⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
Authors:Zuwei Long, Yunhang Shen, Chaoyou Fu, Heting Gao, Lijiang Li, Peixian Chen, Mengdan Zhang, Hang Shao, Jian Li, Jinlong Peng, Haoyu Cao, Ke Li, Rongrong Ji, Xing Sun
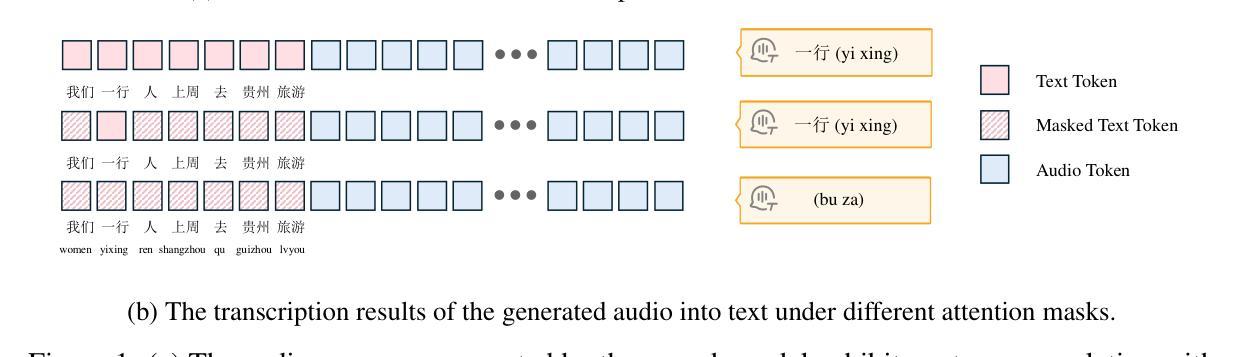
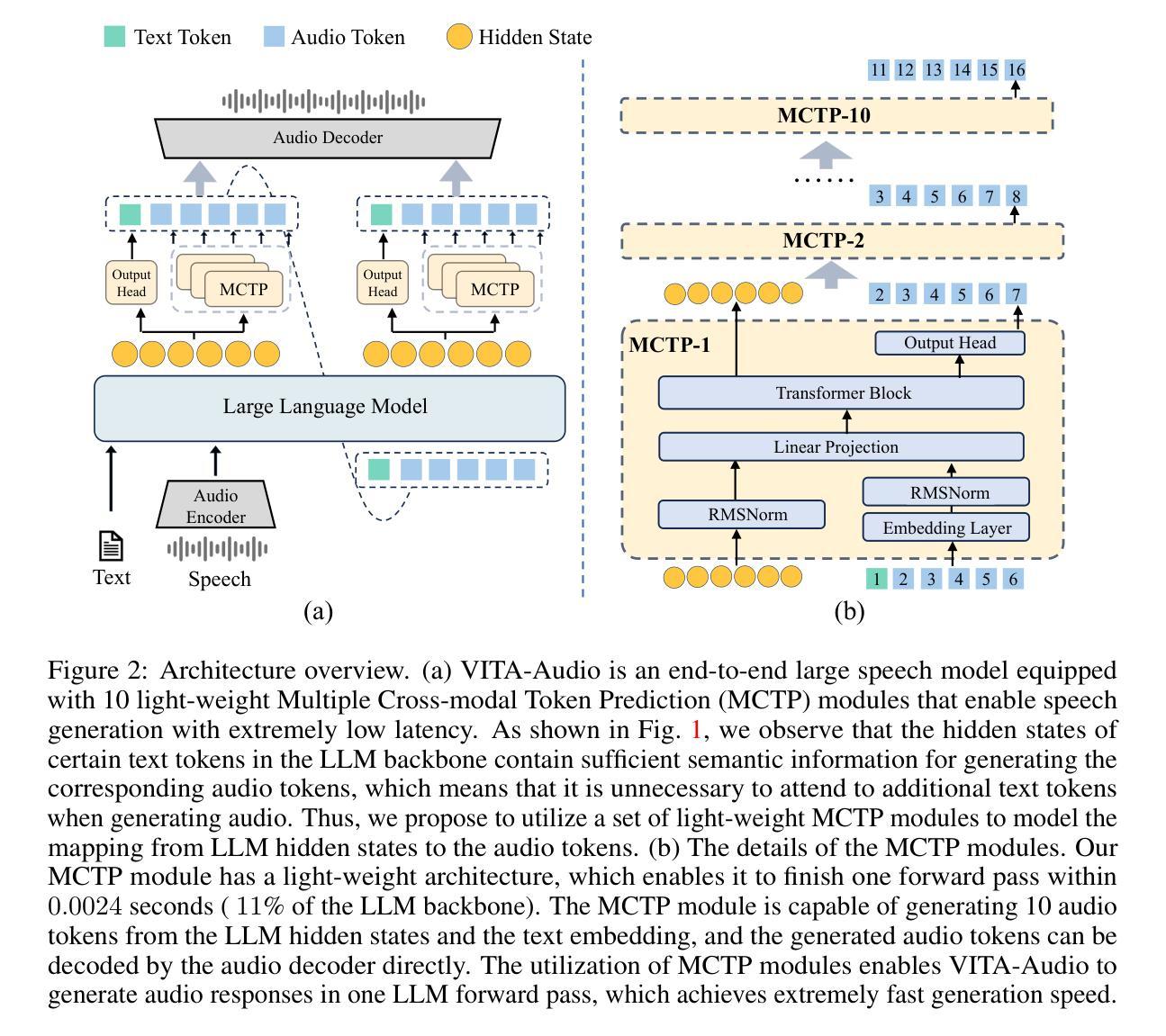
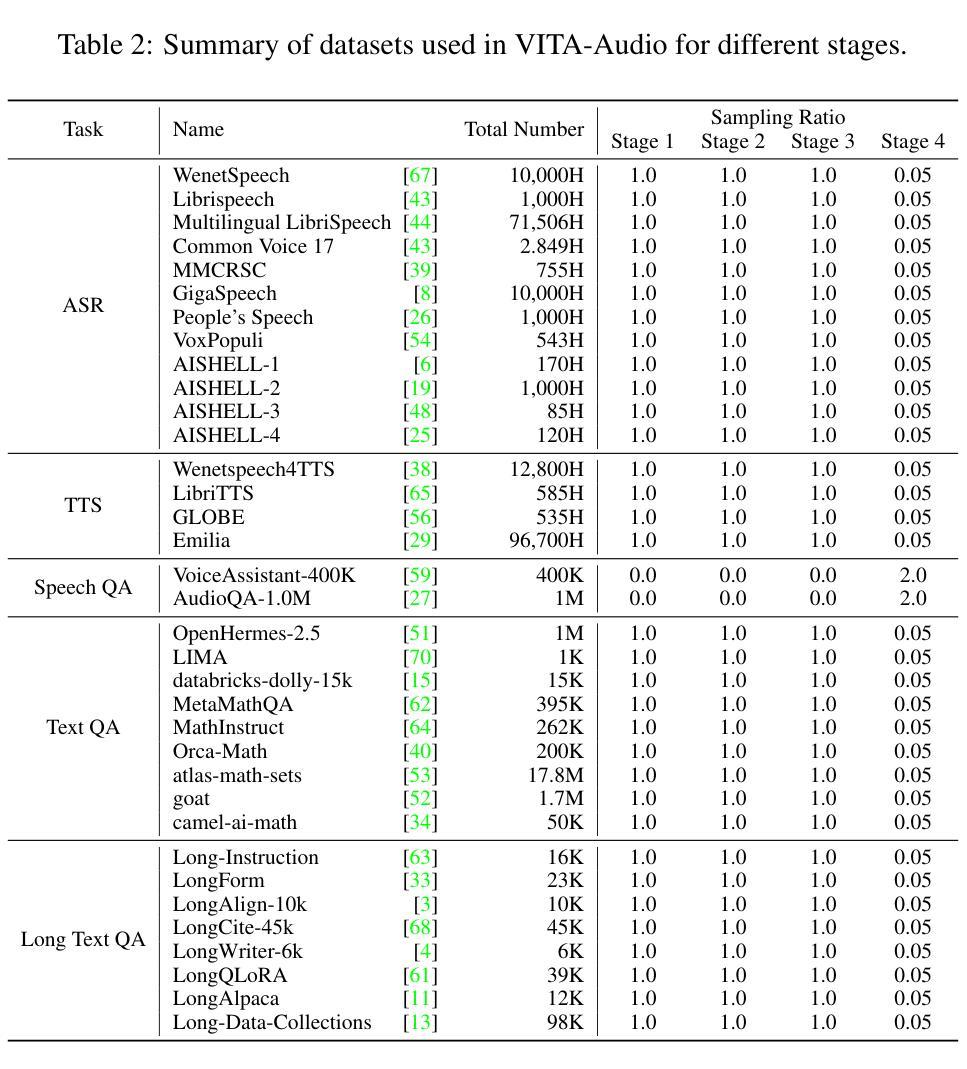
With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
随着人类对自然人机交互的需求不断增长,语音系统作为日常沟通的最常见形式之一,受到了越来越多的关注。然而,现有的语音模型在流式传输中生成第一个音频令牌时仍然存在较高的延迟,这给部署带来了很大的瓶颈。为了解决这个问题,我们提出了VITA-Audio,一个具有快速音频文本令牌生成的端到端大型语音模型。具体来说,我们引入了一个轻量级的跨模态令牌预测(MCTP)模块,该模块可以在单个模型前向传递过程中有效地生成多个音频令牌,这不仅加速了推理,而且显著降低了流式场景中生成第一个音频的延迟。此外,我们还探索了一种四阶段渐进式训练策略,以在尽可能少的语音质量损失的情况下实现模型加速。据我们所知,VITA-Audio是第一个能够在第一次前向传递过程中生成音频输出的多模态大型语言模型,可实现实时对话功能,延迟极低。VITA-Audio可完全复制,仅使用开源数据进行训练。实验结果表明,我们的模型在7B参数规模上实现了3~5倍的推理速度提升,同时在自动语音识别(ASR)、文本到语音(TTS)和语音问答(SQA)等多个任务上显著优于类似规模的开源模型。
论文及项目相关链接
PDF Training and Inference Codes: https://github.com/VITA-MLLM/VITA-Audio
Summary
针对日益增长的自然人机交互需求,语音系统得到了广泛关注。然而,现有语音模型在流生成首个音频令牌时存在高延迟问题。为此,我们提出VITA-Audio,一个端到端的大型快速音频-文本令牌生成语音模型。通过引入轻量级的跨模态令牌预测模块,我们可以在单次模型前向传递中高效生成多个音频令牌,这不仅加速了推理,而且显著降低了流式场景中生成第一个音频的延迟。此外,我们探索了四阶段渐进训练策略,以在尽可能不损失语音质量的情况下实现模型加速。VITA-Audio是首个能够在首次前向传递中产生音频输出的多模态大型语言模型,具有实时对话能力,延迟极低。
Key Takeaways
- 语音系统因其在日常沟通中的普及性而备受关注。
- 当前语音模型在流式传输生成首个音频令牌时存在高延迟问题。
- VITA-Audio是一个大型端到端的语音模型,旨在解决现有模型的延迟问题。
- VITA-Audio通过引入轻量级的跨模态令牌预测模块来加速推理并降低延迟。
- 四阶段渐进训练策略旨在实现模型加速而不损失语音质量。
- VITA-Audio是首个能在首次前向传递中产生音频输出的多模态大型语言模型。
- VITA-Audio具有实时对话能力,延迟极低,且完全可复现,仅使用开源数据进行训练。
点此查看论文截图



LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
Authors:Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, Yang Feng
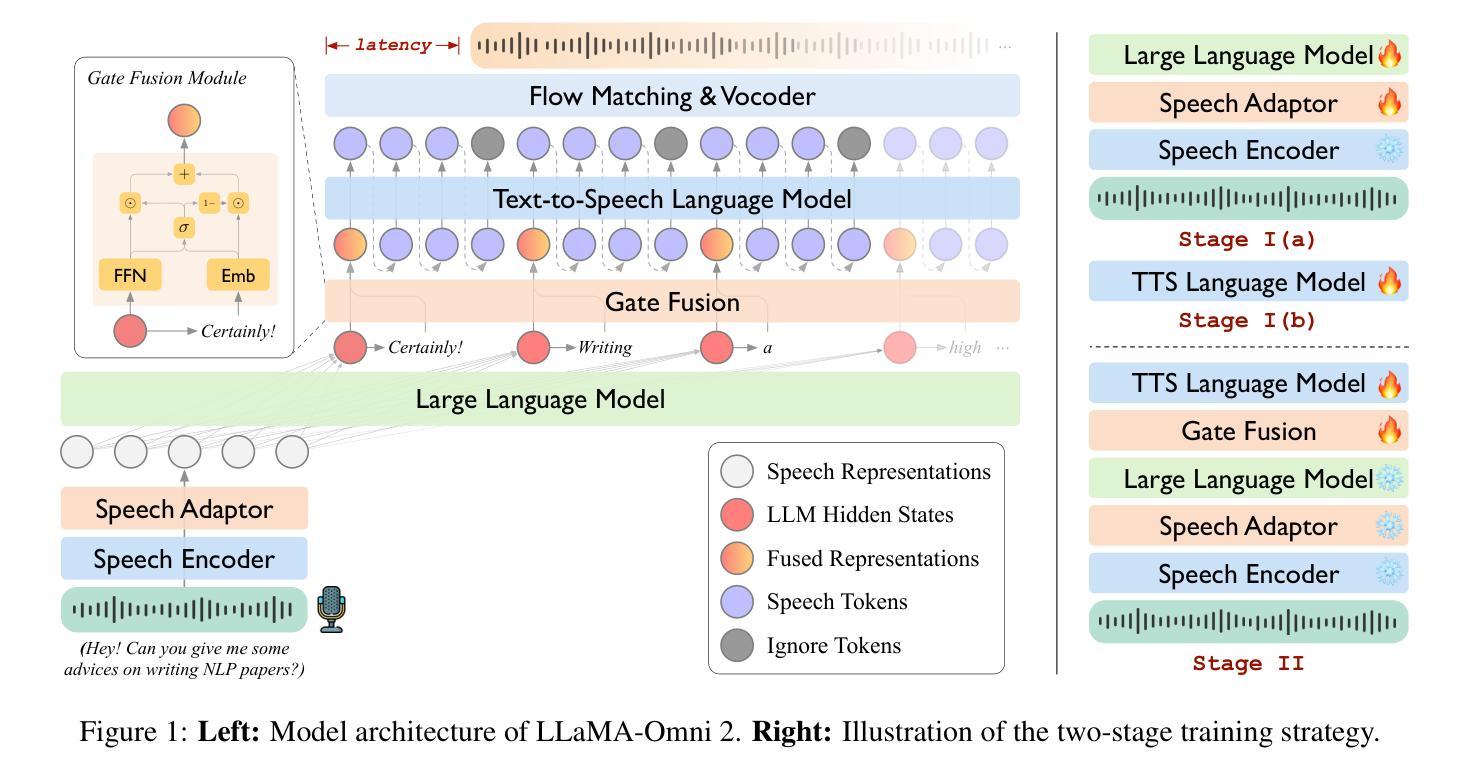
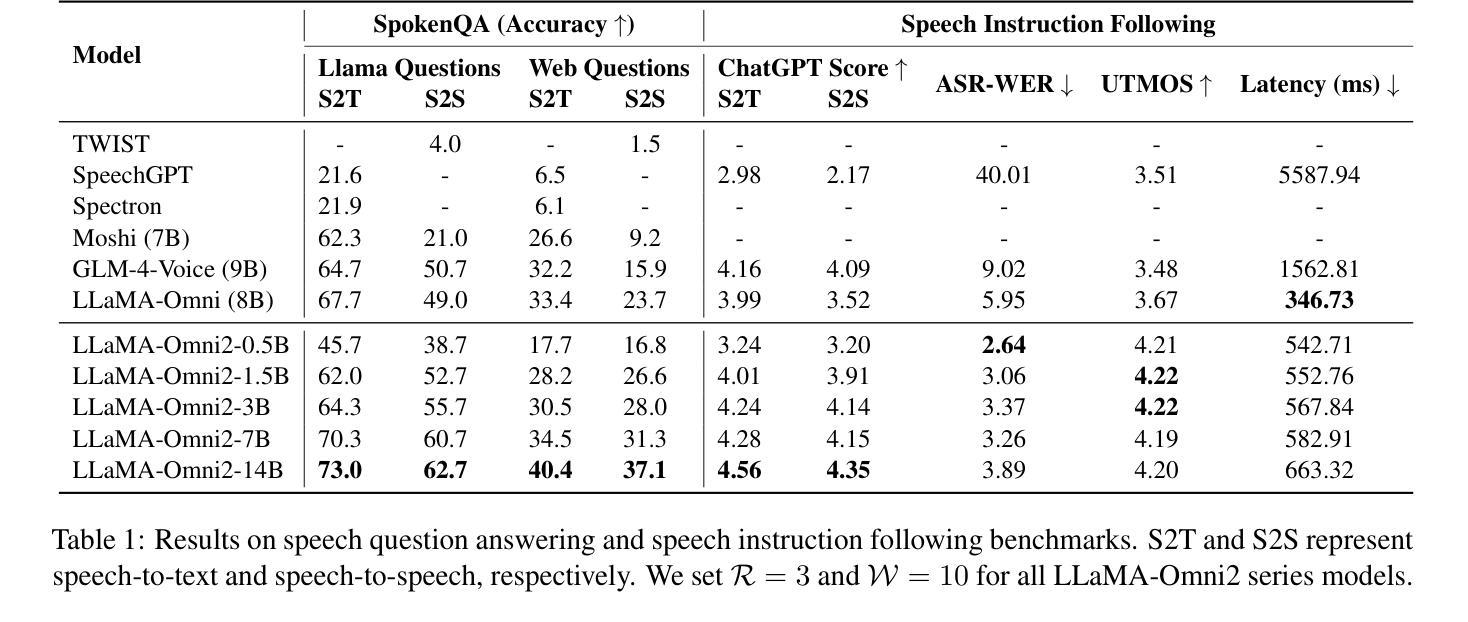
Real-time, intelligent, and natural speech interaction is an essential part of the next-generation human-computer interaction. Recent advancements have showcased the potential of building intelligent spoken chatbots based on large language models (LLMs). In this paper, we introduce LLaMA-Omni 2, a series of speech language models (SpeechLMs) ranging from 0.5B to 14B parameters, capable of achieving high-quality real-time speech interaction. LLaMA-Omni 2 is built upon the Qwen2.5 series models, integrating a speech encoder and an autoregressive streaming speech decoder. Despite being trained on only 200K multi-turn speech dialogue samples, LLaMA-Omni 2 demonstrates strong performance on several spoken question answering and speech instruction following benchmarks, surpassing previous state-of-the-art SpeechLMs like GLM-4-Voice, which was trained on millions of hours of speech data.
实时、智能、自然的语音交互是下一代人机交互的重要组成部分。最近的进展展示了基于大型语言模型(LLM)构建智能语音聊天机器人的潜力。在本文中,我们介绍了LLaMA-Omni 2,这是一系列语音语言模型(SpeechLMs),参数范围从0.5B到14B,能够实现高质量实时语音交互。LLaMA-Omni 2是建立在Qwen2.5系列模型基础上的,融合了语音编码器和自回归流式语音解码器。尽管只接受了20万多个多轮语音对话样本的训练,LLaMA-Omni 2在多个语音问答和语音指令跟随基准测试上表现出了强大的性能,超越了之前最先进的语音语言模型GLM-4-Voice。GLM-4-Voice是在数百万小时的语音数据上训练的。
论文及项目相关链接
PDF Preprint. Project: https://github.com/ictnlp/LLaMA-Omni2
摘要
新一代人机互动的重要组成部分是实现实时、智能和自然的语音交互。近期基于大型语言模型(LLMs)的智能语音聊天机器人的发展,展示了其巨大潜力。本文介绍了LLaMA-Omni 2系列语音语言模型(SpeechLMs),该模型包含从0.5B到14B不等的参数,可实现高质量实时语音交互。LLaMA-Omni 2是在Qwen2.5系列模型的基础上构建的,集成了一个语音编码器和一个自回归流式语音解码器。尽管只在20万条多轮语音对话样本上进行训练,LLaMA-Omni 2在多个语音问答和语音指令跟随基准测试中表现出色,超越了之前先进的SpeechLMs,如经过数百万小时语音数据训练的GLM-4-Voice。
关键见解
- 实时、智能、自然的语音交互是下一代人机互动的核心组成部分。
- LLaMA-Omni 2系列语音语言模型可实现高质量实时语音交互。
- LLaMA-Omni 2基于Qwen2.5系列模型构建,集成了语音编码器和自回归流式语音解码器。
- LLaMA-Omni 2在少量训练样本(仅20万条多轮语音对话样本)下表现优秀。
- LLaMA-Omni 2在语音问答和语音指令跟随基准测试中的表现超越了先前的先进SpeechLMs。
- LLaMA-Omni 2的训练样本数量远少于其他先进的模型(如经过数百万小时语音数据训练的GLM-4-Voice)。
- 这些进展表明了构建高效、实时、强大的智能语音交互系统的潜力和前景。
点此查看论文截图

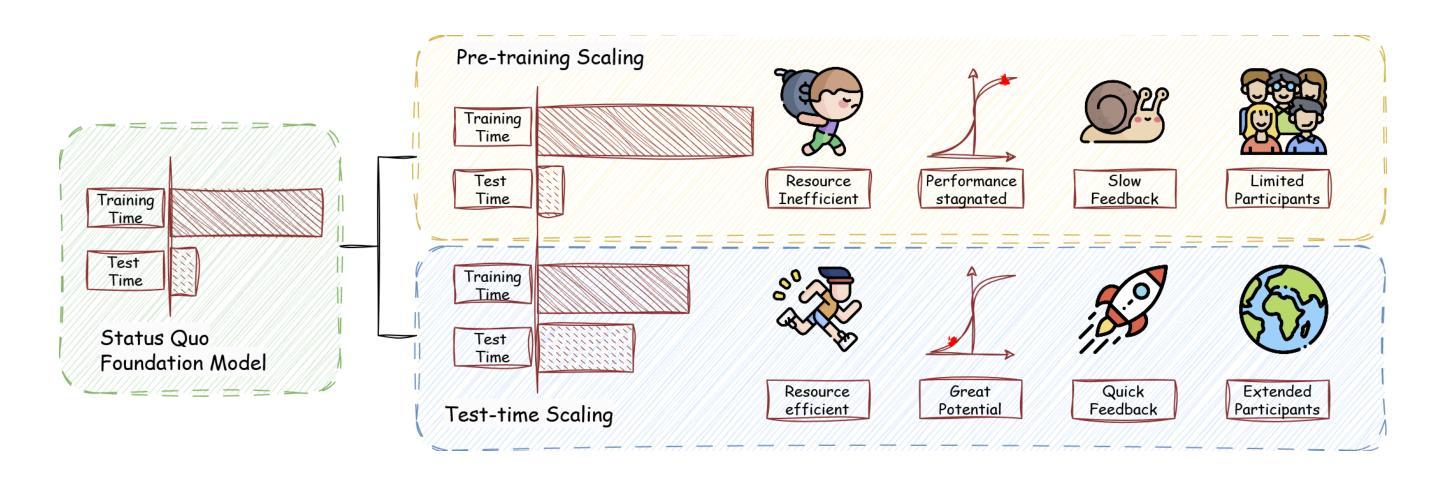
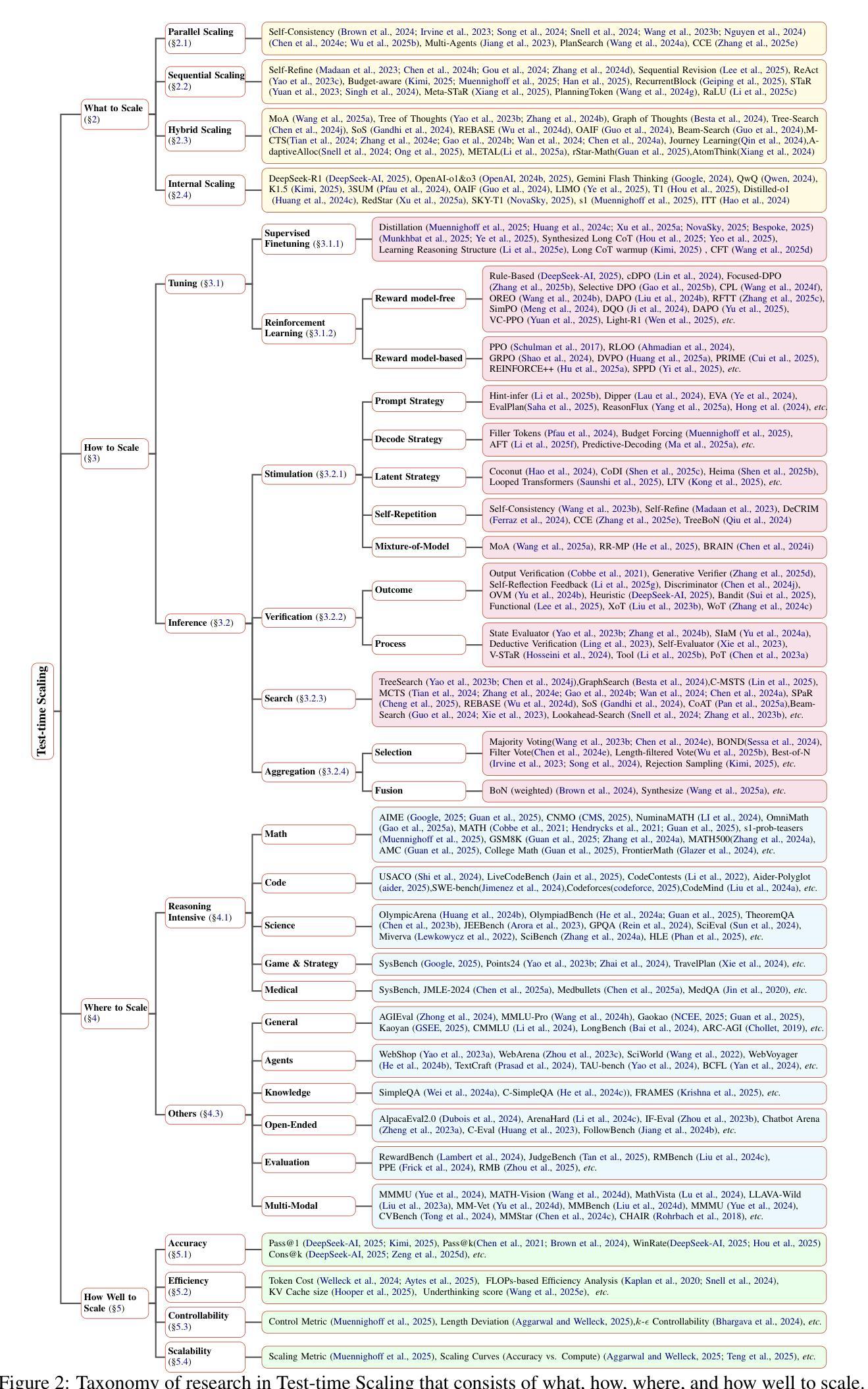
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Authors:Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muennighoff, Irwin King, Xue Liu, Chen Ma
As enthusiasm for scaling computation (data and parameters) in the pretraining era gradually diminished, test-time scaling (TTS), also referred to as ``test-time computing’’ has emerged as a prominent research focus. Recent studies demonstrate that TTS can further elicit the problem-solving capabilities of large language models (LLMs), enabling significant breakthroughs not only in specialized reasoning tasks, such as mathematics and coding, but also in general tasks like open-ended Q&A. However, despite the explosion of recent efforts in this area, there remains an urgent need for a comprehensive survey offering a systemic understanding. To fill this gap, we propose a unified, multidimensional framework structured along four core dimensions of TTS research: what to scale, how to scale, where to scale, and how well to scale. Building upon this taxonomy, we conduct an extensive review of methods, application scenarios, and assessment aspects, and present an organized decomposition that highlights the unique functional roles of individual techniques within the broader TTS landscape. From this analysis, we distill the major developmental trajectories of TTS to date and offer hands-on guidelines for practical deployment. Furthermore, we identify several open challenges and offer insights into promising future directions, including further scaling, clarifying the functional essence of techniques, generalizing to more tasks, and more attributions. Our repository is available on https://github.com/testtimescaling/testtimescaling.github.io/
随着预训练时代扩大计算规模(数据和参数)的热情逐渐消退,测试时扩展(Test-Time Scaling,简称TTS),也称为“测试时计算”,已成为一个突出的研究焦点。最近的研究表明,TTS可以进一步激发大型语言模型(LLM)的问题解决能力,不仅在数学和编码等专项推理任务上实现突破,而且在开放问答等一般任务中也取得重大进展。然而,尽管这一领域的研究工作如雨后春笋般涌现,但仍迫切需要对系统进行全面的综述。为了填补这一空白,我们提出了一个统一的多维框架,该框架沿着TTS研究的四个核心维度构建:扩展什么、如何扩展、在哪里扩展以及如何评估扩展效果。在此基础上,我们对方法、应用场景和评估方面进行了广泛的回顾,并进行了有条理的分析,突出了各种技术在更广泛的TTS领域中的独特功能作用。通过分析,我们提炼了迄今为止TTS的主要发展轨迹,并为实际部署提供了实用指南。此外,我们还确定了几个开放挑战并洞察了未来有前途的研究方向,包括进一步的扩展、澄清技术的功能本质、推广到更多任务以及更多归因。我们的仓库可在https://github.com/testtimescaling/testtimescaling.github.io/访问。
论文及项目相关链接
PDF v3: Expand Agentic and SFT Chapters. Build Website for better visualization
Summary
随着预训练时代对扩大计算规模(数据和参数)的热情逐渐减弱,测试时缩放(TTS)已崭露头角,成为当前研究焦点。近期研究表明,TTS可进一步激发大型语言模型(LLM)的问题解决能力,不仅在数学和编码等专项推理任务中取得突破,而且在开放问答等一般任务中也有出色表现。然而,尽管近期在此领域的努力成果显著,但仍急需一篇全面综述以提供系统了解。本文提出一个统一的、多维度的框架,从TTS研究的四个核心维度(即什么要缩放、如何缩放、在哪里缩放以及如何评估缩放效果)展开全面综述。文章梳理了方法、应用场景和评估方面,呈现了各技术在TTS领域中的独特功能角色。从分析中提炼出TTS至今的主要发展轨迹,并为实际部署提供实用指南。同时,文章还指出了几个开放挑战和未来发展方向。
Key Takeaways
- 测试时缩放(TTS)已成为当前研究焦点,可激发大型语言模型(LLM)的问题解决能力。
- TTS不仅在专项推理任务中表现优异,在一般任务中也有出色表现。
- 文章提出一个多维度的框架,从四个核心维度对TTS进行研究:什么要缩放、如何缩放、在哪里缩放以及如何评估缩放效果。
- 文章梳理了TTS的方法、应用场景和评估方面,呈现了各技术的独特功能角色。
- TTS至今的主要发展轨迹是从简单到复杂,从单一任务到多任务。
- 文章提供了实用指南,为TTS的实际部署提供参考。
点此查看论文截图