⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
CROC: Evaluating and Training T2I Metrics with Pseudo- and Human-Labeled Contrastive Robustness Checks
Authors:Christoph Leiter, Yuki M. Asano, Margret Keuper, Steffen Eger
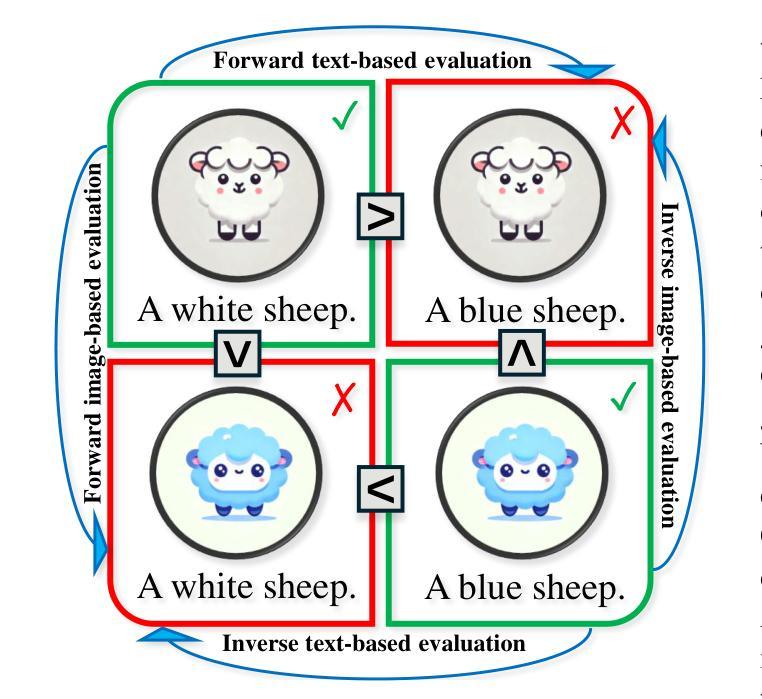
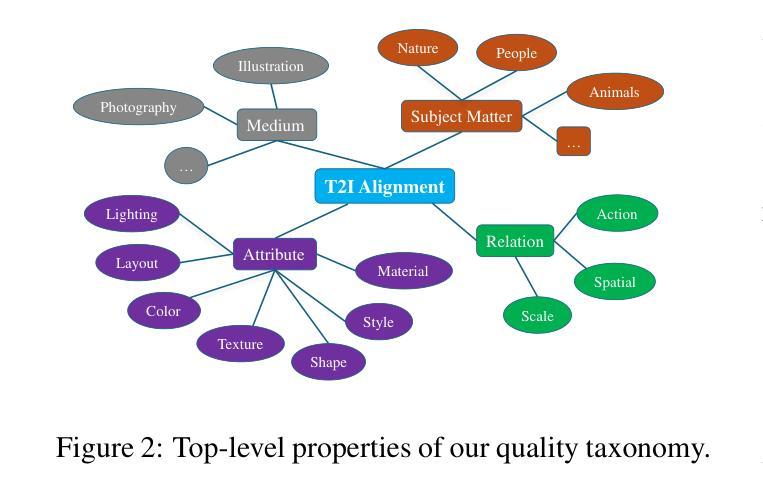
The assessment of evaluation metrics (meta-evaluation) is crucial for determining the suitability of existing metrics in text-to-image (T2I) generation tasks. Human-based meta-evaluation is costly and time-intensive, and automated alternatives are scarce. We address this gap and propose CROC: a scalable framework for automated Contrastive Robustness Checks that systematically probes and quantifies metric robustness by synthesizing contrastive test cases across a comprehensive taxonomy of image properties. With CROC, we generate a pseudo-labeled dataset (CROC$^{syn}$) of over one million contrastive prompt-image pairs to enable a fine-grained comparison of evaluation metrics. We also use the dataset to train CROCScore, a new metric that achieves state-of-the-art performance among open-source methods, demonstrating an additional key application of our framework. To complement this dataset, we introduce a human-supervised benchmark (CROC$^{hum}$) targeting especially challenging categories. Our results highlight robustness issues in existing metrics: for example, many fail on prompts involving negation, and all tested open-source metrics fail on at least 25% of cases involving correct identification of body parts.
评估指标(元评估)的评估在文本到图像(T2I)生成任务中判断现有指标的适宜性至关重要。基于人类的元评估成本高昂且耗时,自动化替代方案却很少见。我们解决了这一空白,提出了CROC:一个用于自动化对比稳健性检查的可扩展框架,它通过合成对比测试用例,系统地探测和量化指标的稳健性,涵盖了广泛的图像属性分类。使用CROC,我们生成了一个伪标记数据集(CROC$^{syn}$),包含超过一百万对比提示-图像对,以实现对评估指标的精细比较。我们还使用该数据集训练了CROCScore,这是一个新的指标,在开源方法中实现了最先进的性能,展示了我们框架的另一个关键应用。为了补充此数据集,我们引入了一个人类监督的基准测试(CROC$^{hum}$),专门针对特别具有挑战性的类别。我们的结果突出了现有指标在稳健性方面的问题:例如,许多指标在处理涉及否定的提示时都会出现问题,所有经过测试的开源指标至少有25%的情况无法正确识别身体部位。
论文及项目相关链接
PDF preprint
Summary
文本主要介绍了评估文本到图像生成任务中现有评价指标的适用性对于确定其适用性至关重要。针对人工评价成本高昂和自动化替代方案稀缺的问题,本文提出了一个可扩展的自动化对比稳健性检查框架CROC,它通过合成对比测试用例,系统地探测和量化指标稳健性,涉及全面的图像属性分类。此外,本文利用CROC生成了一个伪标签数据集CROCsyn,用于精细比较评价指标,并训练了表现突出的新指标CROCScore。为了补充数据集,本文还推出了面向特别挑战类别的人工监督基准CROChum。研究结果揭示了现有指标的稳健性问题。
Key Takeaways
- 评估指标(meta-evaluation)在文本到图像生成任务中非常重要。
- 现有的自动化对比评估方案较少,大部分依赖人工评价,成本高昂且耗时。
- 提出了CROC框架用于自动化对比稳健性检查,通过合成对比测试用例评估指标稳健性。
- CROC框架可以生成伪标签数据集CROCsyn,用于精细比较评价指标。
- 基于CROCsyn数据集训练出的新指标CROCScore表现突出。
- 除了数据集CROCsyn外,还推出了面向特殊挑战的人工监督基准CROChum。
点此查看论文截图