⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
GrowSplat: Constructing Temporal Digital Twins of Plants with Gaussian Splats
Authors:Simeon Adebola, Shuangyu Xie, Chung Min Kim, Justin Kerr, Bart M. van Marrewijk, Mieke van Vlaardingen, Tim van Daalen, Robert van Loo, Jose Luis Susa Rincon, Eugen Solowjow, Rick van de Zedde, Ken Goldberg
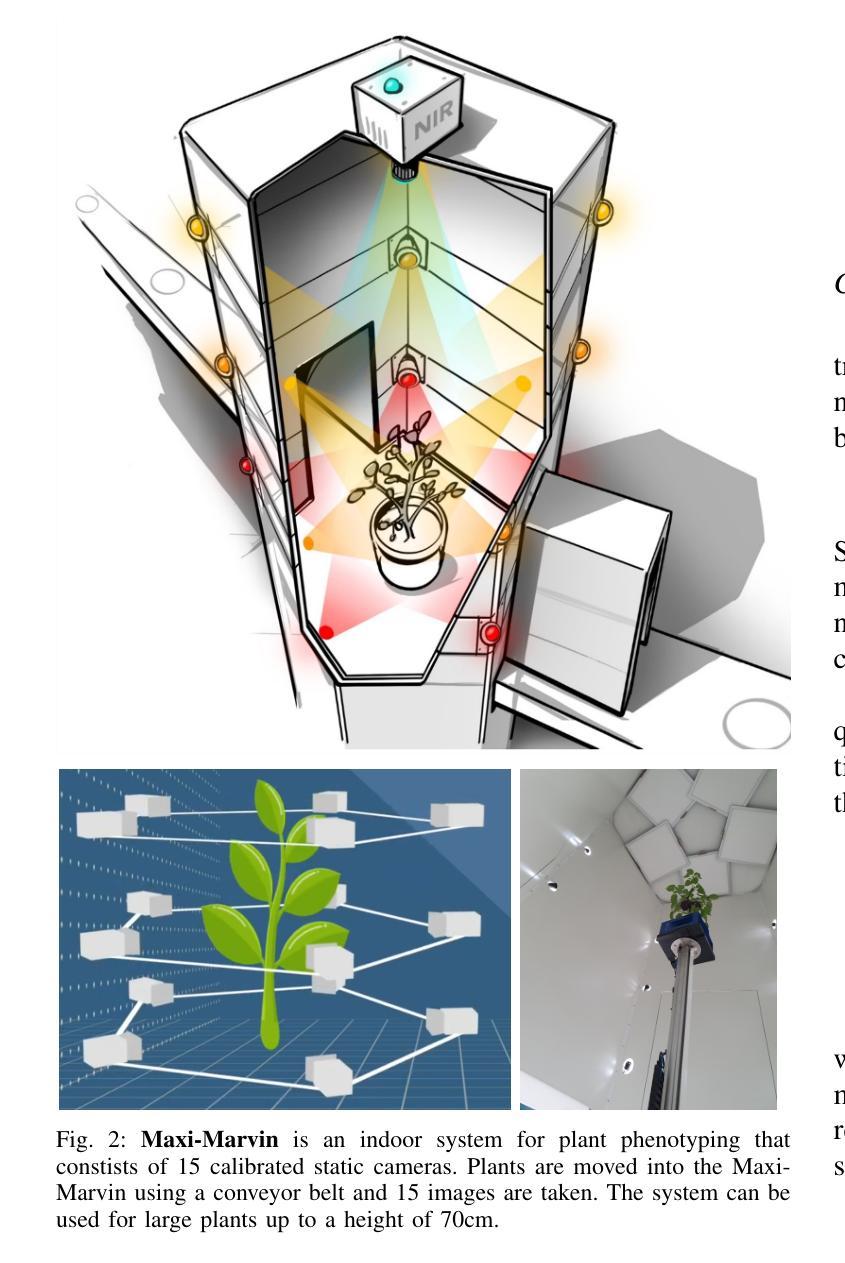
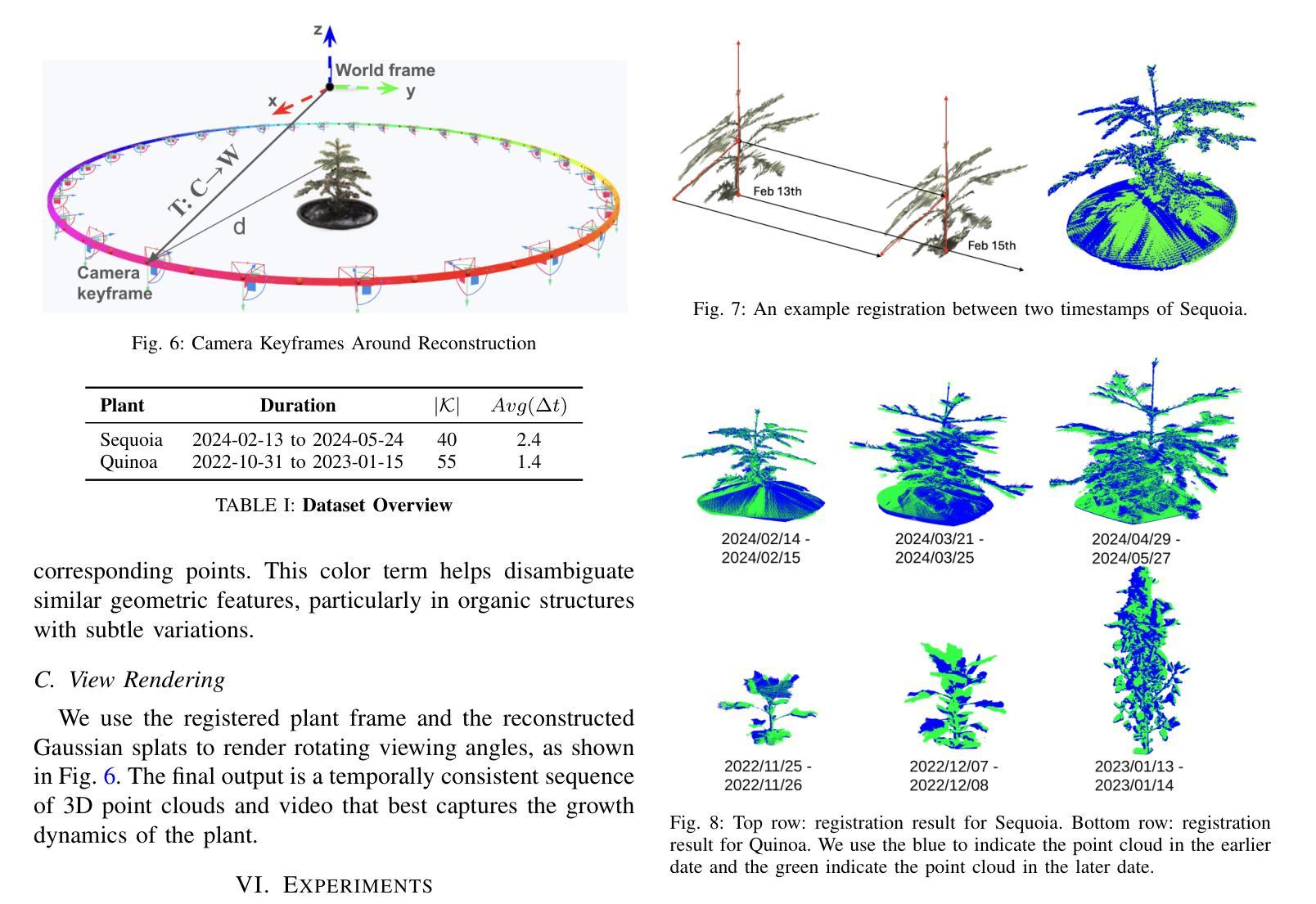
Accurate temporal reconstructions of plant growth are essential for plant phenotyping and breeding, yet remain challenging due to complex geometries, occlusions, and non-rigid deformations of plants. We present a novel framework for building temporal digital twins of plants by combining 3D Gaussian Splatting with a robust sample alignment pipeline. Our method begins by reconstructing Gaussian Splats from multi-view camera data, then leverages a two-stage registration approach: coarse alignment through feature-based matching and Fast Global Registration, followed by fine alignment with Iterative Closest Point. This pipeline yields a consistent 4D model of plant development in discrete time steps. We evaluate the approach on data from the Netherlands Plant Eco-phenotyping Center, demonstrating detailed temporal reconstructions of Sequoia and Quinoa species. Videos and Images can be seen at https://berkeleyautomation.github.io/GrowSplat/
对植物生长进行准确的时间重建对于植物表型和育种至关重要,但由于植物的复杂几何形状、遮挡和非刚性变形,这仍然是一个挑战。我们提出了一种结合3D高斯拼贴和稳健样本对齐流程,构建植物时间数字双胞胎的新框架。我们的方法首先通过多视角相机数据进行高斯拼贴重建,然后采用两阶段注册方法:基于特征的匹配和快速全局注册的粗略对齐,其次是使用迭代最近点法的精细对齐。该流程产生了离散时间步长的植物发育一致4D模型。我们在荷兰植物生态表现中心的数据上评估了该方法,展示了对杉树节和洋蓟物种的详细时间重建。视频和图像可见:[https://berkeleyautomation.github.io/GrowSplat/] 。
论文及项目相关链接
Summary
该文介绍了一种基于3D高斯散斑技术和稳健采样对齐流水线构建植物时序数字双胞胎的新方法。该方法通过多视角相机数据重建高斯散斑,并采用两阶段注册方法实现精细的植物生长模型重建。首先通过基于特征的匹配和快速全局注册进行粗略对齐,然后使用迭代最近点算法进行精细对齐。这种方法在荷兰植物生态表现中心的数据上得到了验证,展示了详细的时序重建能力。
Key Takeaways
- 该方法结合了3D高斯散斑技术和稳健采样对齐流水线,用于构建植物时序数字双胞胎。
- 通过多视角相机数据重建高斯散斑,为植物建模提供基础。
- 采用两阶段注册方法,包括粗略对齐和精细对齐,确保植物生长的准确性。
- 粗略对齐通过基于特征的匹配和快速全局注册实现。
- 精细对齐采用迭代最近点算法,提高模型精度。
- 该方法在荷兰植物生态表现中心的数据上进行了验证,并成功展示了时序重建能力。
点此查看论文截图




EA-3DGS: Efficient and Adaptive 3D Gaussians with Highly Enhanced Quality for outdoor scenes
Authors:Jianlin Guo, Haihong Xiao, Wenxiong Kang
Efficient scene representations are essential for many real-world applications, especially those involving spatial measurement. Although current NeRF-based methods have achieved impressive results in reconstructing building-scale scenes, they still suffer from slow training and inference speeds due to time-consuming stochastic sampling. Recently, 3D Gaussian Splatting (3DGS) has demonstrated excellent performance with its high-quality rendering and real-time speed, especially for objects and small-scale scenes. However, in outdoor scenes, its point-based explicit representation lacks an effective adjustment mechanism, and the millions of Gaussian points required often lead to memory constraints during training. To address these challenges, we propose EA-3DGS, a high-quality real-time rendering method designed for outdoor scenes. First, we introduce a mesh structure to regulate the initialization of Gaussian components by leveraging an adaptive tetrahedral mesh that partitions the grid and initializes Gaussian components on each face, effectively capturing geometric structures in low-texture regions. Second, we propose an efficient Gaussian pruning strategy that evaluates each 3D Gaussian’s contribution to the view and prunes accordingly. To retain geometry-critical Gaussian points, we also present a structure-aware densification strategy that densifies Gaussian points in low-curvature regions. Additionally, we employ vector quantization for parameter quantization of Gaussian components, significantly reducing disk space requirements with only a minimal impact on rendering quality. Extensive experiments on 13 scenes, including eight from four public datasets (MatrixCity-Aerial, Mill-19, Tanks & Temples, WHU) and five self-collected scenes acquired through UAV photogrammetry measurement from SCUT-CA and plateau regions, further demonstrate the superiority of our method.
高效场景表示对于许多现实世界应用至关重要,尤其是涉及空间测量的应用。尽管当前的基于NeRF的方法在建筑规模场景的重建中取得了令人印象深刻的结果,但由于耗时的随机采样,它们仍面临训练速度和推理速度慢的问题。最近,3D高斯喷涂(3DGS)以其高质量渲染和实时速度展示了出色的性能,特别是对于物体和小规模场景。然而,在户外场景中,其基于点的显式表示缺乏有效的调整机制,所需的高达数百万的高斯点往往在训练过程中造成内存约束。为了解决这些挑战,我们提出了EA-3DGS,一种为户外场景设计的高质量实时渲染方法。首先,我们引入一个网格结构,通过利用自适应四面体网格对网格进行分区并在每个面上初始化高斯分量来调节高斯分量的初始化,从而有效地捕捉低纹理区域的几何结构。其次,我们提出了一种高效的高斯修剪策略,该策略评估每个3D高斯对视图的贡献并相应地进行修剪。为了保留关键的几何高斯点,我们还提出了一种结构感知的密集化策略,在低曲率区域密集化高斯点。此外,我们对高斯分量的参数进行了向量量化,显著减少了磁盘空间要求,并且对渲染质量的影响微乎其微。在包括从四个公开数据集(MatrixCity-Aerial、Mill-19、Tanks&Temples和WHU)获得的八个场景以及从SCUT-CA和高原地区通过无人机摄影测量收集的五个自我采集的场景在内的共13个场景的大量实验进一步证明了我们的方法的优越性。
论文及项目相关链接
摘要
高效场景表示在现实世界应用中具有重要意义,尤其是在涉及空间测量的应用中。虽然基于NeRF的方法在建筑规模场景的重建中取得了令人印象深刻的结果,但由于耗时较长的随机采样,其训练和推理速度仍然较慢。最近,3D高斯涂鸦(3DGS)以其高质量渲染和实时速度,在物体和小规模场景的表示上表现出卓越性能。然而,在户外场景中,其基于点的显式表示缺乏有效的调整机制,所需的大量高斯点常常导致训练时的内存限制。针对这些挑战,我们提出了EA-3DGS,一种针对户外场景的高质量实时渲染方法。首先,我们引入网格结构来管理高斯组件的初始化,利用自适应四面体网格对网格进行分区并在每个面上初始化高斯组件,有效地捕捉低纹理区域的几何结构。其次,我们提出了一种有效的高斯修剪策略,评估每个三维高斯对视图的影响并进行修剪。为了保留关键的几何高斯点,我们还提出了一种结构感知的致密化策略,在低曲率区域密集化高斯点。此外,我们采用矢量量化对高斯组件的参数进行量化,显著减少了磁盘空间需求,对渲染质量的影响微乎其微。在包括四个公共数据集(MatrixCity-Aerial、Mill-19、Tanks&Temples、WHU)的八个场景以及通过无人机摄影测量收集的五个场景的大规模实验进一步证明了我们的方法的优越性。
Key Takeaways
- 3DGS在户外场景的高质量实时渲染中展现出良好性能。
- 引入自适应四面体网格结构以更有效地初始化和管理高斯组件。
- 提出高效的高斯修剪策略和结构感知致密化策略,以提高渲染效率和准确性。
- 采用矢量量化技术,显著减少高斯组件参数所需的磁盘空间。
- 在多个公共数据集和自我收集的无人机摄影测量场景中进行了广泛实验验证。
- 方法在户外场景的实时高质量渲染上表现出优越性。
点此查看论文截图


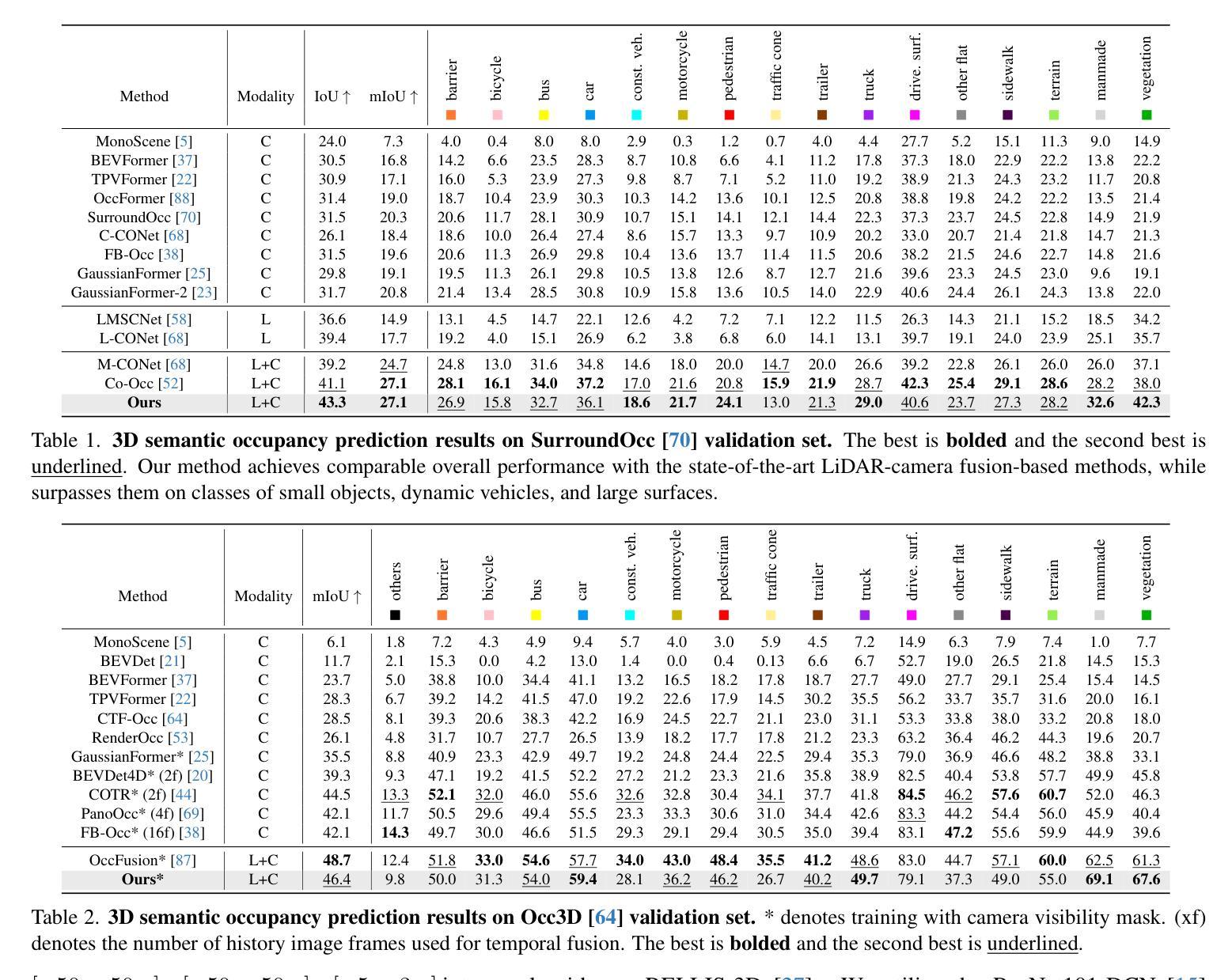
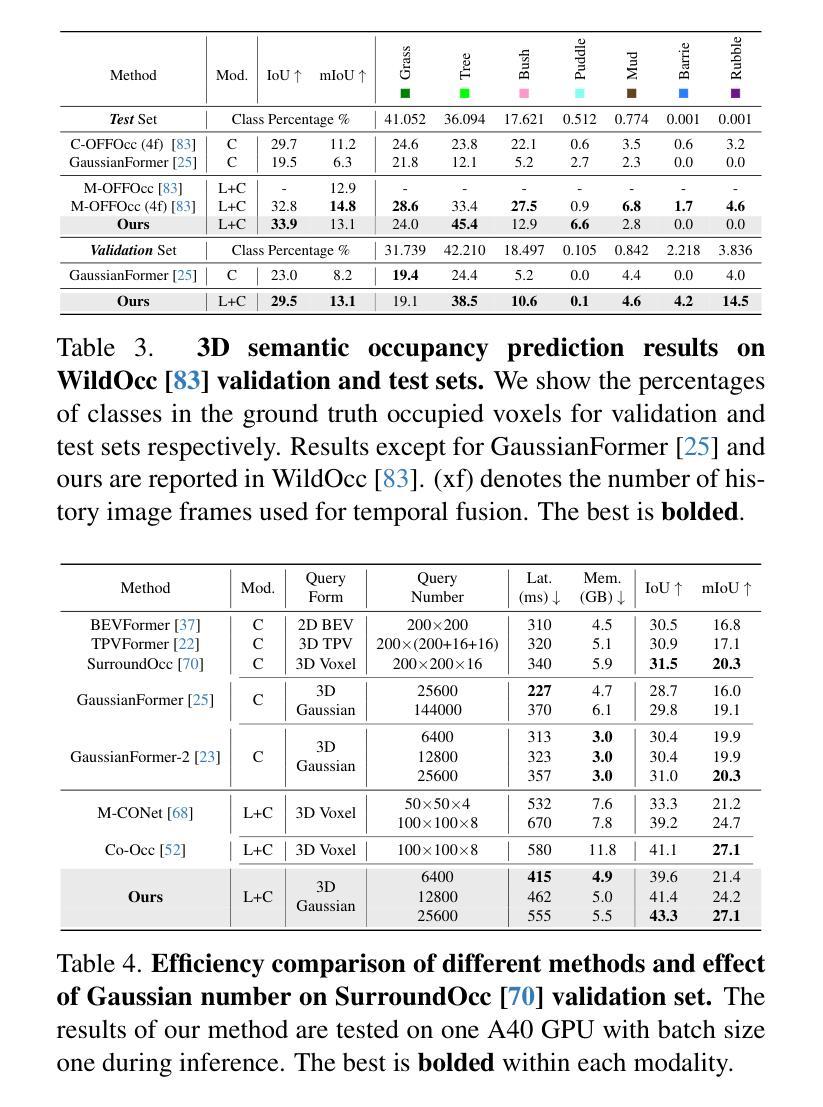
GaussianFormer3D: Multi-Modal Gaussian-based Semantic Occupancy Prediction with 3D Deformable Attention
Authors:Lingjun Zhao, Sizhe Wei, James Hays, Lu Gan
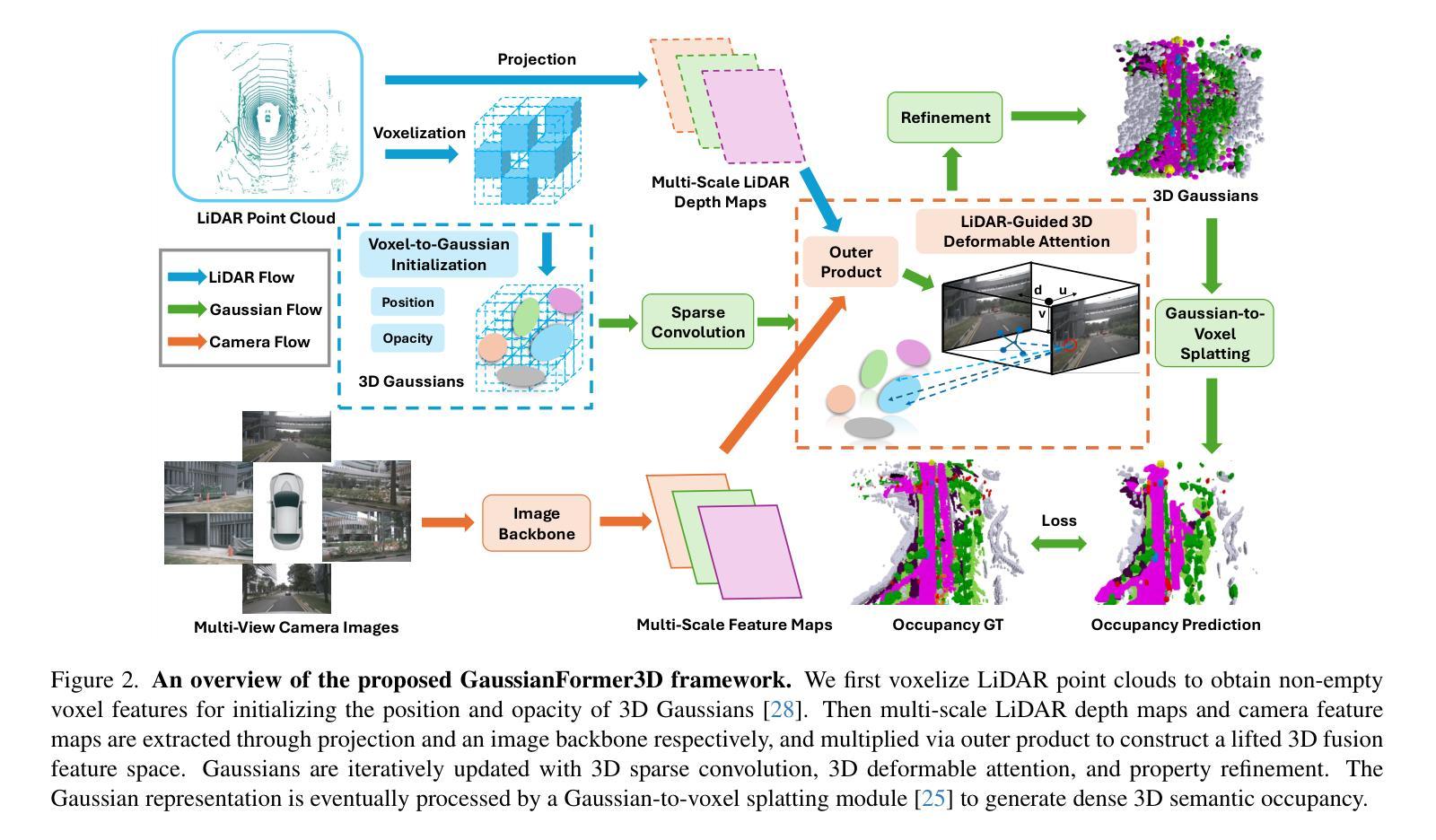
3D semantic occupancy prediction is critical for achieving safe and reliable autonomous driving. Compared to camera-only perception systems, multi-modal pipelines, especially LiDAR-camera fusion methods, can produce more accurate and detailed predictions. Although most existing works utilize a dense grid-based representation, in which the entire 3D space is uniformly divided into discrete voxels, the emergence of 3D Gaussians provides a compact and continuous object-centric representation. In this work, we propose a multi-modal Gaussian-based semantic occupancy prediction framework utilizing 3D deformable attention, named as GaussianFormer3D. We introduce a voxel-to-Gaussian initialization strategy to provide 3D Gaussians with geometry priors from LiDAR data, and design a LiDAR-guided 3D deformable attention mechanism for refining 3D Gaussians with LiDAR-camera fusion features in a lifted 3D space. We conducted extensive experiments on both on-road and off-road datasets, demonstrating that our GaussianFormer3D achieves high prediction accuracy that is comparable to state-of-the-art multi-modal fusion-based methods with reduced memory consumption and improved efficiency.
三维语义占有率预测对实现安全可靠的自动驾驶至关重要。与仅使用相机的感知系统相比,多模式管道,尤其是激光雷达-相机融合方法,可以产生更准确和详细的预测。尽管大多数现有工作使用基于密集网格的表示形式,即将整个三维空间均匀划分为离散体素,但三维高斯的出现提供了一种紧凑且连续的对象中心表示形式。在这项工作中,我们提出了一种基于多模式高斯语义占有率预测框架,利用三维可变形注意力,名为GaussianFormer3D。我们引入了一种从体素到高斯初始化策略,为三维高斯提供来自激光雷达数据的几何先验知识,并设计了一种激光雷达引导的三维可变形注意力机制,以在提升的三维空间中利用激光雷达-相机融合特征细化三维高斯。我们在公路和非公路数据集上进行了大量实验,结果表明,我们的GaussianFormer3D预测精度高,与最新多模式融合方法相当,同时降低了内存消耗并提高了效率。
论文及项目相关链接
Summary
本文介绍了自主驾驶中的三维语义占用预测技术。相比于单一相机感知系统,多模态感知系统特别是激光雷达相机融合方法能提供更为精确和详细的预测。现有方法多采用密集网格表示法,而本文提出一种基于高斯的多模态语义占用预测框架,称为GaussianFormer3D。它利用激光雷达数据的几何先验为三维高斯模型提供初始值,并设计了一种激光雷达引导的3D可变形注意力机制,在提升的三维空间中优化激光雷达相机融合特征的三维高斯模型。实验证明,GaussianFormer3D在道路上和道路外的数据集上都实现了高预测精度,与最新的多模态融合方法相比,内存消耗减少,效率提高。
Key Takeaways
- 自主驾驶的三维语义占用预测对安全可靠性至关重要。
- 多模态感知系统相比单一相机感知系统能提供更准确的预测。
- 现有方法主要使用密集网格表示法,但这种方法有局限性。
- GaussianFormer3D是一个基于高斯的多模态语义占用预测框架。
- 该框架利用激光雷达数据的几何先验进行三维高斯模型的初始化。
- 激光雷达引导的3D可变形注意力机制用于优化三维高斯模型。
- GaussianFormer3D在多种数据集上实现高预测精度,且相比其他方法更加高效。
点此查看论文截图

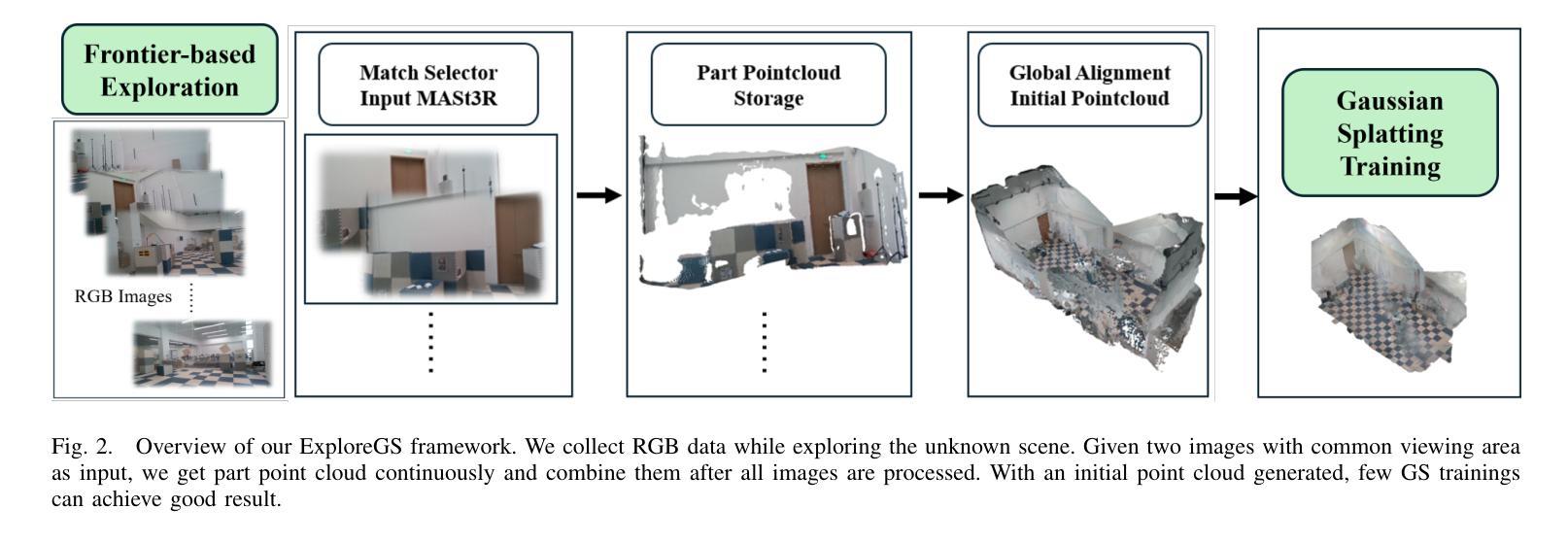
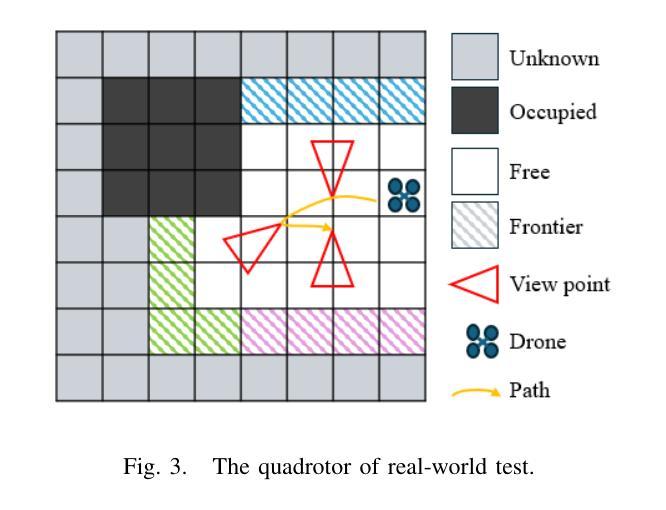
ExploreGS: a vision-based low overhead framework for 3D scene reconstruction
Authors:Yunji Feng, Chengpu Yu, Fengrui Ran, Zhi Yang, Yinni Liu
This paper proposes a low-overhead, vision-based 3D scene reconstruction framework for drones, named ExploreGS. By using RGB images, ExploreGS replaces traditional lidar-based point cloud acquisition process with a vision model, achieving a high-quality reconstruction at a lower cost. The framework integrates scene exploration and model reconstruction, and leverags a Bag-of-Words(BoW) model to enable real-time processing capabilities, therefore, the 3D Gaussian Splatting (3DGS) training can be executed on-board. Comprehensive experiments in both simulation and real-world environments demonstrate the efficiency and applicability of the ExploreGS framework on resource-constrained devices, while maintaining reconstruction quality comparable to state-of-the-art methods.
本文提出了一种用于无人机的低开销、基于视觉的3D场景重建框架,名为ExploreGS。通过利用RGB图像,ExploreGS使用视觉模型替代了传统的基于激光雷达的点云采集过程,以较低的成本实现了高质量的重建。该框架整合了场景探索和模型重建,并利用Bag-of-Words(BoW)模型实现实时处理能力,因此可以在机载设备上执行3D高斯贴图(3DGS)训练。在模拟和真实环境中的综合实验表明,ExploreGS框架在资源受限设备上的效率和适用性,同时保持了与最新技术相当的重构质量。
论文及项目相关链接
Summary
该论文提出了一种基于视觉的无人机三维场景重建框架ExploreGS,采用RGB图像替代传统的激光雷达点云采集过程,实现低成本高质量重建。该框架融合场景探索与模型重建,并采用Bag-of-Words模型实现实时处理能力,可在机上执行3D高斯喷涂(3DGS)训练。在模拟和真实环境中的综合实验表明,该框架在资源受限设备上具有高效性和适用性,同时保持与最新技术相当的重构质量。
Key Takeaways
- ExploreGS是一个基于视觉的无人机三维场景重建框架。
- 使用RGB图像替代激光雷达点云采集,降低成本。
- 融合场景探索与模型重建。
- 采用Bag-of-Words模型实现实时处理能力。
- 可在机上执行3D高斯喷涂(3DGS)训练。
- 在模拟和真实环境中的综合实验验证了其高效性和适用性。
点此查看论文截图

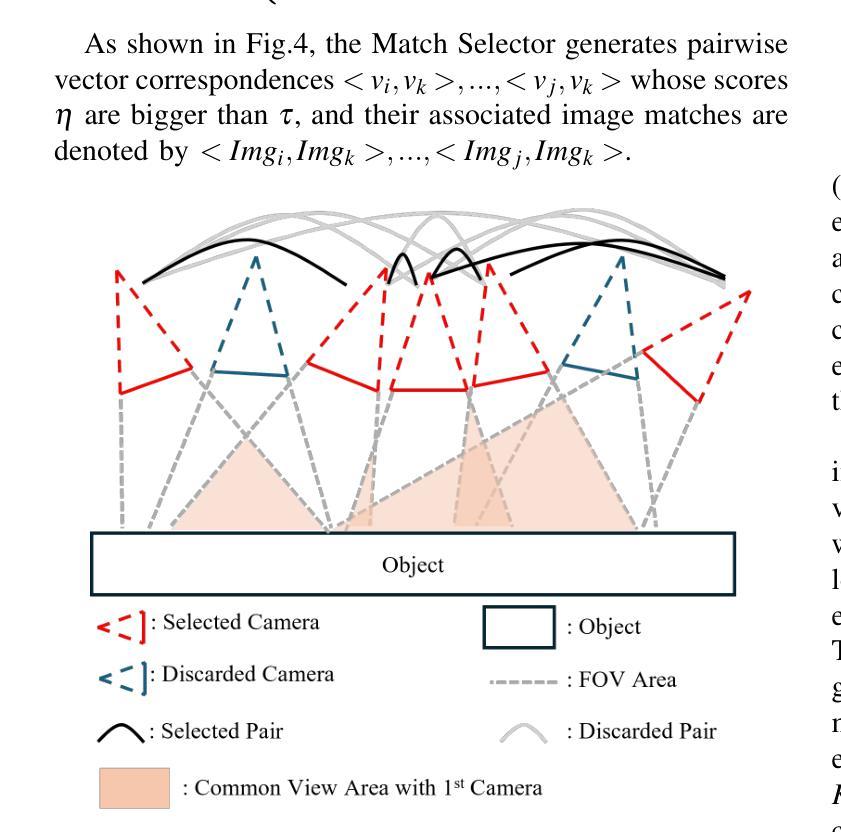
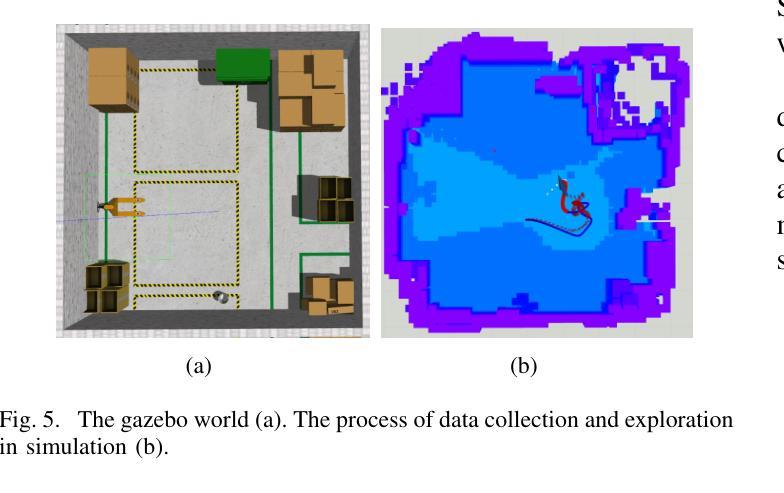



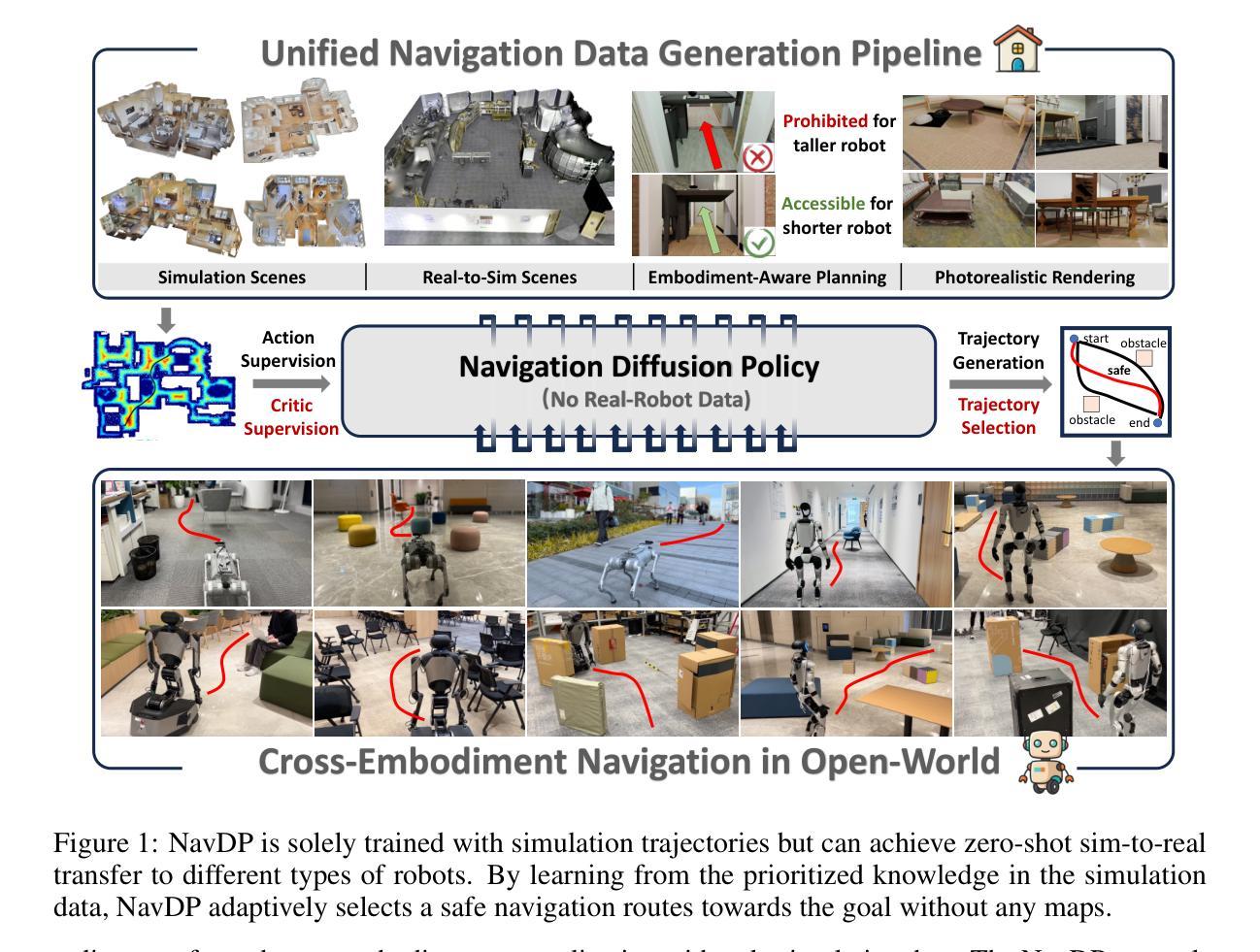
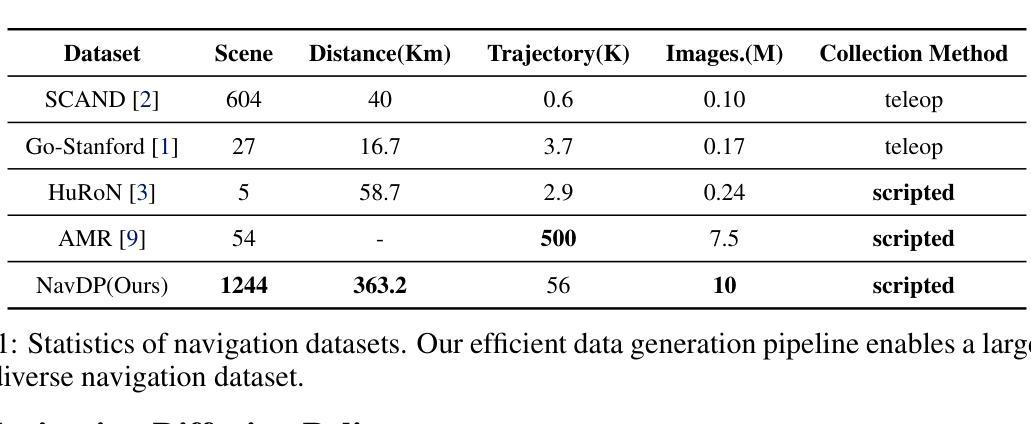
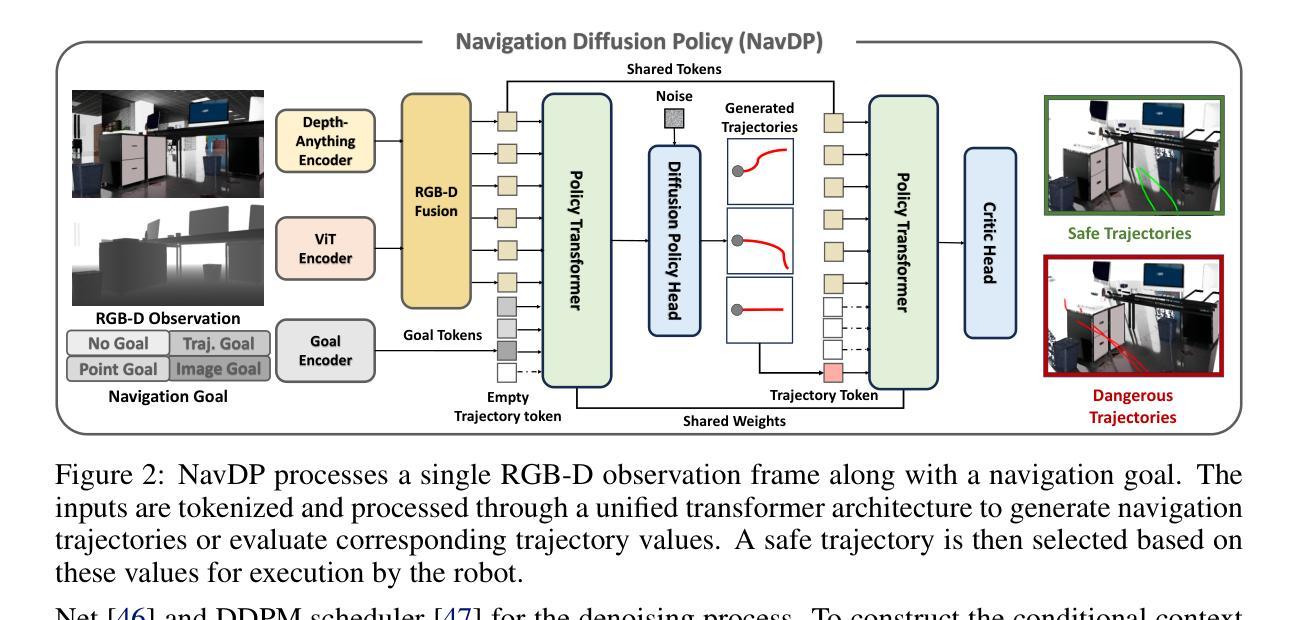
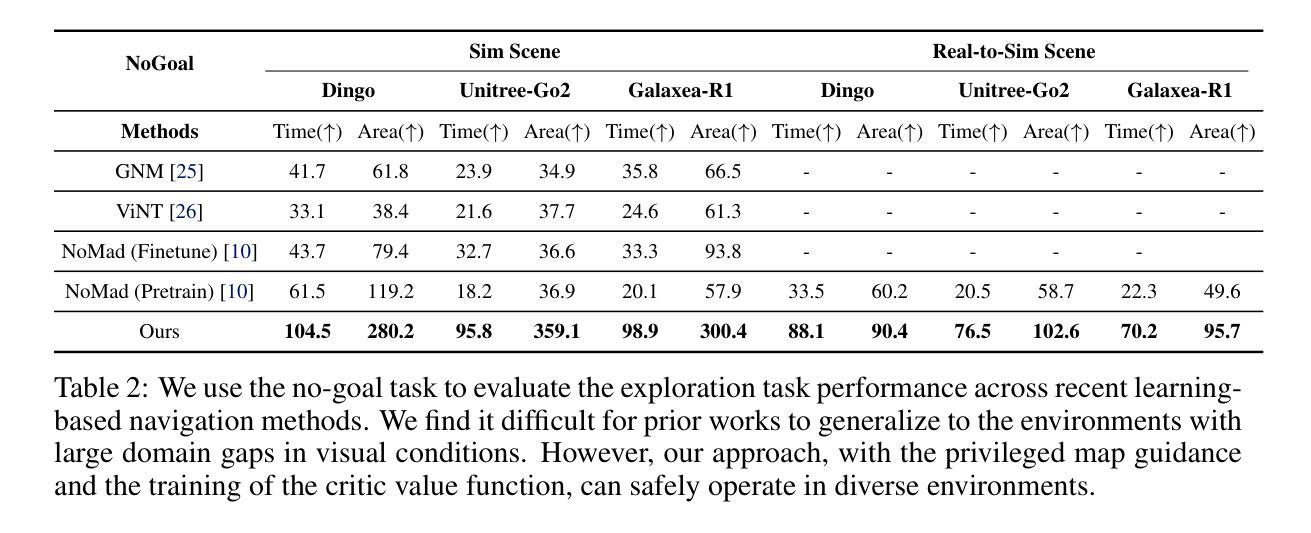
NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance
Authors:Wenzhe Cai, Jiaqi Peng, Yuqiang Yang, Yujian Zhang, Meng Wei, Hanqing Wang, Yilun Chen, Tai Wang, Jiangmiao Pang
Learning navigation in dynamic open-world environments is an important yet challenging skill for robots. Most previous methods rely on precise localization and mapping or learn from expensive real-world demonstrations. In this paper, we propose the Navigation Diffusion Policy (NavDP), an end-to-end framework trained solely in simulation and can zero-shot transfer to different embodiments in diverse real-world environments. The key ingredient of NavDP’s network is the combination of diffusion-based trajectory generation and a critic function for trajectory selection, which are conditioned on only local observation tokens encoded from a shared policy transformer. Given the privileged information of the global environment in simulation, we scale up the demonstrations of good quality to train the diffusion policy and formulate the critic value function targets with contrastive negative samples. Our demonstration generation approach achieves about 2,500 trajectories/GPU per day, 20$\times$ more efficient than real-world data collection, and results in a large-scale navigation dataset with 363.2km trajectories across 1244 scenes. Trained with this simulation dataset, NavDP achieves state-of-the-art performance and consistently outstanding generalization capability on quadruped, wheeled, and humanoid robots in diverse indoor and outdoor environments. In addition, we present a preliminary attempt at using Gaussian Splatting to make in-domain real-to-sim fine-tuning to further bridge the sim-to-real gap. Experiments show that adding such real-to-sim data can improve the success rate by 30% without hurting its generalization capability.
机器人学习动态开放环境中的导航是一项重要且具有挑战性的技能。大多数之前的方法依赖于精确的定位和地图绘制,或者从昂贵的真实世界演示中学习。在本文中,我们提出了导航扩散策略(NavDP),这是一种仅在模拟中训练端到端的框架,可以零射击转移到不同实体的各种真实世界环境中。NavDP网络的关键成分是结合基于扩散的轨迹生成和用于轨迹选择的评论家函数,它们仅基于来自共享政策变压器的局部观察符号。利用模拟中全局环境的特权信息,我们扩大了良好质量的演示来训练扩散策略,并用对比负样本制定评论家值函数的目标。我们的演示生成方法每天每GPU实现约2500条轨迹,比真实世界的数据收集效率高出20倍,并生成了一个大规模导航数据集,其中包括1244个场景的363.2公里轨迹。使用这个模拟数据集进行训练,NavDP在多种室内和室外环境的四足、轮式和人形机器人上达到了最先进的性能,并表现出始终出色的泛化能力。此外,我们初步尝试使用高斯涂布技术进行领域内实到模拟微调,以进一步缩小模拟到真实的差距。实验表明,添加这样的实到模拟数据可以在不影响其泛化能力的情况下将成功率提高36%。
论文及项目相关链接
PDF Project Page: https://wzcai99.github.io/navigation-diffusion-policy.github.io/
摘要
该论文提出了一种名为NavDP的端到端框架,用于在动态开放世界中学习机器人的导航技能。NavDP仅通过模拟训练,并能在不同实体中零射击转移到多种真实世界环境。NavDP网络的关键成分是结合基于扩散的轨迹生成和用于轨迹选择的评价函数,它们仅受来自共享政策转换器的局部观察符号的条件影响。利用模拟中的全局环境特权信息,我们扩大了良好质量的演示来训练扩散政策,并用对比负样本制定评价价值函数目标。我们的演示生成方法每天每GPU实现约2500条轨迹,比真实世界的数据收集效率高出20倍,并产生了一个大规模导航数据集,其中包括在1244个场景中的363.2公里轨迹。使用该模拟数据集进行训练,NavDP在多种室内和室外环境的四足、轮式和人形机器人上实现了最新性能,并始终表现出卓越的总括能力。此外,我们初步尝试使用高斯喷绘进行领域内实到模拟微调,以进一步缩小模拟到现实的差距。实验表明,添加这种实到模拟数据可以在不损害其概括能力的情况下将成功率提高30%。
要点
- 机器人学习在动态开放世界中的导航是一项重要而具有挑战性的技能。
- NavDP是一个端到端的框架,能够在不同的实体中零射击转移到多种真实世界环境。
- NavDP结合扩散轨迹生成和评价函数进行轨迹选择,仅依赖于局部观察符号。
- 利用模拟中的全局环境信息来训练扩散政策和制定评价价值函数目标。
- 演示生成方法高效生成大规模导航数据集,包含多种场景的轨迹。
- NavDP在各种机器人环境中表现出卓越的性能和概括能力。
点此查看论文截图

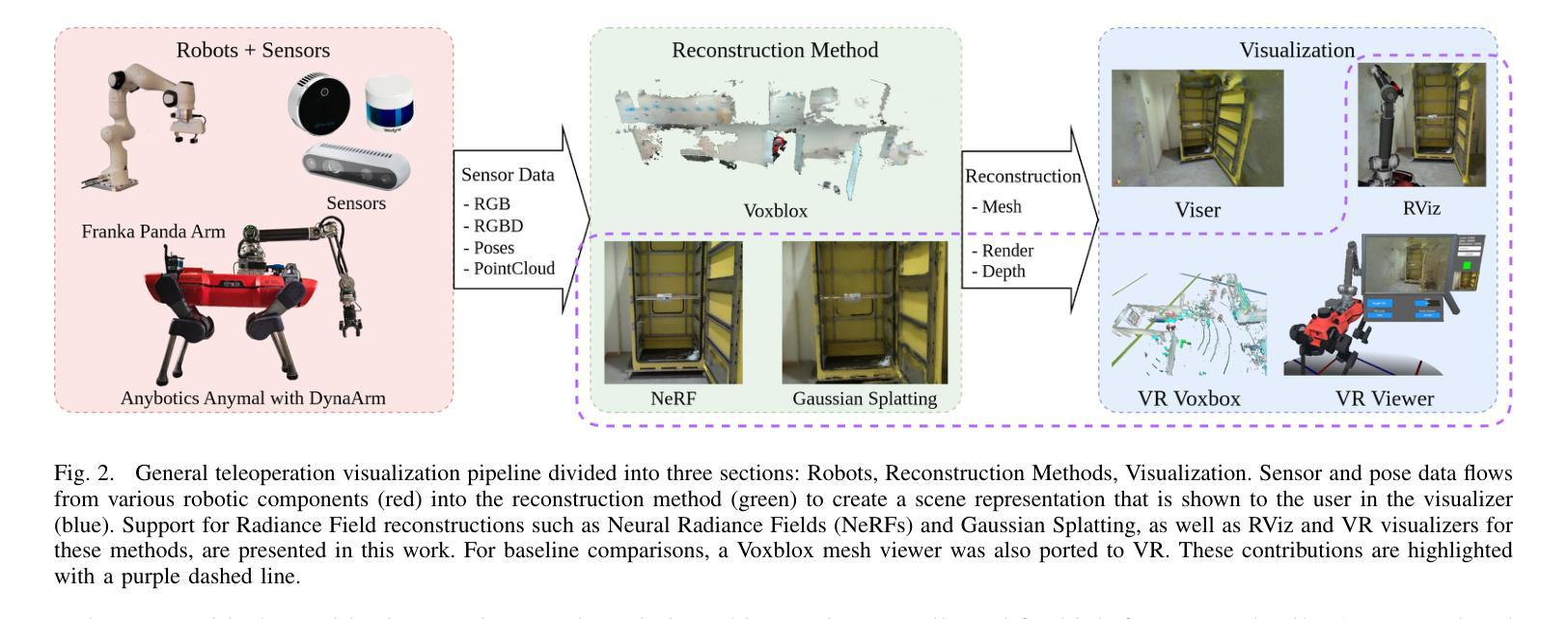
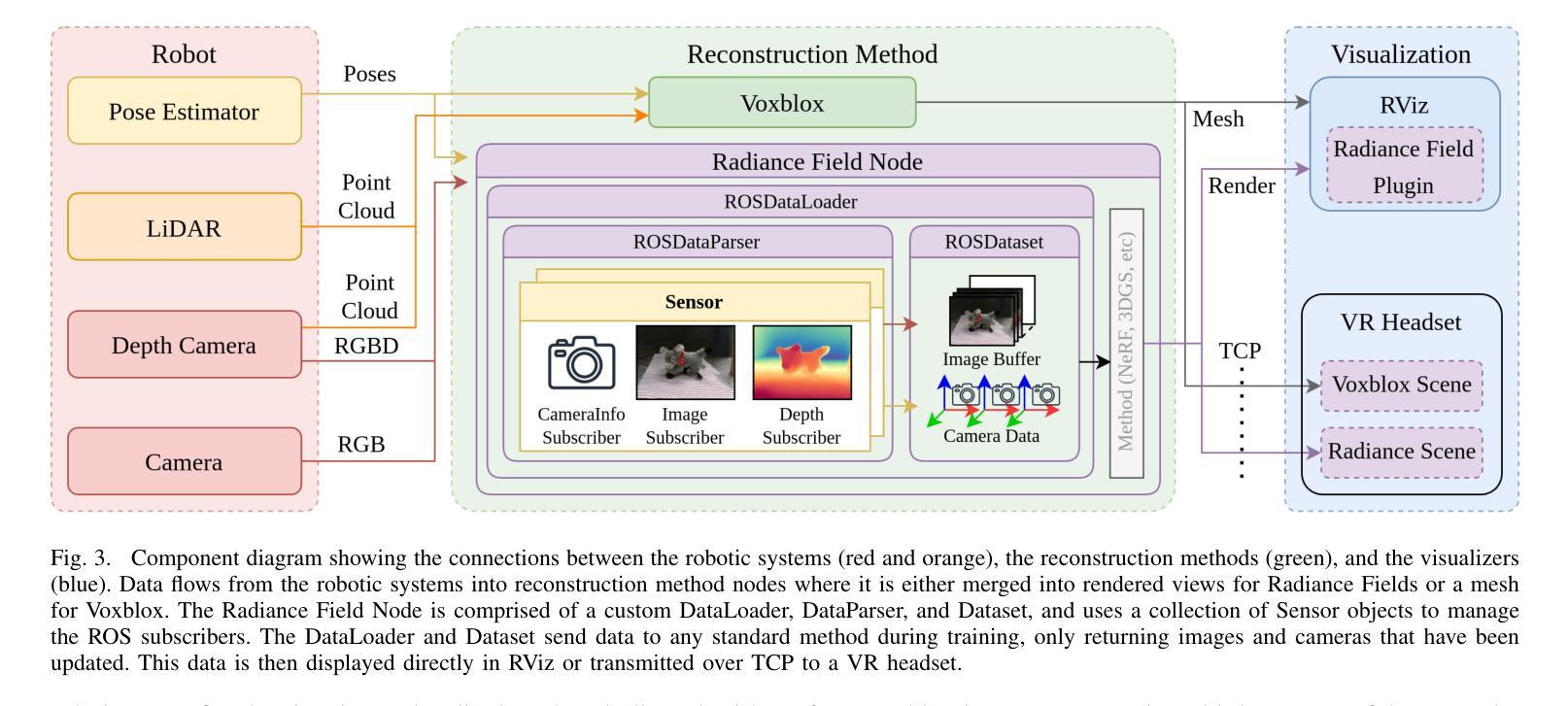
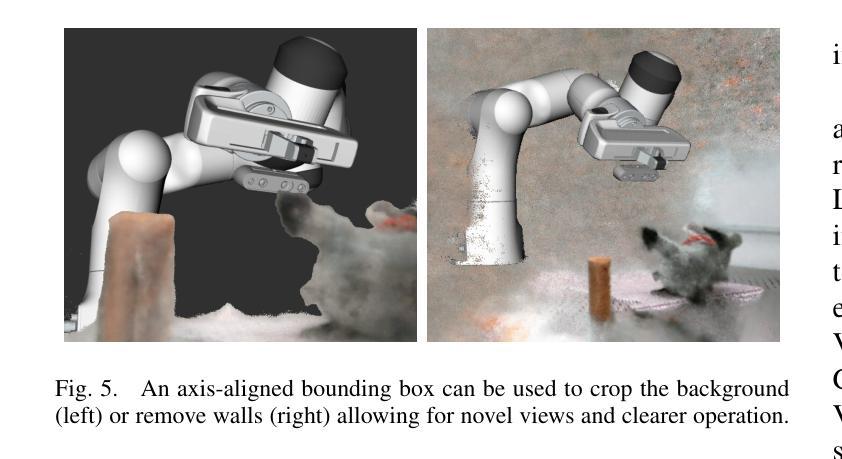
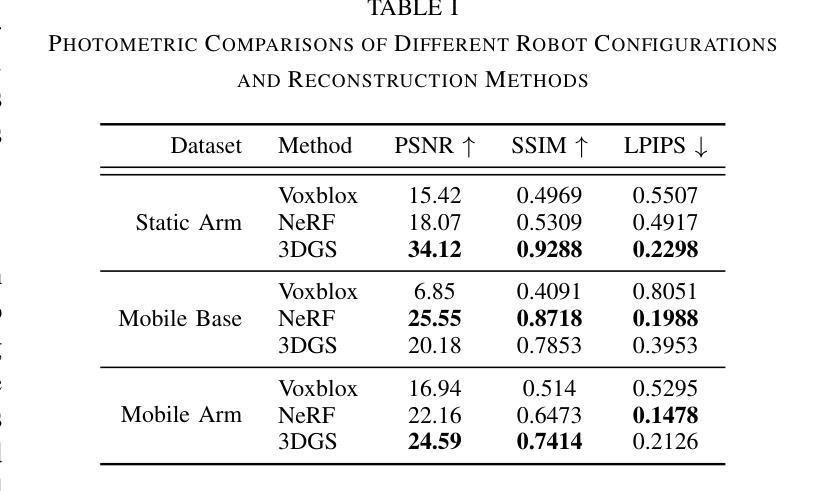
Radiance Fields for Robotic Teleoperation
Authors:Maximum Wilder-Smith, Vaishakh Patil, Marco Hutter
Radiance field methods such as Neural Radiance Fields (NeRFs) or 3D Gaussian Splatting (3DGS), have revolutionized graphics and novel view synthesis. Their ability to synthesize new viewpoints with photo-realistic quality, as well as capture complex volumetric and specular scenes, makes them an ideal visualization for robotic teleoperation setups. Direct camera teleoperation provides high-fidelity operation at the cost of maneuverability, while reconstruction-based approaches offer controllable scenes with lower fidelity. With this in mind, we propose replacing the traditional reconstruction-visualization components of the robotic teleoperation pipeline with online Radiance Fields, offering highly maneuverable scenes with photorealistic quality. As such, there are three main contributions to state of the art: (1) online training of Radiance Fields using live data from multiple cameras, (2) support for a variety of radiance methods including NeRF and 3DGS, (3) visualization suite for these methods including a virtual reality scene. To enable seamless integration with existing setups, these components were tested with multiple robots in multiple configurations and were displayed using traditional tools as well as the VR headset. The results across methods and robots were compared quantitatively to a baseline of mesh reconstruction, and a user study was conducted to compare the different visualization methods. For videos and code, check out https://rffr.leggedrobotics.com/works/teleoperation/.
神经辐射场(NeRFs)或三维高斯拼贴(3DGS)等辐射场方法已经彻底改变了图形和新型视图合成。它们具有以照相写实质量合成新视点以及捕捉复杂体积和镜面场景的能力,使其成为机器人遥操作设置的理想可视化工具。直接相机遥操作提供了高保真操作,但机动性较差,而基于重建的方法提供了可控场景,但保真度较低。鉴于此,我们提出用在线辐射场替换机器人遥操作管道的传统重建-可视化组件,提供具有照相写实质量的高度机动场景。因此,先进技术的三个主要贡献是:(1)使用来自多个相机的实时数据进行在线训练辐射场,(2)支持包括NeRF和3DGS在内的多种辐射方法,(3)这些方法的可视化套件,包括虚拟现实场景。为了实现与现有设置的无缝集成,这些组件已在多种配置的多个机器人上进行了测试,并使用传统工具和VR头盔进行了展示。各种方法和机器人之间的结果通过与网格重建的基准进行定量比较,并且进行了一项用户研究来比较不同的可视化方法。关于视频和代码,请访问https://rffr.leggedrobotics.com/works/teleoperation/。
论文及项目相关链接
PDF 8 pages, 10 figures, Accepted to IROS 2024
Summary
该文本描述了使用实时神经网络渲染(NeRFs)和三维高斯混合(3DGS)技术的光场方法革命性地改变了图形学和场景合成视图的现状。将此类技术与机器人遥操作结合,可在高机动场景中实现具有逼真画质的新型视图合成。该文提出了将机器人遥操作管道的传统重建可视化组件替换为在线光场技术的主要观点,并介绍了在线训练光场技术使用多摄像头采集的实时数据的方法支持包括NeRF和3DGS在内的多种光场方法可视化套件的技术在虚拟现实场景中的应用等三项主要贡献。所有组件均在多种配置的多个机器人上进行了测试,并与网格重建进行了定量比较。同时,通过用户研究对比了不同的可视化方法。其研究结果将对现有机器人遥操作系统的发展产生重大影响。详情参见:[https://rffr.leggedrobotics.com/works/teleoperation/]进行了解。简言之,光场技术与机器人遥操作的结合有望改变机器人技术的未来发展方向。这项研究极具前景和潜力。
Key Takeaways
以下是关于该文本的关键见解:
- 光场方法(如神经网络渲染(NeRFs)和三维高斯混合(3DGS))已对图形学和场景合成视图产生重大影响。
- 光场技术结合机器人遥操作可实现高机动场景中的逼真画质的新型视图合成。这种结合了在线训练光场技术的新方法为机器人遥操作提供了新的可能性。
- 该研究提出了用在线光场技术替换传统机器人遥操作的可视化组件的想法,以及一系列基于光场的方法包括可视化套件在内三项重要贡献。该领域的技术发展对于未来机器人遥操作系统的发展具有重要影响。
点此查看论文截图