⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-17 更新
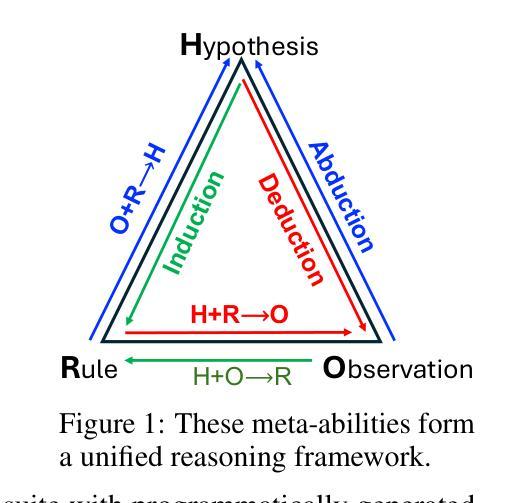
Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
Authors:Zhiyuan Hu, Yibo Wang, Hanze Dong, Yuhui Xu, Amrita Saha, Caiming Xiong, Bryan Hooi, Junnan Li
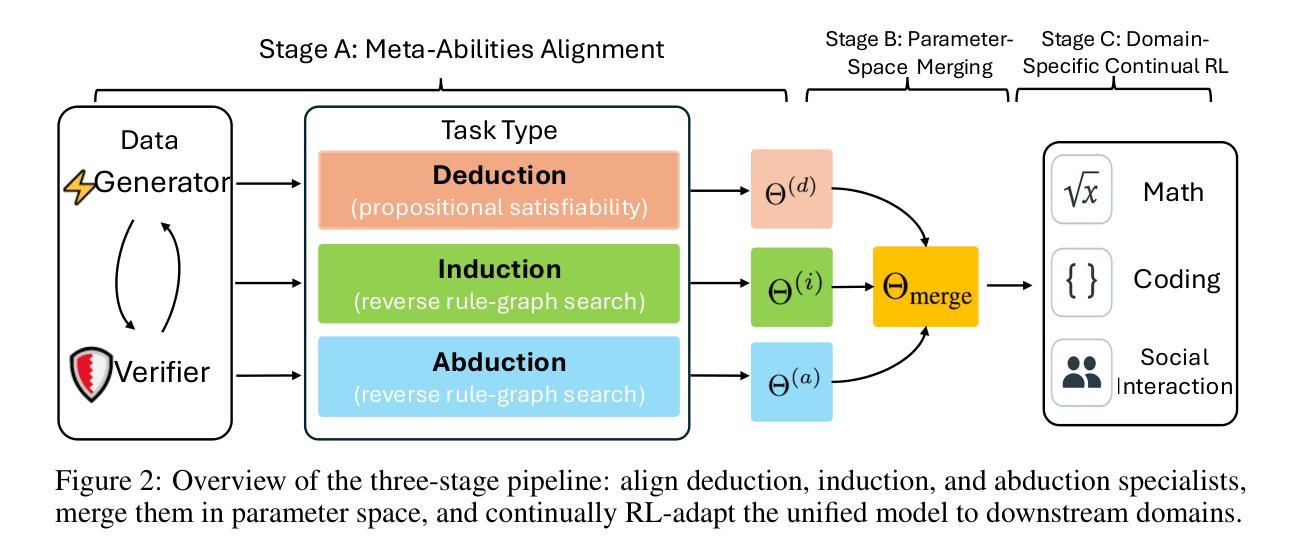
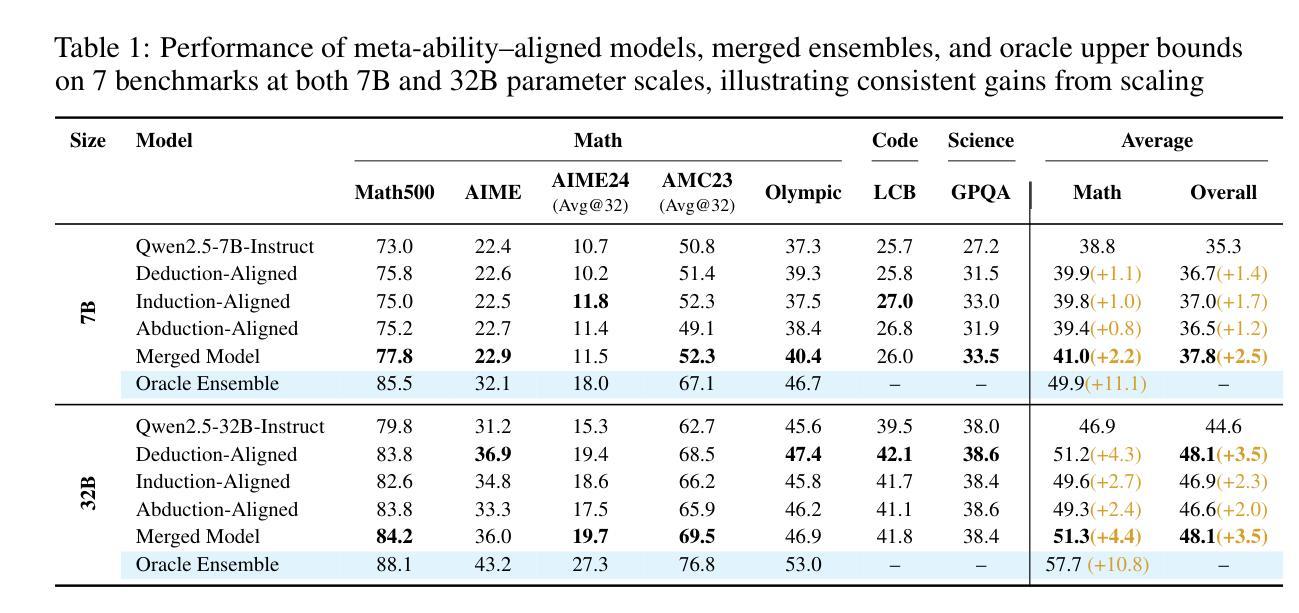
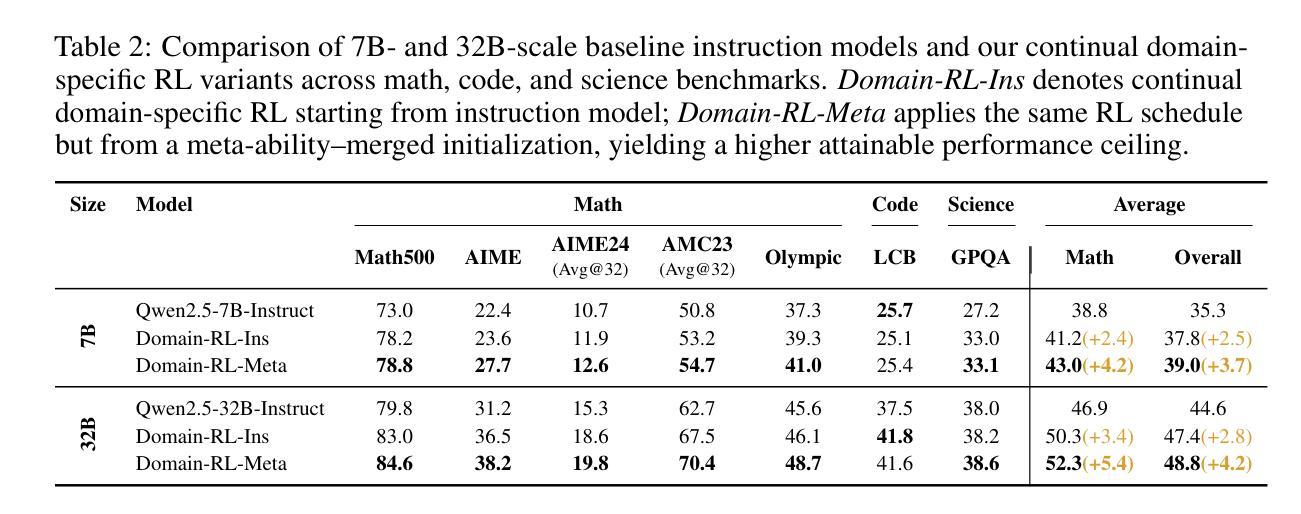
Large reasoning models (LRMs) already possess a latent capacity for long chain-of-thought reasoning. Prior work has shown that outcome-based reinforcement learning (RL) can incidentally elicit advanced reasoning behaviors such as self-correction, backtracking, and verification phenomena often referred to as the model’s “aha moment”. However, the timing and consistency of these emergent behaviors remain unpredictable and uncontrollable, limiting the scalability and reliability of LRMs’ reasoning capabilities. To address these limitations, we move beyond reliance on prompts and coincidental “aha moments”. Instead, we explicitly align models with three meta-abilities: deduction, induction, and abduction, using automatically generated, self-verifiable tasks. Our three stage-pipeline individual alignment, parameter-space merging, and domain-specific reinforcement learning, boosting performance by over 10% relative to instruction-tuned baselines. Furthermore, domain-specific RL from the aligned checkpoint yields an additional 2% average gain in the performance ceiling across math, coding, and science benchmarks, demonstrating that explicit meta-ability alignment offers a scalable and dependable foundation for reasoning. Code is available at: https://github.com/zhiyuanhubj/Meta-Ability-Alignment
大型推理模型(LRMs)已经具备了潜在的长链思维推理能力。之前的研究表明,基于结果的强化学习(RL)可以偶然激发高级推理行为,如自我修正、回溯和验证现象,这些常被看作是模型的“顿悟时刻”。然而,这些突发行为的时机和一致性仍然不可预测和不可控制,限制了LRMs推理能力的可扩展性和可靠性。为了解决这个问题,我们不再依赖提示和偶然的“顿悟时刻”。相反,我们通过使用自动生成的、可自我验证的任务,明确地将模型与三种元能力(演绎、归纳和溯因)对齐。我们的三阶段管道包括个人对齐、参数空间合并和领域特定强化学习,相对于指令调整基准线,性能提升了超过10%。此外,从对齐检查点进行的领域特定RL提高了数学、编码和科学基准测试的性能上限,平均额外增益为2%,这表明明确的元能力对齐为推理提供了可扩展和可靠的基石。代码可用在:https://github.com/zhiyuanhubj/Meta-Ability-Alignment
论文及项目相关链接
PDF In Progress
Summary:大型推理模型(LRMs)具有潜在的长期思维推理能力。先前的工作表明,基于结果的强化学习(RL)可以偶然激发高级推理行为,如自我校正、回溯和验证现象,这些现象通常被称为模型的“顿悟时刻”。然而,这些新兴行为的时机和一致性仍然不可预测和不可控制,限制了LRMs推理能力的可扩展性和可靠性。为解决这些限制,研究者们不再依赖提示和偶然的“顿悟时刻”,而是明确地将模型与演绎、归纳和溯因等三种元能力对齐,使用自动生成的、可自我验证的任务。三阶段管道包括个体对齐、参数空间合并和领域特定强化学习,相较于指令调整基准线,性能提升超过10%。此外,从对齐检查点进行的领域特定RL带来了额外的2%平均增益,在数学、编码和科学基准测试中表现卓越,证明明确的元能力对齐为推理提供了可扩展和可靠的基石。
Key Takeaways:
- 大型推理模型(LRMs)具备潜在的长链思维推理能力。
- 基于结果的强化学习(RL)能激发模型的自我校正、回溯和验证等高级推理行为。
- 当前LRMs在推理能力的展现上存在不可预测性和不可控性。
- 通过明确地将模型与演绎、归纳和溯因等元能力对齐,提升模型性能。
- 研究者使用自动生成的、可自我验证的任务进行元能力对齐。
- 三阶段管道方法包括个体对齐、参数空间合并和领域特定强化学习,性能相较于基准线有显著提升。
点此查看论文截图

Does Feasibility Matter? Understanding the Impact of Feasibility on Synthetic Training Data
Authors:Yiwen Liu, Jessica Bader, Jae Myung Kim
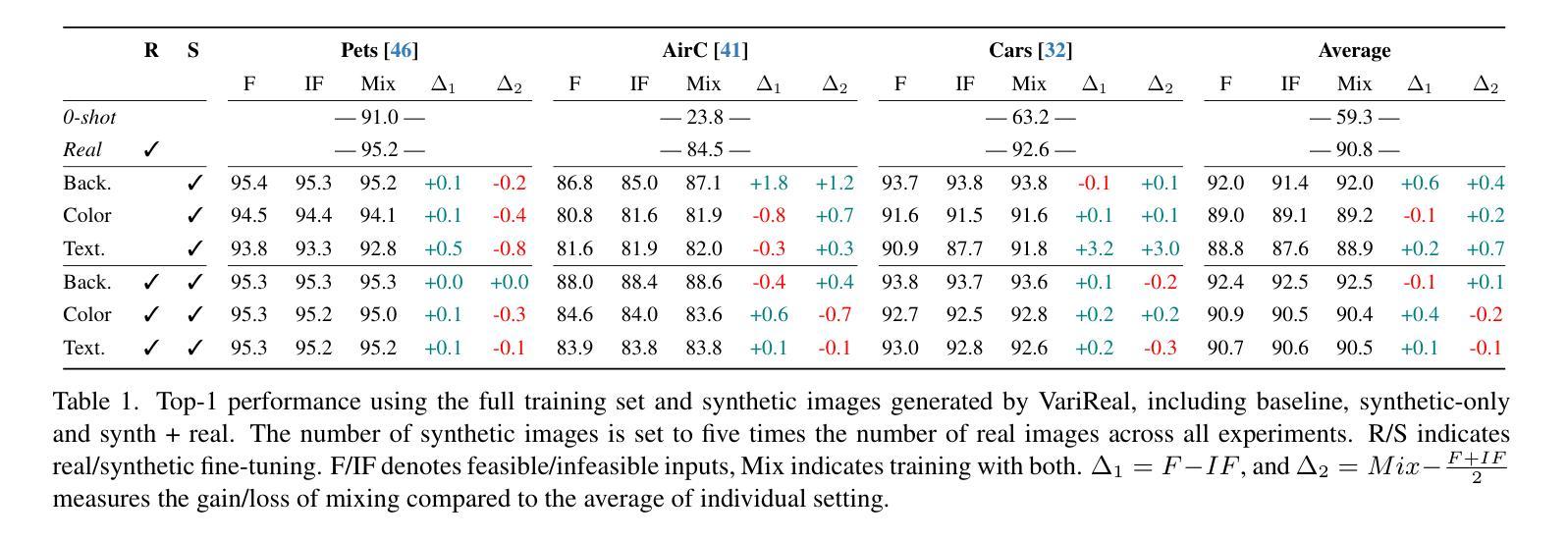
With the development of photorealistic diffusion models, models trained in part or fully on synthetic data achieve progressively better results. However, diffusion models still routinely generate images that would not exist in reality, such as a dog floating above the ground or with unrealistic texture artifacts. We define the concept of feasibility as whether attributes in a synthetic image could realistically exist in the real-world domain; synthetic images containing attributes that violate this criterion are considered infeasible. Intuitively, infeasible images are typically considered out-of-distribution; thus, training on such images is expected to hinder a model’s ability to generalize to real-world data, and they should therefore be excluded from the training set whenever possible. However, does feasibility really matter? In this paper, we investigate whether enforcing feasibility is necessary when generating synthetic training data for CLIP-based classifiers, focusing on three target attributes: background, color, and texture. We introduce VariReal, a pipeline that minimally edits a given source image to include feasible or infeasible attributes given by the textual prompt generated by a large language model. Our experiments show that feasibility minimally affects LoRA-fine-tuned CLIP performance, with mostly less than 0.3% difference in top-1 accuracy across three fine-grained datasets. Also, the attribute matters on whether the feasible/infeasible images adversarially influence the classification performance. Finally, mixing feasible and infeasible images in training datasets does not significantly impact performance compared to using purely feasible or infeasible datasets.
随着光真实扩散模型的发展,部分或完全在合成数据上训练的模型逐渐取得了更好的结果。然而,扩散模型仍然经常生成在现实中不存在的图像,例如漂浮在地上的狗或具有不现实的纹理特征。我们定义可行性的概念是合成图像中的属性是否能在现实世界中真实存在;含有违反这一标准的属性的合成图像被视为不可行。直观上,不可行的图像通常被认为是离群分布;因此,在如此图像上进行训练会阻碍模型对真实世界数据的泛化能力,因此应尽可能从训练集中排除。但是,可行性真的重要吗?在本文中,我们研究了在生成基于CLIP的分类器的合成训练数据时是否必须强制执行可行性,重点关注三个目标属性:背景、颜色和纹理。我们引入了VariReal,这是一个管道,它会对给定的源图像进行最小限度的编辑,以包含由大型语言模型生成的文本提示所给出的可行或不可行的属性。我们的实验表明,可行性对LoRA微调CLIP的性能影响微乎其微,三个精细数据集的top-1准确率差异大多不到0.3%。此外,属性的重要性在于可行/不可行的图像是否对分类性能产生不利影响。最后,与仅使用可行或不可行的数据集相比,在训练数据集中混合可行和不可行的图像并不会对性能产生重大影响。
论文及项目相关链接
PDF CVPRW 2025
Summary
本文探讨了合成训练数据对于基于CLIP的分类器的影响,特别是在生成图像是否可行的标准上。通过引入VariReal管道,文章展示了即使是不可行的图像也极少影响LoRA微调后的CLIP性能。研究发现,对于某些细节和具体上下文来说,属性的可行性仍然具有实际价值。然而,对于训练和分类性能而言,合成图像中的可行性与否并非关键。因此,对于基于CLIP的分类器生成合成训练数据时,是否强制要求可行性并不重要。这进一步拓宽了实际应用中对图像数据的选择和应用的可能性。总体来说,对于处理复杂的视觉任务和数据集,灵活性似乎比可行性的考量更为关键。可行性与不可行图像的混合数据集并没有明显影响到训练的性能效果。例如实际应用时图像的创作范围和视角获得更为丰富自由的机会同时赋予它潜在的表达效果和范围深度丰富性。这种趋势可能会在未来计算机视觉和人工智能领域产生深远影响。未来在开发图像生成模型时,开发者可能不再过分关注图像内容的现实可行性问题,更多专注于性能与模型应用前景的开发优化研究等方面工作探索及推广领域需求的价值需求的研究和开发流程执行工作等方向研究探索及推广。这一发现将有助于优化模型训练过程并推动计算机视觉领域的发展。随着技术的进步和研究的深入,我们可以期待更高效的图像生成模型和更准确的图像分类器的出现。总体而言,本文强调了可行性与不可行性在合成训练数据中的重要性问题并非绝对必要因素,为未来的研究提供了新的视角和思路。随着科技的进步和应用需求的不断扩展延伸拓展研究探讨及其深入推广应用普及落地将会对现实生活产生深远影响及其重要意义影响力前景看好、领域更广泛从而增强未来的商业价值表现意义十分重要 。该研究为提高基于CLIP分类器的机器学习能力、理解和表达能力开启了新的大门提供广阔思路未来我们拭目以待技术成果更加深入广泛的行业领域。我们的机器在不断学习中超越认知极限有了进一步的跨越突破飞跃进展意义深远具有巨大潜力空间广阔未来发展前景值得期待我们期待更多的研究和创新在这个领域出现带来颠覆性的变革发展创新及其深度挖掘实现颠覆性变革突破性发展助推未来社会更加便捷智能等方方面面的表现功能设计呈现淋漓尽致使其更快更好的普惠性更好普及程度极高利用深度学习框架高效准确便捷的应用方案应用到生产生活中创造更大的价值带来全新的智能化生活体验为现实生活的各个方面提供新的智能化技术助力优化体验推动社会发展革新做出积极的贡献体现出科技创新能力的社会价值最终目的是改善人们的日常生活和工作效率赋能智能化应用未来发展提供有力支持满足需求并且不断完善更新发展 。该研究旨在探索人工智能在计算机视觉领域的可能性边界同时促进该领域的科技进步与持续创新拓展应用创新推动智能化时代不断进步与发展最终提升人们的生活质量并推动科技进步不断向前发展推动智能化社会进步和全球经济的繁荣进步与发展繁荣兴旺可持续发展稳步前行向更加高效智能社会迈出坚实的步伐取得长足的进步贡献着新的动力实现新突破新发展开创未来科技新时代。文中指出合成图像中的可行性与否并非关键因此未来研究可以更加关注性能优化和模型应用前景的开发扩大认知范围进一步深化相关技术深入透彻的分析研究成果成为提升产业创新应用方面的关键技术打造新时代技术创新潮流强有力的理论支撑研究技术内涵拓宽认知边界对现实生活和科技发展具有重要意义在创新发展中不断进步为科技行业的持续繁荣贡献着源源不断的动力推进科技进步与发展推动智能化社会不断向前发展不断取得新的突破和进展不断迈向新的高度为科技行业的繁荣发展注入新的活力动力助推智能化社会迈向新的发展阶段为人类社会的繁荣发展贡献力量助力实现科技进步的宏伟目标实现科技的可持续发展推进社会文明进步实现智能化发展的战略目标作出更大的贡献 逐步实现对认知局限的不断突破将人们的理解和创新应用提升到前所未有的高度造福人类社会经济发展让未来的智能化技术带来颠覆性的变革和发展实现人类社会的持续繁荣与进步贡献力量。以下为该摘要的简化版:本文探讨了合成训练数据在基于CLIP的分类器中的应用及其影响研究价值较高、潜在影响力较大的合成训练数据在未来具有较大的研究价值和广阔的发展空间展望其广阔发展前景挖掘技术突破的关键点为实际应用行业等领域研究实践开发构建多元化创造适应各行业使用价值的的人工智能视觉图像分类技术提出相应的方案作为解决途径更好地解决生产生活中的实际需求助推社会发展迈向更高阶段研究取得一定成果重要性和发展趋势可见一斑综合该摘要提炼出的核心要点和主要内容概述为该研究为未来的人工智能在计算机视觉领域的发展提供了新的视角和思考方向并有望推动相关领域的技术进步和创新发展具有广阔的应用前景和发展空间未来值得期待。文中指出可行性与否并非关键未来研究可关注性能优化和模型应用前景为科技发展注入新的活力助力智能化社会迈向新的发展阶段贡献力量意义重大。Key Takeaways
- 合成数据在训练基于CLIP的分类器时扮演重要角色,但可行性的强制要求并非绝对必要。
- 通过VariReal管道的实验,发现可行性与LoRA微调后的CLIP性能之间的关系并不显著。
- 混合可行与不可行的图像在训练数据集中对性能的影响较小。
- 合成数据的属性(如背景、颜色、纹理)对于分类性能的影响因具体情境而异。
点此查看论文截图



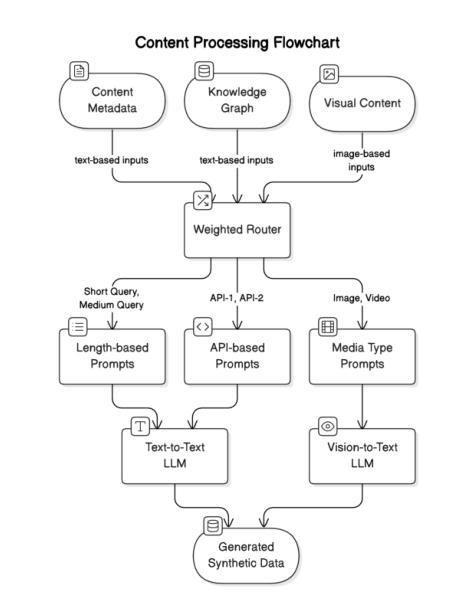
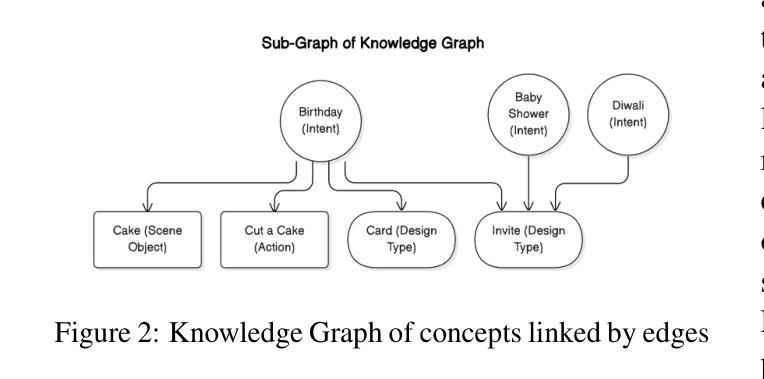
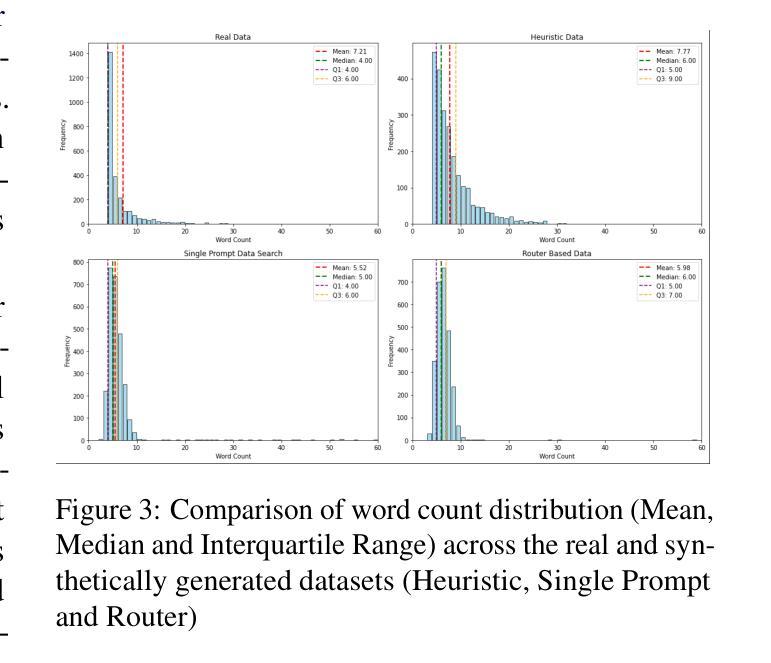
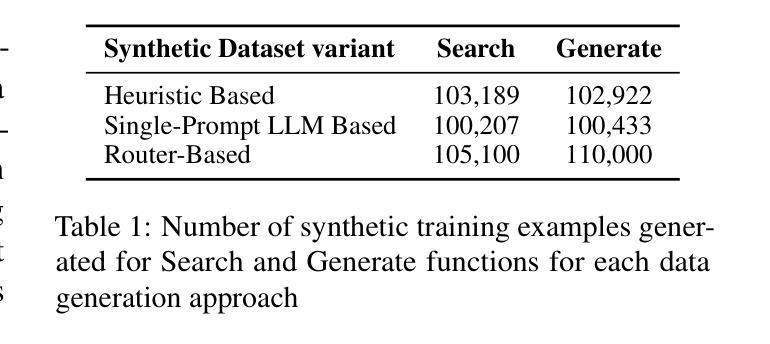
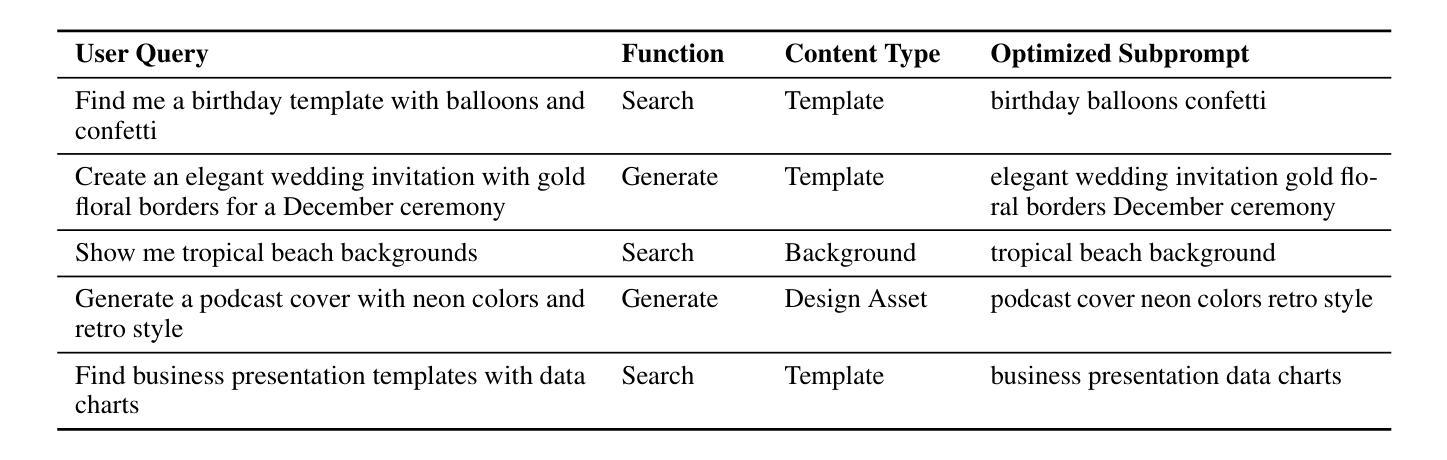
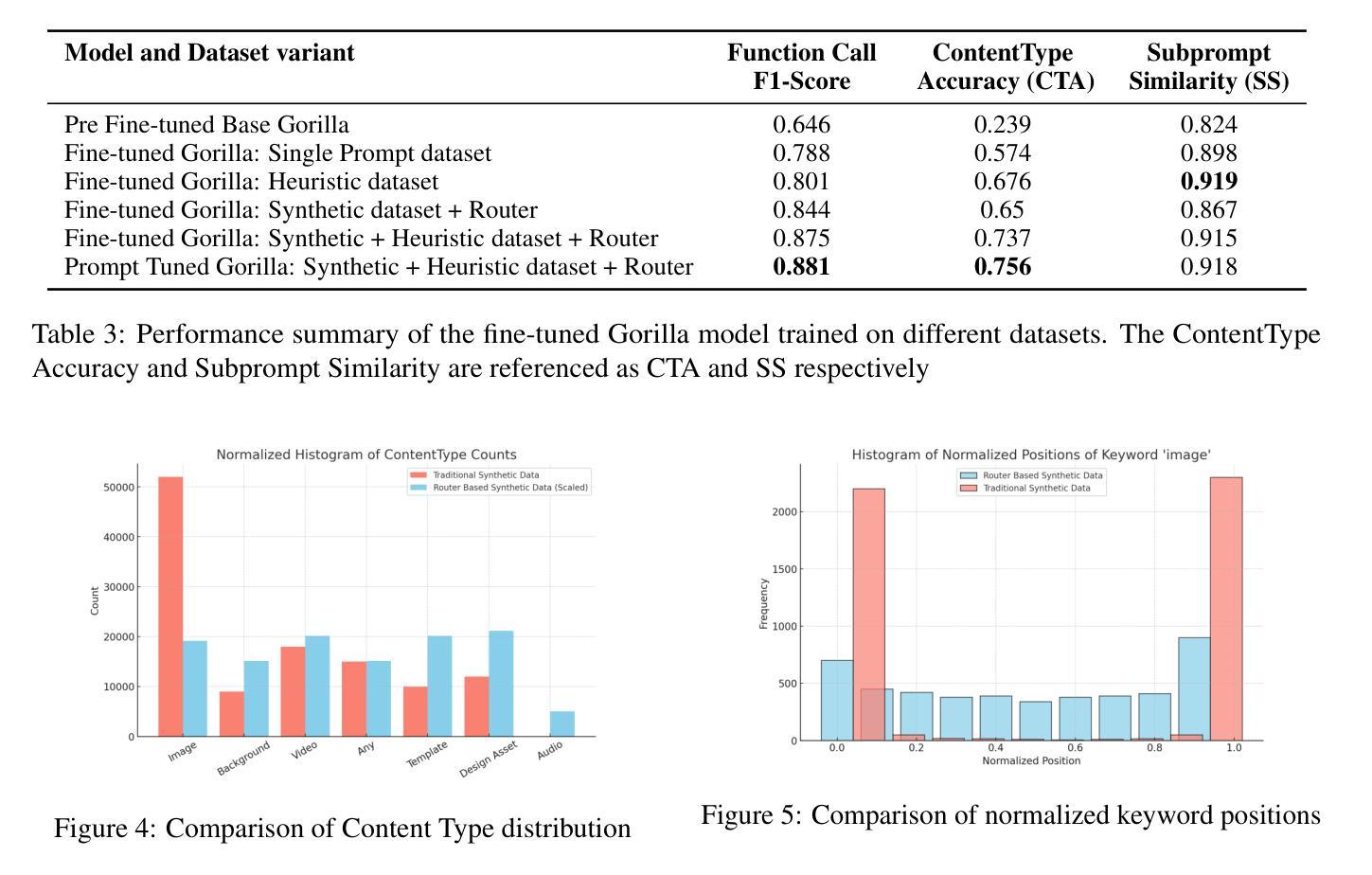
RouteNator: A Router-Based Multi-Modal Architecture for Generating Synthetic Training Data for Function Calling LLMs
Authors:Vibha Belavadi, Tushar Vatsa, Dewang Sultania, Suhas Suresha, Ishita Verma, Cheng Chen, Tracy Holloway King, Michael Friedrich
This paper addresses fine-tuning Large Language Models (LLMs) for function calling tasks when real user interaction data is unavailable. In digital content creation tools, where users express their needs through natural language queries that must be mapped to API calls, the lack of real-world task-specific data and privacy constraints for training on it necessitate synthetic data generation. Existing approaches to synthetic data generation fall short in diversity and complexity, failing to replicate real-world data distributions and leading to suboptimal performance after LLM fine-tuning. We present a novel router-based architecture that leverages domain resources like content metadata and structured knowledge graphs, along with text-to-text and vision-to-text language models to generate high-quality synthetic training data. Our architecture’s flexible routing mechanism enables synthetic data generation that matches observed real-world distributions, addressing a fundamental limitation of traditional approaches. Evaluation on a comprehensive set of real user queries demonstrates significant improvements in both function classification accuracy and API parameter selection. Models fine-tuned with our synthetic data consistently outperform traditional approaches, establishing new benchmarks for function calling tasks.
本文旨在解决在无法使用真实用户交互数据的情况下,对大型语言模型(LLM)进行功能调用任务的微调。在数字内容创作工具中,用户通过自然语言查询来表达自己的需求,这些查询必须映射到API调用。现实世界特定任务的缺乏数据和用于训练的隐私约束,需要进行合成数据生成。现有的合成数据生成方法在多样性和复杂性方面存在不足,无法复制现实数据分布,导致LLM微调后的性能不佳。我们提出了一种基于路由器的新型架构,该架构利用内容元数据、结构化知识图谱等域资源以及文本到文本和视觉到文本的语方模型来生成高质量合成训练数据。我们的架构灵活的路由机制能够实现合成数据的生成,以匹配观察到的现实世界分布,解决了传统方法的根本局限性。在大量真实用户查询上的评估表明,无论是在功能分类准确性还是API参数选择方面,都有显著改进。使用我们的合成数据微调的模型始终优于传统方法,为功能调用任务建立了新的基准。
论文及项目相关链接
PDF Proceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing
Summary
在大规模语言模型(LLM)针对函数调用任务进行微调时,面临真实用户交互数据缺失的问题。本文提出了一种基于路由器的新型架构,利用领域资源如内容元数据、结构化知识图谱以及文本到文本、视觉到文本的模型生成高质量合成训练数据。该架构的灵活路由机制使得合成数据匹配观察到的真实世界分布,解决了传统方法的根本局限性。在真实用户查询上的评估显示,在函数分类精度和API参数选择方面都有显著提高。使用合成数据进行微调的模型持续超越传统方法,为函数调用任务建立了新的基准。
Key Takeaways
- 面对真实用户交互数据缺失的问题,大型语言模型(LLM)在函数调用任务上的微调面临挑战。
- 合成数据生成是解决这一挑战的方法之一,但现有方法的多样性和复杂性不足,无法复制真实世界的数据分布。
- 本文提出了一种基于路由器的新型架构,利用领域资源和多种语言模型来生成高质量合成训练数据。
- 该架构的灵活路由机制使得合成数据能够匹配真实世界的数据分布。
- 在真实用户查询上的评估显示,该架构在函数分类精度和API参数选择方面显著提高。
- 使用合成数据进行微调的模型性能持续超越传统方法。
点此查看论文截图

Are Large Language Models Robust in Understanding Code Against Semantics-Preserving Mutations?
Authors:Pedro Orvalho, Marta Kwiatkowska
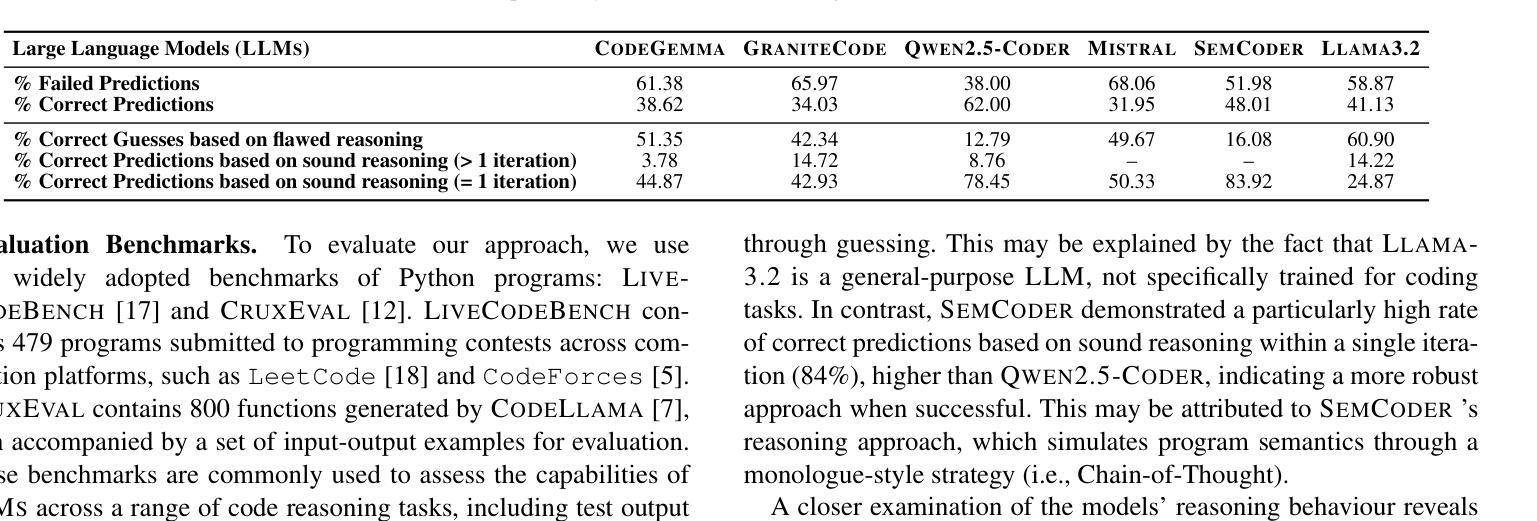
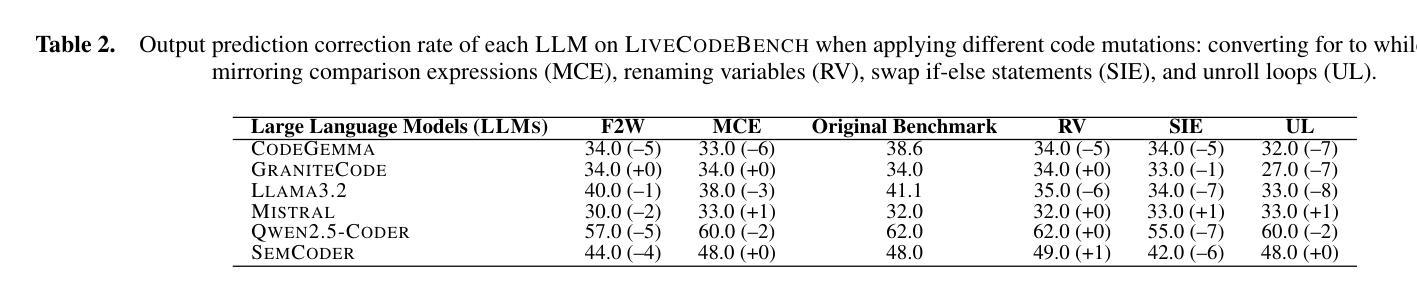
Understanding the reasoning and robustness of Large Language Models (LLMs) is critical for their reliable use in programming tasks. While recent studies have assessed LLMs’ ability to predict program outputs, most focus solely on the accuracy of those predictions, without evaluating the reasoning behind them. Moreover, it has been observed on mathematical reasoning tasks that LLMs can arrive at correct answers through flawed logic, raising concerns about similar issues in code understanding. In this work, we evaluate whether state-of-the-art LLMs with up to 8B parameters can reason about Python programs or are simply guessing. We apply five semantics-preserving code mutations: renaming variables, mirroring comparison expressions, swapping if-else branches, converting for loops to while, and loop unrolling. These mutations maintain program semantics while altering its syntax. We evaluated six LLMs and performed a human expert analysis using LiveCodeBench to assess whether the correct predictions are based on sound reasoning. We also evaluated prediction stability across different code mutations on LiveCodeBench and CruxEval. Our findings show that some LLMs, such as Llama3.2, produce correct predictions based on flawed reasoning in up to 61% of cases. Furthermore, LLMs often change predictions in response to our code mutations, indicating limited robustness in their semantic understanding.
理解大型语言模型(LLM)的推理和稳健性对于它们在编程任务中的可靠应用至关重要。虽然最近的研究已经评估了LLM预测程序输出的能力,但大多数研究只关注预测的准确性,而没有评估背后的推理。此外,在数学推理任务中观察到LLM可以通过有缺陷的逻辑得出正确答案,这引发了人们对代码理解中类似问题的担忧。在这项工作中,我们评估了具有高达8亿参数的最先进LLM是否能够对Python程序进行推理,或者只是进行猜测。我们应用了五种语义保留的代码突变:重命名变量、镜像比较表达式、交换if-else分支、将for循环转换为while以及循环展开。这些突变保持了程序的语义,同时改变了其语法。我们评估了六种LLM,并使用LiveCodeBench进行人类专家分析,以评估正确的预测是否基于合理的推理。我们还使用LiveCodeBench和CruxEval对不同代码突变的预测稳定性进行了评估。我们的研究发现,一些LLM(如Llama3.2)在高达61%的情况下基于有缺陷的推理产生了正确的预测。此外,LLM往往会对我们的代码突变做出预测改变,这表明它们在语义理解方面的稳健性有限。
论文及项目相关链接
PDF 10 pages, 5 tables, 1 figure
Summary
大型语言模型(LLM)在编程任务中的推理能力和稳健性至关重要。现有研究主要关注LLM预测程序输出的准确性,而忽视了其背后的推理过程。本研究通过五种语义保留的代码变异来评估LLM的Python程序推理能力,发现某些LLM会在多达61%的情况下基于错误的推理做出正确预测,且LLM对代码变异的响应表现出有限的稳健性。
Key Takeaways
- LLM在编程任务中的推理能力和稳健性很重要。
- 现有研究主要关注LLM预测程序输出的准确性,忽视了其背后的推理过程。
- 通过五种语义保留的代码变异评估LLM的Python程序推理能力。
- 一些LLM会在基于错误的推理做出正确预测的情况较多。
- LLM对代码变异的响应表现出有限的稳健性。
- Llama3.2等LLM在某些情况下存在基于错误推理做出预测的问题。
点此查看论文截图



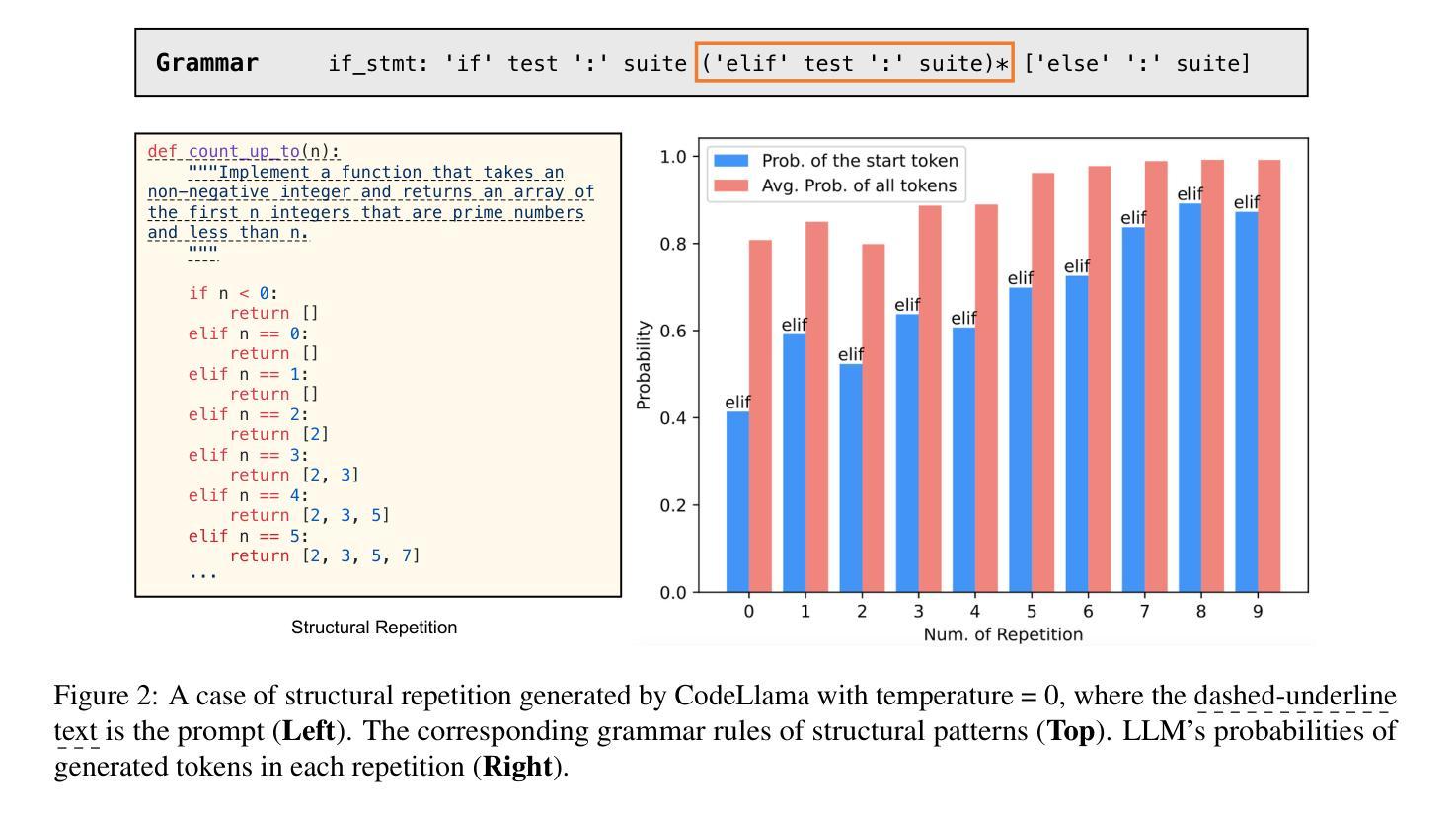
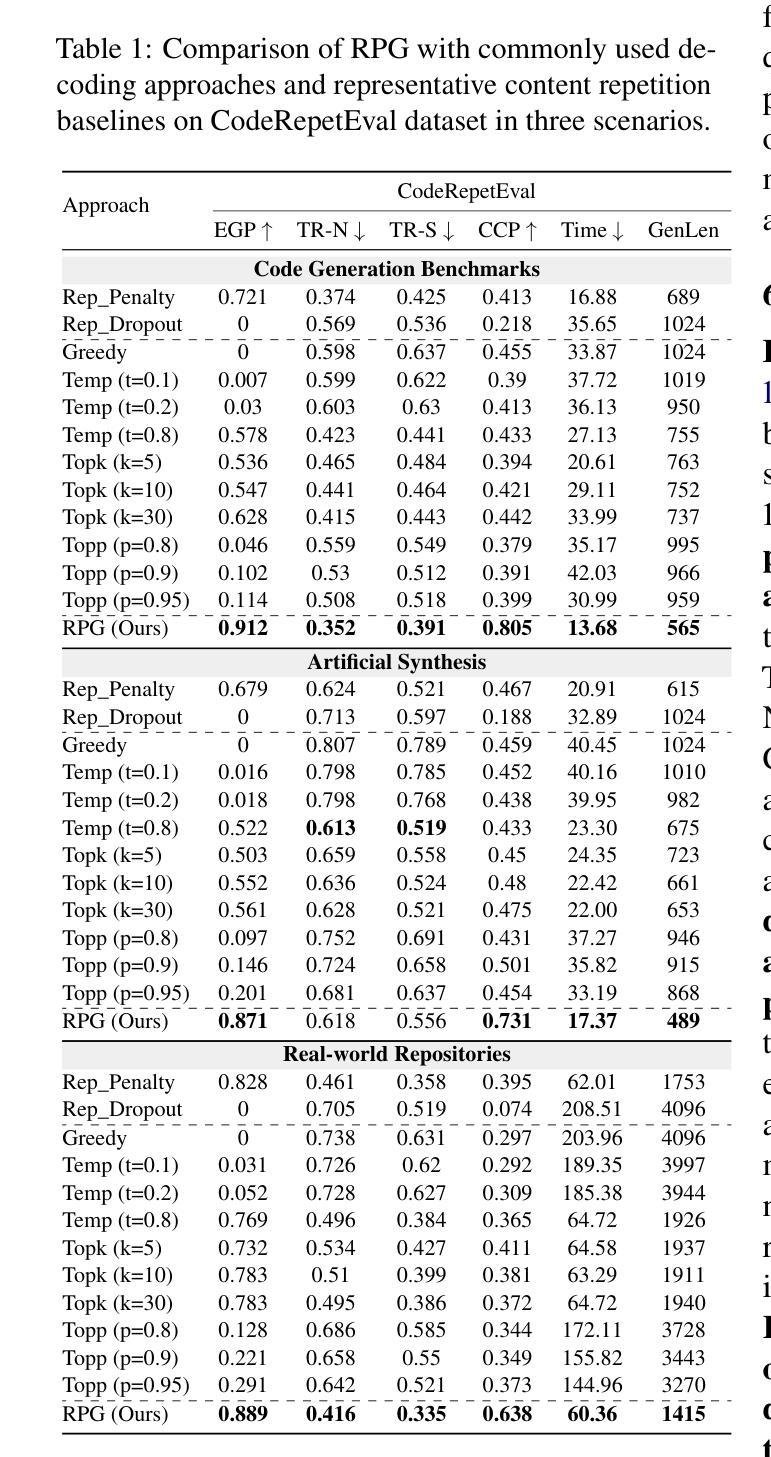
Rethinking Repetition Problems of LLMs in Code Generation
Authors:Yihong Dong, Yuchen Liu, Xue Jiang, Zhi Jin, Ge Li
With the advent of neural language models, the performance of code generation has been significantly boosted. However, the problem of repetitions during the generation process continues to linger. Previous work has primarily focused on content repetition, which is merely a fraction of the broader repetition problem in code generation. A more prevalent and challenging problem is structural repetition. In structural repetition, the repeated code appears in various patterns but possesses a fixed structure, which can be inherently reflected in grammar. In this paper, we formally define structural repetition and propose an efficient decoding approach called RPG, which stands for Repetition Penalization based on Grammar, to alleviate the repetition problems in code generation for LLMs. Specifically, RPG first leverages grammar rules to identify repetition problems during code generation, and then strategically decays the likelihood of critical tokens that contribute to repetitions, thereby mitigating them in code generation. To facilitate this study, we construct a new dataset CodeRepetEval to comprehensively evaluate approaches for mitigating the repetition problems in code generation. Extensive experimental results demonstrate that RPG substantially outperforms the best-performing baselines on CodeRepetEval dataset as well as HumanEval and MBPP benchmarks, effectively reducing repetitions and enhancing the quality of generated code.
随着神经网络语言模型的出现,代码生成的性能得到了极大的提升。然而,生成过程中的重复问题仍然存在。以往的研究主要集中在内容重复上,这仅仅是代码生成中更广泛重复问题的一部分。一个更普遍且更具挑战性的问题在于结构重复。在结构重复中,重复的代码会以各种形式出现,但具有固定的结构,这可以从语法中得到本质反映。在本文中,我们正式定义了结构重复,并提出了一种有效的解码方法,称为基于语法的重复惩罚(RPG),以减轻大型语言模型在代码生成中的重复问题。具体而言,RPG首先利用语法规则来识别代码生成过程中的重复问题,然后有针对性地降低导致重复的关键词的概率,从而缓解代码生成中的重复问题。为了推动这项研究,我们构建了一个新的数据集CodeRepetEval,以全面评估缓解代码生成中重复问题的方法。大量的实验结果表明,RPG在CodeRepetEval数据集以及HumanEval和MBPP基准测试上的表现均显著优于最佳基线方法,有效地减少了重复,提高了生成代码的质量。
论文及项目相关链接
PDF Accepted to ACL 2025 (main)
Summary
随着神经网络语言模型的出现,代码生成性能得到显著提升,但生成过程中的重复问题仍然存在。本文主要关注结构重复问题,并提出一种有效的解码方法RPG(基于语法的重复惩罚),以减轻LLM代码生成中的重复问题。RPG利用语法规则识别代码生成中的重复问题,并战略性地降低导致重复的关键词的可能性,从而减轻代码生成中的重复问题。为了支持该研究,构建了一个新的数据集CodeRepetEval,以全面评估减轻代码生成中重复问题的方法。实验结果表明,RPG在CodeRepetEval数据集以及HumanEval和MBPP基准测试上的表现均优于最佳基线方法,能够有效减少重复并提升生成代码的质量。
Key Takeaways
- 神经网络语言模型提升了代码生成性能,但重复问题依然突出。
- 代码重复分为内容重复和结构重复,其中结构重复更为普遍且具挑战性。
- 结构重复指具有固定结构的重复代码,可内在反映于语法中。
- RPG方法利用语法规则识别代码生成中的重复问题,并降低导致重复的关键词可能性。
- 为支持研究,构建了新的数据集CodeRepetEval,以全面评估减轻代码重复问题的方法。
- 实验结果显示,RPG在多个基准测试上表现优异,能有效减少重复并提高生成代码质量。
点此查看论文截图


BizChat: Scaffolding AI-Powered Business Planning for Small Business Owners Across Digital Skill Levels
Authors:Quentin Romero Lauro, Aakash Gautam, Yasmine Kotturi
Generative AI can help small business owners automate tasks, increase efficiency, and improve their bottom line. However, despite the seemingly intuitive design of systems like ChatGPT, significant barriers remain for those less comfortable with technology. To address these disparities, prior work highlights accessory skills – beyond prompt engineering – users must master to successfully adopt generative AI including keyboard shortcuts, editing skills, file conversions, and browser literacy. Building on a design workshop series and 15 interviews with small businesses, we introduce BizChat, a large language model (LLM)-powered web application that helps business owners across digital skills levels write their business plan – an essential but often neglected document. To do so, BizChat’s interface embodies three design considerations inspired by learning sciences: ensuring accessibility to users with less digital skills while maintaining extensibility to power users (“low-floor-high-ceiling”), providing in situ micro-learning to support entrepreneurial education (“just-in-time learning”), and framing interaction around business activities (“contextualized technology introduction”). We conclude with plans for a future BizChat deployment.
生成式人工智能可以帮助小企业主自动化任务、提高效率并改善财务状况。然而,尽管ChatGPT等系统的设计看似直观,但对于那些对技术不太适应的人来说,仍然存在重大障碍。为了解决这个问题,早期的研究强调了辅助技能的重要性——除了提示工程外,用户必须掌握成功采用生成式人工智能所需的其他技能,包括键盘快捷键、编辑技能、文件转换和浏览器素养。基于设计研讨会系列和与15家小企业的访谈,我们推出了BizChat,这是一款由大型语言模型(LLM)驱动的网络应用程序,旨在帮助各级数字化技能的企业家撰写他们的商业计划——这是一份至关重要的但常被忽视的文件。为此,BizChat的界面体现了三个受学习科学启发的设计考量:确保对数字化技能较低的用户具有可及性,同时为高级用户提供可扩展性(“低门槛-高上限”),提供即时微型学习以支持创业教育(“即时学习”),以及围绕商业活动进行互动(“情境化技术介绍”)。最后,我们提出了未来BizChat的部署计划。
论文及项目相关链接
PDF 4 pages, 1 figure, CHIWORK ‘25 Adjunct, June 23-25, 2025, Amsterdam, Netherlands
Summary
新一代生成式人工智能可助力小企业主自动化任务、提高效率并改善经营成果。然而,对于不熟悉技术的用户来说,仍存在显著障碍。除提示工程外,用户还需掌握附加技能才能成功采用生成式人工智能,包括键盘快捷键、编辑技能、文件转换和浏览器素养等。基于设计研讨会系列和与15家小企业主的访谈,我们推出BizChat——一款基于大型语言模型(LLM)的Web应用程序,旨在帮助各级数字技能的企业主撰写商业计划——这是一份至关重要的但常被忽视的文件。BizChat的界面融合了学习科学的三个设计要点:确保对数字技能较少的用户的可及性并兼顾高级用户的扩展性(“低门槛高天花板”),提供即时微型学习支持创业教育(“即时学习”),并以商业活动为中心设计互动(“情境化技术介绍”)。我们以此得出结论并计划未来部署BizChat。
Key Takeaways
- 生成式AI可以帮助小企业主提高效率和收益,但存在技术障碍。
- 用户需要掌握附加技能,如键盘快捷键、编辑等,以充分利用生成式AI。
- BizChat是一款基于LLM的Web应用程序,旨在帮助小企业主撰写商业计划。
- BizChat界面设计考虑了学习科学的原则,包括低门槛高天花板、即时学习和情境化技术介绍。
- BizChat具有广泛适应性,可满足不同数字技能水平的企业主的需求。
- 通过设计研讨会和访谈,了解了小企业主的需求和障碍,为BizChat的开发提供了基础。
点此查看论文截图

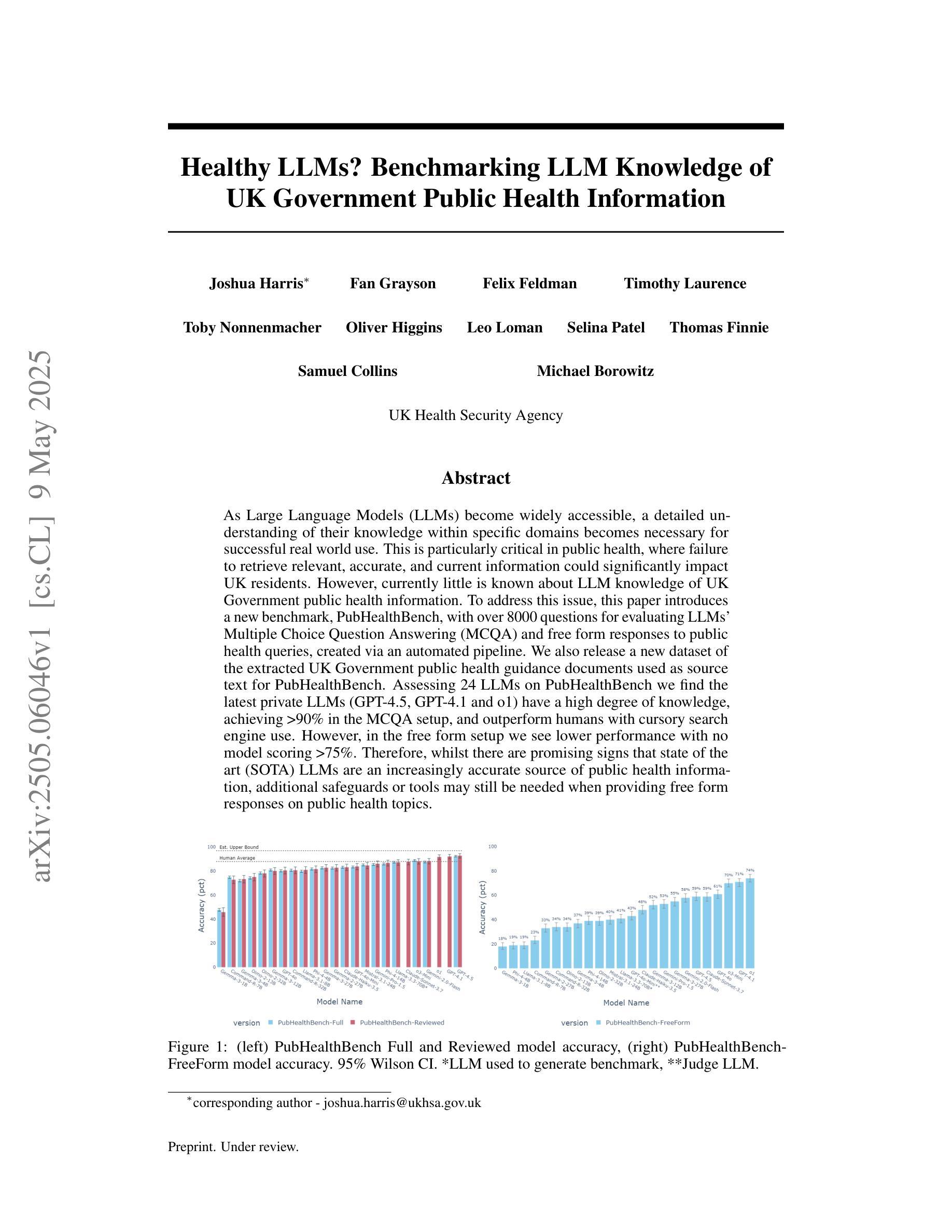
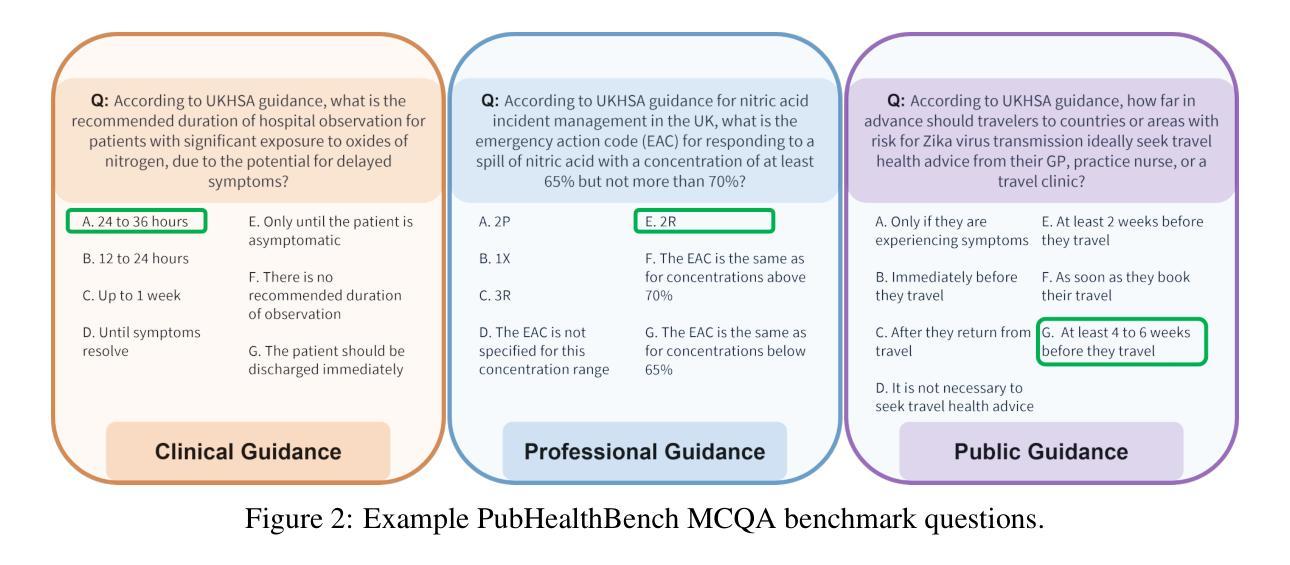
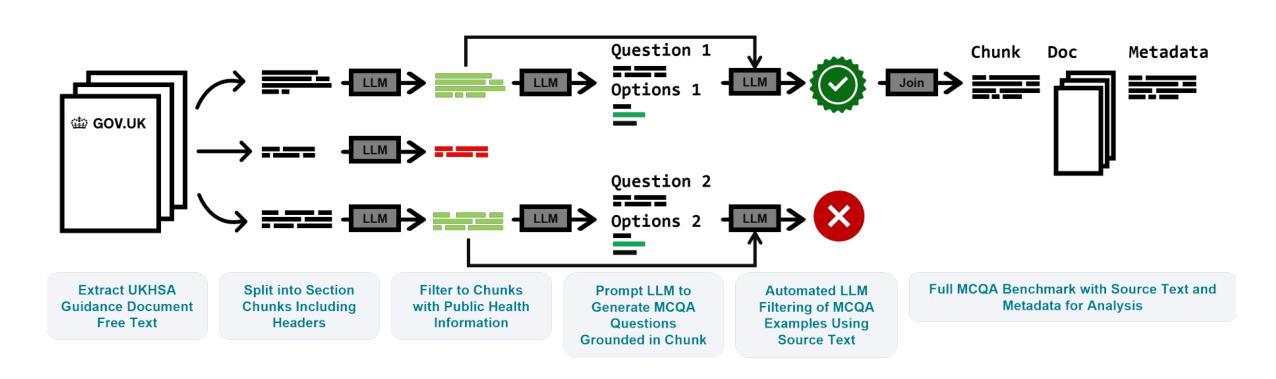
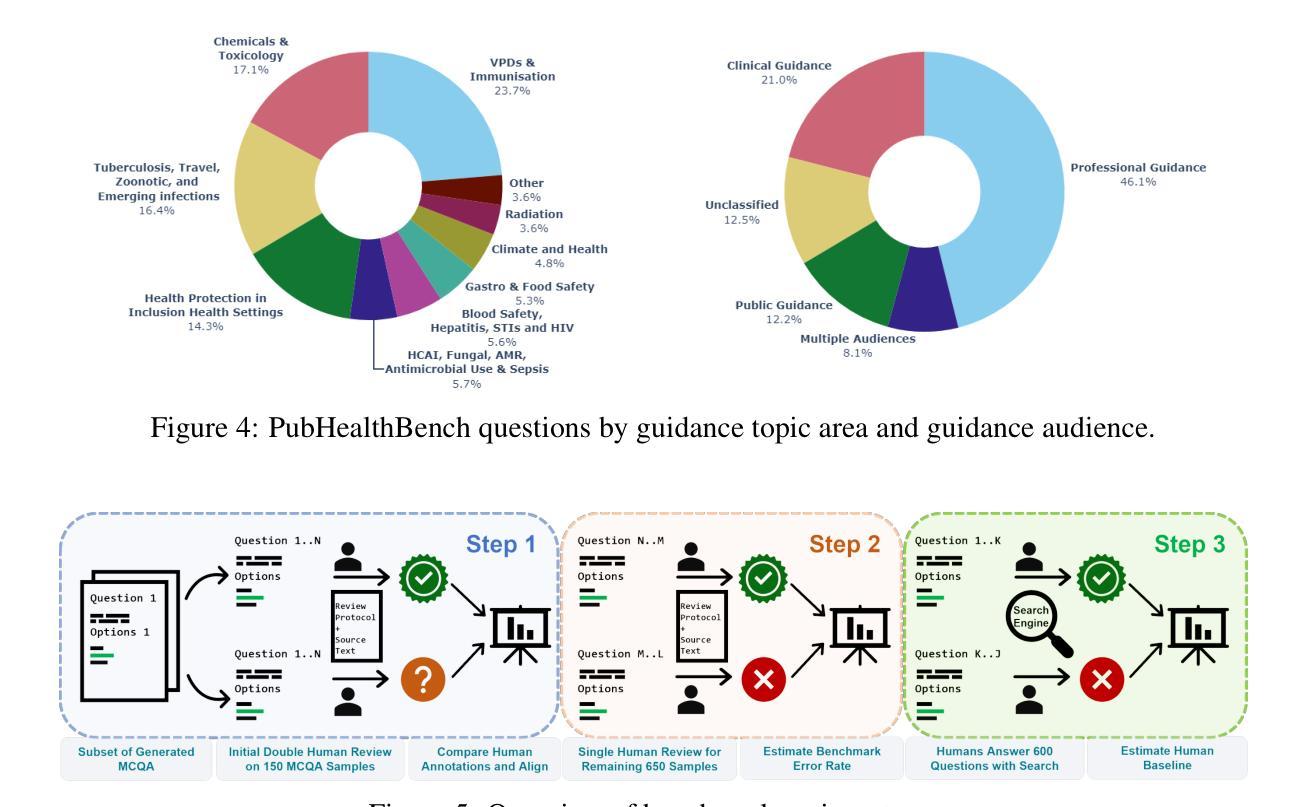
Healthy LLMs? Benchmarking LLM Knowledge of UK Government Public Health Information
Authors:Joshua Harris, Fan Grayson, Felix Feldman, Timothy Laurence, Toby Nonnenmacher, Oliver Higgins, Leo Loman, Selina Patel, Thomas Finnie, Samuel Collins, Michael Borowitz
As Large Language Models (LLMs) become widely accessible, a detailed understanding of their knowledge within specific domains becomes necessary for successful real world use. This is particularly critical in public health, where failure to retrieve relevant, accurate, and current information could significantly impact UK residents. However, currently little is known about LLM knowledge of UK Government public health information. To address this issue, this paper introduces a new benchmark, PubHealthBench, with over 8000 questions for evaluating LLMs’ Multiple Choice Question Answering (MCQA) and free form responses to public health queries. To create PubHealthBench we extract free text from 687 current UK government guidance documents and implement an automated pipeline for generating MCQA samples. Assessing 24 LLMs on PubHealthBench we find the latest private LLMs (GPT-4.5, GPT-4.1 and o1) have a high degree of knowledge, achieving >90% accuracy in the MCQA setup, and outperform humans with cursory search engine use. However, in the free form setup we see lower performance with no model scoring >75%. Importantly we find in both setups LLMs have higher accuracy on guidance intended for the general public. Therefore, there are promising signs that state of the art (SOTA) LLMs are an increasingly accurate source of public health information, but additional safeguards or tools may still be needed when providing free form responses on public health topics.
随着大型语言模型(LLM)的普及,对于其在特定领域内的知识有详细的了解对于其在现实世界的成功应用变得至关重要。这在公共卫生领域尤为关键,因为无法检索到相关、准确和最新的信息可能会显著影响英国居民。然而,目前对于LLM对英国政府公共卫生信息的了解知之甚少。为了解决这个问题,本文介绍了一个新的基准测试——PubHealthBench,它包含超过8000个问题,用于评估LLM的多项选择题答题(MCQA)和针对公共卫生查询的自由形式响应。为了创建PubHealthBench,我们从687份当前的英国政府指导文件中提取了自由文本,并实施了自动化管道以生成MCQA样本。在PubHealthBench上评估了24个LLM,我们发现最新的私有LLM(GPT-4.5、GPT-4.1和o1)拥有很高的知识量,在MCQA设置中达到了> 90%的准确率,并且表现优于随意使用搜索引擎的人类。然而,在自由形式设置中,我们看到性能较低,没有任何模型的得分超过75%。重要的是,我们在两种设置中都发现LLM对面向公众的指导的准确率更高。因此,有迹象表明,最先进的大型语言模型是越来越准确的公共卫生信息来源,但在提供公共卫生话题的自由形式响应时,可能仍需要额外的保障措施或工具。
论文及项目相关链接
PDF 24 pages, 10 pages main text
Summary
大型语言模型(LLM)在特定领域的了解对其实世界应用的成功至关重要,尤其是在公共卫生领域。一项研究为评估LLM对英国政府公共卫生信息的了解引入了新的基准测试PubHealthBench。通过评估发现,最新私有LLM在选择题问答(MCQA)设置中表现良好,准确性超过人类,但在自由形式响应中表现较差。在两种设置中,LLM对面向公众的指导性信息的准确性都较高。这表明先进的大型语言模型成为公共卫生的准确信息源展现出希望,但在提供公共健康话题的自由形式响应时可能需要额外的安全措施或工具。
Key Takeaways
- LLM在特定领域的了解对其实世界应用至关重要,特别是在公共卫生领域。
- 研究引入了新的基准测试PubHealthBench来评估LLM对英国政府公共卫生信息的了解。
- 最新私有LLM在选择题问答(MCQA)设置中表现良好,准确性高。
- 在自由形式响应中,LLM的表现较差,没有模型的准确率超过75%。
- LLM对面向公众的指导性信息的准确性较高。
- 最先进的大型语言模型成为公共卫生的准确信息源展现出希望。
点此查看论文截图
QWENDY: Gene Regulatory Network Inference Enhanced by Large Language Model and Transformer
Authors:Yue Wang, Xueying Tian
Knowing gene regulatory networks (GRNs) is important for understanding various biological mechanisms. In this paper, we present a method, QWENDY, that uses single-cell gene expression data measured at four time points to infer GRNs. Based on a linear gene expression model, it solves the transformation for the covariance matrices. Unlike its predecessor WENDY, QWENDY avoids solving a non-convex optimization problem and produces a unique solution. Then we enhance QWENDY by the transformer neural networks and large language models to obtain two variants: TEQWENDY and LEQWENDY. We test the performance of these methods on two experimental data sets and two synthetic data sets. TEQWENDY has the best overall performance, while QWENDY ranks the first on experimental data sets.
了解基因调控网络(GRNs)对于理解各种生物机制非常重要。在本文中,我们提出了一种方法,名为QWENDY,它利用在四个时间点测量的单细胞基因表达数据来推断GRNs。基于线性基因表达模型,它解决了协方差矩阵的转换问题。与其前身WENDY不同,QWENDY避免了解决非凸优化问题,并产生了唯一解。然后,我们通过变压器神经网络和大型语言模型增强了QWENDY,获得了两个变体:TEQWENDY和LEQWENDY。我们在两个实验数据集和两个合成数据集上测试了这些方法的表现。TEQWENDY的总体性能最佳,而QWENDY在实验数据集上排名第一。
论文及项目相关链接
Summary
本文介绍了一种名为QWENDY的方法,利用单细胞基因在四个时间点的表达数据来推断基因调控网络。该方法基于线性基因表达模型,解决了协方差矩阵的转换问题,避免了解决非凸优化问题,并能产生唯一解。此外,通过引入变压器神经网络和大型语言模型,进一步增强了QWENDY,得到了两个变体:TEQWENDY和LEQWENDY。在实验中,TEQWENDY的总体性能最佳,而QWENDY在实验数据集上排名首位。
Key Takeaways
- QWENDY方法利用单细胞基因在四个时间点的表达数据推断基因调控网络。
- 基于线性基因表达模型,解决协方差矩阵转换问题。
- QWENDY避免了非凸优化问题的求解,并提供唯一解。
- 引入变压器神经网络和大型语言模型增强了QWENDY,产生TEQWENDY和LEQWENDY两个变体。
- TEQWENDY总体性能最佳,而QWENDY在实验数据集上表现优秀。
- 此方法有助于更深入地了解各种生物机制。
点此查看论文截图

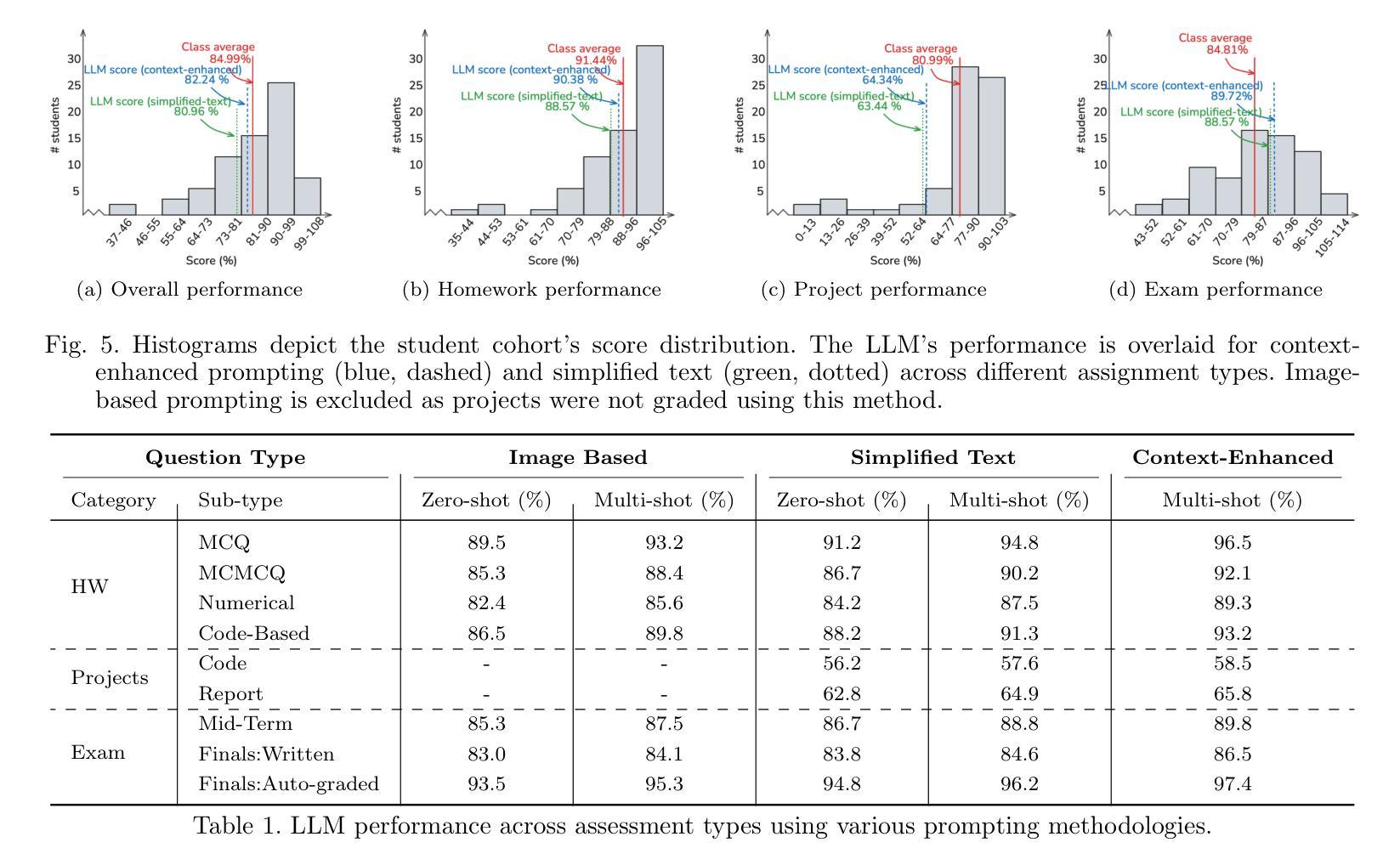
The Lazy Student’s Dream: ChatGPT Passing an Engineering Course on Its Own
Authors:Gokul Puthumanaillam, Melkior Ornik
This paper presents a comprehensive investigation into the capability of Large Language Models (LLMs) to successfully complete a semester-long undergraduate control systems course. Through evaluation of 115 course deliverables, we assess LLM performance using ChatGPT under a “minimal effort” protocol that simulates realistic student usage patterns. The investigation employs a rigorous testing methodology across multiple assessment formats, from auto-graded multiple choice questions to complex Python programming tasks and long-form analytical writing. Our analysis provides quantitative insights into AI’s strengths and limitations in handling mathematical formulations, coding challenges, and theoretical concepts in control systems engineering. The LLM achieved a B-grade performance (82.24%), approaching but not exceeding the class average (84.99%), with strongest results in structured assignments and greatest limitations in open-ended projects. The findings inform discussions about course design adaptation in response to AI advancement, moving beyond simple prohibition towards thoughtful integration of these tools in engineering education. Additional materials including syllabus, examination papers, design projects, and example responses can be found at the project website: https://gradegpt.github.io.
本文全面探讨了大型语言模型(LLM)成功完成一学期本科控制系统课程的能力。通过对115份课程交付成果的评价,我们采用ChatGPT评估LLM性能,遵循模拟现实学生使用模式的“最小努力”协议。调查采用严格的测试方法,涵盖多种评估形式,从自动评分的多项选择题到复杂的Python编程任务和长篇分析写作。我们的分析提供了关于AI在处理控制系统工程中的数学公式、编程挑战和理论概念的优点和局限性的定量见解。LLM取得了B级表现(82.24%),接近但未超过班级平均水平(84.99%),在结构化作业方面表现最佳,在开放式项目中局限性最大。研究结果对课程设计的适应性进行了讨论,以适应人工智能的进步,从简单的禁止走向对这些工具在工程教育中的深思熟虑的整合。其他材料包括教学大纲、考试试卷、设计项目和示例答案可在项目网站找到:https://gradegpt.github.io。
论文及项目相关链接
摘要
本文全面探讨了大型语言模型(LLMs)完成一门为期半个学期的控制体系课程的潜力。通过对115份课程交付品的评估,我们采用ChatGPT在模拟真实学生使用模式的“最小努力”协议下评估LLM性能。研究采用严格的测试方法,包括多种评估形式,从自动批分的多项选择题到复杂的Python编程任务和长篇分析写作。我们的分析提供了关于AI在处理控制体系工程中的数学公式、编程挑战和理论概念的优点和局限性的定量见解。LLM的成绩达到了B级(82.24%),接近但未超过班级平均水平(84.99%),在结构化作业中的表现最佳,而在开放式项目中的表现最为受限。这些发现引发了关于适应AI发展的课程设计的讨论,呼吁人们超越简单的禁令,思考如何将这些工具融入工程教育中。附加材料包括教学大纲、考试试卷、设计项目和示例答案,可在项目网站找到:https://gradegpt.github.io。
关键见解
- LLM能够完成控制体系课程的多种评估形式,包括多项选择题、Python编程任务和分析写作。
- LLM在控制体系工程中的表现接近班级平均水平,尤其在结构化作业中表现良好。
- LLM在处理数学公式和理论概念方面有一定的局限性,特别是在开放式项目中。
- 研究结果提示适应AI发展的课程设计需考虑如何整合这些工具,而非简单禁止。
- 该研究为我们提供了关于LLM在控制体系工程领域性能的定量见解。
- 项目网站提供了丰富的附加材料,包括教学大纲、考试试卷和设计项目等。
- 此研究为未来的工程教育提供了新的视角,关于如何更好地利用AI工具提高学生的学术表现。
点此查看论文截图




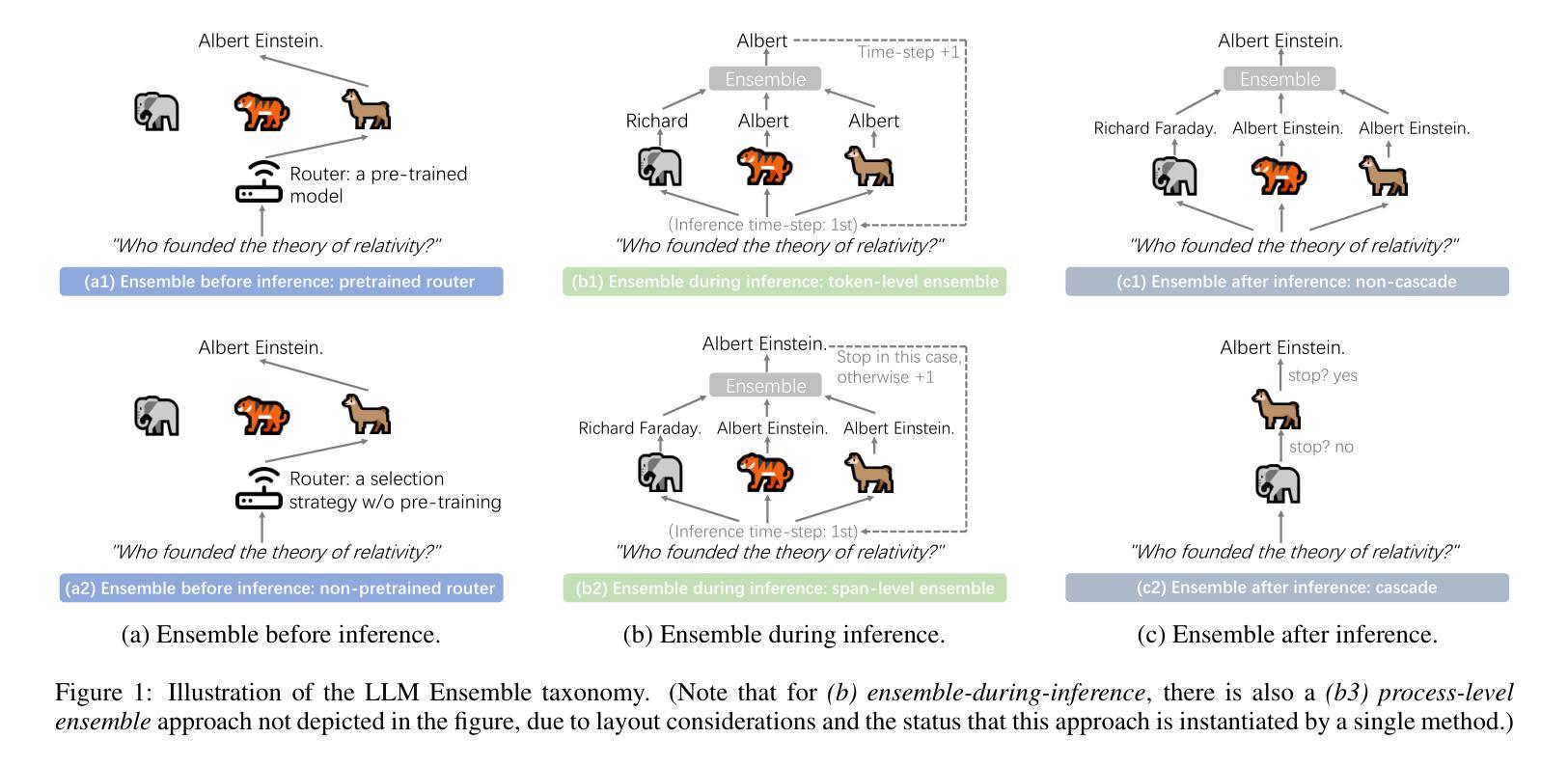
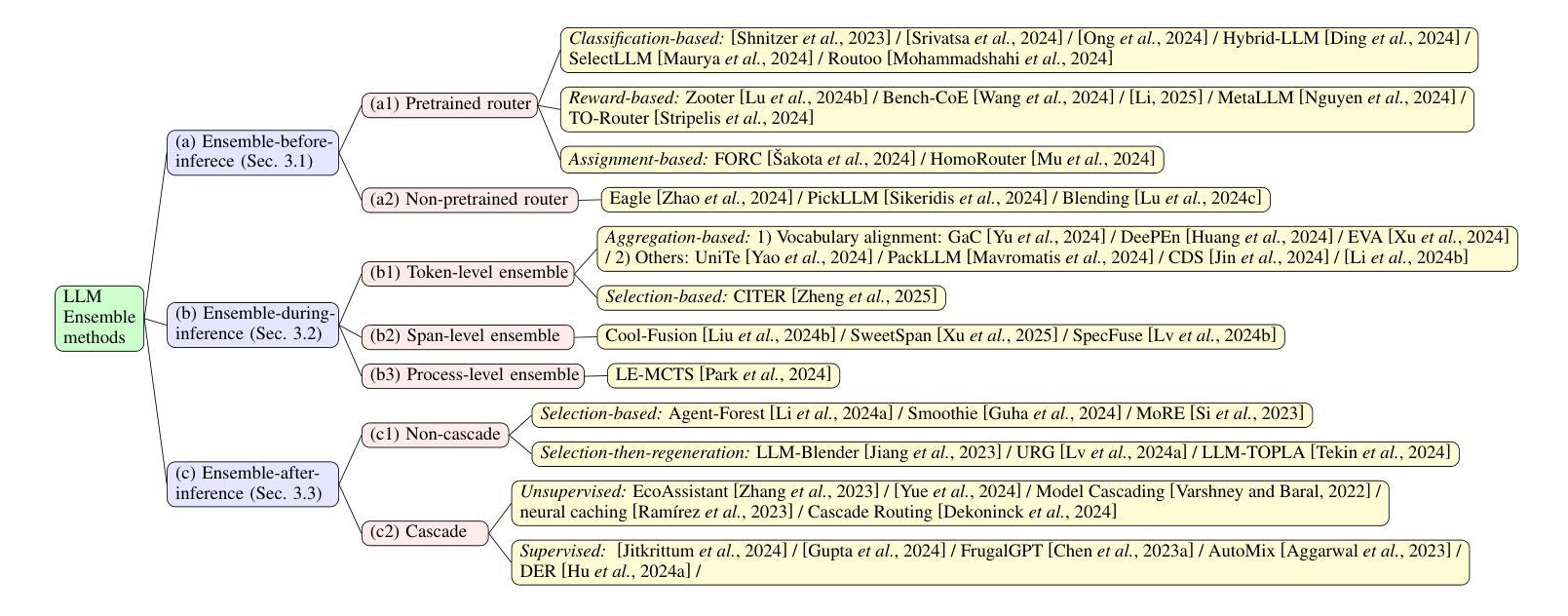
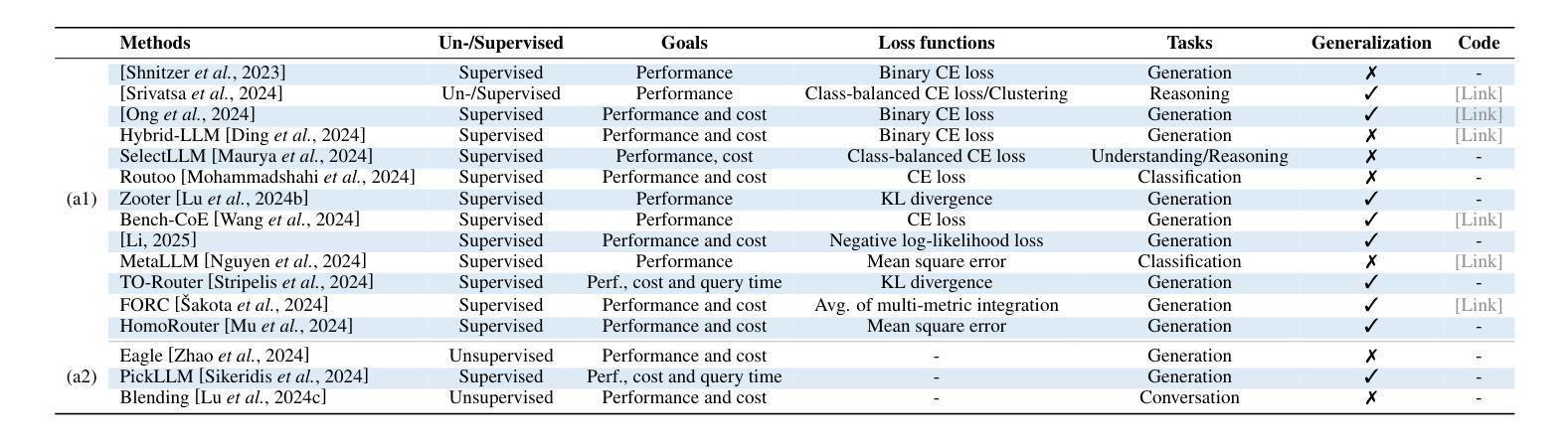
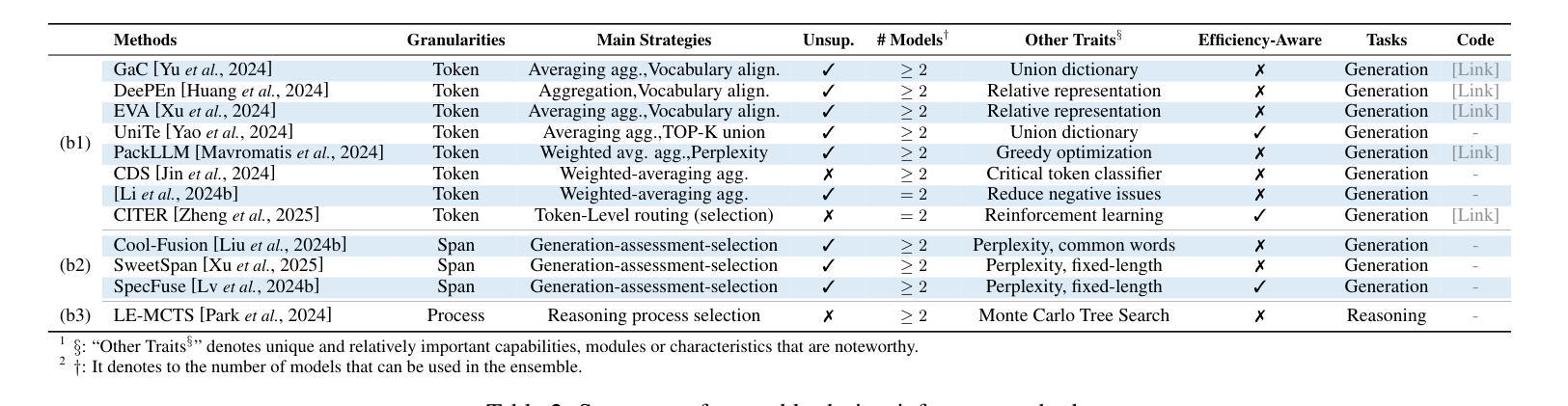
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Authors:Zhijun Chen, Jingzheng Li, Pengpeng Chen, Zhuoran Li, Kai Sun, Yuankai Luo, Qianren Mao, Dingqi Yang, Hailong Sun, Philip S. Yu
LLM Ensemble – which involves the comprehensive use of multiple large language models (LLMs), each aimed at handling user queries during downstream inference, to benefit from their individual strengths – has gained substantial attention recently. The widespread availability of LLMs, coupled with their varying strengths and out-of-the-box usability, has profoundly advanced the field of LLM Ensemble. This paper presents the first systematic review of recent developments in LLM Ensemble. First, we introduce our taxonomy of LLM Ensemble and discuss several related research problems. Then, we provide a more in-depth classification of the methods under the broad categories of “ensemble-before-inference, ensemble-during-inference, ensemble-after-inference’’, and review all relevant methods. Finally, we introduce related benchmarks and applications, summarize existing studies, and suggest several future research directions. A curated list of papers on LLM Ensemble is available at https://github.com/junchenzhi/Awesome-LLM-Ensemble.
LLM集合(LLM Ensemble)——涉及全面使用多个大型语言模型(LLM),每个模型旨在在下游推理过程中处理用户查询,以受益于各自的优势——最近引起了广泛关注。大型语言模型的广泛可用性,以及它们各自的性能优势和开箱即用性,极大地推动了LLM集合领域的发展。本文首次对LLM集合的最新发展进行了系统回顾。首先,我们介绍了LLM集合的分类学,并讨论了几个相关的研究问题。然后,我们在“推理前集合”、“推理中集合”、“推理后集合”的广义类别下,深入剖析了相关方法,并对所有相关方法进行了评述。最后,我们介绍了相关的基准测试和应用程序,总结了现有研究,并提出了几个未来的研究方向。关于LLM集合的论文列表可在https://github.com/junchenzhi/Awesome-LLM-Ensemble找到。
论文及项目相关链接
PDF 9 pages, 2 figures, codebase: https://github.com/junchenzhi/Awesome-LLM-Ensemble
Summary:多语言模型集合(LLM Ensemble)方法通过综合运用多个大型语言模型(LLM),以在下游推理过程中处理用户查询并受益于各自的独特优势,获得了广泛关注。本文系统地综述了LLM Ensemble的最新发展,介绍了分类、相关课题、方法和应用等,总结现有研究并提出未来研究方向。相关论文列表可参见链接。
Key Takeaways:
- LLM Ensemble涉及多个大型语言模型的综合运用,以在下游推理过程中处理用户查询。
- LLM的广泛可用性及其不同的优势和开箱即用性推动了LLM Ensemble的发展。
- 本文首次对LLM Ensemble的最新发展进行系统综述。
- 文章介绍了LLM Ensemble的分类和相关课题,深入探讨了“推理前集合”、“推理中集合”、“推理后集合”等方法。
- 文章还介绍了相关的基准测试和应用程序,总结了现有研究,并提出了未来的研究方向。
- 可以通过提供的链接找到关于LLM Ensemble的精选论文列表。
点此查看论文截图

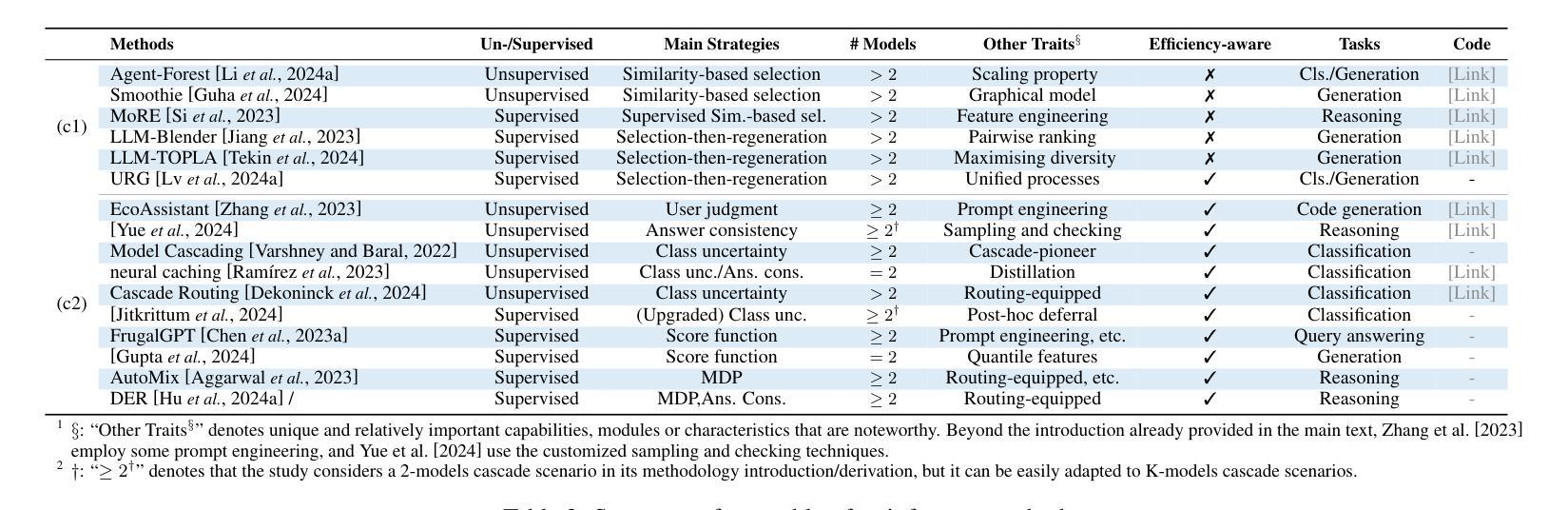
ARR: Question Answering with Large Language Models via Analyzing, Retrieving, and Reasoning
Authors:Yuwei Yin, Giuseppe Carenini
Large language models (LLMs) have demonstrated impressive capabilities on complex evaluation benchmarks, many of which are formulated as question-answering (QA) tasks. Enhancing the performance of LLMs in QA contexts is becoming increasingly vital for advancing their development and applicability. This paper introduces ARR, an intuitive, effective, and general QA solving method that explicitly incorporates three key steps: analyzing the intent of the question, retrieving relevant information, and reasoning step by step. Notably, this paper is the first to introduce intent analysis in QA, which plays a vital role in ARR. Comprehensive evaluations across 10 diverse QA tasks demonstrate that ARR consistently outperforms the baseline methods. Ablation and case studies further validate the positive contributions of each ARR component. Furthermore, experiments involving variations in prompt design indicate that ARR maintains its effectiveness regardless of the specific prompt formulation. Additionally, extensive evaluations across various model sizes, LLM series, and generation settings solidify the effectiveness, robustness, and generalizability of ARR.
大型语言模型(LLM)在复杂的评估基准测试中表现出了令人印象深刻的能力,其中许多被制定为问答(QA)任务。提高LLM在问答语境中的性能对于推动其发展和应用至关重要。本文介绍了一种直观、有效且通用的问答求解方法ARR,它明确包含了三个关键步骤:分析问题的意图、检索相关信息、逐步推理。值得注意的是,本文是首次在问答中引入意图分析,这在ARR中起到了至关重要的作用。在10个不同问答任务上的综合评估表明,ARR始终优于基线方法。消融研究和案例研究进一步验证了ARR每个组件的积极贡献。此外,涉及提示设计变化的实验表明,无论提示表述如何,ARR都能保持其有效性。同时,在不同模型大小、LLM系列和生成设置上的广泛评估,进一步证明了ARR的有效性、稳定性和泛化能力。
论文及项目相关链接
PDF 21 pages. Code: https://github.com/YuweiYin/ARR
Summary
LLMs展现出令人印象深刻的问答任务能力。该论文引入一种名为ARR的新型通用问答解决方法,其显著优势在于分析问题的意图、检索相关信息并逐步推理。该论文首次引入意图分析,对提升问答系统的性能起到了关键作用。实验表明,在各种不同任务上,ARR的性能始终优于基准方法。研究验证了其有效性、鲁棒性和泛化性。
Key Takeaways
- LLM在复杂评估基准测试中表现出强大的能力,尤其在问答任务方面。
- ARR是一种新型问答解决方法,包括分析问题的意图、检索相关信息和逐步推理三个关键步骤。
- 该论文首次引入意图分析在问答中的重要性。
- ARR在各种不同的问答任务上表现出优异的性能,且其有效性得到广泛的实验验证。
- ARR具有显著的有效性、鲁棒性和泛化性,适应不同的模型大小、LLM系列和生成设置。
点此查看论文截图


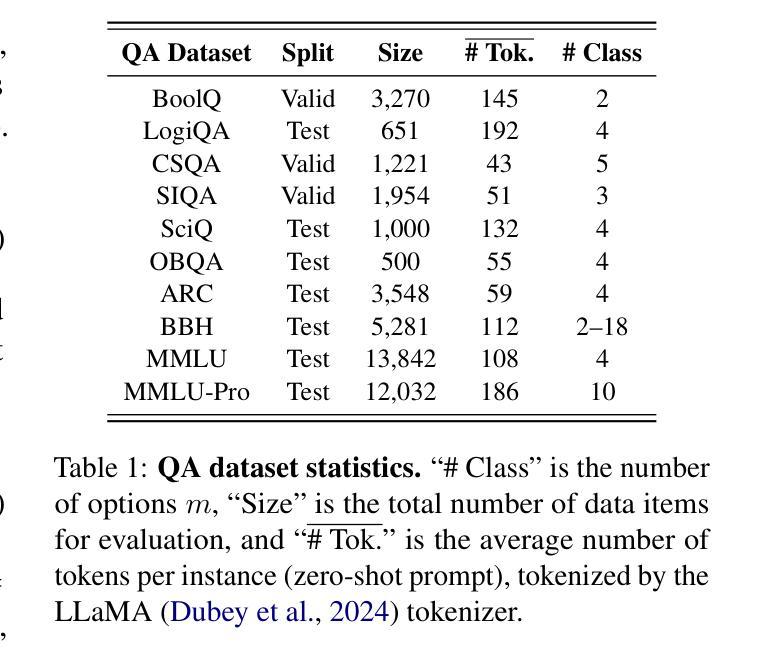
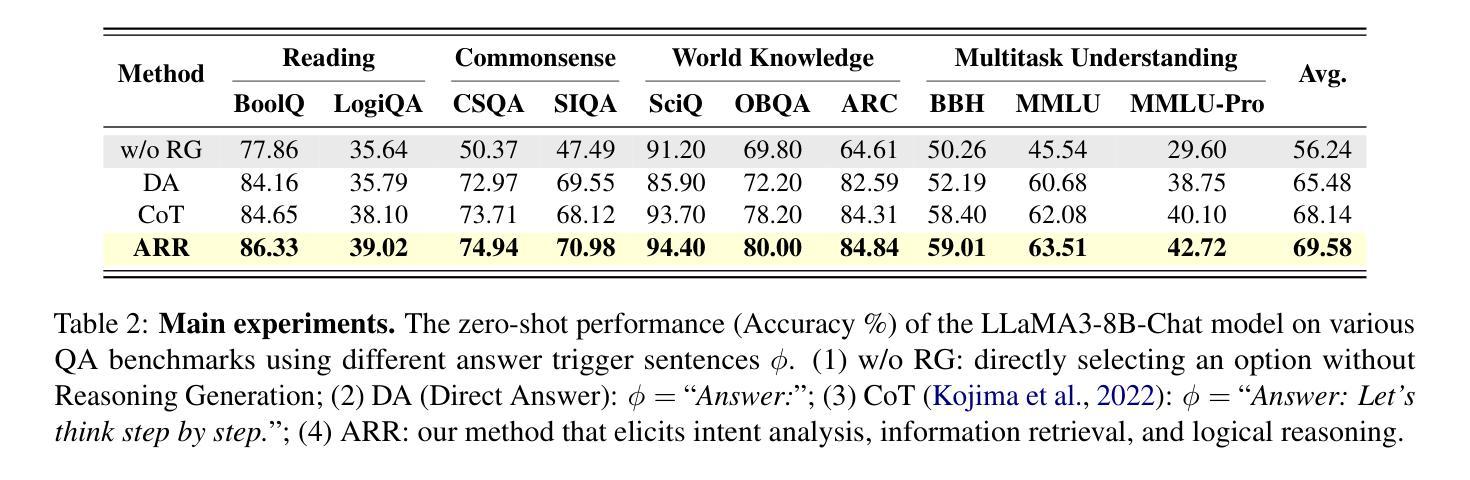
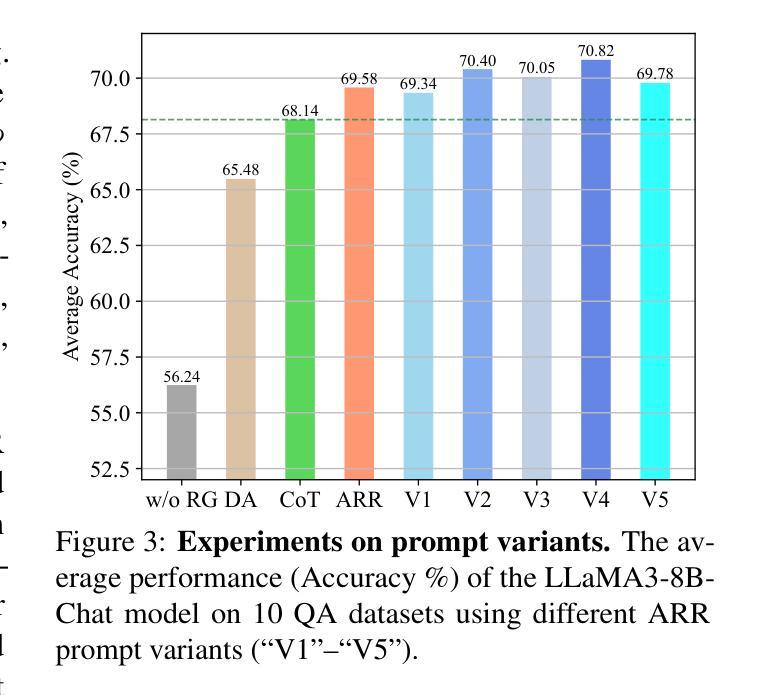
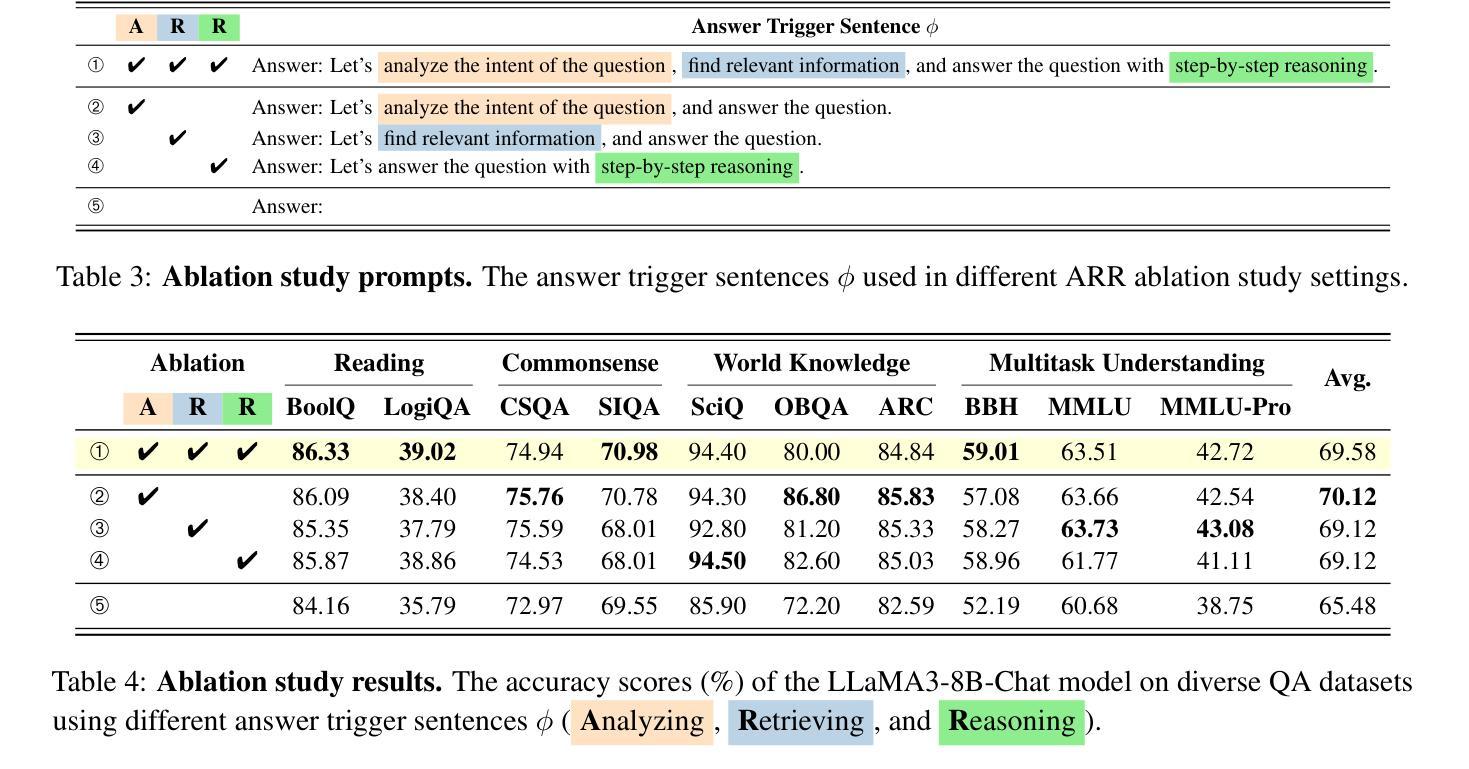
Benchmarking Generative AI for Scoring Medical Student Interviews in Objective Structured Clinical Examinations (OSCEs)
Authors:Jadon Geathers, Yann Hicke, Colleen Chan, Niroop Rajashekar, Justin Sewell, Susannah Cornes, Rene F. Kizilcec, Dennis Shung
Objective Structured Clinical Examinations (OSCEs) are widely used to assess medical students’ communication skills, but scoring interview-based assessments is time-consuming and potentially subject to human bias. This study explored the potential of large language models (LLMs) to automate OSCE evaluations using the Master Interview Rating Scale (MIRS). We compared the performance of four state-of-the-art LLMs (GPT-4o, Claude 3.5, Llama 3.1, and Gemini 1.5 Pro) in evaluating OSCE transcripts across all 28 items of the MIRS under the conditions of zero-shot, chain-of-thought (CoT), few-shot, and multi-step prompting. The models were benchmarked against a dataset of 10 OSCE cases with 174 expert consensus scores available. Model performance was measured using three accuracy metrics (exact, off-by-one, thresholded). Averaging across all MIRS items and OSCE cases, LLMs performed with low exact accuracy (0.27 to 0.44), and moderate to high off-by-one accuracy (0.67 to 0.87) and thresholded accuracy (0.75 to 0.88). A zero temperature parameter ensured high intra-rater reliability ({\alpha} = 0.98 for GPT-4o). CoT, few-shot, and multi-step techniques proved valuable when tailored to specific assessment items. The performance was consistent across MIRS items, independent of encounter phases and communication domains. We demonstrated the feasibility of AI-assisted OSCE evaluation and provided benchmarking of multiple LLMs across multiple prompt techniques. Our work provides a baseline performance assessment for LLMs that lays a foundation for future research into automated assessment of clinical communication skills.
客观结构化临床考试(OSCEs)被广泛用于评估医学生的沟通技巧,但是基于面试的评估打分耗时且可能受到人为偏见的影响。本研究探讨了大型语言模型(LLM)使用大师面试评分量表(MIRS)自动化OSCE评估的潜力。我们比较了四种最新LLM(GPT-4o、Claude 3.5、Llama 3.1和Gemini 1.5 Pro)在评估OSCE转录时的表现,涵盖了MIRS所有28项指标,包括零样本、思维链(CoT)、少样本和多步提示的情况。这些模型是以10个OSCE病例的数据集为基准,共有174个专家共识分数可供使用。模型性能采用三种准确性指标(精确、离一、阈值)进行测量。在所有MIRS项目和OSCE病例上的平均显示,LLM的精确准确性较低(0.27至0.44),离一准确性和阈值准确性为中等至高(0.67至0.87和0.75至0.88)。零温度参数确保了高内部一致性(GPT-4o的α=0.98)。思维链、少样本和多步技术对于特定的评估项目非常有价值。性能在MIRS项目上表现一致,与遭遇阶段和沟通领域无关。我们证明了AI辅助OSCE评估的可行性,并提供了多种LLM在多种提示技术上的基准测试。我们的工作为LLM提供了基线性能评估,为未来的临床沟通技能自动化评估研究奠定了基础。
论文及项目相关链接
PDF 12 pages + 3 pages of references, 4 figures
Summary:该研究探索了大型语言模型(LLMs)在医疗学生临床沟通技能评估中的自动化潜力。通过使用主面试评分量表(MIRS),对比了四种最新LLMs在OSCE评估中的表现。研究结果表明,LLMs在OSCE评估中的准确性较低,但在一定条件下,如链式思维(CoT)、少样本和多步提示等技术可以提高其表现。该研究为AI辅助OSCE评估提供了可行性证明,并为未来临床沟通技能自动化评估的研究提供了基准性能评估。
Key Takeaways:
- LLMs被探索用于自动化评估医疗学生的临床沟通技能。
- 研究使用了主面试评分量表(MIRS)来评估OSCE表现。
- 四种LLMs在OSCE评估中的准确性较低,但CoT、少样本和多步提示等技术可以提高其表现。
- LLMs的表现与MIRS项目一致,不受遇到阶段和沟通领域的影响。
- 研究证明了AI辅助OSCE评价的可行性。
- 此研究为LLMs在自动化评估中的性能提供了基准评估。
点此查看论文截图

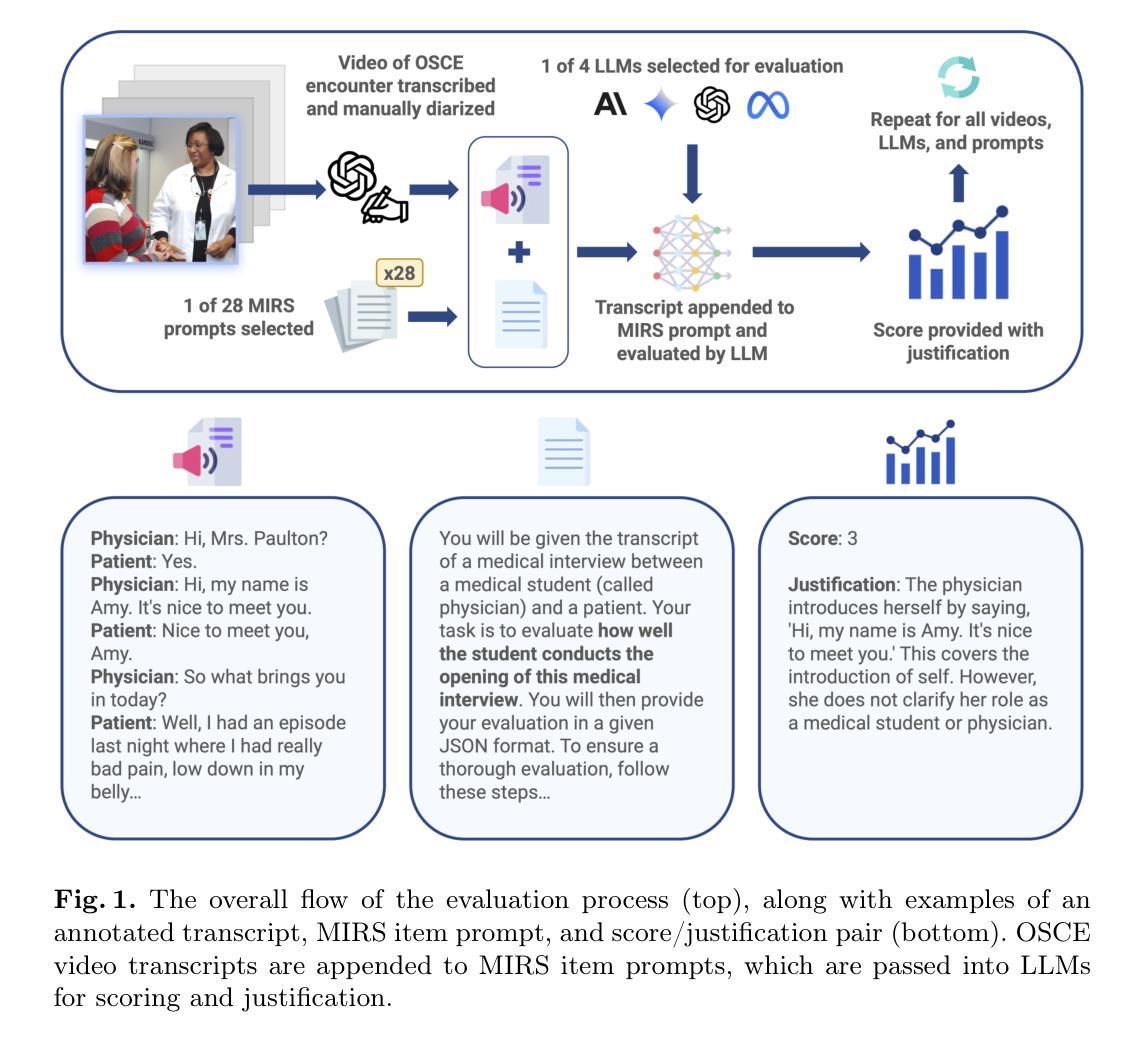
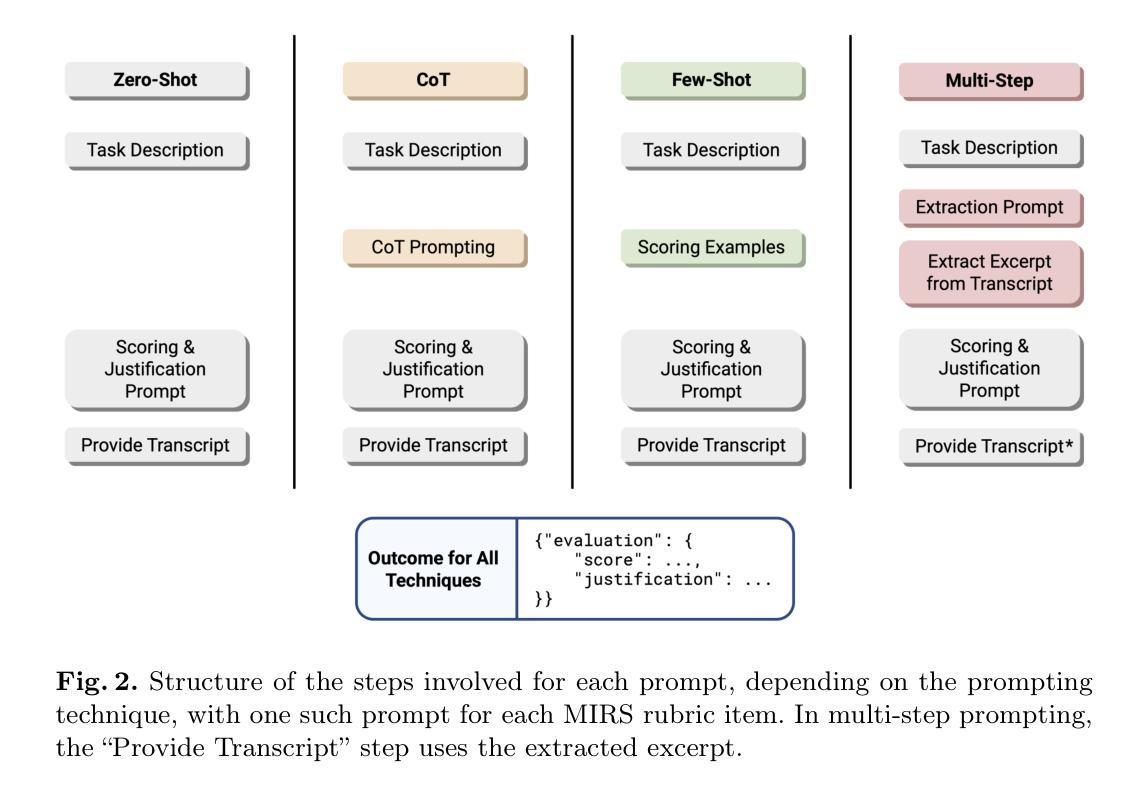
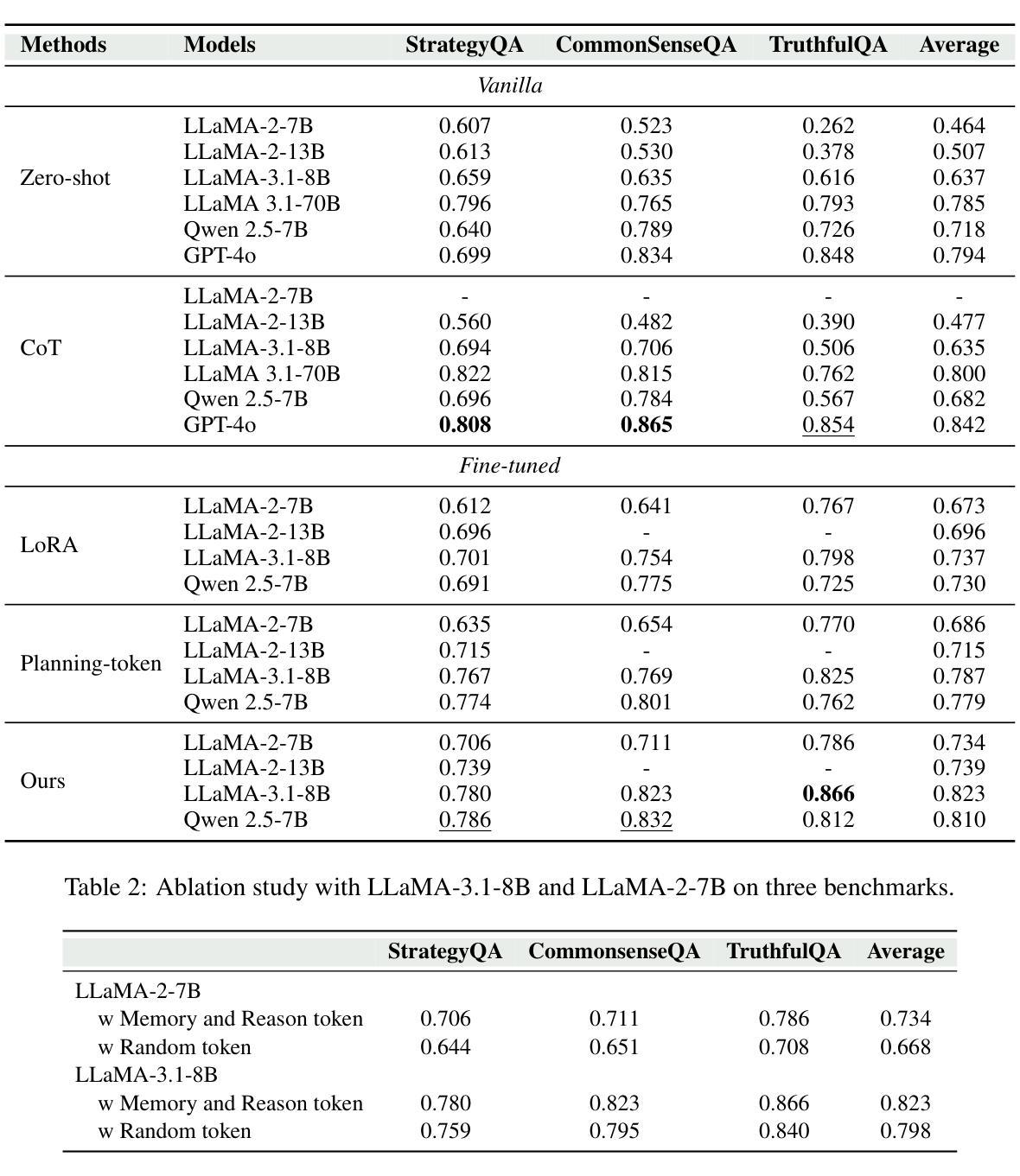
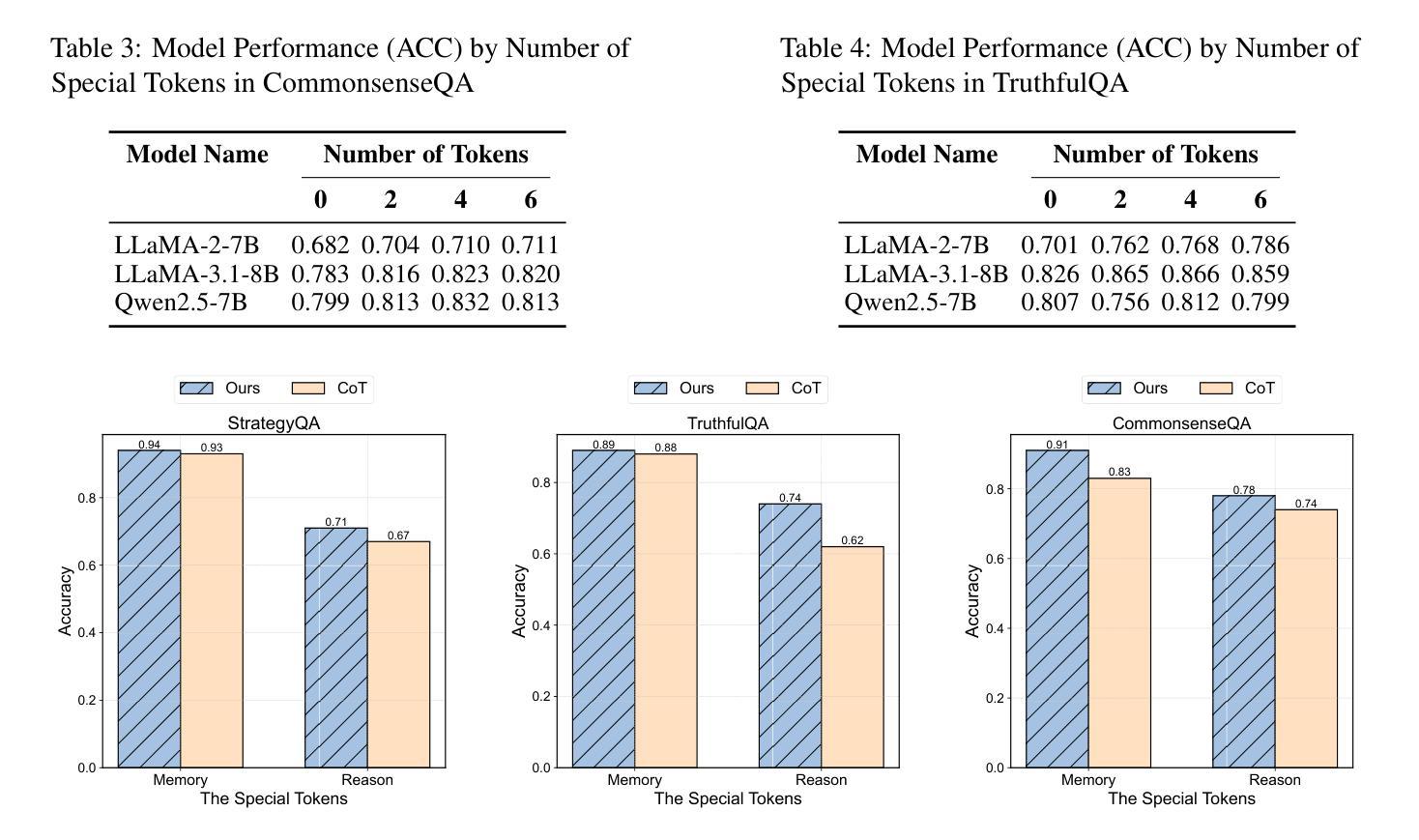
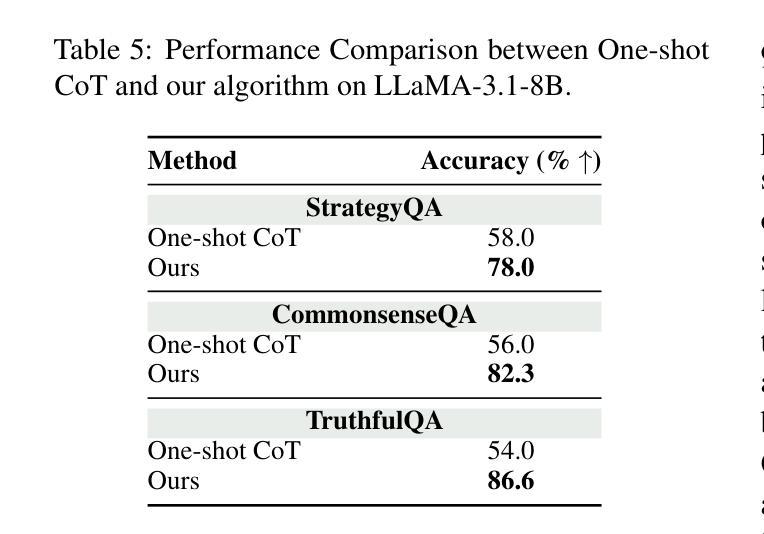
Disentangling Memory and Reasoning Ability in Large Language Models
Authors:Mingyu Jin, Weidi Luo, Sitao Cheng, Xinyi Wang, Wenyue Hua, Ruixiang Tang, William Yang Wang, Yongfeng Zhang
Large Language Models (LLMs) have demonstrated strong performance in handling complex tasks requiring both extensive knowledge and reasoning abilities. However, the existing LLM inference pipeline operates as an opaque process without explicit separation between knowledge retrieval and reasoning steps, making the model’s decision-making process unclear and disorganized. This ambiguity can lead to issues such as hallucinations and knowledge forgetting, which significantly impact the reliability of LLMs in high-stakes domains. In this paper, we propose a new inference paradigm that decomposes the complex inference process into two distinct and clear actions: (1) memory recall: which retrieves relevant knowledge, and (2) reasoning: which performs logical steps based on the recalled knowledge. To facilitate this decomposition, we introduce two special tokens memory and reason, guiding the model to distinguish between steps that require knowledge retrieval and those that involve reasoning. Our experiment results show that this decomposition not only improves model performance but also enhances the interpretability of the inference process, enabling users to identify sources of error and refine model responses effectively. The code is available at https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning.
大型语言模型(LLM)在处理需要广泛知识和推理能力的复杂任务时表现出强大的性能。然而,现有的LLM推理管道作为一个不透明的过程,没有明确地分离知识检索和推理步骤,导致模型的决策过程变得模糊且无序。这种模糊性可能导致幻想和知识遗忘等问题,这在高风险领域显著影响LLM的可靠性。在本文中,我们提出了一种新的推理范式,将复杂的推理过程分解为两个明确且不同的动作:(1)记忆回忆:检索相关知识;(2)推理:基于回忆的知识进行逻辑步骤。为了促进这种分解,我们引入了两个特殊符号“记忆”和“推理”,引导模型区分需要知识检索的步骤和涉及推理的步骤。我们的实验结果表明,这种分解不仅提高了模型性能,还提高了推理过程的可解释性,使用户能够识别错误来源并有效地改进模型响应。代码可在https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning上找到。
论文及项目相关链接
PDF Accepted by ACL 2025
Summary
大型语言模型(LLM)在处理需要广泛知识和推理能力的复杂任务时表现出强大的性能。然而,现有LLM的推理过程不够清晰,缺乏明确的将知识检索和推理步骤分开的机制,导致模型决策过程模糊和混乱。这种模糊性可能导致知识遗忘和幻想等问题,严重影响LLM在高风险领域的可靠性。本文提出了一种新的推理范式,将复杂的推理过程分解为两个明确且清晰的动作:记忆回忆和推理。记忆回忆用于检索相关知识,而推理则基于所回忆的知识进行逻辑步骤。通过引入记忆和推理两个特殊令牌来指导模型区分需要知识检索的步骤和涉及推理的步骤。实验结果表明,这种分解不仅提高了模型性能,还提高了推理过程的可解释性,使用户能够识别错误来源并有效地改进模型响应。
Key Takeaways
- LLM在处理复杂任务时表现出强大的性能,但需要改进其推理过程的清晰度和可解释性。
- 现有LLM的推理过程缺乏明确的知识检索和推理步骤分离,导致决策过程模糊。
- 知识遗忘和幻想等问题可能影响LLM在高风险领域的可靠性。
- 新的推理范式将复杂的推理过程分解为记忆回忆和推理两个明确动作。
- 记忆回忆负责检索相关知识,而推理则基于所回忆的知识进行逻辑推导。
- 通过引入记忆和推理两个特殊令牌,模型能够区分需要知识检索的步骤和涉及推理的步骤。
- 实验结果表明,这种分解提高了模型性能和推理过程的可解释性。
点此查看论文截图

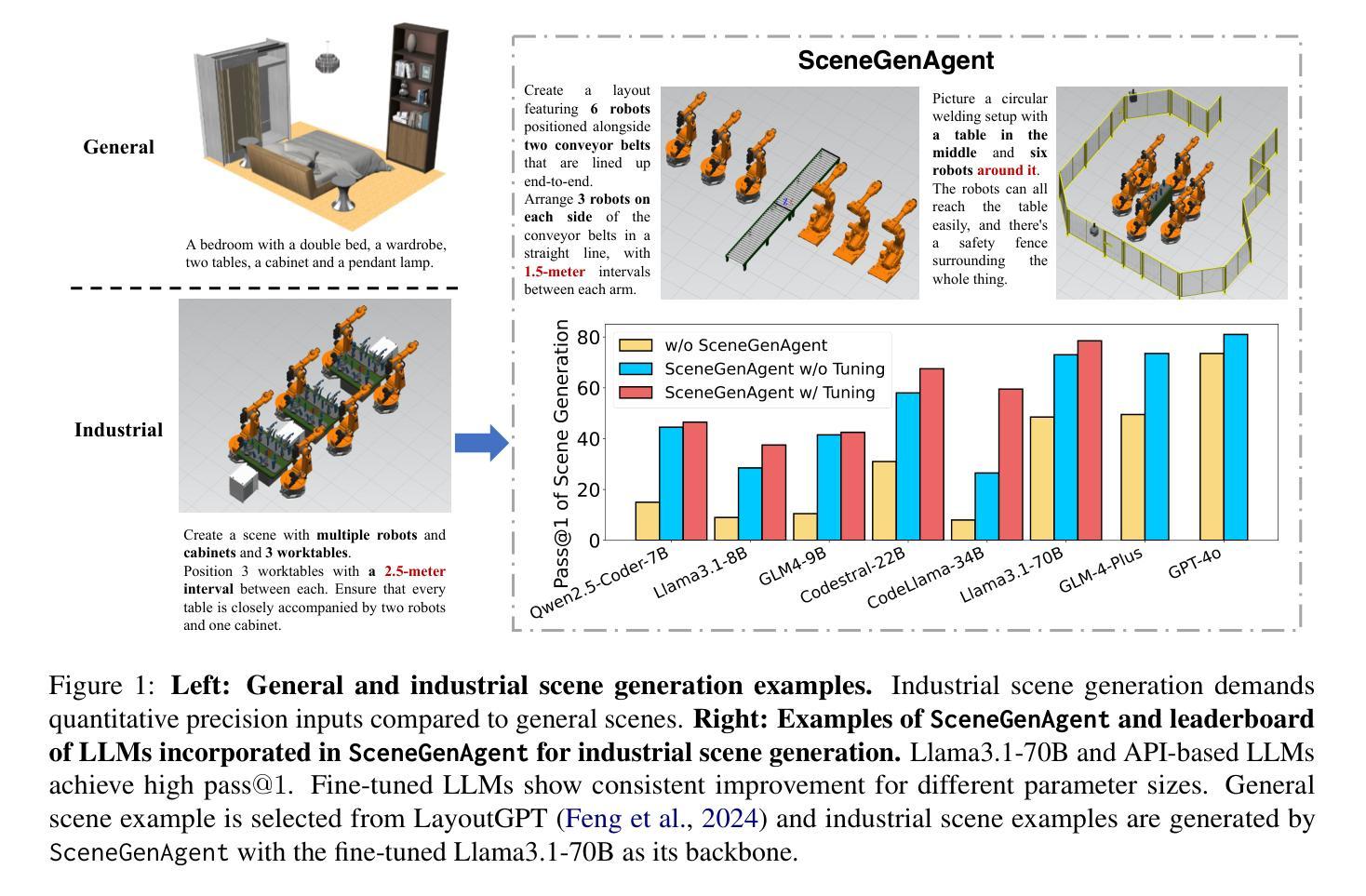
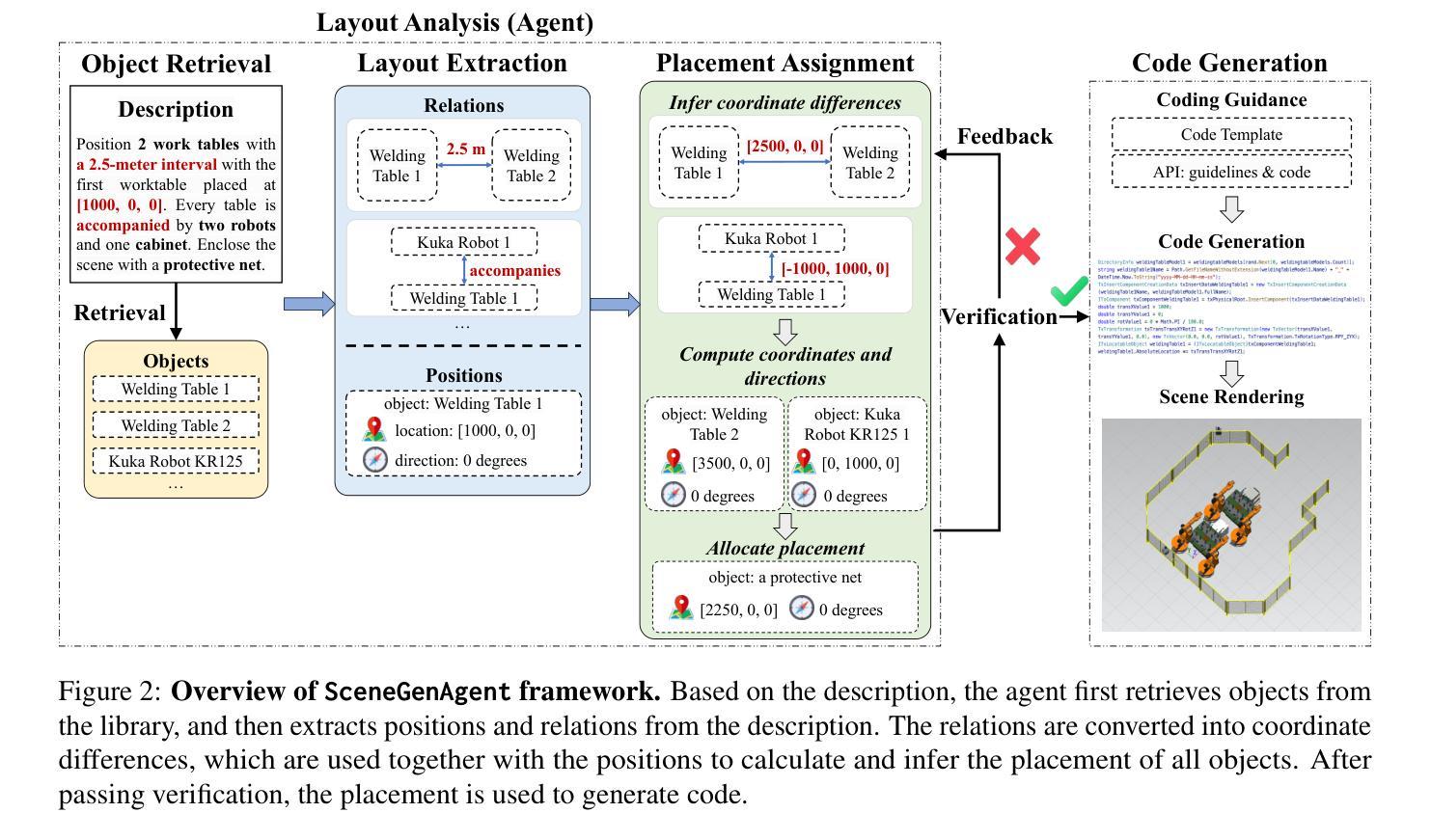
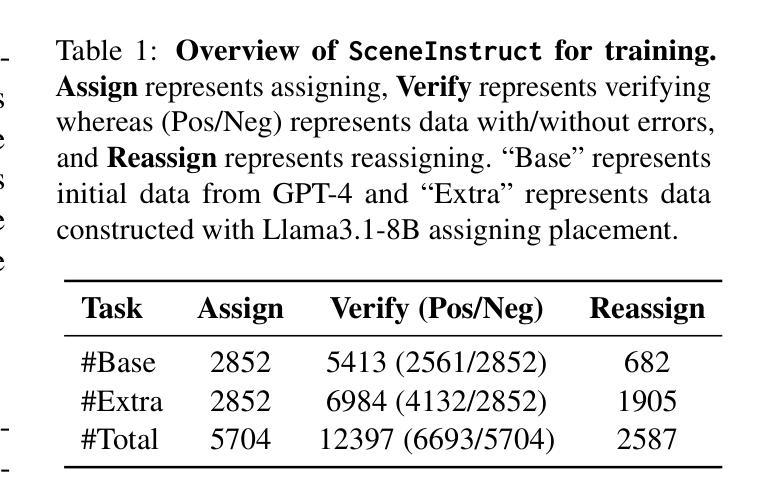
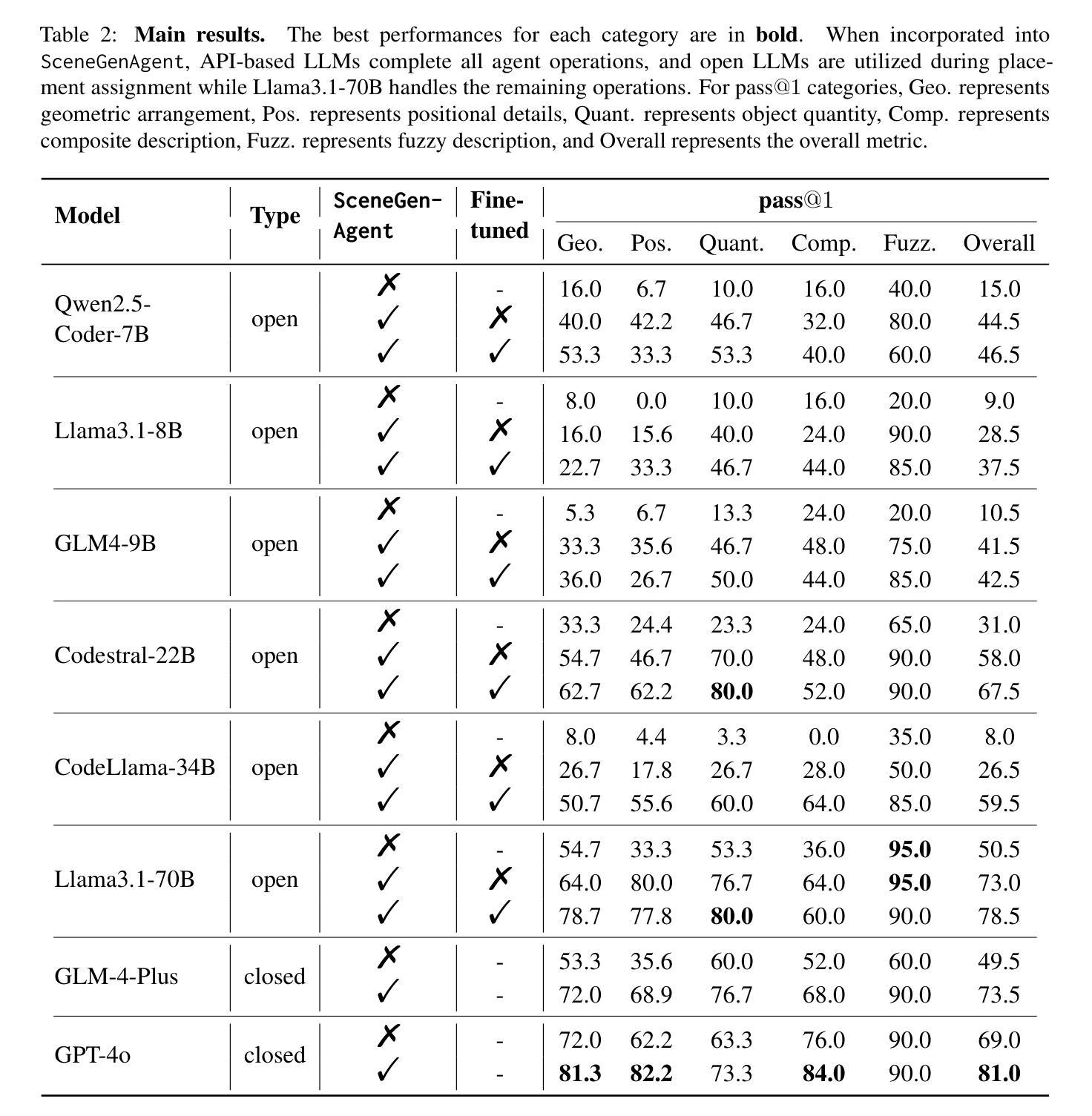
SceneGenAgent: Precise Industrial Scene Generation with Coding Agent
Authors:Xiao Xia, Dan Zhang, Zibo Liao, Zhenyu Hou, Tianrui Sun, Jing Li, Ling Fu, Yuxiao Dong
The modeling of industrial scenes is essential for simulations in industrial manufacturing. While large language models (LLMs) have shown significant progress in generating general 3D scenes from textual descriptions, generating industrial scenes with LLMs poses a unique challenge due to their demand for precise measurements and positioning, requiring complex planning over spatial arrangement. To address this challenge, we introduce SceneGenAgent, an LLM-based agent for generating industrial scenes through C# code. SceneGenAgent ensures precise layout planning through a structured and calculable format, layout verification, and iterative refinement to meet the quantitative requirements of industrial scenarios. Experiment results demonstrate that LLMs powered by SceneGenAgent exceed their original performance, reaching up to 81.0% success rate in real-world industrial scene generation tasks and effectively meeting most scene generation requirements. To further enhance accessibility, we construct SceneInstruct, a dataset designed for fine-tuning open-source LLMs to integrate into SceneGenAgent. Experiments show that fine-tuning open-source LLMs on SceneInstruct yields significant performance improvements, with Llama3.1-70B approaching the capabilities of GPT-4o. Our code and data are available at https://github.com/THUDM/SceneGenAgent .
工业场景的建模对于工业制造中的模拟至关重要。虽然大型语言模型(LLM)在根据文本描述生成一般的3D场景方面取得了显著进展,但使用LLM生成工业场景却构成了一项独特挑战,因为工业场景需要精确的测量和定位,并要求进行复杂的空间布局规划。为了应对这一挑战,我们引入了SceneGenAgent,这是一个基于LLM的代理,通过C#代码生成工业场景。SceneGenAgent通过结构化和可计算格式、布局验证以及迭代优化确保精确布局规划,以满足工业场景的定量要求。实验结果表明,由SceneGenAgent支持的LLM超越了其原始性能,在现实世界工业场景生成任务中的成功率高达8 结余以上,并有效地满足了大多数场景生成要求。为了进一步提高可及性,我们构建了SceneInstruct数据集,用于微调开源LLM以集成到SceneGenAgent中。实验表明,在SceneInstruct上微调开源LLM会显著提高性能,Llama3.1-70B接近GPT-4o的能力。我们的代码和数据集可在https://github.com/THUDM/SceneGenAgent上找到。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的SceneGenAgent在模拟工业制造中的工业场景建模方面具有关键作用。通过C#代码,SceneGenAgent能够确保精确布局规划,满足工业场景的定量要求。实验结果显示,SceneGenAgent使LLM的性能超越了原始水平,在现实世界的工业场景生成任务中达到了81.0%的成功率。为进一步提高可用性,研究者构建了SceneInstruct数据集,用于微调开源LLM以集成到SceneGenAgent中。经过SceneInstruct数据集训练的LLM表现出显著的性能提升。相关代码和数据已上传至GitHub仓库:https://github.com/THUDM/SceneGenAgent 。
Key Takeaways
- 工业场景建模对于工业制造仿真至关重要。
- 大型语言模型(LLM)在生成工业场景时面临精确测量和定位的挑战。
- SceneGenAgent是一个基于LLM的代理,能够通过C#代码生成工业场景,确保精确布局规划。
- SceneGenAgent成功解决了工业场景生成任务中的挑战,达到了高达81.0%的成功率。
- SceneInstruct数据集旨在微调开源LLM以提高性能并集成到SceneGenAgent中。
- 使用SceneInstruct数据集进行微调的LLM表现出显著性能提升。
点此查看论文截图

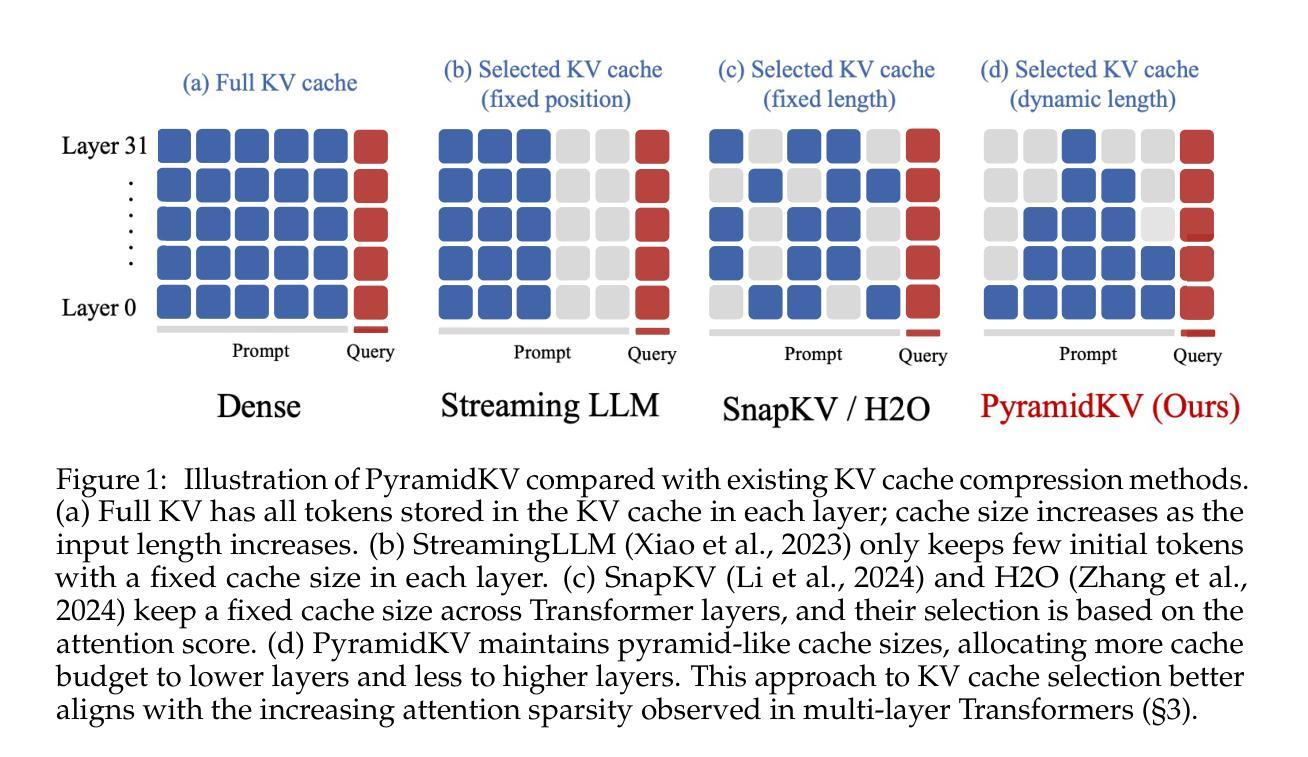
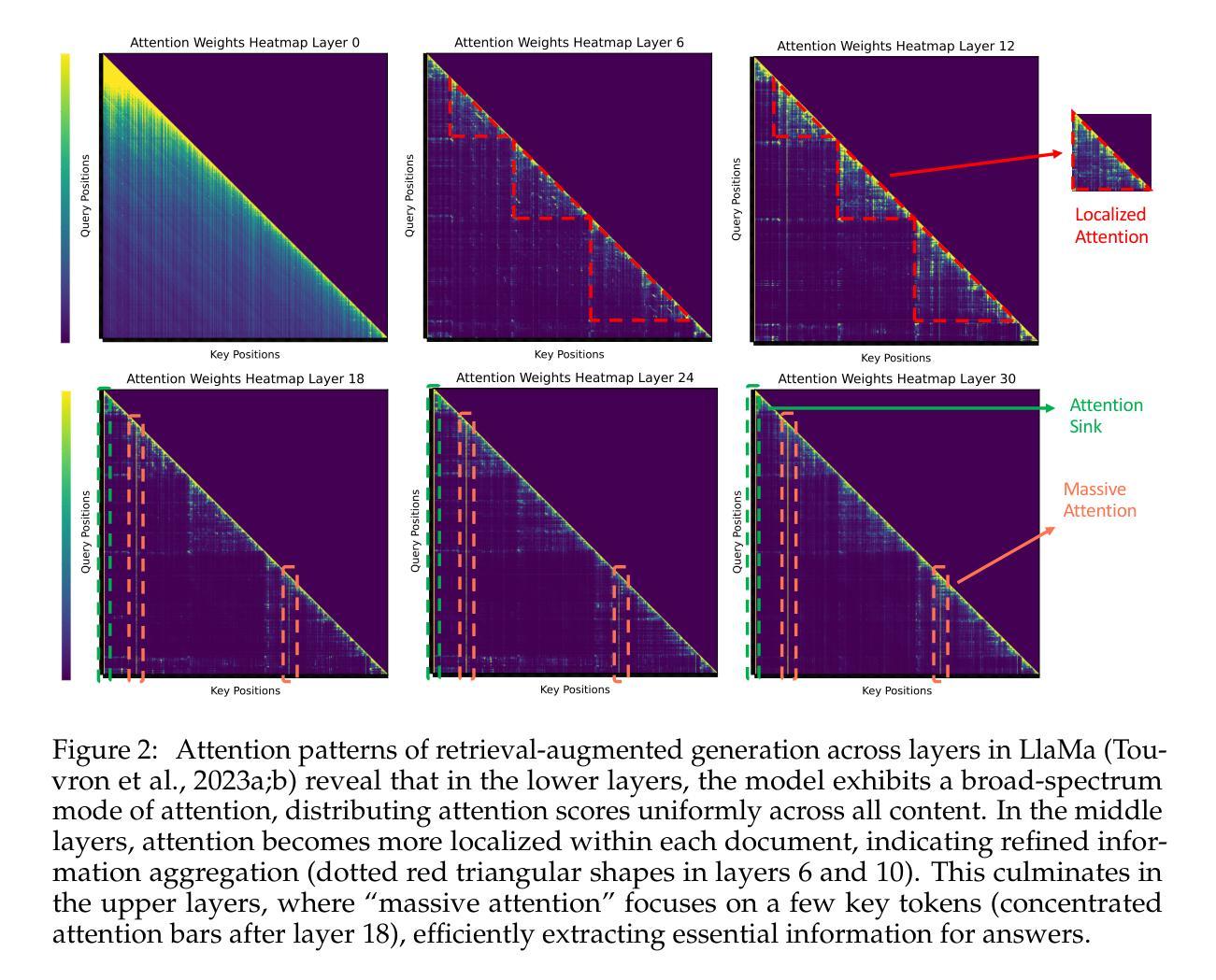
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Authors:Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, Wen Xiao
In this study, we investigate whether attention-based information flow inside large language models (LLMs) is aggregated through noticeable patterns for long context processing. Our observations reveal that LLMs aggregate information through Pyramidal Information Funneling where attention is scattering widely in lower layers, progressively consolidating within specific contexts, and ultimately focusing on critical tokens (a.k.a massive activation or attention sink) in higher layers. Motivated by these insights, we developed PyramidKV, a novel and effective KV cache compression method. This approach dynamically adjusts the KV cache size across different layers, allocating more cache in lower layers and less in higher ones, diverging from traditional methods that maintain a uniform KV cache size. Our experimental evaluations, utilizing the LongBench benchmark, show that PyramidKV matches the performance of models with a full KV cache while retaining only 12% of the KV cache, thus significantly reducing memory usage. In scenarios emphasizing memory efficiency, where only 0.7% of the KV cache is maintained, PyramidKV surpasses other KV cache compression techniques, achieving up to a 20.5 absolute accuracy improvement on TREC dataset. In the Needle-in-a-Haystack experiment, PyramidKV outperforms competing methods in maintaining long-context comprehension in LLMs; notably, retaining just 128 KV cache entries enables the LLAMA-3-70B model to achieve 100.0 Acc. performance.
在这项研究中,我们探究大型语言模型(LLM)中的基于注意力的信息流是否通过显著模式进行长期上下文处理。我们的观察发现,LLM通过金字塔信息汇集来整合信息,其中注意力在下层广泛分散,特定上下文中逐步巩固,并最终聚焦于高层的关键令牌(也称为大量激活或注意力汇)。受这些见解的启发,我们开发了一种新型有效的KV缓存压缩方法——PyramidKV。该方法动态调整不同层的KV缓存大小,在下层分配更多缓存,上层分配较少,这与传统方法保持统一的KV缓存大小不同。我们的实验评估,利用LongBench基准测试,显示PyramidKV在仅保留KV缓存的12%的情况下,就能达到全KV缓存模型的性能,从而显著减少内存使用。在强调内存效率的情境中,仅维持0.7%的KV缓存,PyramidKv超越其他KV缓存压缩技术,在TREC数据集上实现高达20.5的绝对精度提升。在“大海捞针”实验中,PyramidKV在保持LLM的长期上下文理解方面表现优于其他方法,值得注意的是,仅保留128个KV缓存条目就能使LLAMA-3-70B模型达到100.0%的准确率性能。
论文及项目相关链接
Summary
本研究探讨了大型语言模型(LLM)中基于注意力的信息流是否通过显著模式进行长期上下文处理。研究发现LLM通过金字塔信息汇聚来整合信息,注意力在低层广泛分布,然后在特定上下文中逐渐巩固,并最终聚焦于高层的关键标记(即大规模激活或注意力汇)。基于此,研究团队开发了一种新型的KV缓存压缩方法——PyramidKV。该方法动态调整不同层的KV缓存大小,在低层分配更多缓存,高层则分配较少,与传统维持统一KV缓存大小的方法不同。实验评估显示,PyramidKV在仅保留KV缓存的12%时,性能与全KV缓存模型相匹配,显著降低了内存使用。在强调内存效率的情境中,仅维护0.7%的KV缓存时,PyramidKV超越其他KV缓存压缩技术,在TREC数据集上实现了高达20.5的绝对精度提升。在Haystack实验中的“沙里淘金”任务中,PyramidKV在保持LLM的长期上下文理解能力方面表现出色,仅保留128个KV缓存条目,使LLAMA-3-70B模型达到100.0%的准确率。
Key Takeaways
- 大型语言模型(LLM)通过金字塔信息汇聚整合信息,注意力在不同层级有特定的分布模式。
- PyramidKV是一种新型的KV缓存压缩方法,动态调整不同层的KV缓存大小。
- PyramidKV在内存使用方面表现出显著优势,可以在保留较少的KV缓存时仍保持良好的性能。
- 在强调内存效率的情境中,PyramidKV较其他KV缓存压缩技术有更高的精度表现。
- PyramidKV有助于LLM在长期上下文处理中保持高性能。
- 在特定的实验中,PyramidKV使LLAMA-3-70B模型达到100%的准确率,显示出其有效性。
点此查看论文截图