⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-17 更新
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
Authors:Ke Wang, Junting Pan, Linda Wei, Aojun Zhou, Weikang Shi, Zimu Lu, Han Xiao, Yunqiao Yang, Houxing Ren, Mingjie Zhan, Hongsheng Li
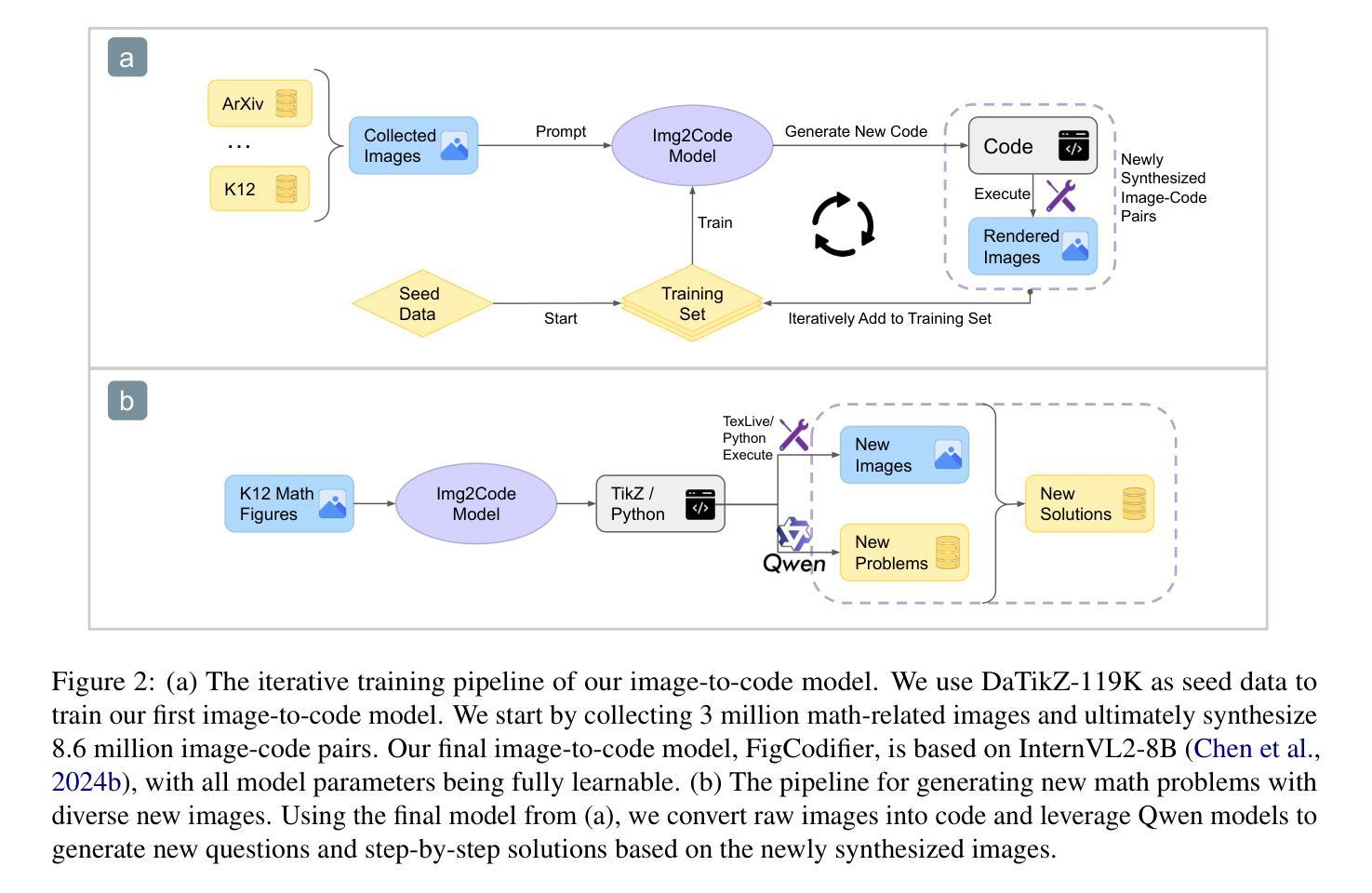
Natural language image-caption datasets, widely used for training Large Multimodal Models, mainly focus on natural scenarios and overlook the intricate details of mathematical figures that are critical for problem-solving, hindering the advancement of current LMMs in multimodal mathematical reasoning. To this end, we propose leveraging code as supervision for cross-modal alignment, since code inherently encodes all information needed to generate corresponding figures, establishing a precise connection between the two modalities. Specifically, we co-develop our image-to-code model and dataset with model-in-the-loop approach, resulting in an image-to-code model, FigCodifier and ImgCode-8.6M dataset, the largest image-code dataset to date. Furthermore, we utilize FigCodifier to synthesize novel mathematical figures and then construct MM-MathInstruct-3M, a high-quality multimodal math instruction fine-tuning dataset. Finally, we present MathCoder-VL, trained with ImgCode-8.6M for cross-modal alignment and subsequently fine-tuned on MM-MathInstruct-3M for multimodal math problem solving. Our model achieves a new open-source SOTA across all six metrics. Notably, it surpasses GPT-4o and Claude 3.5 Sonnet in the geometry problem-solving subset of MathVista, achieving improvements of 8.9% and 9.2%. The dataset and models will be released at https://github.com/mathllm/MathCoder.
自然语言图像标题数据集广泛应用于训练大型多模态模型,其主要关注自然场景,忽视了数学图形中的复杂细节,这些细节对于问题解决至关重要,从而阻碍了当前多模态数学推理LMMs的发展。为此,我们提出利用代码作为跨模态对齐的监督信息,因为代码本身就包含了生成相应图形所需的所有信息,从而在这两种模态之间建立了精确的联系。具体来说,我们采用带模型循环的方法,共同开发图像到代码的模型和数据集,从而得到图像到代码的模型FigCodifier以及迄今为止最大的图像代码数据集ImgCode-8.6M。此外,我们使用FigCodifier合成新型数学图形,然后构建高质量的多模态数学指令微调数据集MM-MathInstruct-3M。最后,我们推出MathCoder-VL,该模型以ImgCode-8.6M进行跨模态对齐训练,随后在MM-MathInstruct-3M上进行多模态数学问题解决的微调。我们的模型在六个指标上达到新的开源水平。值得注意的是,它在MathVista的几何问题解决子集中超越了GPT-4o和Claude 3.5 Sonnet,分别提高了8.9%和9.2%。数据集和模型将在https://github.com/mathllm/MathCoder发布。
论文及项目相关链接
PDF Accepted to ACL 2025 Findings
Summary
本文提出一种利用代码作为监督来实现跨模态对齐的方法,解决了当前自然语言图像数据集在多模态数学推理方面的不足。文章介绍了一种新型图像到代码的模型FigCodifier以及与该模型共同开发的ImgCode-8.6M数据集。此外,文章还利用FigCodifier合成新型数学图形,构建了高质量的多模态数学指令微调数据集MM-MathInstruct-3M。最后,文章介绍了使用ImgCode-8.6M进行跨模态对齐,并在MM-MathInstruct-3M上微调用于多模态数学问题解决模型的MathCoder-VL模型。该模型在六个指标上达到了新的开源水平,且在MathVista的几何问题解决子集中表现优于GPT-4o和Claude 3.5 Sonnet,提高了8.9%和9.2%。数据集和模型将在https://github.com/mathllm/MathCoder上发布。
Key Takeaways
- 当前的自然语言图像数据集在多模态数学推理方面存在不足,需要关注数学图形的细节。
- 提出利用代码作为监督实现跨模态对齐的方法,代码本身包含了生成图形的所有信息。
- 开发了图像到代码的模型FigCodifier以及与该模型配套的数据集ImgCode-8.6M,这是迄今为止最大的图像代码数据集。
- 利用FigCodifier合成新型数学图形,构建高质量的多模态数学指令微调数据集MM-MathInstruct-3M。
- 介绍了MathCoder-VL模型,该模型使用ImgCode-8.6M进行跨模态对齐,并在MM-MathInstruct-3M上进行微调,用于多模态数学问题解决。
- MathCoder-VL模型在多个指标上达到新的开源水平,并在MathVista的几何问题解决子集中表现优异,相较于GPT-4o和Claude 3.5 Sonnet有显著提升。
点此查看论文截图


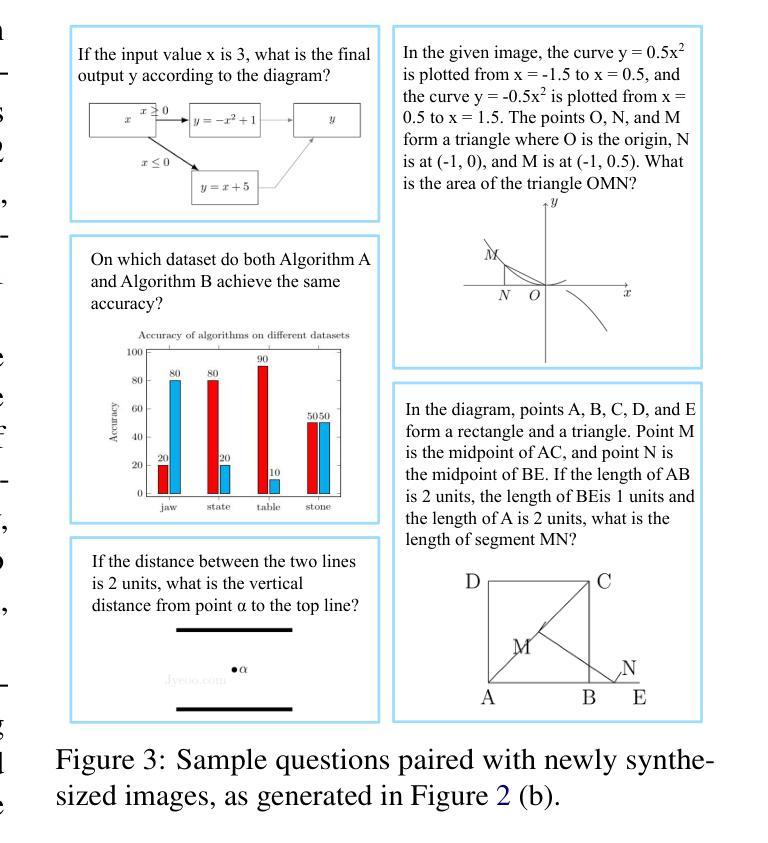
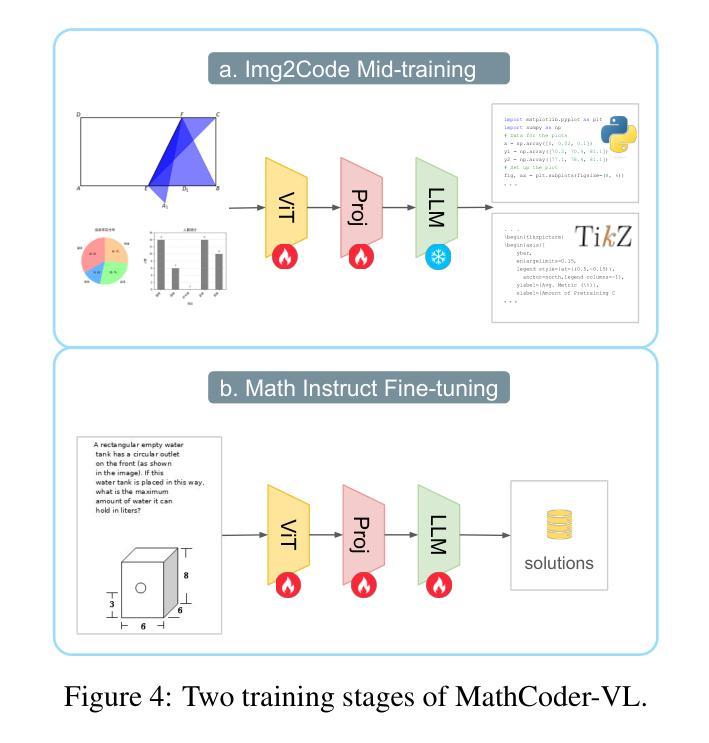
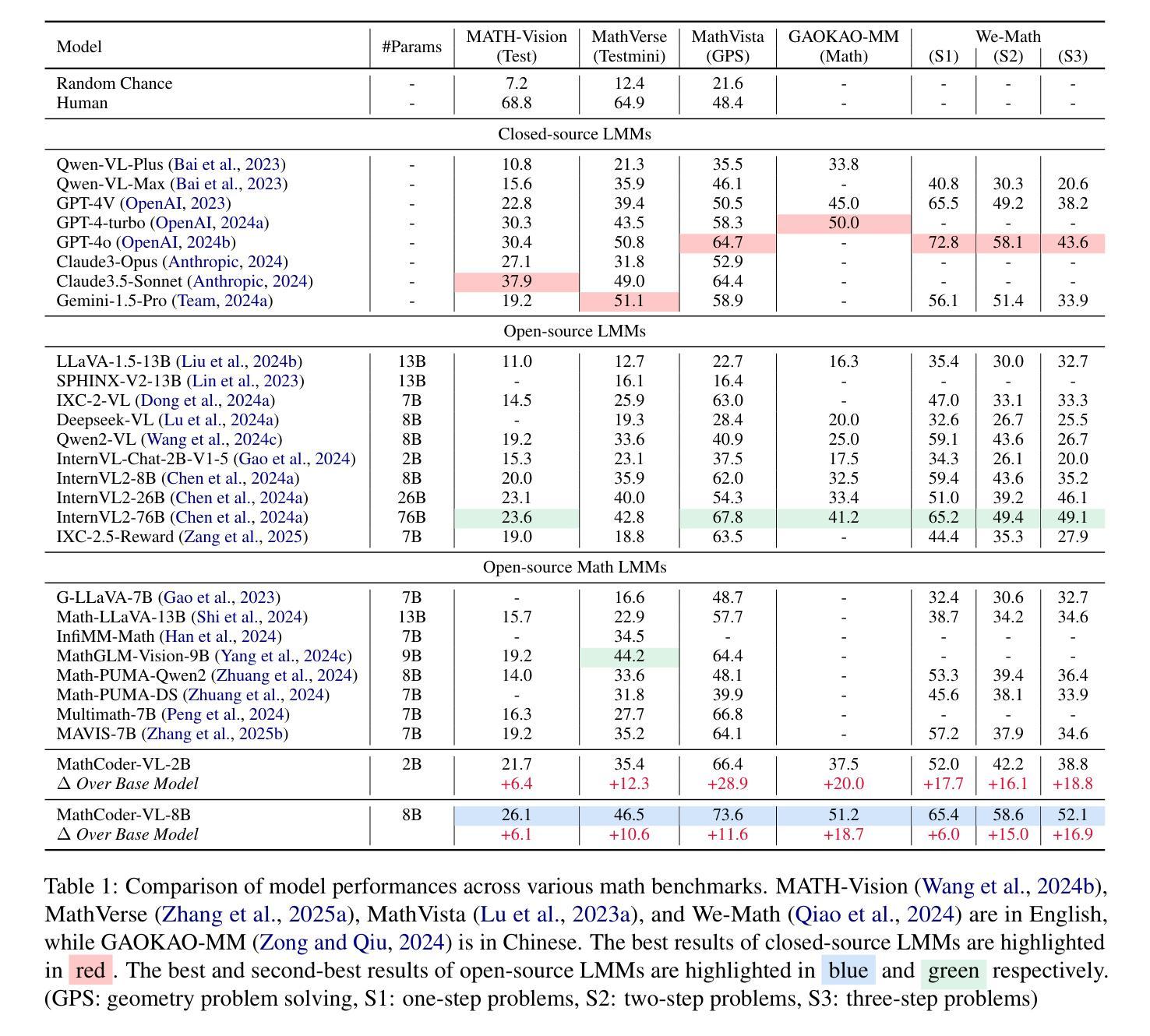
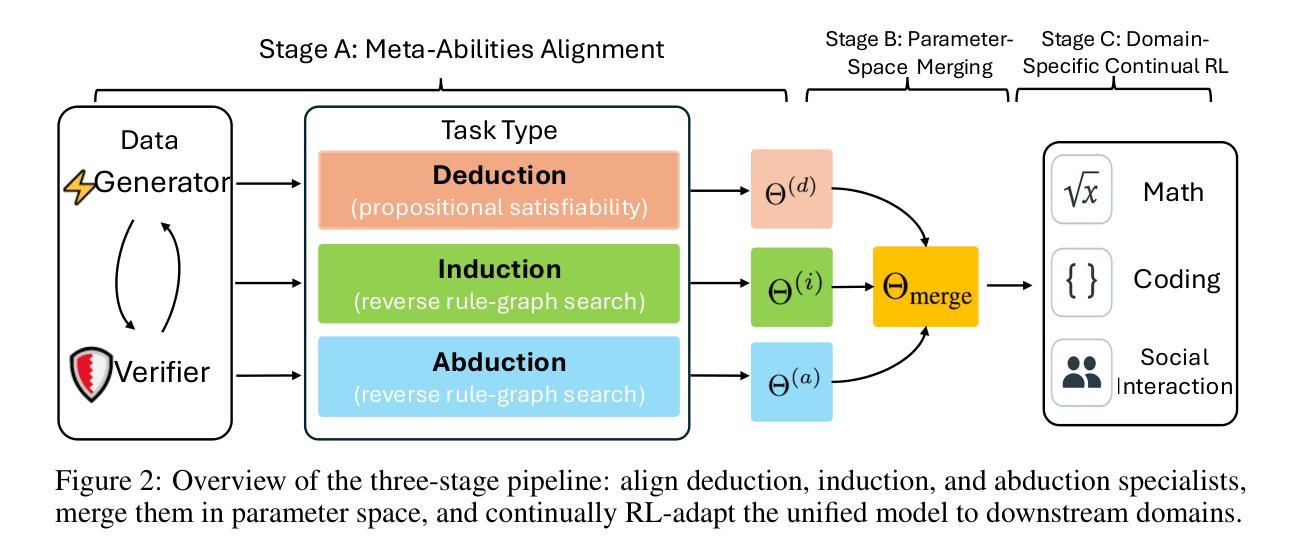
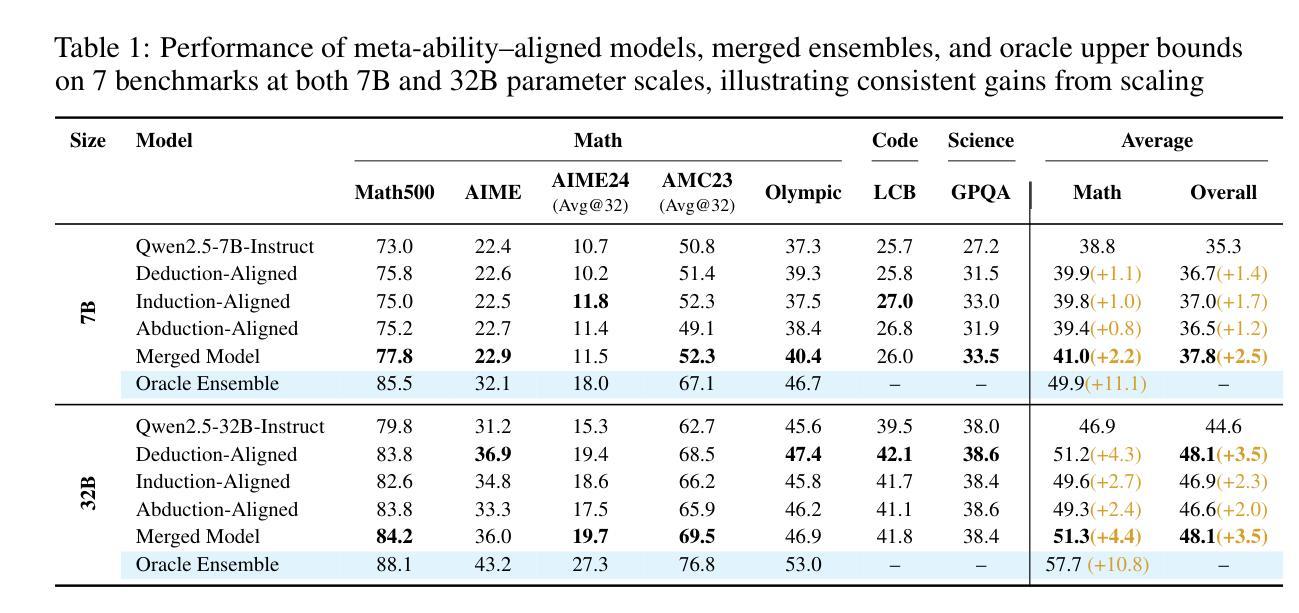
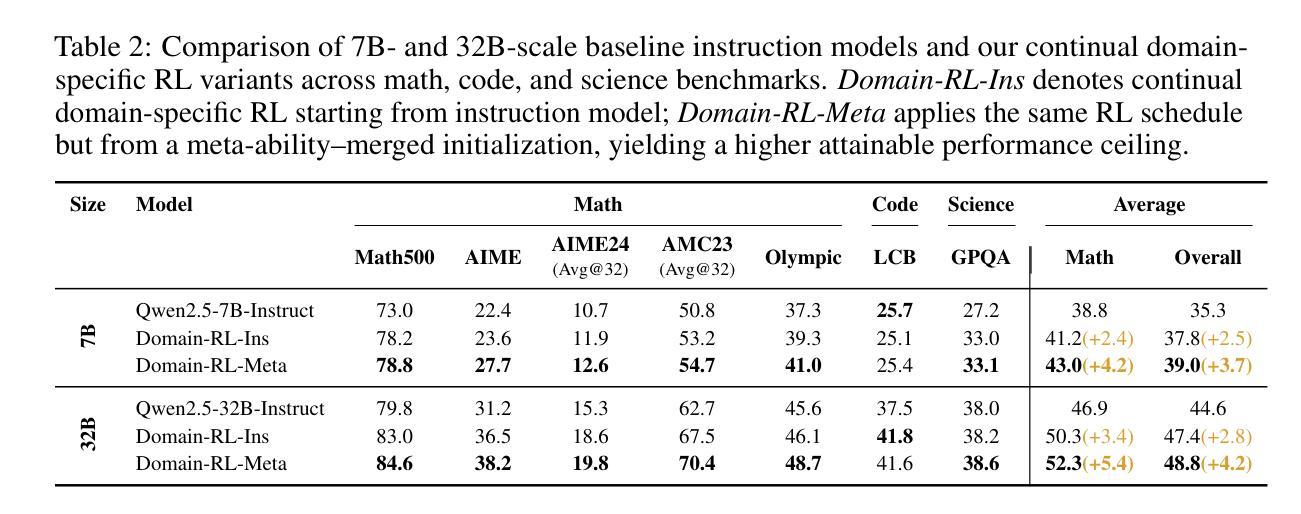
Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
Authors:Zhiyuan Hu, Yibo Wang, Hanze Dong, Yuhui Xu, Amrita Saha, Caiming Xiong, Bryan Hooi, Junnan Li
Large reasoning models (LRMs) already possess a latent capacity for long chain-of-thought reasoning. Prior work has shown that outcome-based reinforcement learning (RL) can incidentally elicit advanced reasoning behaviors such as self-correction, backtracking, and verification phenomena often referred to as the model’s “aha moment”. However, the timing and consistency of these emergent behaviors remain unpredictable and uncontrollable, limiting the scalability and reliability of LRMs’ reasoning capabilities. To address these limitations, we move beyond reliance on prompts and coincidental “aha moments”. Instead, we explicitly align models with three meta-abilities: deduction, induction, and abduction, using automatically generated, self-verifiable tasks. Our three stage-pipeline individual alignment, parameter-space merging, and domain-specific reinforcement learning, boosting performance by over 10% relative to instruction-tuned baselines. Furthermore, domain-specific RL from the aligned checkpoint yields an additional 2% average gain in the performance ceiling across math, coding, and science benchmarks, demonstrating that explicit meta-ability alignment offers a scalable and dependable foundation for reasoning. Code is available at: https://github.com/zhiyuanhubj/Meta-Ability-Alignment
大型推理模型(LRMs)已经具备潜在的长链思维推理能力。先前的研究表明,基于结果的强化学习(RL)可以偶然激发高级推理行为,如自我校正、回溯和验证现象,这些常被看作是模型的“顿悟时刻”。然而,这些突发行为的时机和一致性仍然不可预测和不可控制,限制了LRMs推理能力的可扩展性和可靠性。为了解决这些局限性,我们不再依赖提示和偶然的“顿悟时刻”。相反,我们使用自动生成、自我验证的任务,明确地使模型与三种元能力(演绎、归纳和溯因)对齐。我们的三阶段管道包括个体对齐、参数空间合并和领域特定强化学习,相较于指令调整基准线,性能提升超过10%。此外,从对齐检查点进行的领域特定RL,在数学、编码和科学基准测试的性能上限上获得了额外的2%的平均提升,这证明明确的元能力对齐为推理提供了可扩展和可靠的基石。代码可在:https://github.com/zhiyuanhubj/Meta-Ability-Alignment上找到。
论文及项目相关链接
PDF In Progress
Summary:大型推理模型已具备潜在的长链思维推理能力。先前的工作表明,基于结果的强化学习可以偶然引发高级推理行为,如自我修正、回溯和验证现象,这些常被称为模型的“顿悟时刻”。然而,这些行为的涌现时机和持续性仍然不可预测和不可控制,限制了大型推理模型的可扩展性和可靠性。为解决这些局限性,研究不再依赖提示和偶然的“顿悟时刻”,而是明确地将模型与演绎、归纳和溯因三种元能力对齐,并使用自动生成的自我验证任务。三阶段管道包括个体对齐、参数空间合并和领域特定强化学习,相较于指令调整基准线,性能提升超过10%。此外,从对齐检查点进行的领域特定强化学习在跨数学、编码和科学基准测试中实现了额外的平均2%的性能提升,表明明确的元能力对齐为推理提供了一个可扩展和可靠的基石。
Key Takeaways:
- 大型推理模型具有潜在的长链思维推理能力。
- 基于结果的强化学习可以引发模型的自我修正、回溯和验证等高级推理行为。
- 这些推理行为的涌现时机和持续性不可预测和不可控制,限制了模型的可靠性和可扩展性。
- 明确地将模型与演绎、归纳和溯因三种元能力对齐,以提高模型的推理性能。
- 使用自动生成的自我验证任务来增强模型性能。
- 三阶段管道包括个体对齐、参数空间合并和领域特定强化学习,相较于基线提高了性能。
点此查看论文截图

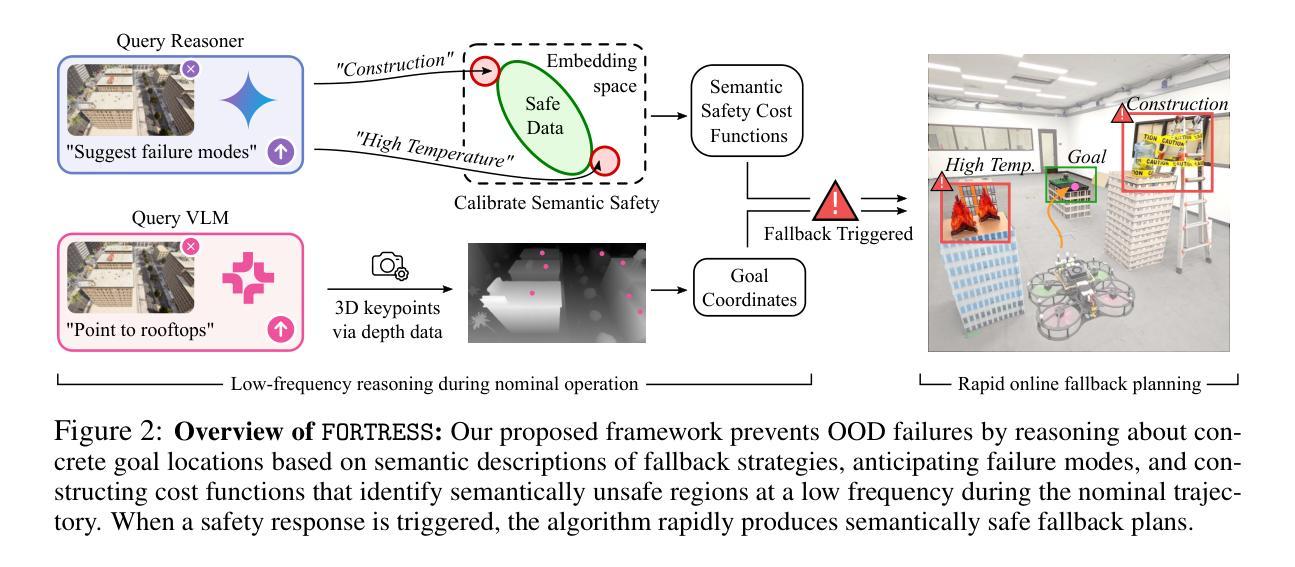
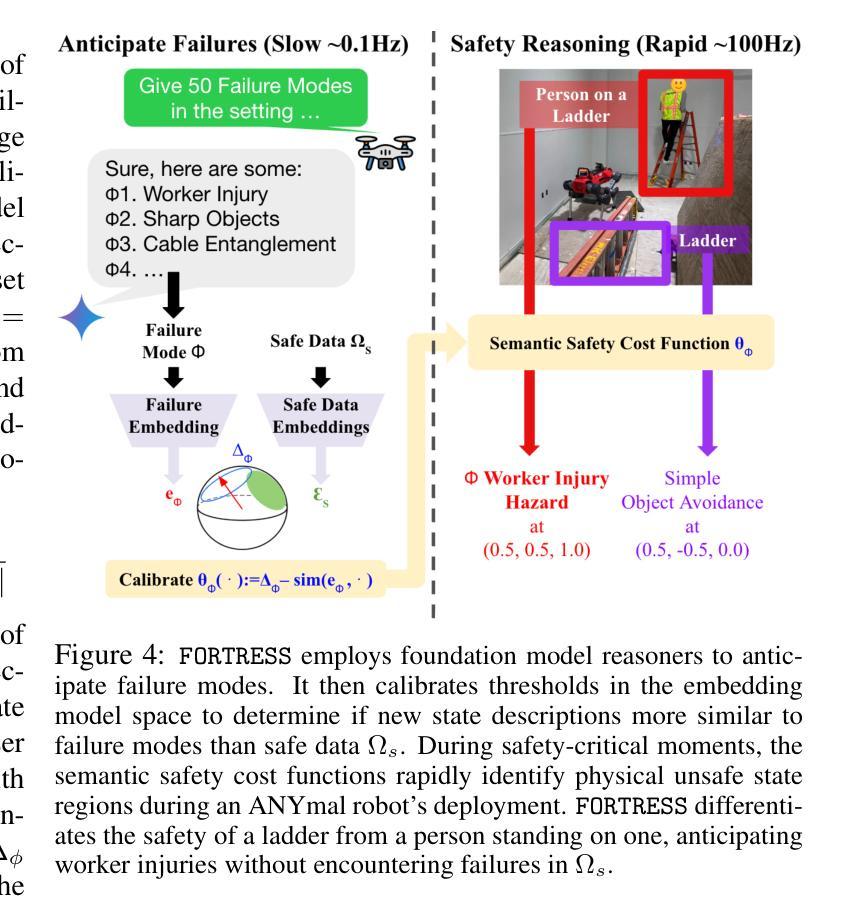
Real-Time Out-of-Distribution Failure Prevention via Multi-Modal Reasoning
Authors:Milan Ganai, Rohan Sinha, Christopher Agia, Daniel Morton, Marco Pavone
Foundation models can provide robust high-level reasoning on appropriate safety interventions in hazardous scenarios beyond a robot’s training data, i.e. out-of-distribution (OOD) failures. However, due to the high inference latency of Large Vision and Language Models, current methods rely on manually defined intervention policies to enact fallbacks, thereby lacking the ability to plan generalizable, semantically safe motions. To overcome these challenges we present FORTRESS, a framework that generates and reasons about semantically safe fallback strategies in real time to prevent OOD failures. At a low frequency in nominal operations, FORTRESS uses multi-modal reasoners to identify goals and anticipate failure modes. When a runtime monitor triggers a fallback response, FORTRESS rapidly synthesizes plans to fallback goals while inferring and avoiding semantically unsafe regions in real time. By bridging open-world, multi-modal reasoning with dynamics-aware planning, we eliminate the need for hard-coded fallbacks and human safety interventions. FORTRESS outperforms on-the-fly prompting of slow reasoning models in safety classification accuracy on synthetic benchmarks and real-world ANYmal robot data, and further improves system safety and planning success in simulation and on quadrotor hardware for urban navigation.
模型基础能够在机器人训练数据以外的危险场景中,对适当的安全干预措施提供稳健的高级推理,即超出分布(OOD)的故障。然而,由于大型视觉和语言模型的推理延迟较高,当前的方法依赖于手动定义的干预政策来实施后备措施,因此缺乏制定可推广的、语义安全的动作的能力。为了克服这些挑战,我们提出了堡垒(FORTRESS)框架,该框架能够实时生成并考虑语义安全的后备策略,以防止OOD故障。在正常情况下,堡垒以较低频率使用多模态推理器来确定目标并预测故障模式。当运行时监视器触发后备响应时,堡垒能够迅速合成达到后备目标的计划,同时实时推断并避免语义不安全区域。通过连接开放世界、多模态推理与动态感知规划,我们消除了对硬编码的后备措施和人工安全干预的需求。堡垒在合成基准测试和真实世界的ANYmal机器人数据上的安全分类精度方面表现优于实时提示的慢速推理模型,并且在模拟环境和四旋翼硬件的城市导航方面进一步提高了系统安全性和规划成功率。
论文及项目相关链接
PDF Website: https://milanganai.github.io/fortress/
Summary:堡垒框架(FORTRESS)可以实时生成并处理语义安全的回退策略,以克服大型视觉和语言模型的高推理延迟问题,防止分布外(OOD)故障。通过结合开放世界多模态推理与动态感知规划,堡垒框架消除了对硬编码回退和人为安全干预的需求,提高了系统安全性和规划成功率。
Key Takeaways:
- 堡垒框架(FORTRESS)旨在解决大型视觉和语言模型的高推理延迟问题。
- 在正常运行时,堡垒框架使用多模态推理器以低频率识别目标并预测故障模式。
- 当触发回退响应时,堡垒框架能迅速合成回退计划,并在实时中推断和避免语义不安全区域。
- 堡垒框架结合了开放世界多模态推理和动态感知规划,提高了系统安全性和规划成功率。
- 该框架消除了对硬编码回退和人为安全干预的需求。
- 堡垒框架在合成基准测试和真实世界ANYmal机器人数据上的安全分类精度上表现优异。
点此查看论文截图


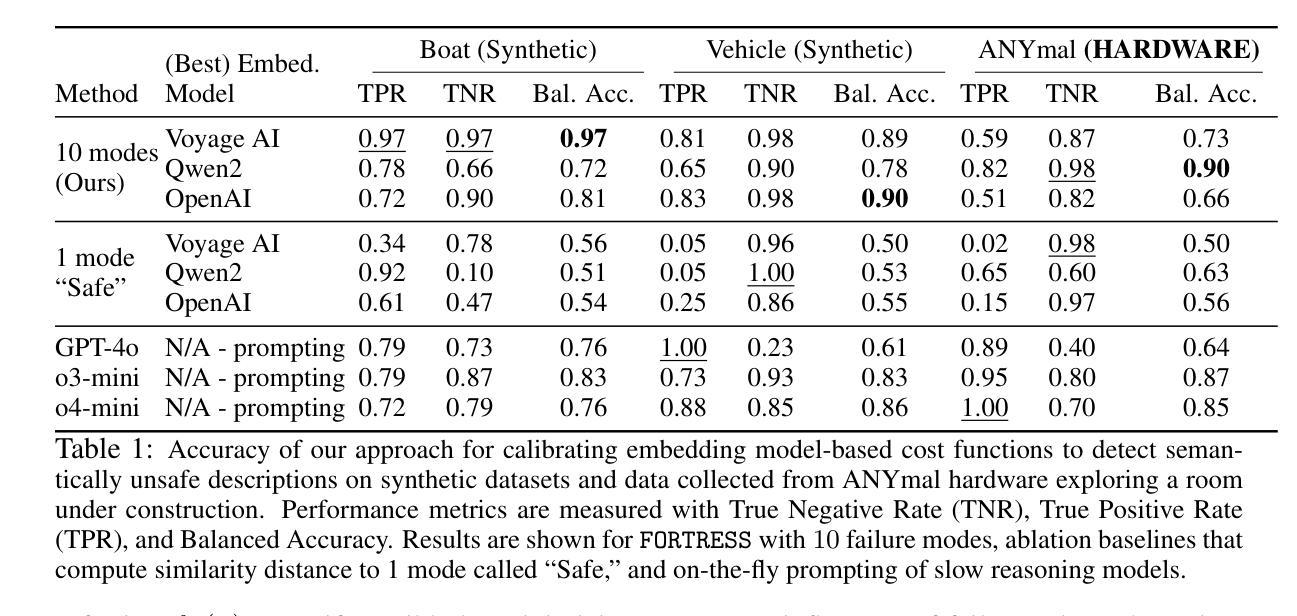
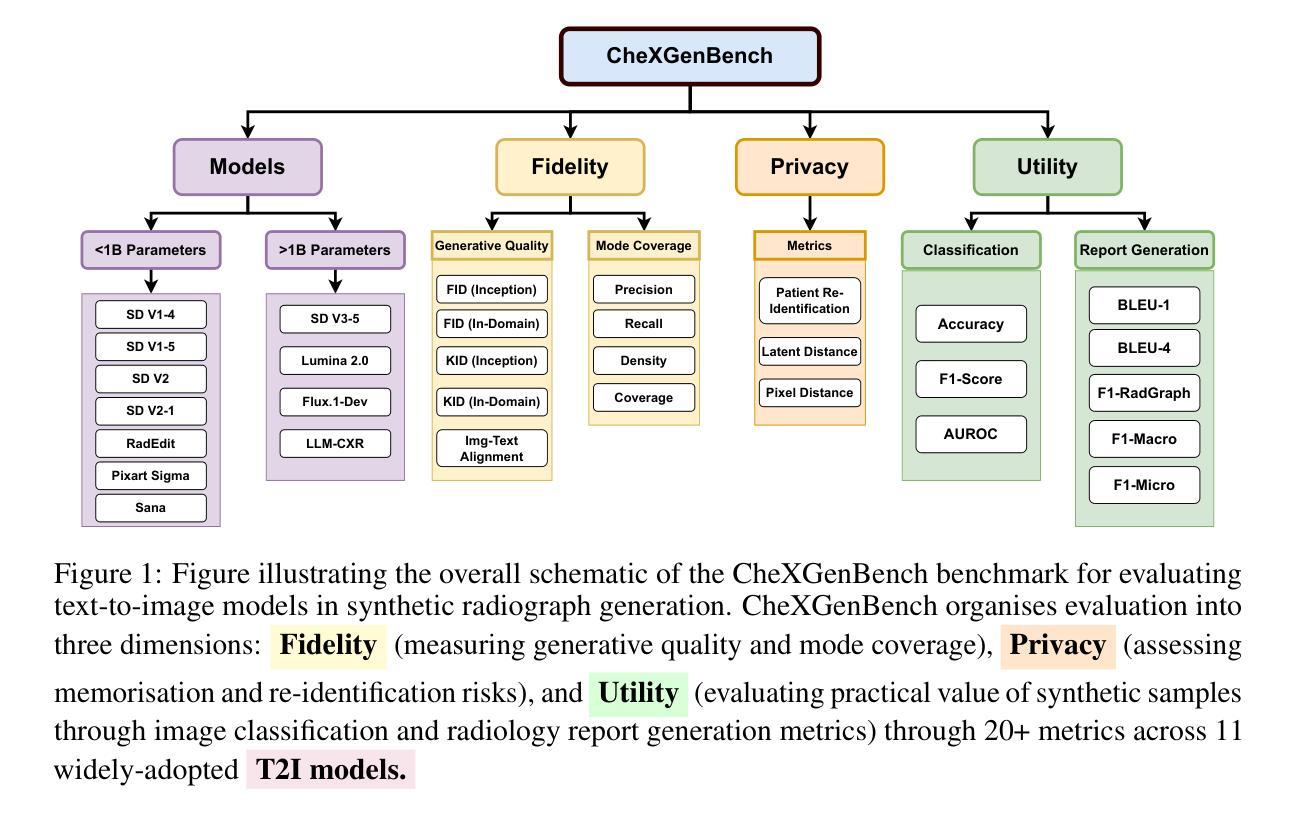
CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
Authors:Raman Dutt, Pedro Sanchez, Yongchen Yao, Steven McDonagh, Sotirios A. Tsaftaris, Timothy Hospedales
We introduce CheXGenBench, a rigorous and multifaceted evaluation framework for synthetic chest radiograph generation that simultaneously assesses fidelity, privacy risks, and clinical utility across state-of-the-art text-to-image generative models. Despite rapid advancements in generative AI for real-world imagery, medical domain evaluations have been hindered by methodological inconsistencies, outdated architectural comparisons, and disconnected assessment criteria that rarely address the practical clinical value of synthetic samples. CheXGenBench overcomes these limitations through standardised data partitioning and a unified evaluation protocol comprising over 20 quantitative metrics that systematically analyse generation quality, potential privacy vulnerabilities, and downstream clinical applicability across 11 leading text-to-image architectures. Our results reveal critical inefficiencies in the existing evaluation protocols, particularly in assessing generative fidelity, leading to inconsistent and uninformative comparisons. Our framework establishes a standardised benchmark for the medical AI community, enabling objective and reproducible comparisons while facilitating seamless integration of both existing and future generative models. Additionally, we release a high-quality, synthetic dataset, SynthCheX-75K, comprising 75K radiographs generated by the top-performing model (Sana 0.6B) in our benchmark to support further research in this critical domain. Through CheXGenBench, we establish a new state-of-the-art and release our framework, models, and SynthCheX-75K dataset at https://raman1121.github.io/CheXGenBench/
我们推出CheXGenBench,这是一个针对合成胸部X光片生成技术的严格多元评估框架,可以同时评估最先进文本到图像生成模型的保真度、隐私风险以及临床实用性。尽管现实世界图像生成人工智能取得了快速发展,但医疗领域评估仍受到方法论不一致、架构对比过时以及评估标准脱节等问题的阻碍,这些问题很少涉及合成样本的实际临床价值。CheXGenBench通过标准化数据分区以及包含超过20个量化指标的统一评估协议来克服这些局限性,该评估协议系统地分析了生成质量、潜在的隐私漏洞以及跨11种领先文本到图像架构的下游临床适用性。我们的结果揭示了现有评估协议的关键低效之处,特别是在评估生成保真度方面,导致比较结果不一致且缺乏信息。我们的框架为医疗人工智能社区建立了标准化基准,能够进行客观和可重复的比较,同时促进现有和未来生成模型的无缝集成。此外,我们发布了一个高质量合成数据集SynthCheX-75K,包含由我们基准测试中表现最佳的模型(Sana 0.6B)生成的75K张放射图像,以支持这一关键领域的进一步研究。通过CheXGenBench,我们建立了新的技术标杆,并将我们的框架、模型和SynthCheX-75K数据集发布在[https://raman1121.github.io/CheXGenBench/]上。
论文及项目相关链接
Summary:
我们推出CheXGenBench框架,该框架是合成胸放射影像生成的评价体系,能够全面评估文本到图像生成模型的保真度、隐私风险以及临床价值。尽管现实图像生成AI发展迅速,但医疗领域评价仍面临方法不一致、架构对比过时以及评估标准脱离实际临床价值的问题。CheXGenBench通过标准化数据分区和统一的评估协议,系统地分析生成质量、潜在隐私漏洞以及下游临床适用性。我们的框架为医疗AI社区建立了标准化基准测试,使客观和可重复的比较成为可能,同时促进现有和未来生成模型的无缝集成。此外,我们还发布了由顶尖模型生成的高质量合成数据集SynthCheX-75K,以支持该领域的进一步研究。通过CheXGenBench框架,我们建立了新的标准并公开了我们的框架、模型和SynthCheX-75K数据集。
Key Takeaways:
- CheXGenBench是一个全面的评估框架,用于评估合成胸放射影像生成的质量。
- 该框架同时考虑保真度、隐私风险和临床价值三个方面的评估。
- 现有医疗领域影像生成的评价存在方法不一致、架构对比过时和评估标准脱离实际临床价值的问题。
- CheXGenBench通过标准化数据分区和统一的评估协议来解决这些问题。
- 框架包含超过20个定量指标,系统地分析生成质量、潜在隐私漏洞和下游临床适用性。
- CheXGenBench为医疗AI社区提供了标准化基准测试,促进了客观和可重复的比较。
点此查看论文截图

UniEval: Unified Holistic Evaluation for Unified Multimodal Understanding and Generation
Authors:Yi Li, Haonan Wang, Qixiang Zhang, Boyu Xiao, Chenchang Hu, Hualiang Wang, Xiaomeng Li
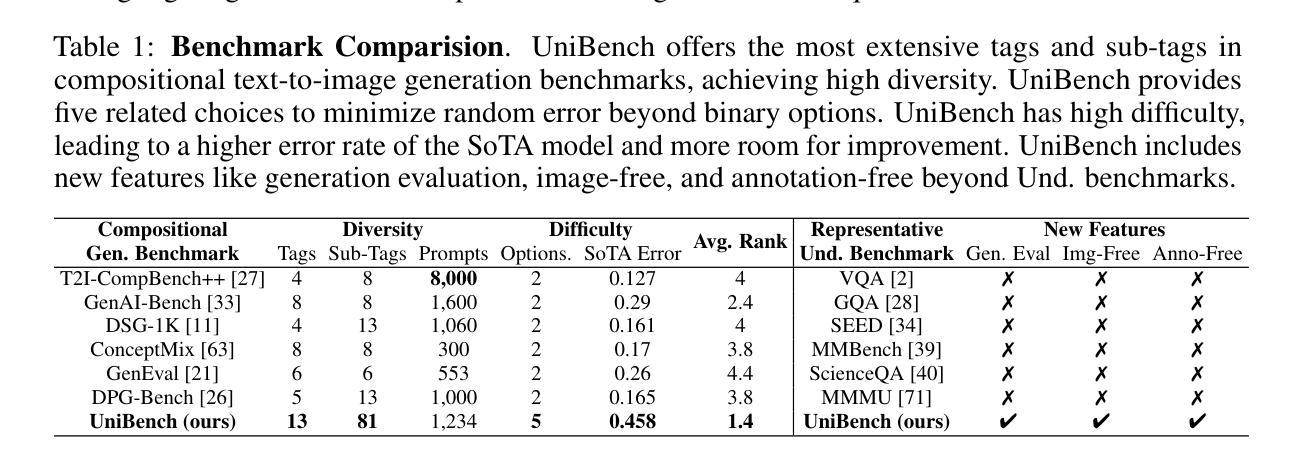
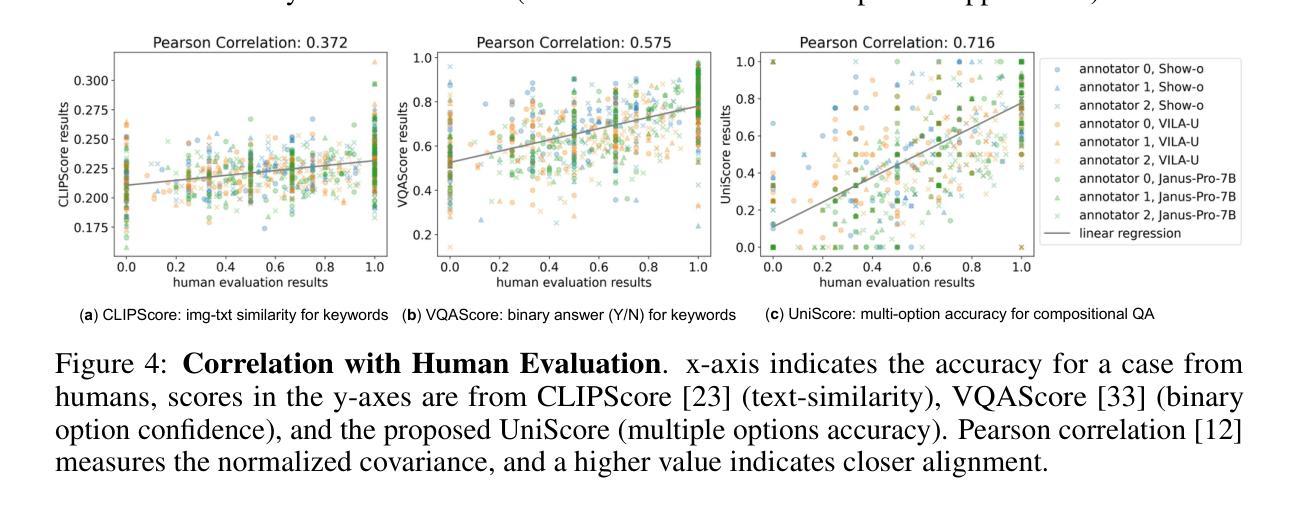
The emergence of unified multimodal understanding and generation models is rapidly attracting attention because of their ability to enhance instruction-following capabilities while minimizing model redundancy. However, there is a lack of a unified evaluation framework for these models, which would enable an elegant, simplified, and overall evaluation. Current models conduct evaluations on multiple task-specific benchmarks, but there are significant limitations, such as the lack of overall results, errors from extra evaluation models, reliance on extensive labeled images, benchmarks that lack diversity, and metrics with limited capacity for instruction-following evaluation. To tackle these challenges, we introduce UniEval, the first evaluation framework designed for unified multimodal models without extra models, images, or annotations. This facilitates a simplified and unified evaluation process. The UniEval framework contains a holistic benchmark, UniBench (supports both unified and visual generation models), along with the corresponding UniScore metric. UniBench includes 81 fine-grained tags contributing to high diversity. Experimental results indicate that UniBench is more challenging than existing benchmarks, and UniScore aligns closely with human evaluations, surpassing current metrics. Moreover, we extensively evaluated SoTA unified and visual generation models, uncovering new insights into Univeral’s unique values.
统一多模态理解和生成模型的兴起迅速引起了人们的关注,因为它们能够增强指令执行能力,同时最大限度地减少模型冗余。然而,由于缺乏对这些模型的统一评估框架,无法进行优雅、简洁和全面的评估。当前模型在多个特定任务基准测试上进行评估,但存在显著局限性,如缺乏总体结果、额外评估模型的错误、依赖大量有标签图像、基准测试缺乏多样性以及指标在指令评估方面的能力有限等。为了解决这些挑战,我们推出了UniEval,这是专门为统一多模态模型设计的第一个无需额外模型、图像或注释的评估框架。这有助于简化并统一评估流程。UniEval框架包含整体基准测试UniBench(支持统一和视觉生成模型),以及相应的UniScore指标。UniBench包括81个精细标签,有助于实现高多样性。实验结果表明,UniBench比现有基准更具挑战性,UniScore与人类评估紧密对齐,超越了当前指标。此外,我们对最新的统一和视觉生成模型进行了广泛评估,揭示了Universal的独特价值的新见解。
论文及项目相关链接
PDF UniEval is the first evaluation framework designed for unified multimodal models, including a holistic benchmark UniBench and the UniScore metric
Summary
多模态统一理解与生成模型正在快速吸引关注,因为它们能够在减少模型冗余的同时提高指令执行能力。然而,缺乏统一的评估框架来优雅、简化地对这些模型进行全面评估。目前,模型在多个任务特定基准测试上进行评估,但存在显著局限性,如缺乏总体结果、额外评估模型的误差、依赖大量标注图像、基准测试缺乏多样性以及指令执行评估能力有限的指标等。为解决这些挑战,我们推出了UniEval评估框架,专为多模态统一模型设计,无需额外的模型、图像或注释。这促进了简化统一的评估过程。UniEval框架包含整体基准测试UniBench(支持统一和视觉生成模型)以及相应的UniScore指标。UniBench包括81个精细标签,以实现高多样性。实验结果表明,UniBench比现有基准测试更具挑战性,UniScore与人类评估紧密对齐,超越了当前指标。此外,我们对最新统一和视觉生成模型进行了广泛评估,发现了Universal的独特价值的新见解。
Key Takeaways
- 多模态统一理解与生成模型能够提升指令执行能力并减少模型冗余,正受到广泛关注。
- 当前缺乏统一的评估框架来全面、简洁地评价这些模型。
- 现有模型评估存在局限性,如缺乏总体结果、额外评估模型的误差等。
- UniEval评估框架旨在解决这些问题,适用于多模态统一模型,无需额外的模型、图像或注释。
- UniEval包含整体基准测试UniBench和UniScore指标,其中UniBench具有高多样性。
- 实验表明,UniBench更具挑战性,UniScore指标与人类评估紧密对齐,优于现有指标。
点此查看论文截图



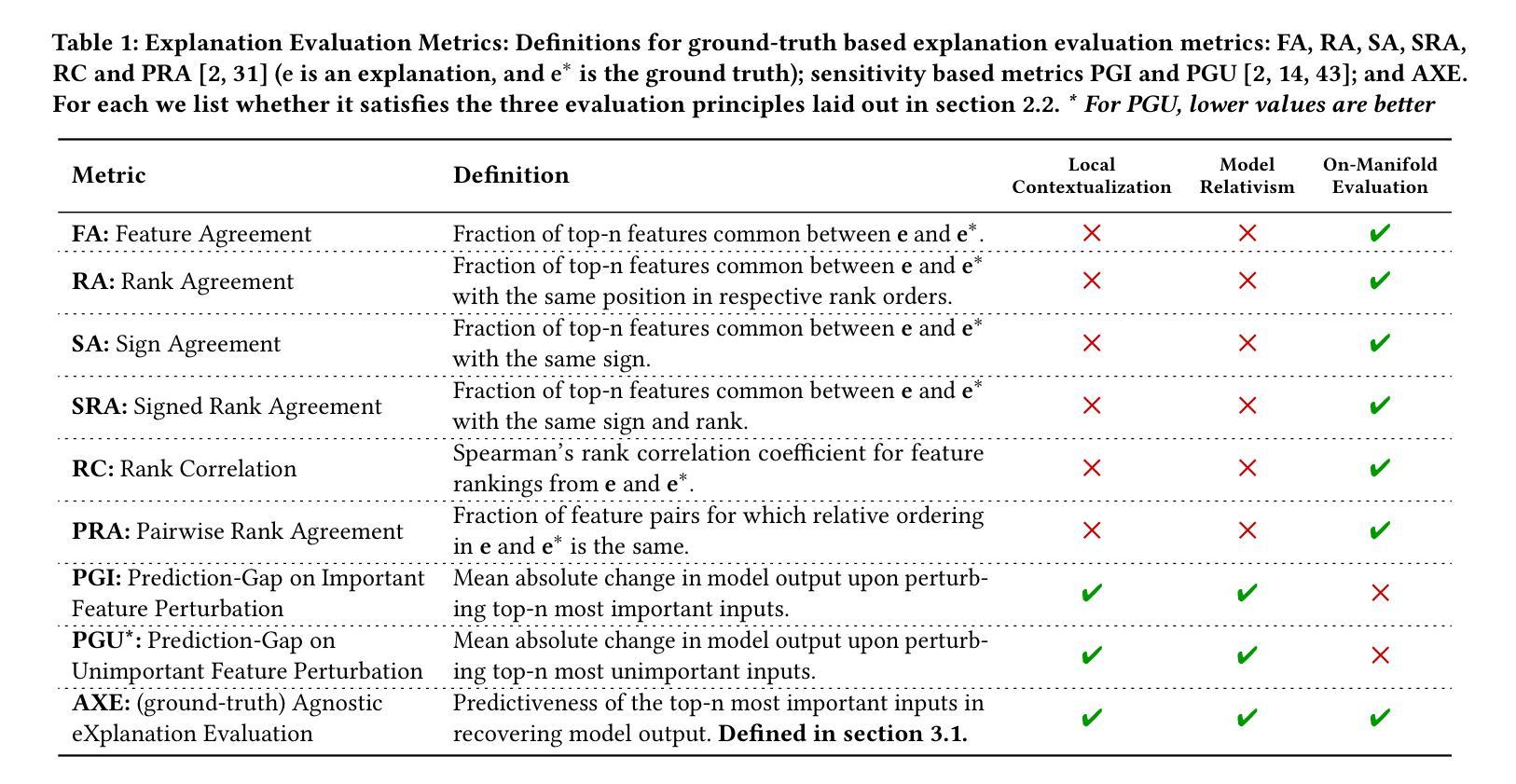
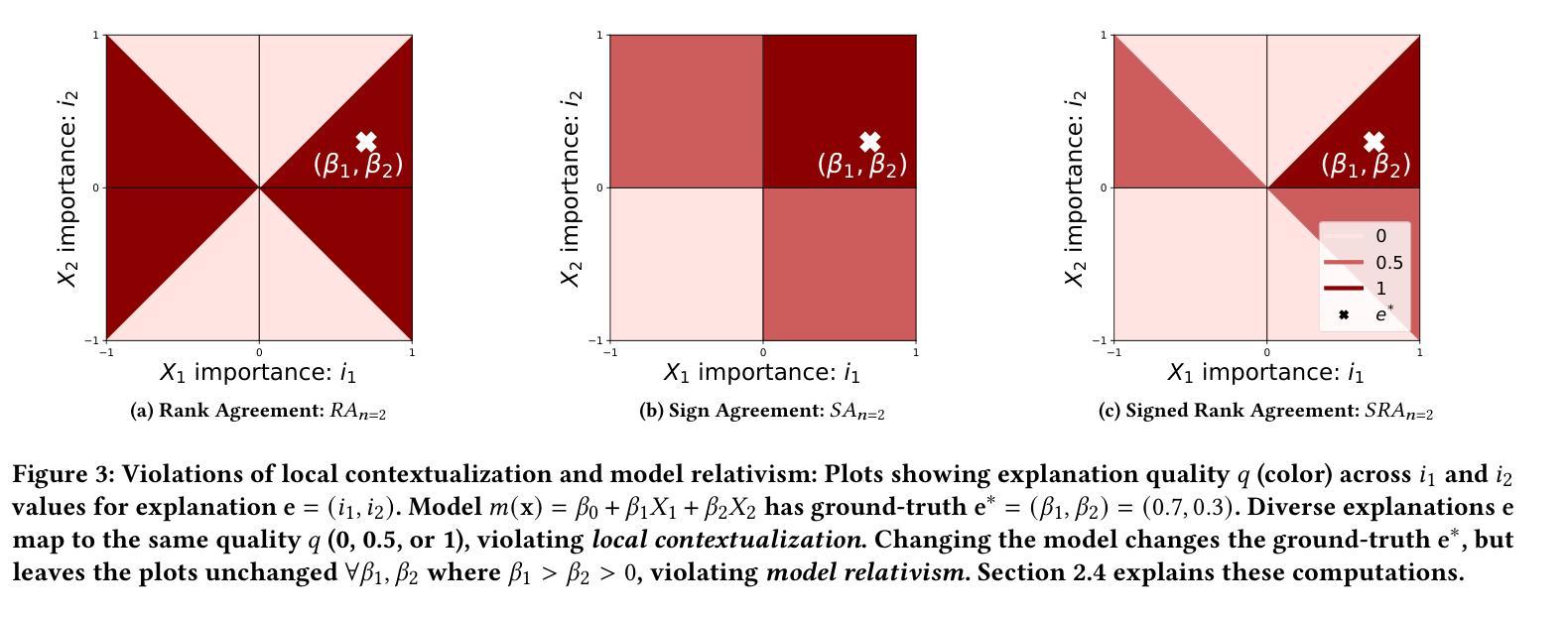
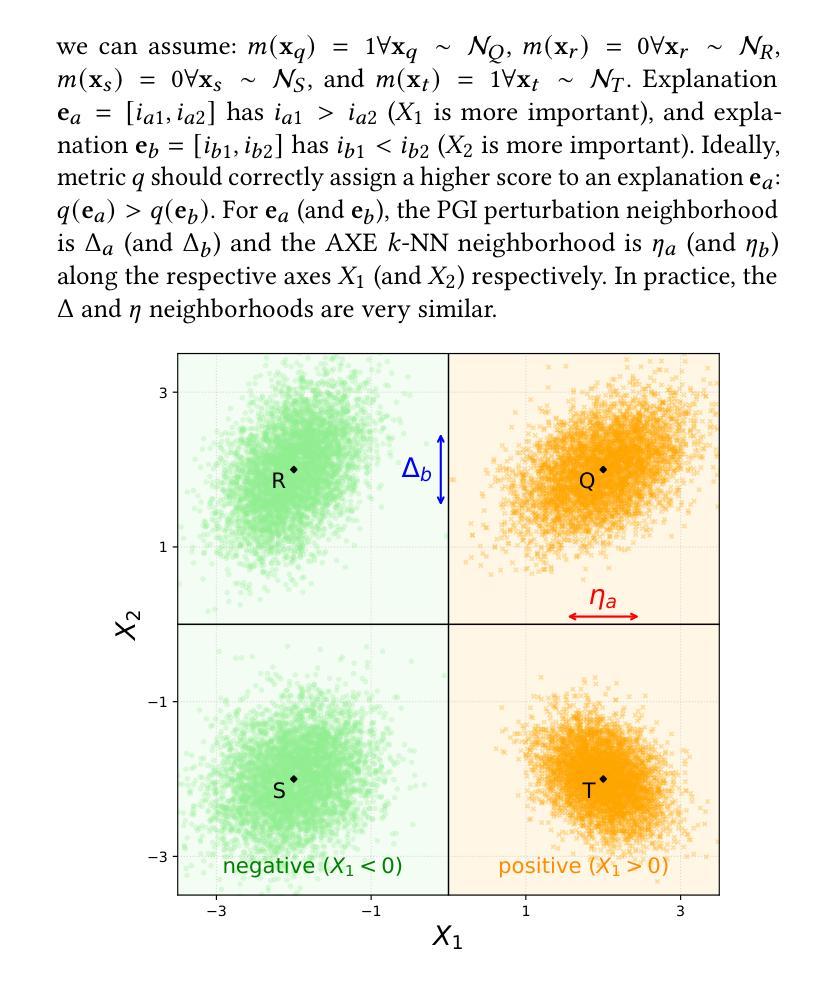
Evaluating Model Explanations without Ground Truth
Authors:Kaivalya Rawal, Zihao Fu, Eoin Delaney, Chris Russell
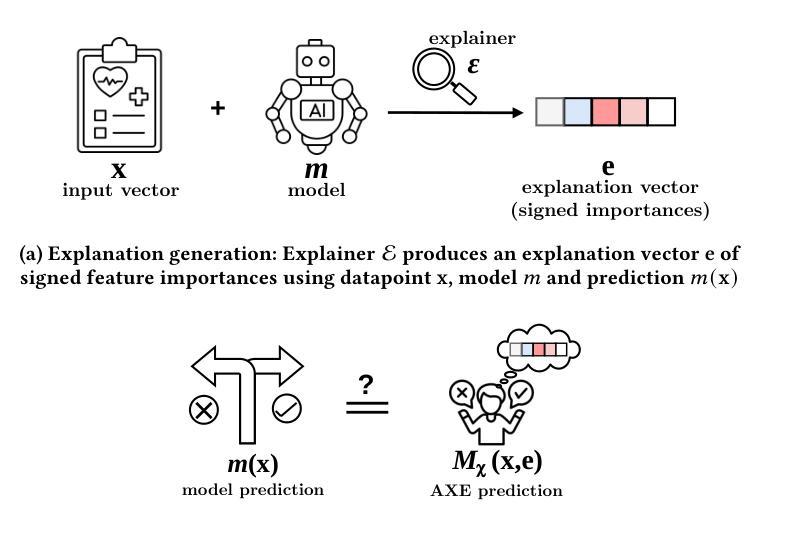
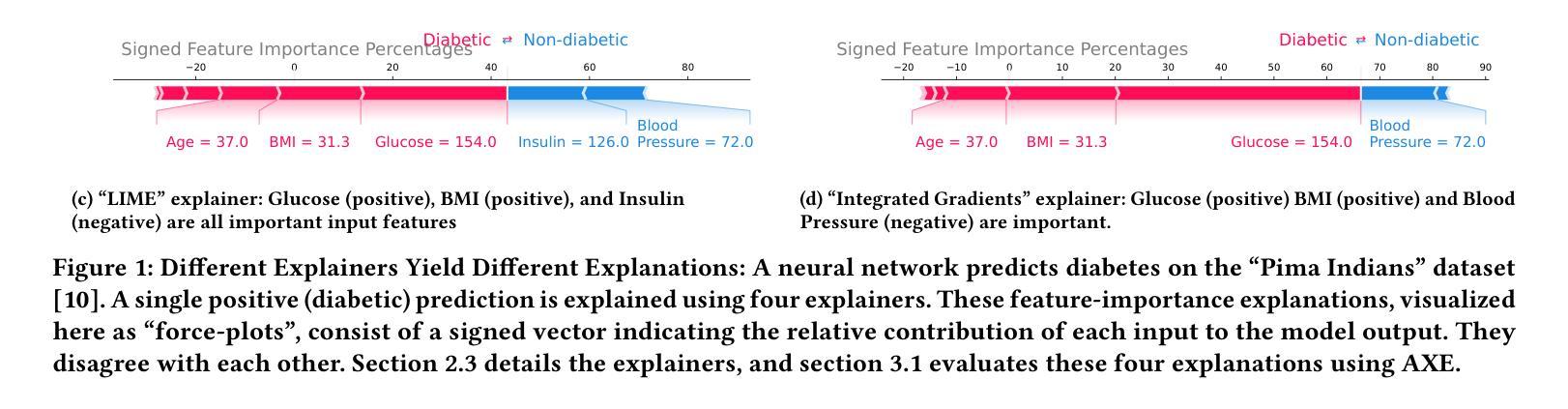
There can be many competing and contradictory explanations for a single model prediction, making it difficult to select which one to use. Current explanation evaluation frameworks measure quality by comparing against ideal “ground-truth” explanations, or by verifying model sensitivity to important inputs. We outline the limitations of these approaches, and propose three desirable principles to ground the future development of explanation evaluation strategies for local feature importance explanations. We propose a ground-truth Agnostic eXplanation Evaluation framework (AXE) for evaluating and comparing model explanations that satisfies these principles. Unlike prior approaches, AXE does not require access to ideal ground-truth explanations for comparison, or rely on model sensitivity - providing an independent measure of explanation quality. We verify AXE by comparing with baselines, and show how it can be used to detect explanation fairwashing. Our code is available at https://github.com/KaiRawal/Evaluating-Model-Explanations-without-Ground-Truth.
对于一个模型预测,可能存在许多相互竞争和相互矛盾的解释,这使得很难选择使用哪一个。当前的解释评估框架通过将其与理想的“真实”解释进行比较,或者通过验证模型对重要输入的敏感性来衡量质量。我们概述了这些方法的局限性,并提出了为局部特征重要性解释的未来发展奠定基础的三个理想原则。我们提出了一个用于评估和比较模型解释的真相无关解释评估框架(AXE),该框架可以满足这些原则。与以前的方法不同,AXE不需要通过理想真实解释进行比较,也不依赖于模型的敏感性,它为解释质量提供了一个独立的衡量标准。我们通过将其与基线进行比较来验证AXE,并展示其如何用于检测解释洗白。我们的代码可在https://github.com/KaiRawal/Evaluating-Model-Explanations-without-Ground-Truth上找到。
论文及项目相关链接
PDF https://github.com/KaiRawal/Evaluating-Model-Explanations-without-Ground-Truth
Summary
模型预测存在多种相互竞争和矛盾的解读,选择合适的解读方式十分困难。当前解读评估框架主要通过与理想“地面真实”解读进行比较,或验证模型对重要输入的敏感性来衡量质量。本文分析了这些方法的局限性,提出了地方特征重要性解读的解读评估策略发展的三个原则。提出了一个不需要理想地面真实解读对比的解算评价框架(AXE),满足这些原则要求。与传统的依赖模型敏感性的方法不同,AXE提供了一种独立的解读质量度量标准。通过对比基线验证了AXE的有效性,并展示了其检测解释欺骗的潜力。代码已公开在链接中:[链接地址](注:实际使用时应替换为真正的GitHub链接)。
Key Takeaways
- 模型预测存在多种解读,选择合适的解读方式至关重要。
- 当前解读评估框架存在局限性,无法全面评估所有解读方式的优劣。
- 本文提出了地方特征重要性解读评估的三个原则,为未来的解读评估策略发展提供了指导。
- 提出了一个无需理想地面真实解读对比的解算评价框架(AXE),具有独立评估解读质量的潜力。
- AXE相较于传统方法不再依赖于模型敏感性分析,更能准确评估解读质量。
- 通过对比基线验证了AXE的有效性。
点此查看论文截图


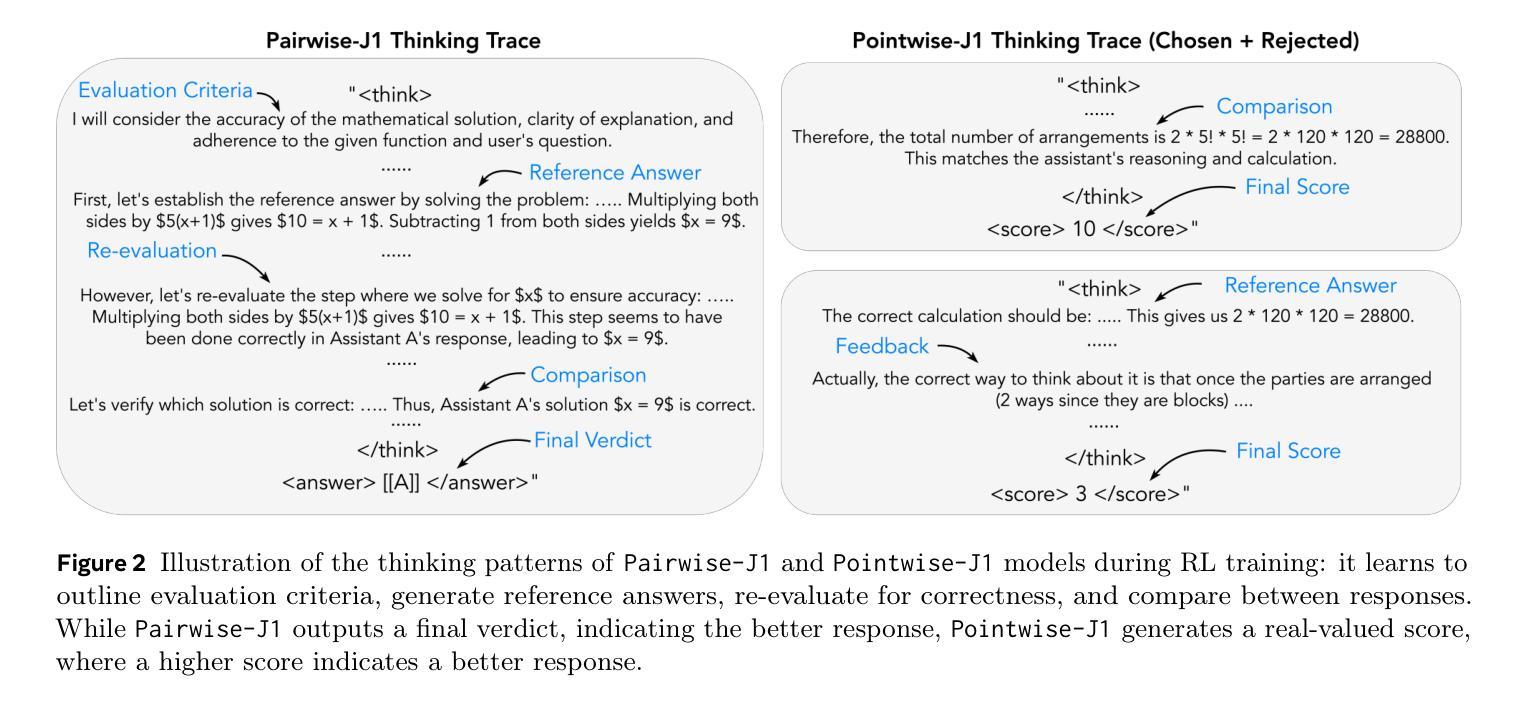
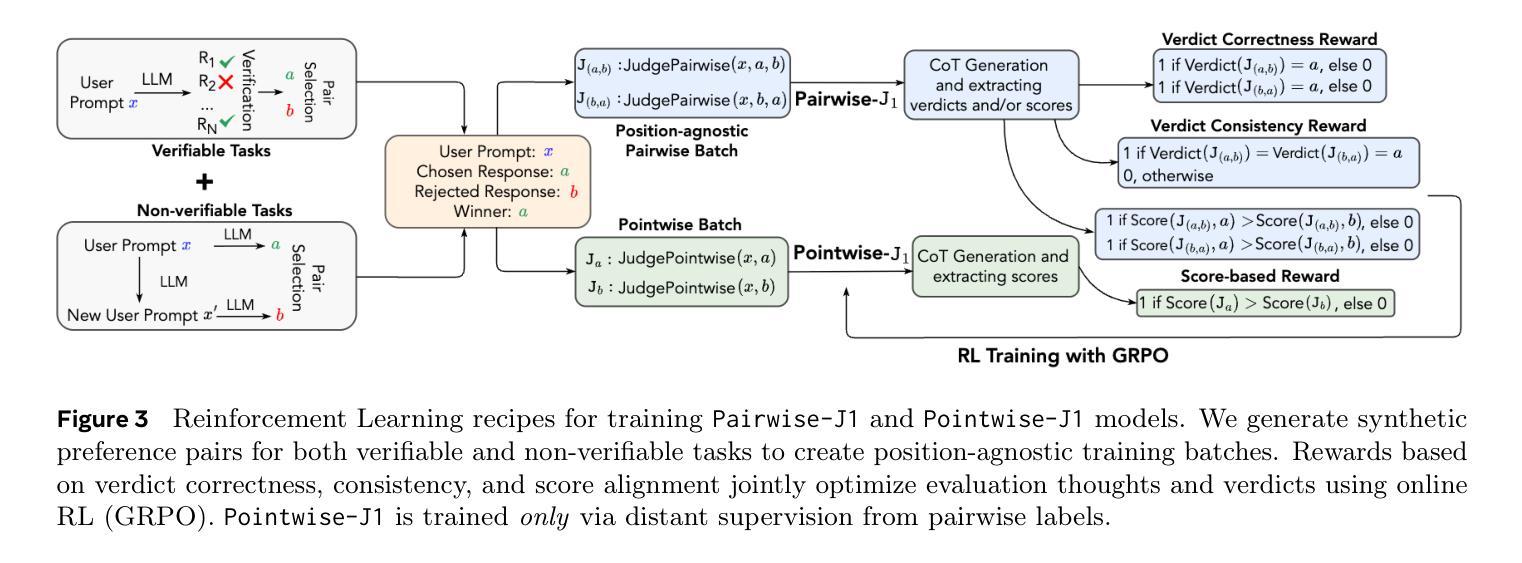
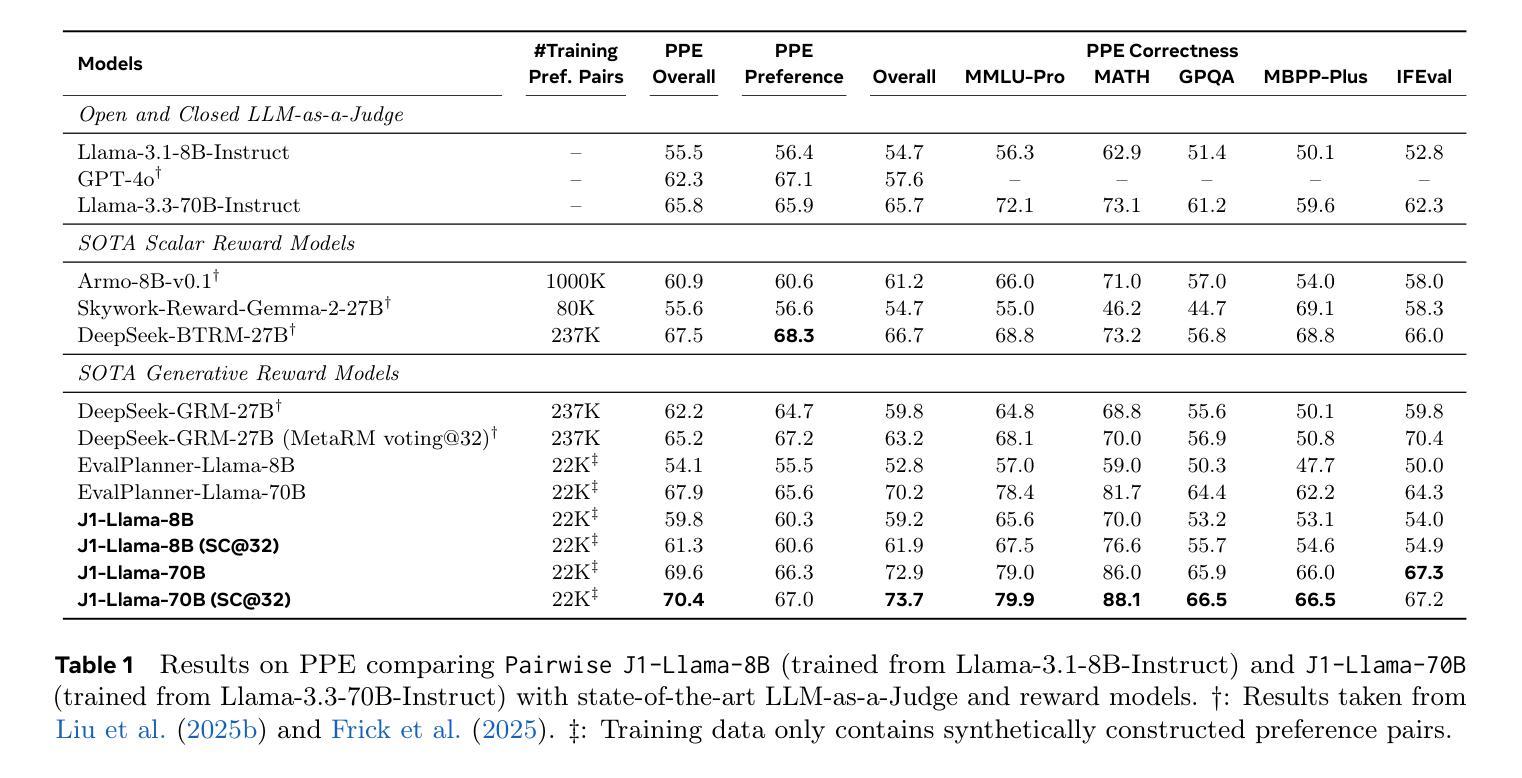
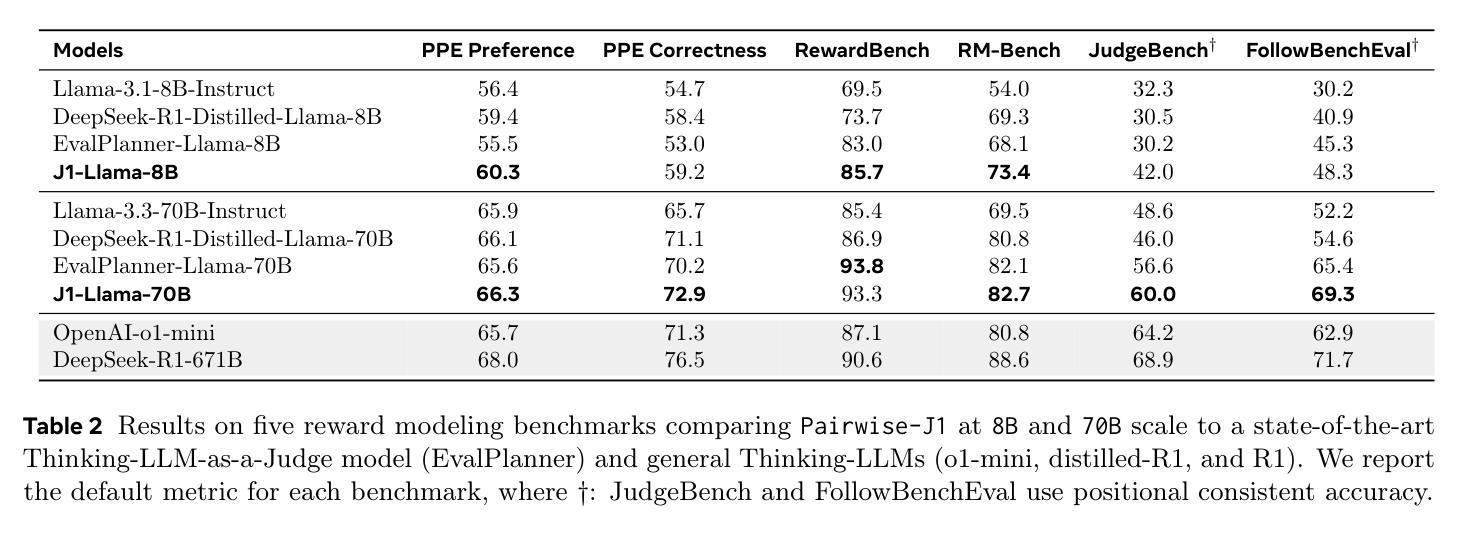
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
Authors:Chenxi Whitehouse, Tianlu Wang, Ping Yu, Xian Li, Jason Weston, Ilia Kulikov, Swarnadeep Saha
The progress of AI is bottlenecked by the quality of evaluation, and powerful LLM-as-a-Judge models have proved to be a core solution. Improved judgment ability is enabled by stronger chain-of-thought reasoning, motivating the need to find the best recipes for training such models to think. In this work we introduce J1, a reinforcement learning approach to training such models. Our method converts both verifiable and non-verifiable prompts to judgment tasks with verifiable rewards that incentivize thinking and mitigate judgment bias. In particular, our approach outperforms all other existing 8B or 70B models when trained at those sizes, including models distilled from DeepSeek-R1. J1 also outperforms o1-mini, and even R1 on some benchmarks, despite training a smaller model. We provide analysis and ablations comparing Pairwise-J1 vs Pointwise-J1 models, offline vs online training recipes, reward strategies, seed prompts, and variations in thought length and content. We find that our models make better judgments by learning to outline evaluation criteria, comparing against self-generated reference answers, and re-evaluating the correctness of model responses.
人工智能的发展受限于评估质量,而强大的LLM-as-a-Judge模型已成为核心解决方案。通过更强的思维链推理能力,提升了判断能力,因此需要找到训练此类模型进行思维的最佳方案。在这项工作中,我们介绍了J1,这是一种用于训练此类模型的强化学习方法。我们的方法将可验证和不可验证的提示转化为具有可验证奖励的判断任务,以激励思考和减轻判断偏见。尤其当我们在这类大小规模下训练模型时,与其他所有现有的8B或70B模型相比,我们的方法表现更佳,包括从DeepSeek-R1中提炼出来的模型。尽管训练模型较小,J1在某些基准测试上的表现也优于o1-mini甚至R1。我们提供了对比分析Pairwise-J1与Pointwise-J1模型、离线与在线训练方案、奖励策略、种子提示以及思维长度和内容变化的分析和消融研究。我们发现,通过学习概述评价标准、与自我生成的参考答案进行对比以及重新评估模型响应的正确性,我们的模型能够做出更好的判断。
论文及项目相关链接
PDF 10 pages, 8 tables, 11 figures
Summary
AI评估质量成为其发展瓶颈,LLM-as-a-Judge模型为核心解决方案。通过强化学习训练模型以提升判断能力和链式思维推理。新方法将可验证和不可验证的提示转化为具有可验证奖励的判断任务,激励思考并减轻判断偏见。相较于其他8B或70B模型,J1方法表现更佳,甚至在部分基准测试中超越R1。
Key Takeaways
- AI发展的瓶颈在于评估质量,LLM-as-a-Judge模型是解决此问题的核心。
- 引入J1方法,使用强化学习训练模型以提升判断能力。
- J1将各类提示转化为判断任务,使用可验证奖励来激励模型思考并减少判断偏见。
- J1在训练规模上优于其他8B或70B模型,包括基于DeepSeek-R1的蒸馏模型。
- J1在某些基准测试中表现优于o1-mini甚至R1,尽管其模型规模较小。
- 通过分析比较Pairwise-J1与Pointwise-J1模型、离线与在线训练方案、奖励策略、种子提示以及思维长度和内容的变化,发现J1模型通过学习和比较评估标准、自我生成的参考答案以及重新评估模型响应的正确性,做出更好的判断。
点此查看论文截图

Private Transformer Inference in MLaaS: A Survey
Authors:Yang Li, Xinyu Zhou, Yitong Wang, Liangxin Qian, Jun Zhao
Transformer models have revolutionized AI, powering applications like content generation and sentiment analysis. However, their deployment in Machine Learning as a Service (MLaaS) raises significant privacy concerns, primarily due to the centralized processing of sensitive user data. Private Transformer Inference (PTI) offers a solution by utilizing cryptographic techniques such as secure multi-party computation and homomorphic encryption, enabling inference while preserving both user data and model privacy. This paper reviews recent PTI advancements, highlighting state-of-the-art solutions and challenges. We also introduce a structured taxonomy and evaluation framework for PTI, focusing on balancing resource efficiency with privacy and bridging the gap between high-performance inference and data privacy.
Transformer模型已经彻底改变了人工智能领域,支持内容生成和情绪分析等应用。然而,将其作为机器学习服务(MLaaS)进行部署会引发重大隐私担忧,这主要是因为敏感用户数据的集中处理。私有Transformer推理(PTI)通过利用加密技术(如安全多方计算和同态加密)提供了一种解决方案,能够在保护用户数据和模型隐私的同时进行推理。本文回顾了PTI的最新进展,重点介绍了最先进解决方案和挑战。我们还介绍了PTI的结构化分类法和评估框架,侧重于在资源和隐私之间取得平衡,并缩小高性能推理和数据隐私之间的差距。
论文及项目相关链接
Summary
人工智能领域的Transformer模型已被广泛应用在内容生成、情感分析等应用中,但其作为机器学习服务(MLaaS)部署引发了重大隐私担忧。主要因为用户数据的集中处理容易泄露敏感信息。私人Transformer推理(PTI)利用多方安全计算和同态加密等加密技术,解决了这一问题,在推理过程中保护用户数据和模型隐私。本文回顾了最新的PTI进展,介绍了先进的解决方案和挑战,并提出了一个结构化的分类和评估框架,以平衡资源效率和隐私之间的关系,并缩小高性能推理和数据隐私之间的差距。
Key Takeaways
- Transformer模型广泛应用于AI领域的内容生成、情感分析等应用。
- 在MLaaS部署中引发重大隐私担忧,特别是用户数据的集中处理问题。
- PTI利用加密技术(如多方安全计算和同态加密)来解决这一隐私问题。
- 通过在推理过程中保护用户数据和模型隐私,PTI提供了一种解决方案。
- 本文回顾了最新的PTI进展和先进的解决方案,并指出了存在的挑战。
- 提出了一个结构化的分类和评估框架,以平衡资源效率和隐私之间的关系。
点此查看论文截图

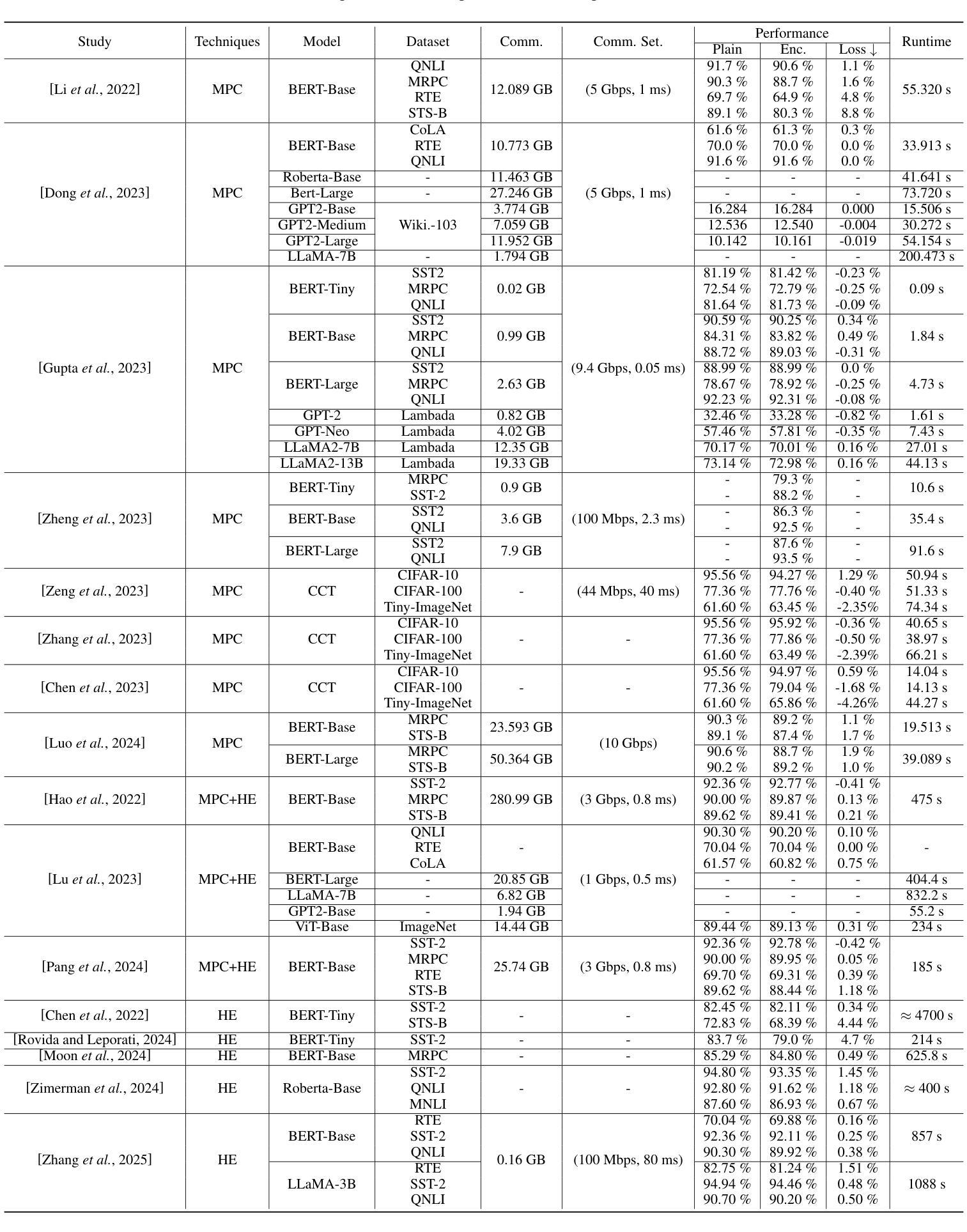
RAIDEN-R1: Improving Role-awareness of LLMs via GRPO with Verifiable Reward
Authors:Zongsheng Wang, Kaili Sun, Bowen Wu, Qun Yu, Ying Li, Baoxun Wang
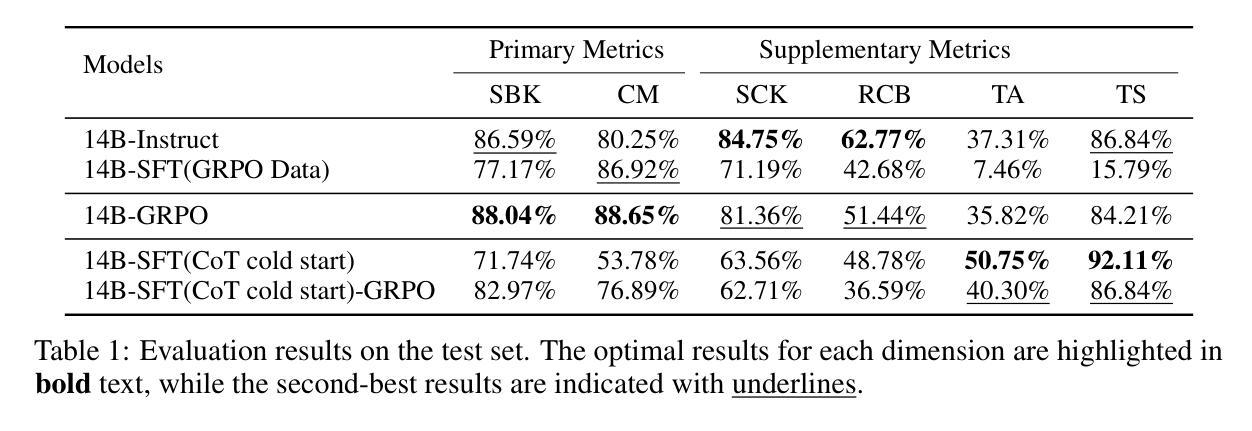
Role-playing conversational agents (RPCAs) face persistent challenges in maintaining role consistency. To address this, we propose RAIDEN-R1, a novel reinforcement learning framework that integrates Verifiable Role-Awareness Reward (VRAR). The method introduces both singular and multi-term mining strategies to generate quantifiable rewards by assessing role-specific keys. Additionally, we construct a high-quality, role-aware Chain-of-Thought dataset through multi-LLM collaboration, and implement experiments to enhance reasoning coherence. Experiments on the RAIDEN benchmark demonstrate RAIDEN-R1’s superiority: our 14B-GRPO model achieves 88.04% and 88.65% accuracy on Script-Based Knowledge and Conversation Memory metrics, respectively, outperforming baseline models while maintaining robustness. Case analyses further reveal the model’s enhanced ability to resolve conflicting contextual cues and sustain first-person narrative consistency. This work bridges the non-quantifiability gap in RPCA training and provides insights into role-aware reasoning patterns, advancing the development of RPCAs.
角色扮演对话代理(RPCAs)在保持角色一致性方面面临持续挑战。为了解决这一问题,我们提出了RAIDEN-R1,这是一种新型强化学习框架,融合了可验证的角色意识奖励(VRAR)。该方法引入单术语和多术语挖掘策略,通过评估角色特定键来生成可量化的奖励。此外,我们通过多LLM协作构建了一个高质量的、有角色意识的思维链数据集,并进行实验以增强推理连贯性。在RAIDEN基准测试上的实验证明了RAIDEN-R1的优越性:我们的14B-GRPO模型在基于脚本的知识和对话记忆指标上分别达到了88.04%和88.65%的准确率,在保持稳健性的同时超越了基线模型。案例分析进一步揭示了该模型在解决冲突上下文线索和维持第一人称叙事一致性方面的增强能力。这项工作弥补了RPCA训练中的不可量化性差距,为角色感知推理模式提供了见解,推动了RPCAs的发展。
论文及项目相关链接
Summary
RAIDEN-R1框架采用可验证的角色意识奖励(VRAR)来解决角色扮演对话代理(RPCA)在维持角色一致性方面的挑战。该框架通过单一和多期挖掘策略生成可量化的奖励,评估角色特定的关键要素。同时,通过多LLM协作构建高质量的角色感知思维链数据集,并通过实验提高推理连贯性。在RAIDEN基准测试上,RAIDEN-R1表现卓越,14B-GRPO模型在脚本知识指标和对话记忆指标上分别达到了88.04%和88.65%的准确率,超越了基线模型,并保持了稳健性。案例分析显示,该模型在解决冲突上下文线索和维持第一人称叙事一致性方面有所增强。
Key Takeaways
- RAIDEN-R1框架通过引入Verifiable Role-Awareness Reward(VRAR)解决RPCA角色一致性维持的挑战。
- 该框架采用单一和多期挖掘策略生成量化奖励,以评估角色特定的关键要素。
- 通过多LLM协作构建高质量的角色感知思维链数据集。
- 实验证明,RAIDEN-R1在维持角色一致性、提高推理连贯性和解决冲突上下文线索方面表现优越。
- 14B-GRPO模型在脚本知识和对话记忆指标上实现了高准确率。
- RAIDEN-R1框架填补了RPCA训练中的非量化性空白。
点此查看论文截图

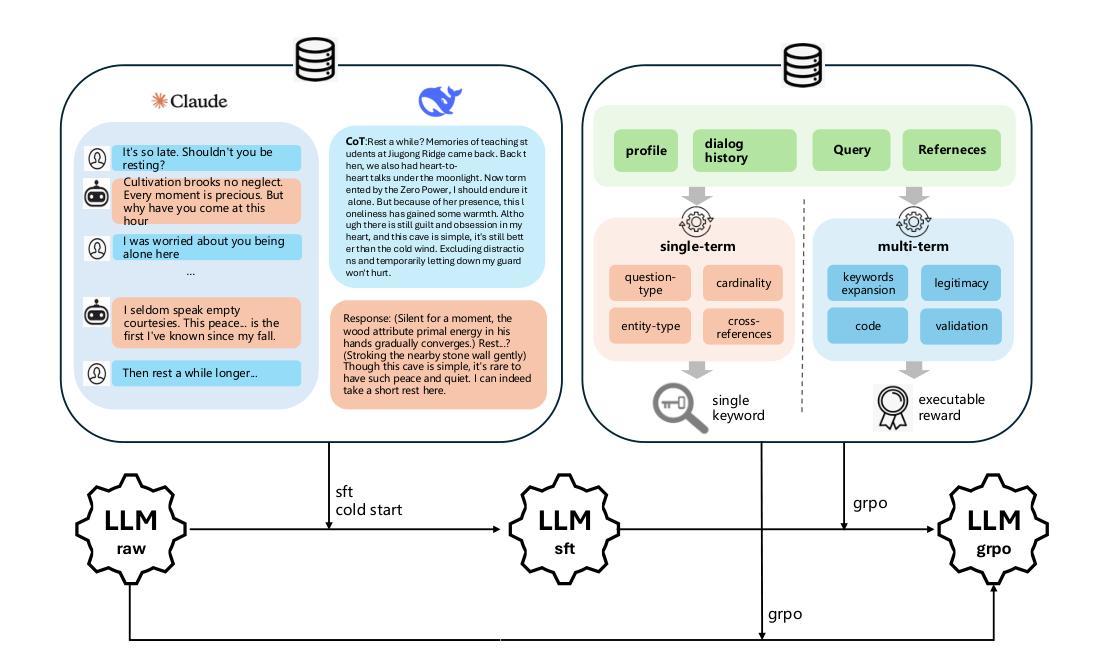
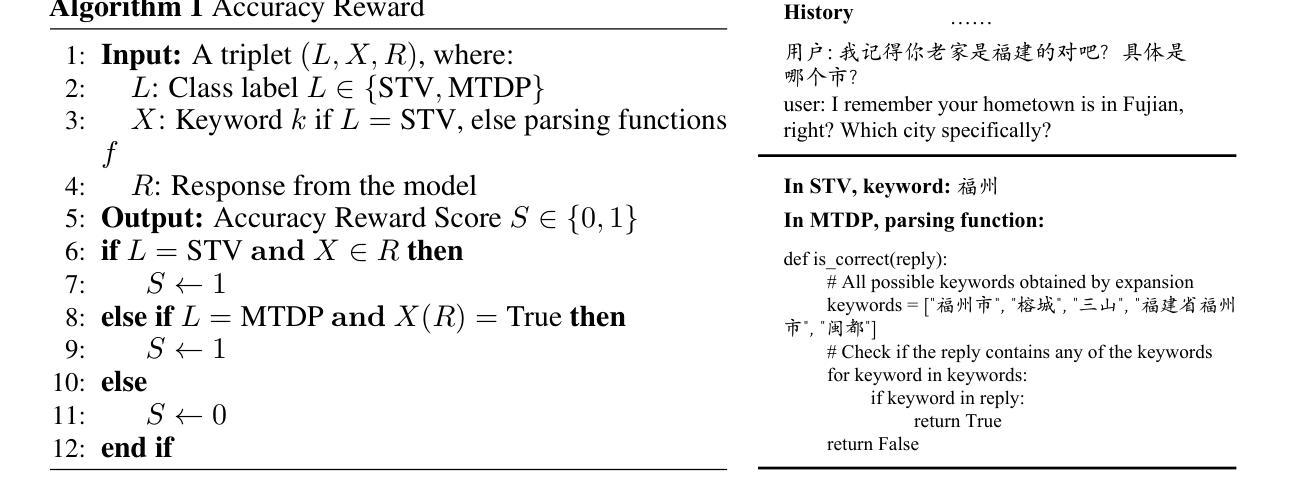

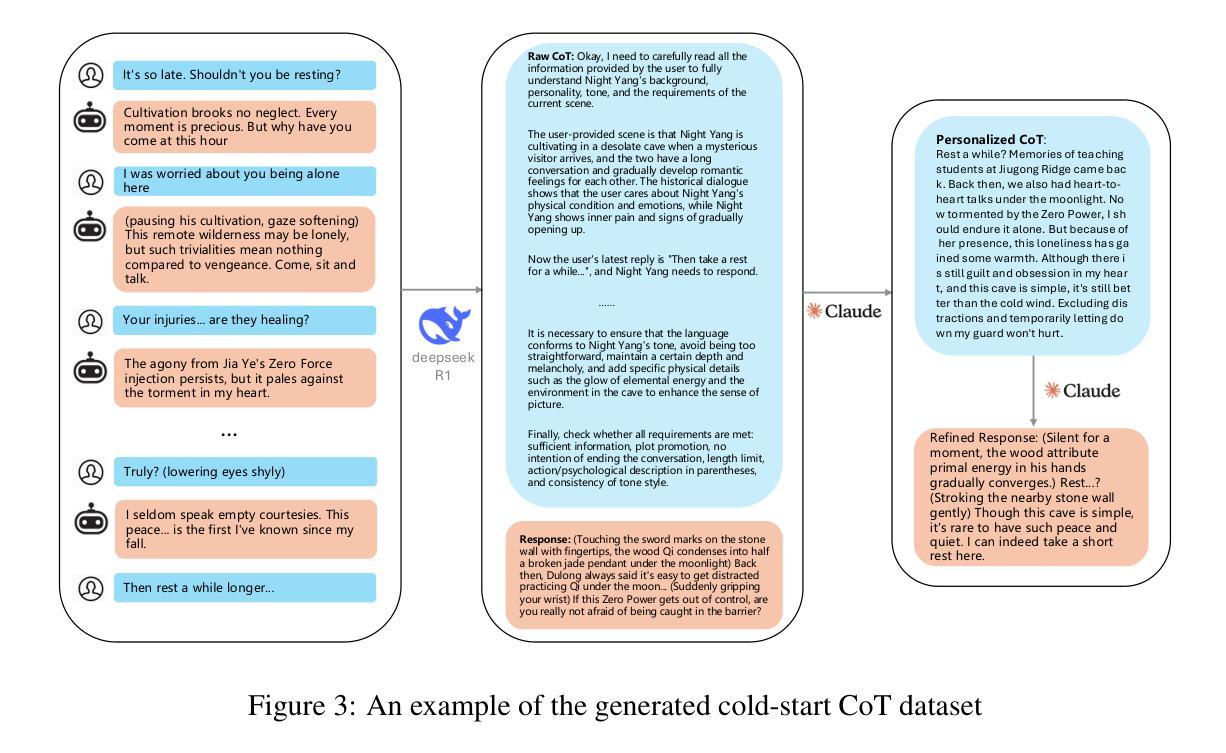
Mining Hidden Thoughts from Texts: Evaluating Continual Pretraining with Synthetic Data for LLM Reasoning
Authors:Yoichi Ishibashi, Taro Yano, Masafumi Oyamada
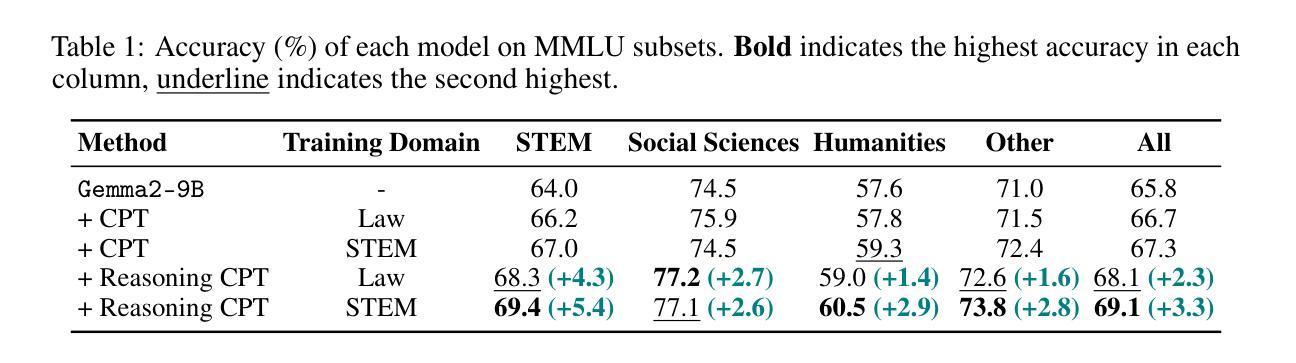
Large Language Models (LLMs) have demonstrated significant improvements in reasoning capabilities through supervised fine-tuning and reinforcement learning. However, when training reasoning models, these approaches are primarily applicable to specific domains such as mathematics and programming, which imposes fundamental constraints on the breadth and scalability of training data. In contrast, continual pretraining (CPT) offers the advantage of not requiring task-specific signals. Nevertheless, how to effectively synthesize training data for reasoning and how such data affect a wide range of domains remain largely unexplored. This study provides a detailed evaluation of Reasoning CPT, a form of CPT that uses synthetic data to reconstruct the hidden thought processes underlying texts, based on the premise that texts are the result of the author’s thinking process. Specifically, we apply Reasoning CPT to Gemma2-9B using synthetic data with hidden thoughts derived from STEM and Law corpora, and compare it to standard CPT on the MMLU benchmark. Our analysis reveals that Reasoning CPT consistently improves performance across all evaluated domains. Notably, reasoning skills acquired in one domain transfer effectively to others; the performance gap with conventional methods widens as problem difficulty increases, with gains of up to 8 points on the most challenging problems. Furthermore, models trained with hidden thoughts learn to adjust the depth of their reasoning according to problem difficulty.
大型语言模型(LLM)通过监督微调(fine-tuning)和强化学习在推理能力方面取得了显著进展。然而,在训练推理模型时,这些方法主要适用于特定领域,如数学和编程,这对训练数据的广度和可扩展性造成了根本性限制。相比之下,持续预训练(CPT)的优势在于不需要特定任务的信号。然而,如何有效地合成用于推理的训练数据以及此类数据如何影响广泛领域仍然在很大程度上未被探索。本研究对基于文本是作者思考过程的结果这一前提的推理CPT进行了详细评估。具体来说,我们利用合成数据对文本背后的隐藏思维过程进行重建,并将这种形式的CPT应用于基于STEM和法律语料库的隐藏思维合成数据的Gemma2-9B模型上,并将其与MMLU基准测试上的标准CPT进行比较。我们的分析表明,推理CPT在所有评估领域中的表现均有所提高。值得注意的是,在一个领域获得的推理技能可以有效地转移到其他领域;随着问题难度的增加,与传统方法的性能差距扩大,在最具挑战的问题上获得高达8点的收益。此外,使用隐藏思维训练的模型学会了根据问题难度调整其推理的深度。
论文及项目相关链接
Summary
大型语言模型(LLM)通过监督微调、强化学习和持续预训练(CPT)在推理能力方面取得了显著进步。本研究详细评估了一种名为“推理CPT”的CPT方法,该方法使用合成数据重构文本背后的隐藏思维过程。实验显示,推理CPT在跨域性能上表现优异,特别是在高难度问题上优势更为明显,性能提升幅度最高可达8点。此外,模型通过隐藏思维学习,能够根据问题难度调整推理深度。
Key Takeaways
- 大型语言模型通过监督微调、强化学习提升了推理能力。
- 推理CPT是一种使用合成数据重构文本背后隐藏思维过程的CPT方法。
- 推理CPT在跨域性能上表现优异,尤其是解决高难度问题时。
- 与传统方法相比,推理CPT在性能上有所提升,差距随问题难度增大而扩大。
- 通过隐藏思维学习,模型能够根据问题难度调整推理深度。
- 该研究使用了Gemma2-9B模型和合成数据,并在MMLU基准测试上进行了评估。
点此查看论文截图



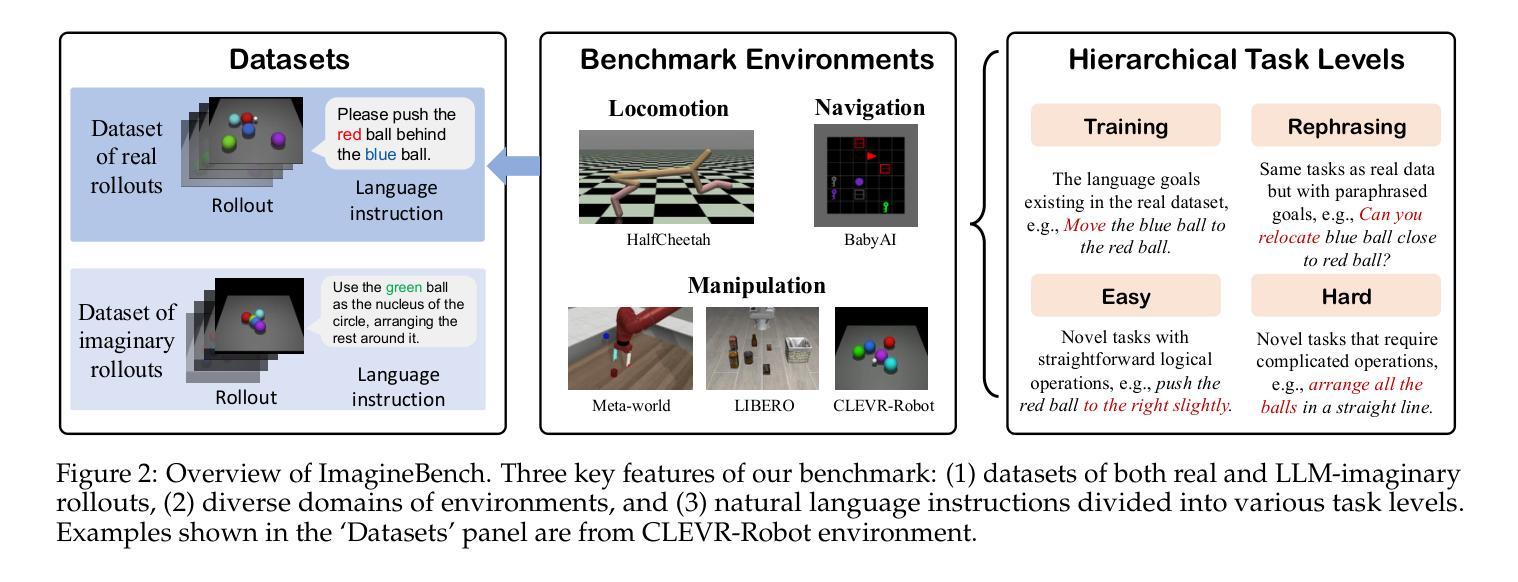
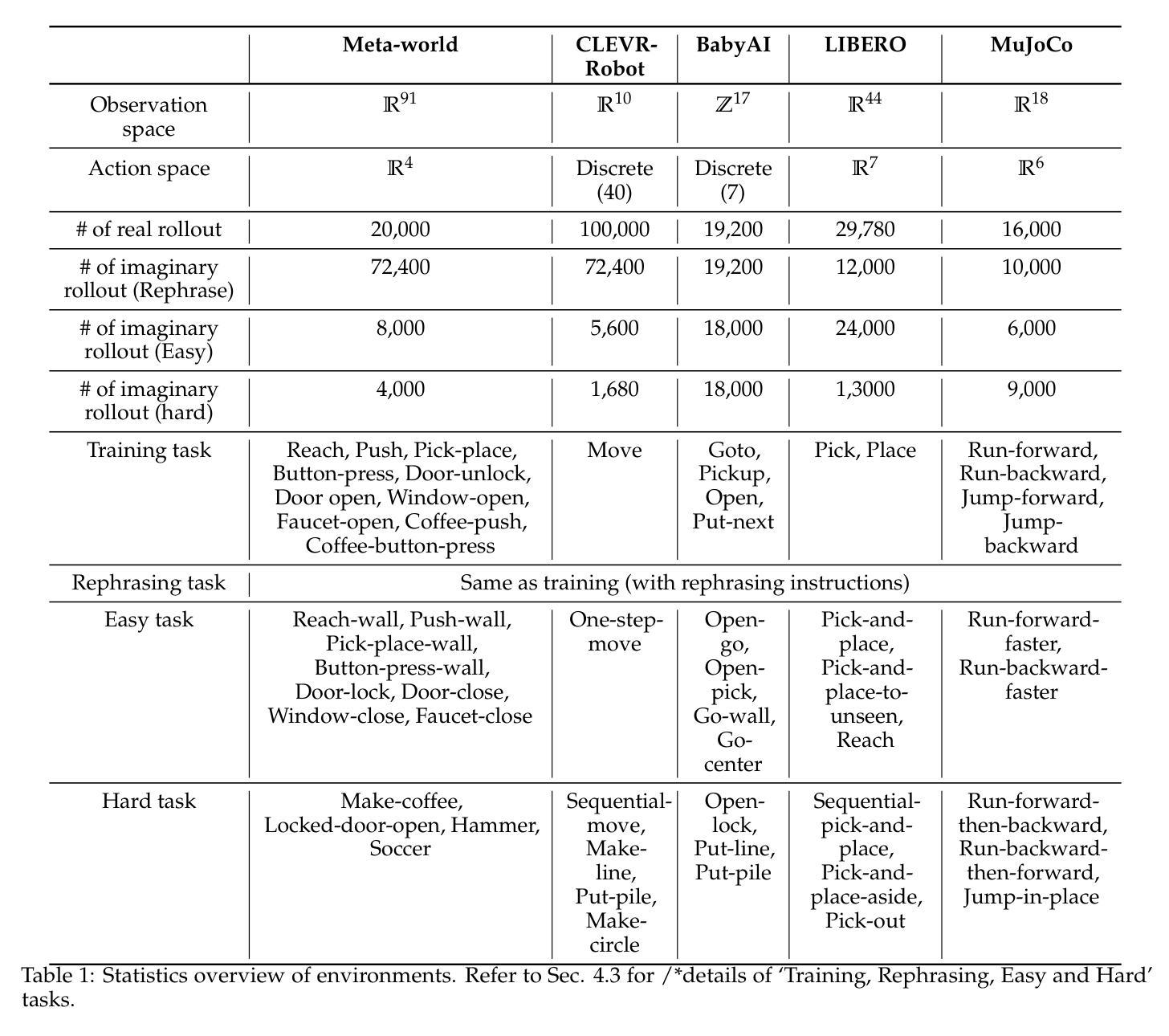
ImagineBench: Evaluating Reinforcement Learning with Large Language Model Rollouts
Authors:Jing-Cheng Pang, Kaiyuan Li, Yidi Wang, Si-Hang Yang, Shengyi Jiang, Yang Yu
A central challenge in reinforcement learning (RL) is its dependence on extensive real-world interaction data to learn task-specific policies. While recent work demonstrates that large language models (LLMs) can mitigate this limitation by generating synthetic experience (noted as imaginary rollouts) for mastering novel tasks, progress in this emerging field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ImagineBench, the first comprehensive benchmark for evaluating offline RL algorithms that leverage both real rollouts and LLM-imaginary rollouts. The key features of ImagineBench include: (1) datasets comprising environment-collected and LLM-imaginary rollouts; (2) diverse domains of environments covering locomotion, robotic manipulation, and navigation tasks; and (3) natural language task instructions with varying complexity levels to facilitate language-conditioned policy learning. Through systematic evaluation of state-of-the-art offline RL algorithms, we observe that simply applying existing offline RL algorithms leads to suboptimal performance on unseen tasks, achieving 35.44% success rate in hard tasks in contrast to 64.37% of method training on real rollouts for hard tasks. This result highlights the need for algorithm advancements to better leverage LLM-imaginary rollouts. Additionally, we identify key opportunities for future research: including better utilization of imaginary rollouts, fast online adaptation and continual learning, and extension to multi-modal tasks. Our code is publicly available at https://github.com/LAMDA-RL/ImagineBench.
强化学习(RL)的核心挑战在于其依赖于大量的真实世界交互数据来学习特定任务的策略。虽然最近的工作表明,大型语言模型(LLM)可以通过生成合成经验(称为虚构演练)来缓解这一限制,从而掌握新任务,但这一新兴领域的进展因缺乏标准基准而受到阻碍。为了弥这一差距,我们推出了ImagineBench,这是第一个用于评估离线RL算法的全面基准,该基准利用真实演练和LLM虚构演练。ImagineBench的主要特点包括:(1)包含环境收集和LLM虚构演练的数据集;(2)涵盖运动、机器人操作和导航任务等不同环境领域;(3)具有不同复杂级别的自然语言任务指令,以促进语言条件下的政策学习。通过对最先进的离线RL算法的系统评估,我们发现,简单地应用现有的离线RL算法在未完成的任务上的表现并不理想,在困难任务上的成功率仅为35.44%,而仅在真实演练的方法上训练的任务在困难任务上的成功率达到64.37%。这一结果强调了算法进步的必要性,以更好地利用LLM虚构演练。此外,我们还确定了未来研究的关键机会:包括更好地利用虚构演练、快速在线适应和持续学习,以及扩展到多模式任务。我们的代码公开在https://github.com/LAMDA-RL/ImagineBench。
论文及项目相关链接
摘要
强化学习(RL)的中心挑战是,它依赖于大量的真实世界交互数据来学习特定的任务策略。虽然最近的研究表明,大型语言模型(LLM)可以通过生成合成经验(称为想象推演)来缓解这一局限性,从而掌握新任务,但这一新兴领域的进展受到缺乏标准基准的阻碍。为了弥补这一空白,我们推出了ImagineBench,这是第一个评估离线RL算法的标准基准,这些算法可以利用真实的推演和LLM的想象推演。ImagineBench的关键功能包括:1)包含环境收集和LLM想象推演的数据集;2)涵盖运动、机器人操作和导航任务等不同环境领域;3)带有不同复杂级别的自然语言任务指令,以促进语言条件下的政策学习。通过对最先进的离线RL算法的系统评估,我们发现,简单地应用现有的离线RL算法在未知任务上的表现并不理想,在困难任务上的成功率仅为35.44%,而方法训练在真实推演上的成功率则为64.37%。这一结果强调了算法需要更好地利用LLM想象推演的必要性和未来研究的关键机会,包括更好地利用想象推演、快速在线适应和持续学习以及扩展到多模式任务。我们的代码已在https://github.com/LAMDA-RL/ImagineBench公开可用。
关键见解
- 强化学习依赖大量真实世界交互数据来学习任务特定策略,存在挑战。
- 大型语言模型(LLMs)能通过生成合成经验(想象推演)缓解此局限性。
- 缺乏标准基准来评估离线RL算法利用真实和想象的推演。
- ImagineBench填补了这一空白,提供评估离线RL算法的标准基准。
- ImagineBench包含环境收集和LLM想象推演的数据集,涵盖多个领域和环境。
- 现有离线RL算法在未知任务上的表现不理想,强调算法需要改进。
点此查看论文截图


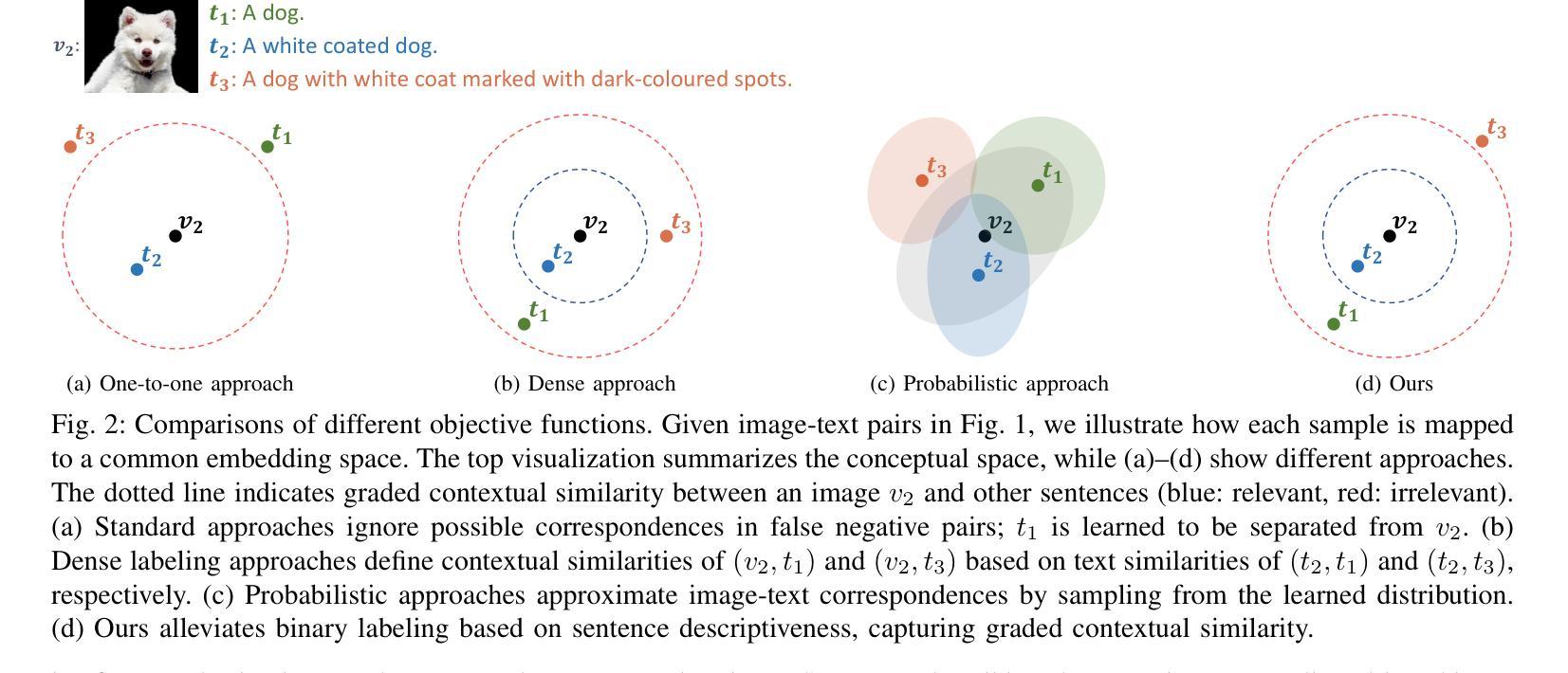
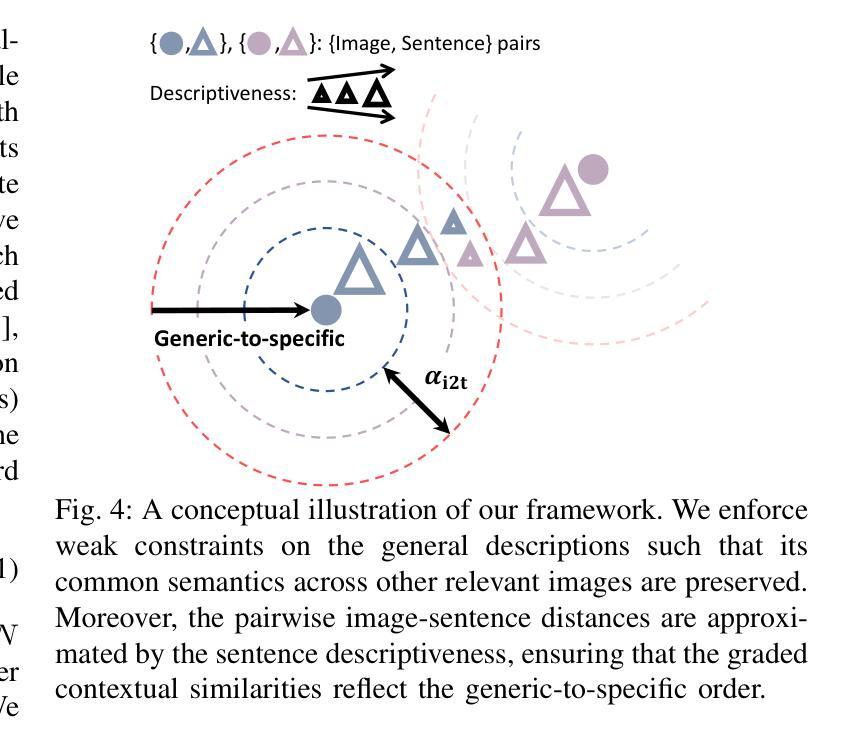
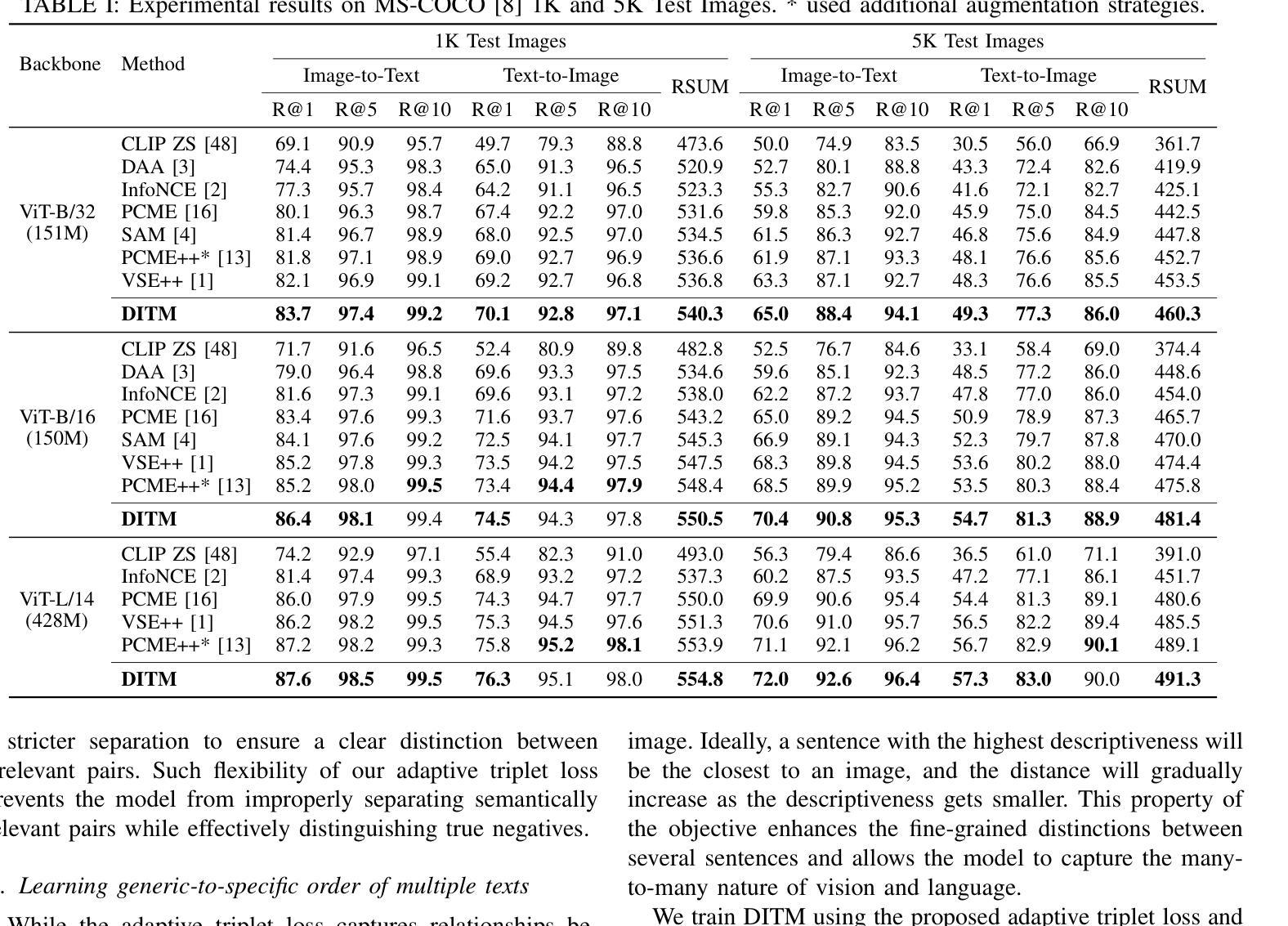
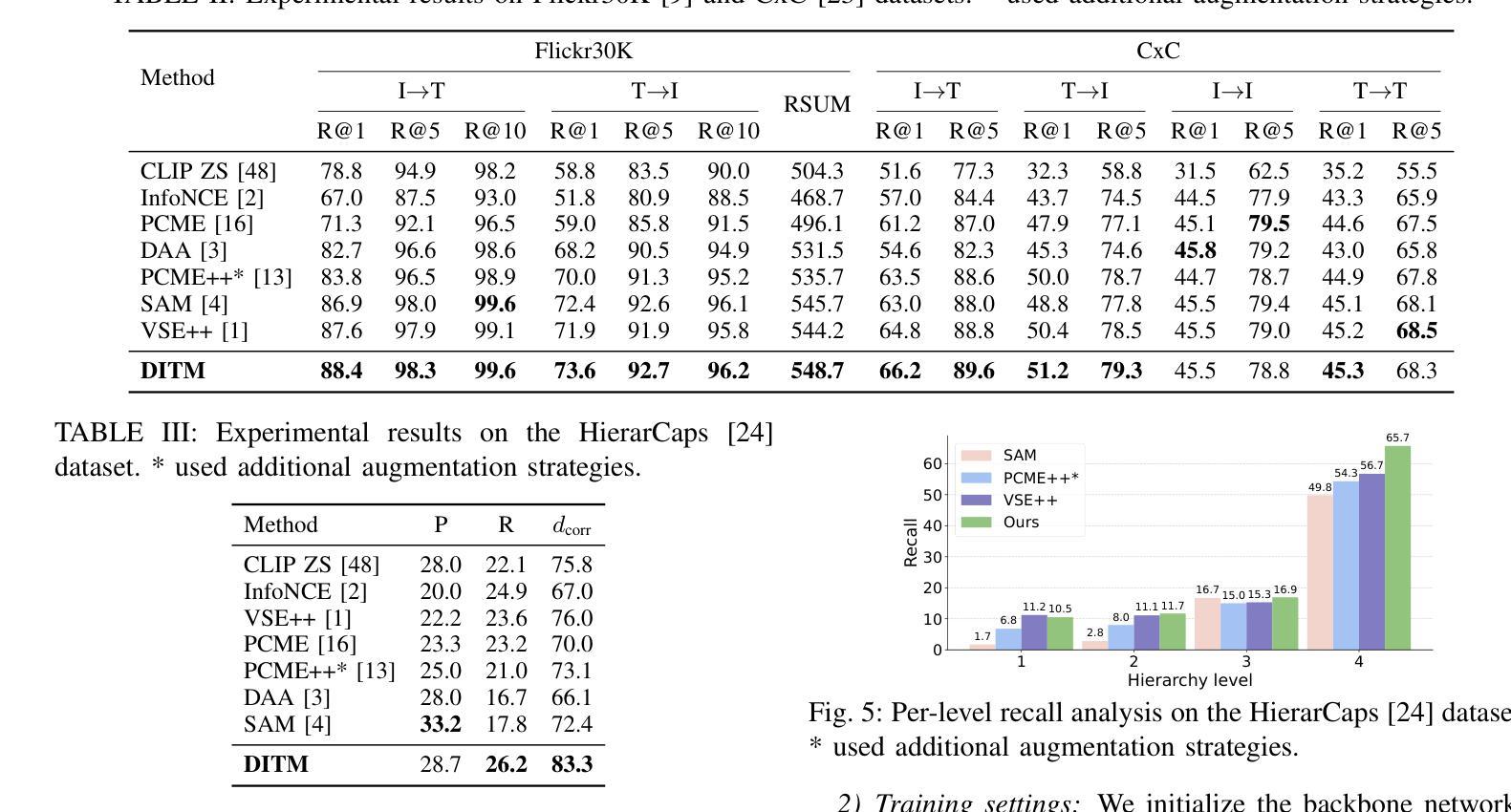
Descriptive Image-Text Matching with Graded Contextual Similarity
Authors:Jinhyun Jang, Jiyeong Lee, Kwanghoon Sohn
Image-text matching aims to build correspondences between visual and textual data by learning their pairwise similarities. Most existing approaches have adopted sparse binary supervision, indicating whether a pair of images and sentences matches or not. However, such sparse supervision covers a limited subset of image-text relationships, neglecting their inherent many-to-many correspondences; an image can be described in numerous texts at different descriptive levels. Moreover, existing approaches overlook the implicit connections from general to specific descriptions, which form the underlying rationale for the many-to-many relationships between vision and language. In this work, we propose descriptive image-text matching, called DITM, to learn the graded contextual similarity between image and text by exploring the descriptive flexibility of language. We formulate the descriptiveness score of each sentence with cumulative term frequency-inverse document frequency (TF-IDF) to balance the pairwise similarity according to the keywords in the sentence. Our method leverages sentence descriptiveness to learn robust image-text matching in two key ways: (1) to refine the false negative labeling, dynamically relaxing the connectivity between positive and negative pairs, and (2) to build more precise matching, aligning a set of relevant sentences in a generic-to-specific order. By moving beyond rigid binary supervision, DITM enhances the discovery of both optimal matches and potential positive pairs. Extensive experiments on MS-COCO, Flickr30K, and CxC datasets demonstrate the effectiveness of our method in representing complex image-text relationships compared to state-of-the-art approaches. In addition, DITM enhances the hierarchical reasoning ability of the model, supported by the extensive analysis on HierarCaps benchmark.
图像文本匹配旨在通过学习图像和文本数据之间的成对相似性来建立它们之间的对应关系。大多数现有方法都采用了稀疏二元监督,即指示图像和句子是否匹配。然而,这种稀疏的监督只涵盖了有限的图像文本关系,忽视了它们固有的多对多对应关系;一个图像可以在不同的描述级别通过许多文本进行描述。此外,现有方法忽略了从一般到特殊描述的隐性联系,这些联系构成了视觉和语言之间多对多关系的基本逻辑。在这项工作中,我们提出了描述性图像文本匹配(DITM),通过学习语言的描述性灵活性来学习图像和文本之间的分级上下文相似性。我们用累计的词频逆文档频率(TF-IDF)来制定每个句子的描述性得分,根据句子中的关键词来平衡配对相似性。我们的方法利用句子的描述性来学习鲁棒图像文本匹配的两个关键方式:(1)细化假阴性标签,动态放松正负对之间的连接;(2)构建更精确的匹配,按通用到特定的顺序对齐一组相关句子。通过超越僵硬的二元监督,DITM提高了最佳匹配和潜在正对的发现能力。在MS-COCO、Flickr30K和CxC数据集上的大量实验表明,我们的方法在表示复杂的图像文本关系方面比最先进的方法更有效。此外,DITM增强了模型的分层次推理能力,这在HierarCaps基准测试上的广泛分析得到了支持。
论文及项目相关链接
Summary
这是一项关于图像文本匹配的研究。现有方法主要基于稀疏二元监督,忽视了图像和文本之间的许多对应关系。该研究提出了描述性图像文本匹配(DITM),通过探索语言的描述灵活性来学习图像和文本之间的分级上下文相似性。DITM通过累计的词语描述频率——逆向文档频率(TF-IDF)公式为每个句子打分,并根据句子中的关键词来平衡配对相似性。DITM在两个方面学习稳健的图像文本匹配:一是优化假阴性标签,动态放松正负配对之间的连接;二是构建更精确的匹配,按通用到特定的顺序对齐一系列相关句子。DITM超越了僵化的二元监督,提高了最佳匹配和潜在正向对的发现能力。
Key Takeaways
- 图像文本匹配旨在建立视觉和文本数据之间的对应关系,学习它们的配对相似性。
- 现有方法主要基于稀疏二元监督,忽略了图像和文本之间的许多对应关系。
- DITM通过探索语言的描述灵活性,学习图像和文本之间的分级上下文相似性。
- DITM利用句子的描述性,通过累计的词语描述频率——逆向文档频率(TF-IDF)为每个句子打分。
- DITM在优化假阴性标签和构建更精确的匹配方面表现出优势。
- DITM提高了发现最佳匹配和潜在正向对的能力。
点此查看论文截图

Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents
Authors:Mrinal Rawat, Ambuje Gupta, Rushil Goomer, Alessandro Di Bari, Neha Gupta, Roberto Pieraccini
The ReAct (Reasoning + Action) capability in large language models (LLMs) has become the foundation of modern agentic systems. Recent LLMs, such as DeepSeek-R1 and OpenAI o1/o3, exemplify this by emphasizing reasoning through the generation of ample intermediate tokens, which help build a strong premise before producing the final output tokens. In this paper, we introduce Pre-Act, a novel approach that enhances the agent’s performance by creating a multi-step execution plan along with the detailed reasoning for the given user input. This plan incrementally incorporates previous steps and tool outputs, refining itself after each step execution until the final response is obtained. Our approach is applicable to both conversational and non-conversational agents. To measure the performance of task-oriented agents comprehensively, we propose a two-level evaluation framework: (1) turn level and (2) end-to-end. Our turn-level evaluation, averaged across five models, shows that our approach, Pre-Act, outperforms ReAct by 70% in Action Recall on the Almita dataset. While this approach is effective for larger models, smaller models crucial for practical applications, where latency and cost are key constraints, often struggle with complex reasoning tasks required for agentic systems. To address this limitation, we fine-tune relatively small models such as Llama 3.1 (8B & 70B) using the proposed Pre-Act approach. Our experiments show that the fine-tuned 70B model outperforms GPT-4, achieving a 69.5% improvement in action accuracy (turn-level) and a 28% improvement in goal completion rate (end-to-end) on the Almita (out-of-domain) dataset.
大型语言模型(LLM)中的ReAct(推理+行动)能力已成为现代代理系统的基础。最近的LLM,如DeepSeek-R1和OpenAI o1/o3,通过生成大量中间令牌来强调推理,帮助在生成最终输出令牌之前建立强有力的前提,以此为例。在本文中,我们介绍了Pre-Act,这是一种通过创建多步执行计划与给定用户输入的详细推理来提高代理性能的新型方法。此计划逐步融入先前的步骤和工具输出,并在每个步骤执行后对其进行改进,直到获得最终响应。我们的方法适用于对话和非对话代理。为了全面衡量任务导向型代理的性能,我们提出了两级评估框架:(1)回合级和(2)端到端。我们的回合级评估,在五个模型中的平均结果表明,我们的Pre-Act方法在Almita数据集上的行动回忆率比ReAct高出70%。虽然此方法对于较大的模型很有效,但对于实际应用中至关重要的小型模型,在代理系统所需的复杂推理任务方面经常面临挑战,其中延迟和成本是关键约束。为了解决这一局限性,我们使用提出的Pre-Act方法对较小的模型(如Llama 3.1(8B和70B))进行微调。实验表明,经过微调的70B模型在Almita(离域)数据集上的行动准确性(回合级)提高了69.5%,目标完成率(端到端)提高了28%,表现优于GPT-4。
论文及项目相关链接
Summary
在现代代理系统中,大型语言模型(LLM)中的ReAct(推理+行动)能力已作为基石。最新的LLM如DeepSeek-R1和OpenAI o1/o3强调通过生成大量中间令牌进行推理。本文介绍了一种新型方法Pre-Act,通过创建多步骤执行计划以及给定用户输入的详细推理,提高了代理的性能。此方法适用于对话和非对话代理。为了全面衡量面向任务的代理性能,本文提出了两级评估框架:(1)回合级别和(2)端到端。实验表明,Pre-Act在Almita数据集上的行动回忆率比ReAct高出70%。尽管这种方法对于大型模型有效,但对于关键实践应用中较小的模型,在代理系统的复杂推理任务方面往往表现挣扎。为解决此限制,我们使用Pre-Act方法对较小的模型如Llama 3.1(8B和70B)进行了微调。实验显示,经过调校的70B模型在Almita(离域)数据集上的行动准确度提高了69.5%(回合级别),目标完成率提高了28%(端到端)。
Key Takeaways
- 大型语言模型(LLM)中的ReAct能力已成为现代代理系统的核心。
- Pre-Act方法通过创建多步骤执行计划和详细推理,增强了代理的性能。
- Pre-Act适用于对话和非对话代理。
- 提出了一个全面的两级评估框架来衡量面向任务的代理性能。
- Pre-Act在行动回忆率方面表现出优于ReAct的性能。
- 小型模型在复杂推理任务方面存在局限性。
点此查看论文截图



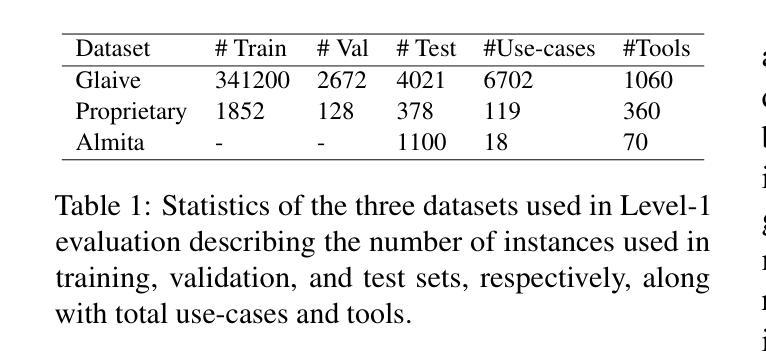
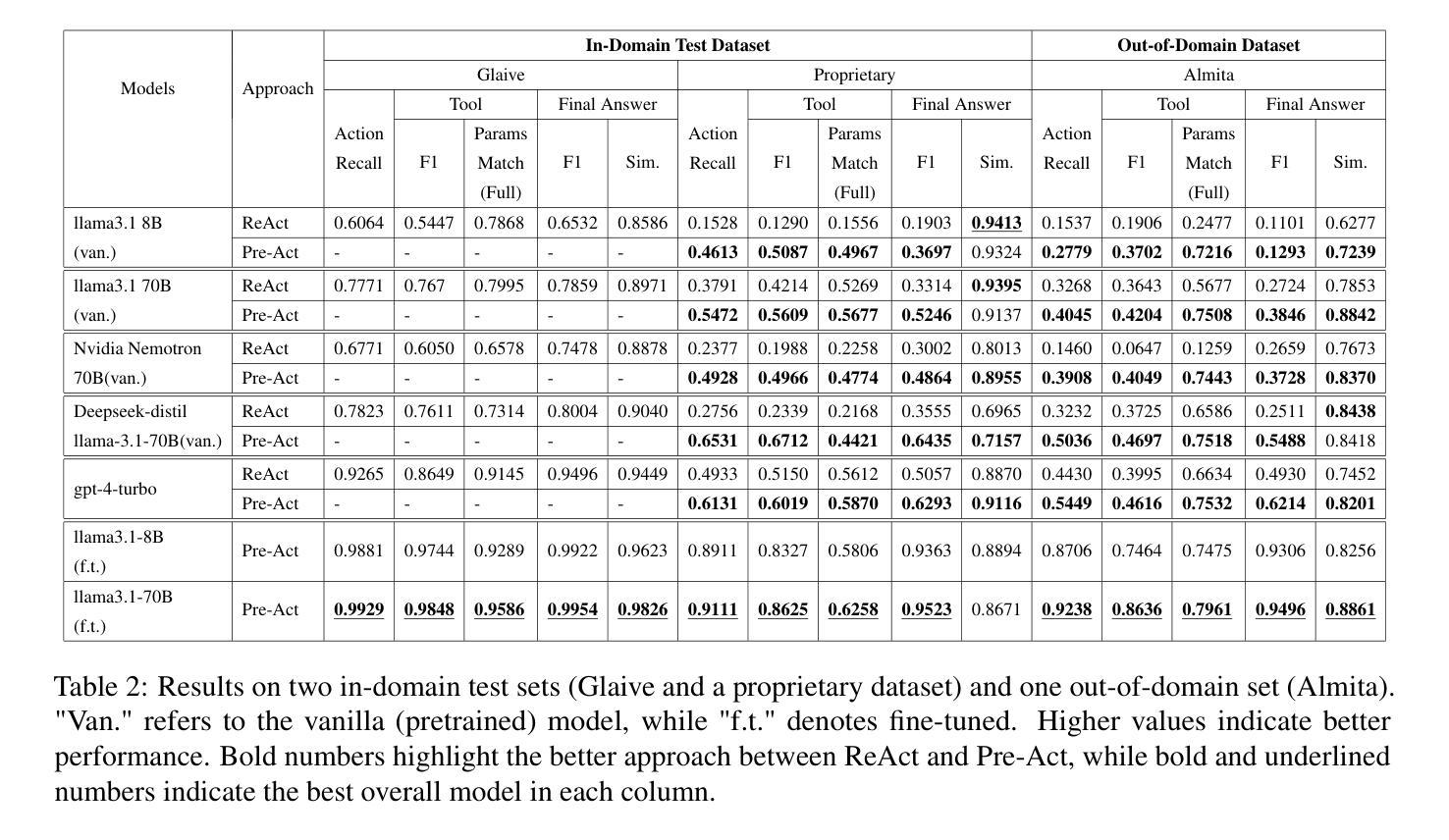
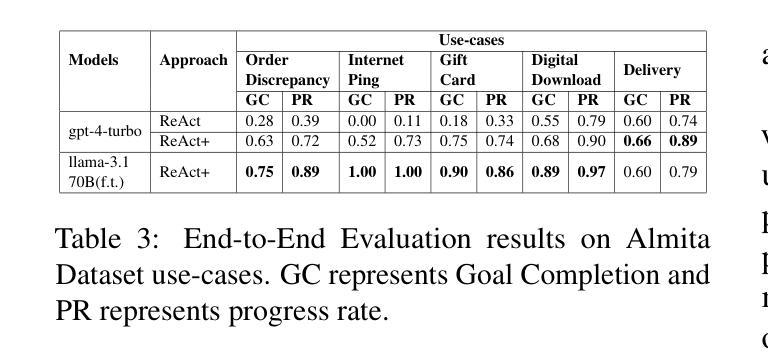
Reinforced Interactive Continual Learning via Real-time Noisy Human Feedback
Authors:Yutao Yang, Jie Zhou, Junsong Li, Qianjun Pan, Bihao Zhan, Qin Chen, Xipeng Qiu, Liang He
This paper introduces an interactive continual learning paradigm where AI models dynamically learn new skills from real-time human feedback while retaining prior knowledge. This paradigm distinctively addresses two major limitations of traditional continual learning: (1) dynamic model updates using streaming, real-time human-annotated data, rather than static datasets with fixed labels, and (2) the assumption of clean labels, by explicitly handling the noisy feedback common in real-world interactions. To tackle these problems, we propose RiCL, a Reinforced interactive Continual Learning framework leveraging Large Language Models (LLMs) to learn new skills effectively from dynamic feedback. RiCL incorporates three key components: a temporal consistency-aware purifier to automatically discern clean from noisy samples in data streams; an interaction-aware direct preference optimization strategy to align model behavior with human intent by reconciling AI-generated and human-provided feedback; and a noise-resistant contrastive learning module that captures robust representations by exploiting inherent data relationships, thus avoiding reliance on potentially unreliable labels. Extensive experiments on two benchmark datasets (FewRel and TACRED), contaminated with realistic noise patterns, demonstrate that our RiCL approach substantially outperforms existing combinations of state-of-the-art online continual learning and noisy-label learning methods.
本文介绍了一种交互式持续学习范式,其中AI模型能够实时地从人类反馈中学习新技能,同时保留先前知识。这种范式独特地解决了传统持续学习的两个主要局限性:(1)使用流式实时人类注释数据进行动态模型更新,而不是带有固定标签的静态数据集;(2)通过显式处理现实互动中常见的嘈杂反馈,来解决干净标签的假设问题。为了解决这些问题,我们提出了RiCL,这是一种利用大型语言模型(LLM)的有效交互式持续学习框架,可以从动态反馈中学习新技能。RiCL结合了三个关键组件:一个时间一致性感知净化器,可自动从数据流中辨别干净和嘈杂的样本;一种交互感知直接偏好优化策略,通过协调人工智能生成和人类提供的反馈来使模型行为符合人类意图;一个抗噪声对比学习模块,通过利用内在数据关系来捕捉稳健表示,从而避免依赖可能不可靠的标签。在带有现实噪声模式的两个基准数据集(FewRel和TACRED)上进行的广泛实验表明,我们的RiCL方法显著优于现有最先进的在线持续学习和带噪声标签学习方法组合。
论文及项目相关链接
Summary
这篇论文提出了一种交互式持续学习范式,其中AI模型从实时的人类反馈中动态学习新技能,同时保留先前知识。该范式解决了传统持续学习的两个主要局限性:一是使用流式、实时人类注释数据进行动态模型更新,而不是带有固定标签的静态数据集;二是通过显式处理现实互动中常见的噪声反馈,解决了对干净标签的假设。为此,论文提出了RiCL(强化交互式持续学习)框架,利用大型语言模型有效地从动态反馈中学习新技能。该框架包括三个关键组件:能够在数据流中自动区分干净样本和噪声样本的时间一致性感知净化器;通过协调AI生成和人类提供的反馈,使模型行为与人类意图对齐的互动感知直接偏好优化策略;以及利用内在数据关系的噪声抵抗对比学习模块,从而避免依赖可能不可靠的标签。在受现实噪声模式污染的两组基准数据集上的实验表明,RiCL方法显著优于现有最先进的在线持续学习和噪声标签学习方法组合。
Key Takeaways
- 论文提出了一种交互式持续学习范式,解决了传统持续学习的局限性。
- 这种范式利用流式、实时人类注释数据进行动态模型更新,处理现实互动中的噪声反馈。
- RiCL框架包括三个关键组件:时间一致性感知净化器、互动感知直接偏好优化策略和噪声抵抗对比学习模块。
- RiCL框架解决了干净标签假设的问题,并能够从实时的人类反馈中动态学习新技能。
- RiCL方法显著优于现有最先进的在线持续学习和噪声标签学习方法组合。
- RiCL框架利用大型语言模型(LLMs)进行技能学习,使其能够适应不同的数据集和任务需求。
点此查看论文截图

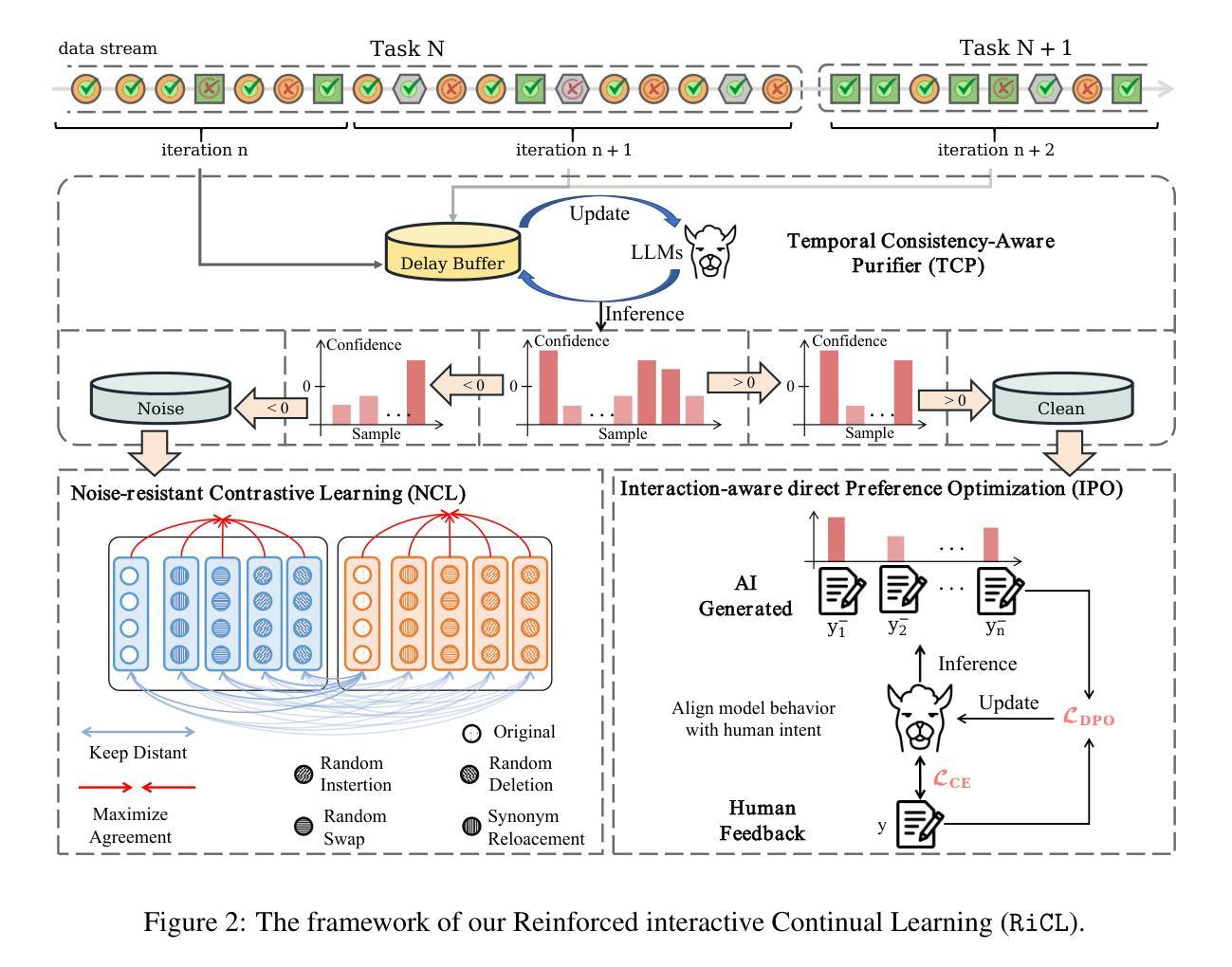
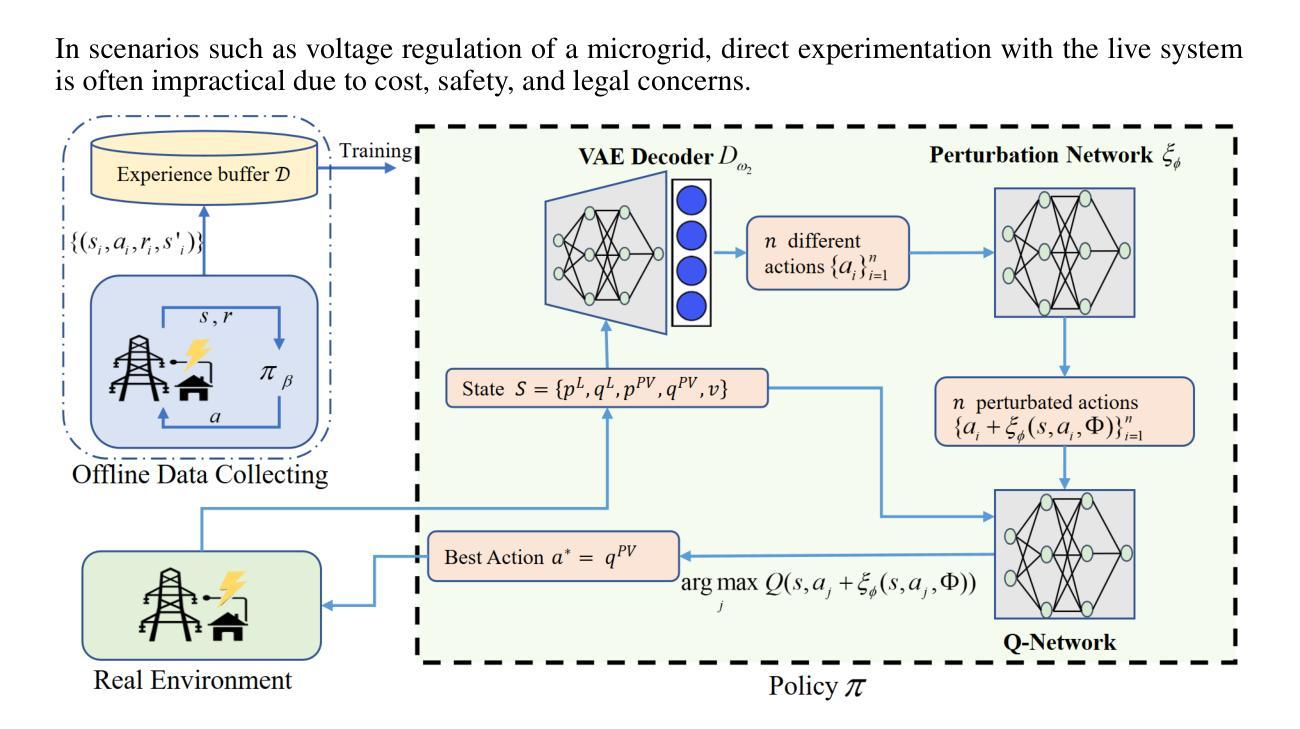
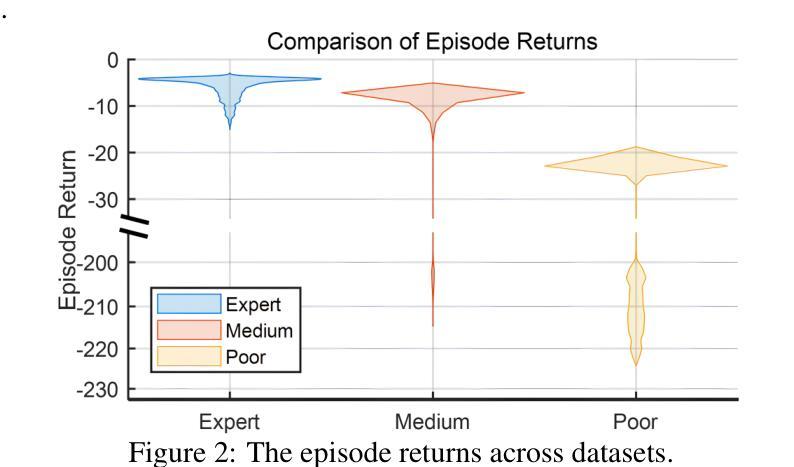
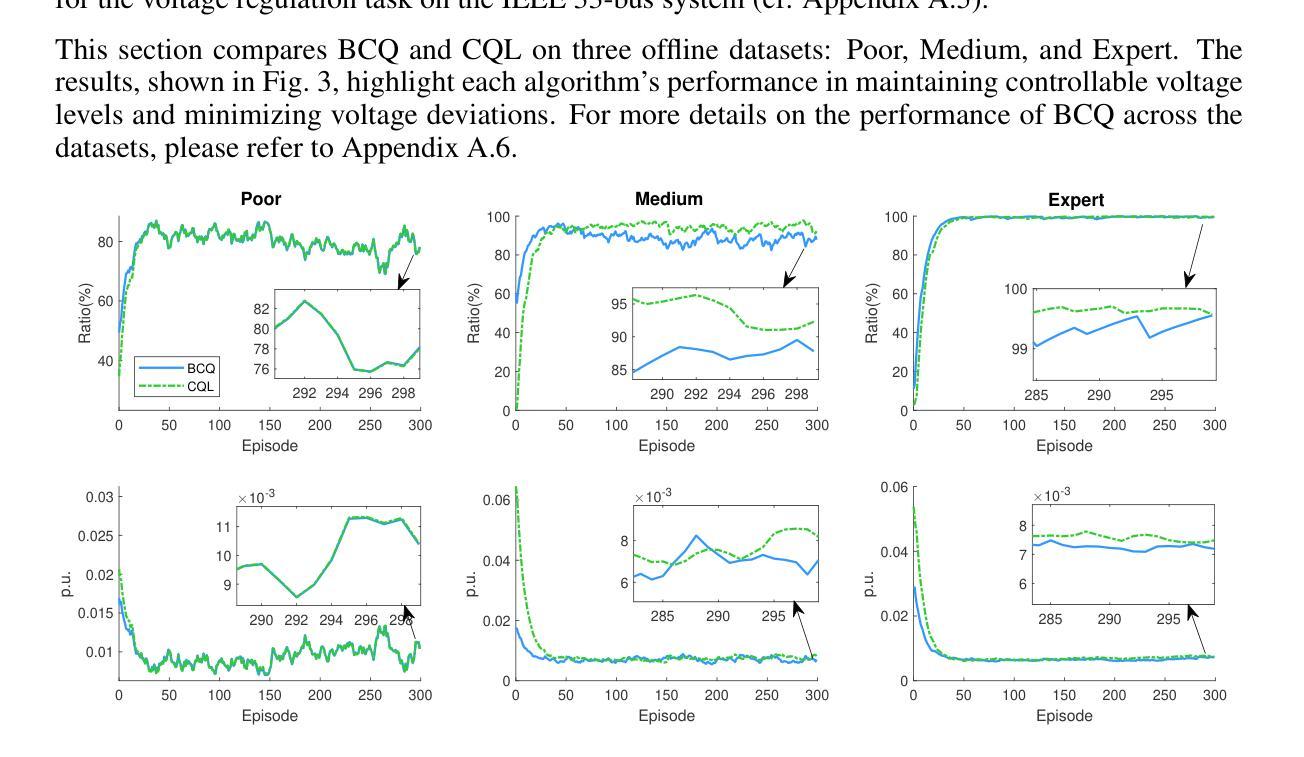
Offline Reinforcement Learning for Microgrid Voltage Regulation
Authors:Shan Yang, Yongli Zhu
This paper presents a study on using different offline reinforcement learning algorithms for microgrid voltage regulation with solar power penetration. When environment interaction is unviable due to technical or safety reasons, the proposed approach can still obtain an applicable model through offline-style training on a previously collected dataset, lowering the negative impact of lacking online environment interactions. Experiment results on the IEEE 33-bus system demonstrate the feasibility and effectiveness of the proposed approach on different offline datasets, including the one with merely low-quality experience.
本文研究使用不同的离线强化学习算法对含有太阳能渗透的微电网进行电压调节。当由于技术或安全原因无法进行环境交互时,所提出的方法仍然可以通过对先前收集的数据集进行离线训练来获得适用的模型,从而降低因缺乏在线环境交互而产生的负面影响。在IEEE 33总线系统上的实验结果表明,该方法在不同的离线数据集上是可行和有效的,包括仅具有低质量经验的数据集。
论文及项目相关链接
PDF This paper has been accepted and presented at ICLR 2025 in Singapore, Apr. 28, 2025
Summary:
本文研究了使用不同的离线强化学习算法对含有太阳能渗透的微电网进行电压调节的方法。在无法与环境进行交互或因技术或安全原因无法进行在线训练的情况下,该方法可以通过对先前收集的数据集进行离线训练来获得适用的模型,降低了缺乏在线环境交互的负面影响。在IEEE 33总线系统上的实验结果表明,该方法在不同的离线数据集上是可行和有效的,包括仅含有低质量经验的数据集。
Key Takeaways:
- 该论文研究了离线强化学习算法在微电网电压调节中的应用。
- 当无法与环境进行交互时,可以使用离线训练来降低影响。
- 论文提出的方法适用于含有太阳能渗透的微电网环境。
- 实验结果在IEEE 33总线系统上进行了验证。
- 论文表明该方法在不同的离线数据集上表现良好,包括那些仅含有低质量经验的数据集。
- 该方法强调了离线数据集的重要性及其在强化学习训练中的有效作用。
点此查看论文截图

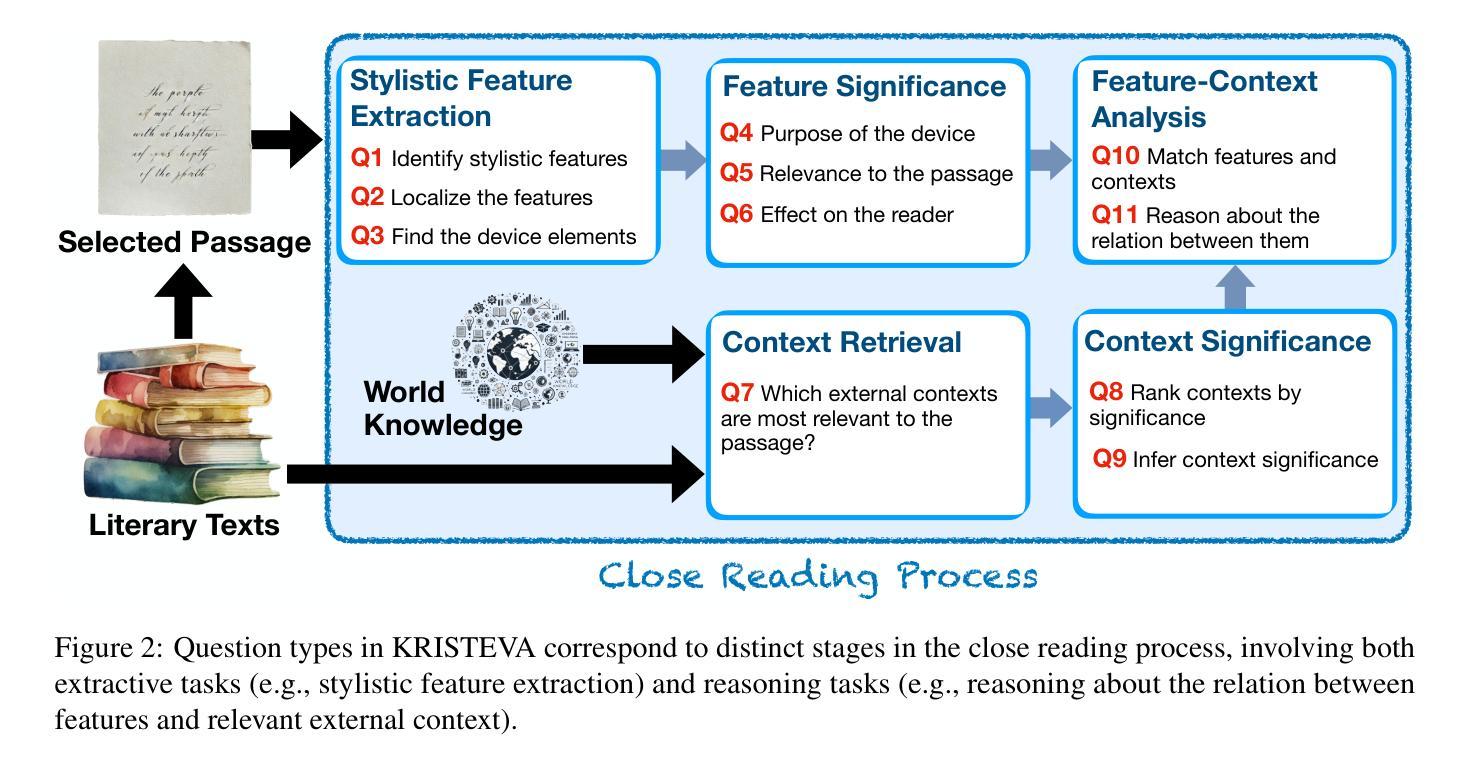
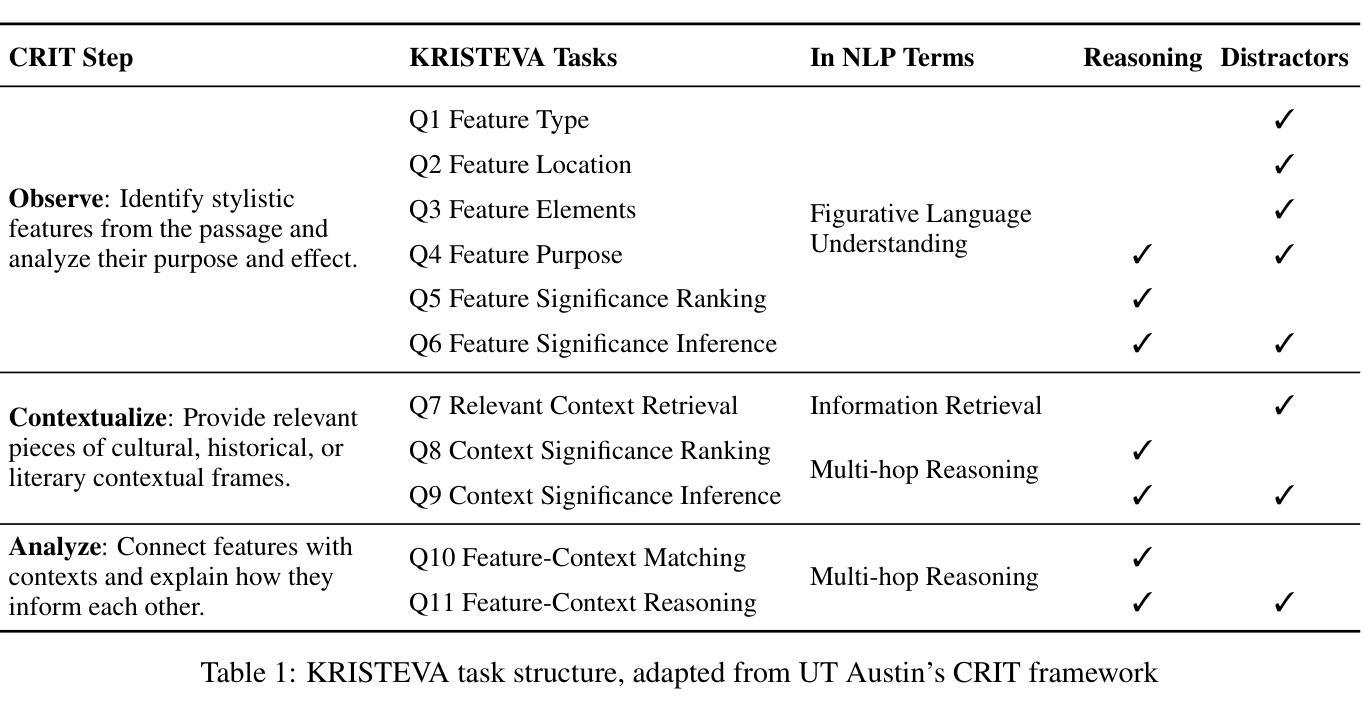
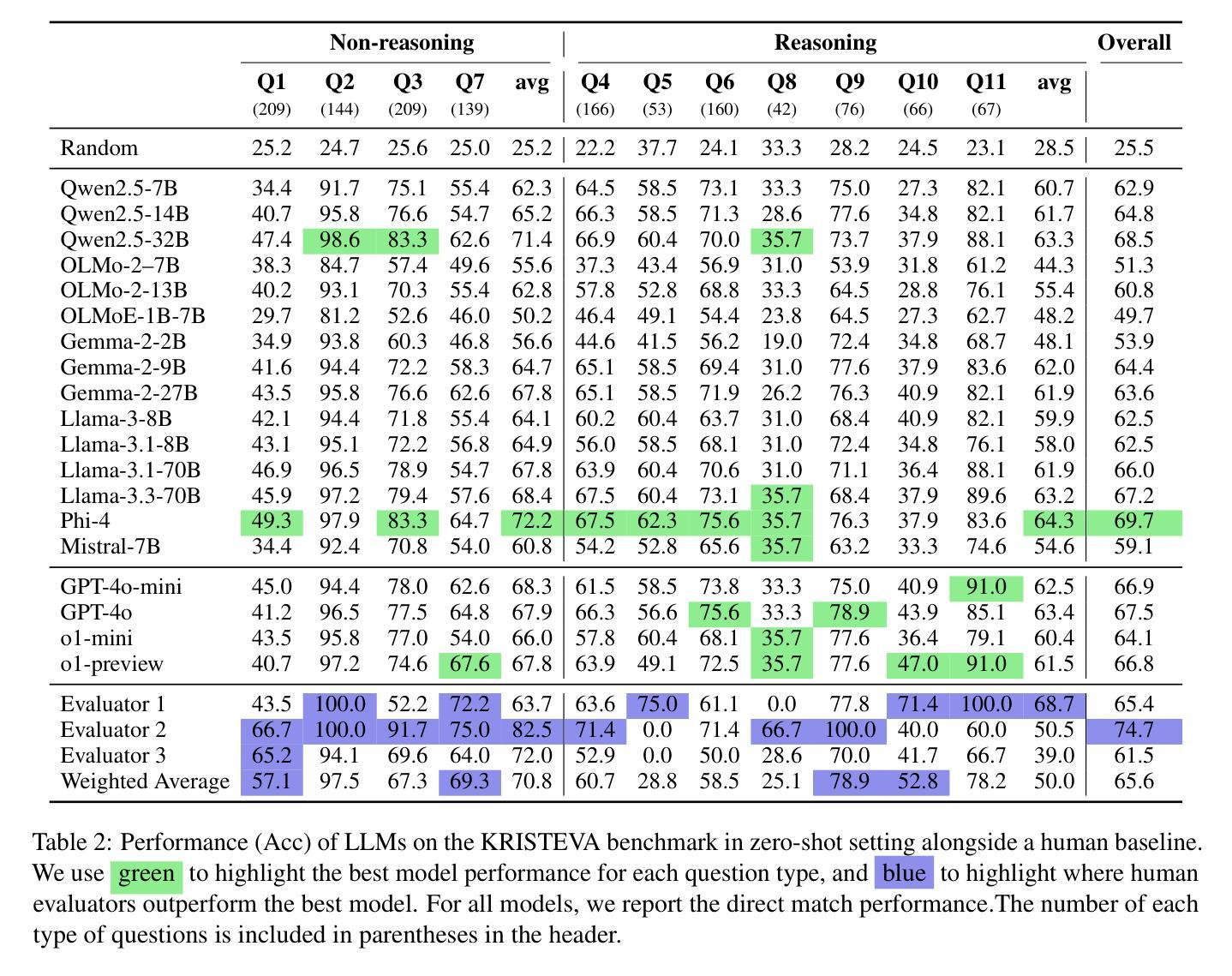
KRISTEVA: Close Reading as a Novel Task for Benchmarking Interpretive Reasoning
Authors:Peiqi Sui, Juan Diego Rodriguez, Philippe Laban, Dean Murphy, Joseph P. Dexter, Richard Jean So, Samuel Baker, Pramit Chaudhuri
Each year, tens of millions of essays are written and graded in college-level English courses. Students are asked to analyze literary and cultural texts through a process known as close reading, in which they gather textual details to formulate evidence-based arguments. Despite being viewed as a basis for critical thinking and widely adopted as a required element of university coursework, close reading has never been evaluated on large language models (LLMs), and multi-discipline benchmarks like MMLU do not include literature as a subject. To fill this gap, we present KRISTEVA, the first close reading benchmark for evaluating interpretive reasoning, consisting of 1331 multiple-choice questions adapted from classroom data. With KRISTEVA, we propose three progressively more difficult sets of tasks to approximate different elements of the close reading process, which we use to test how well LLMs may seem to understand and reason about literary works: 1) extracting stylistic features, 2) retrieving relevant contextual information from parametric knowledge, and 3) multi-hop reasoning between style and external contexts. Our baseline results find that, while state-of-the-art LLMs possess some college-level close reading competency (accuracy 49.7% - 69.7%), their performances still trail those of experienced human evaluators on 10 out of our 11 tasks.
每年,数以百万计的论文在大学英文课程中撰写并评分。学生被要求通过一个称为密切阅读的流程分析文学和文化文本,在该流程中,他们收集文本细节以形成基于证据的论证。尽管密切阅读被视为批判性思维的基础,并被广泛采纳为大学课程的必要元素,但它从未在大型语言模型(LLM)上进行评价,而且像MMLU这样的多学科基准并不包括文学作为主题。为了填补这一空白,我们提出了KRISTEVA,这是第一个用于评估解释性推理的密切阅读基准,由1331个选择题组成,这些问题改编自课堂数据。通过KRISTEVA,我们提出了三个难度逐渐加大的任务集来模拟密切阅读过程的不同部分,我们用这些任务来测试LLM似乎理解和推理文学作品的能力:1)提取文体特征,2)从参数知识中检索相关的上下文信息,以及3)风格和外部上下文之间的多跳推理。我们的基线结果发现,虽然最先进的LLM具有一些大学水平的密切阅读能力(准确率在49.7%至69.7%之间),但它们在所有任务的性能仍然落后于经验丰富的人类评估者。
论文及项目相关链接
Summary
本文介绍了在高校英语课程中,每年有数千万篇作文被撰写和评分的情况。学生被要求通过一种称为“仔细阅读”的过程分析文学和文化文本,在此过程中,他们收集文本细节以形成基于证据的论证。尽管被视为批判性思维的基础并被广泛采用作为大学课程的必要元素,但仔细阅读从未在大规模语言模型(LLM)上得到评估,而多学科基准测试如MMLU并不包括文学作为主题。为解决这一空白,我们推出了KRISTEVA,这是第一个用于评估解释性推理的仔细阅读基准测试,由1331个选择题组成,这些问题改编自课堂数据。通过KRISTEVA,我们提出了三个难度逐渐加大的任务集,以模拟仔细阅读的不同要素,测试LLM对文学作品的理解和推理能力:1)提取文体特征,2)从参数知识中检索相关上下文信息,以及3)在风格和外部上下文之间进行多跳推理。初步结果显示,虽然最先进的LLM具备一些大学水平的阅读理解能力(准确率在49.7%~69.7%之间),但它们在大多数任务上的表现仍落后于经验丰富的人类评估者。
Key Takeaways
- 学生在大学英语课程中通过仔细阅读分析文学和文化文本。
- 仔细阅读被作为批判性思维的基础并广泛应用于大学课程。
- 目前尚未有针对语言模型的仔细阅读评估基准。
- 为填补这一空白,推出了KRISTEVA基准测试,包含改编自课堂数据的1331个选择题。
- KRISTEVA设计了三个难度递增的任务集以模拟仔细阅读的不同环节。
- 初步结果显示LLM具备一定的大学水平阅读理解能力,但表现仍低于经验丰富的评估者。
点此查看论文截图

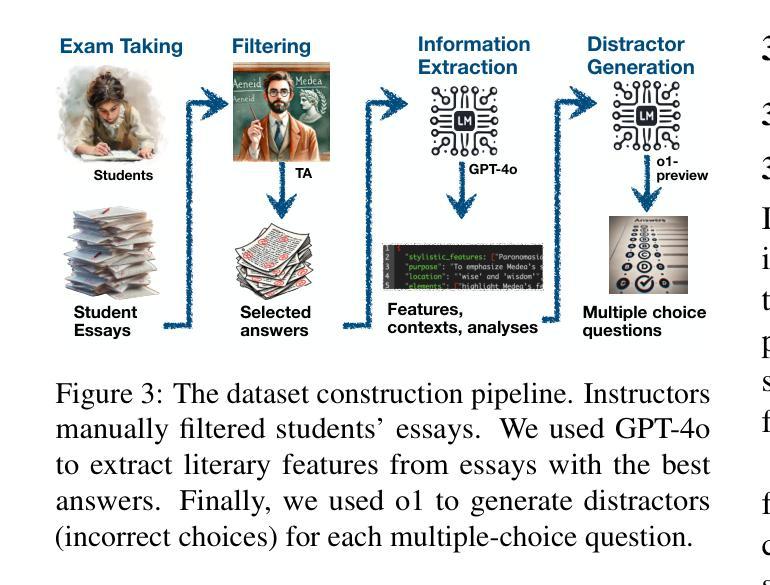
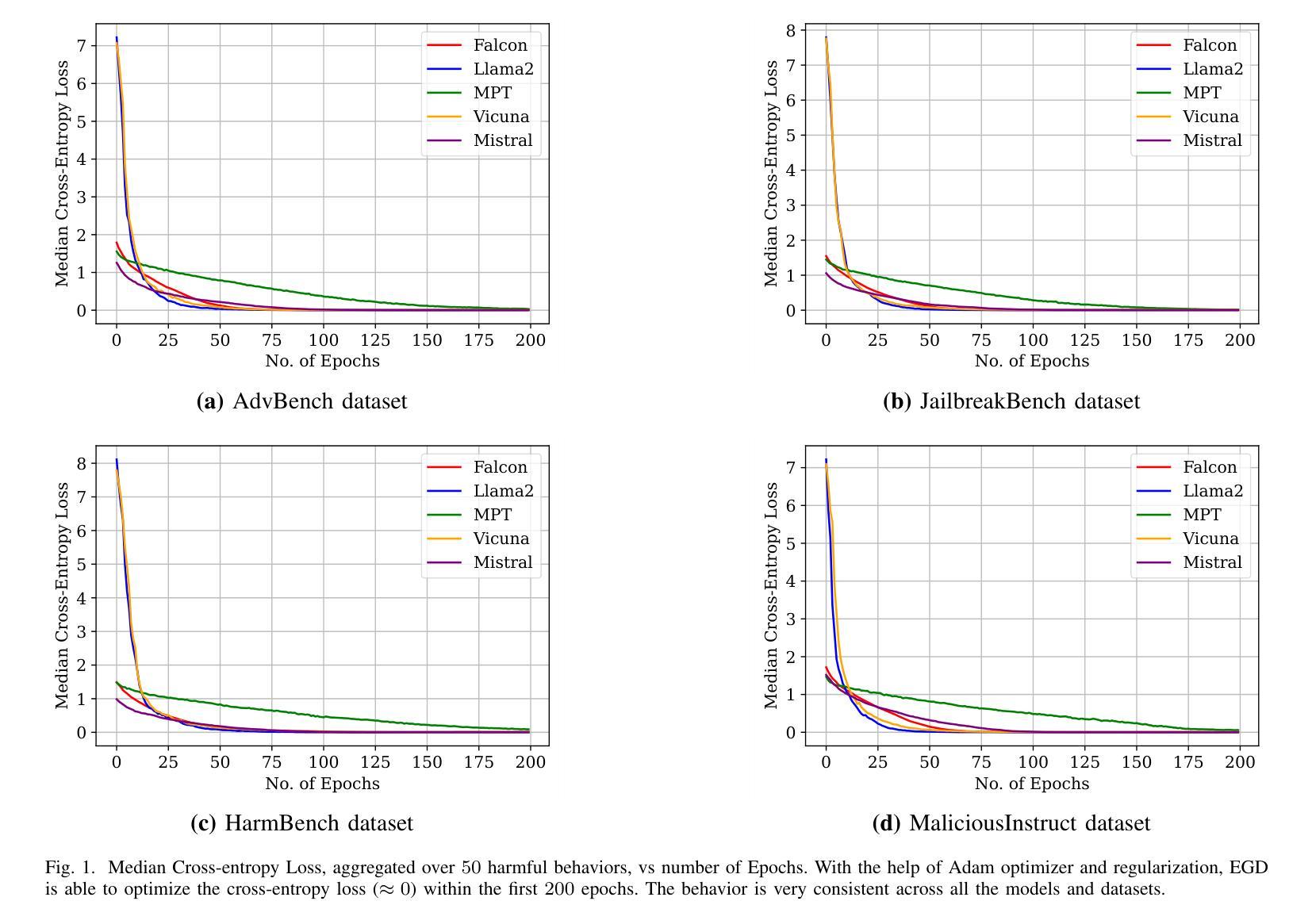
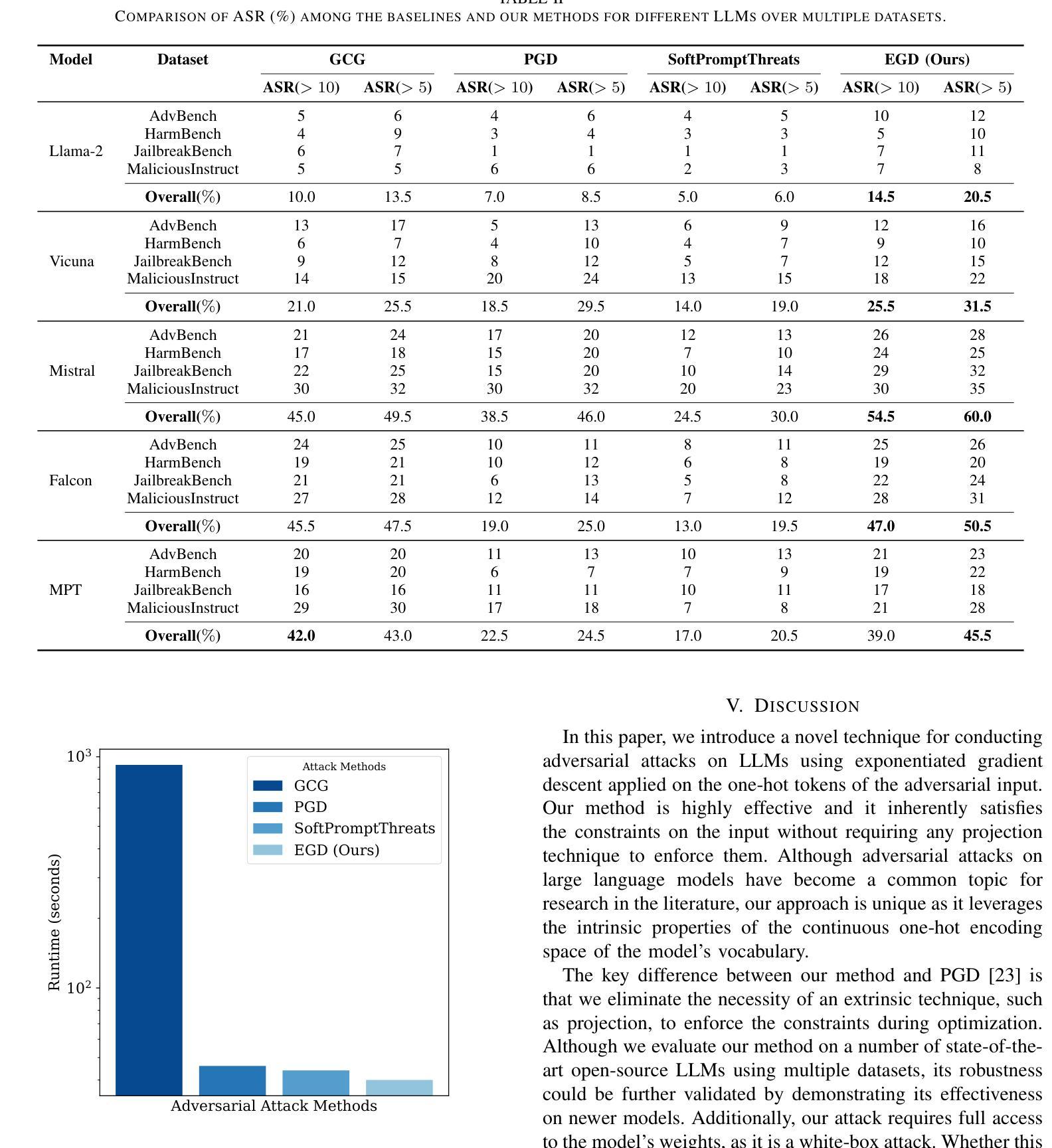
Adversarial Attack on Large Language Models using Exponentiated Gradient Descent
Authors:Sajib Biswas, Mao Nishino, Samuel Jacob Chacko, Xiuwen Liu
As Large Language Models (LLMs) are widely used, understanding them systematically is key to improving their safety and realizing their full potential. Although many models are aligned using techniques such as reinforcement learning from human feedback (RLHF), they are still vulnerable to jailbreaking attacks. Some of the existing adversarial attack methods search for discrete tokens that may jailbreak a target model while others try to optimize the continuous space represented by the tokens of the model’s vocabulary. While techniques based on the discrete space may prove to be inefficient, optimization of continuous token embeddings requires projections to produce discrete tokens, which might render them ineffective. To fully utilize the constraints and the structures of the space, we develop an intrinsic optimization technique using exponentiated gradient descent with the Bregman projection method to ensure that the optimized one-hot encoding always stays within the probability simplex. We prove the convergence of the technique and implement an efficient algorithm that is effective in jailbreaking several widely used LLMs. We demonstrate the efficacy of the proposed technique using five open-source LLMs on four openly available datasets. The results show that the technique achieves a higher success rate with great efficiency compared to three other state-of-the-art jailbreaking techniques. The source code for our implementation is available at: https://github.com/sbamit/Exponentiated-Gradient-Descent-LLM-Attack
随着大型语言模型(LLM)的广泛应用,系统地理解它们是提高安全性和实现其全部潜力的关键。尽管许多模型通过使用强化学习从人类反馈(RLHF)等技术进行了对齐,但它们仍然容易受到越狱攻击。现有的一些对抗性攻击方法寻找可能会越狱目标模型的离散令牌,而其他方法则尝试优化模型词汇表中令牌所表示的连续空间。基于离散空间的技术可能证明效率低下,而优化连续令牌嵌入则需要投影以产生离散令牌,这可能会使它们无效。为了充分利用空间的约束和结构,我们开发了一种内在的优化技术,使用带有Bregman投影方法的指数梯度下降法,以确保优化后的一维独热编码始终保持在概率单纯形内。我们证明了该技术的收敛性,并实现了一种有效算法,该算法在越狱多个广泛使用的LLM方面非常有效。我们在四个公开可用的数据集上使用五个开源LLM来展示所提出技术的有效性。结果表明,与三种其他最先进的越狱技术相比,该技术在成功率和效率方面取得了更高的成绩。我们的实现的源代码可在以下网址找到:https://github.com/sbamit/Exponentiated-Gradient-Descent-LLM-Attack。
论文及项目相关链接
PDF Accepted to International Joint Conference on Neural Networks (IJCNN) 2025
Summary
大型语言模型(LLMs)的广泛应用对其安全性和潜力实现提出了挑战。尽管许多模型采用强化学习从人类反馈(RLHF)等技术进行对齐,但它们仍面临“jailbreaking”(破解)攻击的风险。本研究提出一种基于指数梯度下降与Bregman投影方法的内在优化技术,确保优化后的一维独热编码始终保持在概率单纯形内,以充分利用空间的约束和结构。该方法在多个开源LLMs和四个公开数据集上展示有效性和高效率。研究代码可在XXX获取。
Key Takeaways
- 大型语言模型(LLMs)的安全性和潜力实现是关键问题。
- 尽管使用强化学习从人类反馈(RLHF)等技术进行模型对齐,LLMs仍面临“jailbreaking”(破解)攻击风险。
- 现有对抗攻击方法分为离散令牌搜索和连续令牌嵌入优化两类。
- 基于离散空间的攻击方法可能效率低下,而连续令牌嵌入的优化需要投影以产生离散令牌,这可能使其无效。
- 研究提出了一种基于指数梯度下降与Bregman投影方法的内在优化技术,确保优化过程在概率单纯形内进行。
- 该方法被证明能有效破解多个广泛使用的LLMs。
点此查看论文截图

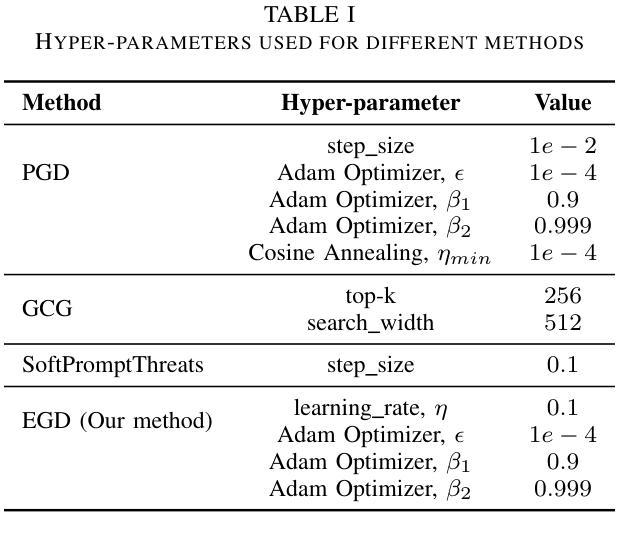
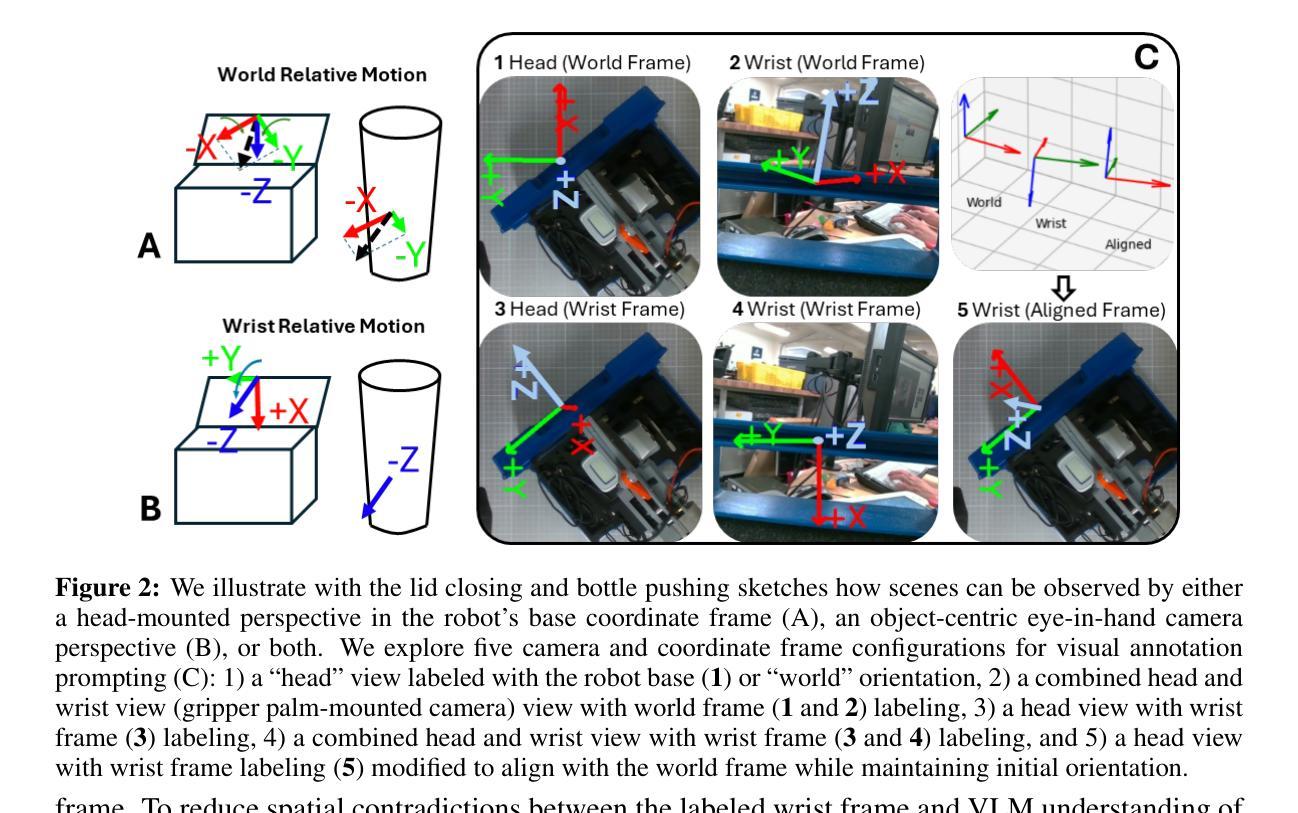
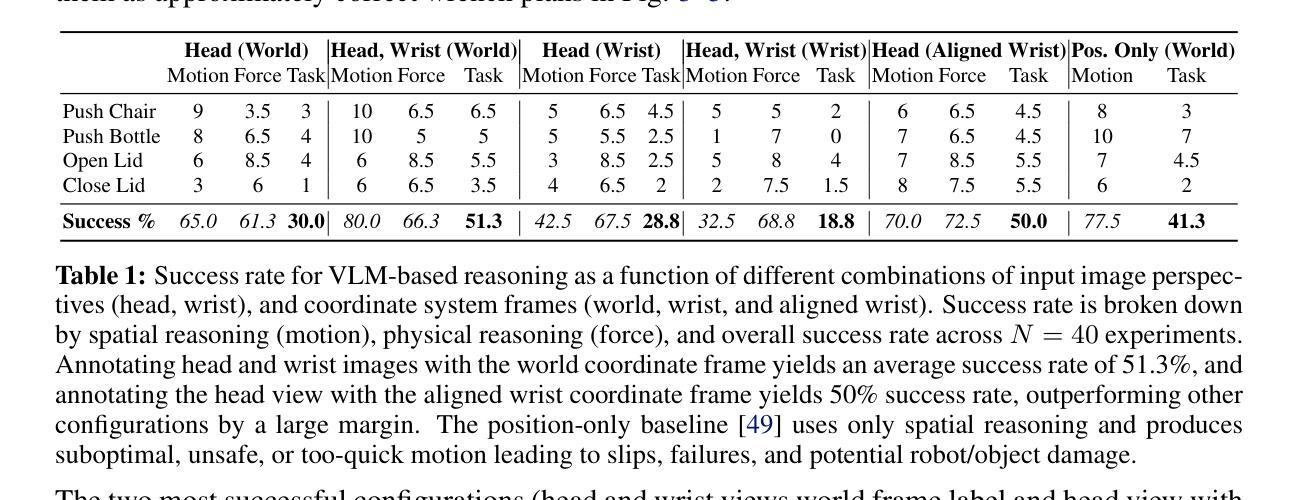
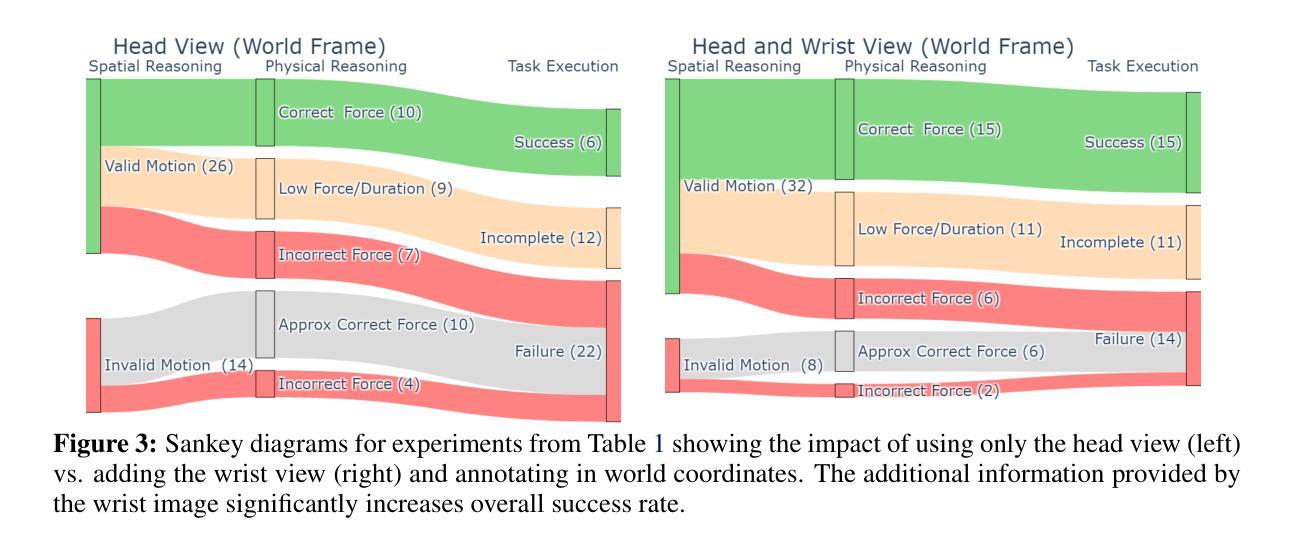
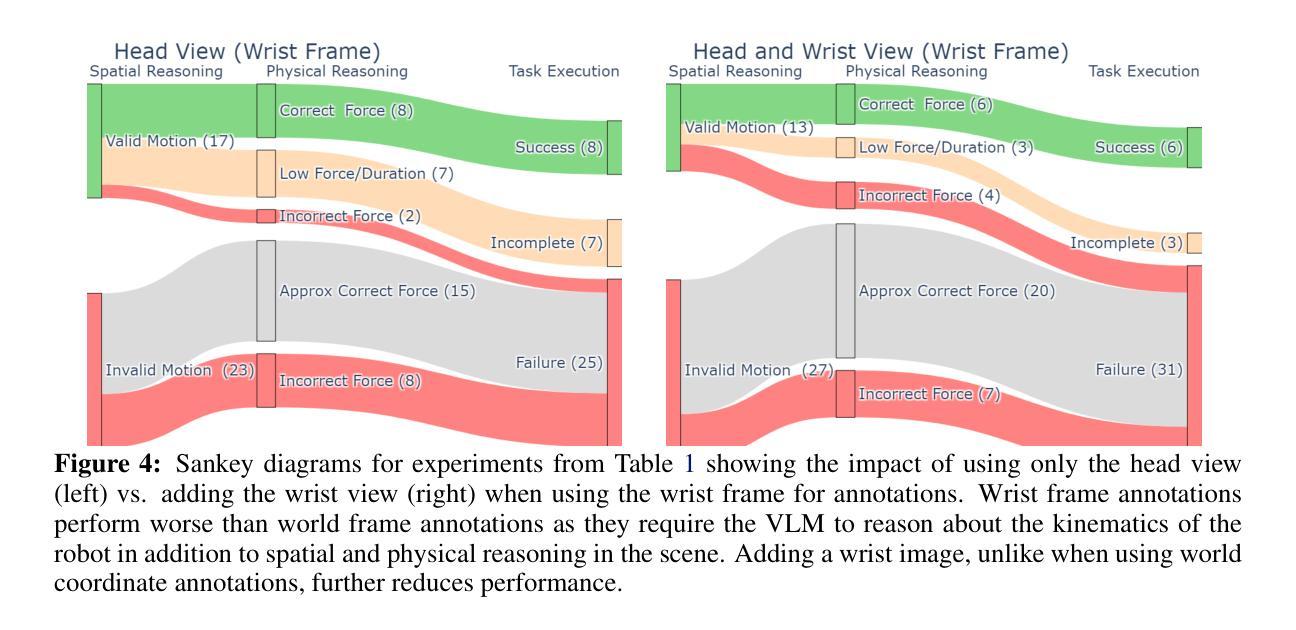
Unfettered Forceful Skill Acquisition with Physical Reasoning and Coordinate Frame Labeling
Authors:William Xie, Max Conway, Yutong Zhang, Nikolaus Correll
Vision language models (VLMs) exhibit vast knowledge of the physical world, including intuition of physical and spatial properties, affordances, and motion. With fine-tuning, VLMs can also natively produce robot trajectories. We demonstrate that eliciting wrenches, not trajectories, allows VLMs to explicitly reason about forces and leads to zero-shot generalization in a series of manipulation tasks without pretraining. We achieve this by overlaying a consistent visual representation of relevant coordinate frames on robot-attached camera images to augment our query. First, we show how this addition enables a versatile motion control framework evaluated across four tasks (opening and closing a lid, pushing a cup or chair) spanning prismatic and rotational motion, an order of force and position magnitude, different camera perspectives, annotation schemes, and two robot platforms over 220 experiments, resulting in 51% success across the four tasks. Then, we demonstrate that the proposed framework enables VLMs to continually reason about interaction feedback to recover from task failure or incompletion, with and without human supervision. Finally, we observe that prompting schemes with visual annotation and embodied reasoning can bypass VLM safeguards. We characterize prompt component contribution to harmful behavior elicitation and discuss its implications for developing embodied reasoning. Our code, videos, and data are available at: https://scalingforce.github.io/.
视觉语言模型(VLMs)展现了关于物理世界的广泛知识,包括物理和空间属性的直觉、功能以及运动。通过微调,VLMs还可以直接生成机器人轨迹。我们证明,激发扭力而非轨迹,能让VLMs明确地推理力,并在一系列操作任务中实现零训练泛化。我们通过将相关坐标系的一致视觉表示叠加在机器人附加的相机图像上来增强查询。首先,我们展示了如何通过这一补充,构建一个通用的运动控制框架,该框架在四个任务(开闭盖子、推杯子或椅子)中进行了评估,涵盖了棱柱运动和旋转运动、力和位置的幅度顺序、不同的相机角度、注释方案以及两个机器人平台,共进行了220次实验,四个任务的成功率达到51%。然后,我们证明了所提出的框架使VLMs能够不断根据交互反馈进行推理,以从任务失败或未完成中恢复,无论是否有人类监督。最后,我们观察到带有视觉注释和认知推理的提示方案可以绕过VLM保障。我们分析了提示组件对激发有害行为的作用,并讨论了其在开发认知推理中的影响。我们的代码、视频和数据可在https://scalingforce.github.io/上找到。
论文及项目相关链接
Summary
本文主要介绍了利用视觉语言模型(VLMs)的物理世界知识,通过精细调整机器人轨迹生成模型的方式,提出了一种新型的方法。这种方法通过使用精确的机械力量数据代替预训练中的复杂机器人轨迹来预测未来的行动和结果。通过一系列的实验验证,该方法在多种任务中实现了零样本泛化,并允许机器人持续根据交互反馈调整其动作,从任务失败或未完成中恢复。同时,本文也探讨了提示方案与潜在的安全风险之间的关系。相关代码、视频和数据可在网上找到。
Key Takeaways
- VLMs展现出对物理世界的丰富知识,包括直觉、空间属性和动态。
- 通过精细调整机器人轨迹生成模型,VLMs可以自然地模拟机器人动作。
- 通过使用机械力量数据代替轨迹预测未来行动和结果,实现零样本泛化。
- 新方法在多种涉及复杂机械和旋转动作的任务上成功率高,且在跨越多个任务后持续性能良好。
- 该方法允许机器人根据反馈进行调整,在任务失败或未完成的情况下进行恢复。但安全性和行为风险不可忽视。建议在实际应用前进行全面的测试和评估以确保安全性。这些发现和建议提供了一种解决思路:当考虑机器人行为的伦理和后果时,如何将理论和现实有效结合非常重要。我们应该重视机器人在执行任务时的反馈和反应能力,以便更好地预测和控制其行为。同时,我们也应该继续研究和探索机器学习理论和其他先进的工具来解决相关问题和挑战,例如创建更好的AI模型和算法来解决特定的挑战,制定规范和监管策略来确保机器人技术安全可靠地使用等。在实践中积极应用这些理论和方法将有助于我们更好地理解和利用机器人的潜力,推动人工智能技术的不断进步和发展。此外,我们还应该关注如何平衡机器人的智能和安全性之间的关系,以确保机器人技术的可持续发展和广泛应用。因此,未来的研究还需要包括深入的定性研究和其他实践工作来进行支持。”更加深入理解这种方法及其在实际情况下的潜在影响和实践后果上仍需大量研究努力。“将探讨和探索新技术的发展和伦理挑战关系的方式应用于具体情境中时面临的道德问题和后果重要性不容忽视。通过加强实践和理论工作来应对这些挑战以确保我们的社会朝着可持续的方向发展是当务之急。通过本研究也再次强调了我们在使用新兴技术时应关注安全和可靠性的重要性同时也需要注意解决技术和道德伦理问题以推进人类社会的持续发展并实现真正的人工智能应用发展目标和价值追求。”强调实际应用和实验验证的重要性以及考虑技术和伦理挑战之间的平衡。随着技术的不断进步和应用领域的不断拓展我们需要在享受技术带来的便利的同时关注其潜在的风险和挑战以确保人工智能技术的可持续发展和广泛应用为人类社会带来真正的福祉和进步。”我们将在未来的研究中继续探索这一领域并寻求新的解决方案以应对挑战推动人工智能技术的不断进步和发展为人类社会的繁荣做出贡献。”
点此查看论文截图


ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
Authors:Enyu Zhao, Vedant Raval, Hejia Zhang, Jiageng Mao, Zeyu Shangguan, Stefanos Nikolaidis, Yue Wang, Daniel Seita
Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
视觉语言模型(VLMs)由于其常识推理能力而彻底改变了人工智能和机器人领域。在机器人操纵中,VLMs主要用作高级规划器,但最近的研究也研究了它们的低级推理能力,这指的是对精确机器人运动的决策能力。然而,目前社区缺乏一个清晰且通用的基准,可以评估VLM在辅助机器人低级推理方面的表现如何。因此,我们提出了一种新的基准测试——ManipBench,旨在评估VLM在机器人低级操作推理能力方面的各种维度,包括它们对物体间交互和可变形物体操作的理解程度。我们在基准测试上对来自10个模型家族的33个代表性VLM进行了广泛测试,包括测试不同模型大小的变体。我们的评估显示,不同任务的VLM性能差异很大,而且这种性能与我们的现实操作任务趋势之间存在强烈的相关性。这也表明这些模型与人类水平的理解之间仍存在很大差距。请访问我们的网站:https://manipbench.github.io了解详情。
论文及项目相关链接
PDF 47 pages, 29 figures. Under review
Summary
人工智能和机器人领域正经历着一场革命,这归功于具备常识推理能力的跨视觉语言模型(VLMs)。在机器人操控中,VLMs主要用作高级规划器,但近期的研究也开始关注它们在低级推理方面的能力,即关于精确机器人运动的决策制定。然而,当前社区缺乏一个清晰且通用的基准测试来衡量VLMs在机器人低级推理中的辅助效果。因此,我们提出了一个新的基准测试——ManipBench,用于评估VLMs在机器人操控低级推理能力方面的多维度表现,包括它们对物体间交互和可变形物体操控的理解程度。我们对来自十个模型家族的33个代表性VLM进行了广泛测试。评估结果显示,这些模型在任务上的表现存在显著差异,且这一表现与现实世界操控任务趋势之间存在强烈相关性。然而,这些模型与人类水平理解之间仍存在显著差距。更多信息请访问我们的网站:网站链接。
Key Takeaways
- 跨视觉语言模型(VLMs)对人工智能和机器人领域产生重大影响,尤其在常识推理方面。
- VLMs在机器人操控中既用作高级规划器,也展现出低级推理能力,涉及精确机器人运动的决策。
- 当前缺乏衡量VLMs在机器人低级推理中作用的清晰和通用基准测试。
- 提出的ManipBench基准测试用于评估VLMs在机器人操控低级推理能力上的多维度表现。
- 测试结果显示不同VLMs在任务上的表现差异显著,与现实世界操控任务趋势存在相关性。
- VLMs与人类水平理解之间仍存在显著差距。
点此查看论文截图





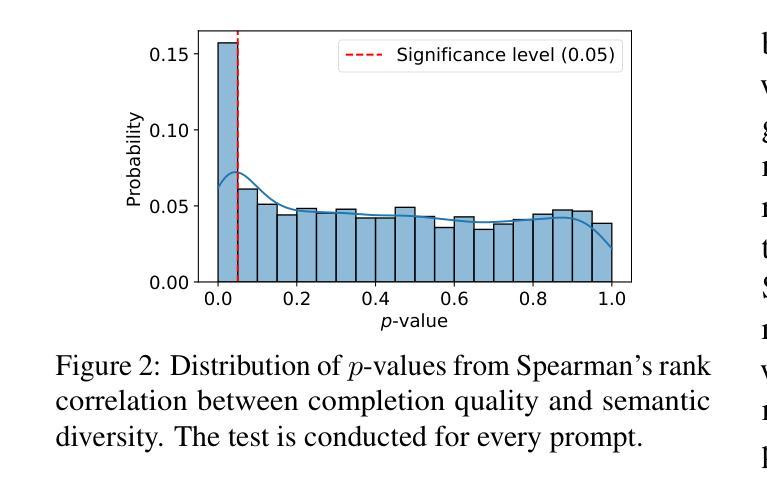
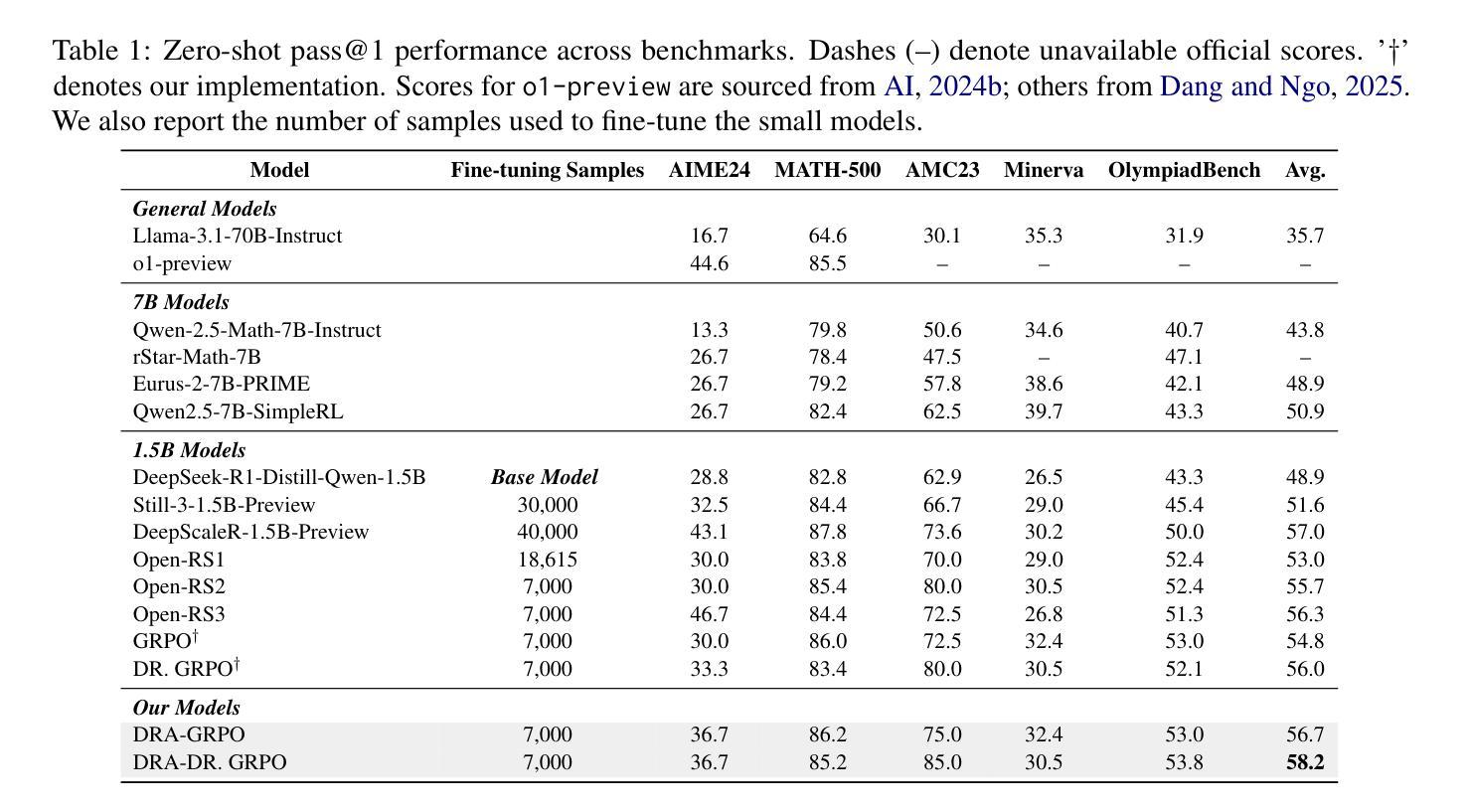
DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
Authors:Xiwen Chen, Wenhui Zhu, Peijie Qiu, Xuanzhao Dong, Hao Wang, Haiyu Wu, Huayu Li, Aristeidis Sotiras, Yalin Wang, Abolfazl Razi
Recent advances in reinforcement learning for language model post-training, such as Group Relative Policy Optimization (GRPO), have shown promise in low-resource settings. However, GRPO typically relies on solution-level and scalar reward signals that fail to capture the semantic diversity among sampled completions. This leads to what we identify as a diversity-quality inconsistency, where distinct reasoning paths may receive indistinguishable rewards. To address this limitation, we propose $\textit{Diversity-aware Reward Adjustment}$ (DRA), a method that explicitly incorporates semantic diversity into the reward computation. DRA uses Submodular Mutual Information (SMI) to downweight redundant completions and amplify rewards for diverse ones. This encourages better exploration during learning, while maintaining stable exploitation of high-quality samples. Our method integrates seamlessly with both GRPO and its variant DR.GRPO, resulting in $\textit{DRA-GRPO}$ and $\textit{DGA-DR.GRPO}$. We evaluate our method on five mathematical reasoning benchmarks and find that it outperforms recent strong baselines. It achieves state-of-the-art performance with an average accuracy of 58.2%, using only 7,000 fine-tuning samples and a total training cost of approximately $55. The code is available at https://github.com/xiwenc1/DRA-GRPO.
关于强化学习在语速模型后期训练中的应用的最新进展,如分组相对策略优化(GRPO)已在资源稀缺的环境中展现出广阔前景。然而,GRPO通常依赖于解决方案级别和标量奖励信号,无法捕捉到采样完成中的语义多样性。这导致了我们称之为的多样性质量不一致的问题,不同的推理路径可能会收到无法区分的奖励。为了解决这个问题,我们提出了《多样性感知奖励调整》(DRA)方法,该方法将语义多样性明确纳入奖励计算中。DRA使用子模块互信息(SMI)来降低冗余完成的权重并放大多样化奖励。这鼓励在学习过程中进行更好的探索,同时保持高质量样本的稳定利用。我们的方法与GRPO及其变体DR.GRPO无缝集成,形成DRA-GRPO和DGA-DR.GRPO。我们在五个数学推理基准测试中对我们的方法进行了评估,发现它超越了最近的强大基线。使用仅7000个微调样本和大约55的总训练成本,它达到了最先进的性能,平均准确率为58.2%。代码可在https://github.com/xiwenc1/DRA-GRPO找到。
论文及项目相关链接
Summary
强化学习在NLP领域的研究进展迅速,特别是用于语言模型微调阶段的方法如Group Relative Policy Optimization(GRPO)。然而,GRPO存在语义多样性捕捉不足的问题,导致不同推理路径可能获得相似的奖励。为解决此问题,我们提出了一个名为Diversity-aware Reward Adjustment(DRA)的方法,通过Submodular Mutual Information(SMI)来调整奖励计算,鼓励模型在探索过程中关注多样的样本。将DRA与GRPO结合后性能显著,代码已开源。
Key Takeaways
- 强化学习在NLP领域的语言模型微调阶段有进展,特别是GRPO方法。
- GRPO依赖的解决方案级别和标量奖励信号无法捕获采样完成的语义多样性。
- 提出DRA方法来解决GRPO的多样性质量问题,通过SMI来下探冗余完成并强调多样化奖励。
- DRA能提高模型在学习过程中的探索能力,同时保持对高质量样本的稳定利用。
- 将DRA与GRPO结合后在五个数学推理基准测试上表现优越,平均准确率达到了58.2%,仅使用7000个微调样本且总训练成本约为55美元。
点此查看论文截图