⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-14 更新
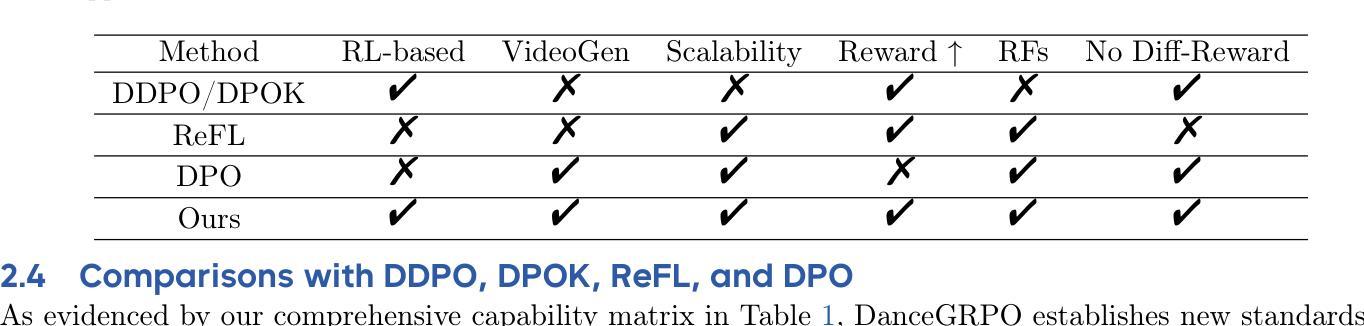
DanceGRPO: Unleashing GRPO on Visual Generation
Authors:Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, Ping Luo
Recent breakthroughs in generative models-particularly diffusion models and rectified flows-have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. Existing reinforcement learning (RL)-based methods for visual generation face critical limitations: incompatibility with modern Ordinary Differential Equations (ODEs)-based sampling paradigms, instability in large-scale training, and lack of validation for video generation. This paper introduces DanceGRPO, the first unified framework to adapt Group Relative Policy Optimization (GRPO) to visual generation paradigms, unleashing one unified RL algorithm across two generative paradigms (diffusion models and rectified flows), three tasks (text-to-image, text-to-video, image-to-video), four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReel-I2V), and five reward models (image/video aesthetics, text-image alignment, video motion quality, and binary reward). To our knowledge, DanceGRPO is the first RL-based unified framework capable of seamless adaptation across diverse generative paradigms, tasks, foundational models, and reward models. DanceGRPO demonstrates consistent and substantial improvements, which outperform baselines by up to 181% on benchmarks such as HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Notably, DanceGRPO not only can stabilize policy optimization for complex video generation, but also enables generative policy to better capture denoising trajectories for Best-of-N inference scaling and learn from sparse binary feedback. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis. The code will be released.
近期生成模型(尤其是扩散模型和校正流)的突破为视觉内容创作带来了革命性的变化,但如何使模型输出与人类偏好保持一致仍然是一个巨大的挑战。现有的基于强化学习(RL)的视觉生成方法面临关键局限性:与现代基于常微分方程(ODE)的采样范式不兼容、大规模训练不稳定、以及视频生成的验证缺乏等。本文介绍了DanceGRPO,这是第一个适应集团相对政策优化(GRPO)的视觉生成范式统一框架,释放了一种统一的强化学习算法,涵盖了两种生成范式(扩散模型和校正流)、三项任务(文本到图像、文本到视频、图像到视频)、四种基础模型(稳定扩散、环远视频、流量、SkyReel-I2V)和五种奖励模型(图像/视频美学、文本-图像对齐、视频运动质量、二元奖励)。据我们所知,DanceGRPO是第一个基于强化学习的统一框架,能够在不同的生成范式、任务、基础模型和奖励模型之间无缝适应。DanceGRPO在HPS-v2.1、CLIP Score、VideoAlign和GenEval等基准测试上实现了持续且显著的改进,超越基线最多达181%。值得一提的是,DanceGRPO不仅能够稳定复杂视频生成的策略优化,还能够使生成策略更好地捕捉去噪轨迹以实现最佳N推理扩展,并从稀疏的二元反馈中学习。我们的结果确立了DanceGRPO在视觉生成中扩展强化学习从人类反馈(RLHF)任务的稳健性和多功能性解决方案,为强化学习与合成之间的和谐提供了新见解。代码将被发布。
论文及项目相关链接
PDF Project Page: https://dancegrpo.github.io/
Summary
本文介绍了DanceGRPO框架,它是基于强化学习的视觉生成统一框架,将群体相对策略优化(GRPO)适应于视觉生成模式。该框架可适应不同的生成模式、任务、基础模型和奖励模型,对复杂的视频生成进行稳定策略优化,并能从稀疏的二元反馈中学习。DanceGRPO显著提高了基准测试的性能,如HPS-v2.1、CLIP Score、VideoAlign和GenEval等,展示了其在视觉生成领域的鲁棒性和通用性。
Key Takeaways
- DanceGRPO是首个统一强化学习框架,适用于视觉生成的多种模式、任务和基础模型。
- 该框架解决了现有强化学习在视觉生成中的关键问题,如与ODEs采样范式的不兼容性、大规模训练的不稳定性以及视频生成的验证缺乏。
- DanceGRPO通过策略优化提高了基准测试性能,最高提升了181%。
- 该框架能够稳定复杂的视频生成策略优化,并从稀疏的二元反馈中学习。
- DanceGRPO能够捕捉去噪轨迹,支持Best-of-N推理扩展。
- 该框架为强化学习从人类反馈(RLHF)任务在视觉生成方面的应用提供了稳健且通用的解决方案。
点此查看论文截图

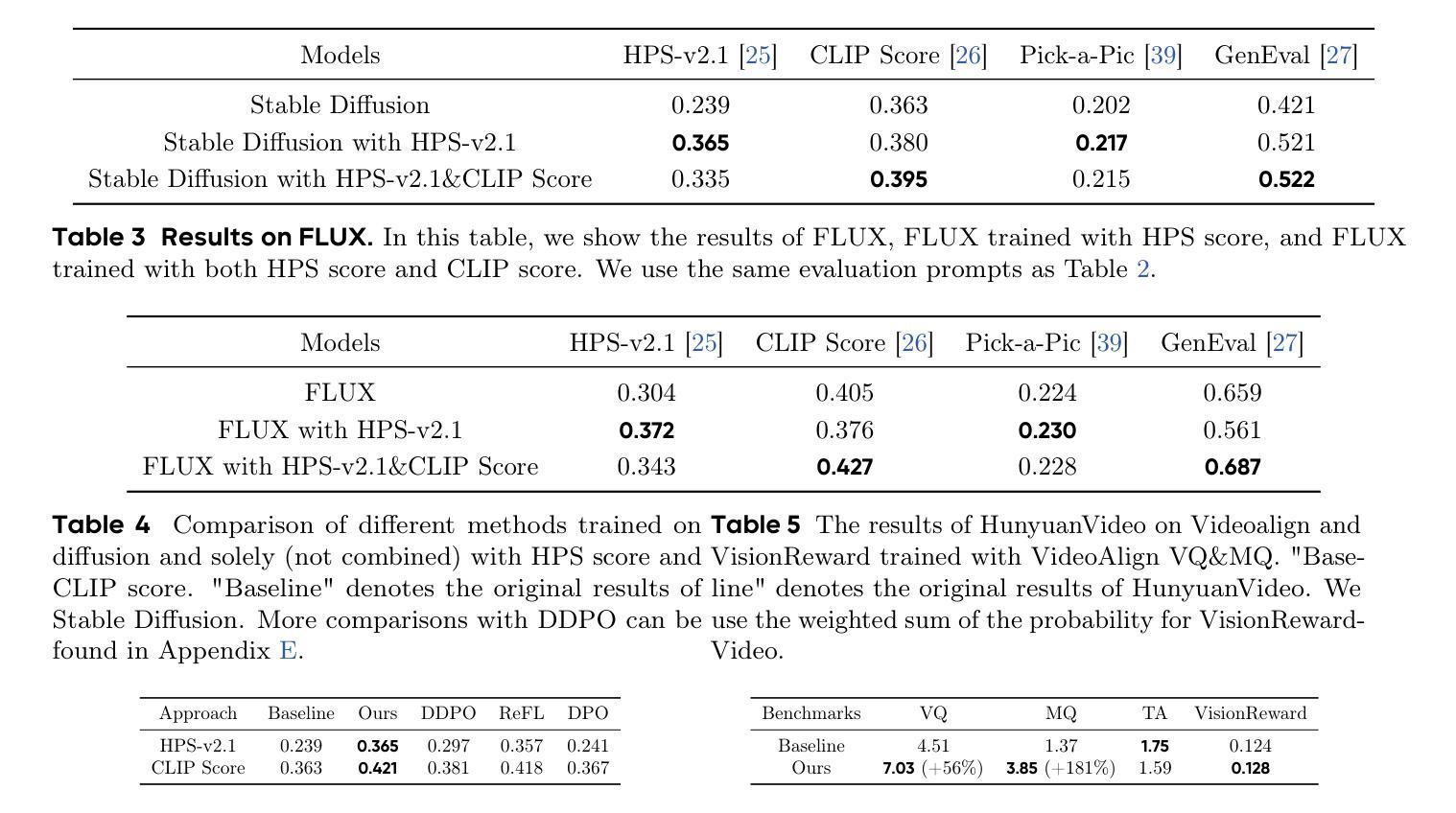
Learning from Peers in Reasoning Models
Authors:Tongxu Luo, Wenyu Du, Jiaxi Bi, Stephen Chung, Zhengyang Tang, Hao Yang, Min Zhang, Benyou Wang
Large Reasoning Models (LRMs) have the ability to self-correct even when they make mistakes in their reasoning paths. However, our study reveals that when the reasoning process starts with a short but poor beginning, it becomes difficult for the model to recover. We refer to this phenomenon as the “Prefix Dominance Trap”. Inspired by psychological findings that peer interaction can promote self-correction without negatively impacting already accurate individuals, we propose Learning from Peers (LeaP) to address this phenomenon. Specifically, every tokens, each reasoning path summarizes its intermediate reasoning and shares it with others through a routing mechanism, enabling paths to incorporate peer insights during inference. However, we observe that smaller models sometimes fail to follow summarization and reflection instructions effectively. To address this, we fine-tune them into our LeaP-T model series. Experiments on AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond show that LeaP provides substantial improvements. For instance, QwQ-32B with LeaP achieves nearly 5 absolute points higher than the baseline on average, and surpasses DeepSeek-R1-671B on three math benchmarks with an average gain of 3.3 points. Notably, our fine-tuned LeaP-T-7B matches the performance of DeepSeek-R1-Distill-Qwen-14B on AIME 2024. In-depth analysis reveals LeaP’s robust error correction by timely peer insights, showing strong error tolerance and handling varied task difficulty. LeaP marks a milestone by enabling LRMs to collaborate during reasoning. Our code, datasets, and models are available at https://learning-from-peers.github.io/ .
大型推理模型(LRMs)即使在推理路径中出错也有自我纠正的能力。然而,我们的研究表明,当推理过程从一个短暂而糟糕的开头开始时,模型很难恢复。我们将这种现象称为“前缀主导陷阱”。受心理学发现的启发,即同伴互动可以促进自我纠正,而不会给已经准确的个体带来负面影响,我们提出了“从同伴学习”(LeaP)来解决这一现象。具体来说,每条推理路径都会汇总其中间推理,并通过路由机制与其他路径分享,从而在推理过程中融入同伴的见解。然而,我们观察到较小的模型有时不能有效地遵循总结和反思指令。为了解决这一问题,我们将它们微调为LeaP-T模型系列。在AIME 2024、AIME 2025、AIMO 2025和GPQA Diamond上的实验表明,LeaP提供了实质性的改进。例如,带有LeaP的QwQ-32B在平均得分上比基线高出近5分,并在三个数学基准测试上超越了DeepSeek-R1-671B,平均提高了3.3分。值得注意的是,我们微调的LeaP-T-7B在AIME 2024上的性能与DeepSeek-R1-Distill-Qwen-14B相匹配。深入分析揭示了LeaP通过及时的同伴见解进行稳健的错误校正,表现出强大的错误容忍能力和处理各种任务难度的能力。LeaP标志着LRMs在推理过程中进行协作的一个里程碑。我们的代码、数据集和模型可在https://learning-from-peers.github.io/找到。
论文及项目相关链接
PDF 29 pages, 32 figures
Summary
大型推理模型(LRMs)具备自我纠错能力,但当推理过程起始于短小的错误开头时,模型难以恢复,这种现象被称为“前缀主导陷阱”。本研究受心理研究的启发,提出了“Learning from Peers”(LeaP)方法来解决这一问题。该方法通过路由机制使每条推理路径汇总其中间推理并与其他路径分享,从而在推理过程中融入同伴见解。针对小型模型在执行总结与反思指令时的不足,我们进行了微调,形成了LeaP-T系列模型。实验表明,LeaP在AIME 2024、AIME 2025、AIMO 2025和GPQA Diamond上的表现有显著提升。例如,QwQ-32B在使用LeaP后平均比基线高出近5个绝对点,并在三个数学基准测试上平均超越了DeepSeek-R1-671B 3.3点。尤其经过调校的LeaP-T-7B在AIME 0上的表现与DeepSeek-R1-Distill-Qwen-14B相匹配。深入分析显示,LeaP通过及时的同伴见解实现了稳健的错误纠正,展现出强大的错误容忍能力和处理不同任务难度的能力。LeaP标志着LRMs在协作推理方面的里程碑式进展。我们的代码、数据集和模型可在https://learning-from-peers.github.io/获取。
Key Takeaways
- 大型推理模型(LRMs)具有自我纠错能力,但在错误开头后难以恢复,称为“前缀主导陷阱”。
- 提出“Learning from Peers”(LeaP)方法,通过同伴间的交互促进自我纠错。
- LeaP方法使每条推理路径能够汇总并分享中间推理,从而融入同伴见解。
- 针对小型模型的不足,进行了微调形成LeaP-T系列。
- LeaP在多个实验中的表现显著优于基线模型,如QwQ-32B和DeepSeek-R1-671B的比较。
- LeaP-T-7B模型经过调校后,在AIME 2024上的表现与高级模型相匹敌。
点此查看论文截图


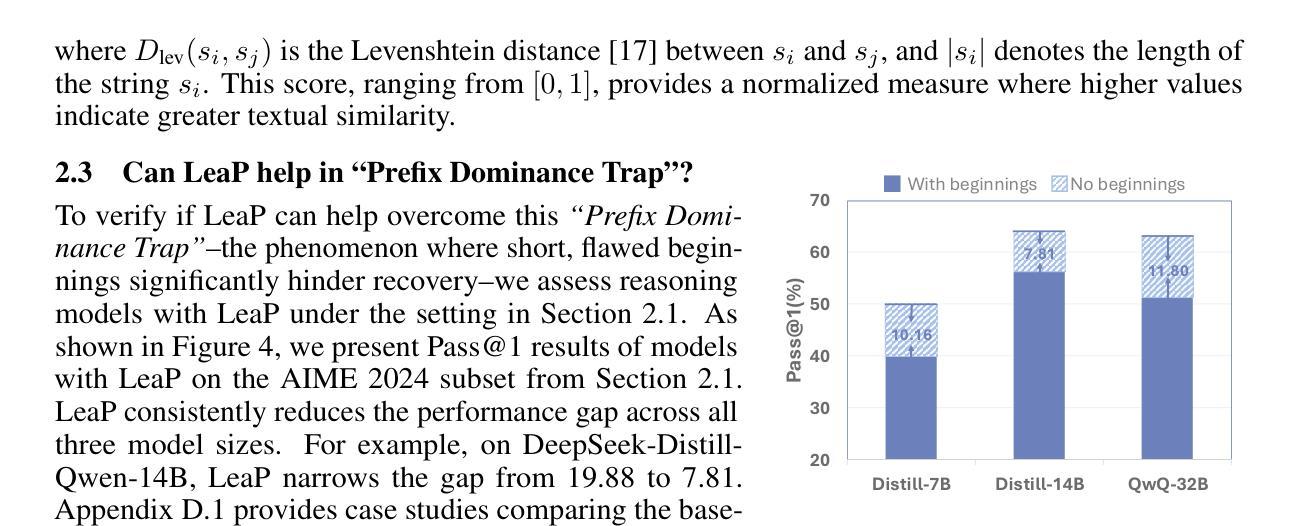
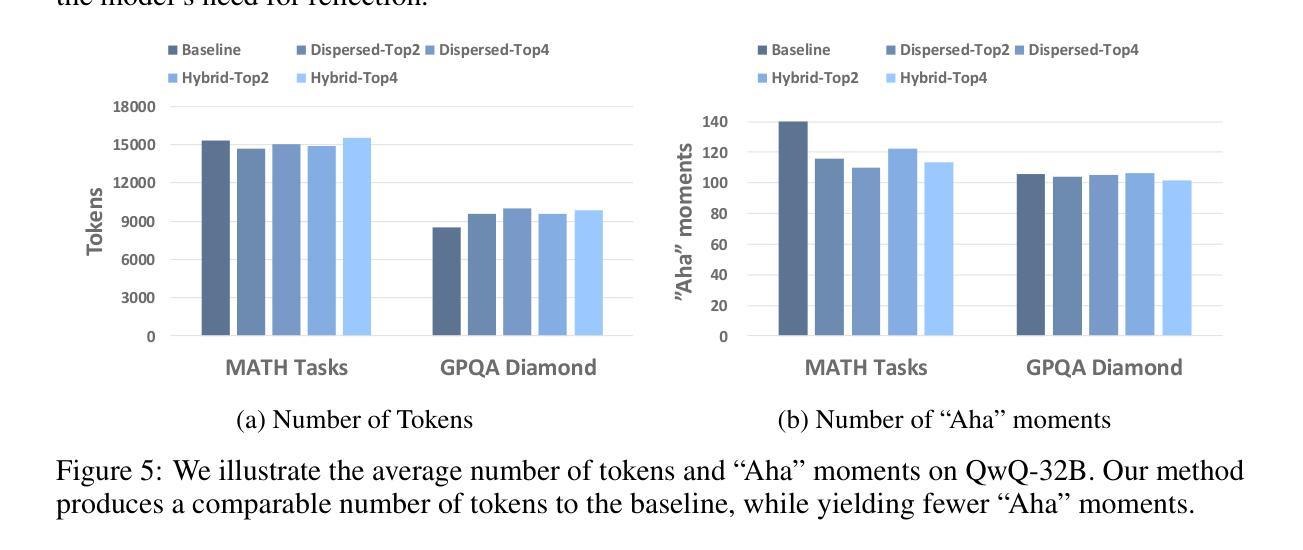
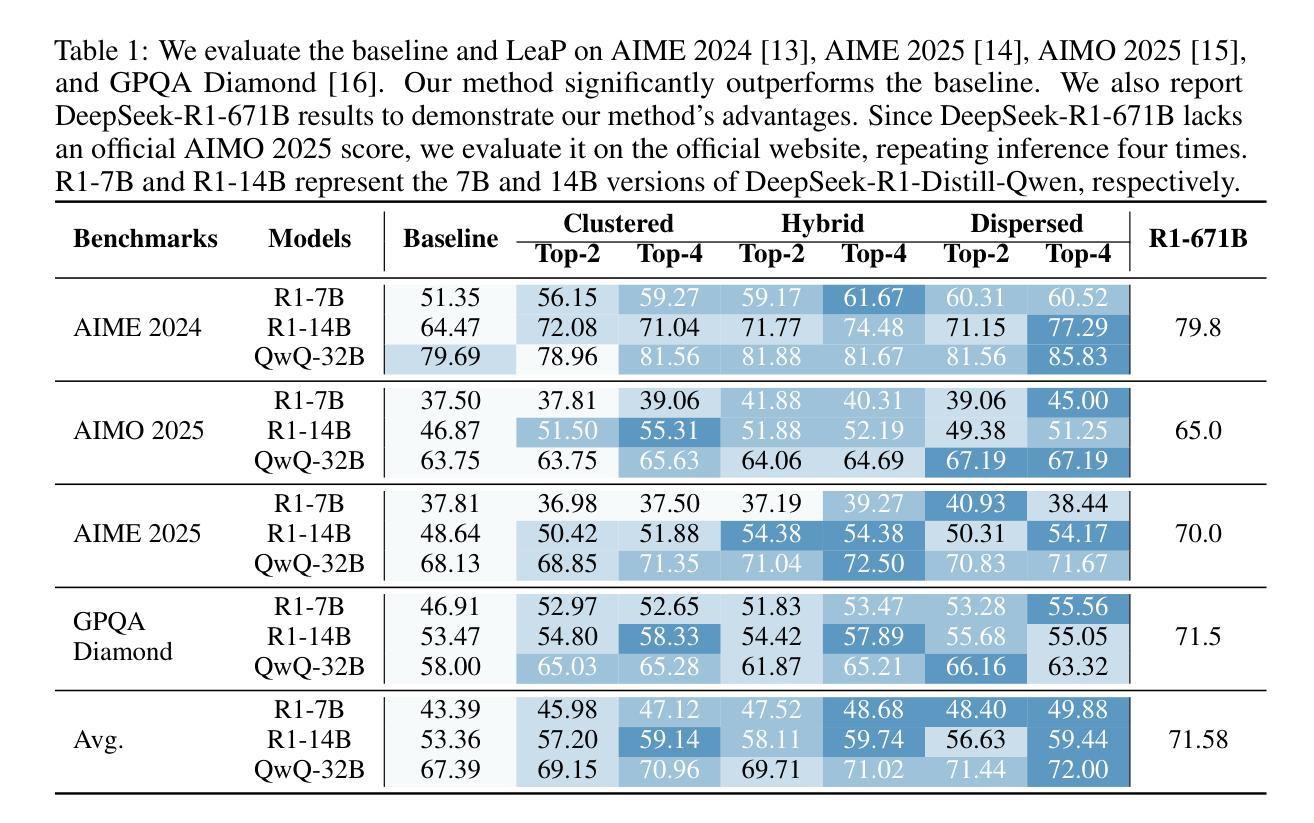
Agent RL Scaling Law: Agent RL with Spontaneous Code Execution for Mathematical Problem Solving
Authors:Xinji Mai, Haotian Xu, Xing W, Weinong Wang, Yingying Zhang, Wenqiang Zhang
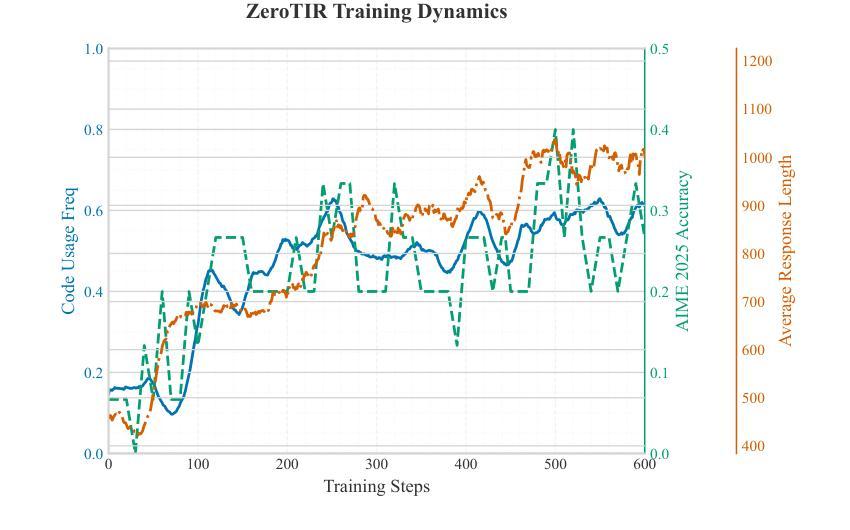
Large Language Models (LLMs) often struggle with mathematical reasoning tasks requiring precise, verifiable computation. While Reinforcement Learning (RL) from outcome-based rewards enhances text-based reasoning, understanding how agents autonomously learn to leverage external tools like code execution remains crucial. We investigate RL from outcome-based rewards for Tool-Integrated Reasoning, ZeroTIR, training base LLMs to spontaneously generate and execute Python code for mathematical problems without supervised tool-use examples. Our central contribution is we demonstrate that as RL training progresses, key metrics scale predictably. Specifically, we observe strong positive correlations where increased training steps lead to increases in the spontaneous code execution frequency, the average response length, and, critically, the final task accuracy. This suggests a quantifiable relationship between computational effort invested in training and the emergence of effective, tool-augmented reasoning strategies. We implement a robust framework featuring a decoupled code execution environment and validate our findings across standard RL algorithms and frameworks. Experiments show ZeroTIR significantly surpasses non-tool ZeroRL baselines on challenging math benchmarks. Our findings provide a foundational understanding of how autonomous tool use is acquired and scales within Agent RL, offering a reproducible benchmark for future studies. Code is released at \href{https://github.com/Anonymize-Author/AgentRL}{https://github.com/Anonymize-Author/AgentRL}.
大型语言模型(LLM)在进行需要精确、可验证计算的数学推理任务时经常遇到困难。虽然基于结果奖励的强化学习(RL)增强了文本推理能力,但了解智能体如何自主学习利用如代码执行等外部工具仍然至关重要。我们研究了基于结果奖励的强化学习在工具集成推理(Tool-Integrated Reasoning)中的应用,即ZeroTIR。我们训练基础LLM,使其能够针对数学问题自发地生成并执行Python代码,无需监督工具使用示例。我们的主要贡献在于证明随着RL训练的进行,关键指标的可预测性。具体来说,我们观察到强烈的正相关关系,其中训练步骤的增加导致自发代码执行频率、平均响应长度和最终任务准确度的提高。这表明在训练过程中投入的计算努力与有效工具增强推理策略的出现之间存在可量化的关系。我们实施了一个稳健的框架,其中包括一个解耦的代码执行环境,并在标准的RL算法和框架上验证了我们的发现。实验表明,ZeroTIR在具有挑战性的数学基准测试上显著超越了非工具ZeroRL的基准。我们的研究为自主工具获取和智能体RL内的扩展提供了基本理解,并为未来的研究提供了一个可复制的标准。代码已发布在https://github.com/Anonymize-Author/AgentRL。
论文及项目相关链接
Summary
大型语言模型(LLMs)在数学推理任务上表现欠佳,需要精确、可验证的计算。本研究通过强化学习(RL)从结果导向奖励出发,提升工具集成推理能力。我们提出了一种名为ZeroTIR的方法,训练基础LLM自主生成并执行Python代码解决数学问题,无需监督工具使用示例。研究发现,随着RL训练的进行,关键指标可预测地增长。如训练步骤的增加导致自主代码执行频率、平均响应长度和任务准确度的提高。这显示了训练投入的计算努力与出现有效工具增强推理策略之间的量化关系。实验证明,ZeroTIR在非工具ZeroRL基准测试上显著超越了具有挑战性的数学基准测试。我们的研究为自主工具获取和Agent RL内的扩展提供了基础理解,并为未来研究提供了可复现的基准。
Key Takeaways
- LLMs面临数学推理任务挑战,需要增强计算精确度。
- 强化学习(RL)能提高工具集成推理能力,尤其是基于结果导向奖励的方法。
- ZeroTIR方法使LLMs能够自主生成并执行Python代码来解决数学问题,无需工具使用示例。
- 随着RL训练的进行,关键性能指标如自主代码执行频率、响应长度和任务准确度呈现正向增长趋势。
- 投入的计算努力与出现有效的工具增强推理策略之间存在量化关系。
- ZeroTIR方法在标准RL算法和框架上表现稳健,显著超越了非工具ZeroRL基准测试。
点此查看论文截图




The Pitfalls of Benchmarking in Algorithm Selection: What We Are Getting Wrong
Authors:Gašper Petelin, Gjorgjina Cenikj
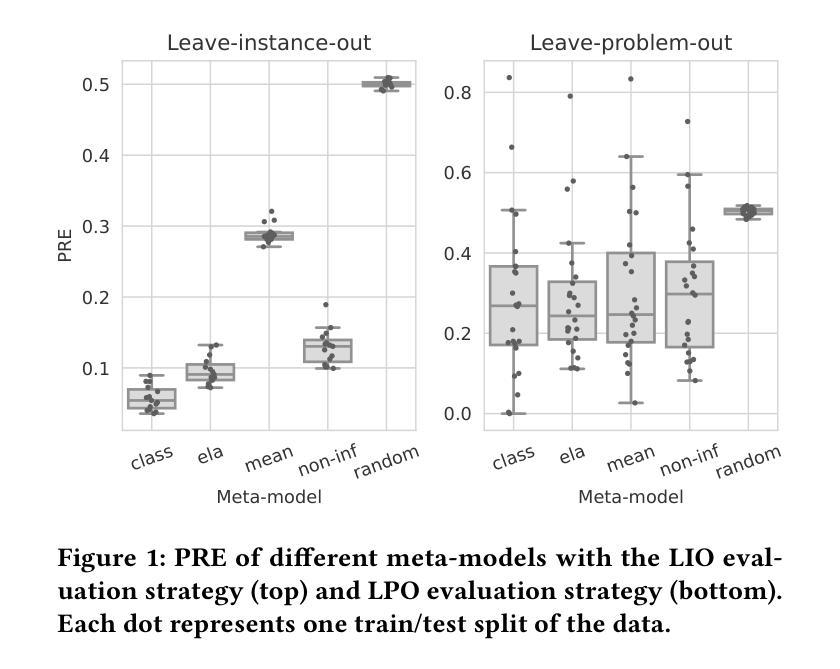
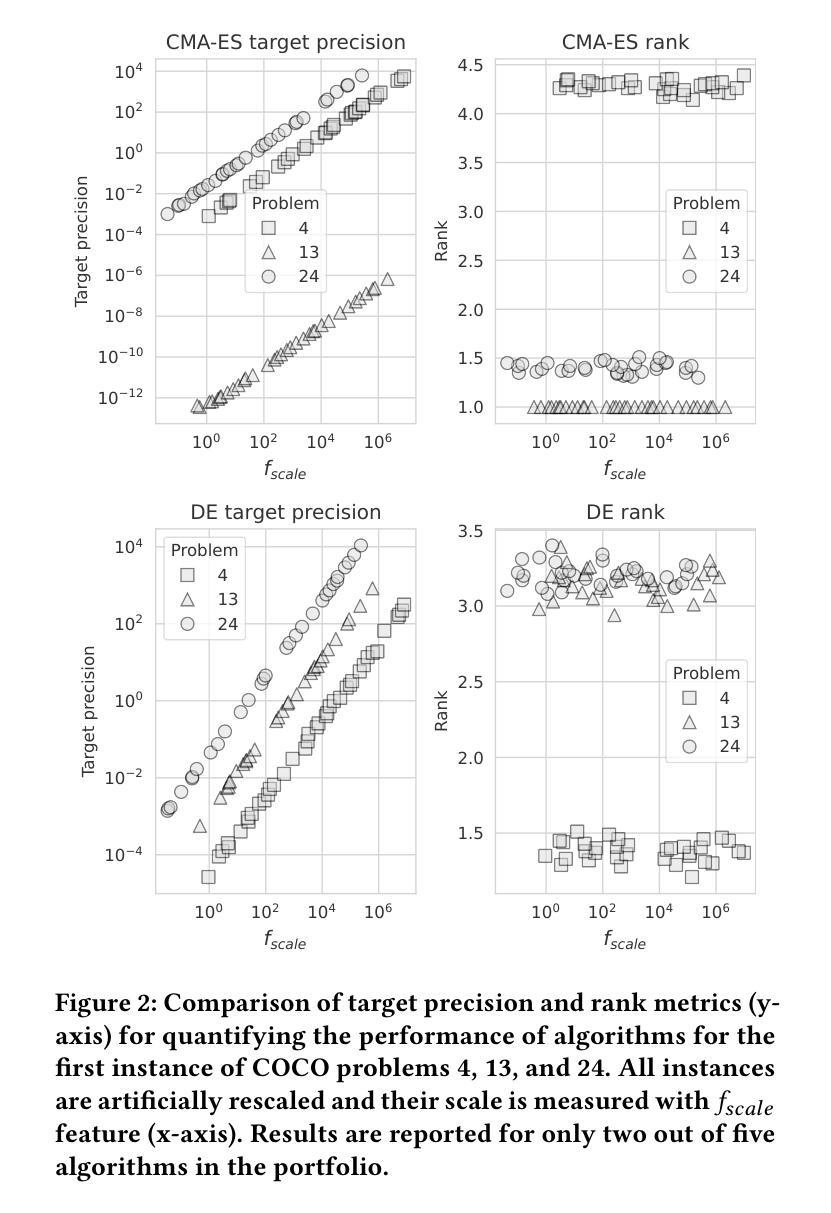
Algorithm selection, aiming to identify the best algorithm for a given problem, plays a pivotal role in continuous black-box optimization. A common approach involves representing optimization functions using a set of features, which are then used to train a machine learning meta-model for selecting suitable algorithms. Various approaches have demonstrated the effectiveness of these algorithm selection meta-models. However, not all evaluation approaches are equally valid for assessing the performance of meta-models. We highlight methodological issues that frequently occur in the community and should be addressed when evaluating algorithm selection approaches. First, we identify flaws with the “leave-instance-out” evaluation technique. We show that non-informative features and meta-models can achieve high accuracy, which should not be the case with a well-designed evaluation framework. Second, we demonstrate that measuring the performance of optimization algorithms with metrics sensitive to the scale of the objective function requires careful consideration of how this impacts the construction of the meta-model, its predictions, and the model’s error. Such metrics can falsely present overly optimistic performance assessments of the meta-models. This paper emphasizes the importance of careful evaluation, as loosely defined methodologies can mislead researchers, divert efforts, and introduce noise into the field
算法选择对于持续的黑盒优化起着至关重要的作用,其目标是为给定问题找到最佳算法。一种常见的方法是通过一系列特征来表示优化函数,然后使用这些特征来训练用于选择适合算法的机器学习元模型。各种方法已经证明了算法选择元模型的有效性。然而,并非所有的评估方法都能有效地评估元模型的性能。我们强调了社区中经常发生的方法论问题,并在评估算法选择方法时应解决这些问题。首先,我们发现了“留一实例”评估技术的缺陷。我们表明,非信息特征和元模型可以达到很高的准确性,这在设计良好的评估框架下是不应出现的。其次,我们证明,使用对目标函数规模敏感的指标来衡量优化算法的性能需要仔细考虑这一点对元模型的构建、预测和模型误差的影响。这样的指标可能会错误地表现出过于乐观的元模型性能评估。本文强调了仔细评估的重要性,因为定义松散的方法可能会误导研究人员、分散精力并为该领域引入噪音。
论文及项目相关链接
Summary
算法选择在连续黑箱优化中起着关键作用,目的是为给定问题选择最佳算法。文中指出评估算法选择元模型性能时存在的问题,如“留出实例”评估技术的缺陷、使用非信息特征和元模型的高精度问题以及目标函数规模对算法性能评估指标的影响等。强调了需要认真对待评估问题,以避免误导研究者、浪费努力以及为领域引入噪声。
Key Takeaways
- 算法选择在连续黑箱优化中的重要性,旨在针对给定问题选择最佳算法。
- 使用特征表示优化函数来训练机器学习元模型进行算法选择的常见方法及其有效性。
- “留出实例”评估技术的缺陷,非信息特征和元模型可能实现高精度,这不应是一个好的评估框架的情况。
- 使用对目标函数规模敏感的指标来评估优化算法的性能的注意事项,及其对元模型的构建、预测和模型误差的影响。
点此查看论文截图

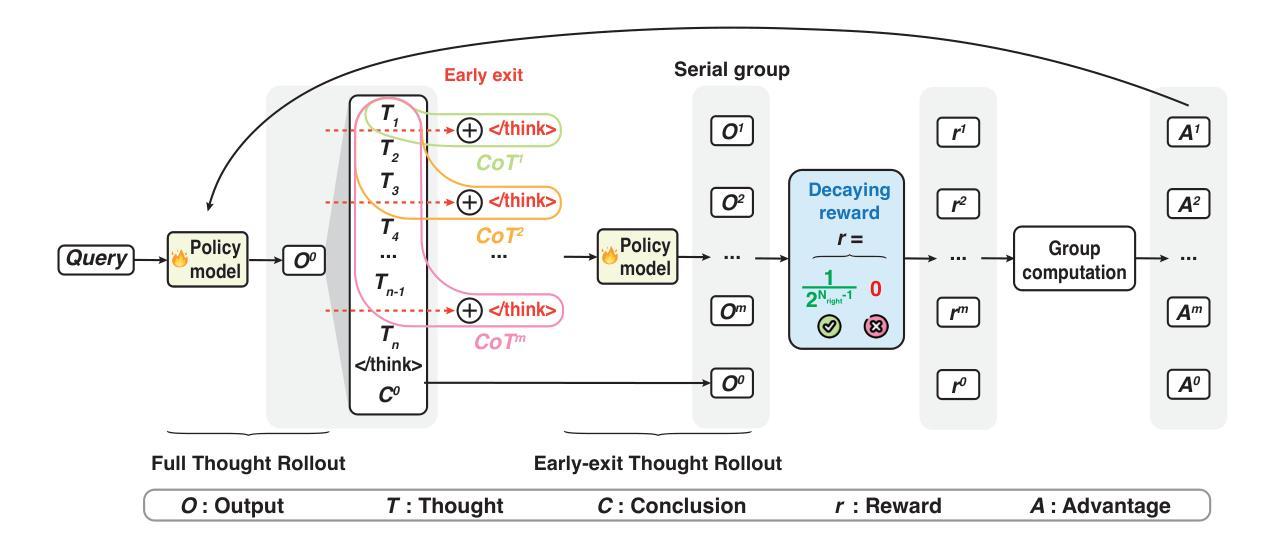
S-GRPO: Early Exit via Reinforcement Learning in Reasoning Models
Authors:Muzhi Dai, Chenxu Yang, Qingyi Si
As Test-Time Scaling emerges as an active research focus in the large language model community, advanced post-training methods increasingly emphasize extending chain-of-thought (CoT) generation length, thereby enhancing reasoning capabilities to approach Deepseek R1-like reasoning models. However, recent studies reveal that reasoning models (even Qwen3) consistently exhibit excessive thought redundancy in CoT generation. This overthinking problem stems from conventional outcome-reward reinforcement learning’s systematic neglect in regulating intermediate reasoning steps. This paper proposes Serial-Group Decaying-Reward Policy Optimization (namely S-GRPO), a novel reinforcement learning method that empowers models with the capability to determine the sufficiency of reasoning steps, subsequently triggering early exit of CoT generation. Specifically, unlike GRPO, which samples multiple possible completions (parallel group) in parallel, we select multiple temporal positions in the generation of one CoT to allow the model to exit thinking and instead generate answers (serial group), respectively. For the correct answers in a serial group, we assign rewards that decay according to positions, with lower rewards towards the later ones, thereby reinforcing the model’s behavior to generate higher-quality answers at earlier phases with earlier exits of thinking. Empirical evaluations demonstrate compatibility with state-of-the-art reasoning models, including Qwen3 and Deepseek-distill models, achieving 35.4% ~ 61.1% sequence length reduction with 0.72% ~ 6.08% accuracy improvements across GSM8K, AIME 2024, AMC 2023, MATH-500, and GPQA Diamond benchmarks.
随着测试时间缩放(Test-Time Scaling)在大语言模型社区中成为一个活跃的研究焦点,先进的后训练方法越来越强调延长思维链(CoT)生成长度,从而提高推理能力,以达到Deepseek R1等推理模型的水平。然而,最近的研究表明,即使在先进的推理模型(如Qwen3)中,思维链生成也存在过多的思维冗余。这种过度思考的问题源于传统结果奖励强化学习在调节中间推理步骤时的系统性忽视。本文提出了串行组衰减奖励策略优化(简称S-GRPO),这是一种新型的强化学习方法,使模型具备判断推理步骤是否充足的能力,从而触发思维链生成的早期退出。具体来说,与GRPO不同,GRPO会并行采样多个可能的完成结果(并行组),而我们选择在一个思维链生成中的多个时间位置,允许模型停止思考并转而生成答案(串行组)。对于串行组中的正确答案,我们根据位置赋予衰减的奖励,后面的答案奖励较低,从而强化模型在较早阶段生成高质量答案的行为,并尽早退出思考。实证评估表明,该方法与包括Qwen3和Deepseek-distill模型在内的最新推理模型兼容,在GSM8K、AIME 2024、AMC 2023、MATH-500和GPQA Diamond等多个基准测试上实现了35.4% ~ 61.1%的序列长度减少,同时准确率提高了0.72% ~ 6.08%。
论文及项目相关链接
Summary
本文探讨了测试时缩放(Test-Time Scaling)作为大型语言模型社区中的活跃研究领域,强调在训练后扩展思维链生成长度的重要性,以增强推理能力并接近Deepseek R1类推理模型。然而,研究发现现有推理模型在思维链生成中存在过度冗余的问题。针对这一问题,本文提出了一种新的强化学习策略——串行分组衰减奖励策略优化(S-GRPO),使模型具备判断推理步骤充分性的能力,从而实现在思维链生成的早期退出。S-GRPO在不同数据集上的实验结果显示其可以兼容最新的推理模型并减少序列长度,同时提高准确性。
Key Takeaways
- 测试时缩放是当前大型语言模型社区的研究重点,旨在提高模型的推理能力。
- 当前推理模型存在思维链生成过度冗余的问题。
- S-GRPO是一种新的强化学习策略,用于优化推理模型的思维链生成。
- S-GRPO通过判断推理步骤的充分性来实现早期退出思维链生成。
- S-GRPO与现有推理模型兼容,如Qwen3和Deepseek-distill模型。
- S-GRPO可以在不同数据集上实现序列长度减少和准确性提高。
点此查看论文截图



MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining
Authors:Xiaomi LLM-Core Team, :, Bingquan Xia, Bowen Shen, Cici, Dawei Zhu, Di Zhang, Gang Wang, Hailin Zhang, Huaqiu Liu, Jiebao Xiao, Jinhao Dong, Liang Zhao, Peidian Li, Peng Wang, Shihua Yu, Shimao Chen, Weikun Wang, Wenhan Ma, Xiangwei Deng, Yi Huang, Yifan Song, Zihan Jiang, Bowen Ye, Can Cai, Chenhong He, Dong Zhang, Duo Zhang, Guoan Wang, Hao Tian, Haochen Zhao, Heng Qu, Hongshen Xu, Jun Shi, Kainan Bao, QingKai Fang, Kang Zhou, Kangyang Zhou, Lei Li, Menghang Zhu, Nuo Chen, Qiantong Wang, Shaohui Liu, Shicheng Li, Shuhao Gu, Shuhuai Ren, Shuo Liu, Sirui Deng, Weiji Zhuang, Weiwei Lv, Wenyu Yang, Xin Zhang, Xing Yong, Xing Zhang, Xingchen Song, Xinzhe Xu, Xu Wang, Yihan Yan, Yu Tu, Yuanyuan Tian, Yudong Wang, Yue Yu, Zhenru Lin, Zhichao Song, Zihao Yue
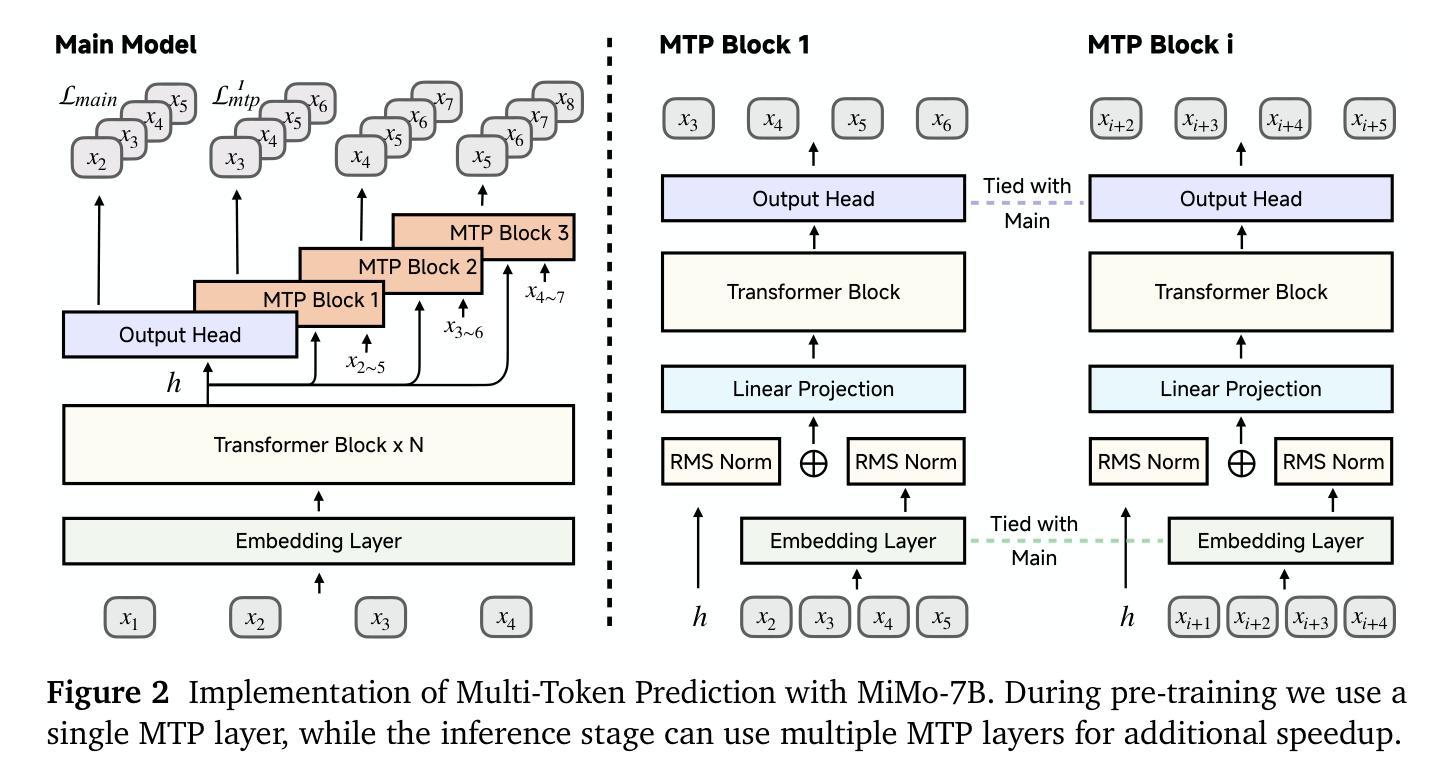
We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model’s reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
我们推出了MiMo-7B,这是一款专为推理任务设计的大型语言模型,在预训练和后训练阶段都进行了优化。在预训练阶段,我们增强了数据预处理流程,并采用了三阶段数据混合策略,以加强基础模型的推理潜力。MiMo-7B-Base在25万亿个令牌上进行预训练,并增加了多令牌预测目标,以提高性能和加速推理速度。在后训练阶段,我们整理了一个包含13万个可验证的数学和编程问题的数据集,用于强化学习。我们采用测试难度驱动的代码奖励方案来缓解稀疏奖励问题,并采用战略数据重采样来稳定训练。广泛评估表明,MiMo-7B-Base具有出色的推理潜力,甚至超过了许多更大的32B模型。最终的RL调优模型MiMo-7B-RL在数学、代码和一般推理任务上表现出卓越的性能,超越了OpenAI o1-mini的性能。该模型的检查点位于 https://github.com/xiaomimimo/MiMo。
论文及项目相关链接
Summary
MiMo-7B是为推理任务设计的大型语言模型,其在预训练和微调阶段进行了优化。预训练阶段增强了数据预处理流程,并采用了三阶段数据混合策略来提升基础模型的推理能力。MiMo-7B-Base在25万亿个令牌上进行预训练,并增加了多令牌预测目标以提高性能和加速推理速度。微调阶段则使用数据集整合强化学习,通过测试难度驱动的奖励方案和策略数据重采样,实现训练的稳定化。评价结果显示,MiMo-7B系列模型表现出强大的推理潜力,尤其是在数学、代码和通用推理任务上超越了其他大型模型。模型的检查点可以在相关链接找到。
Key Takeaways
- MiMo-7B是为推理任务设计的大型语言模型。
- 预训练阶段增强了数据预处理流程并采用三阶段数据混合策略提升模型推理能力。
- MiMo-7B-Base在大量数据上进行预训练,增加多令牌预测目标以提升性能。
- 调和阶段通过整合强化学习来提升模型在数学和编程问题上的表现。
- 模型采用测试难度驱动的奖励方案来解决稀疏奖励问题,并使用战略数据重采样来稳定训练。
- MiMo-7B系列模型展现出强大的推理潜力,在某些任务上超越了更大的模型。
点此查看论文截图
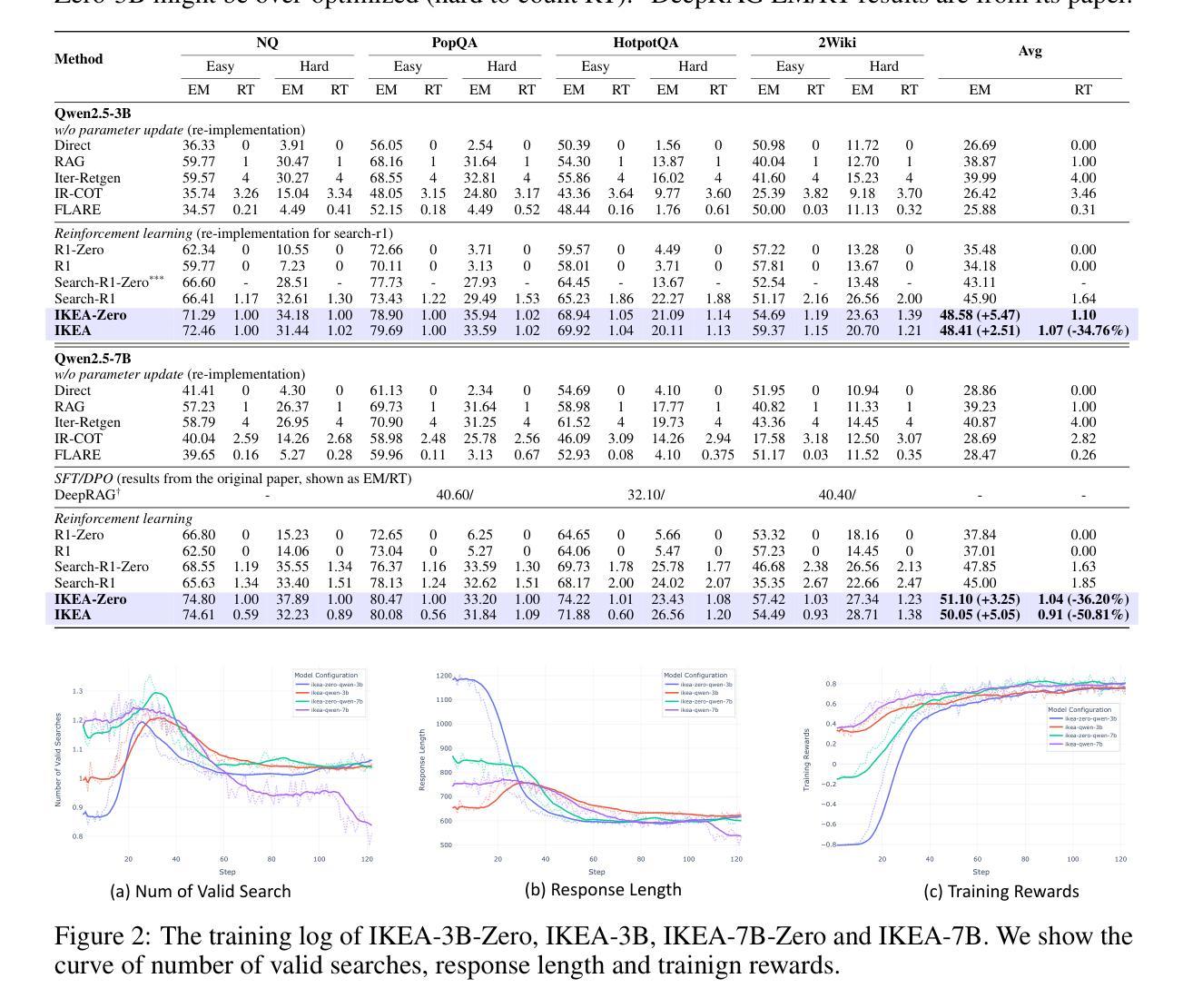
Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search Agent
Authors:Ziyang Huang, Xiaowei Yuan, Yiming Ju, Jun Zhao, Kang Liu
Retrieval-augmented generation (RAG) is a common strategy to reduce hallucinations in Large Language Models (LLMs). While reinforcement learning (RL) can enable LLMs to act as search agents by activating retrieval capabilities, existing ones often underutilize their internal knowledge. This can lead to redundant retrievals, potential harmful knowledge conflicts, and increased inference latency. To address these limitations, an efficient and adaptive search agent capable of discerning optimal retrieval timing and synergistically integrating parametric (internal) and retrieved (external) knowledge is in urgent need. This paper introduces the Reinforced Internal-External Knowledge Synergistic Reasoning Agent (IKEA), which could indentify its own knowledge boundary and prioritize the utilization of internal knowledge, resorting to external search only when internal knowledge is deemed insufficient. This is achieved using a novel knowledge-boundary aware reward function and a knowledge-boundary aware training dataset. These are designed for internal-external knowledge synergy oriented RL, incentivizing the model to deliver accurate answers, minimize unnecessary retrievals, and encourage appropriate external searches when its own knowledge is lacking. Evaluations across multiple knowledge reasoning tasks demonstrate that IKEA significantly outperforms baseline methods, reduces retrieval frequency significantly, and exhibits robust generalization capabilities.
检索增强生成(RAG)是减少大型语言模型(LLM)中出现幻觉的常见策略。虽然强化学习(RL)可以使LLM通过激活检索功能来充当搜索代理,但现有的强化学习通常未能充分利用其内部知识。这可能导致冗余的检索、潜在的有害知识冲突和增加的推理延迟。为了解决这些局限性,迫切需要一种高效且自适应的搜索代理,该代理能够辨别最佳的检索时间,并协同整合参数化(内部)和检索(外部)知识。本文介绍了强化内部与外部知识协同推理代理(IKEA),该代理能够识别其自身的知识边界,并优先利用内部知识,仅在认为内部知识不足时才求助于外部搜索。这是通过使用新型的知识边界感知奖励函数和知识边界感知训练数据集来实现的,这些是为了面向内部和外部知识协同的RL设计的,激励模型提供准确答案,减少不必要的检索,并在自身知识不足时鼓励适当的外部搜索。在多个知识推理任务上的评估表明,IKEA显著优于基准方法,大大降低了检索频率,并表现出稳健的泛化能力。
论文及项目相关链接
Summary:本研究提出了增强型内部外部知识协同推理模型(IKEA),能有效减少冗余检索并应对潜在的外部知识冲突。该模型采用知识边界意识奖励函数和训练数据集设计,使模型能精准区分最优检索时机,并协同利用内部和外部知识。相较于基线方法,IKEA在多个知识推理任务上表现优异,显著减少了检索频率并展现出强大的泛化能力。
Key Takeaways:
- IKEA模型能有效解决大型语言模型中常见的检索增强生成(RAG)策略的局限性问题。
- 模型采用强化学习(RL)技术,使得大型语言模型能够作为搜索代理来激活检索能力。
- 现有模型通常忽视内部知识的利用,可能导致冗余检索和知识冲突。
- IKEA能够确定自身知识边界,优先利用内部知识,只在必要时进行外部搜索。
- 模型通过知识边界意识奖励函数和训练数据集设计实现内部和外部知识的协同。
- 实验结果显示,IKEA在多个知识推理任务上表现优越,能显著提高答案的准确性,减少不必要的检索并促进适当的外部搜索。
点此查看论文截图


Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
Authors:Bohan Wang, Zhongqi Yue, Fengda Zhang, Shuo Chen, Li’an Bi, Junzhe Zhang, Xue Song, Kennard Yanting Chan, Jiachun Pan, Weijia Wu, Mingze Zhou, Wang Lin, Kaihang Pan, Saining Zhang, Liyu Jia, Wentao Hu, Wei Zhao, Hanwang Zhang
We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior – mirroring the causal structure of language – into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture – like that in LLMs – without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
我们完全摒弃了传统的空间先验图像表示方法,并引入了一种新型离散视觉分词器:自洽分词器(Selftok)。在设计核心,我们通过图像生成的逆向扩散过程,将自回归(AR)先验——反映语言的因果结构——融入视觉标记中。AR特性使得Selftok在以下几个方面与传统的空间标记有着根本的区别:首先,Selftok为整合扩散和AR的视语言模型(VLMs)提供了优雅且极简的方法:通过Selftok令牌表示图像,我们可以使用纯离散自回归架构来训练VLM,类似于大型语言模型(LLM),无需额外的模块或训练目标。其次,我们从理论上证明了AR先验满足贝尔曼方程,而空间先验则不满足。因此,Selftok支持用于视觉生成的强化学习(RL),其效果可与LLM所实现的效果相当。除了AR特性外,Selftok还是一种先进的分词器,实现了高质量重建和压缩率之间的有利权衡。我们使用Selftok为视觉理解和生成任务构建纯AR的VLM。令人印象深刻的是,不使用任何文本-图像训练对,一个简单的策略梯度RL在视觉令牌中可以显著提高视觉生成基准测试成绩,大大超越现有模型。因此,我们认为Selftok有效地解决了长期存在的挑战,即视觉令牌无法支持有效的RL。当与RL在LLM中的既定优势相结合时,这使我们离实现真正的多模态LLM又近了一步。项目页面:https://selftok-team.github.io/report/。
论文及项目相关链接
Summary
本文摒弃了传统的空间先验图像表示方法,提出了一种新型离散视觉令牌器:自洽令牌器(Selftok)。其设计核心是通过图像生成的逆向扩散过程,使用自回归(AR)先验来生成视觉令牌,这反映了语言的因果结构。Selftok在以下两个方面使传统空间令牌相形见绌:一、它为融合扩散和AR的视听语言模型(VLMs)提供了一种优雅而简洁的方法;二、理论证明AR先验满足贝尔曼方程,而空间先验则不满足。Selftok支持强化学习(RL)在视觉生成方面的应用,效果与大型语言模型(LLMs)相当。此外,Selftok还是一个先进的令牌化器,实现了高质量重建与压缩率之间的良好平衡。我们利用Selftok建立了一个纯AR的VLM,用于视觉理解和生成任务。在不使用任何文本-图像训练对的情况下,简单的基于视觉令牌的策略梯度RL可以显著提高视觉生成基准测试的性能,大大超越现有模型。因此,我们相信Selftok有效地解决了长期存在的挑战,即视觉令牌无法支持有效的RL。
Key Takeaways
- 引入了一种新型离散视觉令牌器——自洽令牌器(Selftok),摒弃了传统空间先验图像表示方法。
- Selftok的核心设计是运用自回归(AR)先验生成视觉令牌,这反映了语言的因果结构。
- Selftok在视觉令牌化方面表现优异,实现了高质量重建与压缩率之间的平衡。
- Selftok为视听语言模型(VLMs)提供了一种融合扩散和AR的简洁方法,并能在不依赖额外模块或训练目标的情况下训练VLM。
- AR先验满足贝尔曼方程,适合用于强化学习(RL)在视觉生成方面的应用。
- 在不使用文本-图像训练对的情况下,基于Selftok的视觉令牌能通过简单的策略梯度RL显著提高视觉生成性能。
点此查看论文截图

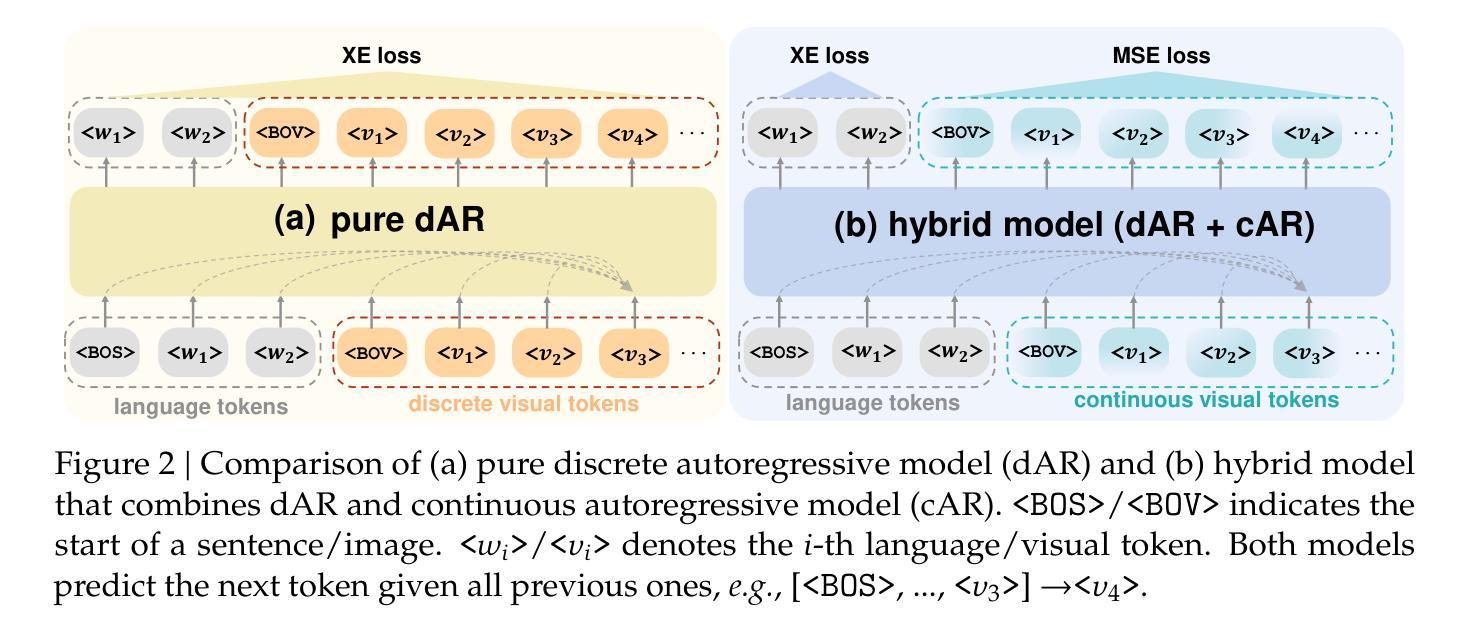

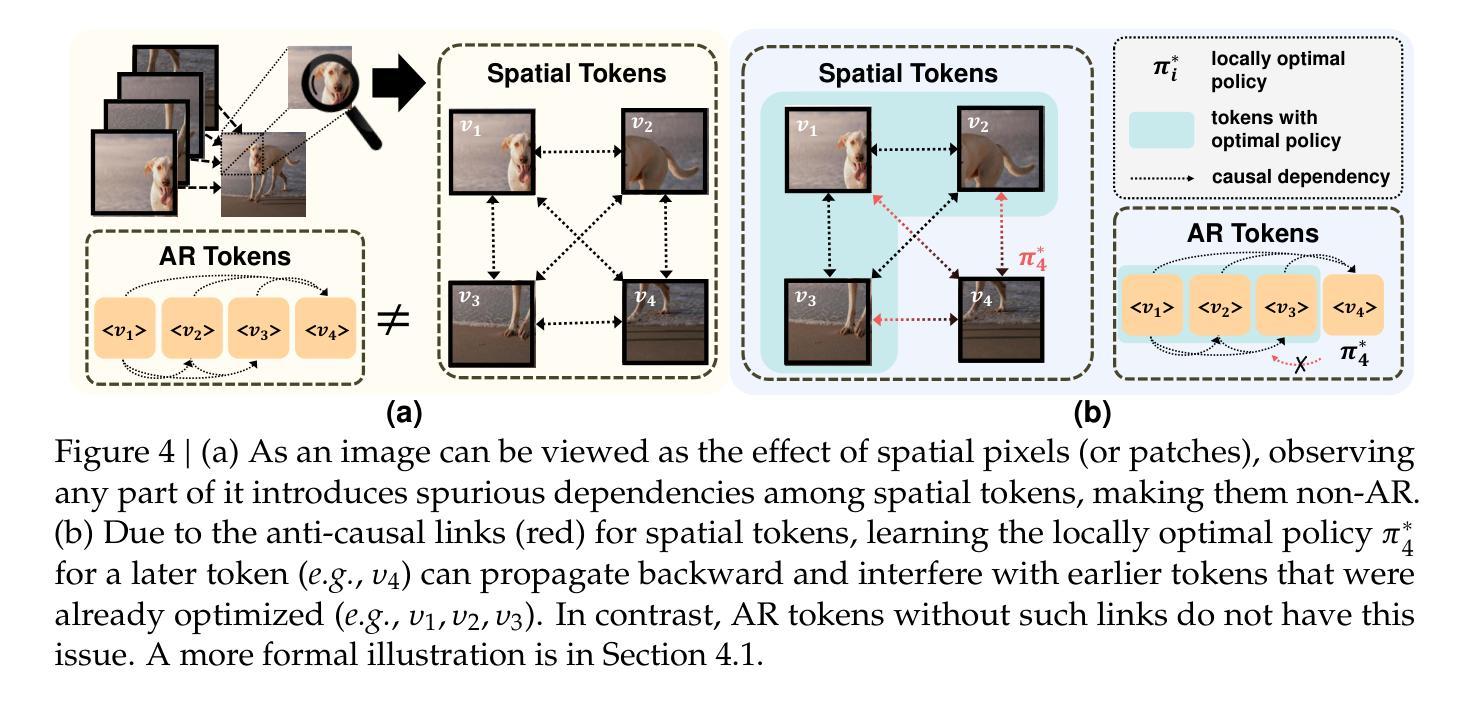
Kalman Filter Enhanced GRPO for Reinforcement Learning-Based Language Model Reasoning
Authors:Hu Wang, Congbo Ma, Ian Reid, Mohammad Yaqub
Reward baseline is important for Reinforcement Learning (RL) algorithms to reduce variance in policy gradient estimates. Recently, for language modeling, Group Relative Policy Optimization (GRPO) is proposed to compute the advantage for each output by subtracting the mean reward, as the baseline, for all outputs in the group. However, it can lead to inaccurate advantage estimates in environments with highly noisy rewards, potentially introducing bias. In this work, we propose a model, called Kalman Filter Enhanced Group Relative Policy Optimization (KRPO), by using lightweight Kalman filtering to dynamically estimate the latent reward mean and variance. This filtering technique replaces the naive batch mean baseline, enabling more adaptive advantage normalization. Our method does not require additional learned parameters over GRPO. This approach offers a simple yet effective way to incorporate multiple outputs of GRPO into advantage estimation, improving policy optimization in settings where highly dynamic reward signals are difficult to model for language models. Through experiments and analyses, we show that using a more adaptive advantage estimation model, KRPO can improve the stability and performance of GRPO. The code is available at https://github.com/billhhh/KRPO_LLMs_RL
奖励基线在强化学习(RL)算法中非常重要,可以减少策略梯度估计中的方差。最近,对于语言建模,提出了集团相对策略优化(GRPO),通过减去所有输出组的平均奖励作为基线,为每个输出计算优势。然而,在奖励高度嘈杂的环境中,这可能导致优势估计不准确,从而引入偏见。在这项工作中,我们提出了一种模型,称为卡尔曼滤波增强型集团相对策略优化(KRPO),通过使用轻量级的卡尔曼滤波来动态估计潜在奖励的平均值和方差。这种滤波技术替代了简单的批量均值基线,使优势归一化更加自适应。我们的方法不需要在GRPO之上学习额外的参数。这种方法为将GRPO的多个输出纳入优势估计提供了一种简单而有效的方法,特别是在难以对语言模型进行建模的高度动态奖励信号环境中,可以改善策略优化。通过实验和分析,我们证明了使用更自适应的优势估计模型KRPO可以提高GRPO的稳定性和性能。代码可在https://github.com/billhhh/KRPO_LLMs_RL找到。
论文及项目相关链接
Summary
强化学习中奖励基线对于减少策略梯度估计的方差至关重要。针对语言建模,提出了Group Relative Policy Optimization (GRPO),通过减去所有输出组的平均奖励作为基线来计算每个输出的优势。然而,在奖励高度嘈杂的环境中,这可能导致优势估计不准确,并可能引入偏见。本研究提出了Kalman Filter Enhanced Group Relative Policy Optimization (KRPO),利用轻量级Kalman滤波动态估计潜在奖励均值和方差,替代了基于批量均值基线的简单策略。该方法允许更好地进行优势归一化,而无需在GRPO之上引入额外的学习参数。这种方法提供了一种简单有效的方法,可以将GRPO的多个输出纳入优势估计中,并在高度动态的奖励信号难以建模的情况下改进策略优化。实验和分析表明,使用更自适应的优势估计模型KRPO可以提高GRPO的稳定性和性能。
Key Takeaways
- 强化学习中奖励基线对于减少策略梯度估计的方差至关重要。
- Group Relative Policy Optimization (GRPO) 提出通过减去组内的平均奖励作为基线来计算每个输出的优势。
- 在高噪音奖励环境下,GRPO可能导致优势估计不准确。
- Kalman Filter Enhanced Group Relative Policy Optimization (KRPO) 利用Kalman滤波动态估计奖励均值和方差,改进了优势估计。
- KRPO方法提高了GRPO的稳定性和性能。
- KRPO方法无需在GRPO基础上引入额外的学习参数。
- 实验和分析验证了KRPO在动态奖励信号环境下的有效性。
点此查看论文截图

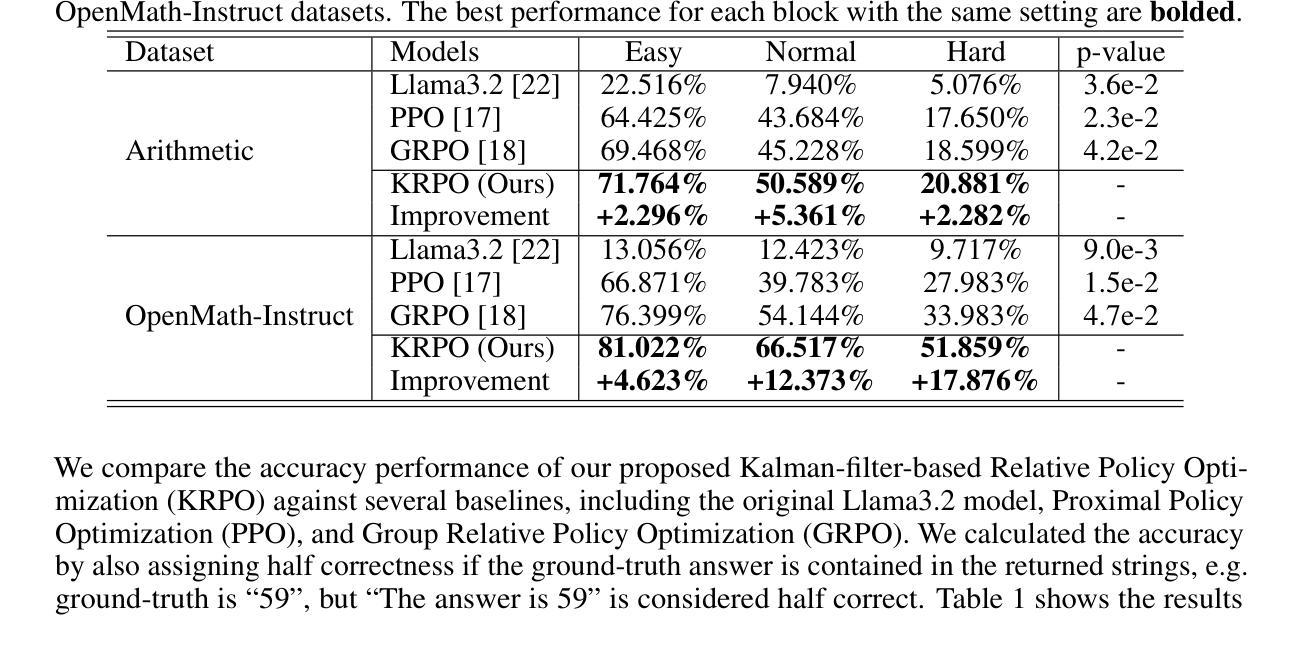
Learning to Reason and Navigate: Parameter Efficient Action Planning with Large Language Models
Authors:Bahram Mohammadi, Ehsan Abbasnejad, Yuankai Qi, Qi Wu, Anton Van Den Hengel, Javen Qinfeng Shi
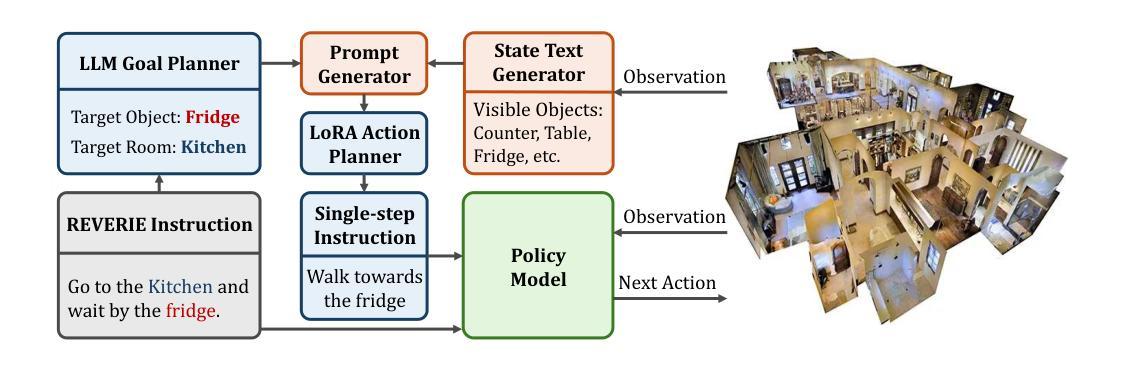
The remote embodied referring expression (REVERIE) task requires an agent to navigate through complex indoor environments and localize a remote object specified by high-level instructions, such as “bring me a spoon”, without pre-exploration. Hence, an efficient navigation plan is essential for the final success. This paper proposes a novel parameter-efficient action planner using large language models (PEAP-LLM) to generate a single-step instruction at each location. The proposed model consists of two modules, LLM goal planner (LGP) and LoRA action planner (LAP). Initially, LGP extracts the goal-oriented plan from REVERIE instructions, including the target object and room. Then, LAP generates a single-step instruction with the goal-oriented plan, high-level instruction, and current visual observation as input. PEAP-LLM enables the embodied agent to interact with LAP as the path planner on the fly. A simple direct application of LLMs hardly achieves good performance. Also, existing hard-prompt-based methods are error-prone in complicated scenarios and need human intervention. To address these issues and prevent the LLM from generating hallucinations and biased information, we propose a novel two-stage method for fine-tuning the LLM, consisting of supervised fine-tuning (STF) and direct preference optimization (DPO). SFT improves the quality of generated instructions, while DPO utilizes environmental feedback. Experimental results show the superiority of our proposed model on REVERIE compared to the previous state-of-the-art.
远程实体参照表达(REVERIE)任务要求智能体在复杂的室内环境中进行导航,并定位由高级指令指定的远程对象,例如“给我拿一个勺子”,无需预先探索。因此,有效的导航计划对于最终的成功至关重要。本文提出了一种新的参数高效动作规划器,使用大型语言模型(PEAP-LLM),在每个位置生成单步指令。所提出的模型由两个模块组成,即LLM目标规划器(LGP)和LoRA动作规划器(LAP)。首先,LGP从REVERIE指令中提取目标导向计划,包括目标对象和房间。然后,LAP以目标导向计划、高级指令和当前视觉观察为输入,生成单步指令。PEAP-LLM使实体智能体能够即时与LAP作为路径规划器进行交互。单纯地将大型语言模型直接应用很难取得良好的性能。此外,现有的基于硬提示的方法在复杂场景中容易出现错误,需要人工干预。为了解决这些问题,防止LLM产生幻觉和偏见信息,我们提出了一种新颖的两阶段微调LLM的方法,包括监督微调(STF)和直接偏好优化(DPO)。STF提高了生成指令的质量,而DPO则利用了环境反馈。实验结果证明,与先前的最先进的模型相比,我们在REVERIE上的模型具有优越性。
论文及项目相关链接
Summary
本文介绍了远程实体指代表达(REVERIE)任务中,一个智能体如何在复杂的室内环境中导航并定位由高级指令指定的远程对象。为提高效率,本文提出了一种使用大型语言模型的参数高效动作规划器(PEAP-LLM)。该模型包含LLM目标规划器(LGP)和LoRA动作规划器(LAP)。LGP从REVERIE指令中提取目标导向的计划,包括目标对象和房间。LAP则根据目标导向的计划、高级指令和当前视觉观察生成单步指令。PEAP-LLM使得智能体能够作为路径规划器即时与LAP互动。为解决直接使用LLM的问题和防止LLM产生幻觉和偏见信息,本文提出了一种新型的两阶段微调LLM方法,包括监督微调(STF)和直接偏好优化(DPO)。STF提高了生成指令的质量,而DPO则利用环境反馈。实验结果表明,与之前的先进技术相比,本文提出的模型在REVERIE任务上具有优势。
Key Takeaways
- REVERIE任务要求智能体在复杂的室内环境中导航并定位由高级指令指定的远程对象。
- PEAP-LLM是一种使用大型语言模型的参数高效动作规划器,包含LLM目标规划器(LGP)和LoRA动作规划器(LAP)。
- LGP从REVERIE指令中提取目标导向的计划,包括目标对象和房间;LAP则生成单步指令。
- PEAP-LLM使得智能体能够作为路径规划器即时与LAP互动,提高导航效率。
- 直接应用LLM存在问题和偏见信息风险,因此提出了监督微调(STF)和直接偏好优化(DPO)的两阶段方法来解决这些问题。
- STF提高了生成指令的质量,而DPO利用环境反馈来优化模型表现。
点此查看论文截图

Towards Multi-Agent Reasoning Systems for Collaborative Expertise Delegation: An Exploratory Design Study
Authors:Baixuan Xu, Chunyang Li, Weiqi Wang, Wei Fan, Tianshi Zheng, Haochen Shi, Tao Fan, Yangqiu Song, Qiang Yang
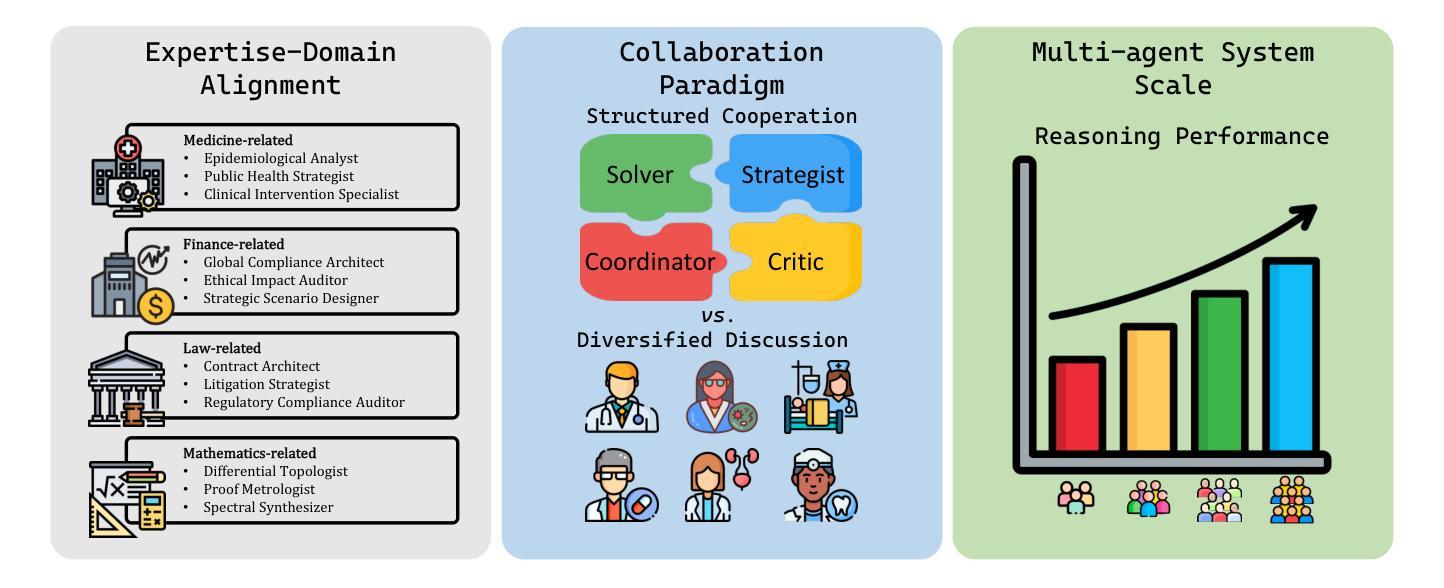
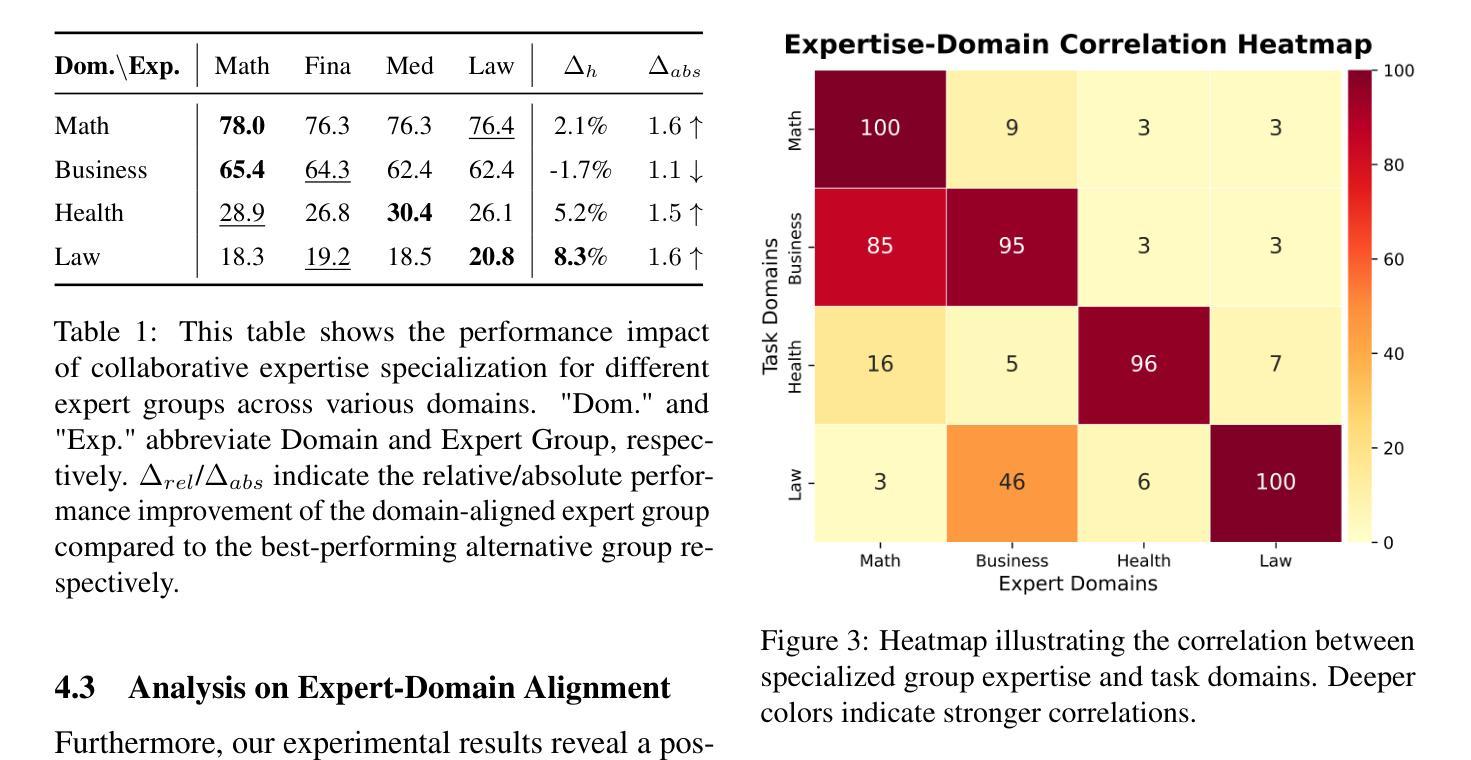
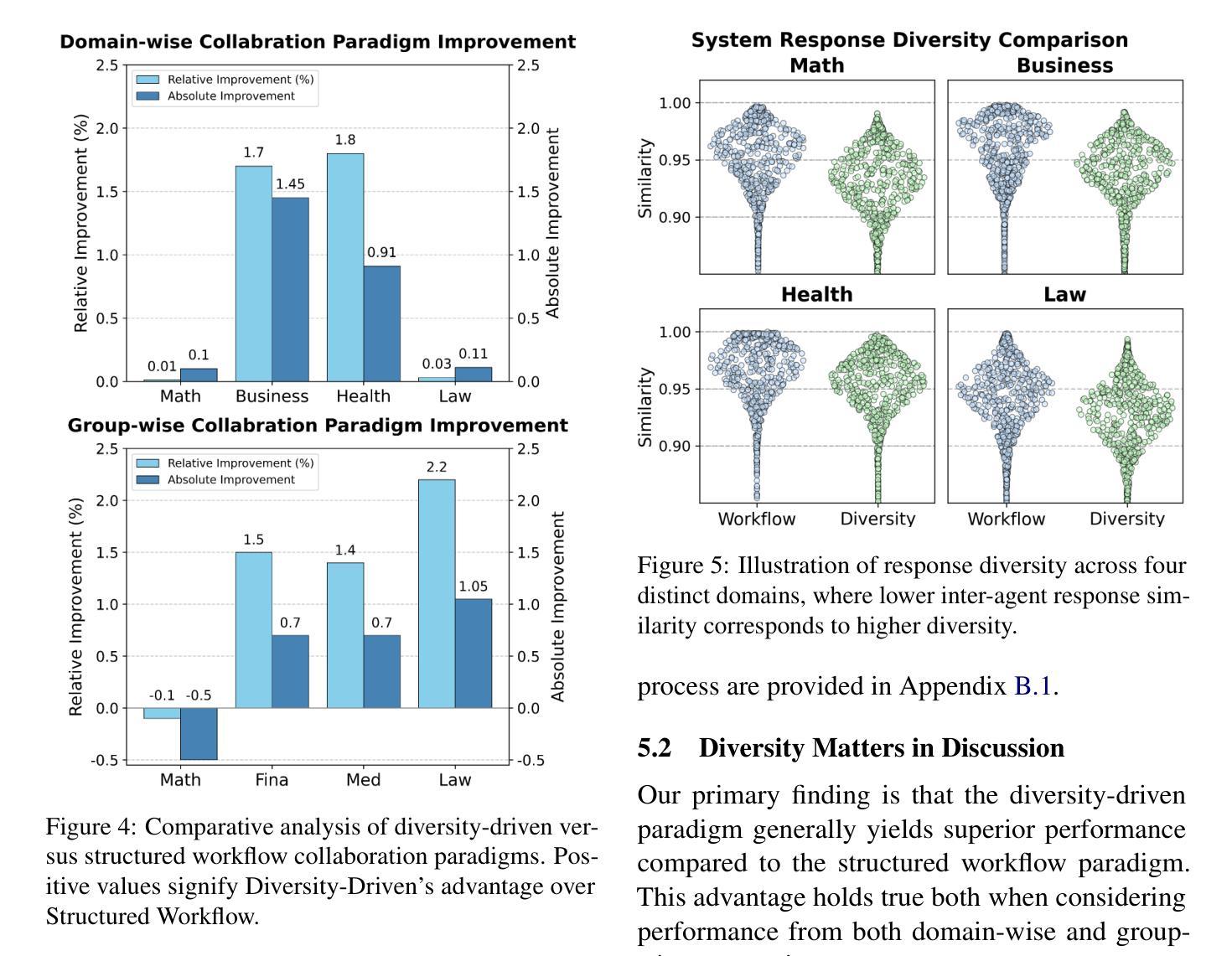
Designing effective collaboration structure for multi-agent LLM systems to enhance collective reasoning is crucial yet remains under-explored. In this paper, we systematically investigate how collaborative reasoning performance is affected by three key design dimensions: (1) Expertise-Domain Alignment, (2) Collaboration Paradigm (structured workflow vs. diversity-driven integration), and (3) System Scale. Our findings reveal that expertise alignment benefits are highly domain-contingent, proving most effective for contextual reasoning tasks. Furthermore, collaboration focused on integrating diverse knowledge consistently outperforms rigid task decomposition. Finally, we empirically explore the impact of scaling the multi-agent system with expertise specialization and study the computational trade off, highlighting the need for more efficient communication protocol design. This work provides concrete guidelines for configuring specialized multi-agent system and identifies critical architectural trade-offs and bottlenecks for scalable multi-agent reasoning. The code will be made available upon acceptance.
在多智能体LLM系统中设计有效的协作结构以提升集体推理能力至关重要,但这一领域的研究仍然不足。在本文中,我们系统地研究了三个关键设计维度如何影响协作推理性能:(1)专业领域知识与技能的匹配度;(2)协作范式(结构化工作流程与多样性驱动集成);以及(3)系统规模。我们发现专业技能匹配的优势高度依赖于特定领域,对于语境推理任务最为有效。此外,聚焦于整合多样化知识的协作方式持续优于僵化的任务分解方式。最后,我们通过实证探索了通过专业技能专业化扩展多智能体系统的影响,并研究了计算折衷方案,强调了需要设计更高效的通信协议。这项工作为配置专业化的多智能体系统提供了具体指导,并确定了可扩展的多智能体推理的关键架构折衷方案和瓶颈。代码将在接受后提供。
论文及项目相关链接
PDF 18 pages
Summary
本文系统探讨了如何设计多智能体大型语言模型系统的协作结构以提升集体推理效能。研究分析了三个关键设计维度——专业知识的领域一致性、协作范式和系统规模的影响。研究表明专业知识的一致性在不同领域中表现出良好的上下文推理任务效益,通过集成多元化知识为基础的协作持续优于硬性任务分解方式。同时,论文实证探索了专业技能分工对于规模化多智能体系统的影响,强调了更高效沟通协议设计的必要性。该研究为多智能体系统的配置提供了实际指导,并指出了可规模化多智能体推理的关键架构权衡和瓶颈。代码将在接受后公开。
Key Takeaways
- 多智能体大型语言模型系统的协作结构设计对于提升集体推理效能至关重要。
- 研究分析了专业知识的领域一致性、协作范式和系统规模三个关键设计维度。
- 专业知识的一致性在上下文推理任务中表现出良好的效益,且效益高度依赖于领域。
- 以集成多元化知识为基础的协作持续优于硬性任务分解方式。
- 论文实证探索了专业技能分工对于规模化多智能体系统的影响。
- 更高效的沟通协议设计对于实现多智能体系统的协作和规模化至关重要。
点此查看论文截图

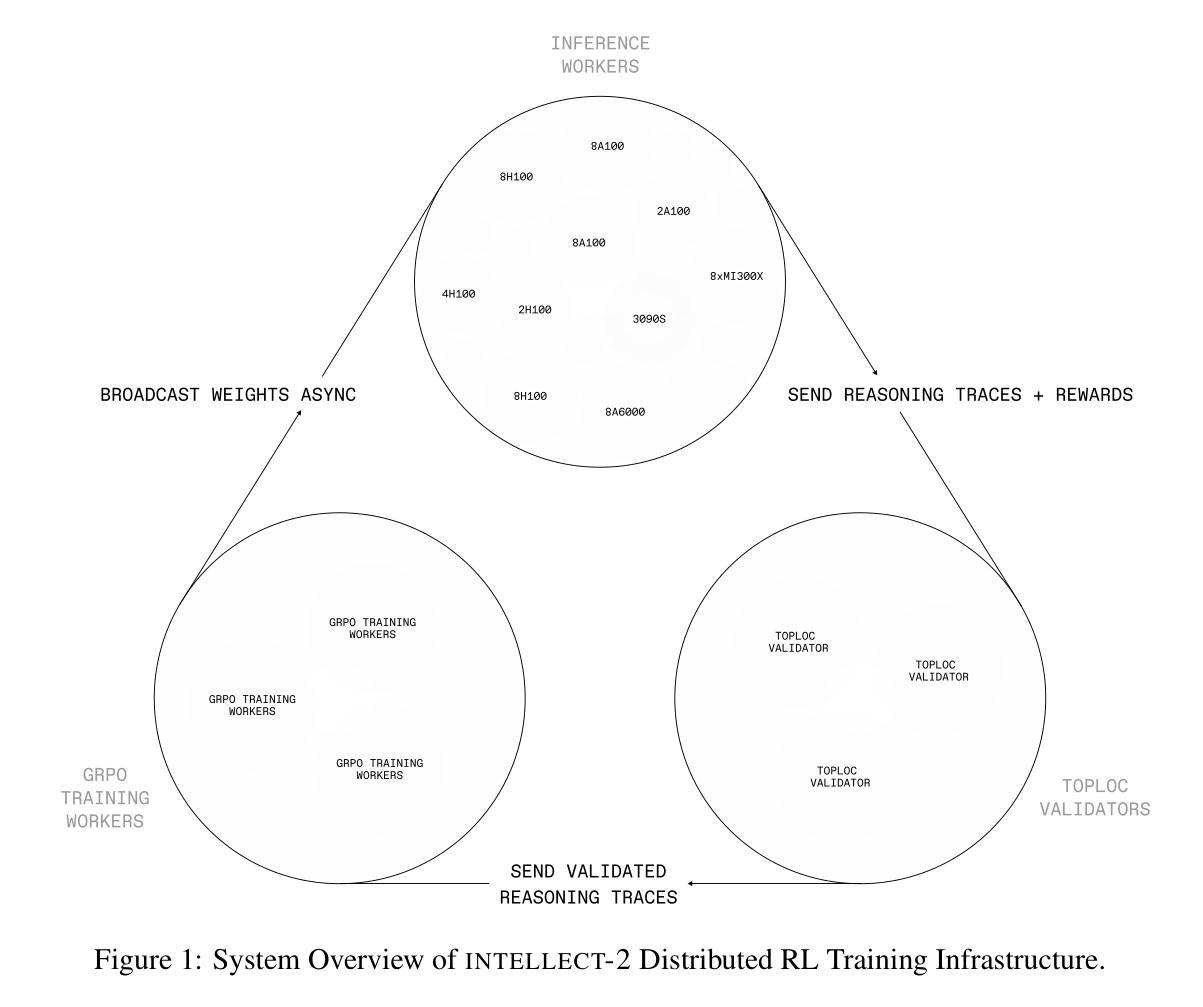
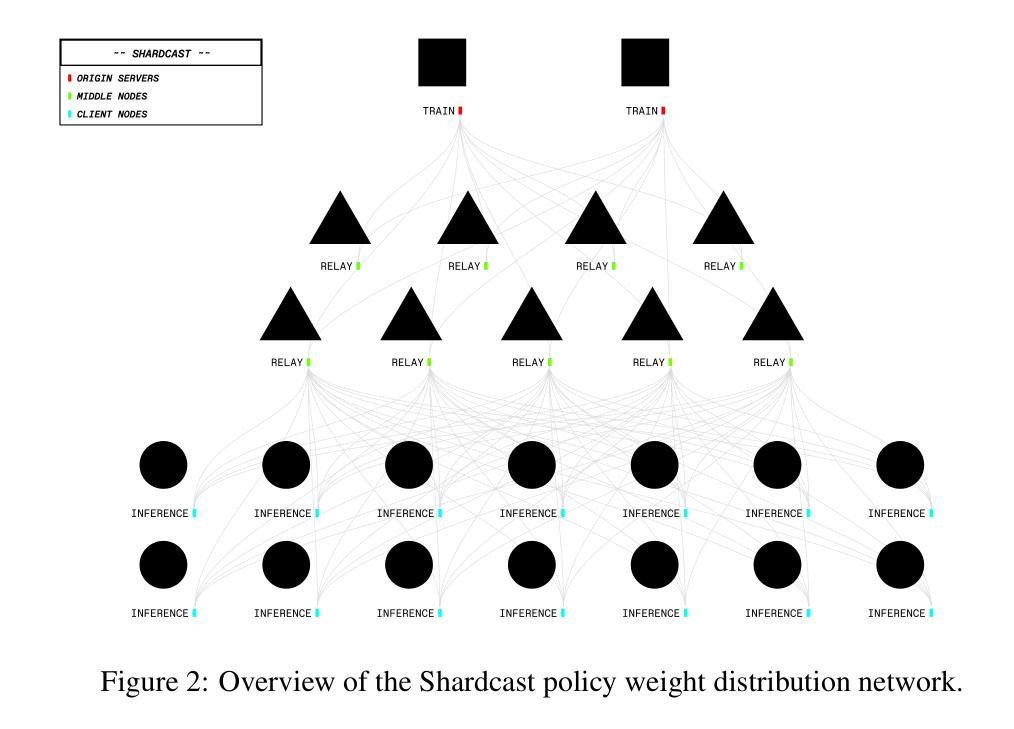
INTELLECT-2: A Reasoning Model Trained Through Globally Decentralized Reinforcement Learning
Authors: Prime Intellect Team, Sami Jaghouar, Justus Mattern, Jack Min Ong, Jannik Straube, Manveer Basra, Aaron Pazdera, Kushal Thaman, Matthew Di Ferrante, Felix Gabriel, Fares Obeid, Kemal Erdem, Michael Keiblinger, Johannes Hagemann
We introduce INTELLECT-2, the first globally distributed reinforcement learning (RL) training run of a 32 billion parameter language model. Unlike traditional centralized training efforts, INTELLECT-2 trains a reasoning model using fully asynchronous RL across a dynamic, heterogeneous swarm of permissionless compute contributors. To enable a training run with this unique infrastructure, we built various components from scratch: we introduce PRIME-RL, our training framework purpose-built for distributed asynchronous reinforcement learning, based on top of novel components such as TOPLOC, which verifies rollouts from untrusted inference workers, and SHARDCAST, which efficiently broadcasts policy weights from training nodes to inference workers. Beyond infrastructure components, we propose modifications to the standard GRPO training recipe and data filtering techniques that were crucial to achieve training stability and ensure that our model successfully learned its training objective, thus improving upon QwQ-32B, the state of the art reasoning model in the 32B parameter range. We open-source INTELLECT-2 along with all of our code and data, hoping to encourage and enable more open research in the field of decentralized training.
我们介绍了INTELLECT-2,这是首个全球分布的强化学习(RL)训练运行的32亿参数语言模型。不同于传统的集中化训练努力,INTELLECT-2使用完全异步的强化学习在一个动态、异构的无需许可的计算贡献者集群上训练推理模型。为了在这种独特的架构上进行训练,我们从零开始构建了各种组件:我们推出了PRIME-RL,这是专为分布式异步强化学习构建的训练框架,基于新型组件,如TOPLOC(用于验证来自不受信任推理工作者的运行结果)和SHARDCAST(用于有效地将策略权重从训练节点广播到推理工作者)。除了架构组件之外,我们对标准GRPO训练配方和数据过滤技术进行了修改,这对于实现训练稳定性和确保我们的模型成功学习其训练目标是至关重要的,从而在32B参数范围内的最先进的推理模型QwQ-32B的基础上进行了改进。我们公开了INTELLECT-2以及我们所有的代码和数据,希望鼓励和促进分布式训练领域的研究。
论文及项目相关链接
PDF 26 pages, 12 figures
Summary
该文章介绍了首个全球分布式强化学习训练运行的“INTELLECT-2”。这是一项采用异步强化学习在动态、异构的分布式计算集群上进行的训练推理模型的工作。文章详细描述了为实现这一训练所开发的训练框架、基础设施组件和技术改进,包括验证来自不可信推理工作者的推理结果的TOPLOC、广播训练节点策略权重的SHARDCAST以及对标准GRPO训练食谱和数据过滤技术的改进。最后,作者开源了“INTELLECT-2”和相关代码数据,以促进分布式训练领域的研究开放。
Key Takeaways
- “INTELLECT-2”是全球首个基于强化学习的分布式训练推理模型。
- 该模型使用异步强化学习在动态、异构的分布式计算集群上进行训练。
- 文章介绍了为实现这一训练所开发的训练框架PRIME-RL。
- 文章详细描述了用于验证推理结果的TOPLOC技术和广播策略权重的SHARDCAST技术。
- 该模型改进了GRPO训练方法和数据过滤技术,实现了训练稳定性和学习成果的提升。
- 该模型超越了现有的32B参数范围内的最佳模型QwQ-32B。
点此查看论文截图

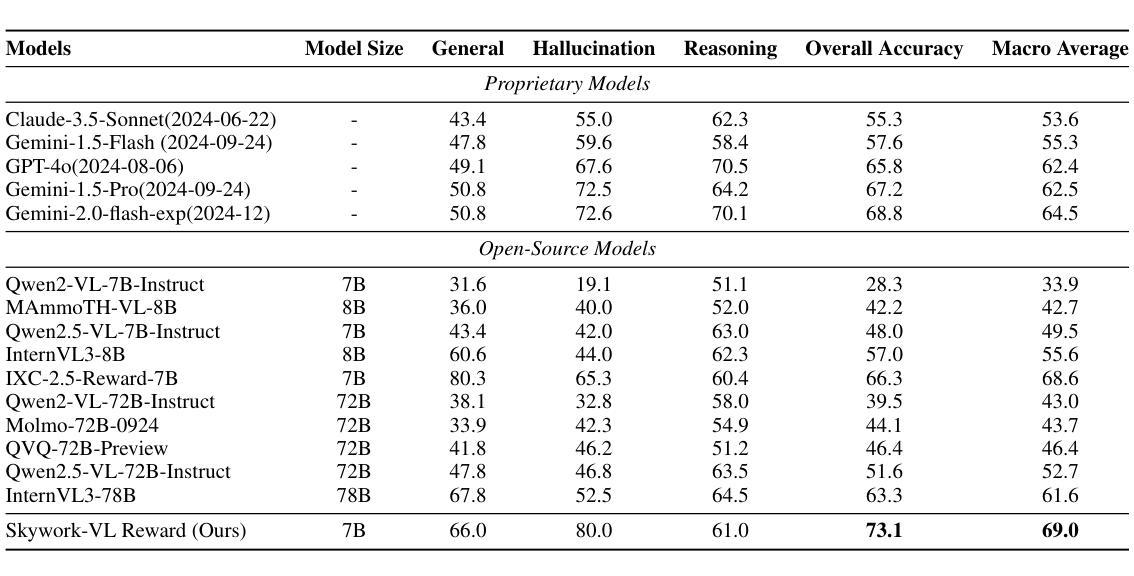
Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning
Authors:Xiaokun Wang, Chris, Jiangbo Pei, Wei Shen, Yi Peng, Yunzhuo Hao, Weijie Qiu, Ai Jian, Tianyidan Xie, Xuchen Song, Yang Liu, Yahui Zhou
We propose Skywork-VL Reward, a multimodal reward model that provides reward signals for both multimodal understanding and reasoning tasks. Our technical approach comprises two key components: First, we construct a large-scale multimodal preference dataset that covers a wide range of tasks and scenarios, with responses collected from both standard vision-language models (VLMs) and advanced VLM reasoners. Second, we design a reward model architecture based on Qwen2.5-VL-7B-Instruct, integrating a reward head and applying multi-stage fine-tuning using pairwise ranking loss on pairwise preference data. Experimental evaluations show that Skywork-VL Reward achieves state-of-the-art results on multimodal VL-RewardBench and exhibits competitive performance on the text-only RewardBench benchmark. Furthermore, preference data constructed based on our Skywork-VL Reward proves highly effective for training Mixed Preference Optimization (MPO), leading to significant improvements in multimodal reasoning capabilities. Our results underscore Skywork-VL Reward as a significant advancement toward general-purpose, reliable reward models for multimodal alignment. Our model has been publicly released to promote transparency and reproducibility.
我们提出了Skywork-VL Reward这一多模态奖励模型,该模型为理解和推理任务提供奖励信号。我们的技术方法主要包括两个关键部分:首先,我们构建了一个大规模的多模态偏好数据集,涵盖广泛的任务和场景,收集的响应既来自标准的视觉语言模型(VLMs),也包括先进的VLM推理器。其次,我们以Qwen2.5-VL-7B-Instruct为基础设计奖励模型架构,整合奖励头部,利用成对的偏好数据使用成对排名损失进行多阶段微调。实验评估表明,Skywork-VL Reward在多模态VL-RewardBench上达到了最先进的水平,并在只有文本的RewardBench基准测试中表现出了竞争力。此外,基于我们Skywork-VL Reward构建的偏好数据被证明对训练混合偏好优化(MPO)高度有效,极大地提高了多模态推理能力。我们的研究结果表明,Skywork-VL Reward在多模态对齐的通用可靠奖励模型方面取得了重大进展。我们的模型已经公开发布,以促进透明度和可重复性。
论文及项目相关链接
Summary
Skywork-VL Reward是一个多模态奖励模型,用于理解和推理任务。其技术方法包括构建大规模多模态偏好数据集和基于Qwen2.5-VL-7B-Instruct设计奖励模型架构。实验评估显示,Skywork-VL Reward在多模态VL-RewardBench上取得最佳结果,并在纯文本RewardBench基准测试中表现出竞争力。此外,基于Skywork-VL Reward构建的偏好数据对Mixed Preference Optimization (MPO)的训练非常有效,能显著提高多模态推理能力。此模型已公开,以促进透明度和可重复性。
Key Takeaways
- Skywork-VL Reward是一个多模态奖励模型,旨在提供理解和推理任务中的奖励信号。
- 技术方法包括构建大规模多模态偏好数据集,涵盖广泛的任务和场景。
- 奖励模型架构基于Qwen2.5-VL-7B-Instruct设计,并集成了奖励头。
- 实验评估显示,Skywork-VL Reward在多模态VL-RewardBench上取得最佳结果。
- 该模型在纯文本RewardBench基准测试中也表现出竞争力。
- 基于Skywork-VL Reward的偏好数据对MPO的训练非常有效。
点此查看论文截图


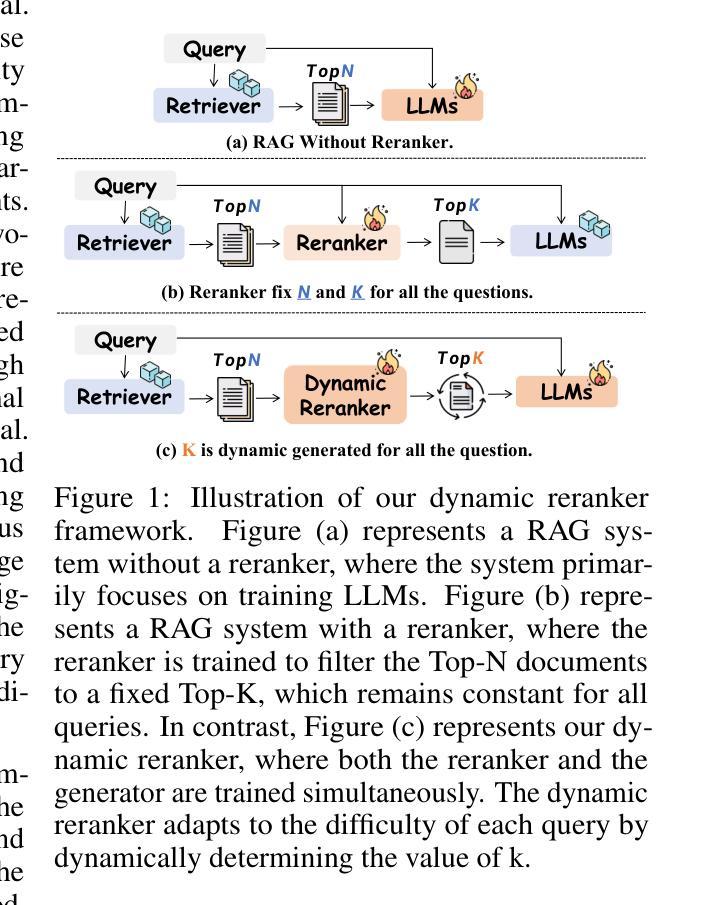
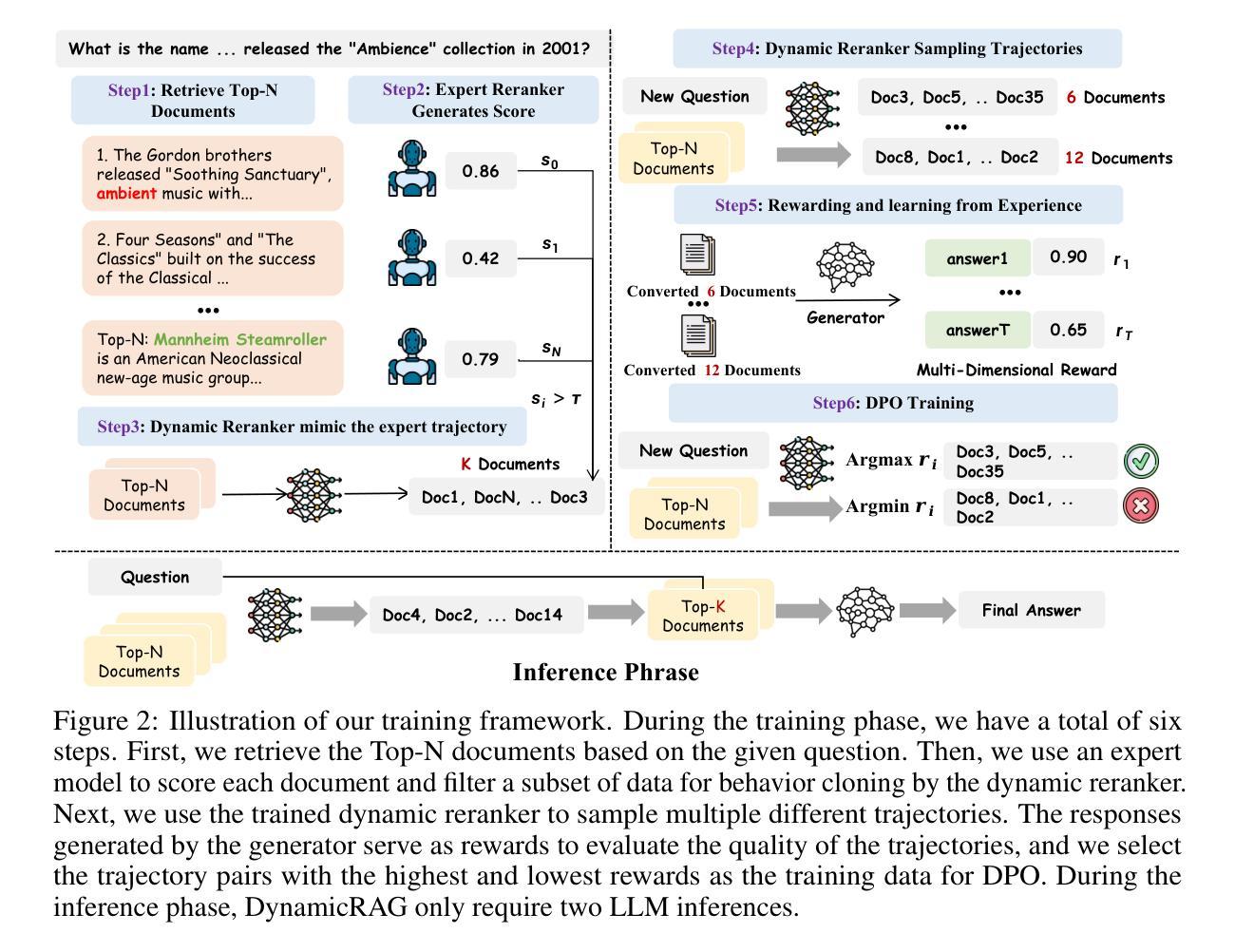
DynamicRAG: Leveraging Outputs of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation
Authors:Jiashuo Sun, Xianrui Zhong, Sizhe Zhou, Jiawei Han
Retrieval-augmented generation (RAG) systems combine large language models (LLMs) with external knowledge retrieval, making them highly effective for knowledge-intensive tasks. A crucial but often under-explored component of these systems is the reranker, which refines retrieved documents to enhance generation quality and explainability. The challenge of selecting the optimal number of documents (k) remains unsolved: too few may omit critical information, while too many introduce noise and inefficiencies. Although recent studies have explored LLM-based rerankers, they primarily leverage internal model knowledge and overlook the rich supervisory signals that LLMs can provide, such as using response quality as feedback for optimizing reranking decisions. In this paper, we propose DynamicRAG, a novel RAG framework where the reranker dynamically adjusts both the order and number of retrieved documents based on the query. We model the reranker as an agent optimized through reinforcement learning (RL), using rewards derived from LLM output quality. Across seven knowledge-intensive datasets, DynamicRAG demonstrates superior performance, achieving state-of-the-art results. The model, data and code are available at https://github.com/GasolSun36/DynamicRAG
检索增强生成(RAG)系统结合了大型语言模型(LLM)和外部知识检索,使其成为知识密集型任务的高效工具。这些系统中的关键但经常被忽视的部分是重排器,它会对检索到的文档进行精炼,以提高生成质量和可解释性。选择最佳文档数量(k)的挑战仍未解决:太少可能会遗漏关键信息,而太多则会引入噪音和效率问题。尽管最近的研究已经探索了基于LLM的重排器,但它们主要利用内部模型知识,并忽视了LLM可以提供的丰富监督信号,例如使用响应质量作为优化重排决策的反馈。在本文中,我们提出了DynamicRAG,这是一种新型RAG框架,其中重排器会根据查询动态调整检索到的文档的排序和数量。我们将重排器建模为通过强化学习(RL)优化的代理,使用从LLM输出质量中获得的奖励。在七个知识密集型数据集上,DynamicRAG表现出了卓越的性能,达到了最新的结果。模型、数据和代码可在链接地址找到。
论文及项目相关链接
PDF 24 pages, 6 figures, 15 tables
Summary
本文介绍了基于检索增强的生成(RAG)系统,该系统结合了大型语言模型(LLM)和外部知识检索,对于知识密集型任务非常有效。文章重点介绍了其中的关键组件——重排器(reranker),它能够优化检索到的文档,提高生成质量和可解释性。尽管选择最佳文档数量(k)的问题尚未解决,但本文提出了一种新的RAG框架——DynamicRAG,其中重排器能够根据查询动态调整检索到的文档的顺序和数量。DynamicRAG使用强化学习(RL)优化重排器,并从LLM输出质量中获取奖励。在七个知识密集型数据集上,DynamicRAG表现出卓越的性能,达到最新技术水平。
Key Takeaways
- 检索增强生成(RAG)系统结合了大型语言模型(LLM)和外部知识检索,适用于知识密集型任务。
- 重排器(reranker)是RAG系统中的一个关键组件,能优化检索到的文档,提高生成质量和可解释性。
- 选择最佳文档数量(k)是RAG系统面临的挑战,需要平衡获取信息的同时避免引入噪声和效率低下。
- 最近的研究主要利用内部模型知识来构建LLM重排器,但忽略了LLM提供的丰富监督信号。
- 本文提出了DynamicRAG框架,重排器可根据查询动态调整检索到的文档的顺序和数量。
- DynamicRAG使用强化学习(RL)优化重排器,从LLM输出质量中获取奖励。
- 在多个知识密集型数据集上,DynamicRAG表现出卓越性能,达到最新技术水平。
点此查看论文截图

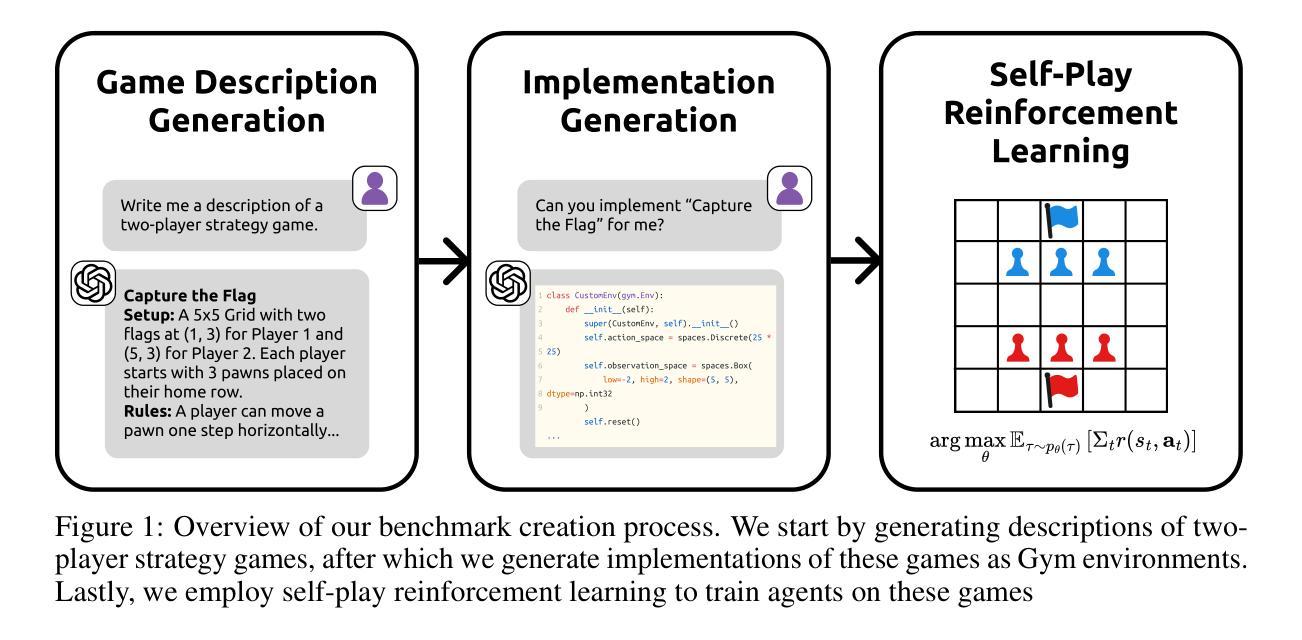
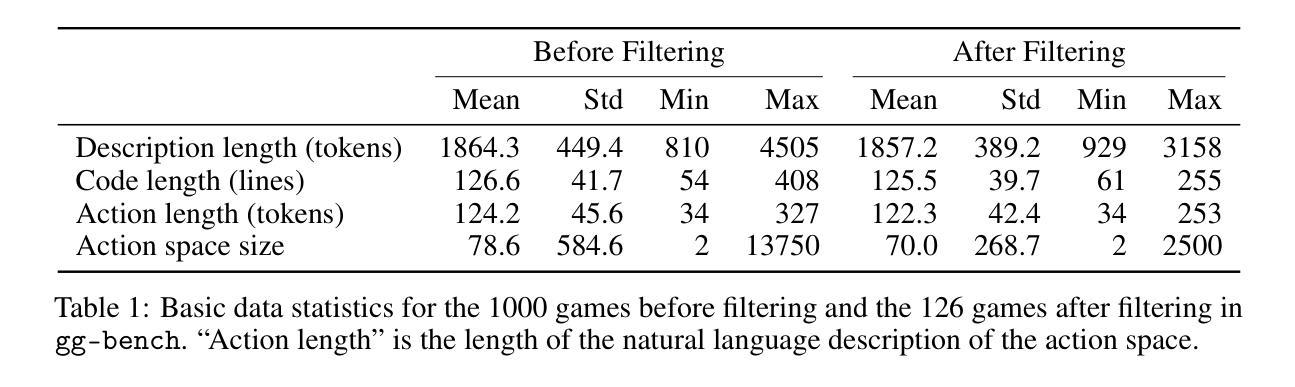
Measuring General Intelligence with Generated Games
Authors:Vivek Verma, David Huang, William Chen, Dan Klein, Nicholas Tomlin
We present gg-bench, a collection of game environments designed to evaluate general reasoning capabilities in language models. Unlike most static benchmarks, gg-bench is a data generating process where new evaluation instances can be generated at will. In particular, gg-bench is synthetically generated by (1) using a large language model (LLM) to generate natural language descriptions of novel games, (2) using the LLM to implement each game in code as a Gym environment, and (3) training reinforcement learning (RL) agents via self-play on the generated games. We evaluate language models by their winrate against these RL agents by prompting models with the game description, current board state, and a list of valid moves, after which models output the moves they wish to take. gg-bench is challenging: state-of-the-art LLMs such as GPT-4o and Claude 3.7 Sonnet achieve winrates of 7-9% on gg-bench using in-context learning, while reasoning models such as o1, o3-mini and DeepSeek-R1 achieve average winrates of 31-36%. We release the generated games, data generation process, and evaluation code in order to support future modeling work and expansion of our benchmark.
我们推出gg-bench,这是一系列用于评估语言模型中通用推理能力的游戏环境集合。不同于大多数静态基准测试,gg-bench是一个数据生成过程,可以按需生成新的评估实例。具体而言,gg-bench是通过以下方式合成生成的:(1)使用大型语言模型(LLM)生成新型游戏的自然语言描述;(2)使用LLM将每个游戏编码为Gym环境;(3)通过在生成的游戏上进行自我对抗训练强化学习(RL)代理。我们通过提示模型游戏描述、当前棋盘状态和有效动作列表来评估语言模型,模型会输出它们想采取的行动。gg-bench具有挑战性:最先进的LLM,如GPT-4o和Claude 3.7 Sonnet,在gg-bench上使用上下文学习,胜率为7-9%,而推理模型如o1、o3-mini和DeepSeek-R1的平均胜率为31-36%。我们发布生成的游戏、数据生成过程和评估代码,以支持未来的建模工作和我们基准测试的扩展。
论文及项目相关链接
Summary
gg-bench是一套用于评估语言模型通用推理能力的游戏环境集合。它通过大型语言模型生成自然语言描述的新游戏,将游戏转化为Gym环境,并通过自我对弈的强化学习代理进行训练。通过根据游戏描述、当前棋盘状态和有效行动列表提示模型,评估语言模型的胜率。gg-bench具有挑战性,因为现有的语言模型在此环境中的胜率较低,而一些推理模型的胜率较高。我们发布了生成的游戏、数据生成过程和评估代码,以支持未来的建模工作和基准测试的扩展。
Key Takeaways
- gg-bench是一个用于评估语言模型通用推理能力的动态基准测试。
- 它通过大型语言模型生成自然语言的描述来创建新的游戏环境。
- gg-bench的游戏环境被转化为Gym环境,以便进行强化学习训练。
- 通过自我对弈的强化学习代理来训练语言模型。
- 语言模型在gg-bench上的胜率较低,而一些推理模型的胜率较高。
- 该研究发布了生成的游戏、数据生成过程和评估代码,以促进未来的研究和基准测试的扩展。
点此查看论文截图


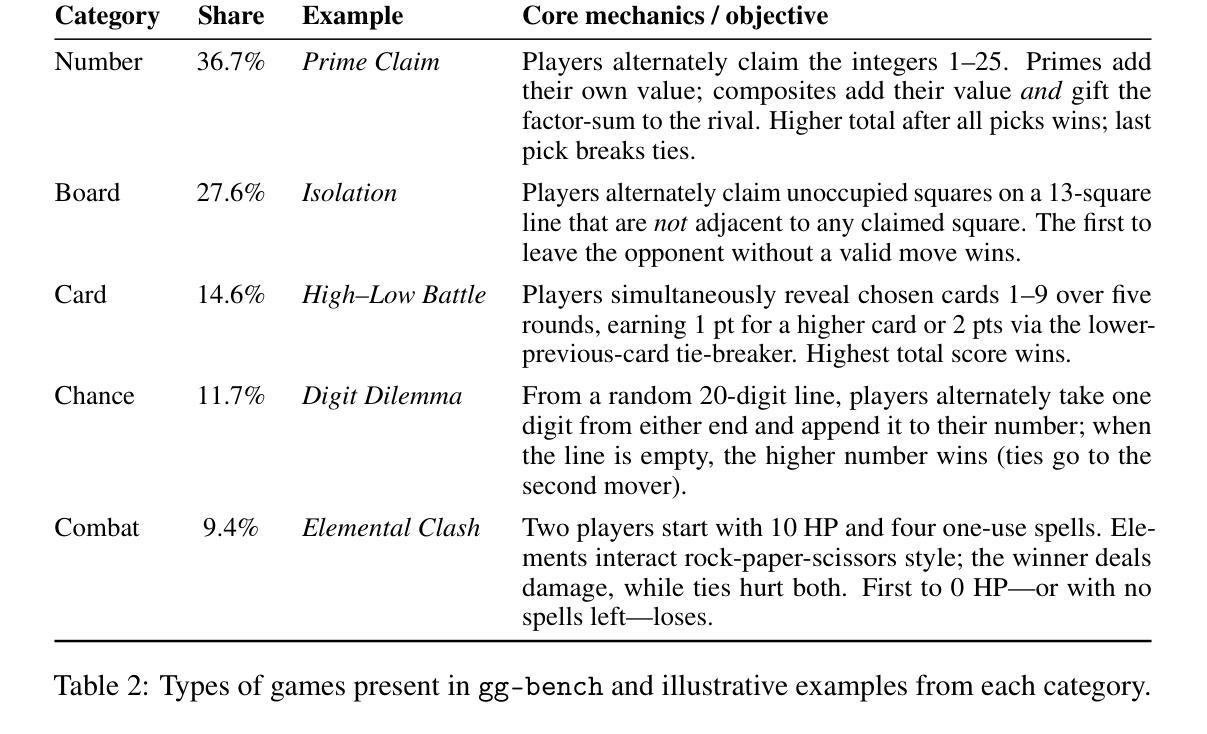
Seed1.5-VL Technical Report
Authors:Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, Jingji Chen, Jingjia Huang, Kang Lei, Liping Yuan, Lishu Luo, Pengfei Liu, Qinghao Ye, Rui Qian, Shen Yan, Shixiong Zhao, Shuai Peng, Shuangye Li, Sihang Yuan, Sijin Wu, Tianheng Cheng, Weiwei Liu, Wenqian Wang, Xianhan Zeng, Xiao Liu, Xiaobo Qin, Xiaohan Ding, Xiaojun Xiao, Xiaoying Zhang, Xuanwei Zhang, Xuehan Xiong, Yanghua Peng, Yangrui Chen, Yanwei Li, Yanxu Hu, Yi Lin, Yiyuan Hu, Yiyuan Zhang, Youbin Wu, Yu Li, Yudong Liu, Yue Ling, Yujia Qin, Zanbo Wang, Zhiwu He, Aoxue Zhang, Bairen Yi, Bencheng Liao, Can Huang, Can Zhang, Chaorui Deng, Chaoyi Deng, Cheng Lin, Cheng Yuan, Chenggang Li, Chenhui Gou, Chenwei Lou, Chengzhi Wei, Chundian Liu, Chunyuan Li, Deyao Zhu, Donghong Zhong, Feng Li, Feng Zhang, Gang Wu, Guodong Li, Guohong Xiao, Haibin Lin, Haihua Yang, Haoming Wang, Heng Ji, Hongxiang Hao, Hui Shen, Huixia Li, Jiahao Li, Jialong Wu, Jianhua Zhu, Jianpeng Jiao, Jiashi Feng, Jiaze Chen, Jianhui Duan, Jihao Liu, Jin Zeng, Jingqun Tang, Jingyu Sun, Joya Chen, Jun Long, Junda Feng, Junfeng Zhan, Junjie Fang, Junting Lu, Kai Hua, Kai Liu, Kai Shen, Kaiyuan Zhang, Ke Shen, Ke Wang, Keyu Pan, Kun Zhang, Kunchang Li, Lanxin Li, Lei Li, Lei Shi, Li Han, Liang Xiang, Liangqiang Chen, Lin Chen, Lin Li, Lin Yan, Liying Chi, Longxiang Liu, Mengfei Du, Mingxuan Wang, Ningxin Pan, Peibin Chen, Pengfei Chen, Pengfei Wu, Qingqing Yuan, Qingyao Shuai, Qiuyan Tao, Renjie Zheng, Renrui Zhang, Ru Zhang, Rui Wang, Rui Yang, Rui Zhao, Shaoqiang Xu, Shihao Liang, Shipeng Yan, Shu Zhong, Shuaishuai Cao, Shuangzhi Wu, Shufan Liu, Shuhan Chang, Songhua Cai, Tenglong Ao, Tianhao Yang, Tingting Zhang, Wanjun Zhong, Wei Jia, Wei Weng, Weihao Yu, Wenhao Huang, Wenjia Zhu, Wenli Yang, Wenzhi Wang, Xiang Long, XiangRui Yin, Xiao Li, Xiaolei Zhu, Xiaoying Jia, Xijin Zhang, Xin Liu, Xinchen Zhang, Xinyu Yang, Xiongcai Luo, Xiuli Chen, Xuantong Zhong, Xuefeng Xiao, Xujing Li, Yan Wu, Yawei Wen, Yifan Du, Yihao Zhang, Yining Ye, Yonghui Wu, Yu Liu, Yu Yue, Yufeng Zhou, Yufeng Yuan, Yuhang Xu, Yuhong Yang, Yun Zhang, Yunhao Fang, Yuntao Li, Yurui Ren, Yuwen Xiong, Zehua Hong, Zehua Wang, Zewei Sun, Zeyu Wang, Zhao Cai, Zhaoyue Zha, Zhecheng An, Zhehui Zhao, Zhengzhuo Xu, Zhipeng Chen, Zhiyong Wu, Zhuofan Zheng, Zihao Wang, Zilong Huang, Ziyu Zhu, Zuquan Song
We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
我们推出Seed1.5-VL,这是一款旨在推进通用多模态理解和推理的视听语言基础模型。Seed1.5-VL由带有5.32亿参数(注:应指的是亿字符参数数量)的视觉编码器和带有2万亿(活跃参数)混合专家知识(MoE)的大型语言模型组成。尽管其结构相对紧凑,但它在广泛的公共视觉语言模型基准测试和内部评估套件中表现出色,在公共基准测试中的前六十项基准测试中取得了其中三十八个的最新性能水平。此外,在面向代理的任务(如GUI控制和游戏)中,Seed1.5-VL在包括OpenAI CUA和Claude 3.7在内的领先的多模态系统中表现出色。除了视觉和视频理解之外,它还展示了强大的推理能力,对于视觉谜题等多模态推理挑战特别有效。我们相信这些功能将在各种任务中得到广泛应用。本报告主要全面回顾了我们在构建Seed1.5-VL模型设计、数据构建和训练过程中的经验,希望这份报告能激发进一步的研究。现在可以通过访问https://www.volcengine.com/(火山引擎模型ID:doubao-1-5-thinking-vision-pro-250428)来了解更多关于Seed1.5-VL的信息。
论文及项目相关链接
Summary
Seed1.5-VL是一款用于推进通用多模态理解和推理的跨视觉语言基础模型。它包含一个532M参数的视觉编码器和含有20B活跃参数的混合专家(MoE)大型语言模型。尽管架构相对紧凑,但在广泛的公开VLM基准测试和内部评估套件上表现优异,其中在38个公共基准测试中达到最新技术水平。此外,在代理中心任务(如GUI控制和游戏)和多模态推理挑战(如视觉谜题)中表现优秀。该模型有助于各种任务的广泛应用。访问地址:https://www.volcengine.com/(火山引擎模型ID:doubao-1-5-thinking-vision-pro-250428)。
Key Takeaways
- Seed1.5-VL是一个多模态基础模型,旨在提高通用多模态理解和推理能力。
- 它结合了视觉编码器和混合专家大型语言模型,具有紧凑的架构和高效的性能。
- 在广泛的公共基准测试中,Seed1.5-VL表现出卓越的性能,达到最新技术水平。
- 在代理中心任务和多模态推理挑战中,Seed1.5-VL具有出色的表现。
- 该模型适用于各种任务应用,并可通过访问特定网站获取详细信息。
- Seed1.5-VL的设计、数据构建和训练各阶段都有详细的经验分享,以激发进一步的研究灵感。
点此查看论文截图



DialogueReason: Rule-Based RL Sparks Dialogue Reasoning in LLMs
Authors:Yubo Shu, Zhewei Huang, Xin Wu, Chen Hu, Shuchang Zhou, Daxin Jiang
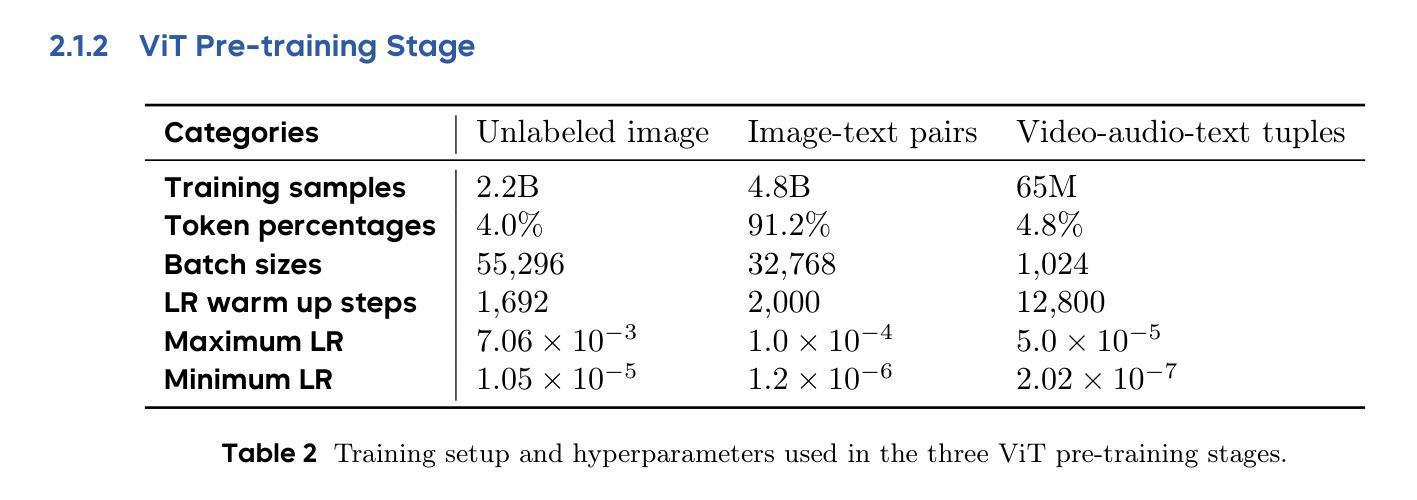
We propose DialogueReason, a reasoning paradigm that uncovers the lost roles in monologue-style reasoning models, aiming to boost diversity and coherency of the reasoning process. Recent advances in RL-based large reasoning models have led to impressive long CoT capabilities and high performance on math and science benchmarks. However, these reasoning models rely mainly on monologue-style reasoning, which often limits reasoning diversity and coherency, frequently recycling fixed strategies or exhibiting unnecessary shifts in attention. Our work consists of an analysis of monologue reasoning patterns and the development of a dialogue-based reasoning approach. We first introduce the Compound-QA task, which concatenates multiple problems into a single prompt to assess both diversity and coherency of reasoning. Our analysis shows that Compound-QA exposes weaknesses in monologue reasoning, evidenced by both quantitative metrics and qualitative reasoning traces. Building on the analysis, we propose a dialogue-based reasoning, named DialogueReason, structured around agents, environment, and interactions. Using PPO with rule-based rewards, we train open-source LLMs (Qwen-QWQ and Qwen-Base) to adopt dialogue reasoning. We evaluate trained models on MATH, AIME, and GPQA datasets, showing that the dialogue reasoning model outperforms monologue models under more complex compound questions. Additionally, we discuss how dialogue-based reasoning helps enhance interpretability, facilitate more intuitive human interaction, and inspire advances in multi-agent system design.
我们提出了DialogueReason,这是一种揭示独白式推理模型中缺失角色的推理范式,旨在提高推理过程的多样性和连贯性。基于RL的大型推理模型的最新进展表现出了令人印象深刻的长期推理能力和在数学与科学基准测试上的卓越性能。然而,这些推理模型主要依赖于独白式推理,这往往限制了推理的多样性和连贯性,经常重复使用固定策略或表现出不必要的注意力转移。我们的工作包括对独白推理模式的分析和基于对话的推理方法的发展。我们首先引入了Compound-QA任务,该任务将多个问题连接成一个单一的提示,以评估推理的多样性和连贯性。我们的分析表明,Compound-QA暴露了独白推理的弱点,这由定量指标和定性推理轨迹证明。在分析的基础上,我们提出了基于对话的推理方法,名为DialogueReason,以代理、环境和交互为中心构建。使用带有基于规则奖励的PPO算法,我们训练开源LLM(Qwen-QWQ和Qwen-Base)采用对话式推理。我们在MATH、AIME和GPQA数据集上评估了训练模型的表现,结果表明对话式推理模型在更复杂的问题组合上优于独白模型。此外,我们还讨论了基于对话的推理如何帮助增强可解释性、促进更直观的人类互动,并激发多智能体系统设计的进步。
论文及项目相关链接
Summary
本文提出了DialogueReason这一对话推理范式,旨在解决独白式推理模型在多样性和连贯性方面的不足。文章分析了当前基于RL的大型推理模型在处理复合问题时出现的局限性,并介绍了新的对话式推理方法DialogueReason。该方法通过引入多代理交互,提高了模型的推理多样性和连贯性。实验结果表明,在复杂复合问题上,对话推理模型优于独白模型。同时,该模型还增强了可解释性,便于人类直观交互,并为多代理系统设计提供了启示。
Key Takeaways
- DialogueReason旨在解决独白式推理模型在多样性和连贯性方面的不足。
- 对话式推理方法通过引入多代理交互提高了模型的推理能力。
- Compound-QA任务用于评估模型的多样性和连贯性。
- 基于PPO和规则奖励训练的大型语言模型(如Qwen-QWQ和Qwen-Base)能够采用对话式推理。
- 在复杂复合问题上,对话推理模型优于独白模型。
- 对话式推理模型增强了模型的解释性,便于人类直观交互。
点此查看论文截图


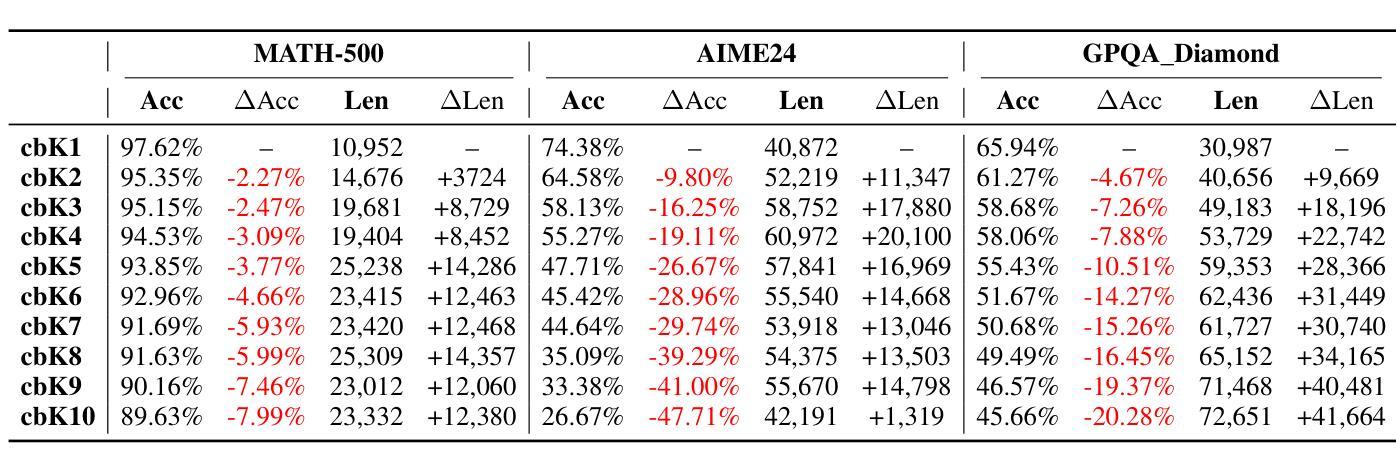

From Knowledge to Reasoning: Evaluating LLMs for Ionic Liquids Research in Chemical and Biological Engineering
Authors:Gaurab Sarkar, Sougata Saha
Although Large Language Models (LLMs) have achieved remarkable performance in diverse general knowledge and reasoning tasks, their utility in the scientific domain of Chemical and Biological Engineering (CBE) is unclear. Hence, it necessitates challenging evaluation benchmarks that can measure LLM performance in knowledge- and reasoning-based tasks, which is lacking. As a foundational step, we empirically measure the reasoning capabilities of LLMs in CBE. We construct and share an expert-curated dataset of 5,920 examples for benchmarking LLMs’ reasoning capabilities in the niche domain of Ionic Liquids (ILs) for carbon sequestration, an emergent solution to reducing global warming. The dataset presents different difficulty levels by varying along the dimensions of linguistic and domain-specific knowledge. Benchmarking three less than 10B parameter open-source LLMs on the dataset suggests that while smaller general-purpose LLMs are knowledgeable about ILs, they lack domain-specific reasoning capabilities. Based on our results, we further discuss considerations for leveraging LLMs for carbon capture research using ILs. Since LLMs have a high carbon footprint, gearing them for IL research can symbiotically benefit both fields and help reach the ambitious carbon neutrality target by 2050. Dataset link: https://github.com/sougata-ub/llms_for_ionic_liquids
尽管大型语言模型(LLMs)在多样化和通用的知识和推理任务中取得了显著的性能,它们在化学和生物工程(CBE)科学领域的应用尚不清楚。因此,需要具有挑战性的评估基准,能够衡量LLM在基于知识和推理的任务中的表现,而这一点正是我们所缺乏的。作为基础步骤,我们通过实证研究测量LLM在CBE中的推理能力。我们构建并共享了一个包含5920个样本的专家级数据集,用于评估离子液体(ILs)这一新兴碳捕获解决方案领域中的LLM推理能力。数据集通过语言和领域特定知识的维度展现不同的难度级别。在数据集上评估三个少于10B参数的开源LLM,结果表明,虽然较小的通用LLM对离子液体有一定的了解,但它们缺乏特定领域的推理能力。基于我们的研究结果,我们进一步讨论了利用离子液体进行碳捕获研究中利用LLM的注意事项。由于LLM的碳足迹较高,将其用于离子液体研究可以互利共赢,有助于实现到2050年实现雄心勃勃的碳中和目标。数据集链接:https://github.com/sougata-ub/llms_for_ionic_liquids
Translation into Simplified Chinese
论文及项目相关链接
Summary
大型语言模型(LLMs)在化学与生物工程(CBE)领域的实用性尚不清楚,因此需要具有挑战性的评估基准来衡量其在知识与推理任务中的表现。本研究首次对LLMs在离子液体(ILs)领域的推理能力进行了实证测量,并构建了一个专家审核的数据库用于评估LLMs在碳捕获领域的表现。研究结果显示,小型通用LLMs虽然了解离子液体,但在特定领域推理能力上有所欠缺。考虑到LLMs的高碳排放和对离子液体研究的应用潜力,需要更精细地利用它们来推动碳捕获研究,助力实现碳中和目标。
Key Takeaways
- 大型语言模型(LLMs)在化学与生物工程(CBE)领域的实用性尚待明确。
- 需要具有挑战性的评估基准来衡量LLMs在知识与推理任务中的表现。
- 研究实证测量了LLMs在离子液体(ILs)领域的推理能力。
- 构建了一个专家审核的数据库用于评估LLMs在碳捕获领域的表现。
- 小型通用LLMs了解离子液体,但在特定领域推理能力上有所欠缺。
- LLMs在碳捕获研究中有潜力,但需要更精细的应用。
点此查看论文截图

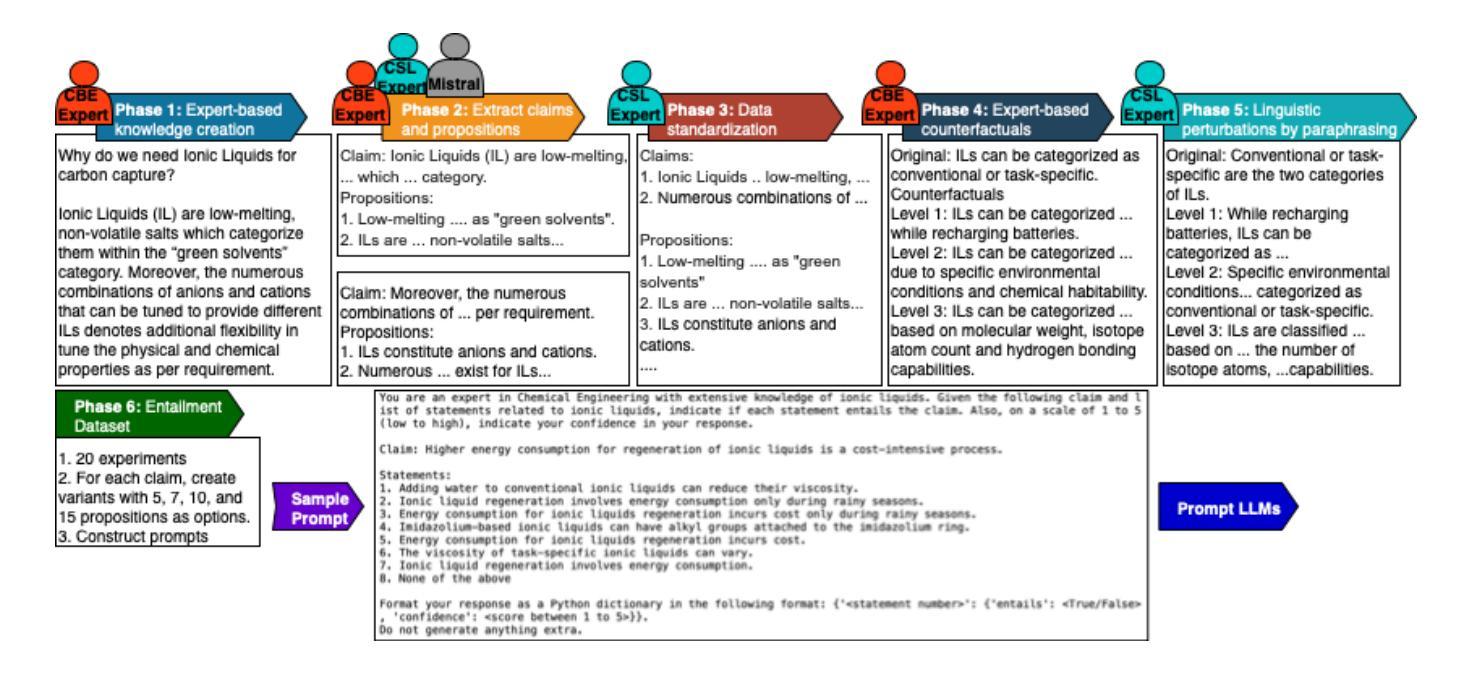
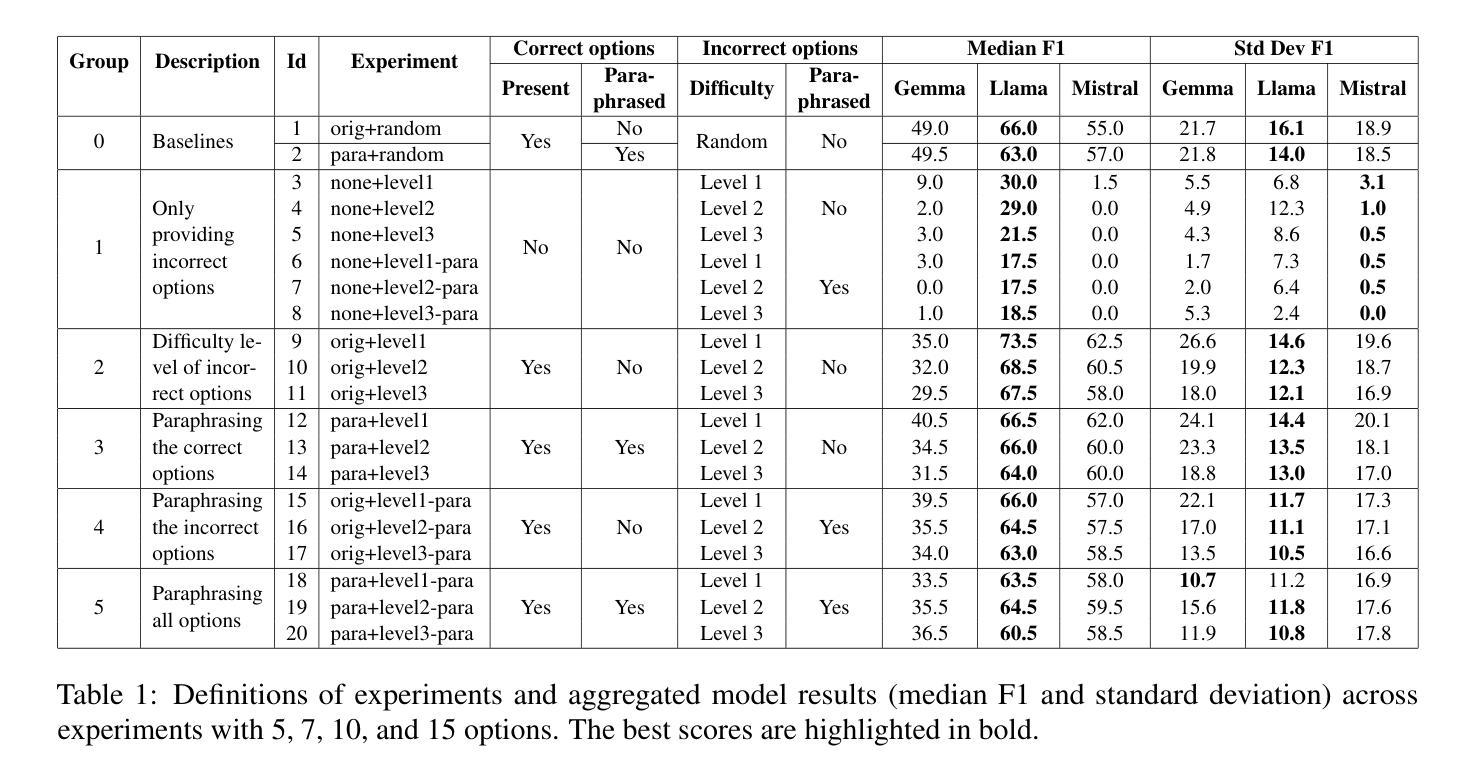
LineFlow: A Framework to Learn Active Control of Production Lines
Authors:Kai Müller, Martin Wenzel, Tobias Windisch
Many production lines require active control mechanisms, such as adaptive routing, worker reallocation, and rescheduling, to maintain optimal performance. However, designing these control systems is challenging for various reasons, and while reinforcement learning (RL) has shown promise in addressing these challenges, a standardized and general framework is still lacking. In this work, we introduce LineFlow, an extensible, open-source Python framework for simulating production lines of arbitrary complexity and training RL agents to control them. To demonstrate the capabilities and to validate the underlying theoretical assumptions of LineFlow, we formulate core subproblems of active line control in ways that facilitate mathematical analysis. For each problem, we provide optimal solutions for comparison. We benchmark state-of-the-art RL algorithms and show that the learned policies approach optimal performance in well-understood scenarios. However, for more complex, industrial-scale production lines, RL still faces significant challenges, highlighting the need for further research in areas such as reward shaping, curriculum learning, and hierarchical control.
许多生产线需要主动控制机制,如自适应路由、工人重新分配和重新调度,以维持最佳性能。然而,由于各种原因,设计这些控制系统具有挑战性。虽然强化学习(RL)在应对这些挑战方面显示出潜力,但仍缺乏标准化和通用的框架。在这项工作中,我们介绍了LineFlow,这是一个可扩展的开源Python框架,用于模拟任意复杂度的生产线并训练RL代理来控制它们。为了展示LineFlow的能力并验证其基础理论假设,我们以有利于数学分析的方式主动制定了生产线控制的核心子问题。对于每个问题,我们都提供了最佳解决方案进行对比。我们对最新的强化学习算法进行了基准测试,并证明在明确理解的场景中,学习到的策略接近最佳性能。然而,对于更复杂、工业规模的生产线,RL仍然面临重大挑战,这突显了需要在奖励塑造、课程学习和分层控制等领域进行进一步研究的必要性。
论文及项目相关链接
PDF Accepted at ICML 2025
Summary
自动化生产线需要主动控制机制来维持最佳性能,如自适应路由、工人重新分配和重新调度等。在设计这些控制系统方面存在挑战,虽然强化学习已展现出解决这些挑战的希望,但仍缺乏标准化和通用的框架。在此工作中,我们推出LineFlow,这是一个可扩展的开源Python框架,可模拟任意复杂度的生产线并训练RL代理来控制它们。为证明LineFlow的能力和验证其理论假设,我们以便于数学分析的方式制定了主动线路控制的核心子问题,并针对每个问题提供了最优解进行对比。我们评估了最先进的RL算法,并展示了在已知场景中,学习到的策略接近最优性能。然而,对于更复杂、工业规模的生产线,RL仍面临重大挑战,强调了对奖励塑造、课程学习和分层控制等领域进一步研究的必要性。
Key Takeaways
- 生产线的主动控制机制对于维持最佳性能至关重要,包括自适应路由、工人重新分配和重新调度等。
- 设计生产控制系统中存在挑战,缺乏标准化和通用的框架来应对这些挑战。
- LineFlow是一个可扩展的开源Python框架,用于模拟任意复杂度的生产线并训练RL代理进行控制。
- LineFlow通过制定核心子问题并为其提供最优解进行对比来验证其能力和理论假设。
- 最先进的RL算法已被评估,并在某些场景中表现出接近最优性能的表现。
- 在更复杂、工业规模的生产线应用中,RL仍面临奖励塑造、课程学习和分层控制等关键领域的挑战。
点此查看论文截图

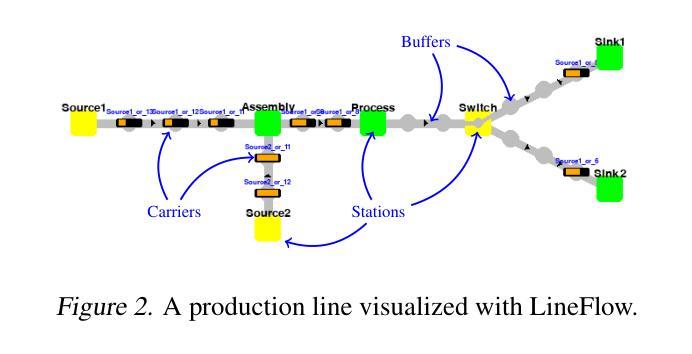
From Rankings to Insights: Evaluation Should Shift Focus from Leaderboard to Feedback
Authors:Zongqi Wang, Tianle Gu, Chen Gong, Xin Tian, Siqi Bao, Yujiu Yang
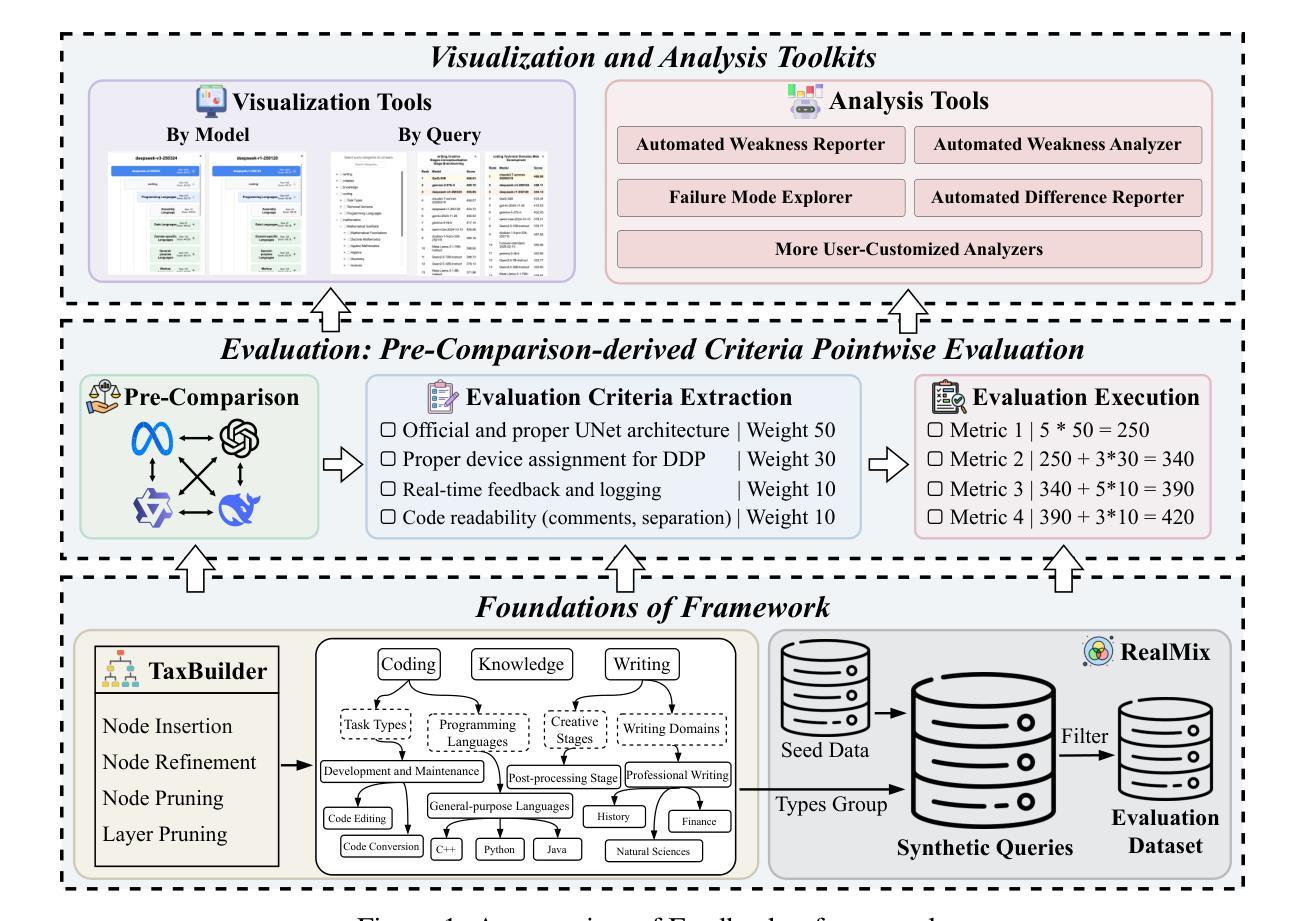
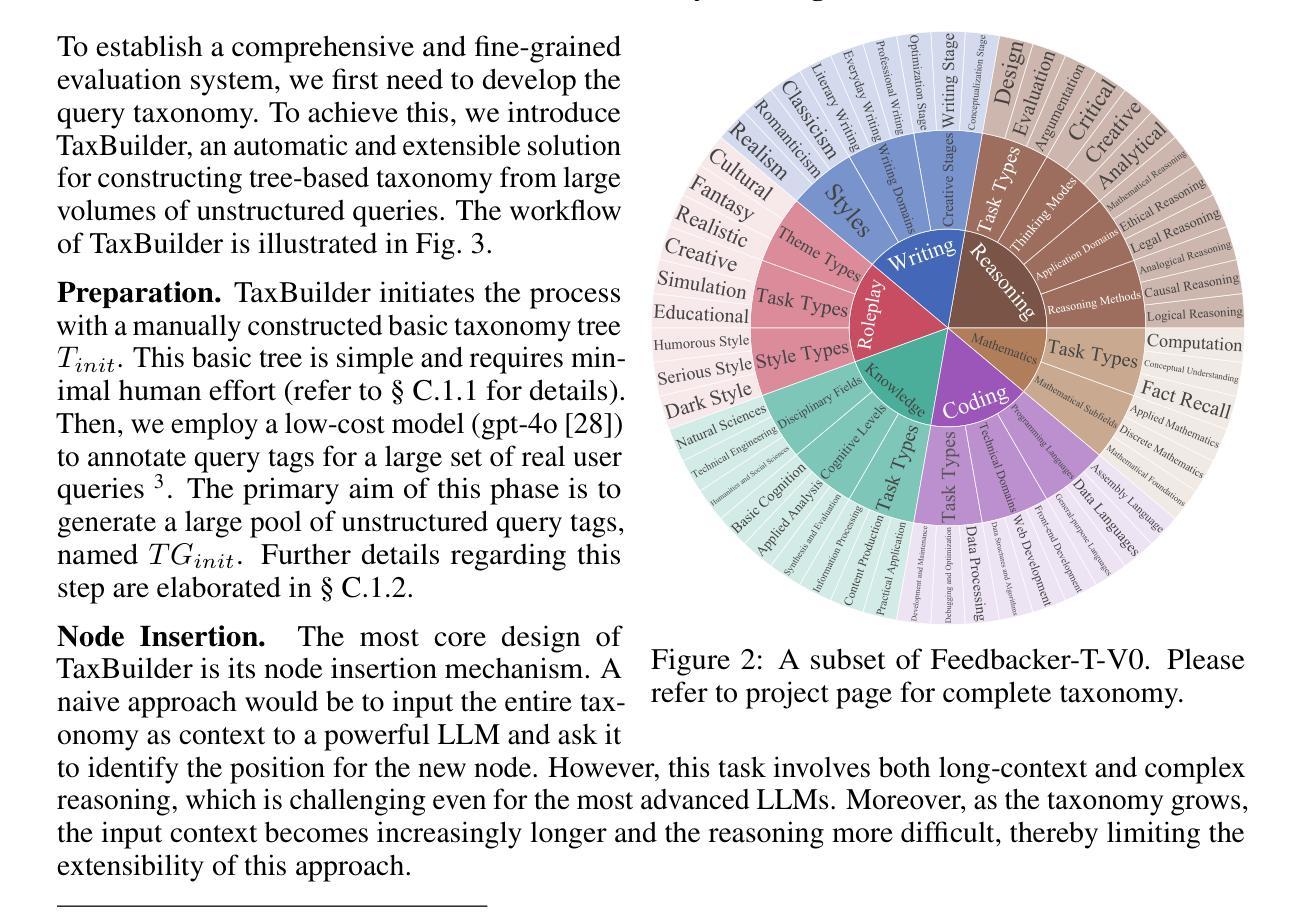
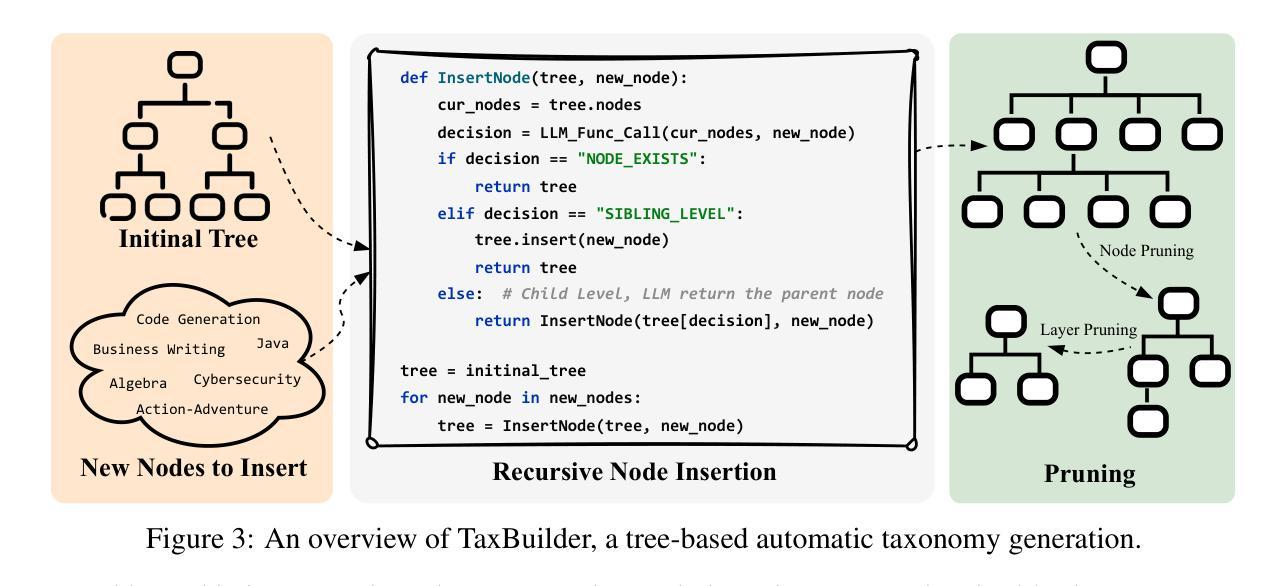
Automatic evaluation benchmarks such as MT-Bench, Arena-Hard, and Auto-Arena are seeing growing adoption for the evaluation of Large Language Models (LLMs). Existing research has primarily focused on approximating human-based model rankings using limited data and LLM-as-a-Judge. However, the fundamental premise of these studies, which attempts to replicate human rankings, is flawed. Specifically, these benchmarks typically offer only overall scores, limiting their utility to leaderboard rankings, rather than providing feedback that can guide model optimization and support model profiling. Therefore, we advocate for an evaluation paradigm shift from approximating human-based model rankings to providing feedback with analytical value. To this end, we introduce Feedbacker, an evaluation framework that provides comprehensive and fine-grained results, thereby enabling thorough identification of a model’s specific strengths and weaknesses. Such feedback not only supports the targeted optimization of the model but also enhances the understanding of its behavior. Feedbacker comprises three key components: an extensible tree-based query taxonomy builder, an automated query synthesis scheme, and a suite of visualization and analysis tools. Furthermore, we propose a novel LLM-as-a-Judge method: PC2 (Pre-Comparison-derived Criteria) pointwise evaluation. This method derives evaluation criteria by pre-comparing the differences between several auxiliary responses, achieving the accuracy of pairwise evaluation while maintaining the time complexity of pointwise evaluation. Finally, leveraging the evaluation results of 17 mainstream LLMs, we demonstrate the usage of Feedbacker and highlight its effectiveness and potential. Our homepage project is available at https://liudan193.github.io/Feedbacker.
自动评估基准(如MT-Bench、Arena-Hard和Auto-Arena)在评估大型语言模型(LLM)方面正越来越受到关注。目前的研究主要集中在利用有限数据模拟基于人类的模型排名以及以LLM作为法官的方法上。然而,这些研究试图复制人类排名的基本前提是有缺陷的。具体来说,这些基准通常只提供总体得分,使其仅限于排行榜排名,而无法提供可以指导模型优化和模型分析的有价值反馈。因此,我们主张从模拟基于人类的模型排名转向提供具有分析价值的反馈意见的评价范式转变。为此,我们引入了Feedbacker评估框架,它提供全面而精细的结果,从而能够彻底识别模型的特定优点和缺点。这种反馈不仅支持模型的针对性优化,还提高了对模型行为的理解。Feedbacker包含三个关键组件:可扩展的树形查询分类构建器、自动化查询合成方案以及一套可视化工具和数据分析工具。此外,我们提出了一种新的以LLM作为法官的方法:PC2(基于预比较标准)的点级评估。这种方法通过预先比较多个辅助响应之间的差异来推导评估标准,实现了配对评估的准确性同时保持点级评估的时间复杂度。最后,通过对17种主流LLM的评估结果加以利用,我们展示了Feedbacker的使用情况并强调了其有效性和潜力。我们的主页项目可在:https://liudan193.github.io/Feedbacker访问。
论文及项目相关链接
Summary
这是一项关于自然语言处理领域中大型语言模型评估的研究。研究团队指出了当前自动评估基准(如MT-Bench、Arena-Hard和Auto-Arena)存在的局限性,并提出了一个名为Feedbacker的新评估框架。该框架旨在提供具有分析价值的反馈,包括一个可扩展的树形查询分类构建器、自动化查询合成方案和可视化分析工具套件。此外,研究还提出了一种新型的LLM-as-a-Judge方法:PC2(基于预比较标准逐点评估),可更有效地进行语言模型评估。该项目已经对所获得的评估结果进行初步使用展示其效果和潜力,详情可在https://liudan193.github.io/Feedbacker中查阅。这项研究的重点是提供更准确的评估结果以优化和改进模型性能。
Key Takeaways
以下是关于该文本的关键见解:
- 当前自动评估基准主要关注于使用有限数据近似人类模型排名,但存在缺陷。这些基准往往仅提供总体得分,仅限于排名榜单的展示。为此需要评价范式从近似人类模型排名转向提供具有分析价值的反馈。
- Feedbacker是一个新的评估框架,旨在提供全面且精细的结果,有助于识别模型的特定优势和劣势。这不仅能够支持模型的针对性优化,还能增强对模型行为的理解。
- Feedbacker框架包括三个关键组件:可扩展的树形查询分类构建器、自动化查询合成方案和可视化分析工具套件。此外还提出了一种新型的LLM评估方法:PC2点对点评价法。此方法能够利用预先比较的差别生成新的评价准则,并在维持点对点评价的时间复杂度的同时提高配对评价的准确性。
点此查看论文截图