⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-10 更新
Teochew-Wild: The First In-the-wild Teochew Dataset with Orthographic Annotations
Authors:Linrong Pan, Chenglong Jiang, Gaoze Hou, Ying Gao
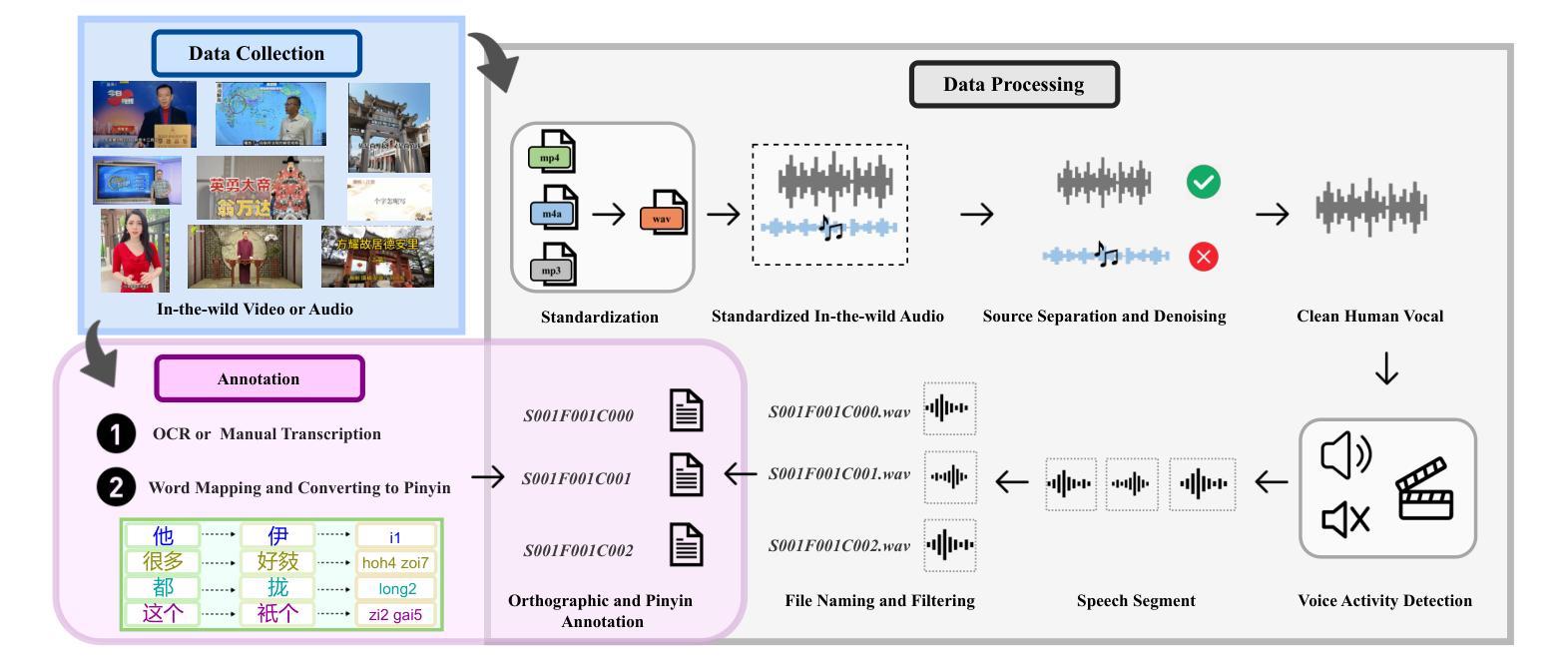
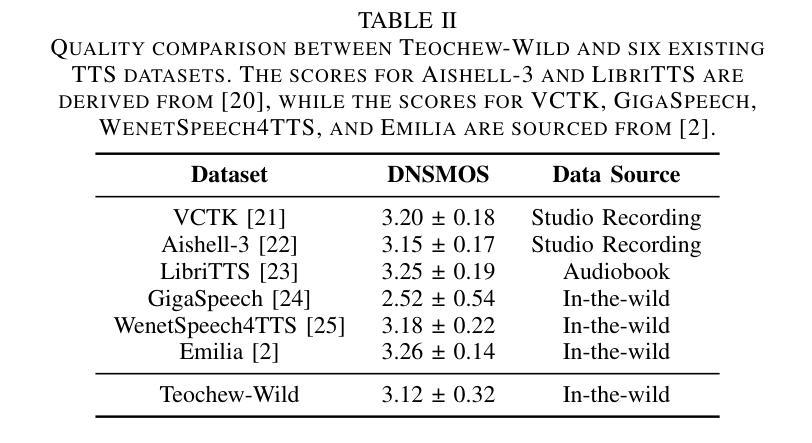
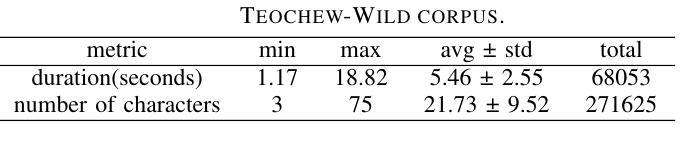
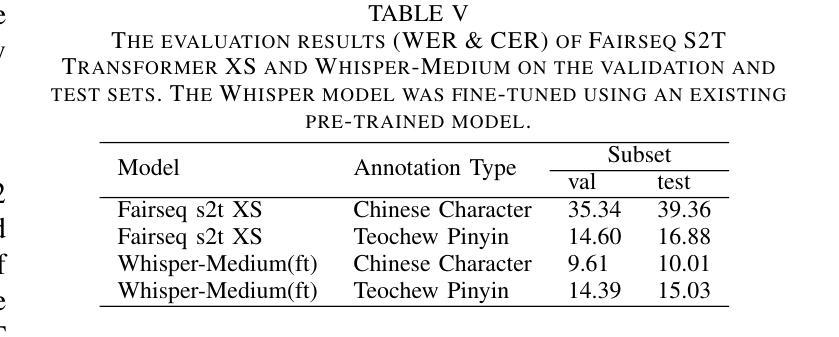
This paper reports the construction of the Teochew-Wild, a speech corpus of the Teochew dialect. The corpus includes 18.9 hours of in-the-wild Teochew speech data from multiple speakers, covering both formal and colloquial expressions, with precise orthographic and pinyin annotations. Additionally, we provide supplementary text processing tools and resources to propel research and applications in speech tasks for this low-resource language, such as automatic speech recognition (ASR) and text-to-speech (TTS). To the best of our knowledge, this is the first publicly available Teochew dataset with accurate orthographic annotations. We conduct experiments on the corpus, and the results validate its effectiveness in ASR and TTS tasks.
本文报道了潮汕方言语音语料库“Teochew-Wild”的构建情况。该语料库包含来自多名发音人的18.9小时的自然状态下的潮汕方言语音数据,涵盖正式和口语表达,具有精确的正字法和拼音标注。此外,我们还提供了补充的文本处理工具和资源,以推动这一低资源语言在语音任务(如自动语音识别(ASR)和文本到语音(TTS))的研究和应用。据我们所知,这是第一个具有精确正字法注释的公开可用的潮汕数据集。我们在语料库上进行了实验,结果验证了其在ASR和TTS任务中的有效性。
论文及项目相关链接
Summary
本文介绍了Teochew-Wild语料库的建设,这是一个包含潮汕方言的语音语料库。该语料库包含来自多个发言人的18.9小时的自然环境下的潮汕方言语音数据,涵盖正式和口语表达,具有精确的汉字和拼音注释。此外,还提供用于推动该低资源语言语音任务研究与应用(如语音识别和文本到语音转换)的补充文本处理工具和资源。据我们所知,这是第一个具有精确汉字注释的公开潮汕方言数据集。实验结果验证了其在语音识别和文本到语音转换任务中的有效性。
Key Takeaways
- Teochew-Wild语料库是首个包含潮汕方言语音数据的公开数据集。
- 数据集包含18.9小时的多种场景下的潮汕方言语音数据。
- 数据集中涵盖正式和口语表达,数据具有精确的汉字和拼音注释。
- 提供用于潮汕方言语音任务(如语音识别和文本到语音转换)的文本处理工具和资源。
- 数据集可用于推动潮汕方言的研究与应用。
- 实验结果表明该数据集在语音识别和文本到语音转换任务中的有效性。
点此查看论文截图