⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-18 更新
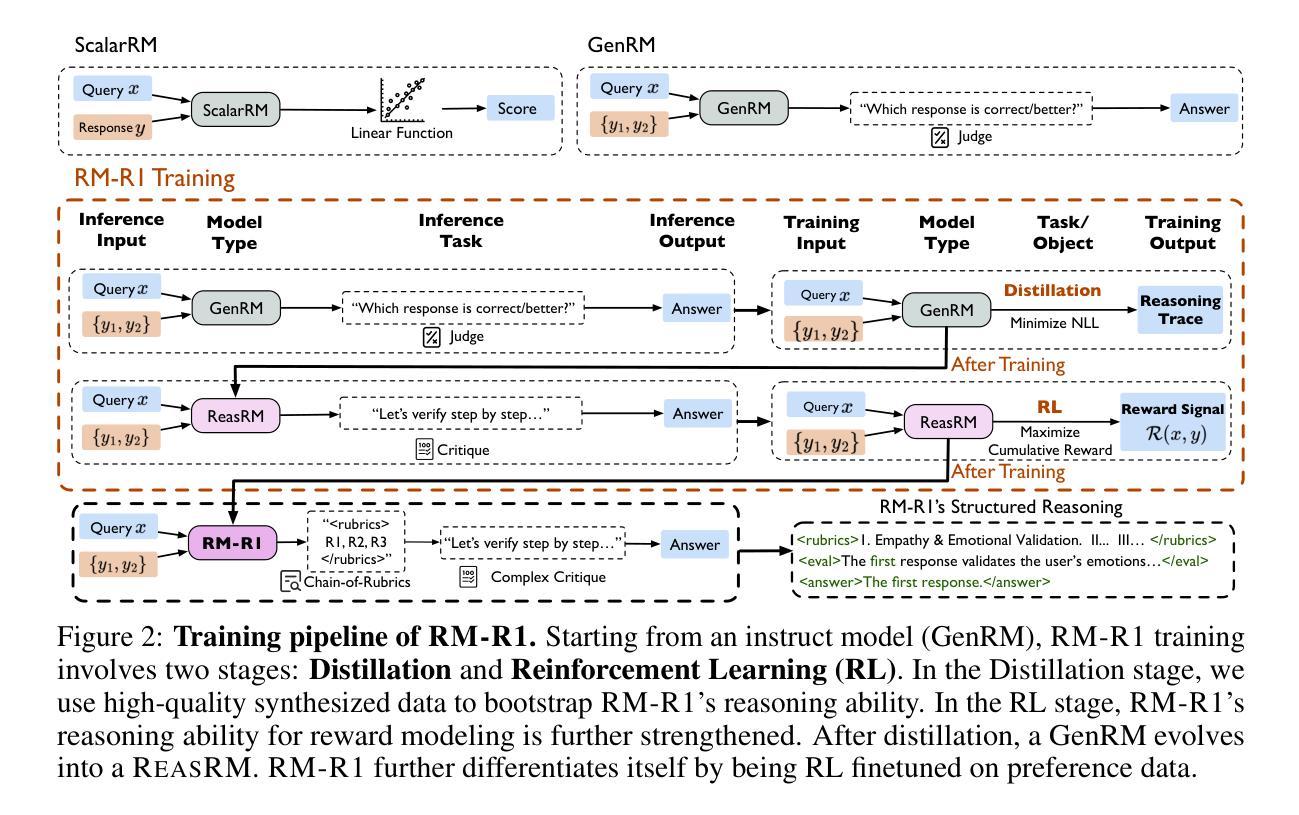
RM-R1: Reward Modeling as Reasoning
Authors:Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, Hanghang Tong, Heng Ji
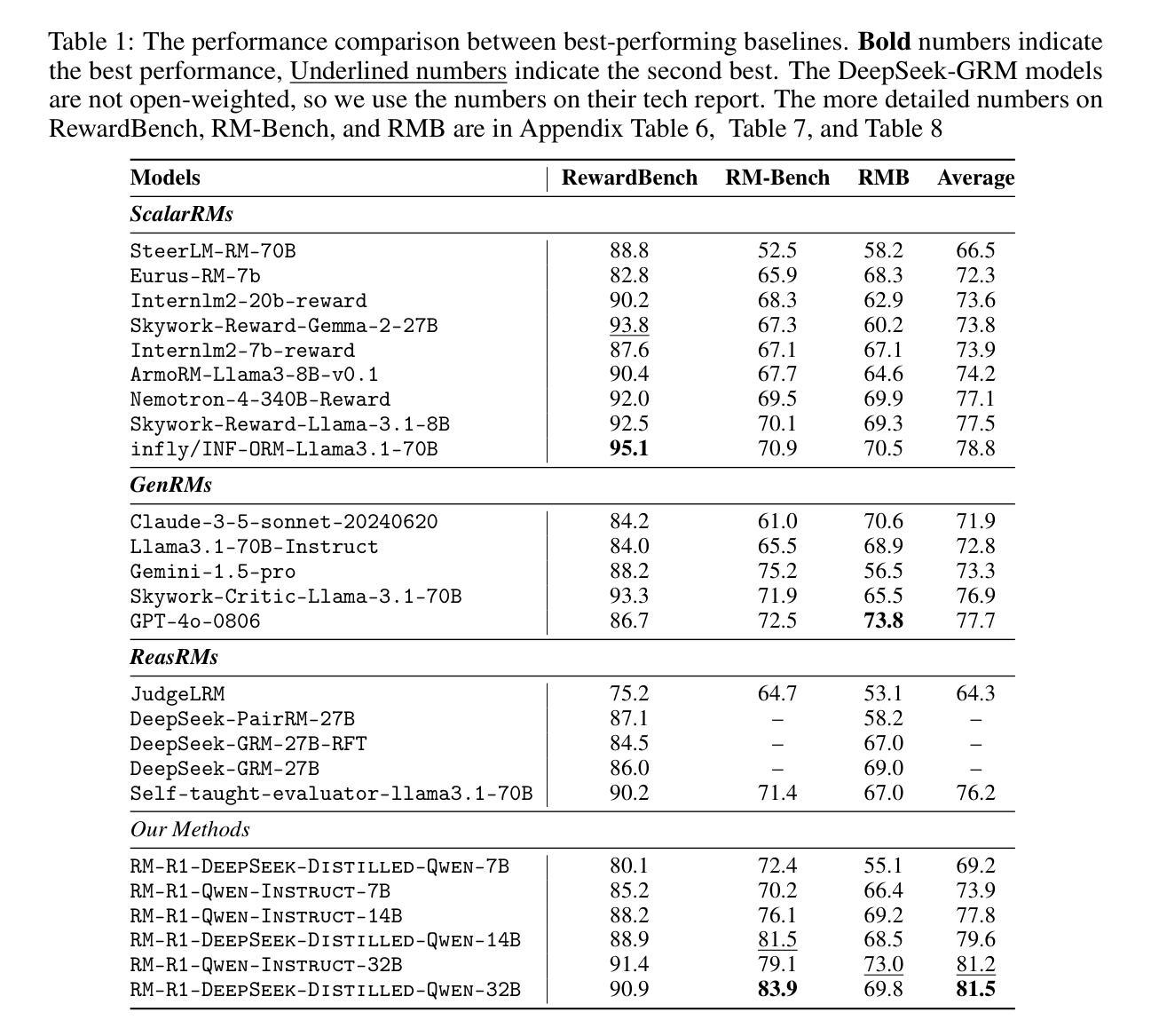
Reward modeling is essential for aligning large language models (LLMs) with human preferences through reinforcement learning (RL). To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM’s interpretability and performance. To this end, we introduce a new class of generative reward models – Reasoning Reward Models (ReasRMs) – which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. RM-R1 features a chain-of-rubrics (CoR) mechanism – self-generating sample-level chat rubrics or math/code solutions, and evaluating candidate responses against them. The training of M-R1 consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. Empirically, our models achieve state-of-the-art performance across three reward model benchmarks on average, outperforming much larger open-weight models (e.g., INF-ORM-Llama3.1-70B) and proprietary ones (e.g., GPT-4o) by up to 4.9%. Beyond final performance, we perform thorough empirical analysis to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six ReasRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.
奖励建模对于通过强化学习(RL)使大型语言模型(LLM)与人类偏好对齐至关重要。为了提供准确的奖励信号,奖励模型(RM)应在分配分数或判断之前刺激深度思考并进行可解释的推理。受近期长链思维(CoT)在推理密集型任务上进步的启发,我们假设并将验证将推理能力融入奖励建模可以显著增强RM的可解释性和性能。为此,我们引入了一种新型生成奖励模型——推理奖励模型(ReasRM),将奖励建模表述为推理任务。我们提出了面向推理的训练管道,并训练了一系列ReasRMs,即RM-R1。RM-R1的特点是拥有链式提纲(CoR)机制——自我生成样本级聊天提纲或数学/代码解决方案,并评估候选响应与之相对应。RM-R1的训练包括两个关键阶段:(1)高质量推理链的提炼;(2)可验证奖励的强化学习。从实证角度看,我们的模型在三个奖励模型基准测试上的平均表现达到了最新水平,平均优于更大的开源模型(例如INF-ORM-Llama3.1-70B)和专有模型(例如GPT-4o)高达4.9%。除了最终表现外,我们还进行了详尽的实证分析,以了解成功训练ReasRM的关键因素。为了便于未来研究,我们在https://github.com/RM-R1-UIUC/RM-R1上发布了六个ReasRM模型以及相关的代码和数据。
论文及项目相关链接
PDF 24 pages, 8 figures
Summary
奖励建模对于通过强化学习对齐大型语言模型(LLM)与人类偏好至关重要。为提供准确的奖励信号,奖励模型(RM)应在分配分数或判断之前进行深度思考和可解释推理。受长链思维(CoT)在推理密集型任务上的最新进展的启发,我们假设并将推理能力融入奖励建模,可显著增强RM的可解释性和性能。为此,我们引入了一类新的生成奖励模型——推理奖励模型(ReasRMs),将奖励建模制定为推理任务。我们提出了面向推理的训练管道,并训练了一系列ReasRMs,即RM-R1。RM-R1具有链式规范(CoR)机制,可自我生成样本级聊天规范或数学/代码解决方案,并评估候选响应。RM-R1的训练包括两个关键阶段:高质量推理链的蒸馏和可验证奖励的强化学习。实证显示,我们的模型在三个奖励模型基准测试上的平均表现达到了业界最佳水平,相较于更大型的开权模型(例如INF-ORM-Llama3.1-70B)和专有模型(例如GPT-4o)高出4.9%。我们不仅关注最终表现,还进行了深入实证分析以了解成功的ReasRM训练的关键要素。为推动未来研究,我们在https://github.com/RM-R1-UIUC/RM-R1上发布了六个ReasRM模型及相关代码和数据。
Key Takeaways
- 奖励建模对于对齐大型语言模型与人类偏好至关重要。
- 奖励模型应在分配奖励前进行深度思考和可解释推理。
- 引入推理奖励模型(ReasRMs),将奖励建模作为推理任务。
- 提出面向推理的训练管道和RM-R1模型。
- RM-R1具有链式规范(CoR)机制,自我生成评估标准并评估候选响应。
- RM-R1训练包括两个阶段:高质量推理链蒸馏和强化学习。
- ReasRMs在基准测试中表现优异,并进行了深入实证分析以理解其成功要素。
点此查看论文截图



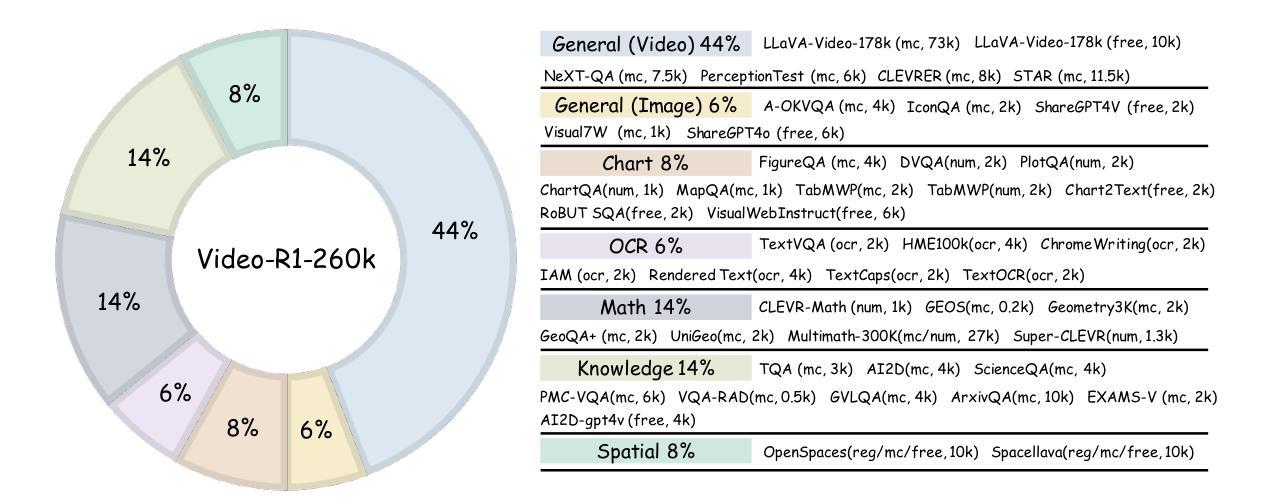
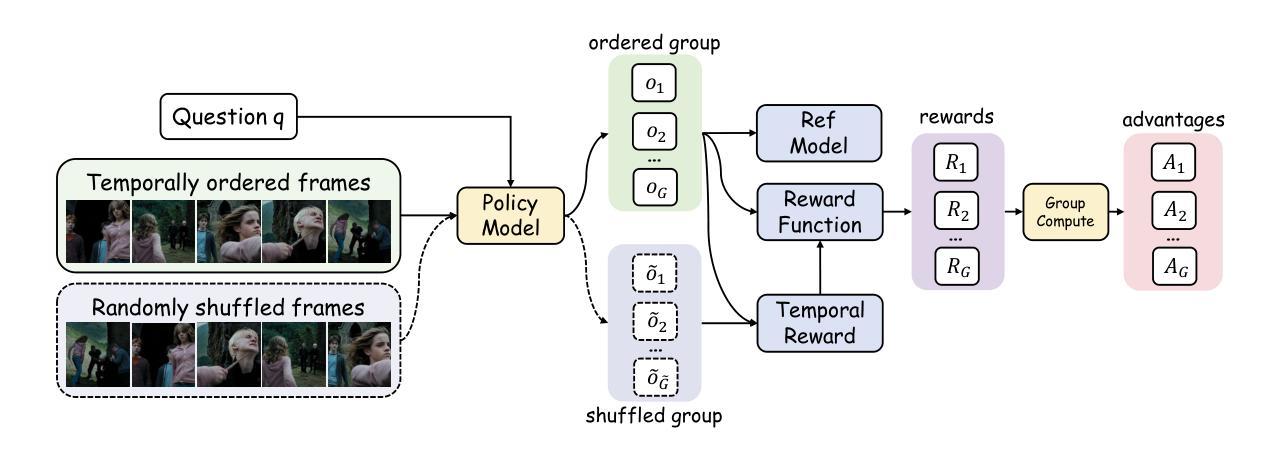
Video-R1: Reinforcing Video Reasoning in MLLMs
Authors:Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, Xiangyu Yue
Inspired by DeepSeek-R1’s success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for incentivizing video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-CoT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 37.1% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All code, models, and data are released in: https://github.com/tulerfeng/Video-R1.
受DeepSeek-R1通过基于规则的强化学习(RL)激发推理能力的成功的启发,我们推出了Video-R1,这是首次尝试系统地探索R1范式,以在多模态大型语言模型(MLLMs)中激励视频推理。然而,直接将RL训练和GRPO算法应用于视频推理面临两个主要挑战:(i)视频推理缺乏时间建模;(ii)高质量视频推理数据的稀缺。为了解决这些问题,我们首先提出T-GRPO算法,该算法鼓励模型在推理时利用视频中的时间信息。此外,我们并没有仅依赖视频数据,而是将高质量图像推理数据纳入训练过程。我们构建了两个数据集:用于SFT冷启动的Video-R1-CoT-165k和用于RL训练的视频R1-260k,这两个数据集都包含图像和视频数据。实验结果表明,Video-R1在视频推理基准测试(如VideoMMMU和VSI-Bench)以及通用视频基准测试(如MVBench和TempCompass等)上取得了显著改进。值得注意的是,Video-R1-7B在视频空间推理基准VSI-bench上达到了37.1%的准确率,超过了商业专有模型GPT-4o。所有代码、模型和数据都在https://github.com/tulerfeng/Video-R f释放。
论文及项目相关链接
PDF Project page: https://github.com/tulerfeng/Video-R1
Summary
视频R1是首个在多模态大型语言模型中激励视频推理的系统性尝试。然而,将RL训练与GRPO算法直接应用于视频推理面临两大挑战:缺乏视频推理的时空建模和高质量视频推理数据的稀缺性。为解决这些问题,我们提出了T-GRPO算法,鼓励模型利用视频中的时空信息进行推理;并不仅仅依赖视频数据,我们还将高质量的图像推理数据纳入训练过程。实验结果证明,Video-R1在视频推理基准测试如VideoMMMU和VSI-Bench上取得了显著改进,并在通用视频基准测试如MVBench和TempCompass上也表现出色。所有代码、模型和资料均已公开。
Key Takeaways
- Video-R1首次尝试在多模态大型语言模型中激励视频推理。
- 直接应用RL训练与GRPO算法于视频推理面临两大挑战:缺乏时空建模与高质量数据稀缺。
- 为解决这些挑战,提出了T-GRPO算法,鼓励模型利用视频的时空信息。
- 整合高质量图像推理数据到训练过程中。
- Video-R1在多个视频推理基准测试上取得显著进展。
- Video-R1使用的代码、模型和资料均已公开。
点此查看论文截图