⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-15 更新
PrePrompt: Predictive prompting for class incremental learning
Authors:Libo Huang, Zhulin An, Chuanguang Yang, Boyu Diao, Fei Wang, Yan Zeng, Zhifeng Hao, Yongjun Xu
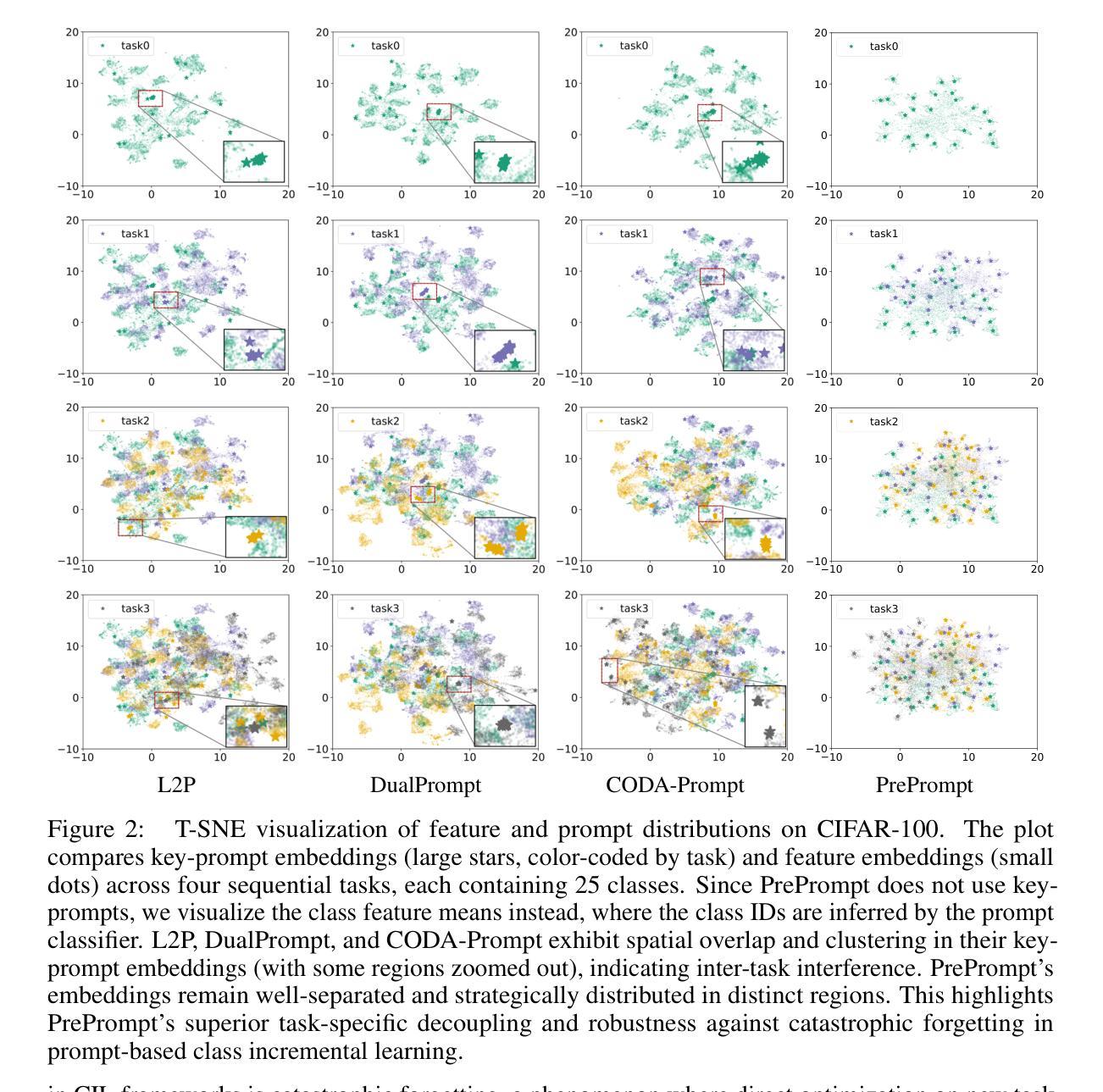
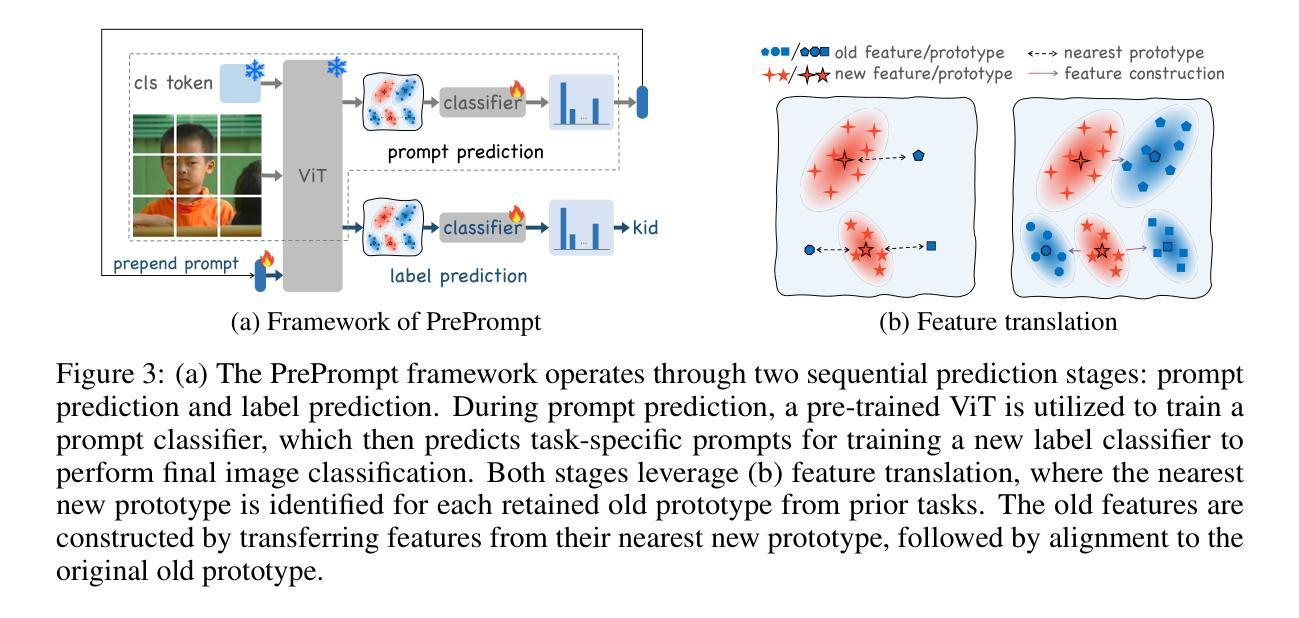
Class Incremental Learning (CIL) based on pre-trained models offers a promising direction for open-world continual learning. Existing methods typically rely on correlation-based strategies, where an image’s classification feature is used as a query to retrieve the most related key prompts and select the corresponding value prompts for training. However, these approaches face an inherent limitation: fitting the entire feature space of all tasks with only a few trainable prompts is fundamentally challenging. We propose Predictive Prompting (PrePrompt), a novel CIL framework that circumvents correlation-based limitations by leveraging pre-trained models’ natural classification ability to predict task-specific prompts. Specifically, PrePrompt decomposes CIL into a two-stage prediction framework: task-specific prompt prediction followed by label prediction. While theoretically appealing, this framework risks bias toward recent classes due to missing historical data for older classifier calibration. PrePrompt then mitigates this by incorporating feature translation, dynamically balancing stability and plasticity. Experiments across multiple benchmarks demonstrate PrePrompt’s superiority over state-of-the-art prompt-based CIL methods. The code will be released upon acceptance.
基于预训练模型的类增量学习(CIL)为开放世界持续学习提供了有前景的方向。现有方法通常依赖于基于关联的策略,其中使用图像的分类特征作为查询来检索最相关的关键提示,并选择相应的值提示进行训练。然而,这些方法面临一个固有局限性:仅使用少数可训练提示来适应所有任务的整体特征空间,这从根本上具有挑战性。我们提出了预测提示(PrePrompt),这是一种新型CIL框架,它通过利用预训练模型的天然分类能力来预测任务特定提示,从而规避了基于关联的限制。具体来说,PrePrompt将CIL分解为两阶段预测框架:首先是任务特定提示预测,然后是标签预测。虽然从理论上看很有吸引力,但由于缺少旧分类器的历史数据进行校准,该框架可能存在偏向新类的风险。PrePrompt然后通过结合特征翻译,动态平衡稳定性和可塑性,来缓解这一问题。在多个基准测试上的实验表明,PrePrompt优于最新的基于提示的CIL方法。论文被接受后将会发布代码。
论文及项目相关链接
PDF 16 pages, 29 figures, conference
Summary
基于预训练模型的类增量学习(CIL)为开放世界持续学习提供了有前景的方向。现有方法通常依赖于基于关联的策略,使用图像的识别特征作为查询来检索最相关的关键提示并选择相应的值提示进行训练。然而,这些方法面临内在局限:用少数可训练提示来适应所有任务的整个特征空间具有根本挑战性。我们提出预测提示(PrePrompt)这一新型CIL框架,它利用预训练模型的天然分类能力来预测任务特定提示,从而规避了基于关联的限制。PrePrompt将CIL分解为两个阶段:首先是任务特定提示预测,其次是标签预测。尽管理论上有吸引力,但该框架可能因缺少旧分类器的历史数据而偏向于新类别。PrePrompt通过融入特征翻译来动态平衡稳定性和可塑性,从而缓解这一问题。在多个基准测试上的实验表明,PrePrompt优于最先进的基于提示的CIL方法。
Key Takeaways
- 类增量学习(CIL)在开放世界持续学习中具有前景。
- 现有方法主要依赖基于关联的策略,使用图像分类特征进行查询和训练。
- 基于预训练模型的PrePrompt框架通过预测任务特定提示来规避基于关联的限制。
- PrePrompt将CIL分解为任务特定提示预测和标签预测两个阶段。
- PrePrompt可能因缺少旧分类器的历史数据而偏向于新类别。
- PrePrompt通过特征翻译来平衡稳定性和可塑性。
点此查看论文截图

DArFace: Deformation Aware Robustness for Low Quality Face Recognition
Authors:Sadaf Gulshad, Abdullah Aldahlawi Thakaa
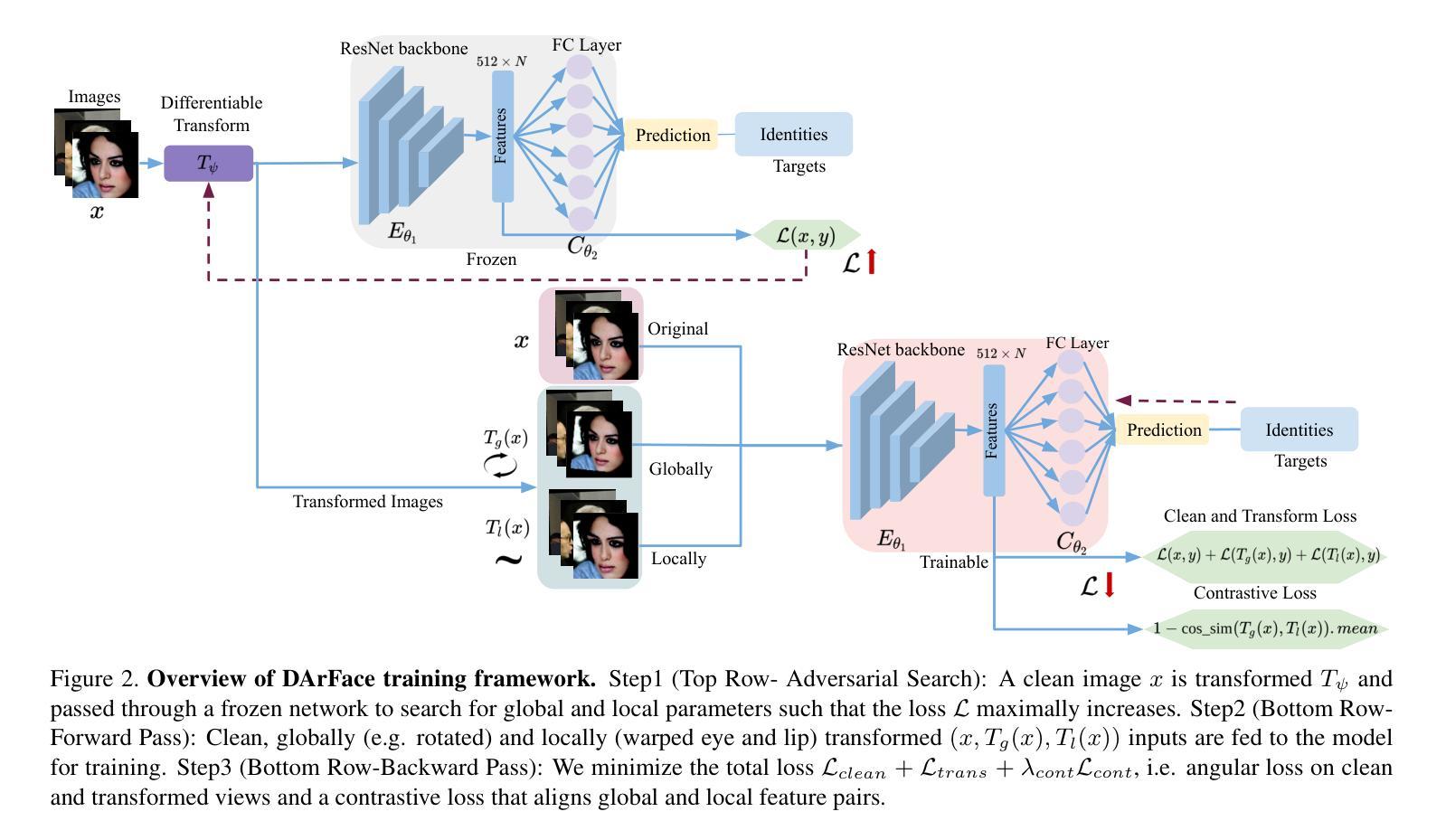
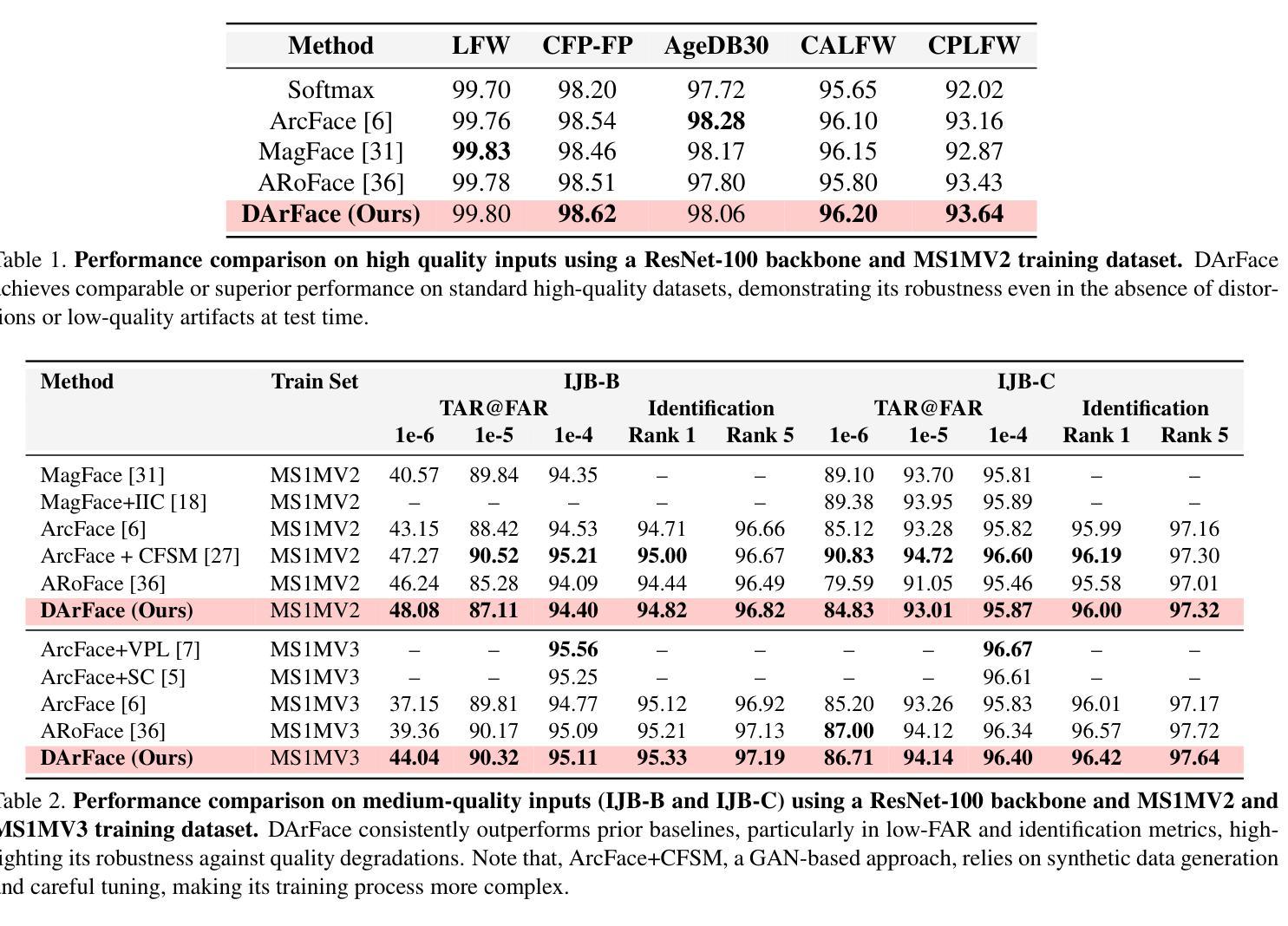
Facial recognition systems have achieved remarkable success by leveraging deep neural networks, advanced loss functions, and large-scale datasets. However, their performance often deteriorates in real-world scenarios involving low-quality facial images. Such degradations, common in surveillance footage or standoff imaging include low resolution, motion blur, and various distortions, resulting in a substantial domain gap from the high-quality data typically used during training. While existing approaches attempt to address robustness by modifying network architectures or modeling global spatial transformations, they frequently overlook local, non-rigid deformations that are inherently present in real-world settings. In this work, we introduce DArFace, a Deformation-Aware robust Face recognition framework that enhances robustness to such degradations without requiring paired high- and low-quality training samples. Our method adversarially integrates both global transformations (e.g., rotation, translation) and local elastic deformations during training to simulate realistic low-quality conditions. Moreover, we introduce a contrastive objective to enforce identity consistency across different deformed views. Extensive evaluations on low-quality benchmarks including TinyFace, IJB-B, and IJB-C demonstrate that DArFace surpasses state-of-the-art methods, with significant gains attributed to the inclusion of local deformation modeling.
人脸识别系统通过利用深度神经网络、先进的损失函数和大规模数据集取得了显著的成功。然而,它们在涉及低质量面部图像的现实世界场景中性能往往会下降。这种退化在监控录像或远程成像中很常见,包括低分辨率、运动模糊和各种失真,与训练期间通常使用的高质量数据之间存在很大的领域差距。虽然现有方法试图通过修改网络架构或建模全局空间变换来提高稳健性,但它们经常忽略现实环境中固有的局部非刚性变形。在这项工作中,我们引入了DArFace,一个基于变形的稳健人脸识别框架,提高了对这种退化的稳健性,而无需配对高质量和低质量的训练样本。我们的方法通过对面部进行全局变换(如旋转、平移)和局部弹性变形的对抗性集成来进行训练,以模拟现实世界的低质量条件。此外,我们引入了一个对比目标来强制不同变形视图之间的身份一致性。在包括TinyFace、IJB-B和IJB-C在内的低质量基准测试上的广泛评估表明,DArFace超越了最先进的方法,其显著的提升得益于局部变形建模的引入。
论文及项目相关链接
Summary
本文介绍了基于深度神经网络的人脸识别系统在实际应用中面临的挑战,特别是在低质量人脸图像下的性能下降问题。为解决这一问题,提出了一种名为DArFace的变形感知稳健人脸识别框架,通过模拟低质量条件下的全局变换和局部弹性变形,增强了对降质的鲁棒性。同时引入对比目标,强化不同变形视角下的身份一致性。在多个低质量基准测试上的评估结果表明,DArFace超越了现有方法,局部变形建模的引入起到了重要作用。
Key Takeaways
- 人脸识别系统在实际应用中面临低质量图像挑战,如低分辨率、运动模糊和各种失真。
- 现有方法主要通过修改网络架构或建模全局空间变换来提高鲁棒性,但忽略了现实场景中固有的局部非刚性变形。
- DArFace框架通过模拟低质量条件下的全局变换和局部弹性变形,增强了对降质的鲁棒性。
- DArFace引入对比目标,以在不同变形视角下保持身份一致性。
- 广泛评估表明,DArFace在多个低质量基准测试上表现超越现有方法。
- DArFace的成功在很大程度上归功于局部变形建模的引入。
点此查看论文截图

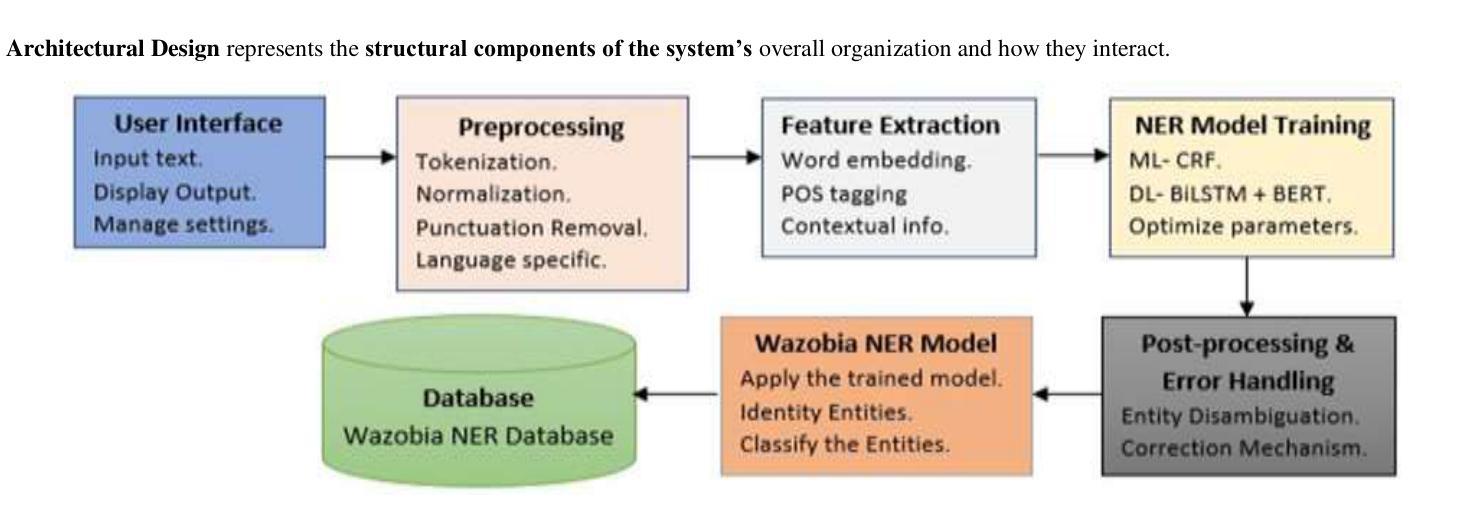
Development of a WAZOBIA-Named Entity Recognition System
Authors:S. E Emedem, I. E Onyenwe, E. G Onyedinma
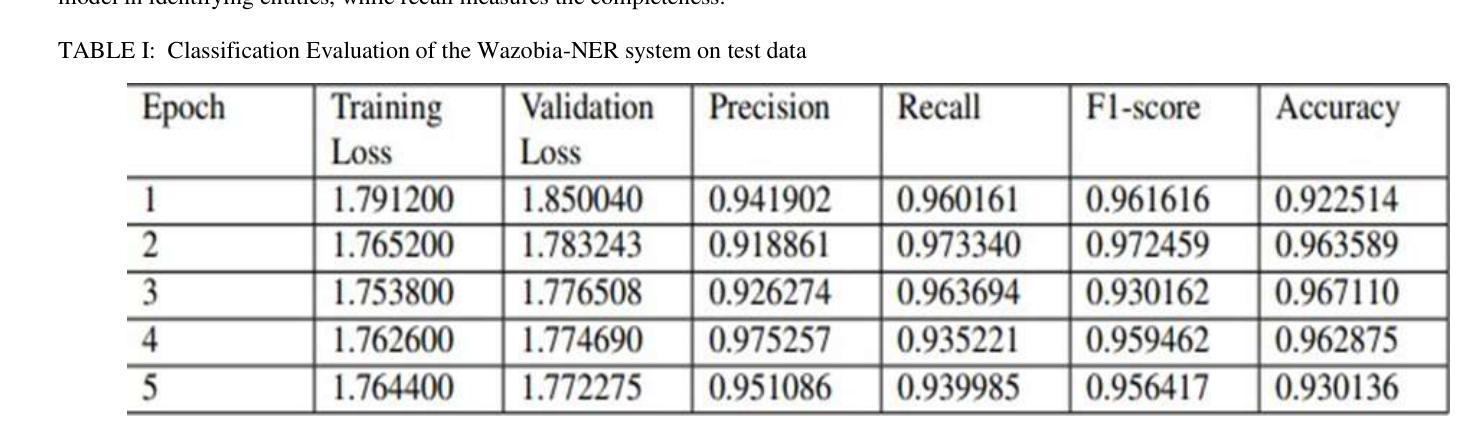
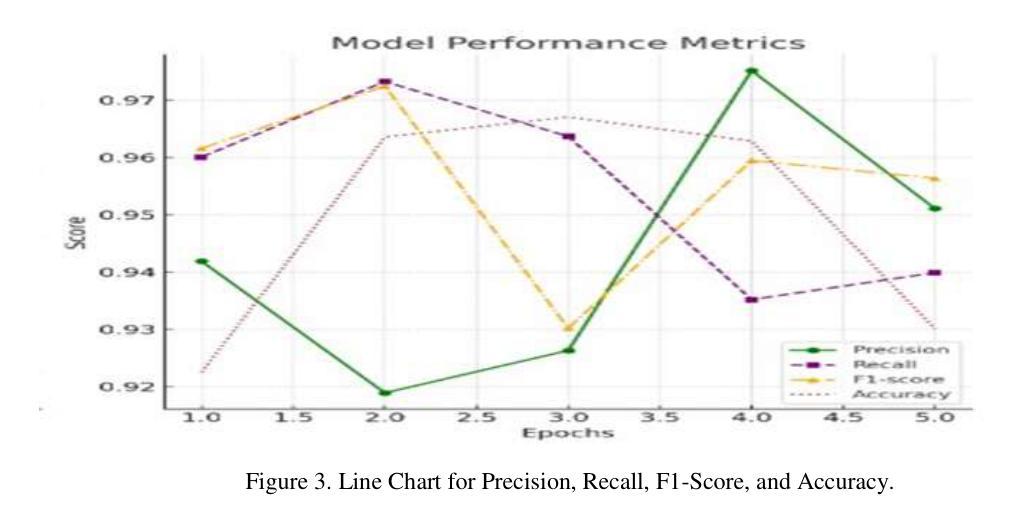
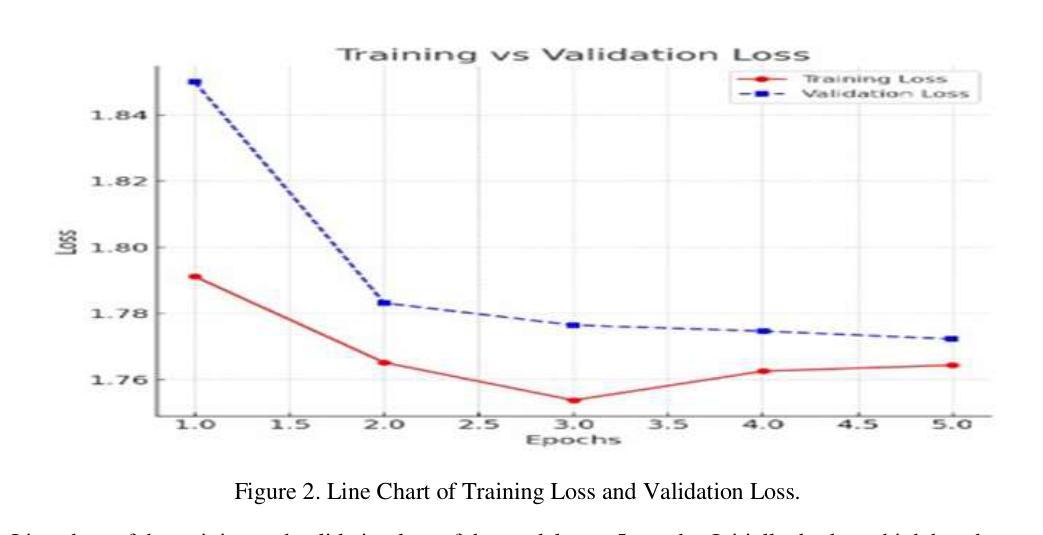
Named Entity Recognition NER is very crucial for various natural language processing applications, including information extraction, machine translation, and sentiment analysis. Despite the ever-increasing interest in African languages within computational linguistics, existing NER systems focus mainly on English, European, and a few other global languages, leaving a significant gap for under-resourced languages. This research presents the development of a WAZOBIA-NER system tailored for the three most prominent Nigerian languages: Hausa, Yoruba, and Igbo. This research begins with a comprehensive compilation of annotated datasets for each language, addressing data scarcity and linguistic diversity challenges. Exploring the state-of-the-art machine learning technique, Conditional Random Fields (CRF) and deep learning models such as Bidirectional Long Short-Term Memory (BiLSTM), Bidirectional Encoder Representation from Transformers (Bert) and fine-tune with a Recurrent Neural Network (RNN), the study evaluates the effectiveness of these approaches in recognizing three entities: persons, organizations, and locations. The system utilizes optical character recognition (OCR) technology to convert textual images into machine-readable text, thereby enabling the Wazobia system to accept both input text and textual images for extraction purposes. The system achieved a performance of 0.9511 in precision, 0.9400 in recall, 0.9564 in F1-score, and 0.9301 in accuracy. The model’s evaluation was conducted across three languages, with precision, recall, F1-score, and accuracy as key assessment metrics. The Wazobia-NER system demonstrates that it is feasible to build robust NER tools for under-resourced African languages using current NLP frameworks and transfer learning.
命名实体识别(NER)对于各种自然语言处理应用至关重要,包括信息提取、机器翻译和情感分析。尽管非洲语言在计算语言学中的兴趣日益增长,但现有的NER系统主要集中在英语、欧洲和少数其他全球语言上,为资源匮乏的语言留下了巨大空白。本研究介绍了针对尼日利亚三种主要语言——豪萨语、约鲁巴语和伊博语量身定制的WAZOBIA-NER系统的发展。该研究首先从每个语言的综合编译注释数据集开始,解决数据稀缺和语言多样性的挑战。本研究探讨了最先进的机器学习技术——条件随机字段(CRF)和深度学习模型,如双向长短时记忆网络(BiLSTM)、基于Transformer的双向编码器表示(BERT)以及与循环神经网络(RNN)微调等,评估了这些方法在识别三种实体方面的有效性:人、组织和地点。该系统利用光学字符识别(OCR)技术将文本图像转换为机器可读的文本,从而使Wazobia系统能够为了提取目的接受文本输入和文本图像输入。系统在精确度上达到了0.9511,召回率达到了0.9400,F1分数为0.9564,准确度为0.9301。该模型的评估是在三种语言上进行的,精确度、召回率、F1分数和准确度是主要评估指标。Wazobia-NER系统表明,利用当前的NLP框架和迁移学习为资源匮乏的非洲语言构建稳健的NER工具是可行的。
论文及项目相关链接
PDF 6 pages, 3 figures, 1 table
Summary
本研究开发了一种针对尼日利亚三种主要语言——豪萨语、约鲁巴语和伊博语的WAZOBIA-NER系统。研究从为每种语言全面整合注释数据集开始,解决了数据稀缺和语言多样性挑战。研究探讨了最新的机器学习技术,如条件随机字段(CRF)和深度学习模型,如双向长短时记忆网络(BiLSTM)、基于变压器的双向编码器表示(BERT)以及使用循环神经网络(RNN)进行微调,评估了这些方法在识别人员、组织和地点三个实体方面的有效性。该系统利用光学字符识别(OCR)技术将文本图像转换为机器可读的文本,从而使Wazobia系统能够为了提取目的而接受输入文本和文本图像。该系统的性能达到了精确度0.9511,召回率0.9400,F1分数为0.9564和准确度为0.9301。这一模型在三种语言上的评估表现是以精确度、召回率、F1分数和准确度为主要评价指标。这表明利用现有的自然语言处理框架和迁移学习技术为资源匮乏的非洲语言构建稳健的NER工具是可行的。
Key Takeaways
- NER系统在自然语言处理应用中至关重要,但对非洲语言的需求存在显著差距。
- 研究针对尼日利亚主要语言开发了WAZOBIA-NER系统。
- 系统通过综合注释数据集解决了数据稀缺问题。
- 评估了CRF、BiLSTM、BERT和RNN在实体识别方面的性能。
- Wazobia-NER系统结合OCR技术,能处理文本和文本图像输入。
- 系统性能评估指标包括精确度、召回率、F1分数和准确度。
点此查看论文截图