⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-14 更新
GAN-based synthetic FDG PET images from T1 brain MRI can serve to improve performance of deep unsupervised anomaly detection models
Authors:Daria Zotova, Nicolas Pinon, Robin Trombetta, Romain Bouet, Julien Jung, Carole Lartizien
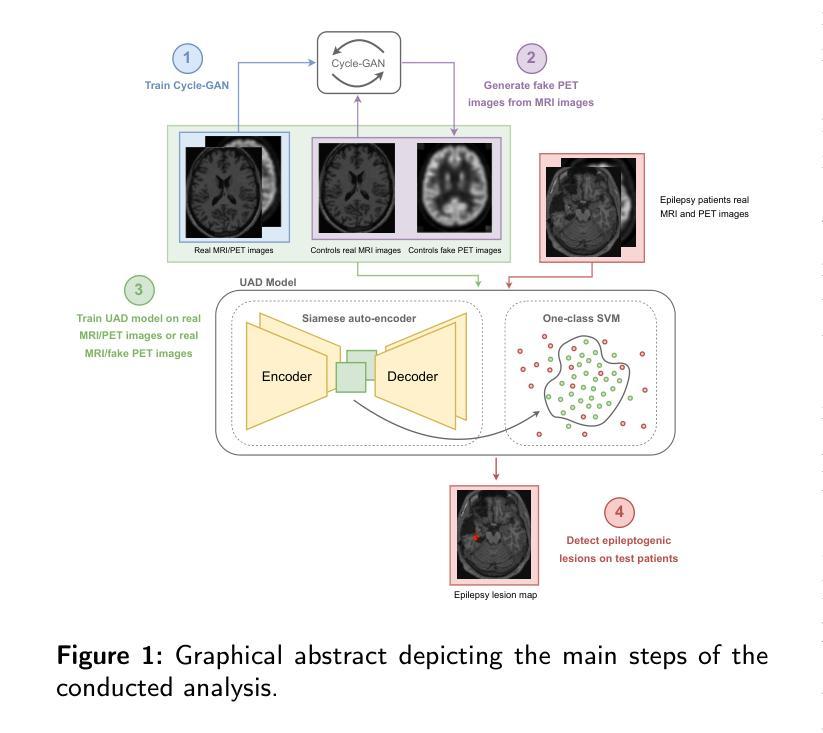
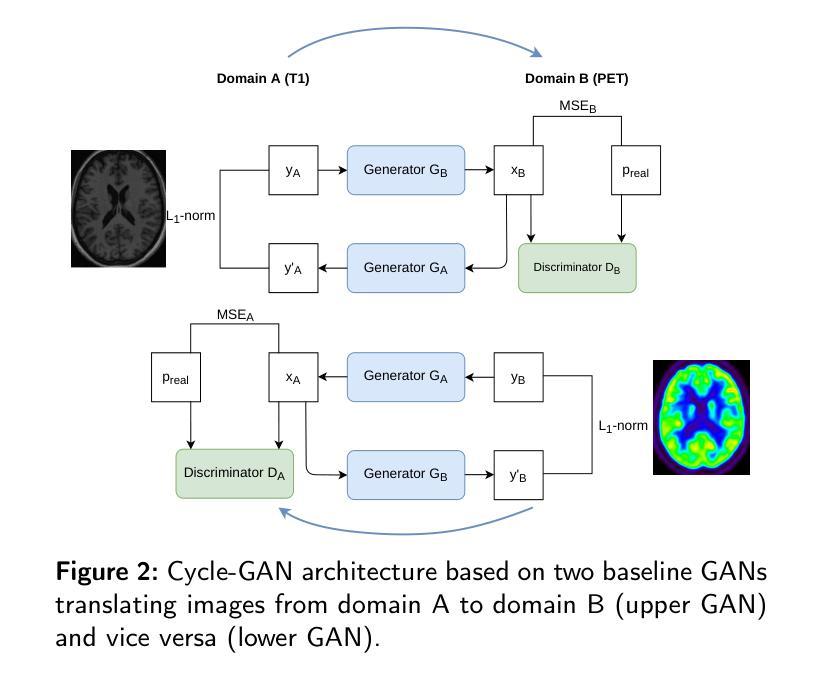
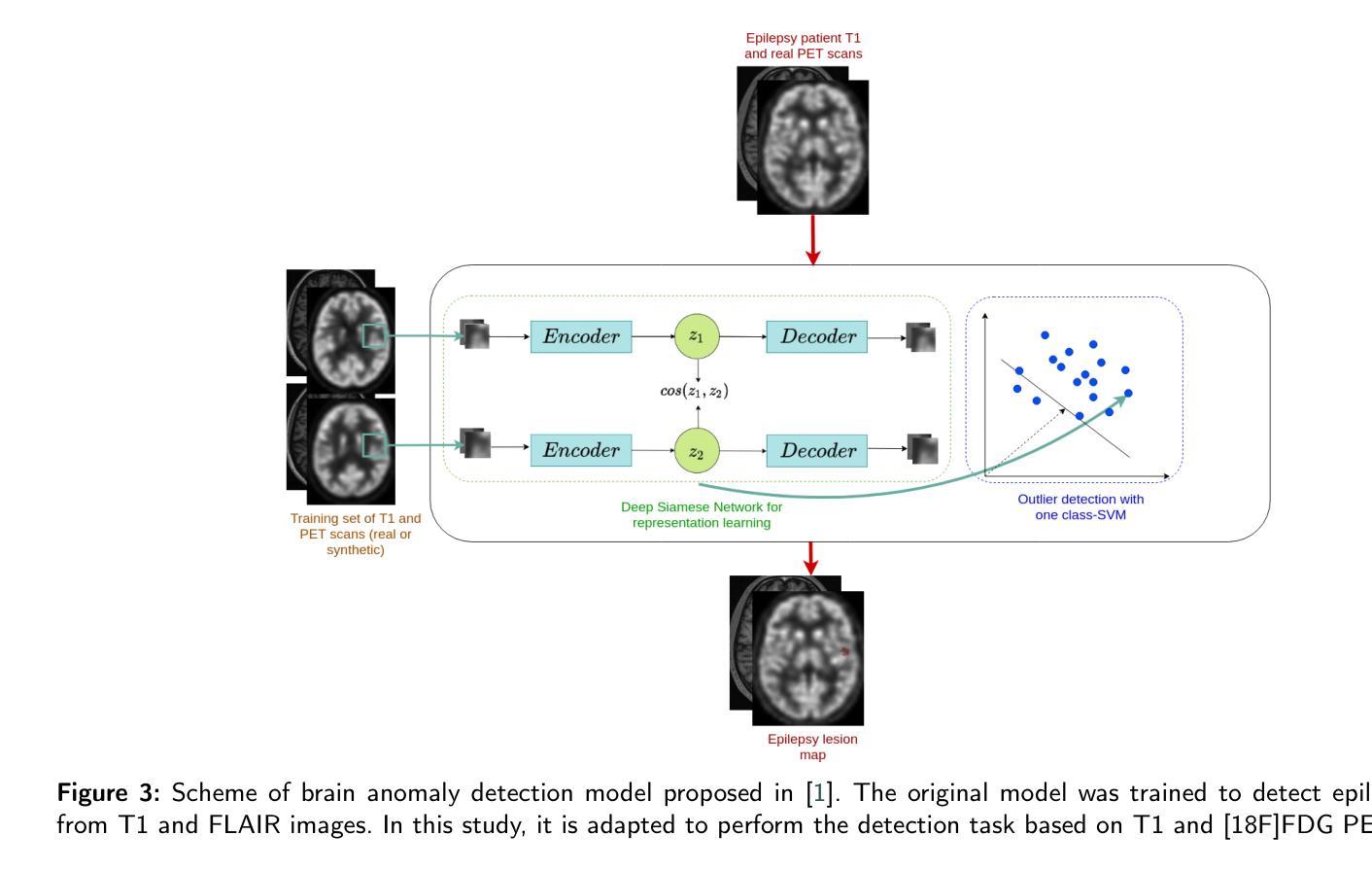
Background and Objective. Research in the cross-modal medical image translation domain has been very productive over the past few years in tackling the scarce availability of large curated multimodality datasets with the promising performance of GAN-based architectures. However, only a few of these studies assessed task-based related performance of these synthetic data, especially for the training of deep models. Method. We design and compare different GAN-based frameworks for generating synthetic brain [18F]fluorodeoxyglucose (FDG) PET images from T1 weighted MRI data. We first perform standard qualitative and quantitative visual quality evaluation. Then, we explore further impact of using these fake PET data in the training of a deep unsupervised anomaly detection (UAD) model designed to detect subtle epilepsy lesions in T1 MRI and FDG PET images. We introduce novel diagnostic task-oriented quality metrics of the synthetic FDG PET data tailored to our unsupervised detection task, then use these fake data to train a use case UAD model combining a deep representation learning based on siamese autoencoders with a OC-SVM density support estimation model. This model is trained on normal subjects only and allows the detection of any variation from the pattern of the normal population. We compare the detection performance of models trained on 35 paired real MR T1 of normal subjects paired either on 35 true PET images or on 35 synthetic PET images generated from the best performing generative models. Performance analysis is conducted on 17 exams of epilepsy patients undergoing surgery. Results. The best performing GAN-based models allow generating realistic fake PET images of control subject with SSIM and PSNR values around 0.9 and 23.8, respectively and in distribution (ID) with regard to the true control dataset. The best UAD model trained on these synthetic normative PET data allows reaching 74% sensitivity. Conclusion. Our results confirm that GAN-based models are the best suited for MR T1 to FDG PET translation, outperforming transformer or diffusion models. We also demonstrate the diagnostic value of these synthetic data for the training of UAD models and evaluation on clinical exams of epilepsy patients. Our code and the normative image dataset are available.
背景与目的。近年来,基于GAN架构在解决大型精选多模态数据集稀缺的问题方面表现出巨大的潜力,跨模态医学图像翻译领域的研究成果十分丰硕。然而,仅有少数研究评估了这些合成数据在任务相关的性能,尤其是用于训练深度学习模型方面的性能。方法。我们设计并比较了基于不同GAN的框架,用于从T1加权MRI数据生成合成的大脑氟代脱氧葡萄糖(FDG)PET图像。我们首先进行标准的定性和定量视觉质量评估。然后,我们进一步探讨了使用这些假PET数据在训练用于检测T1 MRI和FDG PET图像中微妙癫痫病灶的深度无监督异常检测(UAD)模型的影响。我们针对无监督检测任务引入了针对合成FDG PET数据的新型诊断任务导向的质量指标,然后使用这些假数据训练一个用例UAD模型,该模型结合了基于孪生自编码器的深度表示学习与OC-SVM密度支持估计模型。该模型仅对正常受试者进行训练,能够检测出任何与正常人群模式的偏差。我们比较了在35对正常受试者的真实MR T1上训练的模型的表现,这些模型配对的是35张真实PET图像或来自表现最佳的生成模型的35张合成PET图像。性能分析是在接受手术的17名癫痫患者身上进行的。 结果。表现最佳的基于GAN的模型能够生成逼真的假PET图像,其控制对象的结构相似性度量(SSIM)和峰值信噪比(PSNR)值分别为约0.9和23.8,并且与真实控制数据集在分布上一致。使用这些合成规范性PET数据训练的最好UAD模型的敏感性达到74%。 结论。我们的结果证实,基于GAN的模型最适合于MR T1到FDG PET的翻译,优于转换器或扩散模型。我们还证明了这些合成数据对于训练UAD模型和评估癫痫患者的临床检查中的诊断价值。我们的代码和规范图像数据集可供使用。
论文及项目相关链接
Summary
本研究利用不同GAN框架生成模拟脑[18F]氟脱氧葡萄糖(FDG)PET图像,从T1加权MRI数据中探索其在深度模型训练中的表现。实验通过对比真实与模拟的PET图像质量评估GAN性能,并将生成的图像用于训练用于检测癫痫病变的无监督异常检测模型。结果显示,最佳GAN模型生成的模拟图像与现实图像相似度极高,且训练的无监督检测模型使用模拟数据可实现对癫痫患者的敏感性达到约74%。这表明GAN模型适合MRI至PET图像的转换,并在临床癫痫患者的检测中有实用价值。代码及标准化图像数据集可供下载。
Key Takeaways
- GAN在生成模拟脑FDG PET图像方面具有潜力,尤其在处理跨模态医学图像翻译领域的大型数据集稀缺时。
- 通过比较不同GAN框架的性能,研究验证了GAN模型在生成图像质量上的优越性,特别是与Transformer或扩散模型相比。
- 研究利用模拟PET数据训练了一个无监督异常检测模型,用于检测癫痫病变。这是首个利用合成数据在任务特定场景下进行的训练研究。
- 模拟数据生成的图像具有良好的现实感,其质量评估指标如SSIM和PSNR值均表现优异。这表明生成的图像对于深度学习模型的训练具有良好的实用价值。
点此查看论文截图

PC-SRGAN: Physically Consistent Super-Resolution Generative Adversarial Network for General Transient Simulations
Authors:Md Rakibul Hasan, Pouria Behnoudfar, Dan MacKinlay, Thomas Poulet
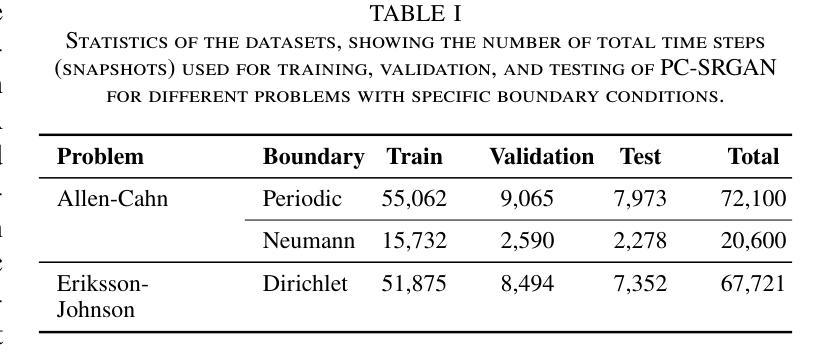
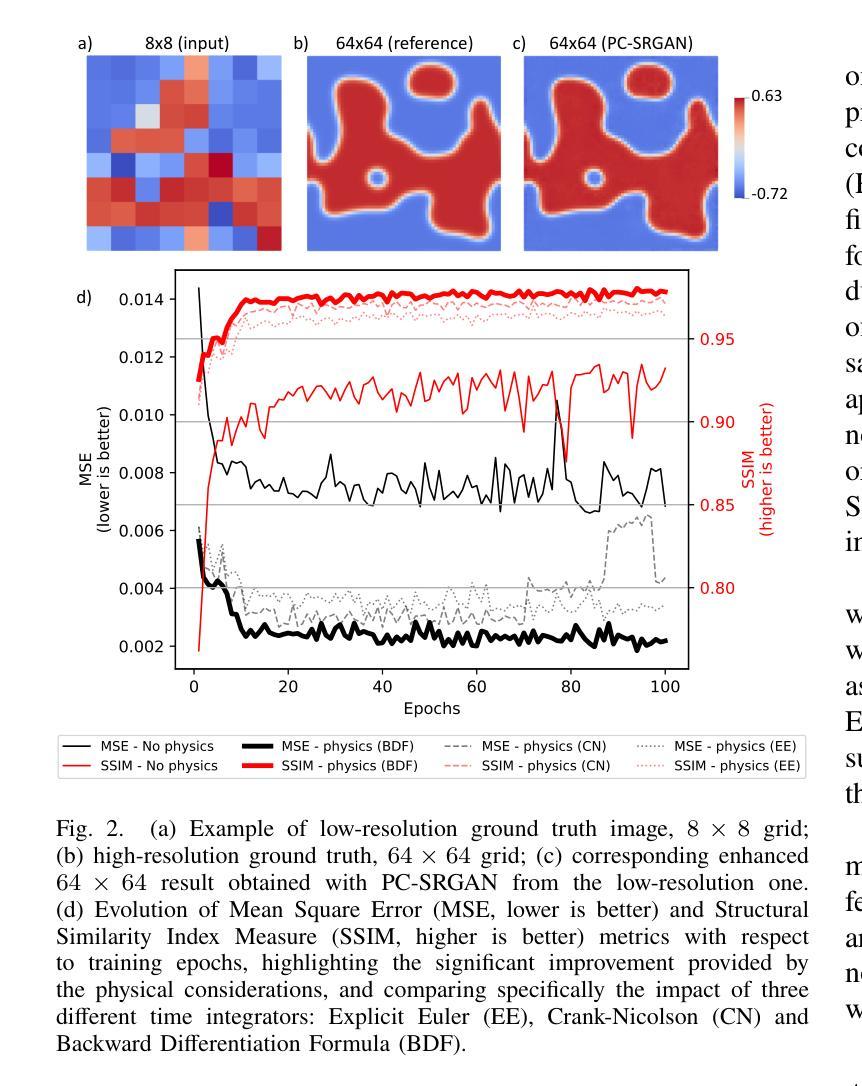
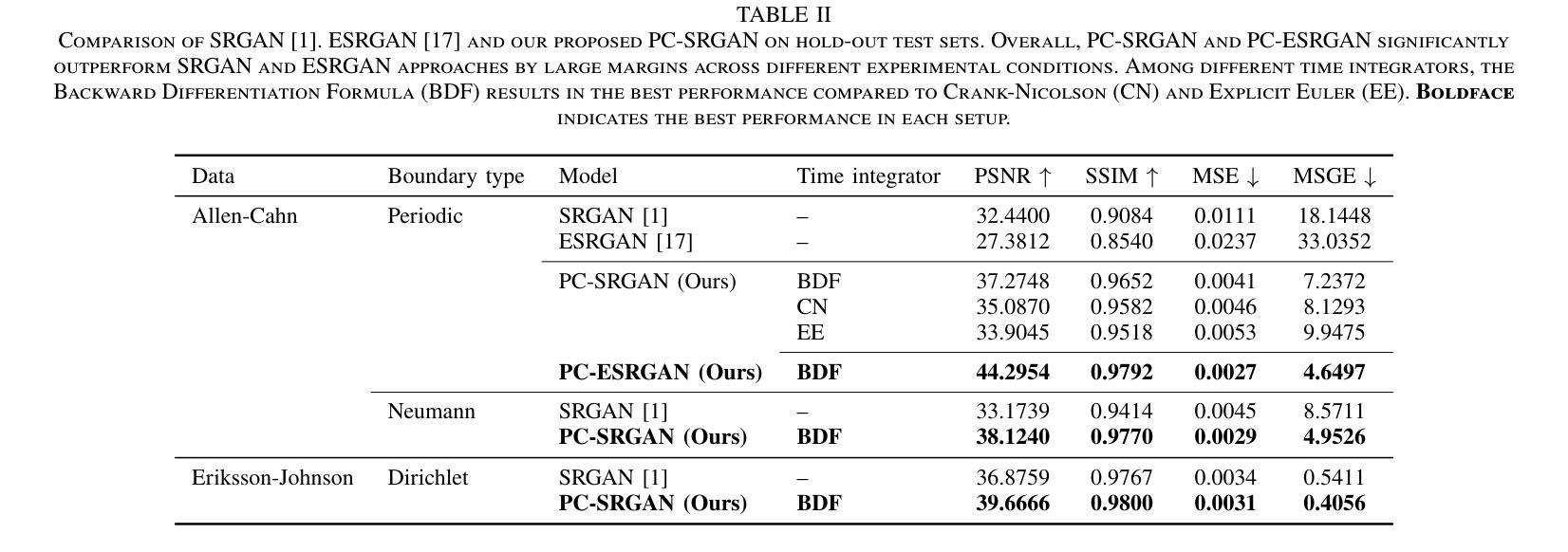
Machine Learning, particularly Generative Adversarial Networks (GANs), has revolutionised Super Resolution (SR). However, generated images often lack physical meaningfulness, which is essential for scientific applications. Our approach, PC-SRGAN, enhances image resolution while ensuring physical consistency for interpretable simulations. PC-SRGAN significantly improves both the Peak Signal-to-Noise Ratio and the Structural Similarity Index Measure compared to conventional methods, even with limited training data (e.g., only 13% of training data required for SRGAN). Beyond SR, PC-SRGAN augments physically meaningful machine learning, incorporating numerically justified time integrators and advanced quality metrics. These advancements promise reliable and causal machine-learning models in scientific domains. A significant advantage of PC-SRGAN over conventional SR techniques is its physical consistency, which makes it a viable surrogate model for time-dependent problems. PC-SRGAN advances scientific machine learning, offering improved accuracy and efficiency for image processing, enhanced process understanding, and broader applications to scientific research. The source codes and data will be made publicly available at https://github.com/hasan-rakibul/PC-SRGAN upon acceptance of this paper.
机器学习,特别是生成对抗网络(GANs),已经实现了超分辨率(SR)的革新。然而,生成的图像通常缺乏物理意义,这对于科学应用至关重要。我们的PC-SRGAN方法在提升图像分辨率的同时,确保了物理一致性,为可解释的模拟提供了支持。与传统的超分辨率方法相比,即使在有限的训练数据下(例如仅需要SRGAN的13%),PC-SRGAN在峰值信噪比和结构相似性指数度量方面都取得了显著改善。除了SR之外,PC-SRGAN增强了具有物理意义的机器学习,融合了经过数值验证的时间积分器和先进的质量指标。这些进步承诺在科学领域建立可靠和因果的机器学习模型。PC-SRGAN相对于传统SR技术的显著优势在于其物理一致性,使其成为时间依赖问题的可行替代模型。PC-SRGAN推动了科学机器学习的发展,为图像处理提供了更高的准确性和效率,增强了过程理解,并扩大了在科学研究中的广泛应用。论文被接受后,源代码和数据将在https://github.com/hasan-rakibul/PC-SRGAN上公开。
论文及项目相关链接
Summary
PC-SRGAN通过结合机器学习和物理规律,革新了超分辨率(SR)技术。它在保证图像分辨率的同时,确保了物理一致性,为可解释的模拟提供了可能。相比传统方法,PC-SRGAN在峰值信噪比和结构相似性指数度量上有了显著改善,甚至在训练数据量有限的情况下也是如此。除了SR,PC-SRGAN还促进了具有物理意义的机器学习的发展,融入了数值验证的时间积分器和高级质量指标。这些进步为科学领域的可靠和因果机器学习模型提供了希望。PC-SRGAN的物理一致性是其相较于传统SR技术的一大优势,使其成为时间依赖问题的可行替代模型。
Key Takeaways
- PC-SRGAN结合了机器学习和物理规律,革新了超分辨率(SR)技术。
- PC-SRGAN在保证图像分辨率的同时,确保了物理一致性,增强了图像的物理意义。
- PC-SRGAN在峰值信噪比和结构相似性指数度量上相较于传统方法有显著改善。
- PC-SRGAN在训练数据量有限的情况下也能表现出良好的性能。
- PC-SRGAN促进了具有物理意义的机器学习的发展,并融入了数值验证的时间积分器和高级质量指标。
- PC-SRGAN为科学领域的可靠和因果机器学习模型提供了希望。
点此查看论文截图


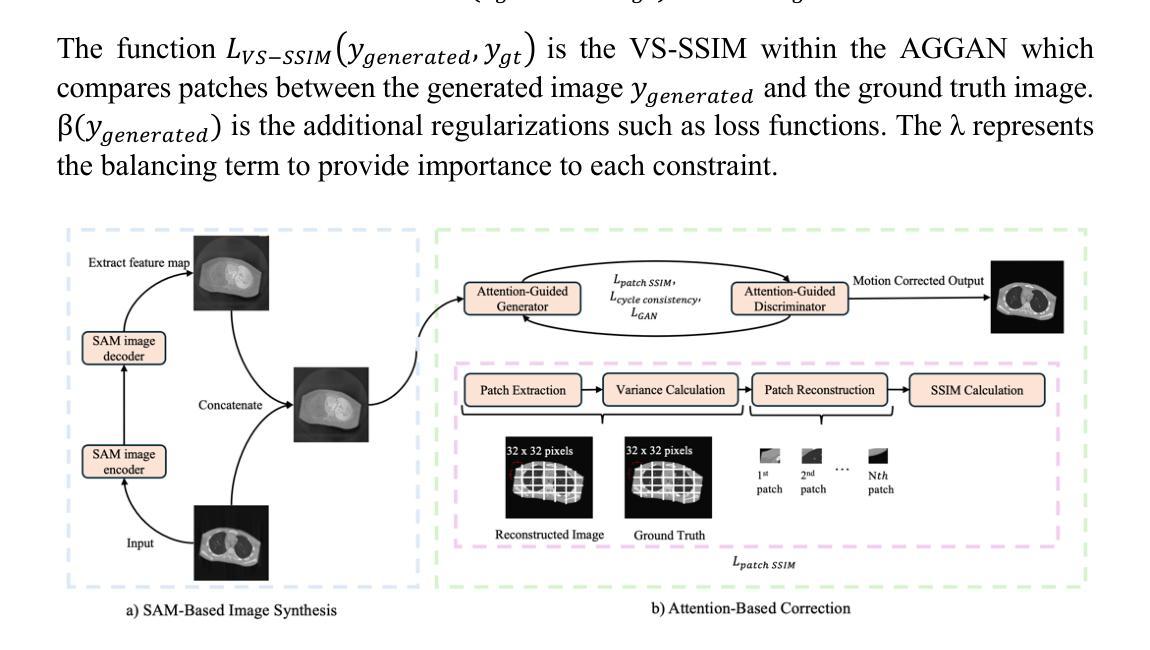
MAISY: Motion-Aware Image SYnthesis for Medical Image Motion Correction
Authors:Andrew Zhang, Hao Wang, Shuchang Ye, Michael Fulham, Jinman Kim
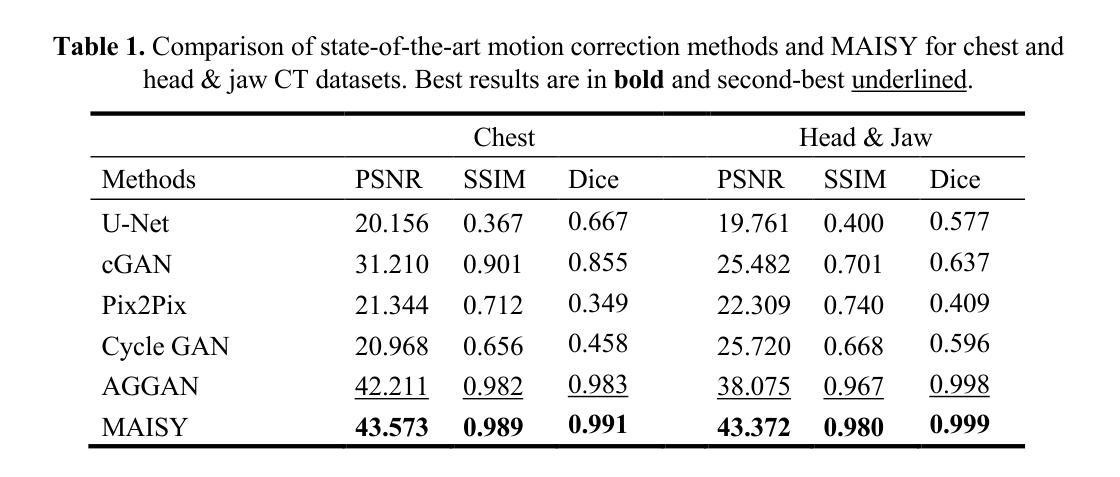
Patient motion during medical image acquisition causes blurring, ghosting, and distorts organs, which makes image interpretation challenging. Current state-of-the-art algorithms using Generative Adversarial Network (GAN)-based methods with their ability to learn the mappings between corrupted images and their ground truth via Structural Similarity Index Measure (SSIM) loss effectively generate motion-free images. However, we identified the following limitations: (i) they mainly focus on global structural characteristics and therefore overlook localized features that often carry critical pathological information, and (ii) the SSIM loss function struggles to handle images with varying pixel intensities, luminance factors, and variance. In this study, we propose Motion-Aware Image SYnthesis (MAISY) which initially characterize motion and then uses it for correction by: (a) leveraging the foundation model Segment Anything Model (SAM), to dynamically learn spatial patterns along anatomical boundaries where motion artifacts are most pronounced and, (b) introducing the Variance-Selective SSIM (VS-SSIM) loss which adaptively emphasizes spatial regions with high pixel variance to preserve essential anatomical details during artifact correction. Experiments on chest and head CT datasets demonstrate that our model outperformed the state-of-the-art counterparts, with Peak Signal-to-Noise Ratio (PSNR) increasing by 40%, SSIM by 10%, and Dice by 16%.
患者在医学影像采集过程中的运动会导致图像模糊、鬼影和器官扭曲,从而使图像解读具有挑战性。当前最先进的算法使用基于生成对抗网络(GAN)的方法,它们能够通过结构相似性指数度量(SSIM)损失来学习失真图像与其真实图像之间的映射,从而有效地生成无运动图像。然而,我们发现了以下局限性:(i)它们主要关注全局结构特征,因此忽略了通常携带关键病理信息的局部特征;(ii)SSIM损失函数在处理像素强度、亮度和方差各异的图像时遇到困难。本研究提出了运动感知图像合成(MAISY),它首先表征运动,然后利用运动进行校正:通过利用分段任何模型(SAM)的基础模型,动态学习解剖边界处的空间模式,其中运动伪影最为突出;引入方差选择性SSIM(VS-SSIM)损失,自适应地强调像素方差高的空间区域,在伪影校正过程中保留重要的解剖细节。在胸部和头部CT数据集上的实验表明,我们的模型优于最先进的同类模型,峰值信噪比(PSNR)提高了40%,结构相似性指数度量(SSIM)提高了10%,狄氏系数提高了16%。
论文及项目相关链接
Summary
本文介绍了在医学图像采集过程中患者运动引起的图像模糊、鬼影和器官扭曲问题,使得图像解读具有挑战性。当前最先进的算法使用基于生成对抗网络(GAN)的方法,通过结构相似性指数测量(SSIM)损失来学习畸变图像与地面实况之间的映射,有效生成无运动图像。然而,本文主要关注全局结构特征而忽略了携带关键病理信息的局部特征,以及SSIM损失函数在处理像素强度、亮度和方差变化的图像时的挣扎。本文提出了运动感知图像合成(MAISY),它首先表征运动,然后通过利用分段任何模型(SAM)和引入方差选择性SSIM(VS-SSIM)损失进行校正,以在矫正伪影时保留重要的解剖细节。实验表明,该模型在胸部和头部CT数据集上的表现优于最先进的同行,峰值信噪比(PSNR)提高40%,结构相似性指数测量(SSIM)提高10%,狄克系数提高16%。
Key Takeaways
- 患者运动在医学图像采集过程中会导致图像模糊、鬼影和器官扭曲,增加图像解读难度。
- 当前GAN算法主要通过SSIM损失学习畸变图像与真实图像之间的映射来生成无运动图像。
- 当前方法主要关注全局结构特征而忽略了局部特征的重要性,这些局部特征可能包含关键的病理信息。
- SSIM损失在处理像素强度、亮度和方差变化的图像时存在局限性。
- 本文提出了Motion-Aware Image SYnthesis (MAISY)模型来解决上述问题。
- MAISY利用Segment Anything Model (SAM)来动态学习解剖边界的空间模式,并根据这些模式进行运动校正。
点此查看论文截图

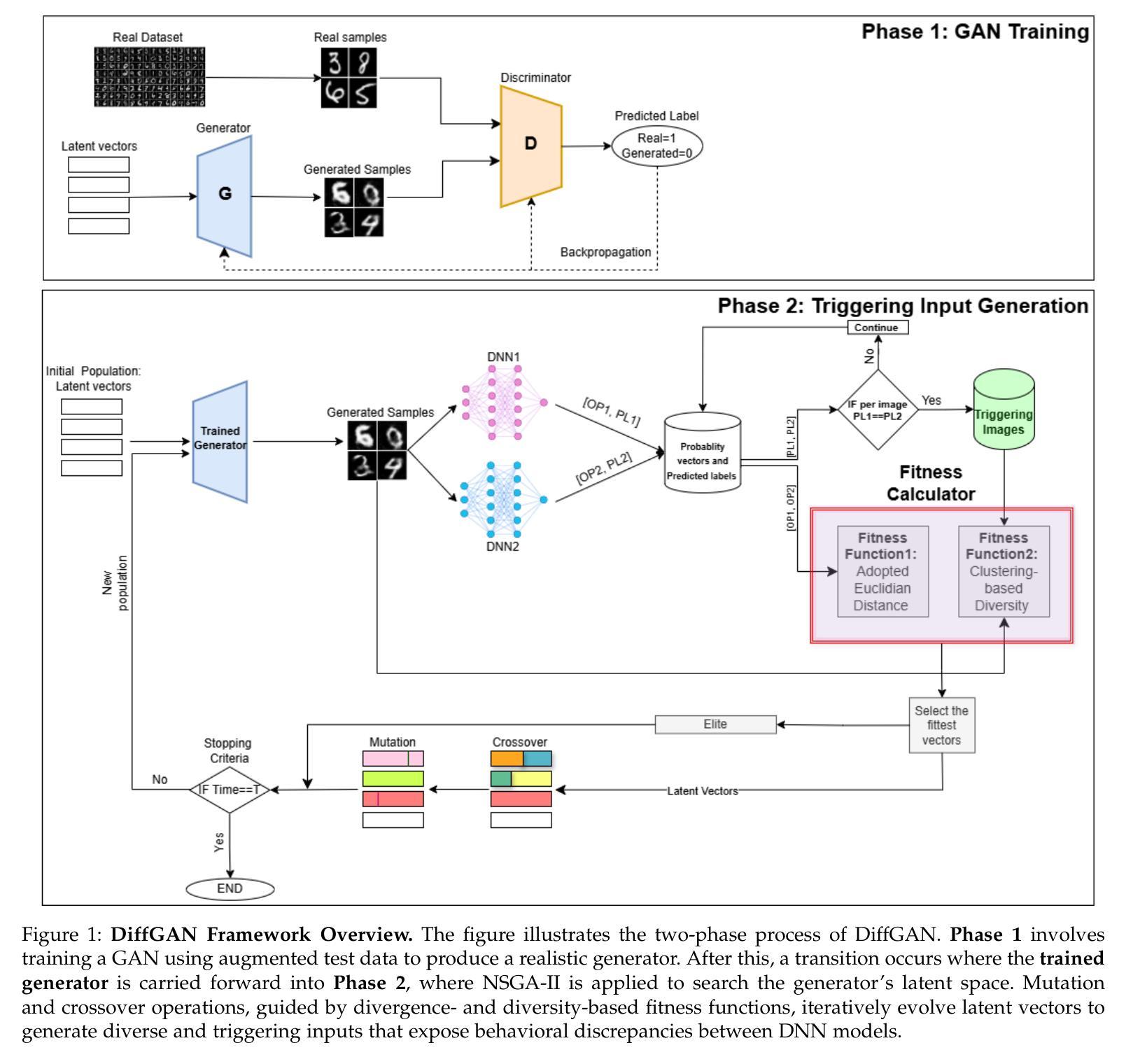
DiffGAN: A Test Generation Approach for Differential Testing of Deep Neural Networks
Authors:Zohreh Aghababaeyan, Manel Abdellatif, Lionel Briand, Ramesh S
Deep Neural Networks (DNNs) are increasingly deployed across applications. However, ensuring their reliability remains a challenge, and in many situations, alternative models with similar functionality and accuracy are available. Traditional accuracy-based evaluations often fail to capture behavioral differences between models, especially with limited test datasets, making it difficult to select or combine models effectively. Differential testing addresses this by generating test inputs that expose discrepancies in DNN model behavior. However, existing approaches face significant limitations: many rely on model internals or are constrained by available seed inputs. To address these challenges, we propose DiffGAN, a black-box test image generation approach for differential testing of DNN models. DiffGAN leverages a Generative Adversarial Network (GAN) and the Non-dominated Sorting Genetic Algorithm II to generate diverse and valid triggering inputs that reveal behavioral discrepancies between models. DiffGAN employs two custom fitness functions, focusing on diversity and divergence, to guide the exploration of the GAN input space and identify discrepancies between models’ outputs. By strategically searching this space, DiffGAN generates inputs with specific features that trigger differences in model behavior. DiffGAN is black-box, making it applicable in more situations. We evaluate DiffGAN on eight DNN model pairs trained on widely used image datasets. Our results show DiffGAN significantly outperforms a SOTA baseline, generating four times more triggering inputs, with greater diversity and validity, within the same budget. Additionally, the generated inputs improve the accuracy of a machine learning-based model selection mechanism, which selects the best-performing model based on input characteristics and can serve as a smart output voting mechanism when using alternative models.
深度神经网络(DNN)在各类应用中的部署日益增多。然而,确保其可靠性仍然是一个挑战。在许多情况下,存在具有相似功能和准确度的替代模型。传统的基于准确度的评估方法往往无法捕捉模型之间的行为差异,特别是在有限的测试数据集下,使得有效地选择或组合模型变得困难。差异测试通过生成暴露DNN模型行为差异的测试输入来解决这个问题。然而,现有方法存在重大局限:许多方法依赖于模型内部,或受到可用种子输入的约束。为了解决这些挑战,我们提出了DiffGAN,这是一种用于DNN模型差异测试的黑盒测试图像生成方法。DiffGAN利用生成对抗网络(GAN)和非支配排序遗传算法II,生成多样且有效的触发输入,以揭示模型之间的行为差异。DiffGAN采用两个自定义的适应度函数,专注于多样性和发散性,以指导GAN输入空间的探索,并识别模型输出之间的差异。通过有针对性地搜索这个空间,DiffGAN生成具有特定特征的输入,这些输入会触发模型行为的差异。DiffGAN是黑盒的,使其能在更多情况下适用。我们在广泛使用的图像数据集上评估了八个DNN模型对DiffGAN的表现。结果表明,DiffGAN显著优于最新基线,在相同的预算内生成了四倍多的触发输入,具有更大的多样性和有效性。此外,生成的输入提高了基于机器学习的模型选择机制的准确性,该机制根据输入特征选择性能最佳的模型,并可以在使用替代模型时作为智能输出投票机制。
论文及项目相关链接
Summary
本文介绍了深度神经网络(DNN)在应用中部署的可靠性挑战。为解决此问题,提出了DiffGAN方法,这是一种针对DNN模型的差异测试的黑盒测试图像生成方法。DiffGAN利用生成对抗网络(GAN)和非支配排序遗传算法II生成揭示模型行为差异的触发输入。通过专注于多样性及差异性两个定制适应度函数,DiffGAN能够在GAN输入空间中寻找特定特征,从而触发模型行为的差异。在广泛使用的图像数据集上训练的八个DNN模型对的评估表明,DiffGAN显著优于当前最佳基线方法,在相同的预算内生成了更多触发输入,并提高了输入多样性和有效性。此外,生成的输入提高了基于机器学习模型的选型机制的准确性。该机制根据输入特性选择最佳性能的模型,也可作为使用替代模型时的智能输出投票机制。
Key Takeaways
- DNN的可靠性是实际应用中的一大挑战,尤其是在有限的测试数据集下评估模型行为差异的难度较高。
- 传统基于准确性的评估方法无法充分捕捉DNN模型间的行为差异。
- DiffGAN是一种针对DNN模型的差异测试的黑盒测试图像生成方法,通过利用GAN和NSGA-II生成揭示模型行为差异的触发输入。
- DiffGAN利用定制适应度函数来平衡生成输入多样性和差异性。
- 与现有方法相比,DiffGAN生成的触发输入更多、更具多样性和有效性。
- 使用DiffGAN生成的输入能提高机器学习模型选型机制的准确性,为选择最佳模型提供有力支持。
点此查看论文截图