⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-16 更新
MIGRATION-BENCH: Repository-Level Code Migration Benchmark from Java 8
Authors:Linbo Liu, Xinle Liu, Qiang Zhou, Lin Chen, Yihan Liu, Hoan Nguyen, Behrooz Omidvar-Tehrani, Xi Shen, Jun Huan, Omer Tripp, Anoop Deoras
With the rapid advancement of powerful large language models (LLMs) in recent years, a wide range of software engineering tasks can now be addressed using LLMs, significantly enhancing productivity and scalability. Numerous benchmark datasets have been developed to evaluate the coding capabilities of these models, while they primarily focus on problem-solving and issue-resolution tasks. In contrast, we introduce a new coding benchmark MIGRATION-BENCH with a distinct focus: code migration. MIGRATION-BENCH aims to serve as a comprehensive benchmark for migration from Java 8 to the latest long-term support (LTS) versions (Java 17, 21), MIGRATION-BENCH includes a full dataset and its subset selected with $5,102$ and $300$ repositories respectively. Selected is a representative subset curated for complexity and difficulty, offering a versatile resource to support research in the field of code migration. Additionally, we provide a comprehensive evaluation framework to facilitate rigorous and standardized assessment of LLMs on this challenging task. We further propose SD-Feedback and demonstrate that LLMs can effectively tackle repository-level code migration to Java 17. For the selected subset with Claude-3.5-Sonnet-v2, SD-Feedback achieves 62.33% and 27.00% success rate (pass@1) for minimal and maximal migration respectively. The benchmark dataset and source code are available at: https://huggingface.co/collections/AmazonScience and https://github.com/amazon-science/self_debug respectively.
随着近年来强大的大型语言模型(LLM)的快速发展,现在可以使用LLM解决一系列软件工程任务,从而显著提高生产力和可扩展性。已经开发了许多基准数据集来评估这些模型的编码能力,它们主要侧重于问题解决和问题解决任务。相比之下,我们引入了一个新的编码基准MIGRATION-BENCH,其重点有所不同:代码迁移。MIGRATION-BENCH旨在成为从Java 8迁移到最新长期支持(LTS)版本(Java 17、21)的综合性基准。该基准数据集包括一个完整的数据集和分别通过$ 5,102 $和$ 300 $个存储库选择的子集。所选子集经过精心挑选,具有代表性和复杂性,为代码迁移领域的研究提供了丰富的资源。此外,我们提供了一个全面的评估框架,以促进对这一具有挑战性的任务的LLM进行严格和标准化的评估。我们还提出了SD-Feedback并证明LLM可以有效地处理存储库级别的代码迁移到Java 17。对于使用Claude-3.5-Sonnet-v2选择的子集,SD-Feedback在最小迁移和最大迁移上的成功率(pass@1)分别达到62.33%和27.00%。基准数据集和源代码可在:https://huggingface.co/collections/AmazonScience 和 https://github.com/amazon-science/self_debug 获取。
论文及项目相关链接
摘要
随着大型语言模型(LLM)的快速发展,一系列软件工程项目任务都能通过LLM解决,大大提高了生产力和可扩展性。已经开发了许多基准数据集来评估模型的编码能力,主要侧重于问题解决和问题解决任务。与此相反,我们引入了一个新的编码基准MIGRATION-BENCH,重点关注代码迁移。MIGRATION-BENCH旨在成为从Java 8迁移到最新长期支持(LTS)版本(Java 17、21)的综合性基准,包括完整数据集及其子集。所选子集经过复杂的精心挑选,为这个领域的研究提供了一个通用资源。此外,我们还提供了一个全面的评估框架,以协助对这一具有挑战性的任务进行严格的标准化评估。通过SD-Feedback进一步提出并证明LLM可以有效解决存储库级别的代码迁移到Java 17的问题。对于选定的子集使用Claude-3.5-Sonnet-v2的SD-Feedback实现了最小迁移和最大迁移的成功率分别为62.33%和27.0%。基准数据集和源代码可在以下网址找到:https://huggingface.co/collections/AmazonScience 和 https://github.com/amazon-science/self_debug。
关键见解
- 大型语言模型(LLM)在软件工程项目中发挥着越来越重要的作用,提高了生产力和可扩展性。
- MIGRATION-BENCH是一个新的编码基准,专注于代码迁移任务,旨在从Java 8迁移到最新的LTS版本。
- MIGRATION-BENCH包括一个完整数据集及其精选子集,为研究领域提供通用资源。
- 提供了一个全面的评估框架,以进行严格的标准化评估。
- SD-Feedback方法可以有效解决存储库级别的代码迁移到Java 17的问题。
- 对于所选子集,使用Claude-3.5-Sonnet-v2的SD-Feedback方法的最小迁移和最大迁移成功率分别为62.33%和27.0%。
点此查看论文截图

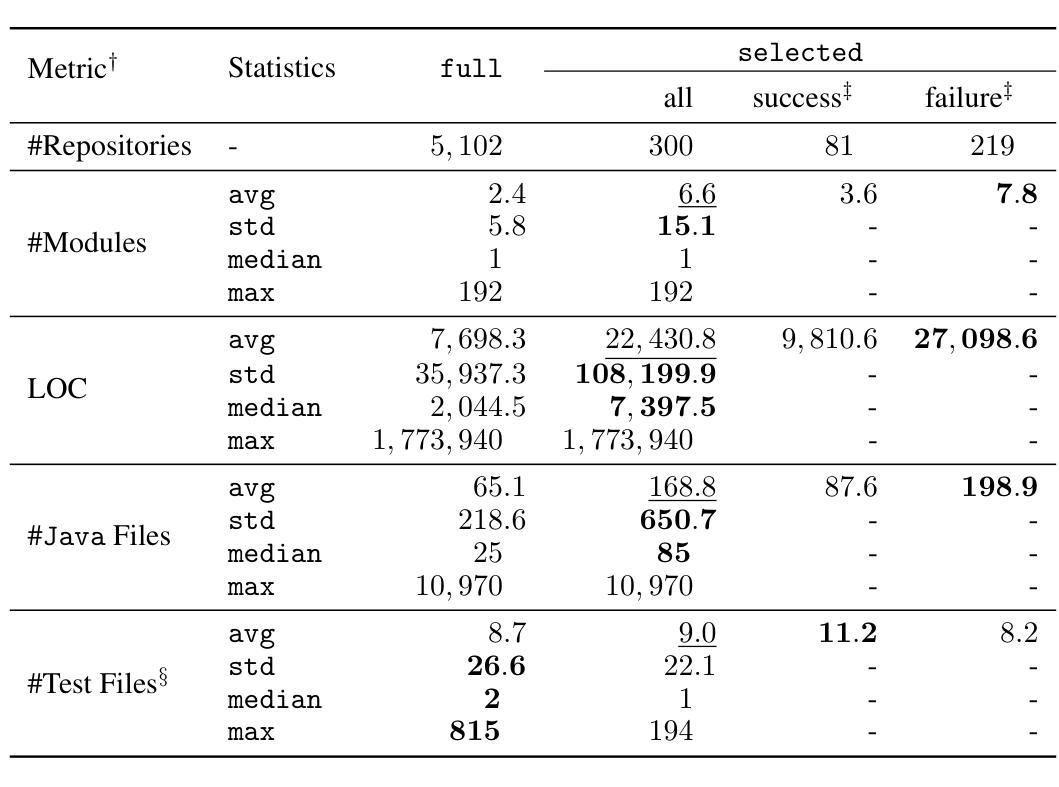
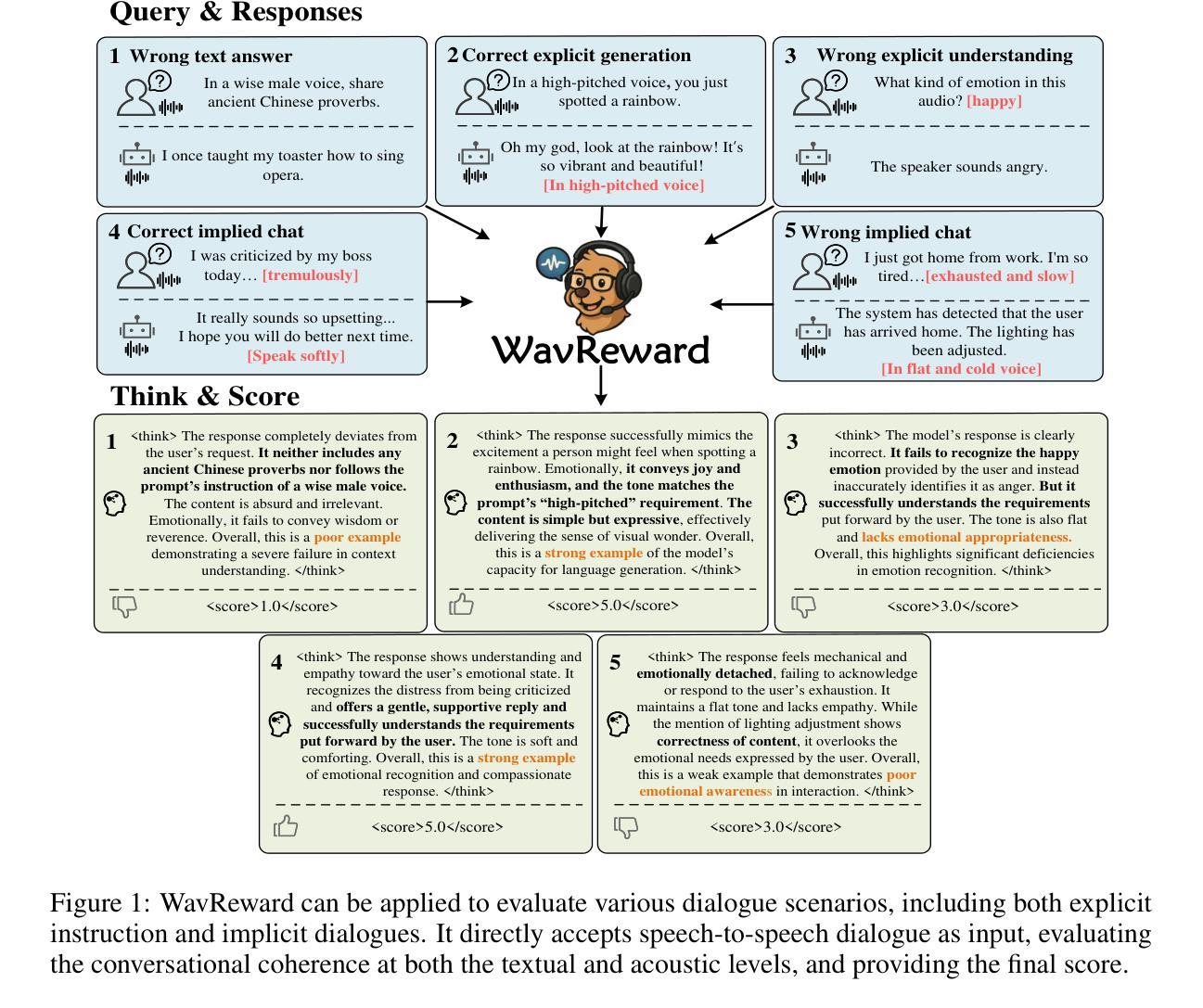
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
Authors:Shengpeng Ji, Tianle Liang, Yangzhuo Li, Jialong Zuo, Minghui Fang, Jinzheng He, Yifu Chen, Zhengqing Liu, Ziyue Jiang, Xize Cheng, Siqi Zheng, Jin Xu, Junyang Lin, Zhou Zhao
End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models’ conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$%$ to 91.5$%$. In subjective A/B testing, WavReward also leads by a margin of 83$%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
最近,端到端的口语对话模型,如GPT-4o-audio,在语音领域引起了极大的关注。然而,口语对话模型的会话性能评估却被大大忽视了。这主要是因为智能聊天机器人传达了大量的非文本信息,这些信息无法轻易地使用基于文本的模型进行评估,如ChatGPT。为了弥补这一空白,我们提出了WavReward,一个基于音频语言模型的奖励反馈模型,它可以使用语音输入评估口语对话系统的智商和情商。具体来说,1)WavReward基于音频语言模型,融入了深度推理过程和用于后训练的非线性奖励机制。通过利用强化学习算法的多样本反馈,我们构建了一个专门针对口语对话模型的评估器。2)我们引入了用于训练WavReward的偏好数据集ChatReward-30K。ChatReward-30K涵盖了口语对话模型的理解和生成方面。这些场景包括各种任务,如文本聊天、指令聊天的九个声音特征以及隐式聊天。WavReward在多个口语对话场景中表现出超越先前最先进的评估模型的能力,在客观准确性方面实现了从55.1%到91.5%的显著改进(相较于Qwen2.5-Omni)。在主观的A/B测试中,WavReward的领先幅度也达到了83%。全面的消融研究证实了WavReward每个组件的必要性。论文被接受后,所有数据和代码将在https://github.com/jishengpeng/WavReward上公开。
论文及项目相关链接
Summary:
近期语音领域出现了端到端的对话模型,如GPT-4o-audio。然而,这些对话模型的会话性能评估却被忽视。这是由于智能聊天机器人传达了大量无法通过文本语言模型(如ChatGPT)轻松衡量的非文本信息。为解决这个问题,研究团队提出WavReward模型,基于音频语言模型构建奖励反馈机制,能评估对话系统的智商与情商。该模型结合深度推理过程和非线性奖励机制进行后训练,并采用强化学习算法的多样本反馈构建专门针对对话模型的评估器。此外,还引入了ChatReward-30K数据集来训练WavReward。该数据集包含对话模型的理解和生成方面,涵盖多种任务,如文本聊天、指令聊天的九种声音特征和隐性聊天等。在多种对话场景中,WavReward显著优于之前的先进评估模型,客观准确率从55.1%提高到91.5%。主观A/B测试中,WavReward的领先优势更大。全面的消融研究证实了WavReward每个组件的必要性。相关数据和代码将在论文被接受后公开在https://github.com/jishengpeng/WavReward。
Key Takeaways:
- 端到端的对话模型如GPT-4o-audio在语音领域受到关注,但评估其会话性能非常重要。
- 智能聊天机器人传达的非文本信息无法通过文本语言模型轻松衡量。
- WavReward是一个基于音频语言模型的奖励反馈模型,可以评估对话系统的智商和情商。
- WavReward结合了深度推理和强化学习算法,利用多样本反馈构建专门的对话模型评估器。
- ChatReward-30K数据集用于训练WavReward,包含对话模型的理解和生成方面。
- WavReward在各种对话场景中表现优异,客观准确率显著提高。
点此查看论文截图

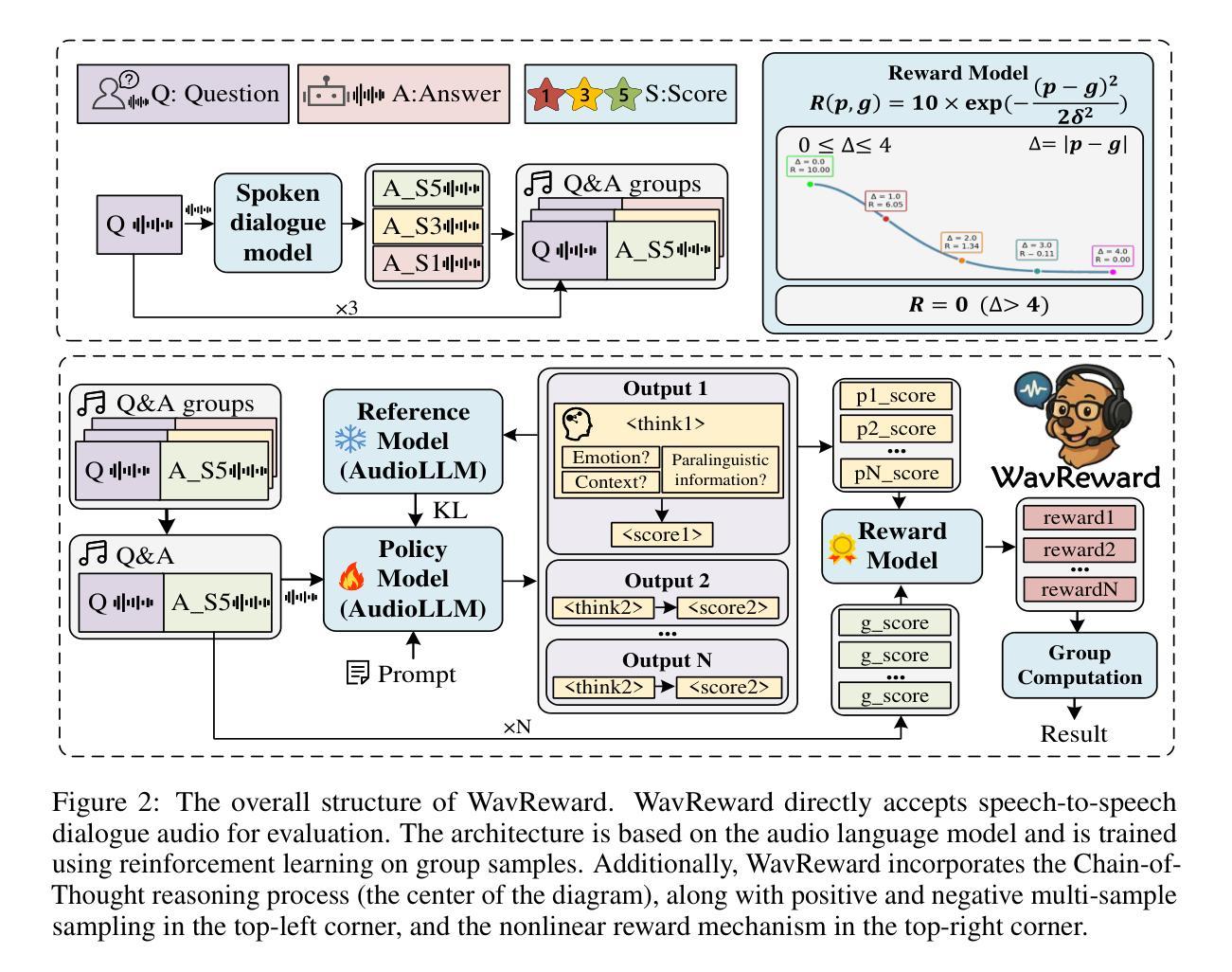
Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
Authors:Andrew Rouditchenko, Saurabhchand Bhati, Edson Araujo, Samuel Thomas, Hilde Kuehne, Rogerio Feris, James Glass
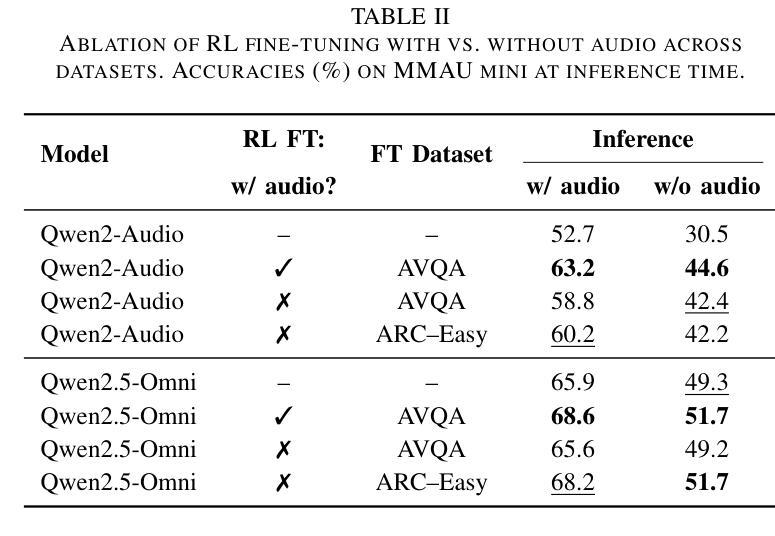
We propose Omni-R1 which fine-tunes a recent multi-modal LLM, Qwen2.5-Omni, on an audio question answering dataset with the reinforcement learning method GRPO. This leads to new State-of-the-Art performance on the recent MMAU benchmark. Omni-R1 achieves the highest accuracies on the sounds, music, speech, and overall average categories, both on the Test-mini and Test-full splits. To understand the performance improvement, we tested models both with and without audio and found that much of the performance improvement from GRPO could be attributed to better text-based reasoning. We also made a surprising discovery that fine-tuning without audio on a text-only dataset was effective at improving the audio-based performance.
我们提出了Omni-R1,它通过强化学习法GRPO对近期多模态大型语言模型Qwen2.5-Omni进行微调,用于音频问答数据集。这在最近的MMAU基准测试中达到了新的技术顶尖表现。Omni-R1在声音、音乐、语音和总体平均类别上均实现了最高准确率,无论是在Test-mini还是Test-full分割上。为了了解性能提升情况,我们对有音频和无音频的模型进行了测试,发现GRPO的大部分性能提升归功于基于文本推理的改进。我们还意外地发现,在只有文本的数据集上不带音频进行微调,也能有效提高基于音频的性能。
论文及项目相关链接
Summary
Omni-R1通过微调多模态大型语言模型Qwen2.5-Omni在音频问答数据集上,采用强化学习的方法GRPO,实现了在最新MMAU基准测试上的最新最佳性能。Omni-R1在声音、音乐、语音及总体平均分类上均达到了最高精度,无论是Test-mini还是Test-full分割都是如此。为了了解性能提升的原因,作者对是否使用音频进行了测试,发现GRPO的大部分性能提升主要归因于基于文本推理的能力。令人惊讶的是,作者在不使用音频的情况下对纯文本数据集进行微调,这同样提升了基于音频的性能。
Key Takeaways
- Omni-R1通过微调多模态大型语言模型Qwen2.5-Omni达到最新最佳性能。
- Omni-R1在多个分类上达到最高精度。
- GRPO强化学习方法对文本推理能力有较大贡献。
- 不使用音频的纯文本数据集微调能提升基于音频的性能。
- Omni-R1模型在某些领域性能显著,特别是在声音、音乐、语音方面。
- 测试结果显示GRPO强化学习可有效提升模型性能。
点此查看论文截图

Evaluating the Robustness of Adversarial Defenses in Malware Detection Systems
Authors:Mostafa Jafari, Alireza Shameli-Sendi
Machine learning is a key tool for Android malware detection, effectively identifying malicious patterns in apps. However, ML-based detectors are vulnerable to evasion attacks, where small, crafted changes bypass detection. Despite progress in adversarial defenses, the lack of comprehensive evaluation frameworks in binary-constrained domains limits understanding of their robustness. We introduce two key contributions. First, Prioritized Binary Rounding, a technique to convert continuous perturbations into binary feature spaces while preserving high attack success and low perturbation size. Second, the sigma-binary attack, a novel adversarial method for binary domains, designed to achieve attack goals with minimal feature changes. Experiments on the Malscan dataset show that sigma-binary outperforms existing attacks and exposes key vulnerabilities in state-of-the-art defenses. Defenses equipped with adversary detectors, such as KDE, DLA, DNN+, and ICNN, exhibit significant brittleness, with attack success rates exceeding 90% using fewer than 10 feature modifications and reaching 100% with just 20. Adversarially trained defenses, including AT-rFGSM-k, AT-MaxMA, improves robustness under small budgets but remains vulnerable to unrestricted perturbations, with attack success rates of 99.45% and 96.62%, respectively. Although PAD-SMA demonstrates strong robustness against state-of-the-art gradient-based adversarial attacks by maintaining an attack success rate below 16.55%, the sigma-binary attack significantly outperforms these methods, achieving a 94.56% success rate under unrestricted perturbations. These findings highlight the critical need for precise method like sigma-binary to expose hidden vulnerabilities in existing defenses and support the development of more resilient malware detection systems.
机器学习是Android恶意软件检测的关键工具,能有效识别应用程序中的恶意模式。然而,基于机器学习的检测器容易受到规避攻击的影响,这些攻击通过细微的定制改变来绕过检测。尽管对抗性防御取得了进展,但在二进制受限领域缺乏全面的评估框架,限制了对其稳健性的理解。我们做出了两个重要的贡献。首先,我们引入了优先二进制舍入技术,该技术可将连续扰动转换为二进制特征空间,同时保持高攻击成功率和小扰动大小。其次,我们提出了sigma-binary攻击,这是一种针对二进制领域的新型对抗性方法,旨在以最小的特征变化实现攻击目标。在Malscan数据集上的实验表明,sigma-binary攻击优于现有攻击,并暴露了先进防御手段的关键漏洞。配备对手检测器的防御手段,如KDE、DLA、DNN+和ICNN,表现出显著的脆弱性,使用少于10个特征修改的攻击成功率超过90%,仅用20个特征修改即可达到100%。对抗性训练防御手段,包括AT-rFGSM-k、AT-MaxMA等,在小预算下提高了稳健性,但仍受到无限制扰动的攻击,成功率分别为99.45%和96.62%。尽管PAD-SMA对最先进的基于梯度的对抗性攻击表现出强大的稳健性,将攻击成功率保持在16.55%以下,但sigma-binary攻击显著优于这些方法,在无限制扰动下的成功率为94.56%。这些发现强调了像sigma-binary这样的精确方法的重要性,可以揭示现有防御手段中的隐藏漏洞,并支持开发更具韧性的恶意软件检测系统。
论文及项目相关链接
PDF Submitted to IEEE Transactions on Information Forensics and Security (T-IFS), 13 pages, 4 figures
Summary
机器学习是安卓恶意软件检测的关键工具,能有效识别应用程序中的恶意模式。然而,基于机器学习的检测器容易受到规避攻击的影响,微小的改变可能会绕过检测。针对这种情况,本文介绍了两种关键贡献:优先二进制舍入法和针对二进制域的Sigma二元攻击法。实验表明,Sigma二元攻击法优于现有攻击方法,揭示了现有防御手段的关键漏洞。即使配备对抗性检测器的防御手段如KDE、DLA、DNN+和ICNN等,仍表现出显著的脆弱性。对抗性训练防御手段如AT-rFGSM-k和AT-MaxMA在小预算下提高稳健性,但在无限制扰动下仍面临漏洞。总体而言,本文强调了对现有防御手段进行精确攻击方法(如Sigma二元攻击)的重要性,以揭示隐藏漏洞,支持开发更具弹性的恶意软件检测系统。
Key Takeaways
- 机器学习是安卓恶意软件检测的重要工具,能够识别应用程序中的恶意模式。
- 基于机器学习的检测器容易受到规避攻击的影响。
- 优先二进制舍入法和Sigma二元攻击法是对抗这种问题的两种关键方法。
- Sigma二元攻击法在实验中表现优于其他攻击方法。
- 即使配备对抗性检测器的防御手段也存在显著漏洞。
- 对抗性训练能提高防御手段的稳健性,但在特定情况下仍面临挑战。
点此查看论文截图


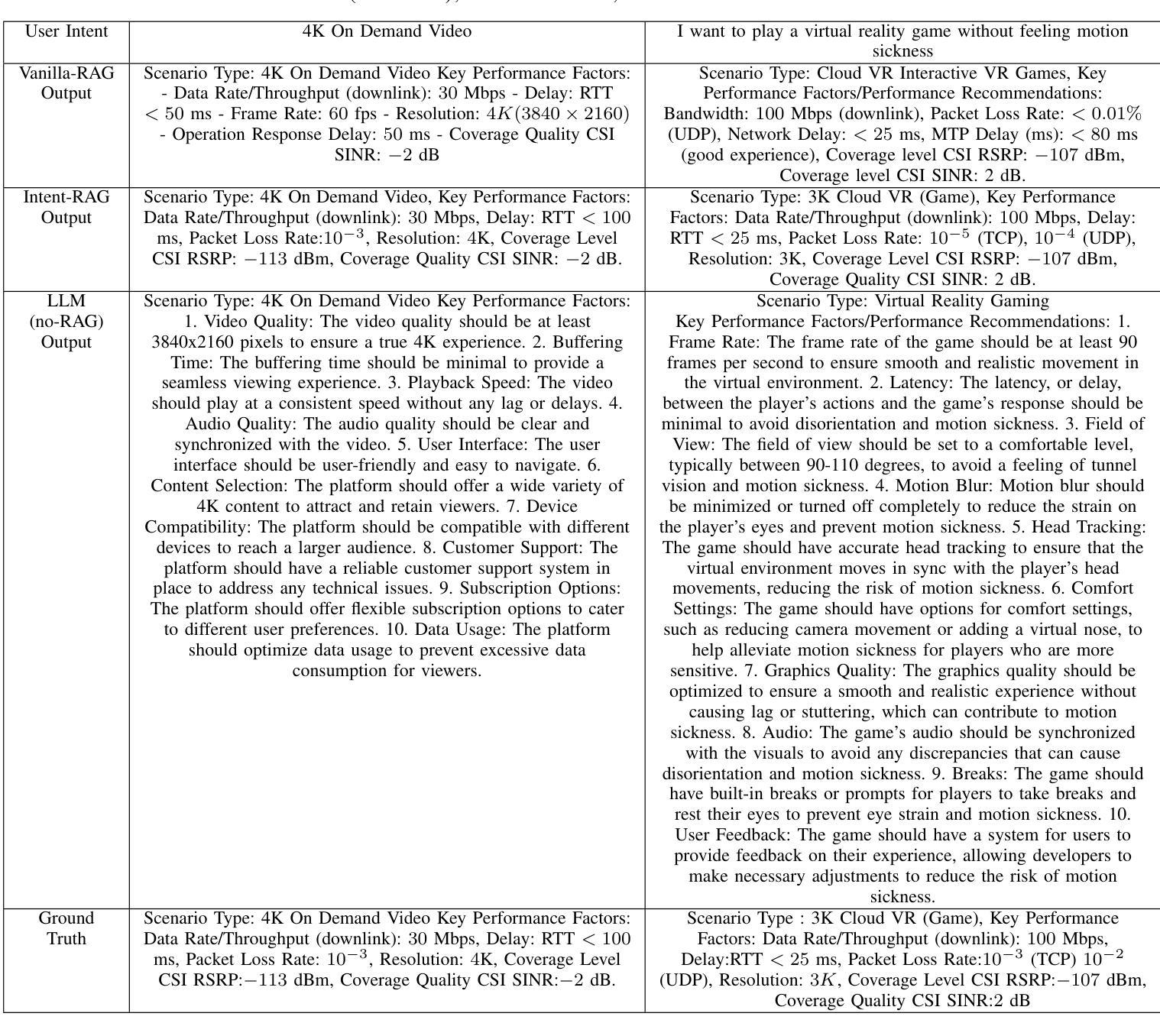
RAG-Enabled Intent Reasoning for Application-Network Interaction
Authors:Salwa Mostafa, Mohamed K. Abdel-Aziz, Mohammed S. Elbamby, Mehdi Bennis
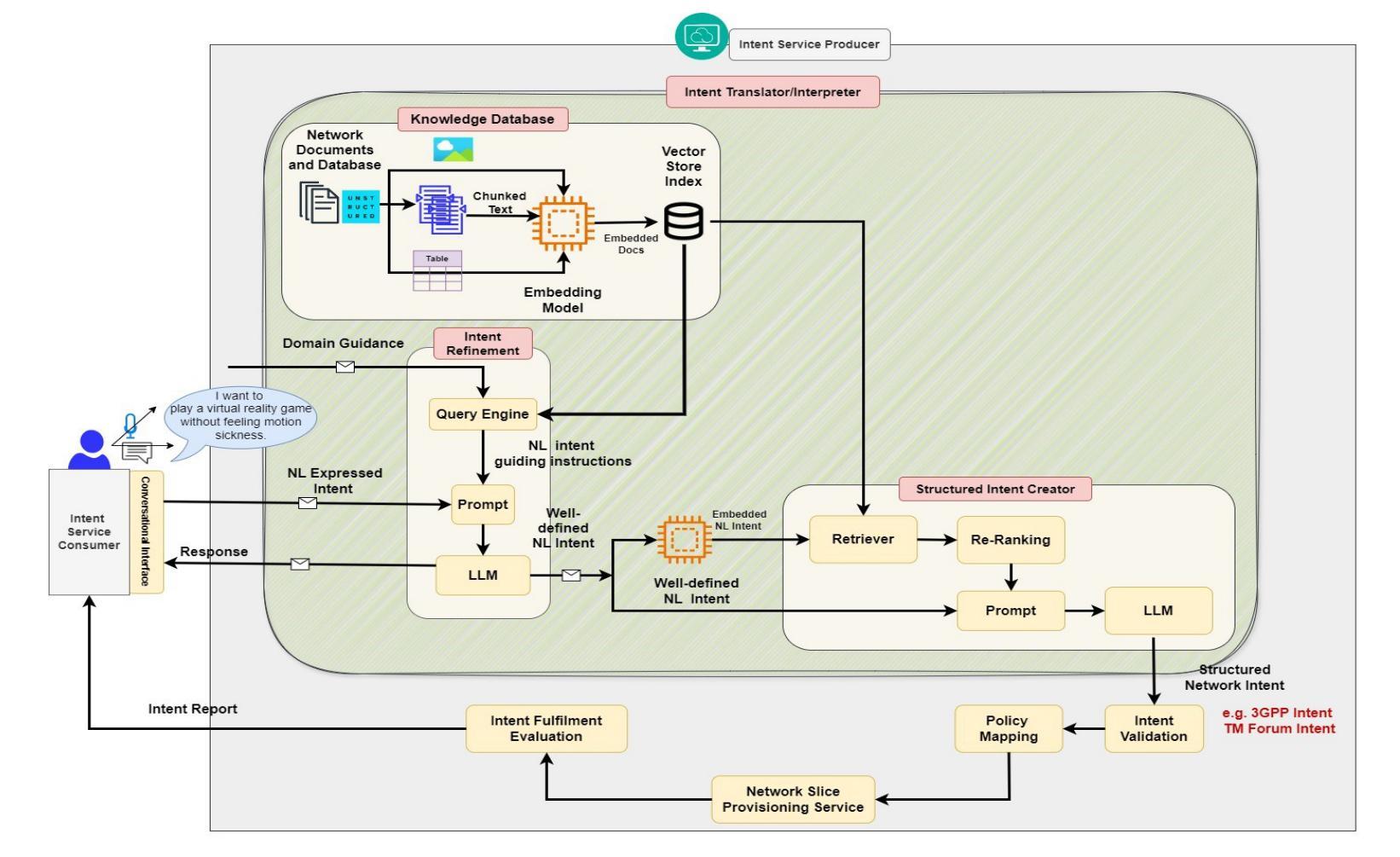
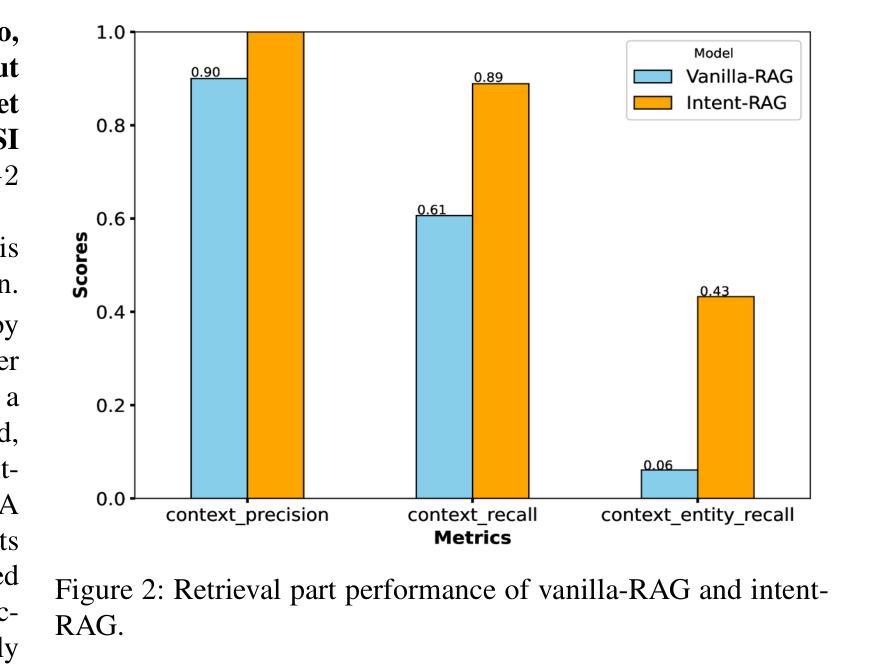
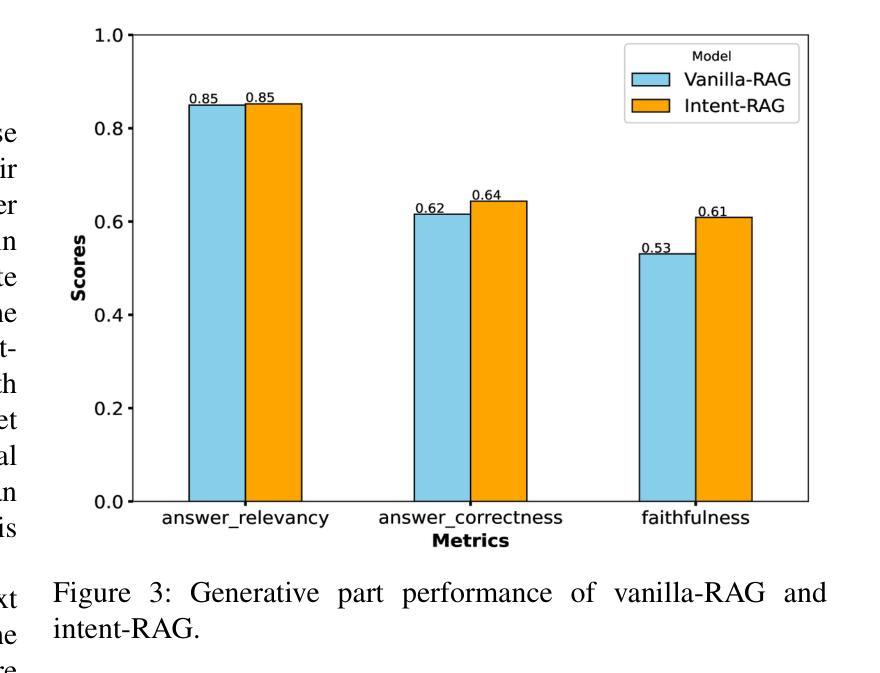
Intent-based network (IBN) is a promising solution to automate network operation and management. IBN aims to offer human-tailored network interaction, allowing the network to communicate in a way that aligns with the network users’ language, rather than requiring the network users to understand the technical language of the network/devices. Nowadays, different applications interact with the network, each with its own specialized needs and domain language. Creating semantic languages (i.e., ontology-based languages) and associating them with each application to facilitate intent translation lacks technical expertise and is neither practical nor scalable. To tackle the aforementioned problem, we propose a context-aware AI framework that utilizes machine reasoning (MR), retrieval augmented generation (RAG), and generative AI technologies to interpret intents from different applications and generate structured network intents. The proposed framework allows for generalized/domain-specific intent expression and overcomes the drawbacks of large language models (LLMs) and vanilla-RAG framework. The experimental results show that our proposed intent-RAG framework outperforms the LLM and vanilla-RAG framework in intent translation.
基于意图的网络(IBN)是自动化网络操作和管理的一种有前途的解决方案。IBN旨在提供符合人类需求的网络交互,让网络能够以与用户语言相符的方式进行通信,而不是要求网络用户理解网络/设备的技术语言。如今,不同的应用程序与网络进行交互,各有其特殊需求和领域语言。创建语义语言(例如基于本体论的语言)并与每个应用程序相关联,以促进意图翻译,但这缺乏技术专业知识,既不实用也不可扩展。为了解决上述问题,我们提出了一个基于上下文感知的人工智能框架,该框架利用机器推理(MR)、检索增强生成(RAG)和生成式人工智能技术来解释来自不同应用程序的意图并生成结构化网络意图。所提出的框架允许通用/特定领域的意图表达,并克服了大型语言模型(LLM)和简单RAG框架的缺点。实验结果表明,我们提出的意图RAG框架在意图翻译方面优于LLM和简单RAG框架。
论文及项目相关链接
Summary
网络意图框架利用AI技术进行自动化管理和操作,采用机器学习、增强检索生成和自然语言处理技术解读应用程序意图并生成结构化网络意图,便于网络与用户之间的交流,促进用户体验的个性化需求。该框架克服了传统语义语言技术的局限性,提高了网络管理的效率和准确性。
Key Takeaways
- 意图网络(IBN)是一个自动管理网络操作的解决方案。
- IBN的目标是提供人性化的网络交互方式,使网络能够与用户的自然语言相对应而不是反过来的专业语言交互方式。因为有许多应用,如网络通信会有特定的需要和语境性专业词汇或业务相关标签与上下文,使用意图网络可以使沟通变得简单。这对于许多领域的应用非常有用。
- 提出了一种基于AI的上下文感知框架,利用机器学习技术解释应用程序意图并生成结构化网络意图。这个框架具有广泛的应用前景,适用于不同领域的应用场景。同时它克服了大型语言模型(LLM)和简单RAG框架的缺点和局限性,进行了个性化的调整,帮助以易于理解的业务自然语言使用者对系统的管理和意图操控工作提出了革命性的新的模型可能性思考路径设计可能性测试和问题确定规则定制化创建简易式资源相关简化展示方式与功能性高效结构集合设计等可能的改革和创新改进方向和增强客户心智功能的倾向及其相互作用的关键依据方面的综合理解增强应用,即:AI通过语义分析和语境理解实现与人类的意图沟通互动的目标并达到系统优化的效果。并且框架设计过程中还考虑了通用和特定领域的意图表达需求。
点此查看论文截图

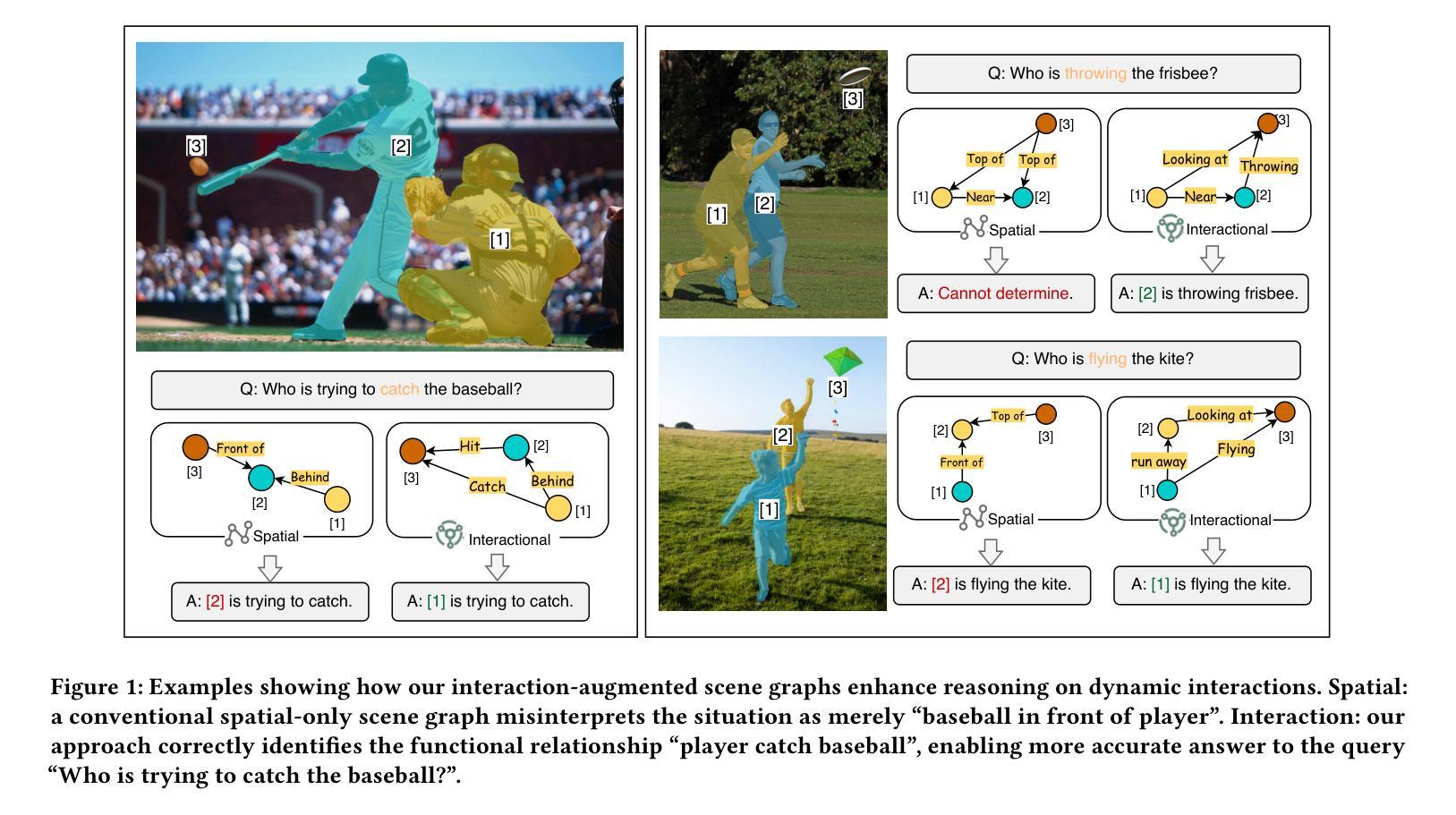
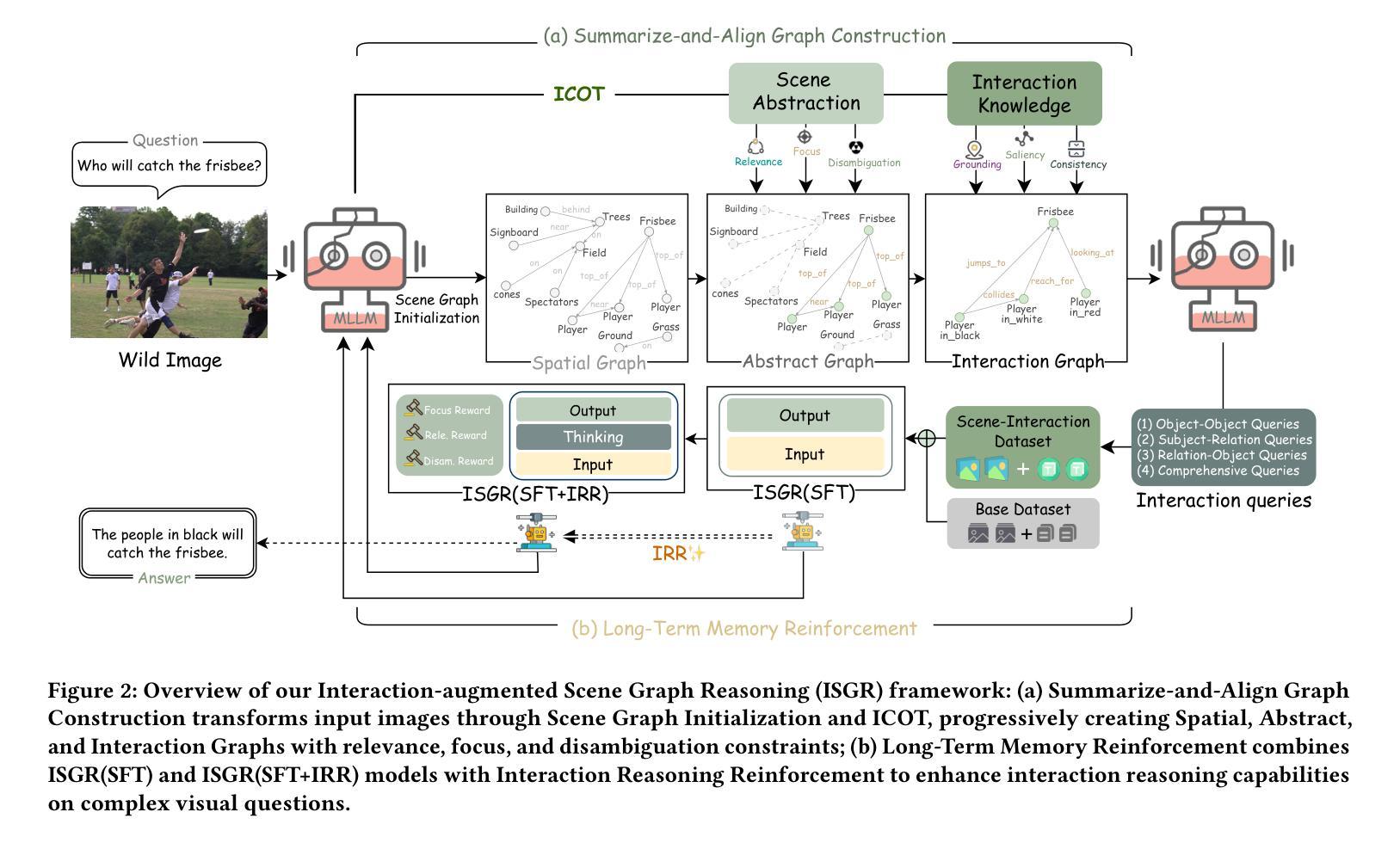
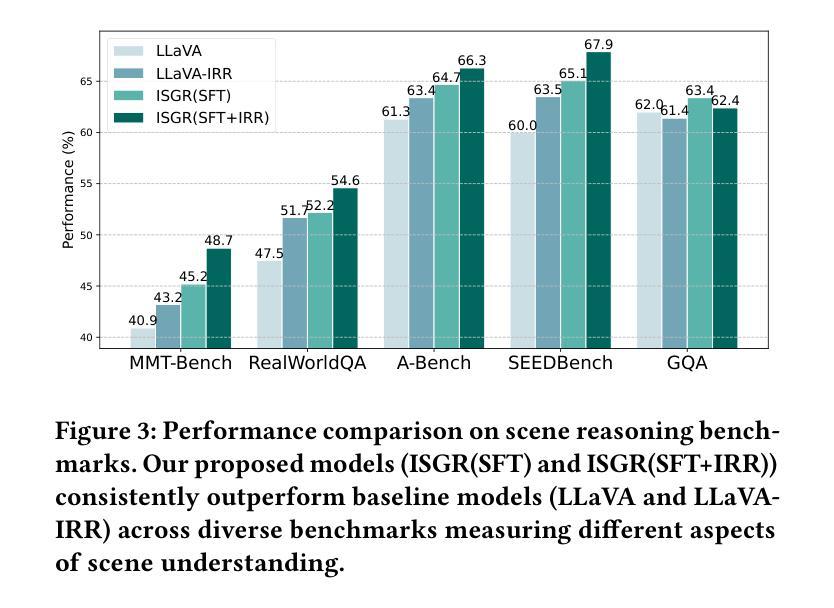
Seeing Beyond the Scene: Enhancing Vision-Language Models with Interactional Reasoning
Authors:Dayong Liang, Changmeng Zheng, Zhiyuan Wen, Yi Cai, Xiao-Yong Wei, Qing Li
Traditional scene graphs primarily focus on spatial relationships, limiting vision-language models’ (VLMs) ability to reason about complex interactions in visual scenes. This paper addresses two key challenges: (1) conventional detection-to-construction methods produce unfocused, contextually irrelevant relationship sets, and (2) existing approaches fail to form persistent memories for generalizing interaction reasoning to new scenes. We propose Interaction-augmented Scene Graph Reasoning (ISGR), a framework that enhances VLMs’ interactional reasoning through three complementary components. First, our dual-stream graph constructor combines SAM-powered spatial relation extraction with interaction-aware captioning to generate functionally salient scene graphs with spatial grounding. Second, we employ targeted interaction queries to activate VLMs’ latent knowledge of object functionalities, converting passive recognition into active reasoning about how objects work together. Finally, we introduce a lone-term memory reinforcement learning strategy with a specialized interaction-focused reward function that transforms transient patterns into long-term reasoning heuristics. Extensive experiments demonstrate that our approach significantly outperforms baseline methods on interaction-heavy reasoning benchmarks, with particularly strong improvements on complex scene understanding tasks. The source code can be accessed at https://github.com/open_upon_acceptance.
传统场景图主要关注空间关系,这限制了视觉语言模型(VLM)对视觉场景中复杂交互进行推理的能力。本文解决了两个关键挑战:(1)传统的检测构建方法产生的是不聚焦的、上下文无关的关系集;(2)现有方法无法形成持久的记忆,以将交互推理推广到新的场景。我们提出了交互增强场景图推理(ISGR)框架,通过三个互补的组件增强VLM的交互推理能力。首先,我们的双流图构造器结合了SAM支持的空间关系提取和交互感知描述生成具有空间定位的功能显著场景图。其次,我们通过有针对性的交互查询激活VLM对对象功能的潜在知识,将被动识别转化为对对象如何协同工作的主动推理。最后,我们引入了一种基于单一术语记忆强化学习的策略,以及一种专门的以交互为中心的奖励函数,将短暂的模式转化为长期的推理启发式。大量实验表明,我们的方法在交互繁重的推理基准测试上显著优于基准方法,特别是在复杂场景理解任务上的改进尤为突出。源代码可在https://github.com/open_upon_acceptance获取。
论文及项目相关链接
Summary
传统场景图主要关注空间关系,限制了视觉语言模型(VLMs)对视觉场景中复杂交互进行推理的能力。本文解决两个关键问题:(1)常规检测构建方法产生的不集中、上下文无关的关系集;(2)现有方法缺乏通用交互推理的持久记忆形成。提出交互增强场景图推理(ISGR)框架,通过三个互补组件增强VLMs的交互推理能力。首先,我们的双流图构造器结合SAM支持的空间关系提取和交互感知描述生成具有空间定位的功能显著场景图。其次,我们通过有针对性的交互查询激活VLMs对对象功能的潜在认识,将被动识别转化为对对象如何协同工作的主动推理。最后,我们引入了一项长期记忆强化学习策略,并配备了专门的交互重点奖励功能,将短暂模式转化为长期推理策略。实验表明,我们的方法在交互重推理基准测试上显著优于基准方法,在复杂场景理解任务上的改进尤其显著。
Key Takeaways
- 传统场景图主要关注空间关系,限制了VLMs在复杂交互推理中的应用。
- 现有方法产生的不集中、上下文无关的关系集是影响VLMs性能的关键问题。
- 提出的ISGR框架通过三个互补组件增强VLMs的交互推理能力。
- 双流图构造器结合空间关系提取和交互感知描述生成功能显著场景图。
- 通过有针对性的交互查询激活VLMs对对象功能的潜在认识。
- 引入长期记忆强化学习策略,配备专门的交互重点奖励功能。
点此查看论文截图

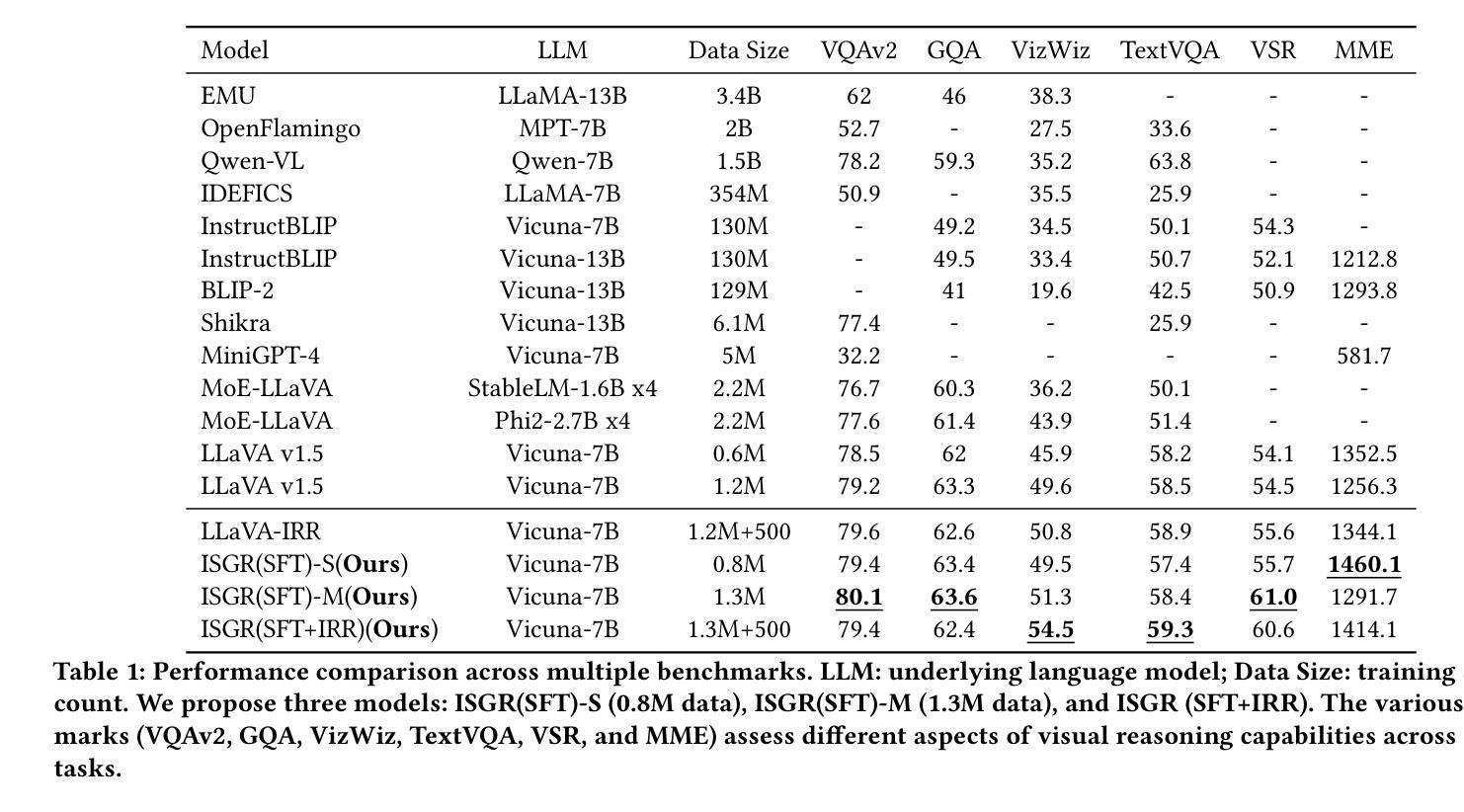
Beyond the Known: Decision Making with Counterfactual Reasoning Decision Transformer
Authors:Minh Hoang Nguyen, Linh Le Pham Van, Thommen George Karimpanal, Sunil Gupta, Hung Le
Decision Transformers (DT) play a crucial role in modern reinforcement learning, leveraging offline datasets to achieve impressive results across various domains. However, DT requires high-quality, comprehensive data to perform optimally. In real-world applications, the lack of training data and the scarcity of optimal behaviours make training on offline datasets challenging, as suboptimal data can hinder performance. To address this, we propose the Counterfactual Reasoning Decision Transformer (CRDT), a novel framework inspired by counterfactual reasoning. CRDT enhances DT ability to reason beyond known data by generating and utilizing counterfactual experiences, enabling improved decision-making in unseen scenarios. Experiments across Atari and D4RL benchmarks, including scenarios with limited data and altered dynamics, demonstrate that CRDT outperforms conventional DT approaches. Additionally, reasoning counterfactually allows the DT agent to obtain stitching abilities, combining suboptimal trajectories, without architectural modifications. These results highlight the potential of counterfactual reasoning to enhance reinforcement learning agents’ performance and generalization capabilities.
决策转换器(DT)在现代强化学习中扮演着至关重要的角色,它利用离线数据集在不同领域取得了令人印象深刻的结果。然而,DT需要高质量、全面的数据才能最优地执行。在真实世界的应用中,训练数据的缺乏以及最优行为的稀缺使得在离线数据集上进行训练具有挑战性,因为次优数据可能会阻碍性能。为了解决这一问题,我们提出了基于反事实推理的决策转换器(CRDT),这是一个受反事实推理启发的新型框架。CRDT通过生成和利用反事实经验,增强了DT在已知数据之外的推理能力,使它在未见过的场景中能够做出更好的决策。在Atari和D4RL基准测试的实验中,包括数据有限和动态变化的情况,表明CRDT在常规DT方法上具有优势。此外,反事实推理还使得DT代理能够获取缝合能力,即结合次优轨迹,而无需进行架构修改。这些结果突显了反事实推理在增强强化学习代理的性能和泛化能力方面的潜力。
论文及项目相关链接
Summary:决策转换器(DT)在现代强化学习中扮演着关键角色,它利用离线数据集在不同领域取得了令人印象深刻的结果。然而,DT需要高质量、全面的数据才能最优地执行。在真实世界应用中,训练数据的缺乏以及最优行为的稀缺使得在离线数据集上进行训练具有挑战性,因为次优数据可能会阻碍性能。为解决此问题,我们提出了受反事实推理启发的决策转换器(CRDT)这一新型框架。CRDT通过生成和利用反事实经验,增强了DT在未知数据之外的推理能力,从而实现了在未见场景中的决策改进。在Atari和D4RL基准测试中的实验,包括数据有限和动态变化的情况,表明CRDT优于传统DT方法。此外,反事实推理还让DT代理获得了缝合能力,能够结合次优轨迹,无需进行架构修改。这些结果突显了反事实推理在增强强化学习代理的性能和泛化能力方面的潜力。
Key Takeaways:
- 决策转换器(DT)在强化学习中利用离线数据集取得显著成果,但需要高质量数据才能最优执行。
- 在真实场景中,训练数据缺乏和最优行为稀缺是训练DT的挑战,次优数据可能阻碍性能。
- 提出的Counterfactual Reasoning Decision Transformer(CRDT)框架通过生成和利用反事实经验,增强了DT的推理能力。
- CRDT在未见场景中的决策改进表现出优势,特别是在数据有限和动态变化的情况下。
- 反事实推理使DT代理获得结合次优轨迹的能力,称为“缝合能力”。
- 反事实推理有助于提升强化学习代理的性能和泛化能力。
点此查看论文截图

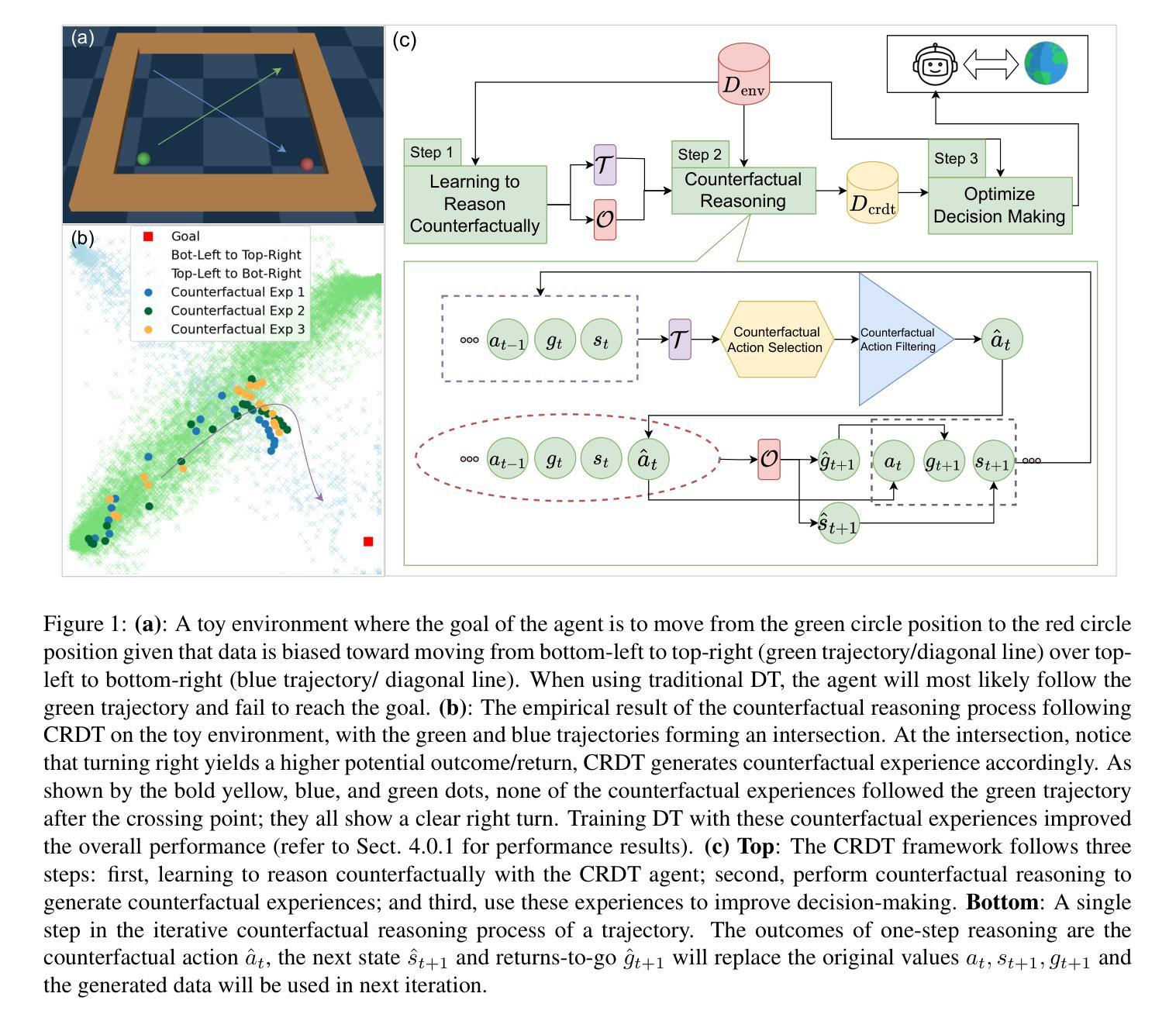
Improved Algorithms for Differentially Private Language Model Alignment
Authors:Keyu Chen, Hao Tang, Qinglin Liu, Yizhao Xu
Language model alignment is crucial for ensuring that large language models (LLMs) align with human preferences, yet it often involves sensitive user data, raising significant privacy concerns. While prior work has integrated differential privacy (DP) with alignment techniques, their performance remains limited. In this paper, we propose novel algorithms for privacy-preserving alignment and rigorously analyze their effectiveness across varying privacy budgets and models. Our framework can be deployed on two celebrated alignment techniques, namely direct preference optimization (DPO) and reinforcement learning from human feedback (RLHF). Through systematic experiments on large-scale language models, we demonstrate that our approach achieves state-of-the-art performance. Notably, one of our algorithms, DP-AdamW, combined with DPO, surpasses existing methods, improving alignment quality by up to 15% under moderate privacy budgets ({\epsilon}=2-5). We further investigate the interplay between privacy guarantees, alignment efficacy, and computational demands, providing practical guidelines for optimizing these trade-offs.
语言模型对齐对于确保大型语言模型(LLM)与人类偏好一致至关重要,然而这通常涉及敏感用户数据,引发了严重的隐私担忧。尽管先前的工作已经将差分隐私(DP)与对齐技术相结合,但其性能仍然有限。在本文中,我们提出了用于隐私保护对齐的新型算法,并在不同的隐私预算和模型上对其有效性进行了严格分析。我们的框架可以部署在两种著名的对齐技术上,即直接偏好优化(DPO)和基于人类反馈的强化学习(RLHF)。通过对大规模语言模型的系统实验,我们证明了我们的方法达到了最新技术水平。值得注意的是,我们的算法之一DP-AdamW与DPO相结合,超越了现有方法,在适度的隐私预算(ε=2-5)下,提高了高达15%的对齐质量。我们还进一步研究了隐私保证、对齐效果和计算需求之间的相互作用,为优化这些权衡提供了实用指南。
论文及项目相关链接
Summary
本文探讨了大型语言模型(LLM)与人类偏好对齐的重要性,并指出在此过程中涉及敏感用户数据带来的隐私担忧。虽然之前的研究已经尝试将差分隐私(DP)与对齐技术相结合,但其性能仍然有限。本文提出新型隐私保护对齐算法,并在不同隐私预算和模型上严格分析其有效性。该研究可将新型算法部署在两种著名的对齐技术,即直接偏好优化(DPO)和基于人类反馈的强化学习(RLHF)上。通过大规模语言模型的系统实验,证明该方法达到业界最佳性能。特别是与DPO结合的DP-AdamW算法在适度隐私预算下,可提高对齐质量达15%。同时,本文还探讨了隐私保障、对齐效果和计算需求之间的平衡,为优化这些权衡提供了实用指南。
Key Takeaways
- 大型语言模型(LLM)与人类偏好对齐至关重要,但涉及敏感用户数据引发隐私担忧。
- 现有结合差分隐私(DP)与对齐技术的性能有限。
- 提出新型隐私保护对齐算法,可部署在直接偏好优化(DPO)和强化学习从人类反馈(RLHF)上。
- 系统实验证明该方法达到业界最佳性能。
- DP-AdamW算法与DPO结合,在适度隐私预算下,提高对齐质量达15%。
- 研究探讨了隐私保障、对齐效果和计算需求之间的平衡。
点此查看论文截图


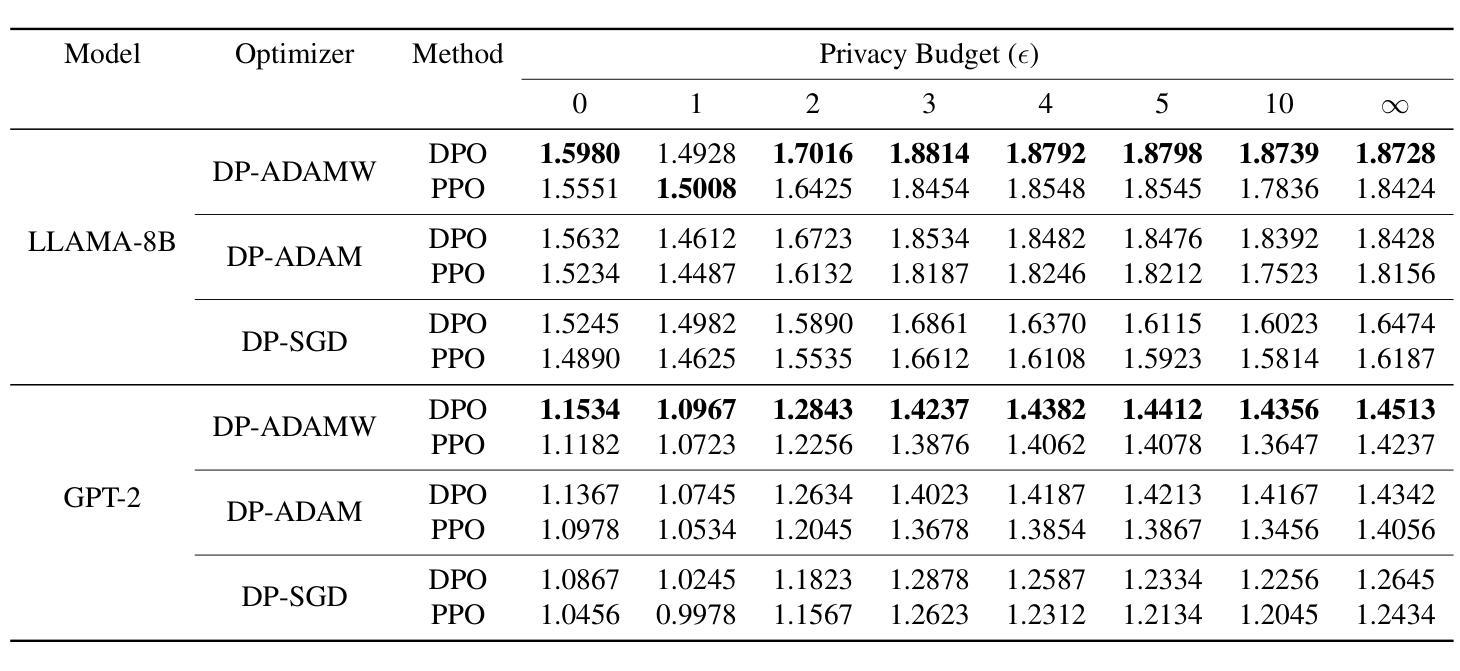
Agent RL Scaling Law: Agent RL with Spontaneous Code Execution for Mathematical Problem Solving
Authors:Xinji Mai, Haotian Xu, Xing W, Weinong Wang, Yingying Zhang, Wenqiang Zhang
Large Language Models (LLMs) often struggle with mathematical reasoning tasks requiring precise, verifiable computation. While Reinforcement Learning (RL) from outcome-based rewards enhances text-based reasoning, understanding how agents autonomously learn to leverage external tools like code execution remains crucial. We investigate RL from outcome-based rewards for Tool-Integrated Reasoning, ZeroTIR, training base LLMs to spontaneously generate and execute Python code for mathematical problems without supervised tool-use examples. Our central contribution is we demonstrate that as RL training progresses, key metrics scale predictably. Specifically, we observe strong positive correlations where increased training steps lead to increases in the spontaneous code execution frequency, the average response length, and, critically, the final task accuracy. This suggests a quantifiable relationship between computational effort invested in training and the emergence of effective, tool-augmented reasoning strategies. We implement a robust framework featuring a decoupled code execution environment and validate our findings across standard RL algorithms and frameworks. Experiments show ZeroTIR significantly surpasses non-tool ZeroRL baselines on challenging math benchmarks. Our findings provide a foundational understanding of how autonomous tool use is acquired and scales within Agent RL, offering a reproducible benchmark for future studies. Code is released at \href{https://github.com/yyht/openrlhf_async_pipline}{https://github.com/yyht/openrlhf\_async\_pipline}.
大型语言模型(LLM)在进行需要精确、可验证计算的数学推理任务时经常遇到困难。虽然基于结果奖励的强化学习(RL)增强了文本推理能力,但了解智能体如何自主学习利用如代码执行等外部工具仍然至关重要。我们研究了基于结果奖励的强化学习在工具集成推理(Tool-Integrated Reasoning)中的应用,即ZeroTIR。我们训练基础LLM,使其能够针对数学问题自发地生成并执行Python代码,而无需监督工具使用示例。我们的主要贡献是,我们证明了随着强化学习训练的进行,关键指标可以预测地扩展。具体来说,我们观察到强烈的正相关关系,训练步骤的增加导致自发代码执行频率、平均响应长度和最终任务准确度的提高。这表明在训练中所投入的计算努力与有效工具增强推理策略的出现之间存在可量化的关系。我们实现了一个稳健的框架,其中包括一个解耦的代码执行环境,并在标准强化学习算法和框架中验证了我们的发现。实验表明,ZeroTIR在具有挑战性的数学基准测试上显著超越了非工具ZeroRL基准测试。我们的研究为如何获得和扩展智能体的自主工具使用提供了基础理解,并为未来的研究提供了一个可复制的基准。相关代码已发布在https://github.com/yyht/openrlhf_async_pipline。
论文及项目相关链接
Summary
大型语言模型(LLMs)在处理需要精确可验证计算的数学推理任务时表现欠佳。本研究通过强化学习(RL)与结果导向奖励来增强文本推理中的工具集成能力,特别是探究了名为ZeroTIR的方法,该方法旨在训练基础LLM自主生成并执行Python代码解决数学问题,而无需监督性的工具使用示例。研究的关键贡献在于展示了随着RL训练的进行,关键指标的可预测性增长。特别是观察到训练步骤的增加与自发代码执行频率、平均响应长度以及最终任务准确率的正相关关系。这暗示了训练投入的计算努力与有效工具增强推理策略的出现之间存在可量化的关系。研究实现了稳健的框架,其中包括独立的代码执行环境,并在标准的RL算法和框架上验证了这些发现。实验表明,ZeroTIR在非工具ZeroRL基准测试上显著超越了对数学挑战的应对。这些发现为自主工具使用的获取和内在Agent RL中的扩展提供了基础理解,并为未来的研究提供了可复制的基准。
Key Takeaways
- 大型语言模型在处理数学推理任务时面临挑战,需要更强大的文本处理能力。
- 强化学习(RL)用于增强工具集成能力,促进自主生成和执行Python代码进行数学计算。
- 随着RL训练的进行,关键指标如自发代码执行频率、平均响应长度和任务准确率呈现正向增长趋势。
- 训练投入的计算努力与有效工具增强推理策略的出现存在可量化的关系。
- 实施了一个包含独立代码执行环境的稳健框架来验证发现。
- ZeroTIR方法在应对数学挑战方面显著超越了非工具ZeroRL基准测试。
点此查看论文截图




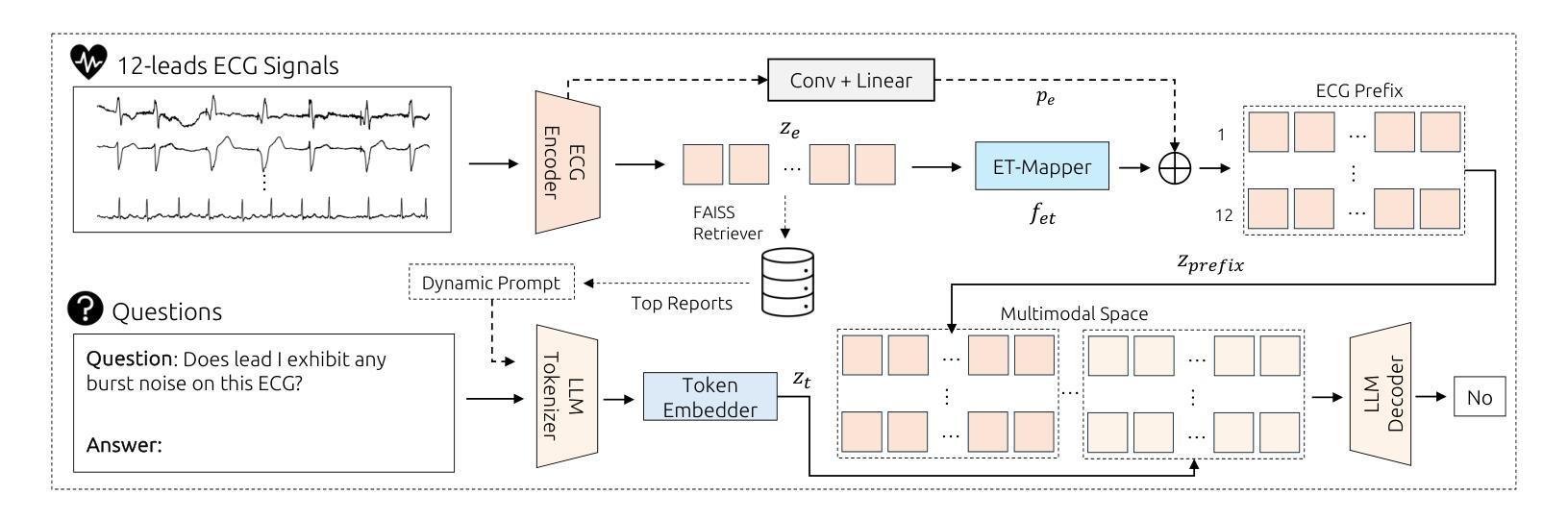
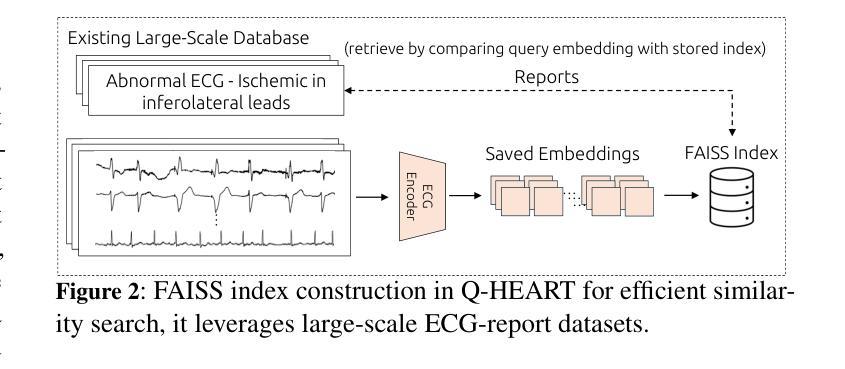
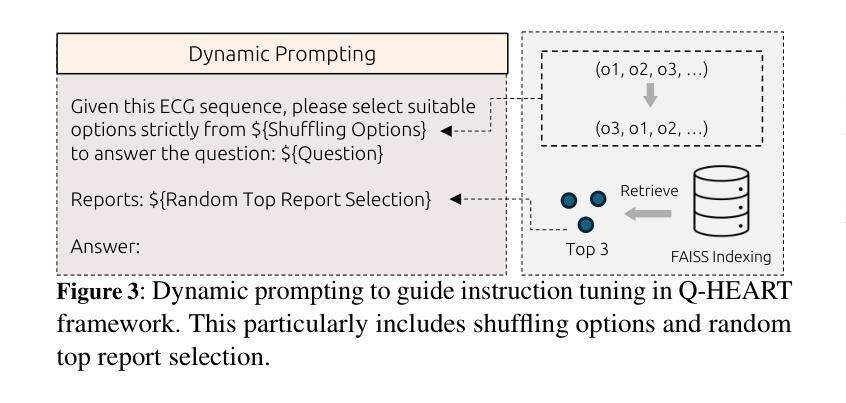
Q-Heart: ECG Question Answering via Knowledge-Informed Multimodal LLMs
Authors:Hung Manh Pham, Jialu Tang, Aaqib Saeed, Dong Ma
Electrocardiography (ECG) offers critical cardiovascular insights, such as identifying arrhythmias and myocardial ischemia, but enabling automated systems to answer complex clinical questions directly from ECG signals (ECG-QA) remains a significant challenge. Current approaches often lack robust multimodal reasoning capabilities or rely on generic architectures ill-suited for the nuances of physiological signals. We introduce Q-Heart, a novel multimodal framework designed to bridge this gap. Q-Heart leverages a powerful, adapted ECG encoder and integrates its representations with textual information via a specialized ECG-aware transformer-based mapping layer. Furthermore, Q-Heart leverages dynamic prompting and retrieval of relevant historical clinical reports to guide tuning the language model toward knowledge-aware ECG reasoning. Extensive evaluations on the benchmark ECG-QA dataset show Q-Heart achieves state-of-the-art performance, outperforming existing methods by a 4% improvement in exact match accuracy. Our work demonstrates the effectiveness of combining domain-specific architectural adaptations with knowledge-augmented LLM instruction tuning for complex physiological ECG analysis, paving the way for more capable and potentially interpretable clinical patient care systems.
心电图(ECG)提供了关于心血管的关键洞察,如识别心律失常和心肌缺血,但是让自动化系统直接从心电图信号中回答复杂临床问题(ECG-QA)仍然是一个重大挑战。当前的方法往往缺乏稳健的多模式推理能力,或者依赖于对于生理信号细微差别不够适应的通用架构。我们引入了Q-Heart,这是一个新型多模式框架,旨在弥补这一差距。Q-Heart利用强大的适应性心电图编码器和通过专业化的心电图感知变压器映射层将其表示与文本信息集成在一起。此外,Q-Heart利用动态提示和检索相关的历史临床报告来指导语言模型向知识感知心电图推理的调整。在基准心电图问答数据集上的广泛评估显示,Q-Heart达到了最先进的性能水平,在精确匹配准确性方面比现有方法提高了4%。我们的工作证明了结合特定领域的架构适应性与知识增强的大型语言模型指令调整,对于复杂生理心电图分析的有效性,为更强大和可解释的临床患者护理系统铺平了道路。
论文及项目相关链接
Summary:
心电图(ECG)在诊断心血管疾病方面发挥着关键作用,如心律失常和心肌缺血等。然而,使自动化系统直接从心电图信号中回答复杂临床问题(ECG-QA)仍存在挑战。当前方法缺乏稳健的多模式推理能力或依赖于不适合生理信号细微差别的通用架构。本研究引入Q-Heart,一种新型多模式框架,旨在弥补这一差距。Q-Heart利用强大的适应性心电图编码器和通过专业的心电图感知变压器映射层与文本信息集成。此外,Q-Heart利用动态提示和检索相关的历史临床报告来指导语言模型向知识感知心电图推理调整。在基准心电图问答数据集上的广泛评估显示,Q-Heart达到了最先进的性能水平,在精确匹配准确性方面比现有方法提高了4%。本研究结合了领域特定的架构适应性和知识增强的大型语言模型指令调整,为复杂生理心电图分析的有效性铺平了道路,为更强大和可解释的临床患者护理系统开辟了道路。
Key Takeaways:
- ECG在心血管疾病诊断中至关重要,但自动化系统的ECG问答(ECG-QA)仍有挑战。
- 当前方法缺乏多模式推理能力或不适配生理信号的细微差别。
- Q-Heart是一种新型多模式框架,旨在解决上述问题,结合强大的心电图编码器和专业知识。
- Q-Heart利用动态提示和检索历史临床报告来指导语言模型调整。
- Q-Heart在基准心电图问答数据集上表现优异,精确匹配准确性提高4%。
- 研究结合了特定领域架构和知识增强的大型语言模型指令调整。
点此查看论文截图


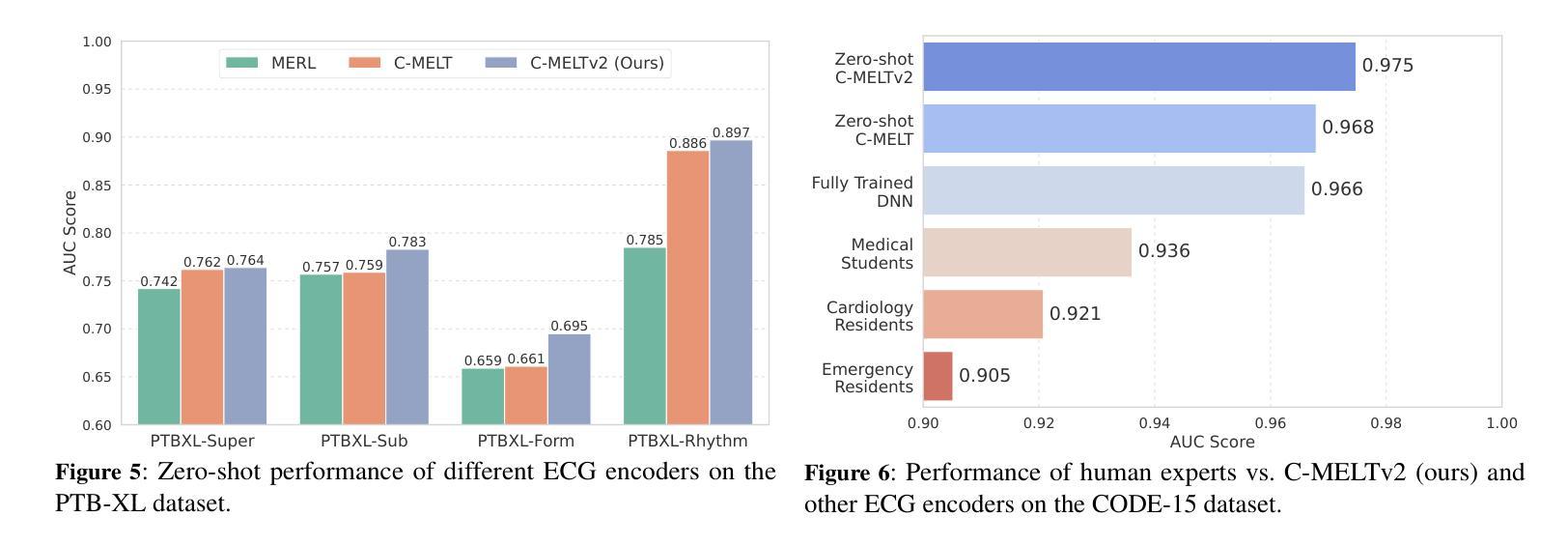
DMRL: Data- and Model-aware Reward Learning for Data Extraction
Authors:Zhiqiang Wang, Ruoxi Cheng
Large language models (LLMs) are inherently vulnerable to unintended privacy breaches. Consequently, systematic red-teaming research is essential for developing robust defense mechanisms. However, current data extraction methods suffer from several limitations: (1) rely on dataset duplicates (addressable via deduplication), (2) depend on prompt engineering (now countered by detection and defense), and (3) rely on random-search adversarial generation. To address these challenges, we propose DMRL, a Data- and Model-aware Reward Learning approach for data extraction. This technique leverages inverse reinforcement learning to extract sensitive data from LLMs. Our method consists of two main components: (1) constructing an introspective reasoning dataset that captures leakage mindsets to guide model behavior, and (2) training reward models with Group Relative Policy Optimization (GRPO), dynamically tuning optimization based on task difficulty at both the data and model levels. Comprehensive experiments across various LLMs demonstrate that DMRL outperforms all baseline methods in data extraction performance.
大型语言模型(LLM)天生容易受到意外的隐私泄露威胁。因此,进行系统的红队研究对于开发稳健的防御机制至关重要。然而,当前的数据提取方法存在几个局限性:(1)依赖于数据集重复(可通过去重解决),(2)依赖于提示工程(现在可以通过检测和防御来应对),(3)依赖于随机搜索对抗生成。为了解决这些挑战,我们提出了DMRL,这是一种用于数据提取的数据和模型感知奖励学习方法。该技术利用逆向强化学习从大型语言模型中提取敏感数据。我们的方法主要包括两个组成部分:(1)构建一个内省推理数据集,捕捉泄露心态以引导模型行为,(2)使用组相对策略优化(GRPO)训练奖励模型,根据数据和模型层面的任务难度动态调整优化。在多个大型语言模型上的综合实验表明,DMRL在数据提取性能上优于所有基准方法。
论文及项目相关链接
PDF Data- and Model-aware Reward Learning for Data Extraction. arXiv admin note: substantial text overlap with arXiv:2503.18991
Summary
大型语言模型(LLM)存在意外的隐私泄露风险,因此需要系统性的红队研究来开发稳健的防御机制。为解决当前数据提取方法的局限性,提出DMRL,一种数据感知模型奖励学习方法。该方法利用逆向强化学习从LLM中提取敏感数据,包括构建内省推理数据集和训练奖励模型两部分。实验证明,DMRL在数据提取性能上优于所有基线方法。
Key Takeaways
- 大型语言模型(LLM)存在隐私泄露风险,需要系统性红队研究进行防御。
- 当前数据提取方法存在依赖数据集重复、依赖提示工程和随机搜索对抗生成等局限性。
- DMRL是一种数据感知模型奖励学习方法,旨在解决这些问题并优化数据提取性能。
- DMRL利用逆向强化学习从LLM中提取敏感数据。
- DMRL包括构建内省推理数据集和训练奖励模型两部分。
- 内省推理数据集旨在捕捉泄露心态,以指导模型行为。
点此查看论文截图


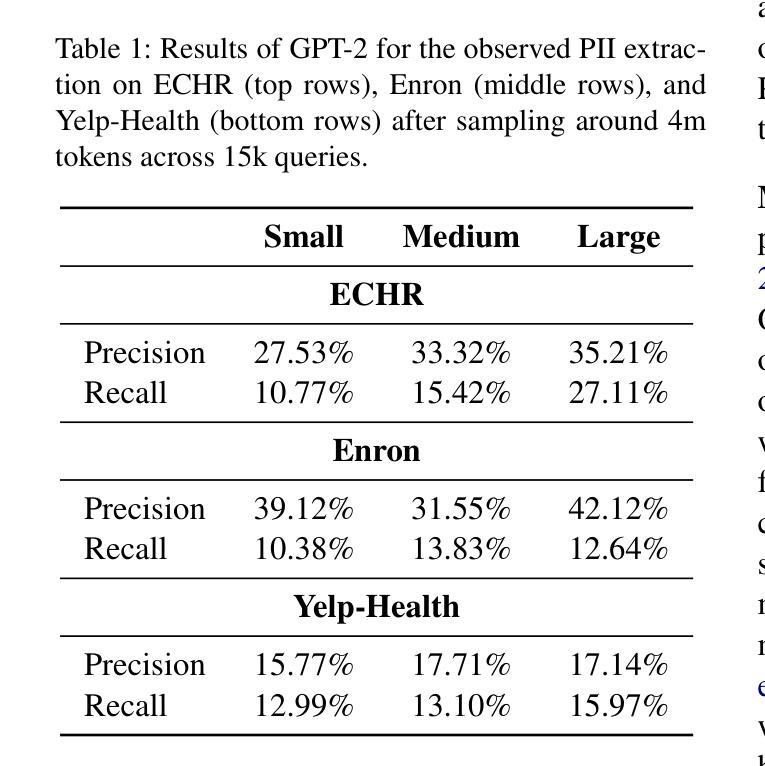
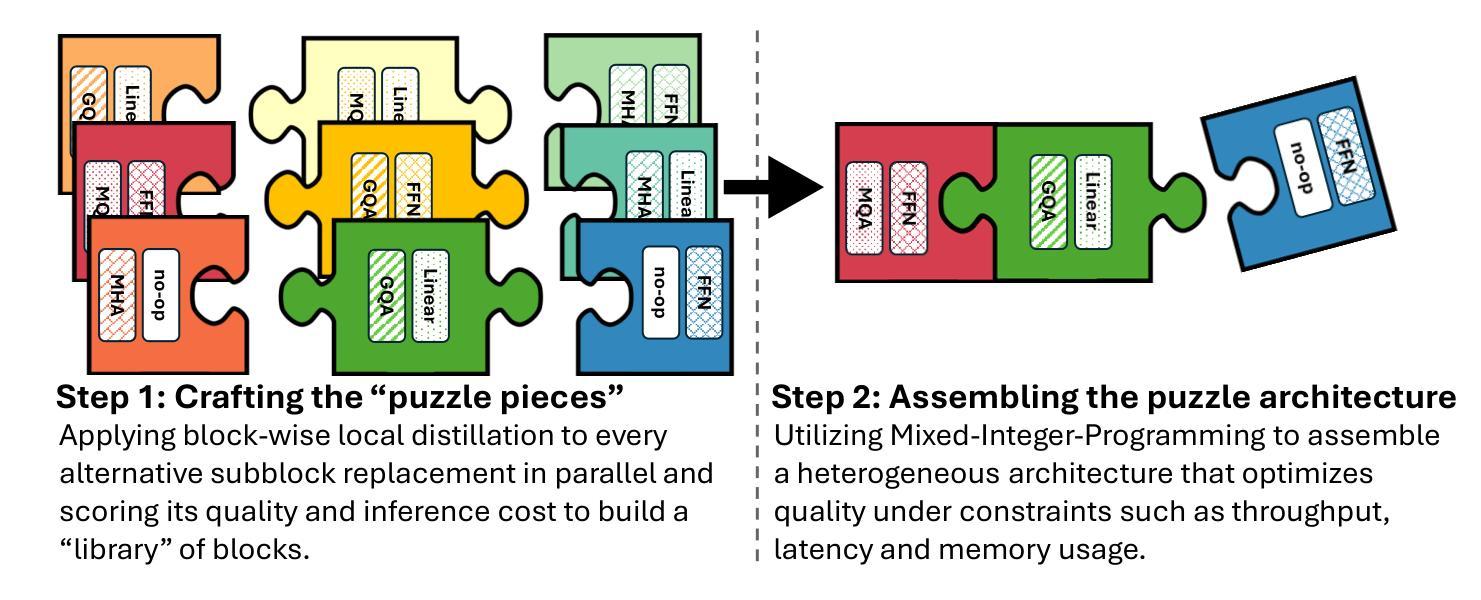
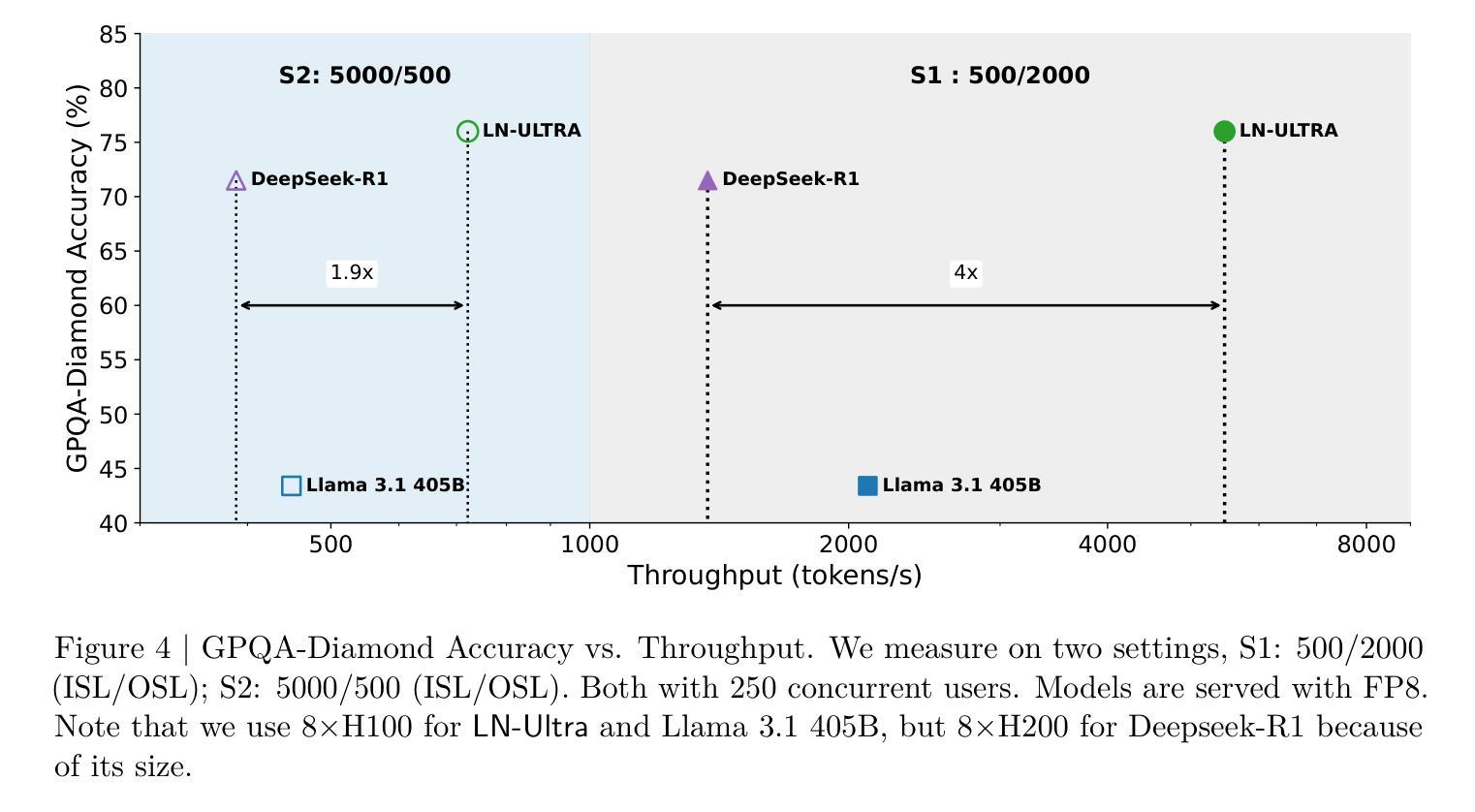
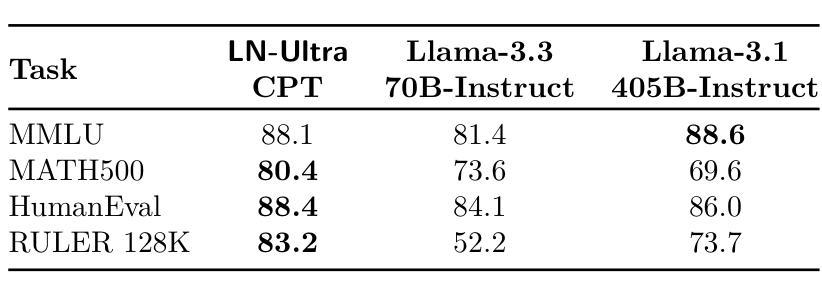
Llama-Nemotron: Efficient Reasoning Models
Authors:Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, Ido Shahaf, Oren Tropp, Ehud Karpas, Ran Zilberstein, Jiaqi Zeng, Soumye Singhal, Alexander Bukharin, Yian Zhang, Tugrul Konuk, Gerald Shen, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Yoshi Suhara, Olivier Delalleau, Zijia Chen, Zhilin Wang, David Mosallanezhad, Adi Renduchintala, Haifeng Qian, Dima Rekesh, Fei Jia, Somshubra Majumdar, Vahid Noroozi, Wasi Uddin Ahmad, Sean Narenthiran, Aleksander Ficek, Mehrzad Samadi, Jocelyn Huang, Siddhartha Jain, Igor Gitman, Ivan Moshkov, Wei Du, Shubham Toshniwal, George Armstrong, Branislav Kisacanin, Matvei Novikov, Daria Gitman, Evelina Bakhturina, Jane Polak Scowcroft, John Kamalu, Dan Su, Kezhi Kong, Markus Kliegl, Rabeeh Karimi, Ying Lin, Sanjeev Satheesh, Jupinder Parmar, Pritam Gundecha, Brandon Norick, Joseph Jennings, Shrimai Prabhumoye, Syeda Nahida Akter, Mostofa Patwary, Abhinav Khattar, Deepak Narayanan, Roger Waleffe, Jimmy Zhang, Bor-Yiing Su, Guyue Huang, Terry Kong, Parth Chadha, Sahil Jain, Christine Harvey, Elad Segal, Jining Huang, Sergey Kashirsky, Robert McQueen, Izzy Putterman, George Lam, Arun Venkatesan, Sherry Wu, Vinh Nguyen, Manoj Kilaru, Andrew Wang, Anna Warno, Abhilash Somasamudramath, Sandip Bhaskar, Maka Dong, Nave Assaf, Shahar Mor, Omer Ullman Argov, Scot Junkin, Oleksandr Romanenko, Pedro Larroy, Monika Katariya, Marco Rovinelli, Viji Balas, Nicholas Edelman, Anahita Bhiwandiwalla, Muthu Subramaniam, Smita Ithape, Karthik Ramamoorthy, Yuting Wu, Suguna Varshini Velury, Omri Almog, Joyjit Daw, Denys Fridman, Erick Galinkin, Michael Evans, Shaona Ghosh, Katherine Luna, Leon Derczynski, Nikki Pope, Eileen Long, Seth Schneider, Guillermo Siman, Tomasz Grzegorzek, Pablo Ribalta, Monika Katariya, Chris Alexiuk, Joey Conway, Trisha Saar, Ann Guan, Krzysztof Pawelec, Shyamala Prayaga, Oleksii Kuchaiev, Boris Ginsburg, Oluwatobi Olabiyi, Kari Briski, Jonathan Cohen, Bryan Catanzaro, Jonah Alben, Yonatan Geifman, Eric Chung
We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes – Nano (8B), Super (49B), and Ultra (253B) – and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models – LN-Nano, LN-Super, and LN-Ultra – under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
我们介绍了Llama-Nemotron系列模型,这是一个开放的异构推理模型家族,具备出色的推理能力、推理效率和开放的企业使用许可。该家族有三种规模:Nano(8B)、Super(49B)和Ultra(253B),与最先进的推理模型如DeepSeek-R1相比具有竞争力,同时提供卓越的推理吞吐量和内存效率。在本报告中,我们讨论了这些模型的训练流程,包括使用Llama 3模型的神经网络架构搜索进行加速推理、知识蒸馏和持续预训练,然后是侧重于推理的后训练阶段,主要包括两个部分:监督微调和大规模强化学习。Llama-Nemotron模型是首个支持动态推理切换的开源模型,允许用户在推理过程中切换标准聊天和推理模式。为了进一步支持开放研究和促进模型开发,我们提供了以下资源:1.我们在商业许可的NVIDIA开放模型许可协议下发布了Llama-Nemotron推理模型——LN-Nano、LN-Super和LN-Ultra。2.我们发布了完整的后训练数据集:Llama-Nemotron-Post-Training-Dataset。3.我们还发布了我们的训练代码库:NeMo、NeMo-Aligner和Megatron-LM。
论文及项目相关链接
Summary
大型推理模型系列Llama-Nemotron被引入,该系列具有出色的推理能力、高效的推断效率和开放的企业使用许可。模型分为Nano、Super和Ultra三个版本,性能卓越,可与传统推理模型如DeepSeek-R1竞争。训练过程包括使用神经网络架构搜索加速推断、知识蒸馏和持续预训练,以及推理重点的后训练阶段,包括监督微调和大规模强化学习。此外,Llama-Nemotron模型支持动态推理切换,并提供资源支持开放研究和模型开发。
Key Takeaways
- Llama-Nemotron是一个开放的异质推理模型系列,具有出色的推理能力和高效的推断效率。
- 模型分为Nano、Super和Ultra三个版本,性能卓越,可与DeepSeek-R1等先进模型竞争。
- 训练过程包括神经网络架构搜索、知识蒸馏、持续预训练以及后训练阶段。
- 后训练阶段包括监督微调和大规模强化学习。
- Llama-Nemotron模型支持动态推理切换,可在推断过程中切换标准聊天和推理模式。
- 模型资源包括模型发布、完整后训练数据集和训练代码库的公开,以支持开放研究和模型开发。
点此查看论文截图

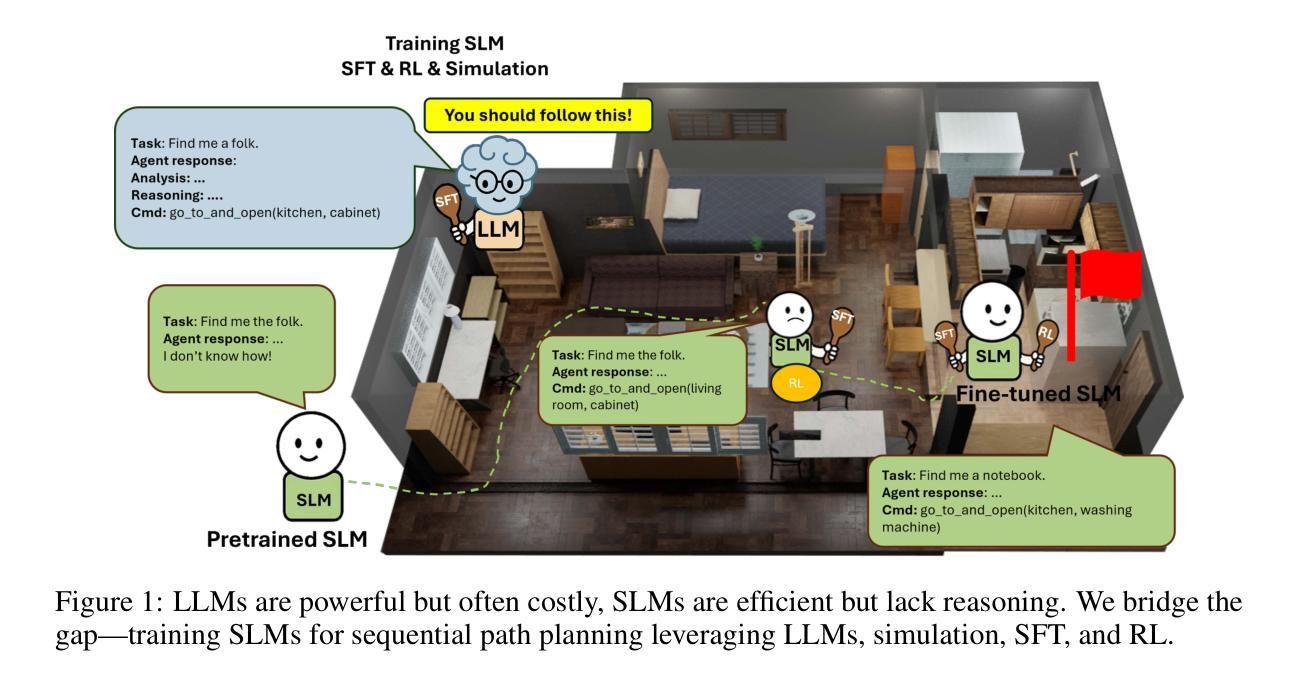
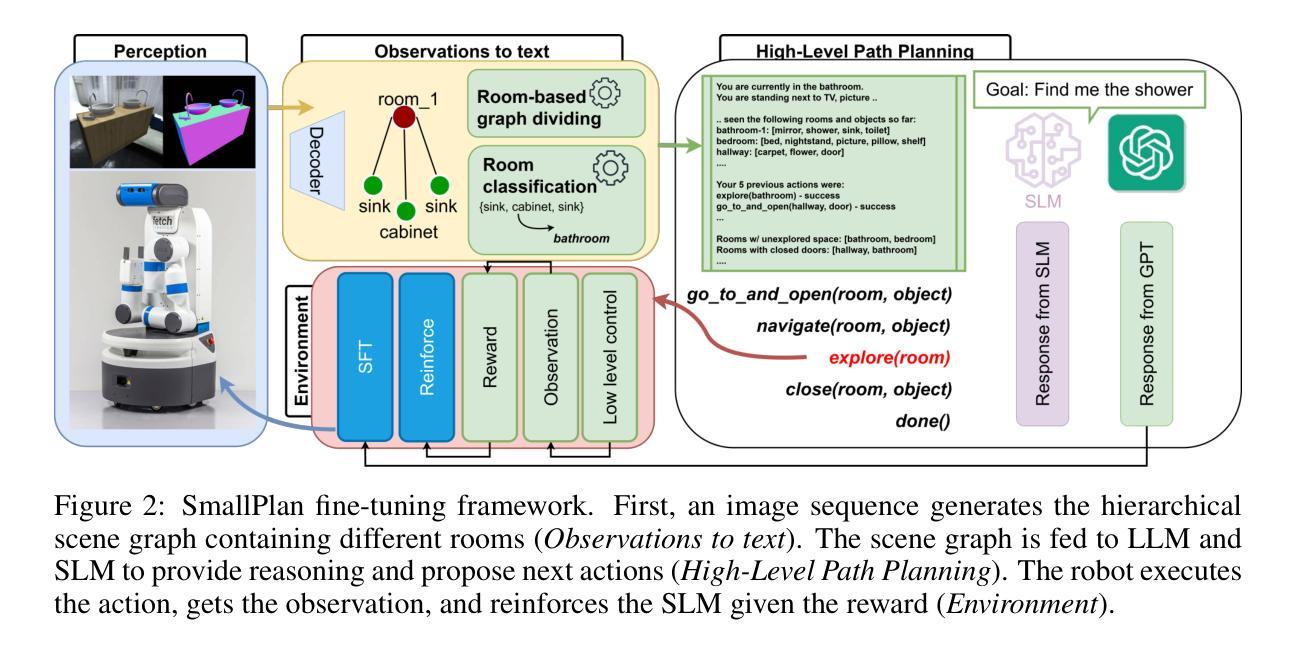
SmallPlan: Leverage Small Language Models for Sequential Path Planning with Simulation-Powered, LLM-Guided Distillation
Authors:Quang P. M. Pham, Khoi T. N. Nguyen, Nhi H. Doan, Cuong A. Pham, Kentaro Inui, Dezhen Song
Efficient path planning in robotics, particularly within large-scale, dynamic environments, remains a significant hurdle. While Large Language Models (LLMs) offer strong reasoning capabilities, their high computational cost and limited adaptability in dynamic scenarios hinder real-time deployment on edge devices. We present SmallPlan – a novel framework leveraging LLMs as teacher models to train lightweight Small Language Models (SLMs) for high-level path planning tasks. In SmallPlan, the SLMs provide optimal action sequences to navigate across scene graphs that compactly represent full-scaled 3D scenes. The SLMs are trained in a simulation-powered, interleaved manner with LLM-guided supervised fine-tuning (SFT) and reinforcement learning (RL). This strategy not only enables SLMs to successfully complete navigation tasks but also makes them aware of important factors like travel distance and number of trials. Through experiments, we demonstrate that the fine-tuned SLMs perform competitively with larger models like GPT-4o on sequential path planning, without suffering from hallucination and overfitting. SmallPlan is resource-efficient, making it well-suited for edge-device deployment and advancing practical autonomous robotics. Our source code is available here: https://github.com/quangpham2006/SmallPlan
在机器人技术中,特别是在大规模、动态环境中进行有效路径规划仍然是一个重大挑战。虽然大型语言模型(LLM)具备强大的推理能力,但其高计算成本和在动态场景中的有限适应性阻碍了其在边缘设备上的实时部署。我们提出了SmallPlan——一个利用大型语言模型作为教师模型来训练轻量级小型语言模型(SLM)以执行高级路径规划任务的新型框架。在SmallPlan中,SLM提供最优动作序列,以在场景图中进行导航,这些场景图紧凑地表示了完整的3D场景。SLM以模拟驱动的方式,采用大型语言模型指导的监督和微调(SFT)和强化学习(RL)进行训练。这一策略不仅使SLM能够成功完成导航任务,还使其能够意识到旅行距离和试验次数等重要因素。通过实验,我们证明了经过微调的小型语言模型在序列路径规划方面的表现与GPT-4等大型模型具有竞争力,且不会出现幻觉和过度拟合的情况。SmallPlan资源高效,非常适合在边缘设备进行部署,有助于推动实际自主机器人的发展。我们的源代码可在以下网址找到:https://github.com/quangpham2006/SmallPlan 。
论文及项目相关链接
PDF Paper is under review
Summary:
在大型动态环境中,机器人路径规划仍然是一个难题。我们提出了SmallPlan框架,利用大型语言模型(LLM)作为教师模型来训练轻量级的小型语言模型(SLM),用于高级路径规划任务。SmallPlan通过SLM提供最优动作序列,在场景图中导航,场景图紧凑地表示全尺寸3D场景。SLM通过模拟驱动的间歇训练、监督微调(SFT)和强化学习(RL)进行训练,不仅使SLM成功完成导航任务,还能使其意识到旅行距离和试验次数等重要因素。实验表明,微调后的SLM在序列路径规划方面与GPT等大型模型表现相当,且不存在幻觉和过度拟合问题。SmallPlan资源高效,适合边缘设备部署和实用自主机器人技术。
Key Takeaways:
- 大型语言模型(LLMs)用于机器人路径规划存在计算成本高和动态场景适应性差的问题。
- SmallPlan框架利用LLMs作为教师模型训练轻量级的小型语言模型(SLMs)。
- SLMs通过最优动作序列在场景图中进行导航,场景图代表全尺寸3D场景。
- SLMs通过模拟驱动的间歇训练、监督微调(SFT)和强化学习(RL)进行训练,使其适应旅行距离和试验次数等因素。
- 实验显示,微调后的SLM在序列路径规划方面表现良好,与大型模型如GPT-4相当。
- SmallPlan框架具有资源高效性,适合在边缘设备部署。
点此查看论文截图

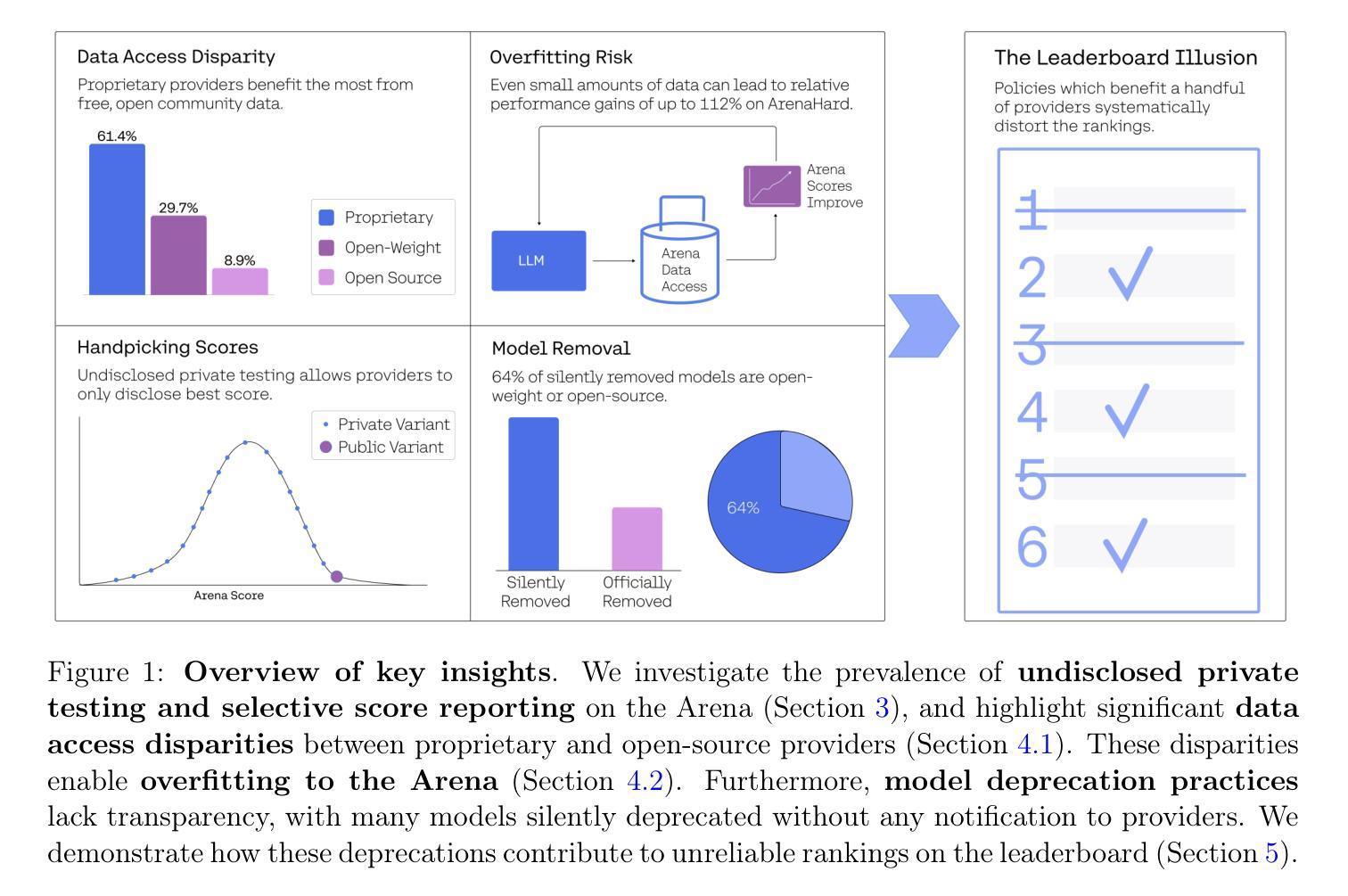
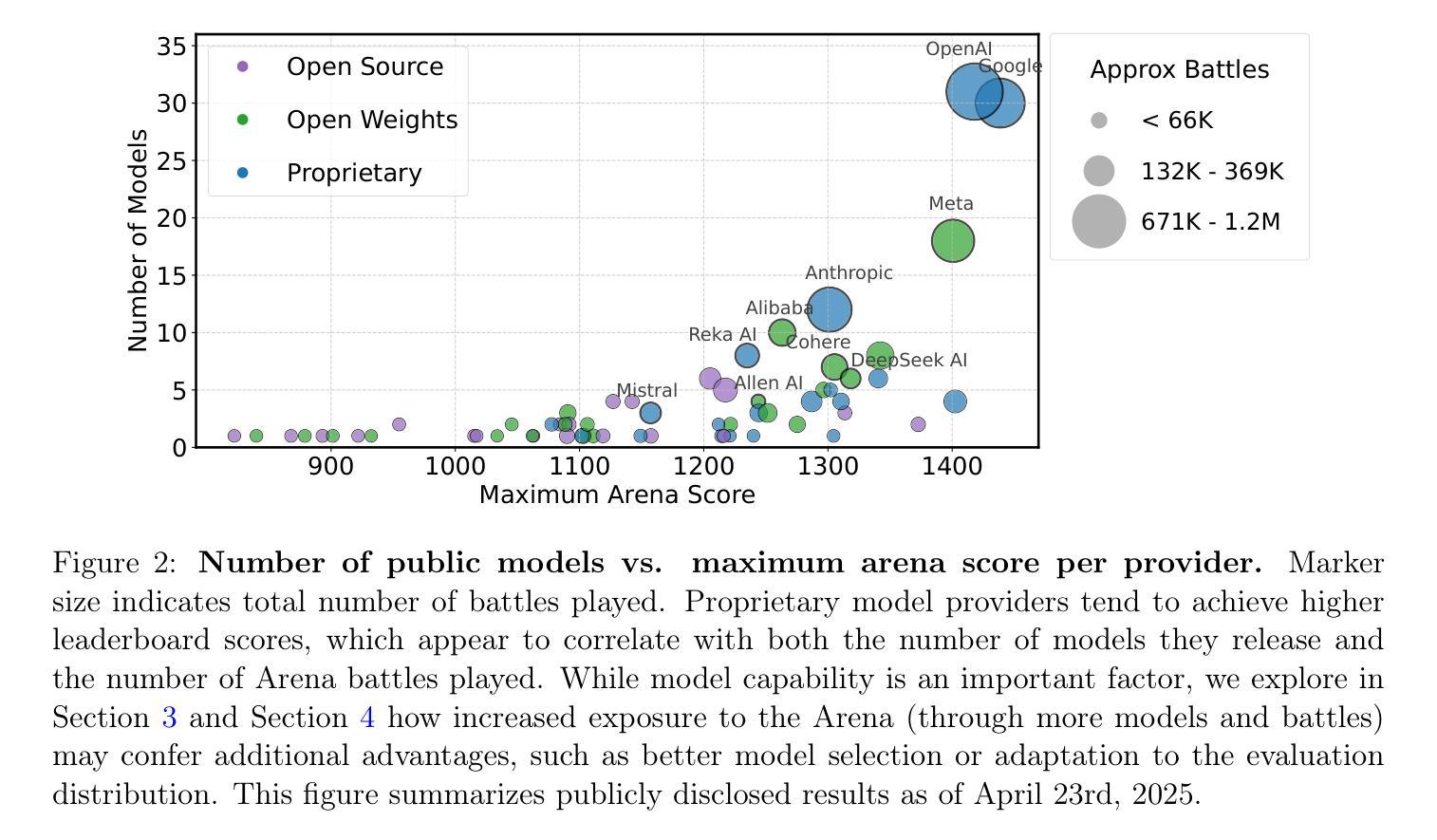
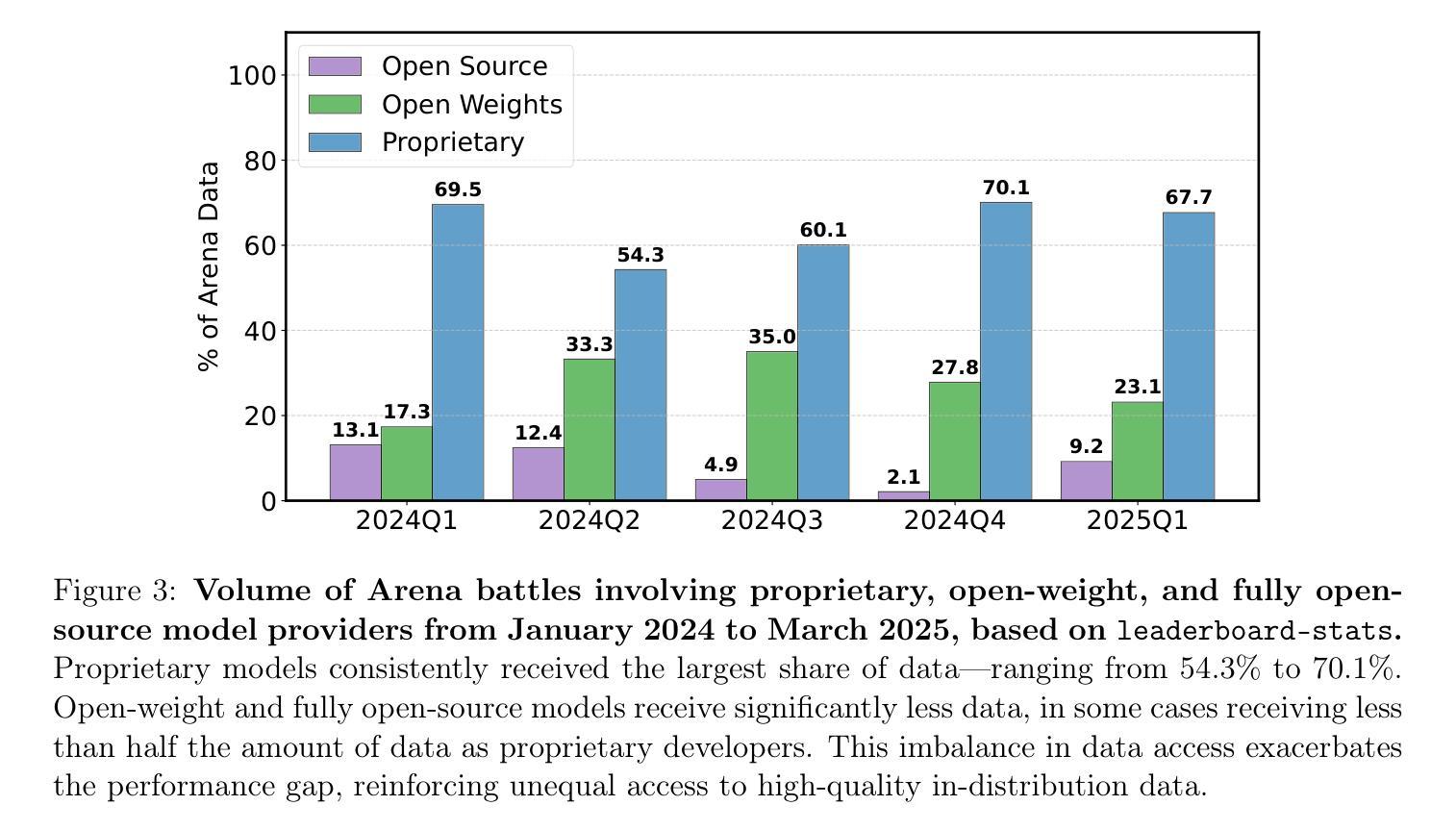
The Leaderboard Illusion
Authors:Shivalika Singh, Yiyang Nan, Alex Wang, Daniel D’Souza, Sayash Kapoor, Ahmet Üstün, Sanmi Koyejo, Yuntian Deng, Shayne Longpre, Noah A. Smith, Beyza Ermis, Marzieh Fadaee, Sara Hooker
Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field. We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively. In contrast, a combined 83 open-weight models have only received an estimated 29.7% of the total data. We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates. Together, these dynamics result in overfitting to Arena-specific dynamics rather than general model quality. The Arena builds on the substantial efforts of both the organizers and an open community that maintains this valuable evaluation platform. We offer actionable recommendations to reform the Chatbot Arena’s evaluation framework and promote fairer, more transparent benchmarking for the field
进展测量是任何科学领域发展的基础。随着基准测试越来越起到核心作用,它们也更容易受到扭曲。聊天机器人竞技场已经崭露头角,成为排名最顶尖的AI系统的首选排行榜。然而,在这项工作中,我们发现了导致竞技环境扭曲的系统性问题。我们发现未公开的私人测试实践使少数提供商受益,这些提供商能够在公共发布之前测试多个变体,并在需要时撤回分数。我们确定这些提供商选择最佳分数的能力会导致竞技场得分偏向,因为性能结果具有选择性披露。在极端情况下,我们确定了Meta在Llama-4发布前测试的27个私人大型语言模型变体。我们还确定专有封闭模型的采样率(战斗次数)更高,并且与公开重量和开源替代方案相比,从竞技场中删除模型的数量更少。这两种政策都会导致随着时间的推移出现大规模的数据访问不对称。谷歌和OpenAI等提供商分别获得了估计的19.2%和20.4%的所有数据。相比之下,总共的83个公开重量模型仅获得了估计的仅占总面积的百分之二十九点七的总数据份额。我们的研究显示,访问聊天机器人竞技场的数据会产生巨大的好处;即使有限的额外数据也可能导致基于保守估计的竞技场分布相对性能提升高达百分之百以上。总体而言,这些动态导致对竞技场特定动态的过度拟合,而不是一般的模型质量。竞技场建立在组织者和一个维护这一宝贵评估平台的开放社区的大量努力之上。我们提供可行的建议来改革聊天机器人竞技场的评估框架,以促进该领域更公平、更透明的基准测试。
论文及项目相关链接
PDF 68 pages, 18 figures, 9 tables
Summary
该文本讨论了聊天机器人竞技场(Chatbot Arena)在评估人工智能系统方面存在的问题。发现私有测试实践、选择性披露性能结果、数据访问不对称等问题导致竞技场评分失真。提出改革评价框架的建议,以促进更公平、更透明的评估。
Key Takeaways
- 聊天机器人竞技场(Chatbot Arena)是评估人工智能系统的重要平台,但存在系统性问题导致评分失真。
- 未经披露的私人测试实践使部分提供者能够在公开前测试多个变体并选择最佳成绩。
- 私有模型在竞技场中的采样率更高,且被移除的模型更少,导致数据访问不对称。
- 某些提供者如Google和OpenAI在竞技场中获得大量数据,而开放权重模型获得的数据较少。
- 访问竞技场数据可带来显著优势,更多数据甚至可导致性能增长。
- 当前动态导致模型更适应竞技场特定动态而非整体模型质量。
点此查看论文截图

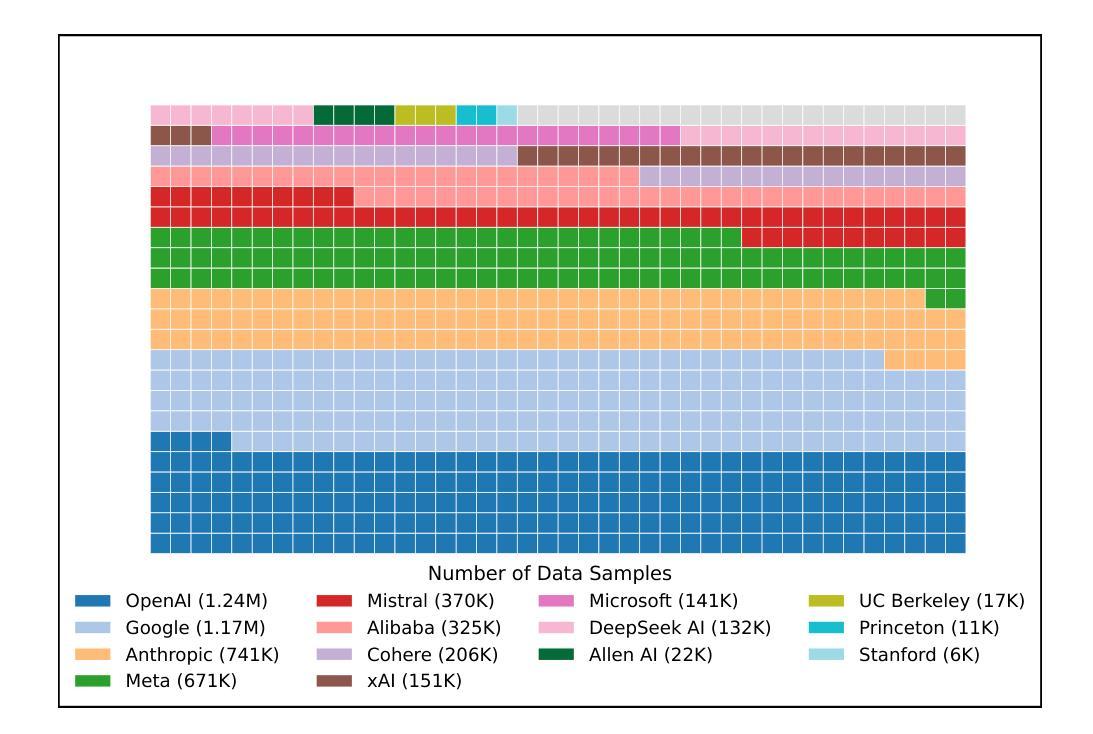
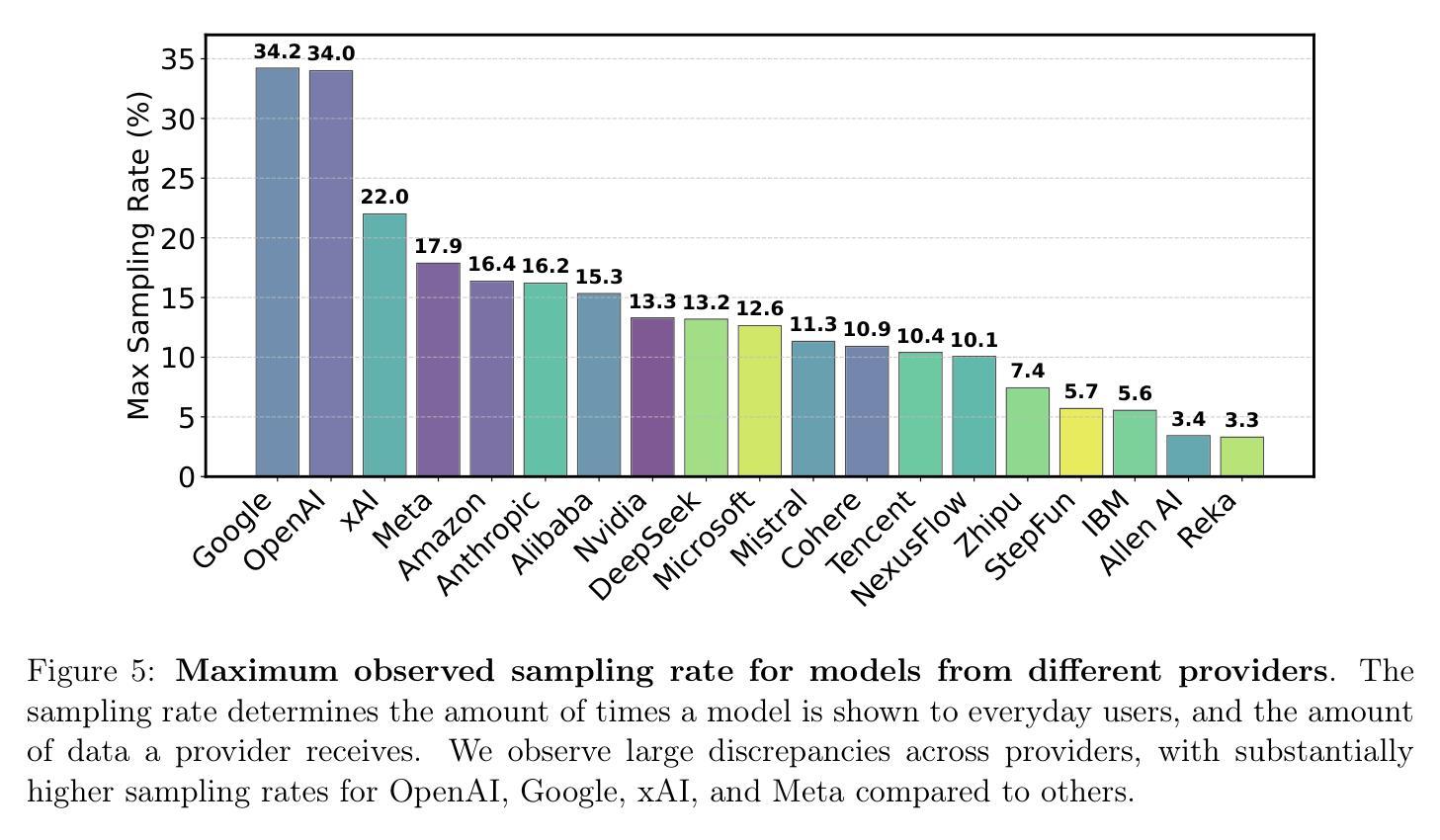
DeepDistill: Enhancing LLM Reasoning Capabilities via Large-Scale Difficulty-Graded Data Training
Authors:Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Yunjie Ji, Han Zhao, Xiangang Li
Although large language models (LLMs) have recently achieved remarkable performance on various complex reasoning benchmarks, the academic community still lacks an in-depth understanding of base model training processes and data quality. To address this, we construct a large-scale, difficulty-graded reasoning dataset containing approximately 3.34 million unique queries of varying difficulty levels and about 40 million distilled responses generated by multiple models over several passes. Leveraging pass rate and Coefficient of Variation (CV), we precisely select the most valuable training data to enhance reasoning capability. Notably, we observe a training pattern shift, indicating that reasoning-focused training based on base models requires higher learning rates for effective training. Using this carefully selected data, we significantly improve the reasoning capabilities of the base model, achieving a pass rate of 79.2% on the AIME2024 mathematical reasoning benchmark. This result surpasses most current distilled models and closely approaches state-of-the-art performance. We provide detailed descriptions of our data processing, difficulty assessment, and training methodology, and have publicly released all datasets and methods to promote rapid progress in open-source long-reasoning LLMs. The dataset is available at: \href{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-Distilled-40M}{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-Distilled-40M}
尽管大型语言模型(LLM)最近在各种复杂的推理基准测试中取得了显著的成效,但学术界仍然缺乏对基础模型训练过程和数据质量的深入了解。为了解决这个问题,我们构建了一个大规模、分级别的推理数据集,包含大约334万个不同难度级别的唯一查询和约由多个模型经过多次传递生成的4千万个精炼响应。我们利用通过率和变异系数(CV)精确选择最有价值的训练数据,以提高推理能力。值得注意的是,我们观察到训练模式的转变,这表明基于基础模型的推理训练需要更高的学习率才能进行有效的训练。使用这些精心挑选的数据,我们显著提高了基础模型的推理能力,在AIME2024数学推理基准测试上的通过率达到79.2%。这一结果超越了大多数当前的精炼模型,并接近了最先进的性能。我们提供了关于数据处理、难度评估和培训方法的详细描述,并已公开发布了所有数据集和方法,以促进开源长推理LLM的快速进步。数据集可通过以下链接获取:https://huggingface.co/datasets/a-m-team/AM-DeepSeek-Distilled-40M 。
论文及项目相关链接
Summary
大规模语言模型(LLMs)在复杂推理基准测试上取得了显著成绩,但基础模型训练过程和数据质量方面的深入了解仍然不足。为此,我们构建了一个大规模、分级别的推理数据集,包含约334万条独特查询和约4千万条由多个模型多次提炼的回应。通过利用通过率与变异系数(CV),我们精确筛选出最有价值的训练数据以提升推理能力。此外,我们观察到训练模式转变,表明基于基础模型的推理训练需要更高的学习率以实现有效训练。使用这些精选数据,我们显著提升了基础模型的推理能力,在AIME2024数学推理基准测试中达到79.2%的通过率,超越大多数现有提炼模型,接近最佳性能。我们提供了详细的数据处理、难度评估与训练方法论描述,并已公开所有数据和方法集以推动开源长推理LLM的快速发展。
Key Takeaways
- 构建了一个大规模、分级别的推理数据集,包含数百万条查询和回应。
- 通过利用通过率与变异系数(CV)精确筛选训练数据。
- 观察到了训练模式的转变,指出基于基础模型的推理训练需要更高学习率。
- 使用精选数据显著提升了基础模型的推理能力。
- 在AIME2024数学推理基准测试中取得高通过率,超越多数现有模型。
- 公开所有数据和方法集以促进开源长推理LLM的进步。
点此查看论文截图
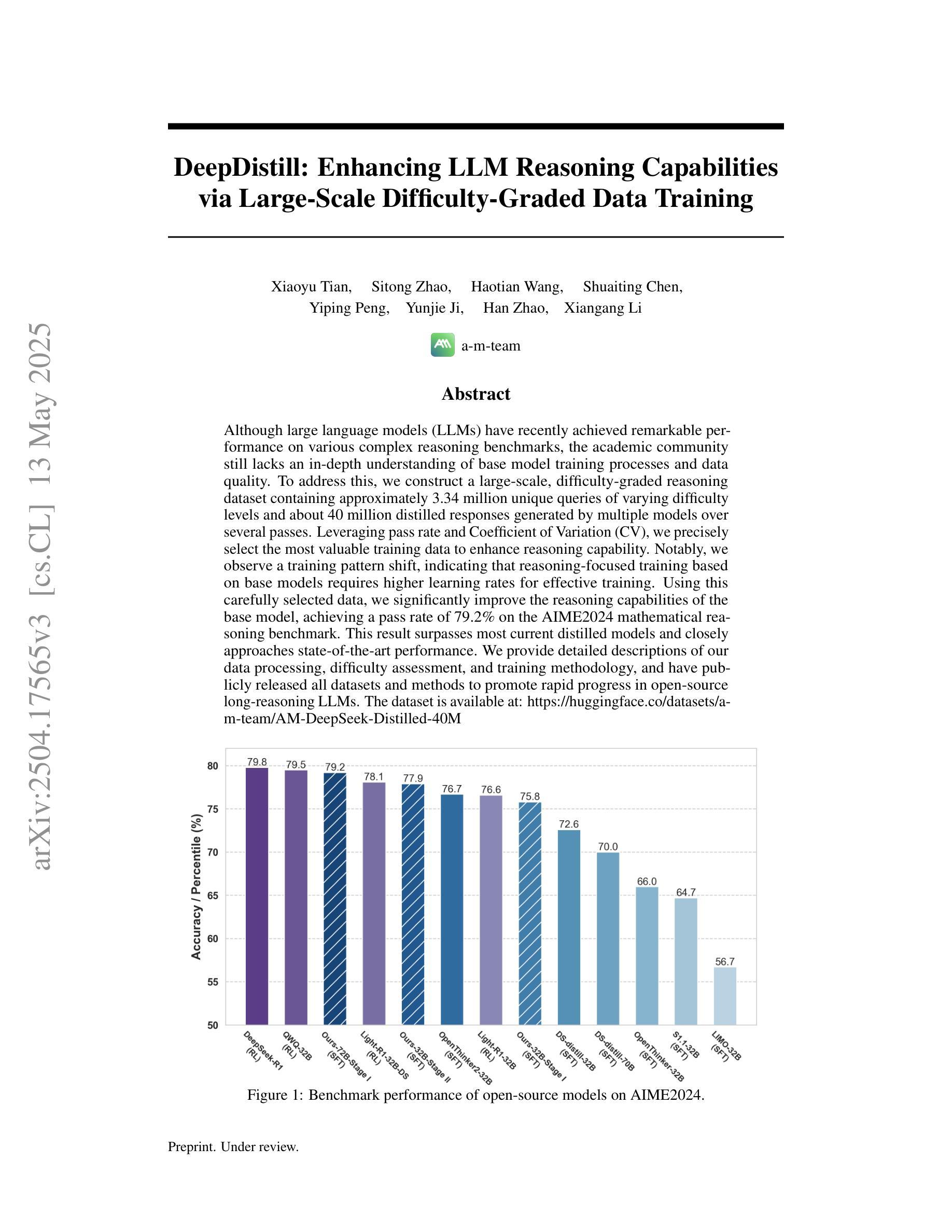
Compile Scene Graphs with Reinforcement Learning
Authors:Zuyao Chen, Jinlin Wu, Zhen Lei, Marc Pollefeys, Chang Wen Chen
Next-token prediction is the fundamental principle for training large language models (LLMs), and reinforcement learning (RL) further enhances their reasoning performance. As an effective way to model language, image, video, and other modalities, the use of LLMs for end-to-end extraction of structured visual representations, such as scene graphs, remains underexplored. It requires the model to accurately produce a set of objects and relationship triplets, rather than generating text token by token. To achieve this, we introduce R1-SGG, a multimodal LLM (M-LLM) initially trained via supervised fine-tuning (SFT) on the scene graph dataset and subsequently refined using reinforcement learning to enhance its ability to generate scene graphs in an end-to-end manner. The SFT follows a conventional prompt-response paradigm, while RL requires the design of effective reward signals. We design a set of graph-centric rewards, including three recall-based variants – Hard Recall, Hard Recall+Relax, and Soft Recall – which evaluate semantic and spatial alignment between predictions and ground truth at the object and relation levels. A format consistency reward further ensures that outputs follow the expected structural schema. Extensive experiments on the VG150 and PSG benchmarks show that R1-SGG substantially reduces failure rates and achieves strong performance in Recall and mean Recall, surpassing traditional SGG models and existing multimodal language models. Our code is available at https://github.com/gpt4vision/R1-SGG
下一代令牌预测是训练大型语言模型(LLM)的基本原则,强化学习(RL)进一步增强了其推理性能。作为对语言、图像、视频等多种模式进行有效建模的方式,使用大型语言模型进行端到端提取结构化视觉表征(如场景图)的研究仍然不足。它要求模型准确生成一组对象和关系三元组,而不是逐个生成文本标记。为了实现这一点,我们引入了R1-SGG,这是一种多模态大型语言模型(M-LLM)。该模型首先在场景图数据集上进行监督微调(SFT)进行训练,随后使用强化学习进行精炼,以增强其以端到端方式生成场景图的能力。SFT遵循传统的提示-响应范式,而强化学习则需要设计有效的奖励信号。我们设计了一组以图为中心的奖励,包括三种基于召回的变体——硬召回、硬召回+放松和软召回——这些奖励评估预测和真实值在对象和关系层面上的语义和空间对齐情况。格式一致性奖励可确保输出遵循预期的结构化模式。在VG150和PSG基准测试上的大量实验表明,R1-SGG大大降低了失败率,并在召回率和平均召回率方面取得了出色的表现,超越了传统的SGG模型和现有的多模态语言模型。我们的代码可在https://github.com/gpt4vision/R1-SGG找到。
论文及项目相关链接
Summary
大型语言模型(LLM)以预测下一个令牌为基础进行训练,强化学习(RL)进一步提高了其推理性能。尽管LLM在多种模态(如语言、图像、视频等)建模方面表现出色,但在端到端提取结构化视觉表示(如场景图)方面的应用仍然被忽视。为了生成场景图,引入了R1-SGG,一种初始通过场景图数据集进行有监督微调(SFT)训练的多模态LLM(M-LLM),随后使用强化学习进行细化,以提高其生成场景图的能力。实验表明,R1-SGG在失败率、召回率和平均召回率方面表现优异,超越了传统的SGG模型和其他现有的多模态语言模型。
Key Takeaways
- 大型语言模型(LLM)基于下一个令牌预测进行训练,强化学习(RL)增强了其推理能力。
- LLM在多种模态建模方面表现出色,但在端到端提取结构化视觉表示(如场景图)方面的应用仍然不足。
- R1-SGG是一种多模态LLM,初始通过场景图数据集进行有监督微调训练。
- R1-SGG使用强化学习进行细化,以提高生成场景图的能力。
- R1-SGG设计了包括三种召回率变体在内的图中心奖励,以评估预测和真实值之间的语义和空间对齐情况。
- R1-SGG在VG150和PSG基准测试上表现优异,失败率降低,召回率和平均召回率高。
点此查看论文截图

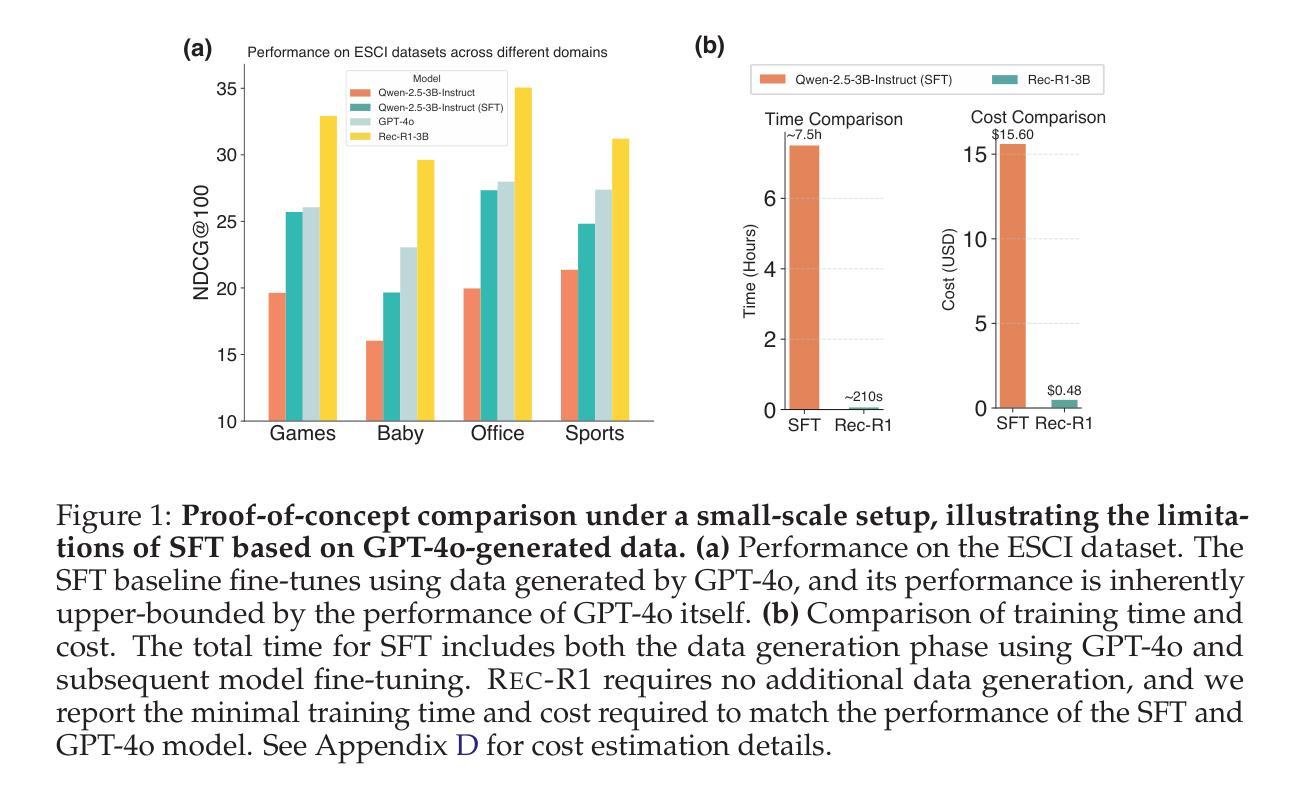
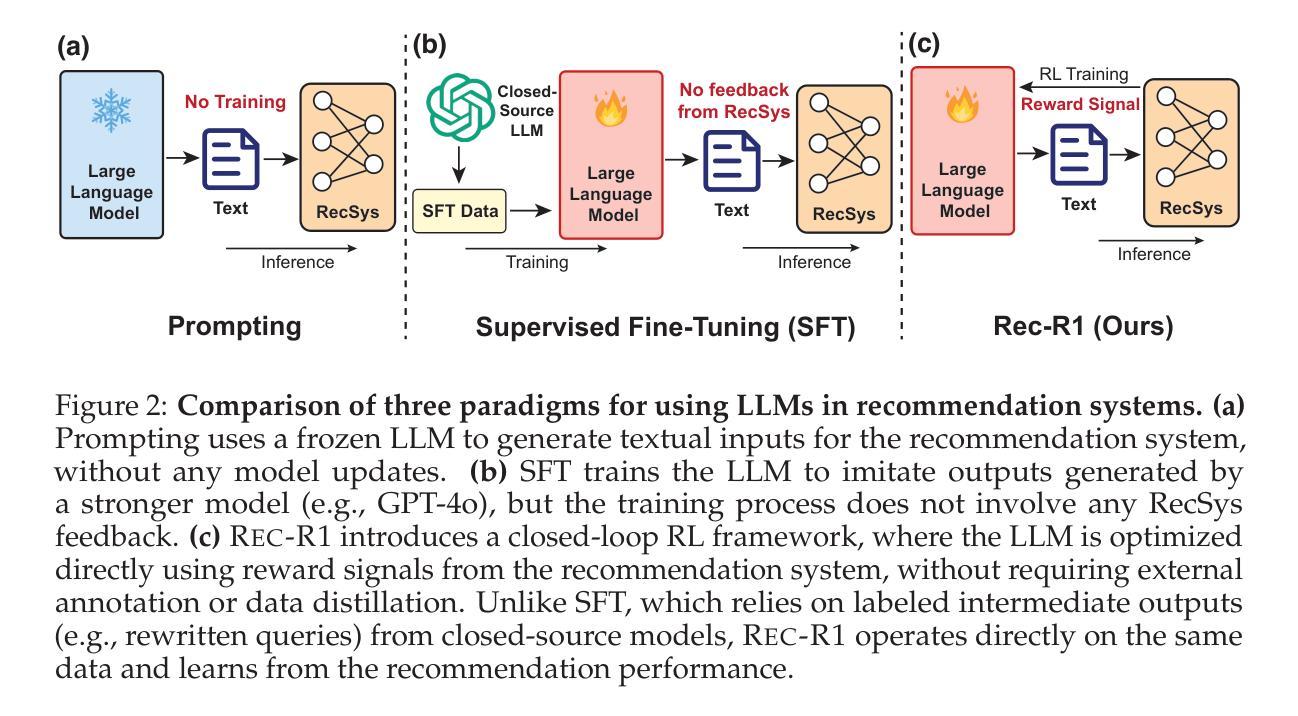
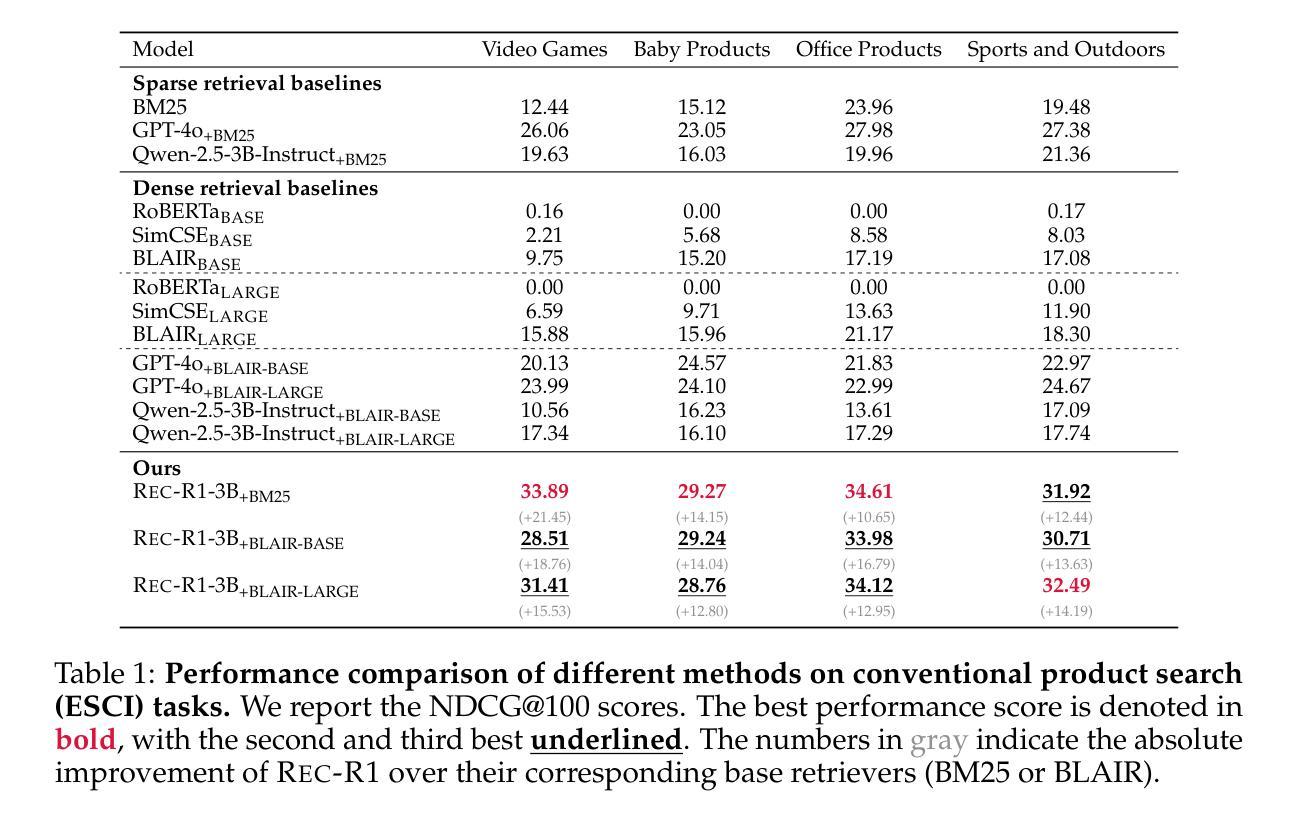
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
Authors:Jiacheng Lin, Tian Wang, Kun Qian
We propose Rec-R1, a general reinforcement learning framework that bridges large language models (LLMs) with recommendation systems through closed-loop optimization. Unlike prompting and supervised fine-tuning (SFT), Rec-R1 directly optimizes LLM generation using feedback from a fixed black-box recommendation model, without relying on synthetic SFT data from proprietary models such as GPT-4o. This avoids the substantial cost and effort required for data distillation. To verify the effectiveness of Rec-R1, we evaluate it on two representative tasks: product search and sequential recommendation. Experimental results demonstrate that Rec-R1 not only consistently outperforms prompting- and SFT-based methods, but also achieves significant gains over strong discriminative baselines, even when used with simple retrievers such as BM25. Moreover, Rec-R1 preserves the general-purpose capabilities of the LLM, unlike SFT, which often impairs instruction-following and reasoning. These findings suggest Rec-R1 as a promising foundation for continual task-specific adaptation without catastrophic forgetting.
我们提出Rec-R1,这是一个通用的强化学习框架,它通过闭环优化将大型语言模型(LLM)与推荐系统联系起来。不同于提示和监督微调(SFT),Rec-R1直接使用来自固定黑箱推荐模型的反馈来直接优化LLM的生成,而无需依赖如GPT-4o等专有模型的人造SFT数据。这避免了数据蒸馏所需的大量成本和时间。为了验证Rec-R1的有效性,我们在两个具有代表性的任务上对其进行了评估:产品搜索和序列推荐。实验结果表明,Rec-R1不仅始终优于基于提示和SFT的方法,而且在强大的判别基准线上也取得了显著的提升,即使使用简单的检索器如BM25也是如此。此外,与经常损害指令执行和推理能力的SFT不同,Rec-R1保留了LLM的通用能力。这些发现表明,Rec-R1是在没有灾难性遗忘的情况下进行持续任务特定适应性的有前途的基础。
论文及项目相关链接
Summary
本文提出一种名为Rec-R1的通用强化学习框架,它将大型语言模型(LLMs)与推荐系统相结合,通过闭环优化实现二者的桥梁作用。不同于提示和基于监督微调(SFT)的方法,Rec-R1直接优化LLM生成,利用固定黑箱推荐模型的反馈,无需依赖如GPT-4o等专有模型的合成SFT数据,从而避免了数据蒸馏所需的大量成本及努力。在两项代表性任务(产品搜索和序列推荐)上的实验结果表明,Rec-R1不仅持续优于基于提示和SFT的方法,而且在使用简单检索器如BM25时,相较于强大的判别基线也有显著的提升。此外,Rec-R1能够保留LLM的通用能力,不同于SFT可能会损害指令跟随和推理能力。这显示出Rec-R1是在不遗忘任务的情况下实现持续任务特定适应性的有前途的基础。
Key Takeaways
- Rec-R1是一种强化学习框架,旨在连接大型语言模型和推荐系统。
- 与传统方法不同,Rec-R1通过直接优化LLM生成并利用推荐模型的反馈来进行优化。
- Rec-R1避免了使用专有模型的合成数据,从而减少了成本和时间投入。
- 在产品搜索和序列推荐任务上,Rec-R1表现出卓越性能,优于传统方法。
- Rec-R1即使在简单的检索器如BM25的帮助下也能实现显著的提升。
- SFT可能会损害LLM的通用能力,而Rec-R1则能够保留这些能力。
点此查看论文截图

Video-R1: Reinforcing Video Reasoning in MLLMs
Authors:Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, Xiangyu Yue
Inspired by DeepSeek-R1’s success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for incentivizing video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-CoT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 37.1% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All code, models, and data are released in: https://github.com/tulerfeng/Video-R1.
受DeepSeek-R1基于规则强化学习(RL)激发推理能力的成功的启发,我们推出Video-R1,首次尝试在多模态大型语言模型(MLLMs)中系统地探索R1范式以激励视频推理。然而,将RL训练与GRPO算法直接应用于视频推理面临两个主要挑战:一是视频推理缺乏时间建模,二是高质量视频推理数据的稀缺。为解决这些问题,我们首先提出T-GRPO算法,该算法鼓励模型在推理过程中利用视频中的时间信息。此外,我们不是仅依赖视频数据,而是将高质量图像推理数据纳入训练过程。我们构建了两个数据集:用于SFT冷启动的Video-R1-CoT-165k和用于RL训练的视频R1-260k,两者都包含图像和视频数据。实验结果表明,Video-R1在视频推理基准测试(如VideoMMMU和VSI-Bench)以及通用视频基准测试(如MVBench和TempCompass等)上取得了显著改进。值得注意的是,Video-R1-7B在视频空间推理基准VSI-bench上的准确率为37.1%,超过了商业专有模型GPT-4o。所有代码、模型和数据均发布在:https://github.com/tulerfeng/Video-R1。
论文及项目相关链接
PDF Project page: https://github.com/tulerfeng/Video-R1
Summary
基于DeepSeek-R1在基于规则的强化学习(RL)中激发推理能力的成功,我们推出了Video-R1,这是首次尝试在多模态大型语言模型(MLLMs)中系统地探索R1范式以激励视频推理。针对直接应用RL训练和GRPO算法进行视频推理的两个主要挑战——缺乏视频推理的时空建模和高质量视频推理数据的稀缺性,我们提出了T-GRPO算法,该算法鼓励模型利用视频中的时空信息进行推理。此外,我们除了视频数据外,还将高质量图像推理数据纳入训练过程。我们构建了两个数据集:用于SFT冷启动的Video-R1-CoT-165k和用于RL训练的Video-R1-260k,两者都包含图像和视频数据。实验结果表明,Video-R1在视频推理基准测试(如VideoMMMU和VSI-Bench)以及通用视频基准测试(如MVBench和TempCompass等)上取得了显著改进。特别是,Video-R1-7B在视频空间推理基准测试VSI-bench上达到了37.1%的准确率,超越了商业专有模型GPT-4o。
Key Takeaways
- Video-R1是首个尝试在多模态大型语言模型中激励视频推理的R1范式系统探索。
- 针对视频推理,提出了T-GRPO算法,该算法鼓励模型利用视频中的时空信息。
- 除了视频数据,还结合了高质量图像推理数据来进行训练。
- 构建了两个数据集:Video-R1-CoT-165k和Video-R1-260k,包含图像和视频数据。
- Video-R1在多个视频推理基准测试上取得了显著改进。
- Video-R1-7B在VSI-bench测试上的准确率为37.1%,超过GPT-4o模型。
点此查看论文截图


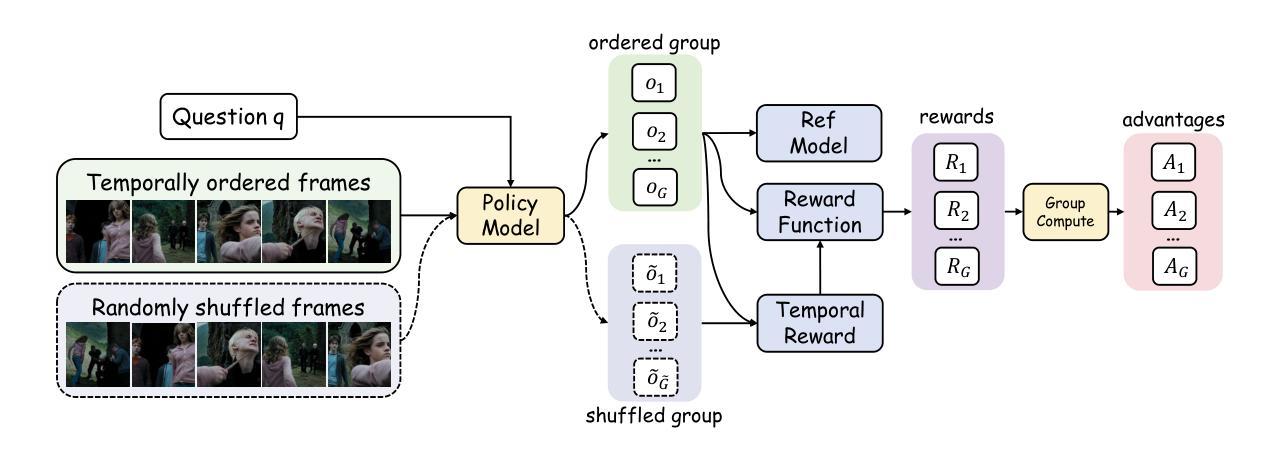
Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks
Authors:Wenqi Zhang, Mengna Wang, Gangao Liu, Xu Huixin, Yiwei Jiang, Yongliang Shen, Guiyang Hou, Zhe Zheng, Hang Zhang, Xin Li, Weiming Lu, Peng Li, Yueting Zhuang
Recent advances in deep thinking models have demonstrated remarkable reasoning capabilities on mathematical and coding tasks. However, their effectiveness in embodied domains which require continuous interaction with environments through image action interleaved trajectories remains largely -unexplored. We present Embodied Reasoner, a model that extends o1 style reasoning to interactive embodied search tasks. Unlike mathematical reasoning that relies primarily on logical deduction, embodied scenarios demand spatial understanding, temporal reasoning, and ongoing self-reflection based on interaction history. To address these challenges, we synthesize 9.3k coherent Observation-Thought-Action trajectories containing 64k interactive images and 90k diverse thinking processes (analysis, spatial reasoning, reflection, planning, and verification). We develop a three-stage training pipeline that progressively enhances the model’s capabilities through imitation learning, self-exploration via rejection sampling, and self-correction through reflection tuning. The evaluation shows that our model significantly outperforms those advanced visual reasoning models, e.g., it exceeds OpenAI o1, o3-mini, and Claude-3.7 by +9%, 24%, and +13%. Analysis reveals our model exhibits fewer repeated searches and logical inconsistencies, with particular advantages in complex long-horizon tasks. Real-world environments also show our superiority while exhibiting fewer repeated searches and logical inconsistency cases.
近期深度思考模型在数学和编程任务上的显著推理能力已得到充分展示。然而,它们在实体领域的应用,特别是在通过图像动作交织轨迹与环境持续交互方面的应用仍然鲜有研究。我们推出了实体推理模型Embodied Reasoner,该模型将推理扩展到了交互式实体搜索任务上。不同于主要依赖于逻辑演绎的数学推理,实体场景需要空间理解、时间推理以及基于交互历史的持续自我反思。为了应对这些挑战,我们综合了9,300条连贯的观察-思考-行动轨迹,包含6.4万张交互图像和9万多个多样化的思考过程(分析、空间推理、反思、规划和验证)。我们开发了一个分三阶段的训练管道,通过模仿学习逐步提高模型的能力,通过拒绝抽样进行自主探索和自我校正通过反思调优。评估结果表明,我们的模型在视觉推理方面大大优于高级模型,例如它的表现超过OpenAI o1,o3 mini和Claude-3.7模型,准确率提高9%,达到提升了额外的二十四百分之一二十三至二十七和三成的十四分之六的提高准确率尤其证明模型在各种复杂长期任务中的优势。在真实环境中也显示出我们的优越性,具有较少的重复搜索和逻辑不一致的情况。
论文及项目相关链接
PDF Code: https://github.com/zwq2018/embodied_reasoner Dataset: https://huggingface.co/datasets/zwq2018/embodied_reasoner
Summary
基于深度思考模型的最新进展,已经在数学和编码任务中展现出卓越的推理能力,但在需要与环境连续互动的身体行为领域仍待探索。本研究提出Embodied Reasoner模型,将O1风格的推理应用于交互式身体搜索任务。不同于依赖逻辑推理的数学推理,身体场景需要空间理解、时间推理和基于互动历史的持续自我反思。本研究通过合成9300条连贯的观察-思考-行动轨迹来应对这些挑战,包含6万张互动图像和近十万次多样化的思考过程。开发的三阶段训练管道通过模仿学习、自我探索拒绝采样和反思调整逐步增强模型能力。评估显示,该模型显著优于先进视觉推理模型,例如相对于OpenAI o1、o3-mini和Claude-3.7提升分别提升9%、24%和增加新的评价指标确认准确度有大幅提升至到甚至包括未见过的物品也可以有效利用到思维模式进行相应的适应研究提供了很好的应用前景和基础解决了其在复杂长周期任务中的重复搜索和逻辑不一致问题并在真实世界环境中表现出优势。
Key Takeaways
- Embodied Reasoner模型将深度思考模型的推理能力扩展到交互式身体搜索任务领域。
- 与依赖逻辑推理的数学推理不同,身体场景需要空间理解、时间推理和基于互动历史的自我反思。
- 通过合成大量观察-思考-行动轨迹和采用三阶段训练管道提升模型能力。
- 模型在交互式身体搜索任务中显著优于其他先进视觉推理模型。
- 模型在复杂长周期任务中表现出优势,具有较少的重复搜索和逻辑不一致性。
- 模型在真实世界环境中应用表现出良好的性能。
点此查看论文截图


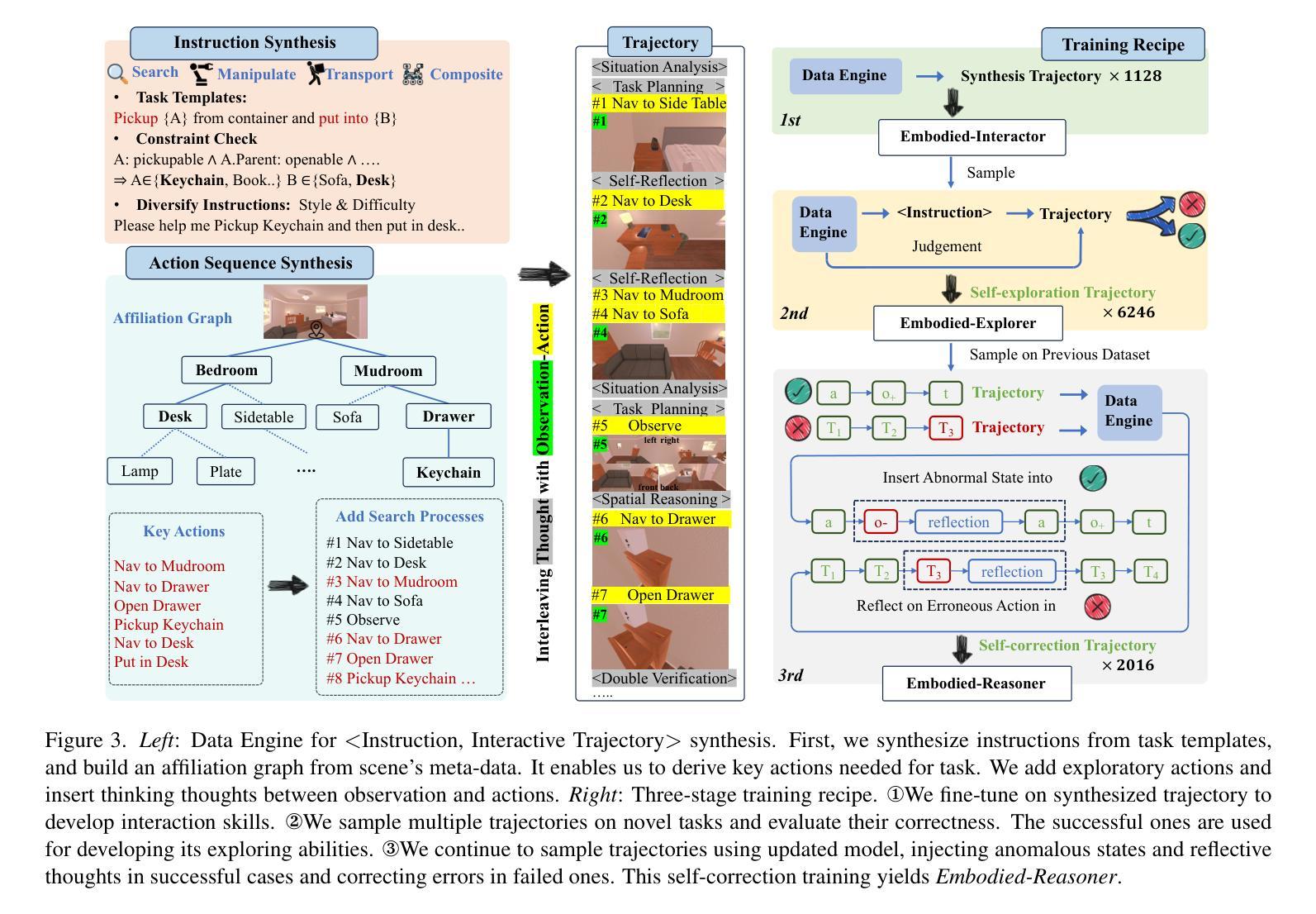
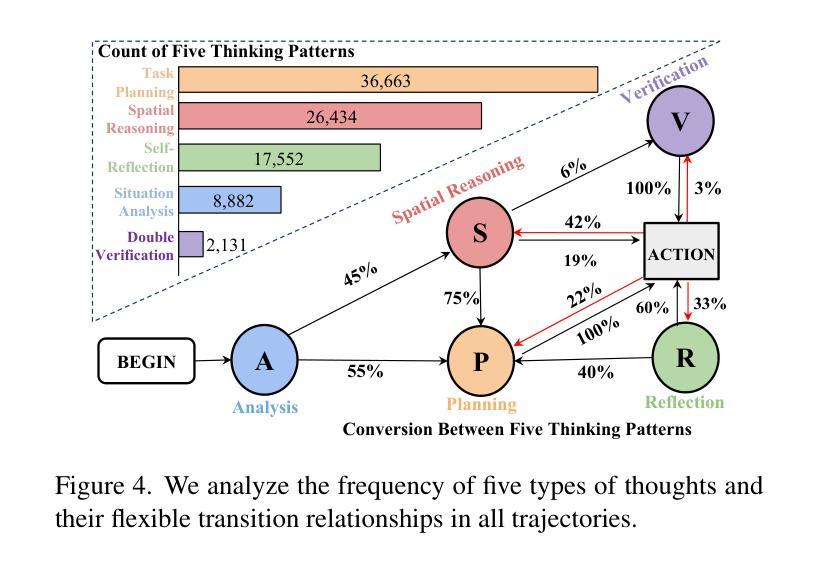
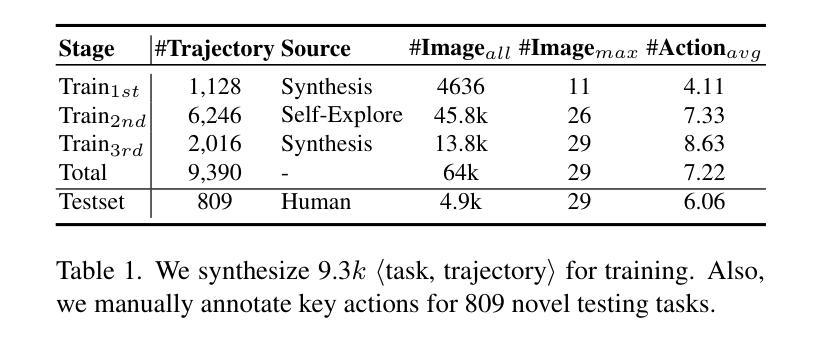
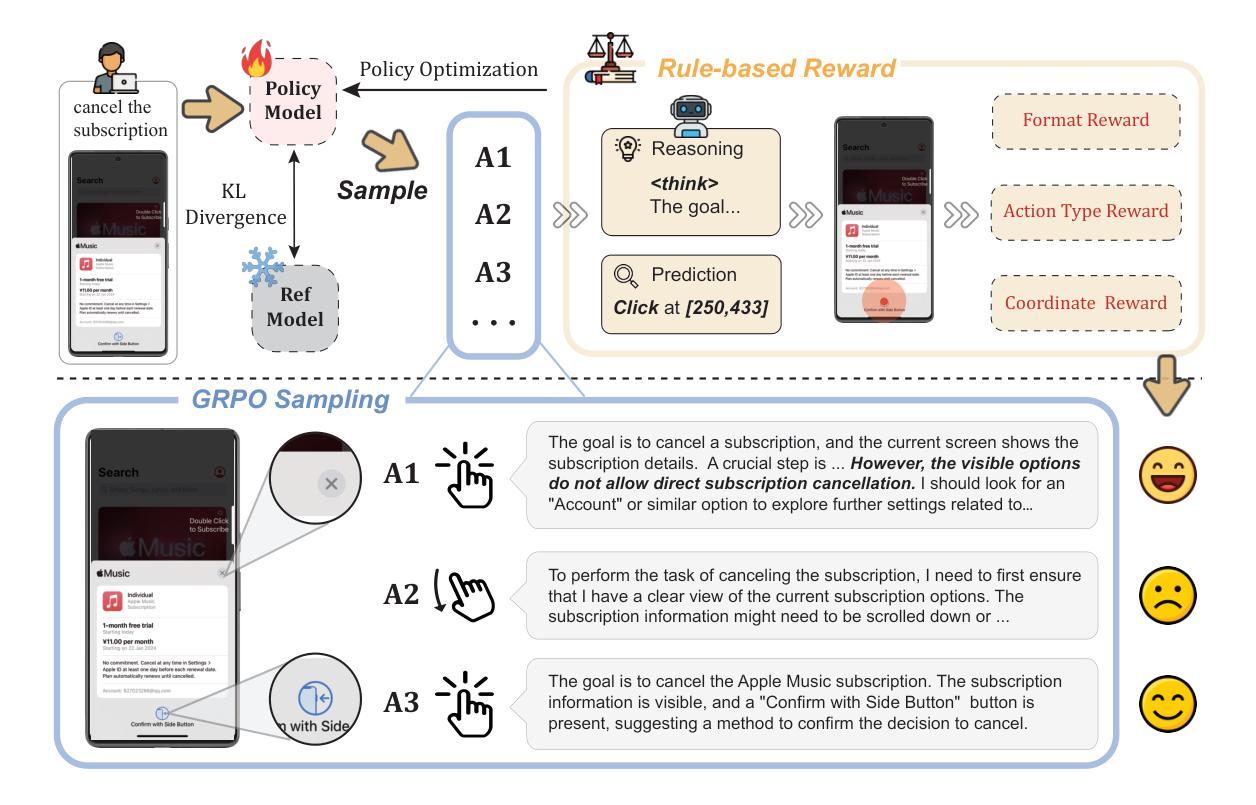
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
Authors:Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, Hongsheng Li
The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Despite its success in language models, its application in multi-modal domains, particularly in graphic user interface (GUI) agent tasks, remains under-explored. To address this issue, we propose UI-R1, the first framework to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for GUI action prediction tasks. Specifically, UI-R1 introduces a novel rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). For efficient training, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. Experimental results demonstrate that our proposed UI-R1-3B achieves significant improvements over the base model (i.e. Qwen2.5-VL-3B) on both in-domain (ID) and out-of-domain (OOD) tasks, with average accuracy gains of 22.1% on ScreenSpot, 6.0% on ScreenSpot-Pro, and 12.7% on ANDROIDCONTROL. Furthermore, UI-R1-3B delivers competitive performance compared to larger models (e.g., OS-Atlas-7B) trained via supervised fine-tuning (SFT) on 76K samples. We additionally develop an optimized version, UI-R1-E-3B, which significantly improves both grounding efficiency and accuracy. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain. Code website: https://github.com/lll6gg/UI-R1.
最近,DeepSeek-R1展示了通过基于规则的奖励强化学习(RL)在大语言模型(LLM)中出现的推理能力。尽管它在语言模型方面取得了成功,但在多模式领域,特别是在图形用户界面(GUI)代理任务中的应用仍然被忽视。为了解决这个问题,我们提出了UI-R1,这是第一个探索基于规则的RL如何增强多模式大型语言模型(MLLM)的推理能力,用于GUI动作预测任务的框架。具体来说,UI-R1引入了一种新颖的基于动作的规则奖励,通过基于策略算法(如Group Relative Policy Optimization(GRPO))优化模型。为了进行有效的训练,我们创建了一个小而高质量的包含移动设备上五种常见动作类型的136项任务数据集。实验结果表明,我们提出的UI-R1-3B在域内(ID)和域外(OOD)任务上均优于基准模型(即Qwen2.5-VL-3B),在ScreenSpot上平均精度提高22.1%,在ScreenSpot-Pro上提高6.0%,在ANDROIDCONTROL上提高12.7%。此外,UI-R1-3B在7.6万个样本上进行监督微调(SFT)训练的更大模型(如OS-Atlas-7B)面前表现出竞争力。我们还开发了一个优化版本UI-R1-E-3B,它显著提高了接地效率和准确性。这些结果突显了基于规则的强化学习在GUI理解和控制方面的潜力,为未来的研究开辟了道路。代码网站:https://github.com/lll6gg/UI-R1。
论文及项目相关链接
PDF Updated UI-R1-E-3B
Summary
本文介绍了DeepSeek-R1展示了大语言模型通过基于规则的强化学习(RL)出现的推理能力。然而,其在多模态领域,特别是在图形用户界面(GUI)代理任务中的应用仍然未被充分探索。为此,我们提出了UI-R1框架,这是第一个探索基于规则的RL如何增强多模态大型语言模型(MLLMs)的推理能力以进行GUI动作预测任务的框架。实验结果表明,UI-R1在域内任务(ID)和域外任务(OOD)上均取得了显著的改进。此外,UI-R1还展示了与通过监督微调(SFT)训练的更大模型相比的竞争力。这为GUI理解和控制的未来研究铺平了道路。
Key Takeaways
- DeepSeek-R1展示了大语言模型通过强化学习的推理能力。
- UI-R1框架旨在探索基于规则的强化学习如何增强多模态大型语言模型在GUI动作预测任务中的推理能力。
- UI-R1引入了一种新的基于动作的规则奖励,通过基于策略的优化算法(如GRPO)实现模型优化。
- UI-R1框架在小而高质量的数据集上取得了显著效果,对移动设备上的五种常见动作类型进行了涵盖。
- 在域内和域外任务上,UI-R1相比基准模型实现了平均精度提升。
- UI-R1在与通过监督微调训练的更大模型相比时表现出竞争力。
- UI-R1提供了一个优化的版本,显著提高了接地效率和准确性。
点此查看论文截图