⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-14 更新
Lightweight End-to-end Text-to-speech Synthesis for low resource on-device applications
Authors:Biel Tura Vecino, Adam Gabryś, Daniel Mątwicki, Andrzej Pomirski, Tom Iddon, Marius Cotescu, Jaime Lorenzo-Trueba
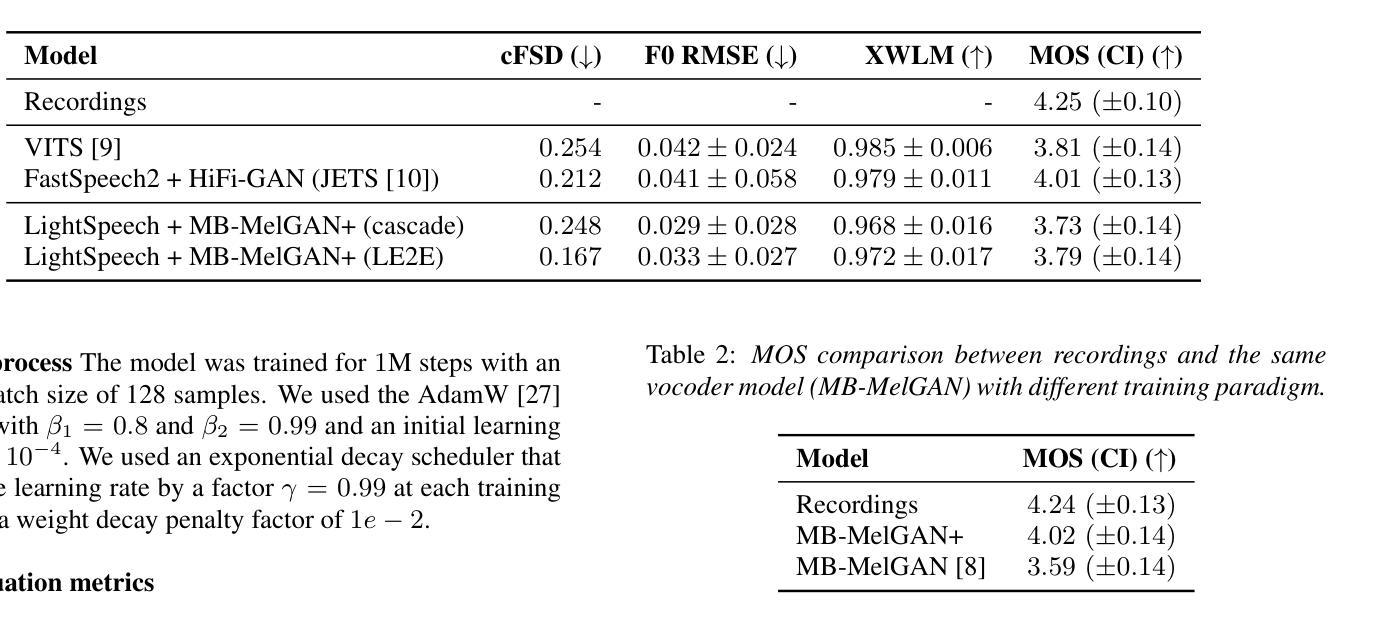
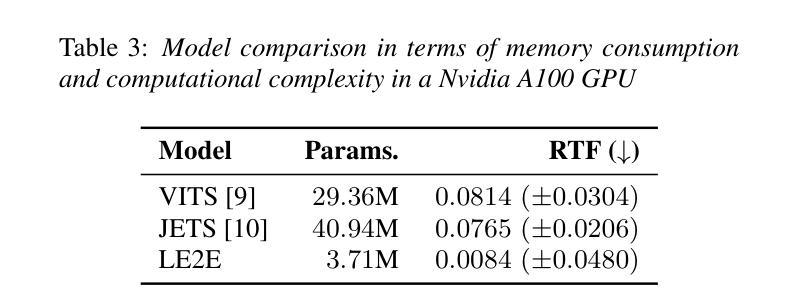
Recent works have shown that modelling raw waveform directly from text in an end-to-end (E2E) fashion produces more natural-sounding speech than traditional neural text-to-speech (TTS) systems based on a cascade or two-stage approach. However, current E2E state-of-the-art models are computationally complex and memory-consuming, making them unsuitable for real-time offline on-device applications in low-resource scenarios. To address this issue, we propose a Lightweight E2E-TTS (LE2E) model that generates high-quality speech requiring minimal computational resources. We evaluate the proposed model on the LJSpeech dataset and show that it achieves state-of-the-art performance while being up to $90%$ smaller in terms of model parameters and $10\times$ faster in real-time-factor. Furthermore, we demonstrate that the proposed E2E training paradigm achieves better quality compared to an equivalent architecture trained in a two-stage approach. Our results suggest that LE2E is a promising approach for developing real-time, high quality, low-resource TTS applications for on-device applications.
最新研究表明,采用端到端(E2E)方式直接从文本模拟原始波形产生的语音比基于级联或两阶段方法的传统神经文本到语音(TTS)系统产生的语音更自然。然而,当前先进的E2E模型计算复杂、内存消耗大,不适用于低资源场景下的实时离线设备端应用。为了解决这一问题,我们提出了一种轻量级的E2E-TTS(LE2E)模型,该模型能够在要求极小计算资源的情况下生成高质量的语音。我们在LJSpeech数据集上评估了所提出的模型,并证明其在达到最新性能的同时,模型参数减少了高达90%,实时因子速度提高了10倍。此外,我们还证明了所提出的E2E训练范式与采用两阶段方法训练的等效架构相比,实现了更好的质量。我们的结果表明,LE2E对于开发实时、高质量、低资源的TTS应用是一个有前途的方法,特别适用于设备端应用。
论文及项目相关链接
PDF Published as a conference paper at SSW 2023
摘要
提出一种轻量级端到端文本转语音(LE2E)模型,该模型可在低资源场景下生成高质量语音且计算资源需求小。与当前端到端模型相比,LE2E模型参数减少90%,实时因子速度提高10倍,同时在性能上达到最新水平。此外,对比两阶段训练方法,LE2E的端到端训练范式能生成更高质量的语音。表明LE2E对于开发实时、高质量、低资源的在线设备文本转语音应用具有前景。
关键见解
- 端到端(E2E)模型直接建模文本到原始波形能产生更自然的语音。
- 当前先进的E2E模型计算复杂且内存消耗大,不适合低资源场景下的实时离线设备应用。
- 提出的轻量级E2E-TTS(LE2E)模型能在计算资源需求较小的情况下生成高质量语音。
- LE2E模型参数比现有模型减少90%,实时因子速度提高10倍。
- LE2E的端到端训练范式比两阶段训练方法生成更高质量的语音。
- LE2E在LJSpeech数据集上的性能达到最新水平。
- LE2E模型对于开发实时、高质量、低资源的在线设备文本转语音应用具有前景。
点此查看论文截图

VTutor: An Animated Pedagogical Agent SDK that Provide Real Time Multi-Model Feedback
Authors:Eason Chen, Chenyu Lin, Yu-Kai Huang, Xinyi Tang, Aprille Xi, Jionghao Lin, Kenneth Koedinger
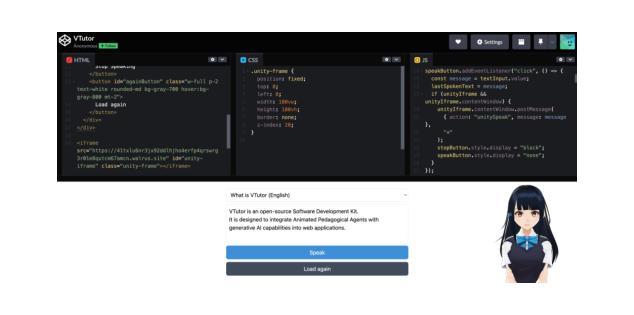
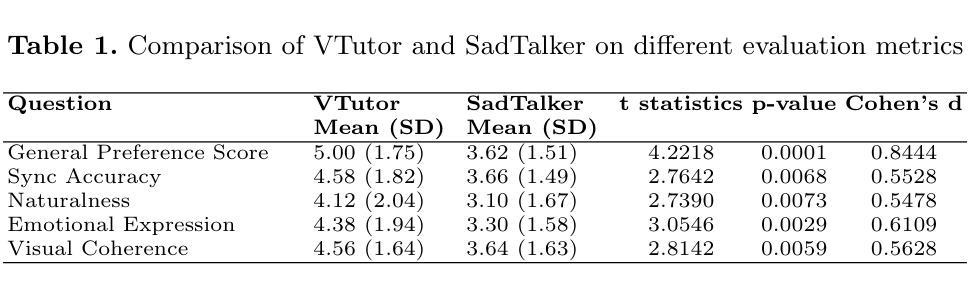
Pedagogical Agents (PAs) show significant potential for boosting student engagement and learning outcomes by providing adaptive, on-demand support in educational contexts. However, existing PA solutions are often hampered by pre-scripted dialogue, unnatural animations, uncanny visual realism, and high development costs. To address these gaps, we introduce VTutor, an open-source SDK leveraging lightweight WebGL, Unity, and JavaScript frameworks. VTutor receives text outputs from a large language model (LLM), converts them into audio via text-to-speech, and then renders a real-time, lip-synced pedagogical agent (PA) for immediate, large-scale deployment on web-based learning platforms. By providing on-demand, personalized feedback, VTutor strengthens students’ motivation and deepens their engagement with instructional material. Using an anime-like aesthetic, VTutor alleviates the uncanny valley effect, allowing learners to engage with expressive yet comfortably stylized characters. Our evaluation with 50 participants revealed that VTutor significantly outperforms the existing talking-head approaches (e.g., SadTalker) on perceived synchronization accuracy, naturalness, emotional expressiveness, and overall preference. As an open-source project, VTutor welcomes community-driven contributions - from novel character designs to specialized showcases of pedagogical agent applications - that fuel ongoing innovation in AI-enhanced education. By providing an accessible, customizable, and learner-centered PA solution, VTutor aims to elevate human-AI interaction experience in education fields, ultimately broadening the impact of AI in learning contexts. The demo link to VTutor is at https://vtutor-aied25.vercel.app.
教学代理(PAs)在教育环境中通过提供自适应的即时支持,展现出提高学生参与度和学习成果的显著潜力。然而,现有的PA解决方案通常受到预设对话、不自然的动画、奇异的视觉真实感和高昂的开发成本等限制。为了解决这些差距,我们推出了VTutor,一个利用轻量级WebGL、Unity和JavaScript框架的开源SDK。VTutor接收来自大型语言模型(LLM)的文本输出,通过文本到语音的转换,将其转化为音频,然后渲染出实时同步的唇部同步教学代理(PA),可在基于网络的学习平台上进行即时的大规模部署。通过提供即时个性化的反馈,VTutor增强了学生的动力,并加深了他们与教学材料的互动。VTutor采用动漫式的审美风格,减轻了“诡异谷效应”,使学习者能够与表达丰富但风格舒适的角色互动。我们对50名参与者的评估显示,VTutor在感知的同步准确性、自然性、情感表达力和整体偏好上显著优于现有的说话人方法(如SadTalker)。作为一个开源项目,VTutor欢迎社区驱动的贡献——从新型角色设计到教学代理应用程序的专门展示——这些贡献推动人工智能增强教育的持续创新。通过提供可访问、可定制和以学习者为中心PA解决方案,VTutor旨在提升教育领域中人工智能与人类之间的交互体验,最终扩大人工智能在学习环境中的影响力。VTutor的演示链接为:https://vtutor-aied25.vercel.app。
论文及项目相关链接
摘要
教学代理(PAs)在提升学生学习参与度和学习效果方面具有巨大潜力,通过提供适应性和即时支持来增强教育体验。然而,现有的PA解决方案常受限于预设对话、不自然的动画、奇怪的视觉真实感和高昂的开发成本。为解决这些问题,我们推出VTutor,一个开源SDK,利用轻量级WebGL、Unity和JavaScript框架。VTutor接收大型语言模型的文本输出,通过文本转语音转换为音频,并实时渲染一个与嘴唇同步的PAs,可在基于网络的学习平台上大规模部署。VTutor通过提供个性化即时反馈来激发学生的学习动力并加深他们对教材内容的参与程度。采用动漫式美学设计缓解了学习者与表达角色之间的不协调感,使得学习者能与表现生动且风格舒适的个性化角色互动。我们对五十名参与者进行的评估表明,VTutor在感知同步精度、自然度、情感表现力和整体偏好上显著优于现有的讲话人(如SadTalker)。作为一个开源项目,VTutor欢迎各界人士的积极参与,包括新型角色设计和PA应用程序的专门展示等,共同推动人工智能增强教育的持续创新。VTutor旨在提供一种易于访问、可定制化和以学习者为中心的教学代理解决方案,从而改善教育领域中人机交互的体验并扩大人工智能在学习环境中的影响力。VTutor的演示链接为:[链接地址]。
关键见解
- 教学代理(PAs)具有提升学生学习参与度和学习效果的潜力。
- 当前PA解决方案受限于预设对话、动画不自然等因素。
- VTutor是一个新的开源SDK,能生成逼真的教学代理并通过网络学习平台大规模部署。
- VTutor接收大型语言模型的文本输出并转换为音频,实现实时同步的动画效果。
- VTutor采用动漫美学设计减轻学习者的认知冲突并提升交互体验。
- 实验证明VTutor相较于现有方法显著改善感知同步精度、自然度和情感表达等方面。
点此查看论文截图

Bridging the Gap: An Intermediate Language for Enhanced and Cost-Effective Grapheme-to-Phoneme Conversion with Homographs with Multiple Pronunciations Disambiguation
Authors:Abbas Bertina, Shahab Beirami, Hossein Biniazian, Elham Esmaeilnia, Soheil Shahi, Mahdi Pirnia
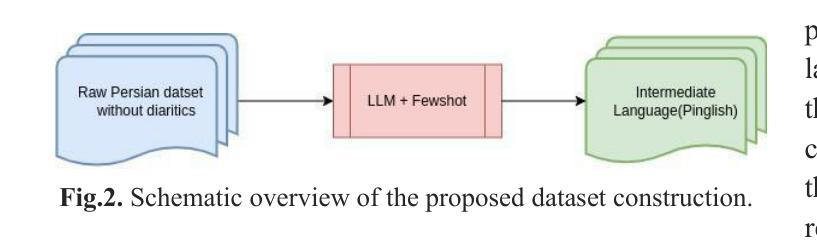
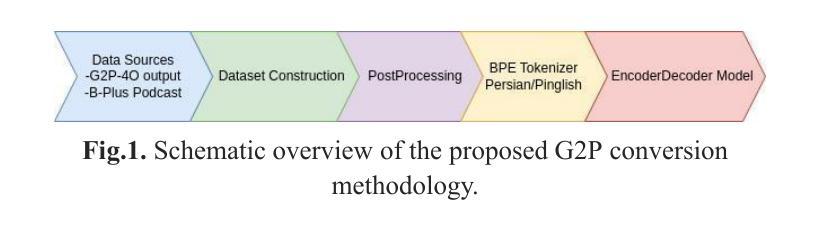
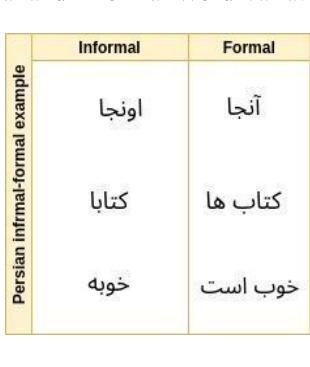
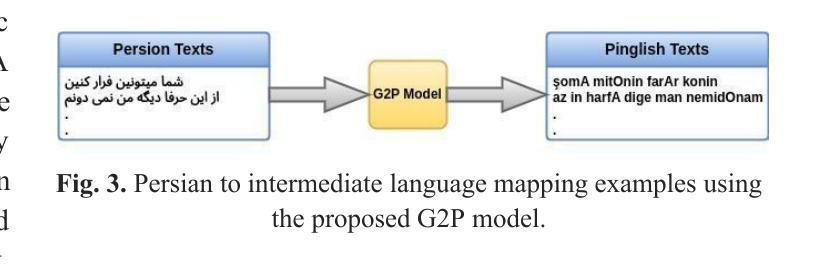
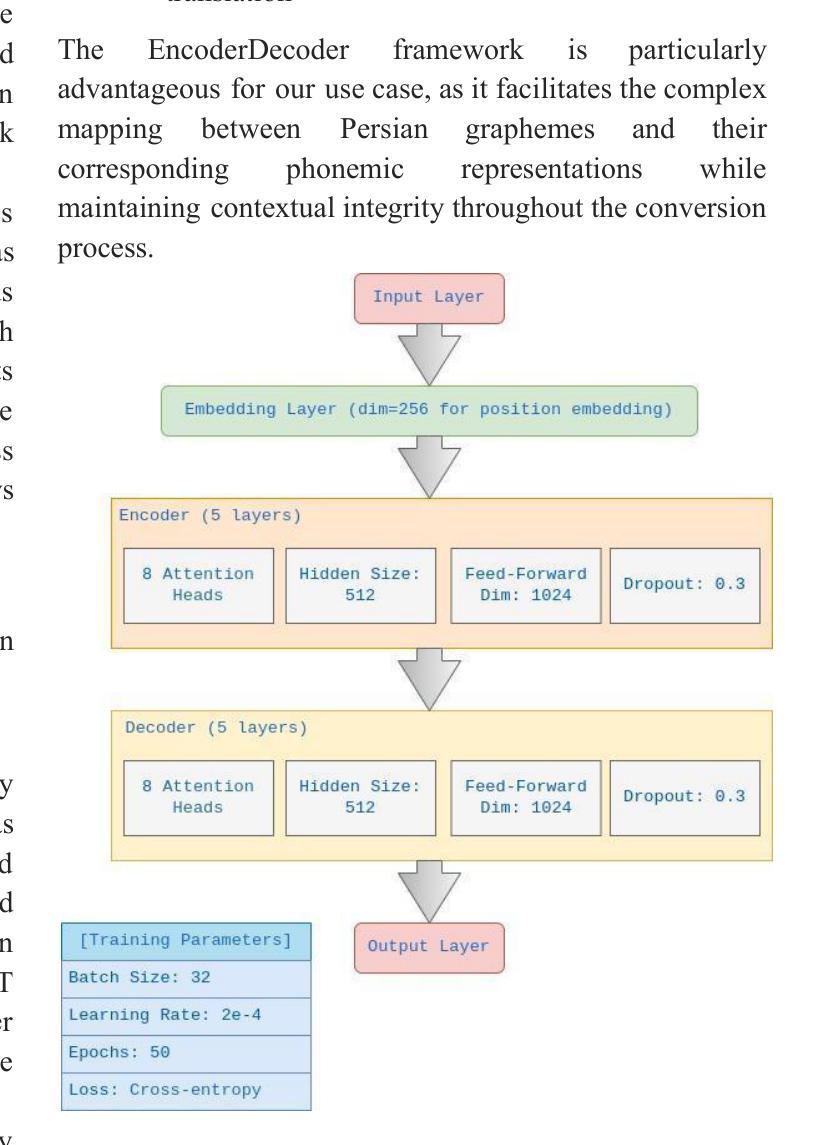
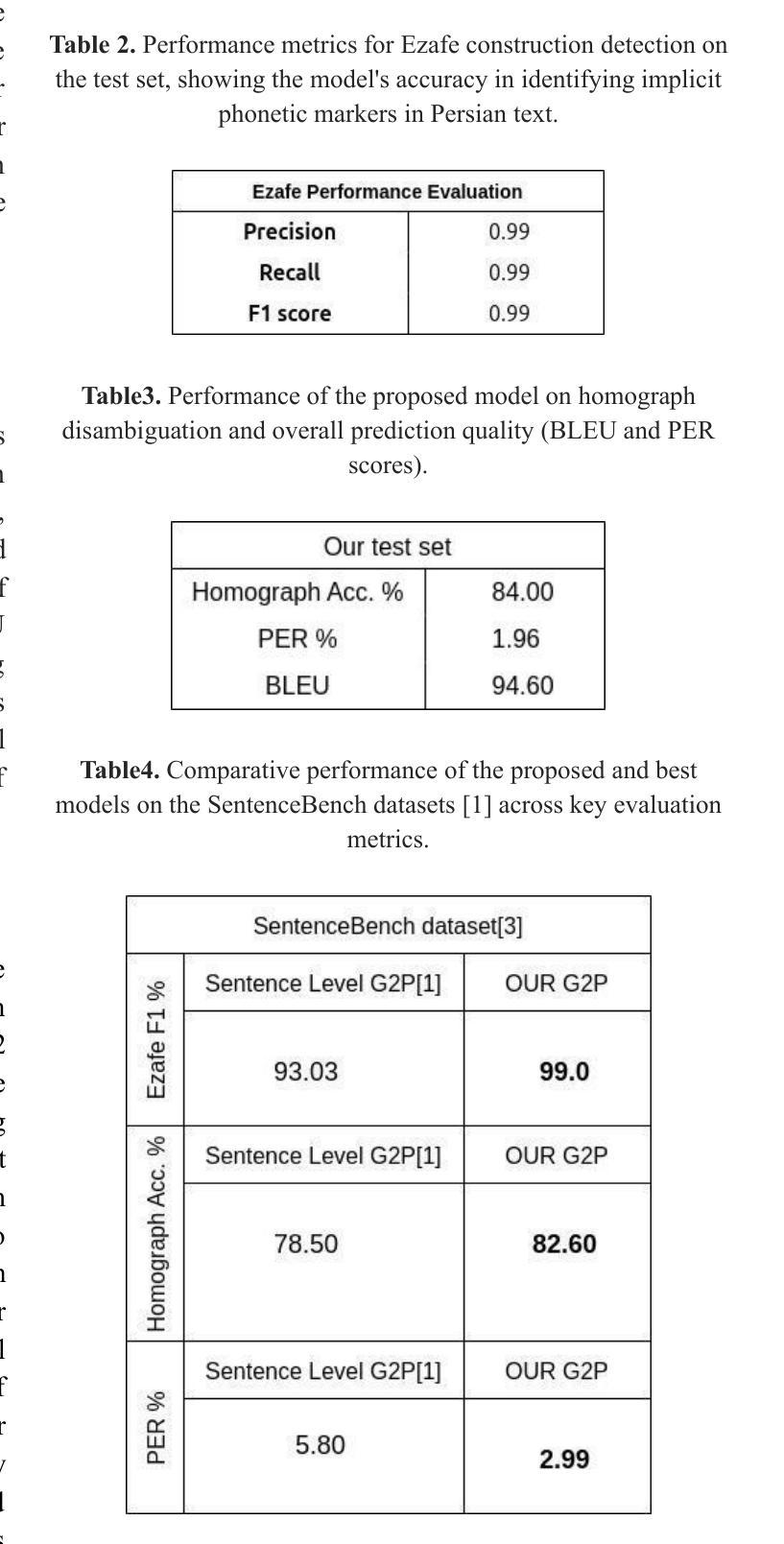
Grapheme-to-phoneme (G2P) conversion for Persian presents unique challenges due to its complex phonological features, particularly homographs and Ezafe, which exist in formal and informal language contexts. This paper introduces an intermediate language specifically designed for Persian language processing that addresses these challenges through a multi-faceted approach. Our methodology combines two key components: Large Language Model (LLM) prompting techniques and a specialized sequence-to-sequence machine transliteration architecture. We developed and implemented a systematic approach for constructing a comprehensive lexical database for homographs with multiple pronunciations disambiguation often termed polyphones, utilizing formal concept analysis for semantic differentiation. We train our model using two distinct datasets: the LLM-generated dataset for formal and informal Persian and the B-Plus podcasts for informal language variants. The experimental results demonstrate superior performance compared to existing state-of-the-art approaches, particularly in handling the complexities of Persian phoneme conversion. Our model significantly improves Phoneme Error Rate (PER) metrics, establishing a new benchmark for Persian G2P conversion accuracy. This work contributes to the growing research in low-resource language processing and provides a robust solution for Persian text-to-speech systems and demonstrating its applicability beyond Persian. Specifically, the approach can extend to languages with rich homographic phenomena such as Chinese and Arabic
波斯语的形音转换(G2P)由于其复杂的语音特征而具有独特的挑战,特别是在正式和非正式语言环境中的同音字和易泽夫(Ezafe)。本文引入了一种专门为波斯语处理设计的中间语言,通过多元方法应对这些挑战。我们的方法结合了两个关键组成部分:大型语言模型(LLM)提示技术和专门的序列到序列机器转录架构。我们开发并实施了一种系统的方法来构建全面的词汇数据库,用于解析具有多种发音的同音字(通常被称为多音字),利用形式概念分析进行语义区分。我们使用两个不同的数据集进行模型训练:由LLM生成的正式和非正式波斯语数据集以及B-Plus播客的非正式语言变体数据集。实验结果证明,与现有的最先进的方法相比,我们的方法在波斯语音素转换的复杂性处理上表现出卓越的性能。我们的模型显著提高了音素错误率(PER)指标,为波斯语形音转换准确性建立了新的基准。这项工作为低资源语言处理研究做出了贡献,为波斯语语音合成系统提供了稳健的解决方案,并展示了其超越波斯语的应用性。特别是,该方法可以扩展到具有丰富同音字现象的语言,如中文和阿拉伯文。
论文及项目相关链接
PDF pdf, 8 pages, 4 figures, 4 tables
Summary
本文介绍了针对波斯语语言处理的中间语言的设计及其在语素到音素(G2P)转换中的应用。通过大型语言模型(LLM)提示技术和专门的序列到序列机器转换架构的结合,解决了波斯语复杂语音特征带来的挑战,如同音异义词和Ezafe等问题。利用形式概念分析进行语义区分,构建了一个全面的词汇数据库。实验结果表明,与现有先进技术相比,该模型在波斯语音素转换的复杂性处理上表现出卓越性能,显著提高了音素错误率(PER)指标,为波斯语的G2P转换准确性建立了新的基准。
Key Takeaways
- 波斯语的G2P转换面临独特挑战,包括复杂的语音特征和同音异义词等问题。
- 引入了一种中间语言,专门用于处理波斯语的语言处理。
- 结合大型语言模型(LLM)提示技术和序列到序列机器转换架构来解决挑战。
- 利用形式概念分析构建词汇数据库,进行语义区分。
- 使用LLM生成的数据集和B-Plus播客数据集进行模型训练。
- 模型在波斯语音素转换的复杂性处理上表现优越,显著提高音素错误率(PER)指标。
点此查看论文截图

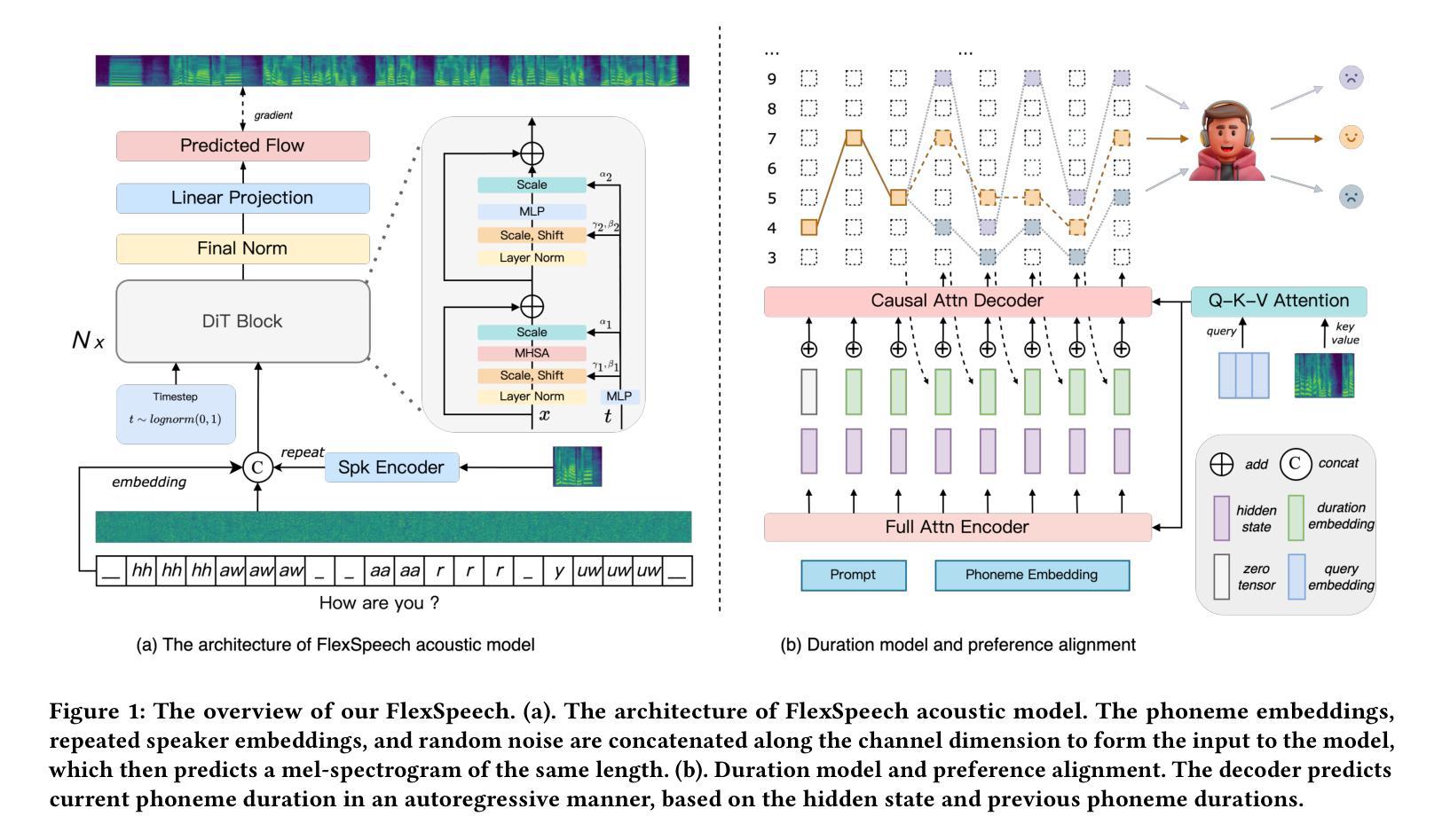
FlexSpeech: Towards Stable, Controllable and Expressive Text-to-Speech
Authors:Linhan Ma, Dake Guo, He Wang, Jin Xu, Lei Xie
Current speech generation research can be categorized into two primary classes: non-autoregressive and autoregressive. The fundamental distinction between these approaches lies in the duration prediction strategy employed for predictable-length sequences. The NAR methods ensure stability in speech generation by explicitly and independently modeling the duration of each phonetic unit. Conversely, AR methods employ an autoregressive paradigm to predict the compressed speech token by implicitly modeling duration with Markov properties. Although this approach improves prosody, it does not provide the structural guarantees necessary for stability. To simultaneously address the issues of stability and naturalness in speech generation, we propose FlexSpeech, a stable, controllable, and expressive TTS model. The motivation behind FlexSpeech is to incorporate Markov dependencies and preference optimization directly on the duration predictor to boost its naturalness while maintaining explicit modeling of the phonetic units to ensure stability. Specifically, we decompose the speech generation task into two components: an AR duration predictor and a NAR acoustic model. The acoustic model is trained on a substantial amount of data to learn to render audio more stably, given reference audio prosody and phone durations. The duration predictor is optimized in a lightweight manner for different stylistic variations, thereby enabling rapid style transfer while maintaining a decoupled relationship with the specified speaker timbre. Experimental results demonstrate that our approach achieves SOTA stability and naturalness in zero-shot TTS. More importantly, when transferring to a specific stylistic domain, we can accomplish lightweight optimization of the duration module solely with about 100 data samples, without the need to adjust the acoustic model, thereby enabling rapid and stable style transfer.
目前的语音生成研究可以主要分为两大类:非自回归和自回归。这两种方法之间的根本区别在于用于预测长度序列的持续时间预测策略。NAR方法通过显式且独立地建模每个语音单元的持续时间,确保语音生成的稳定性。相反,AR方法采用自回归范式,通过隐式地利用马尔可夫属性对压缩语音符号进行预测。尽管这种方法改善了韵律,但它并没有提供保证稳定性的必要结构。为了解决语音生成中的稳定性和自然性问题,我们提出了FlexSpeech,一个稳定、可控、表达性强的TTS模型。FlexSpeech的动机是在持续时间预测器上直接融入马尔可夫依赖和偏好优化,以提高其自然性,同时保持对语音单元的显式建模以确保稳定性。具体来说,我们将语音生成任务分解为两个组件:AR持续时间预测器和NAR声学模型。声学模型经过大量数据训练,学习在给定参考音频韵律和语音单元持续时间的情况下,更稳定地呈现音频。持续时间预测器以轻巧的方式进行优化,以适应不同的风格变化,从而在保持与指定演讲者音色解耦的同时,实现快速风格转换。实验结果表明,我们的方法在非即兴文本到语音转换中实现了最新稳定性和自然性。更重要的是,转移到特定风格领域时,我们仅使用约100个数据样本对持续时间模块进行轻量级优化,无需调整声学模型,从而实现了快速稳定的风格转换。
论文及项目相关链接
PDF 10 pages, 5 figures
Summary
FlexSpeech是一项稳定、可控且富有表现力的文本转语音(TTS)模型。它将语音生成任务分为两个组成部分:自回归(AR)时长预测器和非自回归(NAR)声学模型。FlexSpeech通过结合Markov依赖和偏好优化,在时长预测器中提升其自然度,同时显式建模音素单元以确保稳定性。实验结果表明,FlexSpeech在零样本TTS中实现了先进(SOTA)的稳定性和自然度,并且在特定风格领域转移时,仅通过约100个数据样本对时长模块进行轻量级优化,无需调整声学模型,从而实现快速稳定的风格转移。
Key Takeaways
- 当前语音生成研究可分为非自回归和自回归两大类。它们的主要区别在于对可预测长度序列的持续时间预测策略。
- 非自回归(NAR)方法通过显式建模每个音素单元的持续时间来确保语音生成的稳定性。
- 自回归(AR)方法则通过隐式建模持续时间(具有Markov属性)来预测压缩语音标记,这种方法提高了韵律性,但不提供结构稳定性的保证。
- FlexSpeech模型结合了AR和NAR的特性,旨在同时解决语音生成中的稳定性和自然性问题。
- FlexSpeech将语音生成任务分为两个组成部分:AR时长预测器和NAR声学模型。
- 实验结果表明,FlexSpeech在零样本TTS中表现优异,并且在特定风格领域转移时,能实现快速稳定的风格转移,仅需要少量的数据样本进行时长模块的优化。
点此查看论文截图