⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-14 更新
Multi-Agent Path Finding via Finite-Horizon Hierarchical Factorization
Authors:Jiarui Li, Alessandro Zanardi, Gioele Zardini
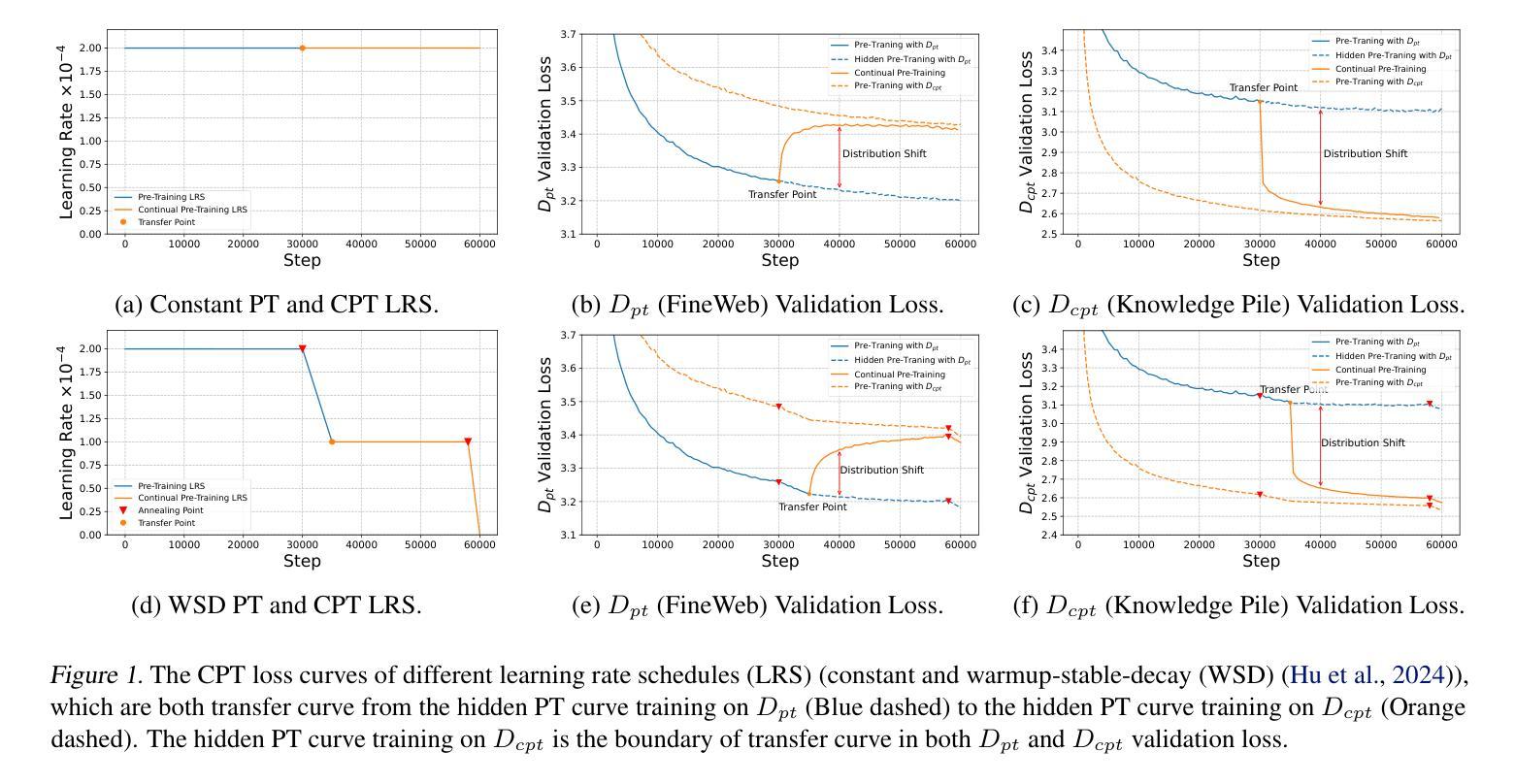
We present a novel algorithm for large-scale Multi-Agent Path Finding (MAPF) that enables fast, scalable planning in dynamic environments such as automated warehouses. Our approach introduces finite-horizon hierarchical factorization, a framework that plans one step at a time in a receding-horizon fashion. Robots first compute individual plans in parallel, and then dynamically group based on spatio-temporal conflicts and reachability. The framework accounts for conflict resolution, and for immediate execution and concurrent planning, significantly reducing response time compared to offline algorithms. Experimental results on benchmark maps demonstrate that our method achieves up to 60% reduction in time-to-first-action while consistently delivering high-quality solutions, outperforming state-of-the-art offline baselines across a range of problem sizes and planning horizons.
我们针对大规模多智能体路径寻找(MAPF)提出了一种新型算法,该算法能够在动态环境(例如自动化仓库)中实现快速、可扩展的规划。我们的方法引入了有限视界分层分解框架,该框架采用后退视界的方式,一步一步进行规划。机器人首先并行计算个体计划,然后根据时空冲突和可达性进行动态分组。该框架考虑了冲突解决、即时执行和并发规划,与离线算法相比,显著减少了响应时间。在基准地图上的实验结果表明,我们的方法实现了首次动作时间减少高达60%,同时持续提供高质量的解决方案,在多种问题规模和规划视界上超越了最新的离线基线。
论文及项目相关链接
Summary
本文提出了一种用于大规模多智能体路径规划(MAPF)的新型算法,该算法能够在动态环境中实现快速、可扩展的规划,如自动化仓库。该算法采用有限视界层次分解法,按时间顺序规划每一步。机器人首先并行计算各自计划,然后根据时空冲突和可达性进行动态分组。该算法考虑了冲突解决和即时执行与并发规划,显著减少了响应时间,与传统线下算法相比有明显优势。在基准图上的实验结果显示,该方法可将时间减少至首次行动的响应时间减少高达60%,并且在不同的问题规模和规划范围内均能提供高质量解决方案,超越现有线下基线。
Key Takeaways
- 提出了一种用于大规模多智能体路径规划(MAPF)的新型算法。
- 算法能在动态环境中进行快速、可扩展的规划,适用于自动化仓库等场景。
- 采用有限视界层次分解法,按时间顺序规划每一步。
- 机器人先计算各自计划,然后根据时空冲突和可达性进行动态分组。
- 算法考虑了冲突解决和即时执行与并发规划,提高了效率。
- 实验结果显示,该算法在响应时间上有显著减少,并能在不同问题规模和规划范围内提供高质量解决方案。
点此查看论文截图

Agent RL Scaling Law: Agent RL with Spontaneous Code Execution for Mathematical Problem Solving
Authors:Xinji Mai, Haotian Xu, Xing W, Weinong Wang, Yingying Zhang, Wenqiang Zhang
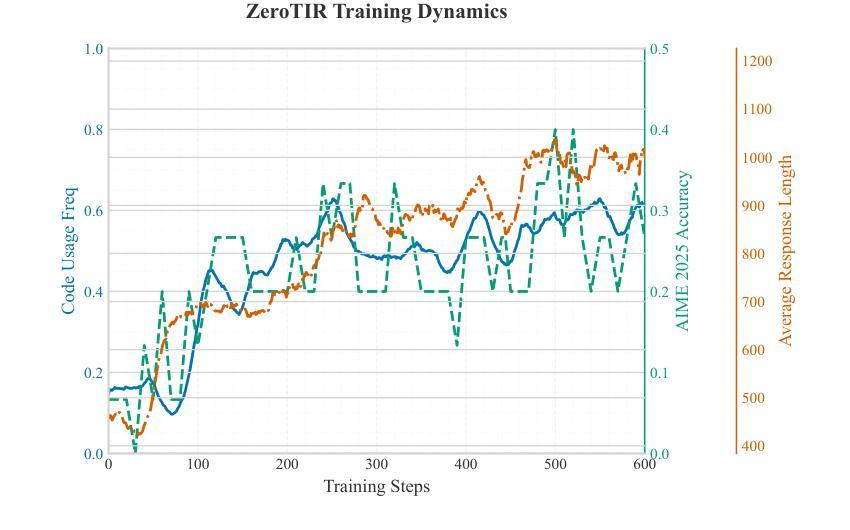
Large Language Models (LLMs) often struggle with mathematical reasoning tasks requiring precise, verifiable computation. While Reinforcement Learning (RL) from outcome-based rewards enhances text-based reasoning, understanding how agents autonomously learn to leverage external tools like code execution remains crucial. We investigate RL from outcome-based rewards for Tool-Integrated Reasoning, ZeroTIR, training base LLMs to spontaneously generate and execute Python code for mathematical problems without supervised tool-use examples. Our central contribution is we demonstrate that as RL training progresses, key metrics scale predictably. Specifically, we observe strong positive correlations where increased training steps lead to increases in the spontaneous code execution frequency, the average response length, and, critically, the final task accuracy. This suggests a quantifiable relationship between computational effort invested in training and the emergence of effective, tool-augmented reasoning strategies. We implement a robust framework featuring a decoupled code execution environment and validate our findings across standard RL algorithms and frameworks. Experiments show ZeroTIR significantly surpasses non-tool ZeroRL baselines on challenging math benchmarks. Our findings provide a foundational understanding of how autonomous tool use is acquired and scales within Agent RL, offering a reproducible benchmark for future studies. Code is released at \href{https://github.com/Anonymize-Author/AgentRL}{https://github.com/Anonymize-Author/AgentRL}.
大型语言模型(LLM)在处理需要精确、可验证计算的数学推理任务时经常遇到困难。虽然基于结果奖励的强化学习(RL)增强了文本推理能力,但了解智能体如何自主学习利用如代码执行等外部工具仍然至关重要。我们研究了基于结果奖励的强化学习在工具集成推理(Tool-Integrated Reasoning)中的应用,即ZeroTIR。我们训练基础LLM,使其能够针对数学问题自发地生成并执行Python代码,而无需监督的工具使用示例。我们的主要贡献是证明随着强化学习的训练进展,关键指标的可预测性。具体来说,我们观察到强烈的正相关关系,更多的训练步骤导致自发代码执行频率、平均响应长度以及最终任务准确度的提高。这表明在训练过程中投入的计算努力与有效工具增强推理策略的出现之间存在着可量化的关系。我们实现了一个稳健的框架,其中包括一个解耦的代码执行环境,并在标准强化学习算法和框架上验证了我们的发现。实验表明,ZeroTIR在具有挑战性的数学基准测试上显著超越了非工具ZeroRL基准测试。我们的研究为如何在强化学习的智能体中获取和扩展自主工具使用提供了基础理解,并为未来的研究提供了一个可复制的基准。代码已发布在https://github.com/Anonymize-Author/AgentRL。
论文及项目相关链接
Summary
本文研究了在强化学习(RL)框架下,大型语言模型(LLM)如何自主学习利用外部工具(如代码执行)进行数学推理。通过实验结果,文章发现随着RL训练的进行,关键指标呈现可预测的增长趋势,如自发代码执行频率、平均响应长度和任务准确度的提高。这显示了训练计算投入与有效工具辅助推理策略的出现之间存在量化关系。文章提出的ZeroTIR方法在非工具ZeroRL基准测试上表现出显著优势。
Key Takeaways
- 大型语言模型(LLM)在需要精确、可验证的计算的数学推理任务上表现不足。
- 强化学习(RL)从结果导向的奖励中增强了文本推理能力。
- 理解自主学习如何利用外部工具(如代码执行)对LLM至关重要。
- 随着RL训练的进行,关键指标如自发代码执行频率、平均响应长度和任务准确度呈现可预测的增长趋势。
- 训练计算投入与有效工具辅助推理策略的出现存在量化关系。
- 文章提出的ZeroTIR方法在挑战性的数学基准测试上显著超越了非工具ZeroRL方法。
点此查看论文截图




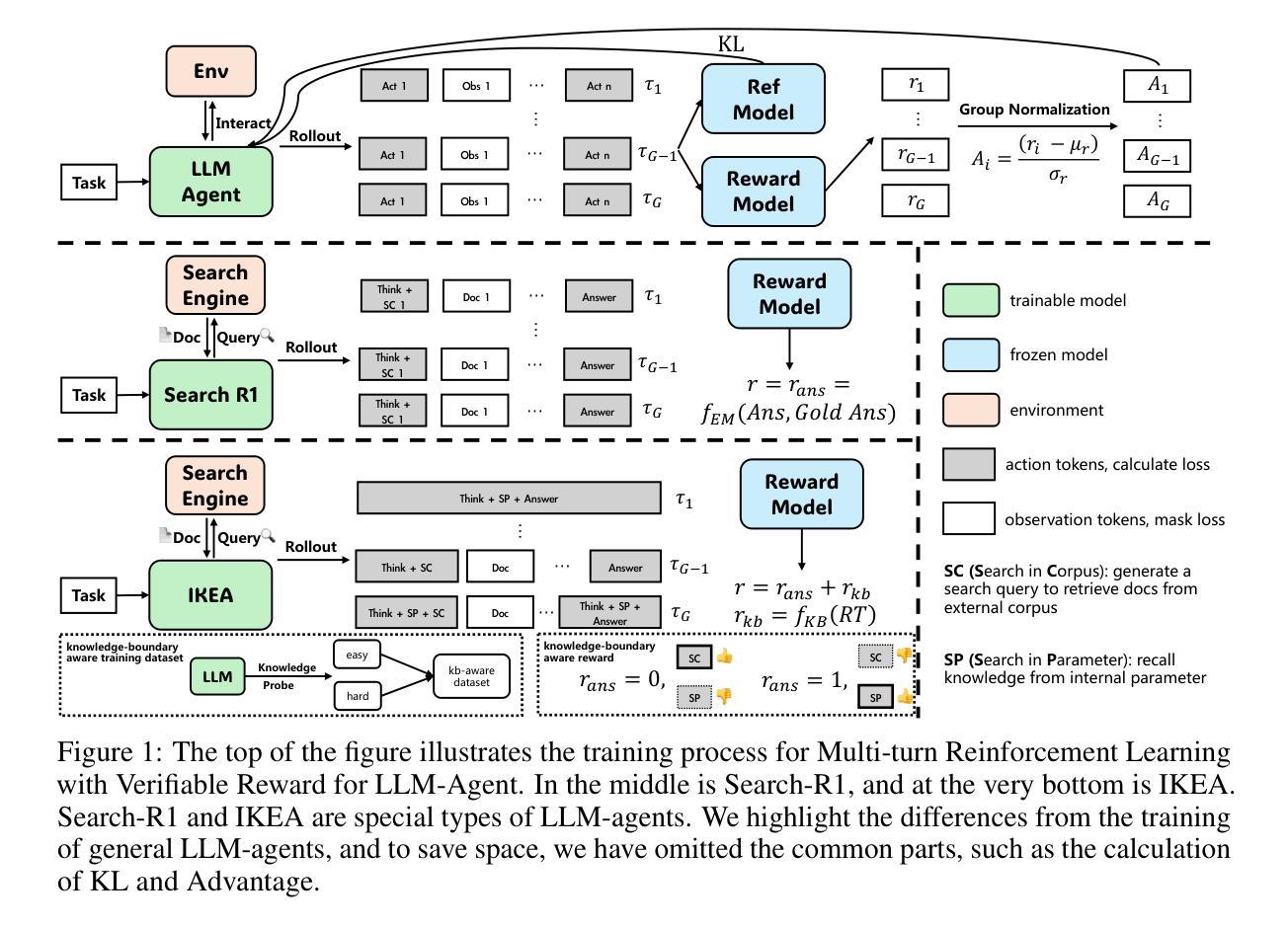
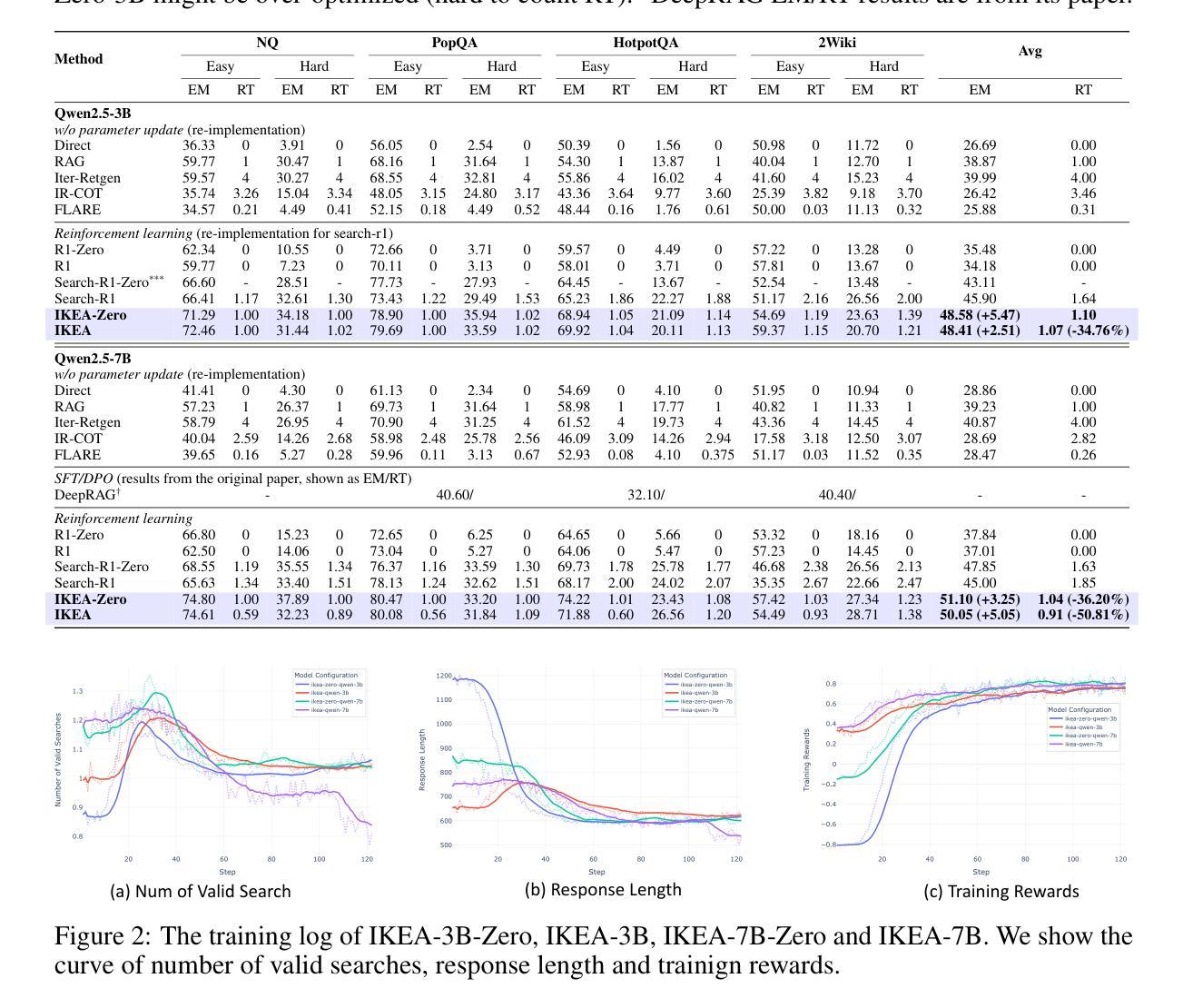
Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search Agent
Authors:Ziyang Huang, Xiaowei Yuan, Yiming Ju, Jun Zhao, Kang Liu
Retrieval-augmented generation (RAG) is a common strategy to reduce hallucinations in Large Language Models (LLMs). While reinforcement learning (RL) can enable LLMs to act as search agents by activating retrieval capabilities, existing ones often underutilize their internal knowledge. This can lead to redundant retrievals, potential harmful knowledge conflicts, and increased inference latency. To address these limitations, an efficient and adaptive search agent capable of discerning optimal retrieval timing and synergistically integrating parametric (internal) and retrieved (external) knowledge is in urgent need. This paper introduces the Reinforced Internal-External Knowledge Synergistic Reasoning Agent (IKEA), which could indentify its own knowledge boundary and prioritize the utilization of internal knowledge, resorting to external search only when internal knowledge is deemed insufficient. This is achieved using a novel knowledge-boundary aware reward function and a knowledge-boundary aware training dataset. These are designed for internal-external knowledge synergy oriented RL, incentivizing the model to deliver accurate answers, minimize unnecessary retrievals, and encourage appropriate external searches when its own knowledge is lacking. Evaluations across multiple knowledge reasoning tasks demonstrate that IKEA significantly outperforms baseline methods, reduces retrieval frequency significantly, and exhibits robust generalization capabilities.
检索增强生成(RAG)是减少大型语言模型(LLM)中的幻觉的常见策略。虽然强化学习(RL)可以通过激活检索功能使LLM充当搜索代理,但现有的LLM通常未能充分利用其内部知识。这可能导致冗余的检索、潜在的有害知识冲突和增加的推理延迟。为了解决这些局限性,迫切需要一种高效且自适应的搜索代理,该代理能够辨别最佳的检索时间,并能够协同整合参数化(内部)和检索到的(外部)知识。本文介绍了强化内部外部知识协同推理代理(IKEA),该代理能够识别其自身的知识边界并优先利用内部知识,仅在认为内部知识不足时才求助于外部搜索。这是通过使用一种新型的知识边界感知奖励函数和知识边界感知训练数据集来实现的。这些设计都是为了面向内部外部知识协同的RL,激励模型提供准确答案,减少不必要的检索,并在自身知识不足时鼓励适当的外部搜索。在多个知识推理任务上的评估表明,IKEA显著优于基准方法,显著减少了检索频率,并表现出稳健的泛化能力。
论文及项目相关链接
Summary
本文介绍了强化内部外部知识协同推理代理(IKEA)来解决大型语言模型(LLM)中的检索增强生成(RAG)策略的问题。IKEA能够识别自身的知识边界,优先利用内部知识,仅在内部知识不足时寻求外部搜索。通过设计用于内部和外部知识协同导向的强化学习奖励函数和训练数据集,IKEA能够在减少不必要检索的同时,鼓励适当外部搜索,并提供准确答案。实验评估表明,IKEA在多个知识推理任务上显著优于基准方法,显著减少检索频率,并展现出稳健的泛化能力。
Key Takeaways
- IKEA旨在解决大型语言模型(LLM)在检索增强生成(RAG)策略中的问题,尤其是关于内部知识利用不足的问题。
- IKEA具有知识边界识别能力,能够优先使用内部知识。
- 当内部知识不足时,IKEA会寻求外部搜索。
- 通过设计新型奖励函数和训练数据集来促进内部和外部知识的协同合作。
- 这种设计旨在提供准确答案,同时减少不必要的检索和鼓励适当的外部搜索。
- 实验评估表明,IKEA在多个知识推理任务上的性能显著优于基准方法。
点此查看论文截图

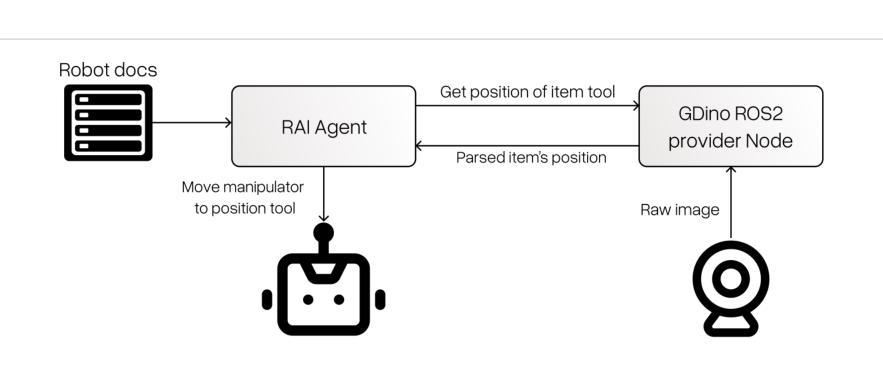
RAI: Flexible Agent Framework for Embodied AI
Authors:Kajetan Rachwał, Maciej Majek, Bartłomiej Boczek, Kacper Dąbrowski, Paweł Liberadzki, Adam Dąbrowski, Maria Ganzha
With an increase in the capabilities of generative language models, a growing interest in embodied AI has followed. This contribution introduces RAI - a framework for creating embodied Multi Agent Systems for robotics. The proposed framework implements tools for Agents’ integration with robotic stacks, Large Language Models, and simulations. It provides out-of-the-box integration with state-of-the-art systems like ROS 2. It also comes with dedicated mechanisms for the embodiment of Agents. These mechanisms have been tested on a physical robot, Husarion ROSBot XL, which was coupled with its digital twin, for rapid prototyping. Furthermore, these mechanisms have been deployed in two simulations: (1) robot arm manipulator and (2) tractor controller. All of these deployments have been evaluated in terms of their control capabilities, effectiveness of embodiment, and perception ability. The proposed framework has been used successfully to build systems with multiple agents. It has demonstrated effectiveness in all the aforementioned tasks. It also enabled identifying and addressing the shortcomings of the generative models used for embodied AI.
随着生成式语言模型能力的增强,对实体人工智能的兴趣也在不断增加。本文介绍了RAI——一个用于创建实体多智能体系统的框架,该框架应用于机器人领域。所提出的框架实现了智能体与机器人堆栈、大型语言模型和模拟器的集成工具。它与最新的系统如ROS 2实现了开箱即用的集成。它还配备了专门的智能体现机制。这些机制已在物理机器人Husarion ROSBot XL上进行了测试,该机器人与其数字双胞胎相结合,可实现快速原型设计。此外,这些机制还部署在两种模拟环境中:(1)机器人手臂操纵器和(2)拖拉机控制器。所有这些部署都根据其控制功能、实体的有效性和感知能力进行了评估。所提出的框架已成功用于构建多智能体系统,在所有上述任务中都表现出有效性。它还使识别和解决用于实体人工智能的生成模型的缺点成为可能。
论文及项目相关链接
PDF 12 pages, 8 figures, submitted to 23rd International Conference on Practical applications of Agents and Multi-Agent Systems (PAAMS’25)
Summary
随着生成式语言模型能力的提升,对嵌入式人工智能(Embodied AI)的兴趣日益浓厚。本文介绍了一个用于创建嵌入式多智能体系统(Multi Agent Systems)的框架——RAI。该框架实现了智能体与机器人堆栈、大型语言模型和模拟器的集成工具。它与ROS 2等最新系统实现了一体化,并拥有专门的智能体实体化机制。这些机制已在物理机器人Husarion ROSBot XL及其数字双胞胎上进行了测试,以加快原型设计速度。此外,这些机制还部署在两种模拟环境中:机械手操纵器和拖拉机控制器。这些部署在控制功能、实体化效果和感知能力方面均得到了评估。使用此框架已成功构建多智能体系统,并在所有任务中表现出有效性,同时解决了生成式模型在嵌入式AI方面的不足。
Key Takeaways
- RAI框架用于创建嵌入式多智能体系统,支持智能体与机器人堆栈、大型语言模型和模拟器的集成。
- RAI实现了与ROS 2等最新系统的一体化。
- 专门的智能体实体化机制已在物理机器人Husarion ROSBot XL及其数字双胞胎上测试过,以加快原型设计速度。
- 该框架已部署在机械手操纵器和拖拉机控制器两种模拟环境中。
- 该框架在控制功能、实体化效果和感知能力方面得到了评估。
- 使用RAI框架成功构建了多智能体系统,并在各项任务中表现出有效性。
点此查看论文截图


Towards Multi-Agent Reasoning Systems for Collaborative Expertise Delegation: An Exploratory Design Study
Authors:Baixuan Xu, Chunyang Li, Weiqi Wang, Wei Fan, Tianshi Zheng, Haochen Shi, Tao Fan, Yangqiu Song, Qiang Yang
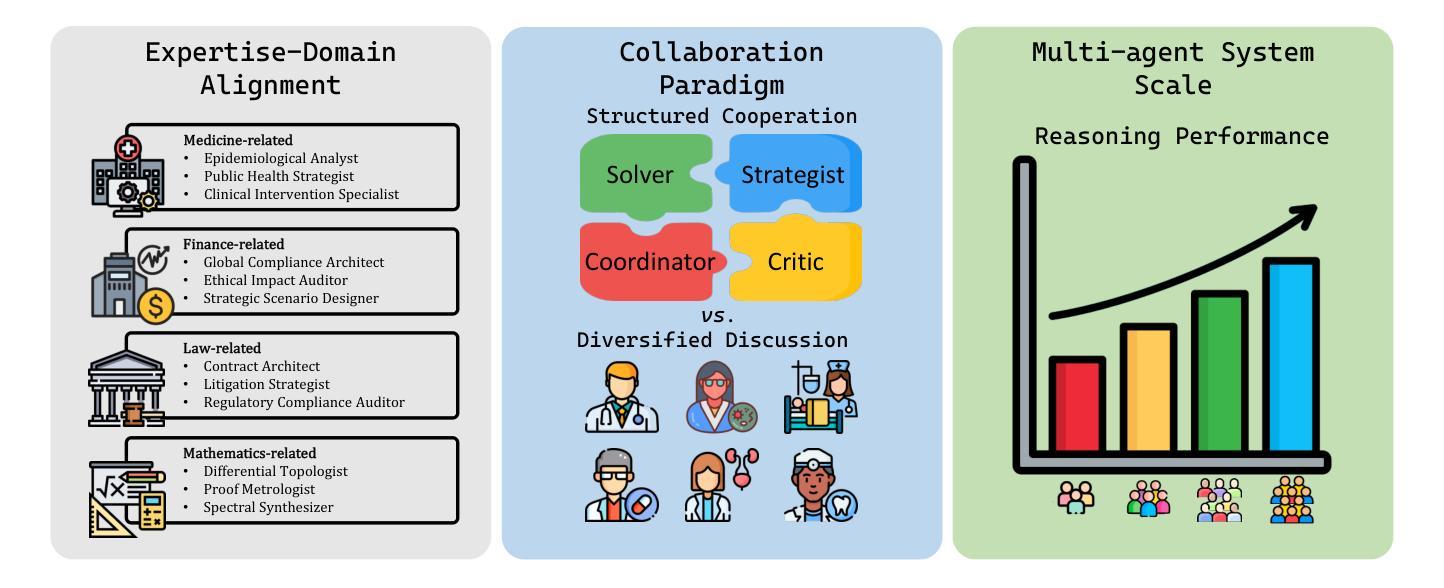
Designing effective collaboration structure for multi-agent LLM systems to enhance collective reasoning is crucial yet remains under-explored. In this paper, we systematically investigate how collaborative reasoning performance is affected by three key design dimensions: (1) Expertise-Domain Alignment, (2) Collaboration Paradigm (structured workflow vs. diversity-driven integration), and (3) System Scale. Our findings reveal that expertise alignment benefits are highly domain-contingent, proving most effective for contextual reasoning tasks. Furthermore, collaboration focused on integrating diverse knowledge consistently outperforms rigid task decomposition. Finally, we empirically explore the impact of scaling the multi-agent system with expertise specialization and study the computational trade off, highlighting the need for more efficient communication protocol design. This work provides concrete guidelines for configuring specialized multi-agent system and identifies critical architectural trade-offs and bottlenecks for scalable multi-agent reasoning. The code will be made available upon acceptance.
为多智能体大型语言模型(LLM)系统设计有效的协作结构以增强集体推理至关重要,但尚未得到充分探索。在本文中,我们系统地研究了三个关键设计维度如何影响协作推理性能:(1)专业领域知识与技能的匹配度;(2)协作范式(结构化工作流程与多样性驱动集成);以及(3)系统规模。我们的研究结果表明,专业知识匹配的好处高度依赖于特定领域,对于情境推理任务最为有效。此外,以整合多样化知识为重点的协作持续优于僵化的任务分解。最后,我们通过实证探索了具有专业技能专长的多智能体系统的规模化影响,并研究了计算上的权衡,强调了需要设计更高效的通信协议。这项工作为配置专业化的多智能体系统提供了具体指导,并确定了可扩展的多智能体推理的关键架构权衡和瓶颈。代码将在接受后提供。
论文及项目相关链接
PDF 18 pages
Summary
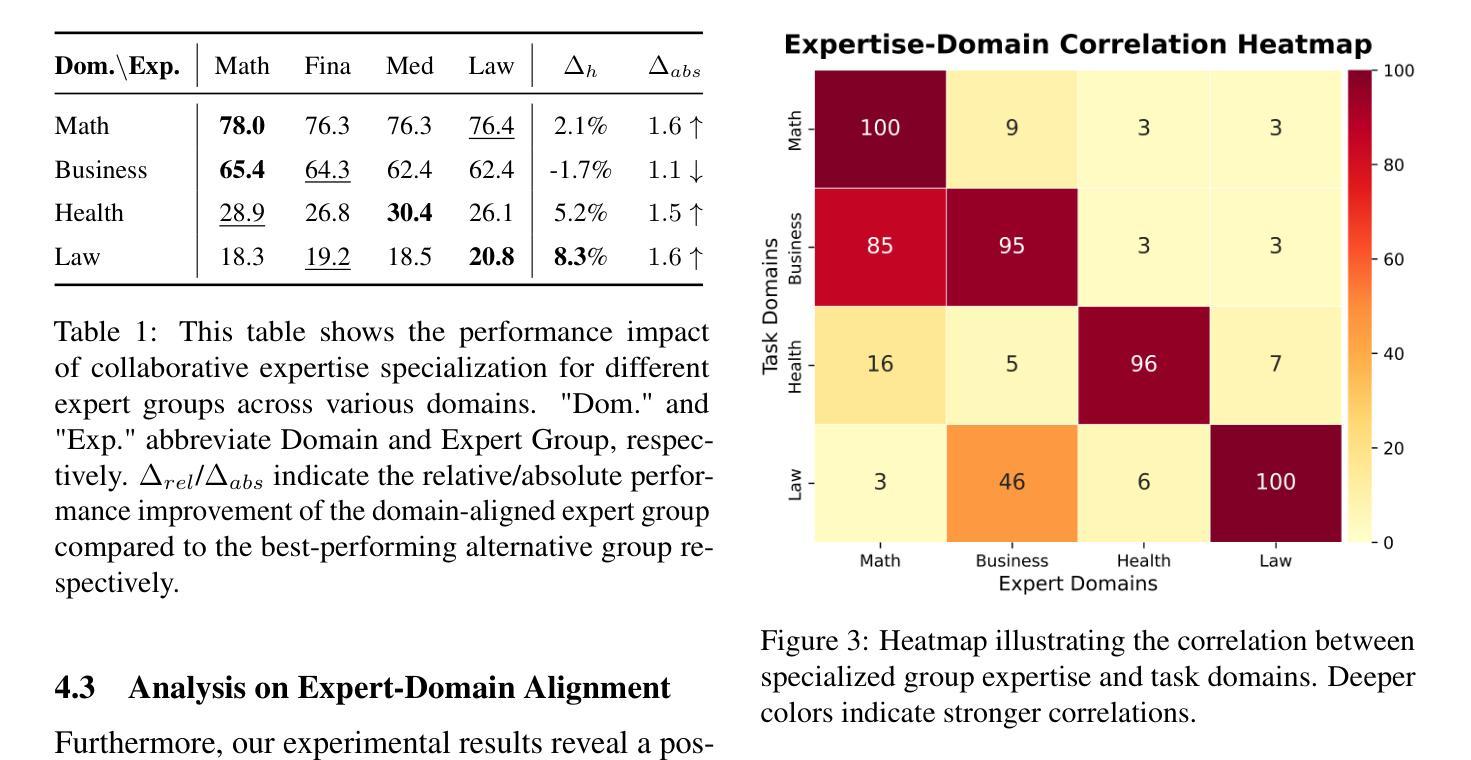
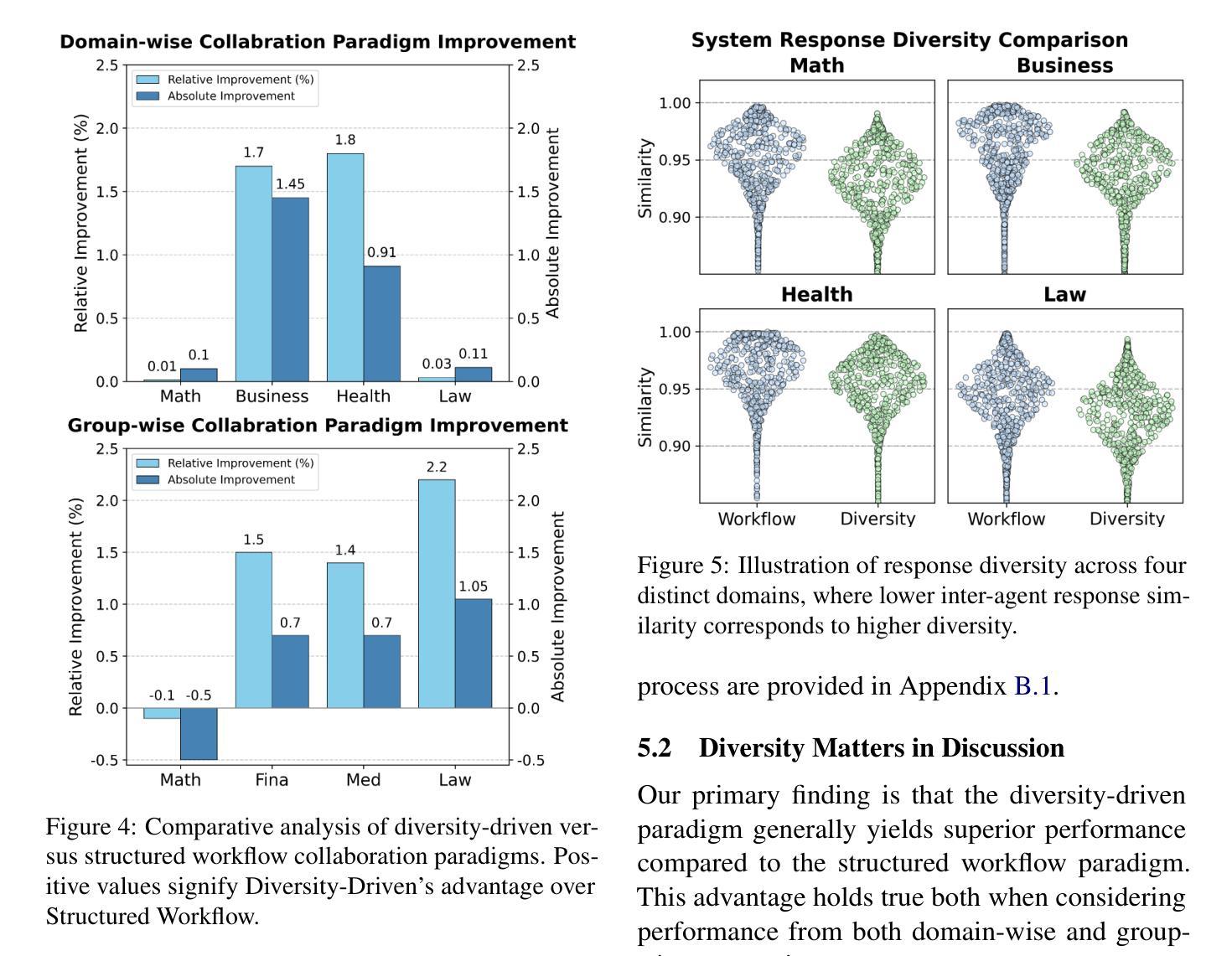
文章探讨了在多智能体LLM系统中设计有效的协作结构以增强集体推理的重要性及其尚未充分探索的现状。通过系统研究,发现协作推理性能受到三个关键设计维度的影响:专业领域知识匹配度、协作范式(结构化工作流程与多样性驱动集成)和系统规模。研究结果显示,专业领域知识匹配度对上下文推理任务最为有效;多样性知识整合的协作方式表现优于刚性任务分解;同时探讨了多智能体系统的规模化与专业知识专业化的影响,并强调了计算效率的重要性,呼吁设计更高效的通信协议。本文提供了配置专业化多智能体系统的具体指导,并指出了可扩展多智能体推理的关键架构权衡和瓶颈。
Key Takeaways
- 文章研究了多智能体LLM系统中设计协作结构以增强集体推理的重要性。
- 探讨了三个关键设计维度:专业领域知识匹配度、协作范式和系统规模对协作推理性能的影响。
- 专业领域知识匹配度对上下文推理任务最为有效。
- 多样性知识整合的协作方式表现优于刚性任务分解。
- 多智能体系统的规模化与专业知识专业化之间存在权衡,需要设计更高效的通信协议。
- 文章提供了配置专业化多智能体系统的具体指导。
- 指出了可扩展多智能体推理的关键架构权衡和瓶颈。
点此查看论文截图

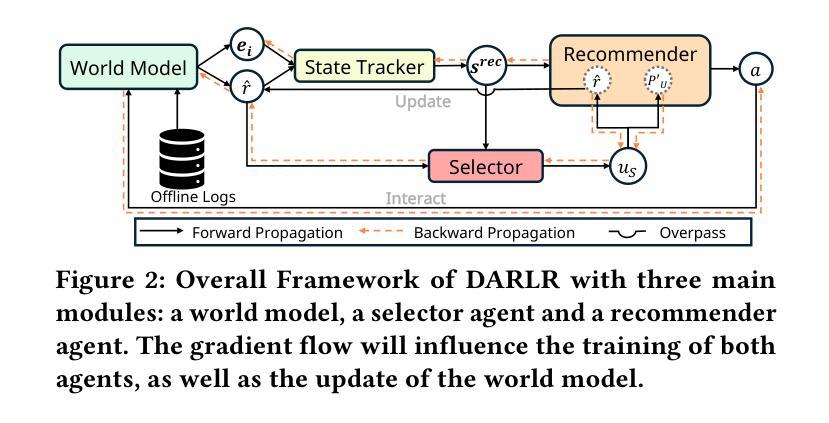
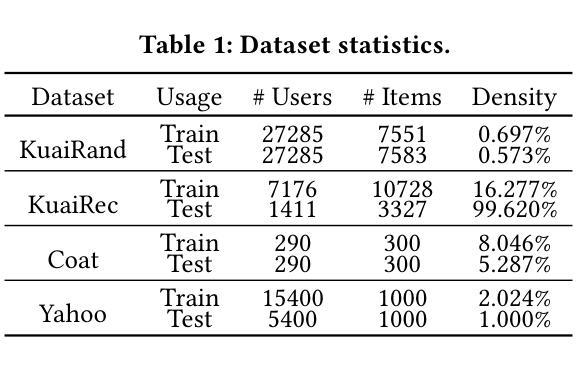
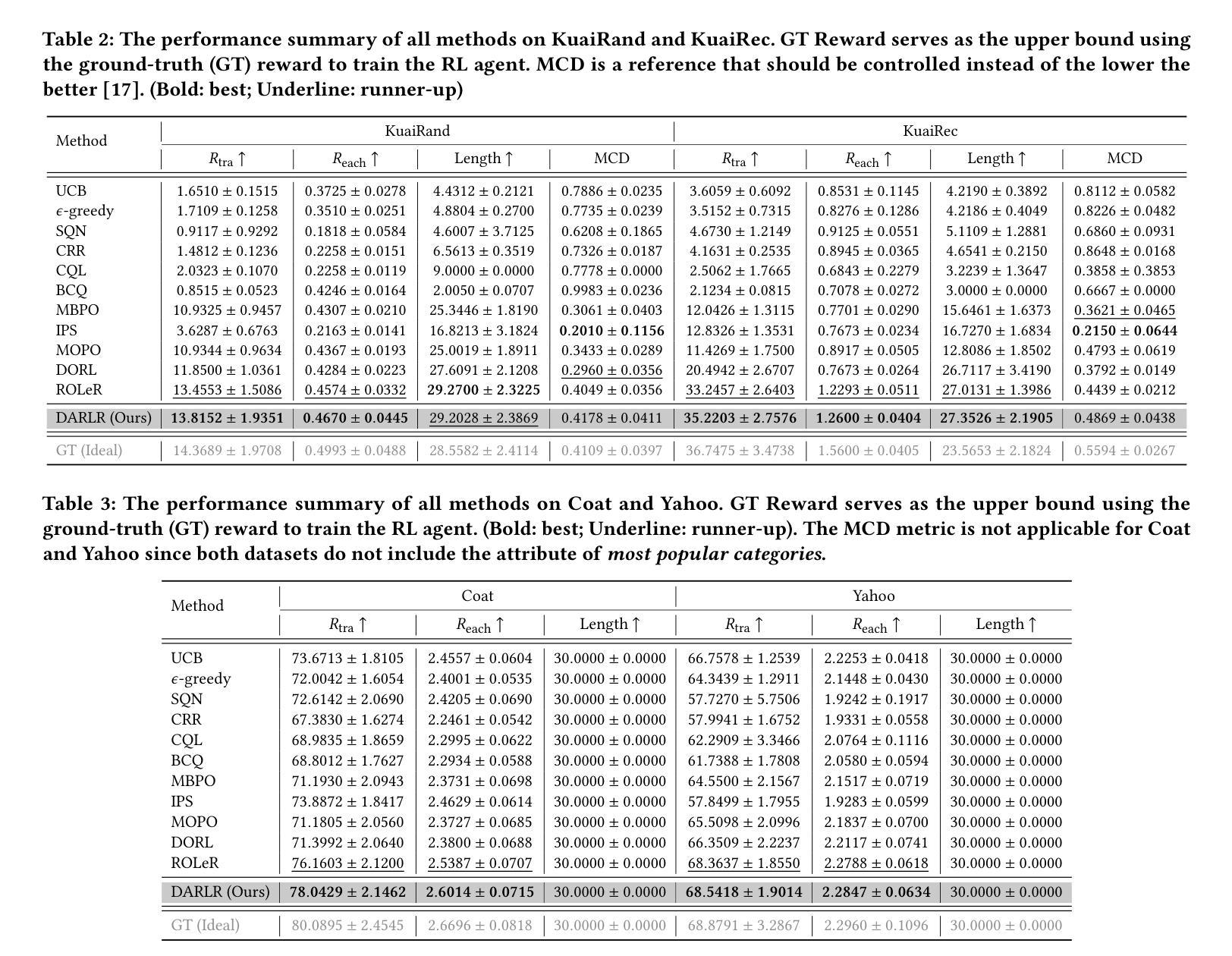
DARLR: Dual-Agent Offline Reinforcement Learning for Recommender Systems with Dynamic Reward
Authors:Yi Zhang, Ruihong Qiu, Xuwei Xu, Jiajun Liu, Sen Wang
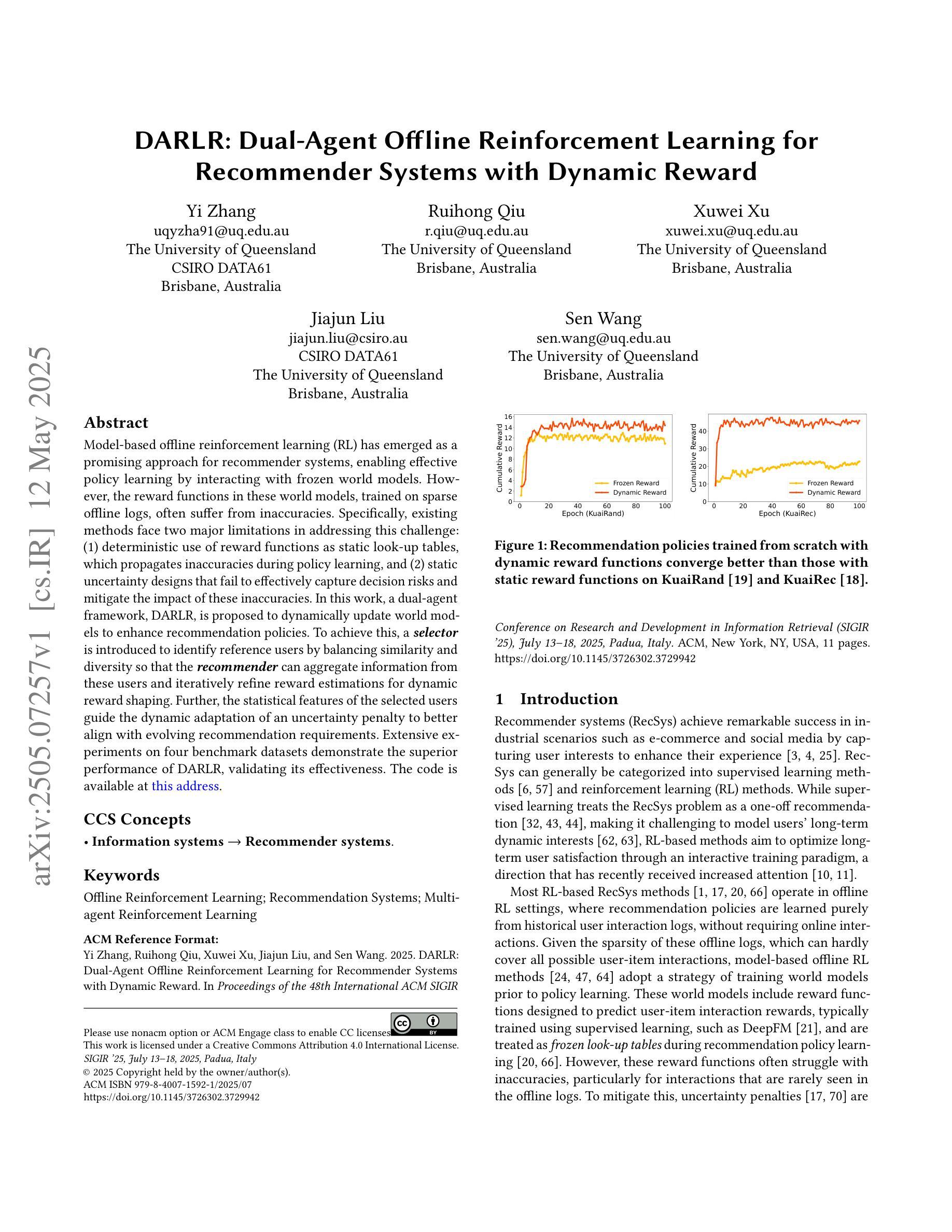
Model-based offline reinforcement learning (RL) has emerged as a promising approach for recommender systems, enabling effective policy learning by interacting with frozen world models. However, the reward functions in these world models, trained on sparse offline logs, often suffer from inaccuracies. Specifically, existing methods face two major limitations in addressing this challenge: (1) deterministic use of reward functions as static look-up tables, which propagates inaccuracies during policy learning, and (2) static uncertainty designs that fail to effectively capture decision risks and mitigate the impact of these inaccuracies. In this work, a dual-agent framework, DARLR, is proposed to dynamically update world models to enhance recommendation policies. To achieve this, a \textbf{\textit{selector}} is introduced to identify reference users by balancing similarity and diversity so that the \textbf{\textit{recommender}} can aggregate information from these users and iteratively refine reward estimations for dynamic reward shaping. Further, the statistical features of the selected users guide the dynamic adaptation of an uncertainty penalty to better align with evolving recommendation requirements. Extensive experiments on four benchmark datasets demonstrate the superior performance of DARLR, validating its effectiveness. The code is available at https://github.com/ArronDZhang/DARLR.
基于模型的离线强化学习(RL)已经成为推荐系统的一种有前途的方法,通过与世界模型进行交互,实现有效的策略学习。然而,这些世界模型中的奖励函数通常基于稀疏的离线日志进行训练,因此存在不准确的问题。具体来说,现有方法在处理这一挑战时面临两大局限:(1)将奖励函数作为静态查找表进行确定性使用,这会在策略学习过程中传播误差;(2)静态不确定性设计无法有效地捕捉决策风险并缓解这些不准确性的影响。本研究提出了一种双智能体框架DARLR,用于动态更新世界模型以增强推荐策略。为此,引入了一个选择器,通过平衡相似性和多样性来识别参考用户,以便推荐器可以聚合这些用户的信息并迭代优化奖励估计以实现动态奖励塑造。此外,所选用户的统计特征指导不确定性惩罚的动态调整,以更好地适应不断变化的推荐需求。在四个基准数据集上的大量实验证明了DARLR的优越性能,验证了其有效性。代码可通过https://github.com/ArronDZhang/DARLR获取。
论文及项目相关链接
PDF SIGIR 2025
Summary
强化学习已经在推荐系统中展现出巨大潜力,然而现有模型存在奖励函数不准确的问题。本文提出了一种双代理框架DARLR,可以动态更新世界模型以提升推荐策略。引入选择器识别参考用户,实现奖励预估的迭代优化;并依据选定用户的统计特征动态调整不确定性惩罚。实验结果证明了DARLR的有效性。
Key Takeaways
- 强化学习在推荐系统中具有巨大潜力,但奖励函数不准确是现有模型的主要挑战。
- DARLR框架被提出以解决这一挑战,通过动态更新世界模型增强推荐策略。
- 引入选择器平衡相似性与多样性,识别参考用户。
- 推荐器能够聚合来自这些用户的信息,迭代优化奖励预估,实现动态奖励塑造。
- 基于选定用户的统计特征,动态调整不确定性惩罚,以更好地满足不断变化的推荐需求。
- 在四个基准数据集上进行的广泛实验验证了DARLR框架的有效性。
点此查看论文截图
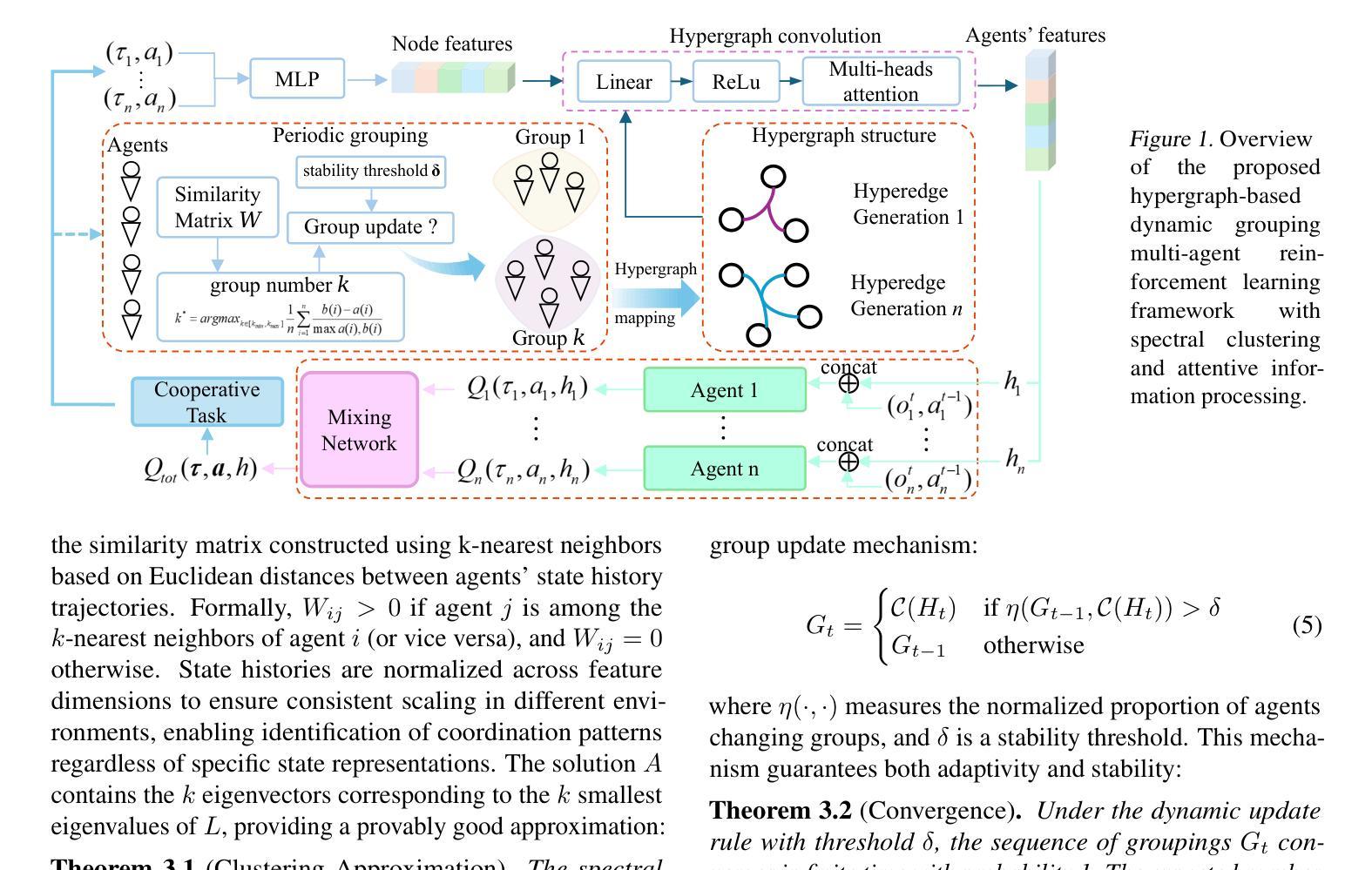
Hypergraph Coordination Networks with Dynamic Grouping for Multi-Agent Reinforcement Learning
Authors:Chiqiang Liu, Dazi Li
Cooperative multi-agent reinforcement learning faces significant challenges in effectively organizing agent relationships and facilitating information exchange, particularly when agents need to adapt their coordination patterns dynamically. This paper presents a novel framework that integrates dynamic spectral clustering with hypergraph neural networks to enable adaptive group formation and efficient information processing in multi-agent systems. The proposed framework dynamically constructs and updates hypergraph structures through spectral clustering on agents’ state histories, enabling higher-order relationships to emerge naturally from agent interactions. The hypergraph structure is enhanced with attention mechanisms for selective information processing, providing an expressive and efficient way to model complex agent relationships. This architecture can be implemented in both value-based and policy-based paradigms through a unified objective combining task performance with structural regularization. Extensive experiments on challenging cooperative tasks demonstrate that our method significantly outperforms state-of-the-art approaches in both sample efficiency and final performance.
在多智能体强化学习中,有效组织智能体关系并促进信息交换面临重大挑战,特别是在智能体需要动态调整协同模式的情况下。本文提出了一种新型框架,该框架结合了动态谱聚类和超图神经网络,以实现多智能体系统中的自适应群组形成和高效信息处理。该框架通过智能体的状态历史进行谱聚类来动态构建和更新超图结构,使高阶关系能够从智能体的交互中自然出现。超图结构通过注意力机制进行选择性信息处理,为建模复杂的智能体关系提供了一种表达高效的方式。该架构可以通过结合任务性能和结构正则化的统一目标,在基于值和基于策略两种范式中实现。在具有挑战性的合作任务上的大量实验表明,我们的方法在样本效率和最终性能上都显著优于现有技术。
论文及项目相关链接
Summary
本文提出了一种结合动态谱聚类与超图神经网络的新型框架,用于实现多智能体系统中的自适应群组形成和高效信息处理。该框架通过智能体的状态历史进行谱聚类,动态构建和更新超图结构,使智能体交互中产生高阶关系。同时,超图结构增强了选择性信息处理的注意力机制,为复杂智能体关系提供了表达和有效的建模方式。该架构可在值基础和政策基础上实现,通过结合任务性能和结构正则化的统一目标。在具有挑战性的合作任务上的广泛实验表明,该方法在样本效率和最终性能上都显著优于现有方法。
Key Takeaways
- 本文提出了一个新型框架,集成了动态谱聚类和超图神经网络,旨在解决多智能体强化学习中智能体关系的组织和信息交换的问题。
- 该框架通过智能体的状态历史进行谱聚类,动态构建和更新超图结构,以自适应地形成群组。
- 超图结构能够自然地展现智能体之间的更高阶关系,并且通过注意力机制增强了选择性信息处理。
- 框架结合了任务性能和结构正则化的统一目标,可在值基础和政策基础上实现。
- 通过广泛实验证明,该框架在样本效率和最终性能上均显著优于现有方法。
- 该框架适用于需要动态调整协调模式的智能体系统。
点此查看论文截图


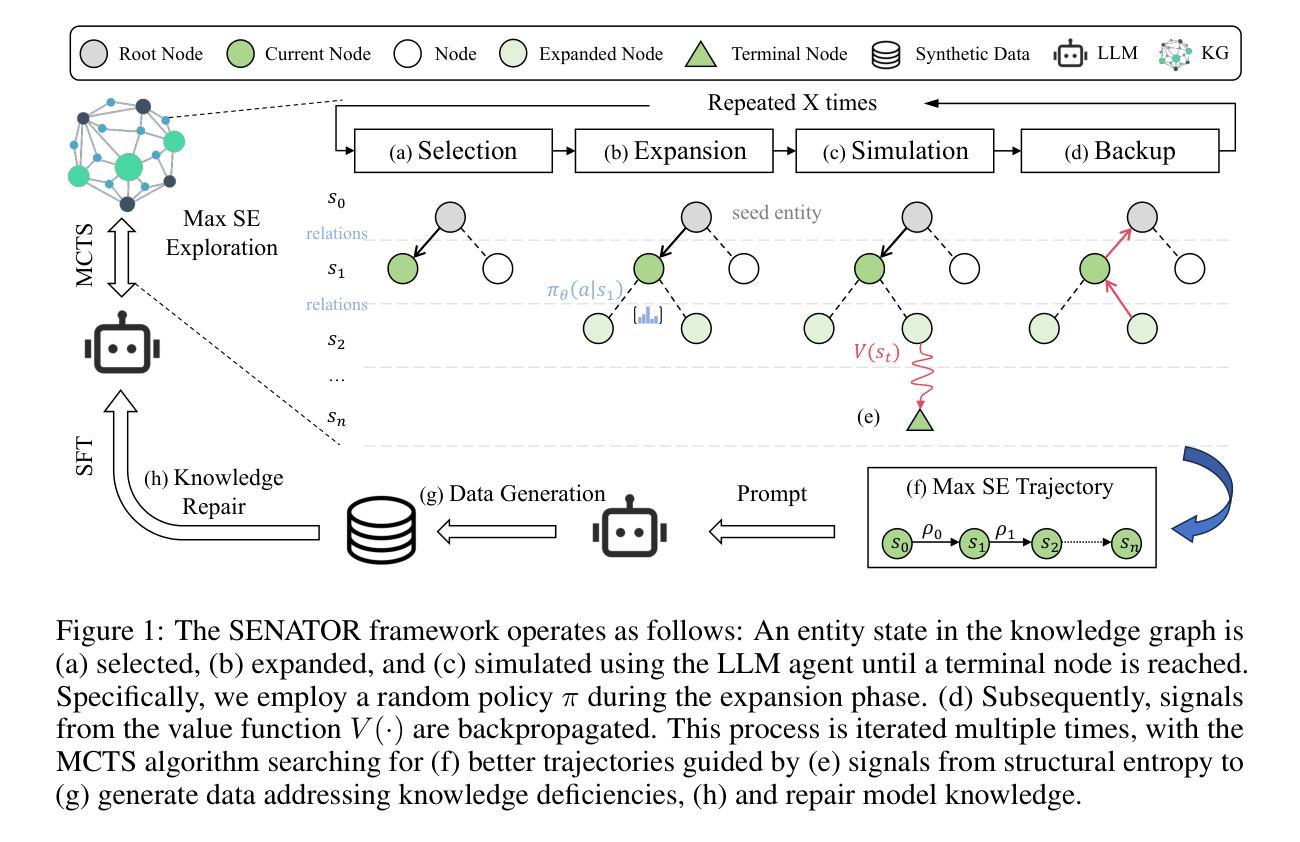
Structural Entropy Guided Agent for Detecting and Repairing Knowledge Deficiencies in LLMs
Authors:Yifan Wei, Xiaoyan Yu, Tengfei Pan, Angsheng Li, Li Du
Large language models (LLMs) have achieved unprecedented performance by leveraging vast pretraining corpora, yet their performance remains suboptimal in knowledge-intensive domains such as medicine and scientific research, where high factual precision is required. While synthetic data provides a promising avenue for augmenting domain knowledge, existing methods frequently generate redundant samples that do not align with the model’s true knowledge gaps. To overcome this limitation, we propose a novel Structural Entropy-guided Knowledge Navigator (SENATOR) framework that addresses the intrinsic knowledge deficiencies of LLMs. Our approach employs the Structure Entropy (SE) metric to quantify uncertainty along knowledge graph paths and leverages Monte Carlo Tree Search (MCTS) to selectively explore regions where the model lacks domain-specific knowledge. Guided by these insights, the framework generates targeted synthetic data for supervised fine-tuning, enabling continuous self-improvement. Experimental results on LLaMA-3 and Qwen2 across multiple domain-specific benchmarks show that SENATOR effectively detects and repairs knowledge deficiencies, achieving notable performance improvements. The code and data for our methods and experiments are available at https://github.com/weiyifan1023/senator.
大规模语言模型(LLMs)通过利用大量的预训练语料库取得了前所未有的性能,但在医学和科学研究等需要高事实精确度的知识密集型领域,其性能仍然不够理想。虽然合成数据为增强领域知识提供了有希望的途径,但现有方法经常生成与模型真实知识空白不匹配的冗余样本。为了克服这一局限性,我们提出了一种新的结构熵引导知识导航器(SENATOR)框架,该框架解决了LLMs的内在知识缺陷。我们的方法采用结构熵(SE)度量来衡量知识图谱路径上的不确定性,并利用蒙特卡洛树搜索(MCTS)有选择地探索模型缺乏领域特定知识的区域。在这些见解的指导下,该框架生成有针对性的合成数据用于监督微调,从而实现持续自我改进。在LLaMA-3和Qwen2上对多个领域特定基准进行的实验结果表明,SENATOR有效地检测和修复了知识缺陷,实现了显著的性能改进。我们方法和实验的代码和数据可在https://github.com/weiyifan1023/senator获取。
论文及项目相关链接
Summary
大规模语言模型(LLM)通过利用大量的预训练语料库取得了前所未有的性能,但在医学和科学研究等需要高事实准确性的知识密集型领域中,其性能仍然不尽人意。为此,我们提出了一个新的结构熵引导知识导航器(SENATOR)框架,以解决LLM的内在知识缺陷问题。该方法采用结构熵(SE)度量来衡量知识图谱路径的不确定性,并利用蒙特卡洛树搜索(MCTS)有选择地探索模型缺乏领域特定知识的区域。通过生成有针对性的合成数据用于监督微调,框架能够实现持续自我改进。实验结果表明,在多个领域特定基准测试中,SENATOR在检测并修复知识缺陷方面表现出色,实现了显著的性能提升。
Key Takeaways
- 大规模语言模型(LLM)在知识密集型领域(如医学和科学研究)中的性能仍然有限,需要提高事实准确性。
- 现有方法生成的数据样本经常冗余,并不符合模型真正的知识缺口。
- SENATOR框架被提出来解决LLM的内在知识缺陷问题。
- 结构熵(SE)被用来度量知识图谱路径的不确定性。
- Monte Carlo Tree Search(MCTS)被用来探索模型缺乏领域特定知识的区域。
- SENATOR通过生成有针对性的合成数据用于监督微调,使模型能够持续自我改进。
点此查看论文截图

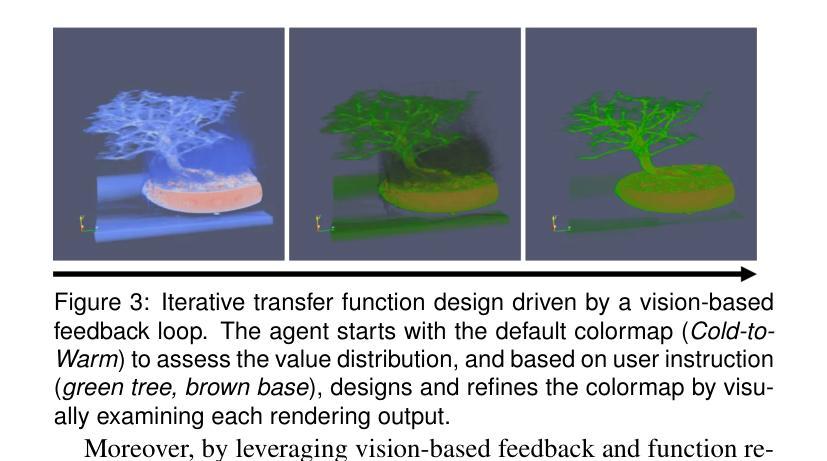
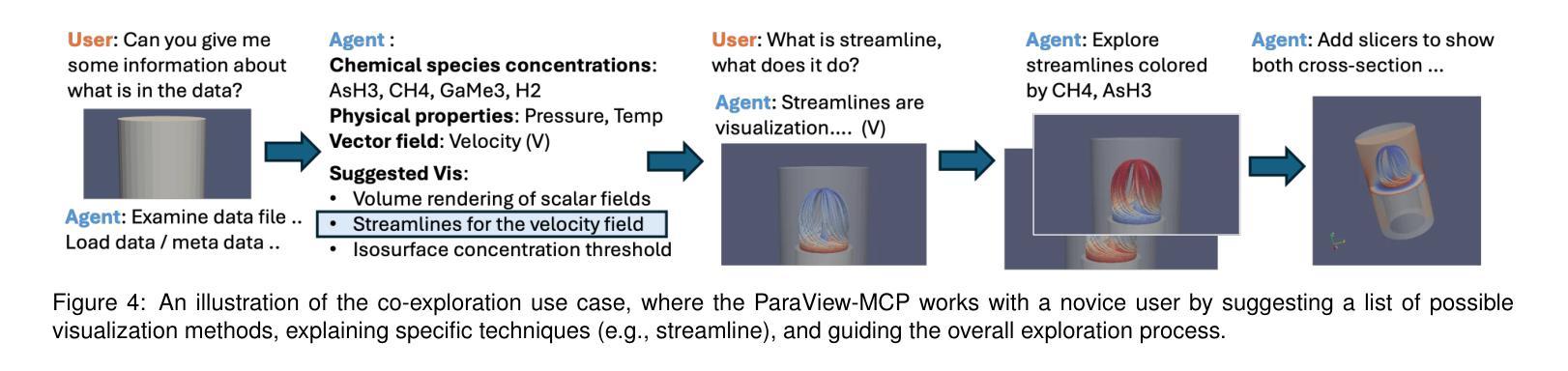
ParaView-MCP: An Autonomous Visualization Agent with Direct Tool Use
Authors:Shusen Liu, Haichao Miao, Peer-Timo Bremer
While powerful and well-established, tools like ParaView present a steep learning curve that discourages many potential users. This work introduces ParaView-MCP, an autonomous agent that integrates modern multimodal large language models (MLLMs) with ParaView to not only lower the barrier to entry but also augment ParaView with intelligent decision support. By leveraging the state-of-the-art reasoning, command execution, and vision capabilities of MLLMs, ParaView-MCP enables users to interact with ParaView through natural language and visual inputs. Specifically, our system adopted the Model Context Protocol (MCP) - a standardized interface for model-application communication - that facilitates direct interaction between MLLMs with ParaView’s Python API to allow seamless information exchange between the user, the language model, and the visualization tool itself. Furthermore, by implementing a visual feedback mechanism that allows the agent to observe the viewport, we unlock a range of new capabilities, including recreating visualizations from examples, closed-loop visualization parameter updates based on user-defined goals, and even cross-application collaboration involving multiple tools. Broadly, we believe such an agent-driven visualization paradigm can profoundly change the way we interact with visualization tools. We expect a significant uptake in the development of such visualization tools, in both visualization research and industry.
虽然ParaView等工具功能强大且已成熟,但它们的学习曲线陡峭,使许多潜在用户望而却步。本文介绍了ParaView-MCP,这是一个自主代理,它将现代多模式大型语言模型(MLLMs)与ParaView集成在一起,不仅降低了入门门槛,而且为ParaView增加了智能决策支持。通过利用MLLMs的最先进推理、命令执行和视觉功能,ParaView-MCP使用户能够通过自然语言视觉输入与ParaView进行交互。具体来说,我们的系统采用了模型上下文协议(MCP)——模型应用程序通信的标准接口——它促进了MLLMs与ParaView的Python API之间的直接交互,从而实现用户、语言模型和可视化工具本身之间的无缝信息交换。此外,通过实现一种视觉反馈机制,允许代理观察视图端口,我们解锁了一系列新功能,包括根据示例重新创建可视化、基于用户定义的目标的闭环可视化参数更新,甚至是涉及多个工具跨应用程序的协作。总的来说,我们认为这种代理驱动的可视化范式可以深刻改变我们与可视化工具的交互方式。我们预期在可视化和工业行业中都将大量采用这种可视化工具的开发。
论文及项目相关链接
Summary
ParaView-MCP将ParaView可视化工具与多模态大型语言模型(MLLMs)相结合,降低了使用难度,并增加了智能决策支持功能。通过采用Model Context Protocol(MCP)标准化接口,实现了用户、语言模型和可视化工具之间的无缝信息交换。此外,视觉反馈机制使代理能够观察视图,从而解锁了一系列新功能。
Key Takeaways
- ParaView-MCP结合了ParaView可视化工具和多模态大型语言模型(MLLMs),提高了易用性并增加了智能决策支持。
- Model Context Protocol(MCP)标准化接口实现了用户、语言模型和可视化工具之间的无缝通信。
- 视觉反馈机制允许代理观察视图,从而提供一系列新能力,如根据示例重建可视化、基于用户定义的目标的闭环可视化参数更新以及跨应用程序协作。
- ParaView-MCP降低了使用门槛,使得更多潜在用户能够使用ParaView工具。
- 这种代理驱动的可视化范式将深刻改变我们与可视化工具的交互方式。
- 预计这种可视化工具的开发将在可视化和工业界得到广泛应用和发展。
点此查看论文截图



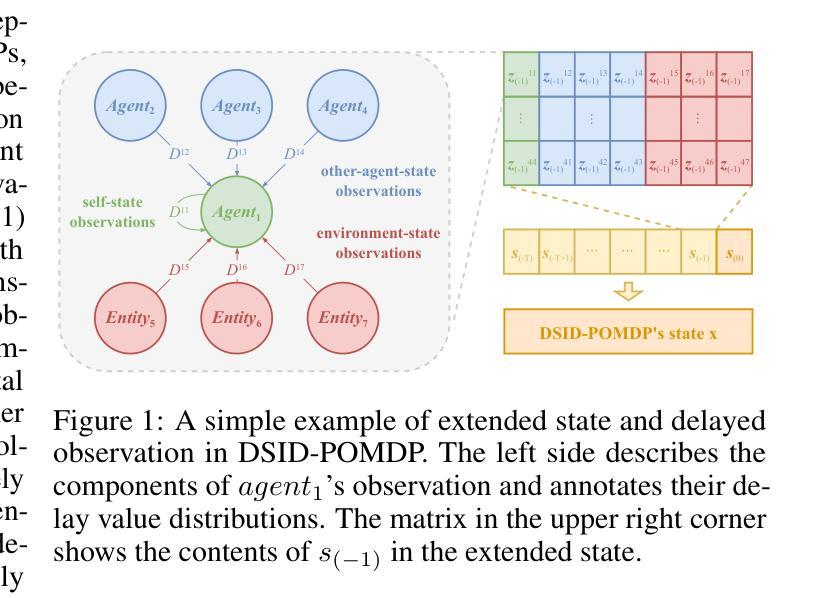
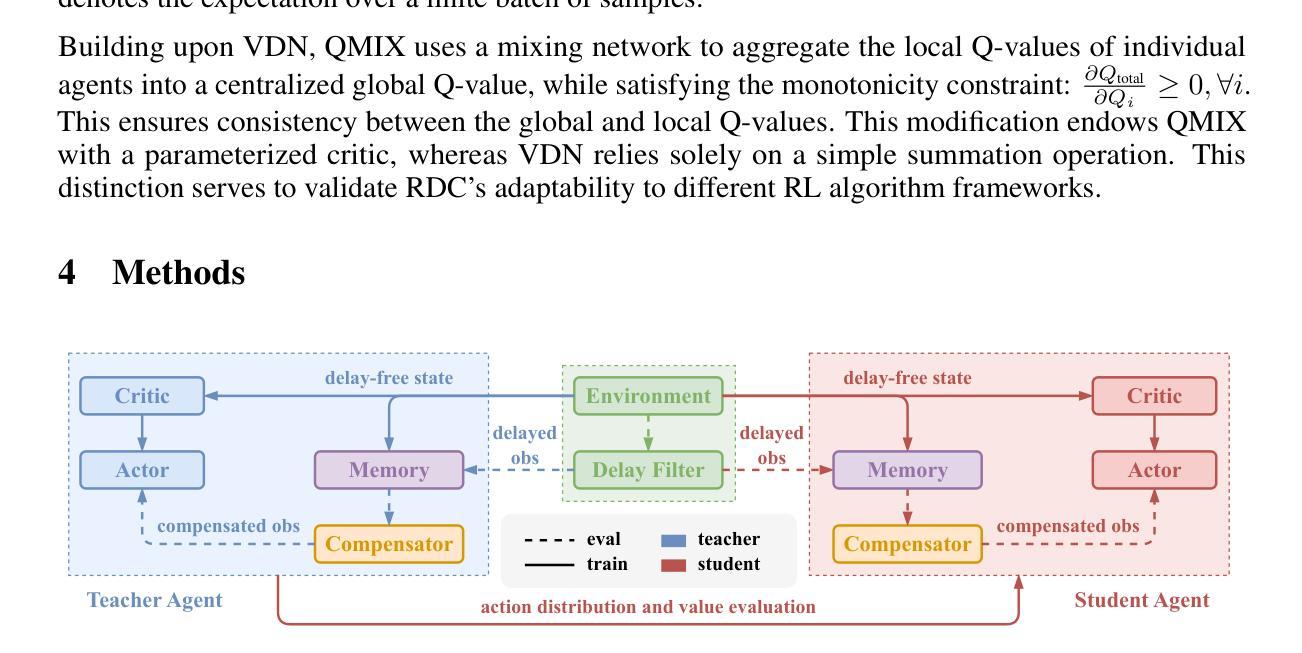
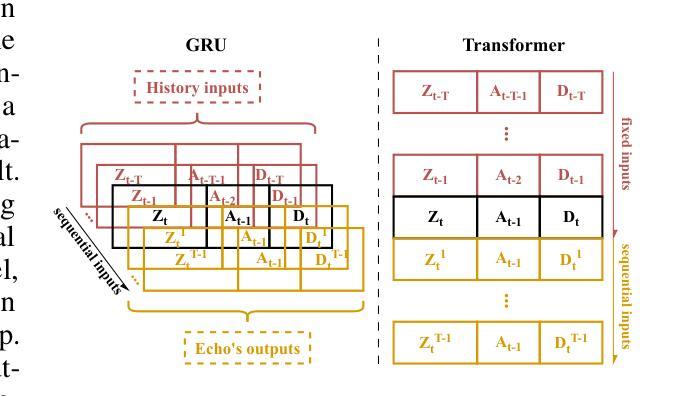
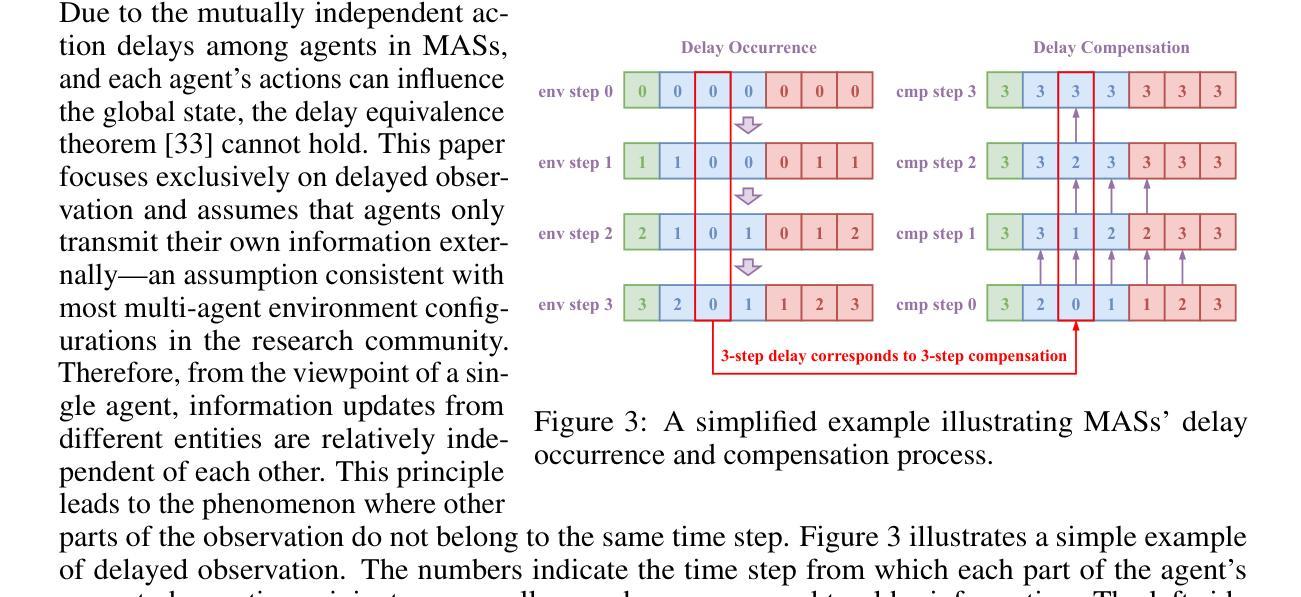
Rainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
Authors:Songchen Fu, Siang Chen, Shaojing Zhao, Letian Bai, Ta Li, Yonghong Yan
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment’s true state. An individual agent’s local observation often consists of multiple components from other agents or dynamic entities in the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP’s observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalizability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework. The source code is available at https://anonymous.4open.science/r/RDC-pymarl-4512/.
在多智能体系统(MAS)的实际应用中,观察延迟是普遍存在的,这阻碍了智能体基于环境真实状态做出决策。单个智能体的局部观察通常包含来自其他智能体或环境中的动态实体的多个组件。这些具有不同延迟特性的离散观察组件为多智能体强化学习(MARL)带来了重大挑战。在本文中,我们首先通过扩展标准的Dec-POMDP来制定去中心化随机个体延迟部分可观测马尔可夫决策过程(DSID-POMDP)。然后,我们提出了Rainbow Delay Compensation(RDC),这是一种针对随机个体延迟的MARL训练框架,并为其组成部分提供了推荐的实现方法。我们使用包括MPE和SMAC在内的标准MARL基准测试实现了DSID-POMDP的观察生成模式。实验表明,在固定和未固定的延迟下,基线MARL方法会遭受严重的性能下降。RDC增强方法缓解了这个问题,在某些延迟场景中实现了理想的无延迟性能,同时保持了泛化能力。我们的工作为多智能体延迟观察问题提供了新的视角,并提供了有效的解决方案框架。源代码可在https://anonymous.4open.science/r/RDC-pymarl-4512/找到。
论文及项目相关链接
PDF The code will be open-sourced in the RDC-pymarl project under https://github.com/linkjoker1006
Summary
本文研究了多智能体系统(MAS)中的观察延迟问题,并提出了Rainbow Delay Compensation(RDC)这一针对随机个体延迟的MARL训练框架。文章通过扩展标准的Dec-POMDP,构建了分散式随机个体延迟部分可观测马尔可夫决策过程(DSID-POMDP)。实验表明,在固定和未固定的延迟下,基准MARL方法性能严重下降,而RDC方法则显著缓解了这一问题,在某些延迟场景下实现了接近无延迟的理想性能。
Key Takeaways
- 多智能体系统(MAS)中普遍存在观察延迟问题,影响智能体基于环境真实状态做出决策。
- 本文通过扩展Dec-POMDP构建了DSID-POMDP模型,以更好地描述多智能体系统中的延迟观察问题。
- 提出了Rainbow Delay Compensation(RDC)这一MARL训练框架,用于解决随机个体延迟问题。
- 实验表明,基准MARL方法在存在延迟时性能严重下降。
- RDC方法能够缓解延迟对智能体性能的影响,并在某些场景下实现接近无延迟的性能。
- RDC方法具有较好的通用性,能够为解决多智能体延迟观察问题提供有效框架。
点此查看论文截图

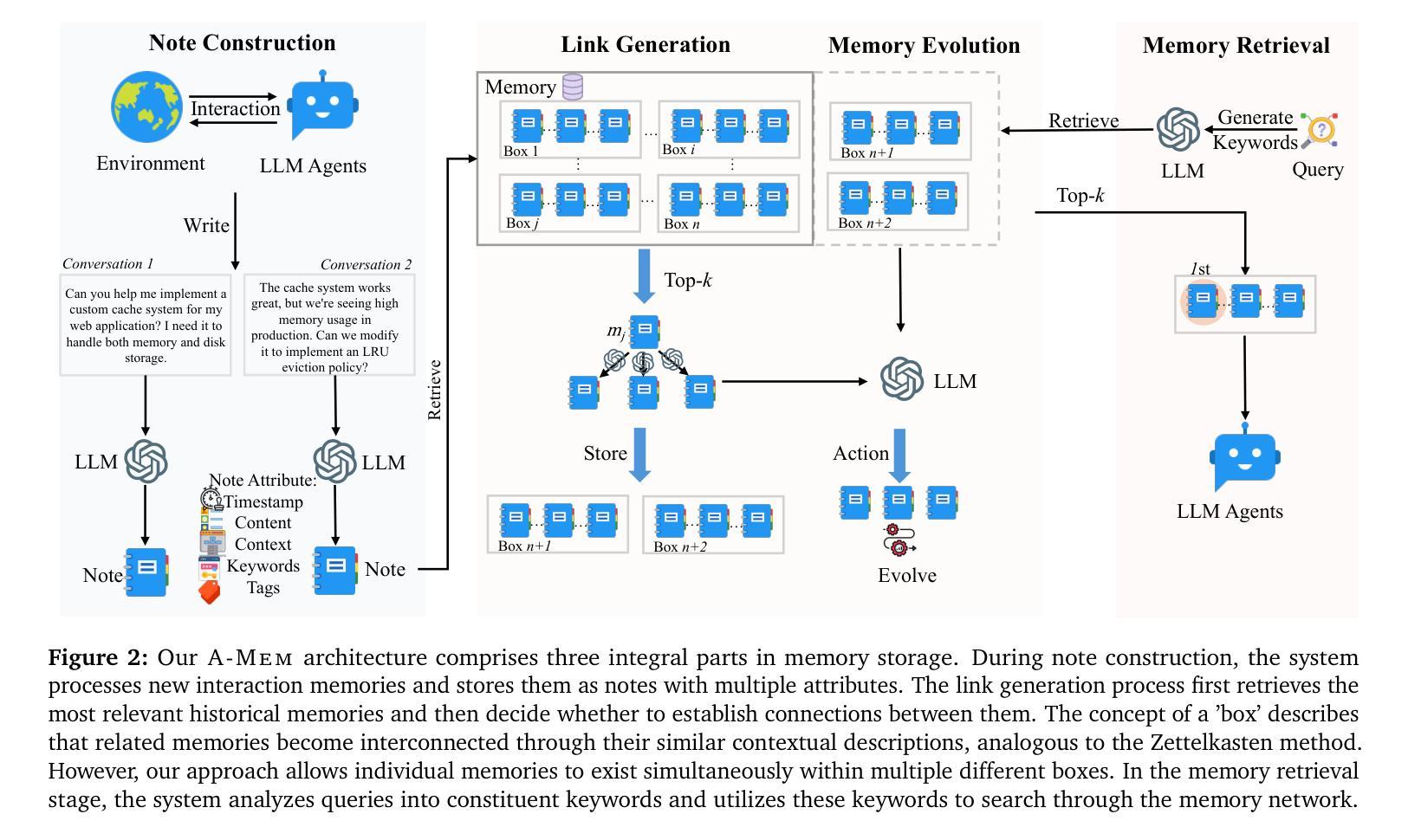
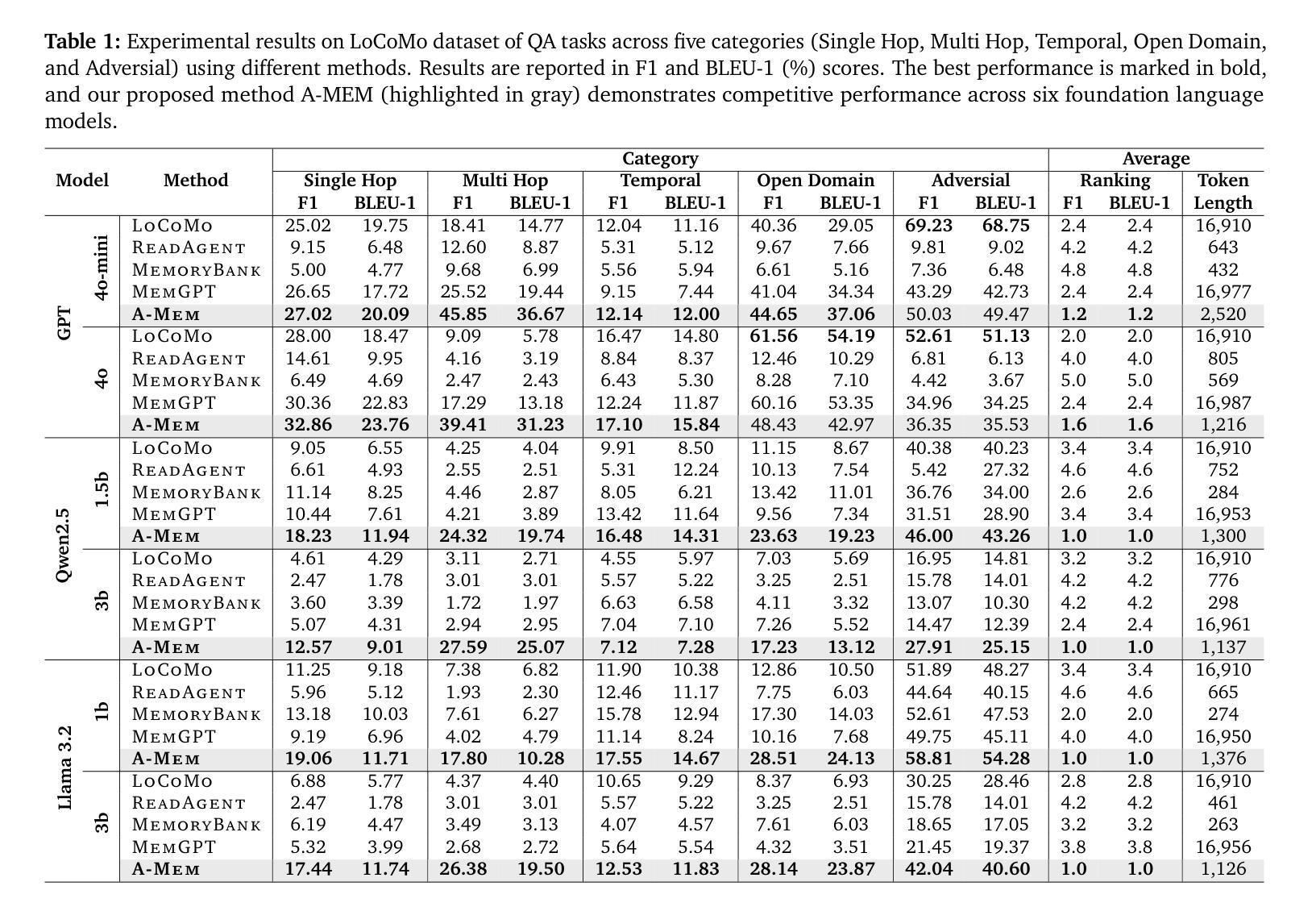
A-MEM: Agentic Memory for LLM Agents
Authors:Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zujie Liang, Yongfeng Zhang
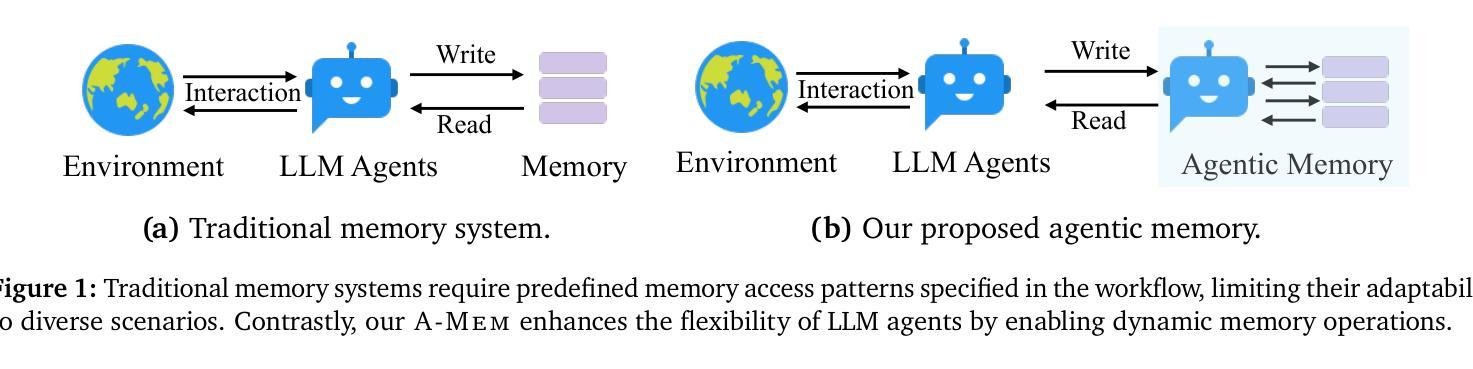
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems’ fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code for evaluating performance is available at https://github.com/WujiangXu/AgenticMemory, while the source code of agentic memory system is available at https://github.com/agiresearch/A-mem.
虽然大型语言模型(LLM)代理可以有效地利用外部工具来完成复杂的现实世界任务,但它们需要记忆系统来利用历史经验。当前的记忆系统虽然可以进行基本的存储和检索,但缺乏高级的记忆组织功能,尽管最近尝试引入了图数据库。此外,这些系统的固定操作和结构限制了它们在各种任务中的适应性。为了解决这一局限性,本文提出了一种用于LLM代理的新型代理记忆系统,该系统能够以代理方式动态组织记忆。遵循Zettelkasten方法的基本原则,我们设计了一个记忆系统,通过动态索引和链接创建相互关联的知识网络。每当添加新记忆时,我们会生成一个包含多个结构化属性的综合笔记,包括上下文描述、关键词和标签。然后,系统分析历史记忆以识别相关连接,并在存在有意义的相似性时建立链接。此外,这个过程使记忆得以进化——随着新记忆的融入,它们可能触发对现有历史记忆的上下文表示和属性的更新,使记忆网络能够不断完善其理解。我们的方法结合了Zettelkasten的结构化组织原则与代理驱动决策的灵活性,从而实现了更具适应性和上下文感知的记忆管理。在六个基础模型上的实证实验表明,与现有的最新技术基准相比,我们的方法具有显著的改进。性能评估的源代码可在https://github.com/WujiangXu/AgenticMemory上找到,而代理记忆系统的源代码则可在https://github.com/agiresearch/A-mem上获得。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理复杂现实世界任务时,虽然能够利用外部工具,但需要记忆系统来利用历史经验。当前记忆系统虽然实现了基本存储和检索功能,但在组织记忆方面缺乏专业性,不能适应多种任务。本文提出了一种新型的LLM代理记忆系统,该系统能够动态地以代理方式组织记忆。该系统基于Zettelkasten方法的基本原则设计,创建通过动态索引和链接相互连接的知识网络。新记忆被添加时,系统会生成包含多个结构化属性的综合笔记,如上下文描述、关键词和标签。然后,系统分析历史记忆以识别相关连接,在存在有意义的相似性时建立链接。此外,这一过程使记忆得以进化——新记忆的集成可以触发对现有历史记忆的上下文表示和属性的更新,使记忆网络能够不断完善其理解。在六个基础模型上的实证实验表明,与现有最先进基线相比,该方法具有显著优势。
Key Takeaways
- 大型语言模型(LLM)在处理复杂任务时需要记忆系统来利用历史经验。
- 当前记忆系统在组织记忆方面存在局限性,缺乏专业性和适应性。
- 本文提出了一种新型的LLM代理记忆系统,能够动态地以代理方式组织记忆。
- 该系统基于Zettelkasten方法,创建相互连接的知识网络。
- 新记忆通过生成包含多个结构化属性的综合笔记被添加到系统中。
- 系统能够分析历史记忆以识别相关连接,并建立链接。
点此查看论文截图

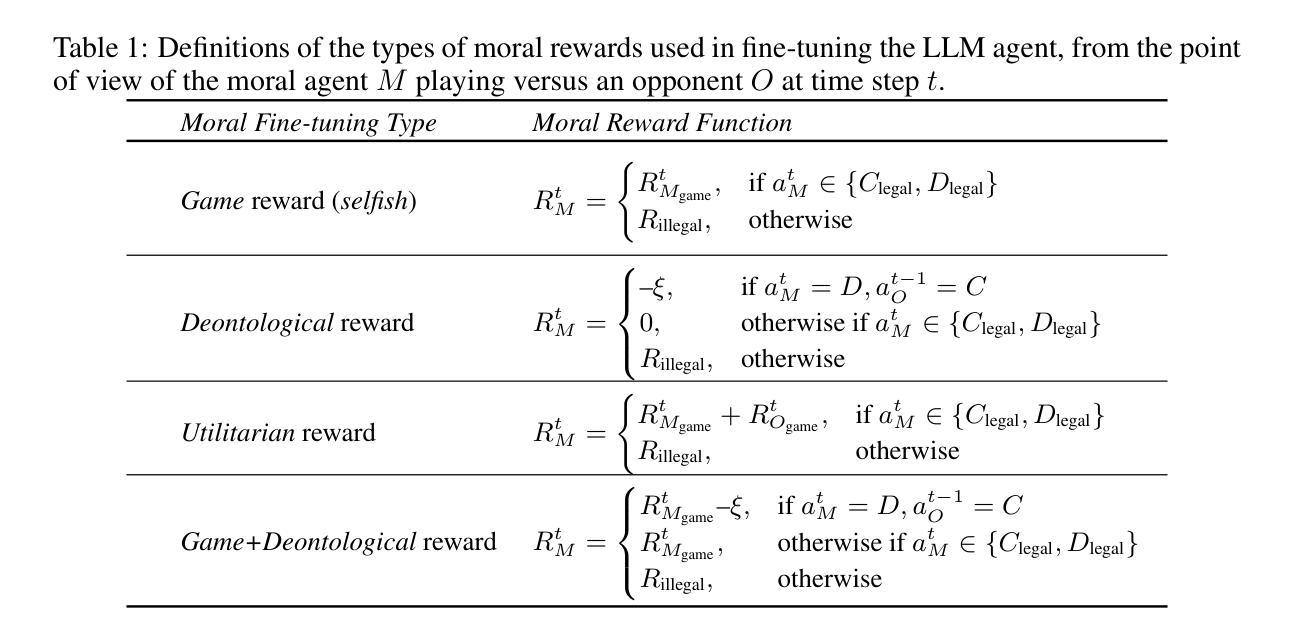
Moral Alignment for LLM Agents
Authors:Elizaveta Tennant, Stephen Hailes, Mirco Musolesi
Decision-making agents based on pre-trained Large Language Models (LLMs) are increasingly being deployed across various domains of human activity. While their applications are currently rather specialized, several research efforts are underway to develop more generalist agents. As LLM-based systems become more agentic, their influence on human activity will grow and their transparency will decrease. Consequently, developing effective methods for aligning them to human values is vital. The prevailing practice in alignment often relies on human preference data (e.g., in RLHF or DPO), in which values are implicit, opaque and are essentially deduced from relative preferences over different model outputs. In this work, instead of relying on human feedback, we introduce the design of reward functions that explicitly and transparently encode core human values for Reinforcement Learning-based fine-tuning of foundation agent models. Specifically, we use intrinsic rewards for the moral alignment of LLM agents. We evaluate our approach using the traditional philosophical frameworks of Deontological Ethics and Utilitarianism, quantifying moral rewards for agents in terms of actions and consequences on the Iterated Prisoner’s Dilemma (IPD) environment. We also show how moral fine-tuning can be deployed to enable an agent to unlearn a previously developed selfish strategy. Finally, we find that certain moral strategies learned on the IPD game generalize to several other matrix game environments. In summary, we demonstrate that fine-tuning with intrinsic rewards is a promising general solution for aligning LLM agents to human values, and it might represent a more transparent and cost-effective alternative to currently predominant alignment techniques.
基于预训练大型语言模型(LLM)的决策代理正越来越多地应用于人类活动的各个领域。虽然目前它们的应用相对专业,但许多研究正在努力开发更通用的代理。随着基于LLM的系统越来越智能,它们对人类活动的影响将增长,而它们的透明度将降低。因此,开发有效的方法将它们与人类价值观对齐至关重要。当前的对齐实践通常依赖于人类偏好数据(例如RLHF或DPO),其中价值观是隐含的、不透明的,本质上是根据对不同模型输出的相对偏好推断出来的。在这项工作中,我们不依赖人类反馈,而是介绍奖励函数的设计,该奖励函数明确、透明地编码人类核心价值观,用于基于强化学习的基础代理模型的微调。具体来说,我们使用内在奖励来实现LLM代理的道德对齐。我们利用传统哲学框架中的道义伦理学理论和功利主义理论来评估我们的方法,在重复囚徒困境(IPD)环境中量化代理的道德奖励(行动和后果)。我们还展示了如何在代理上部署道德微调,以使其能够忘记之前开发的自私策略。最后,我们发现某些在IPD游戏中学习的道德策略可以推广到其他矩阵游戏环境。总之,我们证明了使用内在奖励进行微调是一种有前景的通用解决方案,可将LLM代理与人类的价值观对齐。这可能代表了一种比当前主流的对齐技术更加透明和经济的替代方案。
论文及项目相关链接
PDF Published at the 13th International Conference on Learning Representations (ICLR’25), Singapore, Apr 2025. https://openreview.net/forum?id=MeGDmZjUXy
Summary
基于预训练的大型语言模型(LLM)的决策代理正越来越多地应用于人类活动的各个领域。当前其应用相对专业化和专门化,但正在努力开发更通用的代理。随着LLM为基础的系统变得更加自主,它们对人类活动的影响将增长,并且它们的透明度将下降。因此,开发将它们与人类价值观对齐的有效方法至关重要。本研究提出了一种设计奖励函数的方法,该奖励函数明确且透明地编码了人类的核心价值观,用于强化学习对基础代理模型的微调。我们利用内在奖励来实现LLM代理的道德对齐。我们采用传统的哲学框架——道义论和功利主义来评估我们的方法,在迭代囚徒困境(IPD)环境中量化代理的道德奖励。我们还展示了如何通过道德微调使代理能够撤销之前形成的自私策略。最后,我们发现某些在IPD游戏中学习的道德策略可以推广到其他的矩阵游戏环境。总的来说,我们的研究证明了利用内在奖励进行微调是一种有希望的对齐LLM代理和人类价值观的总体解决方案,并可能代表一种更加透明和经济的替代目前主流的代理对齐技术的方法。
Key Takeaways
- LLM决策代理正广泛应用于多个领域,未来可能会变得更为通用和自主。
- 随着其自主性的增强,需要重视LLM代理与人类价值观的对齐问题。
- 传统基于人类偏好数据的对齐方法存在缺陷,需要寻求更为明确和透明的编码方式以表达人类价值观的方法。本研究引入了一种新的奖励函数设计方法来实现这一目的。
- 本研究强调利用内在奖励进行微调以实现LLM代理的道德对齐。
点此查看论文截图


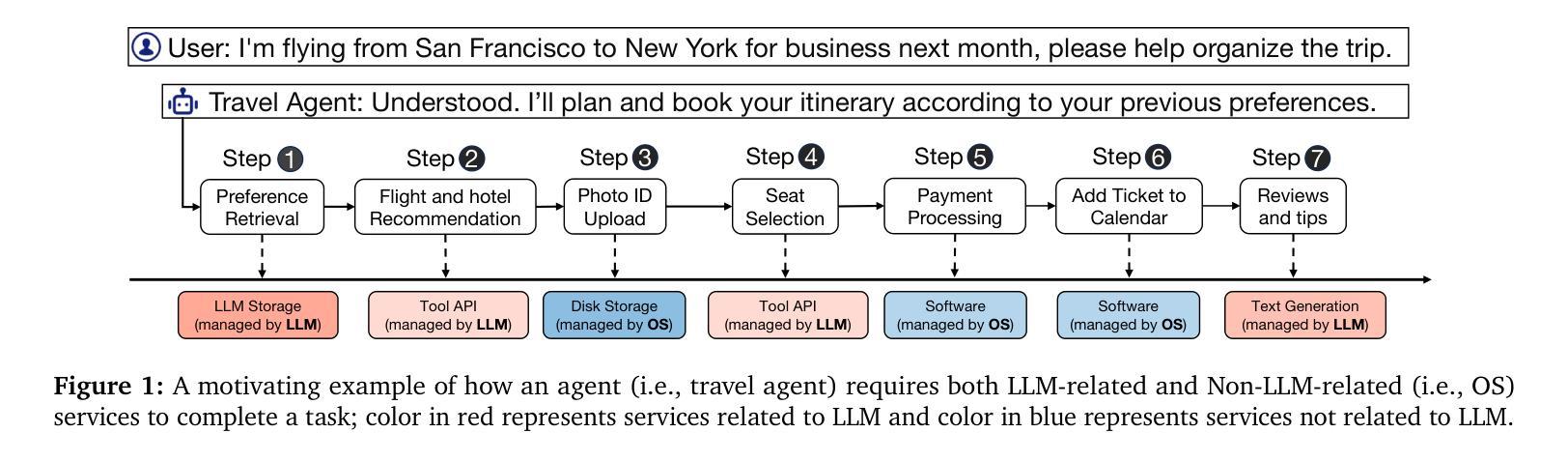
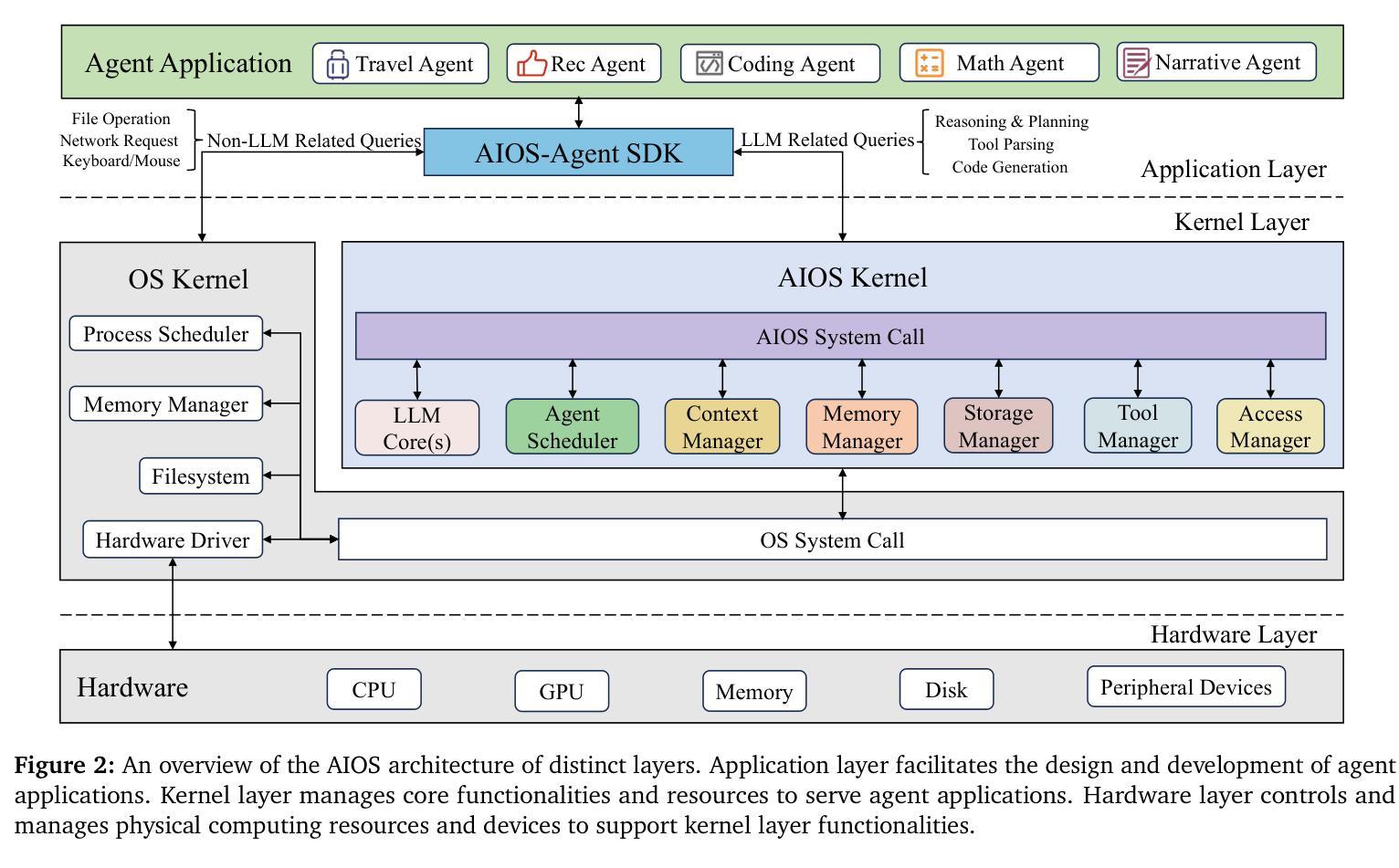
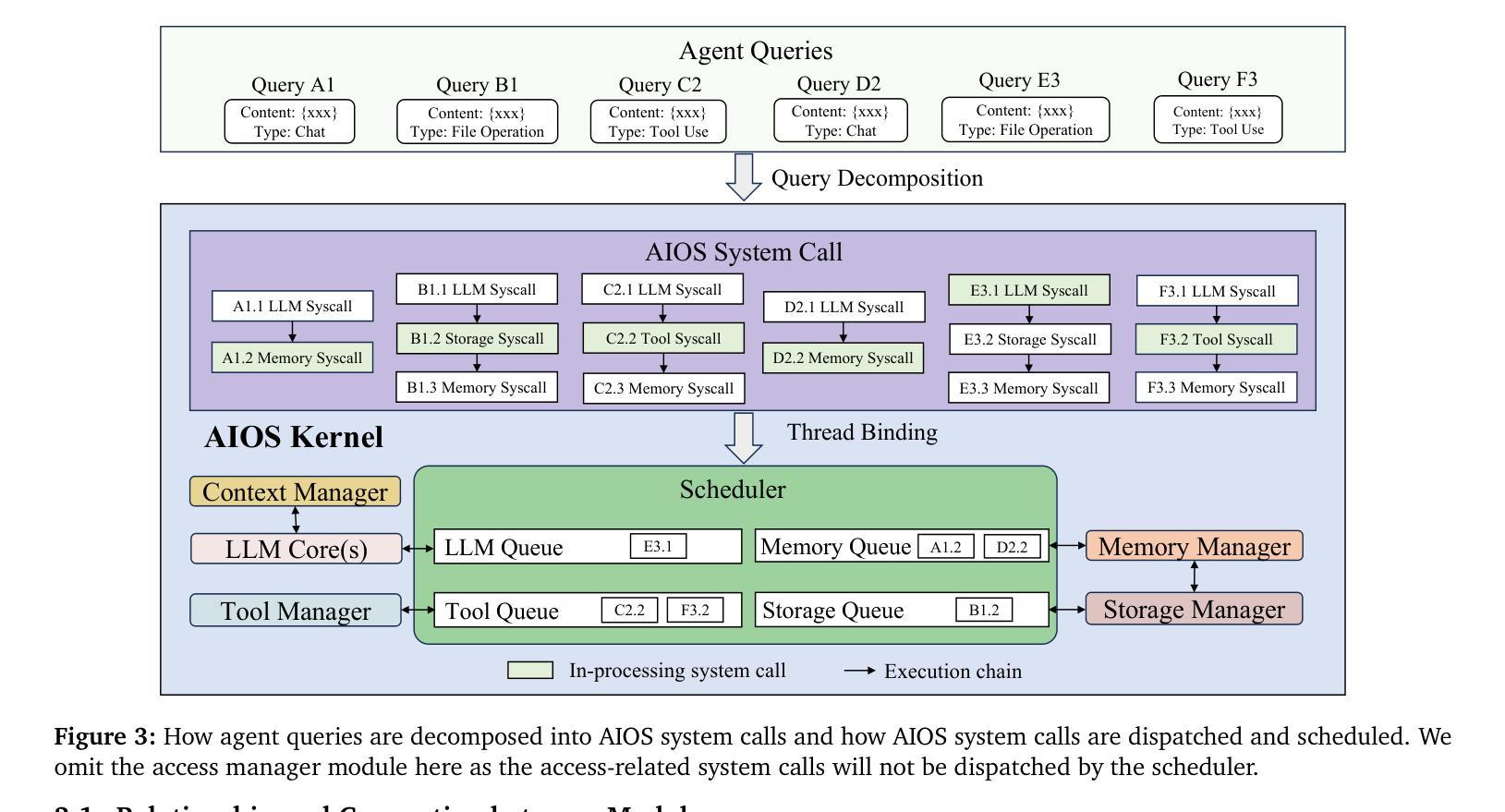
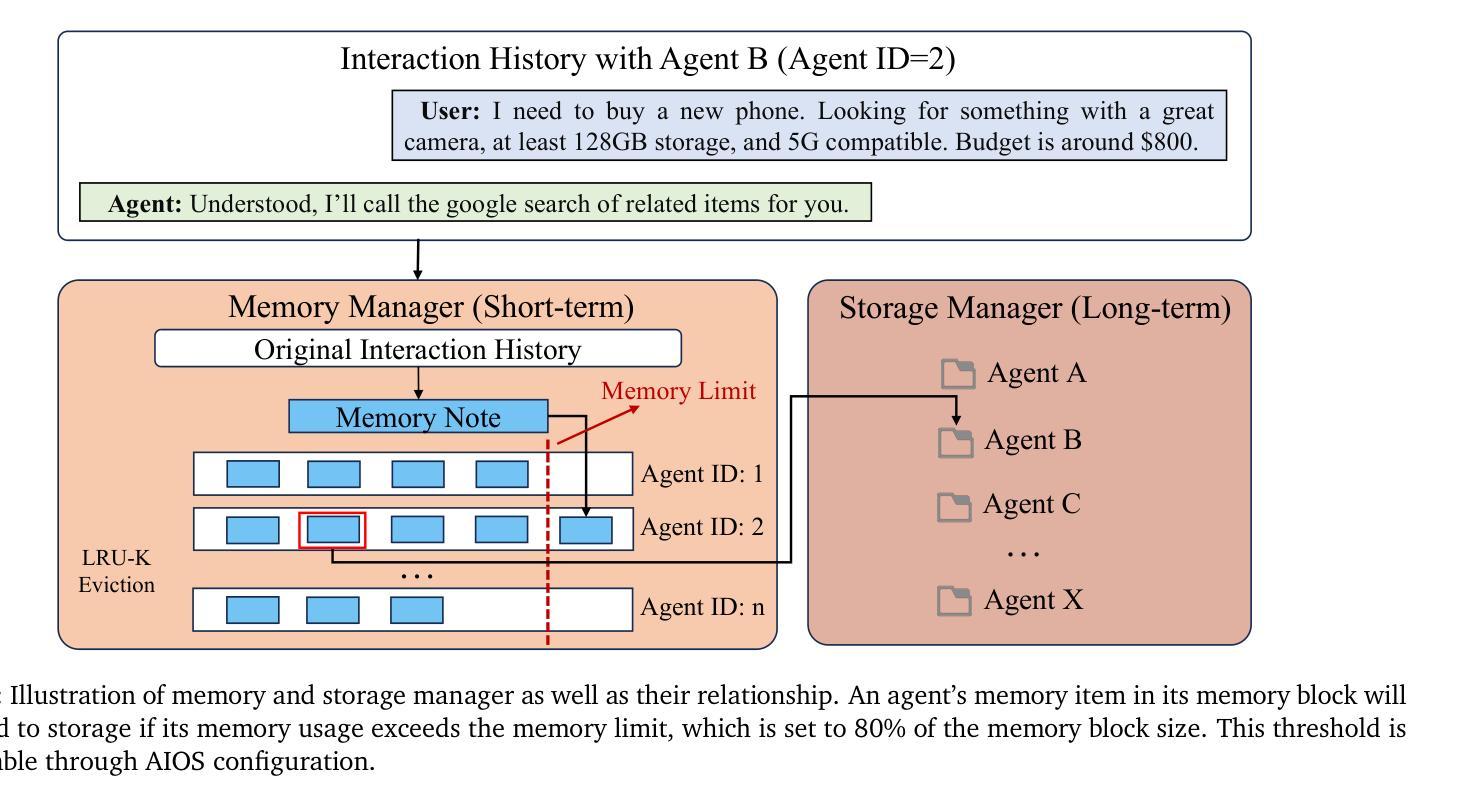
AIOS: LLM Agent Operating System
Authors:Kai Mei, Xi Zhu, Wujiang Xu, Wenyue Hua, Mingyu Jin, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, Yongfeng Zhang
LLM-based intelligent agents face significant deployment challenges, particularly related to resource management. Allowing unrestricted access to LLM or tool resources can lead to inefficient or even potentially harmful resource allocation and utilization for agents. Furthermore, the absence of proper scheduling and resource management mechanisms in current agent designs hinders concurrent processing and limits overall system efficiency. As the diversity and complexity of agents continue to grow, addressing these resource management issues becomes increasingly critical to LLM-based agent systems. To address these challenges, this paper proposes the architecture of AIOS (LLM-based AI Agent Operating System) under the context of managing LLM-based agents. It introduces a novel architecture for serving LLM-based agents by isolating resources and LLM-specific services from agent applications into an AIOS kernel. This AIOS kernel provides fundamental services (e.g., scheduling, context management, memory management, storage management, access control) and efficient management of resources (e.g., LLM and external tools) for runtime agents. To enhance usability, AIOS also includes an AIOS-Agent SDK, a comprehensive suite of APIs designed for utilizing functionalities provided by the AIOS kernel. Experimental results demonstrate that using AIOS can achieve up to 2.1x faster execution for serving agents built by various agent frameworks. The source code is available at https://github.com/agiresearch/AIOS.
基于LLM的智能代理面临着重要的部署挑战,特别是与资源管理有关。对LLM或工具资源的无限制访问可能导致代理的资源分配和利用效率低下,甚至可能产生潜在的危害。此外,当前代理设计中缺乏适当的调度和资源管理机制会阻碍并发处理并限制整体系统效率。随着代理的多样性和复杂性不断增长,解决这些资源管理问题对于基于LLM的代理系统变得愈发关键。
论文及项目相关链接
Summary:针对大型语言模型(LLM)为基础的人工智能代理人所面临的资源管理问题,本文提出了AIOS(人工智能代理操作系统)架构。该架构通过将资源隔离和LLM特定服务从代理应用程序中分离到AIOS内核,实现对LLM代理的有效资源管理。AIOS内核提供基础服务如调度、上下文管理、内存管理等,以提高运行时代理的资源管理效率。同时,AIOS还包括AIOS-Agent SDK,提供一系列API供开发人员使用AIOS内核的功能。实验结果显示,使用AIOS可以提高1至2.1倍的服务代理执行速度。
Key Takeaways:
- LLM-based智能代理人面临资源管理方面的挑战。
- 不受限的资源访问可能导致资源分配和利用效率低下,甚至可能有害。
- 当前代理设计缺乏适当的调度和资源管理机制,影响并发处理和系统整体效率。
- AIOS架构被提出以解决LLM-based代理人的资源管理问题。
- AIOS通过隔离资源和LLM特定服务到AIOS内核来服务LLM-based代理人。
- AIOS内核提供基础服务和资源管理的有效管理。
点此查看论文截图