⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-09 更新
Implicitly Aligning Humans and Autonomous Agents through Shared Task Abstractions
Authors:Stéphane Aroca-Ouellette, Miguel Aroca-Ouellette, Katharina von der Wense, Alessandro Roncone
In collaborative tasks, autonomous agents fall short of humans in their capability to quickly adapt to new and unfamiliar teammates. We posit that a limiting factor for zero-shot coordination is the lack of shared task abstractions, a mechanism humans rely on to implicitly align with teammates. To address this gap, we introduce HA$^2$: Hierarchical Ad Hoc Agents, a framework leveraging hierarchical reinforcement learning to mimic the structured approach humans use in collaboration. We evaluate HA$^2$ in the Overcooked environment, demonstrating statistically significant improvement over existing baselines when paired with both unseen agents and humans, providing better resilience to environmental shifts, and outperforming all state-of-the-art methods.
在协同任务中,自主代理在快速适应新队友和陌生队友方面的能力不及人类。我们认为,零起点协调的一个限制因素是缺乏共享任务抽象,这是人类用来与队友隐性对齐的一种机制。为了弥补这一差距,我们引入了HA$^2$:分层即时通讯代理框架,该框架利用分层强化学习来模仿人类在协作中使用的结构化方法。我们在《煮糊了》环境中对HA$^2$进行了评估,与看不见的代理和人类配对时,它在统计上显著地改进了现有的基线水平,对环境变化的适应性更强,并且超过了所有最新的方法。
论文及项目相关链接
PDF 9 pages (7 paper + 2 references). To be published in IJCAI 2025
Summary
本文指出在协同任务中,自主代理在面对新队友时难以快速适应。本文提出一个假设,即缺乏共享任务抽象是导致零代理协调问题的因素之一。为了解决这个问题,本文提出了HA$^2$框架,该框架利用分层强化学习来模仿人类在协作中的结构化方法。在Overcooked环境中对HA$^2$进行了评估,结果表明与未见过的代理和人类配对时,其性能优于现有基线,并具有更好的环境适应性,超过了所有当前先进的方法。
Key Takeaways
- 在协同任务中,自主代理在新队友面前快速适应的能力有所欠缺。
- 缺乏共享任务抽象是导致零代理协调问题的一个关键因素。
- HA$^2$框架旨在通过模仿人类在协作中的结构化方法来解决此问题。
- HA$^2$框架利用分层强化学习技术。
- 在Overcooked环境中评估HA$^2$时,其性能优于现有基线。
- HA$^2$与未见过的代理和人类配对时表现更好。
点此查看论文截图

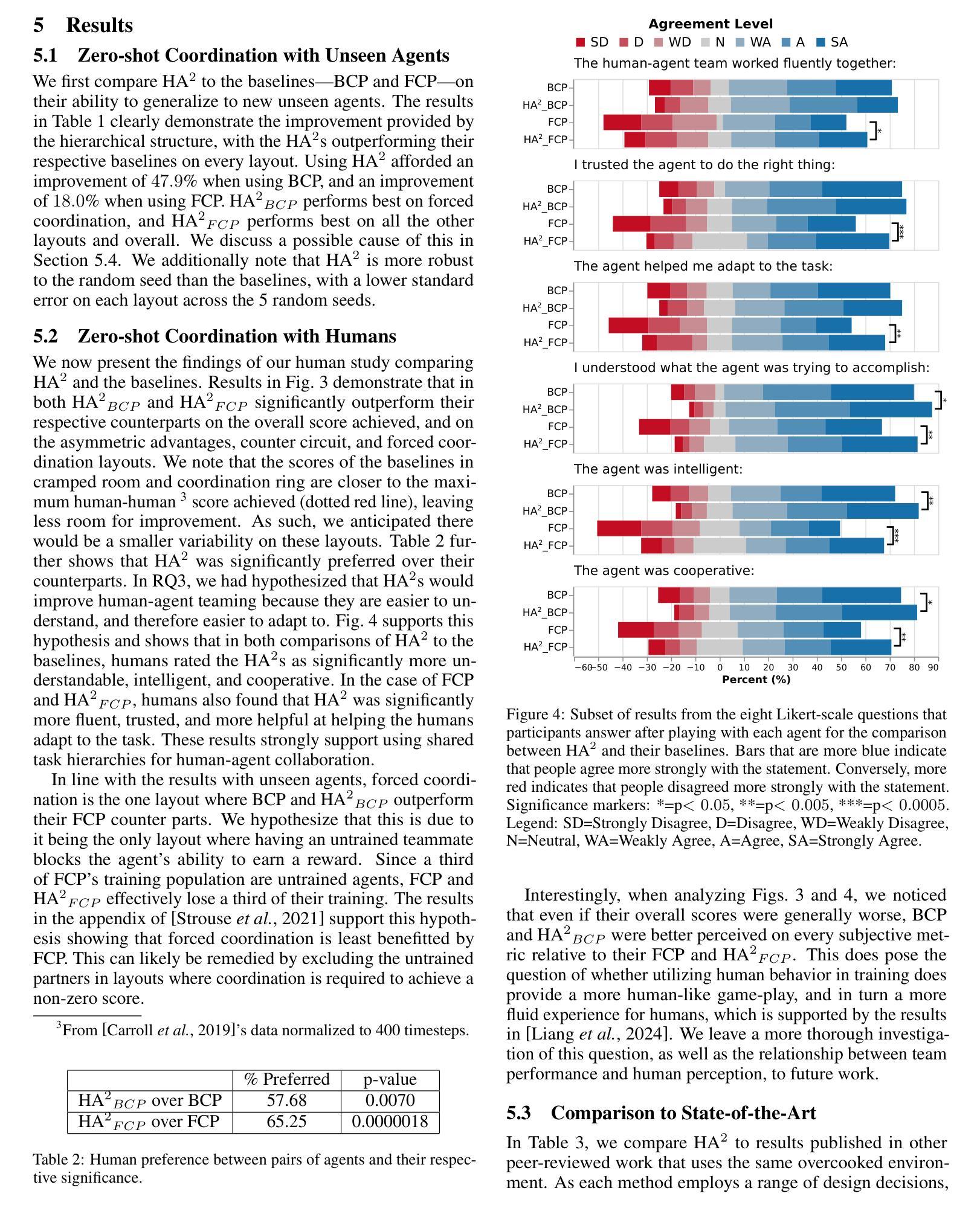
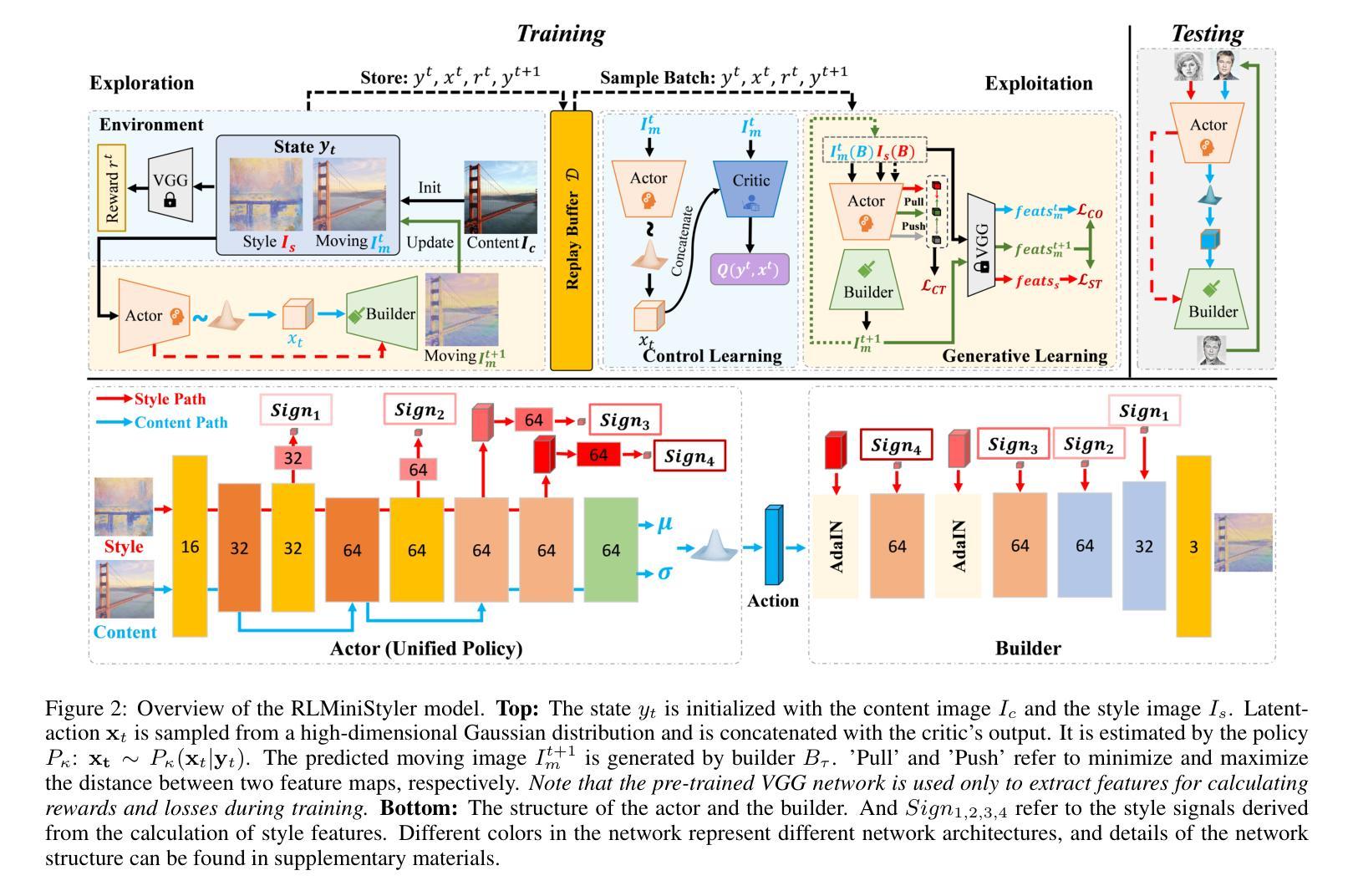
RLMiniStyler: Light-weight RL Style Agent for Arbitrary Sequential Neural Style Generation
Authors:Jing Hu, Chengming Feng, Shu Hu, Ming-Ching Chang, Xin Li, Xi Wu, Xin Wang
Arbitrary style transfer aims to apply the style of any given artistic image to another content image. Still, existing deep learning-based methods often require significant computational costs to generate diverse stylized results. Motivated by this, we propose a novel reinforcement learning-based framework for arbitrary style transfer RLMiniStyler. This framework leverages a unified reinforcement learning policy to iteratively guide the style transfer process by exploring and exploiting stylization feedback, generating smooth sequences of stylized results while achieving model lightweight. Furthermore, we introduce an uncertainty-aware multi-task learning strategy that automatically adjusts loss weights to adapt to the content and style balance requirements at different training stages, thereby accelerating model convergence. Through a series of experiments across image various resolutions, we have validated the advantages of RLMiniStyler over other state-of-the-art methods in generating high-quality, diverse artistic image sequences at a lower cost. Codes are available at https://github.com/fengxiaoming520/RLMiniStyler.
任意风格迁移旨在将给定艺术图像的风格应用到另一个内容图像上。然而,现有的基于深度学习的方法常常需要巨大的计算成本来生成多样化的风格化结果。鉴于此,我们提出了一种新型的基于强化学习的任意风格迁移框架RLMiniStyler。该框架利用统一的强化学习策略,通过探索和利用风格化反馈来迭代指导风格迁移过程,生成平滑的风格化结果序列,同时实现模型轻量化。此外,我们引入了一种基于不确定性感知的多任务学习策略,该策略能够自动调整损失权重以适应不同训练阶段的内容和风格平衡要求,从而加速模型收敛。通过一系列跨越不同分辨率图像的实验,我们已经验证了RLMiniStyler相较于其他先进方法生成高质量、多样化艺术图像序列的优势,并且成本更低。代码可在https://github.com/fengxiaoming520/RLMiniStyler找到。
论文及项目相关链接
PDF IJCAI2025
Summary
任意风格迁移旨在将给定艺术图像的风格应用到另一个内容图像上。然而,现有的基于深度学习方法往往计算成本高昂,难以生成多样化的风格化结果。为此,我们提出一种新型基于强化学习的任意风格迁移框架RLMiniStyler。该框架利用统一的强化学习策略,通过探索和利用风格化反馈来指导风格迁移过程,生成平滑的风格化结果序列,同时实现模型轻量化。此外,我们引入了一种感知不确定性的多任务学习策略,自动调整损失权重以适应不同训练阶段的内容和风格平衡需求,从而加速模型收敛。通过实验验证,RLMiniStyler在生成高质量、多样化的艺术图像序列方面优于其他先进方法,且成本更低。
Key Takeaways
- RLMiniStyler是一个基于强化学习的新型任意风格迁移框架。
- 该框架能生成平滑的风格化结果序列,同时实现模型轻量化。
- RLMiniStyler采用统一的强化学习策略,通过探索与利用风格化反馈来指导风格迁移过程。
- 引入感知不确定性的多任务学习策略,自动调整损失权重以适应不同训练阶段的需求。
- 该方法能在较低的计算成本下生成高质量、多样化的艺术图像序列。
- 实验结果表明,RLMiniStyler在风格迁移任务上表现优于其他先进方法。
点此查看论文截图


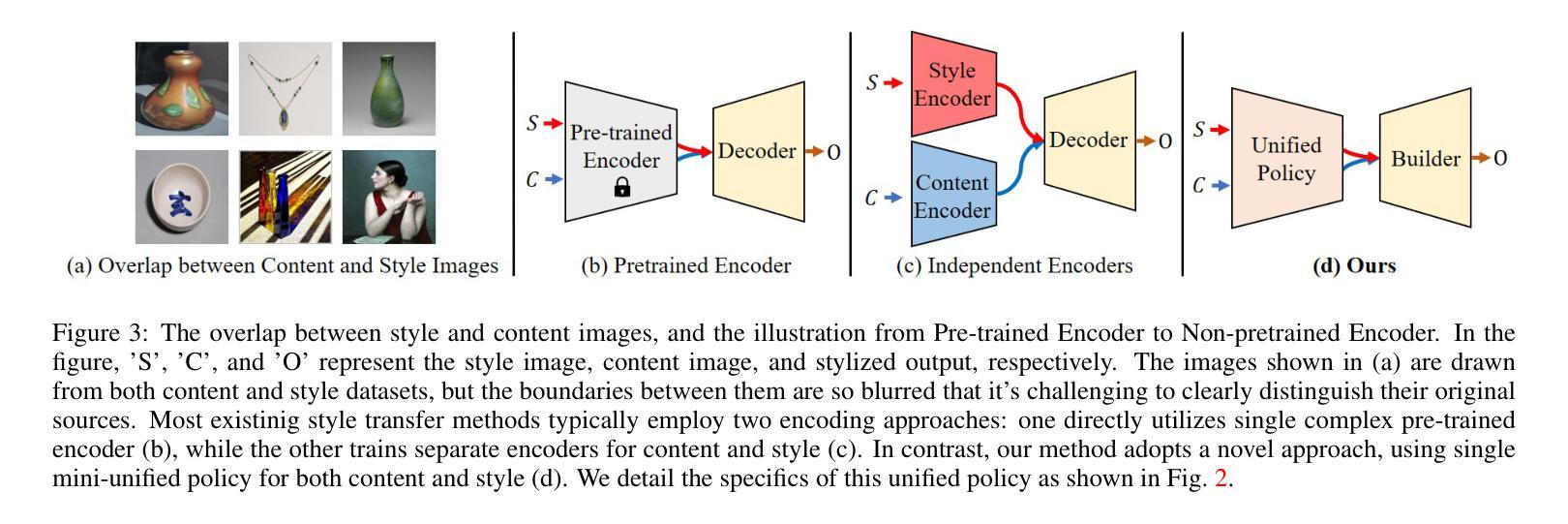

Resist Platform-Controlled AI Agents and Champion User-Centric Agent Advocates
Authors:Sayash Kapoor, Noam Kolt, Seth Lazar
Language model agents could reshape how users navigate and act in digital environments. If controlled by platform companies – either those that already dominate online search, communication, and commerce, or those vying to replace them – platform agents could intensify surveillance, exacerbate user lock-in, and further entrench the incumbent digital giants. This position paper argues that to resist the undesirable effects of platform agents, we should champion agent advocates – agents that are controlled by users, serve the interests of users, and preserve user autonomy and choice. We identify key interventions to enable agent advocates: ensuring public access to compute, developing interoperability protocols and safety standards, and implementing appropriate market regulations.
语言模型代理技术可能会重塑用户如何在数字环境中导航和行动的方式。如果由平台公司控制——无论是那些已经主导在线搜索、通信和电子商务的公司,还是那些试图取代它们的公司——平台代理可能会加强监控,加剧用户锁定,并进一步巩固现有的数字巨头地位。本立场论文认为,要抵抗平台代理的不利影响,我们应该支持用户控制的代理,即为用户服务、维护用户自主权和选择的代理。我们确定了实现代理支持的关键干预措施:确保公众访问计算能力、开发互操作协议和安全标准,并实施适当的市场监管。
论文及项目相关链接
PDF Accepted to ICML 2025 position paper track
Summary
语言模型代理人可能重塑用户如何在数字环境中的导航和行为。若被平台公司控制,无论是已主导在线搜索、通讯和电商的公司,或是意图取而代之的公司,平台代理人可能会强化监视,增加用户锁定效应,并巩固现有的数字巨头地位。本立场论文主张扶持用户控制的代理人——即为用户服务、维护用户自主权和选择的代理人。我们确定了实现代理人主张的关键干预措施:确保计算普及、开发互操作协议和安全标准,以及实施适当的市场监管。
Key Takeaways
- 语言模型代理人可能重塑用户在数字环境中的导航和行为方式。
- 平台公司控制语言模型代理人可能带来不良影响,如强化监视和用户锁定。
- 现有的数字巨头可能会通过控制语言模型代理人来巩固其地位。
- 需要扶持用户控制的代理人(agent advocates),以维护用户自主权和选择。
- 实现代理人主张的关键干预措施包括确保计算普及、开发互操作协议和安全标准。
- 适当的市场监管是确保语言模型代理人服务于用户利益的重要手段。
点此查看论文截图

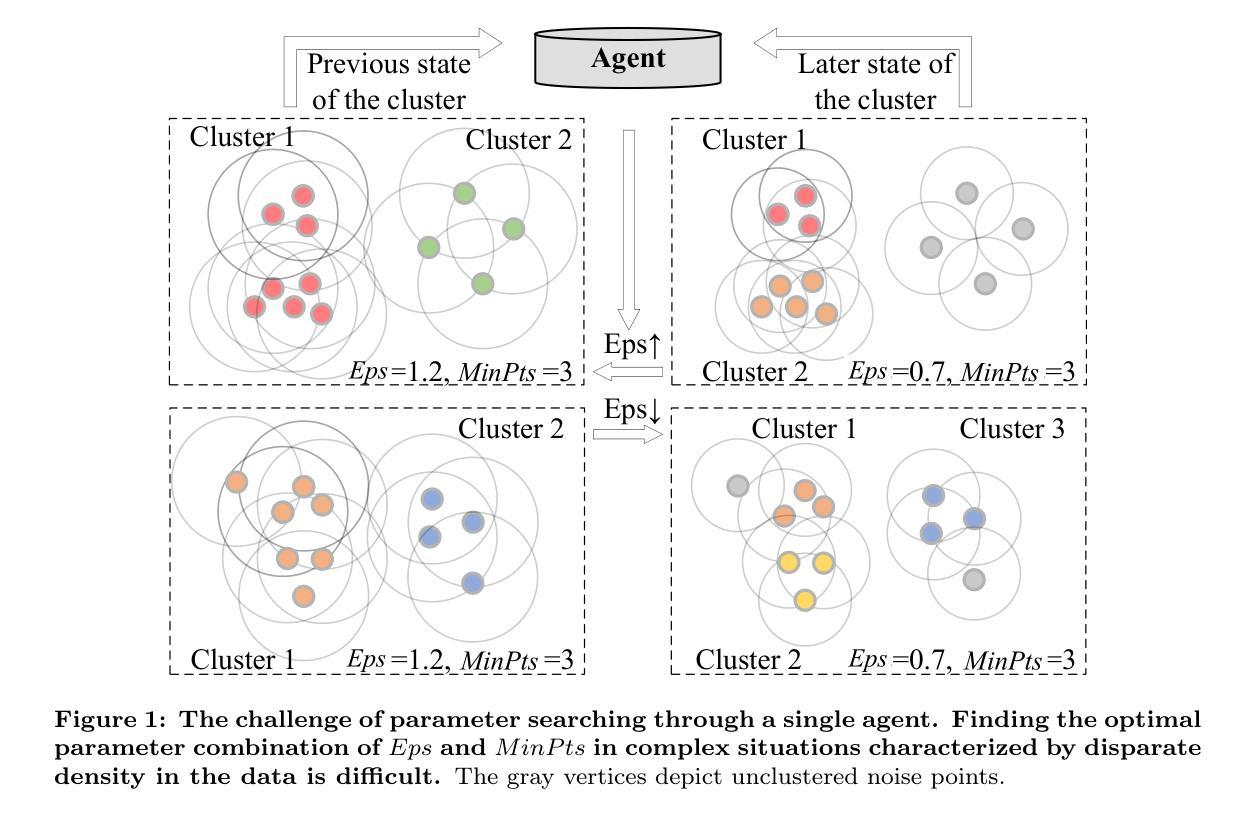
Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning
Authors:Hao Peng, Xiang Huang, Shuo Sun, Ruitong Zhang, Philip S. Yu
DBSCAN, a well-known density-based clustering algorithm, has gained widespread popularity and usage due to its effectiveness in identifying clusters of arbitrary shapes and handling noisy data. However, it encounters challenges in producing satisfactory cluster results when confronted with datasets of varying density scales, a common scenario in real-world applications. In this paper, we propose a novel Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning cluster framework, namely AR-DBSCAN. First, we model the initial dataset as a two-level encoding tree and categorize the data vertices into distinct density partitions according to the information uncertainty determined in the encoding tree. Each partition is then assigned to an agent to find the best clustering parameters without manual assistance. The allocation is density-adaptive, enabling AR-DBSCAN to effectively handle diverse density distributions within the dataset by utilizing distinct agents for different partitions. Second, a multi-agent deep reinforcement learning guided automatic parameter searching process is designed. The process of adjusting the parameter search direction by perceiving the clustering environment is modeled as a Markov decision process. Using a weakly-supervised reward training policy network, each agent adaptively learns the optimal clustering parameters by interacting with the clusters. Third, a recursive search mechanism adaptable to the data’s scale is presented, enabling efficient and controlled exploration of large parameter spaces. Extensive experiments are conducted on nine artificial datasets and a real-world dataset. The results of offline and online tasks show that AR-DBSCAN not only improves clustering accuracy by up to 144.1% and 175.3% in the NMI and ARI metrics, respectively, but also is capable of robustly finding dominant parameters.
DBSCAN是一种众所周知的基于密度的聚类算法,因其能够识别任意形状的簇并处理噪声数据而广受欢迎。然而,在面对密度规模各异的数据集时,它在实际应用中经常面临挑战,无法产生令人满意的聚类结果。针对这一问题,本文提出了一种新型自适应稳健DBSCAN与多智能体强化学习聚类框架,即AR-DBSCAN。首先,我们将初始数据集建模为两级编码树,并根据编码树中确定的信息不确定性将数据顶点分类为不同的密度分区。然后,每个分区被分配给一个智能体,以在无需人工协助的情况下找到最佳的聚类参数。这种分配是密度自适应的,使得AR-DBSCAN能够通过针对不同分区使用不同的智能体来有效地处理数据集中的不同密度分布。其次,设计了一种多智能体深度强化学习引导自动参数搜索过程。通过感知聚类环境来调整参数搜索方向的过程被建模为马尔可夫决策过程。通过弱监督奖励训练策略网络,每个智能体通过与聚类交互来适应性地学习最佳聚类参数。第三,提出了一种适应于数据规模的递归搜索机制,实现了对大型参数空间的有效且受控的探索。在九个模拟数据集和一个真实数据集上进行了广泛的实验。在线和离线任务的结果表明,AR-DBSCAN不仅在NMI和ARI指标上分别提高了144.1%和175.3%的聚类精度,而且能够稳健地找到主要参数。
论文及项目相关链接
摘要
DBSCAN聚类算法在处理具有任意形状和噪声的数据时表现出良好的性能,但面对密度分布差异大的数据集时仍面临挑战。本文提出了一种新型自适应稳健DBSCAN与多智能体强化学习聚类框架——AR-DBSCAN。首先,将初始数据集建模为两级编码树,并根据编码树中确定的信息不确定性将数据顶点分类为不同的密度分区。然后,每个分区被分配给一个智能体,无需人工辅助即可找到最佳聚类参数。其次,设计了一种基于多智能体深度强化学习的自动参数搜索过程。通过感知聚类环境来调整参数搜索方向,并将其建模为马尔可夫决策过程。使用弱监督奖励训练策略网络,每个智能体通过与聚类交互来适应性地学习最佳聚类参数。此外,还提出了一种适应数据规模的递归搜索机制,可实现大型参数空间的有效且受控探索。在九个合成数据集和真实数据集上进行了大量实验。结果表明,AR-DBSCAN不仅在NMI和ARI指标上分别提高了高达144.1%和175.3%的聚类精度,而且能够稳健地找到主要参数。
关键见解
- AR-DBSCAN解决了DBSCAN在处理密度分布差异大的数据集时面临的挑战。
- AR-DBSCAN通过两级编码树对数据进行分类,以适应不同的密度分区。
- 通过多智能体强化学习自动寻找最佳聚类参数,提高了聚类的效率和准确性。
- AR-DBSCAN采用弱监督奖励训练策略网络,使智能体能够适应性地学习最佳聚类参数。
- AR-DBSCAN实现了大型参数空间的有效且受控的探索,通过递归搜索机制。
- 在多个数据集上的实验表明,AR-DBSCAN在NMI和ARI指标上显著提高聚类精度。
点此查看论文截图

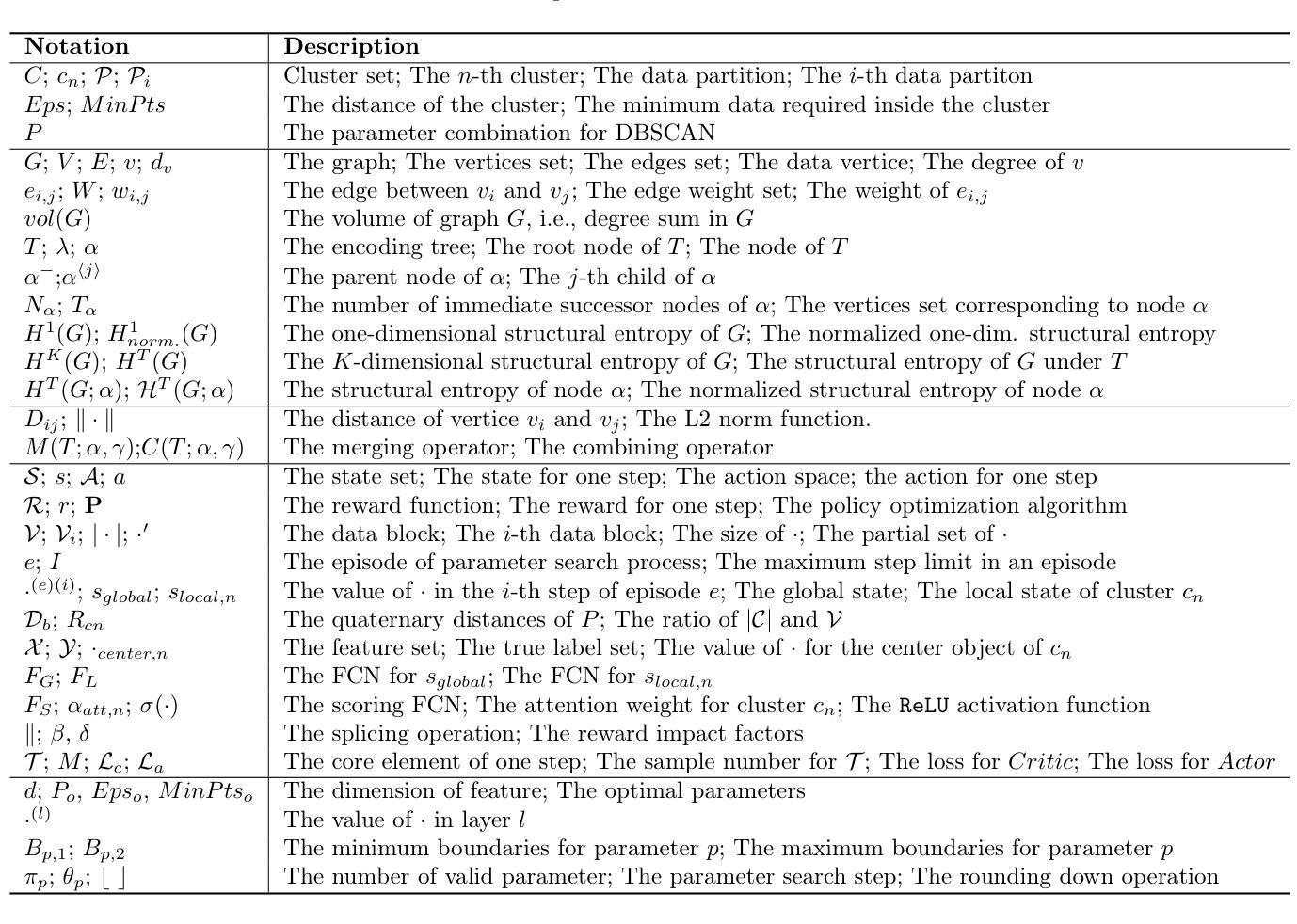
Facilitating Trustworthy Human-Agent Collaboration in LLM-based Multi-Agent System oriented Software Engineering
Authors:Krishna Ronanki
Multi-agent autonomous systems (MAS) are better at addressing challenges that spans across multiple domains than singular autonomous agents. This holds true within the field of software engineering (SE) as well. The state-of-the-art research on MAS within SE focuses on integrating LLMs at the core of autonomous agents to create LLM-based multi-agent autonomous (LMA) systems. However, the introduction of LMA systems into SE brings a plethora of challenges. One of the major challenges is the strategic allocation of tasks between humans and the LMA system in a trustworthy manner. To address this challenge, a RACI-based framework is proposed in this work in progress article, along with implementation guidelines and an example implementation of the framework. The proposed framework can facilitate efficient collaboration, ensure accountability, and mitigate potential risks associated with LLM-driven automation while aligning with the Trustworthy AI guidelines. The future steps for this work delineating the planned empirical validation method are also presented.
多智能体自主系统(MAS)在处理跨多个领域的挑战时,相比单一的自主智能体,更具优势。这在软件工程(SE)领域也是如此。当前SE中关于MAS的研究重点在于将大型语言模型(LLM)整合到自主智能体的核心,以创建基于LLM的多智能体自主(LMA)系统。然而,将LMA系统引入SE带来了众多挑战。其中一项主要挑战是以可靠的方式在人与LMA系统之间进行任务战略分配。为解决这一挑战,本进展中的文章提出了基于RACI的框架,以及实施指南和框架的示例实现。所提出的框架可以促进高效协作,确保问责制,并缓解与LLM驱动的自动化相关的潜在风险,同时符合可信AI指南。本文还介绍了未来工作的下一步计划,详细说明了计划的实证验证方法。
论文及项目相关链接
Summary
多主体自主系统(MAS)在解决跨多个领域挑战方面优于单一自主代理系统,这在软件工程(SE)领域尤为明显。当前研究集中在将大型语言模型(LLM)集成到自主代理系统的核心,构建基于LLM的多主体自主(LMA)系统。然而,引入LMA系统给SE带来诸多挑战,其中一个主要挑战是以可靠的方式实现人与LMA系统的任务战略分配。本工作正在研究并提出一个基于RACI的框架来解决这一挑战,同时提供实施指南和框架的示例实现。该框架能够促进高效协作、确保责任明确并缓解与LLM驱动的自动化相关的潜在风险,同时遵循可信人工智能指南。本文还介绍了未来的工作步骤,详细说明了计划进行的实证验证方法。
Key Takeaways
- 多主体自主系统(MAS)擅长处理跨多个领域的挑战,特别是在软件工程领域。
- 当前的研究趋势是集成大型语言模型(LLM)到自主代理系统中,形成基于LLM的多主体自主(LMA)系统。
- 引入LMA系统到软件工程面临诸多挑战,其中主要挑战是人与LMA系统之间的任务战略分配。
- 提出一个基于RACI的框架来解决人与LMA系统的任务分配挑战,促进高效协作、确保责任明确,并缓解与LLM相关的潜在风险。
- 该框架遵循可信人工智能指南,有助于实现可靠的任务自动化。
- 未来的工作将包括实证验证方法的实施,以评估框架的实际效果。
点此查看论文截图


Appeal and Scope of Misinformation Spread by AI Agents and Humans
Authors:Lynnette Hui Xian Ng, Wenqi Zhou, Kathleen M. Carley
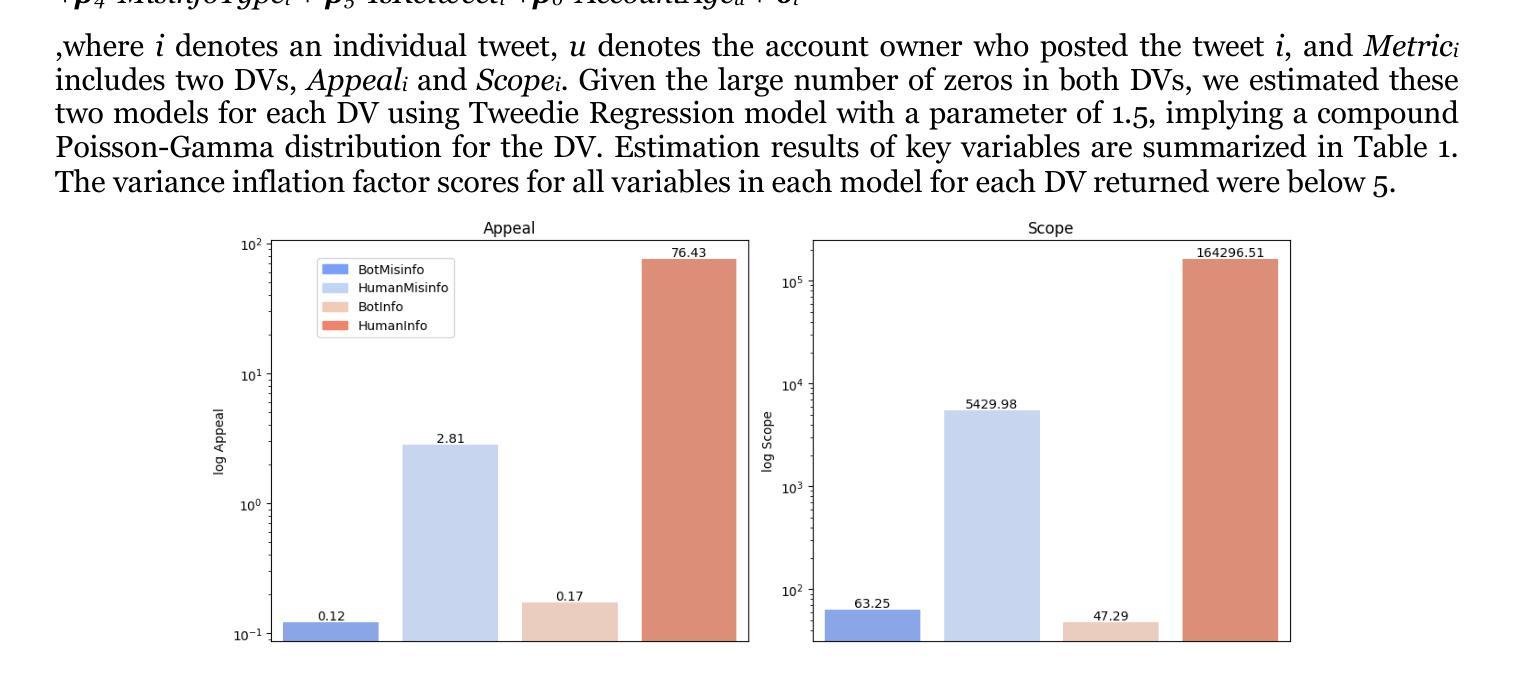
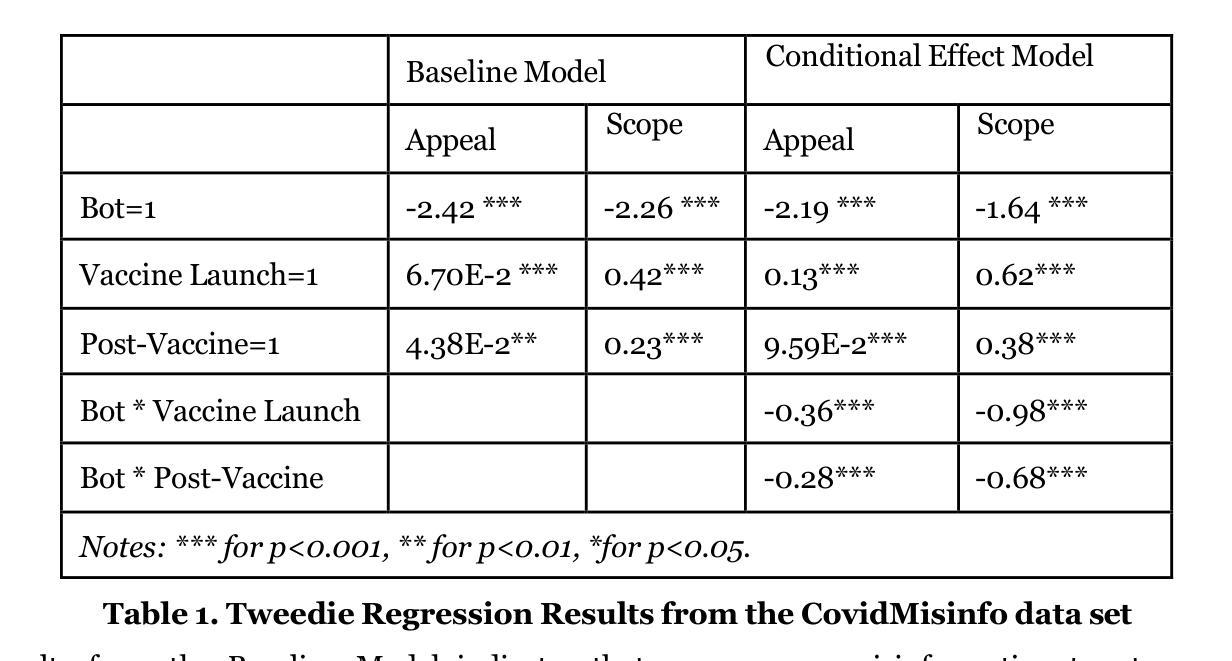
This work examines the influence of misinformation and the role of AI agents, called bots, on social network platforms. To quantify the impact of misinformation, it proposes two new metrics based on attributes of tweet engagement and user network position: Appeal, which measures the popularity of the tweet, and Scope, which measures the potential reach of the tweet. In addition, it analyzes 5.8 million misinformation tweets on the COVID-19 vaccine discourse over three time periods: Pre-Vaccine, Vaccine Launch, and Post-Vaccine. Results show that misinformation was more prevalent during the first two periods. Human-generated misinformation tweets tend to have higher appeal and scope compared to bot-generated ones. Tweedie regression analysis reveals that human-generated misinformation tweets were most concerning during Vaccine Launch week, whereas bot-generated misinformation reached its highest appeal and scope during the Pre-Vaccine period.
本文研究了错误信息的影响以及被称为机器人的AI代理在社会网络平台上的作用。为了量化错误信息的影响,它提出了两个基于推文参与度和用户网络位置属性的新指标:吸引力,衡量推文的受欢迎程度;范围,衡量推文潜在的传播范围。此外,它分析了关于COVID-19疫苗讨论的580万条错误信息推文,分为三个阶段:疫苗前、疫苗发布和疫苗后。结果表明,错误信息在前两个阶段更为普遍。与人类生成的错误信息推文相比,机器人生成的错误信息推文的吸引力和范围往往更高。Tweeddie回归分析显示,在疫苗发布周,人类生成的错误信息推文最令人担忧,而机器人生成的错误信息在疫苗前阶段的吸引力和范围达到最高。
论文及项目相关链接
PDF Accepted to AMCIS 2025
Summary
本文探讨了错误信息的影响以及AI代理(即机器人)在社交平台上的作用。为量化错误信息的影响,提出了两个基于推文参与度和用户网络位置属性的新指标:吸引力,衡量推文的受欢迎程度;覆盖面,衡量推文的潜在影响力范围。此外,文章分析了关于COVID-19疫苗讨论的580万条错误信息推文,分为预疫苗、疫苗发布和后疫苗三个时期。结果表明前两个时期的错误信息更为普遍。人类生成的错误信息推文通常比机器人生成的推文具有更高的吸引力和覆盖范围。Tweedie回归分析显示,在疫苗发布周,人类生成的错误信息推文最为令人担忧,而机器人生成的错误信息在预疫苗期间达到了最高的吸引力和覆盖范围。
Key Takeaways
- 研究了错误信息在社交平台上的影响以及AI代理(机器人)的角色。
- 提出两个新指标:吸引力衡量推文的受欢迎程度,覆盖面衡量推文的潜在影响力范围。
- 分析了关于COVID-19疫苗的580万条错误信息推文,分为预疫苗、疫苗发布和后疫苗三个时期。
- 错误信息在前两个时期更为普遍,人类生成的错误信息推文具有较高的吸引力和覆盖范围。
- 在疫苗发布周,人类生成的错误信息推文的影响最为严重。
- 机器人生成的错误信息在预疫苗期间达到了最高的吸引力和覆盖范围。
点此查看论文截图

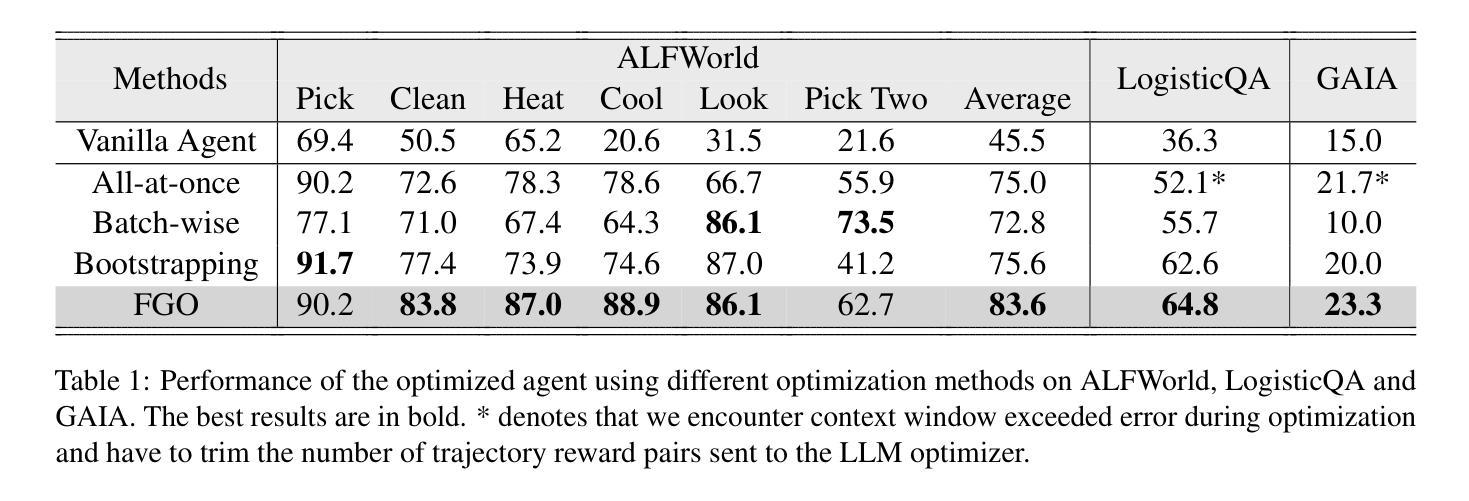
Divide, Optimize, Merge: Fine-Grained LLM Agent Optimization at Scale
Authors:Jiale Liu, Yifan Zeng, Shaokun Zhang, Chi Zhang, Malte Højmark-Bertelsen, Marie Normann Gadeberg, Huazheng Wang, Qingyun Wu
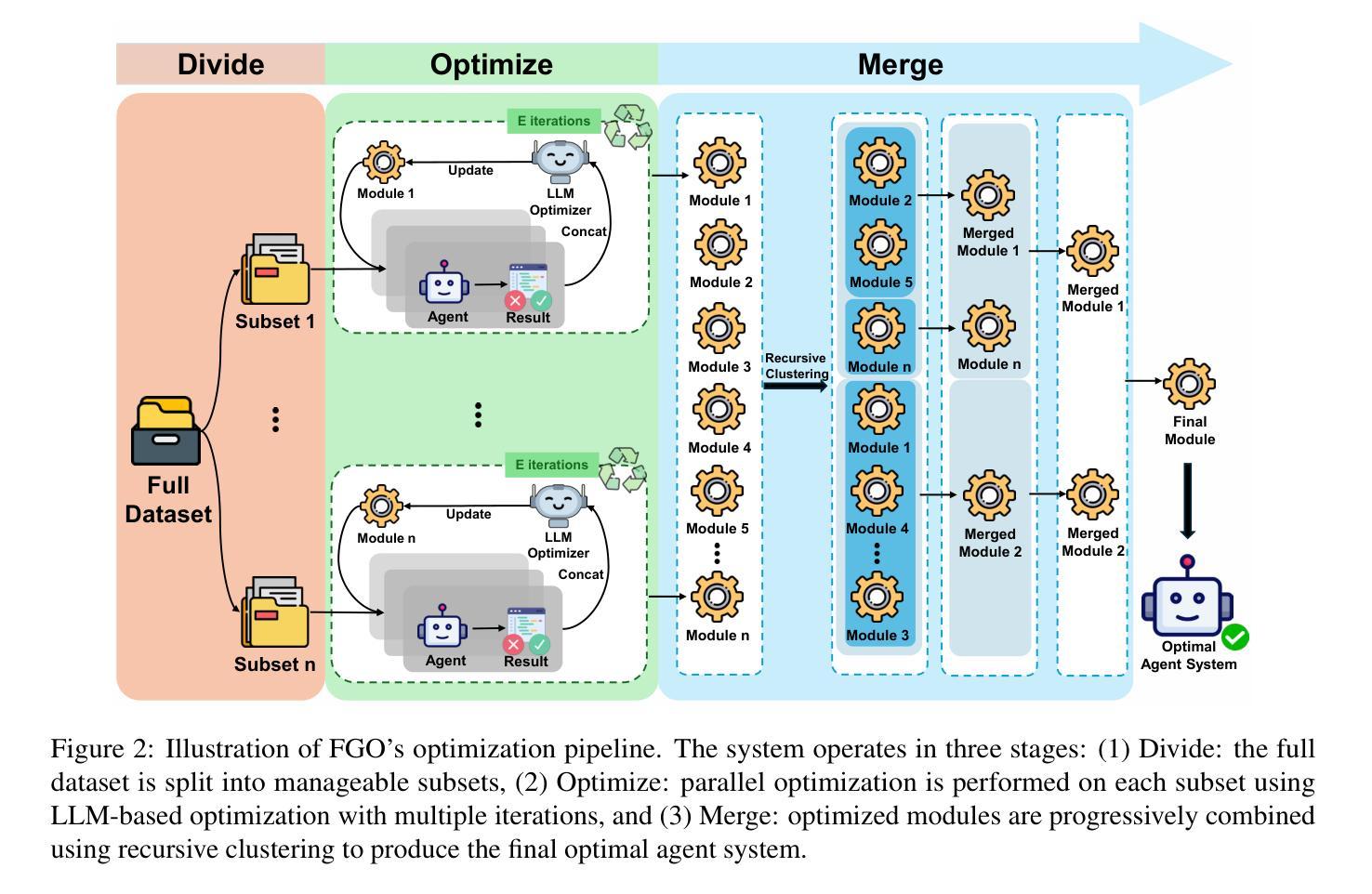
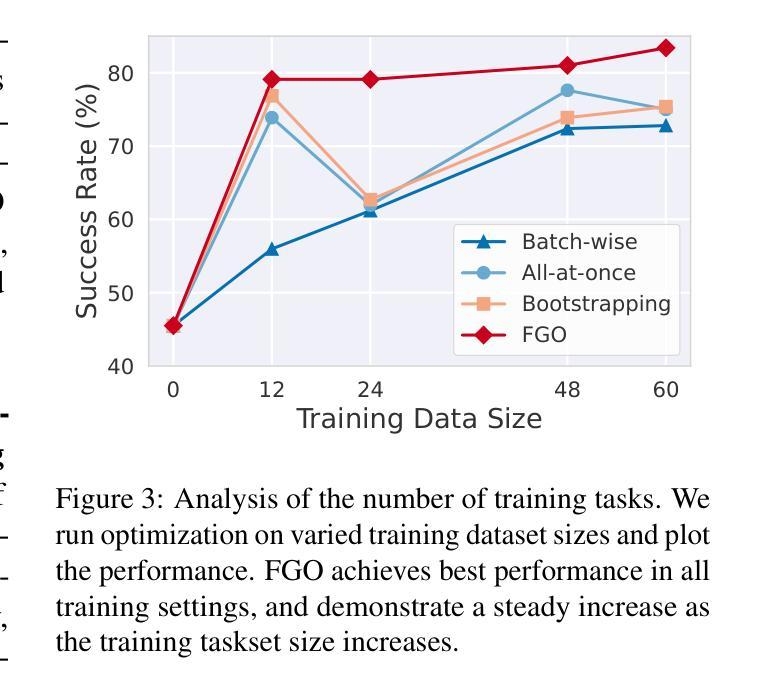
LLM-based optimization has shown remarkable potential in enhancing agentic systems. However, the conventional approach of prompting LLM optimizer with the whole training trajectories on training dataset in a single pass becomes untenable as datasets grow, leading to context window overflow and degraded pattern recognition. To address these challenges, we propose Fine-Grained Optimization (FGO), a scalable framework that divides large optimization tasks into manageable subsets, performs targeted optimizations, and systematically combines optimized components through progressive merging. Evaluation across ALFWorld, LogisticsQA, and GAIA benchmarks demonstrate that FGO outperforms existing approaches by 1.6-8.6% while reducing average prompt token consumption by 56.3%. Our framework provides a practical solution for scaling up LLM-based optimization of increasingly sophisticated agent systems. Further analysis demonstrates that FGO achieves the most consistent performance gain in all training dataset sizes, showcasing its scalability and efficiency.
基于LLM的优化在提升代理系统方面已显示出显著潜力。然而,随着数据集的增长,使用传统方法一次性提供整个训练轨迹来提示LLM优化器的方式变得不可持续,这会导致上下文窗口溢出和模式识别能力下降。为了应对这些挑战,我们提出了精细粒度优化(FGO),这是一个可扩展的框架,它将大型优化任务划分为可管理的子集,执行有针对性的优化,并通过逐步合并系统地组合优化组件。在ALFWorld、 LogisticsQA和GAIA基准测试上的评估表明,FGO的性能比现有方法高出1.6-8.6%,同时平均提示令牌消耗减少56.3%。我们的框架为扩大基于LLM的日益复杂的代理系统的优化提供了实用解决方案。进一步的分析表明,FGO在所有训练数据集大小上都实现了最一致的性能提升,证明了其可扩展性和效率。
论文及项目相关链接
摘要
LLM优化技术在提高代理系统性能方面具有显著潜力。然而,随着数据集的增长,传统的优化器提示方法面临挑战,如上下文窗口溢出和模式识别下降。为解决这些问题,我们提出精细化优化(FGO)框架,其可将大型优化任务分为小型子集进行管理、进行有针对性的优化并通过逐步合并系统地组合优化组件。在ALFWorld、LogisticsQA和GAIA基准测试上的评估显示,FGO在提升性能的同时降低了平均提示令牌消耗。我们的框架为扩展LLM优化日益复杂的代理系统提供了实用解决方案。进一步的分析表明,FGO在所有训练数据集大小上都实现了最一致的性能提升,证明了其可扩展性和效率。
要点摘要
- LLM优化技术在增强代理系统方面展现出显著潜力。
- 传统方法在处理大型数据集时面临上下文窗口溢出和模式识别下降的挑战。
- FGO框架通过细分大型优化任务,进行有针对性的优化,并通过逐步合并优化组件来解决这些问题。
- FGO在多个基准测试上的性能优于现有方法,并降低了平均提示令牌消耗。
- FGO框架适用于扩展LLM优化日益复杂的代理系统。
- FGO在所有训练数据集大小上都实现了性能提升,证明了其可扩展性和效率。
- FGO提供了一种有效的策略来应对随着数据集增长而带来的优化挑战。
点此查看论文截图



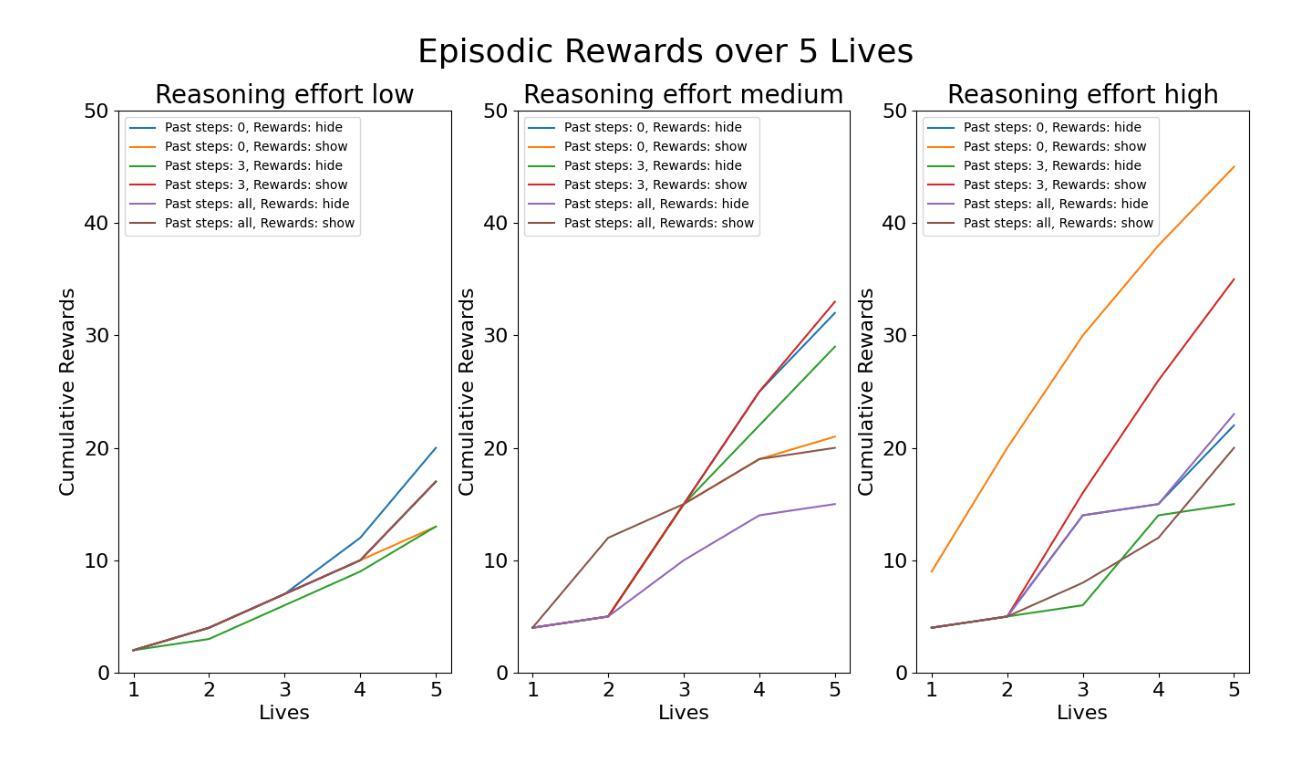
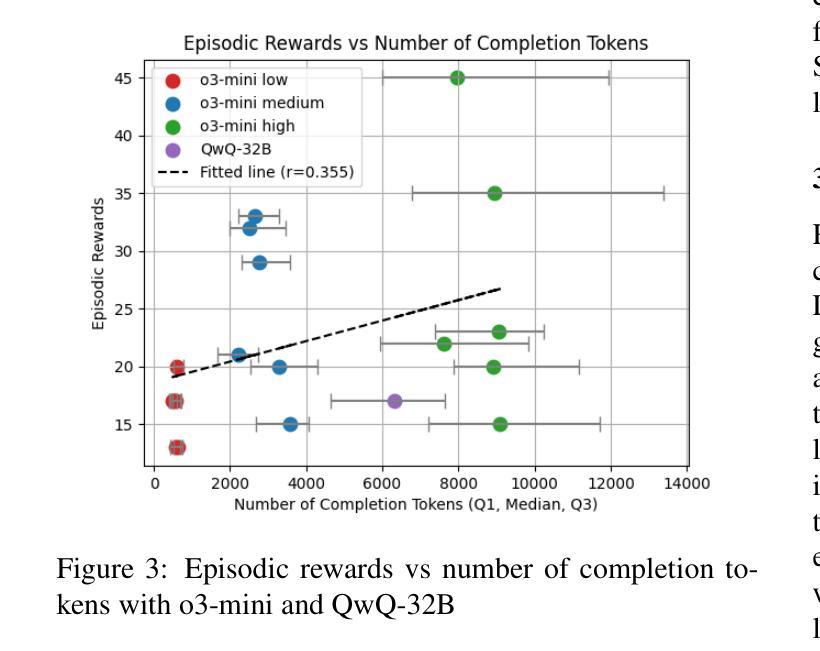
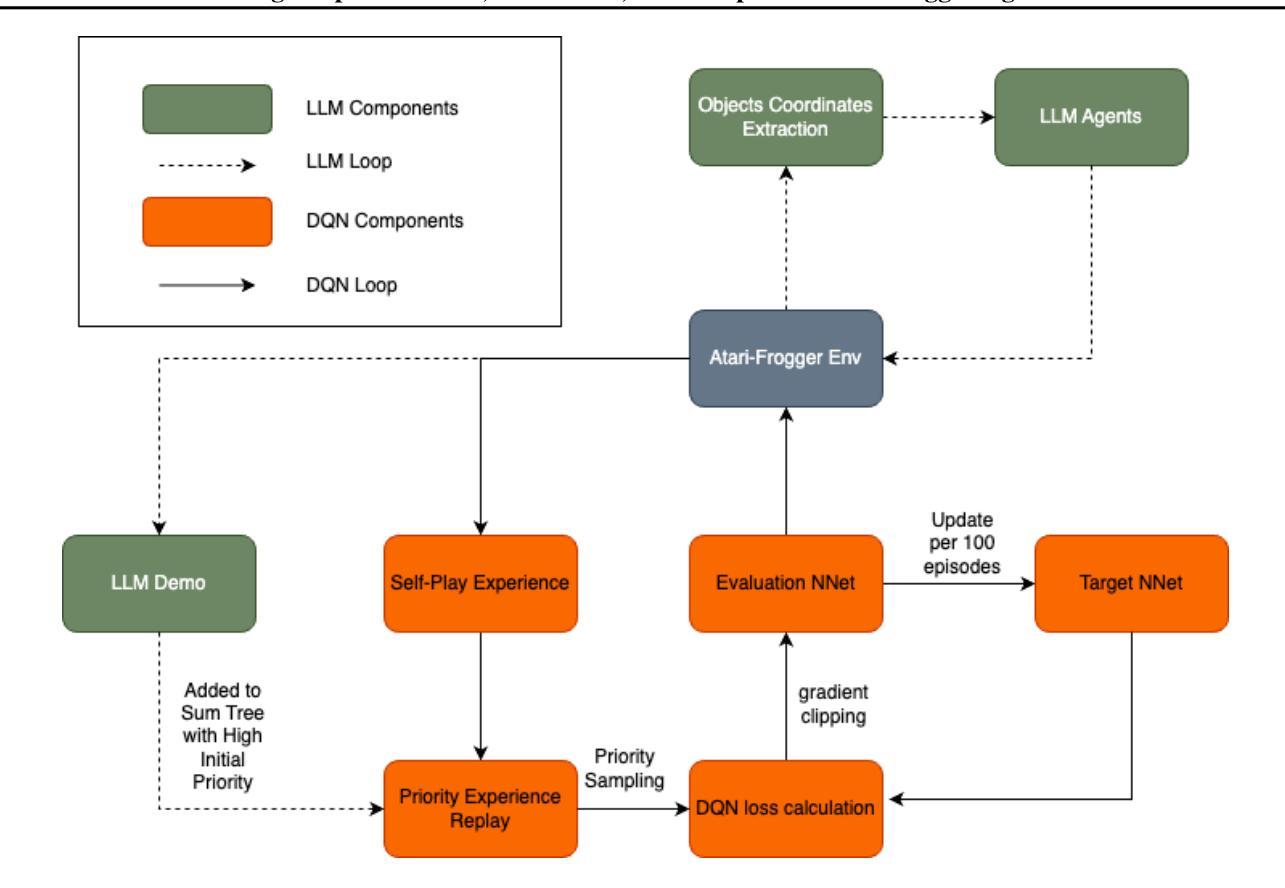
Frog Soup: Zero-Shot, In-Context, and Sample-Efficient Frogger Agents
Authors:Xiang Li, Yiyang Hao, Doug Fulop
One of the primary aspirations in reinforcement learning research is developing general-purpose agents capable of rapidly adapting to and mastering novel tasks. While RL gaming agents have mastered many Atari games, they remain slow and costly to train for each game. In this work, we demonstrate that latest reasoning LLMs with out-of-domain RL post-training can play a challenging Atari game called Frogger under a zero-shot setting. We then investigate the effect of in-context learning and the amount of reasoning effort on LLM performance. Lastly, we demonstrate a way to bootstrap traditional RL method with LLM demonstrations, which significantly improves their performance and sample efficiency. Our implementation is open sourced at https://github.com/AlienKevin/frogger.
强化学习研究的主要目标之一是开发能够迅速适应并掌握新任务的通用智能体。虽然强化学习游戏智能体已经掌握了许多雅达利游戏,但它们仍然需要缓慢且昂贵的训练过程。在这项工作中,我们展示了最新的推理大型语言模型在脱离域的强化学习后训练可以在零样本设置下玩一种挑战性的雅达利游戏——Frogger。然后,我们调查上下文学习的效果以及推理努力对大型语言模型性能的影响。最后,我们展示了如何使用大型语言模型的演示来引导传统的强化学习方法,这显著提高了其性能和样本效率。我们的实现已公开在 https://github.com/AlienKevin/frogger 上。
论文及项目相关链接
Summary
强化学习领域的主要目标之一是开发能够迅速适应并掌握新任务的通用智能体。虽然强化学习游戏智能体已经掌握了众多Atari游戏,但它们对每个游戏的训练速度和成本仍然较慢和较高。本研究展示了最新的推理大型语言模型在经过域外强化学习后处理训练,能够在零样本设置下玩一款名为《青蛙过河》的具有挑战性的Atari游戏。我们还研究了上下文学习和推理努力对大型语言模型性能的影响。最后,我们展示了一种结合传统强化学习与大型语言模型示范的方法,这种方法极大地提高了性能和样本效率。我们的实现已开源在https://github.com/AlienKevin/frogger。
Key Takeaways
- 强化学习领域致力于开发能迅速适应并掌握新任务的通用智能体。
- 推理大型语言模型经过特定训练后,可以在零样本设置下玩复杂的Atari游戏。
- 上下文学习和推理努力对大型语言模型的游戏性能有影响。
- 结合传统强化学习与大型语言模型的示范,可以显著提高智能体的性能和样本效率。
- 该研究提供了一种使用开源代码(位于https://github.com/AlienKevin/frogger)实现上述方法的方式。
- 相比以往的强化学习游戏智能体,该方法的训练速度和成本可能更优。
点此查看论文截图


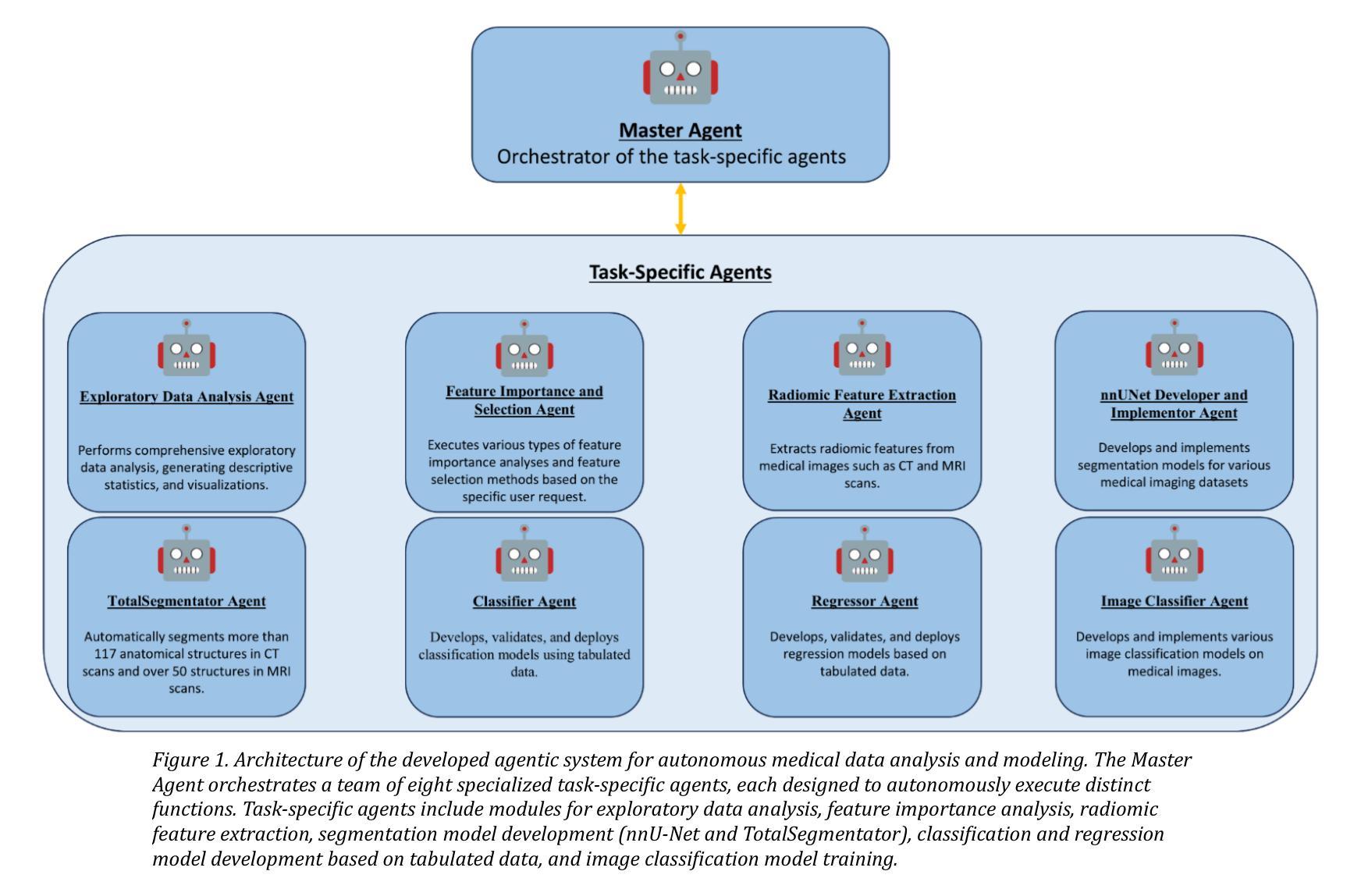
mAIstro: an open-source multi-agentic system for automated end-to-end development of radiomics and deep learning models for medical imaging
Authors:Eleftherios Tzanis, Michail E. Klontzas
Agentic systems built on large language models (LLMs) offer promising capabilities for automating complex workflows in healthcare AI. We introduce mAIstro, an open-source, autonomous multi-agentic framework for end-to-end development and deployment of medical AI models. The system orchestrates exploratory data analysis, radiomic feature extraction, image segmentation, classification, and regression through a natural language interface, requiring no coding from the user. Built on a modular architecture, mAIstro supports both open- and closed-source LLMs, and was evaluated using a large and diverse set of prompts across 16 open-source datasets, covering a wide range of imaging modalities, anatomical regions, and data types. The agents successfully executed all tasks, producing interpretable outputs and validated models. This work presents the first agentic framework capable of unifying data analysis, AI model development, and inference across varied healthcare applications, offering a reproducible and extensible foundation for clinical and research AI integration. The code is available at: https://github.com/eltzanis/mAIstro
基于大型语言模型(LLM)的Agentic系统为医疗保健AI中自动化复杂工作流程提供了有前景的能力。我们介绍了mAIstro,这是一个开源的、自主的多Agentic框架,用于医疗AI模型的端到端开发和部署。该系统通过自然语言接口协调探索性分析、放射组学特征提取、图像分割、分类和回归,无需用户编码。mAIstro采用模块化架构,支持开源和闭源LLM,并使用涵盖广泛成像模式、解剖区域和数据类型的16个开源数据集的大型和多样化的提示集进行了评估。Agent成功执行了所有任务,产生了可解释的输出和经过验证的模型。这项工作提出了第一个能够在各种医疗保健应用中统一数据分析、AI模型开发和推理的Agentic框架,为临床和研究AI集成提供了可重复和可扩展的基础。代码可在:https://github.com/eltzanis/mAIstro找到。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的Agentic系统为医疗保健AI中自动化复杂工作流程提供了有前景的能力。本文介绍了mAIstro,这是一个开源的、自主的多Agentic框架,用于医疗AI模型的端到端开发和部署。该系统通过自然语言接口协调探索性数据分析、放射学特征提取、图像分割、分类和回归,无需用户编码。mAIstro支持开源和闭源LLM,并在涵盖多种成像模式、解剖部位和数据类型的16个开源数据集上进行了广泛的提示评估。代理成功执行所有任务,产生可解释的输出和经过验证的模型。这项工作提出了第一个能够在各种医疗保健应用中统一数据分析、AI模型开发和推理的Agentic框架,为临床和研究AI集成提供了可复制和可扩展的基础。
Key Takeaways
- mAIstro是一个基于大型语言模型的开源多Agentic框架,用于医疗AI的端到端开发和部署。
- 通过自然语言接口,mAIstro能够协调多种任务,包括探索性数据分析、放射学特征提取、图像分割、分类和回归。
- mAIstro支持开源和闭源LLM,并具有模块化的架构。
- 在多个开源数据集上进行了广泛评估,代理成功执行任务,产生可解释的输出和经过验证的模型。
- mAIstro统一了数据分析、AI模型开发和推理,在医疗保健应用中具有广泛的应用潜力。
- mAIstro提供了一个可复制和可扩展的基础,有助于临床和研究AI的集成。
- 可以通过访问https://github.com/eltzanis/mAIstro获取mAIstro的代码。
点此查看论文截图

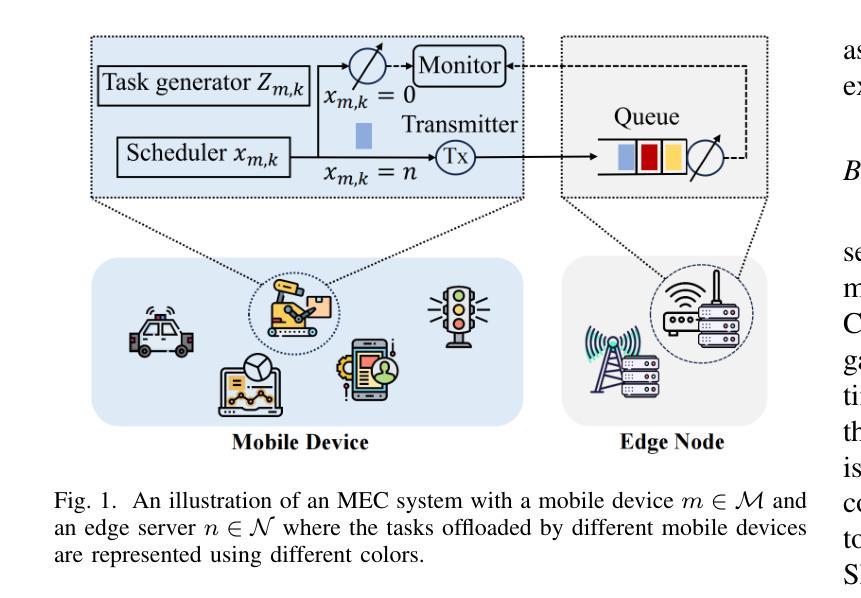
Asynchronous Fractional Multi-Agent Deep Reinforcement Learning for Age-Minimal Mobile Edge Computing
Authors:Lyudong Jin, Ming Tang, Jiayu Pan, Meng Zhang, Hao Wang
In the realm of emerging real-time networked applications like cyber-physical systems (CPS), the Age of Information (AoI) has merged as a pivotal metric for evaluating the timeliness. To meet the high computational demands, such as those in intelligent manufacturing within CPS, mobile edge computing (MEC) presents a promising solution for optimizing computing and reducing AoI. In this work, we study the timeliness of computational-intensive updates and explores jointly optimize the task updating and offloading policies to minimize AoI. Specifically, we consider edge load dynamics and formulate a task scheduling problem to minimize the expected time-average AoI. The fractional objective introduced by AoI and the semi-Markov game nature of the problem render this challenge particularly difficult, with existing approaches not directly applicable. To this end, we present a comprehensive framework to fractional reinforcement learning (RL). We first introduce a fractional single-agent RL framework and prove its linear convergence. We then extend this to a fractional multi-agent RL framework with a convergence analysis. To tackle the challenge of asynchronous control in semi-Markov game, we further design an asynchronous model-free fractional multi-agent RL algorithm, where each device makes scheduling decisions with the hybrid action space without knowing the system dynamics and decisions of other devices. Experimental results show that our proposed algorithms reduce the average AoI by up to 52.6% compared with the best baseline algorithm in our experiments.
在信息时代的网络实时应用领域中,如网络物理系统(CPS),信息时代(AoI)已经成为评估时间性的重要指标。为满足智能制造等CPS中的高计算需求,移动边缘计算(MEC)为优化计算和减少AoI提供了有前途的解决方案。在这项工作中,我们研究了计算密集型更新的时间性,并探索联合优化任务更新和卸载策略以最小化AoI。具体来说,我们考虑了边缘负载动态性,并制定了一个任务调度问题以最小化预期的基于时间的平均AoI。由AoI引入的分式目标和问题的半马尔可夫游戏性质使这一挑战变得特别困难,现有方法无法直接应用。为此,我们提出了分式强化学习(RL)的综合框架。我们首先介绍了一种分式单代理RL框架并证明了其线性收敛性。然后将其扩展到分式多代理RL框架并进行收敛性分析。为了解决半马尔可夫游戏中的异步控制挑战,我们进一步设计了一种异步无模型分式多代理RL算法,其中每个设备在混合动作空间内做出调度决策,无需了解系统动态和其他设备的决策。实验结果表明,我们提出的算法与实验中的最佳基线算法相比,平均降低了高达52.6%的AoI。
论文及项目相关链接
Summary
针对新兴实时网络应用(如网络物理系统)中的信息时效性问题,提出以移动边缘计算优化计算并降低信息时效的策略。研究中探讨了计算密集型更新的时效性,并联合优化任务更新和卸载策略以最小化信息时效。通过引入分数强化学习框架来解决该问题的复杂性。实验结果显示,所提算法平均降低信息时效达52.6%。
Key Takeaways
- 信息时效(AoI)是评估网络物理系统(CPS)实时应用性能的关键指标。
- 移动边缘计算(MEC)对于优化智能制造等计算密集型任务的需求具有潜力。
- 任务调度问题被公式化为最小化预期时间平均信息时效。
- 分数强化学习(RL)框架被提出以解决问题的复杂性。
- 分数单智能体RL框架及其线性收敛性得到证明,后扩展到分数多智能体RL框架。
- 为解决半马尔可夫游戏中的异步控制挑战,设计了异步模型免费分数多智能体RL算法。
点此查看论文截图

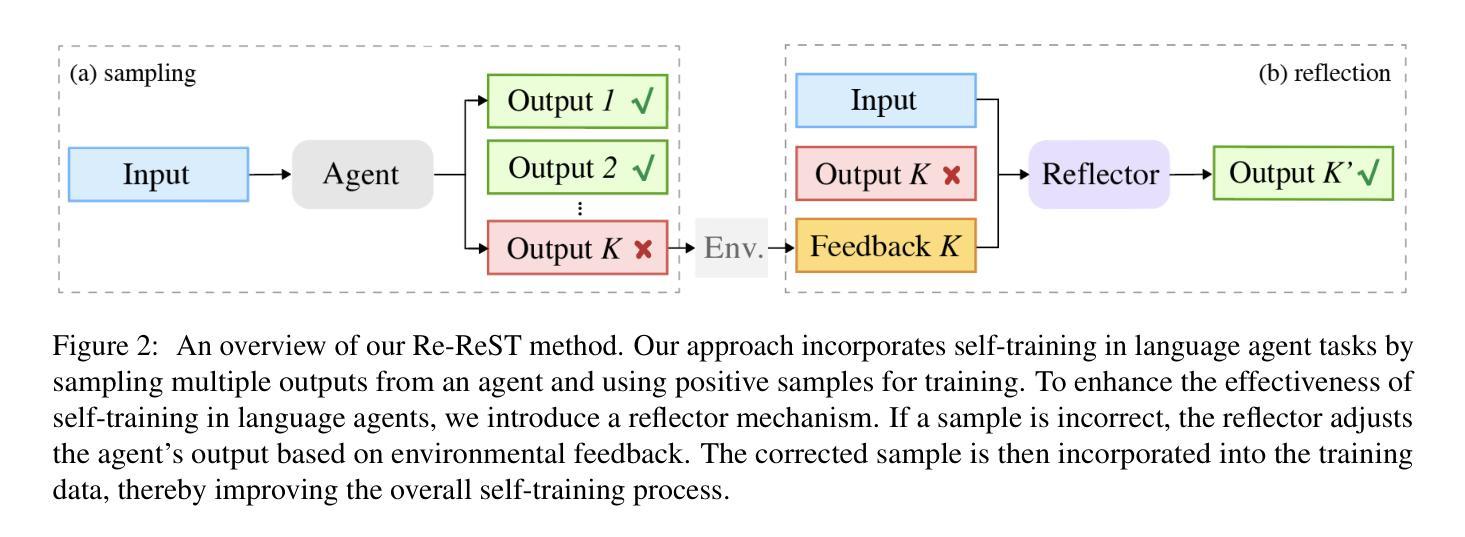
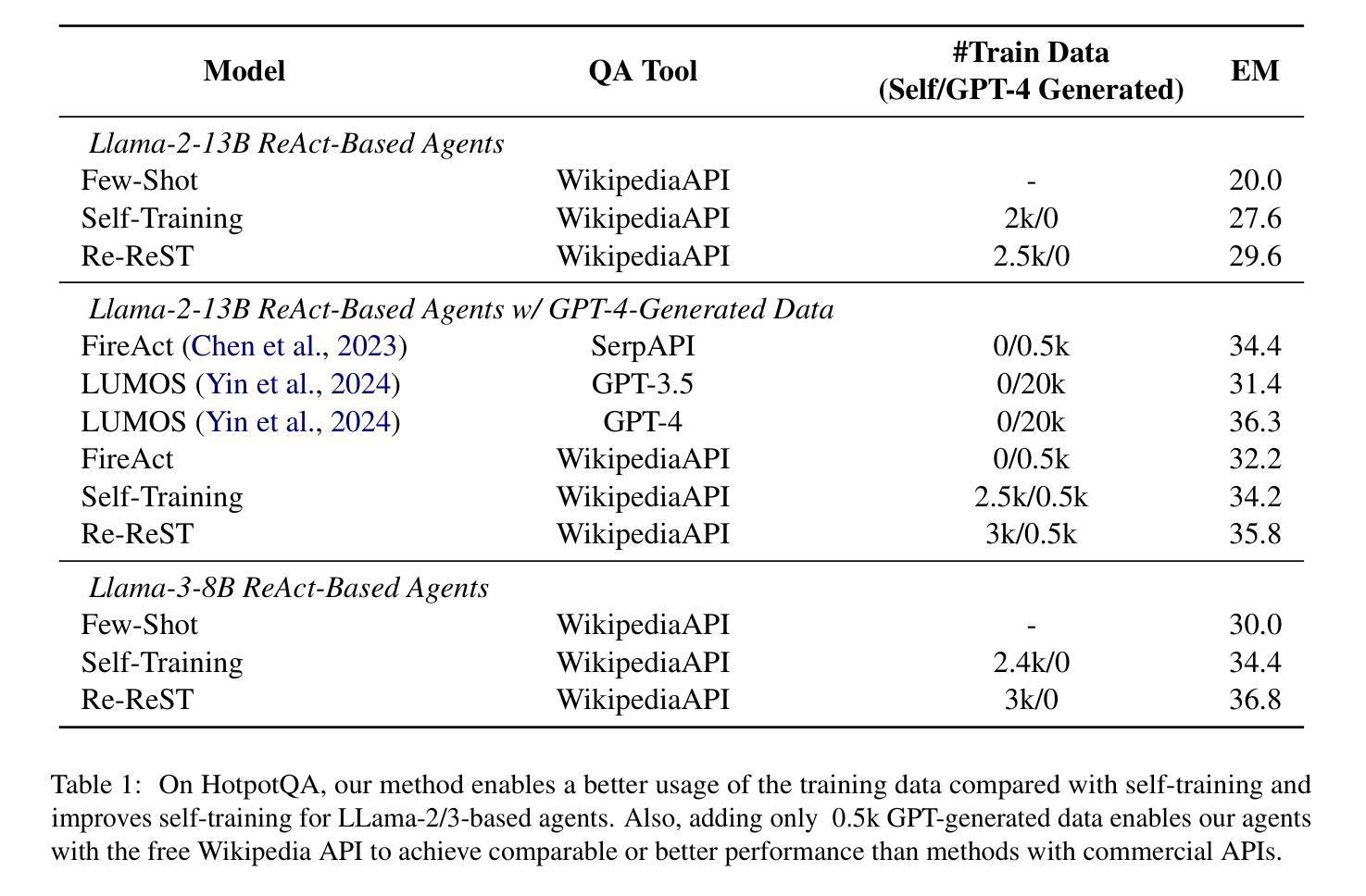
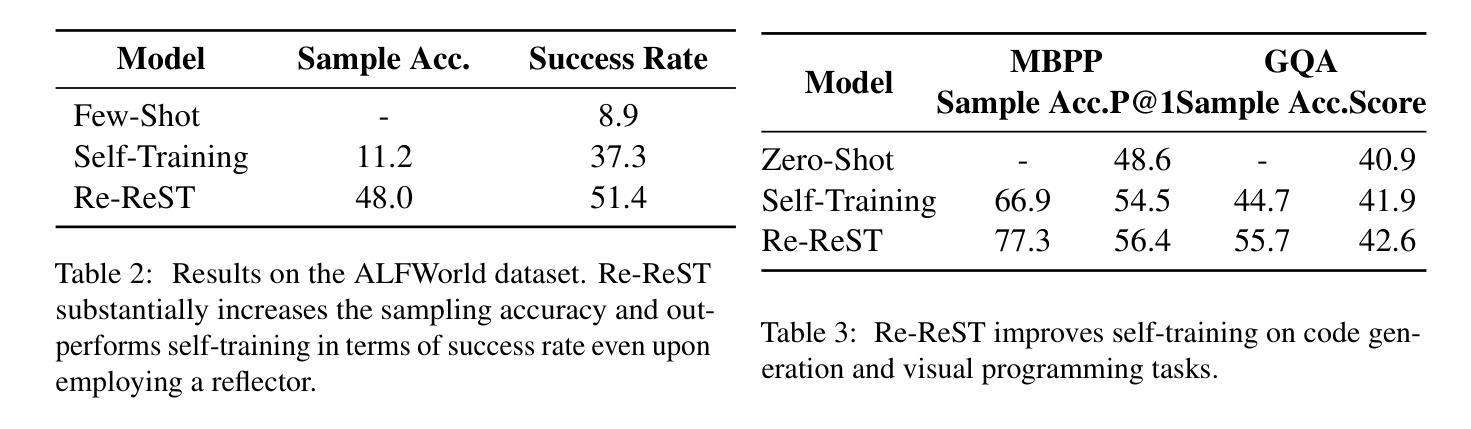
Re-ReST: Reflection-Reinforced Self-Training for Language Agents
Authors:Zi-Yi Dou, Cheng-Fu Yang, Xueqing Wu, Kai-Wei Chang, Nanyun Peng
Finetuning language agents with reasoning-action trajectories is effective, but obtaining these trajectories from human annotations or stronger models is costly and sometimes impractical. In this paper, we investigate the use of self-training in language agents, which can generate supervision from the agent itself, offering a promising alternative without relying on human or stronger model demonstrations. Self-training, however, requires high-quality model-generated samples, which are hard to obtain for challenging language agent tasks. To address this, we present Reflection-Reinforced Self-Training (Re-ReST), which uses a \textit{reflector} to refine low-quality generated samples during self-training. The reflector takes the agent’s output and feedback from an external environment (e.g., unit test results in code generation) to produce improved samples. This technique enhances the quality of inferior samples and efficiently enriches the self-training dataset with higher-quality samples. We conduct extensive experiments on open-source language agents across tasks, including multi-hop question answering, sequential decision-making, code generation, visual question answering, and text-to-image generation. The results demonstrate the effectiveness of self-training and Re-ReST in language agent tasks, with self-training improving baselines by 7.6% on HotpotQA and 28.4% on AlfWorld, and Re-ReST further boosting performance by 2.0% and 14.1%, respectively. Our studies also confirm the efficiency of using a reflector to generate high-quality samples for self-training. Moreover, we demonstrate a method to employ reflection during inference without ground-truth feedback, addressing the limitation of previous reflection work. Our code is released at https://github.com/PlusLabNLP/Re-ReST.
使用推理行动轨迹对语言智能体进行微调是有效的,但要从人类注释或更强大的模型中获得这些轨迹成本高昂,有时不切实际。在本文中,我们研究了语言智能体中的自训练,它可以由智能体本身生成监督信息,提供了一种不需要依赖人类或更强大模型演示的替代方案。然而,自训练需要高质量的模型生成样本,对于具有挑战性的语言智能体任务来说,这是难以获得的。为了解决这个问题,我们提出了反射强化自训练(Re-ReST),它使用一个“反射器”在自训练期间改进低质量生成的样本。反射器以智能体的输出和外部环境的反馈(如代码生成的单元测试结果为示例)为基础来产生改进的样本。该技术提高了较差样本的质量,并有效地用更高质量的样本丰富了自训练数据集。我们对开源语言智能体进行了大量实验,包括多跳问答、序列决策、代码生成、视觉问答和文本到图像生成等任务。结果表明,自训练和Re-ReST在语言智能体任务中效果显著,自训练在HotpotQA上提高了7.6%基线成绩,在AlfWorld上提高了28.4%,Re-ReST分别进一步提升了2.0%和14.1%的性能。我们的研究也证实了使用反射器生成高质量样本进行自训练的有效性。此外,我们展示了一种在推理过程中使用反射的方法,无需真实反馈,解决了之前反射工作的局限性。我们的代码发布在https://github.com/PlusLabNLP/Re-ReST。
论文及项目相关链接
摘要
基于自我训练的语言智能体利用模型自身产生的数据进行监督学习,无需依赖人工或高级模型演示,展现出良好的应用前景。为解决自我训练过程中高质量样本难以获取的问题,本文提出了反射强化自我训练(Re-ReST)方法,通过反射器对低质量样本进行精炼,并结合外部环境反馈优化模型输出样本质量。反射器采用智能体输出与外部环境的反馈相结合的方式,生成改进后的样本。实验结果显示,Re-ReST能有效提高样本质量,丰富自我训练数据集。在多项开源语言智能体任务中,包括多跳问答、序列决策、代码生成、视觉问答和文本图像生成等任务中,自我训练和Re-ReST均展现出良好效果。特别是自我训练在HotpotQA和AlfWorld任务上分别提高了7.6%和28.4%的基础线表现,而Re-ReST进一步提升了2.0%和14.1%。同时,本文提出一种无需真实反馈的推理期间反射方法,解决了之前反射工作的局限性。相关代码已发布在https://github.com/PlusLabNLP/Re-ReST。
关键见解
- 自我训练语言智能体是一种无需依赖人工或高级模型演示的有效方法。
- 反射强化自我训练(Re-ReST)通过反射器提高低质量样本的质量,丰富自我训练数据集。
- Re-ReST在多项语言智能体任务中展现出良好效果,包括多跳问答、序列决策、代码生成等。
- 自我训练在HotpotQA和AlfWorld任务上显著提高基础表现,Re-ReST进一步优化性能。
- 本文提出了一种在推理期间无需真实反馈的反射方法,解决了之前反射工作的局限性。
- 相关代码已公开发布,供研究人员使用。
点此查看论文截图