⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-10 更新
Inter-Diffusion Generation Model of Speakers and Listeners for Effective Communication
Authors:Jinhe Huang, Yongkang Cheng, Yuming Hang, Gaoge Han, Jinewei Li, Jing Zhang, Xingjian Gu
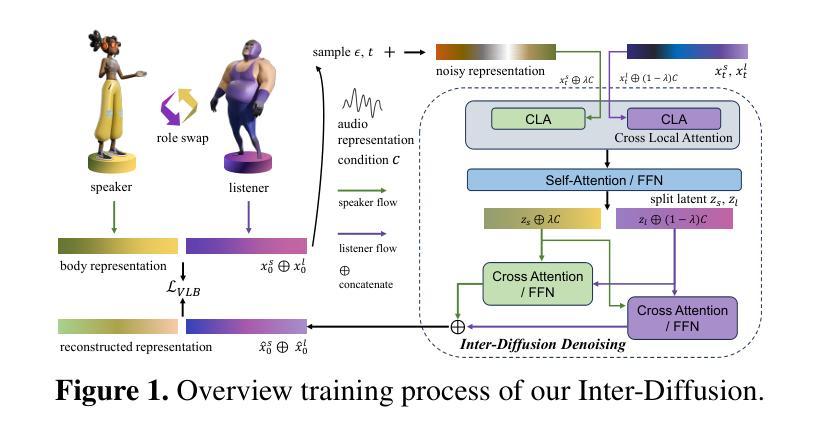
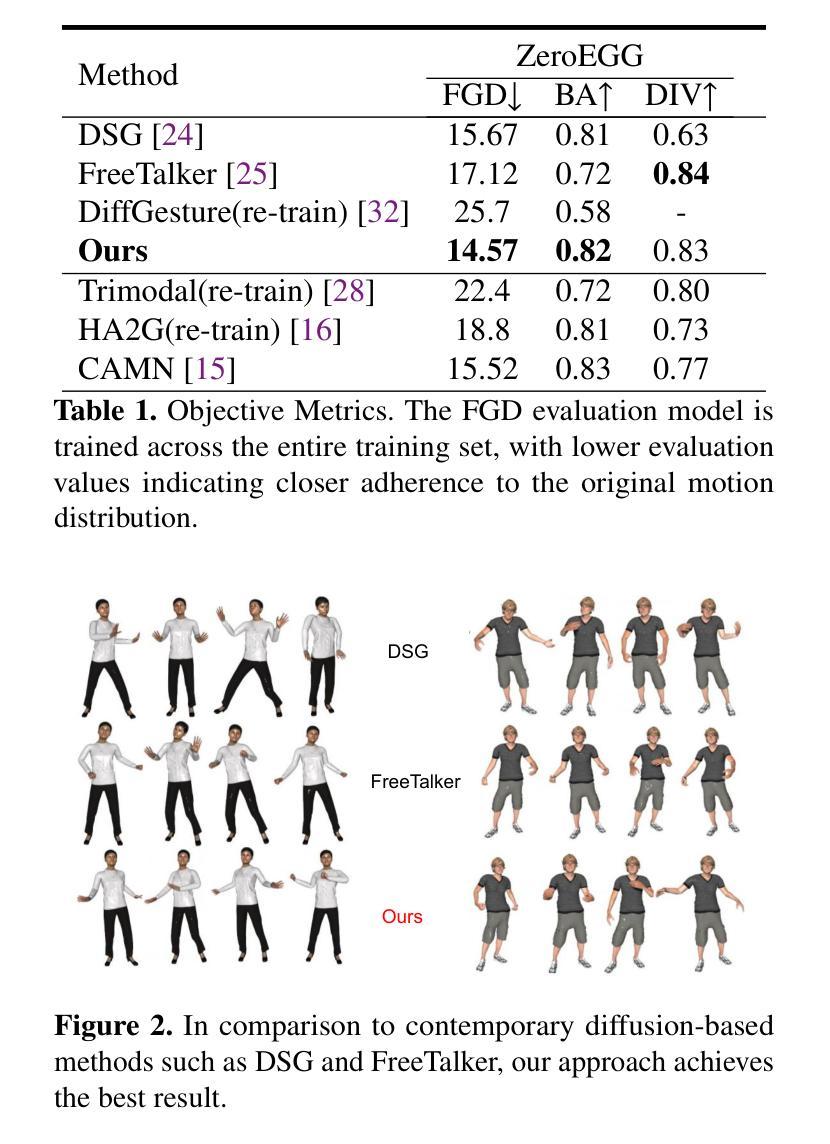
Full-body gestures play a pivotal role in natural interactions and are crucial for achieving effective communication. Nevertheless, most existing studies primarily focus on the gesture generation of speakers, overlooking the vital role of listeners in the interaction process and failing to fully explore the dynamic interaction between them. This paper innovatively proposes an Inter-Diffusion Generation Model of Speakers and Listeners for Effective Communication. For the first time, we integrate the full-body gestures of listeners into the generation framework. By devising a novel inter-diffusion mechanism, this model can accurately capture the complex interaction patterns between speakers and listeners during communication. In the model construction process, based on the advanced diffusion model architecture, we innovatively introduce interaction conditions and the GAN model to increase the denoising step size. As a result, when generating gesture sequences, the model can not only dynamically generate based on the speaker’s speech information but also respond in realtime to the listener’s feedback, enabling synergistic interaction between the two. Abundant experimental results demonstrate that compared with the current state-of-the-art gesture generation methods, the model we proposed has achieved remarkable improvements in the naturalness, coherence, and speech-gesture synchronization of the generated gestures. In the subjective evaluation experiments, users highly praised the generated interaction scenarios, believing that they are closer to real life human communication situations. Objective index evaluations also show that our model outperforms the baseline methods in multiple key indicators, providing more powerful support for effective communication.
全身动作在自然交互中扮演着至关重要的角色,对于实现有效沟通至关重要。然而,现有的大多数研究主要关注说话者的动作生成,忽视了倾听者在交互过程中的重要作用,未能充分探索它们之间的动态交互。本文创新地提出了一种用于有效沟通的说话者与倾听者交互扩散生成模型。我们首次将倾听者的全身动作纳入生成框架。通过设计一种新型交互扩散机制,该模型可以准确捕捉沟通过程中说话者与倾听者之间的复杂交互模式。在模型构建过程中,我们基于先进的扩散模型架构,创新地引入了交互条件和GAN模型,以增加去噪步长。因此,在生成动作序列时,该模型不仅可以基于说话者的语音信息动态生成,还可以实时响应倾听者的反馈,实现两者之间的协同交互。丰富的实验结果证明,与我们目前先进的动作生成方法相比,我们提出的模型在生成动作的自然性、连贯性和语音动作同步方面取得了显著的改进。在主观评估实验中,用户高度赞扬了生成的交互场景,认为它们更接近于现实生活中的人类沟通情境。客观指标评估也表明,我们的模型在多个关键指标上优于基线方法,为有效沟通提供了更有力的支持。
论文及项目相关链接
PDF accepted by ICMR 2025
Summary
本文研究了全身动作在自然交互中的重要作用,并提出一种创新的交互扩散生成模型,该模型首次将听者的全身动作纳入生成框架中。通过设计新颖的交互扩散机制,该模型能准确捕捉交流过程中说话者与听者之间的复杂交互模式。在模型构建过程中,引入先进的扩散模型架构、交互条件和GAN模型,提高去噪步长。该模型不仅能根据说话者的语音信息动态生成动作序列,还能实时响应听者的反馈,实现两者之间的协同交互。实验结果表明,与当前先进的动作生成方法相比,所提出的模型在自然性、连贯性和语音动作同步方面取得了显著改进。
Key Takeaways
1. 全身动作在自然交互中起关键作用,对有效沟通至关重要。
2. 现有研究主要关注说话者的动作生成,忽略了听者在交互中的作用。
3. 提出了一个创新的交互扩散生成模型,将听者的全身动作纳入生成框架中。
4. 通过设计交互扩散机制,该模型能准确捕捉说话者与听者之间的复杂交互模式。
5. 模型结合了先进的扩散模型架构、交互条件和GAN模型,提高了去噪步长。
6. 模型能实时响应听者的反馈,实现说话者与听者之间的协同交互。
点此查看论文截图