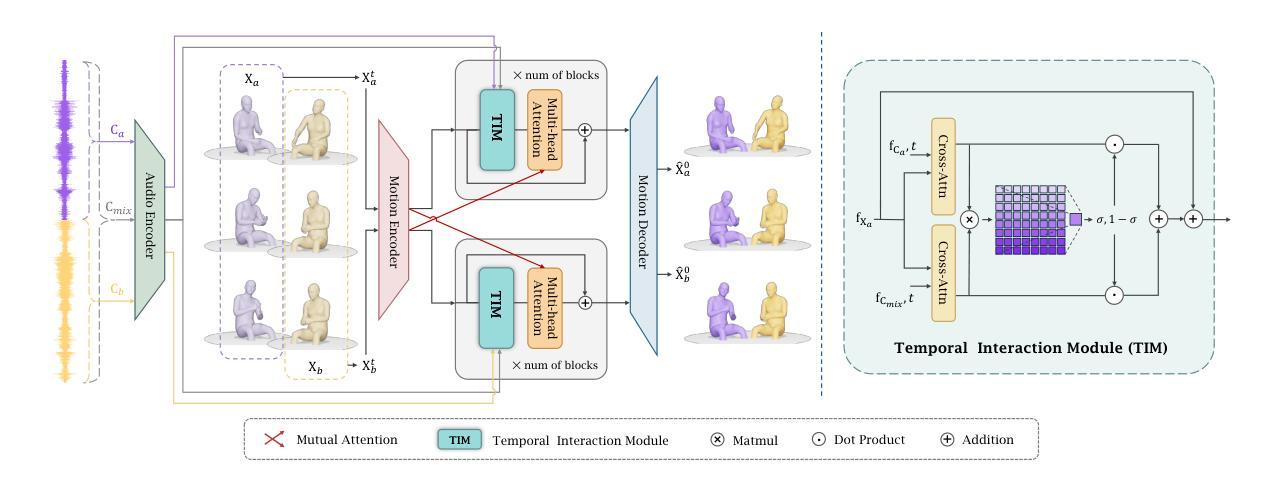
Generating gestures from human speech has gained tremendous progress in animating virtual avatars. While the existing methods enable synthesizing gestures cooperated by individual self-talking, they overlook the practicality of concurrent gesture modeling with two-person interactive conversations. Moreover, the lack of high-quality datasets with concurrent co-speech gestures also limits handling this issue. To fulfill this goal, we first construct a large-scale concurrent co-speech gesture dataset that contains more than 7M frames for diverse two-person interactive posture sequences, dubbed GES-Inter. Additionally, we propose Co$^3$Gesture, a novel framework that enables coherent concurrent co-speech gesture synthesis including two-person interactive movements. Considering the asymmetric body dynamics of two speakers, our framework is built upon two cooperative generation branches conditioned on separated speaker audio. Specifically, to enhance the coordination of human postures with respect to corresponding speaker audios while interacting with the conversational partner, we present a Temporal Interaction Module (TIM). TIM can effectively model the temporal association representation between two speakers’ gesture sequences as interaction guidance and fuse it into the concurrent gesture generation. Then, we devise a mutual attention mechanism to further holistically boost learning dependencies of interacted concurrent motions, thereby enabling us to generate vivid and coherent gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected GES-Inter dataset. The dataset and source code are publicly available at \href{https://mattie-e.github.io/Co3/}{\textit{https://mattie-e.github.io/Co3/}}.
从人类语音生成动作在虚拟角色动画方面取得了巨大的进步。虽然现有方法能够合成个人自言自语时的动作,但它们忽略了双人互动对话时的同步动作建模的实用性。此外,缺乏高质量的同步语音动作数据集也限制了处理这个问题。为了实现这一目标,我们首先构建了一个大规模的同步语音动作数据集GES-Inter,其中包含超过700万帧的多样化双人互动姿势序列。此外,我们提出了Co$^3$Gesture这一新型框架,能够实现包括双人互动在内的连贯同步语音动作合成。考虑到两位发言人的不对称身体动态,我们的框架建立在两个基于不同发言人音频的合作生成分支之上。具体来说,为了增强人类姿势与相应语音的协调性,同时与对话伙伴进行互动,我们提出了时序交互模块(TIM)。TIM可以有效地对两位发言人的动作序列之间的时间关联表示进行建模,将其作为交互指南并融合到同步动作生成中。接着,我们设计了一种相互注意力机制,进一步全面提升交互同步动作的学习依赖关系,从而使我们能够生成生动连贯的动作。大量实验表明,我们的方法在我们的新收集的GES-Inter数据集上的表现优于最新模型。数据集和源代码可在[https://mattie-e.github.io/Co3/]上公开获取。
论文及项目相关链接
PDF Accepted as ICLR 2025 (Spotlight)
Summary
本文关注从人类语音生成动作姿态在虚拟角色动画领域的研究进展。现有方法主要集中在单人自我对话的手势合成上,但在两人互动对话中同步的手势建模实践仍存在局限。为解决这一问题,本文构建了一个大规模的两人互动语音同步手势数据集GES-Inter,包含超过7百万帧数据。同时,提出了一种名为Co$^3$Gesture的新框架,用于实现包括两人互动动作在内的连贯同步语音手势合成。该框架通过两个基于不同说话人音频的合作生成分支构建,考虑了说话人的不对称动态特性。为增强交互对话中姿态与音频的协调性,引入了时序交互模块(TIM),有效建模两位说话人手势序列间的时序关联表示并将其融入同步手势生成。此外,通过设计相互注意力机制进一步强化了互动动作之间的学习依赖性,使得生成的动作更加生动连贯。在收集的新数据集上进行的实验表明,该方法优于现有模型。数据集和源代码已公开提供。
Key Takeaways
- 现有手势合成方法主要关注单人自我对话场景,缺乏处理两人互动对话的实用性。
- 构建了一个大规模的两人互动语音同步手势数据集(GES-Inter),包含丰富的动态场景数据。
- 提出了一种新的框架Co$^3$Gesture,用于连贯的同步语音手势合成,支持两人互动动作。
- 框架通过两个基于不同说话人音频的合作生成分支构建,考虑了说话人的不对称动态特性。
- 引入时序交互模块(TIM),实现了交互动作与语音之间的协调建模。
- 采用相互注意力机制强化互动动作之间的学习依赖性,提升动作生成的生动性和连贯性。
点此查看论文截图

VANPY: Voice Analysis Framework
Authors:Gregory Koushnir, Michael Fire, Galit Fuhrmann Alpert, Dima Kagan
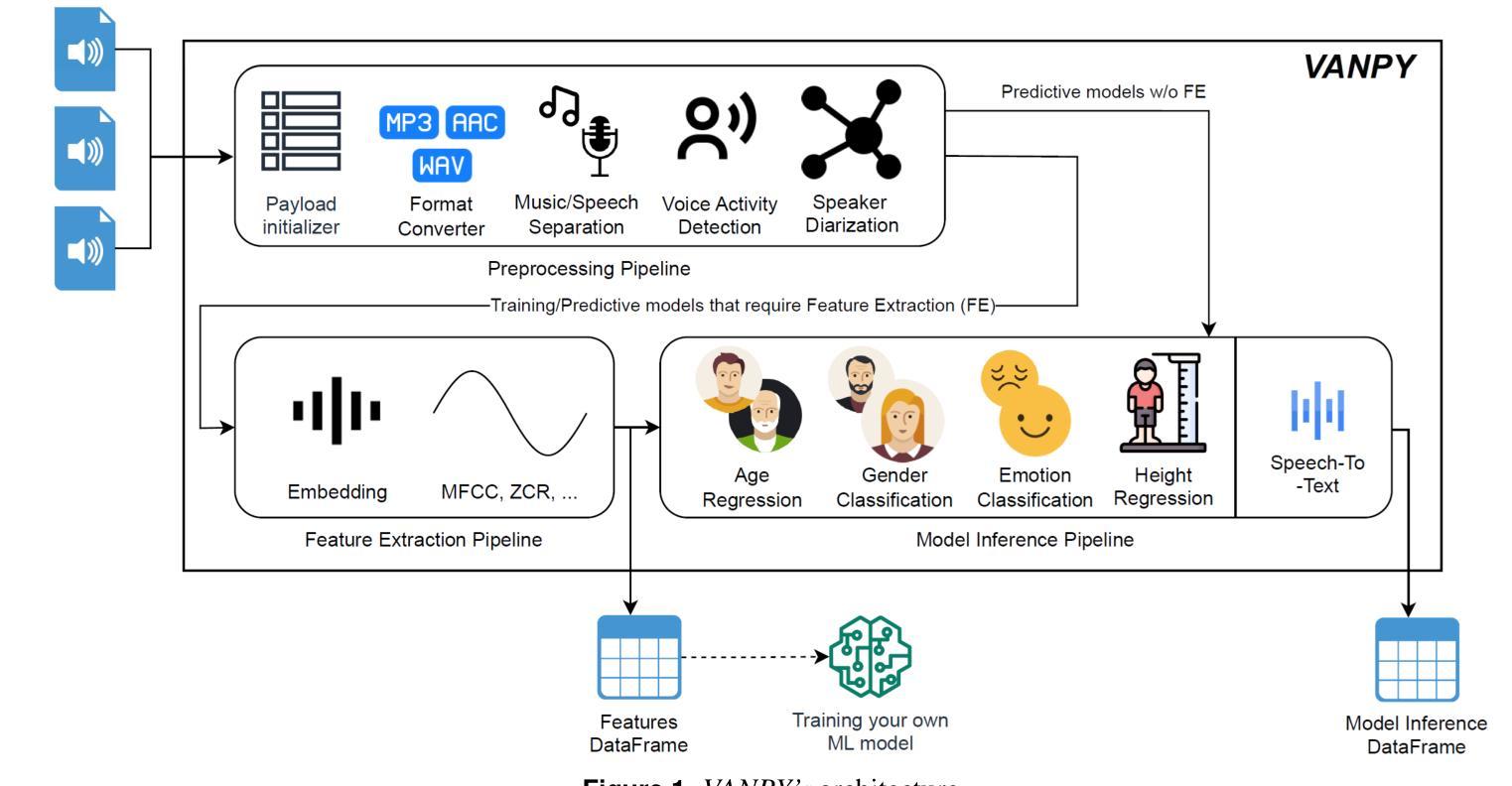
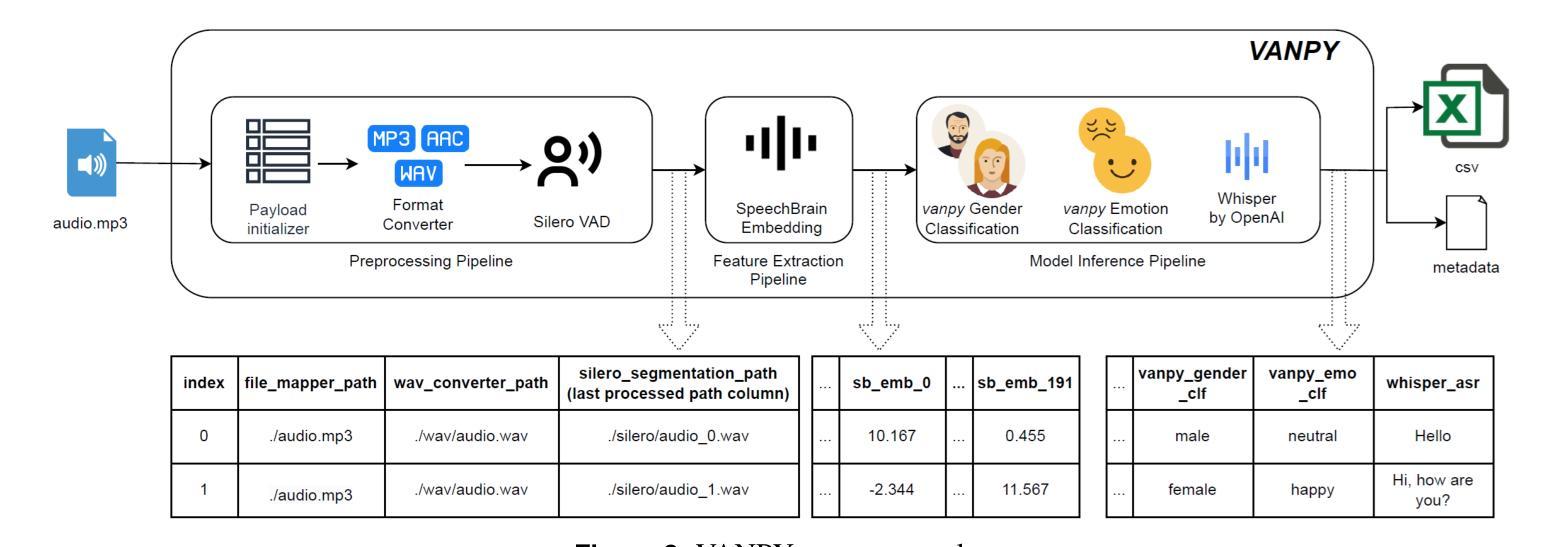
Voice data is increasingly being used in modern digital communications, yet there is still a lack of comprehensive tools for automated voice analysis and characterization. To this end, we developed the VANPY (Voice Analysis in Python) framework for automated pre-processing, feature extraction, and classification of voice data. The VANPY is an open-source end-to-end comprehensive framework that was developed for the purpose of speaker characterization from voice data. The framework is designed with extensibility in mind, allowing for easy integration of new components and adaptation to various voice analysis applications. It currently incorporates over fifteen voice analysis components - including music/speech separation, voice activity detection, speaker embedding, vocal feature extraction, and various classification models. Four of the VANPY’s components were developed in-house and integrated into the framework to extend its speaker characterization capabilities: gender classification, emotion classification, age regression, and height regression. The models demonstrate robust performance across various datasets, although not surpassing state-of-the-art performance. As a proof of concept, we demonstrate the framework’s ability to extract speaker characteristics on a use-case challenge of analyzing character voices from the movie “Pulp Fiction.” The results illustrate the framework’s capability to extract multiple speaker characteristics, including gender, age, height, emotion type, and emotion intensity measured across three dimensions: arousal, dominance, and valence.
语音数据在现代数字通信中的应用越来越广泛,但仍缺乏全面的自动化语音分析和表征工具。为此,我们开发了用于自动化预处理、特征提取和语音分类的VANPY(Python语音分析)框架。VANPY是一个开源的端到端综合框架,旨在从语音数据中实现说话人表征。该框架在设计时考虑了可扩展性,便于集成新组件并适应各种语音分析应用。它目前集成了超过十五种语音分析组件,包括音乐/语音分离、语音活动检测、说话人嵌入、语音特征提取和各种分类模型。为了扩展其说话人表征能力,我们内部开发了四个组件并将其集成到框架中:性别分类、情感分类、年龄回归和身高回归。模型在不同的数据集上表现出稳健的性能,虽然没有达到最先进的性能水平。作为概念验证,我们展示了该框架在分析电影《低俗小说》中的角色声音的应用能力。结果表明,该框架能够提取多个说话人的特征,包括性别、年龄、身高、情感类型和情感强度,这些情感强度是在三个维度上测量的:兴奋度、支配力和价值判断。
论文及项目相关链接
Summary:随着现代数字通信中语音数据的使用越来越普遍,缺乏全面的自动化语音分析和表征工具。为此,我们开发了VANPY(Python中的语音分析)框架,用于自动化预处理、特征提取和语音数据的分类。它是一个开源的端到端综合框架,旨在从语音数据中实现说话人表征。框架设计具有可扩展性,可轻松集成新组件并适应各种语音分析应用程序。目前,它已集成了超过十五种语音分析组件,包括音乐/语音分离、语音活动检测、说话人嵌入、语音特征提取和各种分类模型。我们还开发了四个内部组件并将其集成到框架中,以扩展其说话人表征功能:性别分类、情感分类、年龄回归和身高回归。模型在多个数据集上表现出稳健的性能,尽管没有达到最新技术水平。作为概念验证,我们展示了该框架在分析电影“低俗小说”中的角色声音方面的能力。结果表明该框架能够提取多个说话人的特征,包括性别、年龄、身高、情感类型和情感强度。这三个维度包括兴奋度、支配力和价值感。
Key Takeaways:
- 缺乏全面工具进行自动化语音分析和表征,因此需要开发VANPY框架以处理这一问题。
- VANPY是一个开源的端到端综合框架,用于从语音数据中实现说话人表征。
- 该框架设计具有可扩展性,易于集成新组件并适应各种语音分析应用。
- 目前已集成超过十五种语音分析组件,包括音乐/语音分离等。
- 开发四个内部组件以扩展其说话人表征功能:性别分类、情感分类等。这些组件可在多种数据集上进行性能评估。
- 模型虽然稳健但在性能上并未达到最新技术水平,但仍可作为强有力的工具用于实际场景应用。
点此查看论文截图


HAINAN: Fast and Accurate Transducer for Hybrid-Autoregressive ASR
Authors:Hainan Xu, Travis M. Bartley, Vladimir Bataev, Boris Ginsburg
We present Hybrid-Autoregressive INference TrANsducers (HAINAN), a novel architecture for speech recognition that extends the Token-and-Duration Transducer (TDT) model. Trained with randomly masked predictor network outputs, HAINAN supports both autoregressive inference with all network components and non-autoregressive inference without the predictor. Additionally, we propose a novel semi-autoregressive inference paradigm that first generates an initial hypothesis using non-autoregressive inference, followed by refinement steps where each token prediction is regenerated using parallelized autoregression on the initial hypothesis. Experiments on multiple datasets across different languages demonstrate that HAINAN achieves efficiency parity with CTC in non-autoregressive mode and with TDT in autoregressive mode. In terms of accuracy, autoregressive HAINAN outperforms TDT and RNN-T, while non-autoregressive HAINAN significantly outperforms CTC. Semi-autoregressive inference further enhances the model’s accuracy with minimal computational overhead, and even outperforms TDT results in some cases. These results highlight HAINAN’s flexibility in balancing accuracy and speed, positioning it as a strong candidate for real-world speech recognition applications.
我们提出了混合自回归推理转换器(Hybrid-Autoregressive INference TrANsducers,简称HAINAN),这是一种用于语音识别的新型架构,它扩展了Token-and-Duration Transducer(TDT)模型。通过训练带有随机掩码的预测器网络输出,HAINAN支持包含所有网络组件的自回归推理和非自回归推理。此外,我们还提出了一种新颖的半自回归推理范式,首先使用非自回归推理生成初始假设,然后进行细化步骤,其中每个令牌预测都会基于初始假设使用并行自回归进行重建。在多语言数据集上的实验表明,HAINAN在非自回归模式下与CTC的效率相当,在自回归模式下与TDT的效率相当。在准确性方面,自回归的HAINAN优于TDT和RNN-T,而采用非自回归推理的HAINAN则显著优于CTC。半自回归推理能够进一步提高模型的准确性,同时计算开销较小,在某些情况下甚至超过了TDT的结果。这些结果凸显了HAINAN在平衡准确性和速度方面的灵活性,使其成为现实世界语音识别应用的强大候选者。
论文及项目相关链接
Summary
本文介绍了Hybrid-Autoregressive INference TrANsducers(HAINAN)这一新型语音识别架构。HAINAN扩展了Token-and-Duration Transducer(TDT)模型,通过随机掩盖预测网络输出来进行训练。它支持自回归推理和非自回归推理。HAINAN在多种语言的数据集上的实验表明,它在非自回归模式下与CTC效率相当,在自回归模式下与TDT效率相当。在准确性方面,自回归的HAINAN优于TDT和RNN-T,非自回归的HAINAN则显著优于CTC。半自回归推理进一步提高了模型的准确性,且计算开销较小,有时甚至可以超越TDT的表现。这表明HAINAN在平衡准确性与速度方面表现出色,是现实世界语音识别应用的有力候选者。
Key Takeaways
- HAINAN是一种新型的语音识别架构,扩展了TDT模型。
- HAINAN支持自回归和非自回归两种推理模式。
- HAINAN通过随机掩盖预测网络输出来进行训练。
- 在多种语言的数据集上,HAINAN在效率和准确性方面表现出色。
- 自回归的HAINAN在准确性上优于TDT和RNN-T。
- 非自回归的HAINAN显著优于CTC。
- 半自回归推理提高了模型的准确性,且计算开销较小。
点此查看论文截图




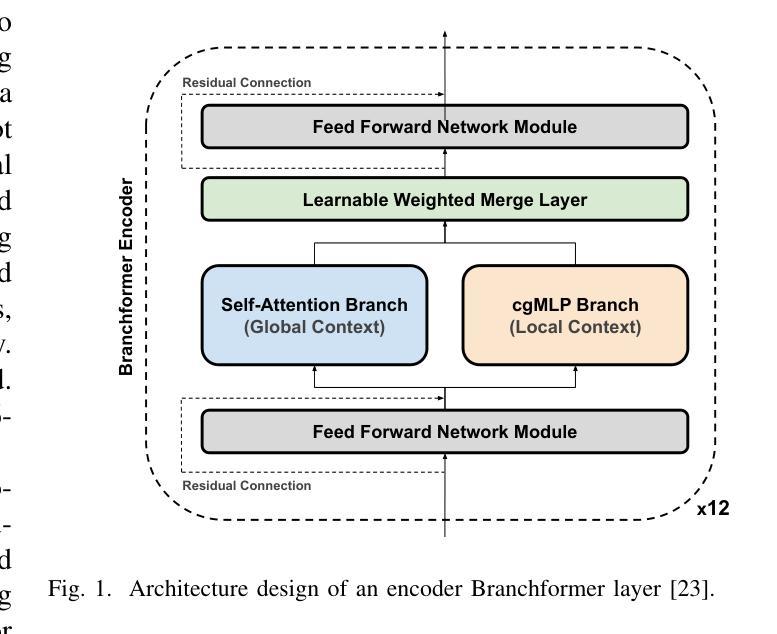
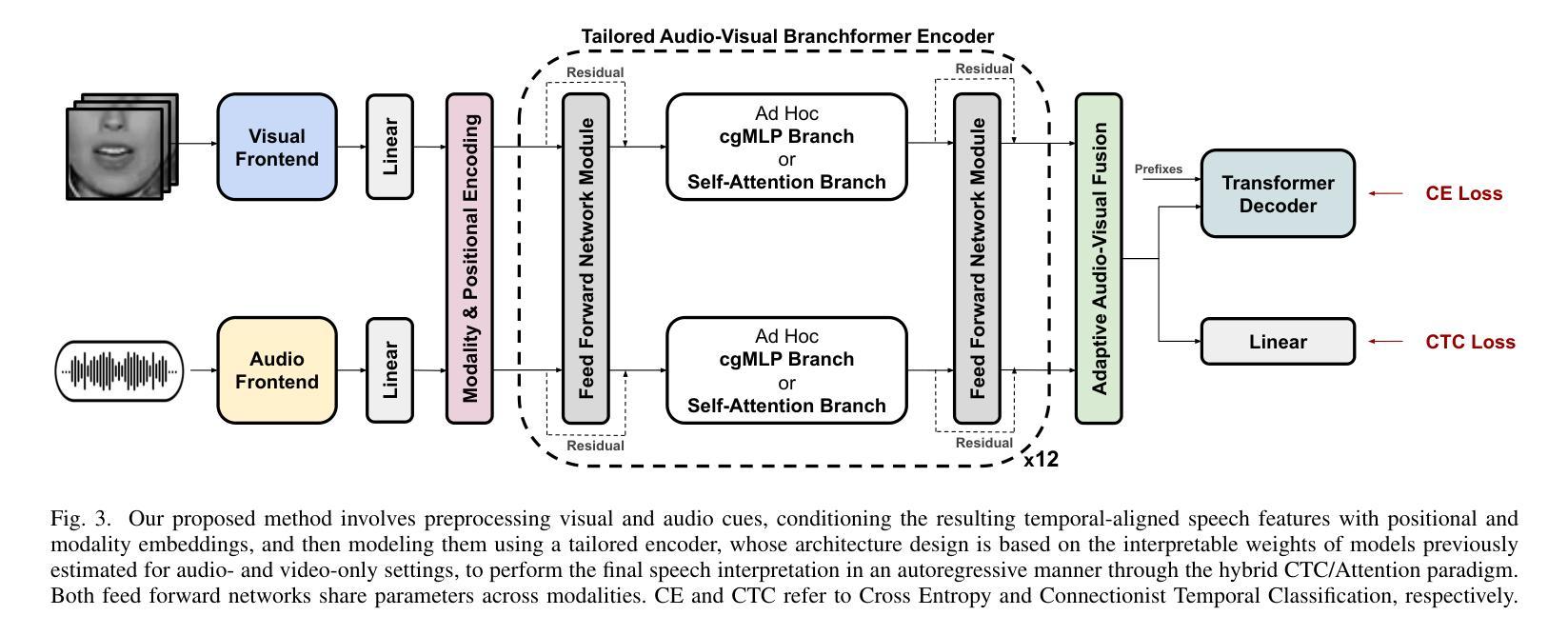
Tailored Design of Audio-Visual Speech Recognition Models using Branchformers
Authors:David Gimeno-Gómez, Carlos-D. Martínez-Hinarejos
Recent advances in Audio-Visual Speech Recognition (AVSR) have led to unprecedented achievements in the field, improving the robustness of this type of system in adverse, noisy environments. In most cases, this task has been addressed through the design of models composed of two independent encoders, each dedicated to a specific modality. However, while recent works have explored unified audio-visual encoders, determining the optimal cross-modal architecture remains an ongoing challenge. Furthermore, such approaches often rely on models comprising vast amounts of parameters and high computational cost training processes. In this paper, we aim to bridge this research gap by introducing a novel audio-visual framework. Our proposed method constitutes, to the best of our knowledge, the first attempt to harness the flexibility and interpretability offered by encoder architectures, such as the Branchformer, in the design of parameter-efficient AVSR systems. To be more precise, the proposed framework consists of two steps: first, estimating audio- and video-only systems, and then designing a tailored audio-visual unified encoder based on the layer-level branch scores provided by the modality-specific models. Extensive experiments on English and Spanish AVSR benchmarks covering multiple data conditions and scenarios demonstrated the effectiveness of our proposed method. Even when trained on a moderate scale of data, our models achieve competitive word error rates (WER) of approximately 2.5% for English and surpass existing approaches for Spanish, establishing a new benchmark with an average WER of around 9.1%. These results reflect how our tailored AVSR system is able to reach state-of-the-art recognition rates while significantly reducing the model complexity w.r.t. the prevalent approach in the field. Code and pre-trained models are available at https://github.com/david-gimeno/tailored-avsr.
近期在视听语音识别(AVSR)方面的进展为该领域带来了前所未有的成就,提高了此类系统在恶劣、嘈杂环境中的稳健性。在大多数情况下,这个问题是通过设计由两个独立编码器组成的模型来解决的,每个编码器都专注于一种特定的模态。然而,尽管近期的工作已经探索了统一的视听编码器,但确定最佳的跨模态架构仍然是一个挑战。此外,这些方法通常依赖于包含大量参数的模型和计算成本高昂的训练过程。在本文中,我们旨在通过引入一种新的视听框架来缩小这一研究差距。据我们所知,我们提出的方法首次利用了编码器架构的灵活性和可解释性,例如Branchformer,在设计参数有效的AVSR系统时。更具体地说,所提出的框架分为两个阶段:首先估计仅音频和仅视频的系统,然后基于模态特定模型提供的层级分支分数设计定制的视听统一编码器。在涵盖多种数据条件和场景的英语和西班牙语AVSR基准测试上的大量实验表明了我们方法的有效性。即使在中等规模的数据上进行训练,我们的模型也实现了约2.5%的英语单词错误率(WER),并超越了现有的西班牙语方法,建立了平均WER约为9.1%的新基准。这些结果反映了我们的定制AVSR系统如何能够在显著降低模型复杂度的同时,达到最先进的识别率。代码和预训练模型可在https://github.com/david-gimeno/tailored-avsr上找到。
论文及项目相关链接
PDF Accepted in Computer Speech & Language journal of Elsevier
Summary
近期音视语音识别的进步推动了该领域的突破性进展,尤其在恶劣噪声环境下提升了系统的稳健性。现有方法通常通过设计包含两个独立编码器的模型来解决此问题,每个编码器专注于一种模态。尽管近期工作开始探索统一的视听编码器,但确定最佳的跨模态架构仍是一个挑战。此外,这些方法常常依赖于庞大的参数和昂贵的计算成本训练过程。本文旨在填补这一研究空白,通过引入一种新颖的视听框架,结合灵活性和可解释性的编码器架构(如Branchformer),设计参数高效的AVSR系统。实验证明,该方法在多种数据条件和场景的英语和西班牙语AVSR基准测试中表现出色。即使在中等规模数据训练下,模型的词错误率(WER)也达到约2.5%的英语竞争水平,并超越现有方法对西班牙语的识别,平均WER约为9.1%,建立了新的基准。该结果表明,我们的定制AVSR系统能够在显著降低模型复杂性的同时达到最先进的识别率。
Key Takeaways
- 音频视觉语音识别(AVSR)领域取得了重大进展,特别是在噪声环境下。
- 当前方法主要依赖包含独立编码器的模型,每个编码器针对一种模态。
- 确定最佳的跨模态架构是一个挑战,且现有方法模型参数庞大、计算成本高。
- 本文提出一种新颖的视听框架,结合编码器架构的灵活性和可解释性。
- 通过两步设计定制AVSR系统:首先估计音频和视频系统,然后基于模态特定模型的层级分支分数设计统一的视听编码器。
- 实验证明该方法在多种基准测试中表现优异,包括英语和西班牙语的AVSR。
点此查看论文截图