⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-17 更新
Large-Scale Gaussian Splatting SLAM
Authors:Zhe Xin, Chenyang Wu, Penghui Huang, Yanyong Zhang, Yinian Mao, Guoquan Huang
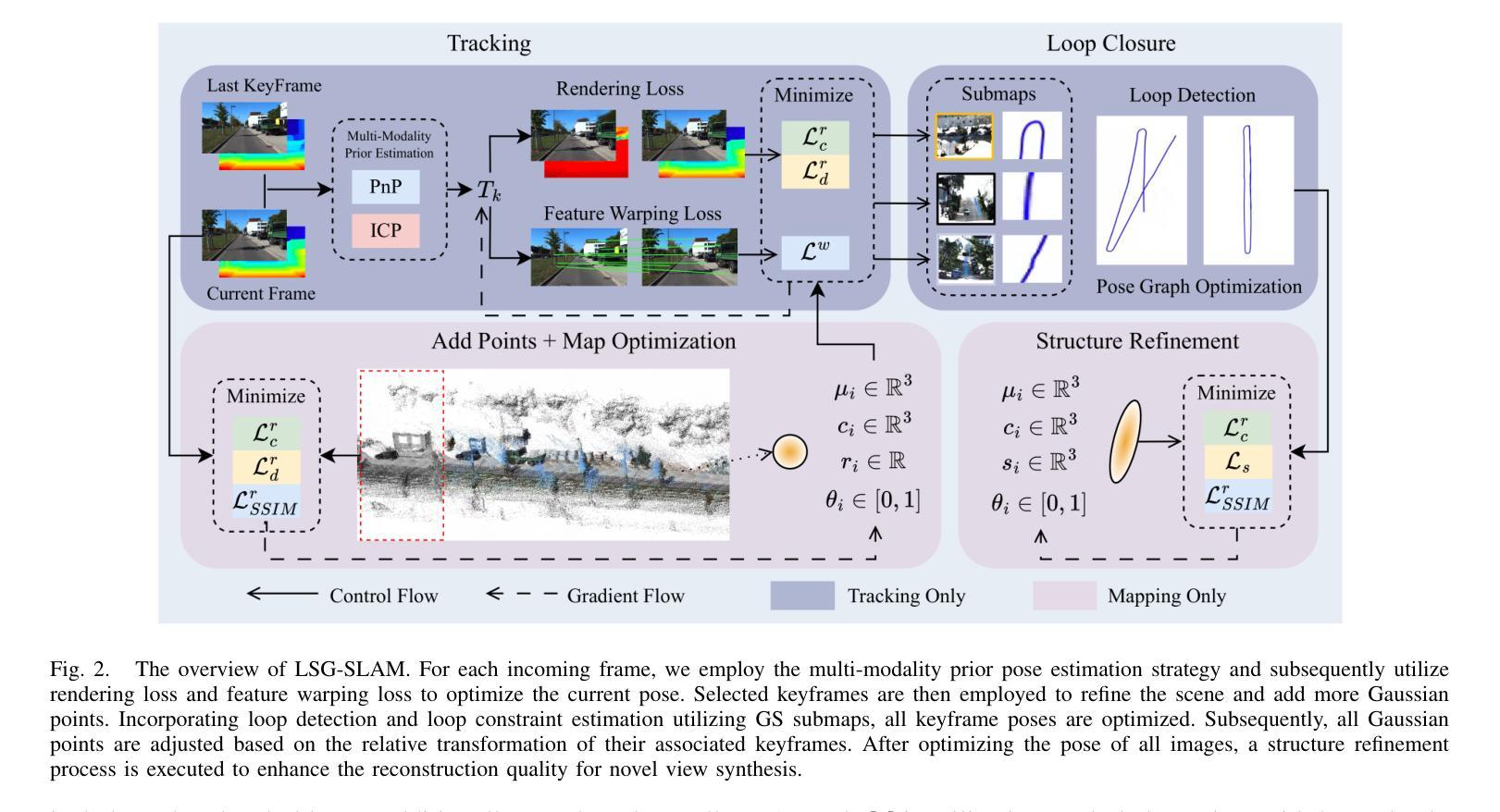
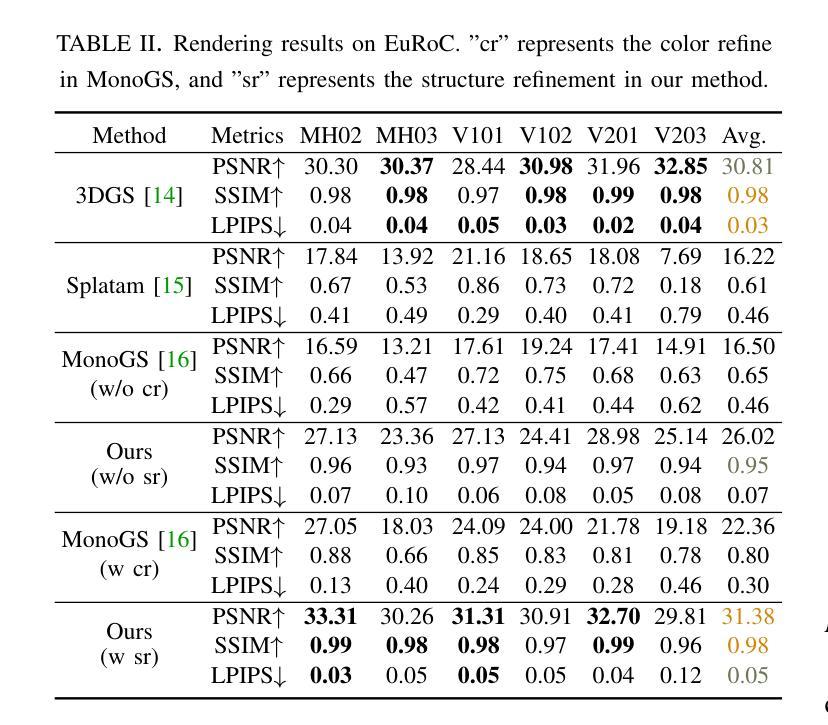
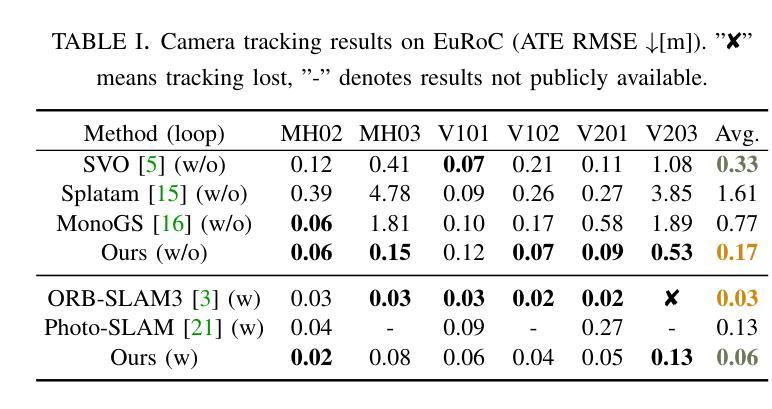
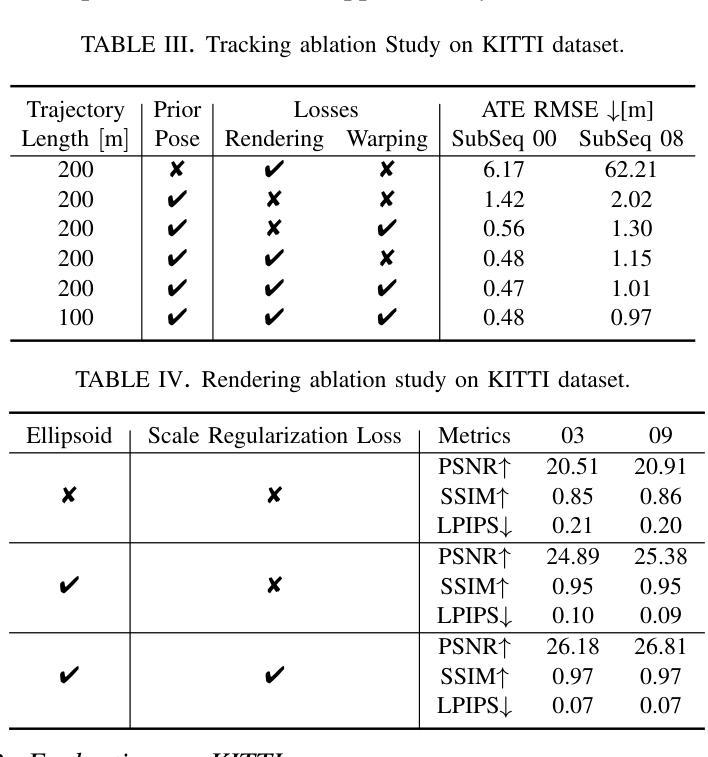
The recently developed Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown encouraging and impressive results for visual SLAM. However, most representative methods require RGBD sensors and are only available for indoor environments. The robustness of reconstruction in large-scale outdoor scenarios remains unexplored. This paper introduces a large-scale 3DGS-based visual SLAM with stereo cameras, termed LSG-SLAM. The proposed LSG-SLAM employs a multi-modality strategy to estimate prior poses under large view changes. In tracking, we introduce feature-alignment warping constraints to alleviate the adverse effects of appearance similarity in rendering losses. For the scalability of large-scale scenarios, we introduce continuous Gaussian Splatting submaps to tackle unbounded scenes with limited memory. Loops are detected between GS submaps by place recognition and the relative pose between looped keyframes is optimized utilizing rendering and feature warping losses. After the global optimization of camera poses and Gaussian points, a structure refinement module enhances the reconstruction quality. With extensive evaluations on the EuRoc and KITTI datasets, LSG-SLAM achieves superior performance over existing Neural, 3DGS-based, and even traditional approaches. Project page: https://lsg-slam.github.io.
最近开发的神经辐射场(NeRF)和三维高斯拼贴(3DGS)在视觉SLAM方面表现出了令人鼓舞和印象深刻的结果。然而,大多数代表性方法都需要RGBD传感器,并且仅适用于室内环境。在大规模室外场景中的重建稳健性尚未得到探索。本文介绍了一种基于大规模三维高斯拼贴的立体视觉SLAM(称为LSG-SLAM)。所提出的LSG-SLAM采用多模态策略来估计大变视角下前的姿态。在跟踪过程中,我们引入了特征对齐的变换约束,以减轻渲染损失中外观相似性对定位产生的不利影响。为了实现大规模场景的扩展性,我们引入连续高斯拼贴子图来处理内存有限的无限场景。通过位置识别检测GS子图之间的环路,并利用渲染和特征变换损失优化环路关键帧之间的相对姿态。在对相机姿态和高斯点进行全局优化后,结构细化模块提高了重建质量。在EuRoc和KITTI数据集上的广泛评估表明,LSG-SLAM在现有的神经网络、基于三维高斯拼贴甚至是传统方法中均表现出卓越性能。项目页面:https://lsg-slam.github.io。
论文及项目相关链接
Summary
本文介绍了基于大规模3D高斯喷绘(3DGS)的视觉SLAM方法,称为LSG-SLAM。该方法采用多模态策略估计大视角变化下的先验姿态,引入特征对齐变换约束减轻渲染损失中的外观相似性带来的不良影响。通过连续高斯喷绘子图处理大规模场景,以有限内存应对无界场景。通过位置识别和渲染及特征变换损失优化循环关键帧之间的相对姿态。经过对EuRoc和KITTI数据集的综合评估,LSG-SLAM相较于现有神经网络、3DGS甚至传统方法表现出卓越性能。
Key Takeaways
- LSG-SLAM是一种基于大规模3DGS的视觉SLAM方法,适用于室外环境。
- 该方法采用多模态策略估计先验姿态,处理大视角变化。
- 引入特征对齐变换约束,减轻渲染损失中的外观相似性影响。
- 通过连续高斯喷绘子图处理大规模场景,以有限内存应对无界场景。
- 通过位置识别优化循环关键帧之间的相对姿态,并利用渲染和特征变换损失进行优化。
- LSG-SLAM在EuRoc和KITTI数据集上的性能超越了现有神经网络、3DGS及传统方法。
点此查看论文截图

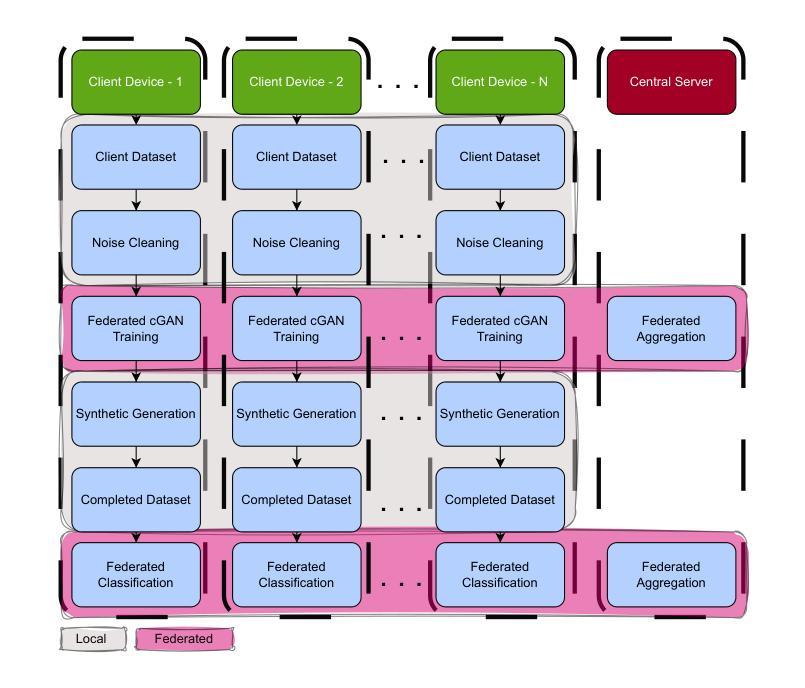
Robust Federated Learning with Confidence-Weighted Filtering and GAN-Based Completion under Noisy and Incomplete Data
Authors:Alpaslan Gokcen, Ali Boyaci
Federated learning (FL) presents an effective solution for collaborative model training while maintaining data privacy across decentralized client datasets. However, data quality issues such as noisy labels, missing classes, and imbalanced distributions significantly challenge its effectiveness. This study proposes a federated learning methodology that systematically addresses data quality issues, including noise, class imbalance, and missing labels. The proposed approach systematically enhances data integrity through adaptive noise cleaning, collaborative conditional GAN-based synthetic data generation, and robust federated model training. Experimental evaluations conducted on benchmark datasets (MNIST and Fashion-MNIST) demonstrate significant improvements in federated model performance, particularly macro-F1 Score, under varying noise and class imbalance conditions. Additionally, the proposed framework carefully balances computational feasibility and substantial performance gains, ensuring practicality for resource constrained edge devices while rigorously maintaining data privacy. Our results indicate that this method effectively mitigates common data quality challenges, providing a robust, scalable, and privacy compliant solution suitable for diverse real-world federated learning scenarios.
联邦学习(FL)为解决分散式客户端数据集的协同模型训练问题并维持数据隐私提供了有效解决方案。然而,标签噪声、缺失类别和分布不均衡等数据质量问题为其带来了巨大挑战。本研究提出了一种联邦学习的方法论,该方法系统解决了数据质量问题,包括噪声、类别不均衡和缺失标签。所提出的方法通过自适应噪声清理、基于协作条件生成对抗网络(GAN)的合成数据生成和稳健的联邦模型训练,系统地提高了数据的完整性。在基准数据集(MNIST和Fashion-MNIST)上进行的实验评估表明,在不同的噪声和类别不均衡条件下,联邦模型的性能,特别是宏F1得分有了显著的提升。此外,所提出的框架在仔细权衡计算可行性和显著性能提升的同时,确保了资源受限的边缘设备的实用性,并严格维持数据隐私。我们的结果表明,该方法有效地缓解了常见的数据质量挑战,提供了一个稳健、可扩展且符合隐私保护要求的解决方案,适用于各种现实世界中的联邦学习场景。
论文及项目相关链接
Summary
联合学习为解决分散数据集上的协作模型训练及数据隐私维护提供了有效方案。然而,标签噪声、类别缺失和分布不均衡等数据质量问题对其有效性构成重大挑战。本研究提出一种联邦学习方法,系统性地解决噪声、类别失衡和标签缺失等问题。通过自适应噪声清理、协作条件生成对抗网络合成数据生成和稳健的联邦模型训练,增强了数据完整性。在基准数据集上的实验评估表明,在不同噪声和类别失衡条件下,联邦模型性能显著提高,尤其是宏观F1分数。此外,该框架在保持数据隐私的同时,实现了计算可行性和显著性能提升之间的平衡,确保了边缘设备的实用性。此方法有效缓解常见数据质量挑战,为多样化的现实联邦学习场景提供稳健、可扩展和隐私合规的解决方案。
Key Takeaways
- 联邦学习是协作模型训练和保持数据隐私的有效方法。
- 数据质量问题(如噪声、类别失衡和标签缺失)对联邦学习的有效性构成挑战。
- 本研究提出一种系统性解决数据质量问题的联邦学习方法。
- 通过自适应噪声清理、协作条件GAN和稳健的联邦模型训练增强数据完整性。
- 实验评估显示,该方法显著提高联邦模型性能,特别是在处理噪声和类别失衡方面。
- 该框架在保持数据隐私的同时,实现了计算可行性和性能提升之间的平衡。
点此查看论文截图


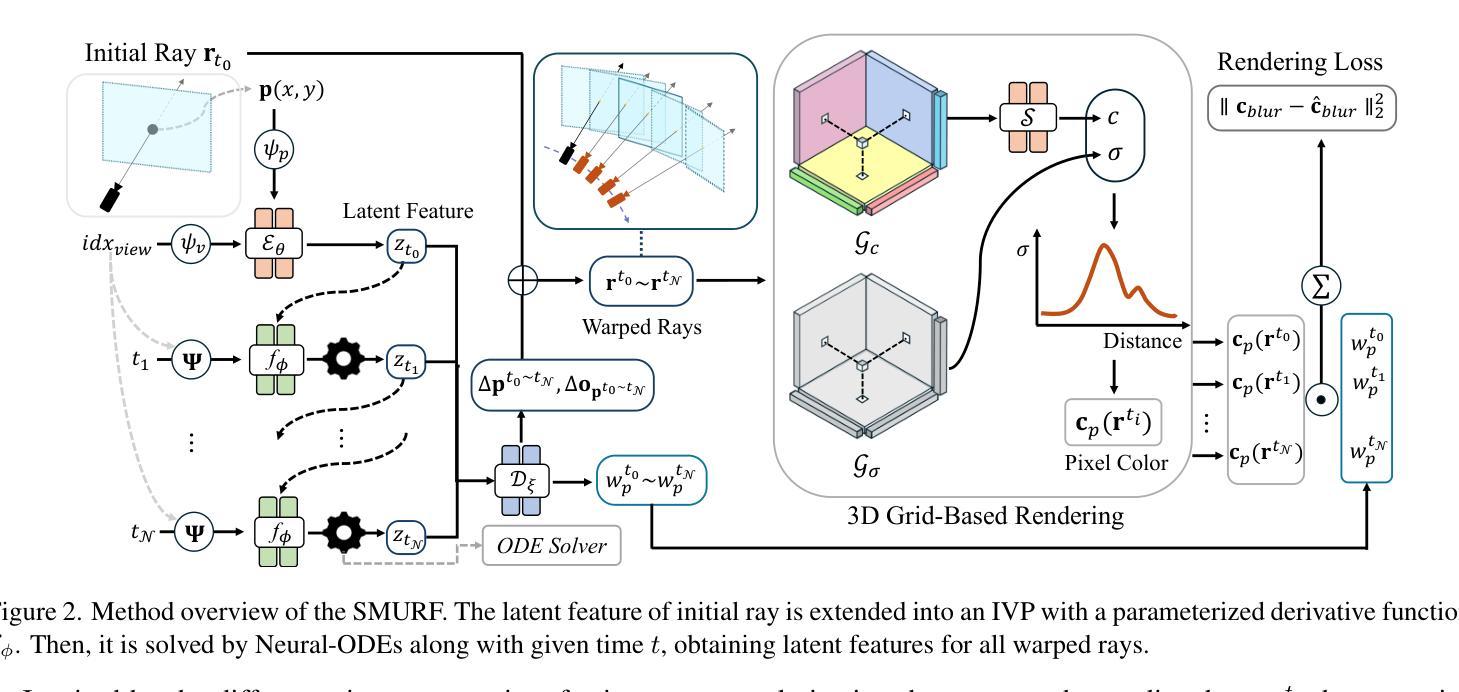
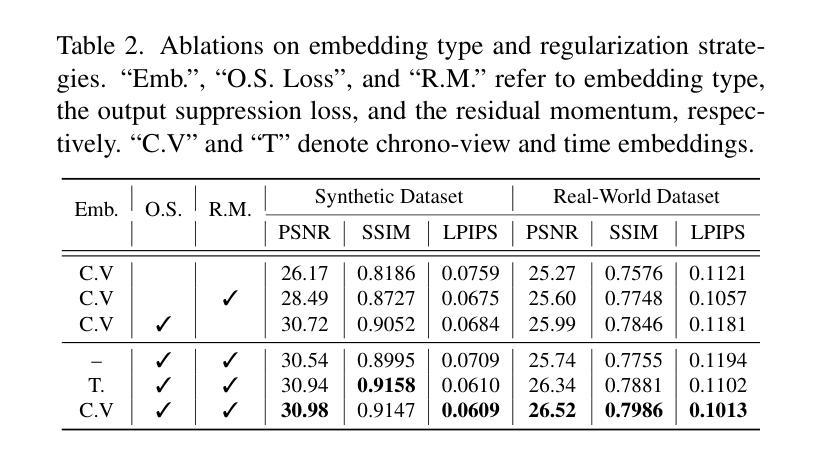
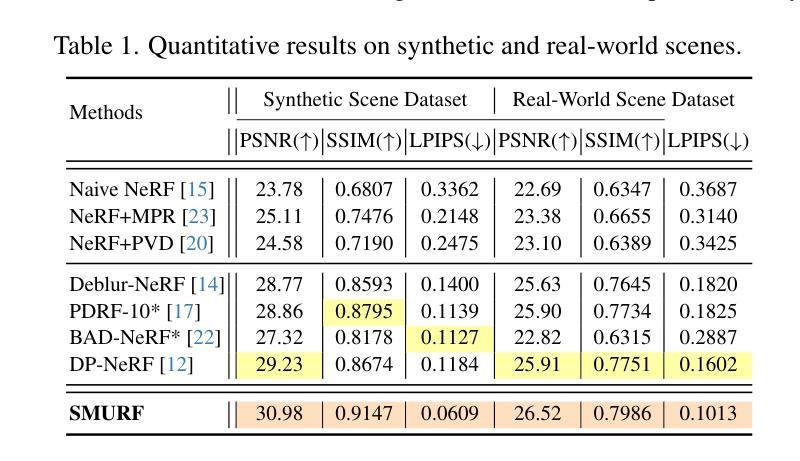
SMURF: Continuous Dynamics for Motion-Deblurring Radiance Fields
Authors:Jungho Lee, Dogyoon Lee, Minhyeok Lee, Donghyung Kim, Sangyoun Lee
Neural radiance fields (NeRF) has attracted considerable attention for their exceptional ability in synthesizing novel views with high fidelity. However, the presence of motion blur, resulting from slight camera movements during extended shutter exposures, poses a significant challenge, potentially compromising the quality of the reconstructed 3D scenes. To effectively handle this issue, we propose sequential motion understanding radiance fields (SMURF), a novel approach that models continuous camera motion and leverages the explicit volumetric representation method for robustness to motion-blurred input images. The core idea of the SMURF is continuous motion blurring kernel (CMBK), a module designed to model a continuous camera movements for processing blurry inputs. Our model is evaluated against benchmark datasets and demonstrates state-of-the-art performance both quantitatively and qualitatively.
神经辐射场(NeRF)因其合成高保真度新视角的卓越能力而备受关注。然而,由于长时间快门曝光过程中相机轻微移动产生的运动模糊,给重建的3D场景质量带来重大挑战。为了有效解决这一问题,我们提出了顺序运动理解辐射场(SMURF),这是一种新型方法,能够模拟连续相机运动,并利用明确的体积表示方法来增强对运动模糊输入图像的稳健性。SMURF的核心思想是连续运动模糊核(CMBK),这是一个专为处理模糊输入而设计的模块,用于模拟连续相机运动。我们的模型在基准测试数据集上进行了评估,并在定量和定性方面都表现出了卓越的性能。
论文及项目相关链接
PDF CVPRW 2025, Neural Fields Beyond Conventional Cameras, Project Page: https://jho-yonsei.github.io/SMURF/
Summary
神经网络辐射场(NeRF)因其高度逼真的三维场景合成能力而受到广泛关注。然而,由于长时间曝光导致的轻微相机运动产生的运动模糊,给重建的三维场景质量带来挑战。为解决此问题,我们提出序贯运动理解辐射场(SMURF),一种新型方法,能够模拟连续相机运动并利用显式体积表示法来应对运动模糊输入图像。SMURF的核心在于连续运动模糊核(CMBK)模块,该模块专为处理模糊输入而设计。在基准数据集上的评估显示,SMURF在定量和定性方面均表现出卓越性能。
Key Takeaways
- NeRF技术因其高度逼真的三维场景合成能力而受到关注。
- 运动模糊是NeRF技术面临的挑战之一,可能影响重建的三维场景质量。
- SMURF是一种新型方法,旨在解决NeRF中的运动模糊问题。
- SMURF通过模拟连续相机运动和利用显式体积表示法来处理运动模糊输入图像。
- CMBK模块是SMURF的核心,专为处理模糊输入而设计。
- SMURF在基准数据集上的表现优于其他方法,具有出色的定量和定性性能。
点此查看论文截图