⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
LipDiffuser: Lip-to-Speech Generation with Conditional Diffusion Models
Authors:Danilo de Oliveira, Julius Richter, Tal Peer, Timo Germann
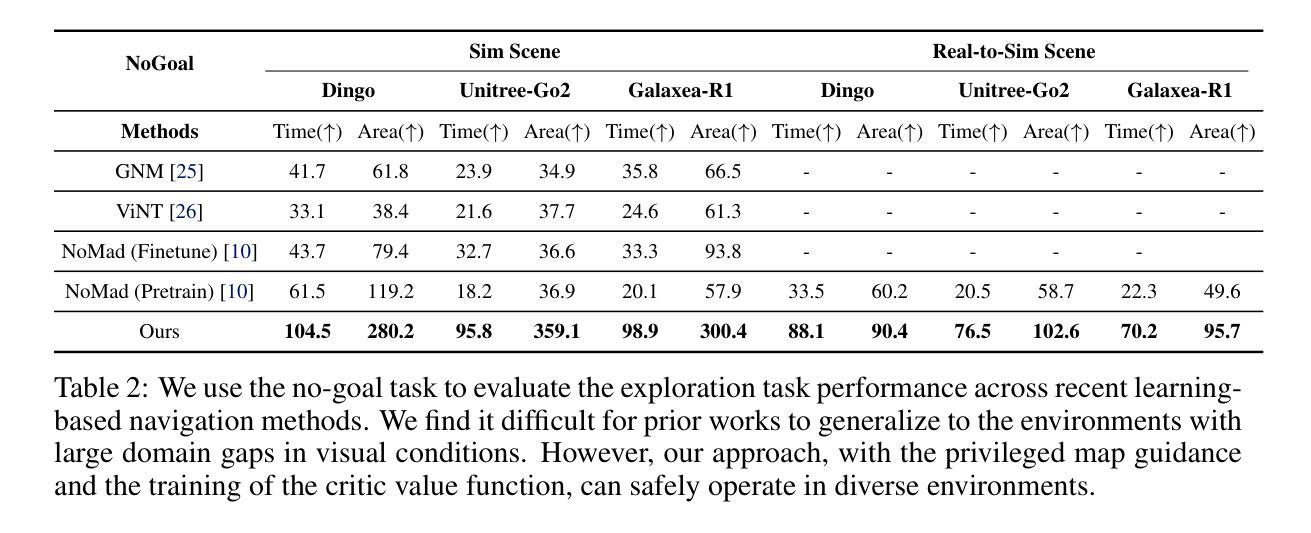
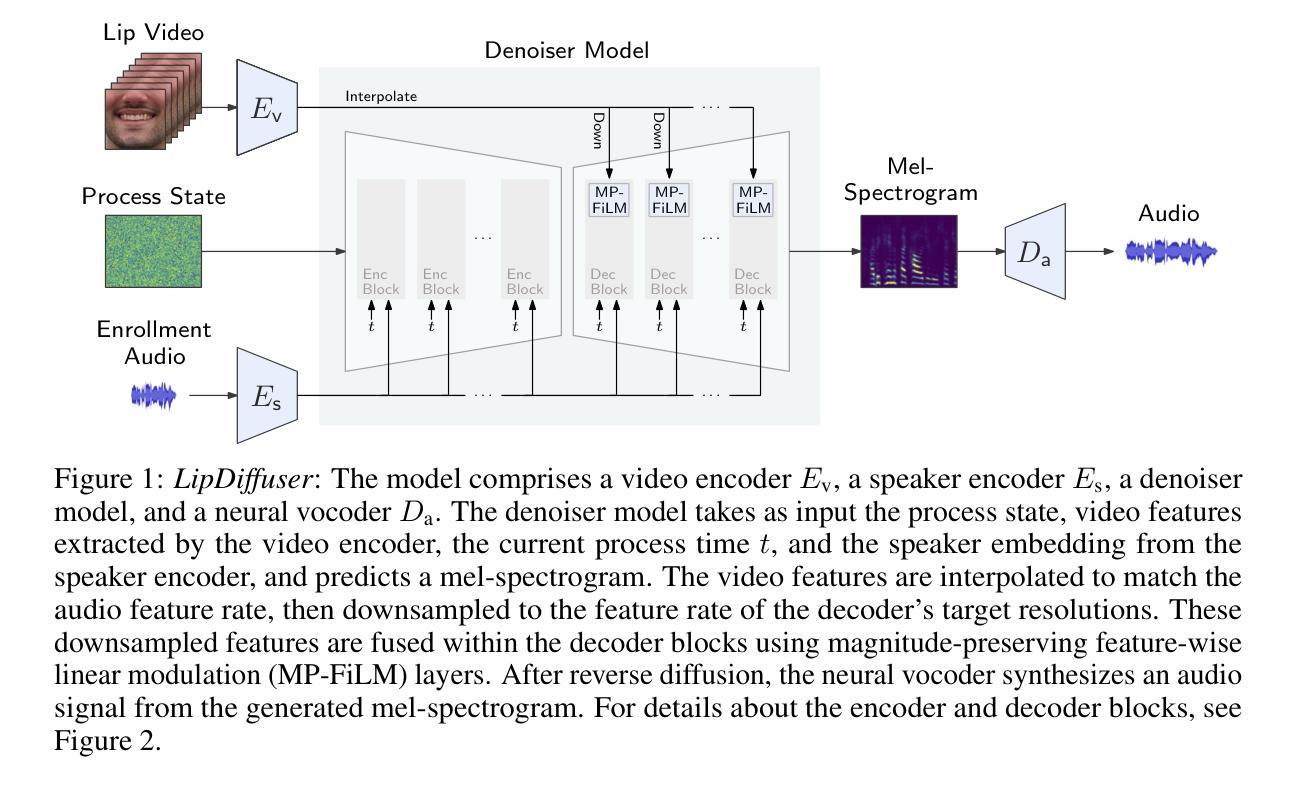
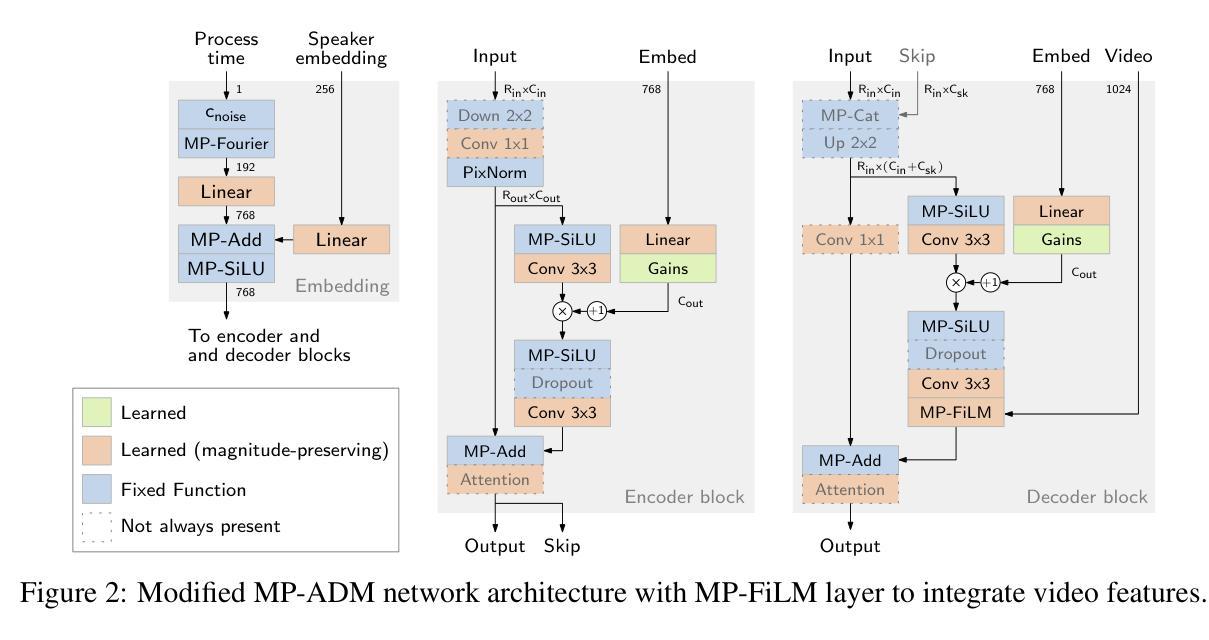
We present LipDiffuser, a conditional diffusion model for lip-to-speech generation synthesizing natural and intelligible speech directly from silent video recordings. Our approach leverages the magnitude-preserving ablated diffusion model (MP-ADM) architecture as a denoiser model. To effectively condition the model, we incorporate visual features using magnitude-preserving feature-wise linear modulation (MP-FiLM) alongside speaker embeddings. A neural vocoder then reconstructs the speech waveform from the generated mel-spectrograms. Evaluations on LRS3 and TCD-TIMIT demonstrate that LipDiffuser outperforms existing lip-to-speech baselines in perceptual speech quality and speaker similarity, while remaining competitive in downstream automatic speech recognition (ASR). These findings are also supported by a formal listening experiment. Extensive ablation studies and cross-dataset evaluation confirm the effectiveness and generalization capabilities of our approach.
我们提出了LipDiffuser,这是一种用于唇语到语音生成的条件扩散模型,它可以直接从无声的视频记录中合成自然和可理解的语音。我们的方法采用幅度保持消融扩散模型(MP-ADM)架构作为去噪模型。为了有效地对模型进行条件处理,我们采用幅度保持特征线性调制(MP-FiLM)结合说话者嵌入来融入视觉特征。然后,神经vocoder从生成的梅尔频谱图中重建语音波形。在LRS3和TCD-TIMIT上的评估表明,LipDiffuser在感知语音质量和说话人相似性方面优于现有的唇语到语音基线,同时在下游自动语音识别(ASR)中保持竞争力。正式听力实验的结果也支持了这些发现。广泛的消融研究和跨数据集评估证实了我们的方法的有效性和泛化能力。
论文及项目相关链接
Summary
本文介绍了LipDiffuser,一种用于唇语生成的条件扩散模型。该模型能够从无声的视频记录中合成自然且可理解的语音。它采用幅度保持消融扩散模型(MP-ADM)架构作为去噪模型,并结合视觉特征和说话人嵌入进行有效条件化。通过神经vocoder从生成的mel光谱图中重建语音波形。在LRS3和TCD-TIMIT上的评估表明,LipDiffuser在感知语音质量和说话人相似性方面优于现有的唇语基线,同时在下游自动语音识别(ASR)中保持竞争力。这些发现得到了正式听力实验的验证。广泛的消融研究和跨数据集评估证实了该方法的有效性和泛化能力。
Key Takeaways
- LipDiffuser是一种基于条件扩散模型的唇语生成技术,能从无声视频合成自然、可理解的语音。
- 采用幅度保持消融扩散模型(MP-ADM)作为去噪模型。
- 结合视觉特征和说话人嵌入进行有效条件化。
- 通过神经vocoder从mel光谱图重建语音波形。
- 在LRS3和TCD-TIMIT数据集上的评估表现优异,优于现有唇语基线。
- 在感知语音质量和说话人相似性方面有明显提升。
点此查看论文截图

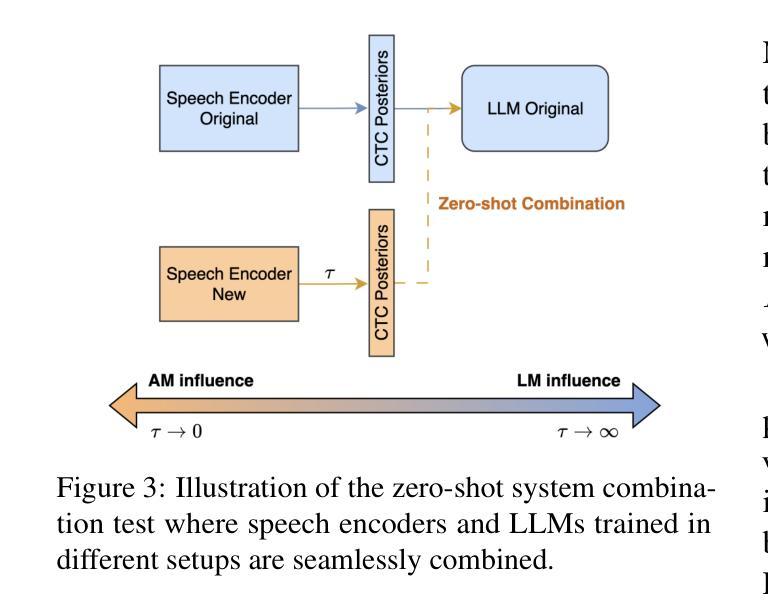
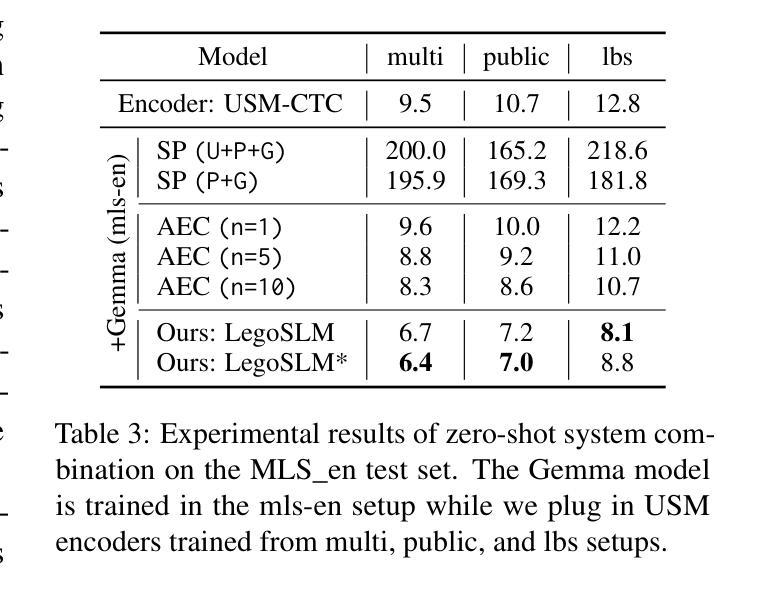
LegoSLM: Connecting LLM with Speech Encoder using CTC Posteriors
Authors:Rao Ma, Tongzhou Chen, Kartik Audhkhasi, Bhuvana Ramabhadran
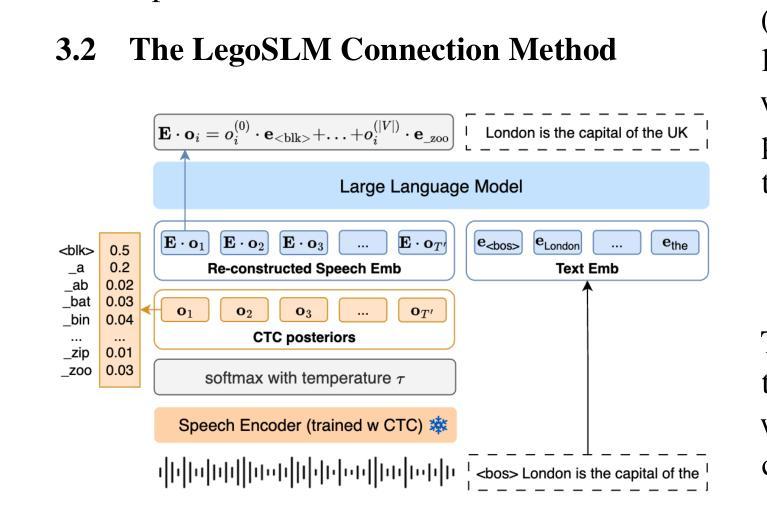
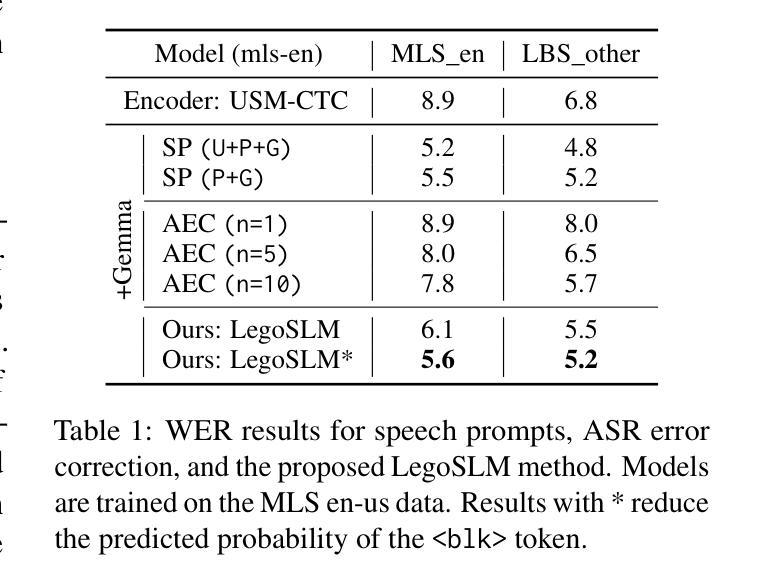
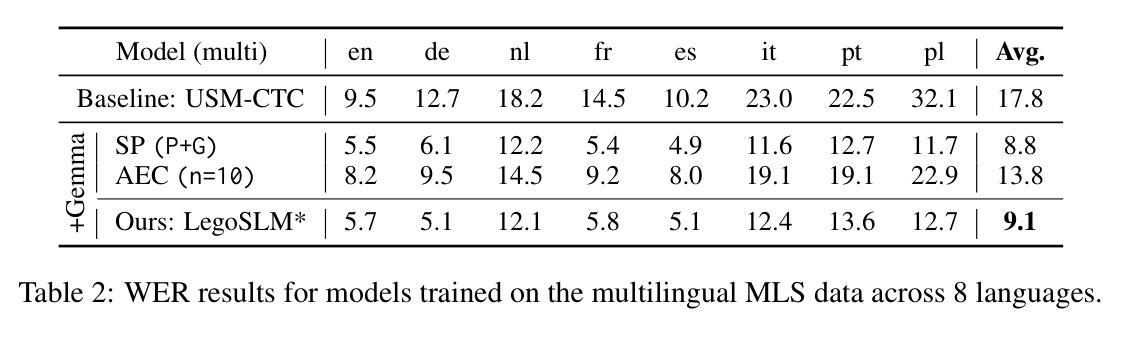
Recently, large-scale pre-trained speech encoders and Large Language Models (LLMs) have been released, which show state-of-the-art performance on a range of spoken language processing tasks including Automatic Speech Recognition (ASR). To effectively combine both models for better performance, continuous speech prompts, and ASR error correction have been adopted. However, these methods are prone to suboptimal performance or are inflexible. In this paper, we propose a new paradigm, LegoSLM, that bridges speech encoders and LLMs using the ASR posterior matrices. The speech encoder is trained to generate Connectionist Temporal Classification (CTC) posteriors over the LLM vocabulary, which are used to reconstruct pseudo-audio embeddings by computing a weighted sum of the LLM input embeddings. These embeddings are concatenated with text embeddings in the LLM input space. Using the well-performing USM and Gemma models as an example, we demonstrate that our proposed LegoSLM method yields good performance on both ASR and speech translation tasks. By connecting USM with Gemma models, we can get an average of 49% WERR over the USM-CTC baseline on 8 MLS testsets. The trained model also exhibits modularity in a range of settings – after fine-tuning the Gemma model weights, the speech encoder can be switched and combined with the LLM in a zero-shot fashion. Additionally, we propose to control the decode-time influence of the USM and LLM using a softmax temperature, which shows effectiveness in domain adaptation.
最近,已经发布了大规模预训练语音编码器和大型语言模型(LLM),它们在包括自动语音识别(ASR)在内的多种口语处理任务上表现出卓越的性能。为了更有效地结合这两种模型以提高性能,采用了连续语音提示和ASR错误校正。然而,这些方法容易出现性能不佳或不够灵活的问题。在本文中,我们提出了一种新的范式LegoSLM,它通过ASR后验矩阵来桥接语音编码器和LLM。语音编码器被训练以生成连接定时分类(CTC)后验概率,覆盖LLM词汇表,然后用于通过计算LLM输入嵌入的加权和来重建伪音频嵌入。这些嵌入与LLM输入空间中的文本嵌入相结合。以表现良好的USM和Gemma模型为例,我们证明了所提出的LegoSLM方法在ASR和语音翻译任务上都具有良好的性能。通过将USM与Gemma模型相结合,我们在8个MLS测试集上相对于USM-CTC基线获得了平均49%的WERR。训练有素的模型在各种设置中也表现出模块化——在微调Gemma模型权重后,可以零射击的方式切换语音编码器并与LLM结合。此外,我们提出使用softmax温度来控制USM和LLM的解码时间影响,这在领域适应方面显示出有效性。
论文及项目相关链接
摘要
最近,大型预训练语音编码器和大型语言模型(LLM)的发布,在包括自动语音识别(ASR)在内的一系列口语处理任务上展现了卓越性能。为了更有效地结合这两种模型以提升性能,采用了连续语音提示和ASR错误校正。然而,这些方法容易出现性能不佳或灵活性不足的问题。本文提出了一种新的模式LegoSLM,它通过ASR的后验矩阵来桥接语音编码器和LLM。语音编码器被训练以生成连接时序分类(CTC)后验概率,这些概率在LLM词汇表上被用于重建伪音频嵌入,通过计算LLM输入嵌入的加权和得到。这些嵌入与LLM输入空间中的文本嵌入进行拼接。以性能良好的USM和Gemma模型为例,我们展示了所提出的LegoSLM方法在ASR和语音翻译任务上的良好表现。通过将USM与Gemma模型相结合,我们在8个MLS测试集上相对于USM-CTC基线获得了平均49%的WERR。训练好的模型在各种设置中也表现出模块化——在微调Gemma模型权重后,可以零射击的方式切换和组合语音编码器和LLM。此外,我们还提出了通过softmax温度控制USM和LLM的解码时间影响,这在领域适配中显示了有效性。
关键见解
- 提出了一种新的模式LegoSLM,通过ASR的后验矩阵结合语音编码器和大型语言模型(LLM)。
- 语音编码器被训练生成连接时序分类(CTC)后验概率,用于重建伪音频嵌入。
- LegoSLM方法在ASR和语音翻译任务上表现出良好性能,相较于基线有显著改善。
- 模型具有模块化特性,可以灵活切换和组合语音编码器和LLM。
- 通过调整softmax温度,可以控制USM和LLM在解码过程中的影响。
- 这种控制策略在领域适配中显示了有效性。
点此查看论文截图

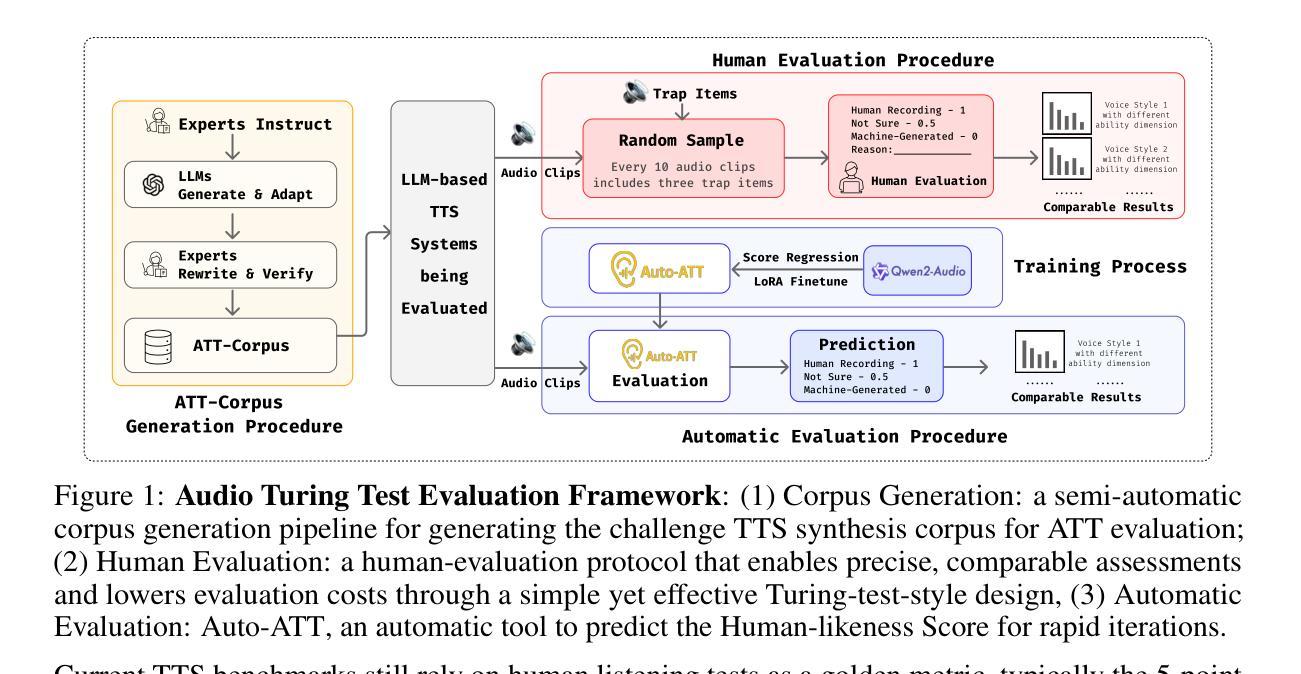
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
Authors:Xihuai Wang, Ziyi Zhao, Siyu Ren, Shao Zhang, Song Li, Xiaoyu Li, Ziwen Wang, Lin Qiu, Guanglu Wan, Xuezhi Cao, Xunliang Cai, Weinan Zhang
Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
最近,大型语言模型(LLM)的进展极大地改善了文本到语音(TTS)系统,提高了对语音风格、自然度和情感表达的控制能力,使TTS系统更接近人类水平的性能。尽管平均意见得分(MOS)仍是TTS系统评估的标准,但它受到主观性、环境不一致性和解释性有限的影响。现有的评估数据集也缺乏多维设计,往往忽略了语音风格、上下文多样性和陷阱话语等因素,这在中文TTS评估中尤其明显。为了解决这些挑战,我们引入了音频图灵测试(ATT),这是一个与简单、受图灵测试启发的评估协议配对的多维中文语料库数据集ATT-Corpus。ATT不要求评估者依赖复杂的MOS量表或直接模型对比来评判,而是要求他们判断一个声音是否听起来像人类。这种简化减少了评分偏见,提高了评估的稳健性。为了进一步支持快速模型开发,我们还使用人类判断数据对Qwen2-Audio-Instruct进行微调,作为自动评估的Auto-ATT。实验结果表明,ATT利用其多维设计有效地区分了不同能力维度的模型。Auto-ATT也与人类评估表现出强烈的对齐,证明其作为快速可靠评估工具的价值。白盒ATT-Corpus和Auto-ATT可在ATT Hugging Face Collection中找到(https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4)。
论文及项目相关链接
PDF Under Review
摘要
近期大型语言模型(LLM)的进步显著提升了文本到语音(TTS)系统的性能,使其在语音风格、自然度和情感表达方面更加可控,更接近人类水平。然而,现有的TTS系统评估主要依赖主观性较强的平均意见得分(MOS),存在环境不一致和解释性有限的问题。为解决这些问题,我们引入了音频图灵测试(ATT)和配套的中文语料库ATT-Corpus,采用简化且基于图灵测试的评估协议。ATT要求评估者判断语音是否听起来像人类,减少评分偏见并提高评估稳健性。为支持快速模型开发,我们还微调了基于人类判断数据的Qwen2-Audio-Instruct作为自动评估工具Auto-ATT。实验结果显示,ATT的多维设计能有效区分不同模型的特定能力维度,而Auto-ATT与人类评估高度一致,成为快速可靠的评估工具。相关资源可于ATT Hugging Face Collection中找到。
关键见解
- 大型语言模型的进步已显著提高文本到语音系统的性能,包括语音风格控制、自然度和情感表达。
- 现有的TTS系统评估方法,如平均意见得分(MOS),存在主观性、环境不一致性和解释性有限的问题。
- 引入音频图灵测试(ATT)作为TTS系统评估的替代方法,要求评估者判断语音是否像人类的声音,从而提高评估的稳健性。
- ATT配套的多维中文语料库ATT-Corpus和基于图灵测试的简单评估协议提升了评估的全面性和准确性。
- 开发了自动评估工具Auto-ATT,以支持快速模型开发,并与人类评估结果高度一致。
- 实验证明,ATT的多维设计能有效区分不同模型的特定能力维度,显示出其在评估模型特定能力方面的有效性。
点此查看论文截图


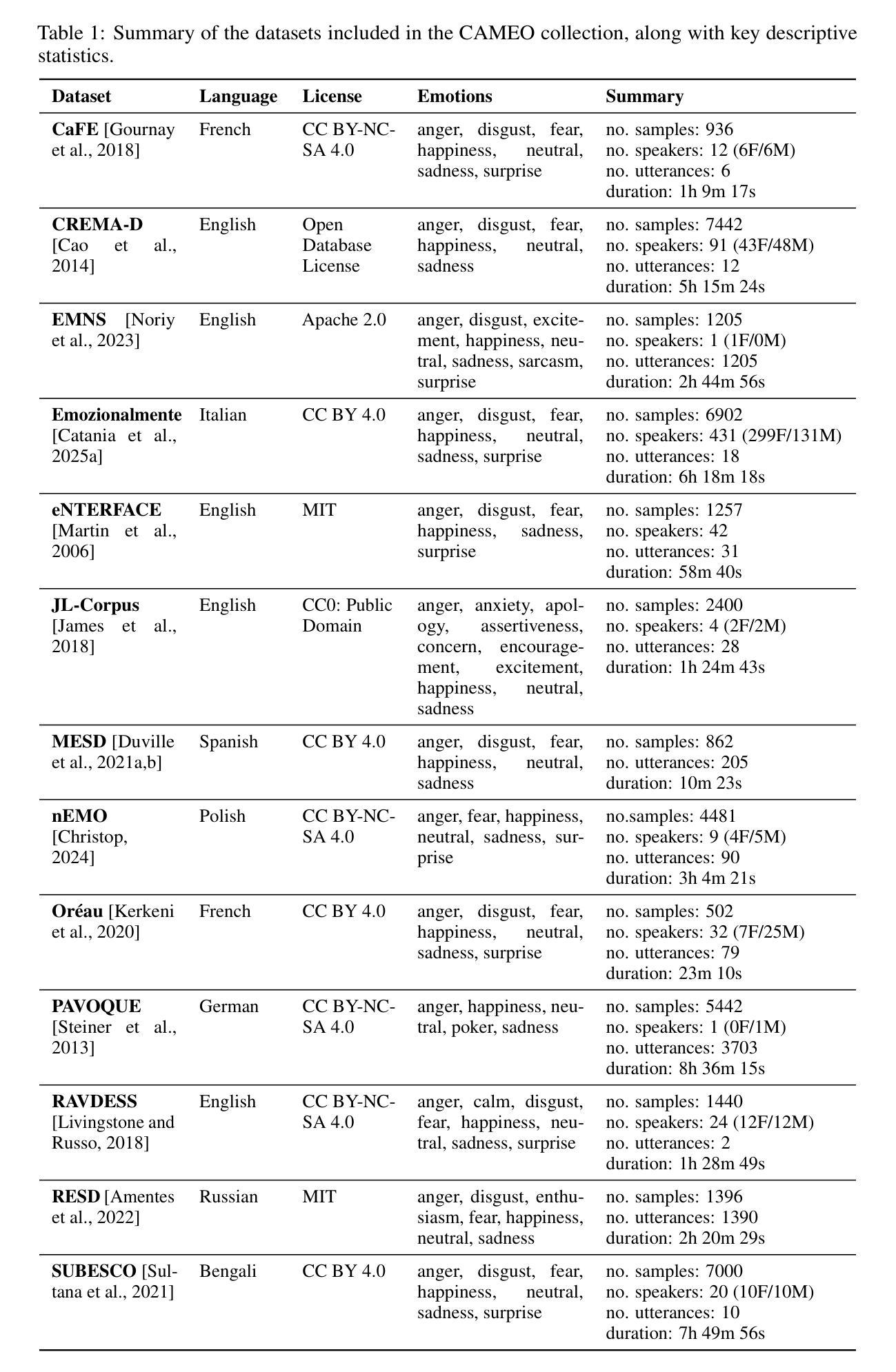
CAMEO: Collection of Multilingual Emotional Speech Corpora
Authors:Iwona Christop, Maciej Czajka
This paper presents CAMEO – a curated collection of multilingual emotional speech datasets designed to facilitate research in emotion recognition and other speech-related tasks. The main objectives were to ensure easy access to the data, to allow reproducibility of the results, and to provide a standardized benchmark for evaluating speech emotion recognition (SER) systems across different emotional states and languages. The paper describes the dataset selection criteria, the curation and normalization process, and provides performance results for several models. The collection, along with metadata, and a leaderboard, is publicly available via the Hugging Face platform.
本文介绍了CAMEO——一个精选的多语言情感语音数据集合集,旨在促进情感识别和其他相关语音任务的研究。主要目标是确保数据的易于访问,以确保结果的可重复性,并提供一个标准化的基准测试,以评估不同情感状态和语言的语音情感识别(SER)系统的性能。本文描述了数据集的选择标准、整理和标准化流程,并为几个模型提供了性能结果。该合集以及元数据和排行榜可通过Hugging Face平台公开访问。
论文及项目相关链接
PDF Under review at NeurIPS
Summary
本文介绍了CAMEO——一个精选的多语言情感语音数据集合集,旨在促进情感识别和其他语音相关任务的研究。其主要目标包括确保数据的轻松访问、允许结果的可重复性,以及为不同情感状态和语言的语音情感识别(SER)系统提供一个标准化的基准评估。
Key Takeaways
- CAMEO是一个多语言情感语音数据集合集,用于促进情感识别研究。
- 数据集易于访问,有利于结果的可重复性。
- 提供了一个标准化的基准评估,用于评估不同情感状态和语言的语音情感识别系统。
- 文章描述了数据集的选择标准、整理和标准化流程。
- 提供了多个模型的表现结果。
- 数据集、元数据和排行榜可通过Hugging Face平台公开访问。
- CAMEO的公开使用有助于推动语音情感识别研究的进步。
点此查看论文截图


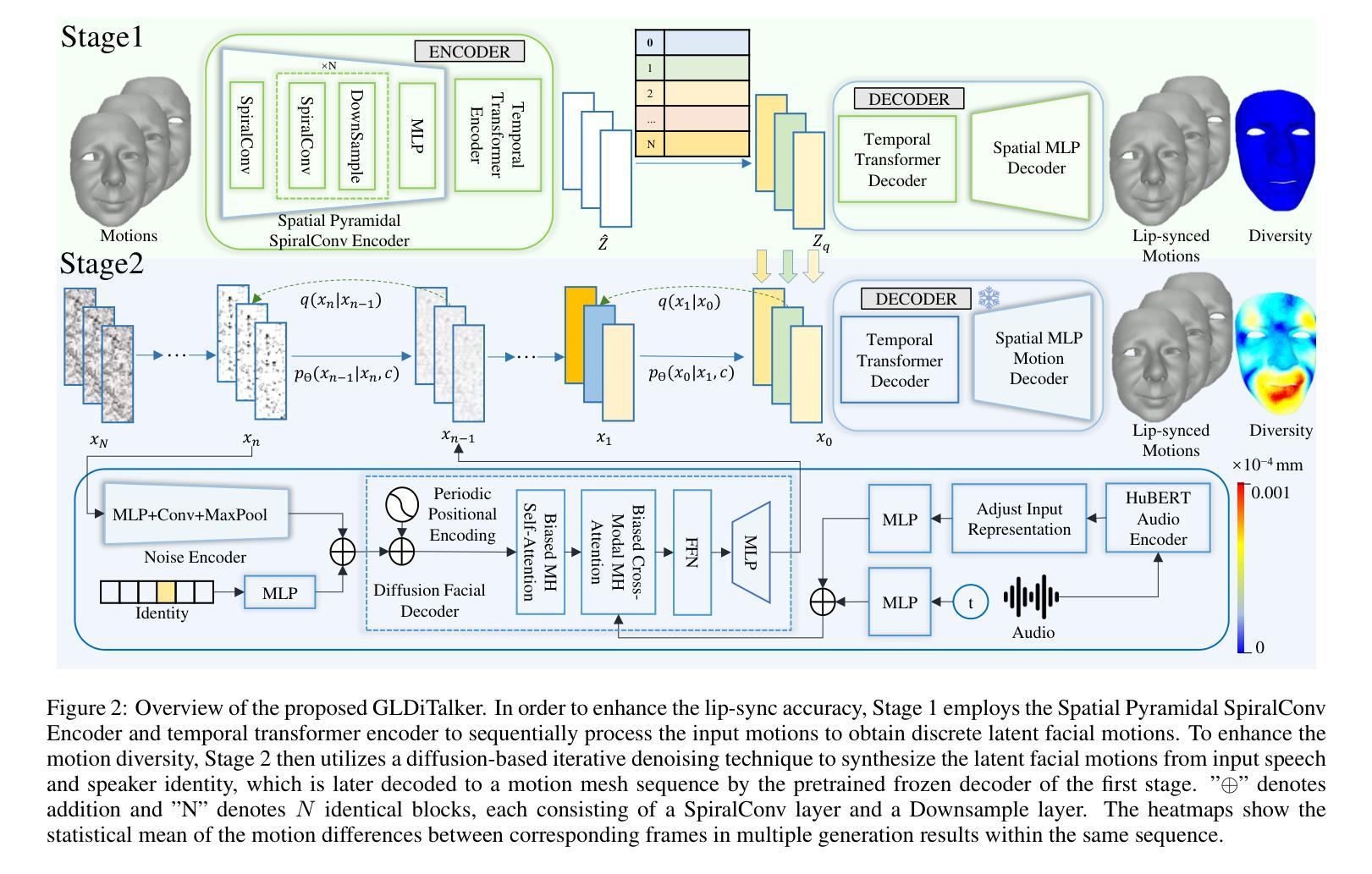
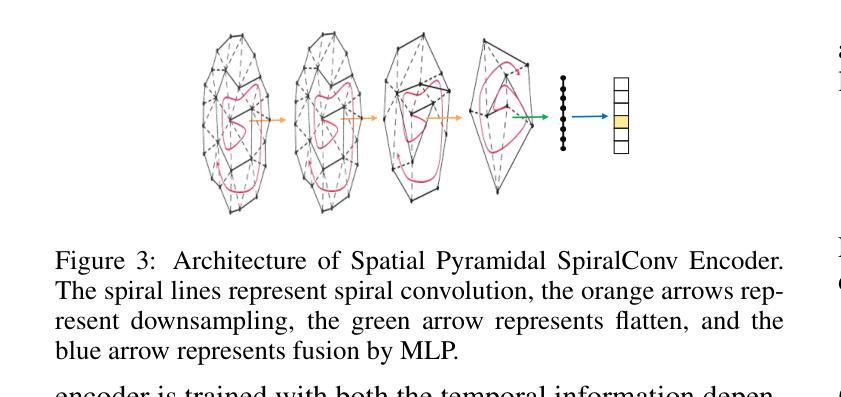
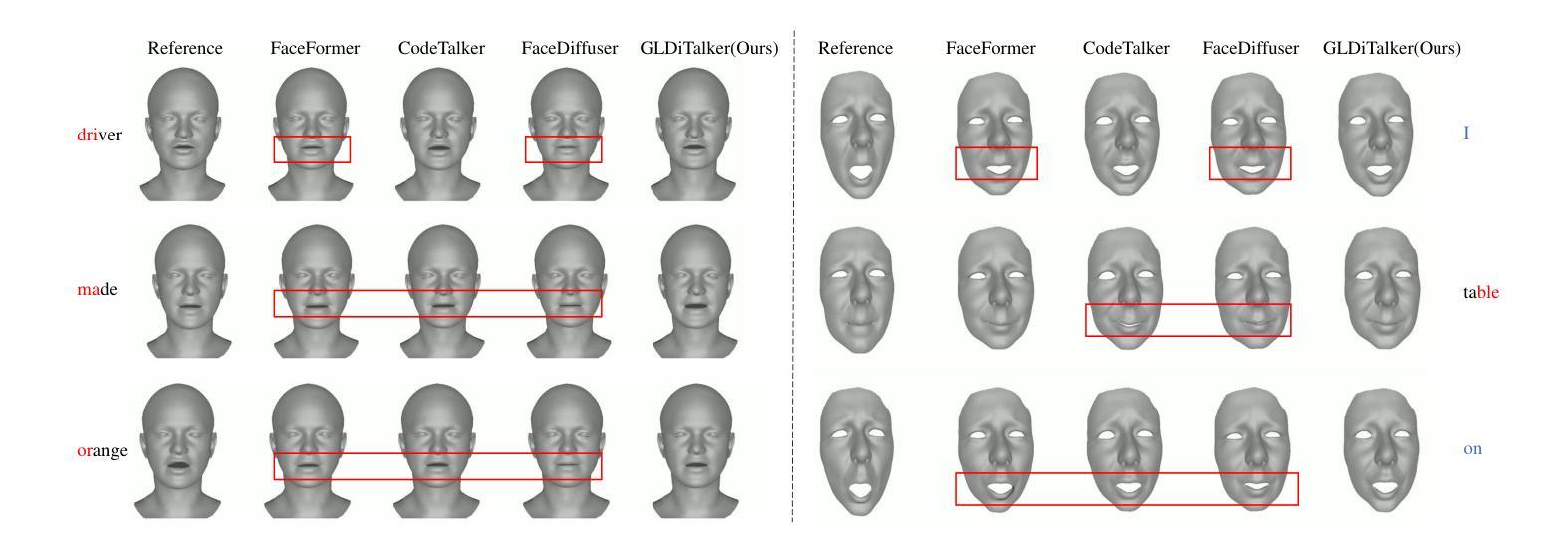
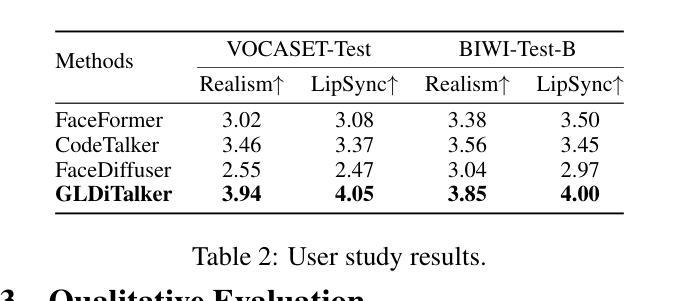
GLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Authors:Yihong Lin, Zhaoxin Fan, Xianjia Wu, Lingyu Xiong, Liang Peng, Xiandong Li, Wenxiong Kang, Songju Lei, Huang Xu
Speech-driven talking head generation is a critical yet challenging task with applications in augmented reality and virtual human modeling. While recent approaches using autoregressive and diffusion-based models have achieved notable progress, they often suffer from modality inconsistencies, particularly misalignment between audio and mesh, leading to reduced motion diversity and lip-sync accuracy. To address this, we propose GLDiTalker, a novel speech-driven 3D facial animation model based on a Graph Latent Diffusion Transformer. GLDiTalker resolves modality misalignment by diffusing signals within a quantized spatiotemporal latent space. It employs a two-stage training pipeline: the Graph-Enhanced Quantized Space Learning Stage ensures lip-sync accuracy, while the Space-Time Powered Latent Diffusion Stage enhances motion diversity. Together, these stages enable GLDiTalker to generate realistic, temporally stable 3D facial animations. Extensive evaluations on standard benchmarks demonstrate that GLDiTalker outperforms existing methods, achieving superior results in both lip-sync accuracy and motion diversity.
语音驱动的头部生成是一项重要且具有挑战性的任务,在增强现实和虚拟人类建模中有广泛的应用。虽然最近使用自回归和扩散模型的方法取得了明显的进步,但它们经常遭受模态不一致的问题,尤其是音频和网格之间的不匹配,导致运动多样性和唇同步精度降低。为了解决这一问题,我们提出了GLDiTalker,这是一个基于图潜在扩散变压器的新型语音驱动3D面部动画模型。GLDiTalker通过量化时空潜在空间内的信号扩散来解决模态不匹配问题。它采用两阶段训练管道:图增强量化空间学习阶段确保唇同步精度,而时空动力潜在扩散阶段增强运动多样性。这两个阶段共同作用,使GLDiTalker能够生成逼真、时间稳定的3D面部动画。在标准基准测试上的广泛评估表明,GLDiTalker优于现有方法,在唇同步精度和运动多样性方面均取得了优越的结果。
论文及项目相关链接
PDF 9 pages, 5 figures
Summary
语音驱动的头部动画生成在增强现实和虚拟人建模中具有关键性和挑战性。新方法在解决音频和网格之间模态不一致问题方面取得了显著进展,但仍面临运动多样性和唇同步准确性问题。为此,我们提出了基于图潜在扩散转换器的GLDiTalker模型。GLDiTalker通过在量化时空潜在空间内扩散信号来解决模态不一致问题。它采用两阶段训练流程:图形增强量化空间学习阶段确保唇同步准确性,时空动力潜在扩散阶段增强运动多样性。这两阶段结合使GLDiTalker能够生成真实、时间稳定的3D面部动画。在标准基准测试上的评估显示,GLDiTalker优于现有方法,在唇同步准确性和运动多样性方面都取得了卓越成果。
Key Takeaways
- 语音驱动的头部动画生成在增强现实和虚拟人建模中具有重要性。
- 现有方法在处理音频和网格之间的模态不一致问题时仍有挑战,导致运动多样性和唇同步准确性下降。
- GLDiTalker是一个基于图潜在扩散转换器的面部动画模型,旨在解决模态不一致问题。
- GLDiTalker通过量化时空潜在空间内的扩散信号来实现模态不一致的解决。
- 模型采用两阶段训练流程,确保唇同步准确性和增强运动多样性。
- GLDiTalker能够生成真实、时间稳定的3D面部动画。
点此查看论文截图