⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-09 更新
Token Coordinated Prompt Attention is Needed for Visual Prompting
Authors:Zichen Liu, Xu Zou, Gang Hua, Jiahuan Zhou
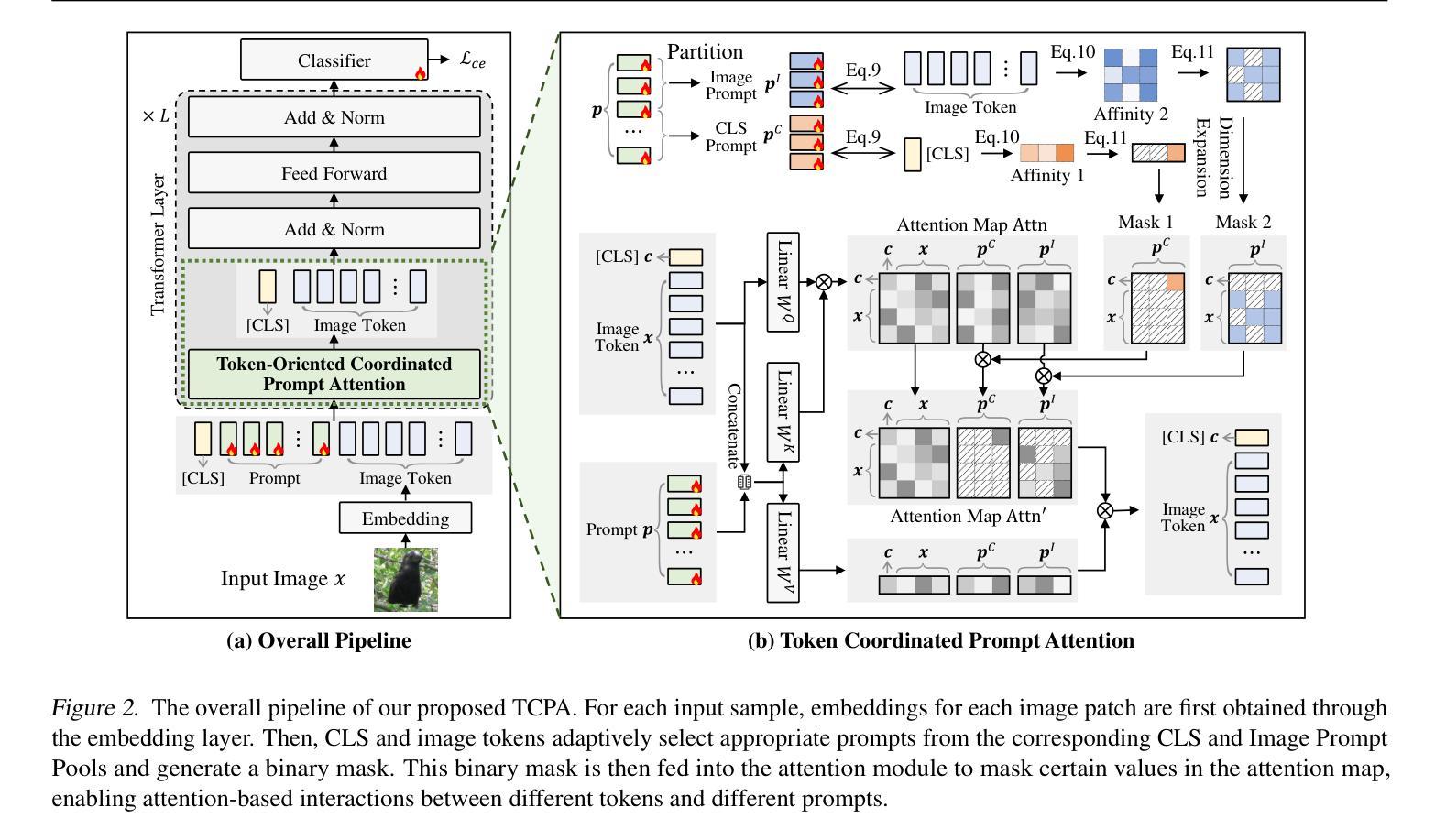
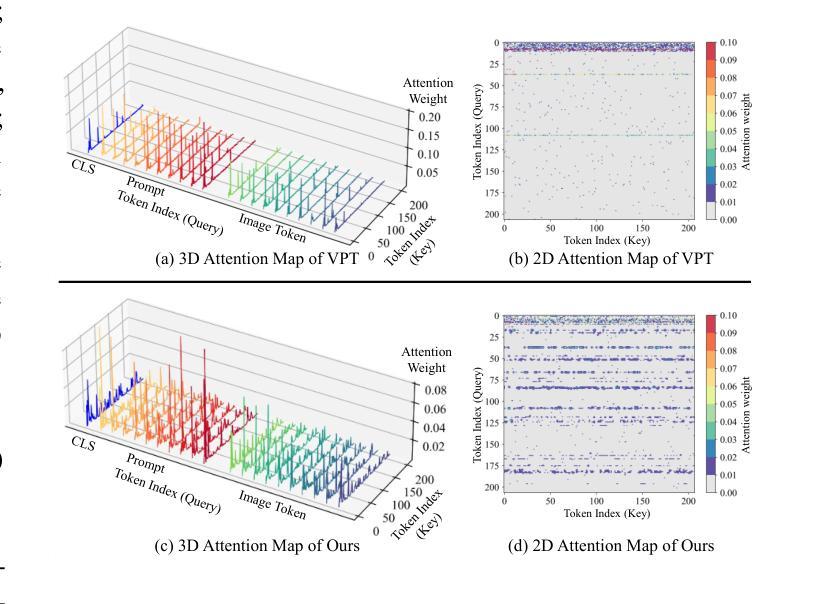
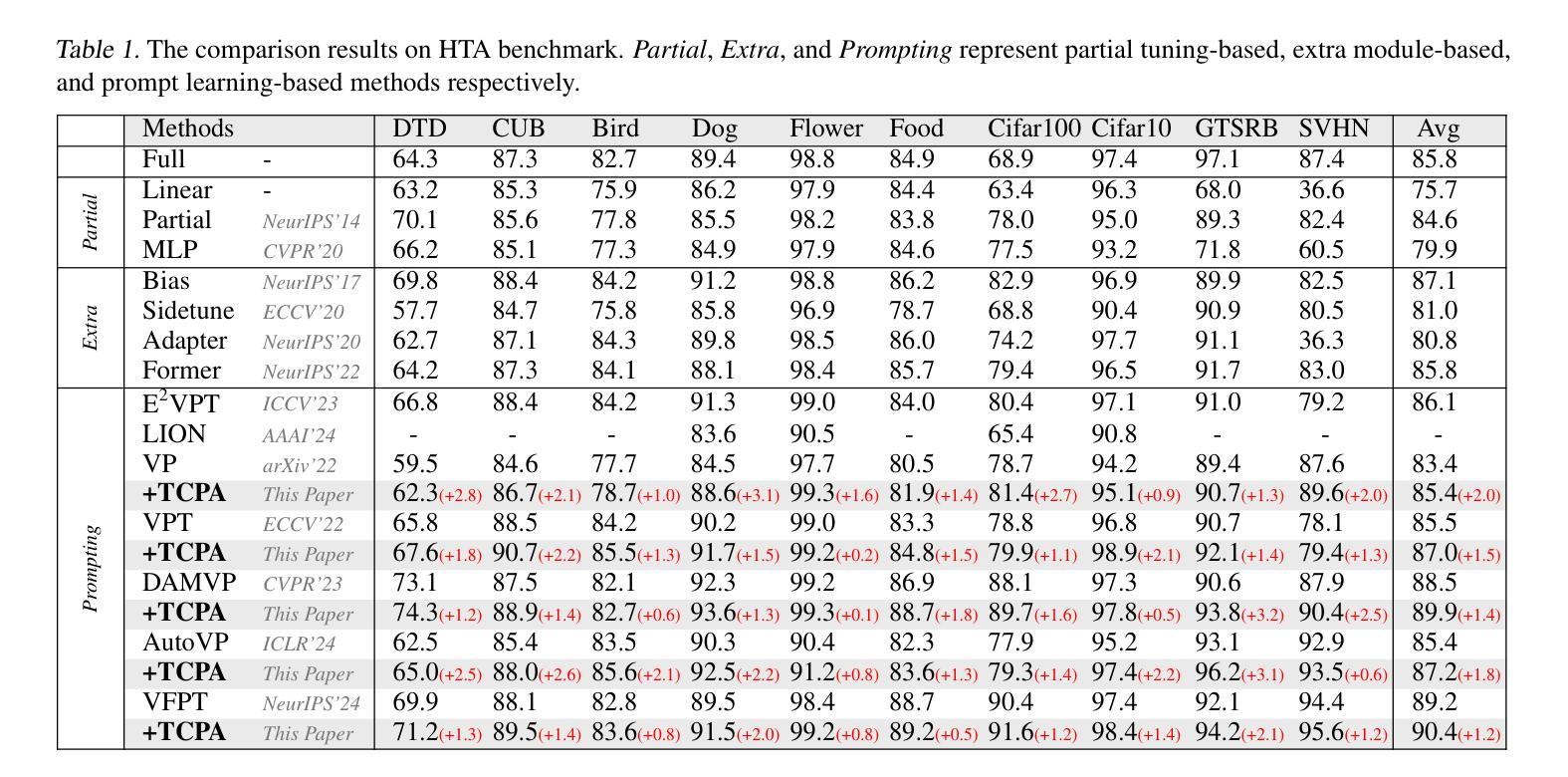
Visual prompting techniques are widely used to efficiently fine-tune pretrained Vision Transformers (ViT) by learning a small set of shared prompts for all tokens. However, existing methods overlook the unique roles of different tokens in conveying discriminative information and interact with all tokens using the same prompts, thereby limiting the representational capacity of ViT. This often leads to indistinguishable and biased prompt-extracted features, hindering performance. To address this issue, we propose a plug-and-play Token Coordinated Prompt Attention (TCPA) module, which assigns specific coordinated prompts to different tokens for attention-based interactions. Firstly, recognizing the distinct functions of CLS and image tokens-global information aggregation and local feature extraction, we disentangle the prompts into CLS Prompts and Image Prompts, which interact exclusively with CLS tokens and image tokens through attention mechanisms. This enhances their respective discriminative abilities. Furthermore, as different image tokens correspond to distinct image patches and contain diverse information, we employ a matching function to automatically assign coordinated prompts to individual tokens. This enables more precise attention interactions, improving the diversity and representational capacity of the extracted features. Extensive experiments across various benchmarks demonstrate that TCPA significantly enhances the diversity and discriminative power of the extracted features. The code is available at https://github.com/zhoujiahuan1991/ICML2025-TCPA.
视觉提示技术被广泛用于通过学习一组共享提示来微调预训练的视觉转换器(ViT)。然而,现有方法忽视了不同标记在传递判别信息方面的独特作用,并使用相同的提示与所有标记进行交互,从而限制了ViT的代表性容量。这通常导致难以区分和偏见的提示提取特征,从而阻碍了性能。为了解决这一问题,我们提出了即插即用的标记协调提示注意力(TCPA)模块,该模块为不同的标记分配特定的协调提示进行基于注意力的交互。首先,我们认识到CLS和图像标记的不同功能——全局信息聚合和局部特征提取,我们将提示信息分解为CLS提示和图像提示,它们通过注意力机制仅与CLS标记和图像标记进行交互,从而增强了各自的判别能力。此外,由于不同的图像标记对应于不同的图像块并包含不同的信息,我们采用匹配函数来自动为单个标记分配协调提示。这能够实现更精确的关注力交互,提高提取特征的多样性和代表性容量。在多个基准测试上的广泛实验表明,TCPA显著提高了提取特征的多样性和判别能力。代码可在https://github.com/zhoujiahuan1991/ICML2025-TCPA上找到。
论文及项目相关链接
Summary
视觉提示技术广泛应用于对预训练的Vision Transformers(ViT)进行微调,通过学习一套共享提示来完成对所有令牌的微调。然而,现有方法忽视了不同令牌在传递判别信息方面的独特作用,并使用相同的提示与所有令牌进行交互,从而限制了ViT的代表性容量。为解决此问题,我们提出了即插即用的令牌协调提示注意力(TCPA)模块,该模块为不同的令牌分配特定的协调提示进行基于注意力的交互。首先,我们认识到CLS令牌和图像令牌在全局信息聚合和局部特征提取方面的不同功能,将提示分解为CLS提示和图像提示,它们通过注意力机制仅与CLS令牌和图像令牌交互。这增强了各自的判别能力。此外,由于不同的图像令牌对应于不同的图像补丁并包含各种信息,我们采用匹配功能自动为个别令牌分配协调提示。这实现了更精确的关注交互,提高了提取特征的多样性和代表性容量。经过广泛实验验证,TCPA显著提高了特征的多样性和判别力。相关代码可在GitHub上进行访问:https://github.com/zhoujiahuan1991/ICML2025-TCPA。
Key Takeaways
一、视觉提示技术用于微调预训练的Vision Transformers(ViT)。但现有方法忽略了不同令牌在传递判别信息中的作用差异。为此,提出了Token Coordinated Prompt Attention(TCPA)模块。此模块可以为不同令牌分配特定协调提示,通过注意力机制实现更精确的交互。这是为了解决现有方法的局限性并提高ViT的性能。
点此查看论文截图