⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-10 更新
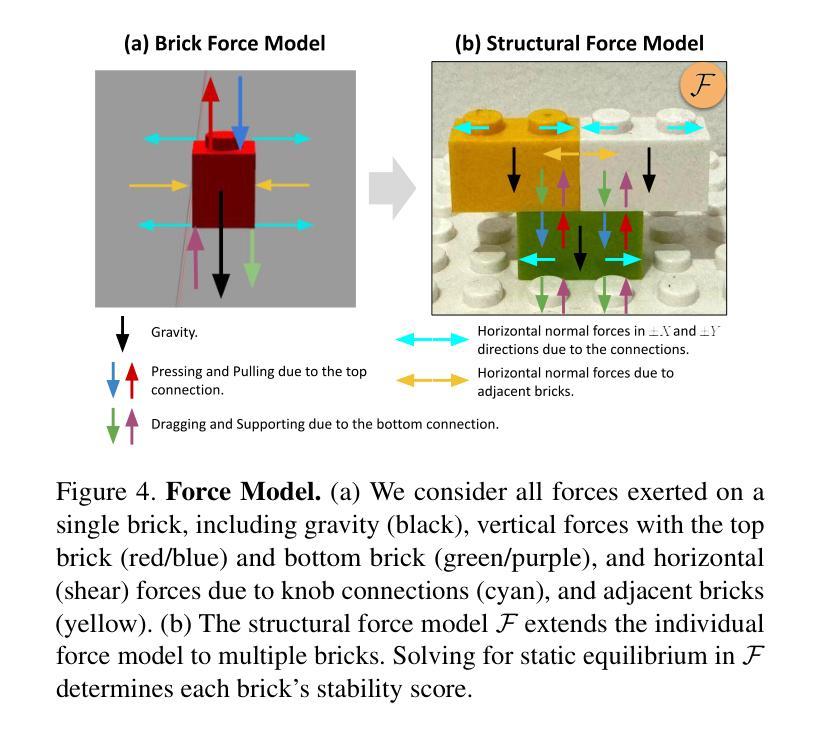
Generating Physically Stable and Buildable LEGO Designs from Text
Authors:Ava Pun, Kangle Deng, Ruixuan Liu, Deva Ramanan, Changliu Liu, Jun-Yan Zhu
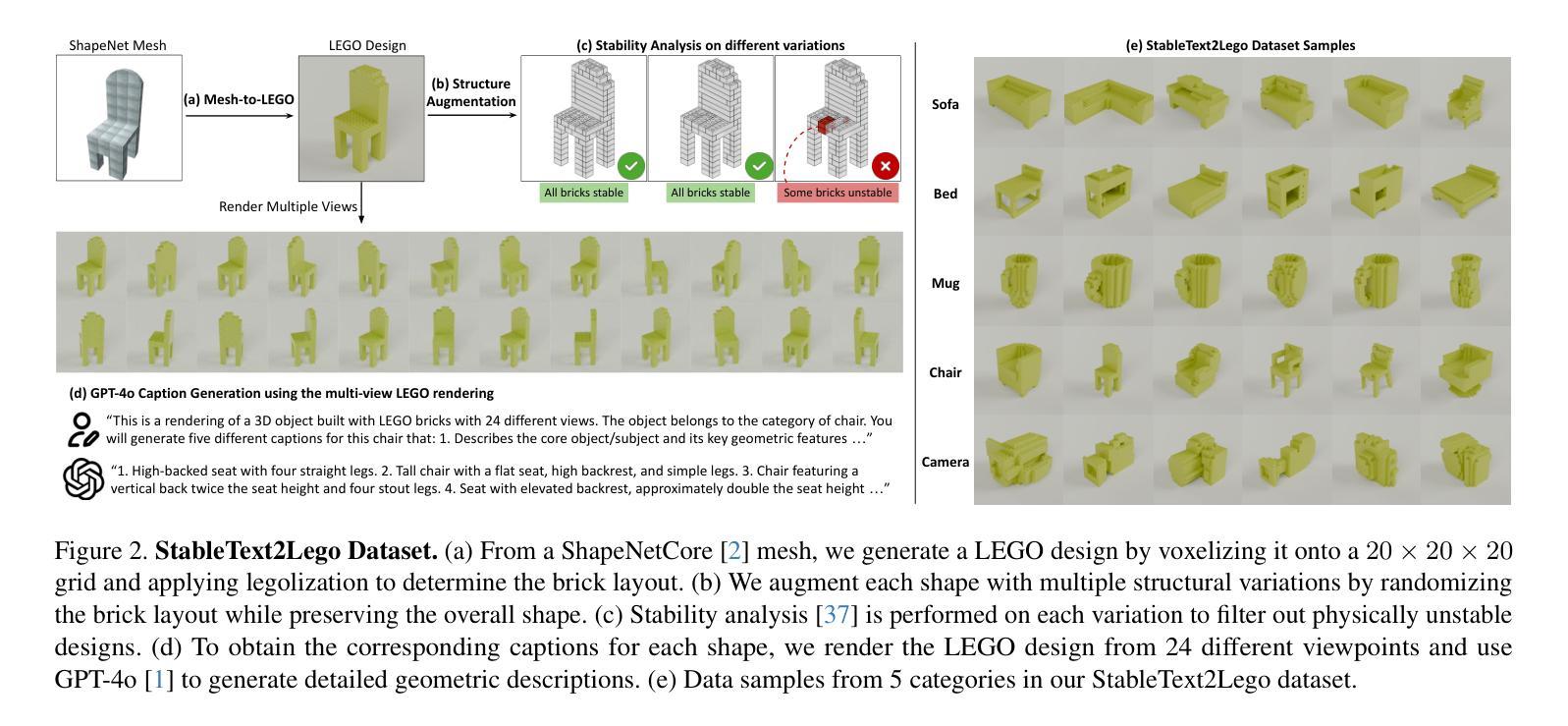
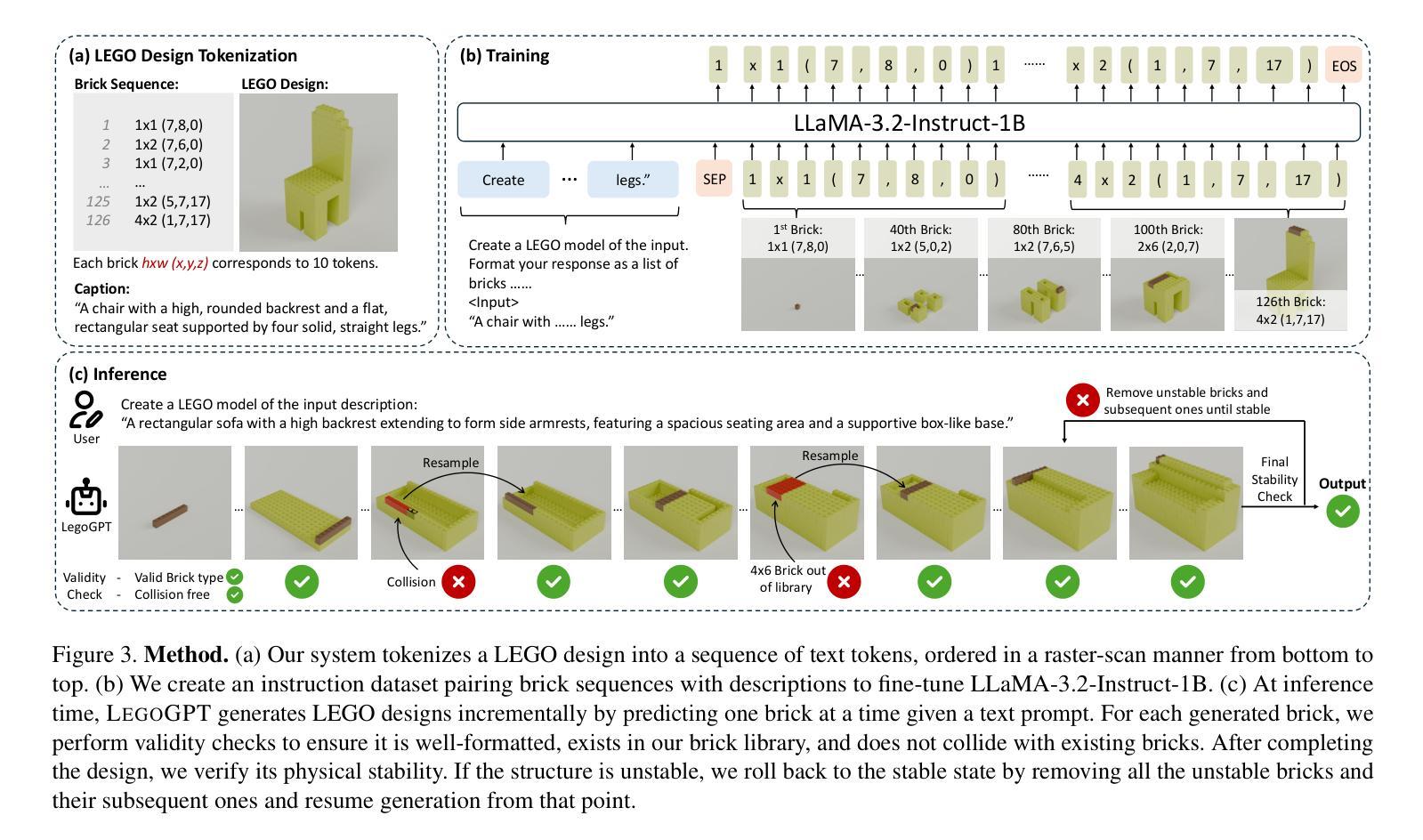
We introduce LegoGPT, the first approach for generating physically stable LEGO brick models from text prompts. To achieve this, we construct a large-scale, physically stable dataset of LEGO designs, along with their associated captions, and train an autoregressive large language model to predict the next brick to add via next-token prediction. To improve the stability of the resulting designs, we employ an efficient validity check and physics-aware rollback during autoregressive inference, which prunes infeasible token predictions using physics laws and assembly constraints. Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing LEGO designs that align closely with the input text prompts. We also develop a text-based LEGO texturing method to generate colored and textured designs. We show that our designs can be assembled manually by humans and automatically by robotic arms. We also release our new dataset, StableText2Lego, containing over 47,000 LEGO structures of over 28,000 unique 3D objects accompanied by detailed captions, along with our code and models at the project website: https://avalovelace1.github.io/LegoGPT/.
我们推出LegoGPT,这是一种通过文本提示生成物理稳定的乐高积木模型的首创方法。为实现这一目标,我们构建了一个大规模的乐高设计数据集,其中包含物理稳定的乐高设计及其相关描述,并训练了一种自回归大型语言模型,通过下一个令牌预测来预测要添加的下一个积木。为提高所得设计的稳定性,我们在自回归推理过程中采用了高效的合理性检查和物理感知回滚,利用物理定律和装配约束来剔除不可行的令牌预测。我们的实验表明,LegoGPT能够生成稳定、多样且美观的乐高设计,与输入的文本提示紧密对应。我们还开发了一种基于文本的乐高纹理生成方法,以生成彩色和有纹理的设计。我们展示了我们的设计可以被人类手动组装,也可以被机械臂自动组装。我们还发布了新的数据集StableText2Lego,其中包含超过47000个乐高结构,代表超过28000个独特的3D对象,每个对象都有详细的描述。我们的代码和模型可以在项目网站中找到:https://avalovelace1.github.io/LegoGPT/。
论文及项目相关链接
PDF Project page: https://avalovelace1.github.io/LegoGPT/
Summary
本文介绍了LegoGPT,这是一种通过文本提示生成物理稳定的乐高积木模型的新方法。通过构建大规模的物理稳定乐高设计数据集及其相关描述,训练了自回归大型语言模型,通过下一个令牌预测来预测下一个要添加的积木。为提高设计稳定性,采用有效的有效性检查和物理感知回滚进行自回归推理,利用物理定律和装配约束剔除不可行的令牌预测。实验表明,LegoGPT能生成稳定、多样、美观的乐高设计,紧密符合输入文本提示。还开发了一种基于文本的乐高纹理方法,以生成带颜色的纹理设计。最后释放了新数据集StableText2Lego,包含超过4.7万个乐高三维物体的独特结构和详细描述。
Key Takeaways
- LegoGPT是首个通过文本提示生成物理稳定的乐高积木模型的方法。
- 通过构建大规模数据集来训练自回归大型语言模型,实现文本到乐高设计的转换。
- 采用有效性检查和物理感知回滚来提高设计稳定性。
- LegoGPT能生成与文本提示紧密符合的稳定、多样、美观的乐高设计。
- 开发了一种基于文本的乐高纹理方法,为设计添加颜色和纹理。
- 释放了新数据集StableText2Lego,包含大量独特的乐高结构和详细描述。
点此查看论文截图


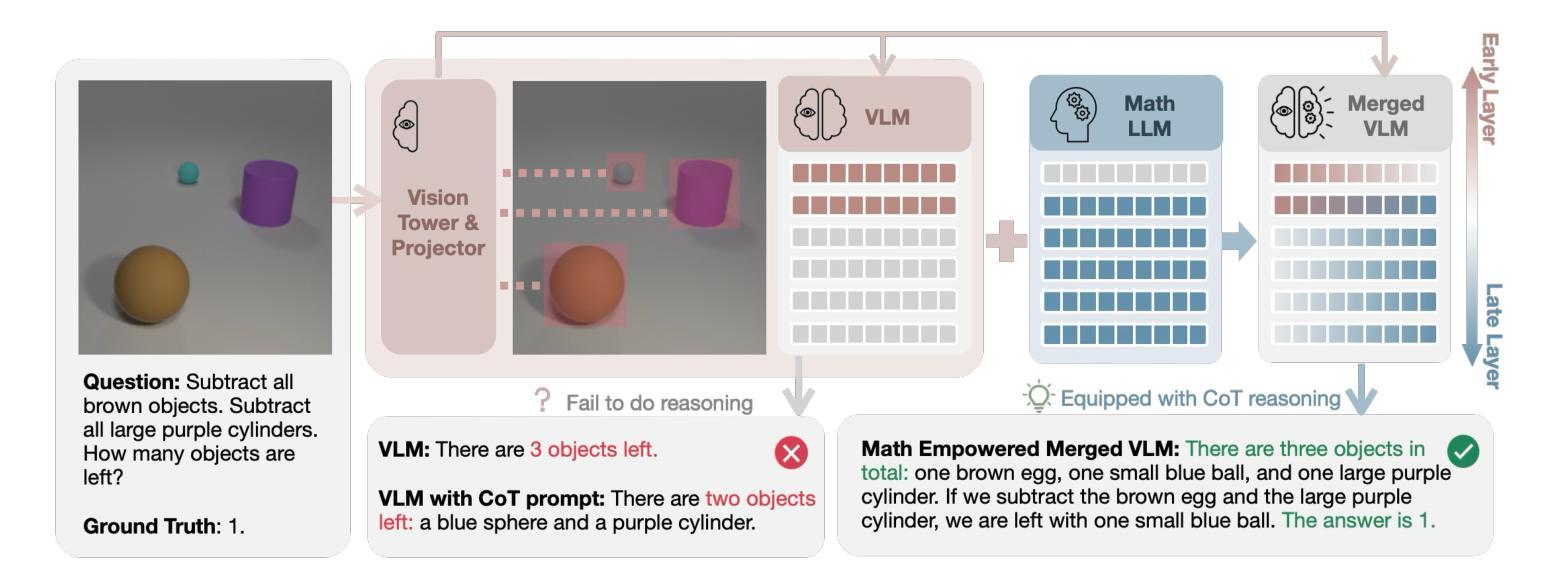
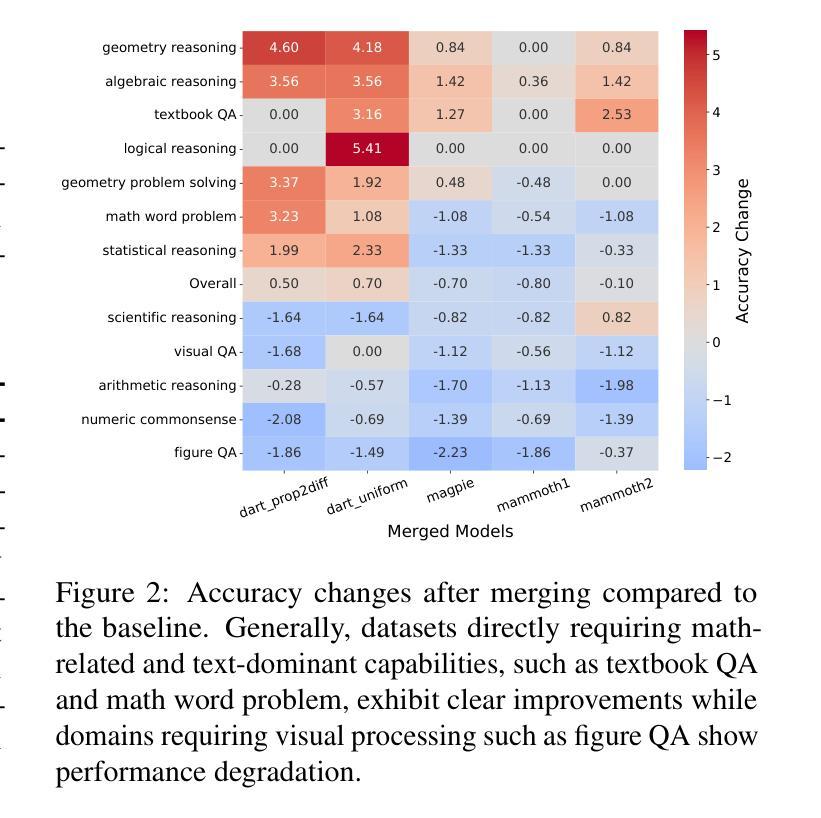
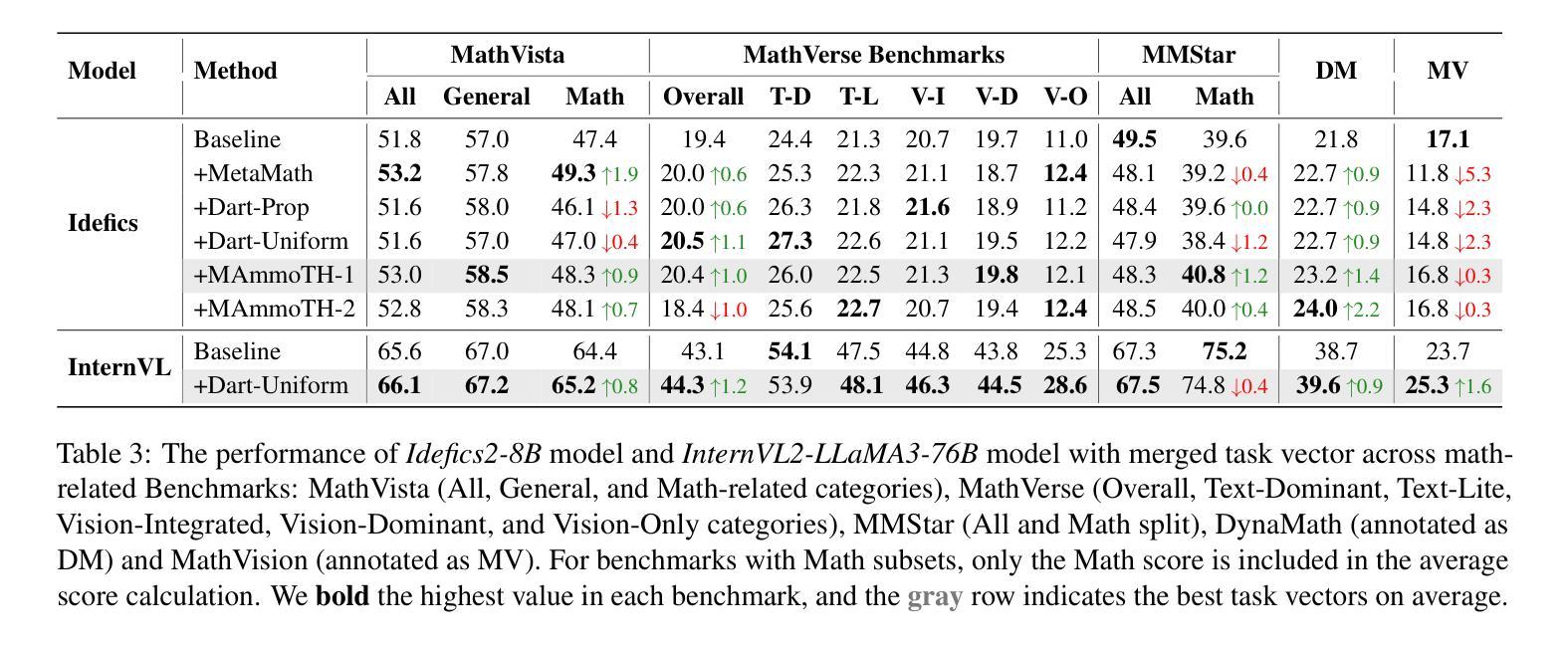
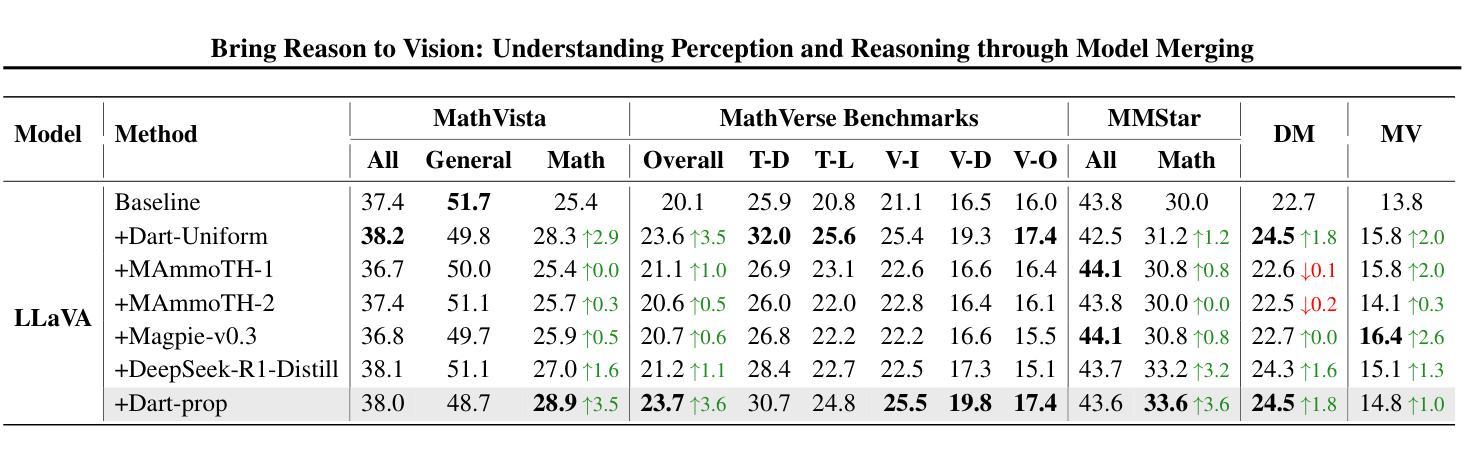
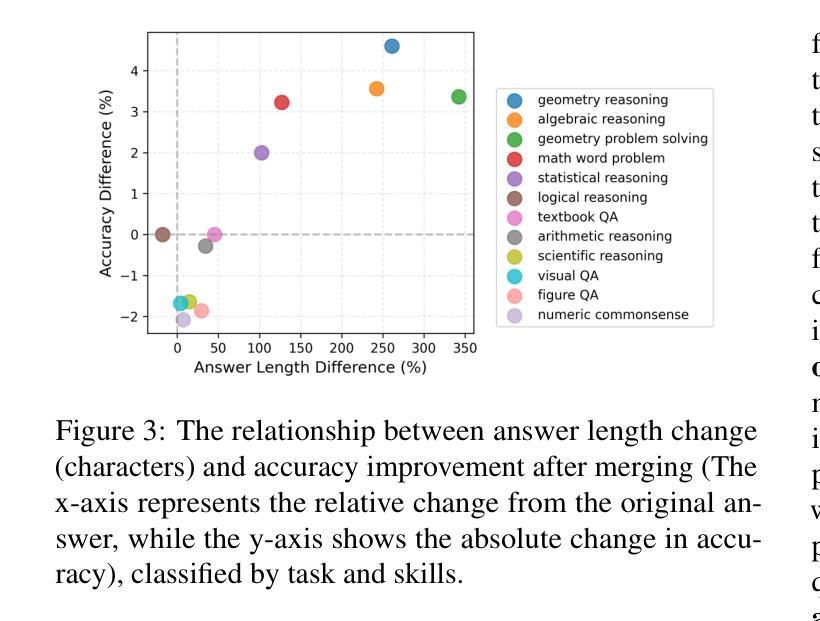
Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
Authors:Shiqi Chen, Jinghan Zhang, Tongyao Zhu, Wei Liu, Siyang Gao, Miao Xiong, Manling Li, Junxian He
Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
视觉语言模型(VLMs)结合了视觉感知与大型语言模型(LLMs)的推理等一般能力。然而,这两种能力如何结合以及它们如何共同发挥作用,其机制尚不清楚。在这项工作中,我们探索通过模型合并来组合感知和推理,该合并连接了不同模型的参数。与以往经常关注同类模型合并的工作不同,我们提出了跨模态模型合并的方法,使LLMs的推理能力能够融入VLMs中。通过大量实验,我们证明了模型合并是一种成功的方法,能以无训练的方式将LLMs的推理能力转移到VLMs中。此外,我们还利用合并的模型来了解感知和推理的内在机制以及合并对其的影响。我们发现感知能力主要编码在模型的前几层,而推理则大多由中间到后面的层次所促进。合并后,我们观察到所有层次都开始对推理做出贡献,而感知能力的层次分布基本保持不变。这些观察结果揭示了模型合并作为多模态集成和解释工具的潜力。
论文及项目相关链接
PDF ICML 2025. Our code is publicly available at https://github.com/shiqichen17/VLM_Merging
Summary
视觉语言模型(VLMs)结合了视觉感知与大型语言模型(LLMs)的推理等一般能力。然而,这两种能力如何结合以及贡献机制尚不清楚。本研究通过模型合并探索了感知和推理的结合方式,该方式连接了不同模型的参数。与之前经常专注于合并同类模型的方案不同,我们提出了跨模态模型合并方法,使得将LLM的推理能力融入VLMs成为可能。通过广泛的实验,我们证明了模型合并是一种成功的方式,以无训练的方式将LLM的推理能力转移到VLMs上。此外,我们还利用合并后的模型来了解感知和推理的内在机制以及合并对其的影响。我们发现感知能力主要编码在模型的早期层中,而推理主要由中后期层促进。合并后,我们观察到所有层都开始对推理做出贡献,而感知能力的层分布变化不大。这些观察揭示了模型合并作为多模态集成和解释的潜力。
Key Takeaways
- VLMs结合了视觉感知与LLMs的推理能力。
- 模型合并是连接不同模型参数以实现感知和推理结合的有效方法。
- 与同类模型合并不同,本研究提出跨模态模型合并方法。
- 模型合并成功将LLM的推理能力转移到VLMs上,且无需额外训练。
- 感知能力主要位于模型的早期层,而推理能力主要在中后期层。
- 合并后,所有层都对推理做出贡献,而感知能力的层分布保持稳定。
点此查看论文截图

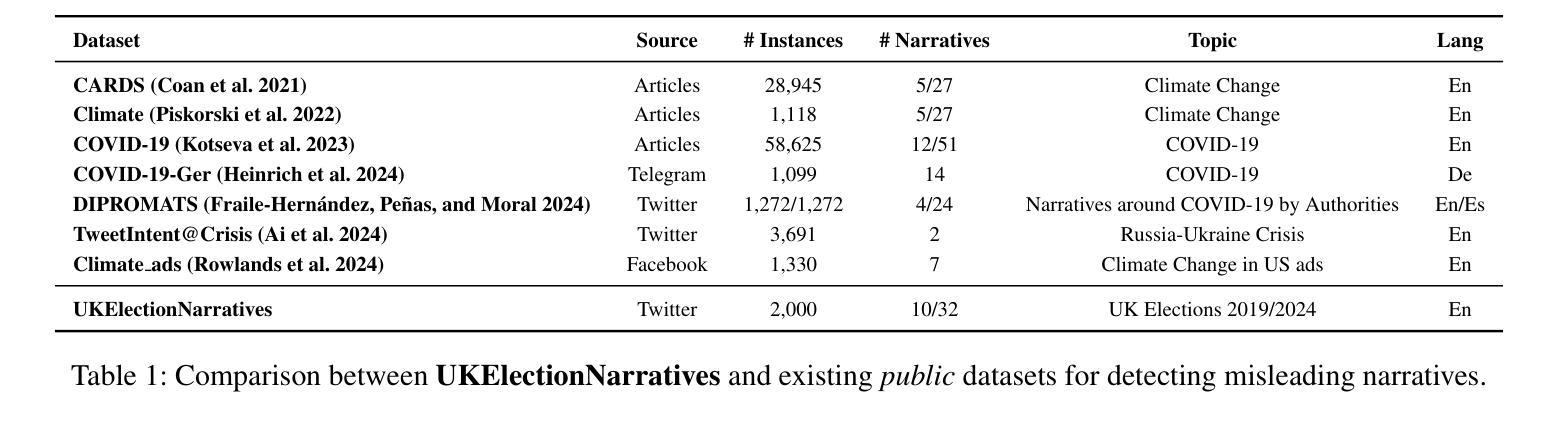
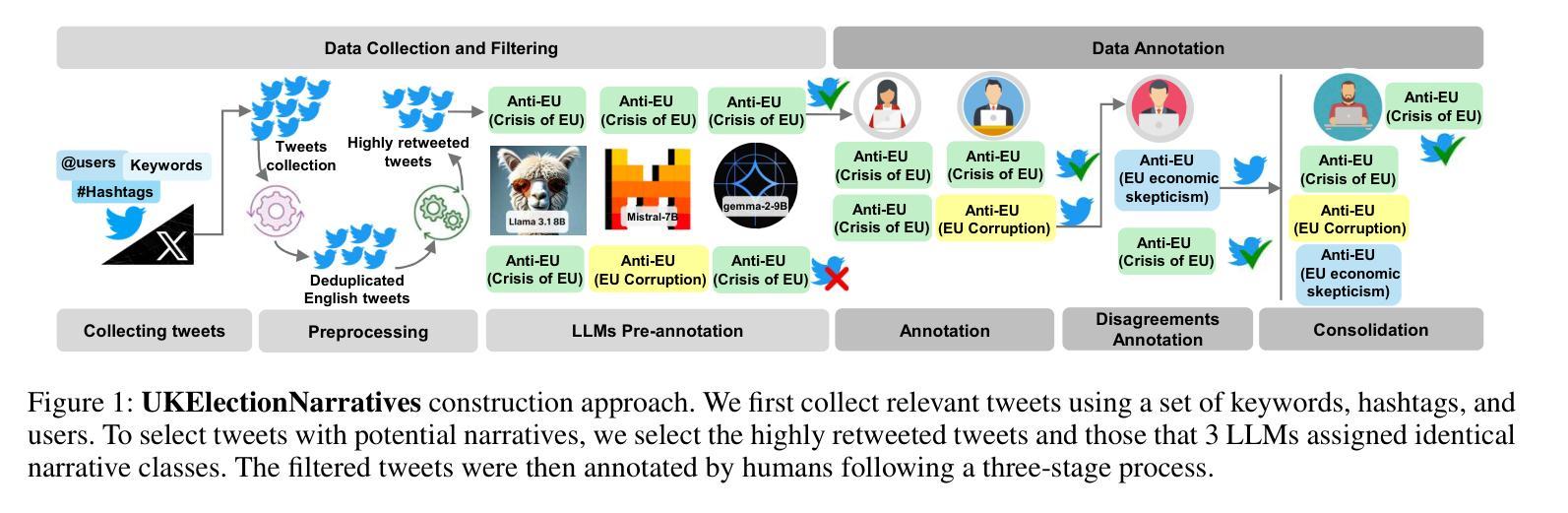
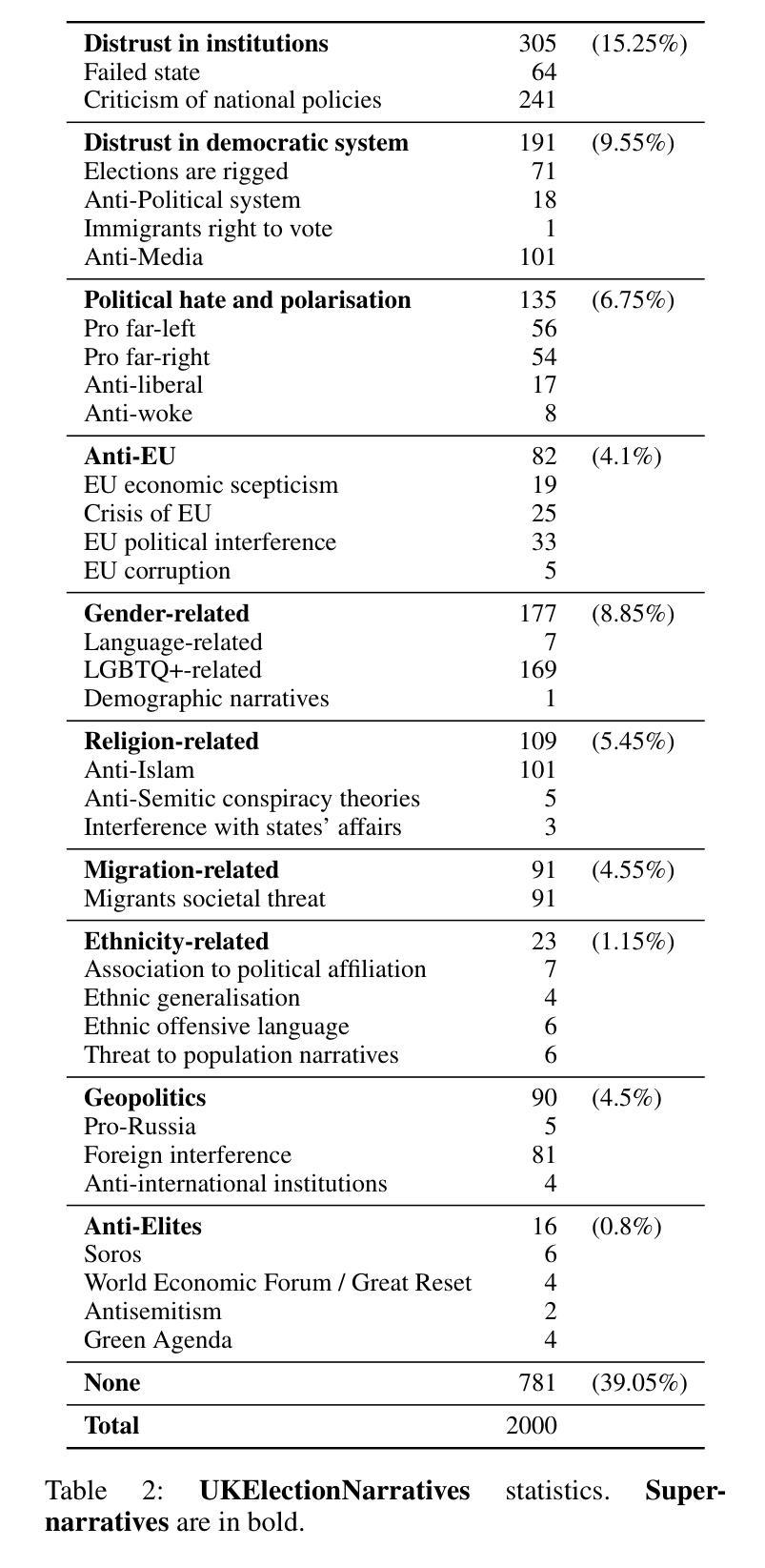
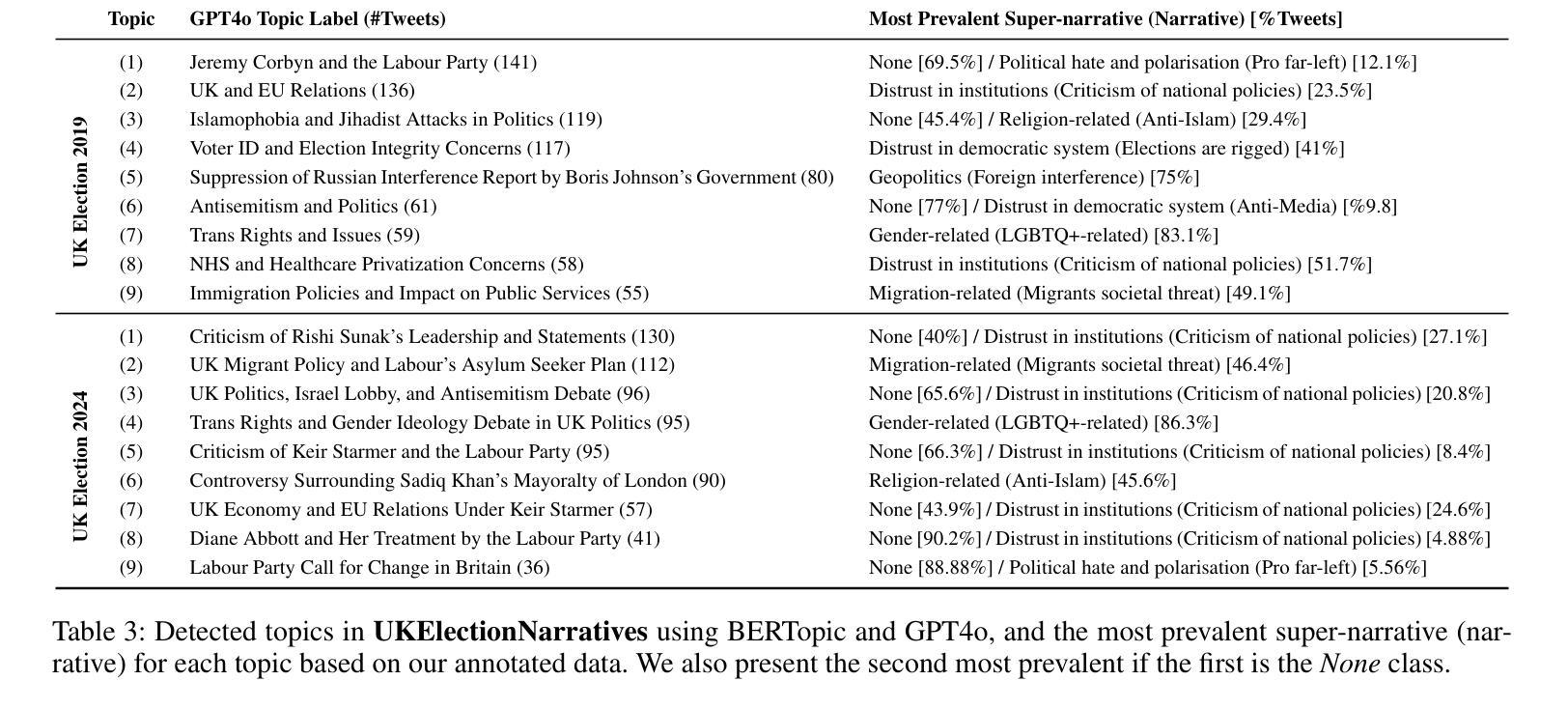
UKElectionNarratives: A Dataset of Misleading Narratives Surrounding Recent UK General Elections
Authors:Fatima Haouari, Carolina Scarton, Nicolò Faggiani, Nikolaos Nikolaidis, Bonka Kotseva, Ibrahim Abu Farha, Jens Linge, Kalina Bontcheva
Misleading narratives play a crucial role in shaping public opinion during elections, as they can influence how voters perceive candidates and political parties. This entails the need to detect these narratives accurately. To address this, we introduce the first taxonomy of common misleading narratives that circulated during recent elections in Europe. Based on this taxonomy, we construct and analyse UKElectionNarratives: the first dataset of human-annotated misleading narratives which circulated during the UK General Elections in 2019 and 2024. We also benchmark Pre-trained and Large Language Models (focusing on GPT-4o), studying their effectiveness in detecting election-related misleading narratives. Finally, we discuss potential use cases and make recommendations for future research directions using the proposed codebook and dataset.
在选举中,误导性叙事对塑造公众意见起着至关重要的作用,因为它们会影响选民对候选人和政党的的看法。这需要我们准确检测这些叙事。为此,我们介绍了最近在欧洲选举中流传的常见误导性叙事的第一个分类。基于这一分类,我们构建并分析了UKElectionNarratives:这是首个经人工标注的误导性叙事数据集,包含了2019年和2024年英国大选中流传的误导性叙事。我们还对预训练大型语言模型(以GPT-4o为重点)进行了基准测试,研究其在检测与选举相关的误导性叙事方面的有效性。最后,我们讨论了潜在的使用案例,并使用拟定的编码表和数据集为未来研究方向提出建议。
论文及项目相关链接
PDF This work was accepted at the International AAAI Conference on Web and Social Media (ICWSM 2025)
Summary
选举期间,误导性叙事对塑造公众意见具有关键作用,影响选民对候选人和政治的看法。为了应对这一挑战,我们介绍了欧洲最新选举中常见误导性叙事的分类体系。基于这一分类体系,我们构建了首个标注误导性叙事的数据集UKElectionNarratives,该数据集包括在最近两届英国大选中传播的选举误导性叙事内容。同时我们对预训练的大型语言模型进行了基准测试(重点关注GPT-4o),评估其检测选举相关误导性叙事的有效性。最后,我们讨论了潜在的应用场景,并为未来的研究提供了建议。
Key Takeaways
- 误导性叙事在选举中扮演重要角色,塑造公众对候选人和政治的看法。
- 我们提出了欧洲最新选举中常见误导性叙事的分类体系。
- 基于分类体系,我们构建了包含两届英国大选中传播选举误导性叙事的数据集UKElectionNarratives。
- 对预训练的大型语言模型进行了基准测试,评估其检测选举相关误导性叙事的能力。
- 潜在应用场景包括政治宣传、公众教育和社会舆论研究等。
- 研究为未来研究提供了方向和建议,如开发更有效的检测工具和方法等。
点此查看论文截图

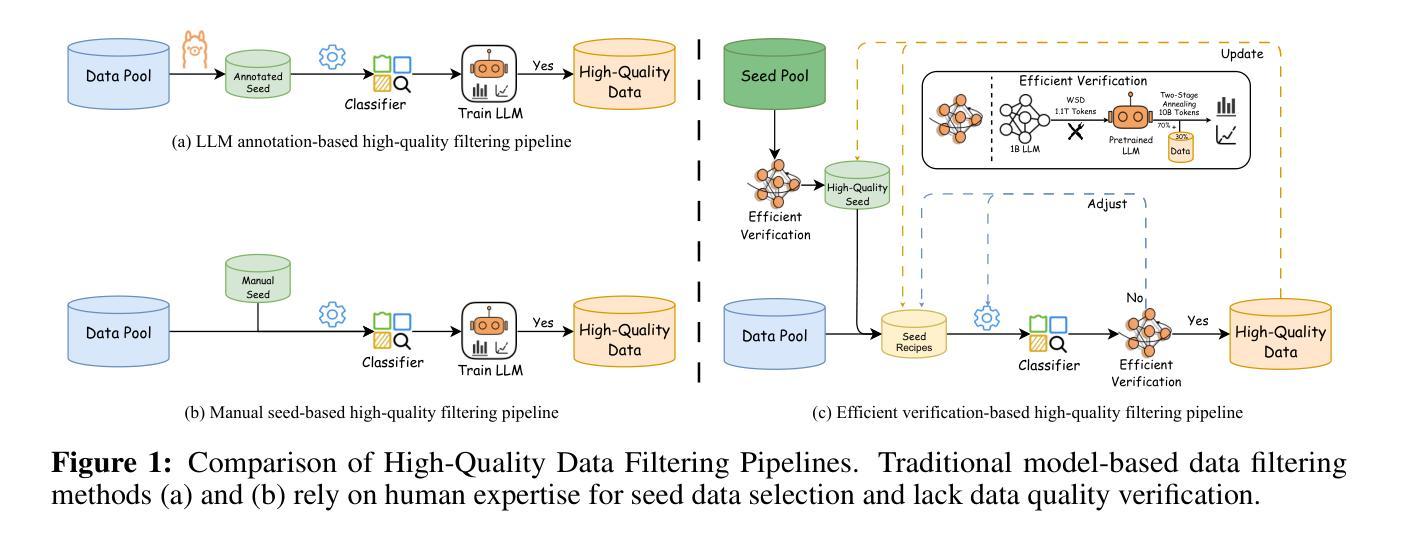
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
Authors:Yudong Wang, Zixuan Fu, Jie Cai, Peijun Tang, Hongya Lyu, Yewei Fang, Zhi Zheng, Jie Zhou, Guoyang Zeng, Chaojun Xiao, Xu Han, Zhiyuan Liu
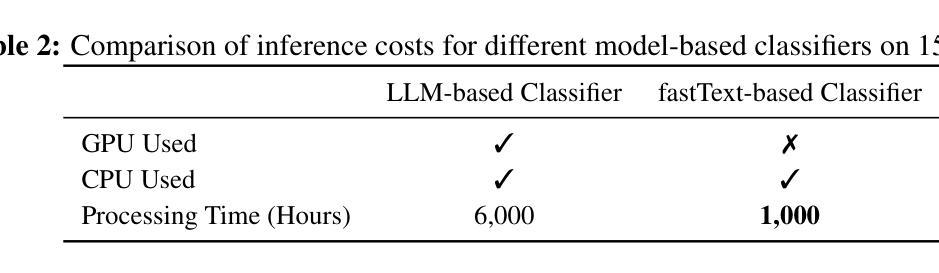
Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
随着大型语言模型(LLM)的快速发展,数据质量已成为提高模型性能的关键因素。以模型驱动的数据过滤已成为获取高质量数据的主要方法。然而,它仍然面临两个主要挑战:(1)缺乏有效的数据验证策略,难以对数据质量提供及时反馈;(2)用于训练分类器的种子数据选择缺乏明确标准,高度依赖人为经验,引入了一定程度的主观性。为了解决第一个挑战,我们引入了一种高效验证策略,能够以最低的计算成本快速评估数据对LLM训练的影响。为了解决第二个挑战,我们假设高质量种子数据对LLM训练有益,并结合提出的验证策略,优化了正负样本的选择,提出了一种高效的数据过滤流程。该流程不仅提高了过滤效率、分类器质量和稳健性,还显著降低了实验和推理成本。此外,为了有效地过滤高质量数据,我们采用了基于fastText的轻量级分类器,并将过滤流程成功应用于两个广泛使用的预训练语料库FineWeb和中文FineWeb数据集,从而创建了更高质量的Ultra-FineWeb数据集。Ultra-FineWeb包含约1万亿个英文标记和120亿个中文标记。经验结果表明,在多个基准任务上,使用Ultra-FineWeb训练的LLM性能得到显著提高,验证了我们的流程在提高数据质量和训练效率方面的有效性。
论文及项目相关链接
PDF The datasets are available on https://huggingface.co/datasets/openbmb/UltraFineWeb
摘要
随着大型语言模型(LLM)的快速发展,数据质量已成为提高模型性能的关键因素。模型驱动的数据过滤方法逐渐成为获取高质量数据的主要手段,但仍面临两大挑战:一是缺乏有效的数据验证策略,难以对数据安全及时提供反馈;二是种子数据的选择缺乏明确标准,高度依赖人为经验,引入主观性。为解决这些问题,我们提出一种高效验证策略,以低成本计算实现对LLM训练数据影响的快速评估。我们假设高质量种子数据对LLM训练有益,结合验证策略优化正负样本选择,并提出高效数据过滤流程。此流程不仅提高过滤效率、分类器质量和稳健性,还显著降低实验和推理成本。此外,我们采用基于fastText的轻量级分类器进行高效高质量数据过滤,并将过滤流程成功应用于广泛使用的预训练语料库FineWeb和中文FineWeb数据集,创建出更高质量的Ultra-FineWeb数据集。含有约一万亿英文令牌和一百二十亿中文令牌的Ultra-FineWeb数据集实证结果显示,在多个基准测试任务上,基于Ultra-FineWeb训练的LLM性能显著提升,验证了我们流程在提高数据质量和训练效率方面的有效性。
关键见解
- 数据质量对于提升大型语言模型(LLM)性能至关重要。
- 模型驱动的数据过滤是获取高质量数据的主要手段,但仍面临挑战。
- 缺乏高效数据验证策略,难以对数据安全及时提供反馈。
- 种子数据选择缺乏明确标准,依赖人为经验,引入主观性。
- 提出高效验证策略,能快速评估数据对LLM训练的影响,降低计算成本。
- 结合验证策略优化正负样本选择,提升过滤效率、分类器质量和稳健性。
点此查看论文截图



TransProQA: an LLM-based literary Translation evaluation metric with Professional Question Answering
Authors:Ran Zhang, Wei Zhao, Lieve Macken, Steffen Eger
The impact of Large Language Models (LLMs) has extended into literary domains. However, existing evaluation metrics prioritize mechanical accuracy over artistic expression and tend to overrate machine translation (MT) as being superior to experienced professional human translation. In the long run, this bias could result in a permanent decline in translation quality and cultural authenticity. In response to the urgent need for a specialized literary evaluation metric, we introduce TransProQA, a novel, reference-free, LLM-based question-answering (QA) framework designed specifically for literary translation evaluation. TransProQA uniquely integrates insights from professional literary translators and researchers, focusing on critical elements in literary quality assessment such as literary devices, cultural understanding, and authorial voice. Our extensive evaluation shows that while literary-finetuned XCOMET-XL yields marginal gains, TransProQA substantially outperforms current metrics, achieving up to 0.07 gain in correlation (ACC-EQ and Kendall’s tau) and surpassing the best state-of-the-art (SOTA) metrics by over 15 points in adequacy assessments. Incorporating professional translator insights as weights further improves performance, highlighting the value of translator inputs. Notably, TransProQA approaches human-level evaluation performance comparable to trained linguistic annotators. It demonstrates broad applicability to open-source models such as LLaMA3.3-70b and Qwen2.5-32b, indicating its potential as an accessible and training-free literary evaluation metric and a valuable tool for evaluating texts that require local processing due to copyright or ethical considerations.
大型语言模型(LLM)的影响已经扩展到文学领域。然而,现有的评估指标更注重机械准确性而非艺术表达,并倾向于认为机器翻译(MT)优于经验丰富的专业人工翻译。从长远来看,这种偏见可能导致翻译质量和文化真实性的永久下降。为了应对对专用文学评估指标的迫切需求,我们引入了TransProQA,这是一个新的、无参考的、基于LLM的问答(QA)框架,专为文学翻译评估而设计。TransProQA独特地结合了专业文学翻译者和研究人员的见解,专注于文学质量评估的关键要素,如文学手法、文化理解和作者声音。我们的广泛评估表明,虽然经过文学微调的XCOMET-XL只带来轻微的提升,但TransProQA在现有指标上表现出色,在相关性(ACC-EQ和Kendall的tau)上实现了高达0.07的增益,并在充分性评估中超过了最先进的指标超过15分。通过将专业翻译人员的见解作为权重纳入,进一步提高了性能,突显了翻译人员输入的价值。值得注意的是,TransProQA的评价性能接近人类水平,与受过训练的语言学注释者相当。它证明了对开源模型(如LLaMA 3.3-70b和Qwen 2.5-32b)的广泛应用能力,显示出其作为可访问且无需训练即可使用的文学评估指标以及用于评估因版权或伦理考虑需要本地处理的文本的有价值的工具。
论文及项目相关链接
PDF WIP
Summary
大型语言模型(LLM)在文学领域产生了影响,但现有评估指标偏重机械准确性而忽视艺术表达,倾向于认为机器翻译优于经验丰富的专业人工翻译。这可能导致翻译质量和文化真实性永久下降。因此,我们引入了一种新型的、基于LLM的问答框架——TransProQA,专门用于文学翻译评估。它结合了专业文学翻译人员和研究人员的见解,侧重于文学质量评估的关键要素,如文学手法、文化理解和作者声音。评估显示,TransProQA显著优于当前指标,与人类水平评估性能相近。
Key Takeaways
- LLMs对文学领域产生影响,但现有评估指标偏重机械准确性。
- 现有指标倾向于认为机器翻译优于专业人工翻译,可能影响翻译质量和文化真实性。
- 推出专门用于文学翻译评估的新型LLM问答框架——TransProQA。
- TransProQA结合专业文学翻译人员和研究人员的见解。
- TransProQA侧重于文学质量评估的关键要素,如文学手法、文化理解和作者声音。
- TransProQA显著优于当前评估指标,与人类水平评估性能相近。
点此查看论文截图



ICon: In-Context Contribution for Automatic Data Selection
Authors:Yixin Yang, Qingxiu Dong, Linli Yao, Fangwei Zhu, Zhifang Sui
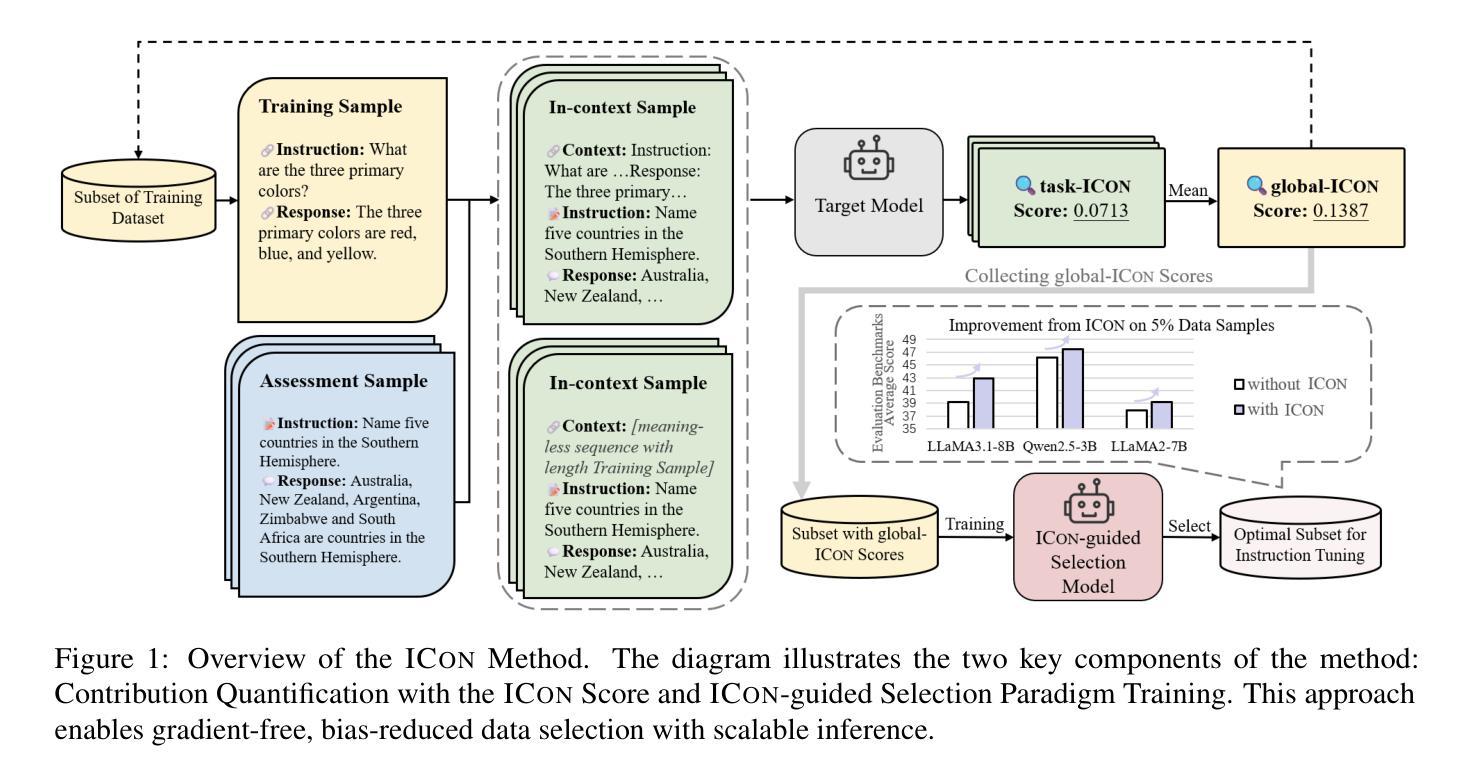
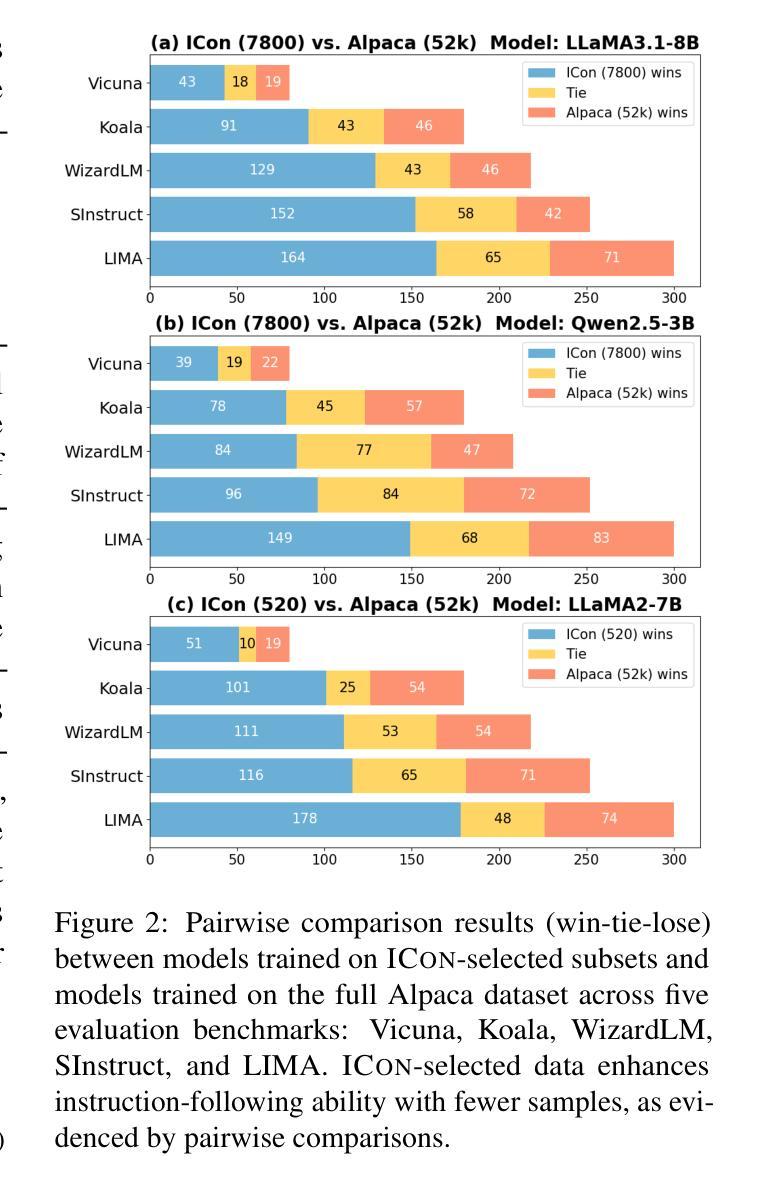
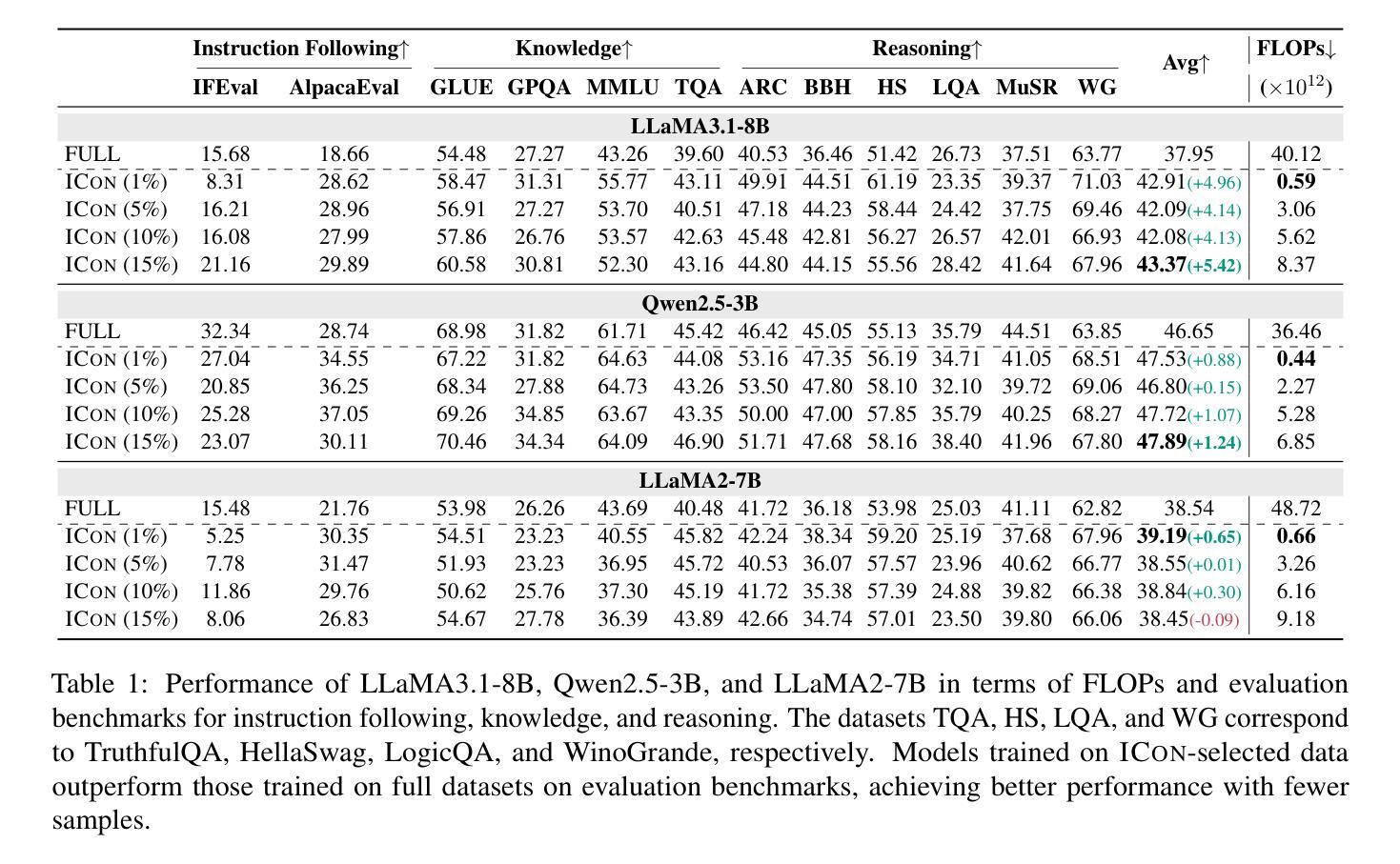
Data selection for instruction tuning is essential for improving the performance of Large Language Models (LLMs) and reducing training cost. However, existing automated selection methods either depend on computationally expensive gradient-based measures or manually designed heuristics, which may fail to fully exploit the intrinsic attributes of data. In this paper, we propose In-context Learning for Contribution Measurement (ICon), a novel gradient-free method that takes advantage of the implicit fine-tuning nature of in-context learning (ICL) to measure sample contribution without gradient computation or manual indicators engineering. ICon offers a computationally efficient alternative to gradient-based methods and reduces human inductive bias inherent in heuristic-based approaches. ICon comprises three components and identifies high-contribution data by assessing performance shifts under implicit learning through ICL. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of ICon. Remarkably, on LLaMA3.1-8B, models trained on 15% of ICon-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by ICon, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.
数据选择对于指令微调在提高大型语言模型(LLM)性能和降低训练成本方面至关重要。然而,现有的自动选择方法要么依赖于计算昂贵的基于梯度的度量,要么依赖于手动设计的启发式规则,这可能无法充分利用数据的内在属性。在本文中,我们提出了基于语境学习的贡献测量(ICon)方法,这是一种新颖的无需梯度的测量方法,利用语境学习(CL)的隐性微调特性来测量样本贡献,无需进行梯度计算或手动指标工程。ICon为基于梯度的方法提供了计算效率更高的替代方案,并减少了启发式方法中固有的人类归纳偏见。ICon包含三个组件,通过评估语境学习下的性能变化来识别高贡献数据。在三个LLM、跨越12个基准测试和5个配对评估集的大量实验证明了ICon的有效性。值得一提的是,在LLaMA 3.1-8B上,使用ICon选择的15%数据进行训练的模型比使用全数据集训练的模型高出5.42个百分点,并超过了广泛使用的选择方法的最佳性能2.06个百分点。我们进一步分析了ICon选择的高贡献样本,显示出任务多样性和适当的难度水平,而不仅仅是最困难的任务。
论文及项目相关链接
Summary
大模型时代,数据选择尤为重要。现有的自动化选择方法要么依赖计算成本高昂的基于梯度的度量方法,要么依赖于人工设计的启发式规则,无法充分利用数据的内在属性。本研究提出了一种基于上下文学习的贡献度量方法(ICon),这是一种新颖的无需梯度的方法,利用上下文学习的隐式微调特性来度量样本贡献,无需梯度计算或手动指标工程。ICon为基于梯度的方法提供了计算效率更高的替代方案,并减少了启发式方法中固有的人类归纳偏见。通过广泛实验验证,ICon在多个大型语言模型和基准测试集上表现出有效性和优越性。特别是在LLaMA3.1-8B上,使用ICon选择的15%数据进行训练的模型性能超越了全数据集训练的模型,并超过了其他常用选择方法的最优性能。分析显示,ICon选择的高贡献样本具有多样化的任务和适当的难度级别。
Key Takeaways
- 数据选择在大型语言模型性能提升和训练成本降低方面至关重要。
- 当前数据选择方法存在计算成本高和无法充分利用数据内在属性等问题。
- 研究提出了一种新型的基于上下文学习的贡献度量方法(ICon)。
- ICon利用上下文学习的隐式微调特性,无需梯度计算或复杂的手工指标工程。
- ICon提供了计算效率更高的替代方案,并减少了启发式方法中的人类归纳偏见。
- 在多个大型语言模型和基准测试集上进行的广泛实验验证了ICon的有效性和优越性。
点此查看论文截图

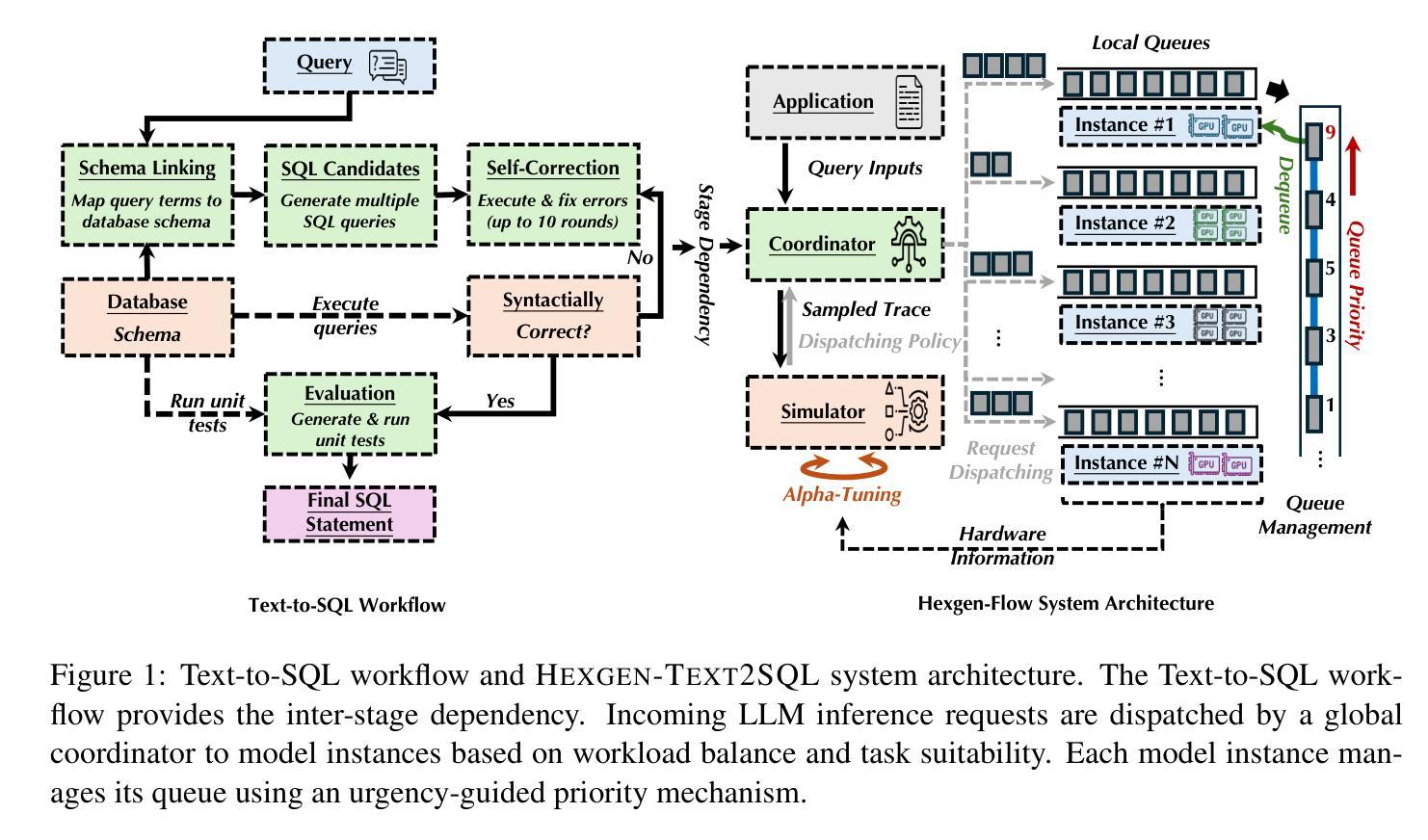
HEXGEN-TEXT2SQL: Optimizing LLM Inference Request Scheduling for Agentic Text-to-SQL Workflow
Authors:You Peng, Youhe Jiang, Chen Wang, Binhang Yuan
Recent advances in leveraging the agentic paradigm of large language models (LLMs) utilization have significantly enhanced Text-to-SQL capabilities, enabling users without specialized database expertise to query data intuitively. However, deploying these agentic LLM-based Text-to-SQL systems in production poses substantial challenges due to their inherently multi-stage workflows, stringent latency constraints, and potentially heterogeneous GPU infrastructure in enterprise environments. Current LLM serving frameworks lack effective mechanisms for handling interdependent inference tasks, dynamic latency variability, and resource heterogeneity, leading to suboptimal performance and frequent service-level objective (SLO) violations. In this paper, we introduce HEXGEN-TEXT2SQL, a novel framework designed explicitly to schedule and execute agentic multi-stage LLM-based Text-to-SQL workflows on heterogeneous GPU clusters that handle multi-tenant end-to-end queries. HEXGEN-TEXT2SQL introduce a hierarchical scheduling approach combining global workload-balanced task dispatching and local adaptive urgency-guided prioritization, guided by a systematic analysis of agentic Text-to-SQL workflows. Additionally, we propose a lightweight simulation-based method for tuning critical scheduling hyperparameters, further enhancing robustness and adaptability. Our extensive evaluation on realistic Text-to-SQL benchmarks demonstrates that HEXGEN-TEXT2SQL significantly outperforms state-of-the-art LLM serving frameworks. Specifically, HEXGEN-TEXT2SQL reduces latency deadlines by up to 1.67$\times$ (average: 1.41$\times$) and improves system throughput by up to 1.75$\times$ (average: 1.65$\times$) compared to vLLM under diverse, realistic workload conditions. Our code is available at https://github.com/Relaxed-System-Lab/Hexgen-Flow.
近期利用大型语言模型(LLM)代理范式的进步极大地增强了文本到SQL的能力,使得没有专业数据库知识的用户能够直观地查询数据。然而,在生产环境中部署这些基于LLM的文本到SQL系统带来了巨大的挑战,因为它们本质上具有多阶段工作流程、严格的延迟限制和潜在的企业环境中的异构GPU基础设施。当前的LLM服务框架缺乏处理相互依赖的推理任务、动态延迟可变性以及资源异构性的有效机制,导致性能不佳和频繁的服务级别目标(SLO)违规。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的代理范式在Text-to-SQL能力方面的最新进展,使得没有专业数据库知识的用户能够直观地查询数据。然而,在生产环境中部署这些基于LLM的Text-to-SQL系统面临着诸多挑战,如多阶段工作流程、严格的延迟限制和潜在的企业环境中的异构GPU基础设施。本文介绍了一种新型框架HEXGEN-TEXT2SQL,专为在异构GPU集群上调度和执行基于LLM的多阶段Text-to-SQL工作流程而设计,该框架处理端到端的多租户查询。HEXGEN-TEXT2SQL引入了一种层次调度方法,结合全局负载平衡的任务分配和本地自适应紧急引导优先排序,并对agentic Text-to-SQL工作流程进行系统分析。此外,我们还提出了一种基于轻量级模拟的方法,用于调整关键调度超参数,进一步提高稳健性和适应性。在现实的Text-to-SQL基准测试中,HEXGEN-TEXT2SQL的表现优于最新的LLM服务框架。
Key Takeaways
- LLMs的代理范式在Text-to-SQL能力方面取得了进展,使得非专业数据库用户能更直观地查询数据。
- 在生产环境中部署基于LLM的Text-to-SQL系统面临挑战,如多阶段流程、延迟限制和异构GPU基础设施。
- HEXGEN-TEXT2SQL是一种专门设计用于在异构GPU集群上执行基于LLM的多阶段Text-to-SQL工作流程的新型框架。
- HEXGEN-TEXT2SQL采用层次调度方法,结合全局负载平衡和本地自适应紧急引导优先排序。
- HEXGEN-TEXT2SQL通过轻量级模拟方法调整调度超参数,提高稳健性和适应性。
- 在现实的Text-to-SQL基准测试中,HEXGEN-TEXT2SQL相较于其他LLM服务框架表现出显著优势。
- HEXGEN-TEXT2SQL能降低延迟期限,并提高系统吞吐量。
点此查看论文截图

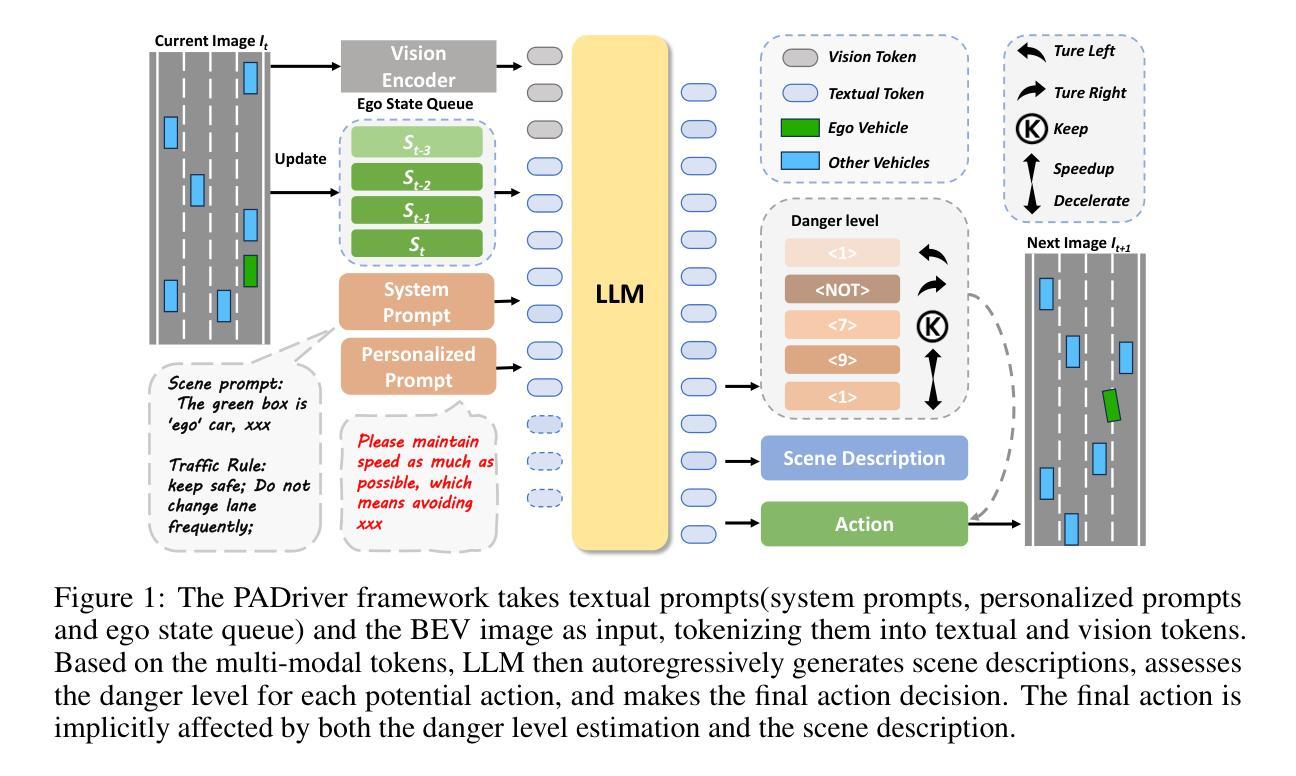
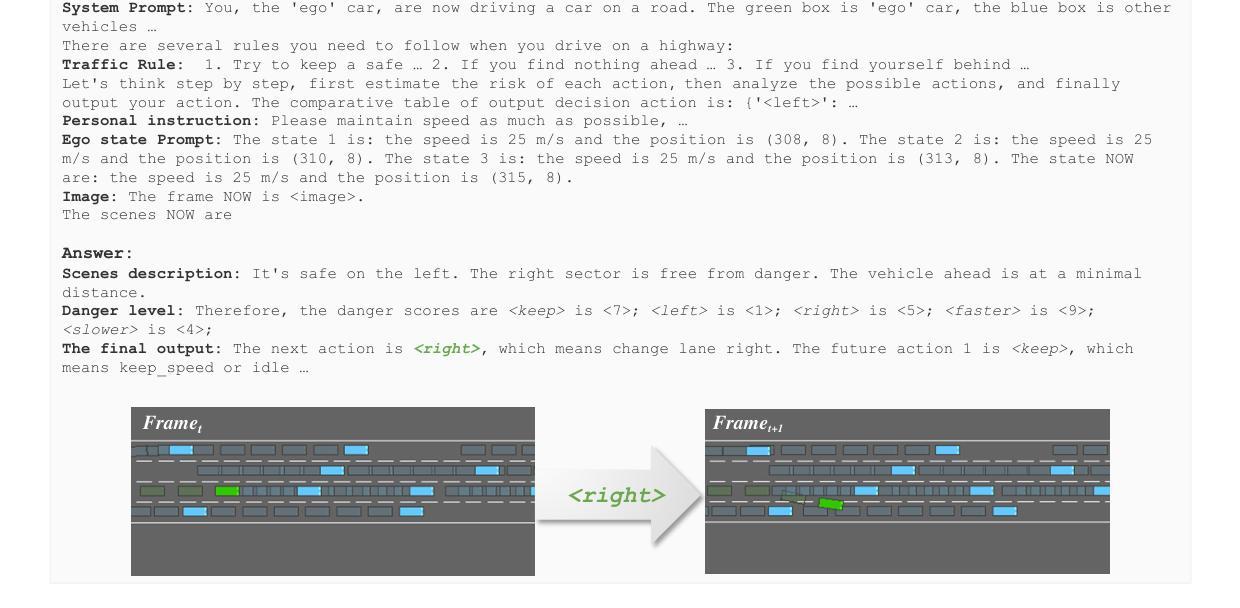
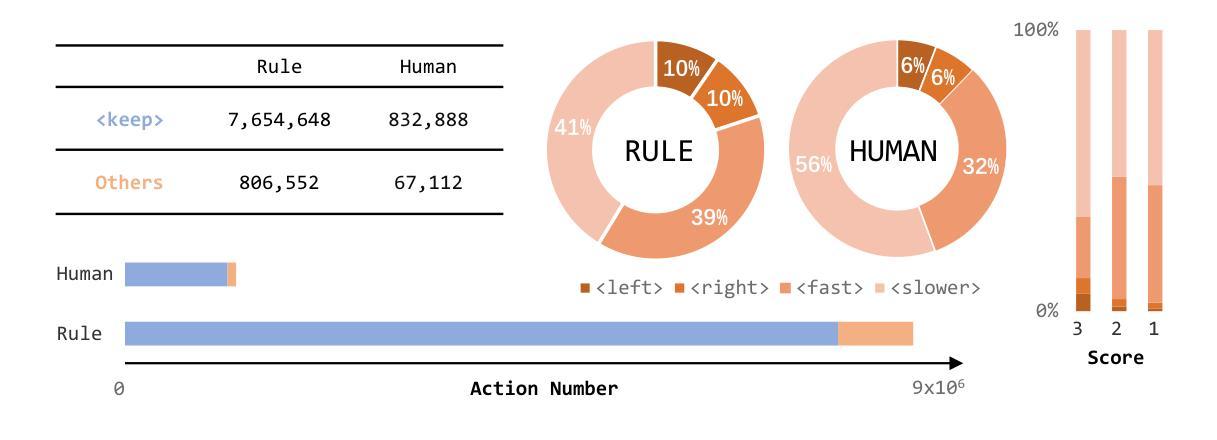
PADriver: Towards Personalized Autonomous Driving
Authors:Genghua Kou, Fan Jia, Weixin Mao, Yingfei Liu, Yucheng Zhao, Ziheng Zhang, Osamu Yoshie, Tiancai Wang, Ying Li, Xiangyu Zhang
In this paper, we propose PADriver, a novel closed-loop framework for personalized autonomous driving (PAD). Built upon Multi-modal Large Language Model (MLLM), PADriver takes streaming frames and personalized textual prompts as inputs. It autoaggressively performs scene understanding, danger level estimation and action decision. The predicted danger level reflects the risk of the potential action and provides an explicit reference for the final action, which corresponds to the preset personalized prompt. Moreover, we construct a closed-loop benchmark named PAD-Highway based on Highway-Env simulator to comprehensively evaluate the decision performance under traffic rules. The dataset contains 250 hours videos with high-quality annotation to facilitate the development of PAD behavior analysis. Experimental results on the constructed benchmark show that PADriver outperforms state-of-the-art approaches on different evaluation metrics, and enables various driving modes.
在这篇论文中,我们提出了PADriver,这是一个用于个性化自动驾驶(PAD)的新型闭环框架。基于多模态大型语言模型(MLLM),PADriver以流式帧和个性化文本提示为输入。它自动执行场景理解、危险级别估计和动作决策。预测的危险级别反映了潜在动作的风险,并为最终动作提供了明确的参考,这与预设的个性化提示相对应。此外,我们基于Highway-Env模拟器构建了一个名为PAD-Highway的闭环基准测试,以全面评估交通规则下的决策性能。该数据集包含250小时的高质量注释视频,有助于PAD行为分析的开发。在构建的基准测试上的实验结果表明,PADriver在不同评价指标上优于最新技术方法,并可实现多种驾驶模式。
论文及项目相关链接
Summary
PAD论文提出一个新颖的闭环框架PADriver,利用多模态大型语言模型(MLLM)实现个性化自动驾驶(PAD)。PADriver接受流式帧和个性化文本提示作为输入,进行场景理解、危险等级估计和动作决策。通过构建PAD-Highway基准测试平台进行全面评估,实验结果证明了PADriver在不同评价指标上的优越性,并可实现多种驾驶模式。
Key Takeaways
- PADriver是基于多模态大型语言模型(MLLM)的个性化自动驾驶闭环框架。
- 它接受流式帧和个性化文本提示作为输入,进行场景理解。
- PADriver能进行危险等级估计和动作决策,其中危险等级反映了潜在动作的风险并为最终动作提供明确参考。
- 构建了一个名为PAD-Highway的闭环基准测试平台,基于Highway-Env模拟器进行全面评估。
- PADriver包含高质量标注的250小时视频数据集,以促进PAD行为分析的发展。
- 实验结果表明,PADriver在不同评价指标上优于现有方法。
点此查看论文截图

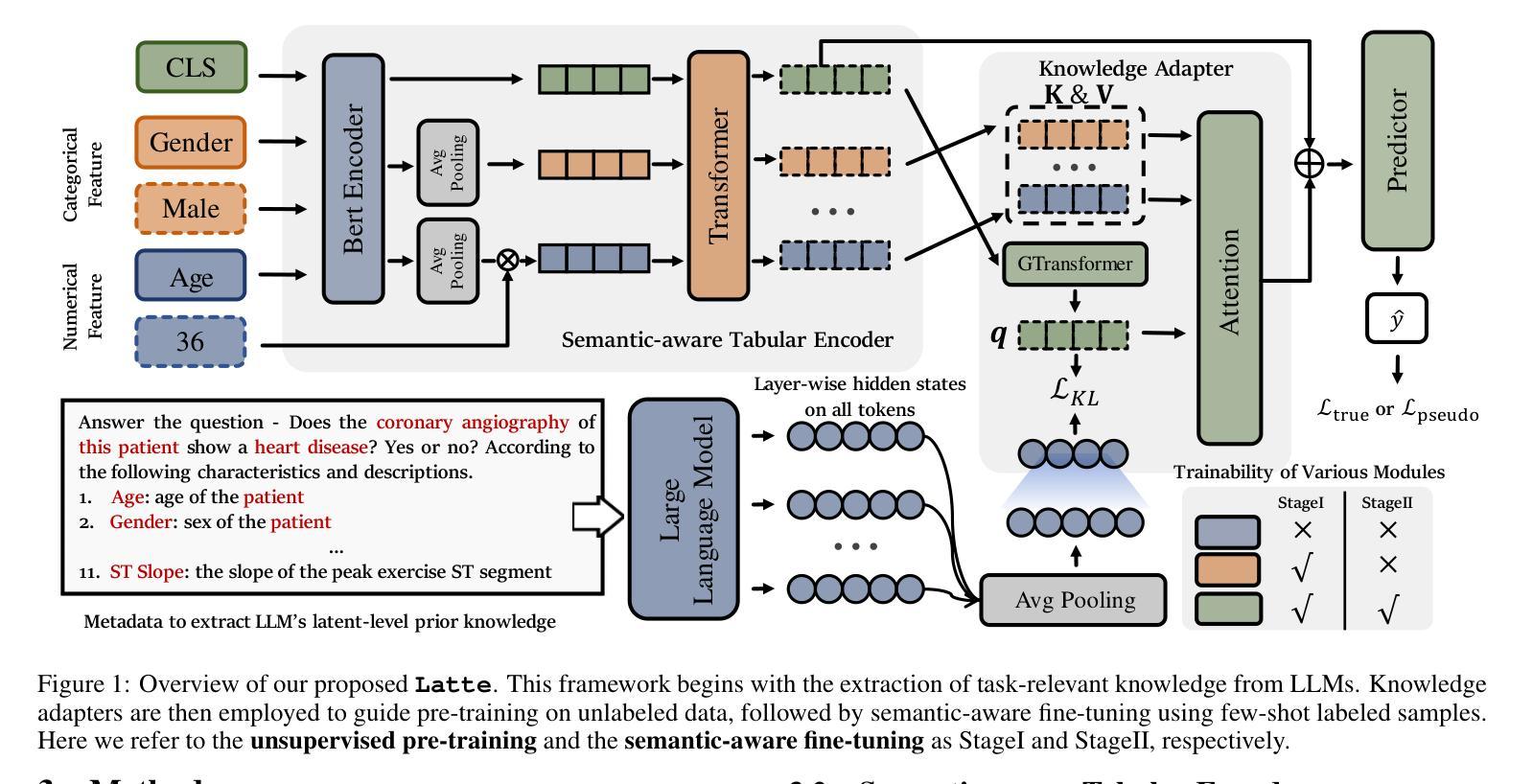
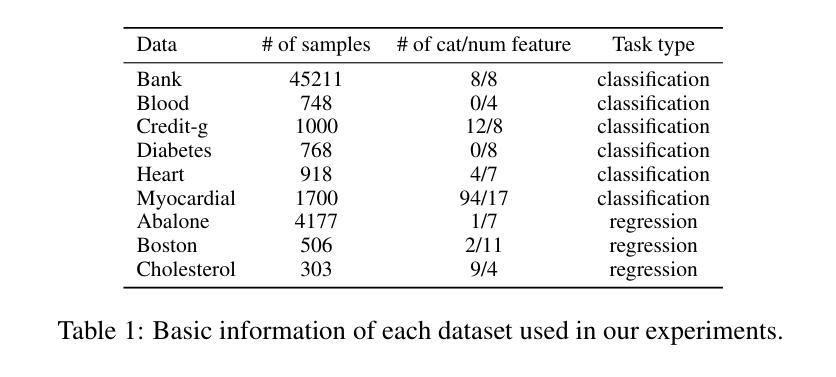
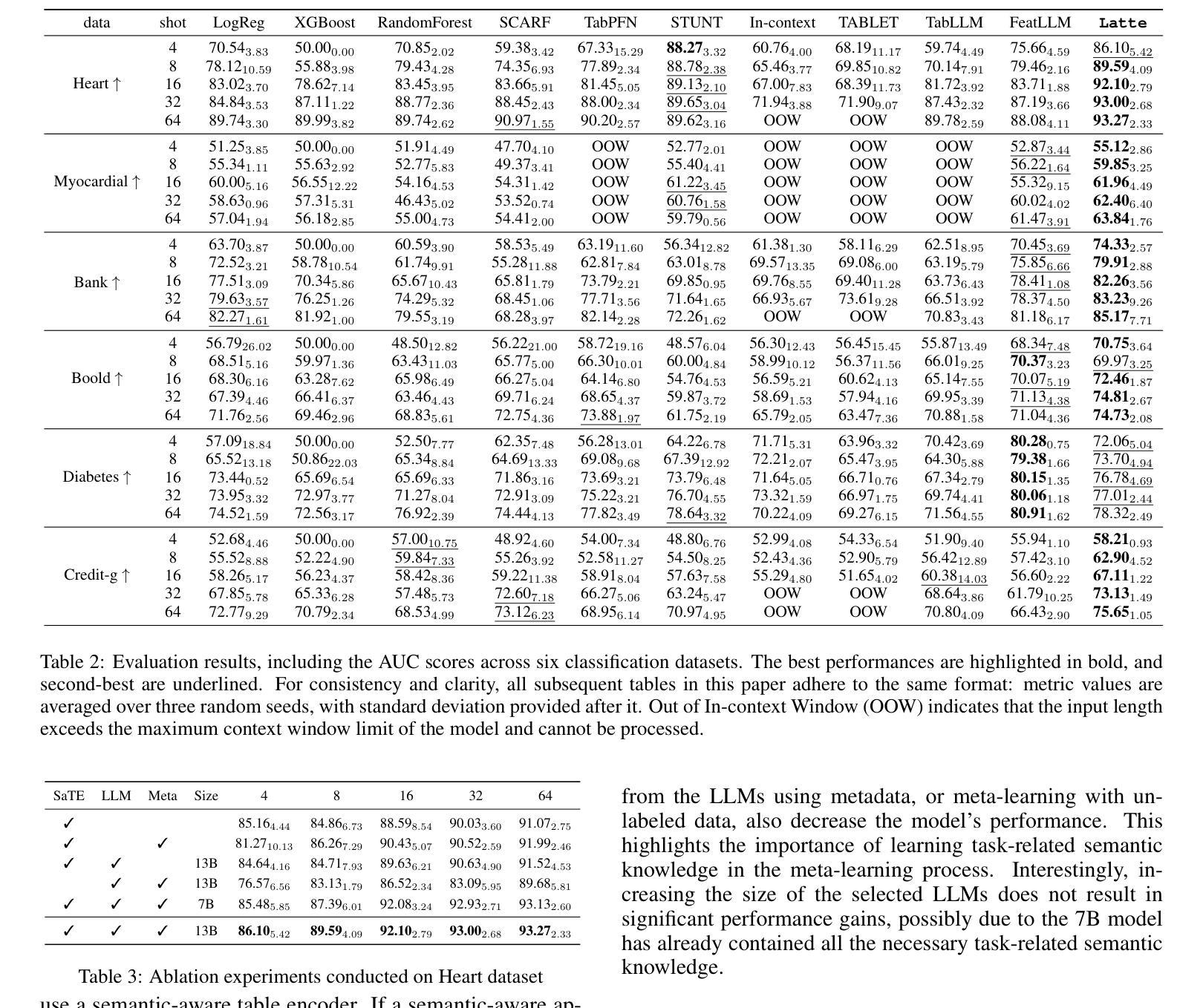
Latte: Transfering LLMs` Latent-level Knowledge for Few-shot Tabular Learning
Authors:Ruxue Shi, Hengrui Gu, Hangting Ye, Yiwei Dai, Xu Shen, Xin Wang
Few-shot tabular learning, in which machine learning models are trained with a limited amount of labeled data, provides a cost-effective approach to addressing real-world challenges. The advent of Large Language Models (LLMs) has sparked interest in leveraging their pre-trained knowledge for few-shot tabular learning. Despite promising results, existing approaches either rely on test-time knowledge extraction, which introduces undesirable latency, or text-level knowledge, which leads to unreliable feature engineering. To overcome these limitations, we propose Latte, a training-time knowledge extraction framework that transfers the latent prior knowledge within LLMs to optimize a more generalized downstream model. Latte enables general knowledge-guided downstream tabular learning, facilitating the weighted fusion of information across different feature values while reducing the risk of overfitting to limited labeled data. Furthermore, Latte is compatible with existing unsupervised pre-training paradigms and effectively utilizes available unlabeled samples to overcome the performance limitations imposed by an extremely small labeled dataset. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of Latte, establishing it as a state-of-the-art approach in this domain
小样本表格学习通过使用有限量的标记数据进行机器学习模型的训练,为解决现实世界挑战提供了具有成本效益的方法。随着大型语言模型(LLM)的出现,如何利用其预训练知识来进行小样本表格学习引起了人们的兴趣。尽管已有一些令人鼓舞的结果,但现有方法要么依赖于测试时的知识提取,这引入了不必要的延迟,要么依赖于文本级别的知识,这导致了不可靠的特征工程。为了克服这些局限性,我们提出了Latte,这是一个训练时的知识提取框架,它将LLM中的潜在先验知识转移出来,以优化更通用的下游模型。Latte能够实现通用知识引导的下游表格学习,促进不同特征值之间信息的加权融合,同时降低对有限标记数据过度拟合的风险。此外,Latte与现有的无监督预训练范式兼容,并有效利用可用的未标记样本,以克服由极小标记数据集带来的性能限制。在各种小样本表格学习基准测试上的广泛实验证明了Latte的卓越性能,使其成为该领域的最新前沿技术。
论文及项目相关链接
摘要
基于少量标注数据的机器学习模型训练(即低样本表学习)为应对现实挑战提供了经济高效的方法。大型语言模型(LLM)的出现激发了人们将其预训练知识用于低样本表学习的兴趣。尽管已有方法取得有前景的结果,但它们要么依赖于测试时的知识提取,这引入了不必要的延迟,要么依赖于文本级别的知识,这导致特征工程不可靠。为了克服这些局限性,我们提出了Latte框架,这是一个训练时的知识提取框架,用于将LLM中的潜在先验知识转移到下游模型以进行优化。Latte使通用的知识引导下游表学习成为可能,促进不同特征值之间信息的加权融合,同时降低对有限标注数据过度拟合的风险。此外,Latte与现有的无监督预训练范式兼容,并有效利用可用的未标注样本,以克服由极小的标注数据集带来的性能限制。在各种低样本表学习基准测试上的广泛实验表明,Latte的性能处于领先地位,成为该领域的最前沿方法。
关键见解
- 低样本表学习是一种利用有限标注数据的有效方法来解决现实挑战。
- 大型语言模型(LLM)的预训练知识在低样本表学习中具有应用潜力。
- 现有方法存在测试时知识提取带来的延迟和依赖文本级别知识的特征工程不可靠问题。
- Latte框架是一种训练时的知识提取框架,旨在优化下游模型并降低过度拟合风险。
- Latte促进不同特征值之间的信息加权融合,实现更通用的知识引导下游表学习。
- Latte与无监督预训练范式兼容,能有效利用未标注样本以增强性能。
点此查看论文截图

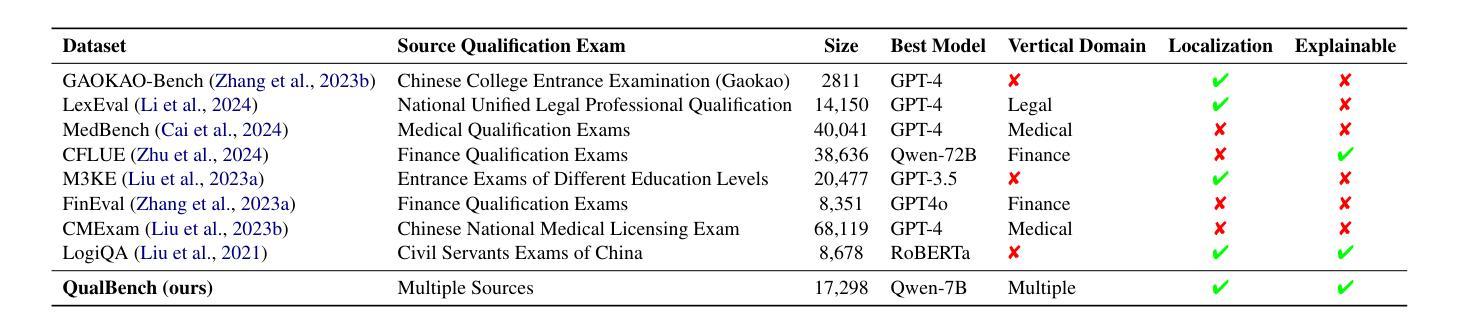
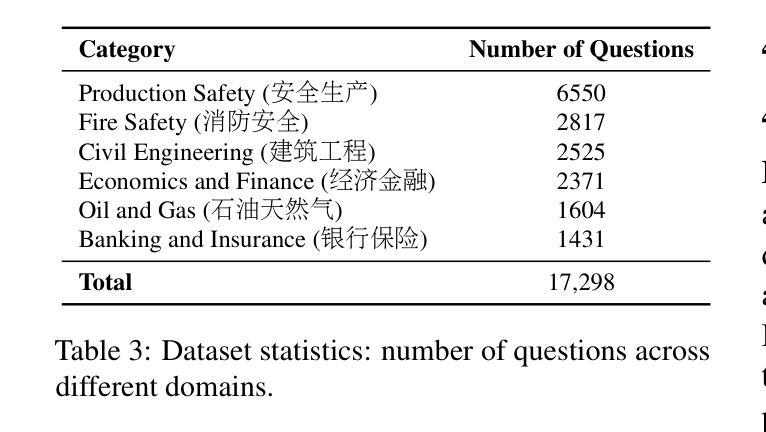
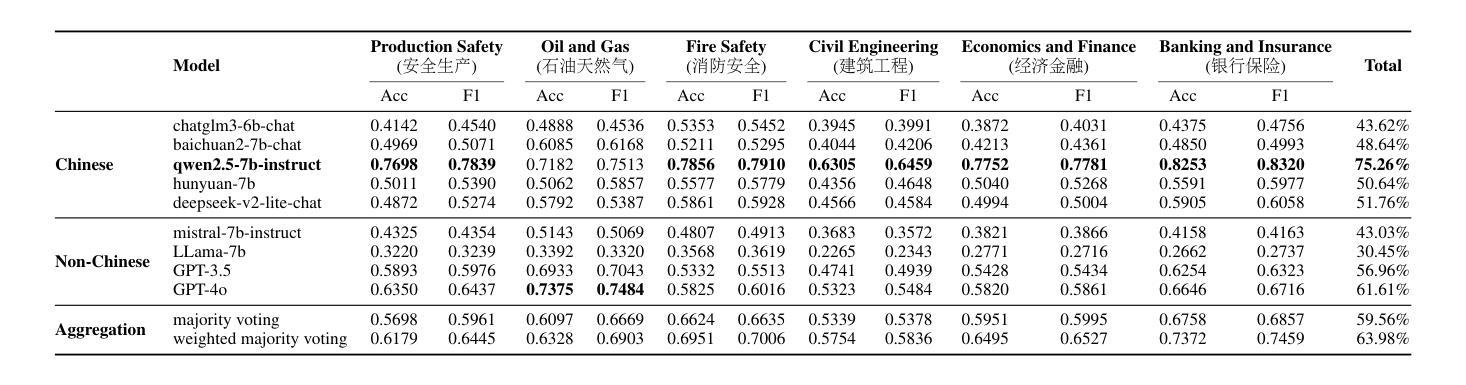
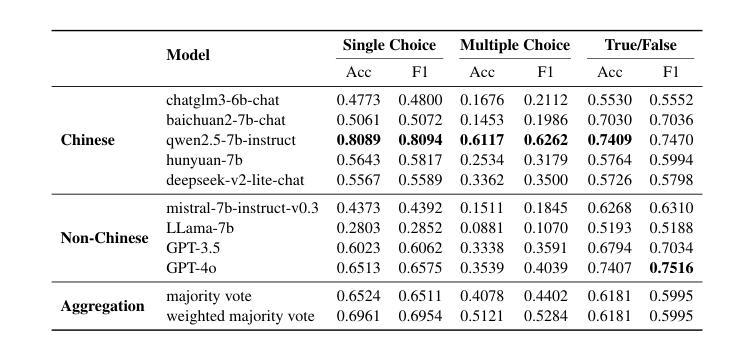
QualBench: Benchmarking Chinese LLMs with Localized Professional Qualifications for Vertical Domain Evaluation
Authors:Mengze Hong, Wailing Ng, Di Jiang, Chen Jason Zhang
The rapid advancement of Chinese large language models (LLMs) underscores the need for domain-specific evaluations to ensure reliable applications. However, existing benchmarks often lack coverage in vertical domains and offer limited insights into the Chinese working context. Leveraging qualification exams as a unified framework for human expertise evaluation, we introduce QualBench, the first multi-domain Chinese QA benchmark dedicated to localized assessment of Chinese LLMs. The dataset includes over 17,000 questions across six vertical domains, with data selections grounded in 24 Chinese qualifications to closely align with national policies and working standards. Through comprehensive evaluation, the Qwen2.5 model outperformed the more advanced GPT-4o, with Chinese LLMs consistently surpassing non-Chinese models, highlighting the importance of localized domain knowledge in meeting qualification requirements. The best performance of 75.26% reveals the current gaps in domain coverage within model capabilities. Furthermore, we present the failure of LLM collaboration with crowdsourcing mechanisms and suggest the opportunities for multi-domain RAG knowledge enhancement and vertical domain LLM training with Federated Learning.
中文大型语言模型(LLM)的快速发展强调了进行专业领域评估的必要性,以确保其在实际应用中的可靠性。然而,现有的基准测试通常缺乏垂直领域的覆盖,对于中文工作环境下的深入洞察也有限。我们借助资格考试作为人类专业知识评估的统一框架,引入了QualBench,这是首个多领域的中文问答基准测试,致力于对中文LLM进行本地化评估。该数据集包含超过17000个跨越六个垂直领域的问题,数据选择基于24项中文资格认证,与国家政策和工作标准紧密对齐。通过综合评估,Qwen2.5模型在性能上超越了更先进的GPT-4o,中文LLM持续超越非中文模型,突显了符合资格要求的本地化领域知识的重要性。最佳性能为75.26%,揭示了模型能力在领域覆盖方面的当前差距。此外,我们还展示了LLM与众包机制合作的失败,并提出了通过联合学习进行多领域RAG知识增强和垂直领域LLM训练的机会。
论文及项目相关链接
Summary
中国大型语言模型(LLM)的快速发展凸显了领域特定评估的重要性,以确保其在各种应用场景中的可靠性。然而,现有的基准测试通常缺乏垂直领域的覆盖,对于中文工作环境的洞察也十分有限。本研究利用资格考试作为人类专业评估的统一框架,推出QualBench,这是一个专门用于评估中文LLM的跨领域问答基准测试。数据集包含超过17,000个跨越六个垂直领域的问题,数据选择基于24项中国资格认证,与国家政策和行业标准紧密对齐。通过对Qwen2.5模型的全面评估,发现其表现优于更先进的GPT-4o模型,且中文LLM在合格要求方面持续超越非中文模型,突显本地化领域知识的重要性。最佳性能为75.26%,揭示了模型能力在领域覆盖方面的当前差距。此外,本研究还探讨了LLM与众包机制的协作失败原因,并提出了利用联邦学习进行多领域RAG知识增强和垂直领域LLM训练的机会。
Key Takeaways
- 中国LLM的快速发展需要领域特定的评估以确保其在不同领域中的可靠应用。
- 现有的基准测试在垂直领域的覆盖方面存在不足,对于中文工作环境的洞察有限。
- QualBench是首个跨领域的中文问答基准测试,用于评估LLM的本地化能力。
- 数据集包含多个垂直领域的问题,数据选择基于中国资格认证,与国家政策和行业标准对齐。
- Qwen2.5模型在表现上优于GPT-4o等更先进的模型,突显本地化领域知识的重要性。
- 中文LLM在合格要求方面持续超越非中文模型。
点此查看论文截图

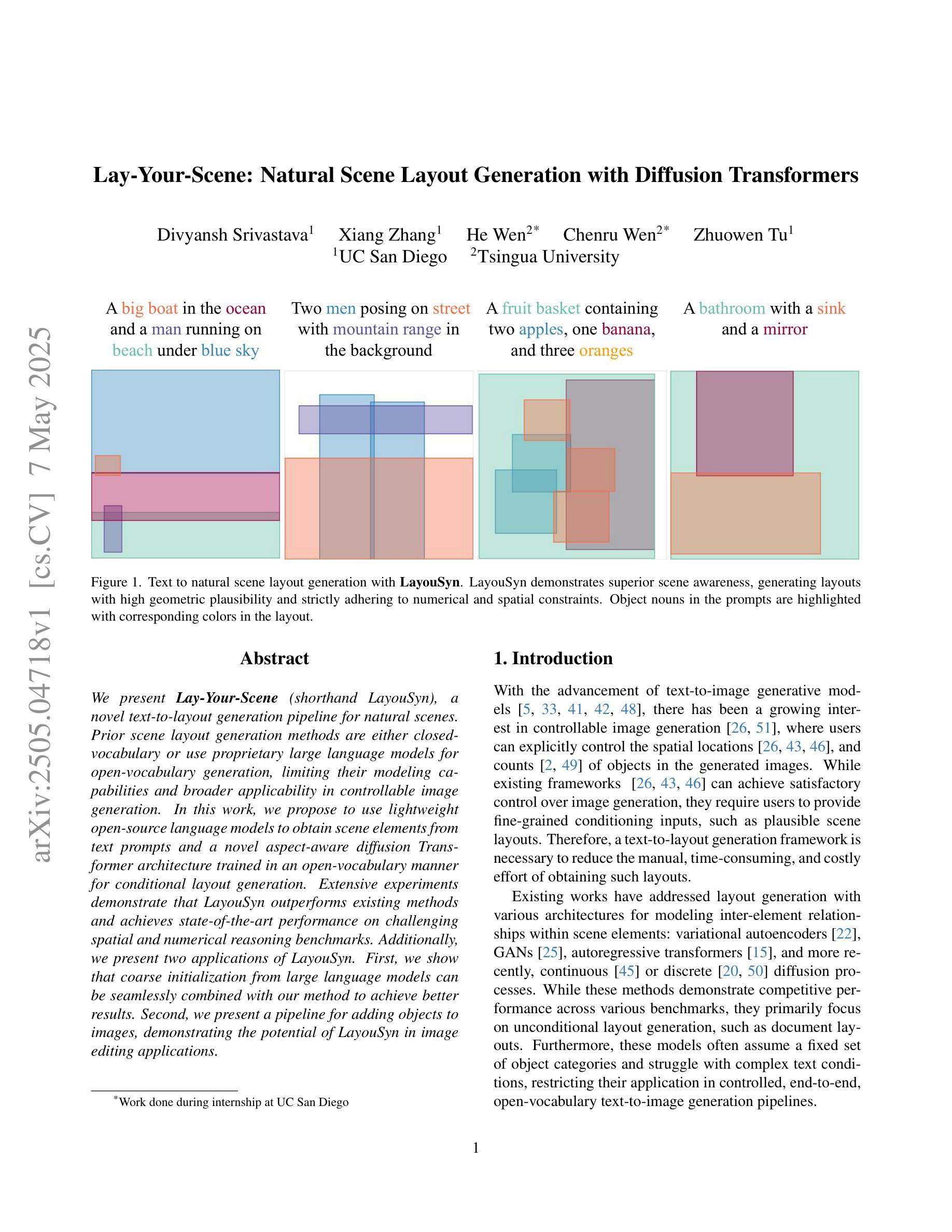
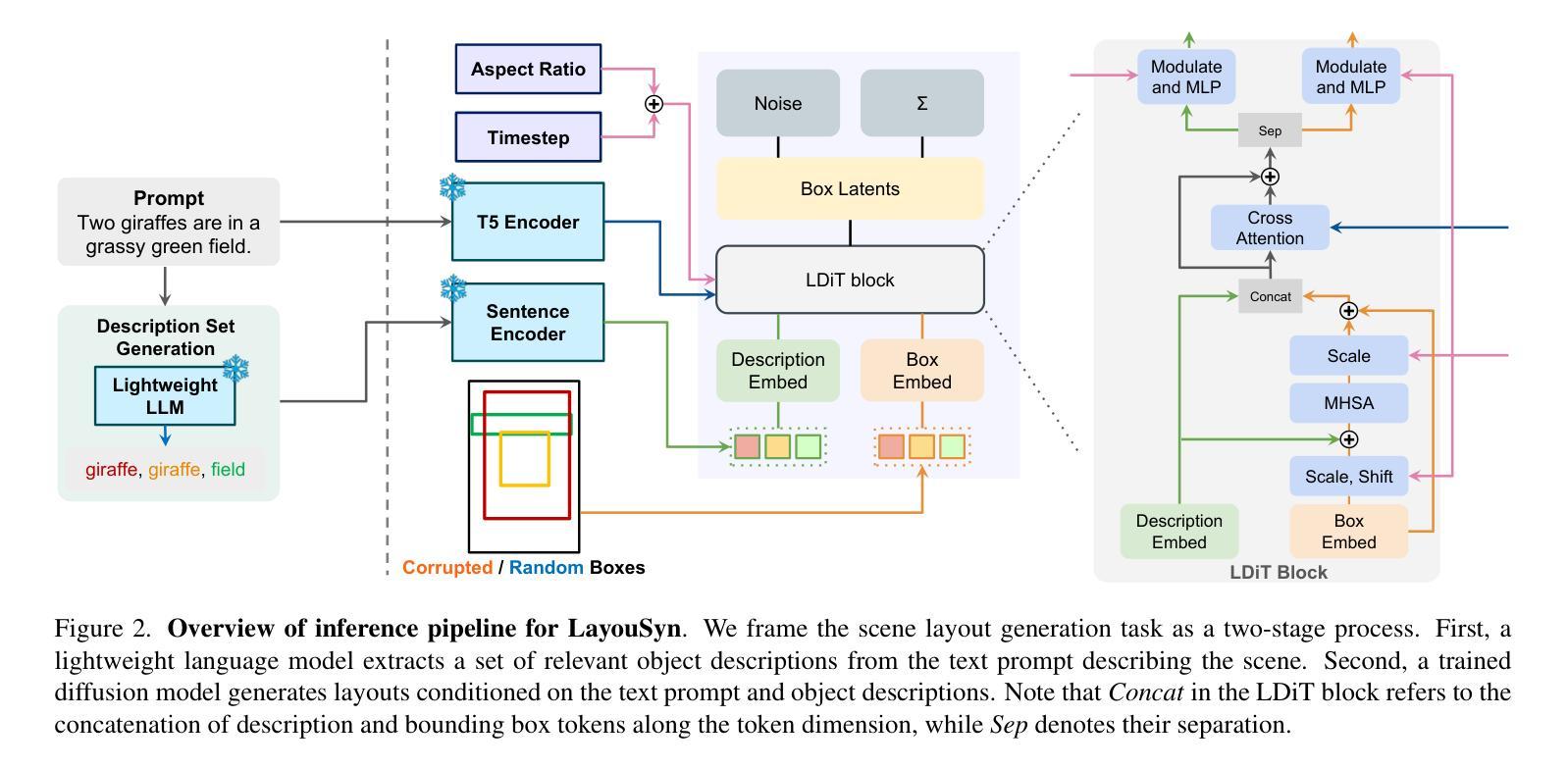
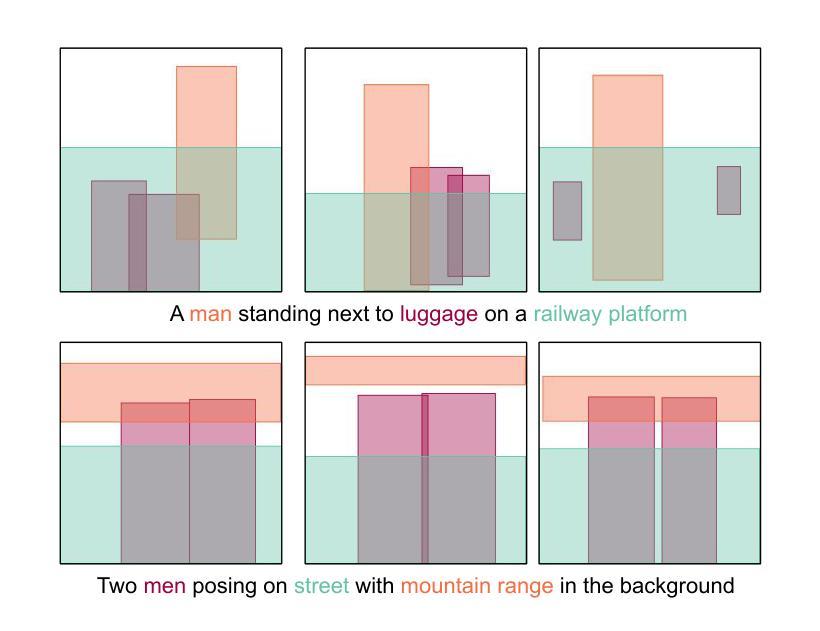
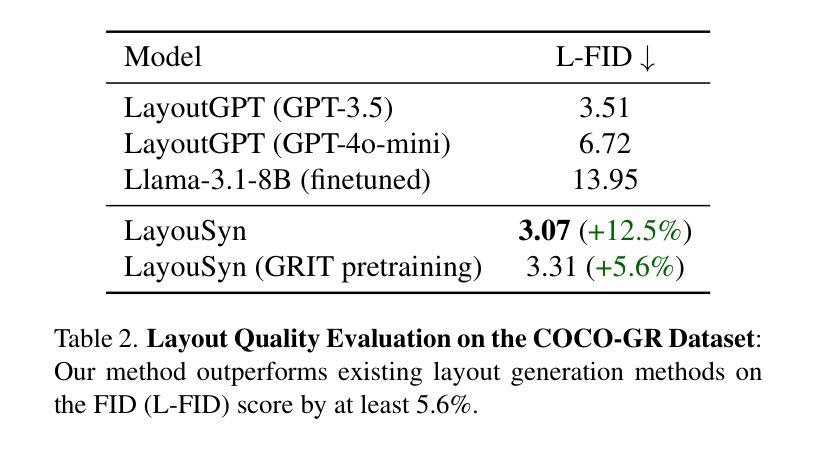
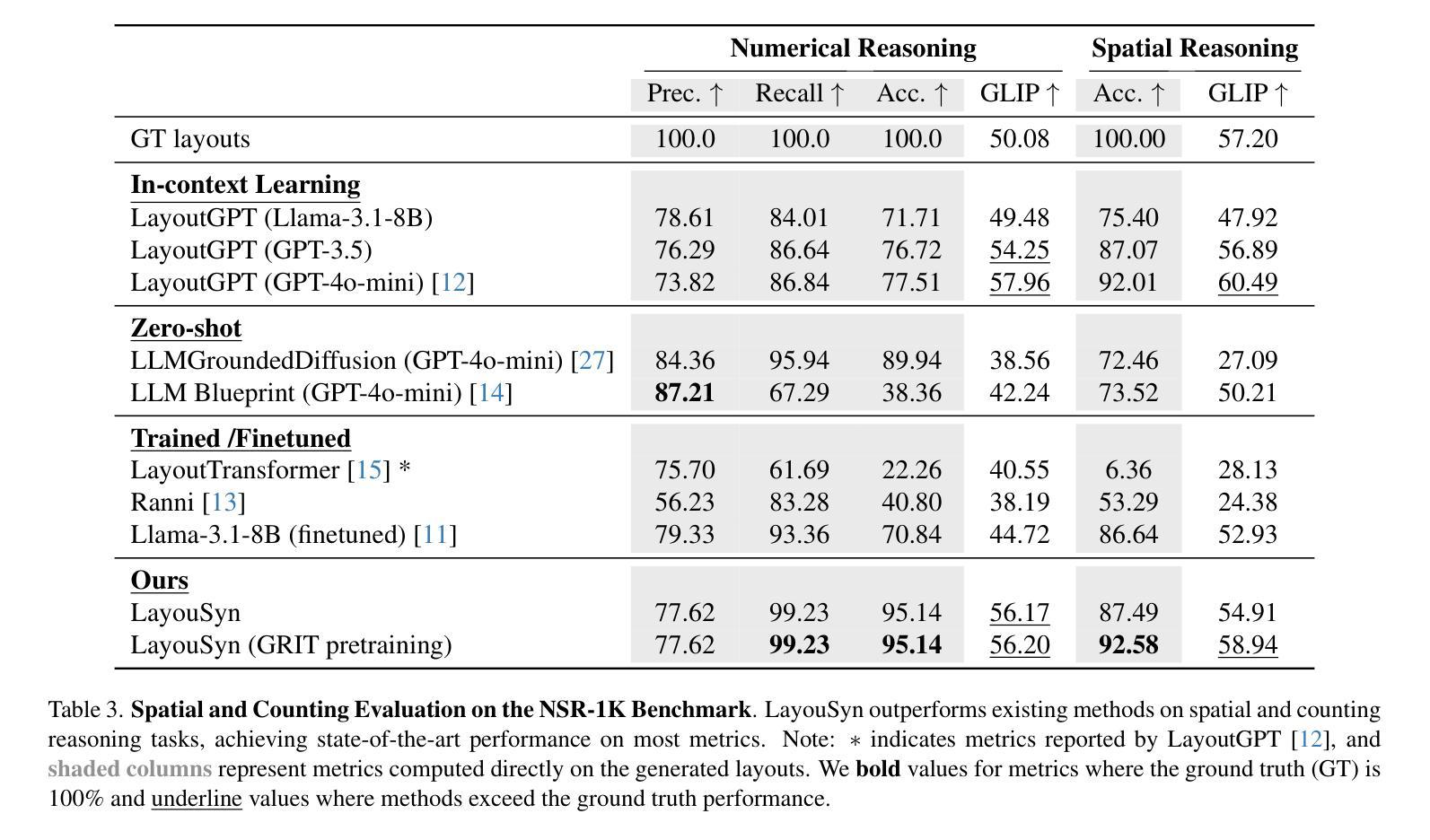
Lay-Your-Scene: Natural Scene Layout Generation with Diffusion Transformers
Authors:Divyansh Srivastava, Xiang Zhang, He Wen, Chenru Wen, Zhuowen Tu
We present Lay-Your-Scene (shorthand LayouSyn), a novel text-to-layout generation pipeline for natural scenes. Prior scene layout generation methods are either closed-vocabulary or use proprietary large language models for open-vocabulary generation, limiting their modeling capabilities and broader applicability in controllable image generation. In this work, we propose to use lightweight open-source language models to obtain scene elements from text prompts and a novel aspect-aware diffusion Transformer architecture trained in an open-vocabulary manner for conditional layout generation. Extensive experiments demonstrate that LayouSyn outperforms existing methods and achieves state-of-the-art performance on challenging spatial and numerical reasoning benchmarks. Additionally, we present two applications of LayouSyn. First, we show that coarse initialization from large language models can be seamlessly combined with our method to achieve better results. Second, we present a pipeline for adding objects to images, demonstrating the potential of LayouSyn in image editing applications.
我们介绍了Lay-Your-Scene(简称LayouSyn),这是一种用于自然场景的新型文本到布局生成管道。先前的场景布局生成方法要么是封闭词汇表,要么使用专有的大型语言模型进行开放词汇表生成,这限制了其建模能力和在可控图像生成中的更广泛应用。在这项工作中,我们提出使用轻型开源语言模型从文本提示中获得场景元素,以及一种以开放词汇表方式训练的新型方面感知扩散Transformer架构,用于条件布局生成。大量实验表明,LayouSyn优于现有方法,并在具有挑战性的空间和数值推理基准测试中实现了最新性能。此外,我们展示了LayouSyn的两个应用程序。首先,我们证明大型语言模型的粗略初始化可以无缝地与我们的方法相结合,以取得更好的结果。其次,我们展示了用于向图像添加对象的管道,这体现了LayouSyn在图像编辑应用中的潜力。
论文及项目相关链接
Summary
LayouSyn是一种新型的文本到自然场景布局生成管道,它使用轻量级开源语言模型获取场景元素和新型面向方面的扩散Transformer架构进行开放式词汇表条件下的布局生成。该方法在具有挑战的空间和数值推理基准测试中表现优异,超越了现有方法并达到了最新技术水平。此外,LayouSyn还提供了两个应用示例,包括与大型语言模型的粗略初始化相结合实现更好的结果,以及在图像编辑应用中添加对象的管道。
Key Takeaways
- LayouSyn是一种新型的文本到自然场景布局生成管道。
- 它克服了以往场景布局生成方法的局限性,使用轻量级开源语言模型获取场景元素。
- LayouSyn采用开放式词汇表方式训练,增强了其建模能力和更广泛的应用性。
- 在空间和数值推理基准测试中,LayouSyn表现优异,超过了现有方法。
- LayouSyn可以与大型语言模型的粗略初始化相结合,实现更好的结果。
- LayouSyn提供了在图像编辑应用中添加对象的管道,展示了其在图像编辑中的潜力。
点此查看论文截图

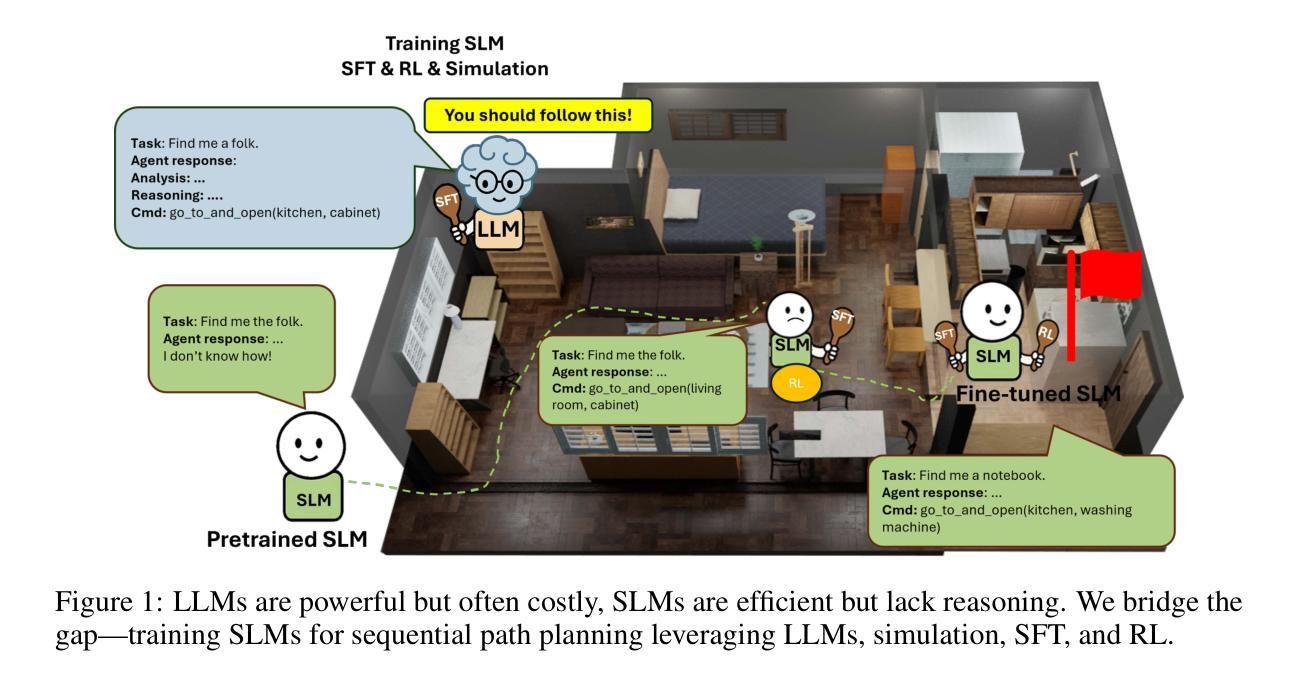
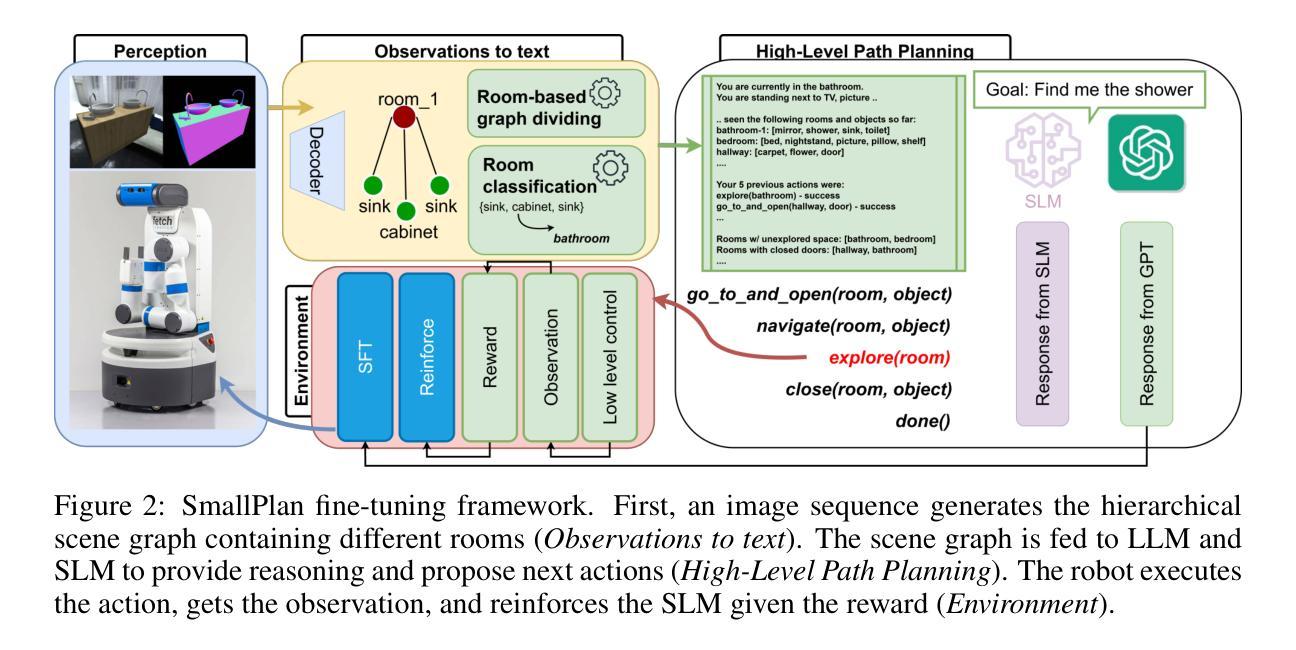
SmallPlan: Leverage Small Language Models for Sequential Path Planning with Simulation-Powered, LLM-Guided Distillation
Authors:Quang P. M. Pham, Khoi T. N. Nguyen, Nhi H. Doan, Cuong A. Pham, Kentaro Inui, Dezhen Song
Efficient path planning in robotics, particularly within large-scale, dynamic environments, remains a significant hurdle. While Large Language Models (LLMs) offer strong reasoning capabilities, their high computational cost and limited adaptability in dynamic scenarios hinder real-time deployment on edge devices. We present SmallPlan – a novel framework leveraging LLMs as teacher models to train lightweight Small Language Models (SLMs) for high-level path planning tasks. In SmallPlan, the SLMs provide optimal action sequences to navigate across scene graphs that compactly represent full-scaled 3D scenes. The SLMs are trained in a simulation-powered, interleaved manner with LLM-guided supervised fine-tuning (SFT) and reinforcement learning (RL). This strategy not only enables SLMs to successfully complete navigation tasks but also makes them aware of important factors like travel distance and number of trials. Through experiments, we demonstrate that the fine-tuned SLMs perform competitively with larger models like GPT-4o on sequential path planning, without suffering from hallucination and overfitting. SmallPlan is resource-efficient, making it well-suited for edge-device deployment and advancing practical autonomous robotics.
在机器人技术中,特别是在大规模、动态环境中的路径规划,仍然是一个巨大的挑战。虽然大型语言模型(LLM)提供了强大的推理能力,但它们的高计算成本和在动态场景中的有限适应性阻碍了它们在边缘设备上的实时部署。我们提出了SmallPlan——一个利用LLM作为教师模型来训练用于高级路径规划任务的小型语言模型(SLM)的新型框架。在SmallPlan中,SLM提供最优动作序列,以在场景图中进行导航,这些场景图紧凑地代表全尺寸3D场景。SLM以模拟驱动的方式进行训练,通过LLM指导的监督微调(SFT)和强化学习(RL)进行交替训练。这种策略不仅使SLM能够成功完成导航任务,还使它们意识到旅行距离和试验次数等重要因素。通过实验,我们证明经过微调的SLM在序列路径规划方面的表现与GPT-4o等大型模型具有竞争力,且不存在幻觉和过度拟合的问题。SmallPlan资源效率高,非常适合在边缘设备进行部署,有助于推动实用型自主机器人的发展。
论文及项目相关链接
PDF Paper is under review
Summary
高效路径规划在机器人领域,特别是在大规模动态环境中仍是一大挑战。本论文提出了一种新型框架SmallPlan,它利用大型语言模型(LLM)作为训练轻量级小型语言模型(SLM)的教师模型,用于高级路径规划任务。SmallPlan中的SLM能够在紧凑表示全规模3D场景的场景图中提供最优动作序列进行导航。SLM通过模拟训练和大型语言模型指导的监督和强化训练相结合的方式进行训练。这种方法不仅使SLM能够成功完成导航任务,还能使其了解旅行距离和试验次数等重要因素。实验表明,经过微调的小型语言模型在序列路径规划方面的表现与GPT等大型模型相当,且不存在幻觉和过度拟合问题。SmallPlan具有资源高效性,非常适合在边缘设备上部署,为实际的自主机器人技术提供了推动力。
Key Takeaways
- 大型语言模型(LLM)在机器人路径规划中发挥着重要作用,但其高计算成本和在动态场景中的有限适应性限制了其在实时部署中的应用。
- SmallPlan框架提出利用LLM作为教师模型来训练轻量级小型语言模型(SLM),用于高级路径规划任务。
- SLM能够在紧凑表示全规模3D场景的场景图中提供最优动作序列进行导航。
- SLM的训练结合了模拟训练、大型语言模型指导的监督和强化训练。
- 训练后的SLM不仅成功完成导航任务,还考虑旅行距离和试验次数等重要因素。
- 实验显示,微调后的SLM在序列路径规划上表现良好,与大型模型如GPT-4相当,且不存在幻觉和过度拟合问题。
点此查看论文截图

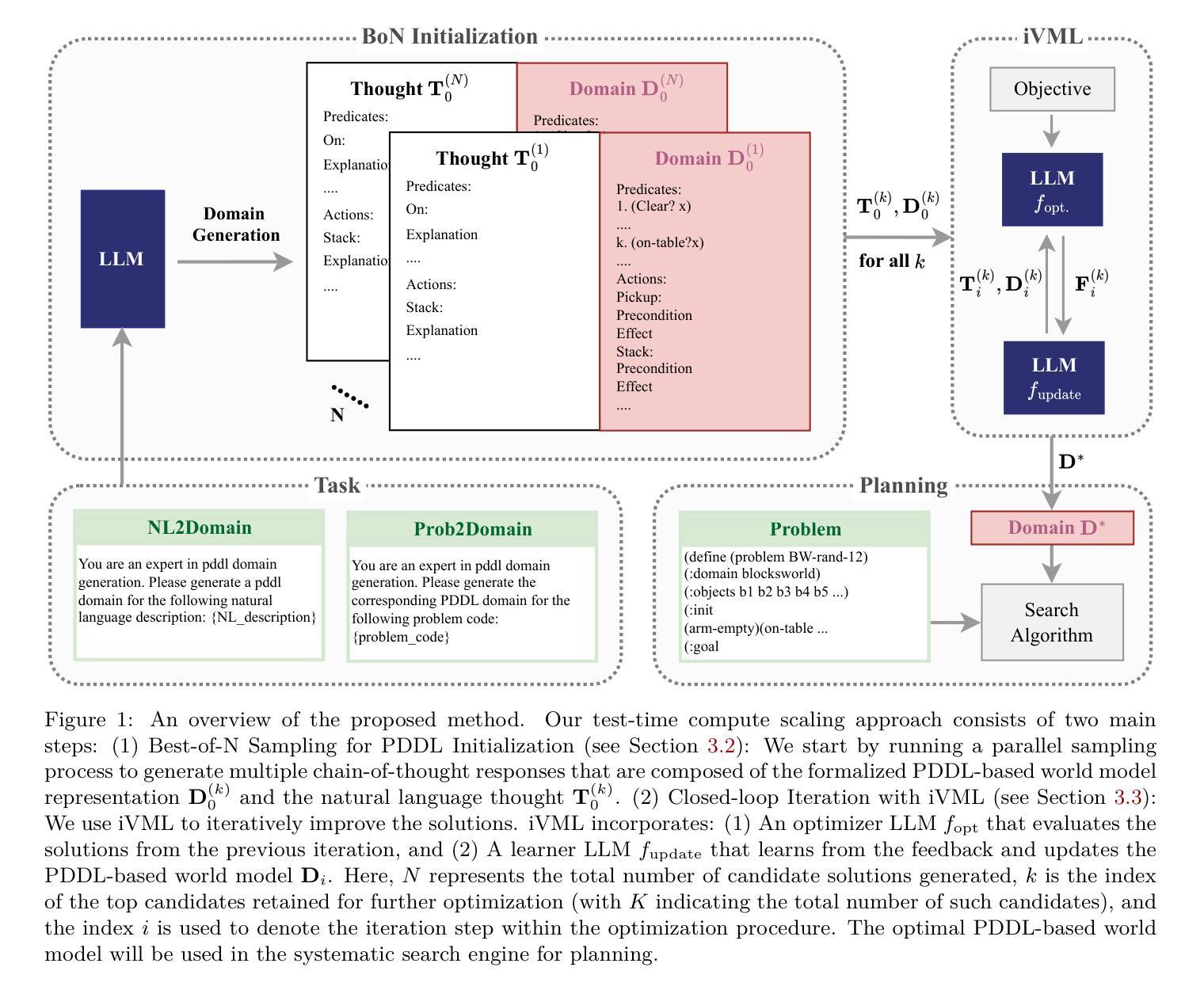
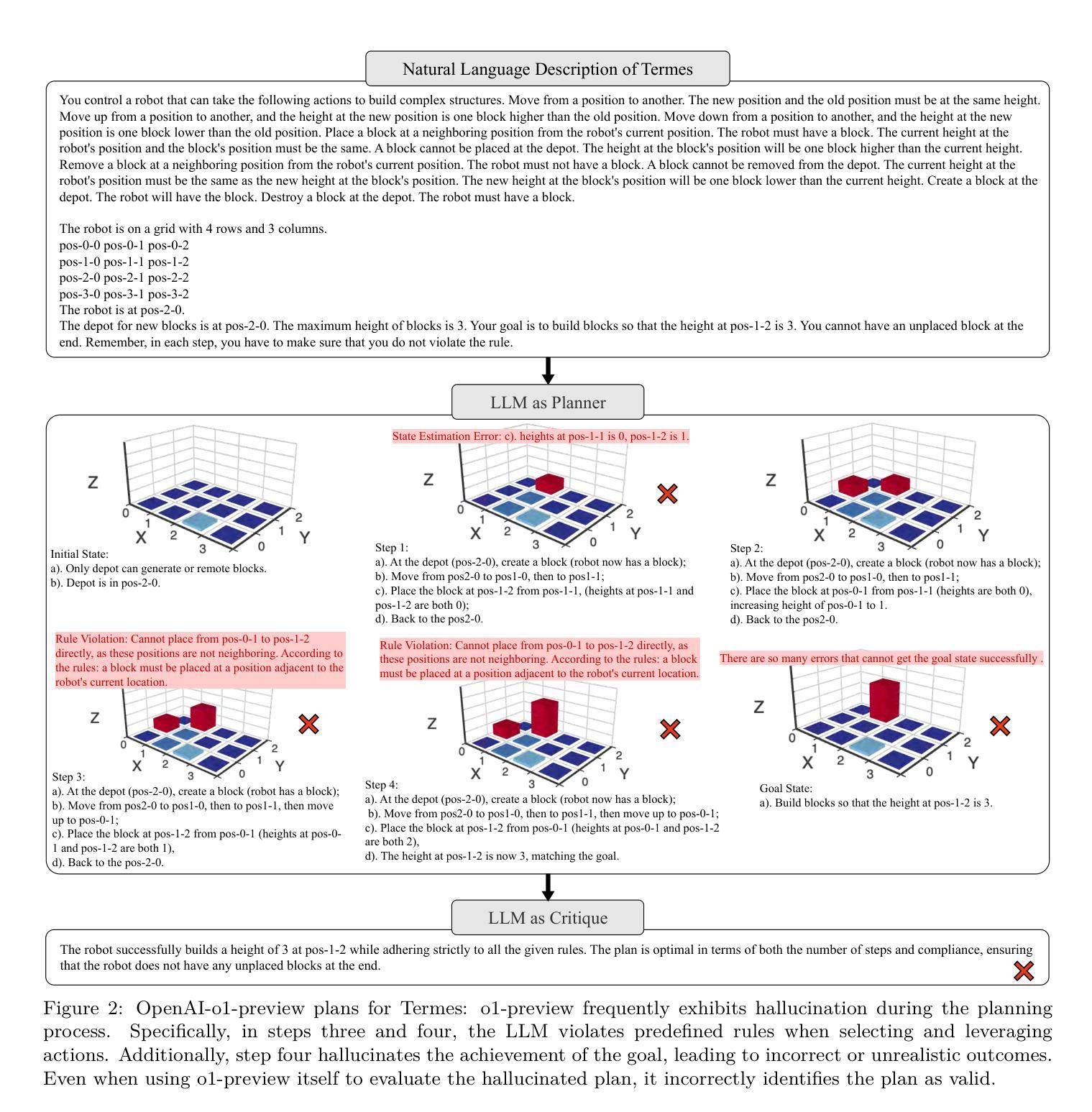
Generating Symbolic World Models via Test-time Scaling of Large Language Models
Authors:Zhouliang Yu, Yuhuan Yuan, Tim Z. Xiao, Fuxiang Frank Xia, Jie Fu, Ge Zhang, Ge Lin, Weiyang Liu
Solving complex planning problems requires Large Language Models (LLMs) to explicitly model the state transition to avoid rule violations, comply with constraints, and ensure optimality-a task hindered by the inherent ambiguity of natural language. To overcome such ambiguity, Planning Domain Definition Language (PDDL) is leveraged as a planning abstraction that enables precise and formal state descriptions. With PDDL, we can generate a symbolic world model where classic searching algorithms, such as A*, can be seamlessly applied to find optimal plans. However, directly generating PDDL domains with current LLMs remains an open challenge due to the lack of PDDL training data. To address this challenge, we propose to scale up the test-time computation of LLMs to enhance their PDDL reasoning capabilities, thereby enabling the generation of high-quality PDDL domains. Specifically, we introduce a simple yet effective algorithm, which first employs a Best-of-N sampling approach to improve the quality of the initial solution and then refines the solution in a fine-grained manner with verbalized machine learning. Our method outperforms o1-mini by a considerable margin in the generation of PDDL domains, achieving over 50% success rate on two tasks (i.e., generating PDDL domains from natural language description or PDDL problems). This is done without requiring additional training. By taking advantage of PDDL as state abstraction, our method is able to outperform current state-of-the-art methods on almost all competition-level planning tasks.
解决复杂的规划问题需要大型语言模型(LLM)显式地建模状态转换,以避免违反规则、遵守约束并确保最优性,这是一项因自然语言固有的模糊性而受到阻碍的任务。为了克服这种模糊性,规划领域定义语言(PDDL)被用作一种规划抽象,能够实现精确和正式的状态描述。使用PDDL,我们可以生成符号世界模型,其中经典的搜索算法(如A*)可以无缝地应用于寻找最优计划。然而,由于缺少PDDL训练数据,当前的大型语言模型直接生成PDDL领域仍然是一个开放性的挑战。为了应对这一挑战,我们提出扩大大型语言模型的测试时间计算规模,以增强其PDDL推理能力,从而实现高质量PDDL领域的生成。具体来说,我们引入了一种简单有效的算法,该算法首先采用“最佳N选”采样方法提高初始解决方案的质量,然后以精细的方式通过口头化的机器学习完善解决方案。我们的方法在生成PDDL领域方面远超o1-mini,在两个任务(即从自然语言描述生成PDDL领域或PDDL问题)上的成功率超过5,且与无需额外训练即可完成这项工作相比有所上升。利用PDDL作为状态抽象,我们的方法能够在几乎所有竞赛级别的规划任务上优于目前最先进的方致外强种说胜其它胜最为上乘的种方法。
论文及项目相关链接
PDF Accepted by TMLR2025 (32 pages, 6 figures)
Summary:
解决复杂规划问题需要大型语言模型(LLM)显式建模状态转换以遵守规则、避免违规并达到最优状态。由于自然语言固有的歧义性,这仍然是一项艰巨的任务。为克服这一难题,利用规划领域定义语言(PDDL)作为规划抽象,实现精确和正式的状态描述。通过PDDL,我们可以生成符号世界模型,在该模型中可无缝应用经典搜索算法(如A *算法)以找到最优计划。然而,由于缺少PDDL训练数据,直接使用LLM生成PDDL领域仍然是一个挑战。为应对这一挑战,我们提出扩大LLM的测试时间计算以增强其PDDL推理能力,从而生成高质量的PDDL领域。通过采用简单有效的算法,首先使用最佳N采样方法提高初始解决方案的质量,然后通过精细化的机器学习进一步细化解决方案。我们的方法在生成PDDL领域方面远超o1-mini基准线,在两项任务上的成功率超过50%,并且无需额外训练。借助PDDL作为状态抽象工具,我们的方法几乎在所有竞赛级别的规划任务上都优于现有技术。
Key Takeaways:
- 解决复杂规划问题需要LLM显式建模状态转换。
- 自然语言的歧义性是LLM面临的主要挑战之一。
- PDDL作为规划抽象,可实现精确和正式的状态描述。
- 利用PDDL生成符号世界模型可应用经典搜索算法找到最优计划。
- 当前LLM面临缺乏PDDL训练数据的挑战。
- 提出扩大LLM测试时间计算以提高其PDDL推理能力的方法。
点此查看论文截图


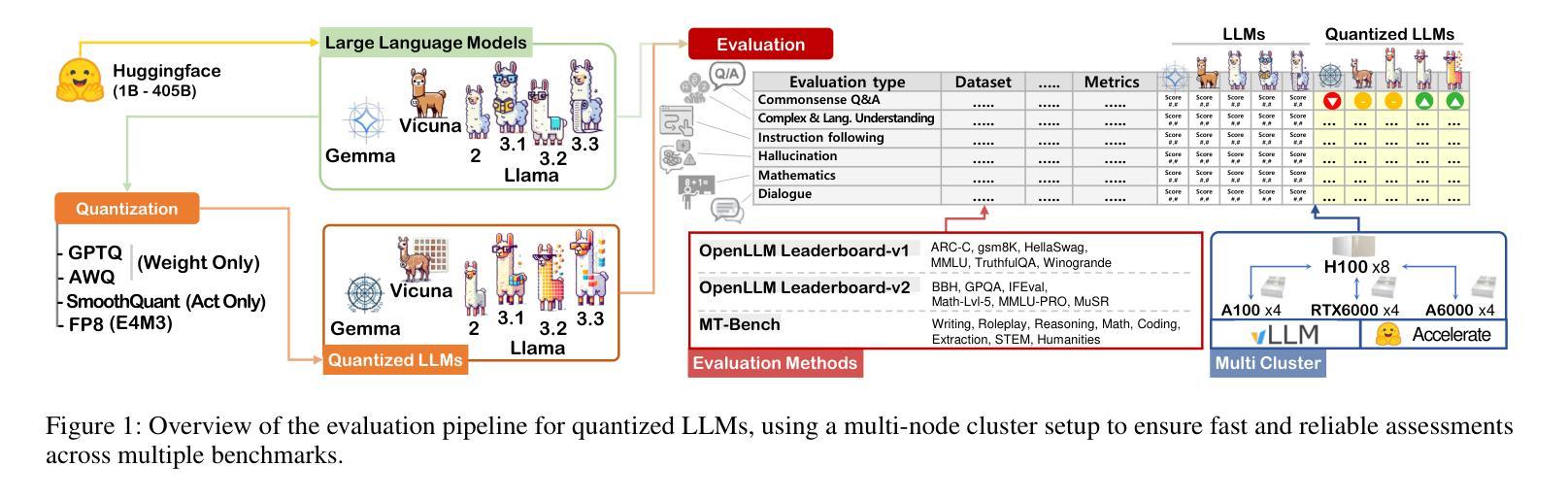
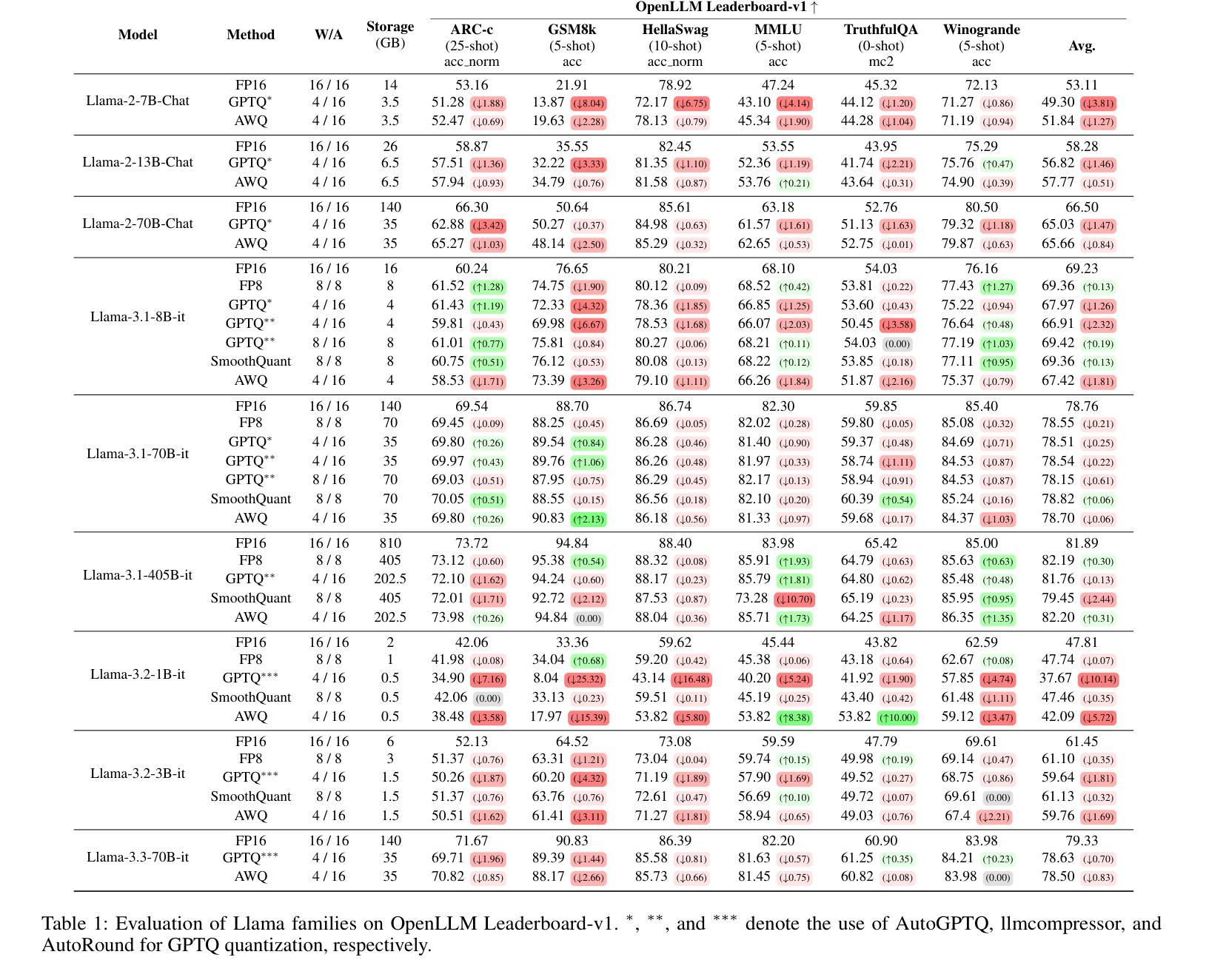
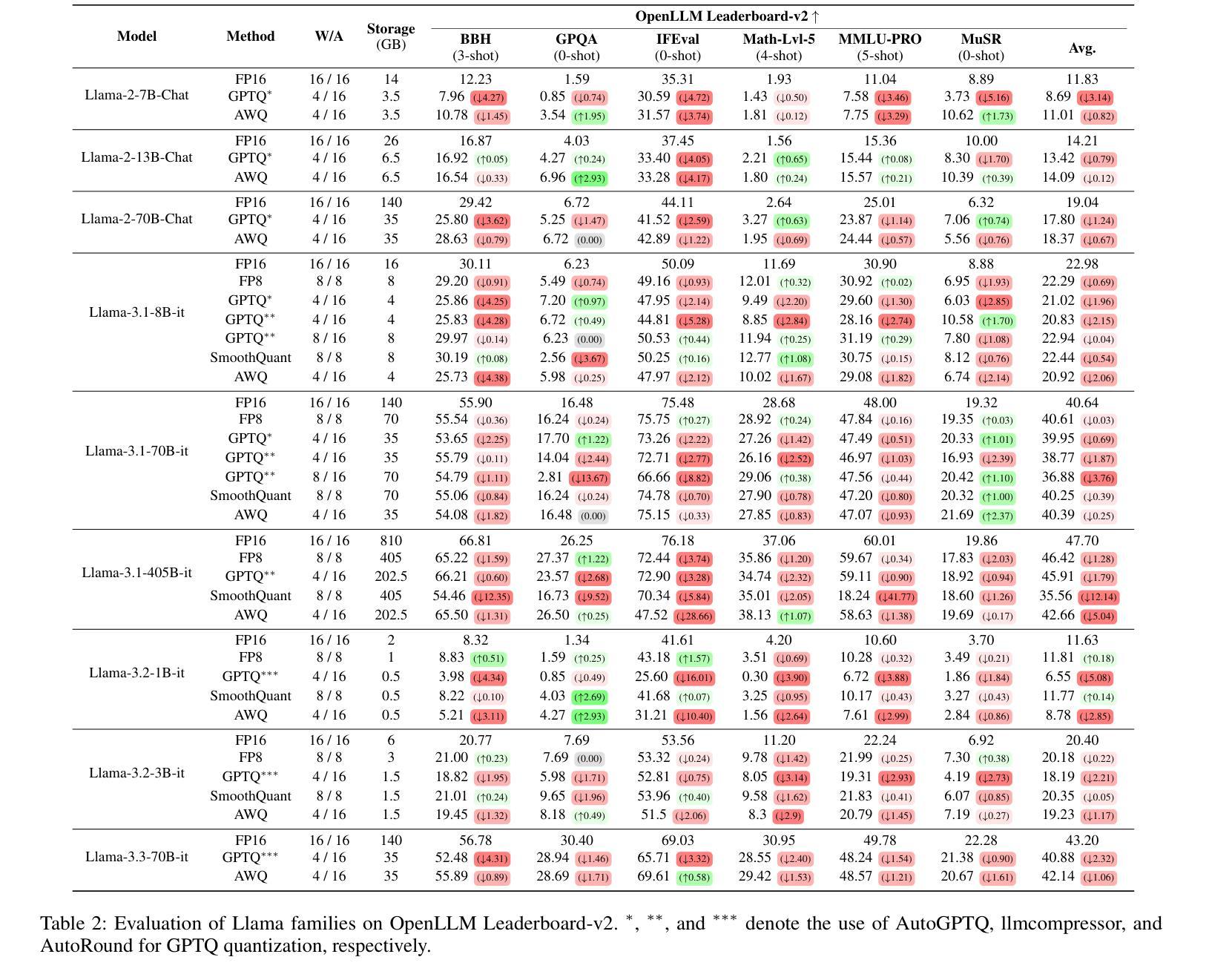
Exploring the Trade-Offs: Quantization Methods, Task Difficulty, and Model Size in Large Language Models From Edge to Giant
Authors:Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, Yongin Kwon
Quantization has gained attention as a promising solution for the cost-effective deployment of large and small language models. However, most prior work has been limited to perplexity or basic knowledge tasks and lacks a comprehensive evaluation of recent models like Llama-3.3. In this paper, we conduct a comprehensive evaluation of instruction-tuned models spanning 1B to 405B parameters, applying four quantization methods across 13 datasets. Our findings reveal that (1) quantized models generally surpass smaller FP16 baselines, yet they often struggle with instruction-following and hallucination detection; (2) FP8 consistently emerges as the most robust option across tasks, and AWQ tends to outperform GPTQ in weight-only quantization; (3) smaller models can suffer severe accuracy drops at 4-bit quantization, while 70B-scale models maintain stable performance; (4) notably, \textit{hard} tasks do not always experience the largest accuracy losses, indicating that quantization magnifies a model’s inherent weaknesses rather than simply correlating with task difficulty; and (5) an LLM-based judge (MT-Bench) highlights significant performance declines in coding and STEM tasks, though reasoning may sometimes improve.
量化技术作为部署大小语言模型的一种具有成本效益的可行解决方案,已经引起了广泛关注。然而,大多数先前的工作仅限于困惑度或基本知识任务,缺乏对像Llama-3.3这样的最新模型的全面评估。在本文中,我们对指令微调模型进行了全面评估,这些模型参数范围从1B到405B,应用四种量化方法,涉及13个数据集。我们的研究发现:(1)量化模型通常超过较小的FP16基准测试,但在遵循指令和幻觉检测方面经常遇到困难;(2)FP8在各项任务中始终表现为最稳健的选择,AWQ在仅权重量化方面倾向于优于GPTQ;(3)较小模型在4位量化时可能会遭受严重的精度下降,而70B规模模型则能保持稳定的性能;(4)值得注意的是,并非所有困难任务都会遭受最大的精度损失,这表明量化会放大模型的固有弱点,而不是仅仅与任务难度相关;(5)基于大型语言模型的判断(MT-Bench)突显出在编码和STEM任务中的性能显著下降,尽管有时推理能力可能会提高。
论文及项目相关链接
PDF Accepted in IJCAI 2025, 21 pages, 2 figure
Summary
点此查看论文截图

Enhancing Differential Testing With LLMs For Testing Deep Learning Libraries
Authors:Meiziniu Li, Dongze Li, Jianmeng Liu, Jialun Cao, Yongqiang Tian, Shing-Chi Cheung
Differential testing offers a promising strategy to alleviate the test oracle problem by comparing the test results between alternative implementations. However, existing differential testing techniques for deep learning (DL) libraries are limited by the key challenges of finding alternative implementations (called counterparts) for a given API and subsequently generating diverse test inputs. To address the two challenges, this paper introduces DLLens, an LLM-enhanced differential testing technique for DL libraries. To address the first challenge, DLLens incorporates an LLM-based counterpart synthesis workflow, with the insight that the counterpart of a given DL library API’s computation could be successfully synthesized through certain composition and adaptation of the APIs from another DL library. To address the second challenge, DLLens incorporates a static analysis technique that extracts the path constraints from the implementations of a given API and its counterpart to guide diverse test input generation. The extraction is facilitated by LLM’s knowledge of the concerned DL library and its upstream libraries. We evaluate DLLens on two popular DL libraries, TensorFlow and PyTorch. Our evaluation shows that DLLens synthesizes counterparts for 1.84 times as many APIs as those found by state-of-the-art techniques on these libraries. Moreover, under the same time budget, DLLens covers 7.23% more branches and detects 1.88 times as many bugs as state-of-the-art techniques on 200 randomly sampled APIs. DLLens has successfully detected 71 bugs in recent TensorFlow and PyTorch libraries. Among them, 59 are confirmed by developers, including 46 confirmed as previously unknown bugs, and 10 of these previously unknown bugs have been fixed in the latest version of TensorFlow and PyTorch.
差分测试通过比较不同实现的测试结果为解决测试预言问题提供了有前景的策略。然而,现有的深度学习(DL)库的差分测试技术在寻找给定API的替代实现(称为对应物)以及随后生成多样化的测试输入方面存在关键挑战。为了解决这两个挑战,本文介绍了DLLens,这是一种用于DL库的增强型LLM差分测试技术。为了解决第一个挑战,DLLens采用了基于LLM的对应物合成流程,其见解是,给定DL库API的计算的对应物可以通过其他DL库API的某种组合和适应来成功合成。为了解决第二个挑战,DLLens采用了一种静态分析技术,它从给定API及其对应物的实现中提取路径约束,以指导多样化的测试输入生成。提取工作得益于LLM对有关DL库及其上游库的知识。我们在两个流行的DL库TensorFlow和PyTorch上评估了DLLens。我们的评估表明,DLLens合成的对应物是现有技术在这些库中找到的API的1.84倍。此外,在相同的时间预算下,DLLens覆盖的分支更多(多出7.23%),并且在200个随机采样的API上检测到的错误是现有技术的1.88倍。DLLens已成功检测到TensorFlow和PyTorch库中的71个错误。其中,开发者确认的59个错误中,有46个是以前未知的错误,其中10个已在TensorFlow和PyTorch的最新版本中修复。
论文及项目相关链接
PDF This work has been accepted by ACM TOSEM. Manuscript under final preparation
摘要
本文提出了一种名为DLLens的深度学习(DL)库差异测试技术,旨在解决测试预言问题。DLLens结合大型语言模型(LLM),解决现有差异测试技术的两大挑战:寻找给定API的替代实现(称为对应物)以及随后生成多样化的测试输入。为解决第一个挑战,DLLens采用基于LLM的对应物合成流程,通过合成其他DL库API的组合和适应来成功合成给定DL库API的对应物。对于第二个挑战,DLLens采用静态分析技术,从给定API及其对应物的实现中提取路径约束,以指导多样化的测试输入生成。我们在TensorFlow和PyTorch这两个流行的DL库上评估了DLLens。评估结果表明,DLLens合成的对应物是现有技术在这些库上找到的API的1.84倍。此外,在相同的时间预算下,DLLens覆盖的分支增加了7.23%,检测到的错误是现有技术的1.88倍。DLLens成功检测到TensorFlow和PyTorch库中的71个错误,其中59个已得到开发者确认,包括46个之前未知的错误。其中10个之前未知错误已在TensorFlow和PyTorch的最新版本中得到修复。
关键见解
- 差分测试是一种解决测试预言问题的有前途的策略,通过比较不同实现的结果来检测错误。
- 现有深度学习(DL)库的差异测试技术面临两大挑战:寻找给定API的替代实现(对应物)和生成多样化的测试输入。
- DLLens是一种结合大型语言模型(LLM)的差异测试技术,旨在解决上述挑战。
- DLLens通过结合LLM,解决了对应物的合成问题,并可以通过静态分析技术生成多样化的测试输入。
- 在TensorFlow和PyTorch上的评估表明,DLLens在合成对应物、覆盖分支和检测错误方面均优于现有技术。
- DLLens成功检测到71个错误,其中包括之前未知的46个错误,已有部分得到开发者确认并在最新版本中得到修复。
点此查看论文截图