⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-14 更新
A Comparative Analysis of Static Word Embeddings for Hungarian
Authors:Máté Gedeon
This paper presents a comprehensive analysis of various static word embeddings for Hungarian, including traditional models such as Word2Vec, FastText, as well as static embeddings derived from BERT-based models using different extraction methods. We evaluate these embeddings on both intrinsic and extrinsic tasks to provide a holistic view of their performance. For intrinsic evaluation, we employ a word analogy task, which assesses the embeddings ability to capture semantic and syntactic relationships. Our results indicate that traditional static embeddings, particularly FastText, excel in this task, achieving high accuracy and mean reciprocal rank (MRR) scores. Among the BERT-based models, the X2Static method for extracting static embeddings demonstrates superior performance compared to decontextualized and aggregate methods, approaching the effectiveness of traditional static embeddings. For extrinsic evaluation, we utilize a bidirectional LSTM model to perform Named Entity Recognition (NER) and Part-of-Speech (POS) tagging tasks. The results reveal that embeddings derived from dynamic models, especially those extracted using the X2Static method, outperform purely static embeddings. Notably, ELMo embeddings achieve the highest accuracy in both NER and POS tagging tasks, underscoring the benefits of contextualized representations even when used in a static form. Our findings highlight the continued relevance of static word embeddings in NLP applications and the potential of advanced extraction methods to enhance the utility of BERT-based models. This piece of research contributes to the understanding of embedding performance in the Hungarian language and provides valuable insights for future developments in the field. The training scripts, evaluation codes, restricted vocabulary, and extracted embeddings will be made publicly available to support further research and reproducibility.
本文全面分析了匈牙利语的多种静态词嵌入方法,包括传统的Word2Vec、FastText模型,以及使用不同提取方法从BERT模型派生的静态嵌入。我们对这些嵌入进行了内在和外在任务的评估,以全面了解它们的性能。内在评估中,我们采用了词汇类比任务,该任务评估嵌入捕获语义和句法关系的能力。结果表明,传统静态嵌入,特别是FastText,在此任务中表现出色,准确度和平均倒数排名(MRR)得分很高。在BERT模型中,用于提取静态嵌入的X2Static方法相对于去上下文化和聚合方法显示出卓越的性能,接近传统静态嵌入的有效性。在外在评估中,我们使用双向LSTM模型执行命名实体识别(NER)和词性标注(POS)任务。结果表明,来自动态模型的嵌入,尤其是使用X2Static方法提取的嵌入,优于纯静态嵌入。值得注意的是,ELMo嵌入在NER和POS标注任务中的准确性最高,突显了即使在静态形式中使用上下文表示的好处。我们的研究结果表明静态词嵌入在NLP应用程序中的持续重要性,以及先进提取方法增强基于BERT的模型的潜力。该研究有助于理解匈牙利语中的嵌入性能,并为该领域的未来发展提供了宝贵的见解。为了支持进一步的研究和可重复性,我们将公开提供训练脚本、评估代码、受限词汇和提取的嵌入。
论文及项目相关链接
Summary
本文全面分析了匈牙利语的多种静态词嵌入方法,包括传统的Word2Vec、FastText模型以及基于BERT的不同提取方法得到的静态嵌入。通过内在和外在任务评估这些嵌入的性能,为它们的表现提供了全面的视角。在内在评估中,采用词类比任务评估嵌入捕捉语义和句法关系的能力,发现FastText等传统静态嵌入表现优秀,准确率和高平均倒数排名(MRR)得分较高。在基于BERT的模型中,X2Static方法提取的静态嵌入表现出卓越性能,接近传统静态嵌入的效果。外在评估中,使用双向LSTM模型进行命名实体识别(NER)和词性标注(POS)任务,发现来自动态模型的嵌入,特别是使用X2Static方法提取的嵌入,优于纯静态嵌入。特别是ELMo嵌入在NER和POS标注任务中的准确性最高,突显了上下文表示的优势,即使以静态形式使用也是如此。研究发现静态词嵌入在自然语言处理应用中持续具有重要意义,先进提取方法有可能增强基于BERT的模型的实用性。该研究为匈牙利语中的嵌入性能提供了理解,并为该领域的未来发展提供了宝贵见解。
Key Takeaways
- 论文对匈牙利语的多种静态词嵌入方法进行了全面分析。
- 内在评估中,传统静态嵌入模型如FastText在词类比任务中表现优秀。
- 在基于BERT的模型中,X2Static方法提取的静态嵌入表现出卓越性能。
- 外在评估中,动态模型的嵌入,特别是在使用X2Static方法时,优于纯静态嵌入。
- ELMo嵌入在命名实体识别(NER)和词性标注(POS)任务中的准确性最高。
- 论文强调了静态词嵌入在自然语言处理应用中的重要性。
点此查看论文截图

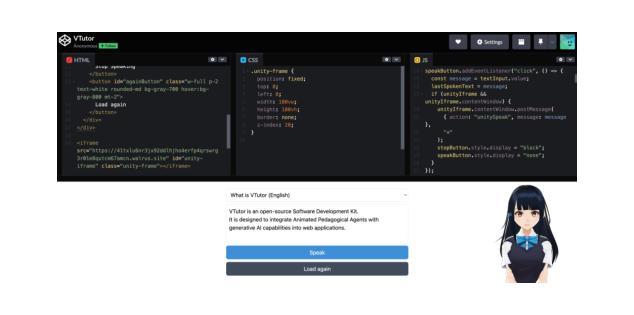
VTutor: An Animated Pedagogical Agent SDK that Provide Real Time Multi-Model Feedback
Authors:Eason Chen, Chenyu Lin, Yu-Kai Huang, Xinyi Tang, Aprille Xi, Jionghao Lin, Kenneth Koedinger
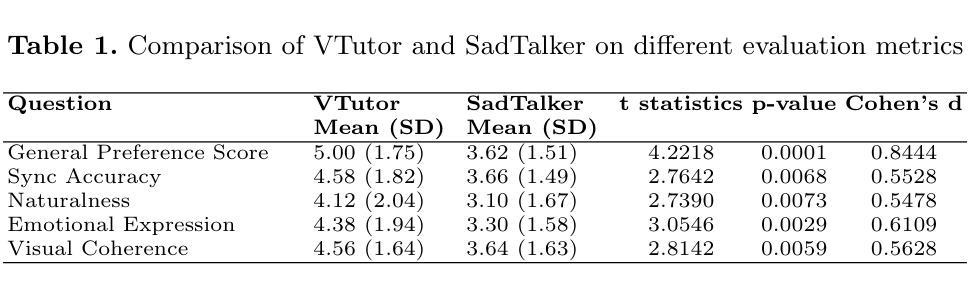
Pedagogical Agents (PAs) show significant potential for boosting student engagement and learning outcomes by providing adaptive, on-demand support in educational contexts. However, existing PA solutions are often hampered by pre-scripted dialogue, unnatural animations, uncanny visual realism, and high development costs. To address these gaps, we introduce VTutor, an open-source SDK leveraging lightweight WebGL, Unity, and JavaScript frameworks. VTutor receives text outputs from a large language model (LLM), converts them into audio via text-to-speech, and then renders a real-time, lip-synced pedagogical agent (PA) for immediate, large-scale deployment on web-based learning platforms. By providing on-demand, personalized feedback, VTutor strengthens students’ motivation and deepens their engagement with instructional material. Using an anime-like aesthetic, VTutor alleviates the uncanny valley effect, allowing learners to engage with expressive yet comfortably stylized characters. Our evaluation with 50 participants revealed that VTutor significantly outperforms the existing talking-head approaches (e.g., SadTalker) on perceived synchronization accuracy, naturalness, emotional expressiveness, and overall preference. As an open-source project, VTutor welcomes community-driven contributions - from novel character designs to specialized showcases of pedagogical agent applications - that fuel ongoing innovation in AI-enhanced education. By providing an accessible, customizable, and learner-centered PA solution, VTutor aims to elevate human-AI interaction experience in education fields, ultimately broadening the impact of AI in learning contexts. The demo link to VTutor is at https://vtutor-aied25.vercel.app.
教学代理(PAs)通过在教育环境中提供自适应、即时支持,显示出巨大的潜力,可以提高学生的学习参与度和学习效果。然而,现有的PA解决方案通常受到预设对话、不自然动画、过度真实的视觉和高昂的开发成本等限制。为了解决这些差距,我们推出了VTutor,一个利用轻量级WebGL、Unity和JavaScript框架的开源SDK。VTutor从大型语言模型(LLM)接收文本输出,通过文本到语音将其转换为音频,然后渲染一个实时、唇同步的教学代理(PA),可在基于网络的学习平台上进行即时、大规模部署。通过提供即时个性化的反馈,VTutor增强了学生的动力,并加深了他们与教材的联系。VTutor采用动漫式的审美风格,减轻了“非真实谷”效应,让学习者能够与表达丰富但风格舒适的角色互动。我们对50名参与者的评估表明,VTutor在感知到的同步精度、自然度、情感表达力和整体偏好上显著优于现有的谈话头方式(如SadTalker)。作为一个开源项目,VTutor欢迎社区驱动的贡献——从新颖的角色设计到教学代理应用程序的专门展示——这些贡献为AI增强教育的持续创新提供了动力。通过提供可访问、可定制、以学生为中心PA解决方案,VTutor旨在提升教育领域中的人机交互体验,最终扩大AI在学习环境中的影响力。VTutor的演示链接为:https://vtutor-aied25.vercel.app。
论文及项目相关链接
Summary
本文介绍了Pedagogical Agents(PAs)在教育领域中的潜力,通过提供自适应、即时支持来提高学生参与度和学习效果。针对现有PA解决方案的局限性,如预编程对话、不自然的动画和高开发成本等,本文引入了一个名为VTutor的开源SDK。VTutor利用轻量级WebGL、Unity和JavaScript框架,从大型语言模型接收文本输出,通过文本转语音转换为音频,并实时渲染一个与语音同步的PA,可在基于网络的学习平台上大规模部署。VTutor通过提供个性化即时反馈来增强学生的学习动力并加深他们对教学材料的理解。VTutor采用动漫式的美学设计,缓解了人与虚拟角色之间的情感落差,让学习者可以与具有表现力的角色舒适互动。评估结果显示,VTutor在感知同步准确性、自然度、情感表达力和整体偏好等方面显著优于现有的谈话头模式。作为开源项目,VTutor欢迎社区贡献者提供新的角色设计和专门的PA应用程序展示,共同推动AI增强教育的创新。
Key Takeaways
- PAs在教育领域具有提高学生学习参与度和效果的潜力。
- 现有PA解决方案受到预编程对话、不自然动画和高开发成本的限制。
- VTutor是一个开源SDK,旨在解决这些问题,提供自适应、即时支持。
- VTutor利用大型语言模型生成文本输出,转换为音频并渲染成实时PA。
- VTutor可大规模部署在基于网络的学习平台上,提供个性化反馈。
- VTutor采用动漫美学设计,增强学习者与角色之间的互动体验。
点此查看论文截图

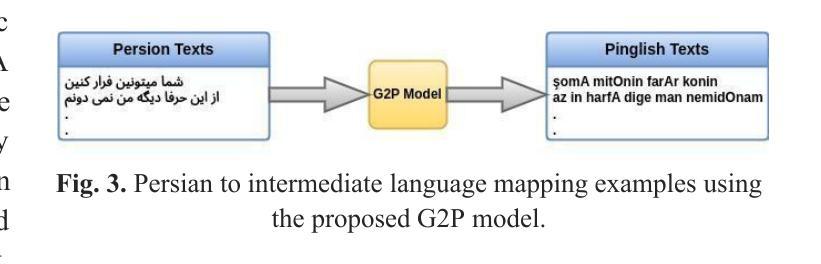
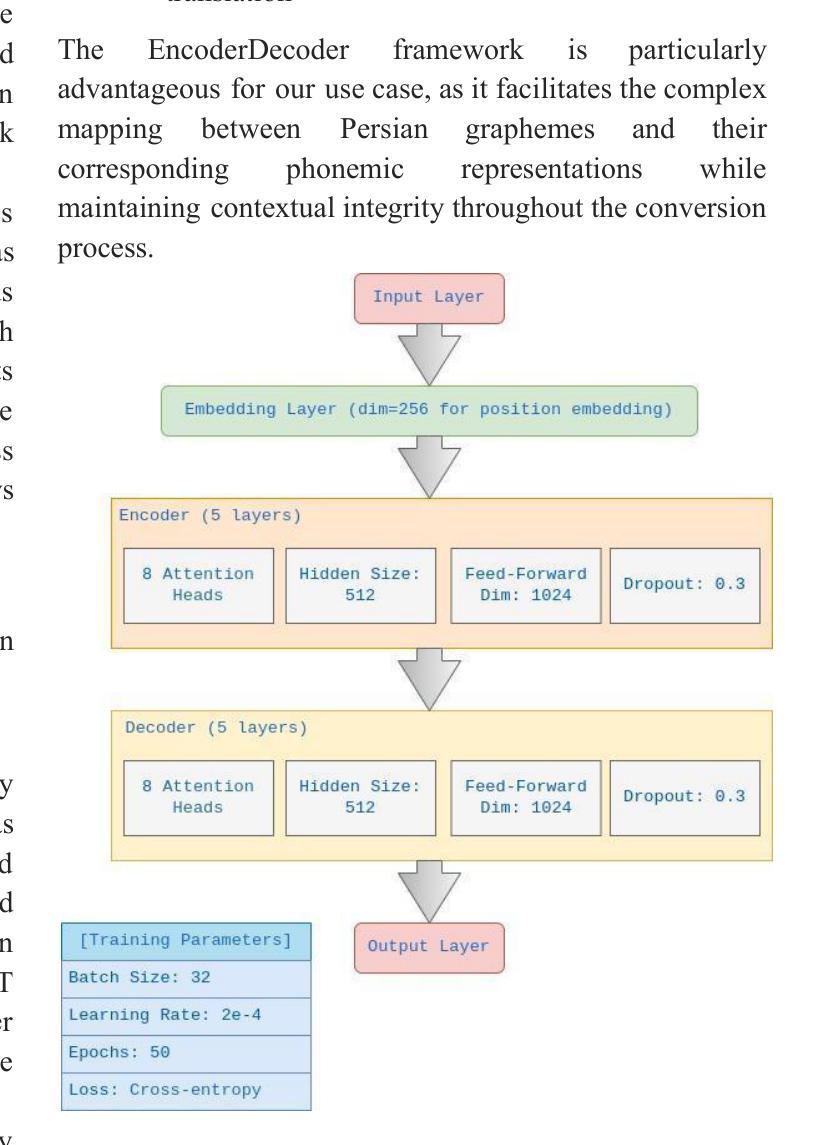
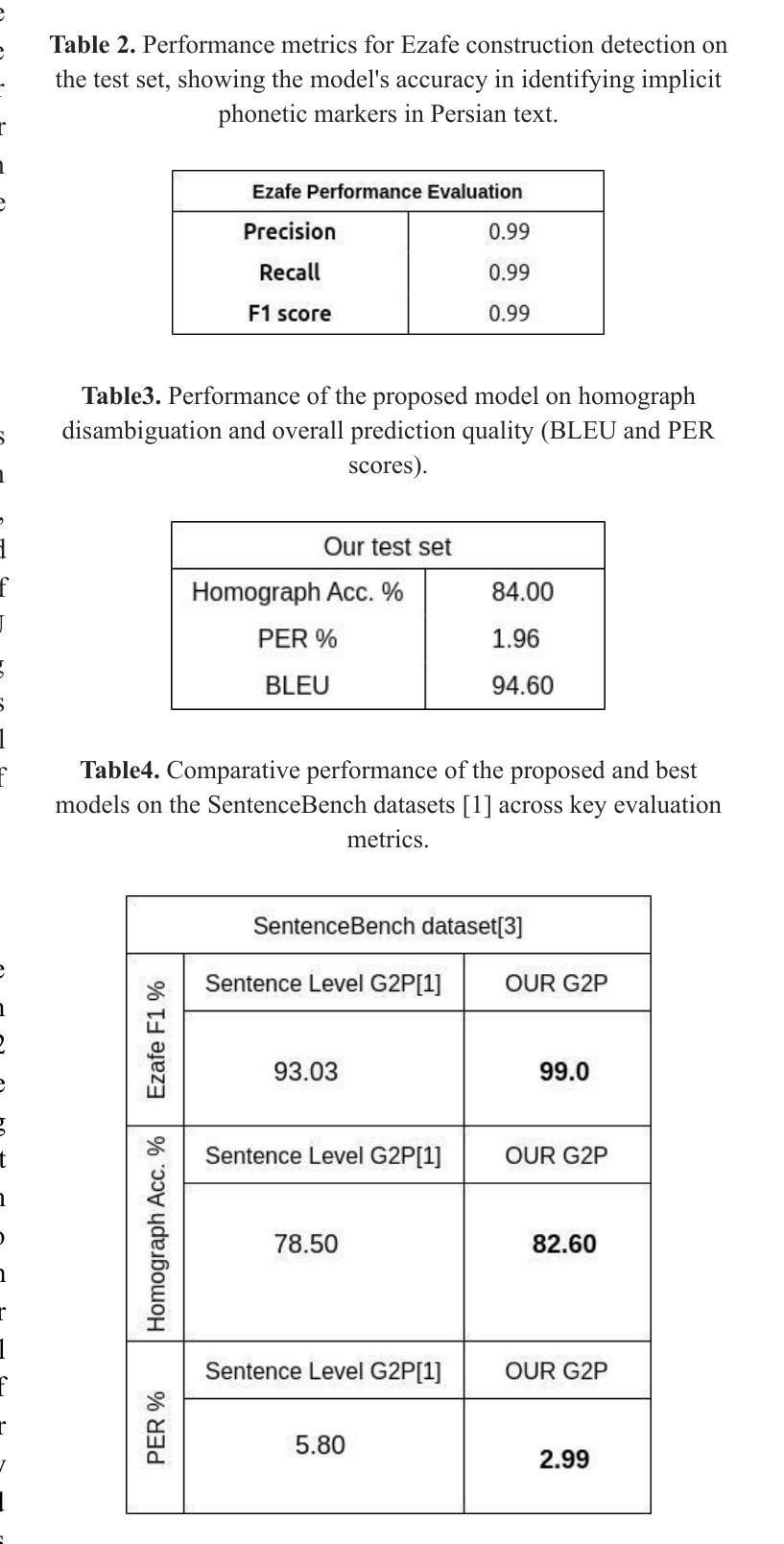
Bridging the Gap: An Intermediate Language for Enhanced and Cost-Effective Grapheme-to-Phoneme Conversion with Homographs with Multiple Pronunciations Disambiguation
Authors:Abbas Bertina, Shahab Beirami, Hossein Biniazian, Elham Esmaeilnia, Soheil Shahi, Mahdi Pirnia
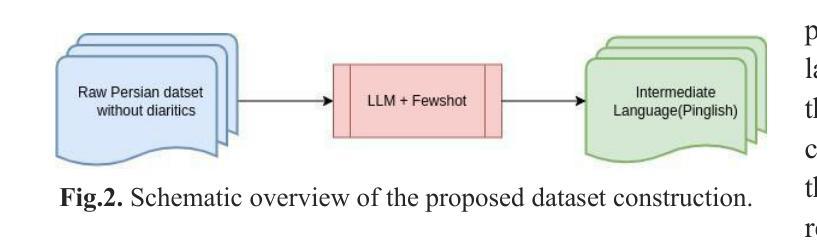
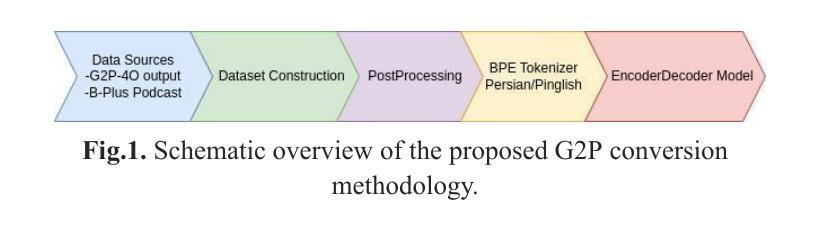
Grapheme-to-phoneme (G2P) conversion for Persian presents unique challenges due to its complex phonological features, particularly homographs and Ezafe, which exist in formal and informal language contexts. This paper introduces an intermediate language specifically designed for Persian language processing that addresses these challenges through a multi-faceted approach. Our methodology combines two key components: Large Language Model (LLM) prompting techniques and a specialized sequence-to-sequence machine transliteration architecture. We developed and implemented a systematic approach for constructing a comprehensive lexical database for homographs with multiple pronunciations disambiguation often termed polyphones, utilizing formal concept analysis for semantic differentiation. We train our model using two distinct datasets: the LLM-generated dataset for formal and informal Persian and the B-Plus podcasts for informal language variants. The experimental results demonstrate superior performance compared to existing state-of-the-art approaches, particularly in handling the complexities of Persian phoneme conversion. Our model significantly improves Phoneme Error Rate (PER) metrics, establishing a new benchmark for Persian G2P conversion accuracy. This work contributes to the growing research in low-resource language processing and provides a robust solution for Persian text-to-speech systems and demonstrating its applicability beyond Persian. Specifically, the approach can extend to languages with rich homographic phenomena such as Chinese and Arabic
针对波斯语的字母发音(G2P)转换由于其复杂的语音特征而面临独特的挑战,特别是在正式和非正式语言环境中的同音字和易泽(Ezafe)。本文介绍了一种专门为波斯语处理设计的中间语言,通过多元方法解决这些挑战。我们的方法结合了两个关键组成部分:大型语言模型(LLM)提示技术和专门的序列到序列机器转译架构。我们开发并实施了一种系统的方法来构建包含多音发音歧义的同音词的全面词汇数据库,通常被称为多音字,并利用形式概念分析进行语义区分。我们使用两个独特的数据集来训练我们的模型:用于正式和非正式波斯语的LLM生成数据集和用于非正式语言变体的B-Plus播客。实验结果表明,与现有的最先进方法相比,我们的模型具有卓越的性能,特别是在处理波斯语音素转换的复杂性方面。我们的模型显著提高了音素错误率(PER)指标,为波斯语的G2P转换精度建立了新的基准。这项工作为低资源语言处理的研究增长做出了贡献,并为波斯语音转文本系统提供了稳健的解决方案,并展示了其超越波斯的适用性。特别是,该方法可以扩展到具有丰富同音字现象的语言,如中文和阿拉伯文。
论文及项目相关链接
PDF pdf, 8 pages, 4 figures, 4 tables
Summary:
本文介绍了针对波斯语Grapeme-to-phoneme(G2P)转换的挑战,提出了一种中间语言处理方法。该方法结合了大型语言模型(LLM)提示技术和序列到序列机器转换架构,建立了一个全面的词汇数据库,用于处理具有多种发音的同名字(Polyphones)。使用正式概念分析进行语义区分,并在正式和非正式波斯语数据集以及B-Plus非正式语言变体数据集上进行训练。实验结果表明,该方法在波斯语音素转换的复杂性处理上表现出卓越性能,显著提高了音素错误率(PER)指标,为波斯语G2P转换准确性建立了新基准。该研究为低资源语言处理研究做出了贡献,并为波斯语音转系统提供了稳健解决方案,同时展示了其在其他语言如汉语和阿拉伯语中的适用性。
Key Takeaways:
- 波斯语Grapeme-to-phoneme(G2P)转换面临复杂挑战,包括同形字和Ezafe等复杂语音特征。
- 引入了一种中间语言处理方法,结合大型语言模型(LLM)提示技术和序列到序列机器转换架构,以应对这些挑战。
- 建立了一个全面的词汇数据库,用于处理具有多种发音的同名字(Polyphones),利用正式概念分析进行语义区分。
- 在正式和非正式波斯语数据集以及B-Plus非正式语言变体数据集上进行训练。
- 实验结果相比现有技术展现了优越性,特别是在处理波斯语音素转换的复杂性方面。
- 显著提高了音素错误率(PER)指标,为波斯语G2P转换准确性建立了新基准。
点此查看论文截图

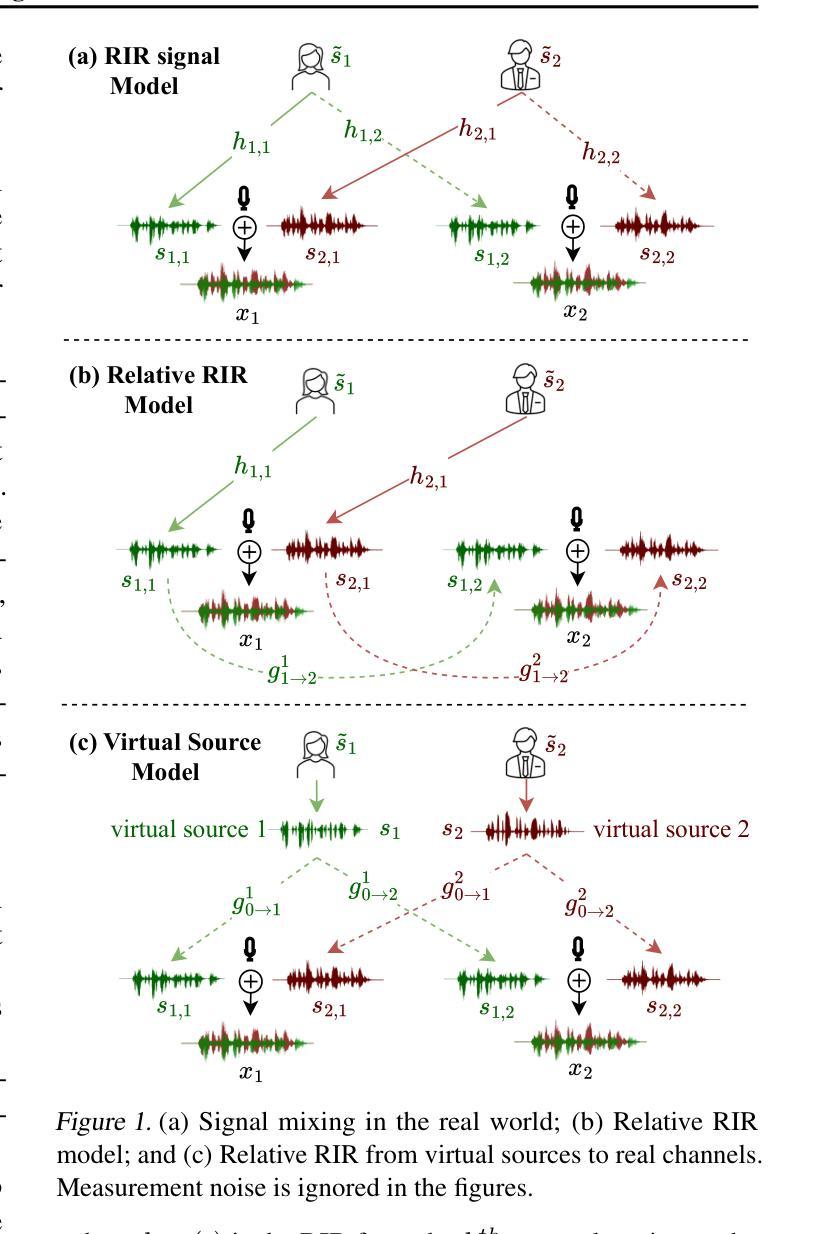
Unsupervised Blind Speech Separation with a Diffusion Prior
Authors:Zhongweiyang Xu, Xulin Fan, Zhong-Qiu Wang, Xilin Jiang, Romit Roy Choudhury
Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
盲语音分离(BSS)旨在从麦克风阵列记录的音频混合中分离出多个语音源。这个问题具有挑战性,因为它是一个盲逆问题,即麦克风阵列的几何形状、房间冲击响应(RIR)和语音源都是未知的。我们提出ArrayDPS以无监督、阵列无关和生成的方式解决BSS问题。核心理念建立在扩散后采样(DPS)的基础上,但不同于DPS中可能性是可追踪的,ArrayDPS必须通过制定一个单独的优化问题来近似可能性。优化的解决方案近似于房间声学以及麦克风之间的相对传递函数。这些近似值,连同扩散先验,在ArrayDPS采样过程中进行迭代,并最终产生分离的语音源。我们只需要一个简单的单讲者语音扩散模型作为先验,以及麦克风记录的混音;不需要麦克风阵列的信息。评估结果表明,ArrayDPS在SDR方面优于所有基线无监督方法,同时与有监督的方法相当。音频演示请访问:https://arraydps.github.io/ArrayDPSDemo/。
论文及项目相关链接
PDF Paper Accepted at ICML2025 Demo: https://arraydps.github.io/ArrayDPSDemo/ Code: https://github.com/ArrayDPS/ArrayDPS
总结
盲语音分离(BSS)旨在从麦克风阵列录制的音频混合中分离多个语音源。这是一个具有挑战性的逆向问题,因为麦克风阵列的几何形状、房间脉冲响应(RIR)和语音源都是未知的。我们提出ArrayDPS以无监督、阵列无关和生成的方式解决BSS问题。其核心思想建立在扩散后采样(DPS)的基础上,但不同于DPS的是,ArrayDPS必须通过制定单独的优化问题来近似可能性。优化问题的解决方案近似于房间声学以及麦克风之间的相对传输函数。这些近似值与扩散先验值一起,在ArrayDPS采样过程中进行迭代,并最终产生分离的语音源。我们只需要一个简单的单说话人语音扩散模型作为先验值,以及麦克风录制的混合声音;无需知道麦克风阵列的信息。评估结果表明,ArrayDPS在无人监督的方法中表现最佳,同时在有监督的方法的信号干扰比(SDR)方面表现良好。音频演示请访问:https://arraydps.github.io/ArrayDPSDemo/。
关键见解
- Blind Speech Separation (BSS)旨在从麦克风阵列录制的音频中分离多个未知的语音源。
- ArrayDPS是一种解决BSS问题的无监督、阵列无关和生成的方法。
- ArrayDPS的核心建立在扩散后采样(DPS)的基础上,但需要单独优化来近似可能性。
- 该优化过程模拟了房间声学及麦克风间的相对传输函数。
- ArrayDPS结合了扩散先验值在采样过程中进行迭代,最终产生分离的语音源。
- 仅需要单说话人语音扩散模型作为先验值,以及麦克风录制的混合声音,无需知道麦克风阵列的具体信息。
点此查看论文截图

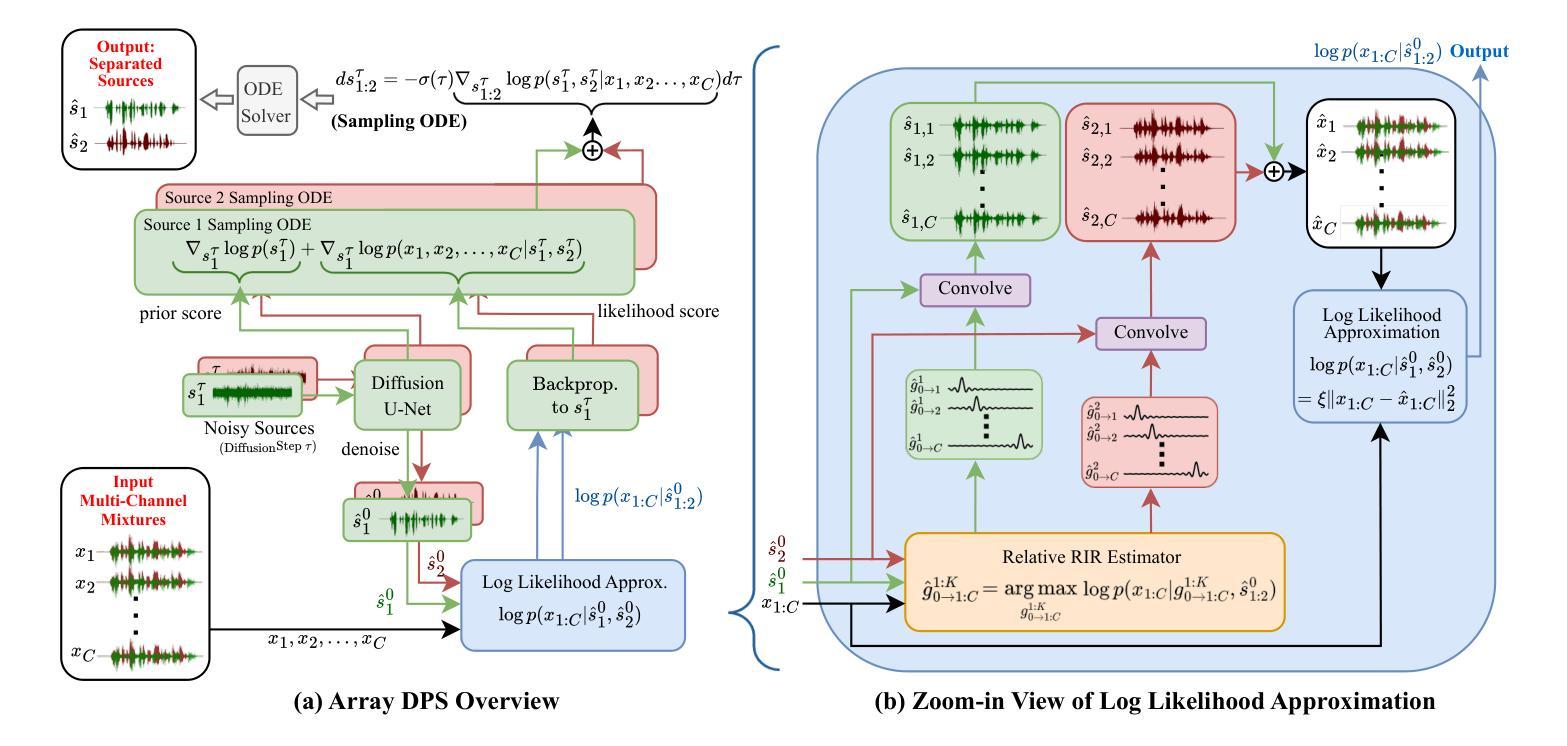

PAHA: Parts-Aware Audio-Driven Human Animation with Diffusion Model
Authors:S. Z. Zhou, Y. B. Wang, J. F. Wu, T. Hu, J. N. Zhang, Z. J. Li, Y. Liu
Audio-driven human animation technology is widely used in human-computer interaction, and the emergence of diffusion models has further advanced its development. Currently, most methods rely on multi-stage generation and intermediate representations, resulting in long inference time and issues with generation quality in specific foreground regions and audio-motion consistency. These shortcomings are primarily due to the lack of localized fine-grained supervised guidance. To address above challenges, we propose PAHA, an end-to-end audio-driven upper-body human animation framework with diffusion model. We introduce two key methods: Parts-Aware Re-weighting (PAR) and Parts Consistency Enhancement (PCE). PAR dynamically adjusts regional training loss weights based on pose confidence scores, effectively improving visual quality. PCE constructs and trains diffusion-based regional audio-visual classifiers to improve the consistency of motion and co-speech audio. Afterwards, we design two novel inference guidance methods for the foregoing classifiers, Sequential Guidance (SG) and Differential Guidance (DG), to balance efficiency and quality respectively. Additionally, we build CNAS, the first public Chinese News Anchor Speech dataset, to advance research and validation in this field. Extensive experimental results and user studies demonstrate that PAHA significantly outperforms existing methods in audio-motion alignment and video-related evaluations. The codes and CNAS dataset will be released upon acceptance.
音频驱动的人类动画技术广泛应用于人机交互领域,扩散模型的出现进一步推动了其发展。目前,大多数方法依赖于多阶段生成和中间表示,导致推理时间长,特定前景区域生成质量和音画同步问题。这些缺点主要是由于缺乏局部精细监督指导。为了解决上述挑战,我们提出了PAHA,这是一个基于扩散模型的端到端音频驱动人体上半身动画框架。我们介绍了两种关键方法:零件感知重加权(PAR)和零件一致性增强(PCE)。PAR根据姿势置信度得分动态调整区域训练损失权重,有效提高视觉效果。PCE构建并训练基于扩散的区域音视频分类器,提高动作和音乐音频的一致性。之后,我们为前述分类器设计了两种新型推理指导方法,即顺序指导(SG)和差分指导(DG),以平衡效率和质量。此外,我们构建了CNAS,即首个公开的中文新闻主播语音数据集,以促进该领域的研究和验证。广泛的实验和用户研究结果表明,PAHA在音频运动对齐和视频相关评估方面显著优于现有方法。代码和CNAS数据集将在接受后发布。
论文及项目相关链接
Summary
基于扩散模型的音频驱动人体动画技术面临多阶段生成带来的问题,如推理时间长、前景区域生成质量及音画同步性不佳。为此,提出PAHA框架及PAR和PCE两大方法,通过动态调整区域训练损失权重和提升姿态置信度来改善视觉质量,并构建扩散模型区域音视频分类器提升动作与音频的一致性。此外,推出两种新型推理引导方法SG和DG,平衡效率与质量。同时建立首个中文新闻主播语音数据集CNAS,推动相关研究验证。实验和用户研究证明PAHA在音画同步和视频评价上显著超越现有方法。
Key Takeaways
- 音频驱动人体动画技术在人机交互中广泛应用,扩散模型的出现进一步推动了其发展。
- 当前方法存在多阶段生成导致的推理时间长、特定前景区域生成质量及音画同步性问题。
- 缺乏局部精细监督指导是上述挑战的主要原因。
- PAHA框架通过引入PAR和PCE两大方法,有效改善视觉质量和音画一致性。
- SG和DG两种新型推理引导方法的提出,旨在平衡效率与质量。
- 建立了首个中文新闻主播语音数据集CNAS,为相关研究提供验证。
点此查看论文截图

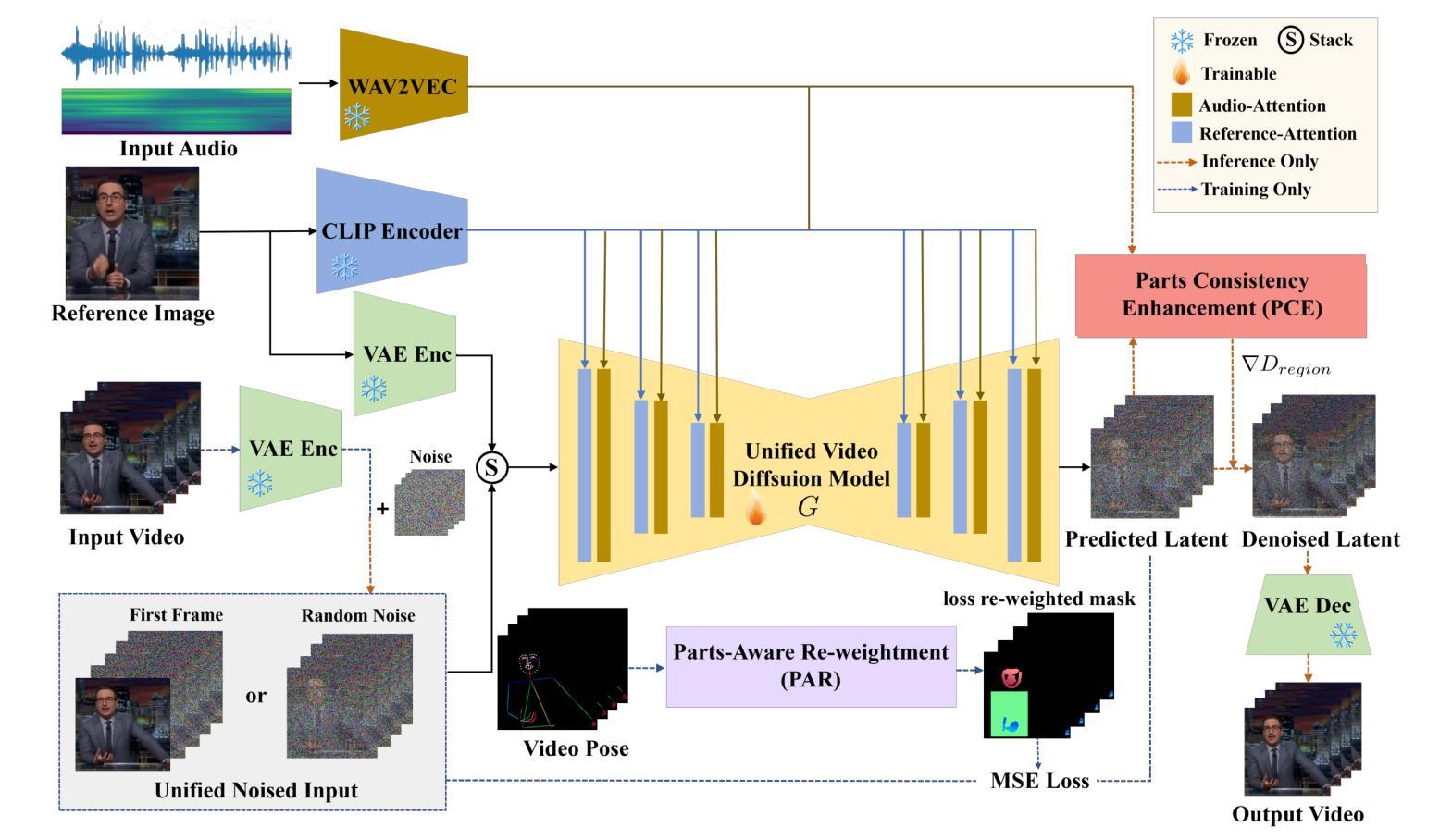

DGSNA: prompt-based Dynamic Generative Scene-based Noise Addition method
Authors:Zihao Chen, Zhentao Lin, Bi Zeng, Linyi Huang, Zhi Li, Jia Cai
To ensure the reliable operation of speech systems across diverse environments, noise addition methods have emerged as the prevailing solution. However, existing methods offer limited coverage of real-world noisy scenes and depend on pre-existing scene-based information and noise. This paper presents prompt-based Dynamic Generative Scene-based Noise Addition (DGSNA), a novel noise addition methodology that integrates Dynamic Generation of Scene-based Information (DGSI) with Scene-based Noise Addition for Speech (SNAS). This integration facilitates automated scene-based noise addition by transforming clean speech into various noise environments, thereby providing a more comprehensive and realistic simulation of diverse noise conditions. Experimental results demonstrate that DGSNA significantly enhances the robustness of speech recognition and keyword spotting models across various noise conditions, achieving a relative improvement of up to 11.21%. Furthermore, DGSNA can be effectively integrated with other noise addition methods to enhance performance. Our implementation and demonstrations are available at https://dgsna.github.io.
为了确保语音系统在不同环境中的可靠运行,噪声添加方法已成为主流的解决方案。然而,现有方法对于真实世界噪声场景覆盖有限,并依赖于基于场景的预先存在信息和噪声。本文提出了基于提示的动态生成场景噪声添加(DGSNA),这是一种新型噪声添加方法,它将基于场景的动态信息生成(DGSI)与基于场景的语音噪声添加(SNAS)相结合。这种结合通过转换干净语音为各种噪声环境,实现了基于场景的自动噪声添加,从而提供了对多种噪声条件的更全面和现实的模拟。实验结果表明,DGSNA显著提高了语音识别和关键词点模型在各种噪声条件下的稳健性,相对改进率最高达11.21%。此外,DGSNA可以与其他噪声添加方法有效结合以提高性能。我们的实现和演示可在https://dgsna.github.io查看。
论文及项目相关链接
摘要
本研究提出一种基于提示的动态生成场景噪声添加方法(DGSNA),集成动态生成场景信息(DGSI)与场景噪声添加技术(SNAS)。该方法可自动模拟多种噪声环境下的语音信号,提高语音识别和关键词识别模型在各种噪声条件下的稳健性,相对改进率高达11.21%。此外,DGSNA可与其他噪声添加方法结合使用,进一步提高性能。
关键见解
- DGSNA是一种新型的噪声添加方法,结合了DGSI和SNAS技术。
- 该方法能够自动模拟多种噪声环境下的语音信号。
- DGSNA提高了语音识别和关键词识别模型在各种噪声条件下的稳健性。
- DGSNA相对改进率高达11.21%。
- DGSNA可与其他噪声添加方法结合,进一步提高性能。
- 该方法的实施和演示可在网上找到。
- DGSNA有助于确保语音系统在不同环境中的可靠运行。
点此查看论文截图
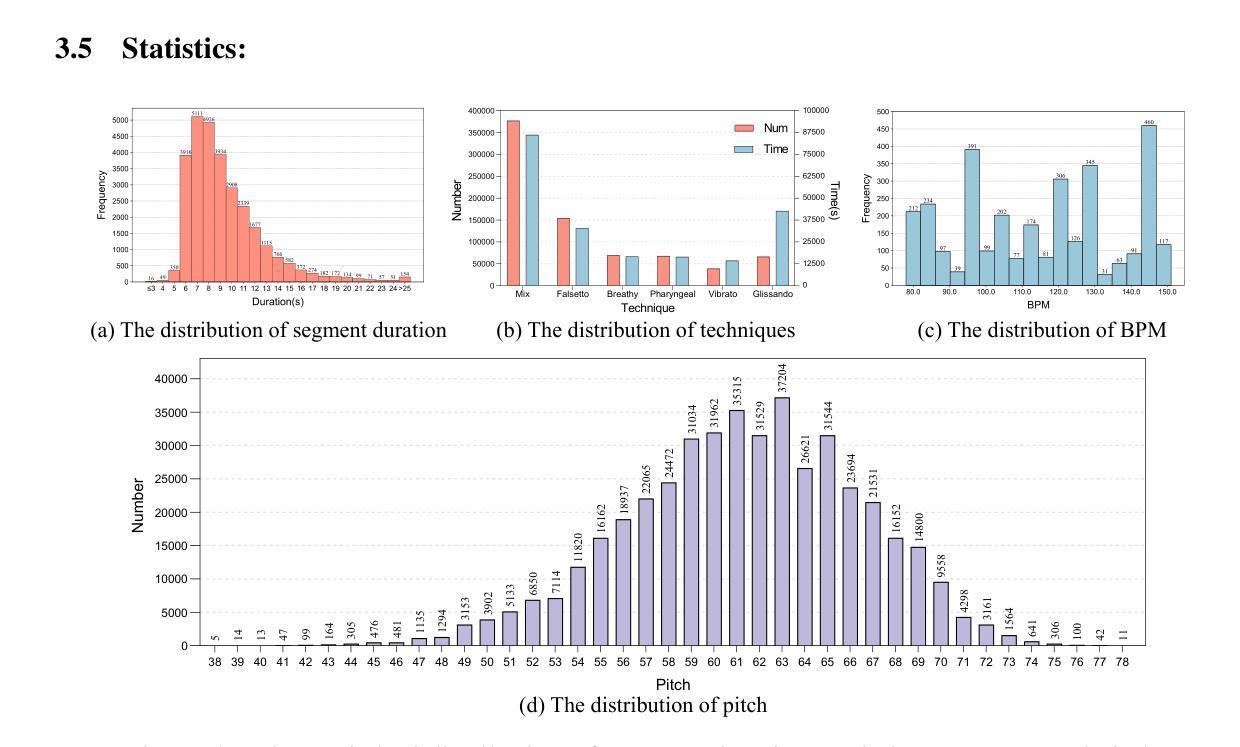
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Authors:Yu Zhang, Changhao Pan, Wenxiang Guo, Ruiqi Li, Zhiyuan Zhu, Jialei Wang, Wenhao Xu, Jingyu Lu, Zhiqing Hong, Chuxin Wang, LiChao Zhang, Jinzheng He, Ziyue Jiang, Yuxin Chen, Chen Yang, Jiecheng Zhou, Xinyu Cheng, Zhou Zhao
The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://aaronz345.github.io/GTSingerDemo/. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/AaronZ345/GTSinger and https://github.com/AaronZ345/GTSinger.
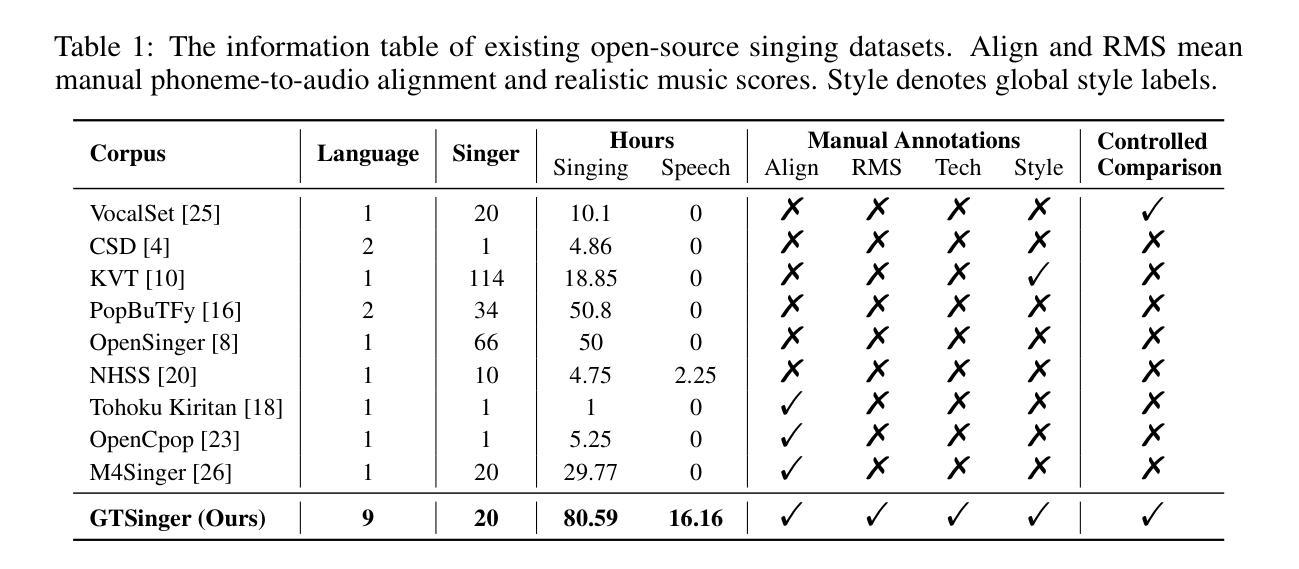
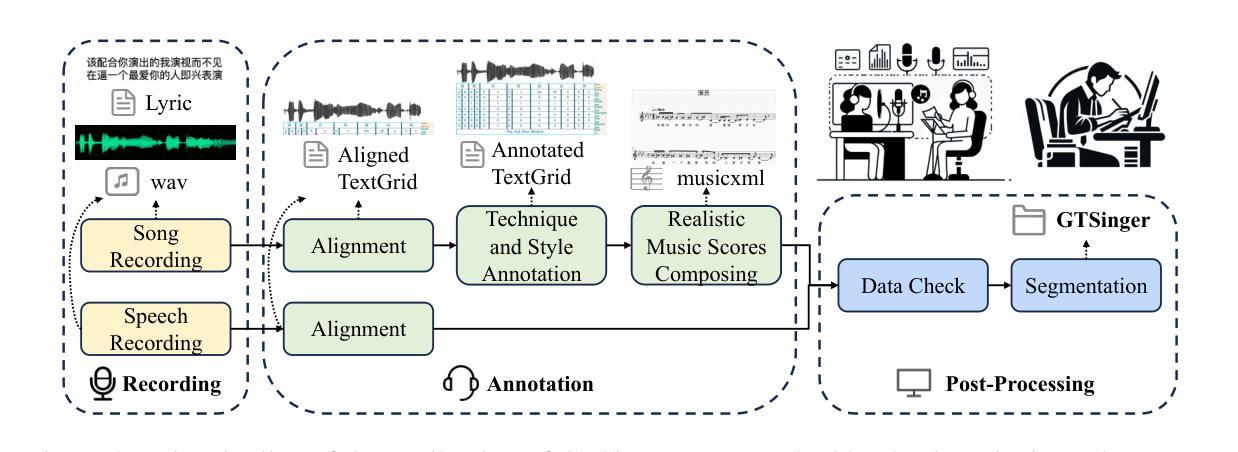
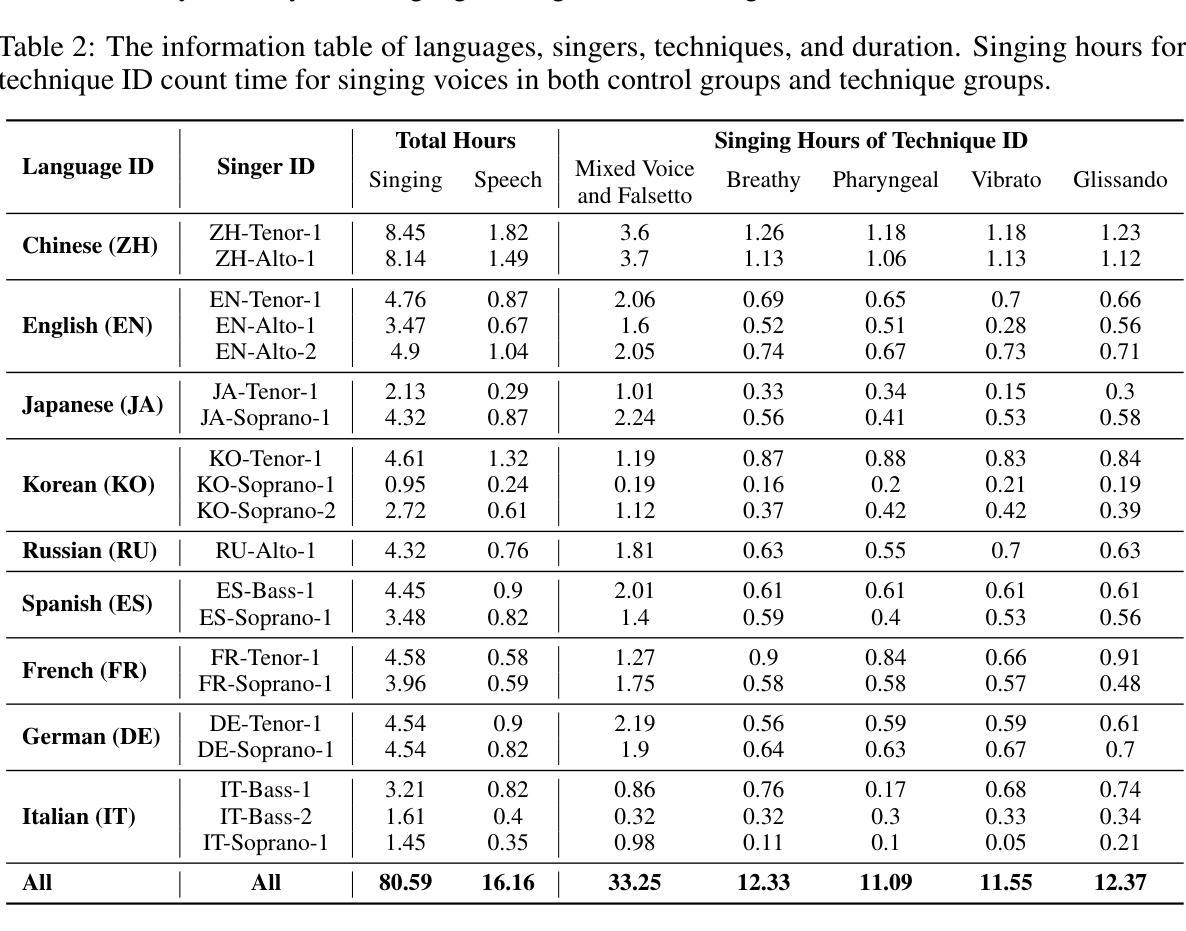
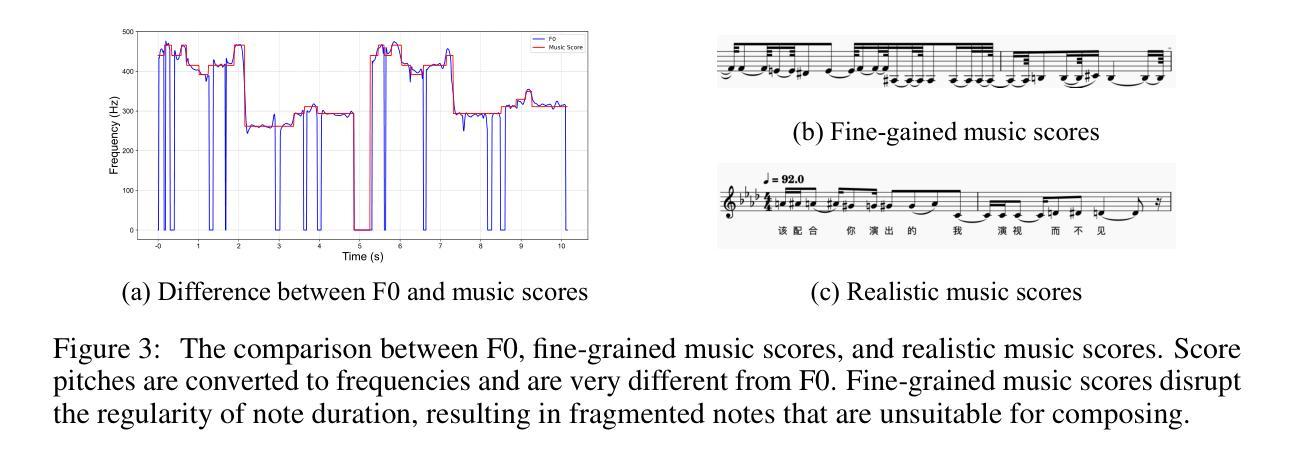
高质量多任务演唱数据集稀缺的问题显著阻碍了多样可控和个性化演唱任务的发展,因为现有的演唱数据集存在质量低、语言及歌手多样性有限、缺乏多技术信息和现实音乐乐谱以及任务适用性差等问题。为了解决这些问题,我们推出了GTSinger,这是一个大型的全球性、多技术、免费使用的高质量演唱语料库,具有现实音乐乐谱,适用于所有演唱任务,以及相应的基准测试。具体来说,(1)我们收集了80.59小时的高质量演唱声音,形成了最大的录制演唱数据集;(2)20名专业歌手跨越九种广泛使用的语言,展现了多样的音色和风格;(3)我们提供了六种常用演唱技术的受控比较和音素级注释,有助于技术建模和控制;(4)GTSinger提供了现实的乐谱,有助于现实音乐创作;(5)演唱声音配有手动音素到音频对齐、全局风格标签,以及用于各种演唱任务的16.16小时配套语音。此外,为了使用GTSinger,我们进行了四项基准测试:技术可控的演唱声音合成、技术识别、风格转换和语音到演唱的转换。语料库和演示可在http://aaronz345.github.io/GTSingerDemo/找到。我们在https://huggingface.co/datasets/AaronZ345/GTSinger和https://github.com/AaronZ345/GTSinger提供了数据集和数据处理及基准测试的代码。
论文及项目相关链接
PDF Accepted by NeurIPS 2024 (Spotlight)
摘要
本文介绍了GTSinger这一全球大型、多技术、免费高质量歌唱数据集。该数据集拥有现实音乐曲目,适用于所有歌唱任务。数据集特点包括:收集80.59小时的高质量歌声,涉及九种广泛使用的语言;包含六种常用歌唱技术的对比和音素级注释;提供现实音乐曲目,辅助现实音乐创作;此外,还有手动音素到音频的对齐、全球风格标签和16.16小时的配对语音,用于各种歌唱任务。同时,为便于使用GTSinger,进行了四项基准实验:技术可控的歌唱声音合成、技术识别、风格转换和语音转歌唱。数据集和相关代码可在指定网站下载。
关键见解
- GTSinger是一个全球性的大型歌唱数据集,旨在解决现有数据集在质量和多样性方面存在的问题。
- 数据集包含80.59小时的高质量歌声录音,是目前最大的已记录歌唱数据集。
- 数据集涵盖九种广泛使用的语言,提供了多样化的音色和风格。
- 数据集中包含六种常用歌唱技术的对比和音素级注释,有助于技术建模和控制。
- GTSinger提供现实音乐曲目,支持真实音乐创作。
- 数据集包含手动音素到音频的对齐、全球风格标签和配对语音,适用于多种歌唱任务。
- 为更好地利用数据集,提供了四项基准实验,包括技术可控的歌唱声音合成等。
点此查看论文截图