⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-10 更新
3D Scene Generation: A Survey
Authors:Beichen Wen, Haozhe Xie, Zhaoxi Chen, Fangzhou Hong, Ziwei Liu
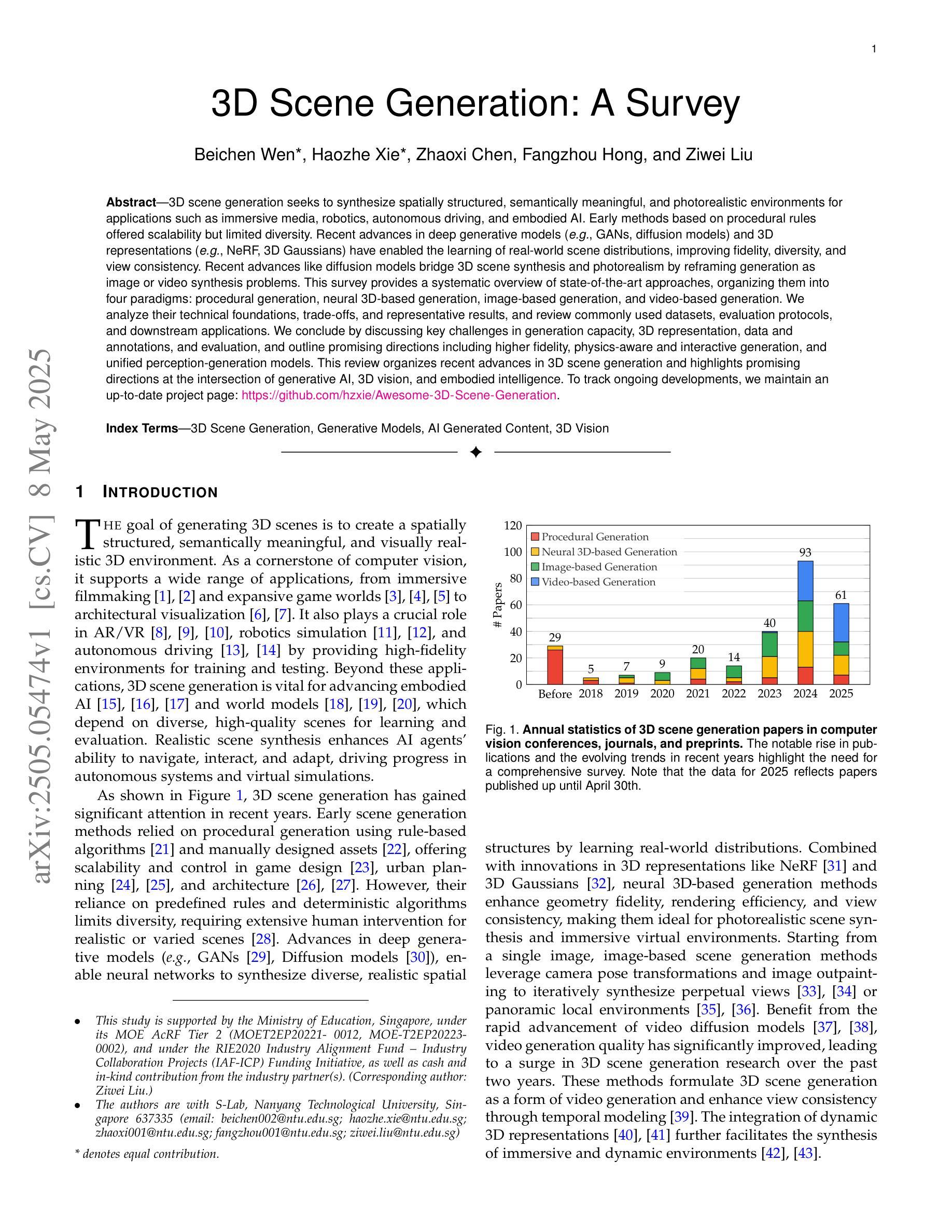
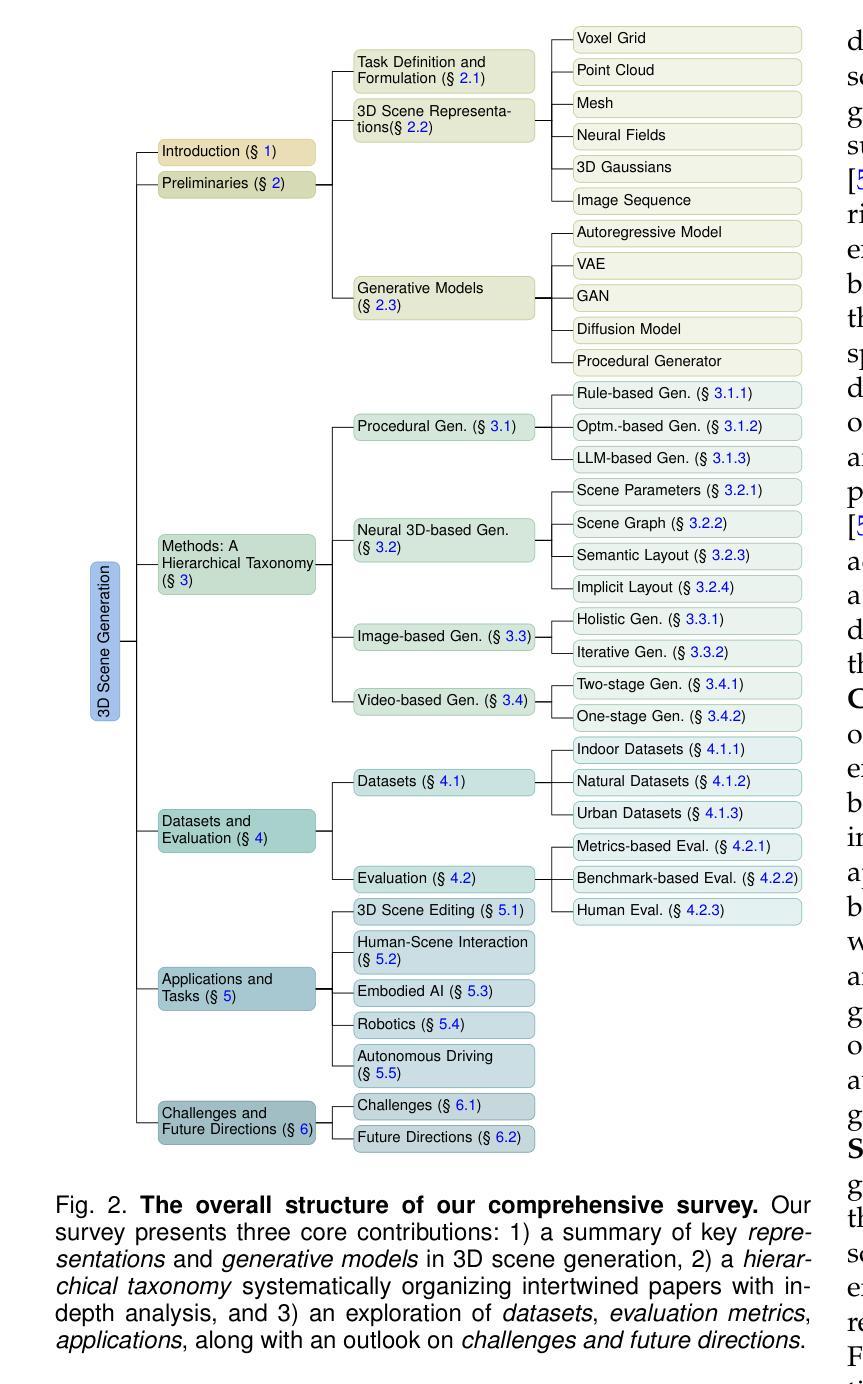
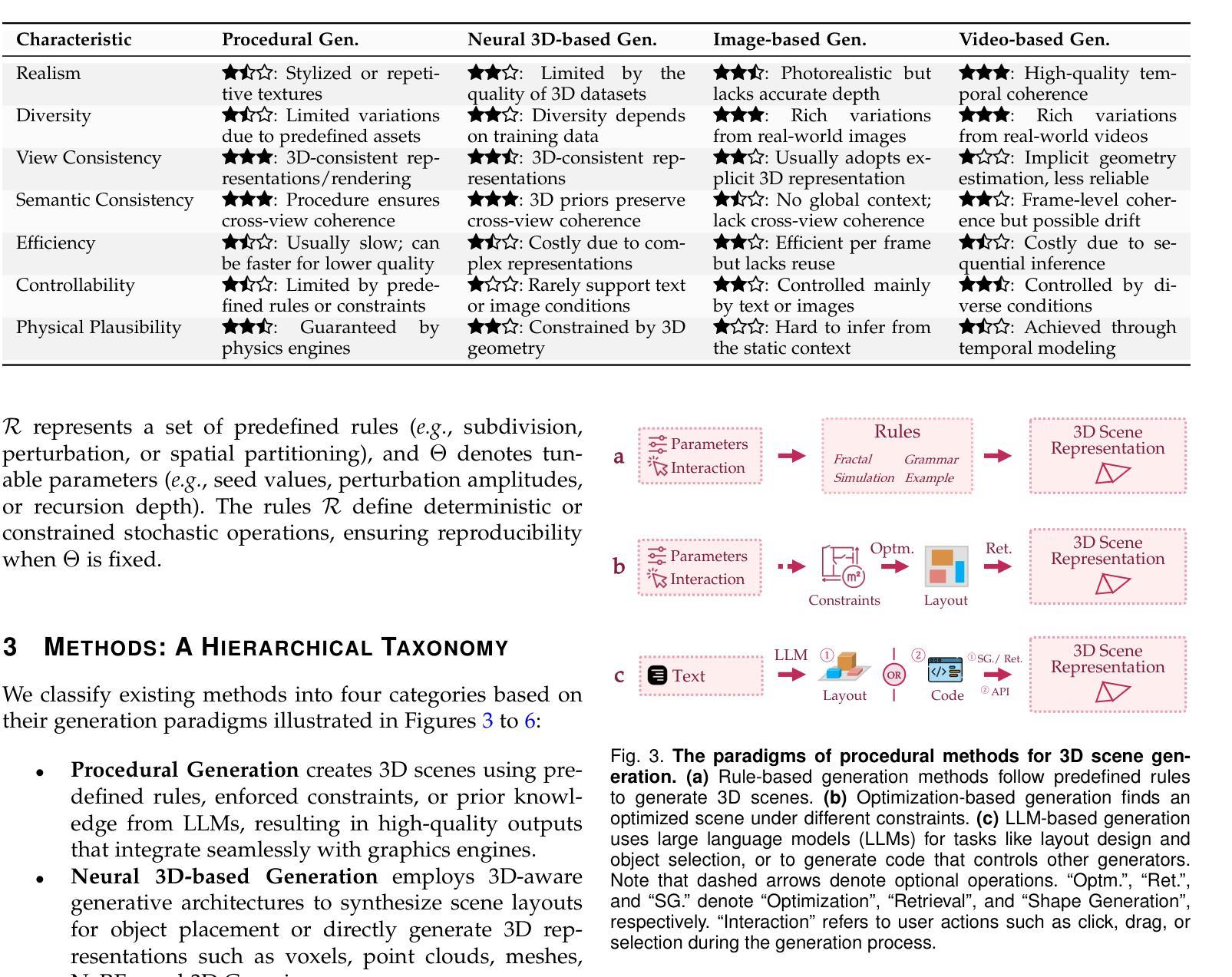
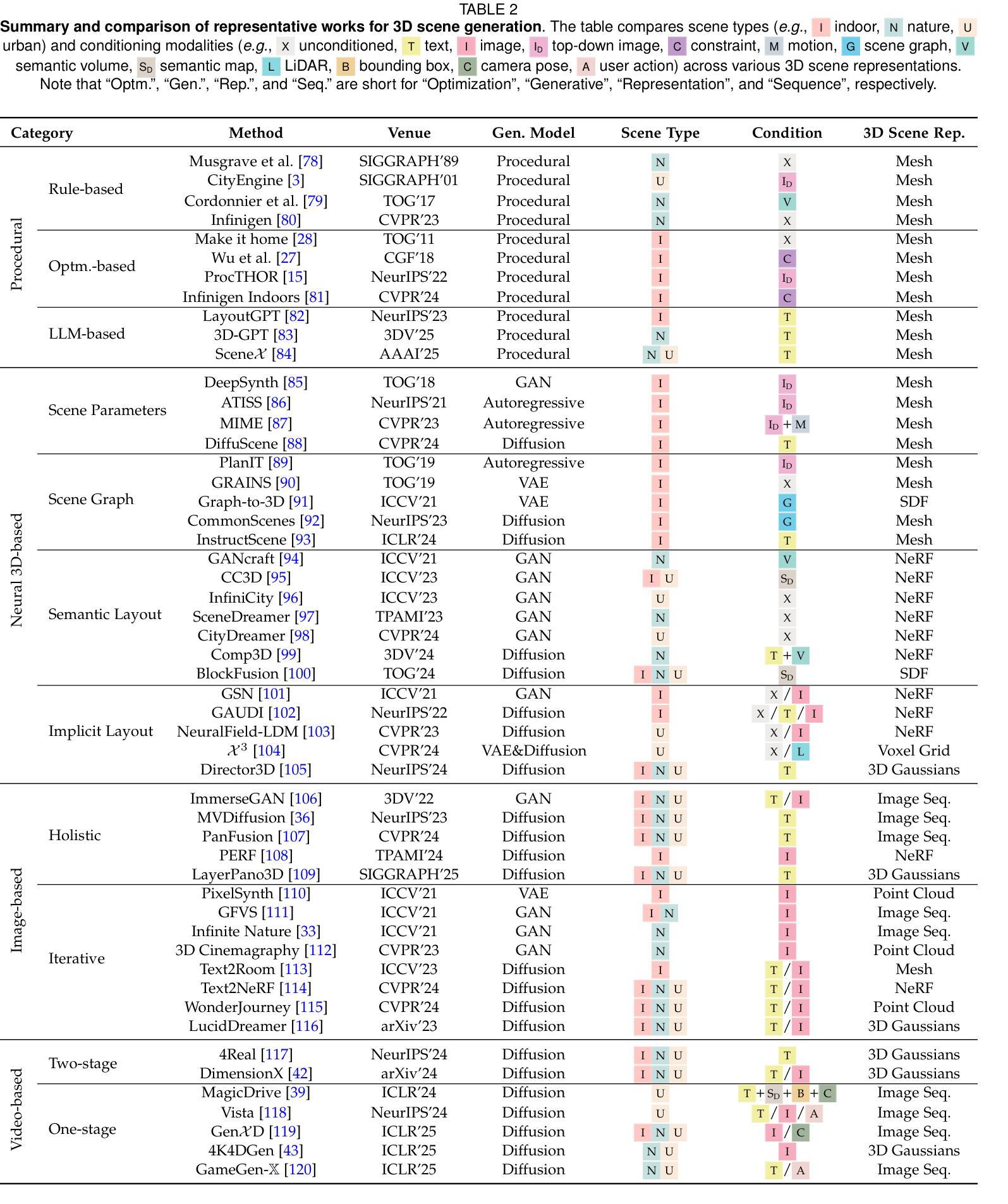
3D scene generation seeks to synthesize spatially structured, semantically meaningful, and photorealistic environments for applications such as immersive media, robotics, autonomous driving, and embodied AI. Early methods based on procedural rules offered scalability but limited diversity. Recent advances in deep generative models (e.g., GANs, diffusion models) and 3D representations (e.g., NeRF, 3D Gaussians) have enabled the learning of real-world scene distributions, improving fidelity, diversity, and view consistency. Recent advances like diffusion models bridge 3D scene synthesis and photorealism by reframing generation as image or video synthesis problems. This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation. We analyze their technical foundations, trade-offs, and representative results, and review commonly used datasets, evaluation protocols, and downstream applications. We conclude by discussing key challenges in generation capacity, 3D representation, data and annotations, and evaluation, and outline promising directions including higher fidelity, physics-aware and interactive generation, and unified perception-generation models. This review organizes recent advances in 3D scene generation and highlights promising directions at the intersection of generative AI, 3D vision, and embodied intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/hzxie/Awesome-3D-Scene-Generation.
三维场景生成旨在合成空间结构完整、语义丰富且逼真的环境,应用于沉浸式媒体、机器人技术、自动驾驶和人工智能等多个领域。早期基于过程规则的方法虽然可扩展性良好,但多样性有限。最近深度生成模型(例如GANs和扩散模型)和三维表示(例如NeRF和三维高斯模型)的进步,使学习现实场景分布成为可能,提高了逼真度、多样性和视图一致性。扩散模型等最新进展通过重新构建生成问题为图像或视频合成问题,实现了三维场景合成与逼真度的桥梁。本文全面概述了最新的方法,将它们分为四种范式:过程生成、基于神经的三维生成、基于图像的生成和基于视频的生成。我们分析了它们的技术基础、权衡和代表性成果,并回顾了常用的数据集、评估协议和下游应用。最后,我们讨论了关于生成能力、三维表示、数据和注释以及评估的关键挑战,概述了有前景的研究方向,包括更高的逼真度、物理感知和交互式生成以及统一的感知生成模型。本文梳理了三维场景生成的最新进展,并强调了生成人工智能、三维视觉和身体智能交叉领域的具有前景的研究方向。要了解最新进展,请访问我们的项目页面:[https://github.com/hzxie/Awesome-3D-Scene-Generation](中文对应页面请自行搜索)。
论文及项目相关链接
PDF Project Page: https://github.com/hzxie/Awesome-3D-Scene-Generation
Summary
本文介绍了三维场景生成技术的最新进展,包括基于神经的方法、图像和视频为基础的方法等四种范式。文章分析了各种方法的技术基础、优缺点和代表性成果,并讨论了数据集、评估协议和下游应用。文章还指出了当前面临的挑战,并展望了未来发展方向,包括更高保真度、物理感知和交互式生成以及统一的感知生成模型等方向。
Key Takeaways
- 3D场景生成技术旨在合成具有空间结构、语义含义和逼真度的环境,广泛应用于沉浸式媒体、机器人技术、自动驾驶和实体人工智能等领域。
- 早期基于程序规则的方法虽然具有良好的可扩展性,但缺乏多样性。
- 基于深度生成模型(如GANs、扩散模型)和3D表示(如NeRF、3D高斯)的最新进展,提高了逼真度、多样性和视角一致性。
- 扩散模型等最新技术通过重新构建生成问题,如图像或视频合成问题,实现了3D场景合成与逼真度的结合。
- 文章概述了最新的3D场景生成方法,包括过程生成、基于神经的3D生成、基于图像的生成和基于视频的生成等四种范式。
- 文章强调了关键挑战,如生成能力、3D表示、数据和注释以及评估等,并指出了有前景的发展方向,包括更高保真度、物理感知和交互式生成以及统一的感知生成模型等。
点此查看论文截图
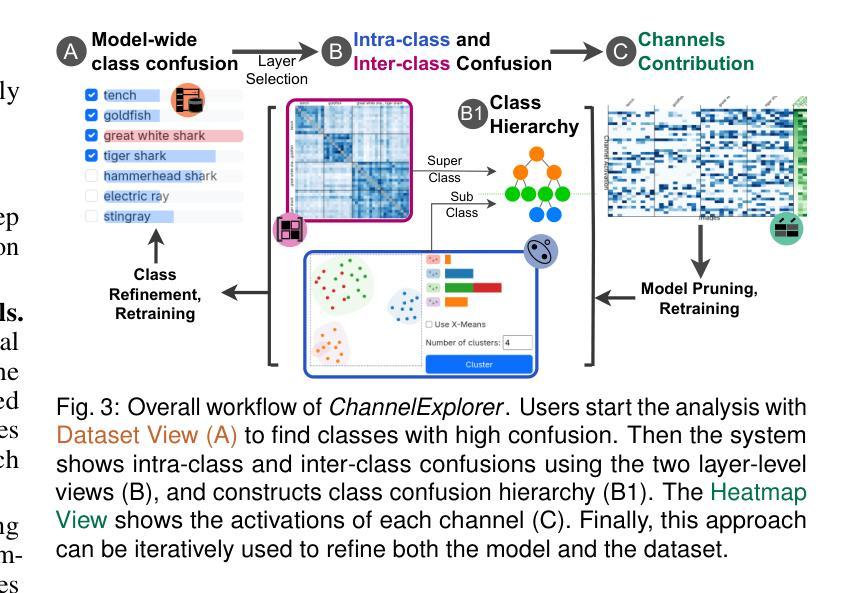
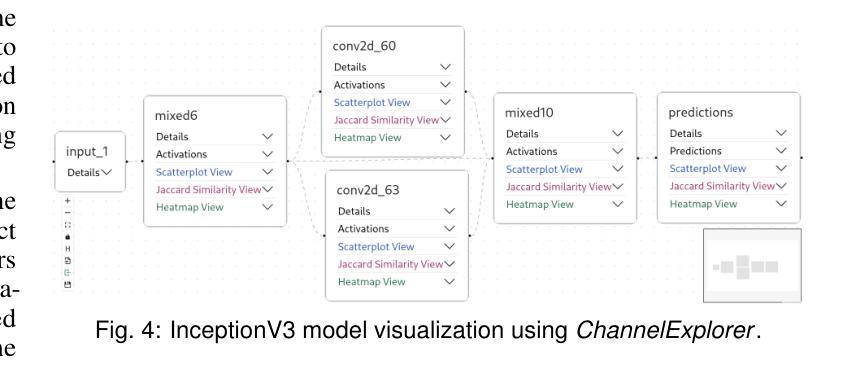
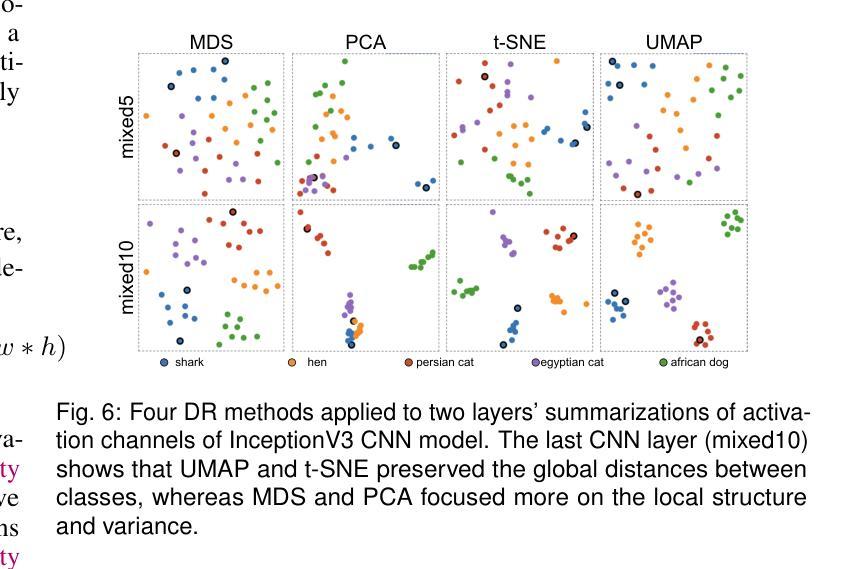
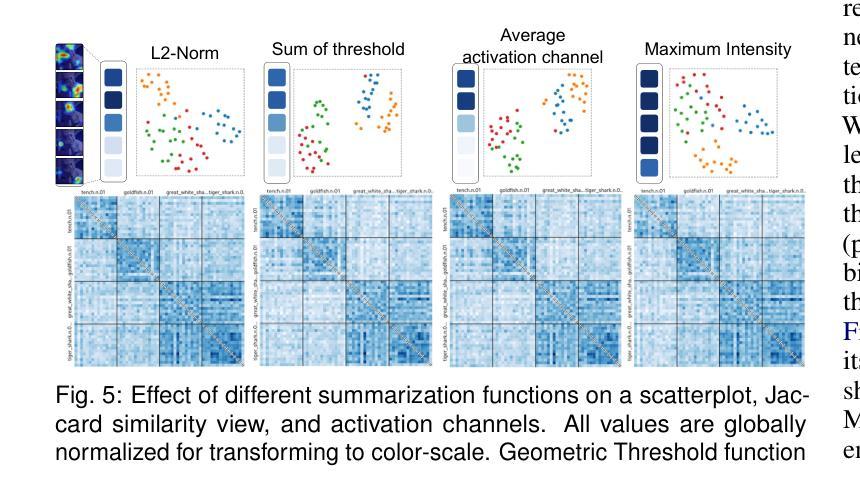
ChannelExplorer: Exploring Class Separability Through Activation Channel Visualization
Authors:Md Rahat-uz- Zaman, Bei Wang, Paul Rosen
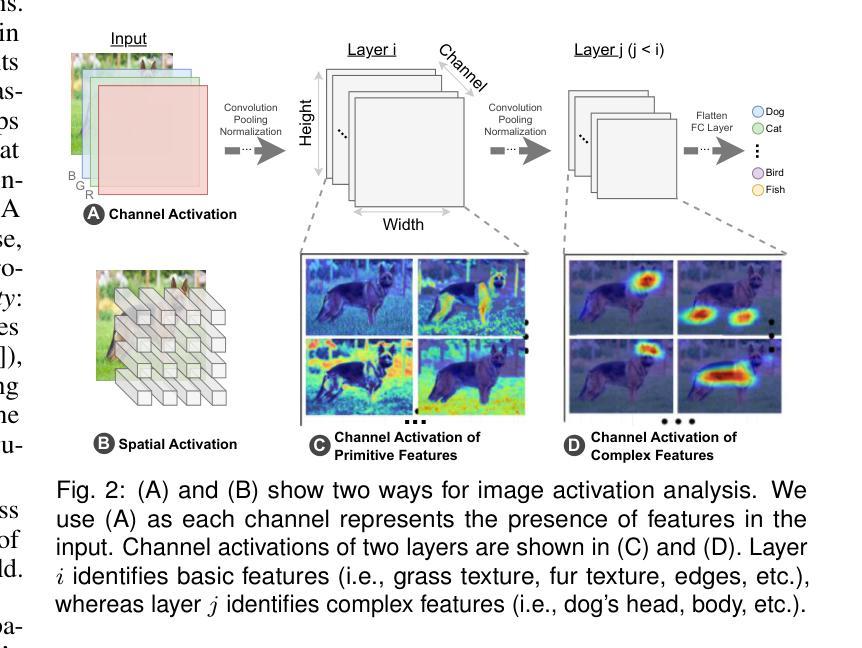
Deep neural networks (DNNs) achieve state-of-the-art performance in many vision tasks, yet understanding their internal behavior remains challenging, particularly how different layers and activation channels contribute to class separability. We introduce ChannelExplorer, an interactive visual analytics tool for analyzing image-based outputs across model layers, emphasizing data-driven insights over architecture analysis for exploring class separability. ChannelExplorer summarizes activations across layers and visualizes them using three primary coordinated views: a Scatterplot View to reveal inter- and intra-class confusion, a Jaccard Similarity View to quantify activation overlap, and a Heatmap View to inspect activation channel patterns. Our technique supports diverse model architectures, including CNNs, GANs, ResNet and Stable Diffusion models. We demonstrate the capabilities of ChannelExplorer through four use-case scenarios: (1) generating class hierarchy in ImageNet, (2) finding mislabeled images, (3) identifying activation channel contributions, and(4) locating latent states’ position in Stable Diffusion model. Finally, we evaluate the tool with expert users.
深度神经网络(DNNs)在许多视觉任务中取得了最先进的性能,但理解其内部行为仍然具有挑战性,尤其是不同层和激活通道如何贡献于类可分性。我们引入了ChannelExplorer,这是一个用于分析模型层中基于图像输出的交互式可视化分析工具,它强调以数据驱动的方式探索类可分性的洞察力,而非架构分析。ChannelExplorer总结了各层的激活,并使用三种主要的协调视图进行可视化:Scatterplot View揭示类间和类内混淆,Jaccard Similarity View量化激活重叠,以及Heatmap View检查激活通道模式。我们的技术支持各种模型架构,包括CNN、GAN、ResNet和Stable Diffusion模型。我们通过四个用例场景展示了ChannelExplorer的能力:(1)在ImageNet中生成类层次结构,(2)查找错误标记的图像,(3)确定激活通道的贡献,以及(4)定位Stable Diffusion模型中潜在状态的位置。最后,我们用专家用户评估了该工具。
论文及项目相关链接
Summary
深度学习网络在视觉任务上表现卓越,但其内部行为理解仍然具有挑战性,特别是不同层级和激活通道如何贡献于类别可分性。为此,我们推出ChannelExplorer工具,用于分析图像输出在不同模型层级的表现。此工具重视数据驱动的洞察而非架构分析以探索类别可分性。它通过三种主要视图来展示激活层次并可视化:Scatterplot View揭示类内和类间混淆,Jaccard Similarity View量化激活重叠,以及Heatmap View检查激活通道模式。此技术适用于多种模型架构,包括CNN、GAN、ResNet和Stable Diffusion模型。通过四个应用场景展示了ChannelExplorer的能力:生成ImageNet类别层次结构、查找错误标记的图像、确定激活通道的贡献以及在Stable Diffusion模型中定位潜在状态的位置。最后我们对工具进行了专家用户评估。
Key Takeaways
- ChannelExplorer是一个用于分析图像输出在不同模型层级的交互式视觉分析工具。
- 它侧重于数据驱动的洞察以探索类别可分性。
- ChannelExplorer通过三种主要视图展示和可视化激活层次:Scatterplot View、Jaccard Similarity View和Heatmap View。
- 此工具适用于多种模型架构,包括CNN、GAN、ResNet和Stable Diffusion模型。
- ChannelExplorer能够应用于生成类别层次结构、查找错误标记的图像、确定激活通道的贡献以及定位潜在状态的位置等多个应用场景。
- 通过专家用户评估证明了ChannelExplorer的有效性。
点此查看论文截图

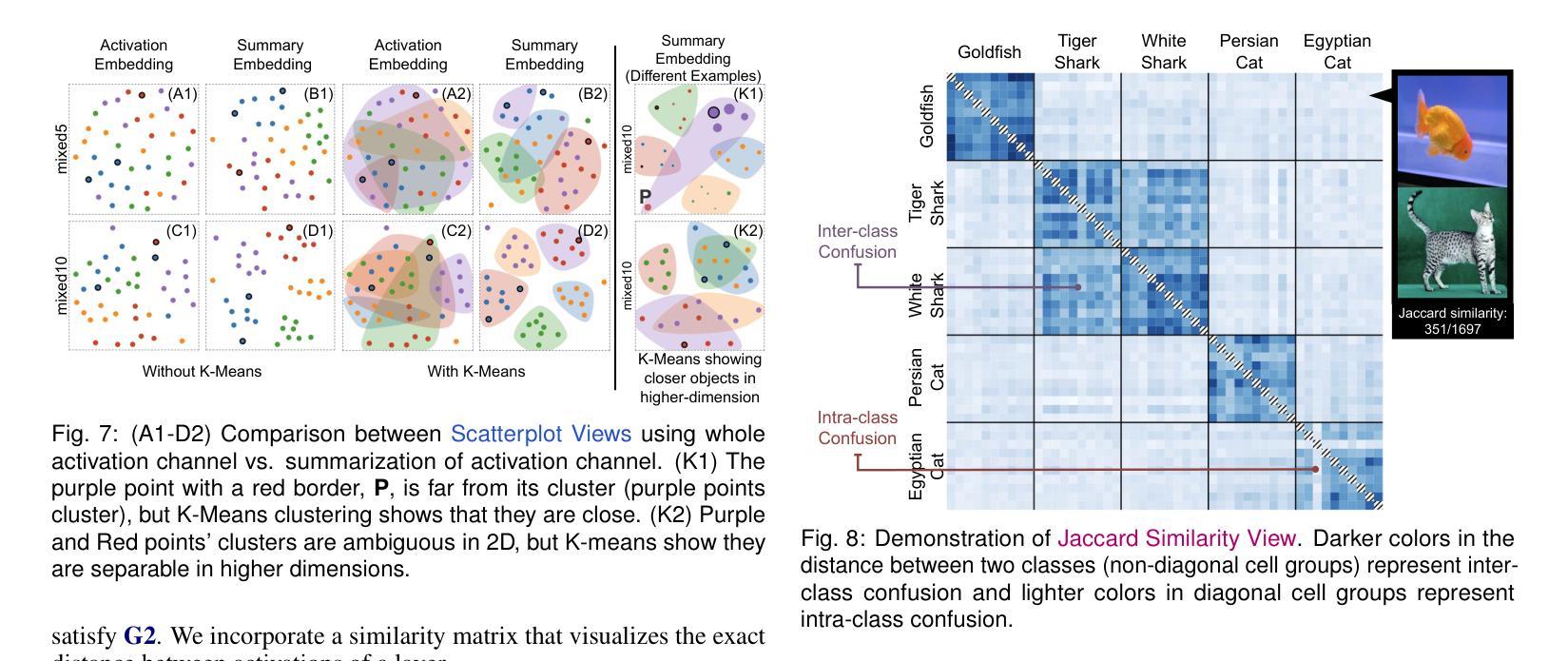
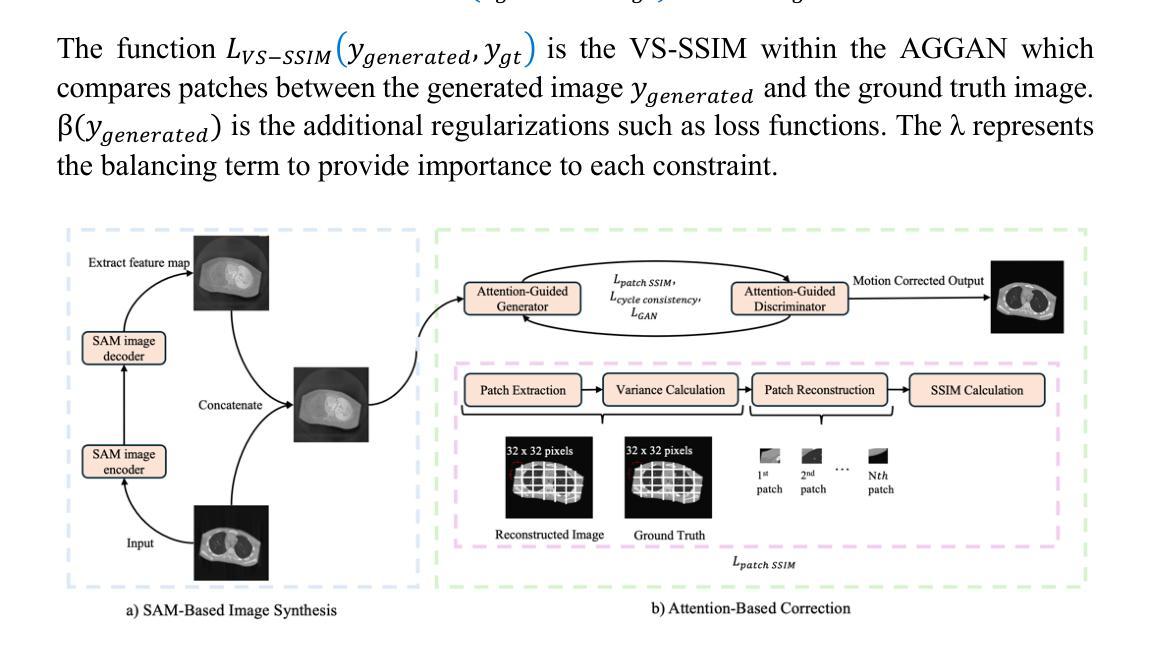
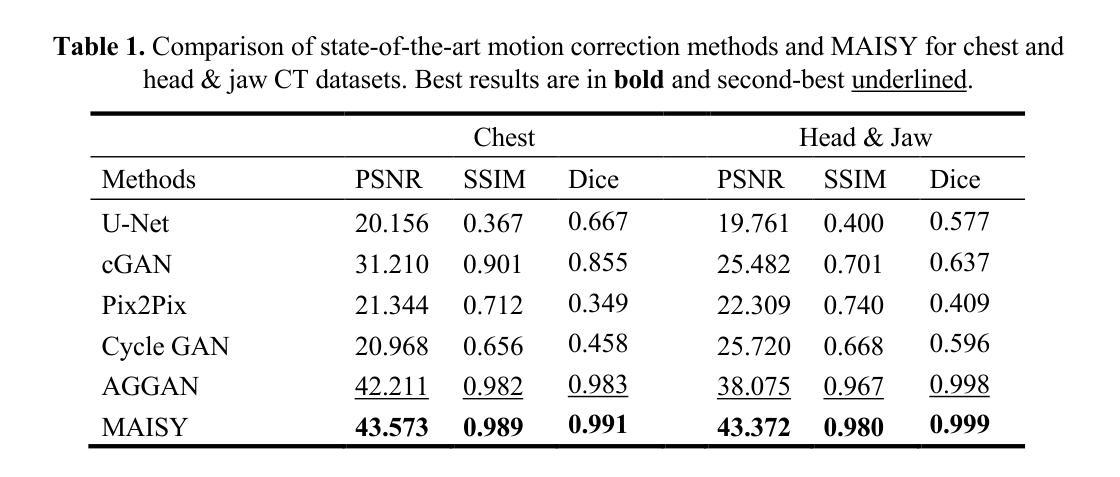
MAISY: Motion-Aware Image SYnthesis for Medical Image Motion Correction
Authors:Andrew Zhang, Hao Wang, Shuchang Ye, Michael Fulham, Jinman Kim
Patient motion during medical image acquisition causes blurring, ghosting, and distorts organs, which makes image interpretation challenging. Current state-of-the-art algorithms using Generative Adversarial Network (GAN)-based methods with their ability to learn the mappings between corrupted images and their ground truth via Structural Similarity Index Measure (SSIM) loss effectively generate motion-free images. However, we identified the following limitations: (i) they mainly focus on global structural characteristics and therefore overlook localized features that often carry critical pathological information, and (ii) the SSIM loss function struggles to handle images with varying pixel intensities, luminance factors, and variance. In this study, we propose Motion-Aware Image SYnthesis (MAISY) which initially characterize motion and then uses it for correction by: (a) leveraging the foundation model Segment Anything Model (SAM), to dynamically learn spatial patterns along anatomical boundaries where motion artifacts are most pronounced and, (b) introducing the Variance-Selective SSIM (VS-SSIM) loss which adaptively emphasizes spatial regions with high pixel variance to preserve essential anatomical details during artifact correction. Experiments on chest and head CT datasets demonstrate that our model outperformed the state-of-the-art counterparts, with Peak Signal-to-Noise Ratio (PSNR) increasing by 40%, SSIM by 10%, and Dice by 16%.
患者在医学影像采集过程中的运动会导致图像模糊、鬼影和器官扭曲,从而使图像解读具有挑战性。当前最先进的算法使用基于生成对抗网络(GAN)的方法,它们能够通过结构相似性指数度量(SSIM)损失来学习失真图像与其真实图像之间的映射,从而有效地生成无运动图像。然而,我们发现了以下局限性:(i)它们主要关注全局结构特征,因此忽略了通常携带关键病理信息的局部特征;(ii)SSIM损失函数在处理像素强度、亮度和方差各异的图像时遇到困难。本研究提出了运动感知图像合成(MAISY),它首先表征运动,然后利用运动进行修正:(a)通过利用基础模型分段任何事情模型(SAM),动态学习解剖边界处的空间模式,此处运动伪影最为明显;(b)引入方差选择性SSIM(VS-SSIM)损失,该损失能够自适应地强调具有高像素方差的区域,从而在纠正伪影时保留重要的解剖细节。在胸部和头部CT数据集上的实验表明,我们的模型性能超过了最先进的同类模型,峰值信噪比(PSNR)提高了40%,结构相似性指数度量(SSIM)提高了10%,迪氏系数提高了16%。
论文及项目相关链接
Summary
该文本介绍了一种名为MAISY的新方法,用于在医学图像采集过程中修正患者运动产生的伪影。该方法结合了分割模型与方差选择性结构相似性度量损失函数,旨在提高图像质量并保留关键解剖细节。实验表明,该方法在胸部和头部CT数据集上的表现优于现有技术。
Key Takeaways
- 患者运动在医学图像采集过程中会导致图像模糊、鬼影和器官扭曲,使得图像解读变得困难。
- 当前最先进的算法使用基于生成对抗网络(GAN)的方法,通过结构相似性指数度量(SSIM)损失来学习映射关系,以生成无运动图像。
- 然而,现有方法主要关注全局结构特征,忽略了携带重要病理信息的局部特征。
- 提出的MAISY方法首先表征运动,然后使用该信息进行修正。
- MAISY利用分割任何模型(SAM)动态学习沿解剖边界的空间模式,其中运动伪影最为明显。
- MAISY引入了方差选择性结构相似性度量(VS-SSIM)损失函数,能够自适应地强调高像素方差的区域,从而在伪影校正过程中保留关键的解剖细节。
点此查看论文截图

DejAIvu: Identifying and Explaining AI Art on the Web in Real-Time with Saliency Maps
Authors:Jocelyn Dzuong
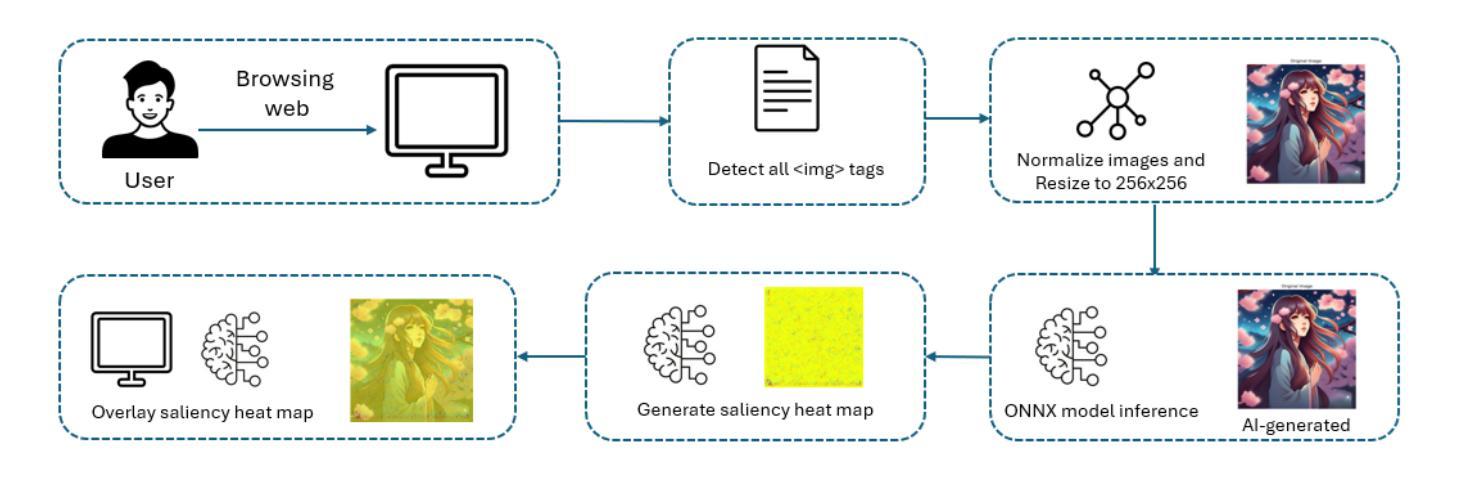
The recent surge in advanced generative models, such as diffusion models and generative adversarial networks (GANs), has led to an alarming rise in AI-generated images across various domains on the web. While such technologies offer benefits such as democratizing artistic creation, they also pose challenges in misinformation, digital forgery, and authenticity verification. Additionally, the uncredited use of AI-generated images in media and marketing has sparked significant backlash from online communities. In response to this, we introduce DejAIvu, a Chrome Web extension that combines real-time AI-generated image detection with saliency-based explainability while users browse the web. Using an ONNX-optimized deep learning model, DejAIvu automatically analyzes images on websites such as Google Images, identifies AI-generated content using model inference, and overlays a saliency heatmap to highlight AI-related artifacts. Our approach integrates efficient in-browser inference, gradient-based saliency analysis, and a seamless user experience, ensuring that AI detection is both transparent and interpretable. We also evaluate DejAIvu across multiple pretrained architectures and benchmark datasets, demonstrating high accuracy and low latency, making it a practical and deployable tool for enhancing AI image accountability. The code for this system can be found at https://github.com/Noodulz/dejAIvu.
近期先进的生成模型,例如扩散模型和生成对抗网络(GANs)的涌现,导致网上各领域的AI生成图像急剧增加。虽然这些技术提供了民主化艺术创作等好处,但它们也带来了关于误导信息、数字伪造和身份验证的挑战。此外,媒体和营销中未经授权使用AI生成的图像引发了在线社区的强烈反对。作为回应,我们推出了DejAIvu,这是一款Chrome网页扩展程序,它结合了实时AI生成图像检测和用户浏览时的基于显著性的解释性。DejAIvu使用经过ONNX优化的深度学习模型,自动分析网站上的图像(如Google Images),通过模型推理识别AI生成的内容,并通过覆盖显著性热图来突出AI相关的伪影。我们的方法整合了高效的浏览器内推理、基于梯度的显著性分析和无缝用户体验,确保AI检测既透明又易于解释。我们还对DejAIvu进行了跨多个预训练架构和基准数据集的评估,展示了其高准确性和低延迟性,使其成为增强AI图像责任制的实用且可部署的工具。该系统的代码可在https://github.com/Noodulz/dejAIvu找到。
论文及项目相关链接
PDF 5 pages, 3 figures. Accepted to IJCAI 2025 Demo Track. Revised version will be uploaded soon
Summary
随着先进的生成模型如扩散模型和生成对抗网络(GANs)的兴起,网上出现了AI生成的图像泛滥现象。这虽带来了民主化的艺术创作等好处,但也引发了虚假信息、数字伪造和身份认证等挑战。针对这一问题,推出了DejAIvu浏览器插件,它结合了实时AI图像检测与基于显著性的解释性。DejAIvu能自动分析网站上的图像,识别AI生成的内容,并覆盖显著性热图以突出AI相关伪影。我们确保了AI检测的透明性和可解释性。评估表明,DejAIvu在多架构和基准数据集上的准确率高、延迟低,是一个实用且可部署的增强AI图像责任性的工具。
Key Takeaways
- 先进的生成模型如扩散模型和GANs的普及导致AI生成的图像在网上泛滥。
- AI生成图像技术的兴起同时带来了虚假信息、数字伪造和身份认证的挑战。
- DejAIvu是一个浏览器插件,能实时检测AI生成的图像并结合显著性解释。
- DejAIvu通过自动分析网站上的图像,识别AI生成的内容,并通过显著性热图突出相关伪影。
- DejAIvu确保了AI检测的透明性和可解释性。
- 评估表明,DejAIvu在多架构和基准数据集上具有高的准确率和低的延迟。
- DejAIvu是一个实用且可部署的工具,用于增强AI图像的责任性。
点此查看论文截图