⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
MTevent: A Multi-Task Event Camera Dataset for 6D Pose Estimation and Moving Object Detection
Authors:Shrutarv Awasthi, Anas Gouda, Sven Franke, Jérôme Rutinowski, Frank Hoffmann, Moritz Roidl
Mobile robots are reaching unprecedented speeds, with platforms like Unitree B2, and Fraunhofer O3dyn achieving maximum speeds between 5 and 10 m/s. However, effectively utilizing such speeds remains a challenge due to the limitations of RGB cameras, which suffer from motion blur and fail to provide real-time responsiveness. Event cameras, with their asynchronous operation, and low-latency sensing, offer a promising alternative for high-speed robotic perception. In this work, we introduce MTevent, a dataset designed for 6D pose estimation and moving object detection in highly dynamic environments with large detection distances. Our setup consists of a stereo-event camera and an RGB camera, capturing 75 scenes, each on average 16 seconds, and featuring 16 unique objects under challenging conditions such as extreme viewing angles, varying lighting, and occlusions. MTevent is the first dataset to combine high-speed motion, long-range perception, and real-world object interactions, making it a valuable resource for advancing event-based vision in robotics. To establish a baseline, we evaluate the task of 6D pose estimation using NVIDIA’s FoundationPose on RGB images, achieving an Average Recall of 0.22 with ground-truth masks, highlighting the limitations of RGB-based approaches in such dynamic settings. With MTevent, we provide a novel resource to improve perception models and foster further research in high-speed robotic vision. The dataset is available for download https://huggingface.co/datasets/anas-gouda/MTevent
移动机器人的速度已达到前所未有的水平,例如Unitree B2和Fraunhofer O3dyn等平台的最快速度已达到5至10米/秒。然而,由于RGB相机的局限性,例如运动模糊以及无法提供实时响应,因此有效利用这种速度仍然是一个挑战。事件相机具有异步操作和低延迟传感功能,为高速机器人感知提供了有前景的替代方案。在这项工作中,我们介绍了MTevent数据集,该数据集旨在用于高度动态环境中的6D姿态估计和运动目标检测,并可在大检测距离中使用。我们的设置包括一个立体事件相机和一个RGB相机,拍摄了75个场景,每个场景平均拍摄16秒,并在具有挑战性的条件下展示了16个唯一对象,例如极端视角、光线变化和遮挡。MTevent是第一个结合了高速运动、远程感知和现实世界对象交互的数据集,使其成为推进机器人事件中基于视觉研究的宝贵资源。为了建立基准线,我们使用NVIDIA的FoundationPose评估RGB图像上的6D姿态估计任务,使用真实遮罩获得平均召回率为0.22,这突显了RGB相机在这种动态环境中的局限性。通过MTevent数据集,我们提供了一个改进感知模型的宝贵资源,并促进高速机器人视觉的进一步研究。该数据集可通过以下链接下载:https://huggingface.co/datasets/anas-gouda/MTevent。
论文及项目相关链接
PDF accepted to CVPR 2025 Workshop on Event-based Vision
Summary:随着移动机器人技术的飞速发展,高速机器人感知技术面临新的挑战。传统RGB相机在高动态环境下存在运动模糊和实时响应能力不足的问题。事件相机为高速机器人感知提供了有前景的替代方案。本文介绍了MTevent数据集,该数据集适用于高动态环境下的6D姿态估计和移动物体检测。该数据集包含立体事件相机和RGB相机捕获的75个场景,每个场景平均持续16秒,展示了具有挑战性的条件下的16个独特物体。MTevent数据集是首个结合高速运动、长距离感知和现实世界物体交互的数据集,对于推进基于事件的机器人视觉研究具有重要价值。
Key Takeaways:
- 移动机器人技术正在迅速发展,最大速度达到5至10米/秒。
- RGB相机在高动态环境下存在运动模糊和实时响应问题。
- 事件相机为高速机器人感知提供了有前景的替代方案。
- 介绍了MTevent数据集,适用于高动态环境下的6D姿态估计和移动物体检测。
- MTevent包含立体事件相机和RGB相机捕获的75个场景,每个场景平均时长16秒,展示具有挑战性的条件下的多个物体。
- MTevent数据集是首个结合高速运动、长距离感知和现实世界物体交互的数据集。
点此查看论文截图





Pseudo-Label Quality Decoupling and Correction for Semi-Supervised Instance Segmentation
Authors:Jianghang Lin, Yilin Lu, Yunhang Shen, Chaoyang Zhu, Shengchuan Zhang, Liujuan Cao, Rongrong Ji
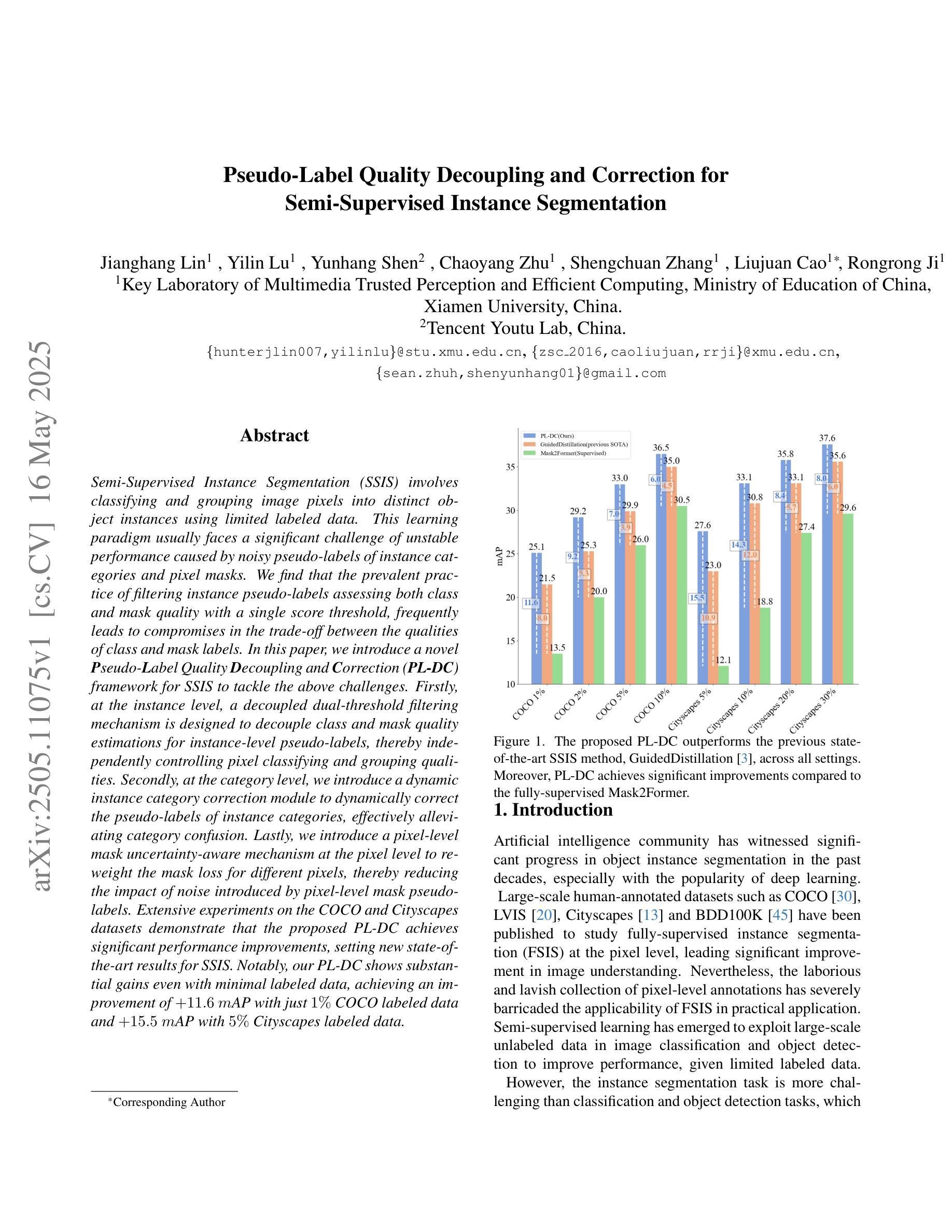
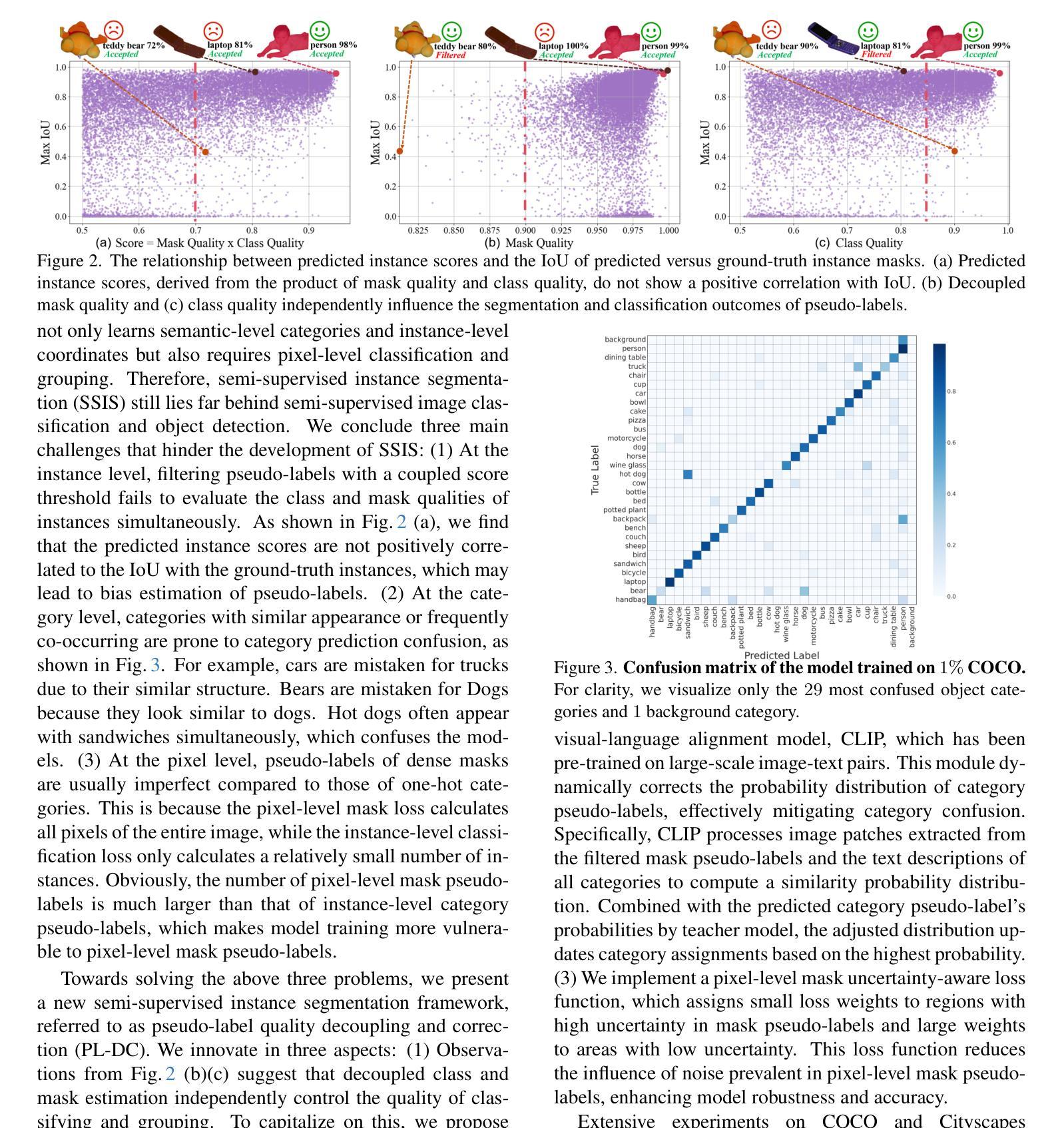
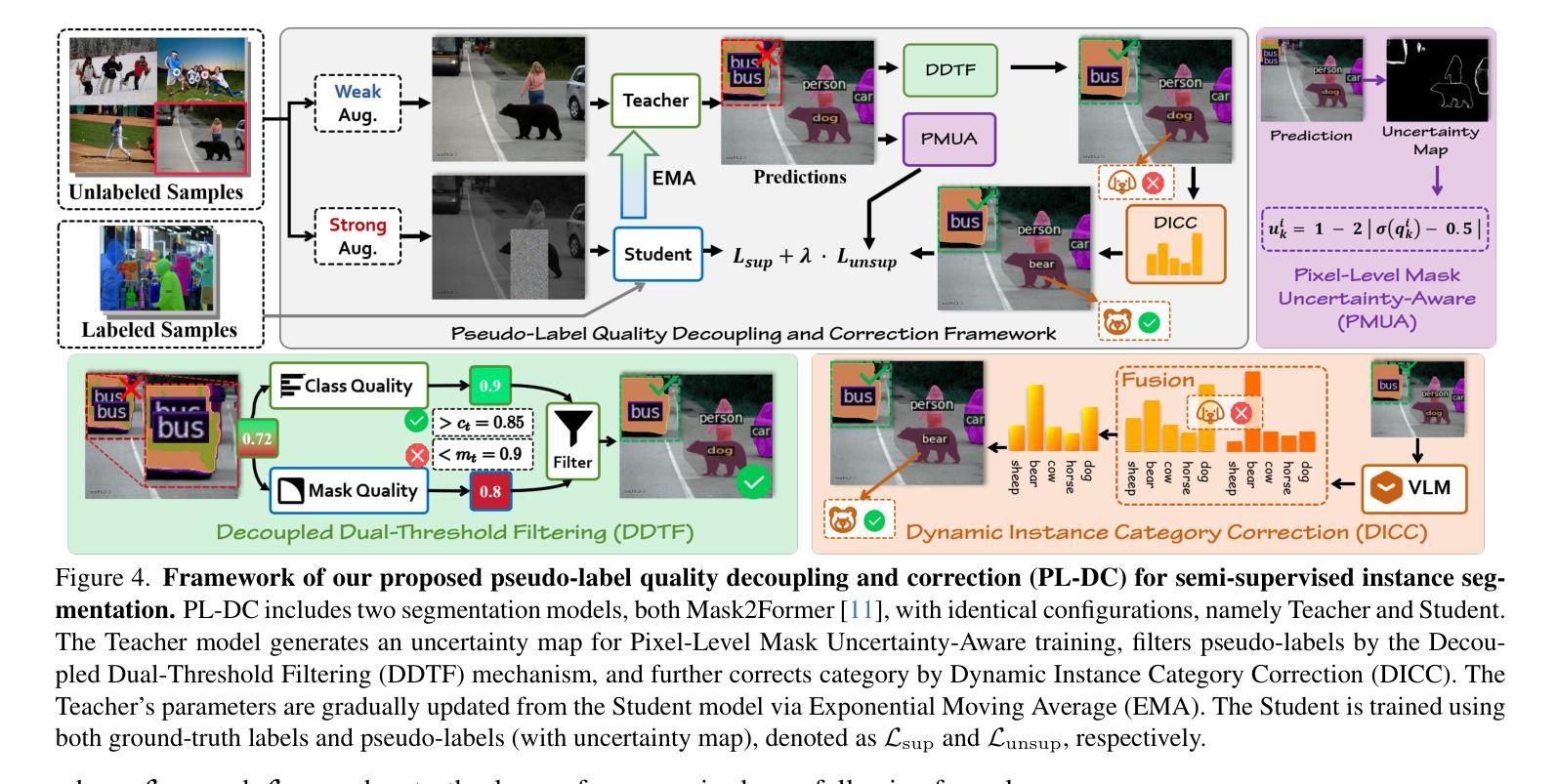
Semi-Supervised Instance Segmentation (SSIS) involves classifying and grouping image pixels into distinct object instances using limited labeled data. This learning paradigm usually faces a significant challenge of unstable performance caused by noisy pseudo-labels of instance categories and pixel masks. We find that the prevalent practice of filtering instance pseudo-labels assessing both class and mask quality with a single score threshold, frequently leads to compromises in the trade-off between the qualities of class and mask labels. In this paper, we introduce a novel Pseudo-Label Quality Decoupling and Correction (PL-DC) framework for SSIS to tackle the above challenges. Firstly, at the instance level, a decoupled dual-threshold filtering mechanism is designed to decouple class and mask quality estimations for instance-level pseudo-labels, thereby independently controlling pixel classifying and grouping qualities. Secondly, at the category level, we introduce a dynamic instance category correction module to dynamically correct the pseudo-labels of instance categories, effectively alleviating category confusion. Lastly, we introduce a pixel-level mask uncertainty-aware mechanism at the pixel level to re-weight the mask loss for different pixels, thereby reducing the impact of noise introduced by pixel-level mask pseudo-labels. Extensive experiments on the COCO and Cityscapes datasets demonstrate that the proposed PL-DC achieves significant performance improvements, setting new state-of-the-art results for SSIS. Notably, our PL-DC shows substantial gains even with minimal labeled data, achieving an improvement of +11.6 mAP with just 1% COCO labeled data and +15.5 mAP with 5% Cityscapes labeled data. The code will be public.
半监督实例分割(SSIS)是利用有限的标记数据将图像像素分类并分组为不同的对象实例。这种学习范式通常面临一个由实例类别的噪声伪标签和像素掩膜引起的性能不稳定性的重大挑战。我们发现,普遍的做法是使用单个得分阈值来评估类和掩膜质量,进而过滤实例伪标签,这通常会在类和掩膜标签质量之间陷入权衡取舍的困境。在本文中,我们为SSIS引入了一个新颖的伪标签质量解耦与校正(PL-DC)框架,以解决上述挑战。首先,在实例层面,设计了一个解耦的双阈值过滤机制,以解耦实例级伪标签的类和掩膜质量估计,从而独立控制像素分类和分组质量。其次,在类别层面,我们引入了一个动态实例类别校正模块,以动态校正实例类别的伪标签,有效地减轻了类别混淆。最后,我们在像素级别引入了一种掩膜不确定性感知机制,对不同像素的掩膜损失进行重新加权,从而减少了由像素级掩膜伪标签引入的噪声的影响。在COCO和Cityscapes数据集上的大量实验表明,所提出的PL-DC实现了显著的性能改进,为SSIS设定了新的最新结果。值得注意的是,我们的PL-DC即使在标记数据很少的情况下也表现出极大的优势,在仅使用COCO 1%标记数据的情况下提高了+11.6 mAP,在Cityscapes 5%标记数据的情况下提高了+15.5 mAP。代码将公开。
论文及项目相关链接
Summary
该论文提出了一种针对半监督实例分割(SSIS)的新框架——伪标签质量解耦与校正(PL-DC)。该框架解决了由于实例伪标签的类别和像素掩膜噪声导致的不稳定性能问题。它采用了三层级的策略,包括解耦的实例层级双阈值过滤机制、动态的实例类别校正模块以及像素级别的掩膜不确定性感知机制。这些策略提高了伪标签的质量,从而提高了模型的性能。在COCO和Cityscapes数据集上的实验表明,PL-DC取得了显著的性能提升,特别是在少量标注数据的情况下。
Key Takeaways
- 半监督实例分割(SSIS)面临由于实例伪标签的类别和像素掩膜噪声导致的性能不稳定问题。
- 伪标签质量解耦与校正(PL-DC)框架通过解耦的实例层级双阈值过滤机制提高伪标签质量。
- 动态实例类别校正模块用于动态校正实例类别的伪标签,减少类别混淆。
- 像素级别的掩膜不确定性感知机制用于降低像素级掩膜伪标签噪声的影响。
- PL-DC在COCO和Cityscapes数据集上取得了显著的性能提升,特别是在少量标注数据的情况下。
- PL-DC框架有望为半监督学习领域提供一种有效的解决方案,尤其是在图像分割任务中。
点此查看论文截图
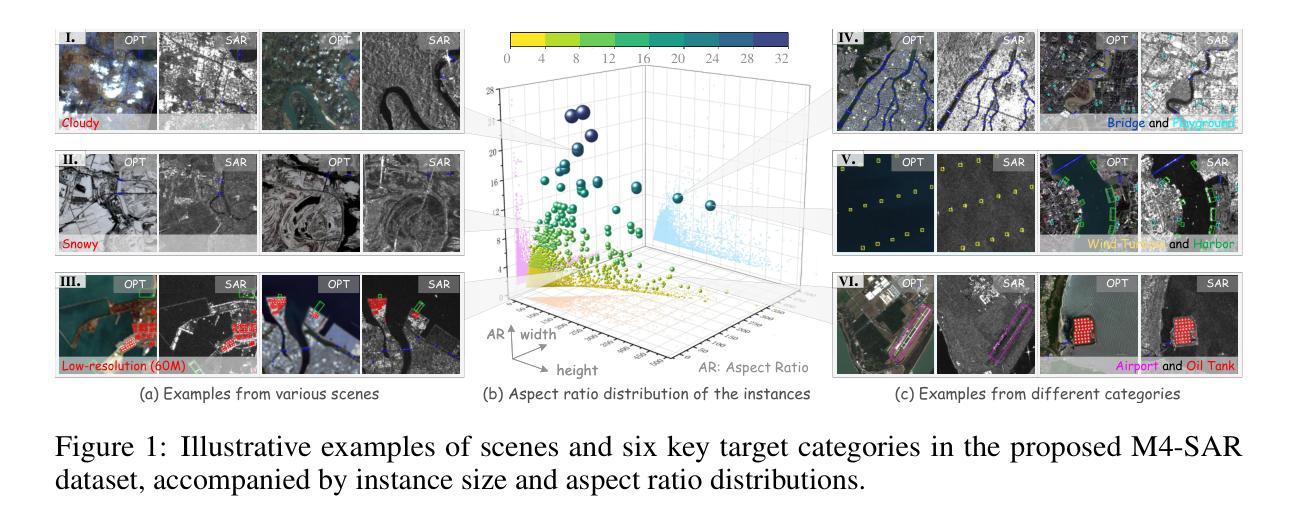
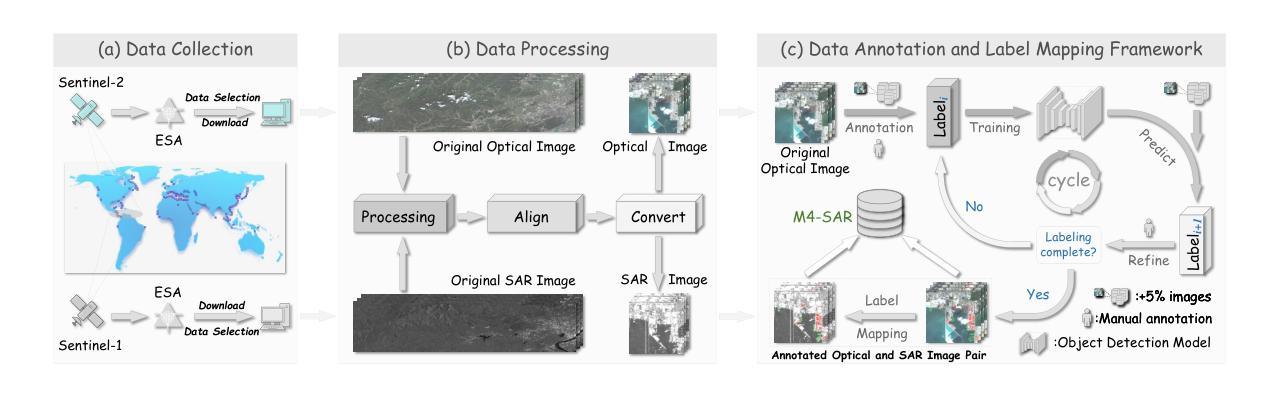
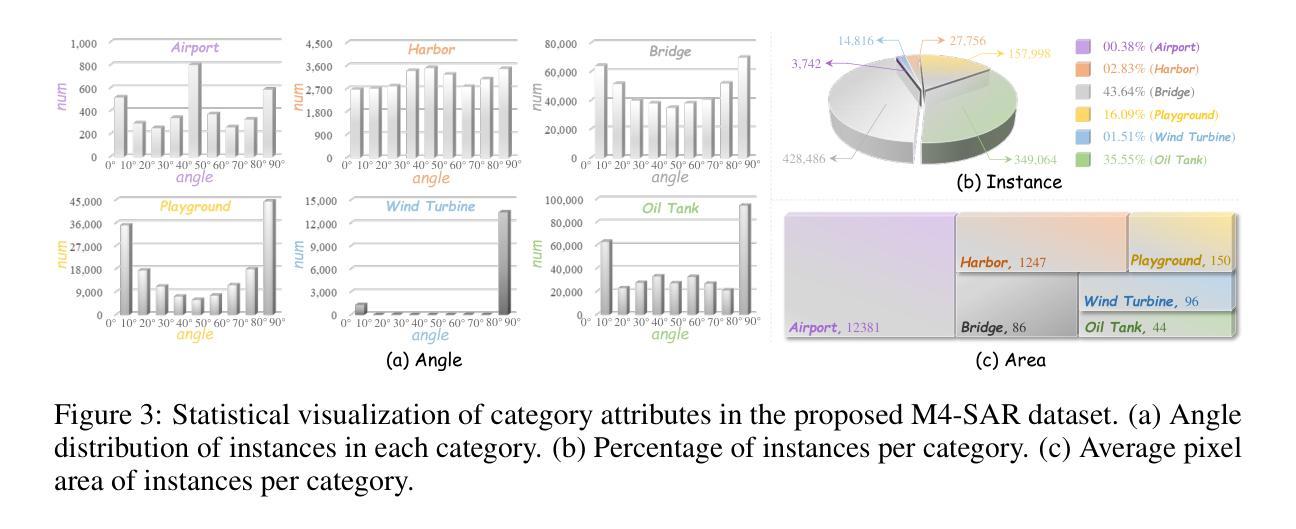
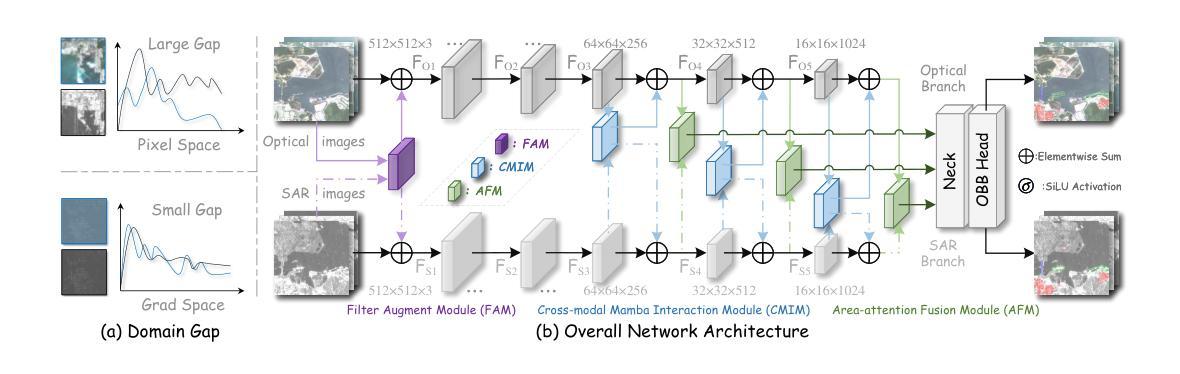
M4-SAR: A Multi-Resolution, Multi-Polarization, Multi-Scene, Multi-Source Dataset and Benchmark for Optical-SAR Fusion Object Detection
Authors:Chao Wang, Wei Lu, Xiang Li, Jian Yang, Lei Luo
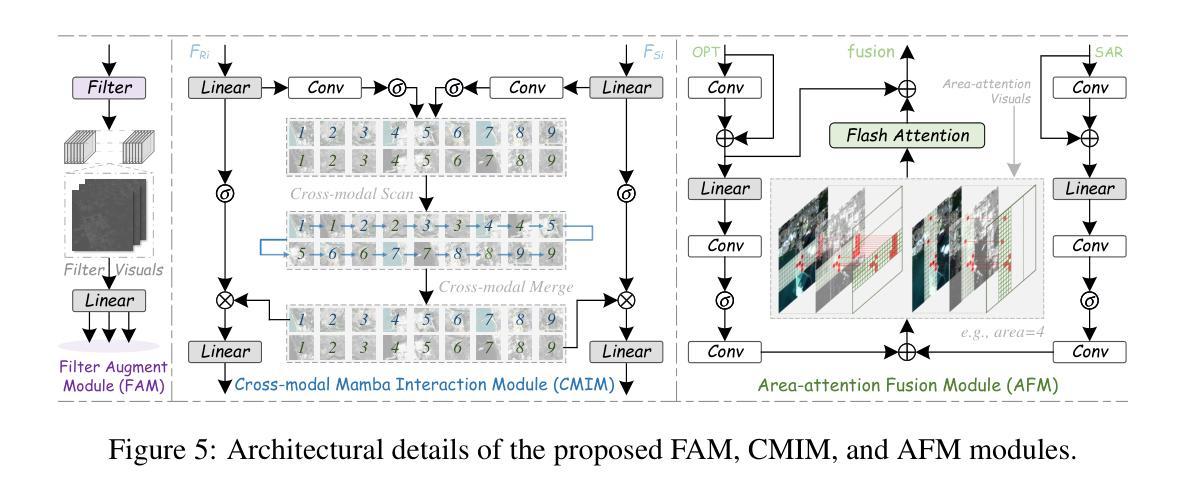
Single-source remote sensing object detection using optical or SAR images struggles in complex environments. Optical images offer rich textural details but are often affected by low-light, cloud-obscured, or low-resolution conditions, reducing the detection performance. SAR images are robust to weather, but suffer from speckle noise and limited semantic expressiveness. Optical and SAR images provide complementary advantages, and fusing them can significantly improve the detection accuracy. However, progress in this field is hindered by the lack of large-scale, standardized datasets. To address these challenges, we propose the first comprehensive dataset for optical-SAR fusion object detection, named Multi-resolution, Multi-polarization, Multi-scene, Multi-source SAR dataset (M4-SAR). It contains 112,184 precisely aligned image pairs and nearly one million labeled instances with arbitrary orientations, spanning six key categories. To enable standardized evaluation, we develop a unified benchmarking toolkit that integrates six state-of-the-art multi-source fusion methods. Furthermore, we propose E2E-OSDet, a novel end-to-end multi-source fusion detection framework that mitigates cross-domain discrepancies and establishes a robust baseline for future studies. Extensive experiments on M4-SAR demonstrate that fusing optical and SAR data can improve $mAP$ by 5.7% over single-source inputs, with particularly significant gains in complex environments. The dataset and code are publicly available at https://github.com/wchao0601/M4-SAR.
在复杂环境中,使用光学或SAR图像进行单源遥感对象检测面临挑战。光学图像虽然具有丰富的纹理细节,但常常受到低光、云层遮蔽或低分辨率条件的影响,降低了检测性能。SAR图像对天气具有鲁棒性,但受到斑点噪声和有限的语义表达能力的限制。光学和SAR图像具有互补优势,融合它们可以显著提高检测精度。然而,该领域的进展受到缺乏大规模、标准化数据集的阻碍。为了应对这些挑战,我们提出了首个用于光学-SAR融合对象检测的综合数据集,命名为多分辨率、多极化、多场景、多源SAR数据集(M4-SAR)。它包含112,184个精确对齐的图像对和近百万个具有任意方向的标记实例,涵盖六个关键类别。为了进行标准化评估,我们开发了一个统一的基准测试工具包,集成了六种最先进的多源融合方法。此外,我们提出了E2E-OSDet,这是一种新型端到端多源融合检测框架,它减轻了跨域差异,并为未来的研究建立了稳健的基准。在M4-SAR上的广泛实验表明,与单源输入相比,融合光学和SAR数据可以提高mAP的5.7%,在复杂环境中尤其显著。数据集和代码可在https://github.com/wchao0601/M4-SAR公开访问。
论文及项目相关链接
Summary:
该文针对单一遥感图像在复杂环境中的目标检测困难问题,提出结合光学图像与SAR图像进行多源融合检测的方法。为解决此领域缺乏大规模标准化数据集的问题,构建了首个综合数据集M4-SAR,包含精确对齐的图像对和大量标记实例。同时,开发了一个统一的基准测试工具包,并提出了E2E-OSDet这一端到端的多源融合检测框架,以缓解跨域差异并建立稳健的基线。实验证明,融合光学和SAR数据可以提高目标检测的准确度。数据集和代码已公开于GitHub上。
Key Takeaways:
- 单一遥感图像在复杂环境中目标检测存在困难。
- 光学图像和SAR图像具有互补优势,融合可提高检测准确性。
- 缺乏大规模标准化数据集是此领域发展的主要挑战之一。
- 提出首个综合数据集M4-SAR,包含精确对齐的图像对和大量标记实例。
- 开发统一的基准测试工具包以进行标准化评估。
- 提出E2E-OSDet这一端到端的多源融合检测框架,缓解跨域差异。
点此查看论文截图


A High-Performance Thermal Infrared Object Detection Framework with Centralized Regulation
Authors:Jinke Li, Yue Wu, Xiaoyan Yang
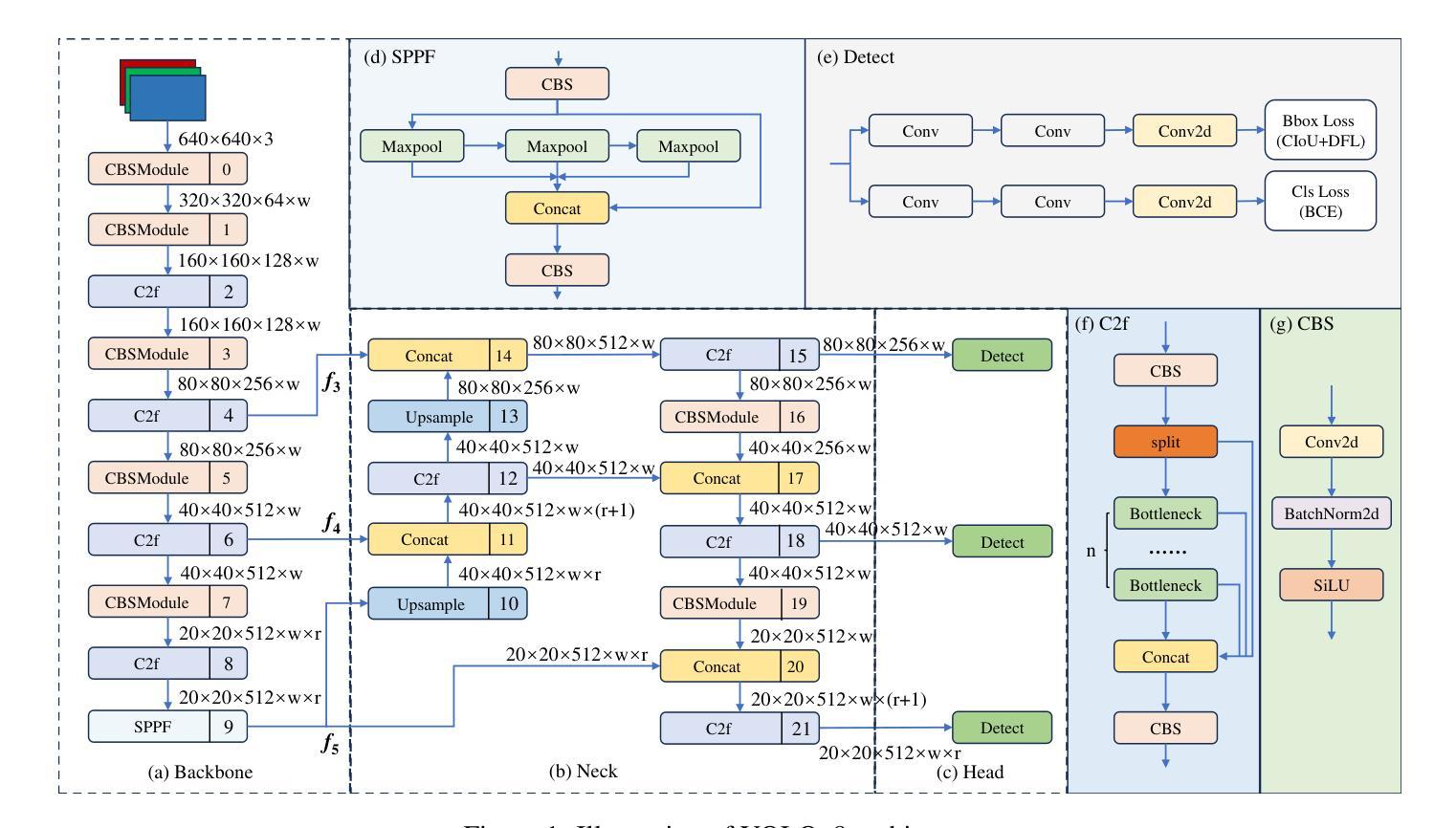
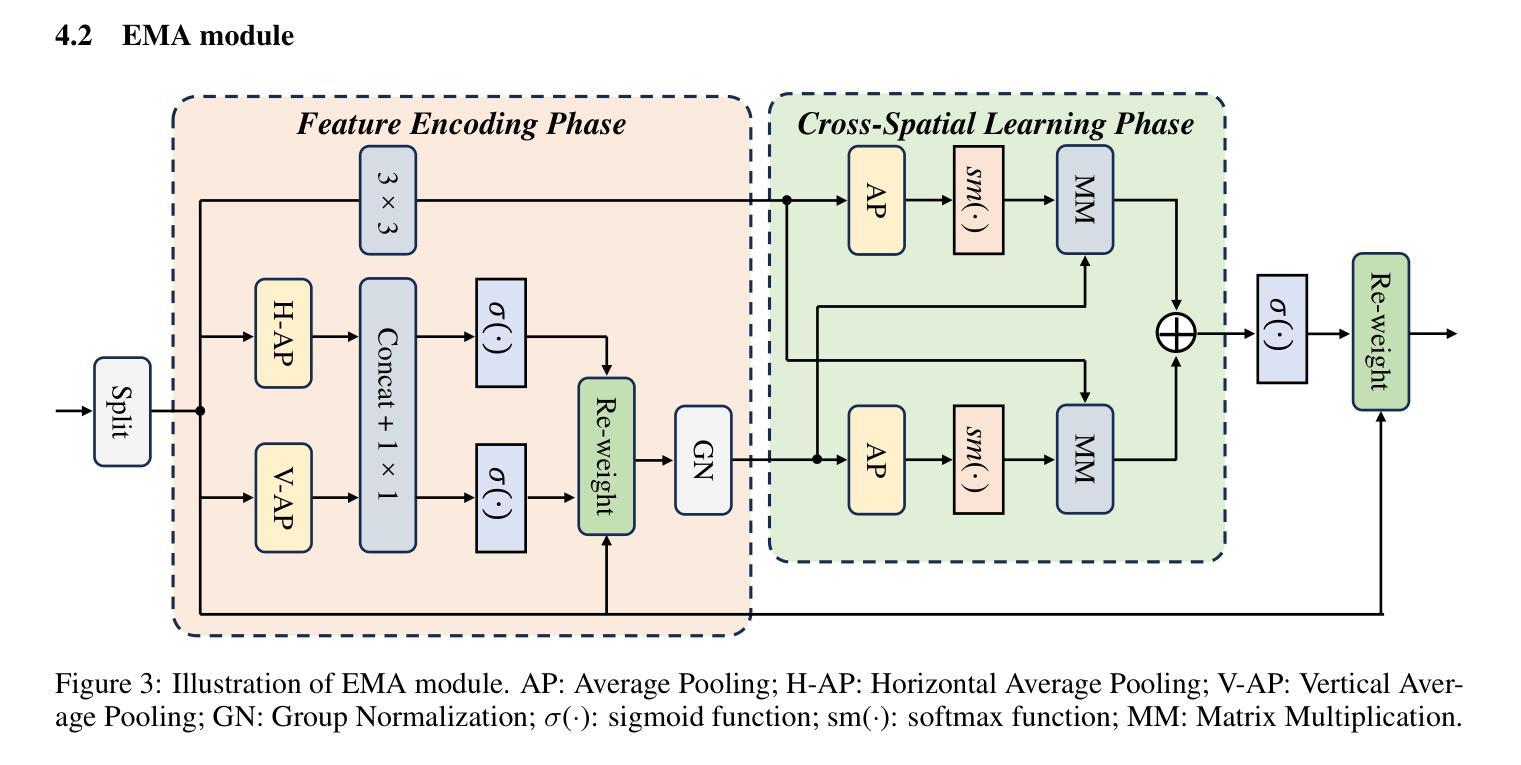
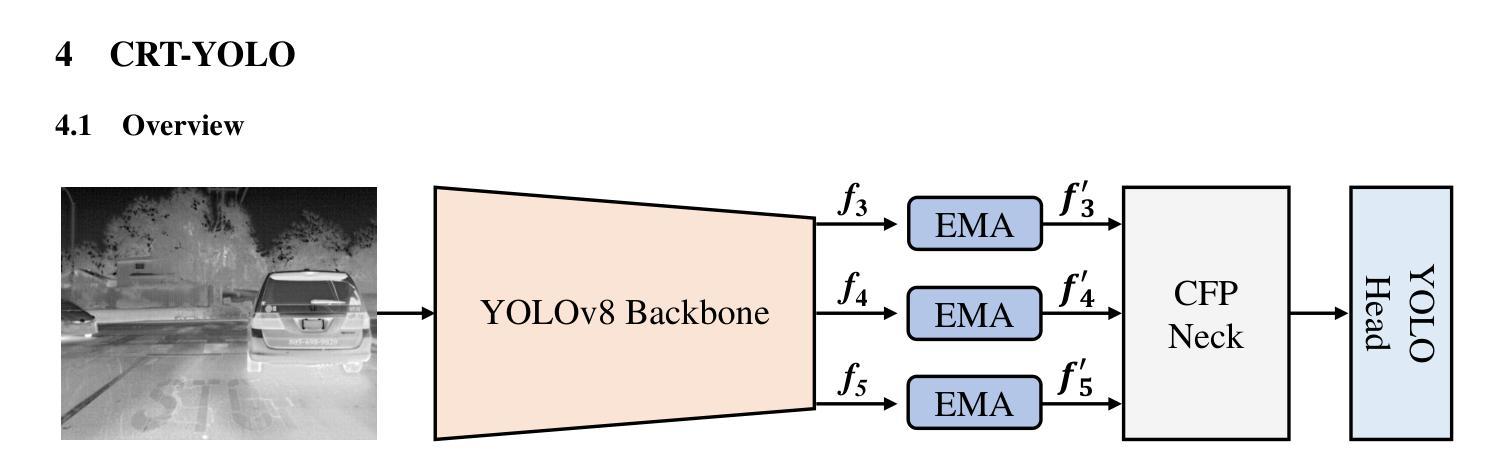
Thermal Infrared (TIR) technology involves the use of sensors to detect and measure infrared radiation emitted by objects, and it is widely utilized across a broad spectrum of applications. The advancements in object detection methods utilizing TIR images have sparked significant research interest. However, most traditional methods lack the capability to effectively extract and fuse local-global information, which is crucial for TIR-domain feature attention. In this study, we present a novel and efficient thermal infrared object detection framework, known as CRT-YOLO, that is based on centralized feature regulation, enabling the establishment of global-range interaction on TIR information. Our proposed model integrates efficient multi-scale attention (EMA) modules, which adeptly capture long-range dependencies while incurring minimal computational overhead. Additionally, it leverages the Centralized Feature Pyramid (CFP) network, which offers global regulation of TIR features. Extensive experiments conducted on two benchmark datasets demonstrate that our CRT-YOLO model significantly outperforms conventional methods for TIR image object detection. Furthermore, the ablation study provides compelling evidence of the effectiveness of our proposed modules, reinforcing the potential impact of our approach on advancing the field of thermal infrared object detection.
热红外(TIR)技术涉及使用传感器检测和测量物体发射的红外辐射,广泛应用于广泛的领域。利用TIR图像进行目标检测方法的进步引起了大量的研究兴趣。然而,大多数传统方法无法有效地提取和融合局部全局信息,这对于红外领域的特征注意力至关重要。本研究提出了一种新型高效的热红外目标检测框架,称为CRT-YOLO,基于集中特征调控,实现了红外信息的全局范围交互。我们提出的模型集成了高效的跨尺度注意力(EMA)模块,该模块能够巧妙地捕捉长距离依赖关系,同时产生极低的计算开销。此外,它利用中央特征金字塔(CFP)网络,对红外特征进行全局调控。在两大基准数据集上进行的广泛实验表明,我们的CRT-YOLO模型在红外图像目标检测方面显著优于传统方法。此外,消融研究为我们提出的模块的有效性提供了有力证据,证明了我们的方法对于推动热红外目标检测领域发展的巨大潜力。
论文及项目相关链接
PDF This manuscript has been accepted for publication in the International Journal for Housing Science and Its Applications (IJHSA), 2025
Summary
本文介绍了一种基于集中式特征调控的高效热红外目标检测框架——CRT-YOLO。该模型能够建立全局范围内的热红外信息交互,并集成高效的多尺度注意力模块,捕捉长距离依赖关系。此外,它采用集中式特征金字塔网络,实现对热红外特征的全局调控。在基准数据集上的实验表明,CRT-YOLO在热红外图像目标检测方面显著优于传统方法。
Key Takeaways
- TIR技术通过传感器检测并测量物体发射的红外辐射,广泛应用于多个领域。
- 大多数传统方法无法有效地提取和融合局部-全局信息,这对于热红外特征注意力至关重要。
- CRT-YOLO是一种新型高效的热红外目标检测框架,基于集中式特征调控,可实现全局范围内的热红外信息交互。
- CRT-YOLO集成了高效的多尺度注意力模块,能够捕捉长距离依赖关系,同时减少计算开销。
- 该模型采用集中式特征金字塔网络,实现热红外特征的全局调控。
- 在基准数据集上的实验表明,CRT-YOLO在热红外图像目标检测方面显著优于传统方法。
点此查看论文截图

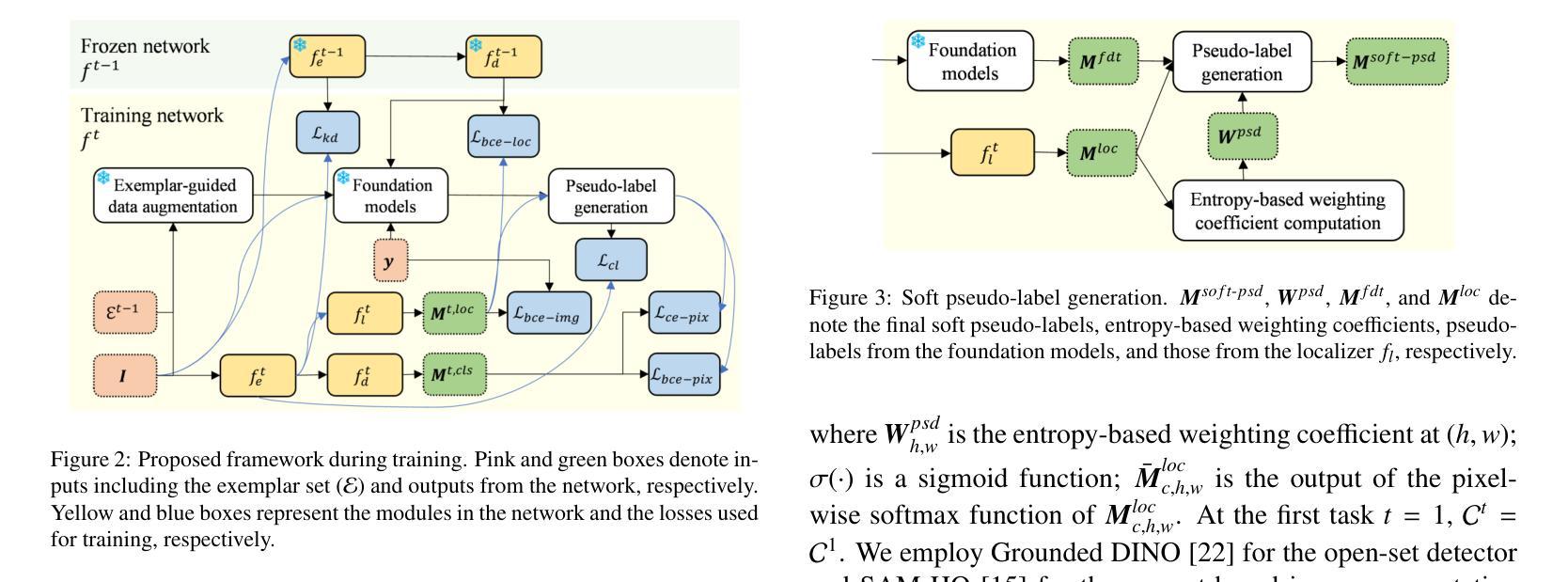
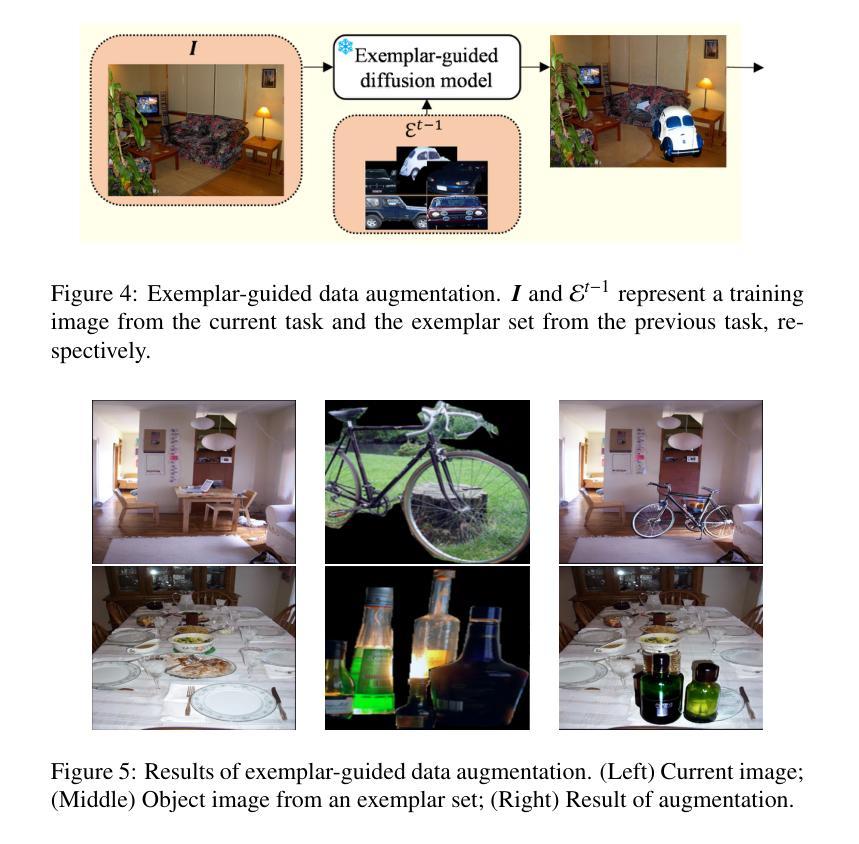
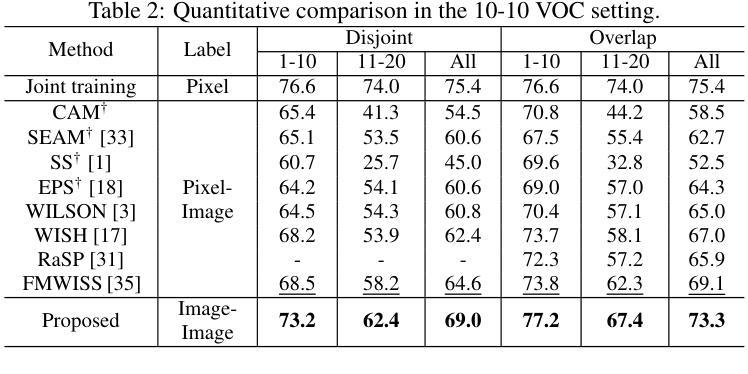
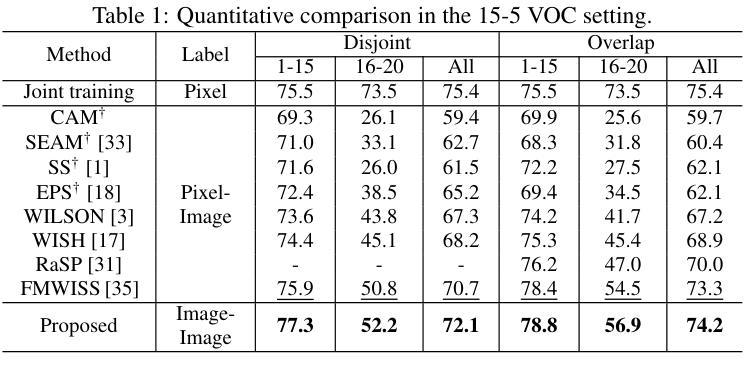
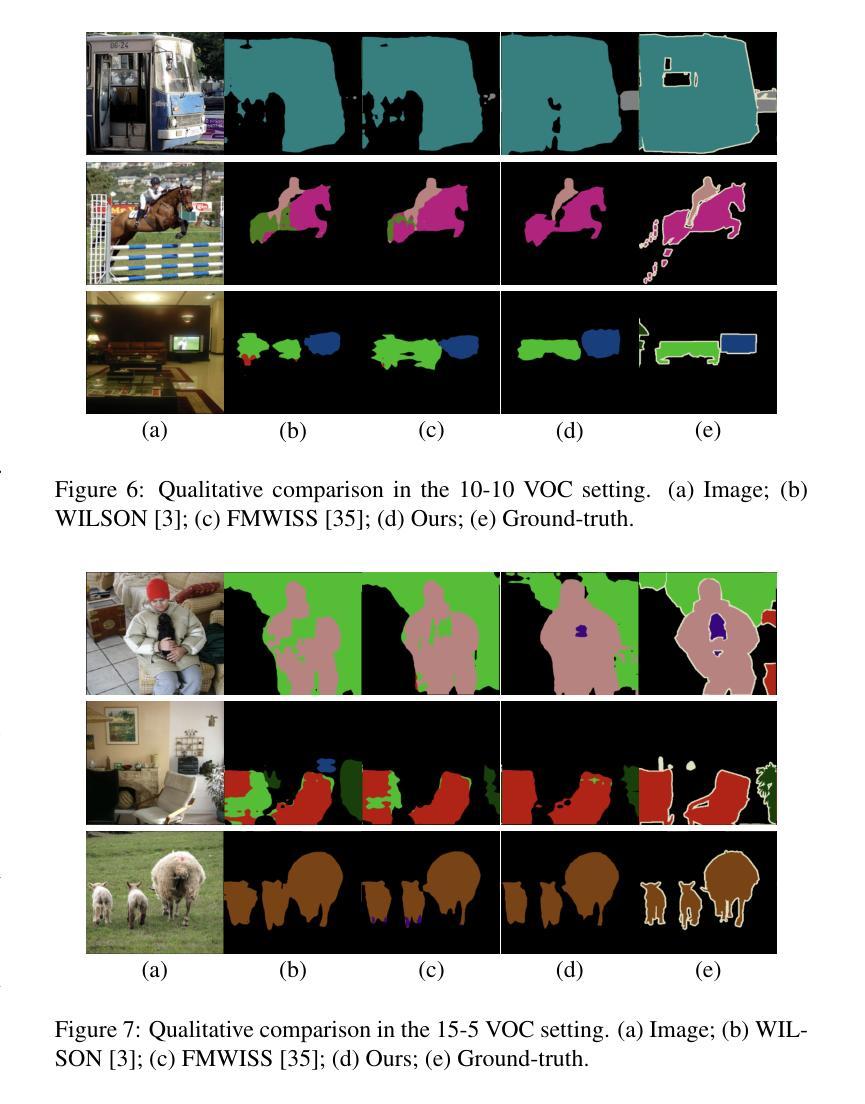
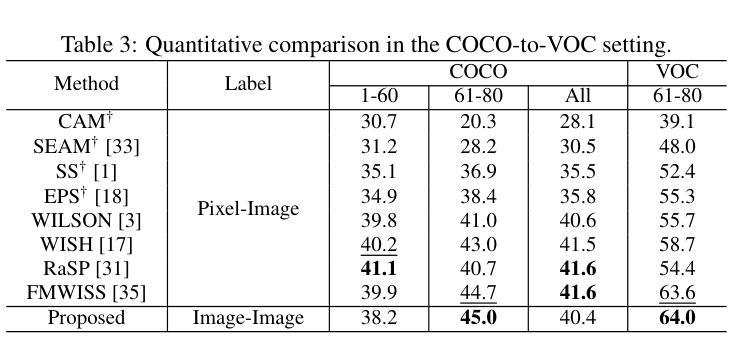
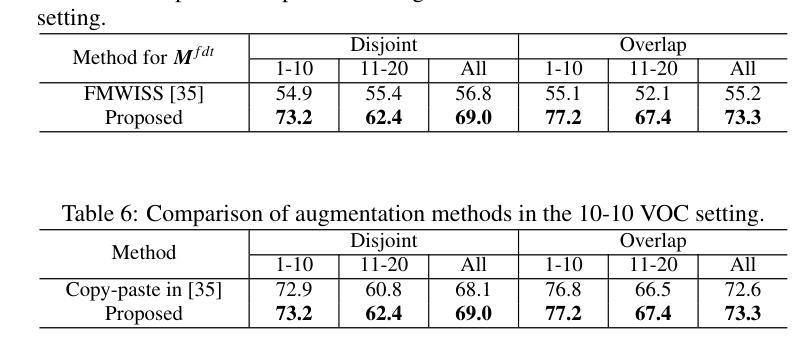
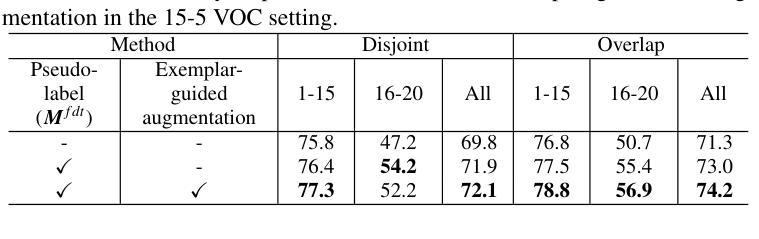
Completely Weakly Supervised Class-Incremental Learning for Semantic Segmentation
Authors:David Minkwan Kim, Soeun Lee, Byeongkeun Kang
This work addresses the task of completely weakly supervised class-incremental learning for semantic segmentation to learn segmentation for both base and additional novel classes using only image-level labels. While class-incremental semantic segmentation (CISS) is crucial for handling diverse and newly emerging objects in the real world, traditional CISS methods require expensive pixel-level annotations for training. To overcome this limitation, partially weakly-supervised approaches have recently been proposed. However, to the best of our knowledge, this is the first work to introduce a completely weakly-supervised method for CISS. To achieve this, we propose to generate robust pseudo-labels by combining pseudo-labels from a localizer and a sequence of foundation models based on their uncertainty. Moreover, to mitigate catastrophic forgetting, we introduce an exemplar-guided data augmentation method that generates diverse images containing both previous and novel classes with guidance. Finally, we conduct experiments in three common experimental settings: 15-5 VOC, 10-10 VOC, and COCO-to-VOC, and in two scenarios: disjoint and overlap. The experimental results demonstrate that our completely weakly supervised method outperforms even partially weakly supervised methods in the 15-5 VOC and 10-10 VOC settings while achieving competitive accuracy in the COCO-to-VOC setting.
这篇论文针对完全弱监督的类增量学习语义分割任务展开研究,旨在仅使用图像级别的标签来学习基础类和新增类的分割。虽然类增量语义分割(CISS)对于处理现实世界中多样且新出现的物体至关重要,但传统的CISS方法需要昂贵的像素级标注来进行训练。为了克服这一局限性,最近提出了部分弱监督的方法。然而,据我们所知,这是第一项引入完全弱监督方法用于CISS的工作。为了实现这一点,我们提出通过结合定位器和基于不确定性的基础模型序列的伪标签来生成稳健的伪标签。此外,为了缓解灾难性遗忘,我们引入了一种示例引导的数据增强方法,该方法生成包含先前和新型类别的各种图像以进行引导。最后,我们在三种常见的实验设置(即15-5 VOC、10-10 VOC和COCO-to-VOC)和两个场景(即不相关和重叠)下进行实验。实验结果表明,我们的完全弱监督方法在15-5 VOC和10-10 VOC设置中甚至超越了部分弱监督方法的表现,同时在COCO-to-VOC设置中也达到了具有竞争力的准确性。
论文及项目相关链接
PDF 8 pages
Summary
本文提出了一种全新的完全弱监督类增量学习方法,用于语义分割。该方法利用仅图像级别的标签,实现对基础类和新增类的学习。通过结合定位器和基础模型的伪标签及其不确定性,生成稳健的伪标签。同时,为缓解灾难性遗忘问题,引入实例引导的数据增强方法。实验结果表明,该方法在弱监督环境下表现优异。
Key Takeaways
- 该研究解决了类增量语义分割(CISS)的完全弱监督学习问题,仅使用图像级别的标签就能学习基础类和新增类的分割。
- 提出了一种结合定位器和基础模型的伪标签生成方法,考虑其不确定性以生成稳健的伪标签。
- 为缓解灾难性遗忘问题,引入了实例引导的数据增强方法,可以生成包含新旧类别的多样化图像。
- 在不同的实验设置和场景下进行了实验验证,包括15-5 VOC、10-10 VOC和COCO-to-VOC的设置,以及分立和重叠场景。
- 在15-5 VOC和10-10 VOC的设置中,完全弱监督方法甚至超越了部分弱监督方法。
- 在COCO-to-VOC设置中,该方法具有竞争力。
点此查看论文截图

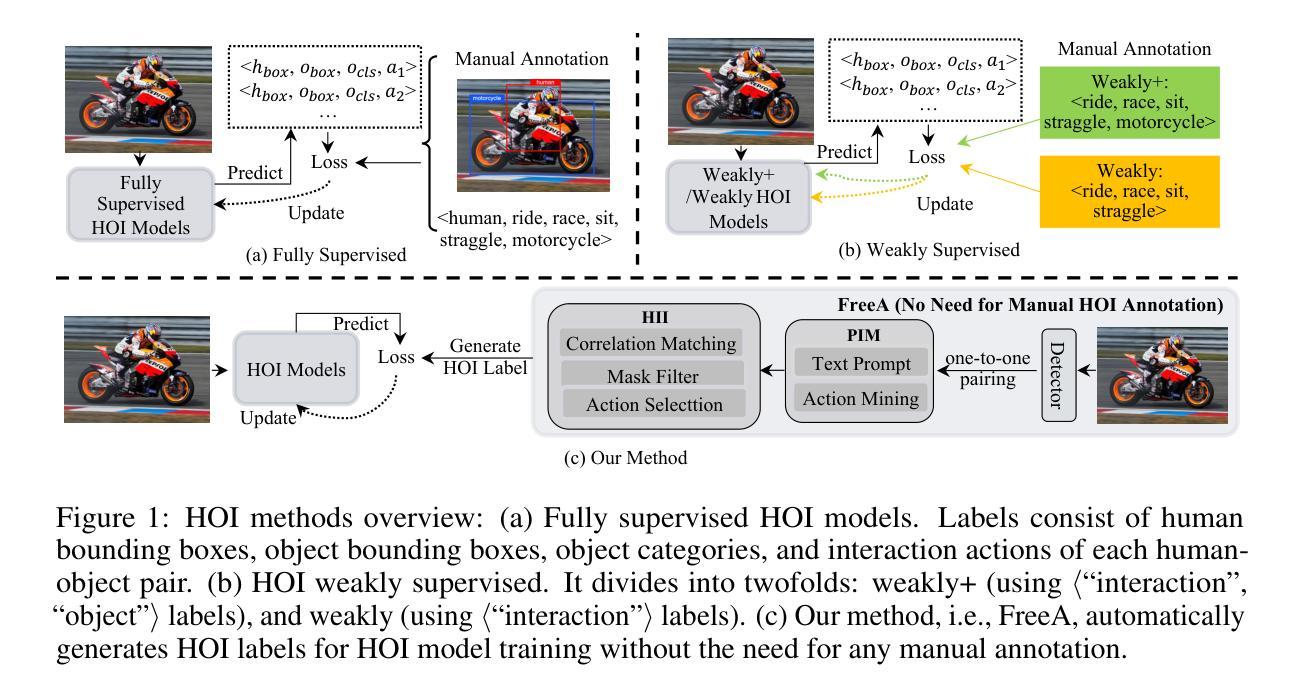
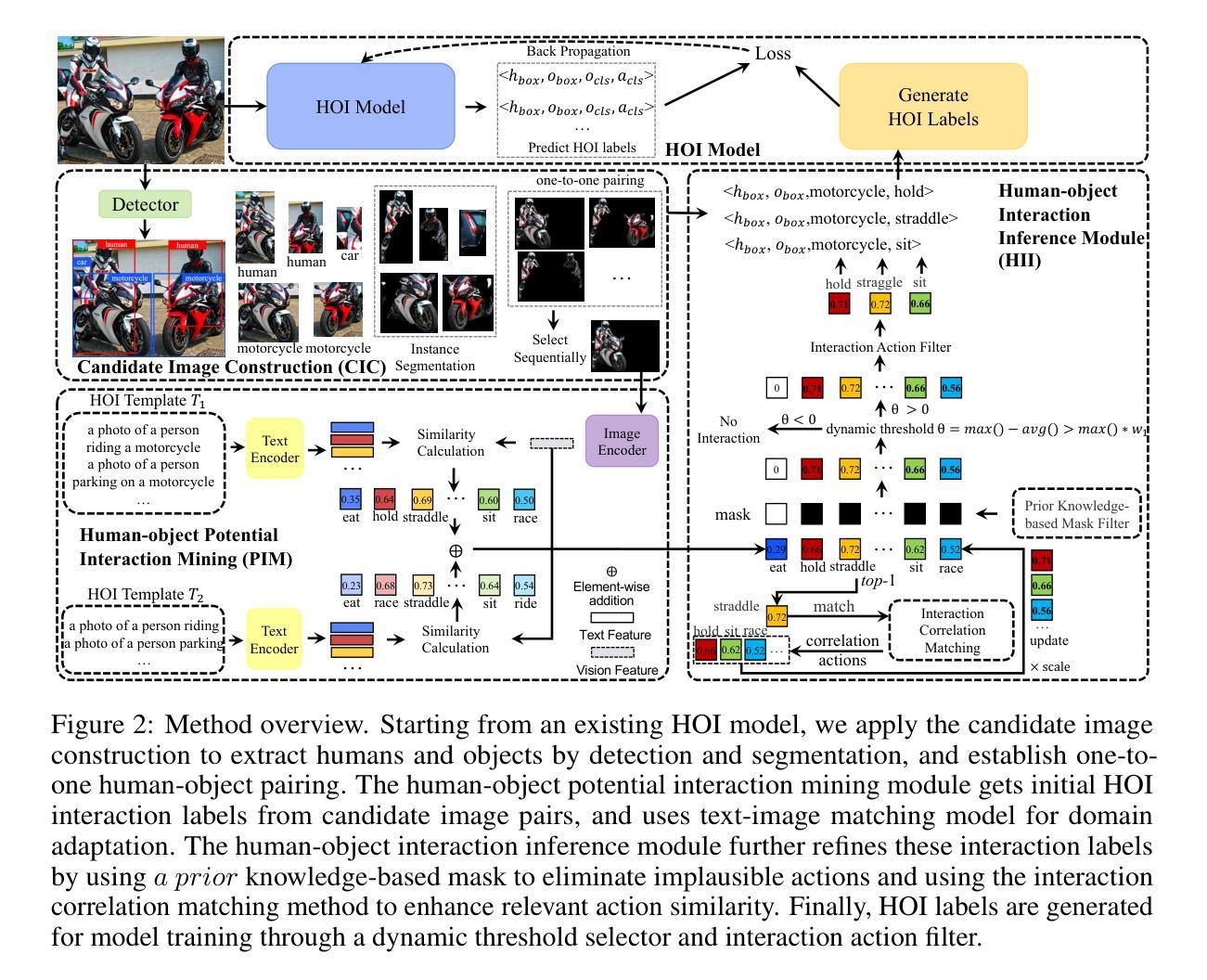
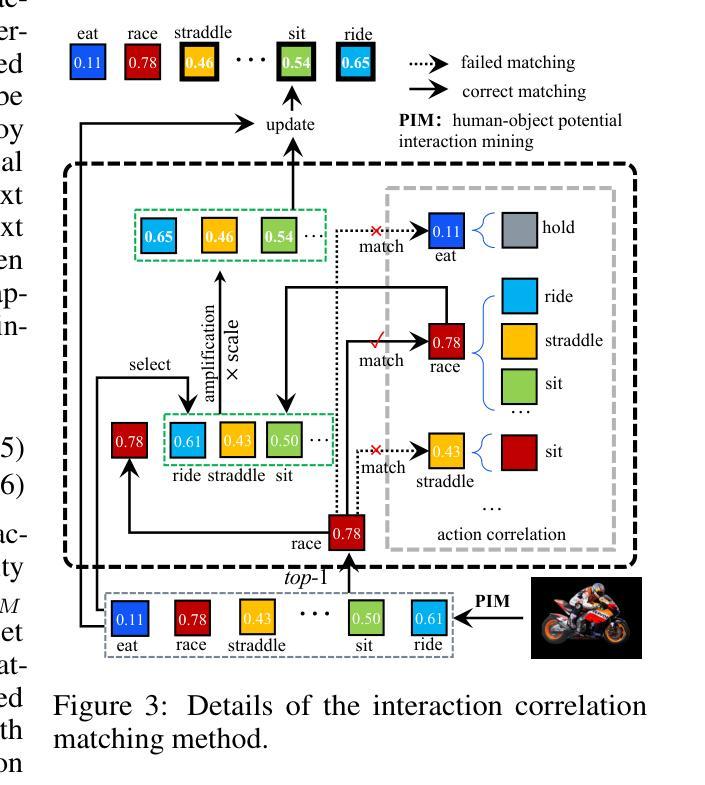
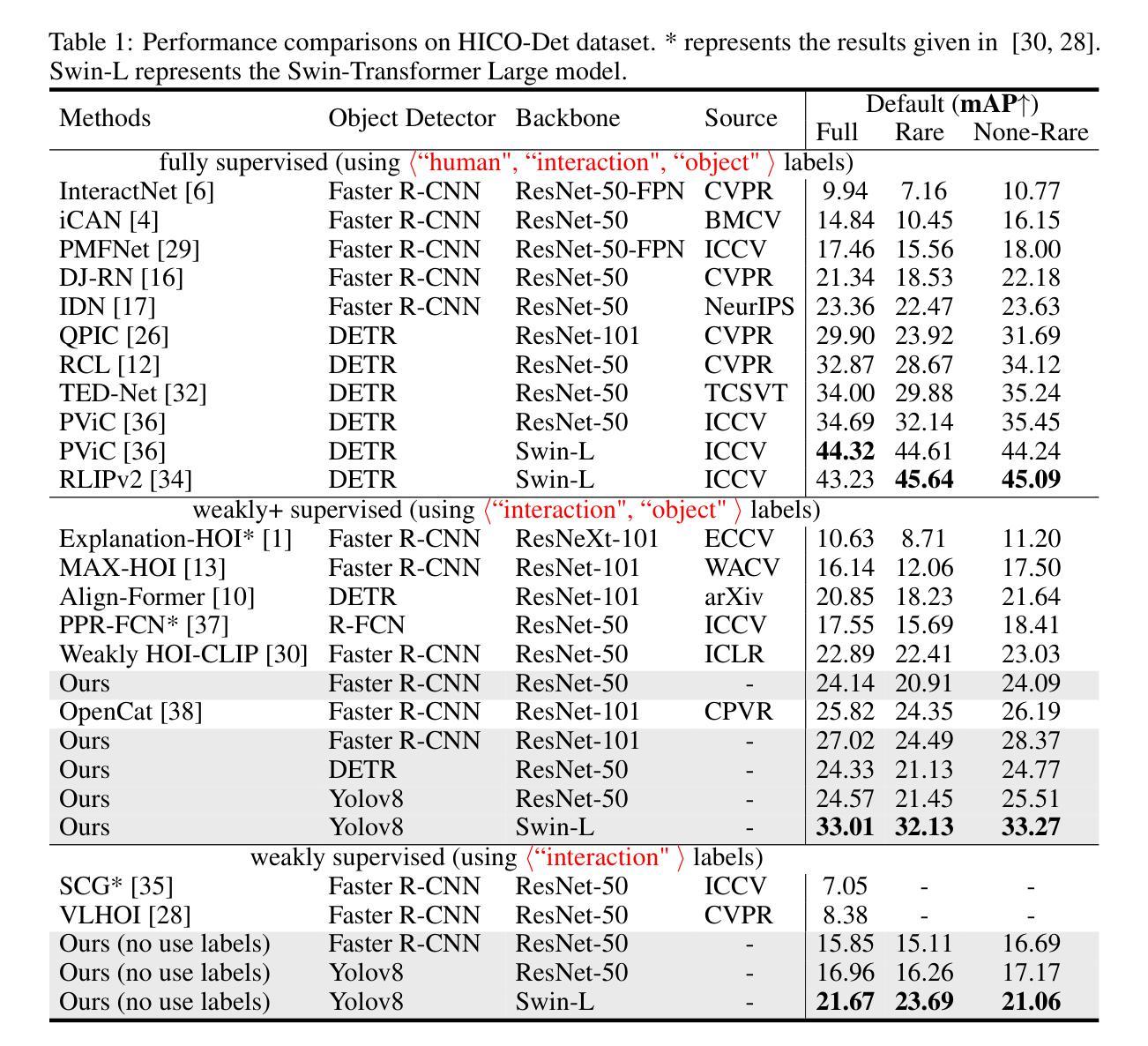
FreeA: Human-object Interaction Detection using Free Annotation Labels
Authors:Qi Liu, Yuxiao Wang, Xinyu Jiang, Wolin Liang, Zhenao Wei, Yu Lei, Nan Zhuang, Weiying Xue
Recent human-object interaction (HOI) detection methods depend on extensively annotated image datasets, which require a significant amount of manpower. In this paper, we propose a novel self-adaptive, language-driven HOI detection method, termed FreeA. This method leverages the adaptability of the text-image model to generate latent HOI labels without requiring manual annotation. Specifically, FreeA aligns image features of human-object pairs with HOI text templates and employs a knowledge-based masking technique to decrease improbable interactions. Furthermore, FreeA implements a proposed method for matching interaction correlations to increase the probability of actions associated with a particular action, thereby improving the generated HOI labels. Experiments on two benchmark datasets showcase that FreeA achieves state-of-the-art performance among weakly supervised HOI competitors. Our proposal gets +\textbf{13.29} (\textbf{159%$\uparrow$}) mAP and +\textbf{17.30} (\textbf{98%$\uparrow$}) mAP than the newest Weakly'' supervised model, and +\textbf{7.19} (\textbf{28\%$\uparrow$}) mAP and +\textbf{14.69} (\textbf{34\%$\uparrow$}) mAP than the latest Weakly+’’ supervised model, respectively, on HICO-DET and V-COCO datasets, more accurate in localizing and classifying the interactive actions. The source code will be made public.
近期的人机交互(HOI)检测方法严重依赖于大量标注的图像数据集,这需要大量的人工操作。在本文中,我们提出了一种新型的自适应语言驱动HOI检测方法,称为FreeA。该方法利用文本图像模型的适应性,无需手动注释即可生成潜在的HOI标签。具体来说,FreeA将人机对图像特征与HOI文本模板对齐,并采用基于知识的遮罩技术来减少不可能的交互。此外,FreeA实现了一种匹配交互关联性的方法,以提高与特定动作相关的动作概率,从而改进生成的HOI标签。在两个基准数据集上的实验表明,FreeA在弱监督HOI竞争对手中实现了最先进的性能。我们的提案在HICO-DET和V-COCO数据集上比最新的“弱”监督模型提高了+13.29(提高159%)和+17.30(提高98%)的mAP,比最新的“弱+”监督模型分别提高了+7.19(提高28%)和+14.69(提高34%)的mAP。在定位和理解交互动作方面更加准确。源代码将公开。
论文及项目相关链接
Summary
本文提出了一种新型的自适应语言驱动的人机交互(HOI)检测模型FreeA,无需手动标注即可生成潜在的HOI标签。该模型通过文本图像模型的适应性,将人机对图像特征对齐,并采用基于知识的遮蔽技术减少不可能的交互。此外,FreeA还提出了一种匹配交互关联的方法,以提高特定动作的关联概率,从而改进生成的HOI标签。实验表明,FreeA在两大基准数据集上均取得了最先进的性能表现。相较于最新的弱监督HOI模型,其在HICO-DET和V-COCO数据集上的平均精度(mAP)分别提升了13.29%(相当于提升159%)和17.30%(相当于提升98%),更能准确地进行交互动作的定位和分类。源代码将公开。
Key Takeaways
- FreeA模型是一种新型的自适应语言驱动的人机交互(HOI)检测模型。
- 该模型通过文本图像模型的适应性生成潜在的HOI标签,无需手动标注。
- FreeA利用基于知识的遮蔽技术减少不可能的交互,并采用了匹配交互关联的方法提高特定动作的关联概率。
- 实验结果显示,FreeA在两大基准数据集上取得了最先进的性能表现,相较于其他模型有明显的精度提升。
- 该模型的源代码将公开。
点此查看论文截图