⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-16 更新
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
Authors:Justin Yu, Letian Fu, Huang Huang, Karim El-Refai, Rares Andrei Ambrus, Richard Cheng, Muhammad Zubair Irshad, Ken Goldberg
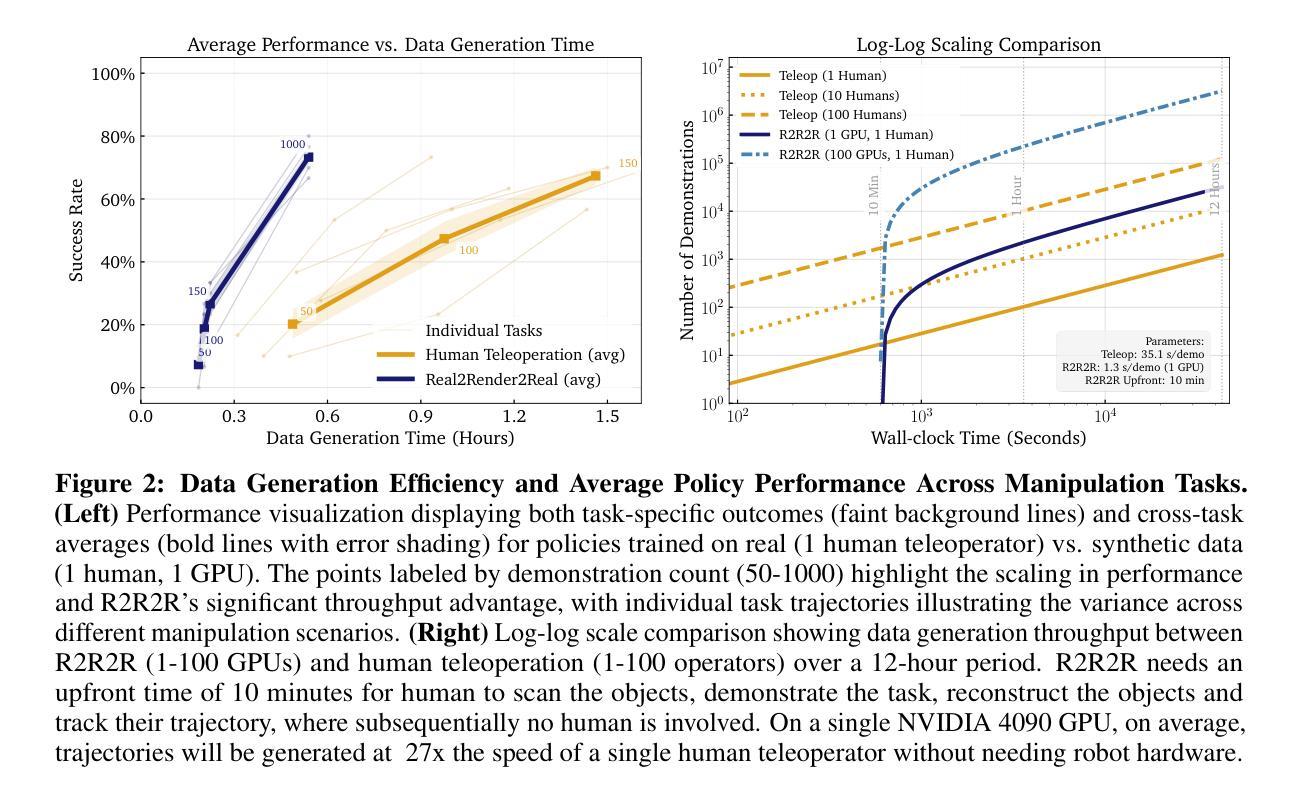
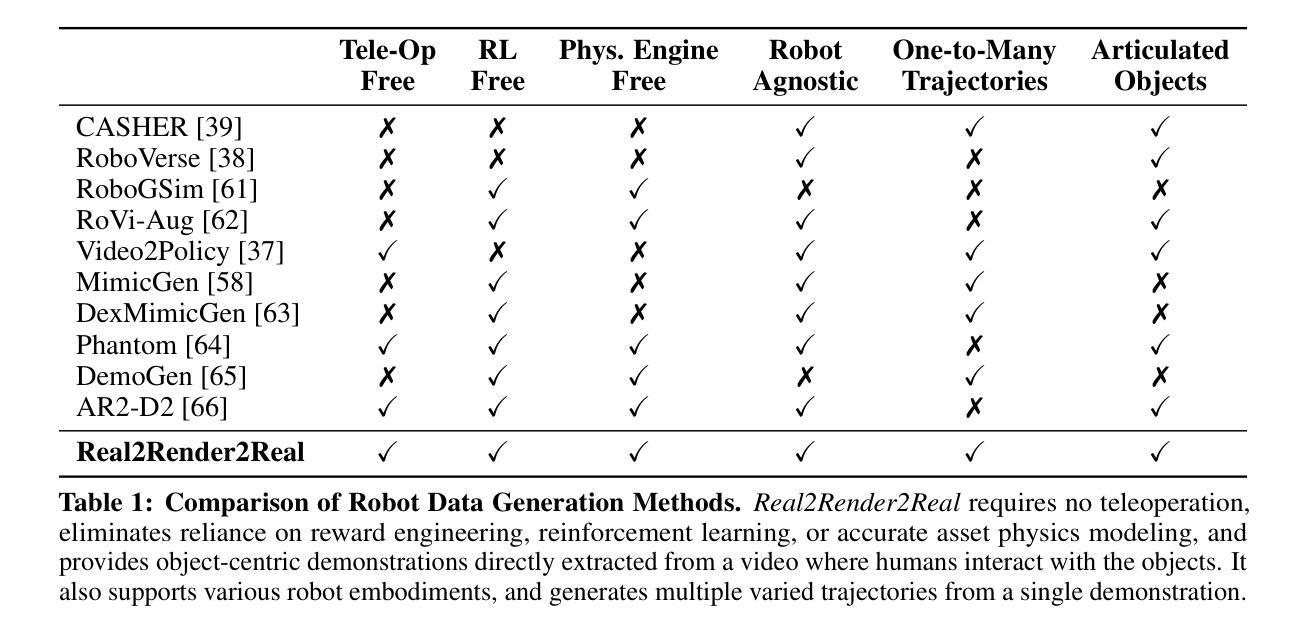
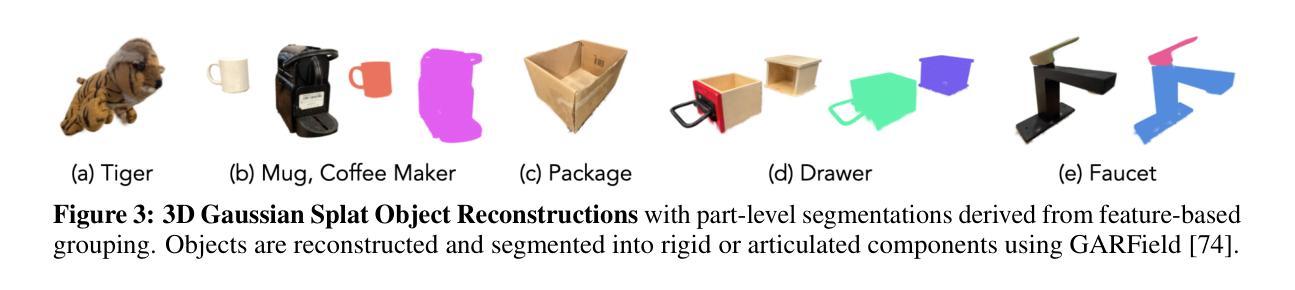
Scaling robot learning requires vast and diverse datasets. Yet the prevailing data collection paradigm-human teleoperation-remains costly and constrained by manual effort and physical robot access. We introduce Real2Render2Real (R2R2R), a novel approach for generating robot training data without relying on object dynamics simulation or teleoperation of robot hardware. The input is a smartphone-captured scan of one or more objects and a single video of a human demonstration. R2R2R renders thousands of high visual fidelity robot-agnostic demonstrations by reconstructing detailed 3D object geometry and appearance, and tracking 6-DoF object motion. R2R2R uses 3D Gaussian Splatting (3DGS) to enable flexible asset generation and trajectory synthesis for both rigid and articulated objects, converting these representations to meshes to maintain compatibility with scalable rendering engines like IsaacLab but with collision modeling off. Robot demonstration data generated by R2R2R integrates directly with models that operate on robot proprioceptive states and image observations, such as vision-language-action models (VLA) and imitation learning policies. Physical experiments suggest that models trained on R2R2R data from a single human demonstration can match the performance of models trained on 150 human teleoperation demonstrations. Project page: https://real2render2real.com
扩展机器人学习需要大量的多样化数据集。然而,目前普遍采用的数据收集方法——人工遥操作,成本高昂并受限于人工操作和物理机器人访问的限制。我们推出了Real2Render2Real(R2R2R)这一新方法,无需依赖物体动力学模拟或机器人硬件的遥操作,即可生成机器人训练数据。输入是一台智能手机拍摄的一个或多个物体的扫描以及一个人类演示的单一视频。R2R2R通过重建物体的详细三维几何形状和外观,并跟踪六自由度物体运动,能够生成数千个高视觉保真度的机器人通用演示。R2R2R使用三维高斯绘图(3DGS)以实现灵活资源生成和刚性和关节物体的轨迹合成,将这些表示转换为网格以维持与可扩展渲染引擎(如IsaacLab)的兼容性,但关闭碰撞建模。通过R2R2R生成的机器人演示数据可以直接与操作机器人自主感知状态和图像观察模型集成,如视觉语言行动模型(VLA)和模仿学习政策。物理实验表明,在单一人类演示的R2R2R数据上训练的模型,其性能可以与在150个人类遥操作演示上训练的模型相匹配。项目页面:https://real2render2real.com
论文及项目相关链接
Summary
机器人学习规模化需要大规模且多样化的数据集。针对当前数据收集范式(如人工遥操作)成本高、受手动工作和物理机器人访问限制的问题,本文提出Real2Render2Real(R2R2R)新方法,用于生成机器人训练数据。该方法仅需智能手机捕捉的一个或多个物体扫描以及单一人类演示视频作为输入,通过重建详细的3D物体几何形状和外观,以及跟踪六自由度(6-DoF)物体运动,生成数千个高视觉真实感的机器人无关演示。R2R2R采用3D高斯喷射技术(3DGS),实现对刚体和柔性物体的灵活素材生成和轨迹合成,将这些表示转换为网格以兼容可扩展的渲染引擎,如IsaacLab。机器人演示数据可直接集成到操作机器人本体感知状态和图像观察模型,如视觉语言动作模型(VLA)和模仿学习政策。物理实验表明,在单一人类演示生成的R2R2R数据训练的模型,其性能可与在150个人工遥操作演示中训练的模型相匹配。
Key Takeaways
- Real2Render2Real(R2R2R)是一种新的方法,用于生成机器人训练数据,无需依赖物体动力学模拟或机器人的硬件遥操作。
- R2R2R使用智能手机捕捉的物体扫描和单一人类演示视频作为输入。
- R2R2R通过重建3D物体几何形状和外观,以及跟踪6-DoF物体运动,生成高视觉真实感的机器人无关演示。
- R2R2R采用3D高斯喷射技术(3DGS)实现灵活素材生成和轨迹合成,适用于刚体和柔性物体。
- 生成的数据可以直接与机器人本体感知状态和图像观察模型集成,例如视觉语言动作模型(VLA)和模仿学习政策。
- R2R2R方法在物理实验中的性能表现优异,与基于人工遥操作的演示数据训练的模型相比具有潜力。
点此查看论文截图



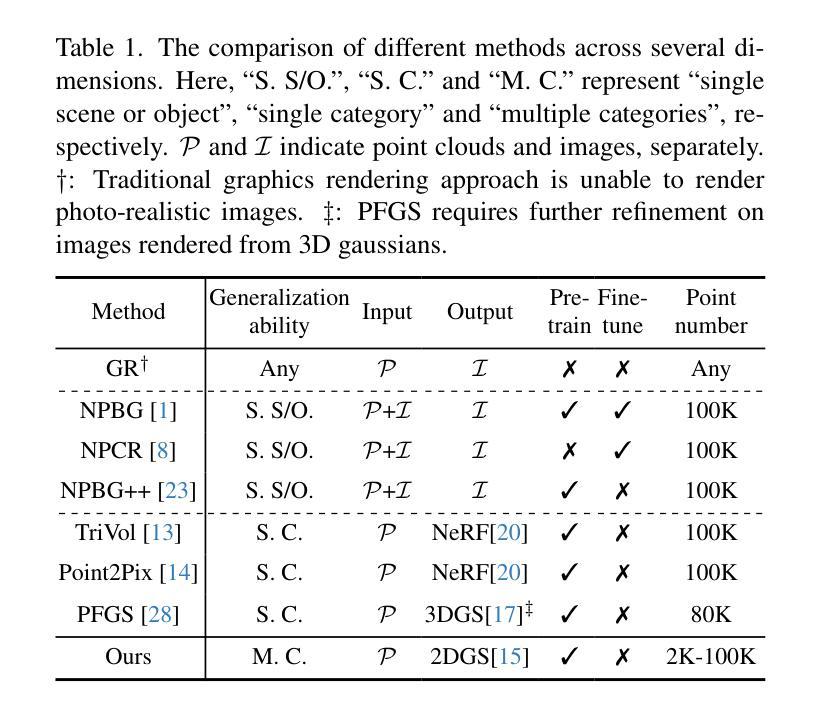
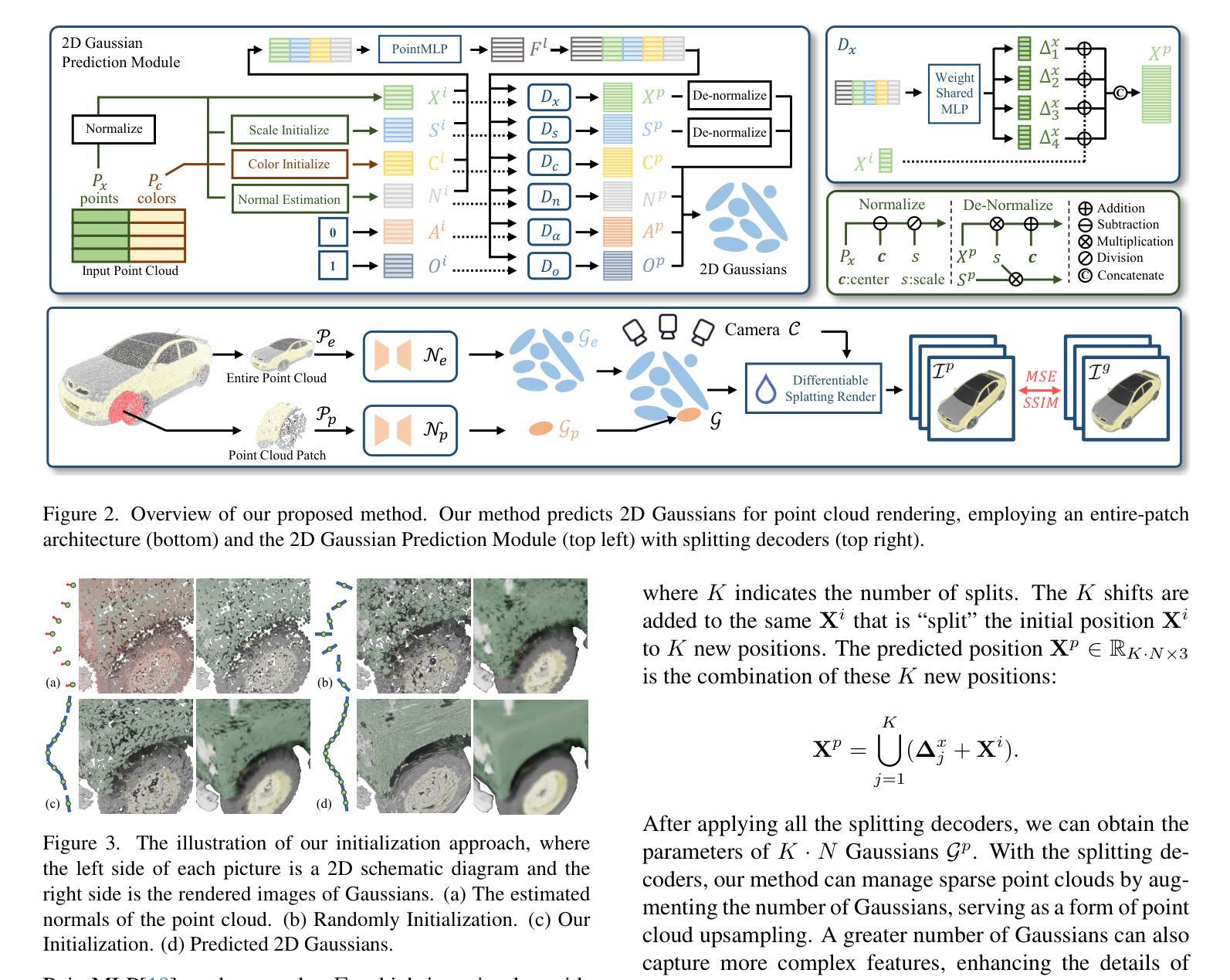
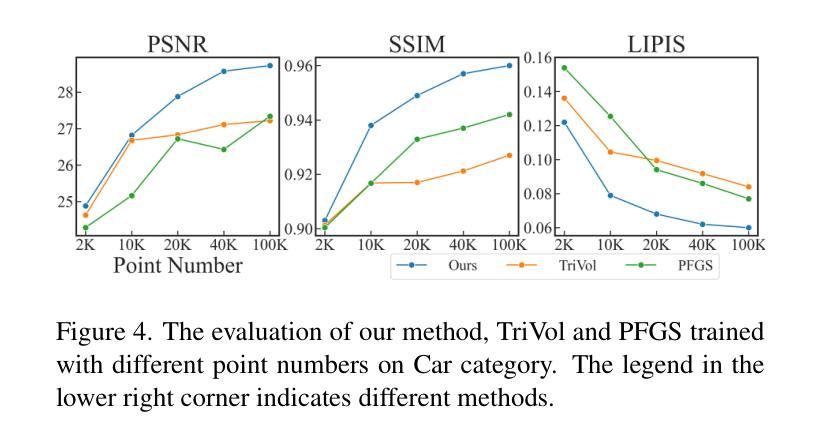
Sparse Point Cloud Patches Rendering via Splitting 2D Gaussians
Authors:Ma Changfeng, Bi Ran, Guo Jie, Wang Chongjun, Guo Yanwen
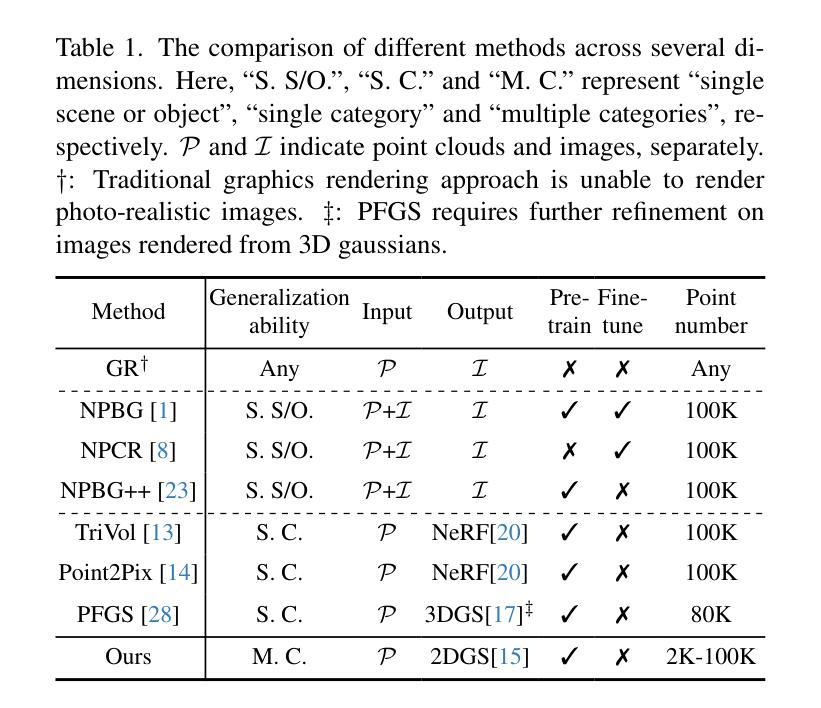
Current learning-based methods predict NeRF or 3D Gaussians from point clouds to achieve photo-realistic rendering but still depend on categorical priors, dense point clouds, or additional refinements. Hence, we introduce a novel point cloud rendering method by predicting 2D Gaussians from point clouds. Our method incorporates two identical modules with an entire-patch architecture enabling the network to be generalized to multiple datasets. The module normalizes and initializes the Gaussians utilizing the point cloud information including normals, colors and distances. Then, splitting decoders are employed to refine the initial Gaussians by duplicating them and predicting more accurate results, making our methodology effectively accommodate sparse point clouds as well. Once trained, our approach exhibits direct generalization to point clouds across different categories. The predicted Gaussians are employed directly for rendering without additional refinement on the rendered images, retaining the benefits of 2D Gaussians. We conduct extensive experiments on various datasets, and the results demonstrate the superiority and generalization of our method, which achieves SOTA performance. The code is available at https://github.com/murcherful/GauPCRender}{https://github.com/murcherful/GauPCRender.
当前基于学习的方法通过点云预测NeRF或3D高斯来实现逼真的渲染,但它们仍然依赖于类别先验、密集点云或额外的细化步骤。因此,我们引入了一种新的点云渲染方法,通过点云预测二维高斯。我们的方法包含两个相同的模块,采用全补丁架构,使网络能够推广到多个数据集。该模块利用点云信息(包括法线、颜色和距离)对高斯进行归一化和初始化。然后,采用分割解码器通过复制高斯来细化初始高斯,并预测更准确的结果,这使得我们的方法能够有效地适应稀疏点云。一旦训练完成,我们的方法会展现出对不同类别点云的直接推广性。预测的二维高斯被直接用于渲染,无需对渲染的图像进行额外优化,保留了二维高斯的优势。我们在各种数据集上进行了大量实验,结果表明我们的方法具有优越性和通用性,实现了最先进的性能。代码可通过链接https://github.com/murcherful/GauPCRender访问。
论文及项目相关链接
PDF CVPR 2025 Accepted
Summary
本文介绍了一种新的点云渲染方法,该方法通过从点云预测二维高斯分布来实现高质量渲染。该方法使用两个相同模块和整个补丁架构,能够推广到多个数据集。利用点云信息(如法线、颜色和距离)对高斯分布进行归一化和初始化,并使用解码器对其进行细化,以处理稀疏点云。实验结果表明,该方法具有卓越的性能和泛化能力,预测的高斯分布可直接用于渲染,无需对渲染图像进行额外优化。
Key Takeaways
- 提出了一种新的点云渲染方法,通过预测二维高斯分布实现从点云到图像的渲染。
- 方法采用两个相同模块和整个补丁架构,提高了网络的泛化能力。
- 利用点云信息(法线、颜色和距离)对高斯分布进行归一化和初始化。
- 使用解码器对初始高斯分布进行细化,以处理稀疏点云。
- 方法在多个数据集上进行了广泛实验,表现出优越的性能和泛化能力。
- 预测的高斯分布可直接用于渲染,无需额外优化。
点此查看论文截图


Monocular Online Reconstruction with Enhanced Detail Preservation
Authors:Songyin Wu, Zhaoyang Lv, Yufeng Zhu, Duncan Frost, Zhengqin Li, Ling-Qi Yan, Carl Ren, Richard Newcombe, Zhao Dong
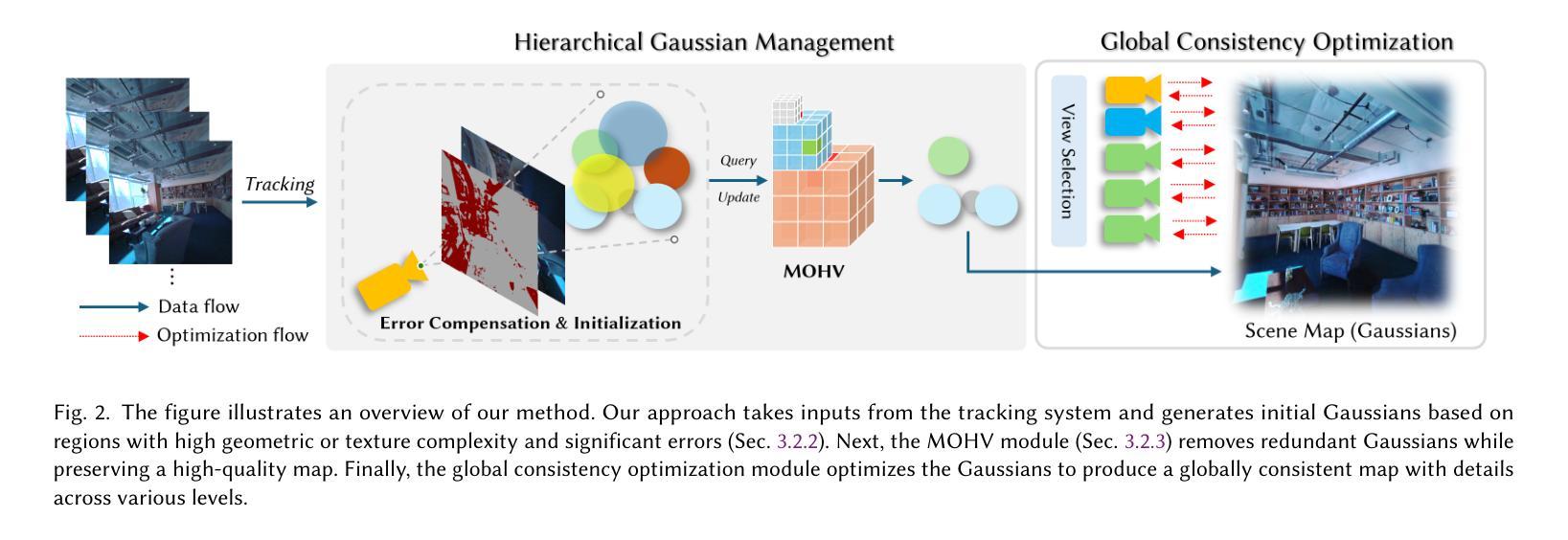
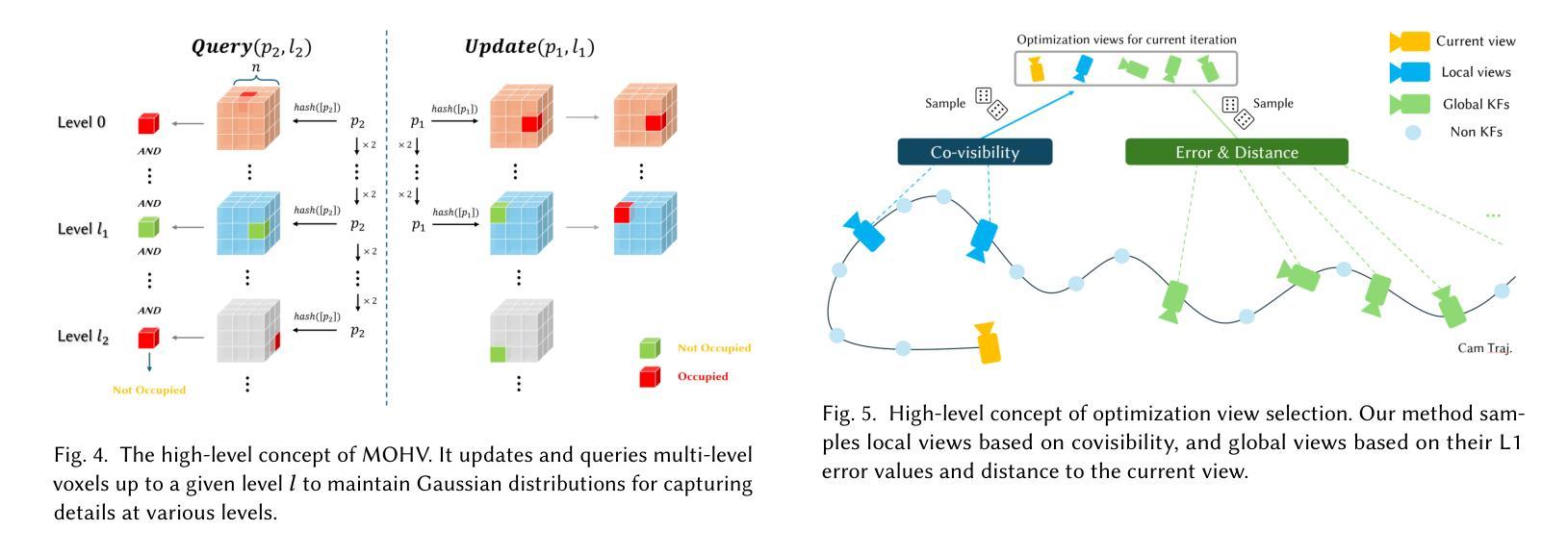
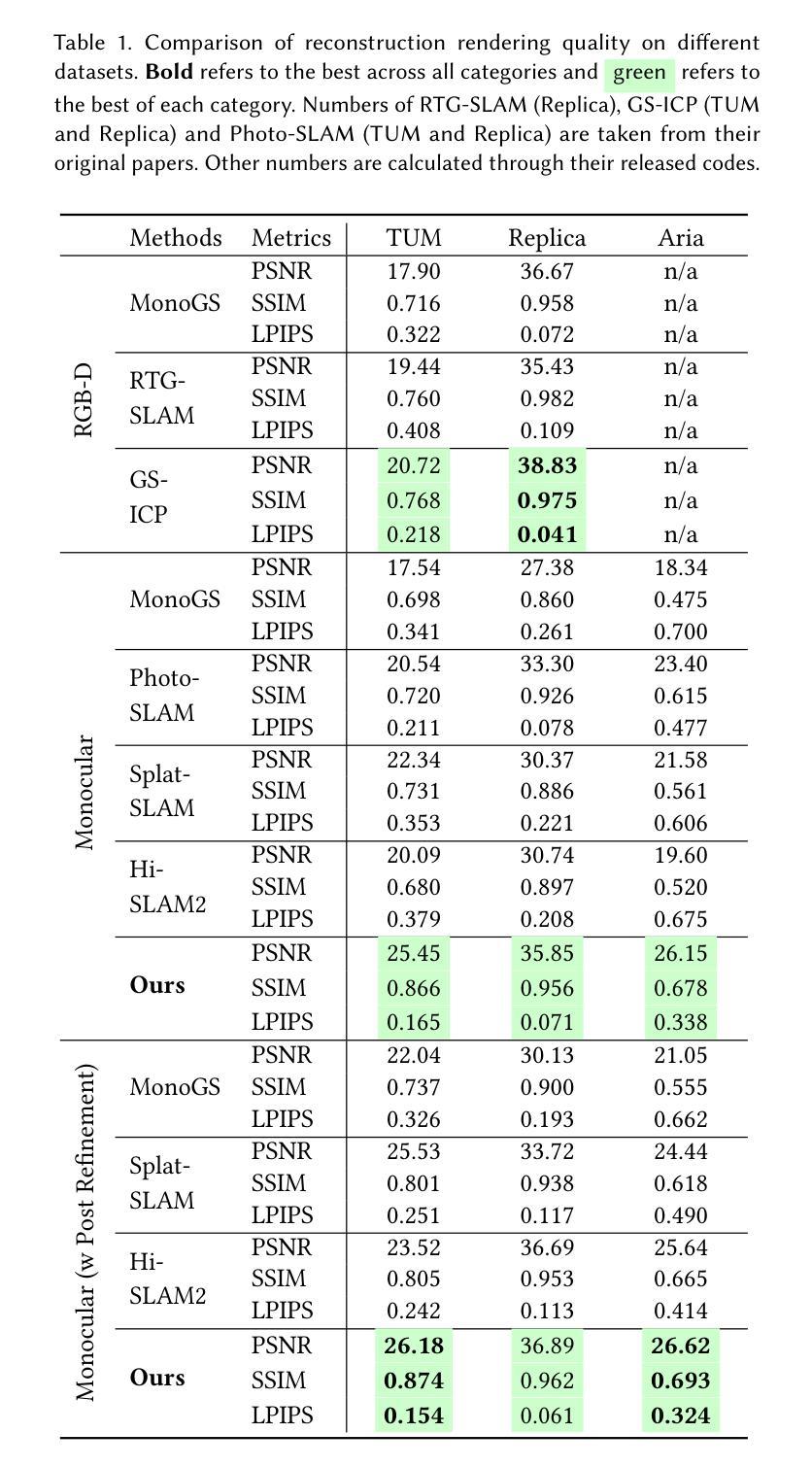
We propose an online 3D Gaussian-based dense mapping framework for photorealistic details reconstruction from a monocular image stream. Our approach addresses two key challenges in monocular online reconstruction: distributing Gaussians without relying on depth maps and ensuring both local and global consistency in the reconstructed maps. To achieve this, we introduce two key modules: the Hierarchical Gaussian Management Module for effective Gaussian distribution and the Global Consistency Optimization Module for maintaining alignment and coherence at all scales. In addition, we present the Multi-level Occupancy Hash Voxels (MOHV), a structure that regularizes Gaussians for capturing details across multiple levels of granularity. MOHV ensures accurate reconstruction of both fine and coarse geometries and textures, preserving intricate details while maintaining overall structural integrity. Compared to state-of-the-art RGB-only and even RGB-D methods, our framework achieves superior reconstruction quality with high computational efficiency. Moreover, it integrates seamlessly with various tracking systems, ensuring generality and scalability.
我们提出了一种基于在线三维高斯密度的映射框架,用于从单目图像流中重建逼真的细节。我们的方法解决了单目在线重建中的两个关键挑战:在不依赖深度图的情况下分配高斯,以及在重建地图中确保局部和全局的一致性。为了实现这一点,我们引入了两个关键模块:分层高斯管理模块,用于有效的高斯分布和全局一致性优化模块,用于在所有尺度上保持对齐和连贯性。此外,我们提出了多级占用哈希体素(MOHV),这是一种使高斯正规化的结构,用于捕获多个粒度级别的细节。MOHV确保精细和粗糙的几何形状和纹理的准确重建,保留细节的同时保持整体结构完整性。与最先进的仅使用RGB甚至是RGB-D方法相比,我们的框架在计算效率高的情况下实现了更高的重建质量。此外,它与各种跟踪系统无缝集成,确保通用性和可扩展性。
论文及项目相关链接
PDF Accepted to SIGGRAPH 2025 (Conference Track). Project page: https://poiw.github.io/MODP
Summary
该文提出了一种在线三维高斯密集映射框架,用于从单目图像流重建真实细节。该方法解决了单目在线重建中的两个关键挑战:无需依赖深度图进行高斯分布以及确保重建地图的局部和全局一致性。为此,引入了分层高斯管理模块进行高效的高斯分布管理以及全局一致性优化模块,以在所有尺度上保持对齐和连贯性。此外,提出了多级占用哈希体素(MOHV),用于规整高斯以捕获多个粒度级别的细节。MOHV能够准确重建精细和粗糙的几何形状和纹理,保留细节的同时保持整体结构完整性。相较于先进的仅使用RGB甚至是RGB-D方法,该框架在计算效率高的同时实现了更高的重建质量,并且能无缝集成各种跟踪系统,确保通用性和可扩展性。
Key Takeaways
- 该研究提出了一种在线三维高斯密集映射框架,适用于从单目图像流进行真实细节重建。
- 该框架解决了两个关键挑战:无需依赖深度图进行高斯分布管理以及确保重建地图的局部和全局一致性。
- 通过引入分层高斯管理模块和全局一致性优化模块,实现了高效的高斯分布管理和全局一致性。
- 提出了多级占用哈希体素(MOHV),用于捕捉多个粒度级别的细节,确保准确重建精细和粗糙的几何形状和纹理。
- 该框架较先进的RGB-only和RGB-D方法,具有更高的重建质量和计算效率。
- 框架能够无缝集成各种跟踪系统,增强其在不同应用场景下的适用性。
点此查看论文截图