⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-17 更新
MIPHEI-ViT: Multiplex Immunofluorescence Prediction from H&E Images using ViT Foundation Models
Authors:Guillaume Balezo, Roger Trullo, Albert Pla Planas, Etienne Decenciere, Thomas Walter
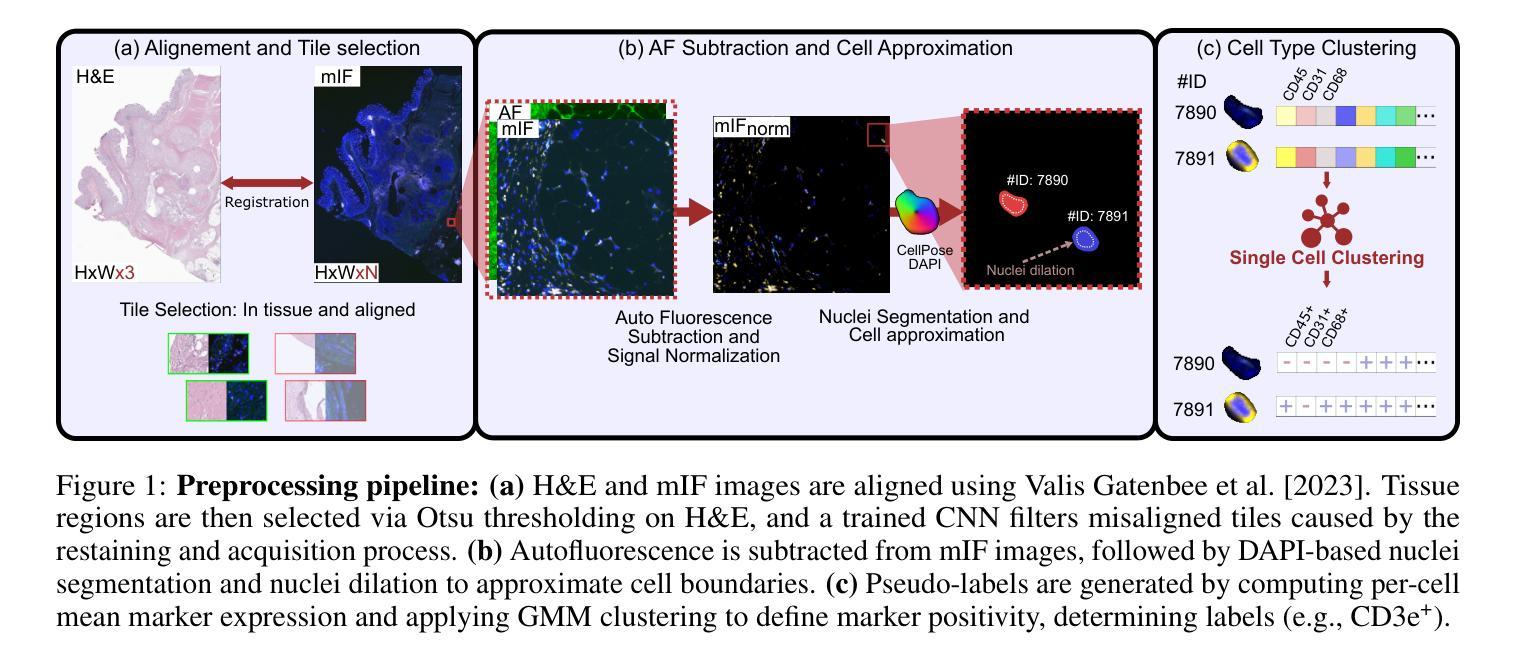
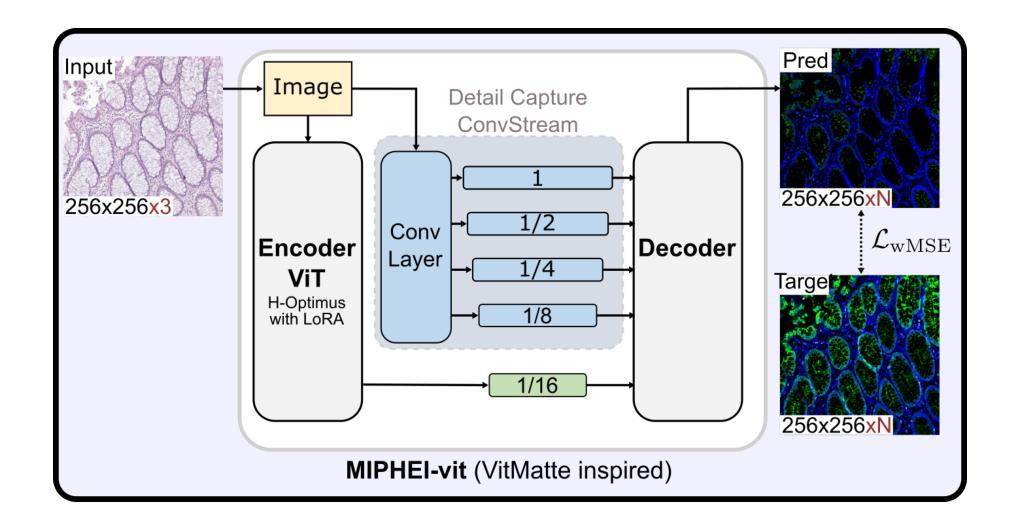
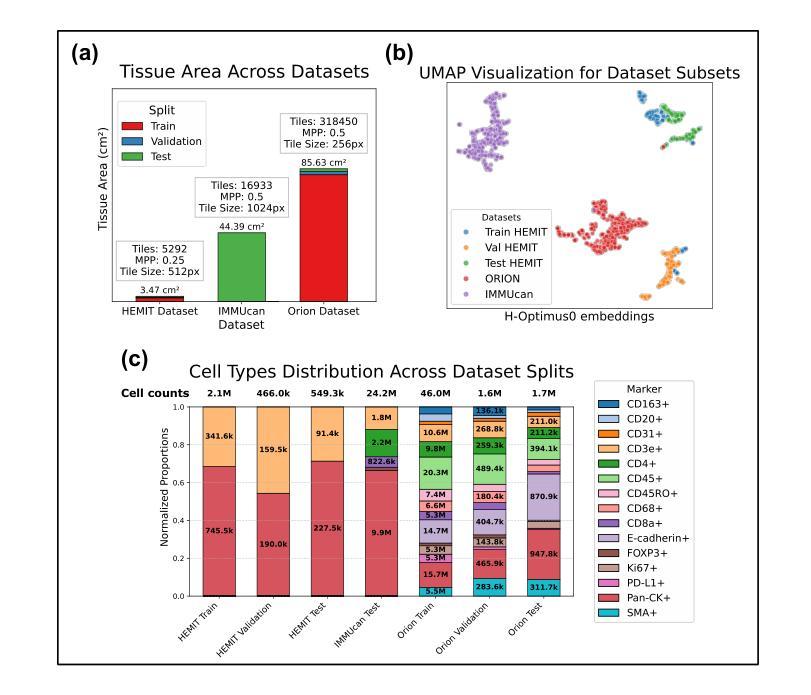
Histopathological analysis is a cornerstone of cancer diagnosis, with Hematoxylin and Eosin (H&E) staining routinely acquired for every patient to visualize cell morphology and tissue architecture. On the other hand, multiplex immunofluorescence (mIF) enables more precise cell type identification via proteomic markers, but has yet to achieve widespread clinical adoption due to cost and logistical constraints. To bridge this gap, we introduce MIPHEI (Multiplex Immunofluorescence Prediction from H&E), a U-Net-inspired architecture that integrates state-of-the-art ViT foundation models as encoders to predict mIF signals from H&E images. MIPHEI targets a comprehensive panel of markers spanning nuclear content, immune lineages (T cells, B cells, myeloid), epithelium, stroma, vasculature, and proliferation. We train our model using the publicly available ORION dataset of restained H&E and mIF images from colorectal cancer tissue, and validate it on two independent datasets. MIPHEI achieves accurate cell-type classification from H&E alone, with F1 scores of 0.88 for Pan-CK, 0.57 for CD3e, 0.56 for SMA, 0.36 for CD68, and 0.30 for CD20, substantially outperforming both a state-of-the-art baseline and a random classifier for most markers. Our results indicate that our model effectively captures the complex relationships between nuclear morphologies in their tissue context, as visible in H&E images and molecular markers defining specific cell types. MIPHEI offers a promising step toward enabling cell-type-aware analysis of large-scale H&E datasets, in view of uncovering relationships between spatial cellular organization and patient outcomes.
组织病理学分析是癌症诊断的核心,常规对所有患者进行苏木精和伊红(H&E)染色,以可视化细胞形态和组织结构。另一方面,多重免疫荧光(mIF)能够通过蛋白质标记进行更精确的细胞类型识别,但由于成本和物流限制,尚未在临床实践中广泛应用。为了弥补这一差距,我们引入了MIPHEI(基于苏木精和伊红的免疫荧光预测多重染色),这是一种受U-Net启发的架构,它集成了最先进的ViT基础模型作为编码器,用于从H&E图像预测mIF信号。MIPHEI旨在定位一系列广泛的标记物,包括核内容、免疫谱系(T细胞、B细胞、髓样细胞)、上皮组织、基质、血管和增殖等。我们使用公开可用的ORION数据集(来自结肠癌组织的苏木精和伊红染色和多重免疫荧光染色图像)来训练我们的模型,并在两个独立的数据集上进行验证。MIPHEI仅凭苏木精和伊红染色就能实现准确的细胞类型分类,泛CK的F1分数为0.88,CD3e的F1分数为0.57,SMA的F1分数为0.56,CD68的F1分数为0.36,CD20的F1分数为0.30,在大多数标记物上显著优于最先进的基线模型和随机分类器。我们的结果表明,我们的模型有效地捕获了苏木精和伊红图像中细胞核形态与其在组织背景下的分子标记之间的复杂关系,这些分子标记定义了特定的细胞类型。MIPHEI为基于大规模苏木精和伊红数据集的细胞类型分析提供了有前景的一步,有助于揭示空间细胞组织与患者结果之间的关系。
论文及项目相关链接
Summary
本文介绍了MIPHEI模型,该模型利用U-Net架构结合先进的Vision Transformer(ViT)模型,通过对H&E染色图像的分析预测多重免疫荧光信号。MIPHEI在结肠直肠癌组织的公开可用数据集上进行了训练与验证,可从单一的H&E染色中实现准确的细胞类型分类。相较于基准模型,MIPHEI在多数标记物上的F1得分更高,展现出其在捕捉细胞核形态与细胞类型标记物间复杂关系上的有效性。MIPHEI为大规模H&E数据集的分析提供了潜力,有助于揭示细胞空间组织与患者预后的关系。
Key Takeaways
- MIPHEI模型结合U-Net架构与ViT模型,用于从H&E染色图像预测多重免疫荧光信号。
- MIPHEI模型实现了对结肠直肠癌组织H&E染色图像的细胞类型分类。
- MIPHEI模型在多数标记物上的表现优于基准模型。
- MIPHEI模型能有效捕捉细胞核形态与细胞类型标记物间的复杂关系。
- MIPHEI模型为分析大规模H&E数据集提供了潜力。
- 该模型有助于揭示细胞空间组织与患者预后的关系。
- 模型的广泛应用可能促进更精确的癌症诊断和治疗策略的发展。
点此查看论文截图

AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
Authors:Bin-Bin Gao, Yue Zhu, Jiangtao Yan, Yuezhi Cai, Weixi Zhang, Meng Wang, Jun Liu, Yong Liu, Lei Wang, Chengjie Wang
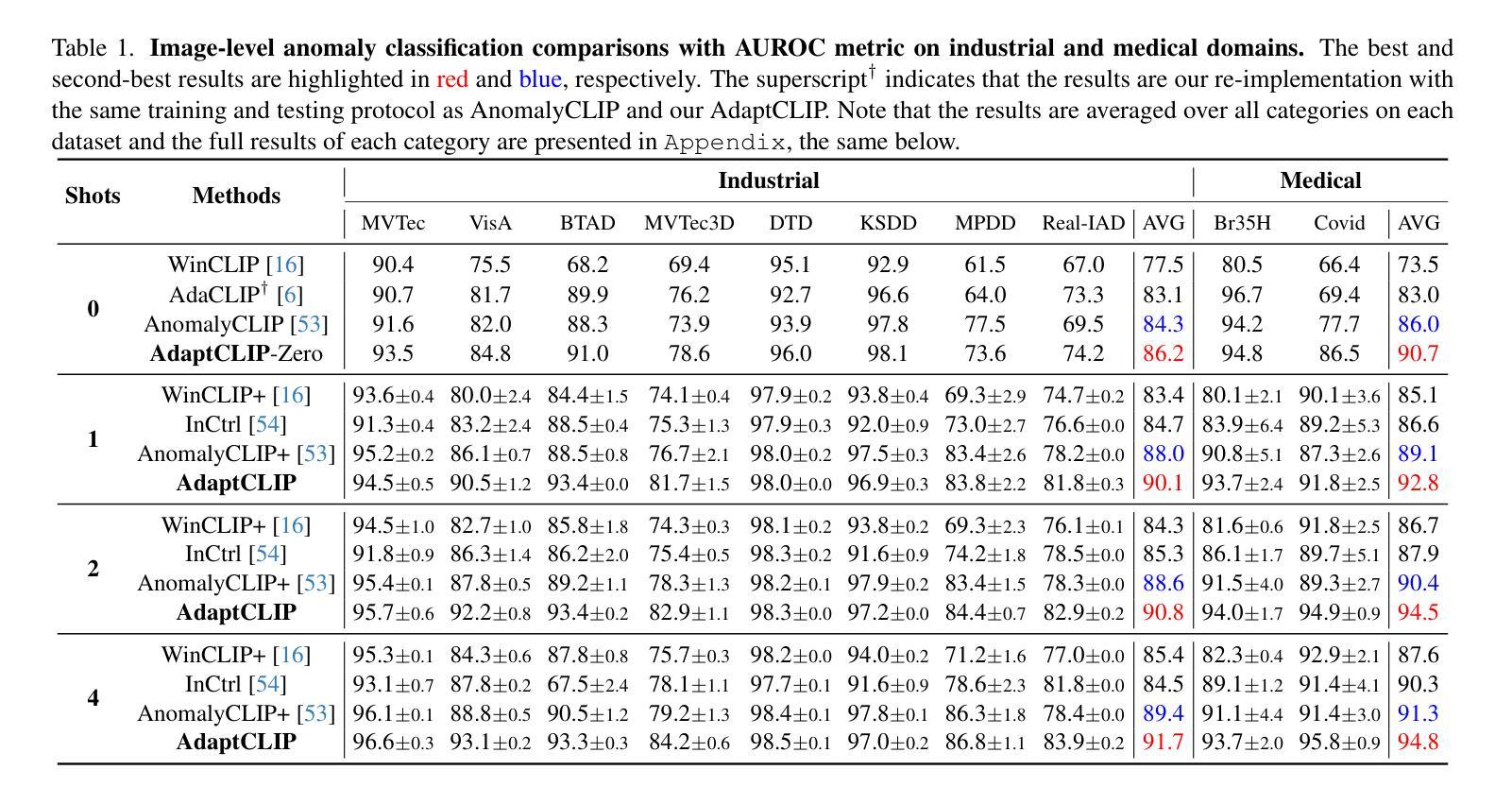
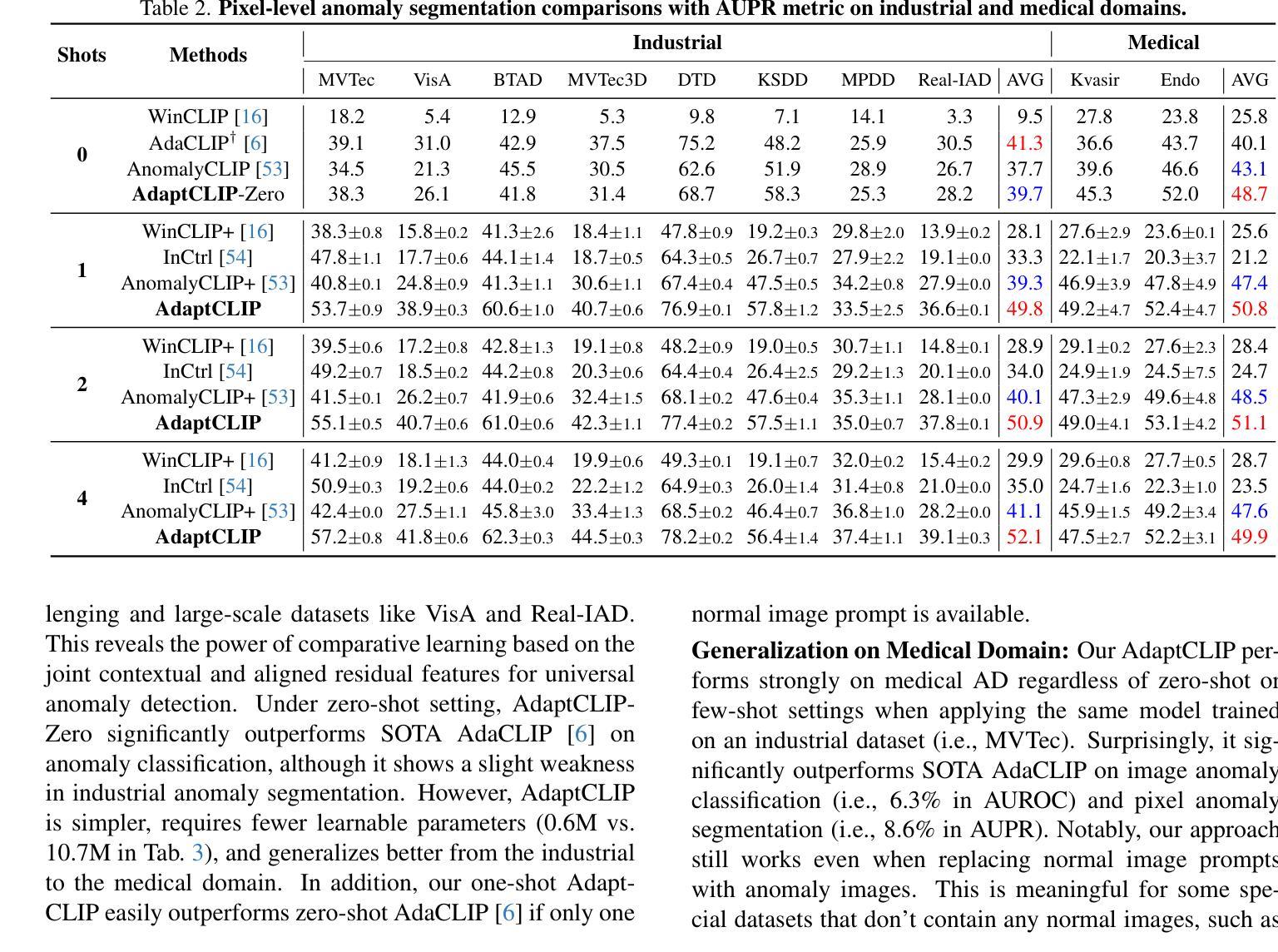
Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
通用视觉异常检测旨在从新型或未见过的视觉领域识别异常值,这在开放场景中至关重要,无需进行额外的微调。最近的研究表明,像CLIP这样的预训练视觉语言模型只需要零张或少数正常图像就能展现出强大的泛化能力。然而,现有方法在设计提示模板、复杂的令牌交互或需要额外的微调方面存在困难,导致灵活性有限。在这项工作中,我们提出了一种简单有效的方法,称为基于两个关键见解的AdaptCLIP。首先,应该交替学习适应性视觉和文本表示,而不是联合学习。其次,查询和正常图像提示之间的比较学习应融入上下文和对齐的残差特征,而不是仅依赖残差特征。AdaptCLIP将CLIP模型作为基础服务,仅在输入或输出端添加三个简单适配器:视觉适配器、文本适配器和提示查询适配器。AdaptCLIP支持跨领域的零/少样本泛化,一旦在基础数据集上进行训练,目标领域即可实现无需训练的方式。AdaptCLIP在12个工业和医疗领域的异常检测基准测试上达到了最先进的性能,显著优于现有的竞争方法。我们将在https://github.com/gaobb/AdaptCLIP上提供AdaptCLIP的代码和模型。
论文及项目相关链接
PDF 27 pages, 15 figures, 22 tables
Summary
适应CLIP模型的异常检测新方法AdaptCLIP被提出,用于解决开放场景下从未见过的视觉域的异常检测问题。通过交替学习视觉和文本表示以及结合查询和正常图像提示的上下文和残差特征的比较学习,该方法展现出强大的泛化能力。只需少量正常图像即可完成训练,并且适用于零样本/少样本域迁移学习场景,且在工业和医疗领域的异常检测基准测试中表现领先。代码和模型将在GitHub上公开。
Key Takeaways
- AdaptCLIP解决了在开放场景中从未见过的视觉域的异常检测问题。
- 该方法基于两个关键见解:交替学习视觉和文本表示以及结合上下文和残差特征的比较学习。
- AdaptCLIP使用CLIP模型作为基础服务,仅通过在其输入或输出端添加三个简单的适配器(视觉适配器、文本适配器和提示查询适配器)来实现强大的泛化能力。
- 该方法需要少量正常图像即可完成训练,并可在目标域上实现零样本或少样本泛化学习。
- AdaptCLIP在各种异常检测基准测试中表现领先,特别是在工业和医疗领域。
- 该方法公开了代码和模型,便于其他研究者使用和进一步改进。
点此查看论文截图



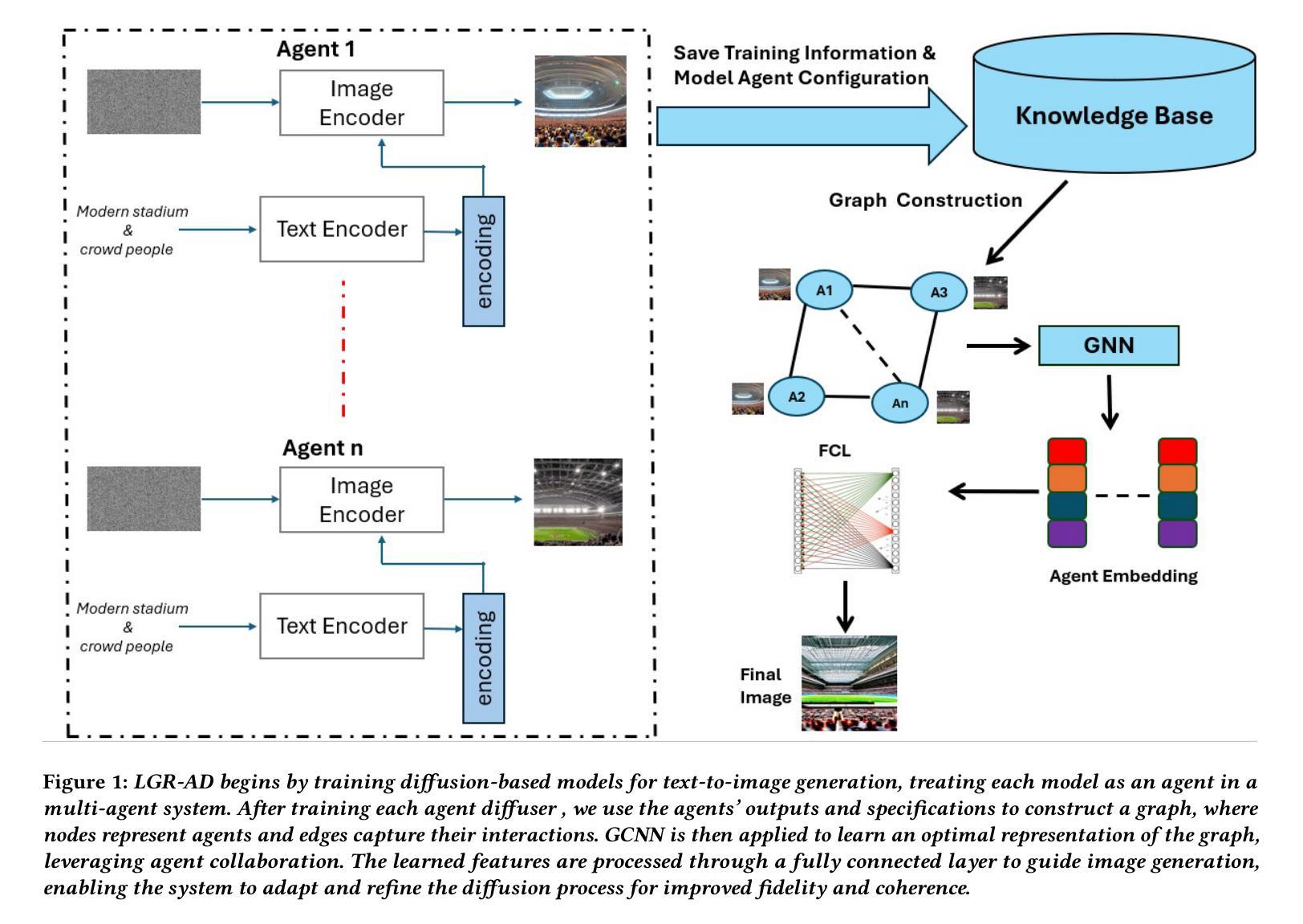
Learning Graph Representation of Agent Diffusers
Authors:Youcef Djenouri, Nassim Belmecheri, Tomasz Michalak, Jan Dubiński, Ahmed Nabil Belbachir, Anis Yazidi
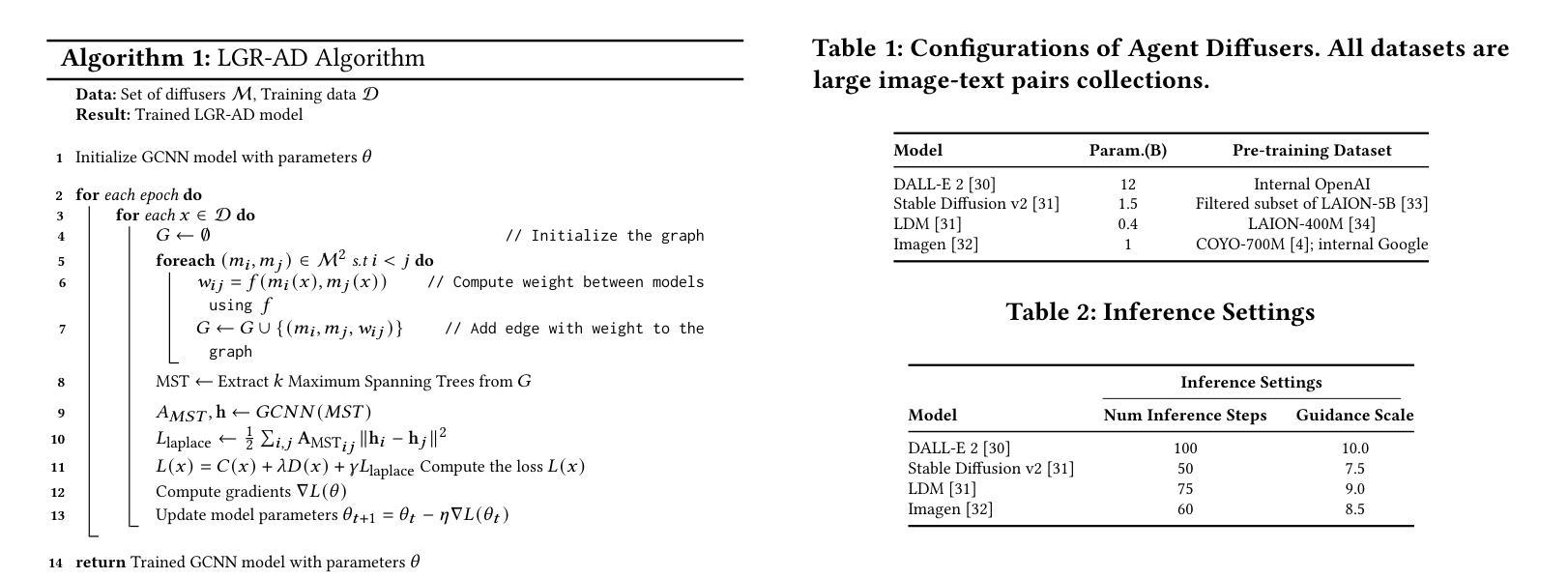
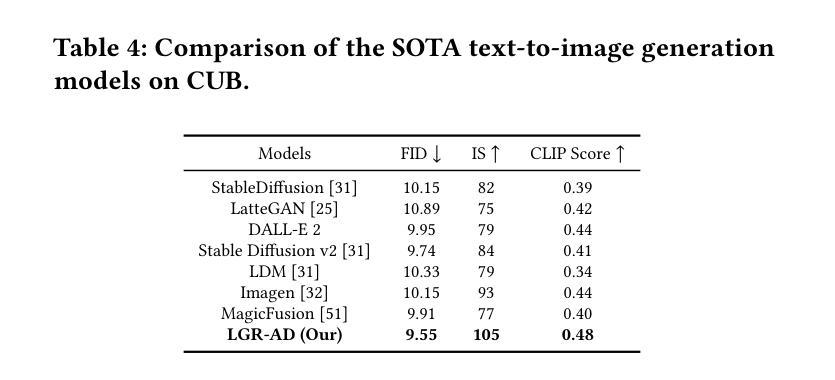
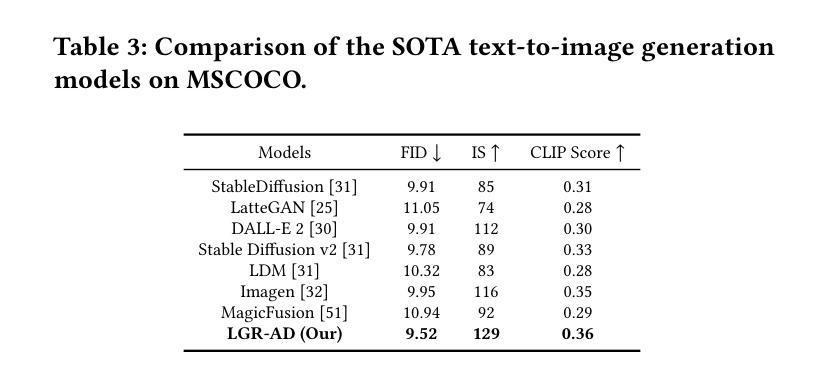
Diffusion-based generative models have significantly advanced text-to-image synthesis, demonstrating impressive text comprehension and zero-shot generalization. These models refine images from random noise based on textual prompts, with initial reliance on text input shifting towards enhanced visual fidelity over time. This transition suggests that static model parameters might not optimally address the distinct phases of generation. We introduce LGR-AD (Learning Graph Representation of Agent Diffusers), a novel multi-agent system designed to improve adaptability in dynamic computer vision tasks. LGR-AD models the generation process as a distributed system of interacting agents, each representing an expert sub-model. These agents dynamically adapt to varying conditions and collaborate through a graph neural network that encodes their relationships and performance metrics. Our approach employs a coordination mechanism based on top-$k$ maximum spanning trees, optimizing the generation process. Each agent’s decision-making is guided by a meta-model that minimizes a novel loss function, balancing accuracy and diversity. Theoretical analysis and extensive empirical evaluations show that LGR-AD outperforms traditional diffusion models across various benchmarks, highlighting its potential for scalable and flexible solutions in complex image generation tasks. Code is available at: https://github.com/YousIA/LGR_AD
基于扩散的生成模型在文本到图像合成方面取得了重大进展,展示了令人印象深刻的文本理解和零样本泛化能力。这些模型根据文本提示从随机噪声中细化图像,最初对文本输入的依赖随着时间的推移转向增强视觉保真度。这种转变表明,静态模型参数可能无法最佳地应对生成的不同阶段。我们引入了LGR-AD(学习Agent扩散图表示),这是一个新型的多智能体系统,旨在提高动态计算机视觉任务的适应性。LGR-AD将生成过程建模为一个交互智能体的分布式系统,每个智能体代表一个专家子模型。这些智能体能适应各种条件并相互协作,通过图神经网络编码其关系和性能指标。我们的方法采用基于top-k最大生成树的协调机制,优化生成过程。每个智能体的决策由元模型指导,该模型最小化一个新型损失函数,在准确性和多样性之间取得平衡。理论分析和广泛的实证评估表明,LGR-AD在各种基准测试中优于传统扩散模型,突显其在复杂图像生成任务中可扩展和灵活解决方案的潜力。代码可从:https://github.com/YousIA/LGR_AD获取。
论文及项目相关链接
PDF Accepted at AAMAS2025 International Conference on Autonomous Agents and Multiagent Systems
Summary
扩散模型在文本到图像合成领域取得了显著进展,展示了令人印象深刻的文本理解和零样本泛化能力。本文提出LGR-AD模型,这是一个新型多智能体系统,旨在提高动态计算机视觉任务的适应性。LGR-AD将生成过程建模为交互智能体的分布式系统,每个智能体代表一个专家子模型。这些智能体能适应不同条件并通过图神经网络协作,该网络编码了它们的关系和性能度量。通过基于top-k最大生成树的协调机制优化生成过程。每个智能体的决策由平衡准确度和多样性的新型损失函数引导的元模型指导。理论分析和广泛的实证研究证明,LGR-AD在多种基准测试中优于传统扩散模型,突显其在复杂图像生成任务中的可扩展和灵活潜力。
Key Takeaways
- 扩散模型在文本到图像合成领域展现显著进展,具备良好文本理解和零样本泛化能力。
- LGR-AD是一个新型多智能体系统,旨在提高动态计算机视觉任务的模型适应性。
- LGR-AD将生成过程建模为交互智能体的分布式系统,智能体代表专家子模型。
- 智能体通过图神经网络协作,并适应不同条件。
- 基于top-k最大生成树的协调机制优化生成过程。
- 每个智能体的决策由平衡准确度和多样性的新型损失函数指导。
点此查看论文截图

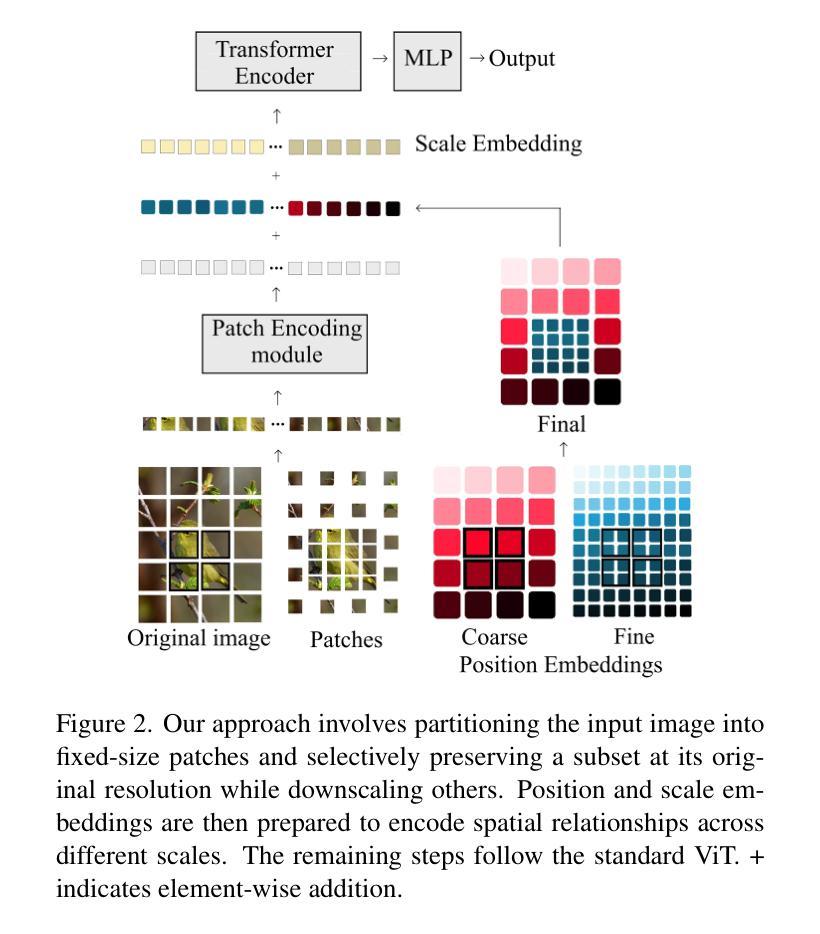
Charm: The Missing Piece in ViT fine-tuning for Image Aesthetic Assessment
Authors:Fatemeh Behrad, Tinne Tuytelaars, Johan Wagemans
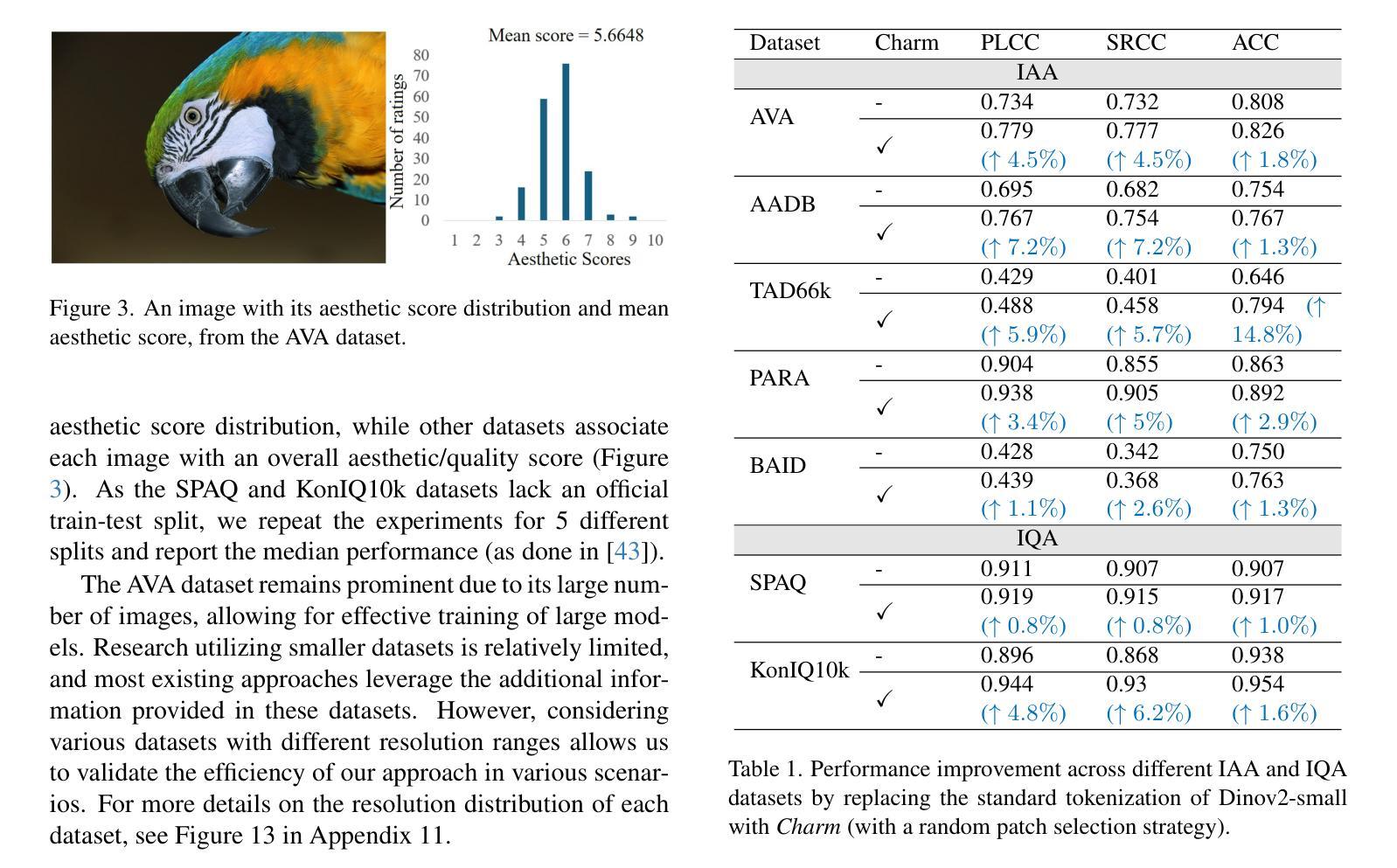
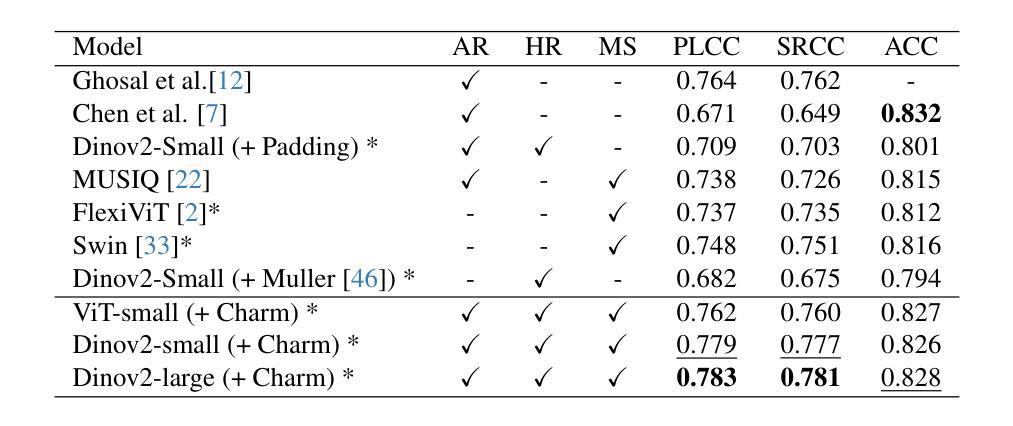
The capacity of Vision transformers (ViTs) to handle variable-sized inputs is often constrained by computational complexity and batch processing limitations. Consequently, ViTs are typically trained on small, fixed-size images obtained through downscaling or cropping. While reducing computational burden, these methods result in significant information loss, negatively affecting tasks like image aesthetic assessment. We introduce Charm, a novel tokenization approach that preserves Composition, High-resolution, Aspect Ratio, and Multi-scale information simultaneously. Charm prioritizes high-resolution details in specific regions while downscaling others, enabling shorter fixed-size input sequences for ViTs while incorporating essential information. Charm is designed to be compatible with pre-trained ViTs and their learned positional embeddings. By providing multiscale input and introducing variety to input tokens, Charm improves ViT performance and generalizability for image aesthetic assessment. We avoid cropping or changing the aspect ratio to further preserve information. Extensive experiments demonstrate significant performance improvements on various image aesthetic and quality assessment datasets (up to 8.1 %) using a lightweight ViT backbone. Code and pre-trained models are available at https://github.com/FBehrad/Charm.
视觉转换器(ViT)处理可变大小输入的能力常常受到计算复杂性和批量处理限制的制约。因此,ViT通常在对通过缩小或裁剪获得的小幅固定大小图像上进行训练。虽然这些方法减轻了计算负担,但它们导致了信息的大量损失,对图像美学评估等任务产生了负面影响。我们引入了Charm,这是一种新型令牌化方法,可以同时保留组合、高分辨率、纵横比和多尺度信息。Charm优先处理特定区域的高分辨率细节,同时缩小其他区域,使ViT能够处理较短的固定大小输入序列,同时融入重要信息。Charm的设计旨在与预训练的ViT及其学习的位置嵌入兼容。通过提供多尺度输入并为输入令牌引入多样性,Charm提高了ViT在图像美学评估方面的性能和通用性。我们避免裁剪或改变纵横比,以进一步保留信息。大量实验表明,在各种图像美学和质量评估数据集上,使用轻量级ViT主干,性能得到了显著提高(最高达8.1%)。代码和预训练模型可在https://github.com/FBehrad/Charm找到。
论文及项目相关链接
PDF CVPR 2025
Summary
Vision Transformer(ViT)在处理可变大小输入时的能力受到计算复杂性和批量处理限制的制约。通常,ViT在通过缩小或裁剪获得的小尺寸图像上进行训练。虽然减轻了计算负担,但这些方法导致了信息的大量丢失,对图像美学评估等任务产生了负面影响。本文介绍了Charm,一种新型tokenization方法,可同时保留组成、高分辨率、纵横比和多尺度信息。Charm优先保留特定区域的高分辨率细节,同时缩小其他区域,使得ViT能够处理更短的固定大小输入序列,同时融入重要信息。Charm的设计旨在与预训练的ViT及其学习的位置嵌入兼容。通过提供多尺度输入并引入各种输入令牌,Charm提高了ViT在图像美学评估方面的性能和通用性。实验证明,使用轻量级ViT主干在各种图像美学和质量评估数据集上的性能有了显著提高(最高达8.1%)。代码和预训练模型可在GitHub上找到。
Key Takeaways
以下是基于文本的关键见解:
* Vision Transformer(ViT)在处理可变大小输入时面临计算复杂性和批量处理限制的挑战。
* 当前训练策略如缩小或裁剪图像虽然减轻了计算负担,但导致了显著的信息丢失,对图像美学评估等任务产生了负面影响。
* Charm是一种新型tokenization方法,旨在解决上述问题,同时保留组成、高分辨率、纵横比和多尺度信息。
* Charm通过优先保留特定区域的高分辨率细节并缩小其他区域,使ViT能够处理更短的固定大小输入序列。
* Charm与预训练的ViT及其位置嵌入兼容,有助于提高ViT在图像美学评估方面的性能和通用性。
* Charm通过提供多尺度输入和引入各种输入令牌改善性能。
* 在多个图像美学和质量评估数据集上,使用Charm和轻量级ViT主干进行实验,性能显著提高。
点此查看论文截图