⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-10 更新
3D Scene Generation: A Survey
Authors:Beichen Wen, Haozhe Xie, Zhaoxi Chen, Fangzhou Hong, Ziwei Liu
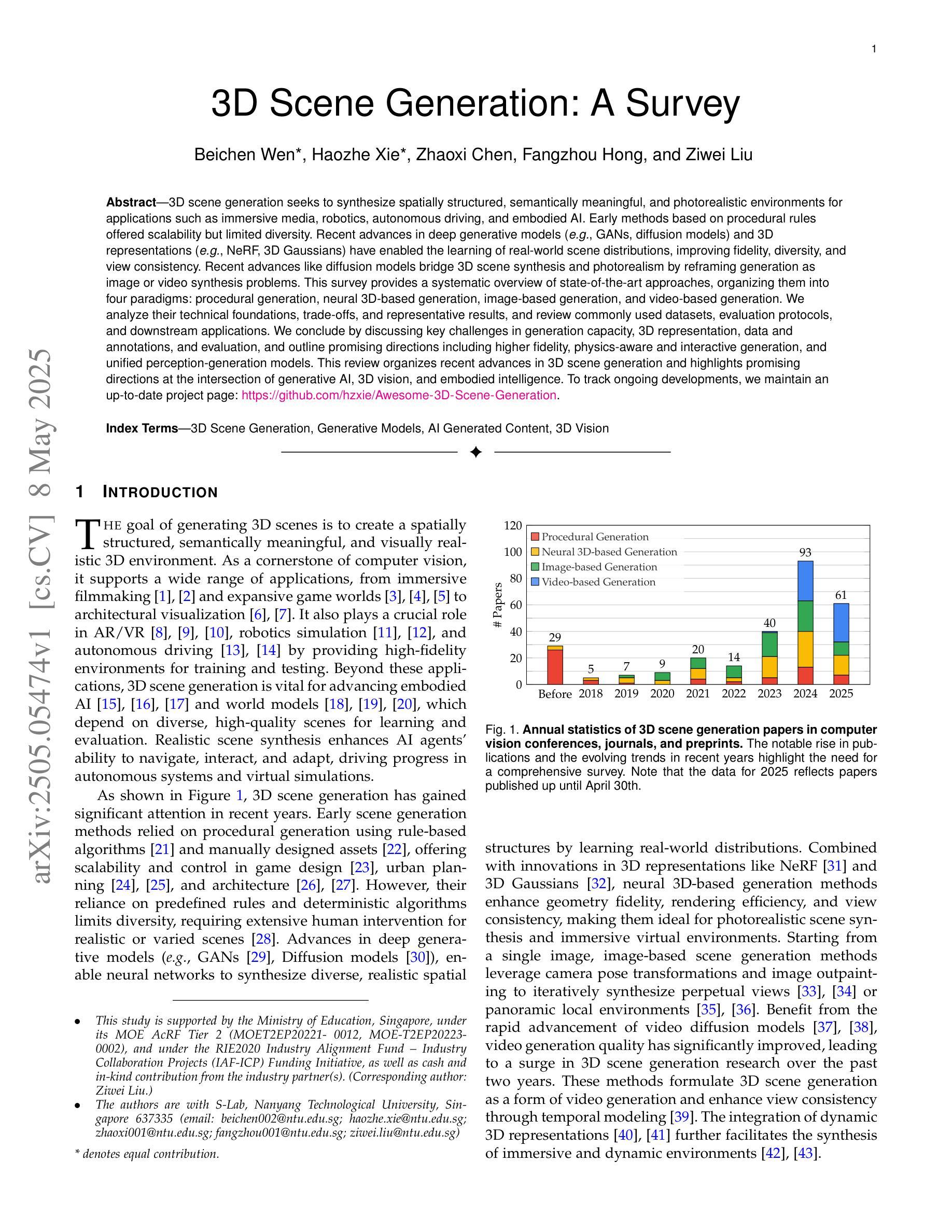
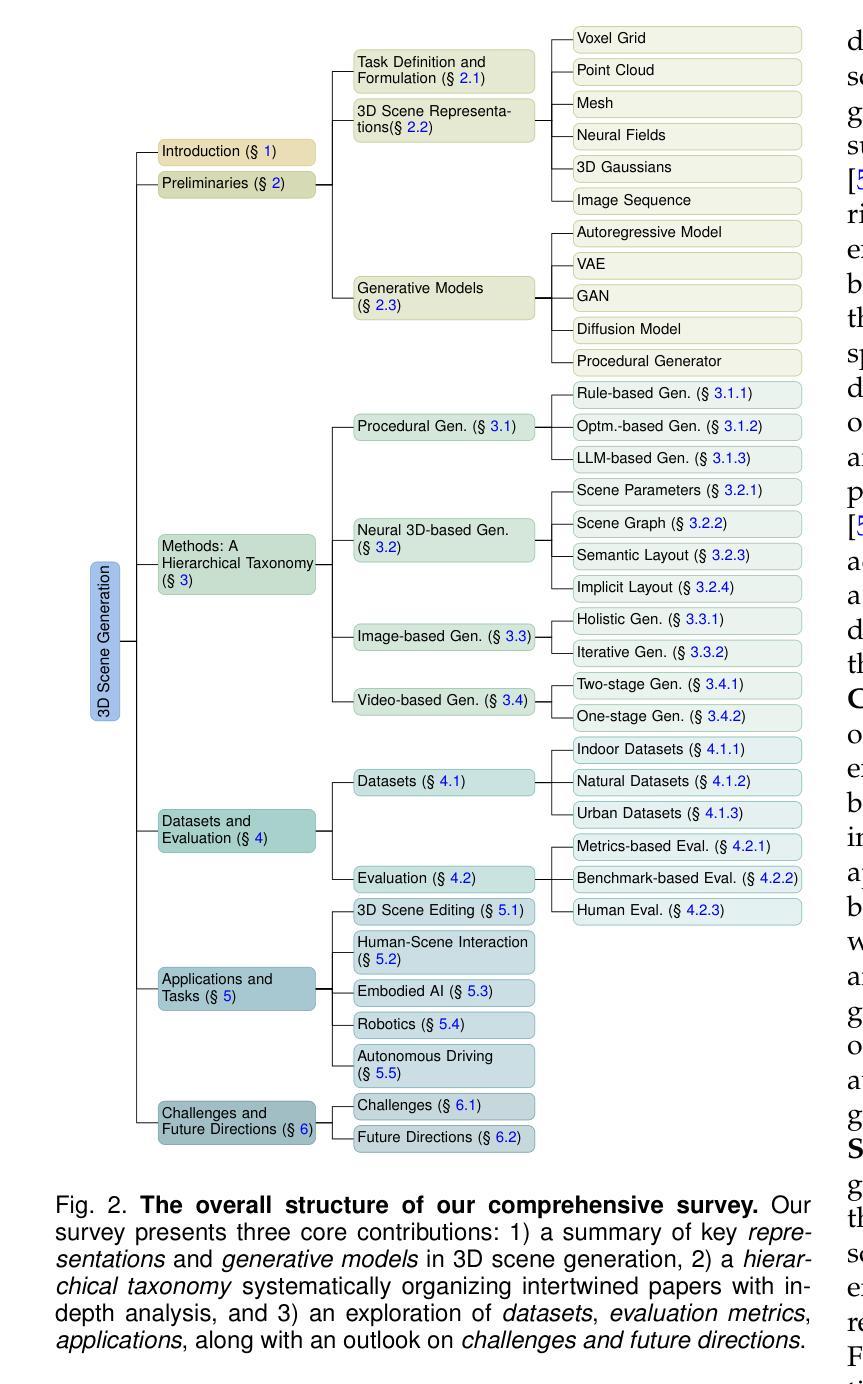
3D scene generation seeks to synthesize spatially structured, semantically meaningful, and photorealistic environments for applications such as immersive media, robotics, autonomous driving, and embodied AI. Early methods based on procedural rules offered scalability but limited diversity. Recent advances in deep generative models (e.g., GANs, diffusion models) and 3D representations (e.g., NeRF, 3D Gaussians) have enabled the learning of real-world scene distributions, improving fidelity, diversity, and view consistency. Recent advances like diffusion models bridge 3D scene synthesis and photorealism by reframing generation as image or video synthesis problems. This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation. We analyze their technical foundations, trade-offs, and representative results, and review commonly used datasets, evaluation protocols, and downstream applications. We conclude by discussing key challenges in generation capacity, 3D representation, data and annotations, and evaluation, and outline promising directions including higher fidelity, physics-aware and interactive generation, and unified perception-generation models. This review organizes recent advances in 3D scene generation and highlights promising directions at the intersection of generative AI, 3D vision, and embodied intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/hzxie/Awesome-3D-Scene-Generation.
三维场景生成旨在合成具有空间结构、语义有意义和逼真的环境,用于沉浸式媒体、机器人技术、自动驾驶和人工智能实体等应用。早期基于程序规则的方法虽然具有良好的可扩展性,但多样性有限。最近深度生成模型(例如GANs、扩散模型)和三维表示(例如NeRF、三维高斯)的进步使得学习真实场景分布成为可能,提高了逼真度、多样性和视图一致性。像扩散模型这样的最新进展通过重新构建生成问题为图像或视频合成问题,从而连接了三维场景合成和逼真度。这篇综述提供了最先进方法的系统概述,将它们组织成四种范式:程序生成、基于神经的三维生成、基于图像的生成和基于视频的生成。我们分析了它们的技术基础、权衡和代表性结果,并回顾了常用数据集、评估协议和下游应用。最后,我们讨论了生成能力、三维表示、数据和注释以及评估方面的关键挑战,并概述了有希望的方向,包括更高的逼真度、物理感知和交互式生成以及统一的感知生成模型。这篇综述整理了三维场景生成的最新进展,并强调了生成人工智能、三维视觉和实体智能交集处有希望的方向。为了跟踪最新发展,我们维护了一个最新的项目页面:https://github.com/hzxie/Awesome-3D-Scene-Generation。
论文及项目相关链接
PDF Project Page: https://github.com/hzxie/Awesome-3D-Scene-Generation
Summary
这篇综述全面概述了当前三维场景生成研究的最新进展,包括过程生成、基于神经的三维生成、基于图像的视频生成等四种范式。文章分析了各种方法的技术基础、优缺点及代表性成果,并讨论了数据集、评估协议和下游应用。文章还指出了生成能力、三维表示、数据和注释以及评估方面的关键挑战,并概述了高保真度、物理感知交互生成和统一感知生成模型等前景方向。
Key Takeaways
- 3D场景生成涉及合成具有空间结构、语义意义和真实感的环境,用于沉浸式媒体、机器人、自动驾驶和人工智能等应用。
- 早期基于程序规则的方法虽然具有良好的可扩展性,但缺乏多样性。
- 深度学习生成模型和三维表示技术的最新进展使得学习真实世界场景分布成为可能,提高了保真度、多样性和视角一致性。
- 综述系统概述了当前最新的三维场景生成方法,包括过程生成、基于神经的三维生成、基于图像的视频生成等四种范式。
- 文章讨论了数据集、评估协议和下游应用的相关问题。
- 当前面临的关键挑战包括生成能力、三维表示技术、数据和标注以及评估方法。
点此查看论文截图
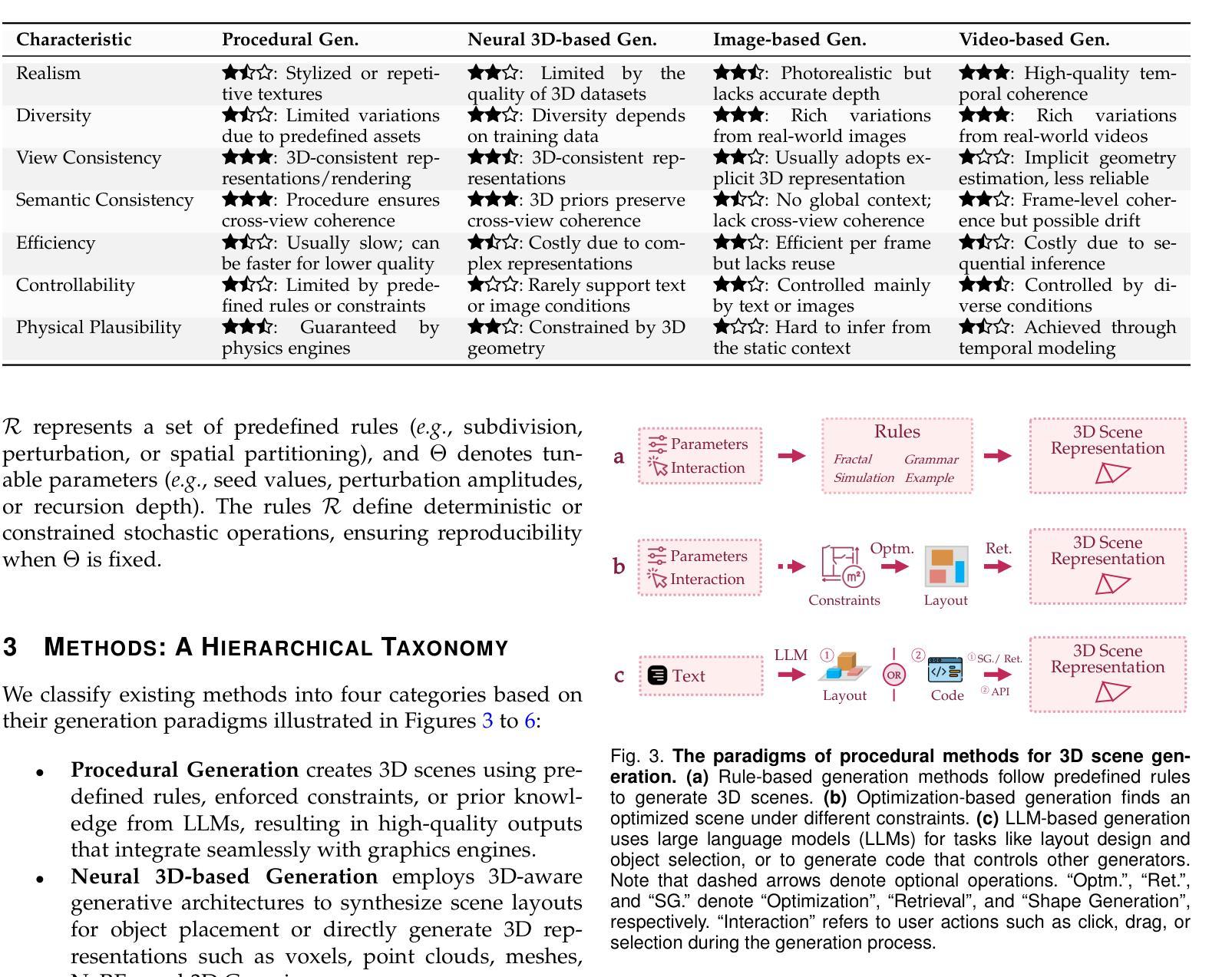
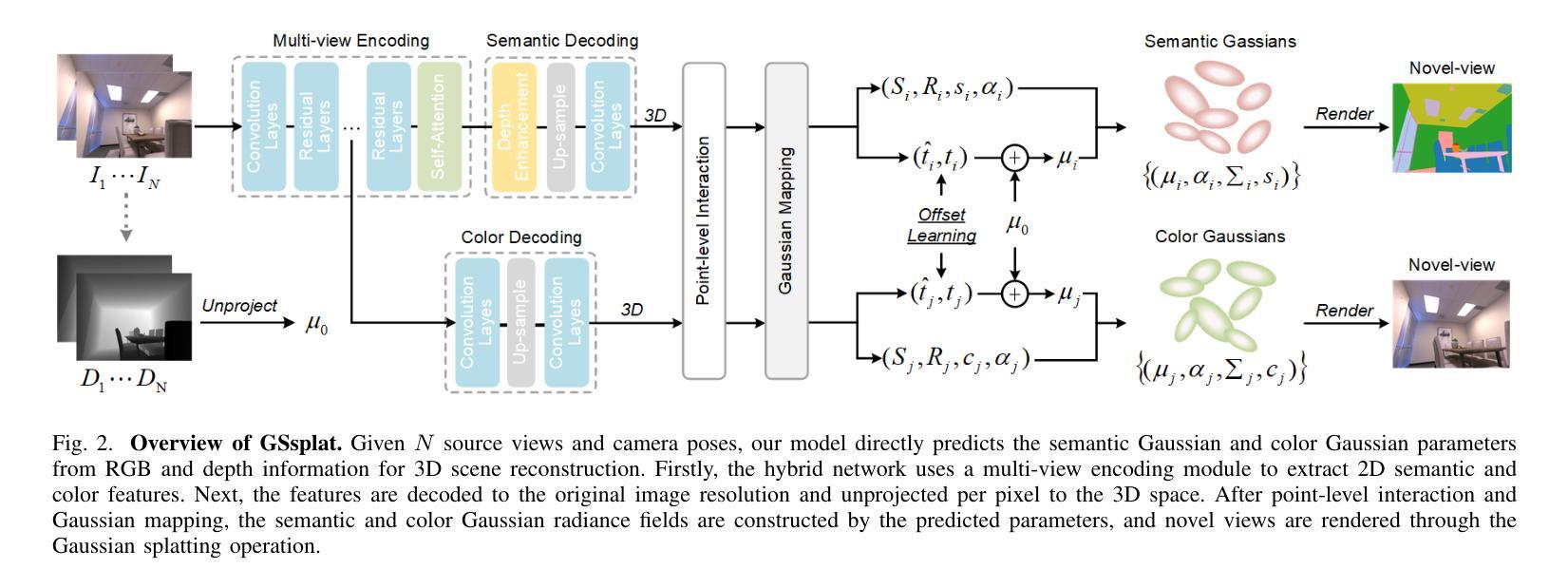
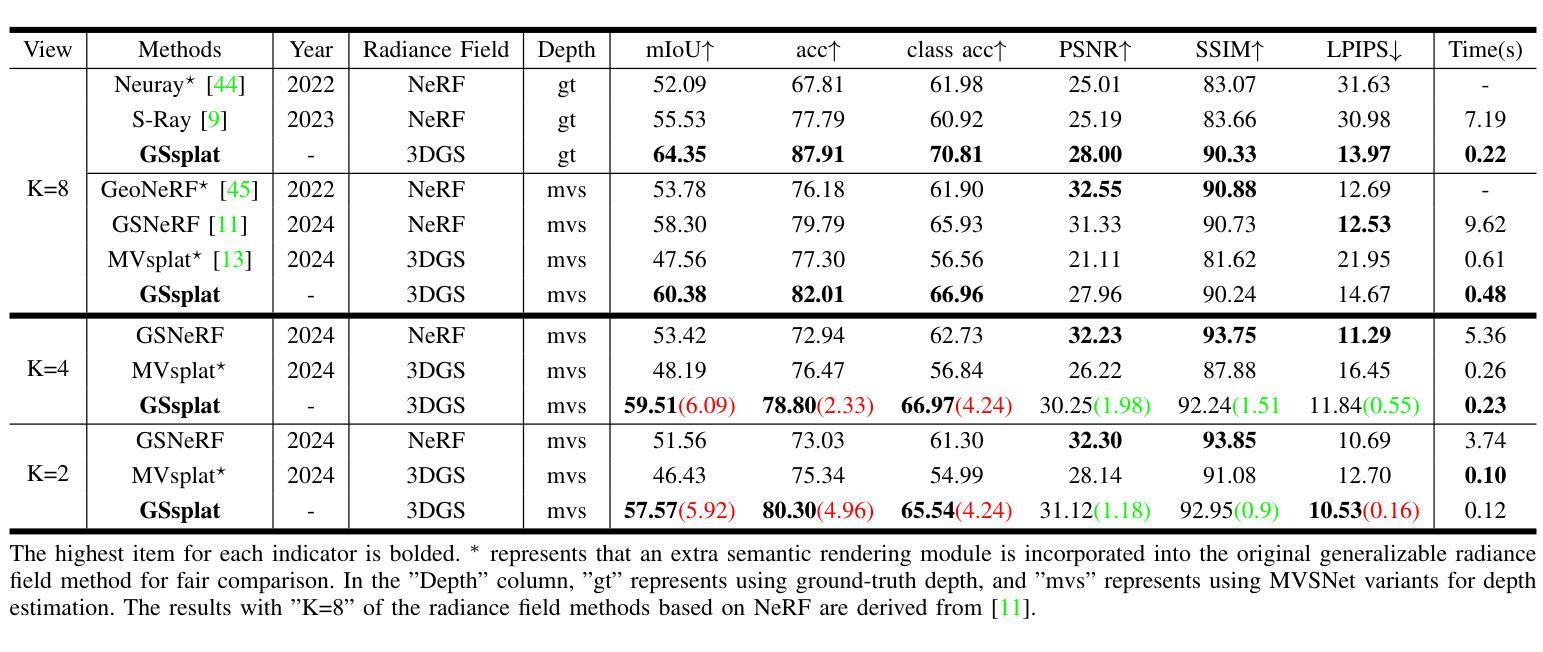
GSsplat: Generalizable Semantic Gaussian Splatting for Novel-view Synthesis in 3D Scenes
Authors:Feng Xiao, Hongbin Xu, Wanlin Liang, Wenxiong Kang
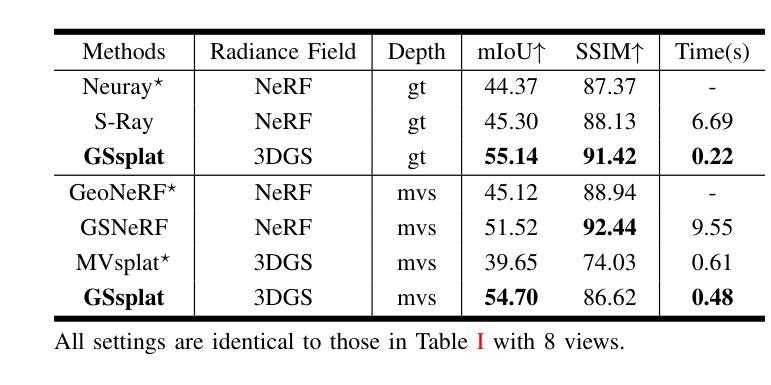
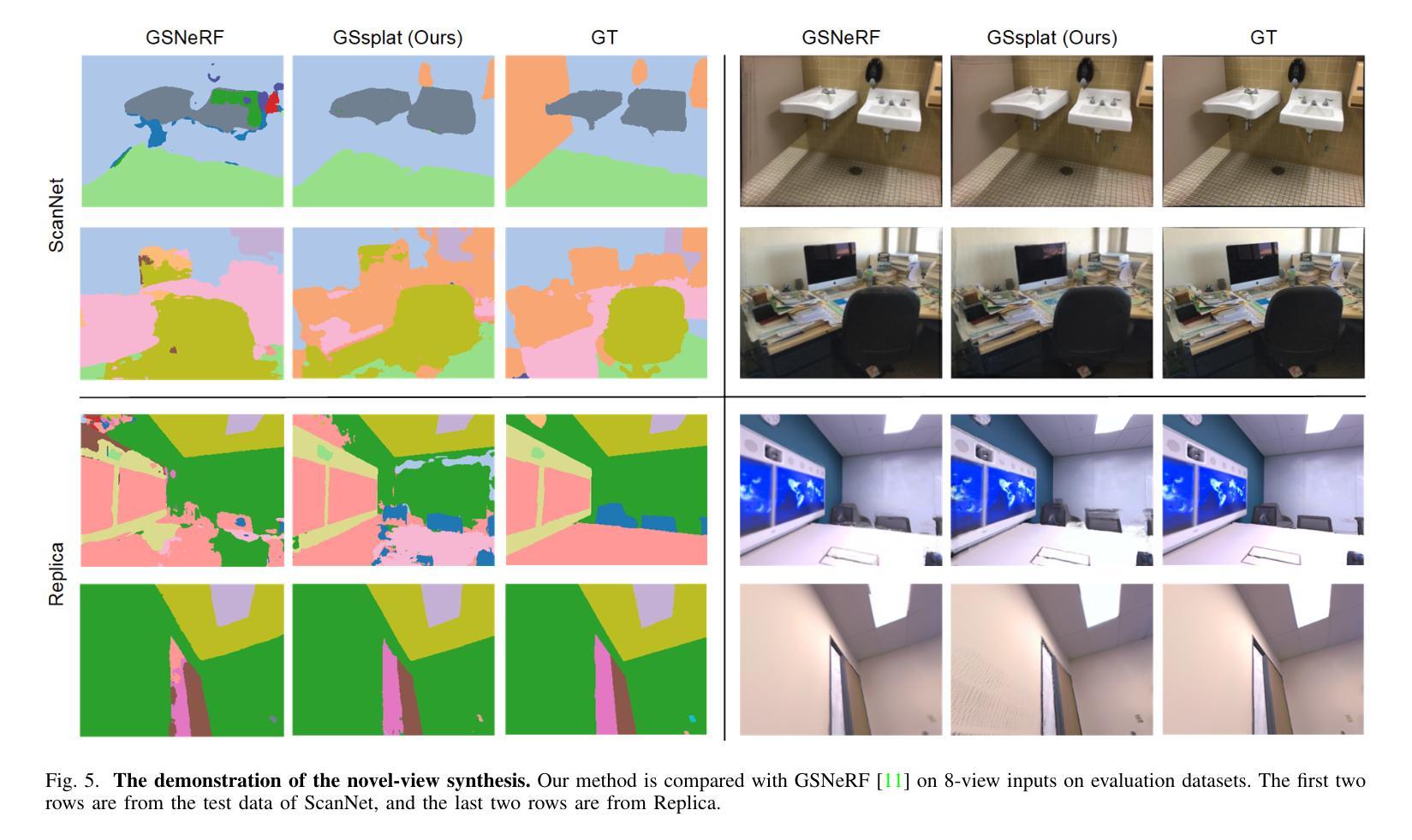
The semantic synthesis of unseen scenes from multiple viewpoints is crucial for research in 3D scene understanding. Current methods are capable of rendering novel-view images and semantic maps by reconstructing generalizable Neural Radiance Fields. However, they often suffer from limitations in speed and segmentation performance. We propose a generalizable semantic Gaussian Splatting method (GSsplat) for efficient novel-view synthesis. Our model predicts the positions and attributes of scene-adaptive Gaussian distributions from once input, replacing the densification and pruning processes of traditional scene-specific Gaussian Splatting. In the multi-task framework, a hybrid network is designed to extract color and semantic information and predict Gaussian parameters. To augment the spatial perception of Gaussians for high-quality rendering, we put forward a novel offset learning module through group-based supervision and a point-level interaction module with spatial unit aggregation. When evaluated with varying numbers of multi-view inputs, GSsplat achieves state-of-the-art performance for semantic synthesis at the fastest speed.
在三维场景理解的研究中,从不同视点进行未见场景语义合成的技术至关重要。当前的方法能够通过重建通用的神经辐射场(Neural Radiance Fields)来生成新视角的图像和语义地图。然而,它们在速度和分割性能上常常存在局限。我们提出了一种通用的语义高斯平铺方法(GSsplat),用于高效的新视角合成。我们的模型通过一次输入即可预测场景自适应高斯分布的位置和属性,从而取代了传统场景特定高斯平铺的密集化和修剪过程。在多任务框架下,我们设计了一个混合网络来提取颜色和语义信息,并预测高斯参数。为了提高高斯的空间感知以实现高质量渲染,我们提出了通过群组监督的新偏移学习模块以及与空间单位聚合的点级交互模块。通过不同数量的多视角输入进行评估,GSsplat在语义合成方面实现了最快速度的最先进性能。
论文及项目相关链接
Summary
本文主要研究了基于语义的未见场景合成技术,提出了一种通用语义高斯Splatting方法(GSsplat),用于高效的新视角合成。该方法通过预测场景自适应的高斯分布位置和属性,改进了传统的场景特定高斯Splatting的密集化和修剪过程。通过多任务框架和新型偏移学习模块,实现了高质量渲染的空间感知增强。在不同数量的多视角输入下,GSsplat在语义合成方面实现了最先进性能和最快速度。
Key Takeaways
- 语义合成在3D场景理解中的重要性:能够从未见场景的多视角进行语义合成是研究的关键。
- 当前方法的局限性:虽然现有方法能够通过重建神经网络辐射场来生成新视角图像和语义地图,但它们常常在速度和分割性能上存在局限。
- GSsplat方法的引入:提出了一种通用语义高斯Splatting(GSsplat)方法,用于高效的新视角合成。该方法改进了传统方法的密集化和修剪过程。
- 多任务框架的设计:设计一个混合网络来提取颜色和语义信息,并预测高斯参数。
- 新型偏移学习模块和点级交互模块:为了提高高斯的空间感知,提出了新型偏移学习模块和点级交互模块,以实现高质量渲染。
- 性能评估:GSsplat在不同数量的多视角输入下,实现了语义合成的最先进的性能和最快速度。
点此查看论文截图


Texture Image Synthesis Using Spatial GAN Based on Vision Transformers
Authors:Elahe Salari, Zohreh Azimifar
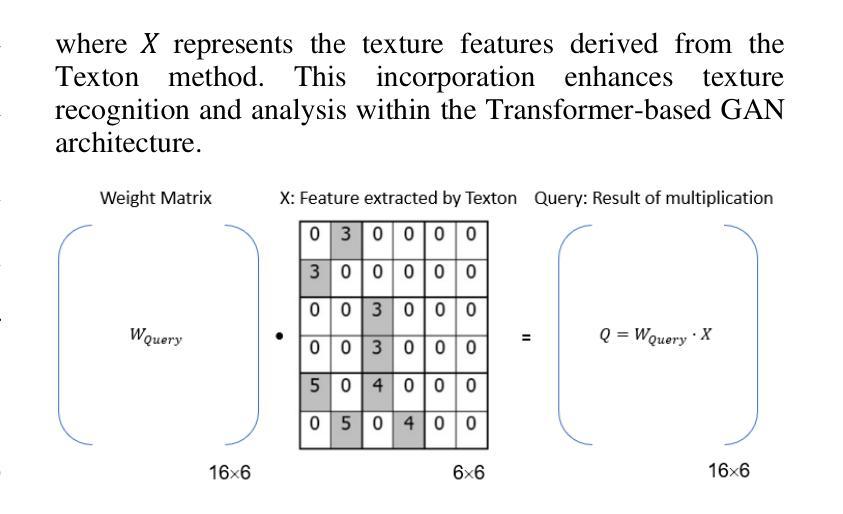
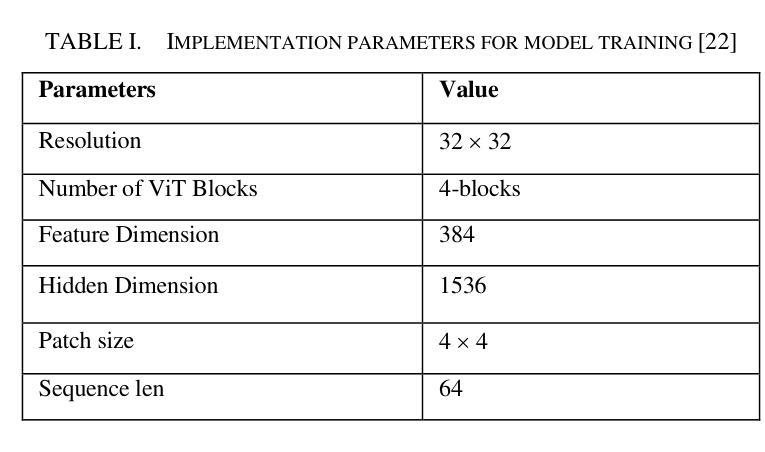
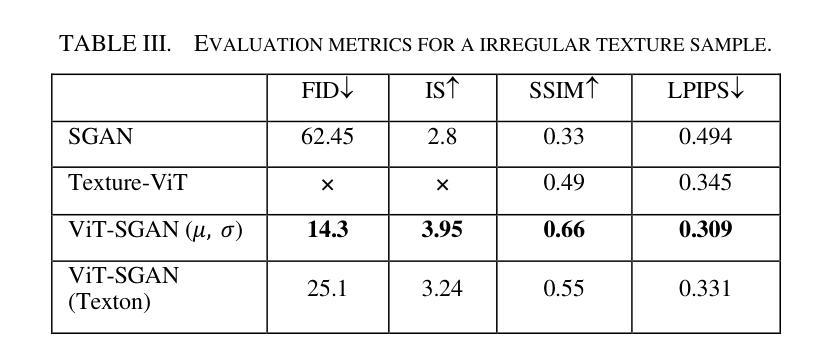
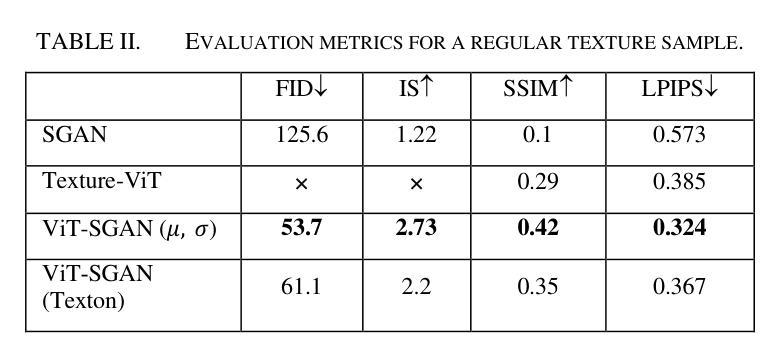
Texture synthesis is a fundamental task in computer vision, whose goal is to generate visually realistic and structurally coherent textures for a wide range of applications, from graphics to scientific simulations. While traditional methods like tiling and patch-based techniques often struggle with complex textures, recent advancements in deep learning have transformed this field. In this paper, we propose ViT-SGAN, a new hybrid model that fuses Vision Transformers (ViTs) with a Spatial Generative Adversarial Network (SGAN) to address the limitations of previous methods. By incorporating specialized texture descriptors such as mean-variance (mu, sigma) and textons into the self-attention mechanism of ViTs, our model achieves superior texture synthesis. This approach enhances the model’s capacity to capture complex spatial dependencies, leading to improved texture quality that is superior to state-of-the-art models, especially for regular and irregular textures. Comparison experiments with metrics such as FID, IS, SSIM, and LPIPS demonstrate the substantial improvement of ViT-SGAN, which underlines its efficiency in generating diverse realistic textures.
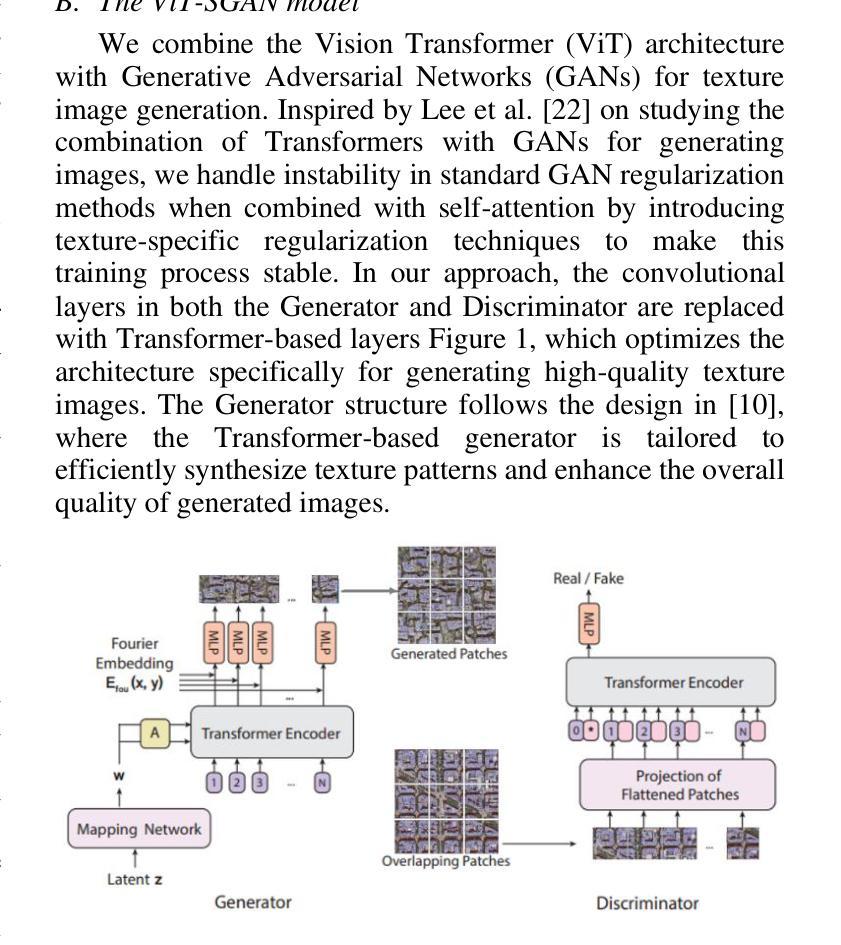
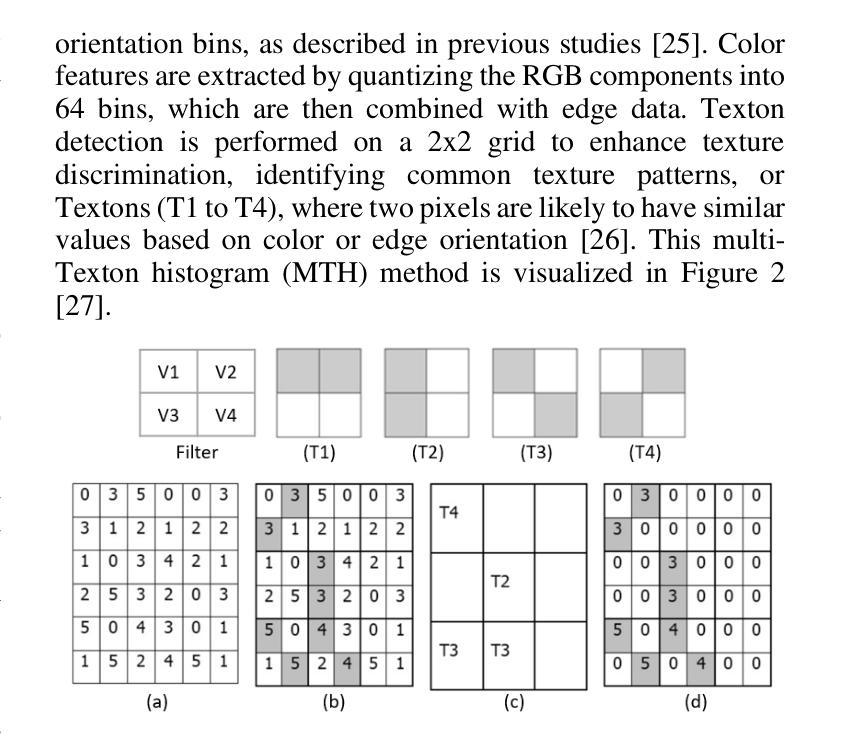
纹理合成是计算机视觉中的一项基本任务,其目标是为从图形到科学模拟的广泛应用生成视觉真实且结构连贯的纹理。传统方法(如平铺和基于补丁的技术)通常难以处理复杂纹理,而深度学习领域的最新进展已彻底改变了这一领域。在本文中,我们提出了ViT-SGAN,这是一个新型混合模型,它将视觉变压器(ViTs)与空间生成对抗网络(SGAN)相结合,以克服以前方法的局限性。通过将均值-方差(mu、sigma)和纹理等专用纹理描述符融入ViTs的自注意力机制中,我们的模型实现了出色的纹理合成。这种方法提高了模型捕捉复杂空间依赖关系的能力,从而产生了优于最新模型的纹理质量,特别是在规则和不规则纹理方面。使用FID、IS、SSIM和LPIPS等指标进行的对比实验证明了ViT-SGAN的大幅改进,这突显了其在生成各种真实纹理方面的效率。
论文及项目相关链接
PDF Preprint
Summary
新一代纹理合成技术通过结合Vision Transformer(ViT)与Spatial Generative Adversarial Network(SGAN)实现了超越现有模型的性能。ViT-SGAN模型引入纹理描述符以增强自我注意力机制,能更高效地捕捉复杂空间依赖性,生成更高质量的纹理。对比实验显示,ViT-SGAN在生成多样且逼真的纹理上表现出显著优势。
Key Takeaways
- 纹理合成是计算机视觉中的基础任务,旨在生成视觉真实且结构连贯的纹理,广泛应用于图形和科学模拟等领域。
- 传统方法如平铺和基于补丁的技术在处理复杂纹理时常常遇到困难。
- 深度学习领域的最新进展已经改变了纹理合成领域。
- ViT-SGAN是一个结合Vision Transformer(ViT)与Spatial Generative Adversarial Network(SGAN)的混合模型。
- ViT-SGAN引入纹理描述符(如均值方差和纹素)到ViT的自我注意力机制中,实现了更高效的复杂空间依赖性捕捉。
- 对比实验证明,ViT-SGAN在生成多样且逼真的纹理方面表现出卓越性能,尤其在常规和不规则纹理上。
点此查看论文截图


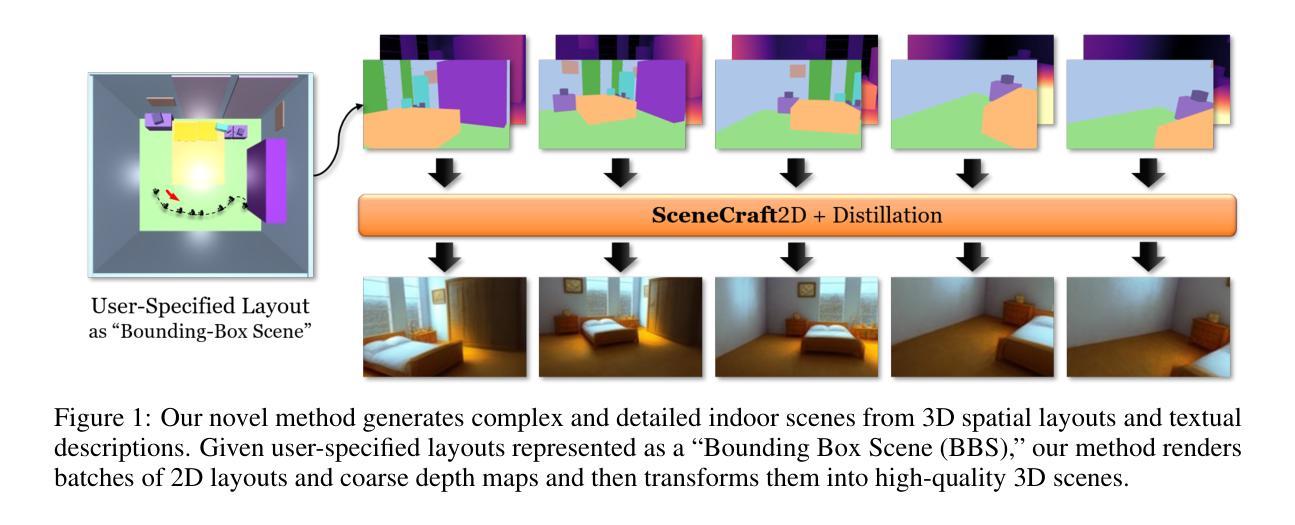
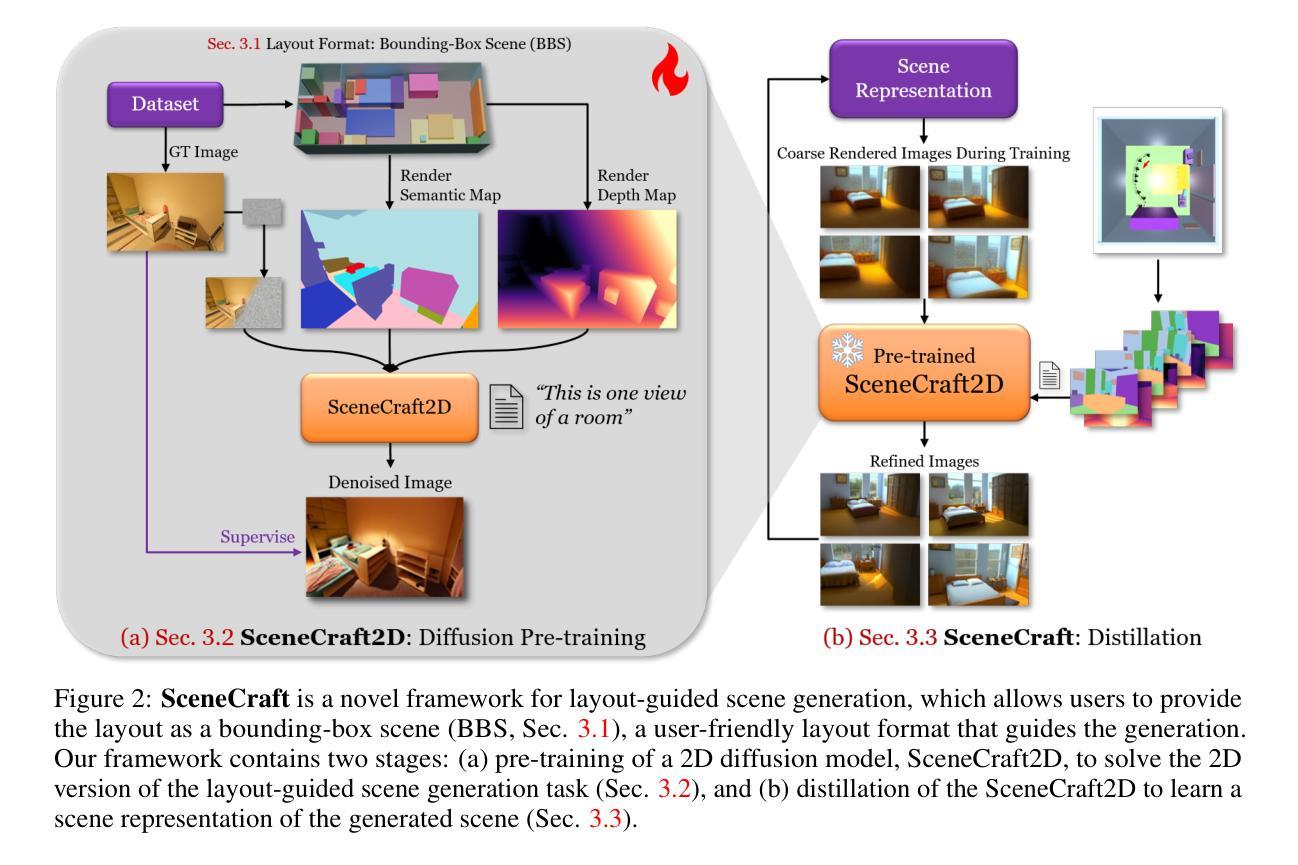
SceneCraft: Layout-Guided 3D Scene Generation
Authors:Xiuyu Yang, Yunze Man, Jun-Kun Chen, Yu-Xiong Wang
The creation of complex 3D scenes tailored to user specifications has been a tedious and challenging task with traditional 3D modeling tools. Although some pioneering methods have achieved automatic text-to-3D generation, they are generally limited to small-scale scenes with restricted control over the shape and texture. We introduce SceneCraft, a novel method for generating detailed indoor scenes that adhere to textual descriptions and spatial layout preferences provided by users. Central to our method is a rendering-based technique, which converts 3D semantic layouts into multi-view 2D proxy maps. Furthermore, we design a semantic and depth conditioned diffusion model to generate multi-view images, which are used to learn a neural radiance field (NeRF) as the final scene representation. Without the constraints of panorama image generation, we surpass previous methods in supporting complicated indoor space generation beyond a single room, even as complicated as a whole multi-bedroom apartment with irregular shapes and layouts. Through experimental analysis, we demonstrate that our method significantly outperforms existing approaches in complex indoor scene generation with diverse textures, consistent geometry, and realistic visual quality. Code and more results are available at: https://orangesodahub.github.io/SceneCraft
使用传统的3D建模工具根据用户规格创建复杂的3D场景一直是一项繁琐且具有挑战性的任务。尽管一些开创性的方法已经实现了自动文本到3D的生成,但它们通常仅限于小规模场景,对形状和纹理的控制有限。我们引入了SceneCraft,这是一种生成详细室内场景的新方法,它根据文本描述和用户提供的空间布局偏好进行生成。我们的方法的核心是基于渲染的技术,将3D语义布局转换为多视角的2D代理地图。此外,我们设计了一个语义和深度控制的扩散模型,生成多视角图像,用于学习神经辐射场(NeRF)作为最终场景表示。我们不受全景图像生成的约束,超越了之前的方法,支持生成单个房间以外的复杂室内空间,甚至支持整个具有不规则形状和布局的多卧室公寓。通过实验分析,我们证明我们的方法在生成具有多样纹理、一致几何结构和逼真视觉质量的复杂室内场景方面显著优于现有方法。相关代码和更多结果请访问:SceneCraft。
论文及项目相关链接
PDF NeurIPS 2024. Code: https://github.com/OrangeSodahub/SceneCraft Project Page: https://orangesodahub.github.io/SceneCraft
Summary
文本介绍了一种名为SceneCraft的新方法,用于根据用户的文本描述和空间布局偏好生成详细的室内场景。该方法基于渲染技术,将3D语义布局转换为多视角的2D代理地图,并使用语义和深度条件扩散模型生成多视角图像。最终场景表示为神经辐射场(NeRF)。该方法支持生成复杂的室内空间,甚至超越单个房间,如复杂的复式公寓等。实验证明,该方法在生成具有多样纹理、一致几何结构和逼真视觉质量的复杂室内场景方面显著优于现有方法。
Key Takeaways
- SceneCraft是一种能够根据用户的文本描述和空间布局偏好生成详细室内场景的新方法。
- 该方法使用渲染技术将3D语义布局转换为多视角的2D代理地图。
- 利用语义和深度条件扩散模型生成多视角图像,作为最终场景表示的神经辐射场(NeRF)。
- 支持生成复杂的室内空间,超越单个房间,如复式公寓等具有不规则形状和布局的场景。
- 实验证明,SceneCraft在生成具有多样纹理、一致几何结构和逼真视觉质量的复杂室内场景方面显著优于现有方法。
- SceneCraft具有广泛的应用前景,可以应用于游戏开发、虚拟现实、电影制作等领域。
点此查看论文截图