⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-10 更新
SVAD: From Single Image to 3D Avatar via Synthetic Data Generation with Video Diffusion and Data Augmentation
Authors:Yonwoo Choi
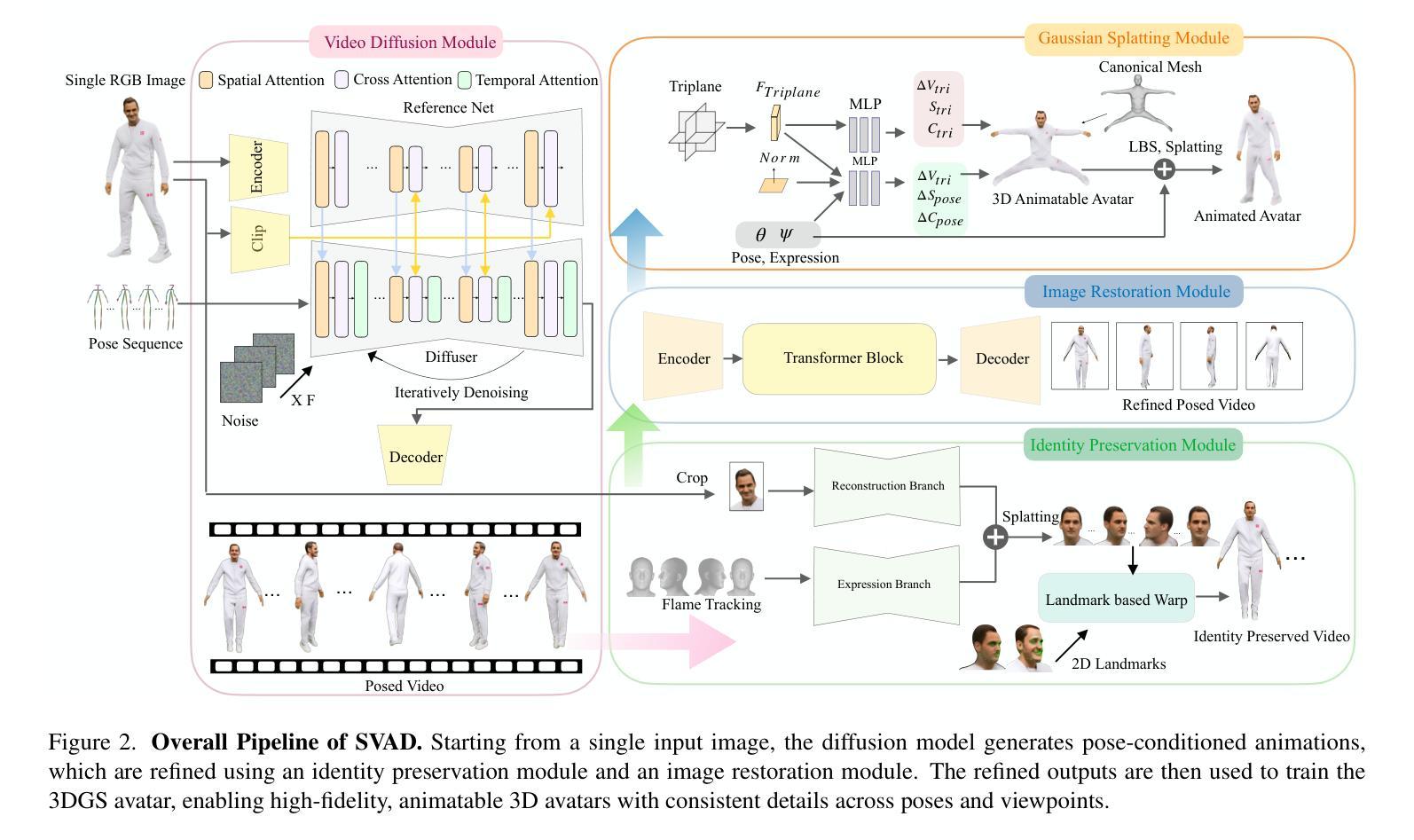
Creating high-quality animatable 3D human avatars from a single image remains a significant challenge in computer vision due to the inherent difficulty of reconstructing complete 3D information from a single viewpoint. Current approaches face a clear limitation: 3D Gaussian Splatting (3DGS) methods produce high-quality results but require multiple views or video sequences, while video diffusion models can generate animations from single images but struggle with consistency and identity preservation. We present SVAD, a novel approach that addresses these limitations by leveraging complementary strengths of existing techniques. Our method generates synthetic training data through video diffusion, enhances it with identity preservation and image restoration modules, and utilizes this refined data to train 3DGS avatars. Comprehensive evaluations demonstrate that SVAD outperforms state-of-the-art (SOTA) single-image methods in maintaining identity consistency and fine details across novel poses and viewpoints, while enabling real-time rendering capabilities. Through our data augmentation pipeline, we overcome the dependency on dense monocular or multi-view training data typically required by traditional 3DGS approaches. Extensive quantitative, qualitative comparisons show our method achieves superior performance across multiple metrics against baseline models. By effectively combining the generative power of diffusion models with both the high-quality results and rendering efficiency of 3DGS, our work establishes a new approach for high-fidelity avatar generation from a single image input.
从单张图像创建高质量的可动画3D人类角色仍然是计算机视觉领域的一大挑战,这主要是因为从单一视角重建完整的3D信息存在固有的难度。当前的方法存在明显的局限性:3D高斯贴片(3DGS)方法虽然能产生高质量的结果,但需要多个视角或视频序列,而视频扩散模型虽然可以从单个图像生成动画,但在一致性和身份保持方面却存在困难。我们提出了SVAD这一新方法,它通过利用现有技术的互补优势来解决这些局限性。我们的方法通过视频扩散生成合成训练数据,使用身份保留和图像恢复模块进行增强,并利用这些精细数据训练3DGS角色。全面评估表明,SVAD在保持身份一致性和精细细节方面优于最先进的单图像方法,并且在新的姿势和视角上实现了实时渲染功能。通过我们的数据增强流程,我们克服了传统3DGS方法通常对密集的单眼或多视角训练数据的依赖。大量的定量和定性对比表明,我们的方法在多个指标上优于基线模型。通过有效地结合扩散模型的生成能力与3DGS的高质量结果和渲染效率,我们的工作建立了一种从单张图像输入生成高保真角色的新方法。
论文及项目相关链接
PDF Accepted by CVPR 2025 SyntaGen Workshop, Project Page: https://yc4ny.github.io/SVAD/
Summary
基于单张图像创建高质量的可动画3D人身像仍是计算机视觉领域的一大挑战,因为从单一视角重建完整的3D信息存在固有的困难。当前的方法有明显的局限性:3D高斯喷射法(3DGS)产生高质量的结果但需要多个视角或视频序列,而视频扩散模型可以从单张图像生成动画但面临一致性和身份保留的问题。本研究提出SVAD新方法,结合现有技术的优势解决上述问题。该方法通过视频扩散生成合成训练数据,增强身份保留和图像恢复模块的功能,并利用这些精细数据训练3DGS化身。评估表明,SVAD在维持身份一致性和细节方面优于单图像方法,在新的姿势和视角上表现更优秀,同时具备实时渲染能力。通过数据增强流程,我们克服了传统3DGS方法通常需要的密集单目或多视角训练数据的依赖。
Key Takeaways
- 创建高质量的单图像3D人身像是一个挑战,因为需要从单一视角重建完整的3D信息。
- 当前方法存在局限性:3DGS方法要求高视角或视频序列,而视频扩散模型虽能从单图像生成动画但缺乏一致性和身份保留。
- SVAD方法结合了视频扩散和3DGS的优势,解决了上述问题。
- SVAD通过视频扩散生成合成训练数据并增强身份保留和图像恢复功能。
- SVAD在维持身份一致性和细节方面优于单图像方法,适应新的姿势和视角,同时实现实时渲染。
- 通过数据增强流程,SVAD克服了传统方法的依赖,不需要密集的单目或多视角训练数据。
点此查看论文截图