⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
Let the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents
Authors:Ratnadira Widyasari, Martin Weyssow, Ivana Clairine Irsan, Han Wei Ang, Frank Liauw, Eng Lieh Ouh, Lwin Khin Shar, Hong Jin Kang, David Lo
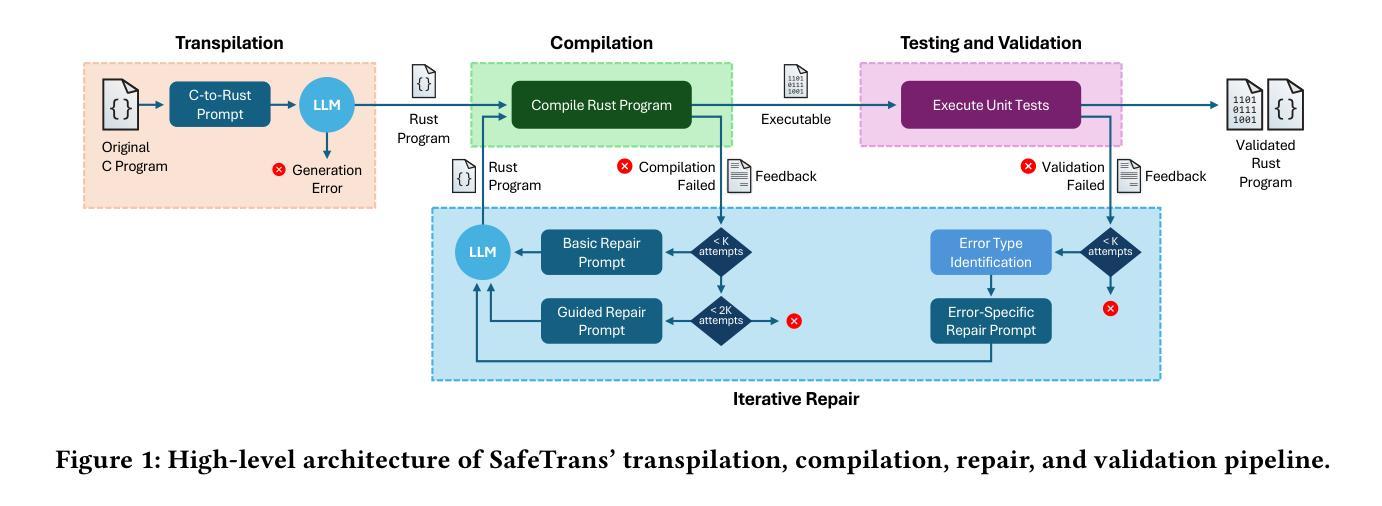
Detecting vulnerabilities in source code remains a critical yet challenging task, especially when benign and vulnerable functions share significant similarities. In this work, we introduce VulTrial, a courtroom-inspired multi-agent framework designed to enhance automated vulnerability detection. It employs four role-specific agents, which are security researcher, code author, moderator, and review board. Through extensive experiments using GPT-3.5 and GPT-4o we demonstrate that Vultrial outperforms single-agent and multi-agent baselines. Using GPT-4o, VulTrial improves the performance by 102.39% and 84.17% over its respective baseline. Additionally, we show that role-specific instruction tuning in multi-agent with small data (50 pair samples) improves the performance of VulTrial further by 139.89% and 118.30%. Furthermore, we analyze the impact of increasing the number of agent interactions on VulTrial’s overall performance. While multi-agent setups inherently incur higher costs due to increased token usage, our findings reveal that applying VulTrial to a cost-effective model like GPT-3.5 can improve its performance by 69.89% compared to GPT-4o in a single-agent setting, at a lower overall cost.
检测源代码中的漏洞仍然是一项至关重要且充满挑战的任务,尤其是当良性函数和易受攻击的共享功能之间存在很大的相似性时。在这项工作中,我们引入了VulTrial,这是一个受法庭启发的多智能体框架,旨在提高自动化漏洞检测能力。它采用了四个角色特定的智能体,分别是安全研究人员、代码作者、管理员和评审委员会。通过利用GPT-3.5和GPT-4o的广泛实验,我们证明了VulTrial在单智能体和多智能体基线方面的优越性。使用GPT-4o,VulTrial的性能分别提高了其基准线的102.39%和84.17%。此外,我们还展示了在多智能体系统中对特定角色的指令进行微调(使用少量数据,如50个配对样本)可以进一步提高VulTrial的性能,分别提高了其基准线的139.89%和提高了性能的基础值的百分之百八十一点三七(%)。进一步地,我们分析了增加智能体交互次数对VulTrial总体性能的影响。虽然多智能体设置由于令牌使用量增加而固有地导致更高的成本,但我们的研究结果表明,将VulTrial应用于像GPT-3.5这样的成本效益型模型可以在单智能体环境中以较低的总成本提高其性能百分之六十九点八十九。
论文及项目相关链接
Summary
本文介绍了一种名为VulTrial的多智能体框架,用于增强自动化漏洞检测。该框架采用四种特定角色智能体,包括安全研究员、代码作者、主持人和审查委员会成员。通过使用GPT-3.5和GPT-4模型进行实验验证,VulTrial在单智能体和多智能体基线的基础上表现出卓越的性能。实验结果显示,VulTrial使用GPT-4模型时的性能比基线提高了高达百分之百。此外,通过特定的角色指令微调可提高VulTrial的性能。尽管多智能体设置导致更高的成本,但使用成本效益高的模型如GPT-3.5能够提高性能,并且性能的提升显著高于成本的增长。总的来说,VulTrial有望改进现有自动化漏洞检测工具的能力。
Key Takeaways
- VulTrial是一个多智能体框架,旨在增强自动化漏洞检测能力。
- 该框架包括四种角色智能体:安全研究员、代码作者、主持人和审查委员会成员。这些智能体共同协作以提高漏洞检测的准确性。
- 通过使用GPT-3.5和GPT-4模型进行的实验表明,VulTrial在单智能体和多智能体基线方面表现出卓越的性能。特别是在使用GPT-4模型时,其性能显著提高。
- 通过角色特定的指令微调可以提高VulTrial的性能。这种微调允许智能体更好地适应其特定角色并更有效地协作。
点此查看论文截图





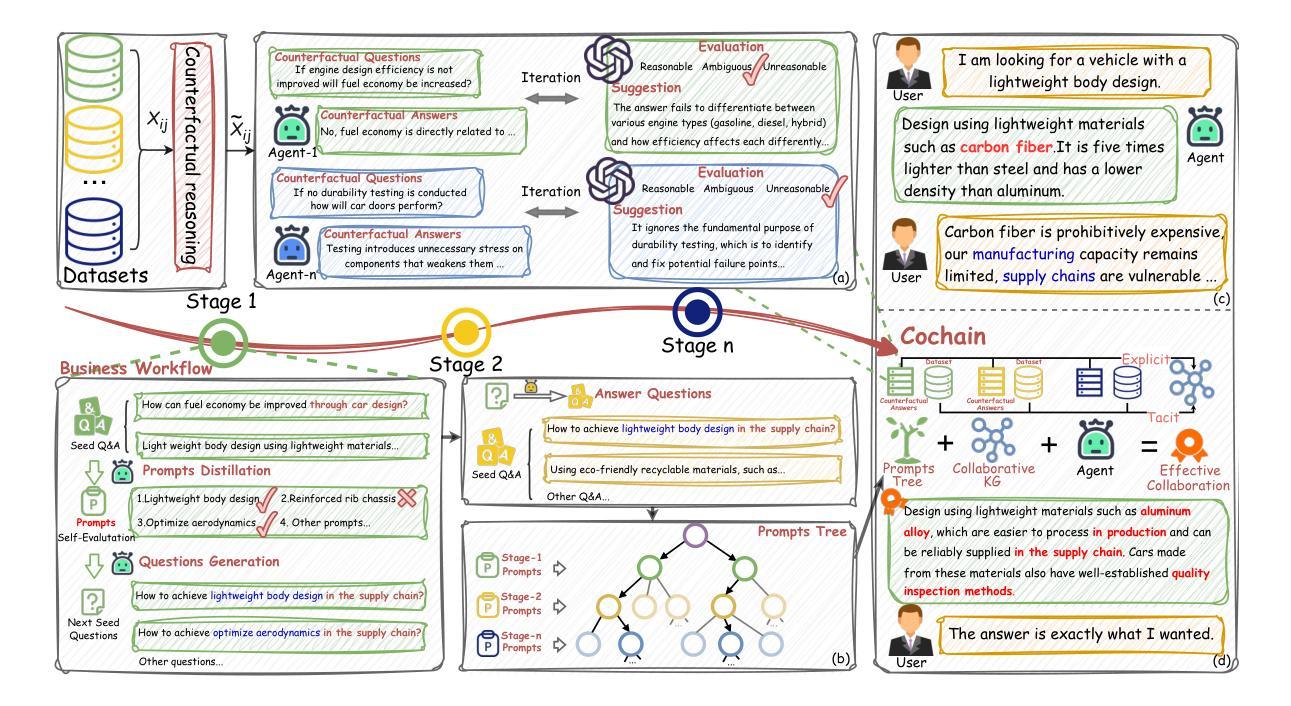
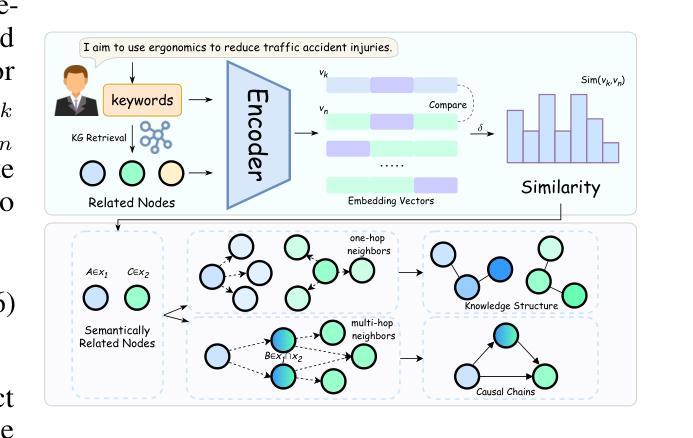
Connecting the Dots: A Chain-of-Collaboration Prompting Framework for LLM Agents
Authors:Jiaxing Zhao, Hongbin Xie, Yuzhen Lei, Xuan Song, Zhuoran Shi, Lianxin Li, Shuangxue Liu, Haoran Zhang
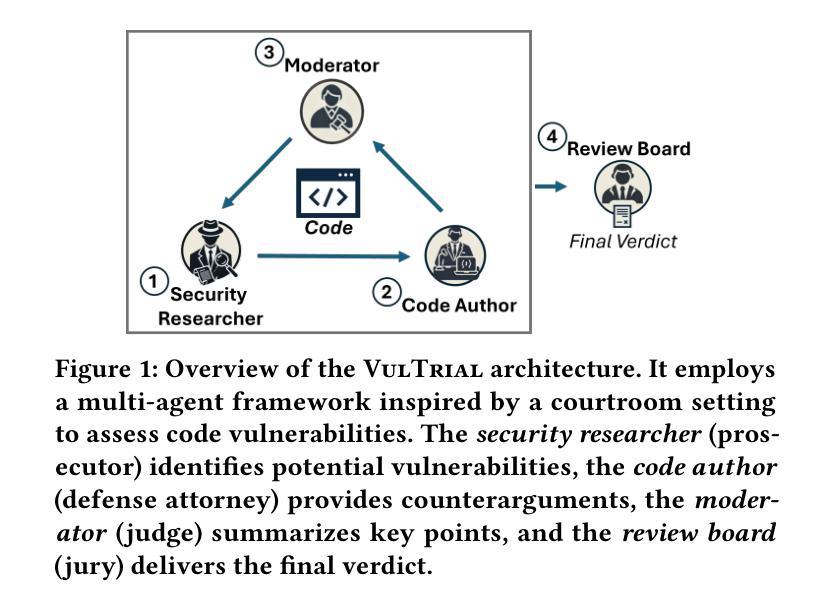
Large Language Models (LLMs) have demonstrated impressive performance in executing complex reasoning tasks. Chain-of-thought effectively enhances reasoning capabilities by unlocking the potential of large models, while multi-agent systems provide more comprehensive solutions by integrating collective intelligence of multiple agents. However, both approaches face significant limitations. Single-agent with chain-of-thought, due to the inherent complexity of designing cross-domain prompts, faces collaboration challenges. Meanwhile, multi-agent systems consume substantial tokens and inevitably dilute the primary problem, which is particularly problematic in business workflow tasks. To address these challenges, we propose Cochain, a collaboration prompting framework that effectively solves business workflow collaboration problem by combining knowledge and prompts at a reduced cost. Specifically, we construct an integrated knowledge graph that incorporates knowledge from multiple stages. Furthermore, by maintaining and retrieving a prompts tree, we can obtain prompt information relevant to other stages of the business workflow. We perform extensive evaluations of Cochain across multiple datasets, demonstrating that Cochain outperforms all baselines in both prompt engineering and multi-agent LLMs. Additionally, expert evaluation results indicate that the use of a small model in combination with Cochain outperforms GPT-4.
大型语言模型(LLMs)在执行复杂的推理任务时表现出了令人印象深刻的性能。思维链通过解锁大型模型的潜力,有效地增强了推理能力,而多智能体系统则通过整合多个智能体的集体智慧提供了更全面的解决方案。然而,这两种方法都面临重大局限性。思维链单一智能体由于设计跨域提示的固有复杂性,面临协作挑战。同时,多智能体系统消耗大量令牌并不可避免地淡化主要问题,这在业务流程任务中尤其成问题。为了解决这些挑战,我们提出了Cochain,这是一个协作提示框架,通过结合知识和提示,以降低成本有效地解决了业务流程协作问题。具体来说,我们构建了一个整合的知识图谱,融合了多个阶段的知识。此外,通过维护和检索提示树,我们可以获得与业务流程其他阶段相关的提示信息。我们在多个数据集上对Cochain进行了广泛评估,结果表明,Cochain在提示工程和多元智能体LLM方面都优于所有基线。此外,专家评估结果表明,使用小型模型结合Cochain的表现优于GPT-4。
论文及项目相关链接
PDF 34 pages, 20 figures
Summary
大型语言模型(LLMs)在执行复杂推理任务时表现出卓越性能。思维链技术通过解锁大型模型的潜力增强了推理能力,而多智能体系统则通过整合多个智能体的集体智慧提供了更全面的解决方案。然而,两者都有显著局限性。思维链方法在设计跨域提示时面临内在复杂性,导致协作挑战;多智能体系统消耗大量令牌并可能淡化主要任务,这在业务流程任务中尤为严重。为解决这些挑战,我们提出了Cochain协作提示框架,通过结合知识和提示,以较低成本有效解决业务流程协作问题。Cochain构建了一个包含多阶段知识的一体化知识图谱,并通过维护和检索提示树,获得与业务流程其他阶段相关的提示信息。跨多个数据集对Cochain的广泛评估表明,它在提示工程和基于多智能体的LLM方面都优于所有基线方法。此外,专家评估结果显示,结合Cochain使用小型模型的表现优于GPT-4。
Key Takeaways
- 大型语言模型(LLMs)在复杂推理任务上表现优异。
- 思维链技术和多智能体系统均增强模型的推理能力,但存在局限性。
- 思维链在设计跨域提示时面临协作挑战。
- 多智能体系统在业务流程任务中消耗大量资源并可能淡化主要任务。
- Cochain框架通过结合知识和提示,旨在解决业务流程协作问题,具有较低成本。
- Cochain构建了一个综合多阶段知识的知识图谱,并通过提示树获取相关提示信息。
点此查看论文截图

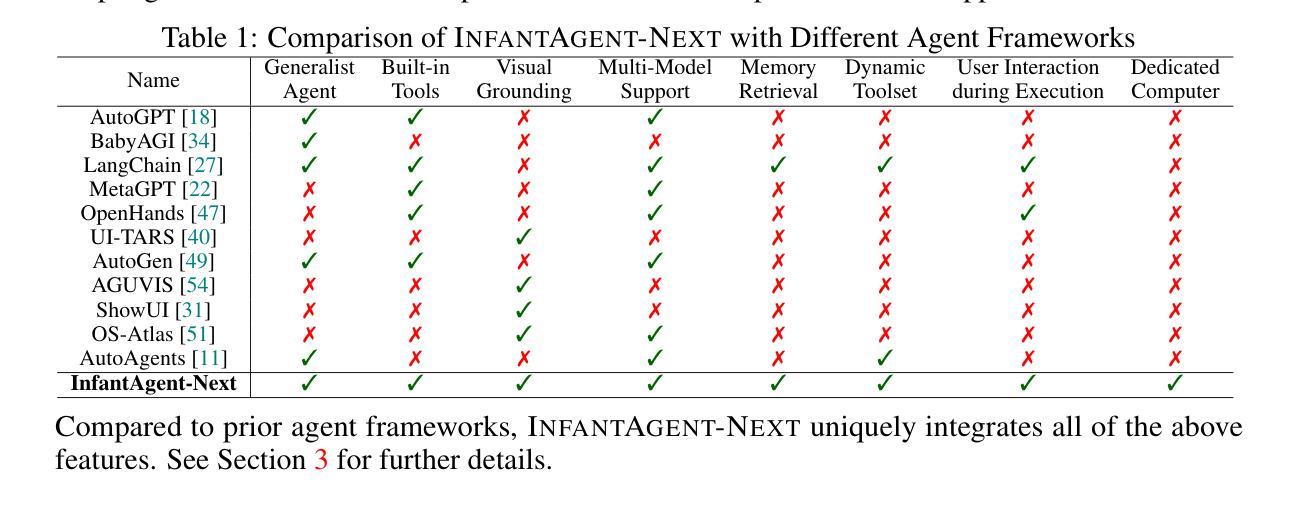
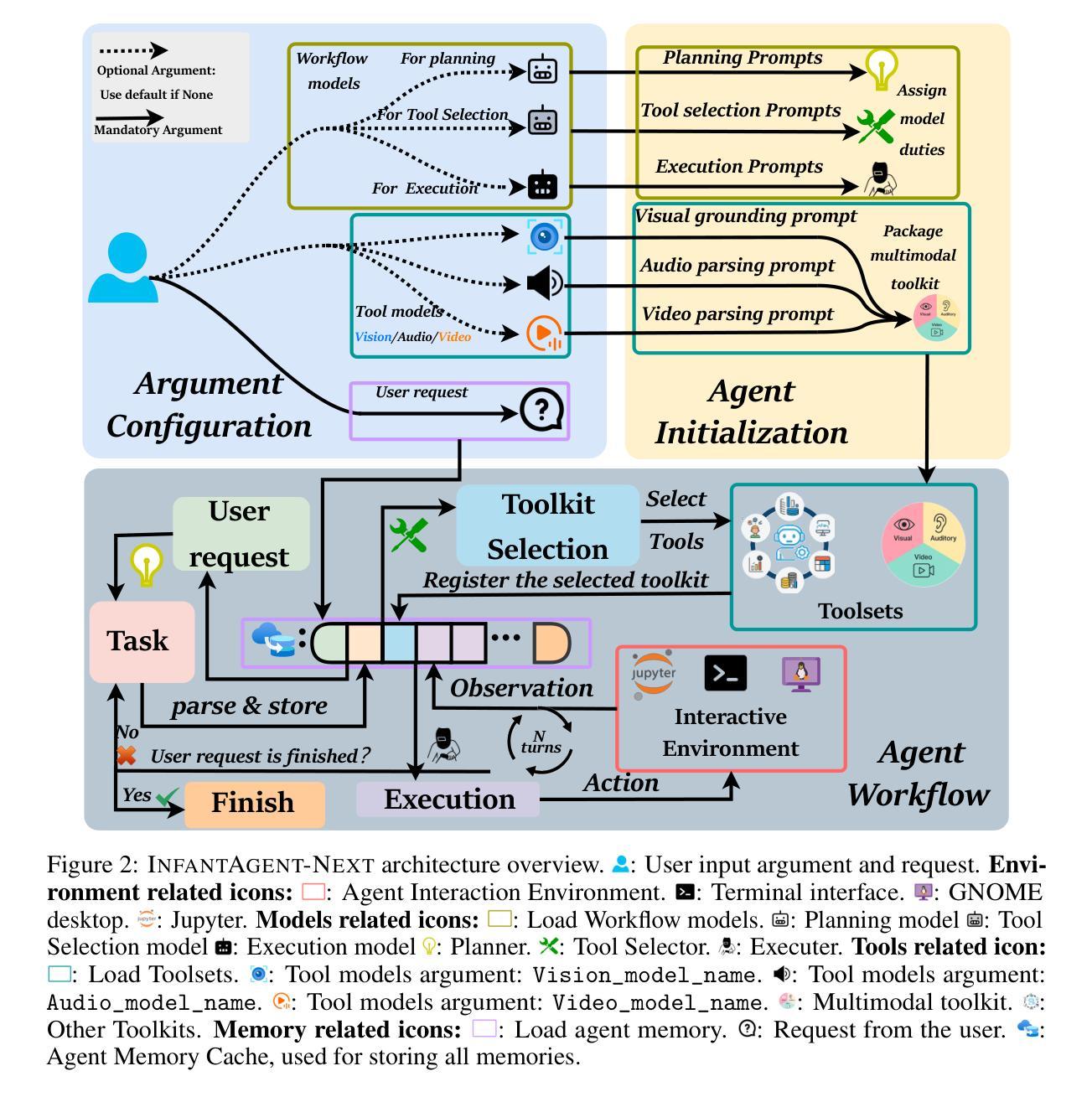
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
Authors:Bin Lei, Weitai Kang, Zijian Zhang, Winson Chen, Xi Xie, Shan Zuo, Mimi Xie, Ali Payani, Mingyi Hong, Yan Yan, Caiwen Ding
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
本文介绍了\textbf{InfantAgent-Next},这是一个通用智能体,能够以多模式的方式与计算机进行交互,涵盖文本、图像、音频和视频。不同于现有方法,它们要么围绕单一大型模型构建复杂的工作流程,要么只提供工作流程的模块化,我们的智能体在一个高度模块化的架构内集成了基于工具和纯视觉的智能体,使不同的模型能够逐步协作解决解耦的任务。我们的通用性体现在我们不仅能够评估基于纯视觉的现实世界基准测试(即OSWorld),还能够评估更一般或工具密集型的基准测试(例如GAIA和SWE-Bench)。具体来说,我们在OSWorld上达到了\textbf{7.27%}的准确率,高于Claude-Computer-Use。代码和评估脚本已公开在https://github.com/bin123apple/InfantAgent。
论文及项目相关链接
Summary
该论文介绍了InfantAgent-Next这一通用型代理(agent),该代理能够以多模态的方式与计算机进行交互,包括文本、图像、音频和视频。不同于现有的构建单一大型模型复杂工作流程或仅提供工作流程模块化的方法,InfantAgent-Next在一个高度模块化架构中集成了工具型和纯视觉型代理,使不同的模型能够分步合作解决分离的任务。它不仅评估了纯视觉型的现实世界基准测试(如OSWorld),而且评估了更通用或工具密集型的基准测试(如GAIA和SWE-Bench)。在OSWorld上取得了7.27%的准确率,超过了Claude-Computer-Use。相关代码和评估脚本已开源至GitHub的bin123apple/InfantAgent。
Key Takeaways
以下是关于该论文的七个关键见解:
- InfantAgent-Next是一个通用型代理,支持多模态交互方式,包括文本、图像、音频和视频。
- 该代理采用高度模块化架构,集成了工具型和纯视觉型代理。
- 不同模型能够在此架构下合作解决分离的任务,采用分步方式进行处理。
- InfantAgent-Next不仅评估纯视觉型的现实世界基准测试,还评估更通用或工具密集型的基准测试。
- 在OSWorld基准测试中,InfantAgent-Next达到了7.27%的准确率。
- 该代理的性能超过了Claude-Computer-Use在OSWorld上的表现。
点此查看论文截图



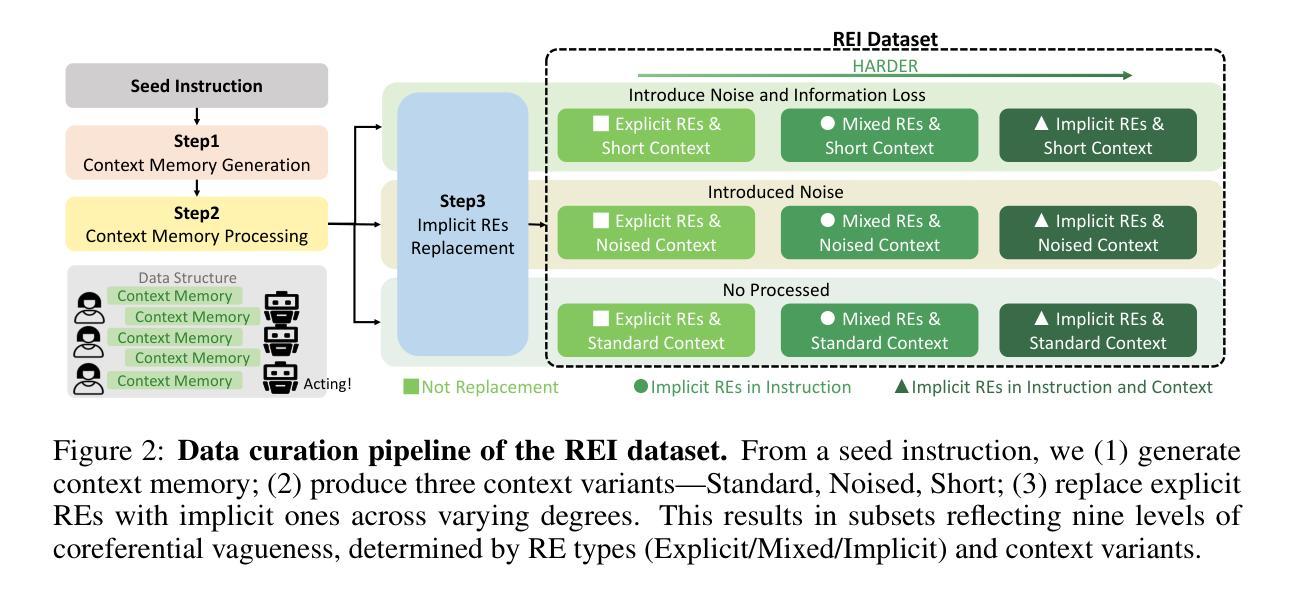
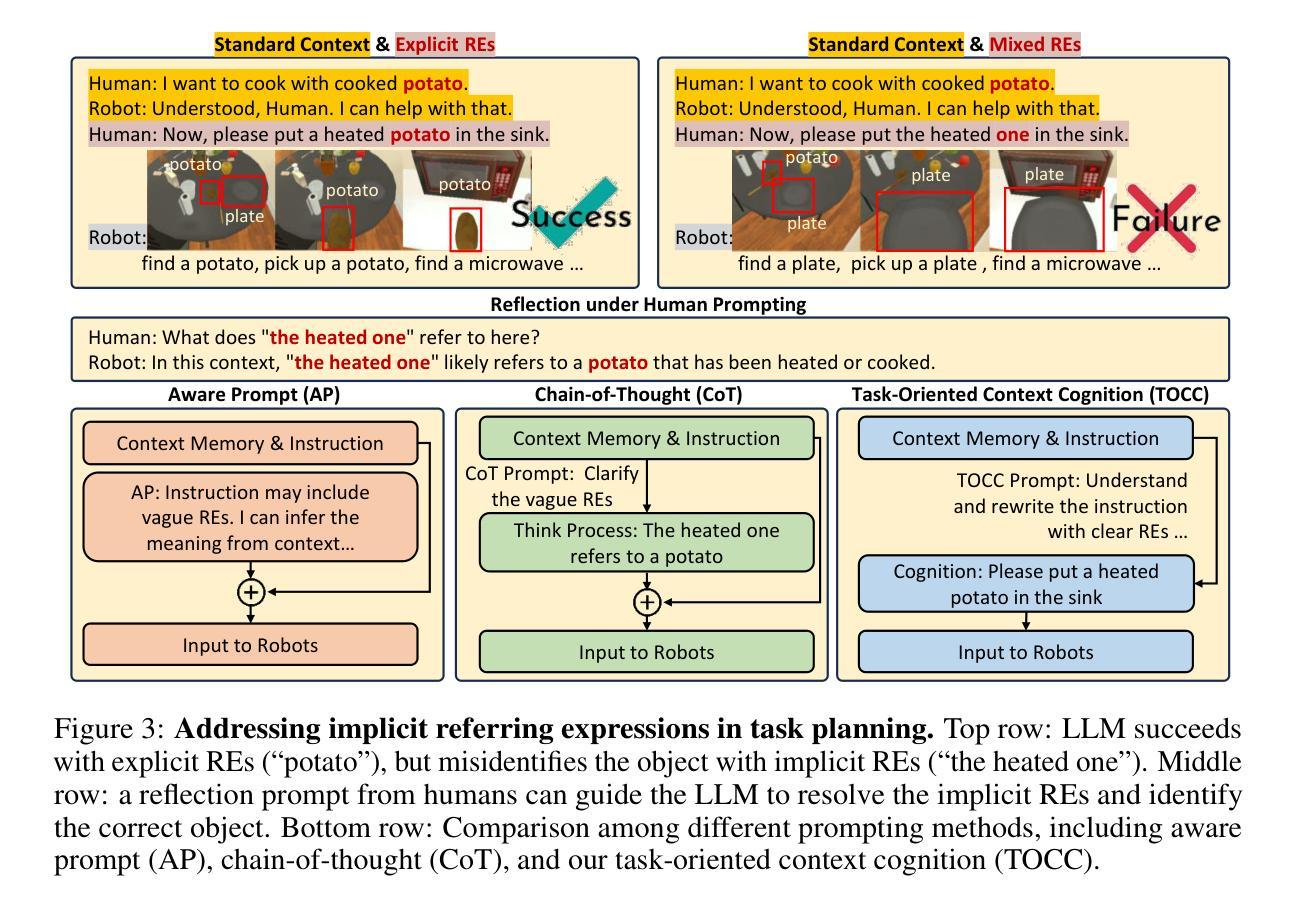
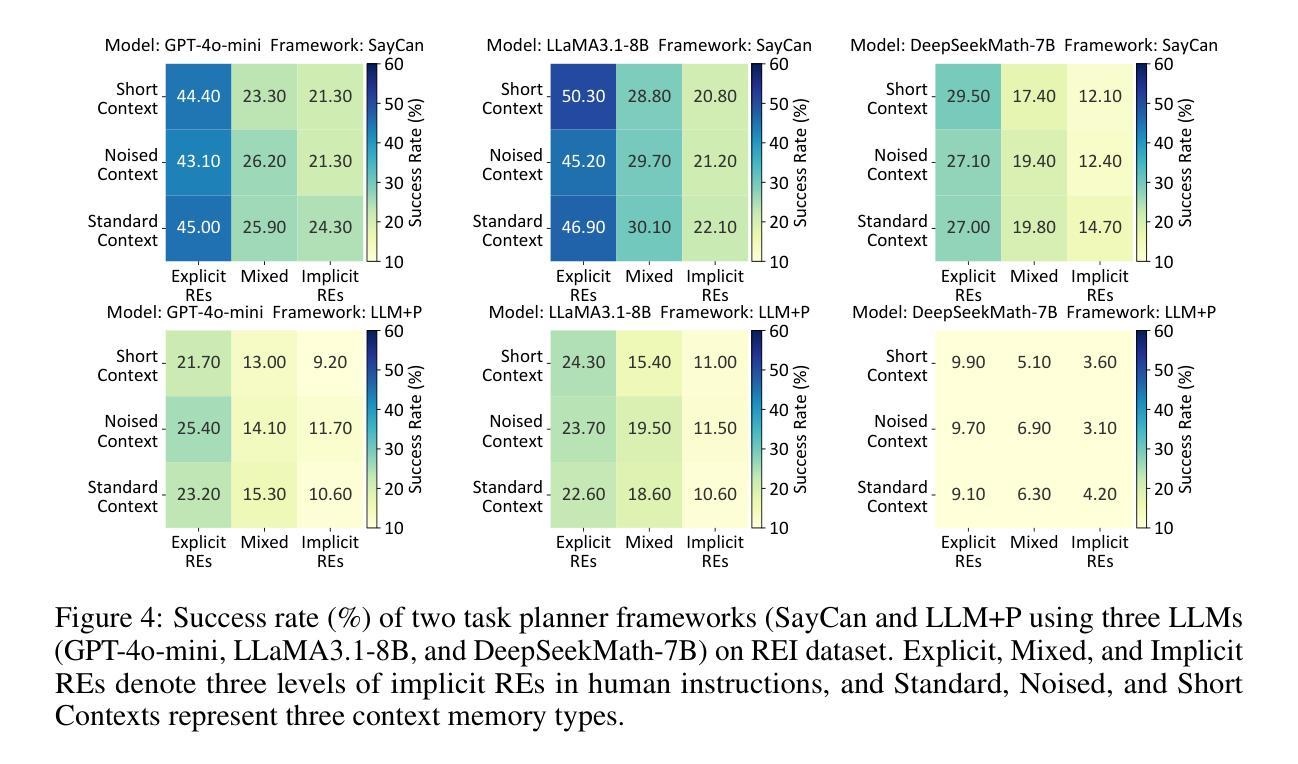
REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
Authors:Chenxi Jiang, Chuhao Zhou, Jianfei Yang
Robot task planning decomposes human instructions into executable action sequences that enable robots to complete a series of complex tasks. Although recent large language model (LLM)-based task planners achieve amazing performance, they assume that human instructions are clear and straightforward. However, real-world users are not experts, and their instructions to robots often contain significant vagueness. Linguists suggest that such vagueness frequently arises from referring expressions (REs), whose meanings depend heavily on dialogue context and environment. This vagueness is even more prevalent among the elderly and children, who robots should serve more. This paper studies how such vagueness in REs within human instructions affects LLM-based robot task planning and how to overcome this issue. To this end, we propose the first robot task planning benchmark with vague REs (REI-Bench), where we discover that the vagueness of REs can severely degrade robot planning performance, leading to success rate drops of up to 77.9%. We also observe that most failure cases stem from missing objects in planners. To mitigate the REs issue, we propose a simple yet effective approach: task-oriented context cognition, which generates clear instructions for robots, achieving state-of-the-art performance compared to aware prompt and chains of thought. This work contributes to the research community of human-robot interaction (HRI) by making robot task planning more practical, particularly for non-expert users, e.g., the elderly and children.
人类指令分解为可执行的动作序列,使机器人能够完成一系列复杂的任务。虽然基于大型语言模型(LLM)的任务规划器取得了惊人的性能,但它们假设人类指令是清晰和直接的。然而,真实世界的用户并非都是专家,他们对机器人的指令通常包含大量的模糊性。语言学家认为,这种模糊性经常来自于指代表达式(REs),其意义很大程度上取决于对话上下文和环境。这种模糊性在老年人和儿童等机器人应该提供更多服务的群体中更为普遍。本文研究了人类指令中的指代表达式(REs)的模糊性如何影响基于LLM的机器人任务规划,并探讨了如何解决这一问题。为此,我们提出了带有模糊REs的第一个机器人任务规划基准测试(REI-Bench),我们发现REs的模糊性会严重降低机器人规划性能,成功率下降高达77.9%。我们还观察到,大多数失败的情况源于规划器中缺少对象。为了缓解REs问题,我们提出了一种简单有效的方法:面向任务的上下文认知,它为机器人生成清晰的指令,与意识提示和思考链相比,取得了最先进的性能。这项工作使人机交互(HRI)研究群体收益,让机器人任务规划更实用,尤其是对于非专业用户,如老年人和儿童。
论文及项目相关链接
PDF Submitted to CoRL 2025, under review
Summary:
机器人任务规划能够将人类指令分解为可执行的动作序列,使机器人能够完成一系列复杂任务。尽管基于大型语言模型的任务规划器取得了惊人的性能,但它们假设人类指令是清晰直接的。然而,真实世界的用户并非专家,他们给机器人的指令常含有大量模糊性。本论文研究人类指令中的参照表达(REs)的模糊性如何影响基于LLM的机器人任务规划,并探讨如何解决这一问题。为此,我们提出了首个含有模糊REs的机器人任务规划基准测试(REI-Bench),发现REs的模糊性会严重降低机器人规划性能,成功率下降高达77.9%。我们还观察到,大多数失败案例源于规划中的目标对象缺失。为缓解REs问题,我们提出了一种简单有效的方法:面向任务的环境认知,为机器人生成清晰指令,实现了与意识提示和思维链相比的先进性能。这项工作促进了人机交互(HRI)领域的研究,使机器人任务规划更加实用,尤其适用于非专业用户,如老年人和儿童。
Key Takeaways:
- 机器人任务规划能将人类指令转化为机器人可执行的动作序列。
- 基于大型语言模型的机器人任务规划器在假设人类指令清晰直接的情况下表现出色。
- 真实世界的用户指令常含有模糊性,这主要来源于参照表达的模糊性。
- 参照表达的模糊性可能导致机器人任务规划性能严重下降,成功率下降高达77.9%。
- 失败案例大多源于目标对象在规划中的缺失。
- 为解决参照表达的模糊性问题,提出了面向任务的环境认知方法。
点此查看论文截图

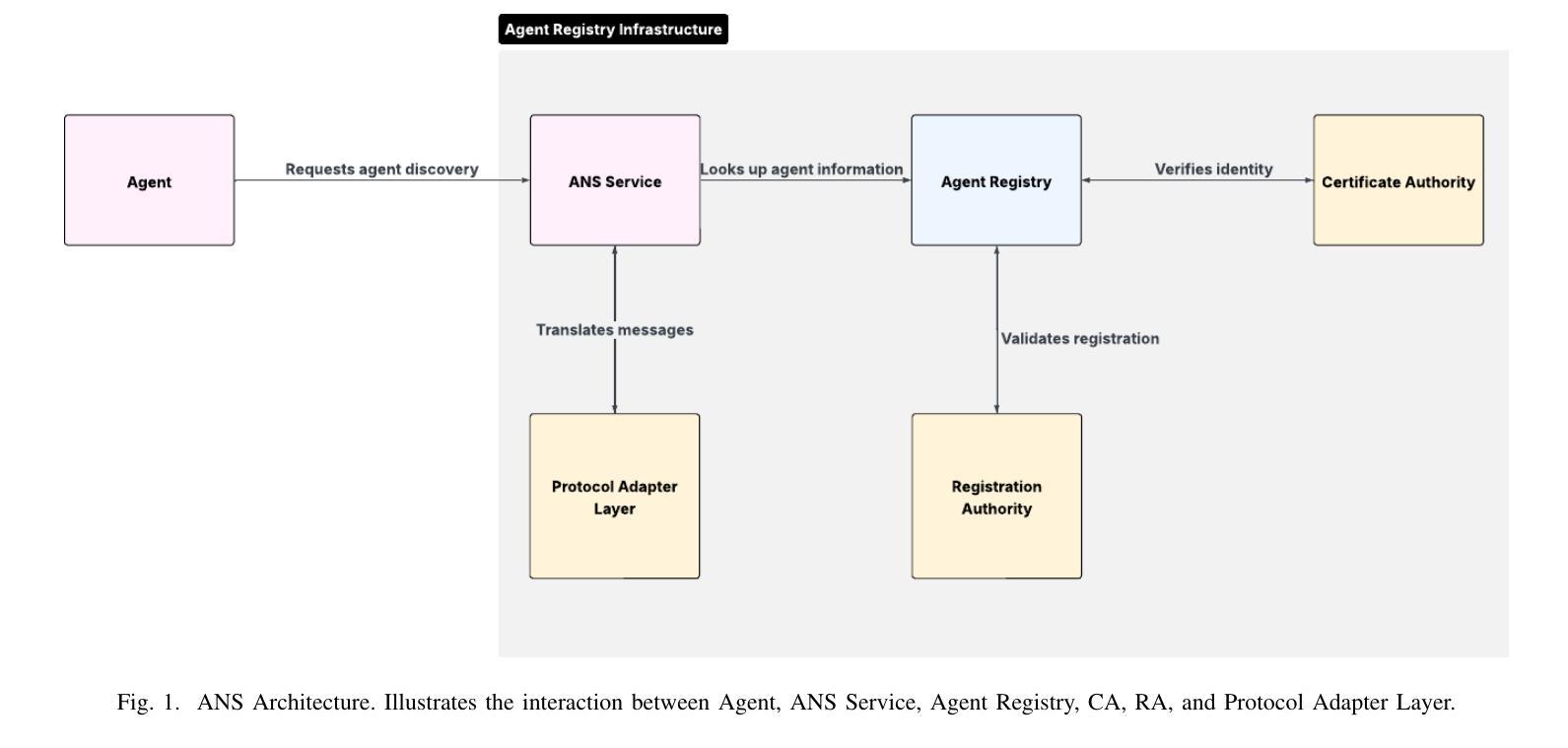
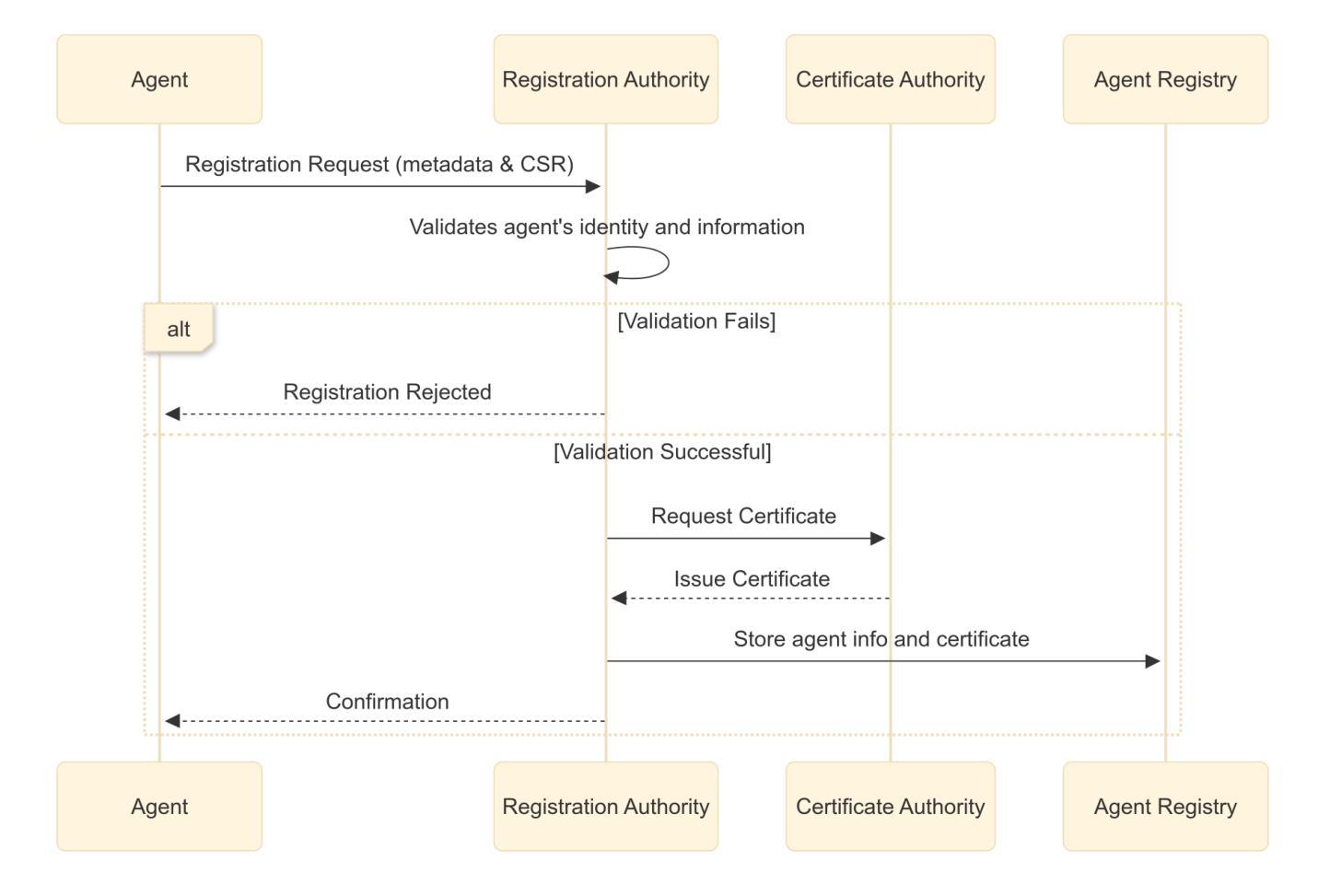
Agent Name Service (ANS): A Universal Directory for Secure AI Agent Discovery and Interoperability
Authors:Ken Huang, Vineeth Sai Narajala, Idan Habler, Akram Sheriff
The proliferation of AI agents requires robust mechanisms for secure discovery. This paper introduces the Agent Name Service (ANS), a novel architecture based on DNS addressing the lack of a public agent discovery framework. ANS provides a protocol-agnostic registry infrastructure that leverages Public Key Infrastructure (PKI) certificates for verifiable agent identity and trust. The architecture features several key innovations: a formalized agent registration and renewal mechanism for lifecycle management; DNS-inspired naming conventions with capability-aware resolution; a modular Protocol Adapter Layer supporting diverse communication standards (A2A, MCP, ACP etc.); and precisely defined algorithms for secure resolution. We implement structured communication using JSON Schema and conduct a comprehensive threat analysis of our proposal. The result is a foundational directory service addressing the core challenges of secured discovery and interaction in multi-agent systems, paving the way for future interoperable, trustworthy, and scalable agent ecosystems.
人工智能代理的普及需要可靠的机制来进行安全发现。本文介绍了基于DNS解决公共代理发现框架缺失问题的Agent Name Service(ANS)新型架构。ANS提供了一种与协议无关的注册基础设施,利用公钥基础设施(PKI)证书进行可验证的代理身份和信任。该架构具有几个关键创新点:用于生命周期管理的正式化的代理注册和更新机制;受DNS启发的命名规范和能力感知解析;支持多种通信标准的模块化协议适配器层(如A2A、MCP、ACP等);以及用于安全解析的精确定义的算法。我们使用JSON Schema实现结构化通信,并对我们的提议进行了全面的威胁分析。结果是一个基础目录服务,解决了多代理系统中安全发现和交互的核心挑战,为未来的可互操作、可靠和可扩展的代理生态系统铺平了道路。
论文及项目相关链接
PDF 15 pages, 6 figures, 6 code listings, Supported and endorsed by OWASP GenAI ASI Project
Summary
基于人工智能代理的激增需求,需要一个可靠的发现机制以确保安全。本文引入了一种名为Agent Name Service(ANS)的新型架构,该架构基于DNS技术解决了公共代理发现框架的缺失问题。ANS提供了一种与协议无关的注册基础设施,利用公钥基础设施(PKI)证书进行代理身份识别和信任验证。该架构的关键创新包括:形式化的代理注册和更新机制用于生命周期管理;借鉴DNS的命名规范并具有能力感知解析功能;具有支持多种通信标准的模块化协议适配器层(如A2A、MCP、ACP等);以及精确定义的用于安全解析的算法。通过JSON Schema实现结构化通信,并对提议进行了全面的威胁分析。结果是一种基础目录服务,解决了多代理系统中安全发现和交互的核心挑战,为未来的可互操作、可靠和可扩展的代理生态系统铺平了道路。
Key Takeaways
- AI代理的普及需要一种可靠的发现机制以确保安全。
- Agent Name Service (ANS) 架构基于DNS技术解决公共代理发现框架缺失问题。
- ANS利用公钥基础设施(PKI)证书进行代理身份识别和信任验证。
- ANS具有形式化的代理注册和更新机制用于生命周期管理。
- ANS借鉴DNS的命名规范并具有能力感知解析功能。
- ANS具有模块化协议适配器层,支持多种通信标准。
点此查看论文截图






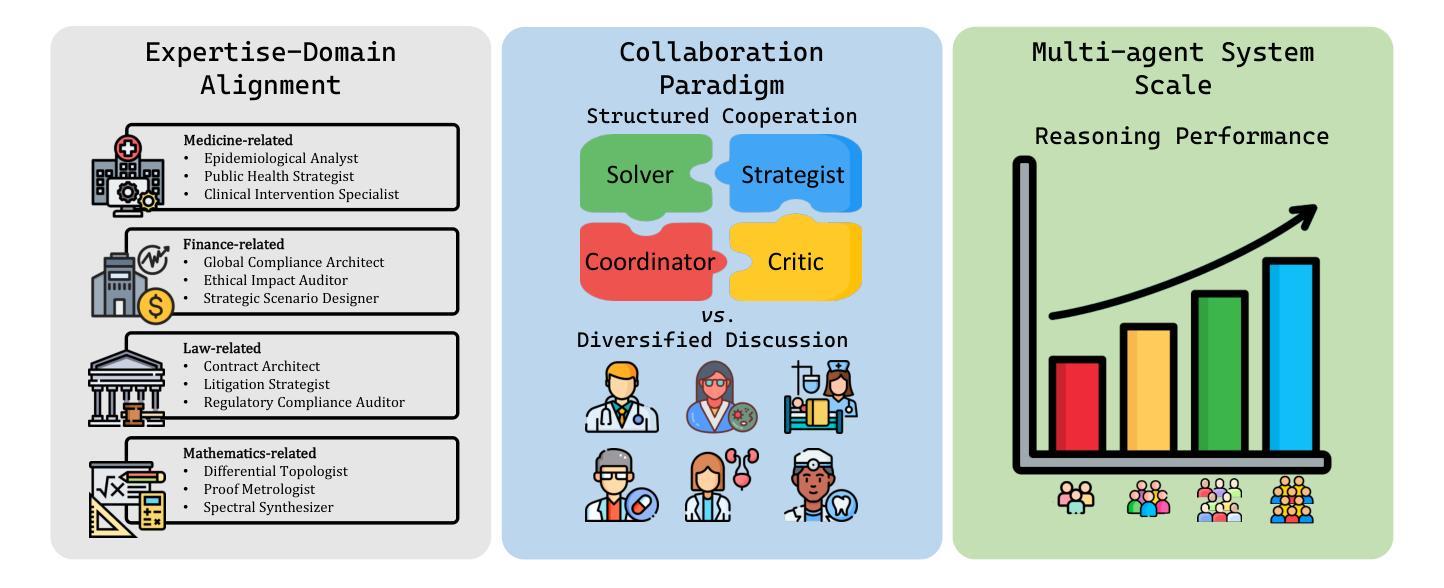
Towards Multi-Agent Reasoning Systems for Collaborative Expertise Delegation: An Exploratory Design Study
Authors:Baixuan Xu, Chunyang Li, Weiqi Wang, Wei Fan, Tianshi Zheng, Haochen Shi, Tao Fan, Yangqiu Song, Qiang Yang
Designing effective collaboration structure for multi-agent LLM systems to enhance collective reasoning is crucial yet remains under-explored. In this paper, we systematically investigate how collaborative reasoning performance is affected by three key design dimensions: (1) Expertise-Domain Alignment, (2) Collaboration Paradigm (structured workflow vs. diversity-driven integration), and (3) System Scale. Our findings reveal that expertise alignment benefits are highly domain-contingent, proving most effective for contextual reasoning tasks. Furthermore, collaboration focused on integrating diverse knowledge consistently outperforms rigid task decomposition. Finally, we empirically explore the impact of scaling the multi-agent system with expertise specialization and study the computational trade off, highlighting the need for more efficient communication protocol design. This work provides concrete guidelines for configuring specialized multi-agent system and identifies critical architectural trade-offs and bottlenecks for scalable multi-agent reasoning. The code will be made available upon acceptance.
设计多代理大型语言模型系统的有效协作结构以增强集体推理至关重要,但尚未得到充分探索。在本文中,我们系统地研究了三个关键设计维度如何影响协作推理性能:(1)专业领域知识与技能的匹配度,(2)协作范式(结构化工作流程与多样性驱动集成),以及(3)系统规模。我们发现,专业领域知识与技能的匹配度的优势高度依赖于特定领域,在情境推理任务中效果最明显。此外,以集成多样化知识为重点的协作始终优于僵化的任务分解。最后,我们通过实证探索了通过专业专长扩展多代理系统的影响,并研究了计算上的权衡,这强调了需要设计更有效的通信协议。这项工作为配置专业多代理系统提供了具体指导,并确定了可扩展多代理推理的关键架构权衡和瓶颈。代码将在接受后提供。
论文及项目相关链接
PDF 19 pages
Summary
本文系统探讨了多主体大型语言模型(LLM)系统的协作推理性能受三个关键设计维度的影响,包括专业知识领域对齐、协作范式(结构化工作流程与多样性驱动集成)和系统规模。研究结果显示,专业知识对齐的效益高度依赖于领域,对上下文推理任务最为有效。此外,注重整合多样知识的协作方式持续优于刚性的任务分解。本文还实证探讨了专业化多主体系统的配置影响,并强调了计算通讯协议设计的权衡和瓶颈问题。此研究为构建专门的多主体系统提供了具体指导,并指出了可扩展多主体推理的关键架构权衡和瓶颈。
Key Takeaways
- 多主体LLM系统的协作结构对集体推理效能至关重要,但相关研究仍不足。
- 专业知识领域对齐是提升多主体系统协作效能的关键手段,尤其在上下文推理任务中效果显著。
- 协作范式影响多主体系统的性能,其中注重知识多样性的集成优于刚性的任务分解。
- 系统规模对多主体LLM系统的协作推理有重要影响,实证探索了专业分工与计算通讯协议设计的权衡。
- 研究指出了在计算通讯协议设计中需要更高效的通信协议设计。
- 该研究为构建专门的多主体系统提供了具体指导,强调了关键架构权衡的重要性。
- 本文强调了可扩展多主体推理的瓶颈问题,为后续研究提供了方向。
点此查看论文截图


Empowering Agentic Video Analytics Systems with Video Language Models
Authors:Yuxuan Yan, Shiqi Jiang, Ting Cao, Yifan Yang, Qianqian Yang, Yuanchao Shu, Yuqing Yang, Lili Qiu
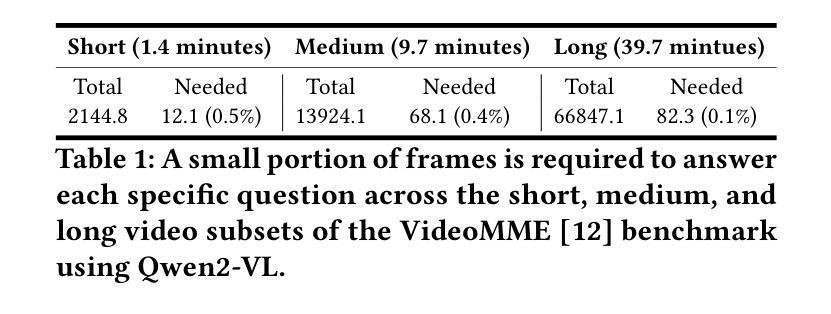
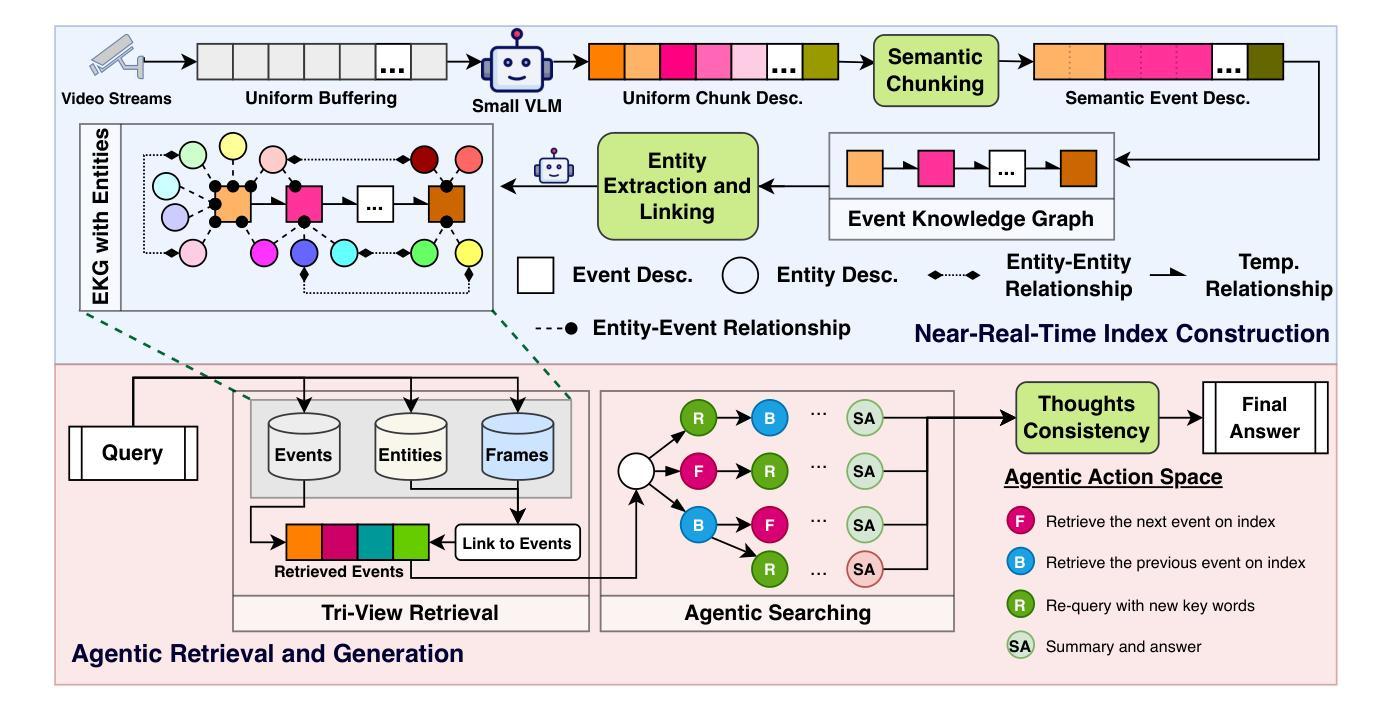
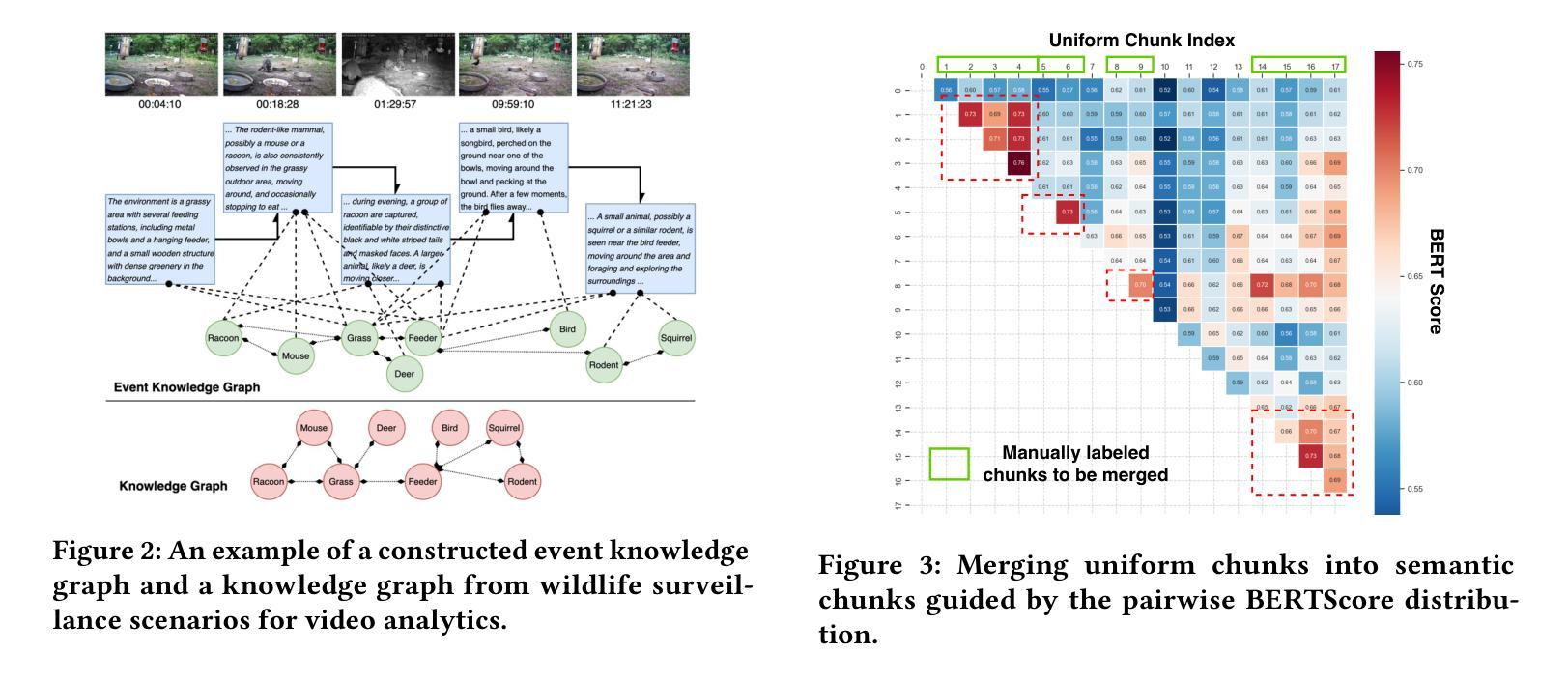
AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
人工智能驱动的视频分析在不同领域变得越来越重要。然而,现有系统通常局限于特定的预定义任务,限制了它们在开放式分析场景中的适应性。最近出现的视频语言模型(VLM)作为变革性技术,为开放式视频理解、推理和分析提供了巨大潜力。然而,它们在处理现实世界应用中普遍存在的超长视频内容时,有限的上下文窗口带来了挑战。为了解决这一问题,我们引入了AVAS,一个用于开放式高级视频分析的VLM驱动系统。AVAS有两个关键创新点:(1)事件知识图(EKG)的近实时构建,用于高效索引长或连续的视频流;(2)一种利用EKG的代理检索生成机制,用于处理复杂和多样的查询。在公开基准测试LVBench和VideoMME-Long上的综合评估表明,AVAS达到了最新技术水平,准确率分别为62.3%和64.1%,显著超越了现有的VLM和视频检索增强生成(RAG)系统。此外,为了评估超长和开放式视频场景中的视频分析,我们引入了新的基准测试AVAS-100。该基准测试包含8个视频,每个视频持续时间超过10小时,以及120个手动注释的、多样化的、复杂的问答对。在AVAS-100上,AVAS以75.8%的准确率达到了顶尖性能。
论文及项目相关链接
PDF 15 pages, AVAS, add latency breakdown
Summary
AI视频分析在各个领域变得至关重要。然而,现有系统通常受限于特定预设任务,难以适应开放式分析场景。最近兴起的视频语言模型(VLM)技术为开放式视频理解、推理和分析提供了巨大潜力。然而,处理超长视频内容时,其有限的上下文窗口带来了挑战。为解决这一问题,我们推出了AVAS系统,一个用于开放式高级视频分析的视频语言模型驱动系统。AVAS通过构建事件知识图谱(EKG)实现高效索引长视频流,并利用EKG处理复杂多样查询。在公开基准测试上,AVAS表现出卓越性能,准确率达到领先水平。此外,我们还推出了新的基准测试AVAS-100,以评估超长开放场景下的视频分析性能。
Key Takeaways
- AI视频分析在多个领域的重要性日益增强,但现有系统的任务特定性限制了其在开放式场景中的应用。
- 视频语言模型(VLM)技术的出现为视频理解、推理和分析提供了巨大潜力。
- 处理超长视频内容时,VLM的上下文窗口限制是一个挑战。
- AVAS系统通过构建事件知识图谱(EKG)实现高效索引长视频流,并引入新型检索生成机制处理复杂查询。
- AVAS在公开基准测试上表现出卓越性能,准确率达到领先水平。
- 为评估超长开放场景下的视频分析性能,推出了新的基准测试AVAS-100。
点此查看论文截图

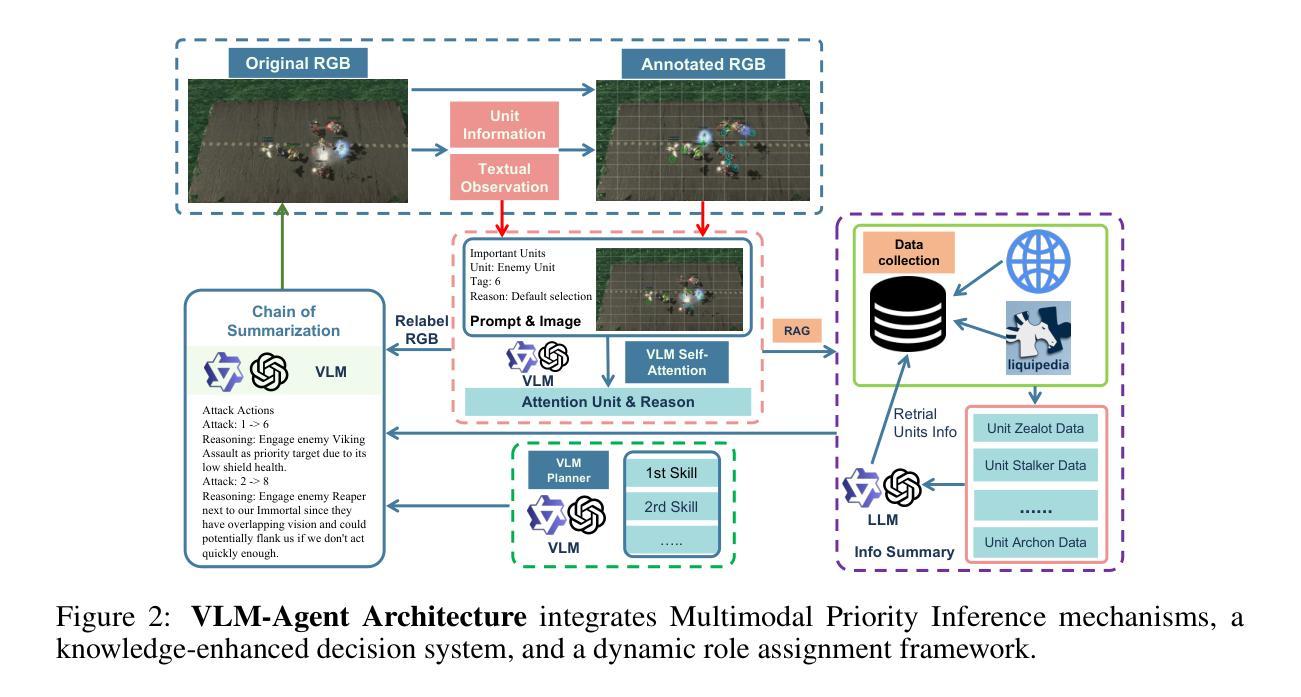
AVA: Attentive VLM Agent for Mastering StarCraft II
Authors:Weiyu Ma, Yuqian Fu, Zecheng Zhang, Bernard Ghanem, Guohao Li
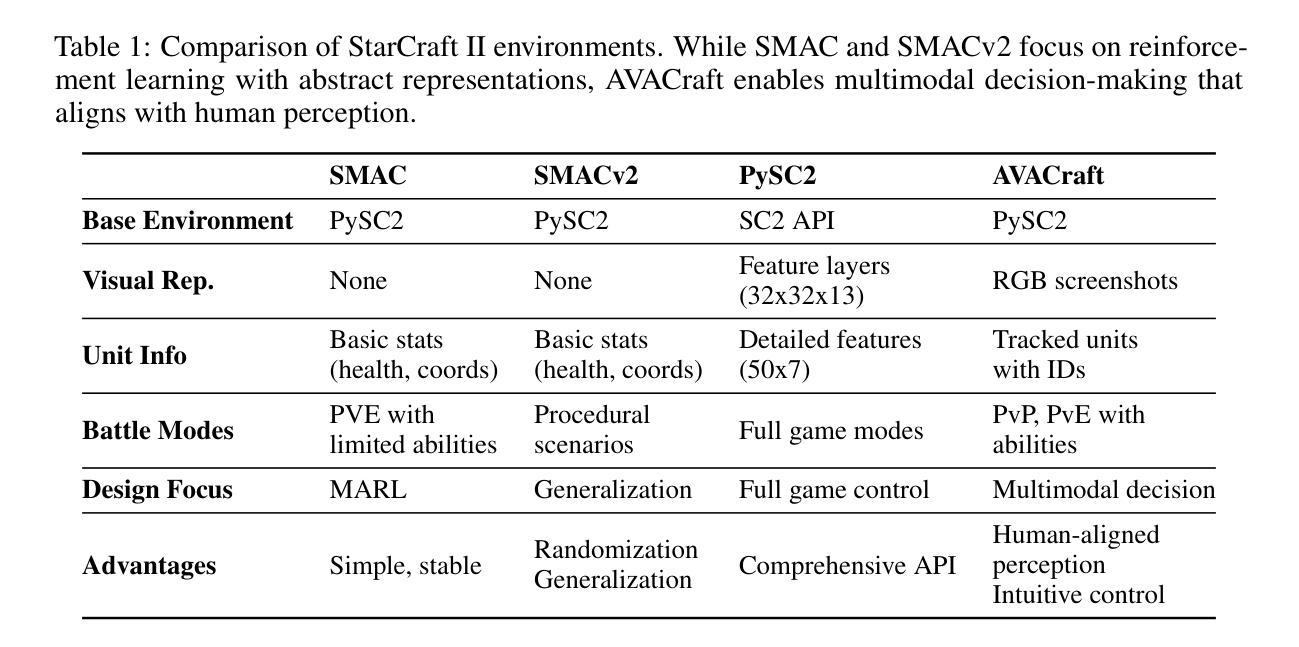
We introduce Attentive VLM Agent (AVA), a multimodal StarCraft II agent that aligns artificial agent perception with the human gameplay experience. Traditional frameworks such as SMAC rely on abstract state representations that diverge significantly from human perception, limiting the ecological validity of agent behavior. Our agent addresses this limitation by incorporating RGB visual inputs and natural language observations that more closely simulate human cognitive processes during gameplay. The AVA architecture consists of three integrated components: (1) a vision-language model enhanced with specialized self-attention mechanisms for strategic unit targeting and battlefield assessment, (2) a retrieval-augmented generation system that leverages domain-specific StarCraft II knowledge to inform tactical decisions, and (3) a dynamic role-based task distribution system that enables coordinated multi-agent behavior. The experimental evaluation in our proposed AVACraft environment, which contains 21 multimodal StarCraft II scenarios, demonstrates that AVA powered by foundation models (specifically Qwen-VL and GPT-4o) can execute complex tactical maneuvers without explicit training, achieving comparable performance to traditional MARL methods that require substantial training iterations. This work establishes a foundation for developing human-aligned StarCraft II agents and advances the broader research agenda of multimodal game AI. Our implementation is available at https://github.com/camel-ai/VLM-Play-StarCraft2.
我们引入了注重视觉语言模型(Attentive VLM Agent,AVA)的多模态《星际争霸II》智能体,它将人工智能感知与人类游戏体验相结合。传统的框架(如SMAC)依赖于抽象状态表示,与人类感知存在很大差异,从而限制了智能体行为的生态效度。我们的智能体通过融入RGB视觉输入和自然语言观测来模拟人类在游戏过程中的认知过程,从而解决了这一局限性。AVA架构由三个集成组件组成:(1)一个增强型的视觉语言模型,该模型配备了专门化的自注意力机制,用于战略单位定位和战场评估;(2)一个利用特定领域《星际争霸II》知识来辅助战术决策的回溯增强生成系统;(3)一个动态的角色任务分配系统,该系统能够协调多智能体的行为。在我们提出的AVACraft环境中的实验评估显示,借助基础模型(特别是Qwen-VL和GPT-4o)驱动的AVA能够在无需明确训练的情况下执行复杂的战术动作,其性能与传统需要大量训练迭代的多智能体强化学习(MARL)方法相当。这项工作为开发与人类感知相符的《星际争霸II》智能体奠定了基础,并推动了多模态游戏AI的更广泛研究议程。我们的实现可在https://github.com/camel-ai/VLM-Play-StarCraft2访问。
论文及项目相关链接
PDF Under Review
Summary:引入了一个多模态的星际争霸II智能体Attentive VLM Agent(AVA),该智能体通过融入RGB视觉输入和自然语言观测,与人类的游戏体验感知对齐,克服了传统框架(如SMAC)中抽象状态表示与人类感知差异显著的局限性。AVA架构包括三个集成组件:具有战略单位定位和战场评估专用自注意力机制的视觉语言模型、利用星际争霸II特定知识指导战术决策检索增强生成系统以及动态基于角色的任务分配系统,实现多智能体的协调行为。在提出的AVACraft环境中的实验评估显示,借助基础模型(特别是Qwen-VL和GPT-4o)的AVA可在无需明确训练的情况下执行复杂的战术动作,其性能与传统需要大量训练迭代的多智能体强化学习(MARL)方法相当。这为开发与人类对齐的星际争霸II智能体奠定基础,推动了多模态游戏AI的更广泛研究议程。
Key Takeaways:
- AVA是一个多模态的星际争霸II智能体,旨在与人类的游戏体验感知对齐。
- 传统的智能体框架在模拟人类感知方面存在局限性,而AVA通过融入RGB视觉和自然语言观测克服了这一缺陷。
- AVA架构集成了三个关键组件:视觉语言模型、检索增强生成系统和动态角色任务分配系统。
- AVA借助基础模型在AVACraft环境中的性能与传统多智能体强化学习(MARL)方法相当。
- AVA可以在无需明确训练的情况下执行复杂的战术动作。
- AVA为开发与人类对齐的星际争霸II智能体奠定了基础。
点此查看论文截图


Infrastructure for AI Agents
Authors:Alan Chan, Kevin Wei, Sihao Huang, Nitarshan Rajkumar, Elija Perrier, Seth Lazar, Gillian K. Hadfield, Markus Anderljung
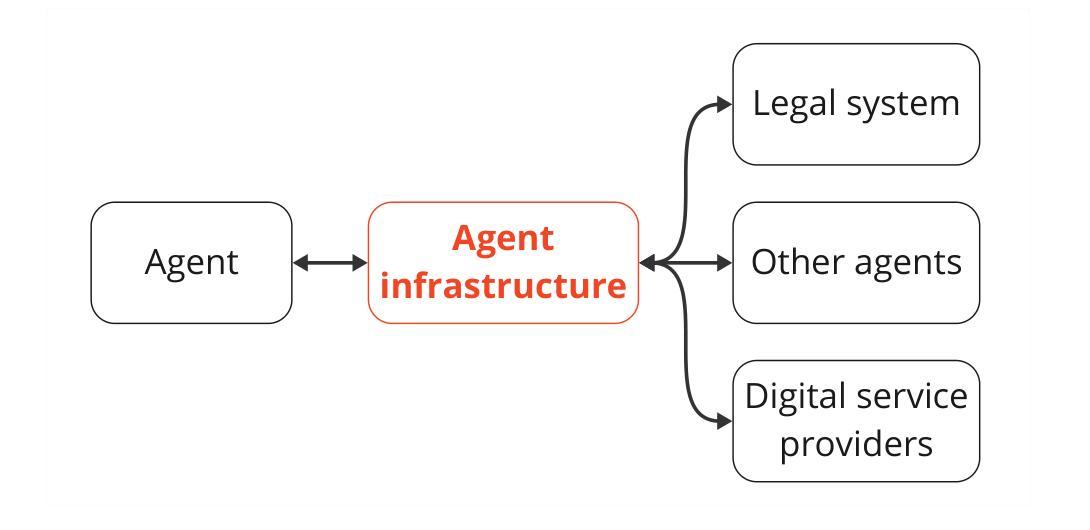
AI agents plan and execute interactions in open-ended environments. For example, OpenAI’s Operator can use a web browser to do product comparisons and buy online goods. To facilitate beneficial interactions and mitigate harmful ones, much research focuses on directly modifying agent behaviour. For example, developers can train agents to follow user instructions. This focus on direct modifications is useful, but insufficient. We will also need external protocols and systems that shape how agents interact with institutions and other actors. For instance, agents will need more efficient protocols to communicate with each other and form agreements. In addition, attributing an agent’s actions to a particular human or other legal entity can help to establish trust, and also disincentivize misuse. Given this motivation, we propose the concept of agent infrastructure: technical systems and shared protocols external to agents that are designed to mediate and influence their interactions with and impacts on their environments. Just as the Internet relies on protocols like HTTPS, our work argues that agent infrastructure will be similarly indispensable to ecosystems of agents. We identify three functions for agent infrastructure: 1) attributing actions, properties, and other information to specific agents, their users, or other actors; 2) shaping agents’ interactions; and 3) detecting and remedying harmful actions from agents. We provide an incomplete catalog of research directions for such functions. For each direction, we include analysis of use cases, infrastructure adoption, relationships to existing (internet) infrastructure, limitations, and open questions. Making progress on agent infrastructure can prepare society for the adoption of more advanced agents.
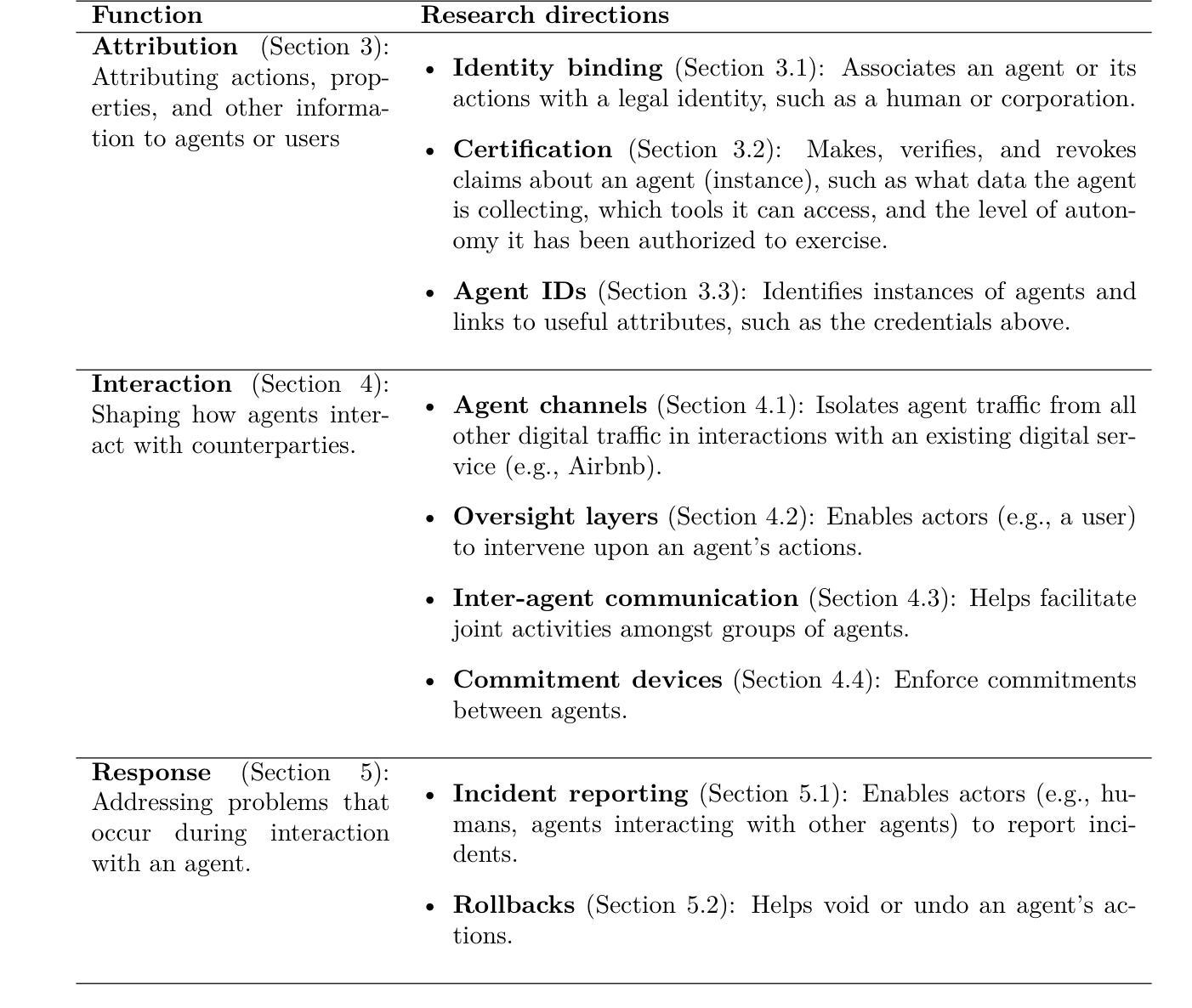
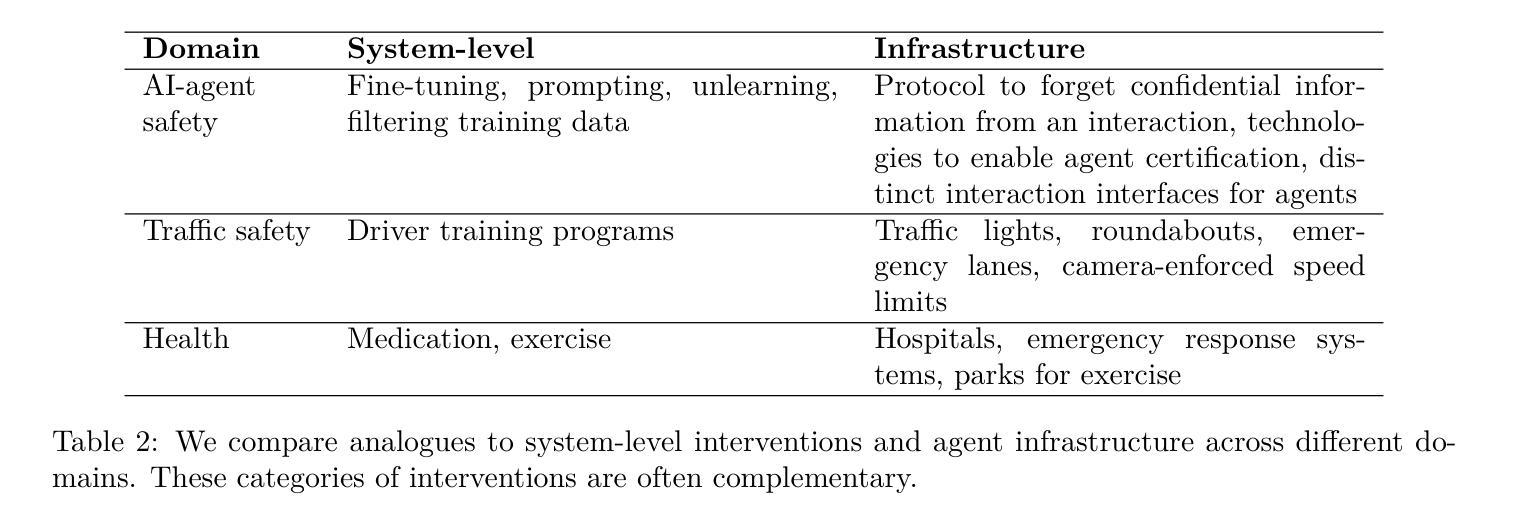
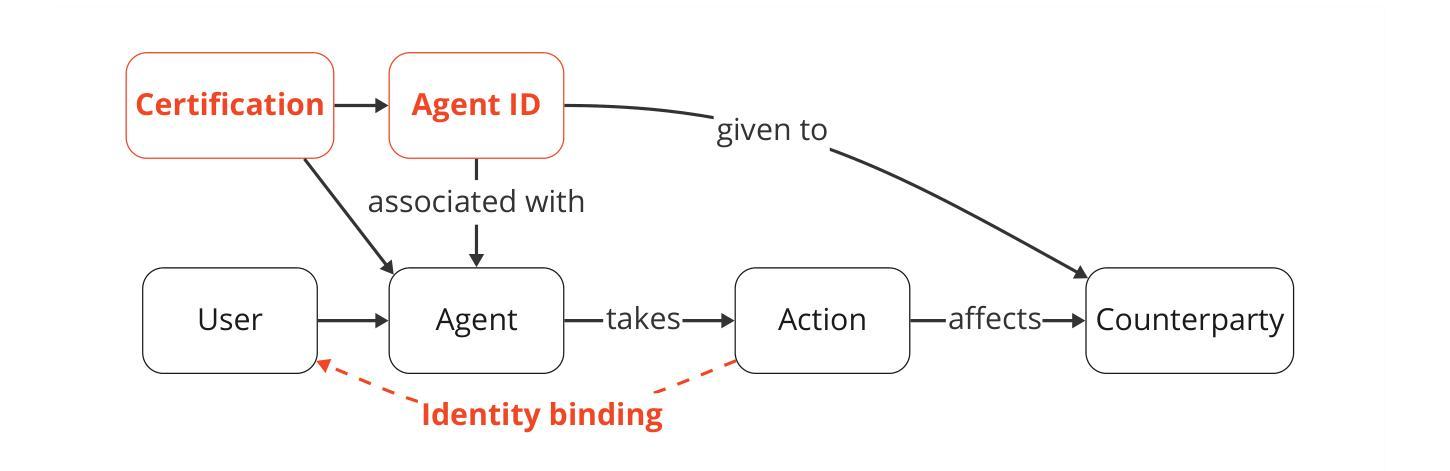
人工智能代理在开放环境中进行规划和执行交互。例如,OpenAI的操作员可以使用网页浏览器进行产品比较并在线购买商品。为了促进有益的交互并减少有害的交互,许多研究集中在直接修改代理行为。例如,开发者可以训练代理遵循用户指令。虽然这种关注直接修改是有用的,但不足以解决所有问题。我们还需要外部协议和系统来塑造代理与机构和其他参与者之间的交互方式。例如,代理需要更有效的协议来进行相互通信并达成协定。此外,将代理的行动归因于特定的人类或其他法律实体有助于建立信任,并遏制滥用行为。基于这一动机,我们提出了代理基础设施的概念:设计用于调解和影响代理与其环境之间交互和影响的外部技术系统和共享协议。正如互联网依赖于HTTPS等协议一样,我们的工作认为代理基础设施对于代理生态系统来说同样不可或缺。我们确定了代理基础设施的三个功能:1)将行动、属性和其他信息归属于特定代理、其用户或其他参与者;2)塑造代理之间的交互;3)检测和补救代理的有害行为。我们提供了此类功能的研究方向的不完全目录。对于每个方向,我们包括对用例、基础设施采用、与现有(互联网)基础设施的关系、局限性和开放问题的分析。在代理基础设施方面取得进展可以为更先进的代理的采用做好准备。
论文及项目相关链接
PDF Accepted to TMLR
摘要
AI代理能够在开放环境中进行规划与互动。例如,OpenAI的Operator可通过网页进行产品对比和在线购物。为研究如何促进有益的互动并避免有害互动,许多研究聚焦于直接调整代理行为,如训练代理遵循用户指令。尽管这种对直接修改的关注非常有帮助,但仍然不足以应对未来需求。未来还需要外部协议和系统来塑造代理与机构和其他参与者之间的互动方式。例如,代理需要更高效的协议进行相互沟通和达成协议。此外,将代理的行动归责于特定人类或其他法律实体有助于建立信任并遏制滥用行为。因此,我们提出了代理基础设施的概念:旨在调解和影响代理与其环境之间互动的外部技术系统和共享协议。正如互联网依赖HTTPS等协议一样,我们的工作认为代理基础设施对于代理生态系统同样不可或缺。我们确定了代理基础设施的三个功能:1)将行动、属性和其他信息归属于特定代理、其用户或其他参与者;2)塑造代理的互动;3)检测和补救代理的有害行为。我们为此类功能提供了一个不完整的研究方向目录,并针对每个方向分析了用例、基础设施采用情况、与现有(互联网)基础设施的关系、局限性和开放性问题。推进代理基础设施建设可为更先进代理的采用做好准备。
关键见解
- AI代理具备在开放环境中进行规划和执行互动的能力,例如使用网页进行产品对比和在线购物。
- 直接修改代理行为是促进有益互动和避免有害互动的关键研究方向,但仅此仍不足以应对未来挑战。
- 外部协议和系统对于塑造代理与机构和其他参与者之间的互动方式至关重要。
- 代理需要更高效的协议来相互沟通和达成协议。
- 将代理行动归责于特定人类或其他法律实体有助于建立信任并遏制滥用行为。
- 提出了代理基础设施的概念,旨在调解和影响代理与其环境之间的互动,类似于互联网对HTTPS等协议的依赖。
- 代理基础设施的三个主要功能包括:将行动和信息归属于特定代理和用户、塑造代理互动以及检测和修复有害的代理行为。
点此查看论文截图