⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-08 更新
PAHA: Parts-Aware Audio-Driven Human Animation with Diffusion Model
Authors:Y. B. Wang, S. Z. Zhou, J. F. Wu, T. Hu, J. N. Zhang, Y. Liu
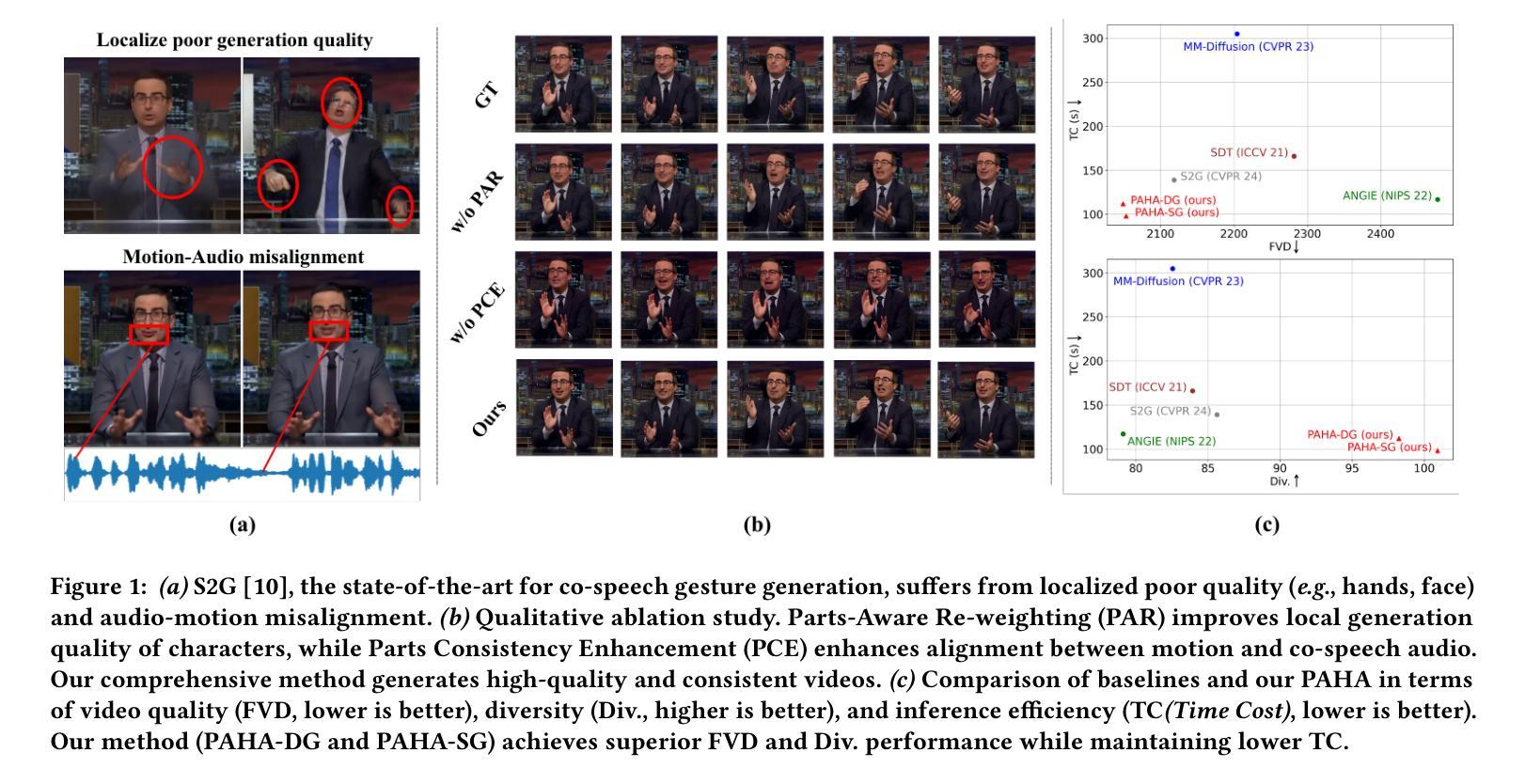
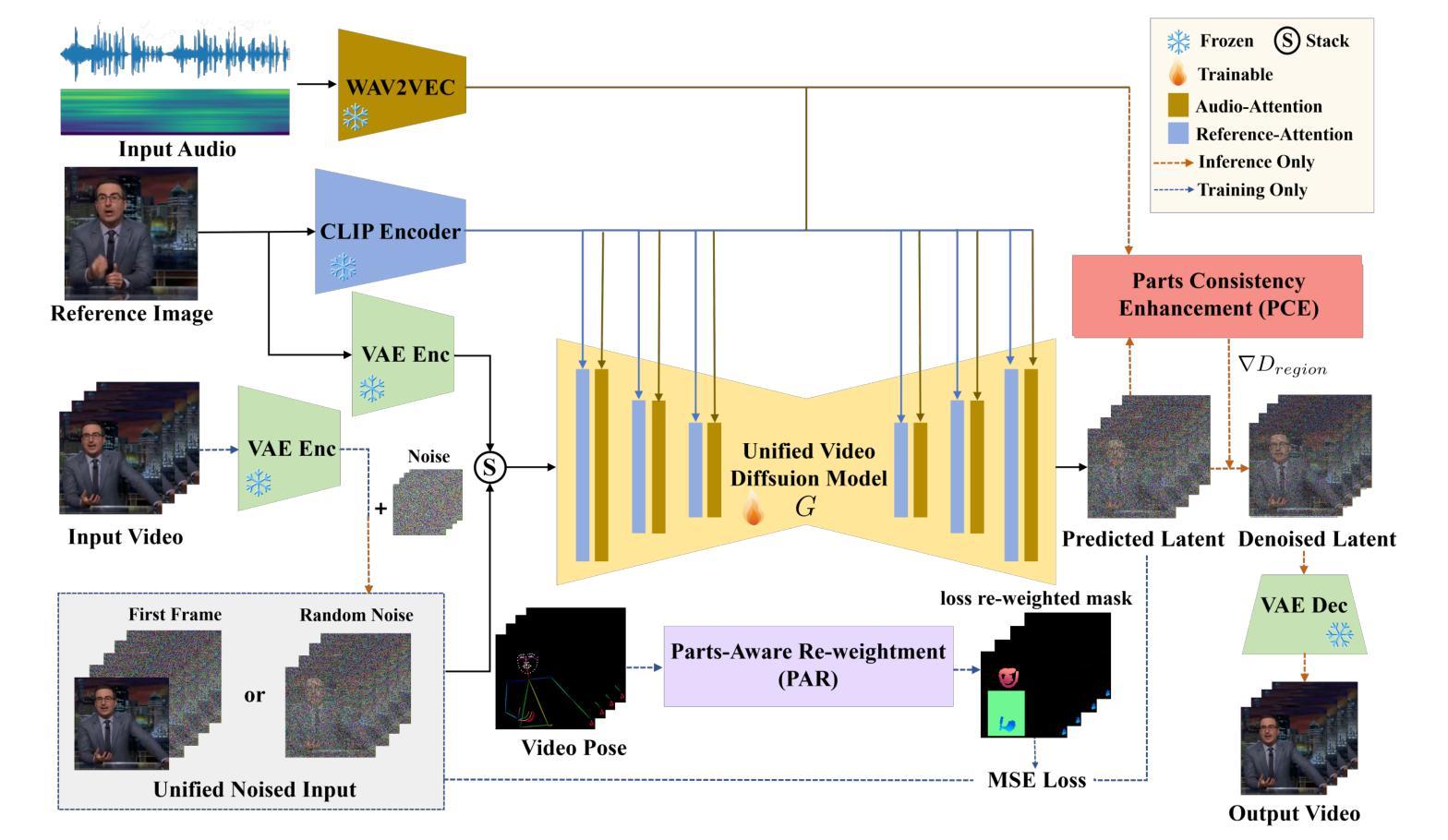
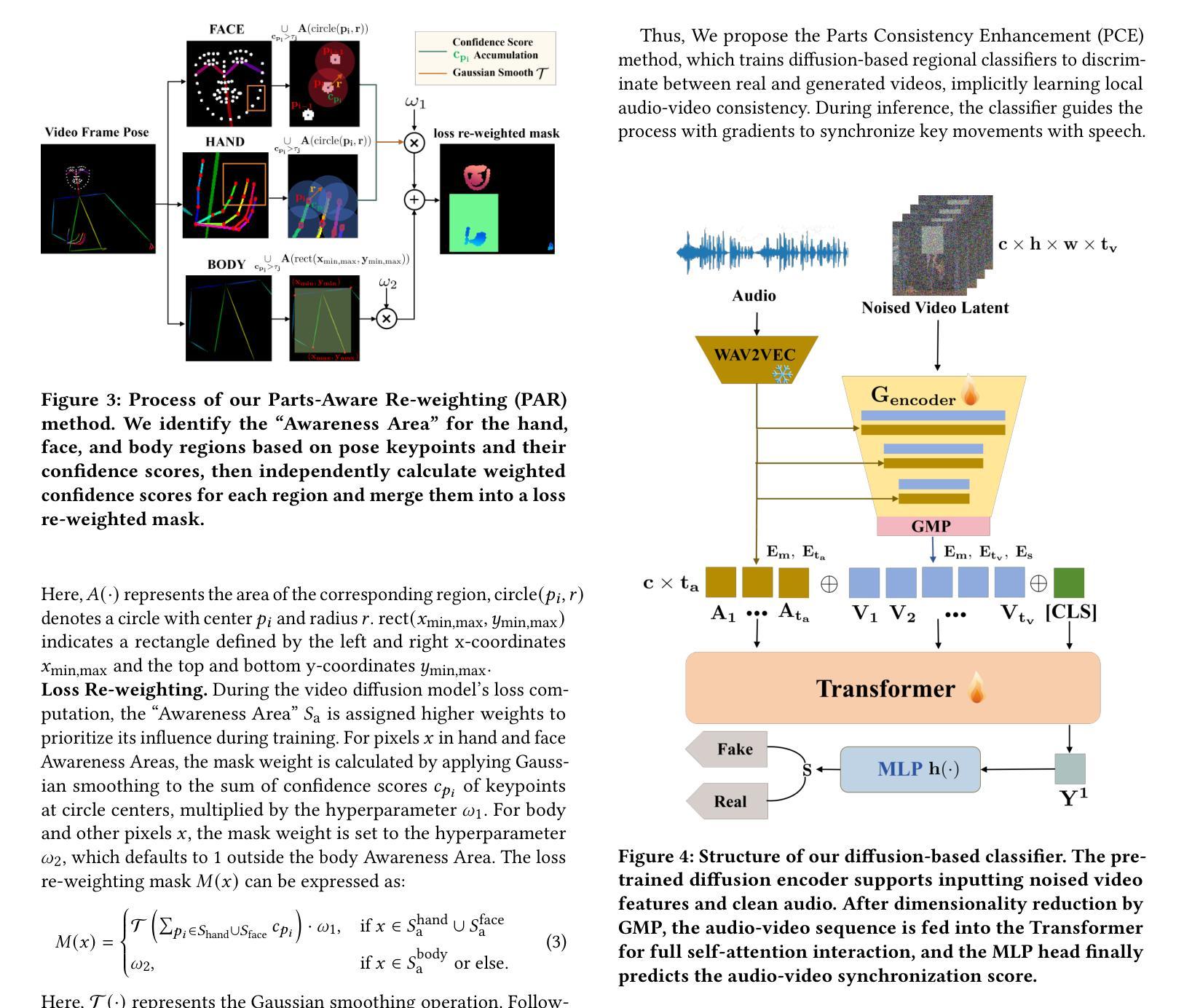
Audio-driven human animation technology is widely used in human-computer interaction, and the emergence of diffusion models has further advanced its development. Currently, most methods rely on multi-stage generation and intermediate representations, resulting in long inference time and issues with generation quality in specific foreground regions and audio-motion consistency. These shortcomings are primarily due to the lack of localized fine-grained supervised guidance. To address above challenges, we propose PAHA, an end-to-end audio-driven upper-body human animation framework with diffusion model. We introduce two key methods: Parts-Aware Re-weighting (PAR) and Parts Consistency Enhancement (PCE). PAR dynamically adjusts regional training loss weights based on pose confidence scores, effectively improving visual quality. PCE constructs and trains diffusion-based regional audio-visual classifiers to improve the consistency of motion and co-speech audio. Afterwards, we design two novel inference guidance methods for the foregoing classifiers, Sequential Guidance (SG) and Differential Guidance (DG), to balance efficiency and quality respectively. Additionally, we build CNAS, the first public Chinese News Anchor Speech dataset, to advance research and validation in this field. Extensive experimental results and user studies demonstrate that PAHA significantly outperforms existing methods in audio-motion alignment and video-related evaluations. The codes and CNAS dataset will be released upon acceptance.
音频驱动的人形动画技术广泛应用于人机交互领域,扩散模型的出现进一步推动了其发展。目前,大多数方法依赖于多阶段生成和中间表示,导致推理时间长,特定前景区域生成质量和音频运动一致性存在问题。这些缺点主要是由于缺乏局部精细监督指导。为了应对上述挑战,我们提出了基于扩散模型的端到端音频驱动上半身人形动画框架PAHA。我们引入了两种关键方法:零件感知重新加权(PAR)和零件一致性增强(PCE)。PAR根据姿势置信度分数动态调整区域训练损失权重,有效提高视觉质量。PCE构建并训练基于扩散的区域音视频分类器,以提高运动和语音音频的一致性。之后,我们为前述分类器设计了两种新型推理指导方法,即顺序指导(SG)和差异指导(DG),以平衡效率和质量。此外,我们构建了首个公共中文新闻主播语音数据集CNAS,以推动该领域的研究和验证。大量的实验和用户研究结果表明,PAHA在音频运动对齐和视频相关评估方面显著优于现有方法。代码和CNAS数据集将在接受后发布。
论文及项目相关链接
Summary
本文介绍了音频驱动的人体动画技术的最新进展,提出了一种基于扩散模型的端到端人体动画框架PAHA,并介绍了其中的两大关键方法:零件感知重加权(PAR)和零件一致性增强(PCE)。PAHA解决了现有方法的长期推理时间和生成质量等问题,通过动态调整区域训练损失权重和提高运动与音频的一致性来提高生成视频的视觉效果。此外,还设计了两种新型推理指导方法SG和DG,并建立了首个中文新闻主播语音数据集CNAS。
Key Takeaways
- 音频驱动的人体动画技术在人机交互中广泛应用,扩散模型的出现进一步推动了其发展。
- 当前方法存在长期推理时间、特定前景区域生成质量和音频运动一致性等问题。
- PAHA框架通过零件感知重加权(PAR)和方法零件一致性增强(PCE)解决上述问题。
- PAR通过动态调整区域训练损失权重提高视觉效果。
- PCE通过构建和训练基于扩散的区域音视频分类器,提高运动与音频的一致性。
- PAHA设计了两种新型推理指导方法SG和DG以平衡效率和质量。
点此查看论文截图

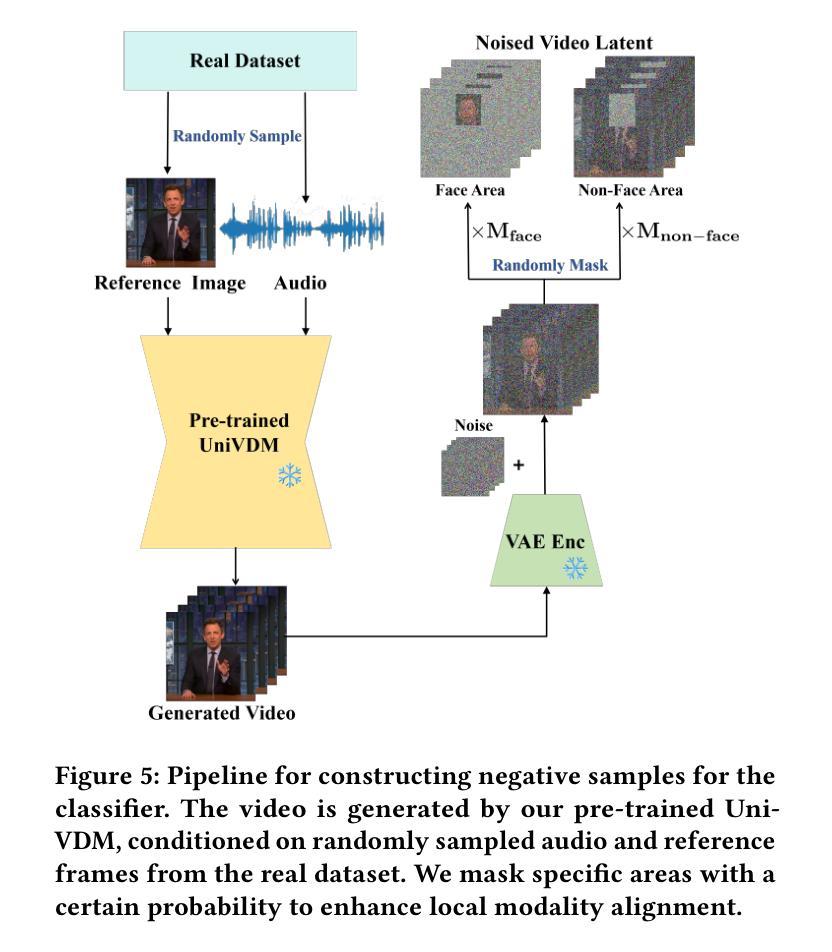
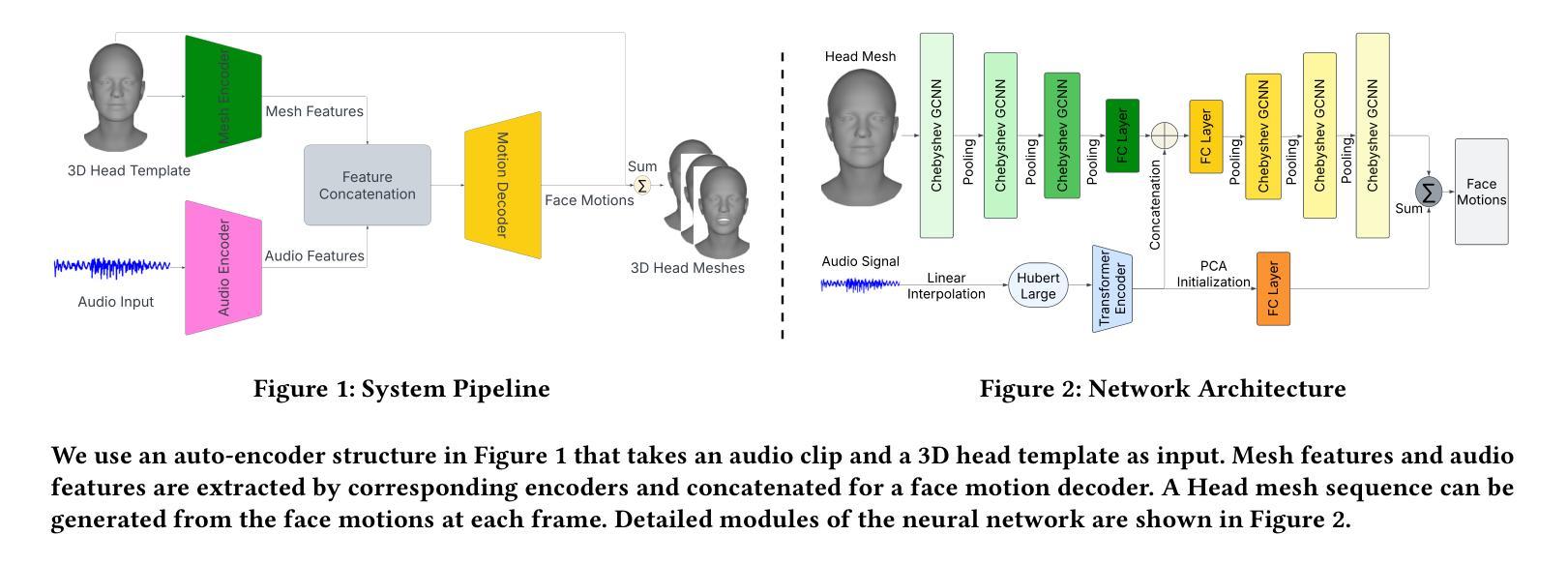
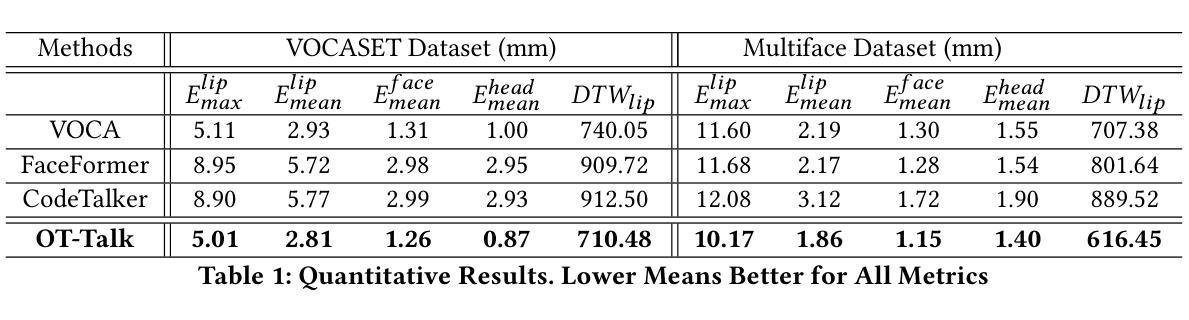
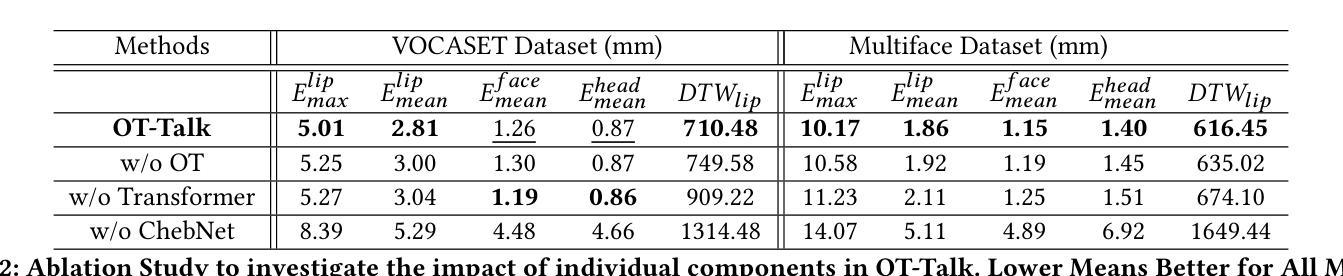
OT-Talk: Animating 3D Talking Head with Optimal Transportation
Authors:Xinmu Wang, Xiang Gao, Xiyun Song, Heather Yu, Zongfang Lin, Liang Peng, Xianfeng Gu
Animating 3D head meshes using audio inputs has significant applications in AR/VR, gaming, and entertainment through 3D avatars. However, bridging the modality gap between speech signals and facial dynamics remains a challenge, often resulting in incorrect lip syncing and unnatural facial movements. To address this, we propose OT-Talk, the first approach to leverage optimal transportation to optimize the learning model in talking head animation. Building on existing learning frameworks, we utilize a pre-trained Hubert model to extract audio features and a transformer model to process temporal sequences. Unlike previous methods that focus solely on vertex coordinates or displacements, we introduce Chebyshev Graph Convolution to extract geometric features from triangulated meshes. To measure mesh dissimilarities, we go beyond traditional mesh reconstruction errors and velocity differences between adjacent frames. Instead, we represent meshes as probability measures and approximate their surfaces. This allows us to leverage the sliced Wasserstein distance for modeling mesh variations. This approach facilitates the learning of smooth and accurate facial motions, resulting in coherent and natural facial animations. Our experiments on two public audio-mesh datasets demonstrate that our method outperforms state-of-the-art techniques both quantitatively and qualitatively in terms of mesh reconstruction accuracy and temporal alignment. In addition, we conducted a user perception study with 20 volunteers to further assess the effectiveness of our approach.
利用音频输入对3D头部网格进行动画设计在AR/VR、游戏和娱乐领域(通过3D化身)具有显著的应用价值。然而,弥合语音信号和面部动态之间的模态鸿沟仍然是一个挑战,通常会导致唇同步不正确和面部动作不自然。为了解决这一问题,我们提出了OT-Talk,这是第一种利用最优传输优化说话人头动画的学习模型的方法。我们建立在现有的学习框架上,利用预先训练的Hubert模型提取音频特征,并利用变压器模型处理时间序列。与以往仅关注顶点坐标或位移的方法不同,我们引入Chebyshev图卷积从三角网格中提取几何特征。为了测量网格之间的差异,我们超越了传统的网格重建误差和相邻帧之间的速度差异。相反,我们将网格表示为概率度量并近似其表面。这使我们能够利用切片Wasserstein距离对网格变化进行建模。这种方法促进了平滑和准确面部动作的学习,从而生成连贯和自然的面部动画。我们在两个公共音频网格数据集上的实验表明,我们的方法在网格重建准确性和时间对齐方面定量和定性地优于最新技术。此外,我们还邀请了20名志愿者进行用户感知研究,以进一步评估我们方法的有效性。
论文及项目相关链接
Summary
基于音频输入的3D头部动画技术在AR/VR、游戏和娱乐领域有广泛应用前景。然而,实现语音信号与面部动态之间的模态桥梁仍存在挑战,导致唇部同步不精确和面部动作不自然。为解决此问题,本文提出OT-Talk方法,首次利用最优传输技术优化头部动画学习模型。该方法基于现有学习框架,使用预训练的Hubert模型提取音频特征,并利用变压器模型处理时序序列。与其他方法不同,本文引入Chebyshev图卷积提取三角网格的几何特征。为衡量网格差异,本文超越传统网格重建误差和相邻帧速度差异,将网格表示为概率度量并近似其表面,利用切片Wasserstein距离建模网格变化。此方法可学习平滑准确的面部动作,实现连贯自然的面部动画。在公开音频网格数据集上的实验证明,该方法在网格重建精度和时间对齐方面均优于现有技术。同时,进行用户感知研究进一步评估其有效性。
Key Takeaways
- 3D头部动画技术在AR/VR、游戏和娱乐领域有广泛应用前景。
- 实现语音信号与面部动态之间的准确同步是重要挑战。
- OT-Talk方法利用最优传输技术优化头部动画学习模型。
- 该方法使用Hubert模型提取音频特征,利用变压器模型处理时序序列。
- 引入Chebyshev图卷积提取三角网格的几何特征。
- 利用切片Wasserstein距离建模网格变化,提高面部动画的准确性和自然度。
- 在公开数据集上的实验和用户感知研究证明了该方法的有效性。
点此查看论文截图


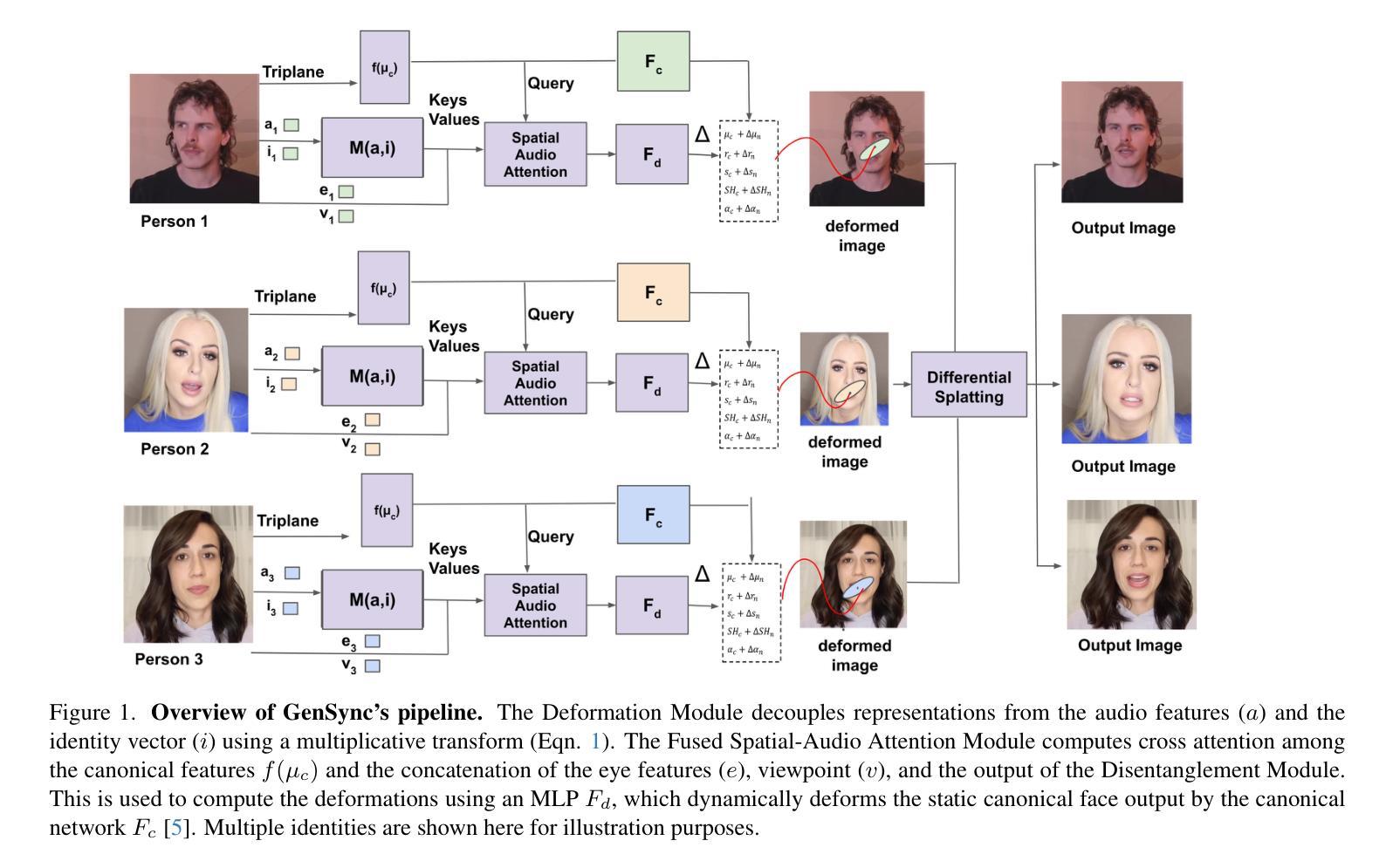
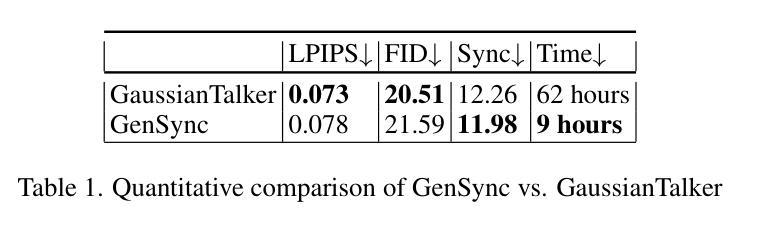
GenSync: A Generalized Talking Head Framework for Audio-driven Multi-Subject Lip-Sync using 3D Gaussian Splatting
Authors:Anushka Agarwal, Muhammad Yusuf Hassan, Talha Chafekar
We introduce GenSync, a novel framework for multi-identity lip-synced video synthesis using 3D Gaussian Splatting. Unlike most existing 3D methods that require training a new model for each identity , GenSync learns a unified network that synthesizes lip-synced videos for multiple speakers. By incorporating a Disentanglement Module, our approach separates identity-specific features from audio representations, enabling efficient multi-identity video synthesis. This design reduces computational overhead and achieves 6.8x faster training compared to state-of-the-art models, while maintaining high lip-sync accuracy and visual quality.
我们介绍了GenSync,这是一个使用3D高斯描画技术的新颖多身份唇同步视频合成框架。与大多数现有3D方法不同,这些方法需要为每个身份训练一个新模型,而GenSync学习了一个统一网络,可以为多个说话者合成唇同步视频。通过引入分离模块,我们的方法能够将身份特定特征从音频表示中分离出来,从而实现高效的多身份视频合成。这种设计减少了计算开销,与最先进模型相比实现了6.8倍的快速训练,同时保持了高唇同步精度和视觉质量。
论文及项目相关链接
Summary
新一代面部合成技术GenSync采用三维高斯混合技术实现多身份同步视频合成。区别于传统需要为每个身份训练独立模型的三维技术,GenSync学习统一网络,为多个说话者合成同步视频。通过引入分离模块,该技术成功分离身份特征音频表达,实现高效多身份视频合成。此方法降低计算成本,较现有模型提速达6.8倍,同时保持高同步精度和视觉质量。
Key Takeaways
- GenSync是一个基于三维高斯混合技术的多身份同步视频合成框架。
- GenSync学习统一网络,无需为每个身份训练独立模型,实现多身份视频合成。
- 通过引入分离模块,成功分离身份特征和音频表达,提升视频合成的效率和准确性。
- GenSync具有较低的计算成本,并且相较于现有模型训练速度提高6.8倍。
- GenSync能够保持高同步精度和视觉质量。
点此查看论文截图



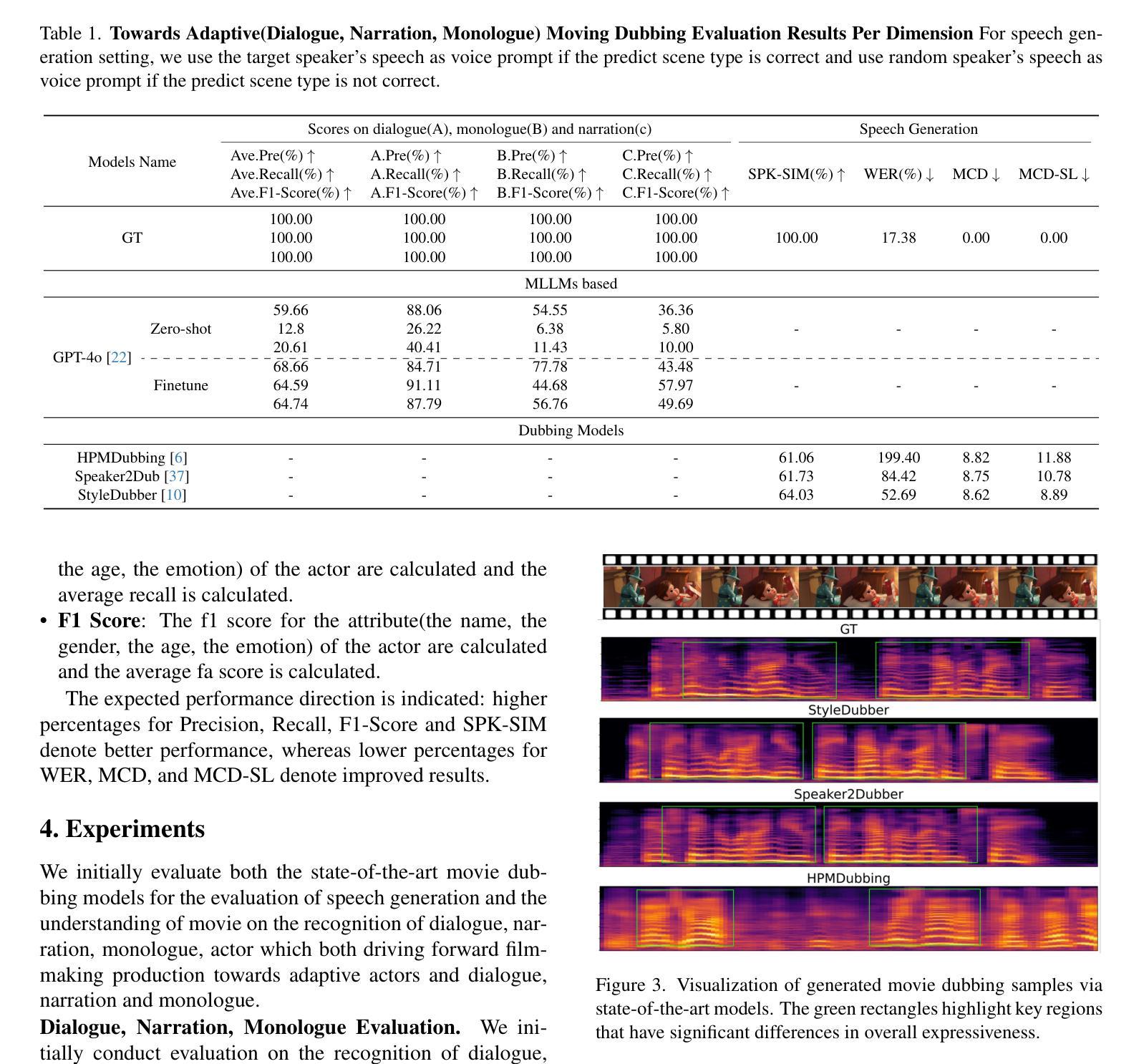
Towards Film-Making Production Dialogue, Narration, Monologue Adaptive Moving Dubbing Benchmarks
Authors:Chaoyi Wang, Junjie Zheng, Zihao Chen, Shiyu Xia, Chaofan Ding, Xiaohao Zhang, Xi Tao, Xiaoming He, Xinhan Di
Movie dubbing has advanced significantly, yet assessing the real-world effectiveness of these models remains challenging. A comprehensive evaluation benchmark is crucial for two key reasons: 1) Existing metrics fail to fully capture the complexities of dialogue, narration, monologue, and actor adaptability in movie dubbing. 2) A practical evaluation system should offer valuable insights to improve movie dubbing quality and advancement in film production. To this end, we introduce Talking Adaptive Dubbing Benchmarks (TA-Dubbing), designed to improve film production by adapting to dialogue, narration, monologue, and actors in movie dubbing. TA-Dubbing offers several key advantages: 1) Comprehensive Dimensions: TA-Dubbing covers a variety of dimensions of movie dubbing, incorporating metric evaluations for both movie understanding and speech generation. 2) Versatile Benchmarking: TA-Dubbing is designed to evaluate state-of-the-art movie dubbing models and advanced multi-modal large language models. 3) Full Open-Sourcing: We fully open-source TA-Dubbing at https://github.com/woka- 0a/DeepDubber- V1 including all video suits, evaluation methods, annotations. We also continuously integrate new movie dubbing models into the TA-Dubbing leaderboard at https://github.com/woka- 0a/DeepDubber-V1 to drive forward the field of movie dubbing.
电影配音已经取得了显著的进步,但评估这些模型在现实世界中的效果仍然具有挑战性。一个全面的评估基准至关重要,主要原因有两点:1)现有指标未能充分捕捉电影配音中对话、旁白、独白和演员适应性的复杂性。2)一个实用的评估系统应该提供有价值的见解,以提高电影配音质量和电影制作的发展。为此,我们引入了电影配音自适应评估基准(TA-Dubbing),旨在通过适应电影配音中的对话、旁白、独白和演员来提高电影制作水平。TA-Dubbing提供了几个关键优势:1)综合维度:TA-Dubbing涵盖了电影配音的多个维度,结合了电影理解和语音生成的指标评估。2)通用基准测试:TA-Dubbing旨在评估最先进的电影配音模型和高级多模态大型语言模型。3)完全开源:我们在https://github.com/woka-0a/DeepDubber-V1上完全开源TA-Dubbing,包括所有视频套件、评估方法和注释。我们还不断将新的电影配音模型集成到TA-Dubbing排行榜中(https://github.com/woka-0a/DeepDubber-V1),以推动电影配音领域的发展。
论文及项目相关链接
PDF 6 pages, 3 figures, accepted to the AI for Content Creation workshop at CVPR 2025 in Nashville, TN
Summary
本文介绍了电影配音的评估基准——Talking Adaptive Dubbing Benchmarks(TA-Dubbing)。该基准弥补了现有评估体系的不足,全面考虑了电影配音中的对话、旁白、独白和演员适应性问题,旨在提高电影配音质量和电影生产效率。其主要优势包括全面评估维度、多种模型评估以及完全开源等。
Key Takeaways
- 电影配音评估一直存在挑战,需要一个全面的评估基准。
- TA-Dubbing基准考虑了电影配音的复杂性,包括对话、旁白、独白和演员适应性。
- TA-Dubbing旨在提高电影配音质量和电影生产效率。
- TA-Dubbing提供了全面的评估维度,包括电影理解和语音生成的评估。
- 该基准可以评估最新的电影配音模型和多模态大型语言模型。
- TA-Dubbing是完全开源的,所有视频素材、评估方法和注释都可在指定链接找到。
点此查看论文截图