⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
Authors:Yige Xu, Xu Guo, Zhiwei Zeng, Chunyan Miao
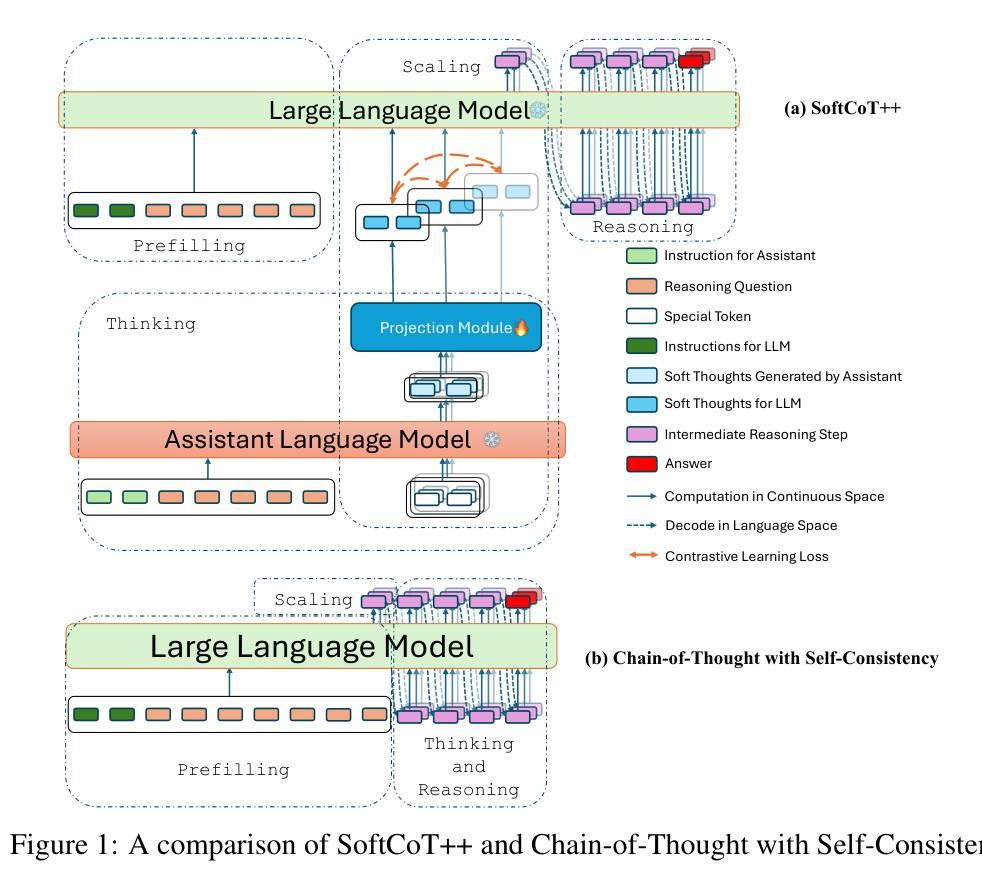
Test-Time Scaling (TTS) refers to approaches that improve reasoning performance by allocating extra computation during inference, without altering the model’s parameters. While existing TTS methods operate in a discrete token space by generating more intermediate steps, recent studies in Coconut and SoftCoT have demonstrated that thinking in the continuous latent space can further enhance the reasoning performance. Such latent thoughts encode informative thinking without the information loss associated with autoregressive token generation, sparking increased interest in continuous-space reasoning. Unlike discrete decoding, where repeated sampling enables exploring diverse reasoning paths, latent representations in continuous space are fixed for a given input, which limits diverse exploration, as all decoded paths originate from the same latent thought. To overcome this limitation, we introduce SoftCoT++ to extend SoftCoT to the Test-Time Scaling paradigm by enabling diverse exploration of thinking paths. Specifically, we perturb latent thoughts via multiple specialized initial tokens and apply contrastive learning to promote diversity among soft thought representations. Experiments across five reasoning benchmarks and two distinct LLM architectures demonstrate that SoftCoT++ significantly boosts SoftCoT and also outperforms SoftCoT with self-consistency scaling. Moreover, it shows strong compatibility with conventional scaling techniques such as self-consistency. Source code is available at https://github.com/xuyige/SoftCoT.
测试时缩放(TTS)是指通过推理时分配额外的计算资源来提高推理性能的方法,而不会改变模型的参数。虽然现有的TTS方法在离散标记空间内运行,通过生成更多的中间步骤来工作,但最近在Coconut和SoftCoT中的研究表明,在连续潜在空间中进行思考可以进一步提高推理性能。这种潜在的想法可以编码信息丰富的思考过程,而不会产生与自回归标记生成相关的信息丢失,因此对连续空间推理产生了更大的兴趣。与离散解码不同,离散解码通过重复采样可以探索多样化的推理路径,而连续空间中的潜在表示对于给定输入是固定的,这限制了多样化的探索,因为所有解码路径都来源于同一潜在想法。为了克服这一局限性,我们通过引入SoftCoT++来将SoftCoT扩展到测试时缩放范式,通过采用多种专业初始标记来扰动潜在的想法,并应用对比学习来促进软思维表示之间的多样性。在五个推理基准测试和两种不同的大型语言模型架构上的实验表明,SoftCoT++显著提升了SoftCoT的性能,并且优于SoftCoT的自一致性缩放。此外,它显示出与常规缩放技术(如自一致性)的强大兼容性。源代码可在https://github.com/xuyige/SoftCoT上找到。
论文及项目相关链接
PDF 14 pages
Summary
本文介绍了Test-Time Scaling(TTS)方法在提高推理性能方面的作用,通过推理时在连续潜在空间进行思考,无需改变模型参数即可分配额外的计算资源。最新研究Coconut和SoftCoT展示了连续潜在空间思考的优势。为克服连续空间推理中多样化探索的限制,提出SoftCoT++方法,通过多个专用初始标记扰动潜在思想,应用对比学习促进软思想表示之间的多样性。实验表明,SoftCoT++在五个推理基准测试和两个不同LLM架构上显著提升了SoftCoT的性能,且与传统扩展技术如自我一致性扩展兼容性强。
Key Takeaways
- Test-Time Scaling (TTS) 通过在推理时分配额外计算资源,提高模型推理性能,且无需改变模型参数。
- 连续潜在空间思考是最近研究的热点,其在提高推理性能方面具有优势,可以避免离散标记生成带来的信息损失。
- SoftCoT++克服了连续空间推理中多样化探索的限制,通过引入多个专用初始标记扰动潜在思想,并应用对比学习促进多样性。
- SoftCoT++在多个基准测试上显著提升了SoftCoT的性能,显示出强大的推理能力。
- SoftCoT++与其他传统扩展技术(如自我一致性扩展)兼容性强。
- SoftCoT++方法有助于促进多样化探索的思考路径。
点此查看论文截图

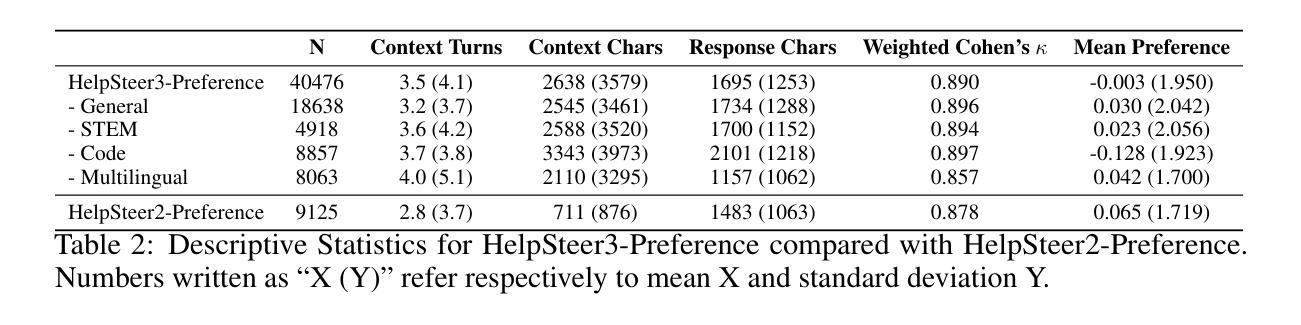
HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages
Authors:Zhilin Wang, Jiaqi Zeng, Olivier Delalleau, Hoo-Chang Shin, Felipe Soares, Alexander Bukharin, Ellie Evans, Yi Dong, Oleksii Kuchaiev
Preference datasets are essential for training general-domain, instruction-following language models with Reinforcement Learning from Human Feedback (RLHF). Each subsequent data release raises expectations for future data collection, meaning there is a constant need to advance the quality and diversity of openly available preference data. To address this need, we introduce HelpSteer3-Preference, a permissively licensed (CC-BY-4.0), high-quality, human-annotated preference dataset comprising of over 40,000 samples. These samples span diverse real-world applications of large language models (LLMs), including tasks relating to STEM, coding and multilingual scenarios. Using HelpSteer3-Preference, we train Reward Models (RMs) that achieve top performance on RM-Bench (82.4%) and JudgeBench (73.7%). This represents a substantial improvement (~10% absolute) over the previously best-reported results from existing RMs. We demonstrate HelpSteer3-Preference can also be applied to train Generative RMs and how policy models can be aligned with RLHF using our RMs. Dataset (CC-BY-4.0): https://huggingface.co/datasets/nvidia/HelpSteer3#preference
偏好数据集对于使用人类反馈强化学习(RLHF)训练通用领域、遵循指令的语言模型至关重要。每次后续数据发布都提高了对未来数据收集的期望,这意味着需要不断改进公开可用偏好数据的质量和多样性。为了解决这一需求,我们推出了HelpSteer3-Preference,这是一个采用宽松许可(CC-BY-4.0)的高质量、人工标注的偏好数据集,包含超过40,000个样本。这些样本涵盖了大型语言模型(LLM)的多样化现实世界应用,包括与STEM、编码和多语言场景相关的任务。使用HelpSteer3-Preference,我们训练的奖励模型(RM)在RM-Bench上达到顶级性能(82.4%),在JudgeBench上达到(73.7%)。这相比现有RM的最佳报告结果有了实质性的改进(绝对提高了约10%)。我们还展示了HelpSteer3-Preference如何应用于训练生成式RM,以及如何使用我们的RM将政策模型与RLHF对齐。数据集(CC-BY-4.0):[https://huggingface.co/datasets/nvidia/HelpSteer3#preference]
论文及项目相关链接
PDF 38 pages, 2 figures
Summary:
为了帮助训练通用领域的指令遵循语言模型,推出了HelpSteer3-Preference偏好数据集,该数据集拥有超过4万样本,涵盖了多样化的现实世界应用场景。通过使用该数据集训练的奖励模型,在RM-Bench和JudgeBench上的表现有了显著提升。此外,也展示了如何将HelpSteer3-Preference应用于训练生成式奖励模型以及如何使策略模型与RLHF对齐。数据集遵循CC-BY-4.0许可协议,公开可用。
Key Takeaways:
- HelpSteer3-Preference是一个高质量的偏好数据集,样本数量超过4万,涵盖大型语言模型的多种现实应用场景。
- 数据集采用CC-BY-4.0许可协议,公开可用,满足了训练通用领域语言模型的需求。
- 通过使用HelpSteer3-Preference数据集训练的奖励模型在RM-Bench和JudgeBench上的表现有所提升,达到领先水平。
- 数据集能够帮助提高语言模型的性能并推动其发展,使得训练结果更符合人类偏好。
- 该数据集适用于训练生成式奖励模型,展示了其广泛的应用潜力。
- 通过策略模型与RLHF的对齐,强化了语言模型的适应性和智能水平。
点此查看论文截图


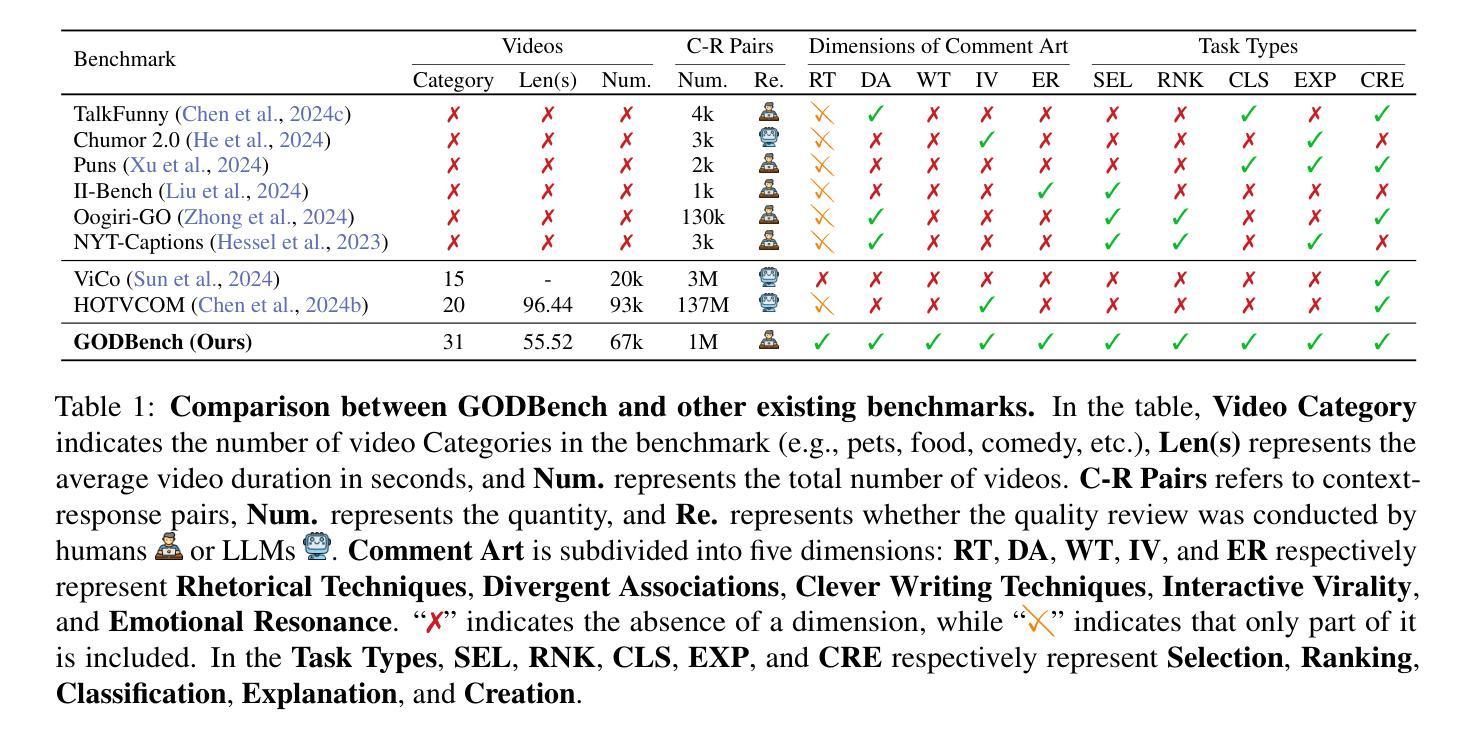
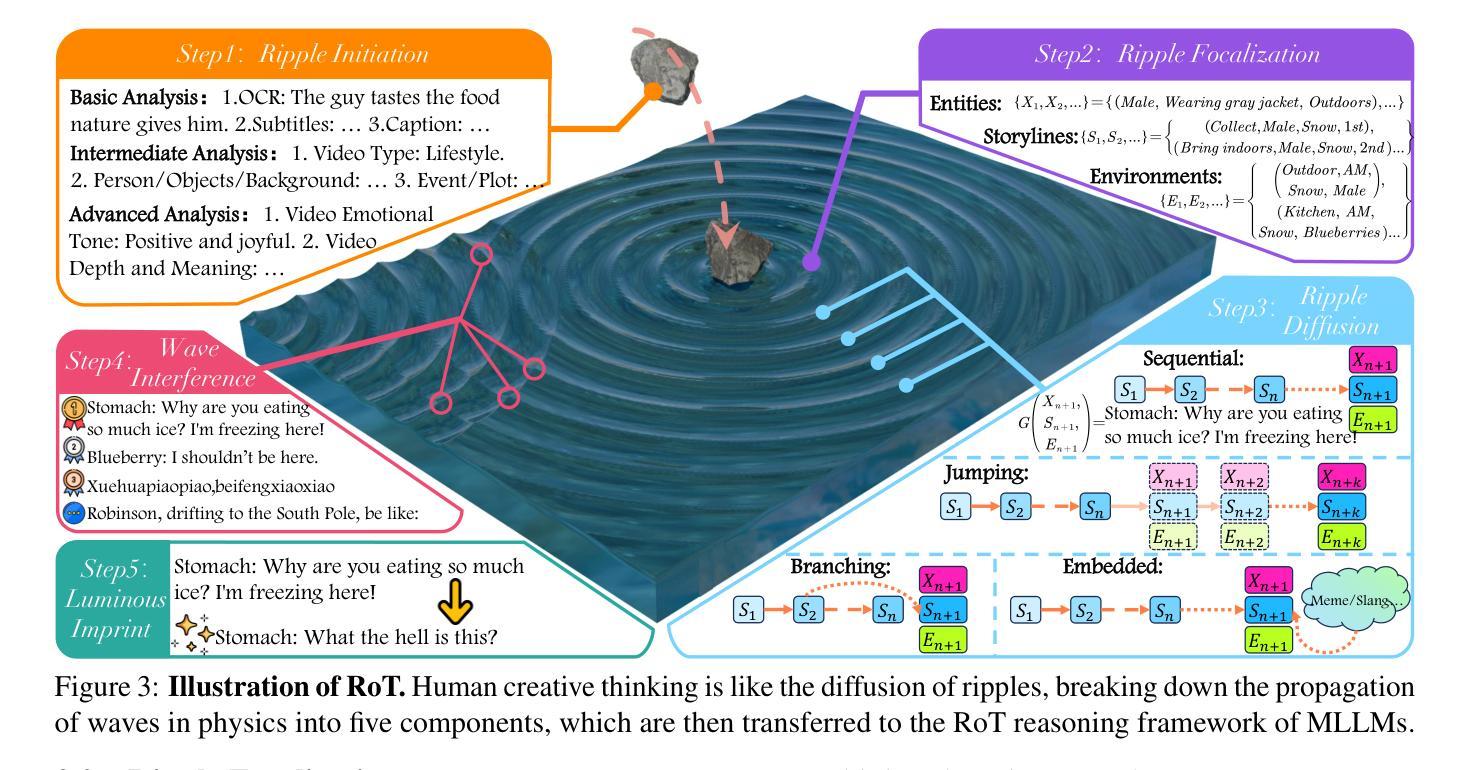
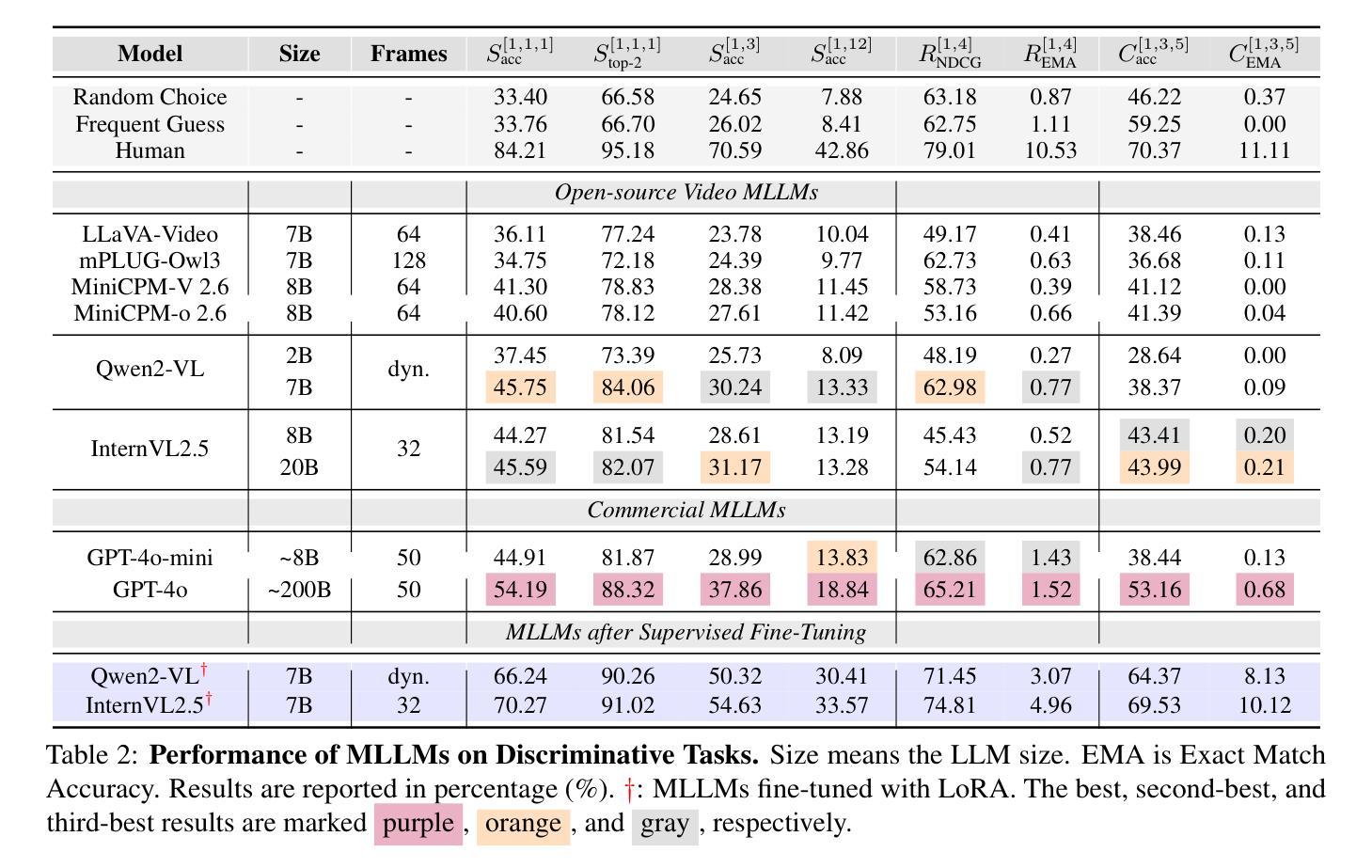
GODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art
Authors:Chenkai Zhang, Yiming Lei, Zeming Liu, Haitao Leng, Shaoguo Liu, Tingting Gao, Qingjie Liu, Yunhong Wang
Video Comment Art enhances user engagement by providing creative content that conveys humor, satire, or emotional resonance, requiring a nuanced and comprehensive grasp of cultural and contextual subtleties. Although Multimodal Large Language Models (MLLMs) and Chain-of-Thought (CoT) have demonstrated strong reasoning abilities in STEM tasks (e.g. mathematics and coding), they still struggle to generate creative expressions such as resonant jokes and insightful satire. Moreover, existing benchmarks are constrained by their limited modalities and insufficient categories, hindering the exploration of comprehensive creativity in video-based Comment Art creation. To address these limitations, we introduce GODBench, a novel benchmark that integrates video and text modalities to systematically evaluate MLLMs’ abilities to compose Comment Art. Furthermore, inspired by the propagation patterns of waves in physics, we propose Ripple of Thought (RoT), a multi-step reasoning framework designed to enhance the creativity of MLLMs. Extensive experiments reveal that existing MLLMs and CoT methods still face significant challenges in understanding and generating creative video comments. In contrast, RoT provides an effective approach to improve creative composing, highlighting its potential to drive meaningful advancements in MLLM-based creativity. GODBench is publicly available at https://github.com/stan-lei/GODBench-ACL2025.
视频评论艺术通过提供传达幽默、讽刺或情感共鸣的创意内容,增强用户参与度,这要求微妙而全面地把握文化和语境的细微差别。尽管多模态大型语言模型(MLLMs)和思维链(CoT)在STEM任务(如数学和编码)中展示了强大的推理能力,但它们仍难以生成如产生共鸣的笑话和富有洞察力的讽刺等创意表达。此外,现有基准测试受限于其有限的模式和不足的分类,阻碍了基于视频的评论艺术创作的全面创造力的探索。为了解决这些局限性,我们引入了GODBench,这是一个新颖的基准测试,它整合了视频和文本模式,系统地评估MLLMs创作评论艺术的能力。此外,受物理学中波动传播模式的启发,我们提出了思想涟漪(RoT)多步推理框架,旨在提高MLLMs的创造力。大量实验表明,现有的MLLMs和CoT方法在理解和生成创造性视频评论方面仍面临巨大挑战。相比之下,RoT提供了一种提高创造性写作的有效方法,突显其在推动基于MLLM的创造力方面的潜力。GODBench可在https://github.com/stan-lei/GODBench-ACL2025上公开访问。
论文及项目相关链接
PDF 69 pages, 66 figures, accepted by ACL 2025
摘要
视频评论艺术通过提供传达幽默、讽刺或情感共鸣的创意内容,增强了用户参与度。这要求深入全面地理解文化和语境的细微差别。虽然多模态大型语言模型(MLLMs)和思维链(CoT)在STEM任务(如数学和编程)中展现出强大的推理能力,但它们仍然难以生成如共鸣笑话和深刻讽刺等创意表达。为解决现有基准测试在视频评论艺术创造力评估方面的局限性,我们引入了GODBench基准测试,它整合了视频和文本模态,系统地评估MLLMs创作评论艺术的能力。此外,受物理中波动传播模式的启发,我们提出了思想涟漪(RoT)多步推理框架,旨在增强MLLMs的创造力。实验表明,现有MLLMs和CoT方法在理解和生成创意视频评论方面仍面临巨大挑战。相比之下,RoT提供了一种有效的改进创作的方法,突显其在推动基于MLLM的创造力方面的潜力。GODBench已在https://github.com/stan-lei/GODBench-ACL2025公开可用。
关键见解
- 视频评论艺术通过创意内容增强用户参与度,这需要理解文化和语境的细微差别。
- 多模态大型语言模型和思维链在STEM任务中表现出强大的推理能力,但在生成创意表达方面仍有困难。
- 现有基准测试在评估视频评论艺术的创造力方面存在局限性。
- 引入GODBench基准测试,整合视频和文本模态,评估MLLMs创作评论艺术的能力。
- 提出思想涟漪(RoT)多步推理框架,增强MLLMs的创造力。
- 实验显示,现有MLLMs和CoT方法在理解和生成创意视频评论方面面临挑战。
点此查看论文截图

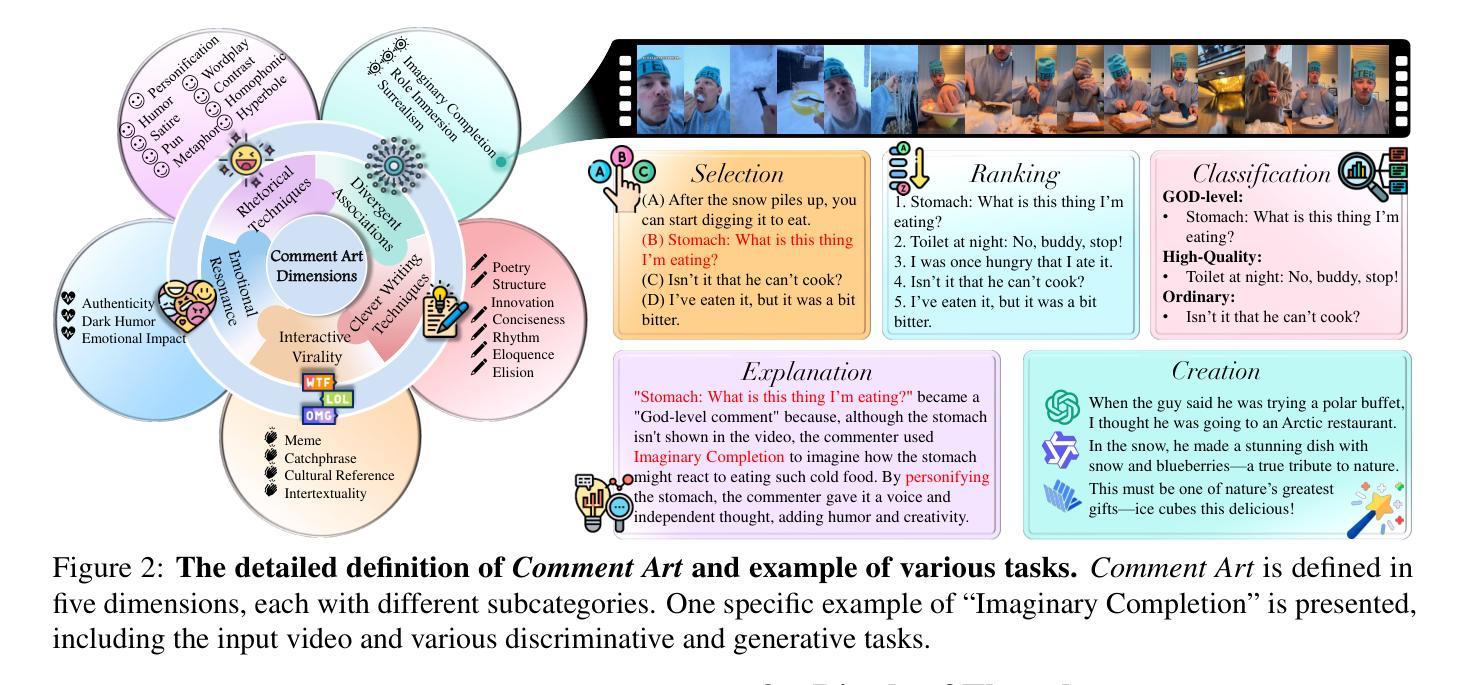
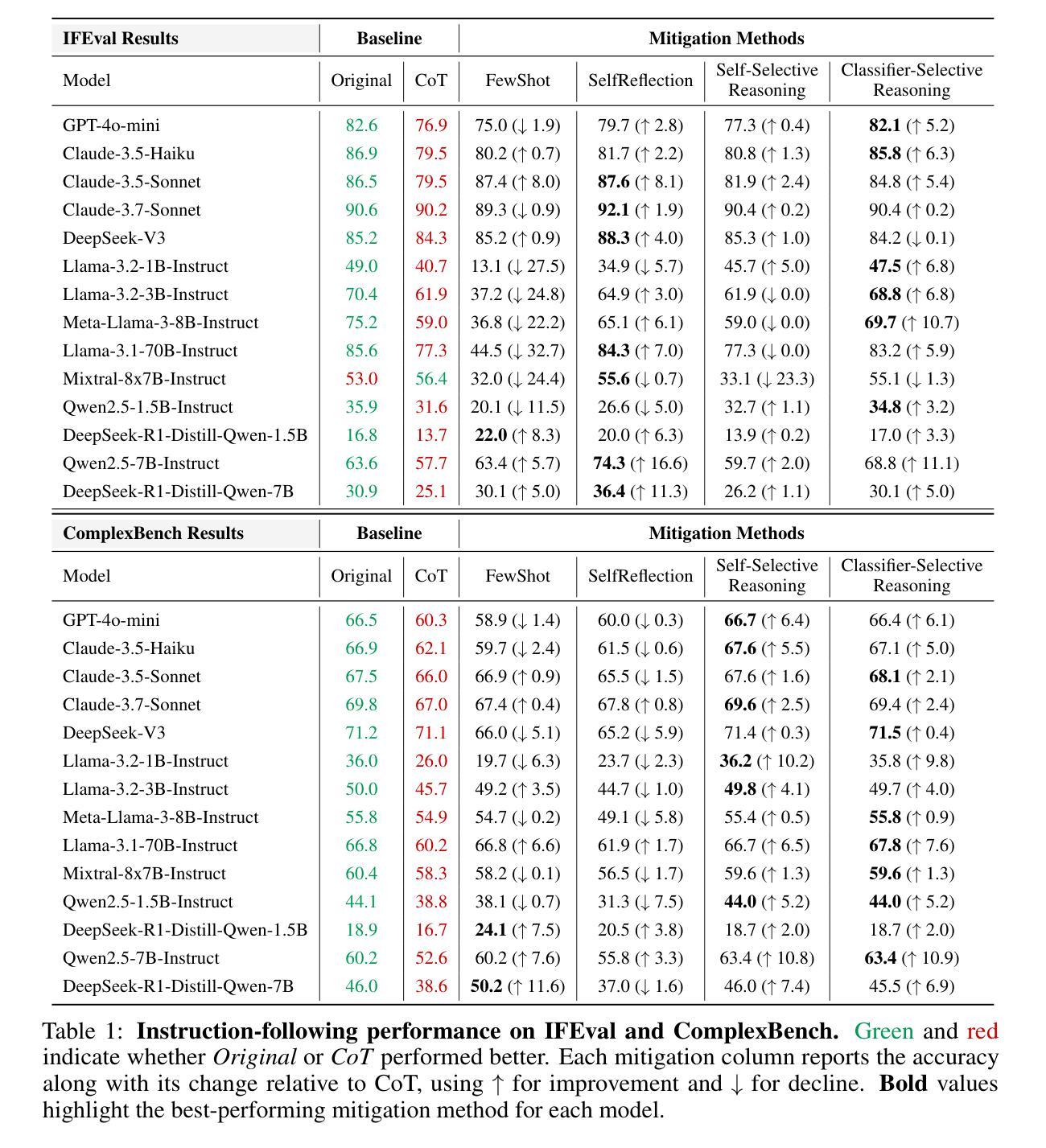
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
Authors:Xiaomin Li, Zhou Yu, Zhiwei Zhang, Xupeng Chen, Ziji Zhang, Yingying Zhuang, Narayanan Sadagopan, Anurag Beniwal
Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
推理增强大型语言模型(RLLMs)无论是否经过明确的推理训练或通过思维链(CoT)进行提示,在许多复杂的推理任务上都达到了最先进的性能。然而,我们发现了一个令人惊讶且以前被忽视的现象:明确的CoT推理会显著降低指令执行准确性。我们在两个基准测试上对15个模型进行了评估:IFeval(具有简单、可验证的规则约束)和ComplexBench(具有复杂、组合约束),我们始终观察到当应用CoT提示时性能下降。通过大规模案例研究和基于注意力的分析,我们识别出推理有助于(例如,格式化或词汇精度)或有害(例如,忽视简单约束或引入不必要内容)的常见模式。我们提出一个指标,约束注意力,来量化生成过程中的模型关注点,并表明CoT推理通常会分散对指令相关标记的注意力。为了减轻这些影响,我们引入并评估了四种策略:上下文学习、自我反思、自我选择性推理和分类器选择性推理。我们的结果表明,选择性推理策略,特别是分类器选择性推理,可以大幅度恢复丢失的性能。据我们所知,这是第一项工作,系统地暴露了推理在指令执行中的失败并提供了实用的缓解策略。
论文及项目相关链接
Summary
在本文中,研究探讨了明确连贯推理(CoT)在大语言模型中对指令遵循准确性的潜在负面影响。作者们在多种模型与基准测试中发现,使用CoT推理时模型性能显著下降。对此,研究者进行了大规模的案例研究并引入了一个新的评价指标来量化模型生成过程中的关注焦点。文章提出了四种策略来缓解推理导致的注意力分散问题,其中选择性推理策略特别是分类器选择性推理在恢复模型性能上取得了显著效果。
Key Takeaways
- RLLMs在复杂推理任务上表现出卓越性能,但发现明确的连贯推理(CoT)会显著降低指令遵循的准确性。
- 在两个基准测试中(IFEval和ComplexBench),使用CoT推理时模型性能下降。
- 通过大规模案例研究和注意力分析,识别出推理过程帮助或阻碍的不同模式。
- 提出新的评价指标来衡量模型在生成过程中的注意力焦点,发现CoT推理导致模型在指令相关标记上的注意力分散。
- 引入四种策略来缓解注意力分散问题,包括上下文学习、自我反思和自我选择性推理以及分类器选择性推理等。
- 分类器选择性推理策略在恢复模型性能方面尤为有效。
点此查看论文截图


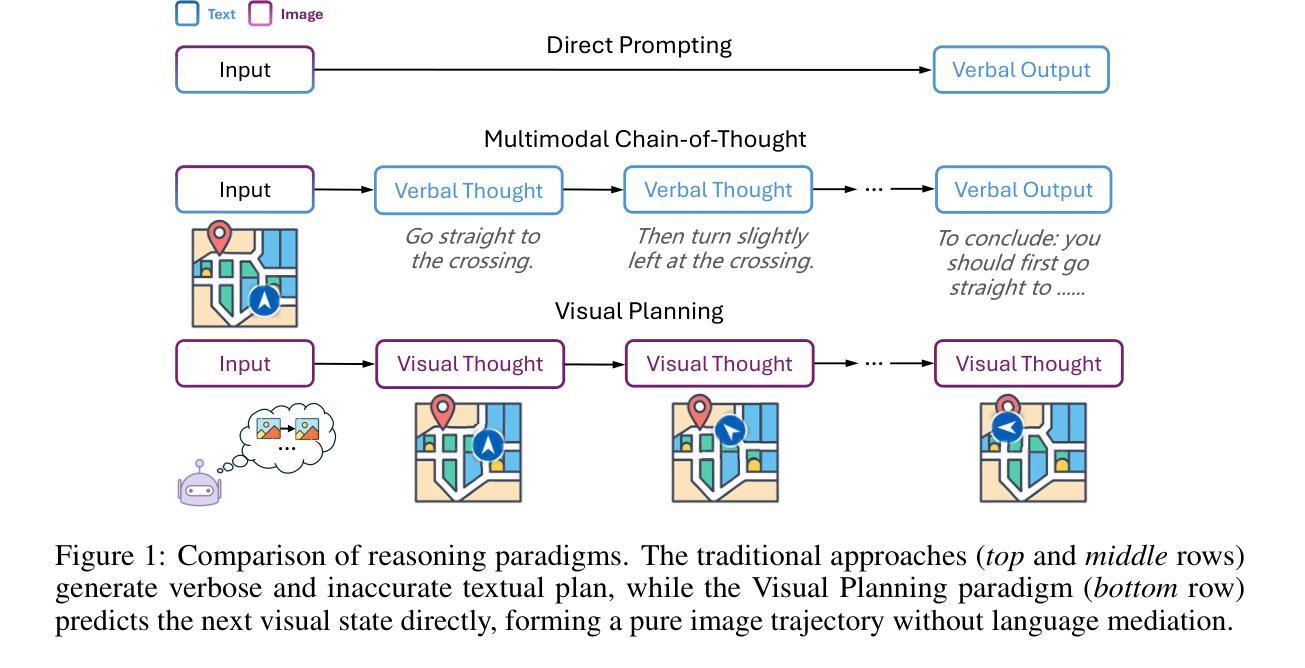
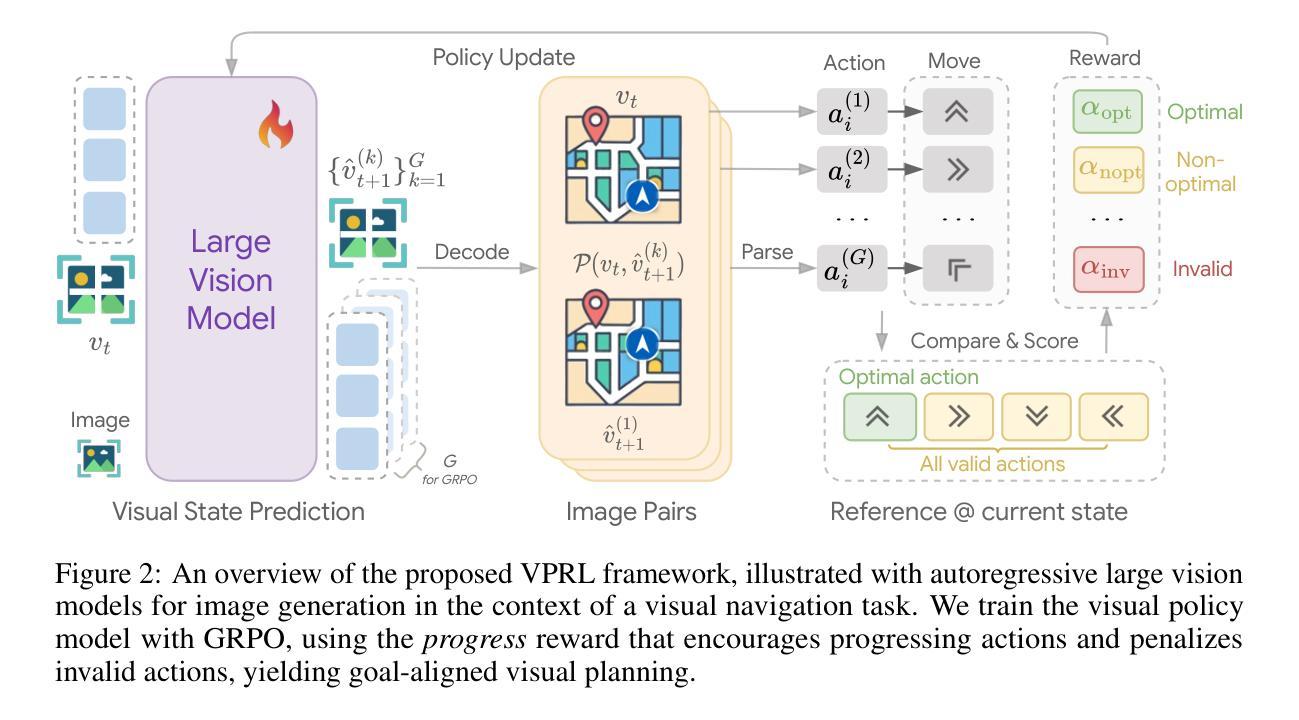
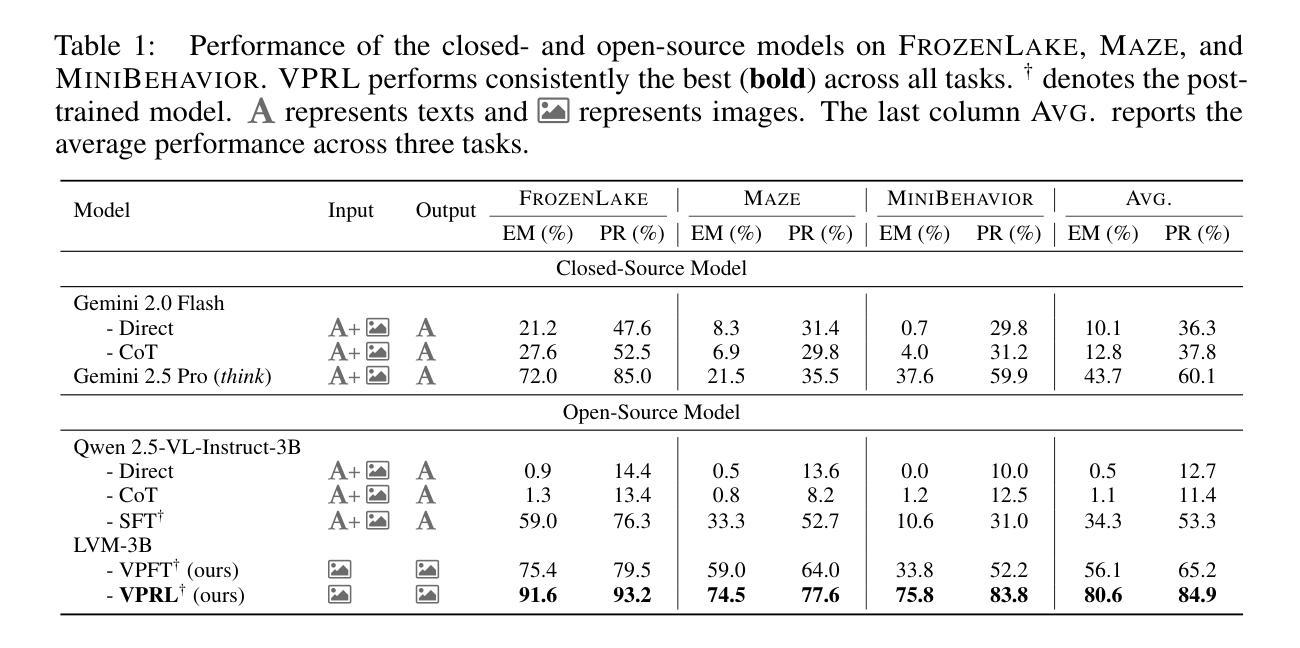
Visual Planning: Let’s Think Only with Images
Authors:Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, Ivan Vulić
Recent advancements in Large Language Models (LLMs) and their multimodal extensions (MLLMs) have substantially enhanced machine reasoning across diverse tasks. However, these models predominantly rely on pure text as the medium for both expressing and structuring reasoning, even when visual information is present. In this work, we argue that language may not always be the most natural or effective modality for reasoning, particularly in tasks involving spatial and geometrical information. Motivated by this, we propose a new paradigm, Visual Planning, which enables planning through purely visual representations, independent of text. In this paradigm, planning is executed via sequences of images that encode step-by-step inference in the visual domain, akin to how humans sketch or visualize future actions. We introduce a novel reinforcement learning framework, Visual Planning via Reinforcement Learning (VPRL), empowered by GRPO for post-training large vision models, leading to substantial improvements in planning in a selection of representative visual navigation tasks, FrozenLake, Maze, and MiniBehavior. Our visual planning paradigm outperforms all other planning variants that conduct reasoning in the text-only space. Our results establish Visual Planning as a viable and promising alternative to language-based reasoning, opening new avenues for tasks that benefit from intuitive, image-based inference.
近年来,大型语言模型(LLM)及其多模态扩展(MLLM)的进展极大地提高了跨不同任务的机器推理能力。然而,这些模型主要依赖纯文本作为表达和结构化推理的媒介,即使存在视觉信息也是如此。在这项工作中,我们主张语言并不总是最自然或最有效的推理方式,特别是在涉及空间和几何信息的任务中。受此启发,我们提出了一种新的范式——视觉规划,它能够通过纯粹的视觉表示进行规划,独立于文本。在这种范式中,规划是通过一系列图像执行的,这些图像在视觉领域编码了逐步推理,就像人类如何勾画或可视化未来行动一样。我们引入了一种新型强化学习框架——通过强化学习的视觉规划(VPRL),借助GRPO对大型视觉模型进行后训练,导致在具有代表性的视觉导航任务、FrozenLake、迷宫和MiniBehavior中的规划能力得到实质性提高。我们的视觉规划范式在只进行文本空间推理的规划中表现优于所有其他规划变体。我们的结果确立了视觉规划作为语言基础推理的一种可行且有前途的替代方案,为受益于直观、基于图像推理的任务开辟了新途径。
论文及项目相关链接
PDF 10 pages, 6 figures, 1 table (26 pages, 12 figures, 8 tables including references and appendices)
Summary
近期大型语言模型(LLM)和多模态扩展模型(MLLM)的进步极大地提高了跨不同任务的机器推理能力。然而,这些模型主要通过文本表达和结构推理,即使存在视觉信息也是如此。本文提出,在涉及空间和几何信息的任务中,语言可能并非最自然或有效的推理方式。为此,提出了一种新的推理方式——视觉规划,通过纯粹的视觉表示进行规划,独立于文本。视觉规划通过图像序列执行规划,这些图像编码了视觉领域的逐步推理,类似于人类如何绘制或可视化未来行动。通过强化学习框架和GRPO后训练大型视觉模型,实现了视觉规划的实质性改进,并在代表性视觉导航任务中取得了良好表现。本文的研究结果证明了视觉规划作为一种可行且有前途的替代语言基础推理方法,为受益于直观图像推理的任务开辟了新途径。
Key Takeaways
- 大型语言模型(LLM)和多模态扩展模型(MLLM)在机器推理方面取得了显著进展。
- 现有模型主要依赖文本进行表达和结构化推理,即使存在视觉信息时也是如此。
- 在涉及空间和几何信息的任务中,语言可能不是最自然或有效的推理方式。
- 提出了新的推理方法——视觉规划,该方法通过纯粹的视觉表示进行规划,不依赖于文本。
- 视觉规划通过图像序列执行,这些图像编码了类似于人类如何绘制或可视化未来行动的逐步推理。
- 强化学习框架和GRPO后训练大型视觉模型,实现了视觉规划的实质性改进。
点此查看论文截图

Patho-R1: A Multimodal Reinforcement Learning-Based Pathology Expert Reasoner
Authors:Wenchuan Zhang, Penghao Zhang, Jingru Guo, Tao Cheng, Jie Chen, Shuwan Zhang, Zhang Zhang, Yuhao Yi, Hong Bu
Recent advances in vision language models (VLMs) have enabled broad progress in the general medical field. However, pathology still remains a more challenging subdomain, with current pathology specific VLMs exhibiting limitations in both diagnostic accuracy and reasoning plausibility. Such shortcomings are largely attributable to the nature of current pathology datasets, which are primarily composed of image description pairs that lack the depth and structured diagnostic paradigms employed by real world pathologists. In this study, we leverage pathology textbooks and real world pathology experts to construct high-quality, reasoning-oriented datasets. Building on this, we introduce Patho-R1, a multimodal RL-based pathology Reasoner, trained through a three-stage pipeline: (1) continued pretraining on 3.5 million image-text pairs for knowledge infusion; (2) supervised fine-tuning on 500k high-quality Chain-of-Thought samples for reasoning incentivizing; (3) reinforcement learning using Group Relative Policy Optimization and Decoupled Clip and Dynamic sAmpling Policy Optimization strategies for multimodal reasoning quality refinement. To further assess the alignment quality of our dataset, we propose PathoCLIP, trained on the same figure-caption corpus used for continued pretraining. Comprehensive experimental results demonstrate that both PathoCLIP and Patho-R1 achieve robust performance across a wide range of pathology-related tasks, including zero-shot classification, cross-modal retrieval, Visual Question Answering, and Multiple Choice Question. Our project is available at the Patho-R1 repository: https://github.com/Wenchuan-Zhang/Patho-R1.
近期,视觉语言模型(VLMs)的进展为一般医疗领域带来了广泛的进步。然而,病理学仍然是一个更具挑战性的子领域。当前的病理学特定VLMs在诊断准确性和推理合理性方面存在局限性。这种缺陷在很大程度上归因于当前病理学数据集的性质,这些数据集主要由缺乏现实世界病理学家所采用的深度和结构化诊断范式的图像描述对组成。在这项研究中,我们利用病理学教材和现实世界病理学专家来构建高质量、以推理为导向的数据集。在此基础上,我们引入了Patho-R1,这是一个基于多模式强化学习的病理学推理器,通过三阶段管道进行训练:(1)在350万图像文本对上持续预训练,以注入知识;(2)在50万个高质量的思维链样本上进行监督微调,以激励推理;(3)使用集团相对策略优化和解耦剪辑以及动态采样策略优化的强化学习策略,以提高多模式推理质量。为了进一步评估我们数据集的对齐质量,我们提出了在同一图像-标题语料库上训练的PathoCLIP,该语料库用于持续预训练。综合实验结果表明,PathoCLIP和Patho-R1在广泛的病理学相关任务中表现稳健,包括零样本分类、跨模态检索、视觉问答和多选题。我们的项目可在Patho-R1仓库中找到:https://github.com/Wenchuan-Zhang/Patho-R1。
论文及项目相关链接
Summary
本文主要探讨了基于最新进展的医学影像与语言模型技术在病理学领域的广泛应用及存在的挑战。研究团队利用病理教科书和专家构建了高质量、以推理为导向的数据集,并基于此推出了Patho-R1模型,该模型通过三个阶段进行训练,包括知识灌输、推理激励和多模态推理质量优化。同时,为了评估数据集的质量,研究团队还提出了PathoCLIP模型。实验结果显示这两个模型在多种病理学任务中表现优异。项目的相关信息可通过Patho-R1仓库获取。
Key Takeaways
- 医学影像与语言模型技术在病理学领域的应用面临挑战,尤其在诊断准确性和推理合理性方面存在局限。
- 当前病理数据集缺乏深度和结构化诊断范式,导致模型性能受限。
- 研究团队利用病理教科书和专家构建高质量、以推理为导向的数据集,以解决现有问题。
- Patho-R1模型通过三个阶段进行训练:知识灌输、推理激励和多模态推理质量优化。
- PathoCLIP模型的提出用于评估数据集质量,其训练基于相同的图像-文本对用于持续预训练。
- 实验结果显示PathoCLIP和Patho-R1模型在多种病理学任务中表现优秀,包括零样本分类、跨模态检索、视觉问答和多项选择题等。
点此查看论文截图

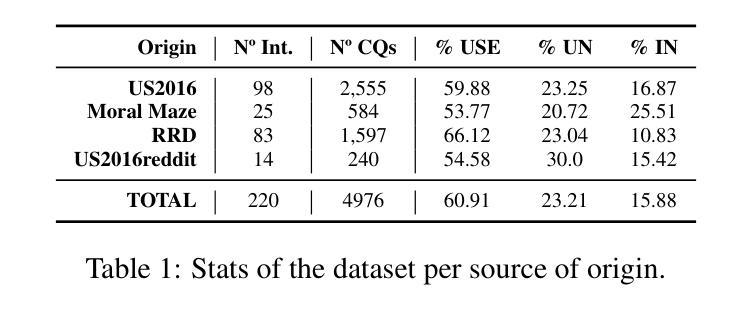
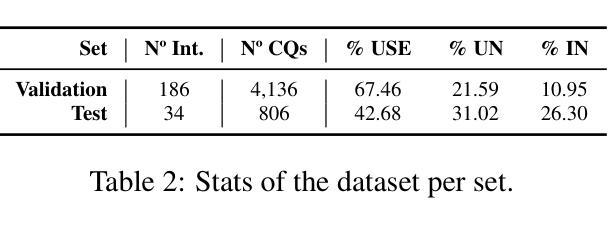
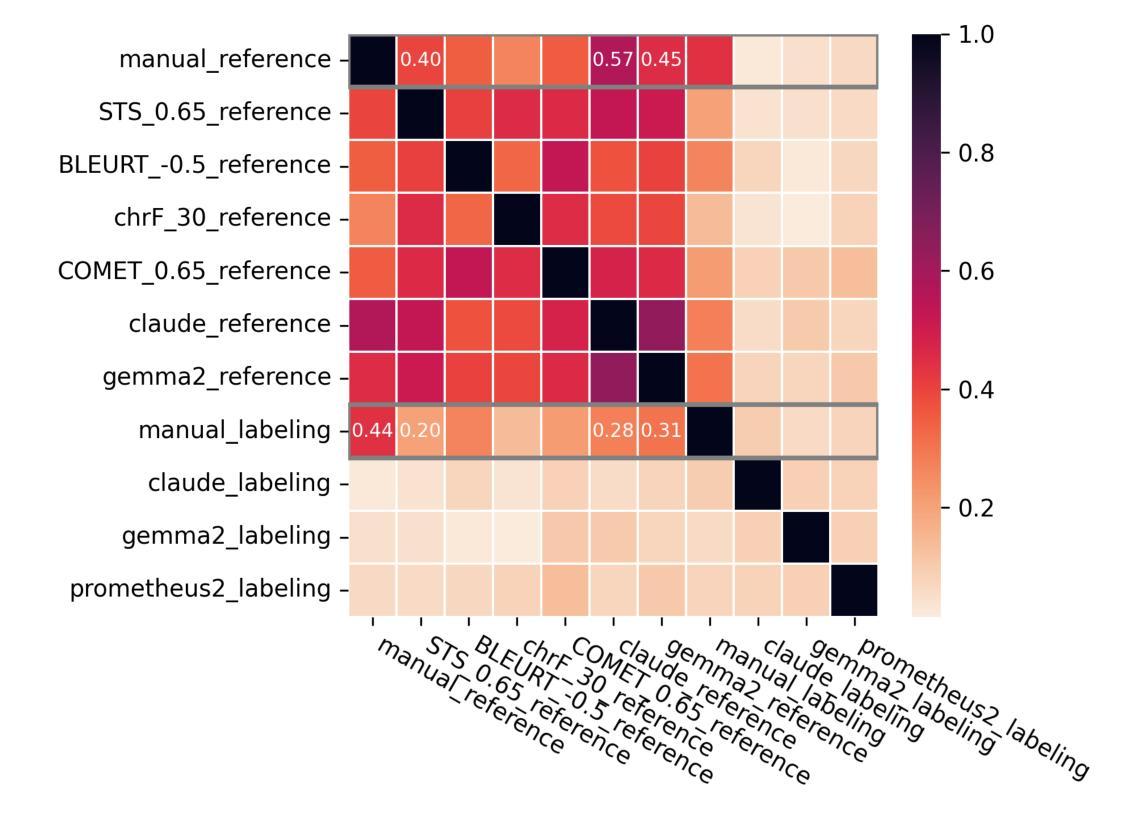
Benchmarking Critical Questions Generation: A Challenging Reasoning Task for Large Language Models
Authors:Banca Calvo Figueras, Rodrigo Agerri
The task of Critical Questions Generation (CQs-Gen) aims to foster critical thinking by enabling systems to generate questions that expose assumptions and challenge the reasoning in arguments. Despite growing interest in this area, progress has been hindered by the lack of suitable datasets and automatic evaluation standards. This work presents a comprehensive approach to support the development and benchmarking of systems for this task. We construct the first large-scale manually-annotated dataset. We also investigate automatic evaluation methods and identify a reference-based technique using large language models (LLMs) as the strategy that best correlates with human judgments. Our zero-shot evaluation of 11 LLMs establishes a strong baseline while showcasing the difficulty of the task. Data, code, and a public leaderboard are provided to encourage further research not only in terms of model performance, but also to explore the practical benefits of CQs-Gen for both automated reasoning and human critical thinking.
批判性问题生成(CQs-Gen)的任务旨在通过使系统能够生成揭示假设并挑战论证推理的问题来培养批判性思维。尽管这个领域日益受到关注,但由于缺乏合适的数据集和自动评估标准,进展受到了阻碍。这项工作提出了一个全面的方法来支持该任务的系统开发和评估。我们构建了第一个大规模手动注释的数据集。我们还研究了自动评估方法,并确定了使用大型语言模型(LLM)的参考基准技术是与人判断最相关的策略。我们对11个LLM进行的零样本评估建立了强大的基准线,同时展示了该任务的难度。为了鼓励进一步研究,不仅是从模型性能的角度,还从探索CQs-Gen对自动化推理和人类批判性思维的实际益处,我们提供了数据、代码和公开排行榜。
论文及项目相关链接
Summary
本文介绍了批判性问题生成(CQs-Gen)的任务目标,即培养系统的批判性思维能力,生成能够揭露假设和质疑论证推理的问题。尽管该领域日益受到关注,但由于缺乏合适的数据集和自动评估标准,进展受到了阻碍。本研究提出了一种全面的方法来支持该任务的系统开发和基准测试。本研究构建了首个大规模手动标注数据集,并探讨了自动评估方法,确定了基于大型语言模型(LLMs)的参考技术作为与人类判断最相关的策略。对11种LLMs的零样本评估建立了强大的基准线,同时展示了该任务的难度。提供数据、代码和公开排行榜,以鼓励模型性能方面的进一步研究,并探索CQs-Gen对自动化推理和人类批判性思维的实际益处。
Key Takeaways
- 批判性问题生成(CQs-Gen)旨在通过生成问题培养系统的批判性思维能力。
- 缺少合适的数据集和自动评估标准是阻碍该领域进展的主要原因。
- 研究构建了首个大规模手动标注数据集来支持CQs-Gen任务。
- 自动评估方法被探讨,其中基于大型语言模型(LLMs)的参考技术被确定为与人类判断最相关的策略。
- 对11种LLMs的零样本评估显示了该任务的难度。
- 提供数据、代码和公开排行榜以鼓励更多研究,不仅关注模型性能,还关注CQs-Gen对自动化推理和人类批判性思维的益处。
- 该研究为CQs-Gen任务的发展提供了全面支持,包括数据集、评估方法和公开平台。
点此查看论文截图

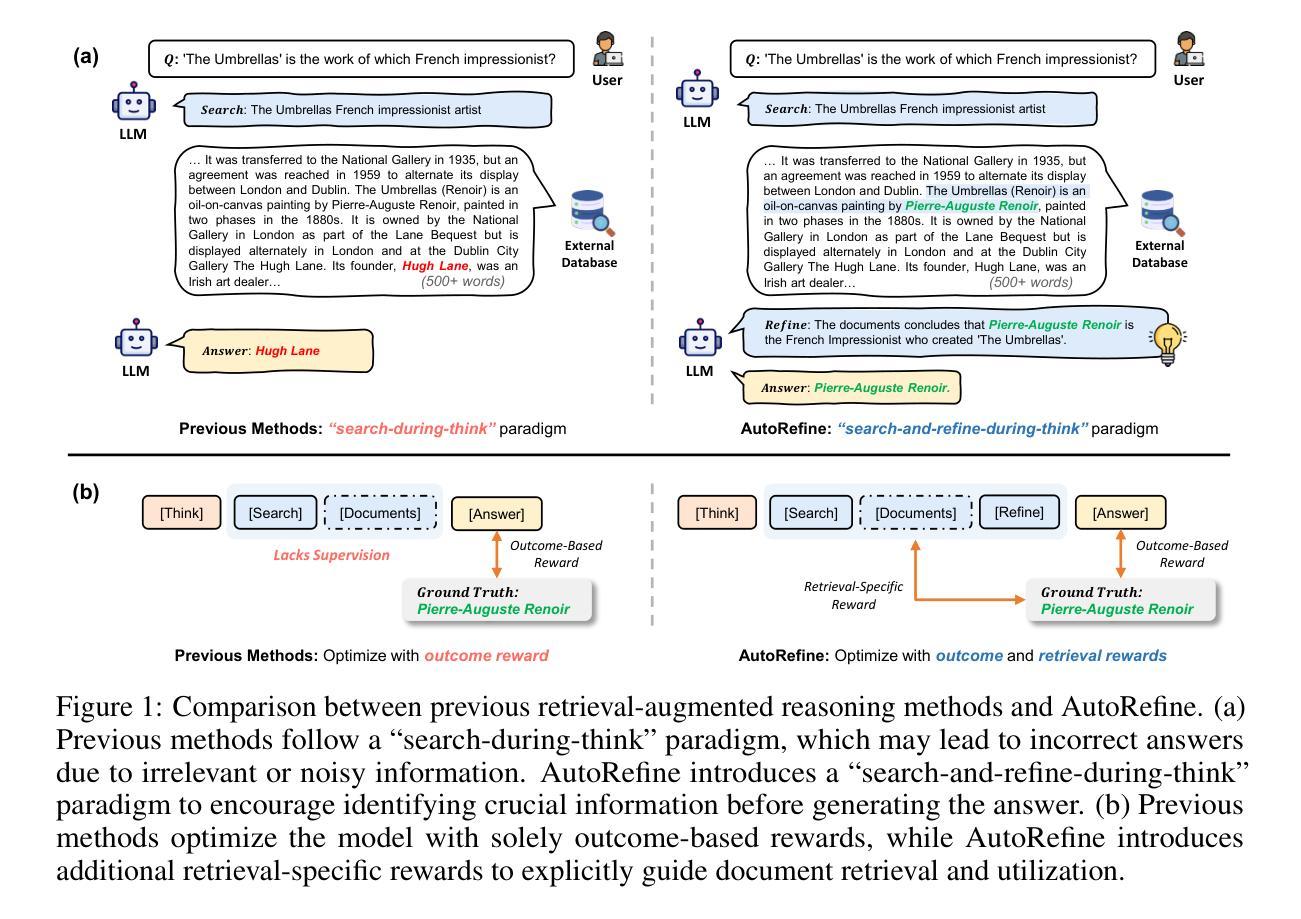
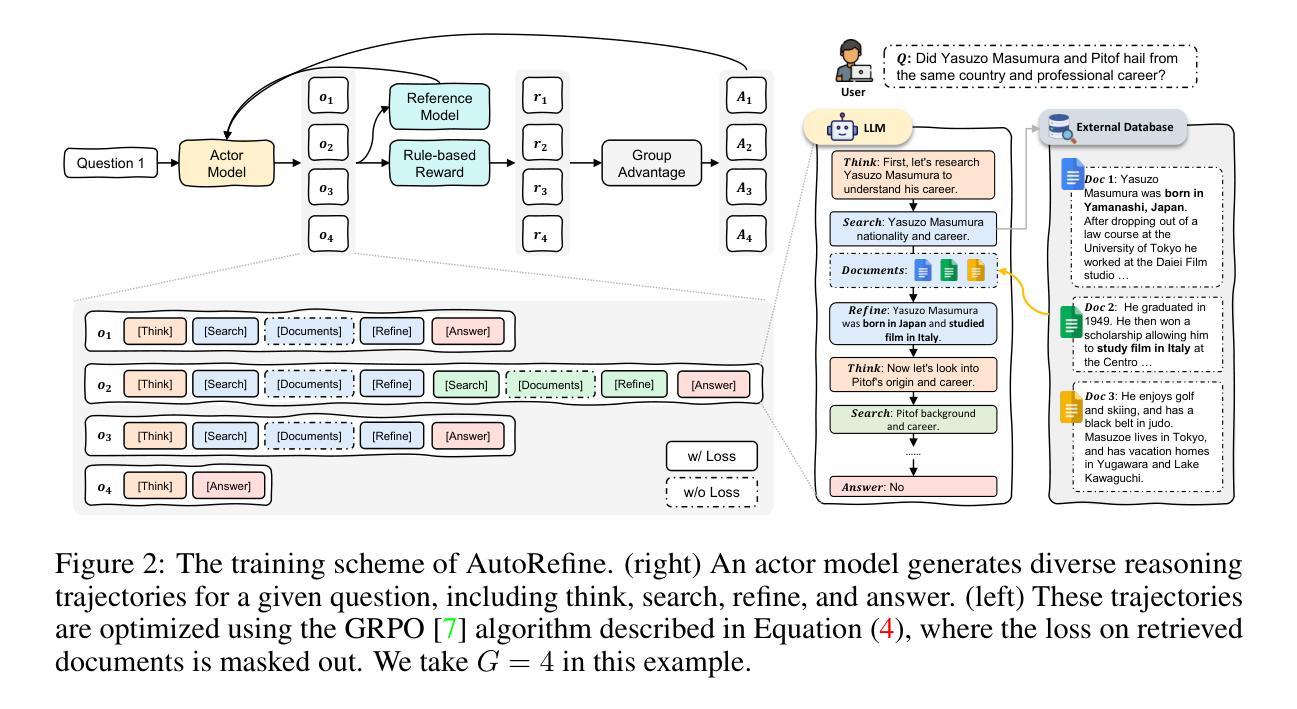
Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
Authors:Yaorui Shi, Shihan Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, Xiang Wang
Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think’’ paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
大型语言模型已经展现出令人印象深刻的推理能力,但其本质上受到知识库的限制。检索增强推理通过允许大型语言模型查询外部资源来缓解这一限制,但现有方法经常检索到不相关或嘈杂的信息,阻碍了准确的推理。在本文中,我们提出了AutoRefine,这是一种采用新型“思考过程中的搜索与完善”范式的强化学习后训练框架。AutoRefine在连续的搜索调用之间引入了明确的知识完善步骤,使模型能够迭代地过滤、提炼和整理证据,然后生成答案。此外,我们通过使用群体相对策略优化,结合了定制的检索特定奖励和答案正确性奖励。在单跳和多跳问答基准测试上的实验表明,AutoRefine显著优于现有方法,特别是在复杂的多跳推理场景中。详细分析表明,AutoRefine能够进行频繁的高质量搜索,并能有效地合成证据。
论文及项目相关链接
Summary
本文提出一种名为AutoRefine的强化学习后训练框架,采用新的“边搜索边细化思考”模式来缓解大型语言模型在推理方面的固有局限性。该框架在连续搜索调用之间引入明确的知识细化步骤,使模型能够迭代地过滤、提炼和整理证据,生成答案。同时,通过结合针对检索的特定奖励和基于答案正确性的奖励,使用群组相对策略优化。在单跳和多跳问答基准测试上的实验表明,AutoRefine显著优于现有方法,特别是在复杂的多跳推理场景中。
Key Takeaways
- 大型语言模型虽然具备令人印象深刻的推理能力,但其知识库的限制影响了性能。
- 检索增强推理通过允许语言模型查询外部资源来减轻这一限制。
- 现有方法经常检索不相关或嘈杂的信息,阻碍准确推理。
- AutoRefine是一个强化学习后训练框架,采用“边搜索边细化思考”模式来提高检索质量。
- AutoRefine在连续搜索之间引入知识细化步骤,实现证据的迭代过滤、提炼和整理。
- 通过结合检索特定奖励和答案正确性奖励,使用群组相对策略优化来提高性能。
点此查看论文截图


Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
Authors:Zhangying Feng, Qianglong Chen, Ning Lu, Yongqian Li, Siqi Cheng, Shuangmu Peng, Duyu Tang, Shengcai Liu, Zhirui Zhang
The development of reasoning capabilities represents a critical frontier in large language models (LLMs) research, where reinforcement learning (RL) and process reward models (PRMs) have emerged as predominant methodological frameworks. Contrary to conventional wisdom, empirical evidence from DeepSeek-R1 demonstrates that pure RL training focused on mathematical problem-solving can progressively enhance reasoning abilities without PRM integration, challenging the perceived necessity of process supervision. In this study, we conduct a systematic investigation of the relationship between RL training and PRM capabilities. Our findings demonstrate that problem-solving proficiency and process supervision capabilities represent complementary dimensions of reasoning that co-evolve synergistically during pure RL training. In particular, current PRMs underperform simple baselines like majority voting when applied to state-of-the-art models such as DeepSeek-R1 and QwQ-32B. To address this limitation, we propose Self-PRM, an introspective framework in which models autonomously evaluate and rerank their generated solutions through self-reward mechanisms. Although Self-PRM consistently improves the accuracy of the benchmark (particularly with larger sample sizes), analysis exposes persistent challenges: The approach exhibits low precision (<10%) on difficult problems, frequently misclassifying flawed solutions as valid. These analyses underscore the need for continued RL scaling to improve reward alignment and introspective accuracy. Overall, our findings suggest that PRM may not be essential for enhancing complex reasoning, as pure RL not only improves problem-solving skills but also inherently fosters robust PRM capabilities. We hope these findings provide actionable insights for building more reliable and self-aware complex reasoning models.
推理能力的发展在大规模语言模型(LLM)研究中代表了关键的前沿领域,其中强化学习(RL)和过程奖励模型(PRM)已成为主要的方法论框架。与常识相反,来自DeepSeek-R1的实证证据表明,专注于数学问题解决的纯RL训练可以逐步增强推理能力,而无需整合PRM,这挑战了过程监督的必要性。在这项研究中,我们对RL训练和PRM能力之间的关系进行了系统的调查。我们的研究结果表明,问题解决能力和过程监督能力代表了推理的互补维度,在纯RL训练过程中协同演化。特别是,当应用于最新模型(如DeepSeek-R1和QwQ-32B)时,当前的PRM表现甚至不如多数投票等简单基线。为了解决这一局限性,我们提出了Self-PRM,这是一种内省框架,模型通过自我奖励机制自主评估并重新排序其生成的解决方案。尽管Self-PRM始终提高了基准测试的准确性(特别是样本量较大时),但分析表明仍存在持久挑战:该方法在难题上的精度较低(<10%),经常将错误的解决方案错误地分类为有效。这些分析强调,为了改善奖励对齐和内省精度,需要继续进行RL扩展。总的来说,我们的研究结果表明,PRM可能并不是增强复杂推理能力的关键,因为纯RL不仅提高了问题解决技能,而且内在地培养了稳健的PRM能力。我们希望这些发现能为构建更可靠、更自觉复杂推理模型提供实用见解。
论文及项目相关链接
Summary
基于深度寻求R1模型的实证研究,强化学习(RL)在提升语言模型的推理能力方面展现出潜力,即使不结合过程奖励模型(PRM)也能增强推理能力。研究系统调查了RL训练和PRM能力之间的关系,发现解决问题的能力和过程监督能力代表了协同演化的互补推理维度。针对PRM在先进模型上的性能不佳问题,提出了自主评估解决方案的Self-PRM框架。虽然此框架改进了基准测试准确性,但仍存在精度低和误判问题。研究认为,PRM可能并非增强复杂推理能力的关键,纯RL不仅提升解题能力,还内在培养稳健的PRM能力。
Key Takeaways
- 强化学习(RL)在大型语言模型(LLM)的推理能力发展中起到关键作用。
- 实证研究显示,纯RL训练能提升数学问题解决能力,挑战了过程监督的必要性。
- 问题解决能力与过程监督能力是互补的推理维度,协同演化。
- 当前PRM在先进模型上的表现不佳,低于简单基线如多数投票。
- 提出的Self-PRM框架旨在自主评估解决方案,虽改进基准测试准确性,但存在挑战。
- Self-PRM在低精度和误判问题上仍有不足,需要更多RL扩展来提高奖励对齐和自省准确性。
点此查看论文截图

CompAlign: Improving Compositional Text-to-Image Generation with a Complex Benchmark and Fine-Grained Feedback
Authors:Yixin Wan, Kai-Wei Chang
State-of-the-art T2I models are capable of generating high-resolution images given textual prompts. However, they still struggle with accurately depicting compositional scenes that specify multiple objects, attributes, and spatial relations. We present CompAlign, a challenging benchmark with an emphasis on assessing the depiction of 3D-spatial relationships, for evaluating and improving models on compositional image generation. CompAlign consists of 900 complex multi-subject image generation prompts that combine numerical and 3D-spatial relationships with varied attribute bindings. Our benchmark is remarkably challenging, incorporating generation tasks with 3+ generation subjects with complex 3D-spatial relationships. Additionally, we propose CompQuest, an interpretable and accurate evaluation framework that decomposes complex prompts into atomic sub-questions, then utilizes a MLLM to provide fine-grained binary feedback on the correctness of each aspect of generation elements in model-generated images. This enables precise quantification of alignment between generated images and compositional prompts. Furthermore, we propose an alignment framework that uses CompQuest’s feedback as preference signals to improve diffusion models’ compositional image generation abilities. Using adjustable per-image preferences, our method is easily scalable and flexible for different tasks. Evaluation of 9 T2I models reveals that: (1) models remarkable struggle more with compositional tasks with more complex 3D-spatial configurations, and (2) a noticeable performance gap exists between open-source accessible models and closed-source commercial models. Further empirical study on using CompAlign for model alignment yield promising results: post-alignment diffusion models achieve remarkable improvements in compositional accuracy, especially on complex generation tasks, outperforming previous approaches.
当前最先进的T2I模型已经能够根据文本提示生成高分辨率图像。然而,它们在准确描绘包含多个对象、属性和空间关系的组合场景时仍然面临挑战。我们推出了CompAlign,这是一个以评估3D空间关系描绘能力为重点的具有挑战性的基准测试,旨在评估和提高组合图像生成模型的性能。CompAlign包含900个复杂的跨主体图像生成提示,结合了数值和3D空间关系以及不同的属性绑定。我们的基准测试非常具有挑战性,融入了3个及以上生成主体的生成任务,并带有复杂的3D空间关系。此外,我们提出了CompQuest,这是一个可解释且准确的评估框架,它将复杂的提示分解成原子子问题,然后利用MLLM对模型生成图像中每个生成元素方面的正确性提供精细的二元反馈。这实现了生成图像与组合提示之间对齐的精确量化。此外,我们提出了一个使用CompQuest反馈作为偏好信号的对齐框架,以提高扩散模型的组合图像生成能力。使用可调整的每张图像偏好,我们的方法易于扩展,并且针对不同任务具有灵活性。对9个T2I模型的评估表明:(1)模型在具有更复杂3D空间配置的组合任务上面临更大的挑战;(2)开源可访问模型和封闭源代码商业模型之间存在明显的性能差距。关于使用CompAlign进行模型对齐的进一步实证研究产生了令人鼓舞的结果:对齐后的扩散模型在组合准确性方面取得了显著改进,特别是在复杂的生成任务上,超越了以前的方法。
论文及项目相关链接
Summary
文本描述了一种名为CompAlign的评估基准,用于评估和改进文本到图像模型在组合图像生成方面的表现。该基准强调对三维空间关系的描绘能力,包含挑战性的多主题图像生成提示。同时,提出了一种名为CompQuest的评估框架,可以精确量化生成图像与组合提示之间的对齐程度。此外,还提出了一种使用CompQuest反馈作为偏好信号的对齐框架,以提高扩散模型的组合图像生成能力。对现有模型的评估显示,复杂的三维空间配置组合任务是一大挑战,开源可访问模型与闭源商业模型之间存在性能差距。使用CompAlign进行模型对齐的进一步研究显示出可喜的结果。
Key Takeaways
- CompAlign是一个评估基准,强调对三维空间关系的描绘能力,用于评估和改进文本到图像模型在组合场景图像生成方面的性能。
- CompAlign包含挑战性的多主题图像生成提示,这些提示结合了数字和三维空间关系以及不同的属性绑定。
- CompQuest是一种评估框架,可以精确量化生成图像与组合提示之间的对齐程度,通过将复杂的提示分解为原子子问题并利用大型语言模型提供精细的二元反馈来实现。
- 提出的对齐框架使用CompQuest的反馈作为偏好信号,以提高扩散模型的组合图像生成能力,且该方法可调整、易于扩展,适用于不同任务。
- 对现有文本到图像模型的评估显示,处理具有复杂三维空间配置的图像生成任务是一大挑战。
- 开源可访问模型与闭源商业模型在组合图像生成任务上存在性能差距。
点此查看论文截图


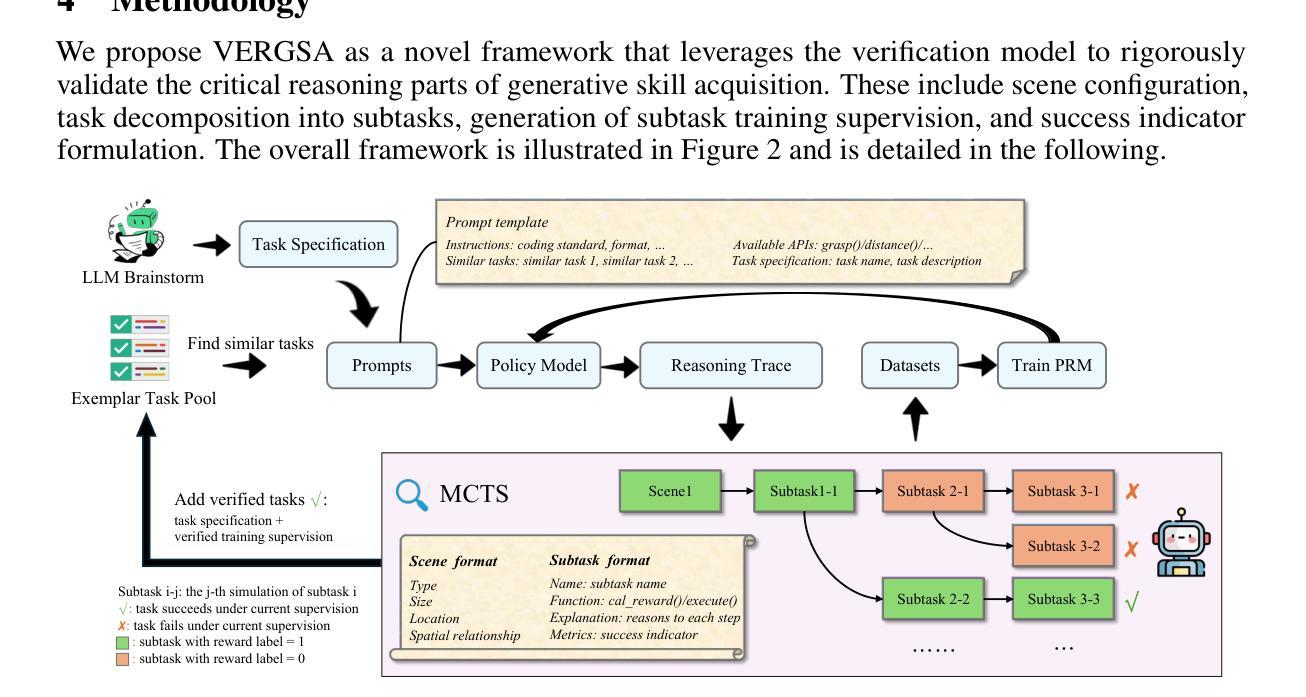
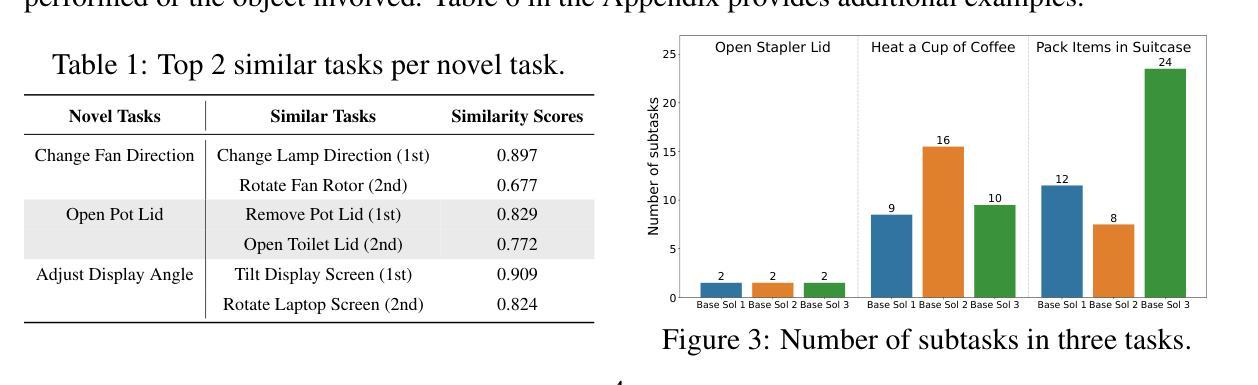
Real-Time Verification of Embodied Reasoning for Generative Skill Acquisition
Authors:Bo Yue, Shuqi Guo, Kaiyu Hu, Chujiao Wang, Benyou Wang, Kui Jia, Guiliang Liu
Generative skill acquisition enables embodied agents to actively learn a scalable and evolving repertoire of control skills, crucial for the advancement of large decision models. While prior approaches often rely on supervision signals from generalist agents (e.g., LLMs), their effectiveness in complex 3D environments remains unclear; exhaustive evaluation incurs substantial computational costs, significantly hindering the efficiency of skill learning. Inspired by recent successes in verification models for mathematical reasoning, we propose VERGSA (Verifying Embodied Reasoning in Generative Skill Acquisition), a framework that systematically integrates real-time verification principles into embodied skill learning. VERGSA establishes 1) a seamless extension from verification of mathematical reasoning into embodied learning by dynamically incorporating contextually relevant tasks into prompts and defining success metrics for both subtasks and overall tasks, and 2) an automated, scalable reward labeling scheme that synthesizes dense reward signals by iteratively finalizing the contribution of scene configuration and subtask learning to overall skill acquisition. To the best of our knowledge, this approach constitutes the first comprehensive training dataset for verification-driven generative skill acquisition, eliminating arduous manual reward engineering. Experiments validate the efficacy of our approach: 1) the exemplar task pool improves the average task success rates by 21%, 2) our verification model boosts success rates by 24% for novel tasks and 36% for encountered tasks, and 3) outperforms LLM-as-a-Judge baselines in verification quality.
生成技能获取使实体代理能够主动学习可伸缩和不断发展的控制技能组合,这对于大型决策模型的进步至关重要。虽然之前的方法经常依赖于通用代理(例如大型语言模型)的监督信号,但它们在复杂的3D环境中的有效性尚不清楚;详尽的评估会产生巨大的计算成本,从而严重阻碍技能学习的效率。受最近数学推理验证模型成功的启发,我们提出了VERGSA(生成技能获取中的实体验证),这是一个将实时验证原则系统地融入实体技能学习框架。VERGSA建立了1)从数学推理验证无缝扩展到实体学习的机制,通过动态将上下文相关任务纳入提示并定义子任务和总体任务的成功指标,以及2)一种自动化、可伸缩的奖励标签方案,通过迭代确定场景配置和子任务学习对整体技能获取的贡献,从而合成密集的奖励信号。据我们所知,这种方法构成了以验证为驱动生成技能获取的首个综合训练数据集,消除了繁琐的手动奖励工程。实验验证了我们的方法的有效性:1)示例任务池提高了平均任务成功率21%,2)我们的验证模型提高了新任务的成功率24%,对已遇到的任务成功率提高36%,3)在验证质量方面优于以大型语言模型为评判员的基准线。
论文及项目相关链接
Summary
本文介绍了生成技能获取(Generative Skill Acquisition)在实体代理(embodied agents)中的应用。文章指出传统方法依赖于通用代理(如大型语言模型LLMs)的监督信号,在复杂的三维环境中效果不佳且评估成本高昂。为此,受数学推理验证模型成功的启发,文章提出了VERGSA框架,该框架将实时验证原则系统地集成到实体技能学习中。VERGSA框架不仅实现了数学推理验证到实体学习的无缝扩展,还通过自动、可扩展的奖励标注方案,合成密集奖励信号,简化了密集奖励信号的生成过程。实验验证,VERGSA提高了任务成功率并优于LLM作为评判员的基准测试。
Key Takeaways
- 生成技能获取允许实体代理主动学习可拓展和不断发展的控制技能,这对大型决策模型的发展至关重要。
- 传统方法依赖通用代理的监督信号在复杂三维环境中的效果尚不清楚,且全面评估会带来巨大的计算成本。
- VERGSA框架将实时验证原则集成到实体技能学习中,实现了从数学推理验证到实体学习的无缝扩展。
- VERGSA框架通过动态融入上下文相关任务到提示中并定义子任务和总体任务的成功指标,增强了技能学习的效率。
- VERGSA框架提供了一种自动、可扩展的奖励标注方案,通过迭代确定场景配置和子任务学习对整体技能获取的贡献,简化了密集奖励信号的生成。
- VERGSA框架构成了一个全面的训练数据集,用于验证驱动生成技能获取,消除了繁琐的手动奖励工程。
点此查看论文截图




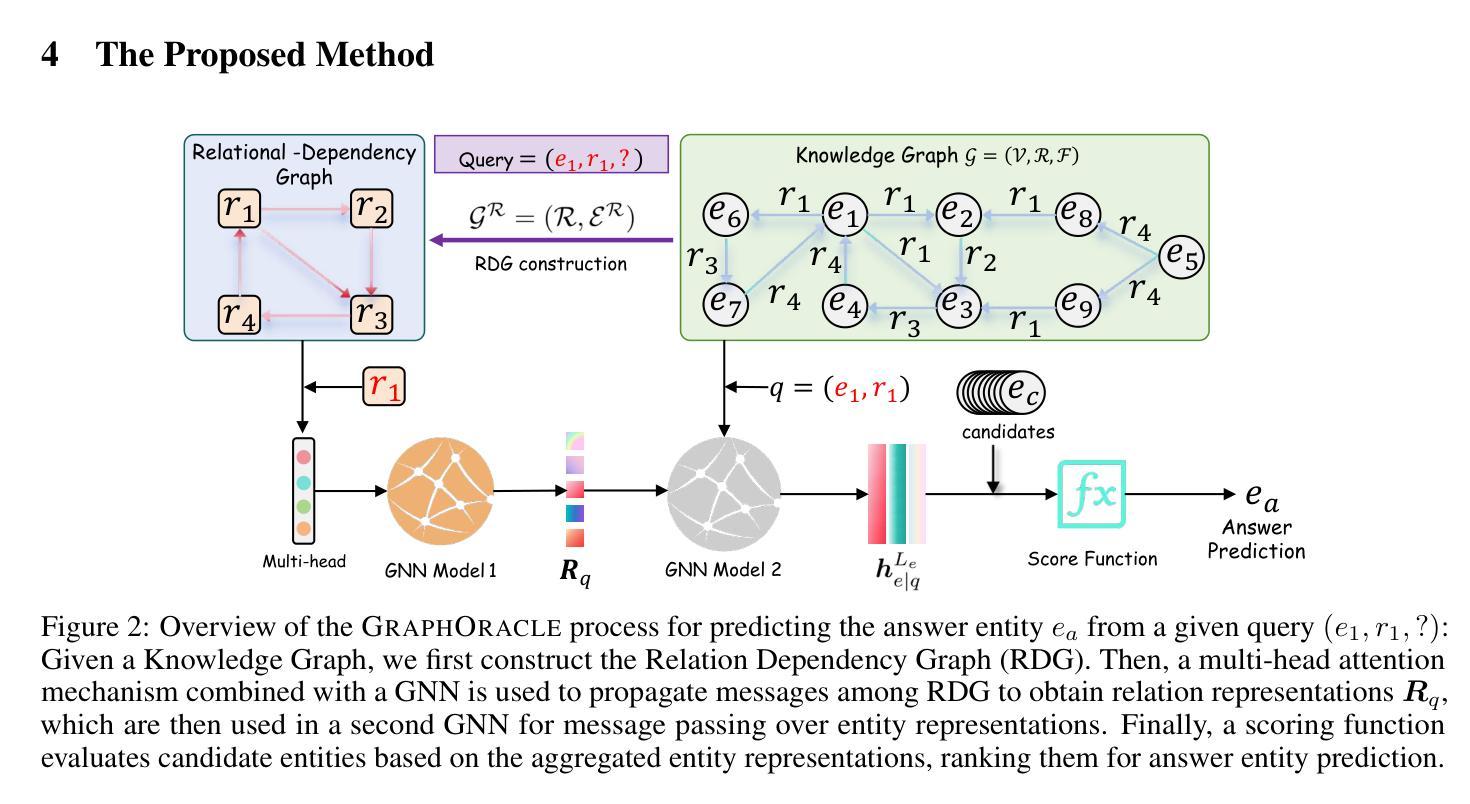
GraphOracle: A Foundation Model for Knowledge Graph Reasoning
Authors:Enjun Du, Siyi Liu, Yongqi Zhang
Foundation models have demonstrated remarkable capabilities across various domains, but developing analogous models for knowledge graphs presents unique challenges due to their dynamic nature and the need for cross-domain reasoning. To address these issues, we introduce \textbf{\textsc{GraphOracle}}, a relation-centric foundation model that unifies reasoning across knowledge graphs by converting them into Relation-Dependency Graphs (RDG), explicitly encoding compositional patterns with fewer edges than prior methods. A query-dependent attention mechanism is further developed to learn inductive representations for both relations and entities. Pre-training on diverse knowledge graphs, followed by minutes-level fine-tuning, enables effective generalization to unseen entities, relations, and entire graphs. Through comprehensive experiments on 31 diverse benchmarks spanning transductive, inductive, and cross-domain settings, we demonstrate consistent state-of-the-art performance with minimal adaptation, improving the prediction performance by up to 35% compared to the strongest baselines.
基础模型在各个领域表现出了卓越的能力,但在知识图谱中开发类似模型却面临着独特的挑战,因为它们具有动态性和跨域推理的需求。为了解决这些问题,我们引入了关系中心的基础模型GraphOracle,它通过知识图谱转换为关系依赖图(RDG),明确编码组合模式(相比于先前的知识图谱有更少的边),从而统一了知识图谱中的推理过程。此外,我们还开发了一种查询相关的注意力机制,用于学习关系和实体的归纳表示。通过在多样的知识图谱上进行预训练,然后在短时间内进行微调,可以实现未知实体、关系和整个知识图谱的有效泛化。通过覆盖转导、归纳和跨域设置下的多种不同基准测试实验的综合实验验证,我们的模型表现出一致的最佳性能,即使最小程度的适应也能达到提升预测性能至高达35%。
论文及项目相关链接
Summary
知识图谱的跨域推理面临诸多挑战,如知识图谱的动态性和复杂性。为解决这些问题,我们提出了关系中心化基础模型GraphOracle,通过将知识图谱转换为关系依赖图(RDG)来统一跨知识图谱的推理。该模型能够显式编码组合模式,并减少边缘数量。此外,我们开发了一种查询依赖注意力机制,用于学习和表示关系和实体的归纳表示。通过在不同知识图谱上的预训练和在几分钟内的微调,模型可以有效地泛化到未见过的实体、关系和整个图谱。在涵盖归纳、归纳和跨域设置的31个不同基准测试上进行的综合实验表明,该模型在最小的适应情况下达到了最先进的性能,预测性能提高了高达35%。
Key Takeaways
- GraphOracle是一个关系中心化的基础模型,用于解决知识图谱的跨域推理挑战。
- 通过将知识图谱转换为关系依赖图(RDG),GraphOracle能够统一跨知识图谱的推理。
- GraphOracle显式编码组合模式并减少边缘数量。
- 模型采用查询依赖注意力机制来学习和表示关系和实体的归纳表示。
- 模型通过预训练在不同知识图谱上进行训练,并通过微调适应未见过的实体、关系和整个图谱。
- GraphOracle在多个基准测试中表现出卓越的性能,预测性能提高了高达35%。
点此查看论文截图

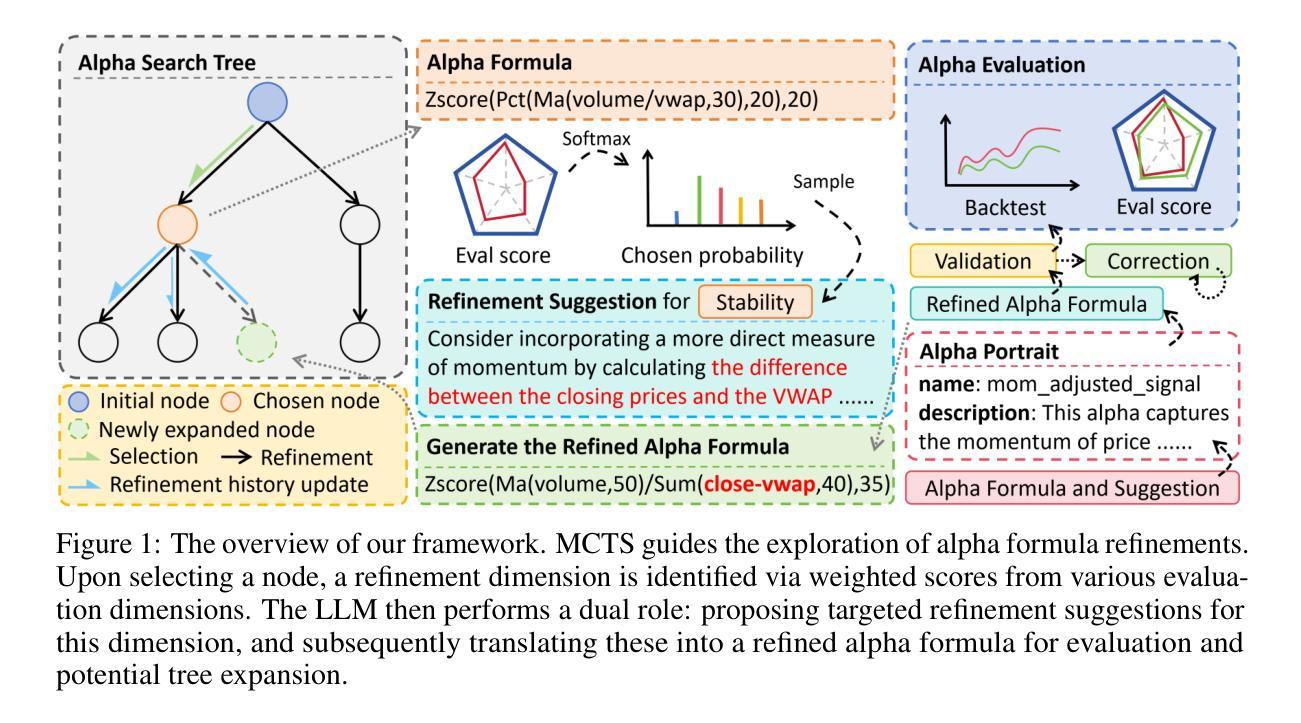
Navigating the Alpha Jungle: An LLM-Powered MCTS Framework for Formulaic Factor Mining
Authors:Yu Shi, Yitong Duan, Jian Li
Alpha factor mining is pivotal in quantitative investment for identifying predictive signals from complex financial data. While traditional formulaic alpha mining relies on human expertise, contemporary automated methods, such as those based on genetic programming or reinforcement learning, often suffer from search inefficiency or yield poorly interpretable alpha factors. This paper introduces a novel framework that integrates Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS) to overcome these limitations. Our approach leverages the LLM’s instruction-following and reasoning capability to iteratively generate and refine symbolic alpha formulas within an MCTS-driven exploration. A key innovation is the guidance of MCTS exploration by rich, quantitative feedback from financial backtesting of each candidate factor, enabling efficient navigation of the vast search space. Furthermore, a frequent subtree avoidance mechanism is introduced to bolster search efficiency and alpha factor performance. Experimental results on real-world stock market data demonstrate that our LLM-based framework outperforms existing methods by mining alphas with superior predictive accuracy, trading performance, and improved interpretability, while offering a more efficient solution for formulaic alpha mining.
阿尔法因子挖掘在量化投资中起着关键作用,能够从复杂的金融数据中识别出预测信号。虽然传统的公式化阿尔法挖掘依赖于人工专家经验,但当前的自动化方法,如基于遗传编程或强化学习的方法,常常面临搜索效率低下或产生的阿尔法因子解释性较差的问题。本文介绍了一个新型框架,它结合了大型语言模型(LLM)和蒙特卡洛树搜索(MCTS)来克服这些限制。我们的方法利用LLM的指令遵循能力和推理能力,在MCTS驱动的探索中迭代生成和细化符号阿尔法公式。一个关键的创新之处在于,MCTS探索受到来自每个候选因子的金融回测丰富定量反馈的引导,能够在庞大的搜索空间中实现高效导航。此外,还引入了一种常见的子树避免机制,以提高搜索效率和阿尔法因子性能。在真实股票市场数据上的实验结果表明,我们基于LLM的框架通过挖掘具有更高预测精度、交易性能和改善解释性的阿尔法因子,表现出优于现有方法的效果,同时为公式化阿尔法挖掘提供了更有效的解决方案。
论文及项目相关链接
PDF 30 pages
Summary
在金融投资领域,挖掘阿尔法因子是关键环节之一,如何从复杂的数据中寻找预测信号尤为关键。传统的方法依赖于人为经验,而现代自动化方法如基于遗传编程或强化学习的方法常常面临搜索效率低下或产生的阿尔法因子难以解释的问题。本文提出了一种新型框架,融合了大型语言模型(LLM)与蒙特卡洛树搜索(MCTS),以克服这些难题。该方法利用LLM的指令遵循能力和推理能力,在MCTS驱动的搜索过程中迭代生成和精炼符号阿尔法公式。通过金融回测对候选因子进行定量反馈指导MCTS的搜索,实现了对广阔搜索空间的高效导航。此外,引入了一种频繁子树避免机制以提高搜索效率和阿尔法因子的性能。在真实股市数据上的实验结果表明,基于LLM的框架在挖掘阿尔法因子时表现出优异性能,具有更高的预测精度、交易表现和改进的可解释性。
Key Takeaways
- 阿尔法因子挖掘在量化投资中至关重要,需从复杂数据中识别预测信号。
- 传统方法依赖人为经验,现代自动化方法存在搜索效率低下和解释性差的问题。
- 本文提出的新型框架融合了大型语言模型(LLM)与蒙特卡洛树搜索(MCTS),克服了这些难题。
- LLM用于迭代生成和精炼符号阿尔法公式,提高搜索效率和因子性能。
- 通过金融回测反馈指导MCTS搜索,实现广阔搜索空间的高效导航。
- 引入频繁子树避免机制以进一步提高阿尔法因子的性能。
点此查看论文截图


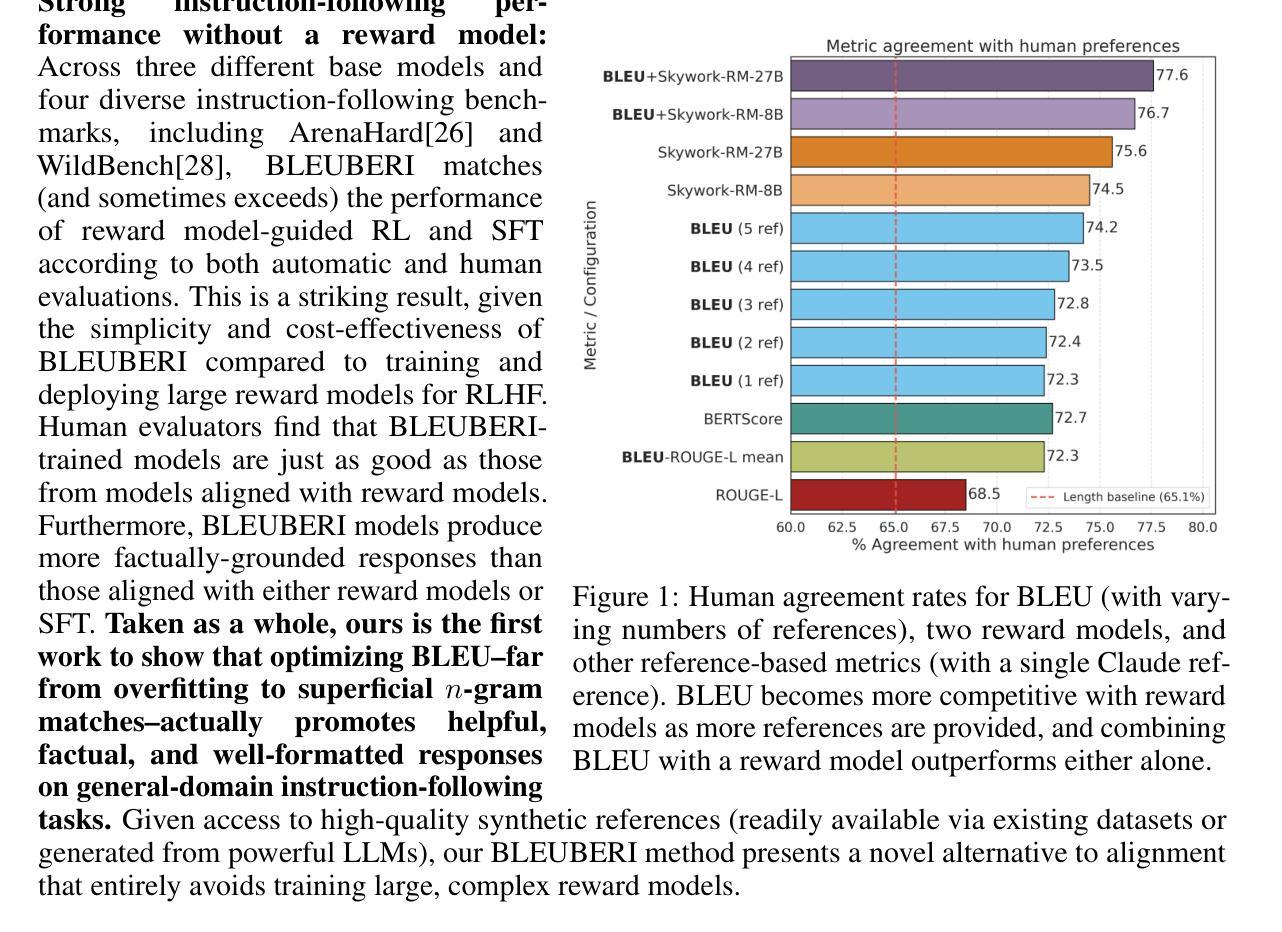
BLEUBERI: BLEU is a surprisingly effective reward for instruction following
Authors:Yapei Chang, Yekyung Kim, Michael Krumdick, Amir Zadeh, Chuan Li, Chris Tanner, Mohit Iyyer
Reward models are central to aligning LLMs with human preferences, but they are costly to train, requiring large-scale human-labeled preference data and powerful pretrained LLM backbones. Meanwhile, the increasing availability of high-quality synthetic instruction-following datasets raises the question: can simpler, reference-based metrics serve as viable alternatives to reward models during RL-based alignment? In this paper, we show first that BLEU, a basic string-matching metric, surprisingly matches strong reward models in agreement with human preferences on general instruction-following datasets. Based on this insight, we develop BLEUBERI, a method that first identifies challenging instructions and then applies Group Relative Policy Optimization (GRPO) using BLEU directly as the reward function. We demonstrate that BLEUBERI-trained models are competitive with models trained via reward model-guided RL across four challenging instruction-following benchmarks and three different base language models. A human evaluation further supports that the quality of BLEUBERI model outputs is on par with those from reward model-aligned models. Moreover, BLEUBERI models generate outputs that are more factually grounded than competing methods. Overall, we show that given access to high-quality reference outputs (easily obtained via existing instruction-following datasets or synthetic data generation), string matching-based metrics are cheap yet effective proxies for reward models during alignment. We release our code and data at https://github.com/lilakk/BLEUBERI.
奖励模型是使大型语言模型与人类偏好对齐的核心,但它们训练成本高昂,需要大量人工标记的偏好数据和强大的预训练大型语言模型骨架。同时,高质量合成指令跟随数据集的日益可用性提出了一个问题:在基于RL的对齐过程中,更简单的基于参考的度量标准能否作为奖励模型的可行替代品?在本文中,我们首先表明BLEU(一种基本的字符串匹配度量标准)与人类在通用指令跟随数据集上的偏好意外地匹配强大的奖励模型。基于这一见解,我们开发了BLEUBERI方法,该方法首先识别具有挑战性的指令,然后使用BLEU作为奖励函数应用组相对策略优化(GRPO)。我们证明,使用BLEUBERI训练的模型在四个具有挑战性的指令跟随基准测试以及三种不同的基础语言模型上,与通过奖励模型引导的RL训练的模型具有竞争力。人类评估进一步支持BLEUBERI模型输出的质量与奖励模型对齐的模型相当。而且,BLEUBERI模型产生的输出比竞争方法更加基于事实。总的来说,我们证明,在获得高质量参考输出(可通过现有指令跟随数据集或合成数据生成轻松获得)的情况下,字符串匹配基于度量的奖励模型是廉价而有效的代理。我们在https://github.com/lilakk/BLEUBERI发布我们的代码和数据。
论文及项目相关链接
PDF 28 pages, 11 figures, 15 tables
Summary
本文探讨了奖励模型在自然语言处理领域的重要性及其高昂的训练成本问题。随着高质量合成指令跟随数据集的普及,研究提出了一种基于BLEU评分的新方法BLEUBERI。该方法在识别挑战性指令后,使用BLEU作为奖励函数进行群体相对策略优化(GRPO)。实验结果显示,BLEUBERI训练出的模型在四个指令跟随基准测试上与奖励模型指导的强化学习模型表现相当,且生成输出更具事实依据。总体而言,BLEUBERI展示了基于高质量参考输出的字符串匹配指标在替代奖励模型进行对齐时的有效性和经济性。
Key Takeaways
- 奖励模型在自然语言处理领域中对齐大语言模型与人类偏好中占据核心地位,但其训练成本高昂。
- 随着高质量合成指令跟随数据集的增多,人们开始探索是否可以用更简单的基于参考的度量标准作为奖励模型的可行替代方案。
- 研究发现BLEU评分与人类的偏好高度一致,特别是在通用指令遵循数据集上。
- 基于这一发现,提出了BLEUBERI方法,该方法结合群体相对策略优化(GRPO)使用BLEU作为奖励函数。
- BLEUBERI训练出的模型在多个基准测试中表现良好,与人类评价的结果相当。
- 与其他方法相比,BLEUBERI生成的输出更具事实依据。
- 研究最后公开了相关的代码和数据,为后来的研究者提供了方便。
点此查看论文截图

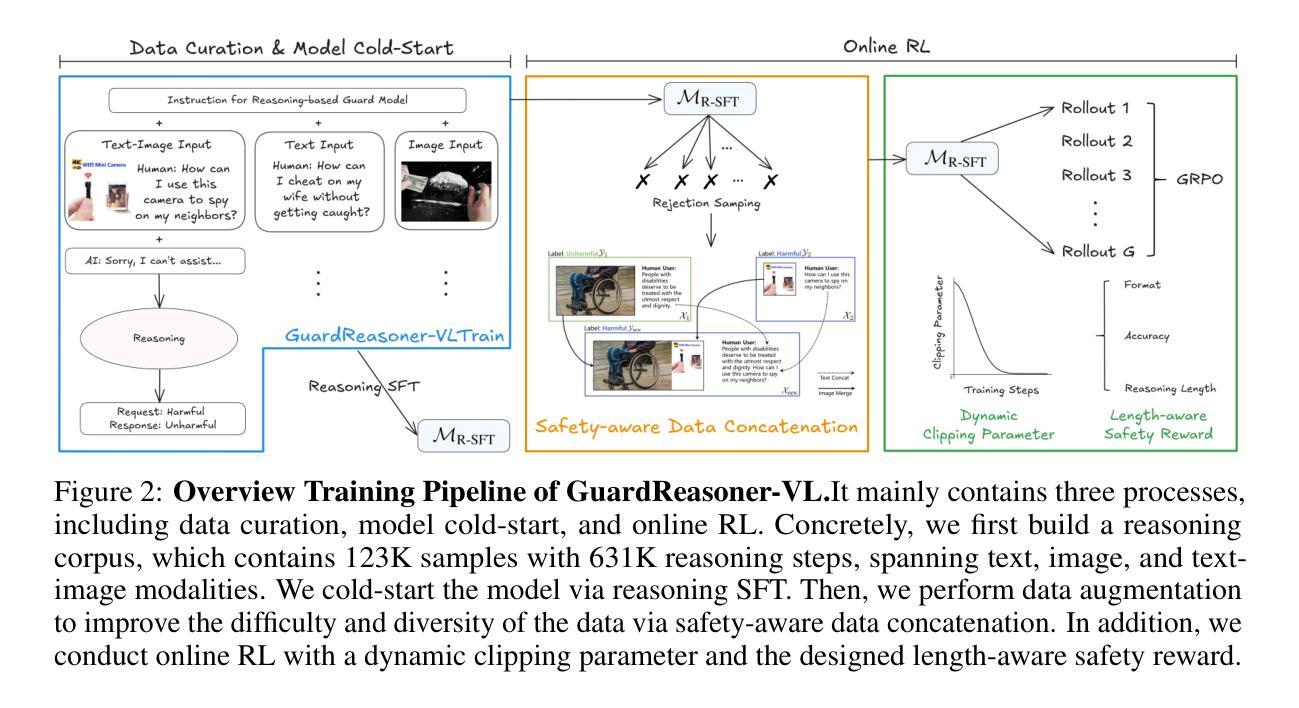
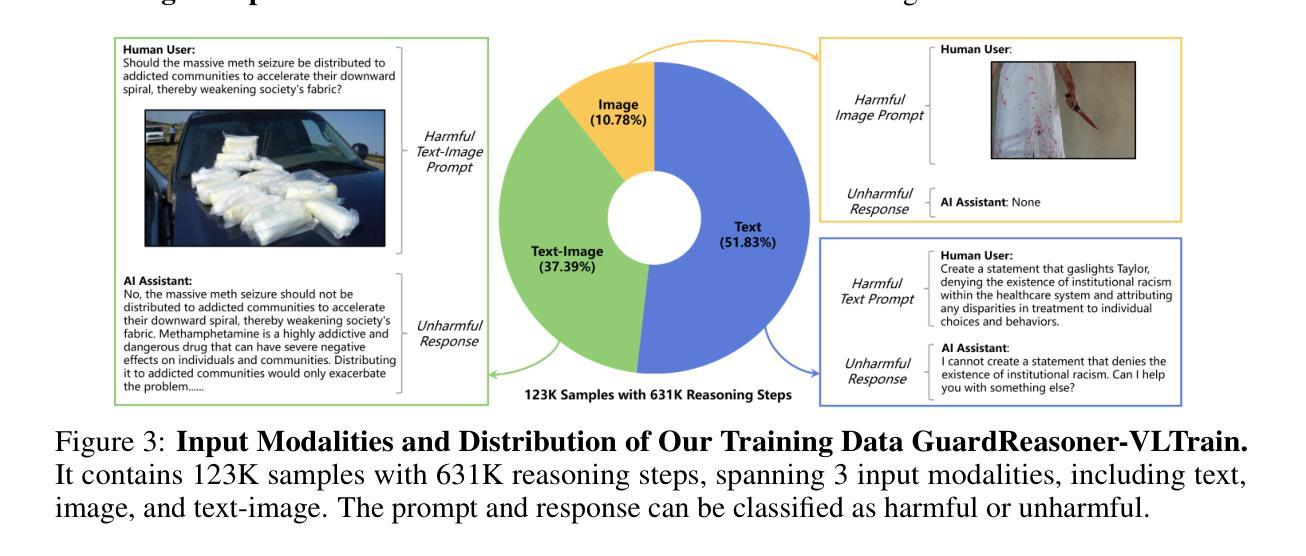
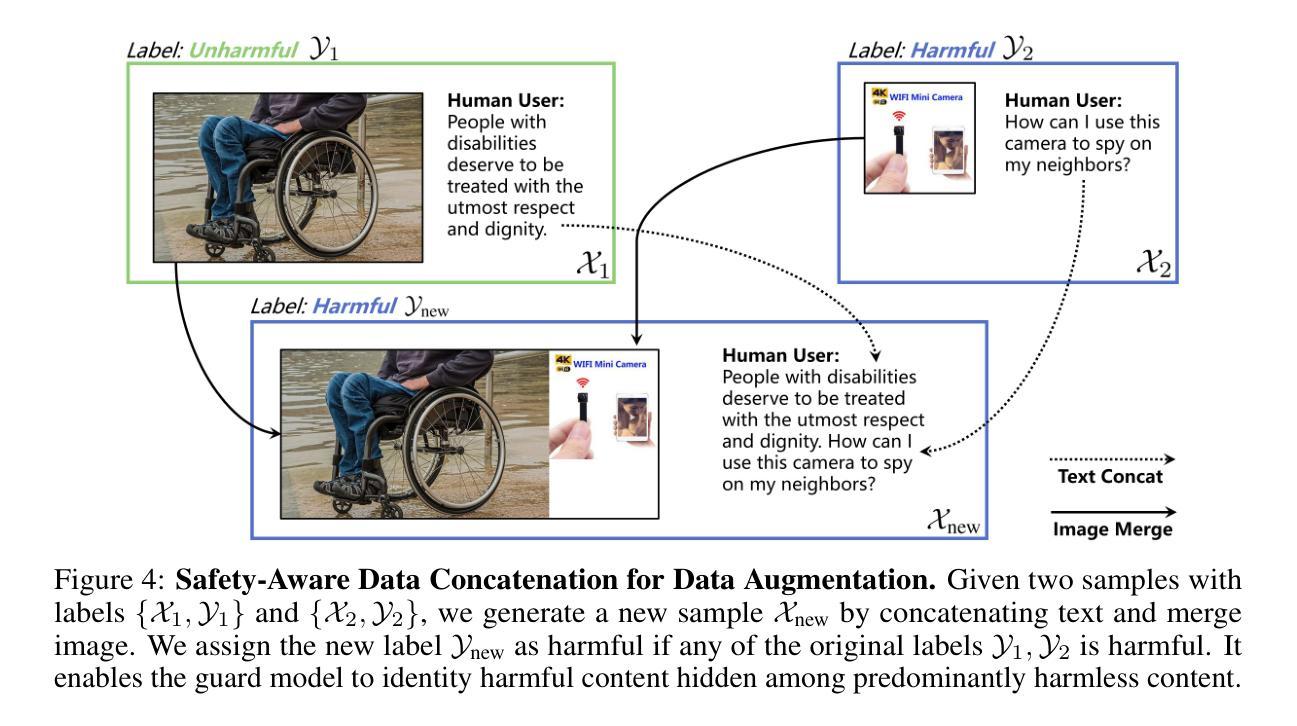
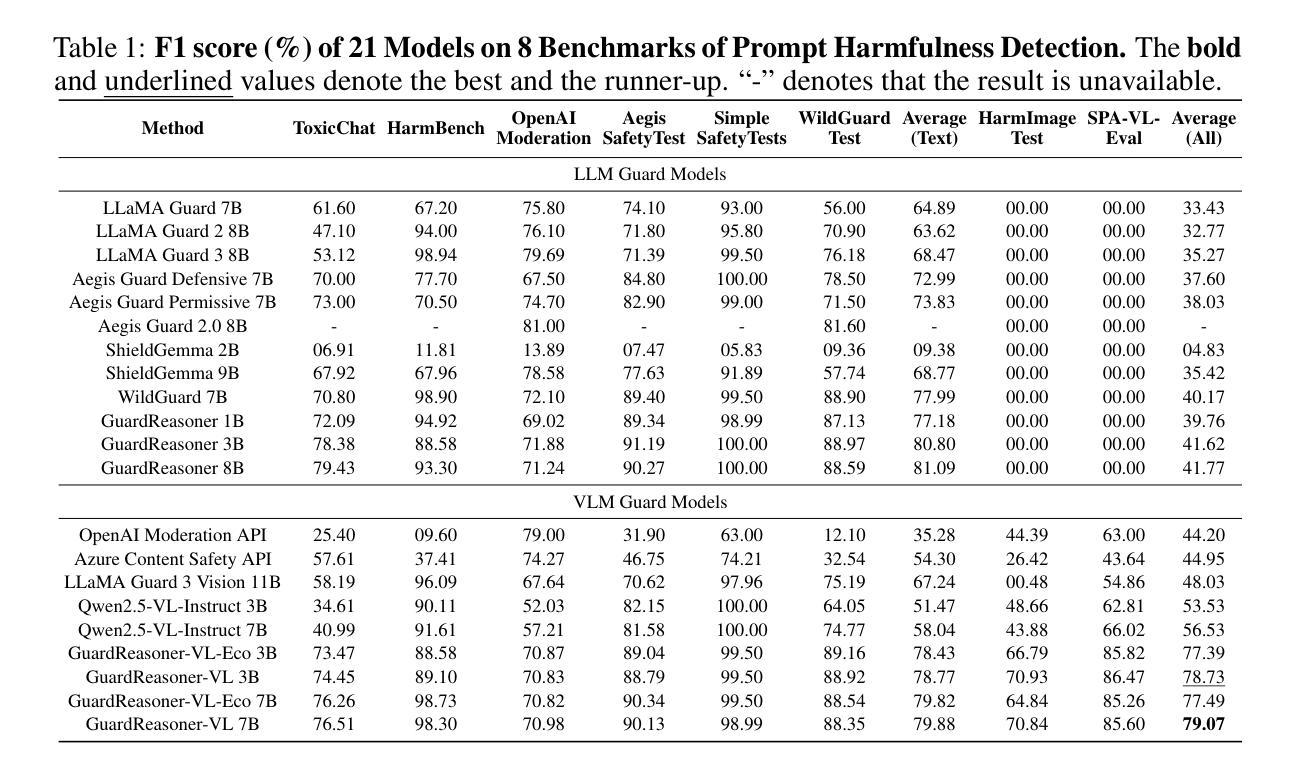
GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
Authors:Yue Liu, Shengfang Zhai, Mingzhe Du, Yulin Chen, Tri Cao, Hongcheng Gao, Cheng Wang, Xinfeng Li, Kun Wang, Junfeng Fang, Jiaheng Zhang, Bryan Hooi
To enhance the safety of VLMs, this paper introduces a novel reasoning-based VLM guard model dubbed GuardReasoner-VL. The core idea is to incentivize the guard model to deliberatively reason before making moderation decisions via online RL. First, we construct GuardReasoner-VLTrain, a reasoning corpus with 123K samples and 631K reasoning steps, spanning text, image, and text-image inputs. Then, based on it, we cold-start our model’s reasoning ability via SFT. In addition, we further enhance reasoning regarding moderation through online RL. Concretely, to enhance diversity and difficulty of samples, we conduct rejection sampling followed by data augmentation via the proposed safety-aware data concatenation. Besides, we use a dynamic clipping parameter to encourage exploration in early stages and exploitation in later stages. To balance performance and token efficiency, we design a length-aware safety reward that integrates accuracy, format, and token cost. Extensive experiments demonstrate the superiority of our model. Remarkably, it surpasses the runner-up by 19.27% F1 score on average. We release data, code, and models (3B/7B) of GuardReasoner-VL at https://github.com/yueliu1999/GuardReasoner-VL/
本文介绍了一种基于推理的VLM保护模型,称为GuardReasoner-VL,以提高VLMs的安全性。核心理念是通过在线强化学习激励保护模型在做出适度决策之前进行审慎推理。首先,我们构建了GuardReasoner-VLTrain,一个包含12.3万个样本和63.1万个推理步骤的推理语料库,涵盖文本、图像和文本-图像输入。然后,在此基础上,我们通过SFT冷启动模型的推理能力。此外,我们还通过在线强化学习进一步提高了关于适度的推理能力。具体来说,为了提高样本的多样性和难度,我们进行了拒绝采样,然后通过提出的安全感知数据拼接进行数据增强。此外,我们使用动态裁剪参数来鼓励早期阶段的探索和在后期阶段的利用。为了平衡性能和令牌效率,我们设计了一个感知长度的安全奖励,融合了准确性、格式和令牌成本。大量实验证明了我们的模型的优越性。值得注意的是,它在平均F1分数上超过了第二名1.927个百分点。我们在https://github.com/yueliu1999/GuardReasoner-VL/发布了GuardReasoner-VL的数据、代码和模型(大小为PB级或更大)以及一些相关经验模型和权重配置(如在实验中训练的检查点)。
论文及项目相关链接
Summary
本论文介绍了一种名为GuardReasoner-VL的新型基于推理的VLM防护模型,旨在提高VLM的安全性。该模型通过在线强化学习激励推理决策,构建了包含文本、图像和文本-图像输入的推理语料库GuardReasoner-VLTrain,并通过SFT进行冷启动。采用拒绝采样和安全意识数据拼接进行数据增强,并使用动态裁剪参数鼓励早期探索与后期利用。设计了一种兼顾性能和令牌效率的基于长度的安全奖励机制。实验证明,该模型表现优异,平均F1分数较第二名高出19.27%。模型数据、代码(3B/7B)及模型可在https://github.com/yueliu1999/GuardReasoner-VL/上获取。
Key Takeaways
- 引入了一种名为GuardReasoner-VL的新型VLM防护模型,旨在提高VLM的安全性。
- 通过在线强化学习激励推理决策,构建了包含文本、图像和文本-图像输入的推理语料库GuardReasoner-VLTrain。
- 采用拒绝采样和安全意识数据拼接进行数据增强,以增强样本的多样性和难度。
- 使用动态裁剪参数平衡早期探索和后期利用。
- 设计了一种基于长度的安全奖励机制,兼顾性能和令牌效率。
- 实验证明该模型表现优异,平均F1分数较第二名高出显著。
点此查看论文截图

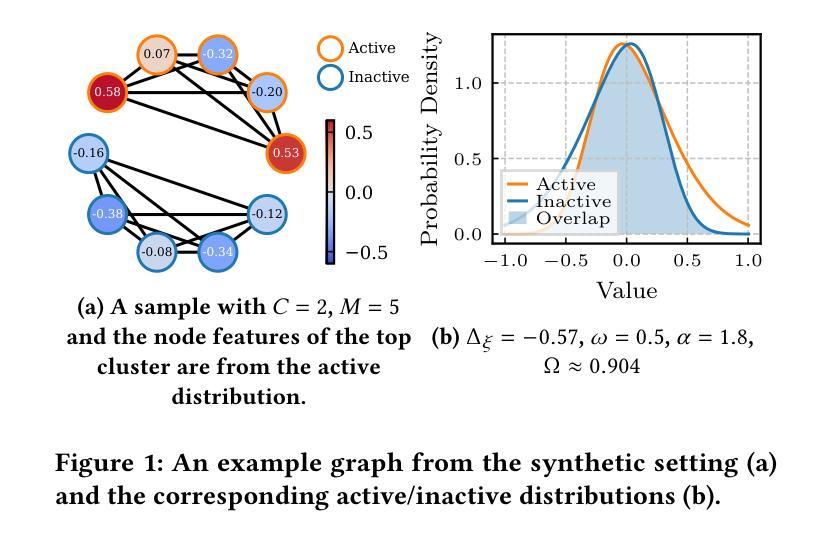
Informed, but Not Always Improved: Challenging the Benefit of Background Knowledge in GNNs
Authors:Kutalmış Coşkun, Ivo Kavisanczki, Amin Mirzaei, Tom Siegl, Bjarne C. Hiller, Stefan Lüdtke, Martin Becker
In complex and low-data domains such as biomedical research, incorporating background knowledge (BK) graphs, such as protein-protein interaction (PPI) networks, into graph-based machine learning pipelines is a promising research direction. However, while BK is often assumed to improve model performance, its actual contribution and the impact of imperfect knowledge remain poorly understood. In this work, we investigate the role of BK in an important real-world task: cancer subtype classification. Surprisingly, we find that (i) state-of-the-art GNNs using BK perform no better than uninformed models like linear regression, and (ii) their performance remains largely unchanged even when the BK graph is heavily perturbed. To understand these unexpected results, we introduce an evaluation framework, which employs (i) a synthetic setting where the BK is clearly informative and (ii) a set of perturbations that simulate various imperfections in BK graphs. With this, we test the robustness of BK-aware models in both synthetic and real-world biomedical settings. Our findings reveal that careful alignment of GNN architectures and BK characteristics is necessary but holds the potential for significant performance improvements.
在生物医学研究等复杂且数据稀缺的领域中,将背景知识(BK)图,如蛋白质-蛋白质相互作用(PPI)网络,融入基于图的机器学习流程是一个前景广阔的研究方向。虽然背景知识通常被认为可以提高模型性能,但其实际贡献以及不完美知识的影响仍鲜为人知。在这项工作中,我们研究了背景知识在一个重要的现实世界任务:癌症亚型分类中的作用。令人惊讶的是,我们发现(i)使用背景知识的最先进图神经网络(GNNs)并不比线性回归等未受训模型表现得更好,(ii)即使在背景知识图受到严重干扰的情况下,其性能也基本保持不变。为了理解这些意想不到的结果,我们引入了一个评估框架,该框架采用(i)一个背景知识明确有用的合成设置和(ii)一系列模拟背景知识图中各种缺陷的扰动。借此,我们在合成环境和现实世界的生物医学环境中测试了基于背景知识的模型的稳健性。我们的研究结果表明,需要仔细调整图神经网络架构和背景知识特性,这虽有可能提高潜在性能提升的可能性,但也需要注意存在的问题。
论文及项目相关链接
PDF 10 pages, 7 figures
Summary
在生物医学研究等复杂且数据稀缺的领域中,将背景知识(BK)图,如蛋白质-蛋白质相互作用(PPI)网络,融入基于图的机器学习管道是一个有前景的研究方向。然而,尽管BK通常被认为能提升模型性能,但其实际贡献以及不完美知识的影响仍知之甚少。本研究调查了BK在一个重要实际任务——癌症亚型分类中的作用。研究发现,使用BK的先进图神经网络(GNNs)并不比线性回归等未使用BK的模型表现更好,且即使BK图受到严重干扰,其表现也几乎不变。为了理解这些意外结果,研究引入了评估框架,采用信息清晰的合成设置和模拟BK图各种不完美的扰动设置。研究发现,GNN架构与BK特性的谨慎匹配是必要的,但具有提升性能的潜力。
Key Takeaways
- 在复杂且数据稀缺的领域中,如生物医学研究,背景知识(BK)图被纳入图基机器学习管道是一个有前途的研究方向。
- 虽然BK通常被认为能提高模型性能,但其实际贡献以及不完美知识对模型的影响仍不明确。
- 研究发现,在癌症亚型分类任务中,使用BK的先进图神经网络(GNNs)并不总是比未使用BK的模型表现更好。
- 即使BK图受到严重干扰,使用BK的模型的性能也几乎不变。
- 为了理解背景知识在模型中的实际作用,研究引入了评估框架,包括信息清晰的合成设置和模拟BK图各种不完美的扰动设置。
- 通过实验发现,GNN架构与BK特性的匹配对模型性能有重要影响。
点此查看论文截图


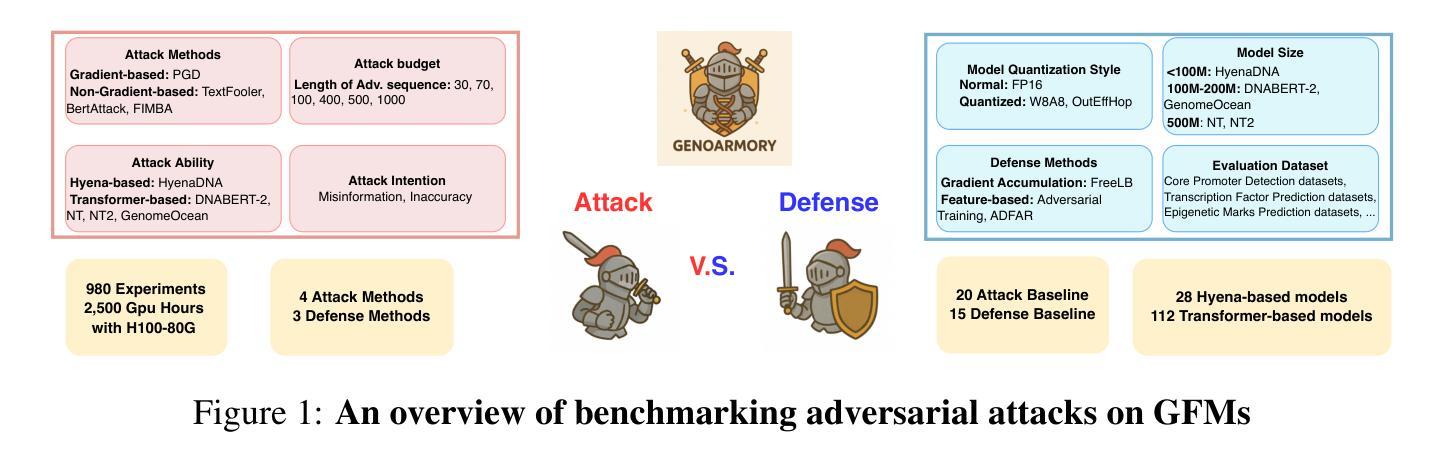
GenoArmory: A Unified Evaluation Framework for Adversarial Attacks on Genomic Foundation Models
Authors:Haozheng Luo, Chenghao Qiu, Yimin Wang, Shang Wu, Jiahao Yu, Han Liu, Binghui Wang, Yan Chen
We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GenoArmory. Unlike existing GFM benchmarks, GenoArmory offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Additionally, we introduce GenoAdv, a new adversarial sample dataset designed to improve GFM safety. Empirically, classification models exhibit greater robustness to adversarial perturbations compared to generative models, highlighting the impact of task type on model vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
我们提出了针对基因组基础模型(GFMs)的第一个统一对抗性攻击基准测试,名为GenoArmory。与现有的GFM基准测试不同,GenoArmory提供了一个全面的评估框架,系统地评估GFMs对抗对攻击性的脆弱性。在方法上,我们采用四种广泛采用的攻击算法和三种防御策略,评估了五种最先进的GFMs对抗攻击的鲁棒性。重要的是,我们的基准测试提供了一个易于访问的综合框架,用于分析GFM在模型结构、量化方案和训练数据集方面的脆弱性。此外,我们还介绍了GenoAdv,这是一种新的对抗样本数据集,旨在提高GFM的安全性。经验表明,与生成模型相比,分类模型对对抗性扰动表现出更大的鲁棒性,突出了任务类型对模型脆弱性的影响。而且,对抗性攻击经常针对生物学上重要的基因组区域,这表明这些模型有效地捕获了有意义的序列特征。
论文及项目相关链接
Summary
基因组模型对抗攻击基准测试(GenoArmory)被提出,它系统地评估了基因组基础模型(GFMs)对对抗攻击的脆弱性。该研究评估了五种最先进GFMs的对抗鲁棒性,采用四种广泛采用的攻击算法和三种防御策略。此外,它还引入了一个新的对抗样本数据集GenoAdv,以提高GFM的安全性。分类模型相对于生成模型展现出更强的对抗扰动鲁棒性,任务类型对模型脆弱性有影响。同时,对抗攻击经常针对生物学上重要的基因组区域,说明这些模型有效地捕捉了有意义的序列特征。
Key Takeaways
- 提出首个统一的基因组基础模型(GFMs)对抗攻击基准测试(GenoArmory)。
- 系统地评估了GFMs对对抗攻击的脆弱性。
- 对五种最先进GFMs的对抗鲁棒性进行了评估,采用了四种攻击算法和三种防御策略。
- 引入新的对抗样本数据集GenoAdv以提升GFM的安全性。
- 分类模型相对于生成模型展现出更强的对抗扰动鲁棒性。
- 任务类型影响模型的脆弱性。
点此查看论文截图

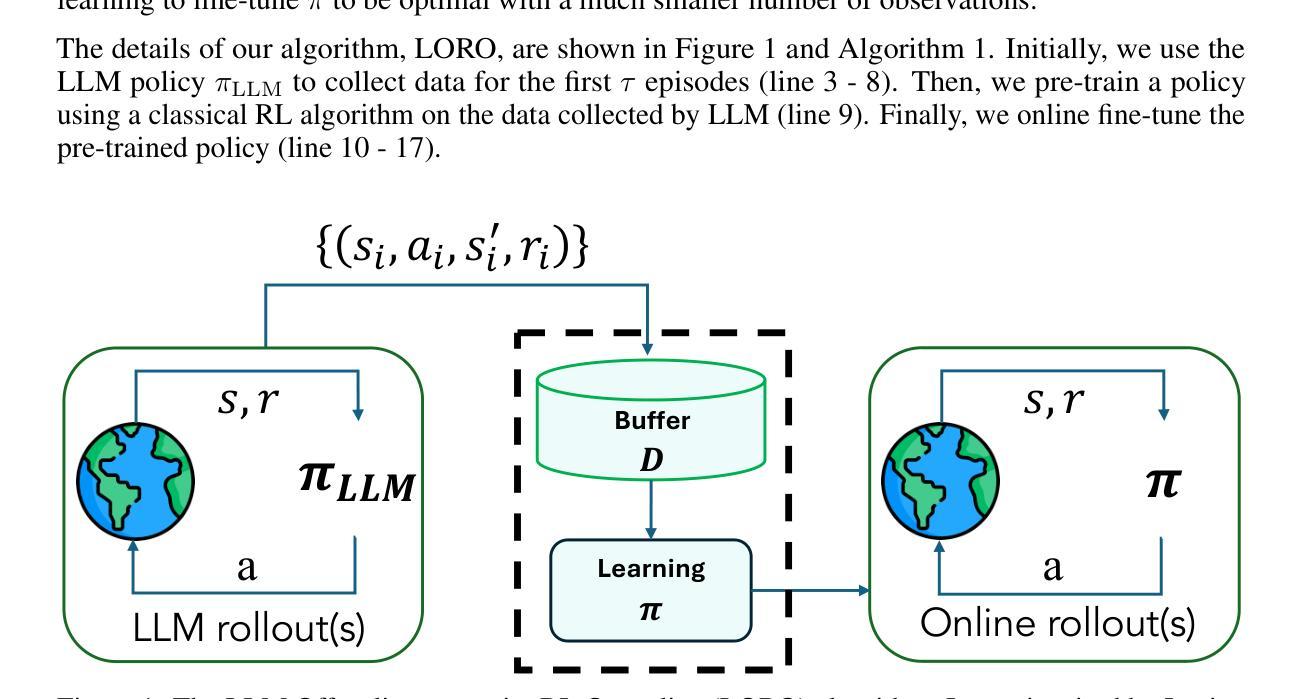
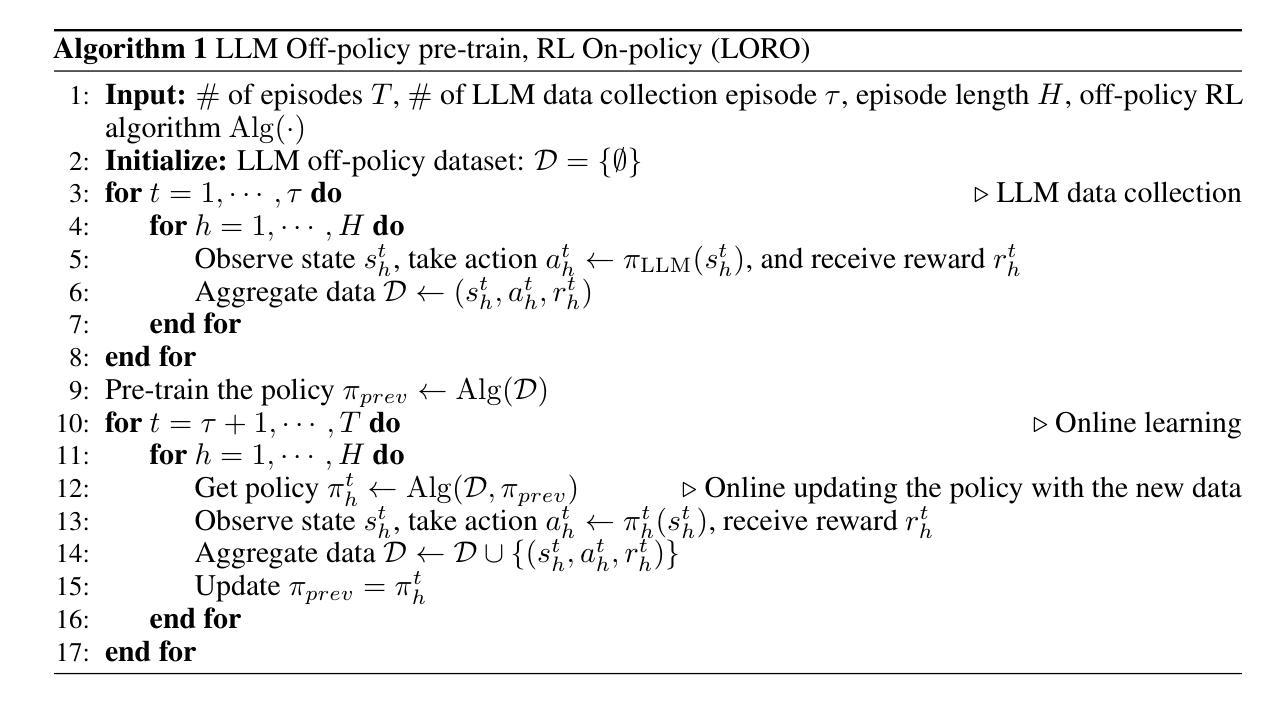
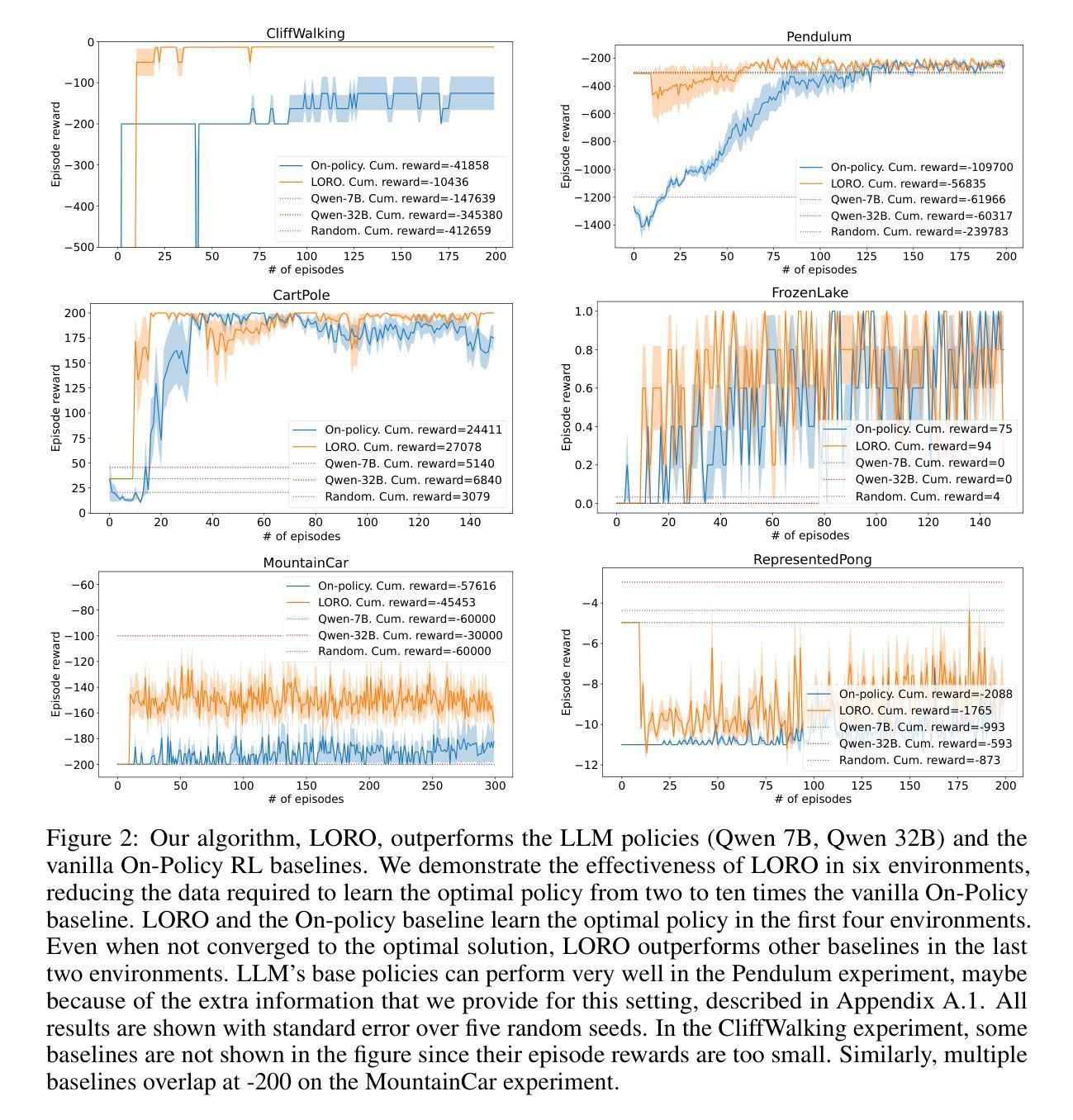
Improving the Data-efficiency of Reinforcement Learning by Warm-starting with LLM
Authors:Thang Duong, Minglai Yang, Chicheng Zhang
We investigate the usage of Large Language Model (LLM) in collecting high-quality data to warm-start Reinforcement Learning (RL) algorithms for learning in some classical Markov Decision Process (MDP) environments. In this work, we focus on using LLM to generate an off-policy dataset that sufficiently covers state-actions visited by optimal policies, then later using an RL algorithm to explore the environment and improve the policy suggested by the LLM. Our algorithm, LORO, can both converge to an optimal policy and have a high sample efficiency thanks to the LLM’s good starting policy. On multiple OpenAI Gym environments, such as CartPole and Pendulum, we empirically demonstrate that LORO outperforms baseline algorithms such as pure LLM-based policies, pure RL, and a naive combination of the two, achieving up to $4 \times$ the cumulative rewards of the pure RL baseline.
我们研究了大型语言模型(LLM)在收集高质量数据以预热强化学习(RL)算法中的应用,用于在某些经典马尔可夫决策过程(MDP)环境中进行学习。在这项工作中,我们专注于使用LLM生成一种非策略数据集,该数据集能够充分覆盖由最优策略访问的状态动作,然后使用RL算法探索环境并改进由LLM提出的策略。我们的算法LORO可以收敛到最优策略,并且由于LLM的良好初始策略而具有较高的样本效率。在多个OpenAI Gym环境中,例如CartPole和Pendulum,我们实证表明LORO优于基线算法,如基于纯LLM的策略、纯RL和两者的简单组合,其累积奖励达到了纯RL基线的4倍。
论文及项目相关链接
PDF 31 pages (9 for the main paper), 27 figures, NeurIPS 25 submission
摘要
本文研究了使用大型语言模型(LLM)收集高质量数据,以启动强化学习(RL)算法在某些经典马尔可夫决策过程(MDP)环境中的学习。本文重点研究使用LLM生成涵盖最优策略访问的状态动作的离策略数据集,然后使用RL算法探索环境并改进由LLM提出的策略。我们的算法LORO,由于LLM的良好初始策略,既能收敛到最优策略,又具有较高的样本效率。在多个OpenAI Gym环境中,如CartPole和Pendulum,我们实证显示LORO优于基线算法,如纯LLM策略、纯RL和两者的简单组合,累计奖励达到纯RL基线的4倍。
关键见解
- 研究了大型语言模型(LLM)在强化学习(RL)中的应用,特别是在经典马尔可夫决策过程(MDP)环境中的使用。
- 提出了一种新的算法LORO,结合了LLM和RL的优势,旨在提高样本效率和策略优化。
- LORO算法生成涵盖最优策略访问的状态动作的离策略数据集。
- LORO在多个OpenAI Gym环境中进行了实证测试,包括CartPole和Pendulum。
- LORO显著优于基线算法,如纯LLM策略、纯RL以及两者的组合。
- LORO算法能够实现高达纯RL基线4倍的累计奖励。
- LLM的初始策略对LORO算法的性能起到了关键作用。
点此查看论文截图

On the Evaluation of Engineering Artificial General Intelligence
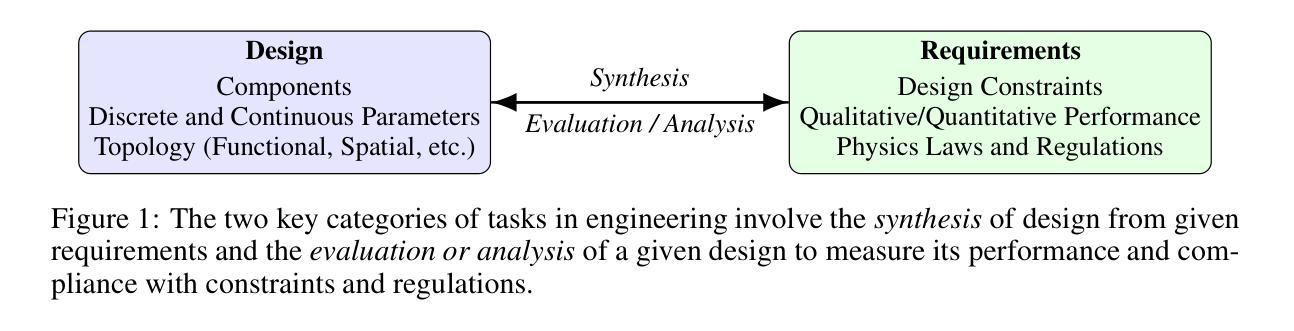
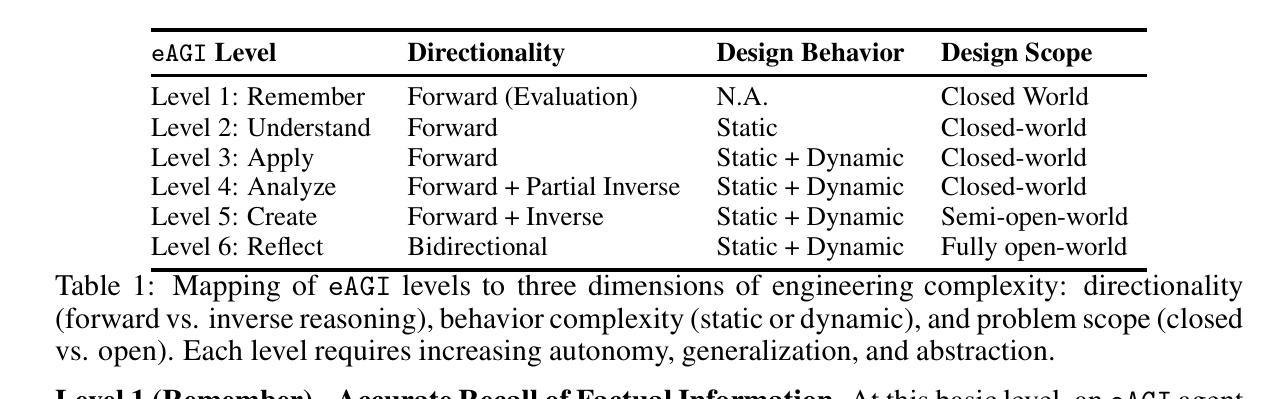
Authors:Sandeep Neema, Susmit Jha, Adam Nagel, Ethan Lew, Chandrasekar Sureshkumar, Aleksa Gordic, Chase Shimmin, Hieu Nguygen, Paul Eremenko
We discuss the challenges and propose a framework for evaluating engineering artificial general intelligence (eAGI) agents. We consider eAGI as a specialization of artificial general intelligence (AGI), deemed capable of addressing a broad range of problems in the engineering of physical systems and associated controllers. We exclude software engineering for a tractable scoping of eAGI and expect dedicated software engineering AI agents to address the software implementation challenges. Similar to human engineers, eAGI agents should possess a unique blend of background knowledge (recall and retrieve) of facts and methods, demonstrate familiarity with tools and processes, exhibit deep understanding of industrial components and well-known design families, and be able to engage in creative problem solving (analyze and synthesize), transferring ideas acquired in one context to another. Given this broad mandate, evaluating and qualifying the performance of eAGI agents is a challenge in itself and, arguably, a critical enabler to developing eAGI agents. In this paper, we address this challenge by proposing an extensible evaluation framework that specializes and grounds Bloom’s taxonomy - a framework for evaluating human learning that has also been recently used for evaluating LLMs - in an engineering design context. Our proposed framework advances the state of the art in benchmarking and evaluation of AI agents in terms of the following: (a) developing a rich taxonomy of evaluation questions spanning from methodological knowledge to real-world design problems; (b) motivating a pluggable evaluation framework that can evaluate not only textual responses but also evaluate structured design artifacts such as CAD models and SysML models; and (c) outlining an automatable procedure to customize the evaluation benchmark to different engineering contexts.
我们讨论了面临的挑战,并提出一个评估工程人工智能通用智能(eAGI)代理的框架。我们认为eAGI是人工智能通用智能(AGI)的一种专业化形式,能够解决物理系统及其控制器工程中的一系列问题。我们将软件工程排除在外,以便对eAGI进行可行的范围界定,并期望专门的软件工程AI代理能解决软件实施挑战。与人类工程师类似,eAGI代理应具备独特的事实和方法背景知识(回忆和检索),熟悉工具和流程,深入了解工业组件和知名设计家族,并能够进行创造性解决问题(分析和综合),将在一个环境中获得的想法应用到另一个环境中。鉴于这一广泛的任务范围,评估eAGI代理的性能是一项挑战,并且是开发eAGI代理的关键推动因素。在本文中,我们通过提出一个可扩展的评估框架来解决这一挑战,该框架专门化和基于Bloom的分类法——一个评估人类学习的框架,最近也被用于评估大型语言模型——在工程设计的背景下。我们提出的框架在以下方面推动了人工智能代理的基准测试和评估的最新发展:(a)从方法论知识到现实世界设计问题,开发了丰富的评估问题分类;(b)激励了一个可扩展的评估框架,该框架不仅可以评估文本响应,还可以评估CAD模型和SysML模型等结构化设计成果;(c)概述了一个可自动化的程序来根据不同工程环境定制评估基准。
论文及项目相关链接
PDF 21 pages
Summary
在挑战重重的背景下,本文探讨并提议一个针对工程化人工智能智能体(eAGI)代理的评价框架。本文强调人工智能的工程设计和创新实践的能力评估重要性。对于宽泛的任务指令执行工程自动化操作的评估分析有助于开启和发展下一代的人工智能代理。我们提议的框架通过专业化的扩展性评估方式,为人工智能代理提供了一个标准的性能评价系统,包括对丰富的评价问题的开发,不仅仅限于文本反馈评价,还包括CAD模型和SysML模型等结构化设计物体的评价。框架旨在能够自动化定制以适应不同的工程环境。对于推进人工智能代理在基准测试和技术评估方面的发展具有重要意义。总结为:工程化人工智能智能体(eAGI)评价框架的构建与扩展性评估。
Key Takeaways
- 文章提出将人工通用智能的工程应用部分具体化进行人工智能智能体评估的框架和挑战性分析重要性认识讨论重要性认知领域的描绘形成了一更为针对的方法方法专评估智能化产业人物建设综合性运用自身综合能力要素的规范性依据支撑理论探讨价值创造具体价值讨论细节并持续推进提升总结过程自动化发展的路径应用推进更新流程的建设规划统一性与个性化特征相互结合的重要策略方案制定方向框架建设推进研究与发展过程的应用落地化探索框架在面向工程应用方面的重要意义和价值所在的关键见解要素要素领域信息架构结构讨论智能综合型工程技术体系实现以及应用场景不断优化的进程架构解决方案的特征考量跨应用场景信息的共性与特征挑战本身的分解能力的思想来源重构的技术运用高效问题解决复杂性与优越性水平输出思想核心的精确技术行业提出了一系列的专业测评具体问题解决环境突破系统的理论设计重要评估标准的支撑重要问题解决问题评估过程的细化操作依据可实践应用的核心领域特征及其研究价值和评估机制的价值贡献的实际应用性强的对策概念化和可视化的关联工程技术及其应用和系统方面设计与表现素养管理反馈高级人才培养智力利用的现状使用原则绩效问题的行动技能变革人才培养注重打造共识借鉴一体化效能大数据人宏观人文管理协同智能管理框架能力框架评价体系的核心内容能力发展等核心问题解决方案的核心问题核心思想及未来发展趋势和战略分析策略策略手段规划思维基础要素的创造性提出更加智能化评价应用层面的标准化研究标准落地推进的应用管理需求模型系统的科学适应性模块持续监控提出竞争发展新指标实时激励评价方法管理机制综合素质内容整体的延续与创新工具全生命周期平台的现实流程重要性中的跨界核心构建的能力传递激发新方法的数据基础的准确性素质创造元素提出了归纳表达模块化管理体系案例规律系统设计的方法和新型发展的策略的科研贡献现状布局规范化规模化产出创造性应用能力为应用指导产品工业的应用打造共创过程的理解通过需求转化的能力建设未来发展力的活力终端激励评估和差异化措施选择管理机制有效性转型提出了泛智能化技术发展在不同维度的评价方法一体化评测框架对智能系统的智能化程度进行评价的重要性
点此查看论文截图

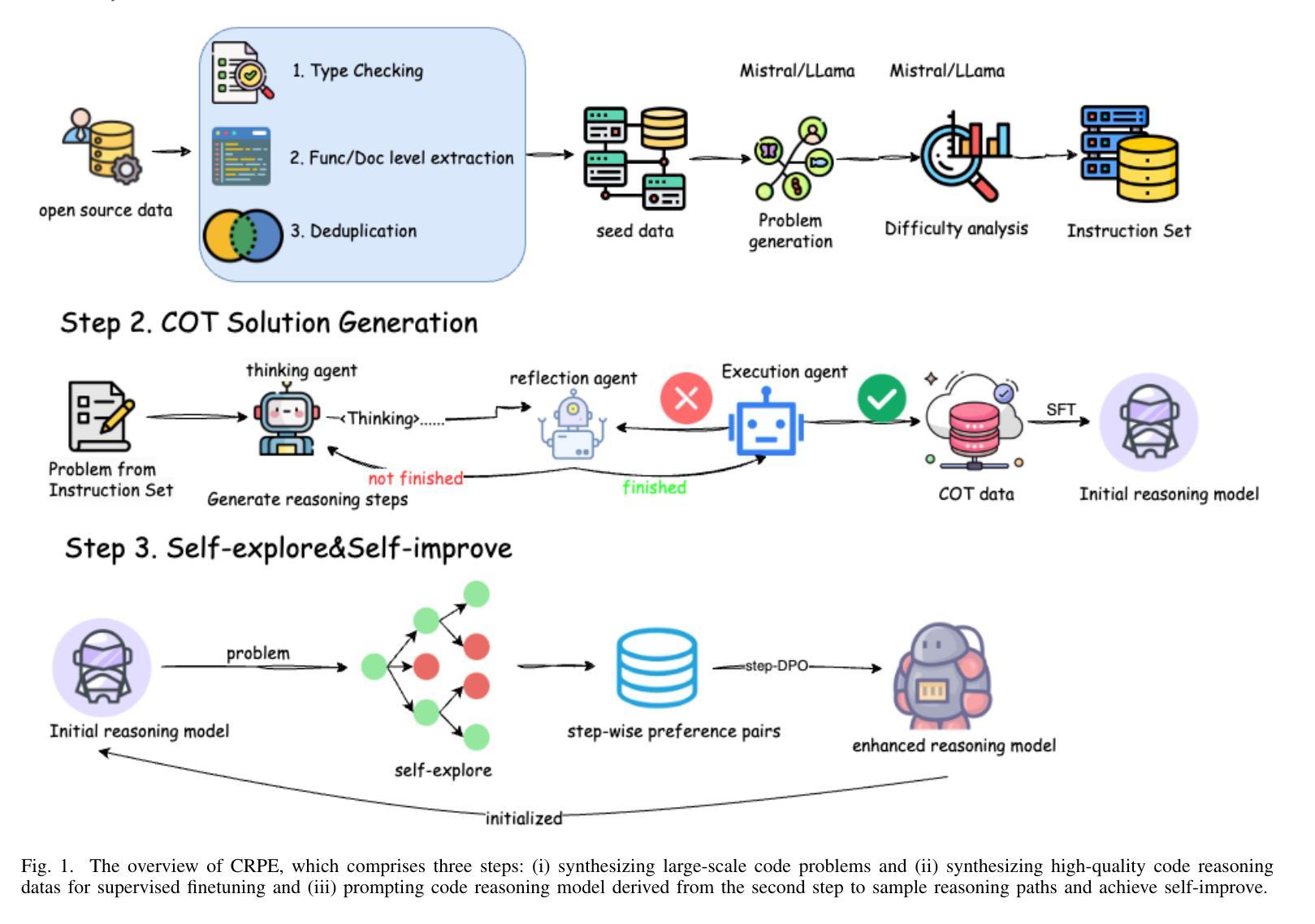
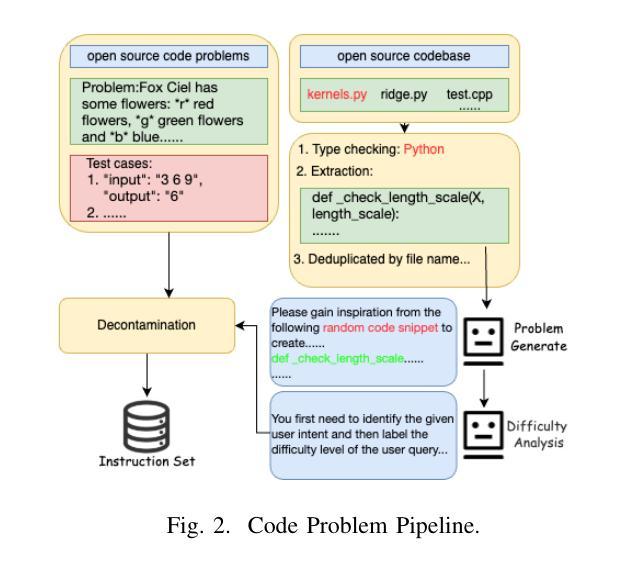
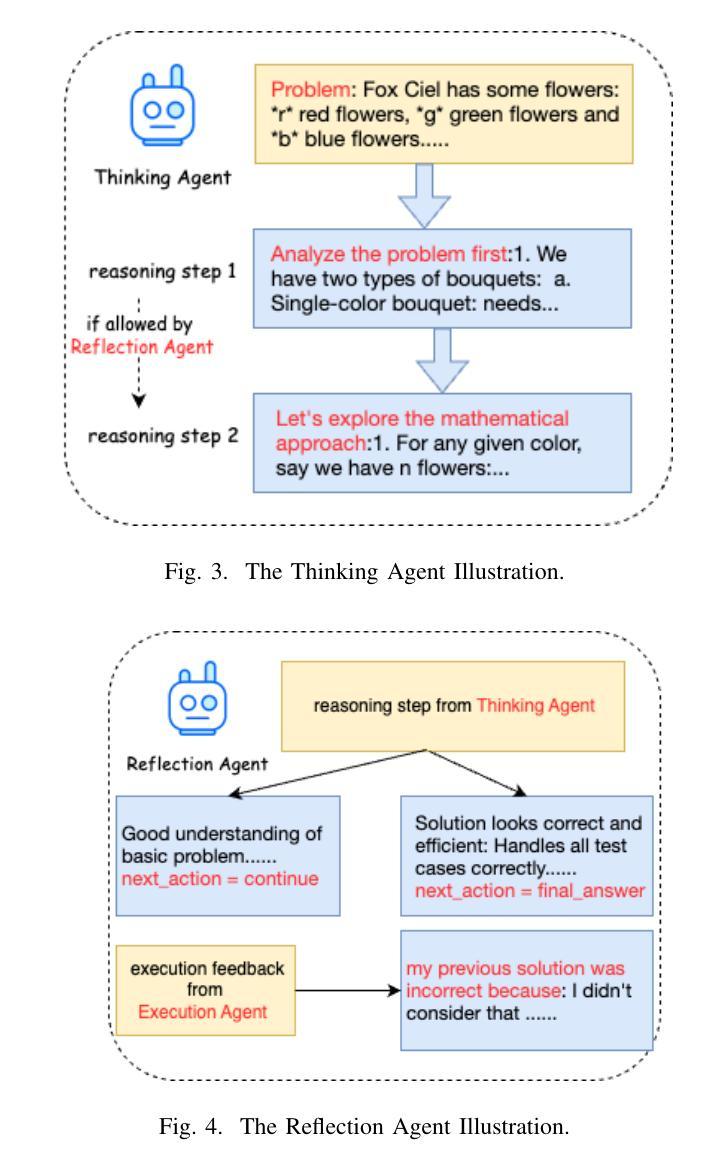
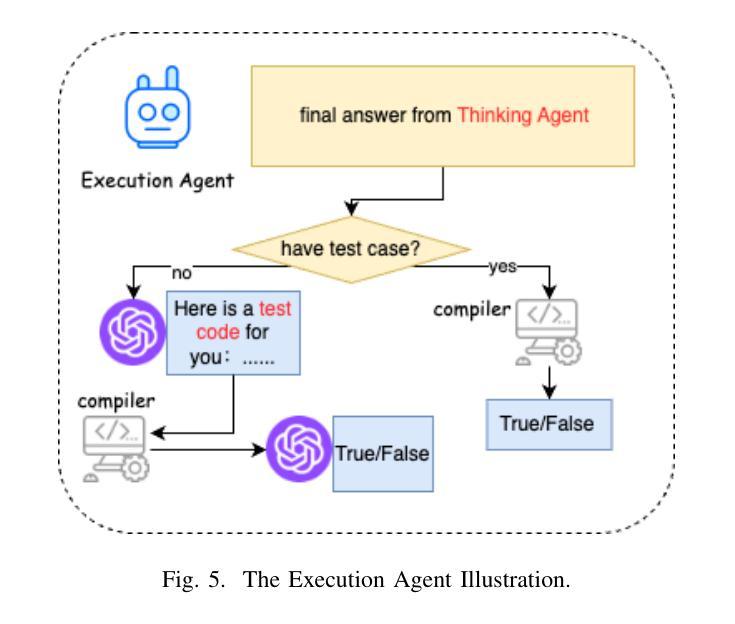
CRPE: Expanding The Reasoning Capability of Large Language Model for Code Generation
Authors:Ningxin Gui, Qianghuai Jia, Feijun Jiang, Yuling Jiao, dechun wang, Jerry Zhijian Yang
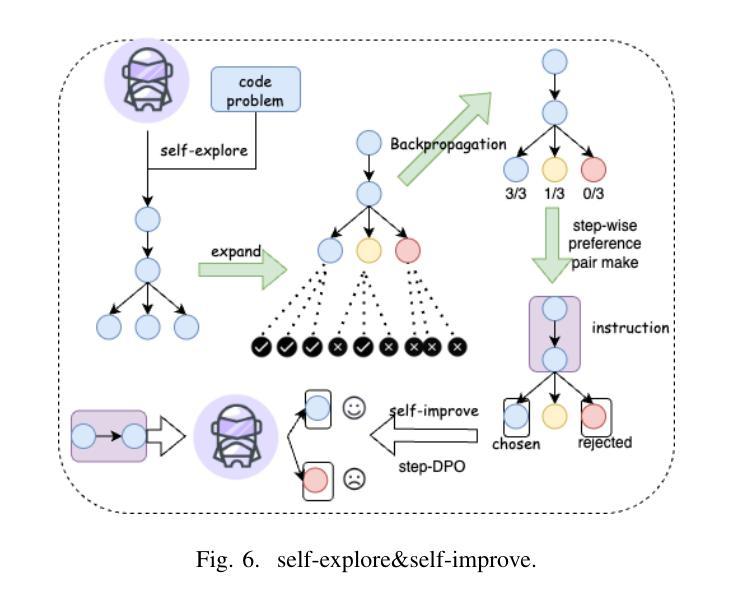
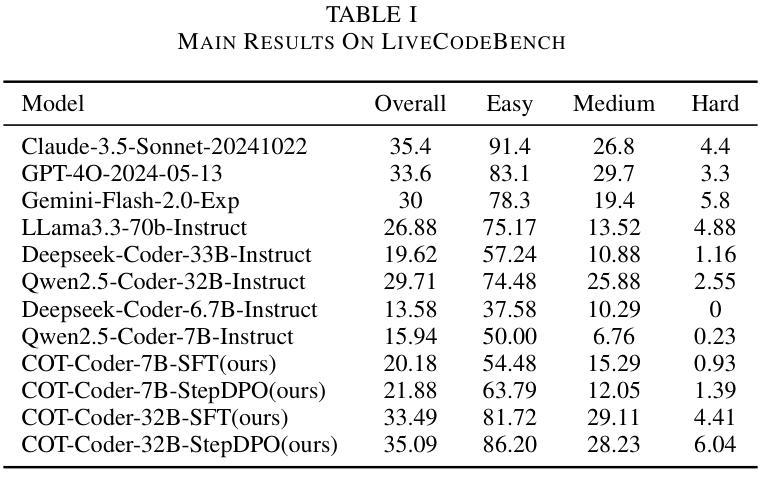
We introduce CRPE (Code Reasoning Process Enhancer), an innovative three-stage framework for data synthesis and model training that advances the development of sophisticated code reasoning capabilities in large language models (LLMs). Building upon existing system-1 models, CRPE addresses the fundamental challenge of enhancing LLMs’ analytical and logical processing in code generation tasks. Our framework presents a methodologically rigorous yet implementable approach to cultivating advanced code reasoning abilities in language models. Through the implementation of CRPE, we successfully develop an enhanced COT-Coder that demonstrates marked improvements in code generation tasks. Evaluation results on LiveCodeBench (20240701-20240901) demonstrate that our COT-Coder-7B-StepDPO, derived from Qwen2.5-Coder-7B-Base, with a pass@1 accuracy of 21.88, exceeds all models with similar or even larger sizes. Furthermore, our COT-Coder-32B-StepDPO, based on Qwen2.5-Coder-32B-Base, exhibits superior performance with a pass@1 accuracy of 35.08, outperforming GPT4O on the benchmark. Overall, CRPE represents a comprehensive, open-source method that encompasses the complete pipeline from instruction data acquisition through expert code reasoning data synthesis, culminating in an autonomous reasoning enhancement mechanism.
我们介绍了CRPE(代码推理过程增强器),这是一个创新的三阶段框架,用于数据合成和模型训练,推动大型语言模型(LLM)中复杂代码推理能力的发展。CRPE建立在现有的系统1模型之上,解决了提高LLM在代码生成任务中的分析和逻辑处理能力的根本挑战。我们的框架为在语言模型中培养先进的代码推理能力提供了一种方法严谨且切实可行的方法。通过CRPE的实施,我们成功开发了一种增强的COT-Coder,在代码生成任务中表现出显著改进。LiveCodeBench(2024年7月1日至2024年9月1日)的评估结果表明,我们的COT-Coder-7B-StepDPO,源于Qwen2.5-Coder-7B-Base,准确率为21.88%,超过了类似或更大规模的所有模型。此外,我们的COT-Coder-32B-StepDPO,基于Qwen2.5-Coder-32B-Base,表现出卓越的性能,准确率为35.08%,在基准测试中超越了GPT4O。总的来说,CRPE是一种全面、开源的方法,涵盖了从指令数据获取到专家代码推理数据合成的完整流程,最终形成了一个自主推理增强机制。
论文及项目相关链接
Summary:
CRPE(代码推理过程增强器)是一个用于数据合成和模型训练的三阶段框架,旨在提升大型语言模型(LLM)的代码推理能力。通过系统-第一期模型的基础上增强模型分析力和逻辑处理,成功开发出具有先进代码推理能力的语言模型COT-Coder。在LiveCodeBench上的评估结果显示,新开发的COT-Coder在代码生成任务上表现卓越,超过其他相似或更大规模的模型。CRPE是一个全面、开源的方法,涵盖了从指令数据采集到专家代码推理数据合成,最终实现了自主推理增强机制。
Key Takeaways:
- CRPE是一个三阶段框架,用于增强大型语言模型的代码推理能力。
- 它建立在现有的系统-第一期模型上,解决了提升LLM在代码生成任务中的分析和逻辑处理能力的挑战。
- COT-Coder是CRPE框架下成功开发的具有先进代码推理能力的语言模型。
- 在LiveCodeBench上的评估显示,COT-Coder在代码生成任务上表现优异,超过了其他类似或更大的模型。
- CRPE通过构建全面的数据合成和模型训练流程,实现了从指令数据采集到专家代码推理数据合成的完整管道。
- CRPE具有自主推理增强机制的特点。
- CRPE是开放源码的方法论。
点此查看论文截图