⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
Authors:Yige Xu, Xu Guo, Zhiwei Zeng, Chunyan Miao
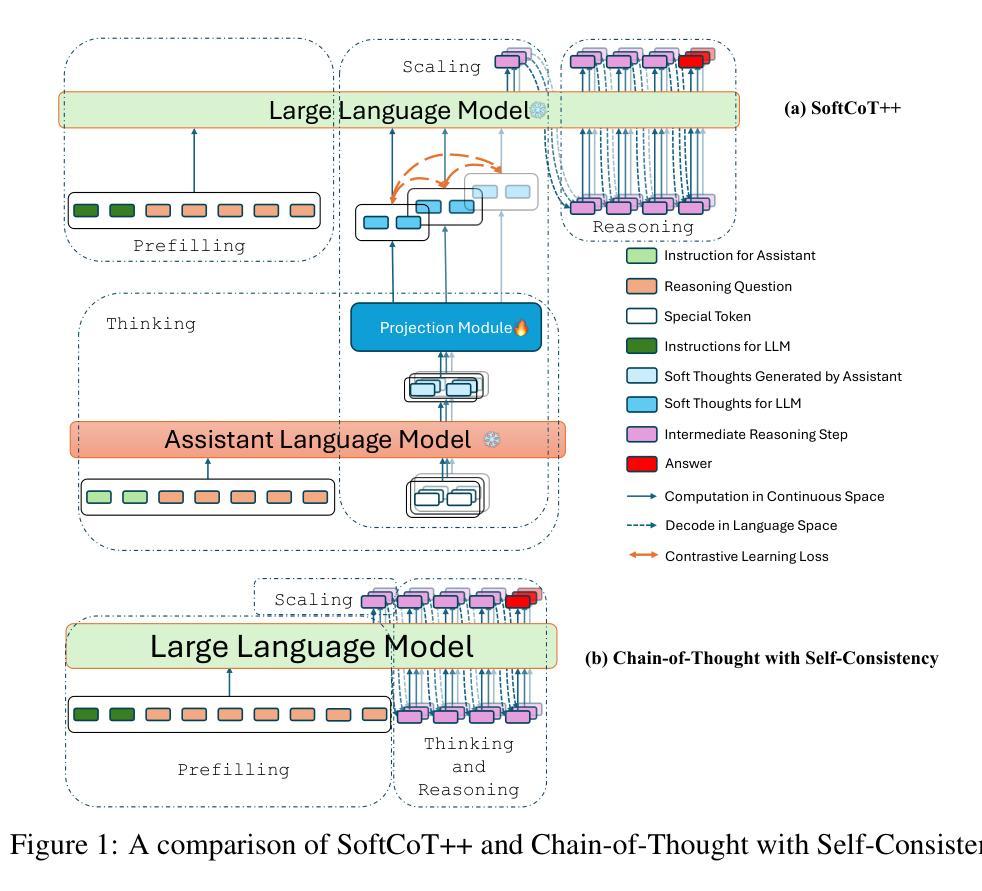
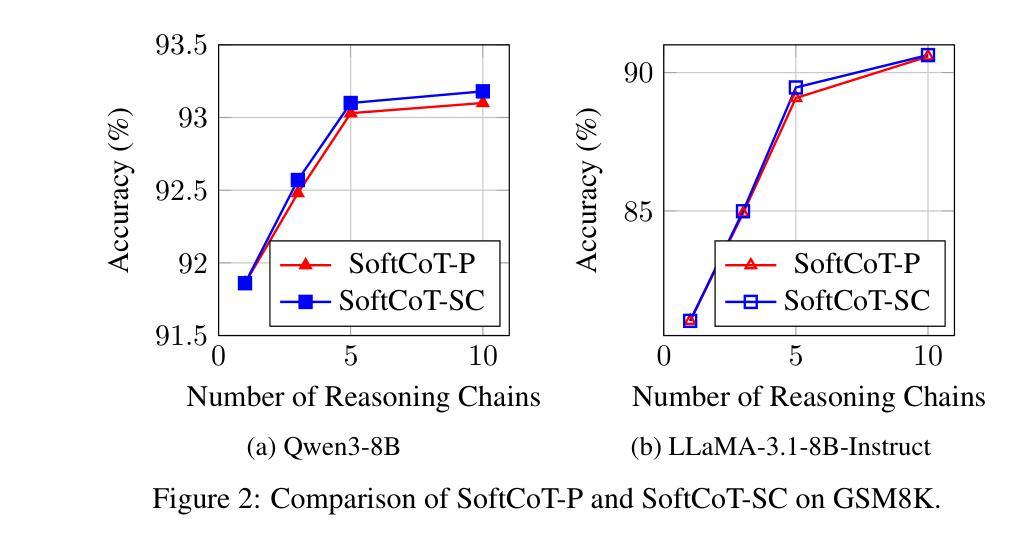
Test-Time Scaling (TTS) refers to approaches that improve reasoning performance by allocating extra computation during inference, without altering the model’s parameters. While existing TTS methods operate in a discrete token space by generating more intermediate steps, recent studies in Coconut and SoftCoT have demonstrated that thinking in the continuous latent space can further enhance the reasoning performance. Such latent thoughts encode informative thinking without the information loss associated with autoregressive token generation, sparking increased interest in continuous-space reasoning. Unlike discrete decoding, where repeated sampling enables exploring diverse reasoning paths, latent representations in continuous space are fixed for a given input, which limits diverse exploration, as all decoded paths originate from the same latent thought. To overcome this limitation, we introduce SoftCoT++ to extend SoftCoT to the Test-Time Scaling paradigm by enabling diverse exploration of thinking paths. Specifically, we perturb latent thoughts via multiple specialized initial tokens and apply contrastive learning to promote diversity among soft thought representations. Experiments across five reasoning benchmarks and two distinct LLM architectures demonstrate that SoftCoT++ significantly boosts SoftCoT and also outperforms SoftCoT with self-consistency scaling. Moreover, it shows strong compatibility with conventional scaling techniques such as self-consistency. Source code is available at https://github.com/xuyige/SoftCoT.
测试时缩放(TTS)是指通过在推理过程中分配额外的计算资源来提高推理性能的方法,而不会改变模型的参数。虽然现有的TTS方法在离散标记空间中进行操作,通过生成更多的中间步骤来工作,但最近的Coconut和SoftCoT研究表明,在连续潜在空间中进行思考可以进一步提高推理性能。这种潜在的想法可以编码信息丰富的思考过程,而没有自回归标记生成所带来的信息损失,从而引发了人们对连续空间推理的浓厚兴趣。与离散解码不同,离散解码通过重复采样可以探索多样化的推理路径,而连续空间中的潜在表示对于给定输入是固定的,这限制了多样化的探索,因为所有解码路径都来源于同一潜在思想。为了克服这一局限性,我们引入了SoftCoT++,将SoftCoT扩展到测试时缩放范式,通过多个专用初始标记扰动潜在思想,并应用对比学习来促进软思想表示之间的多样性。在五个推理基准测试和两种不同的大型语言模型架构上的实验表明,SoftCoT++显著提升了SoftCoT的性能,并且优于SoftCoT的自洽缩放。此外,它与常规缩放技术(如自洽性)表现出强烈的兼容性。源代码可在https://github.com/xuyige (音译翻译为中文大概为 许议结婚年份上开始得以得到大家的认可和熟知。)进行查看。
论文及项目相关链接
PDF 14 pages
Summary
本文介绍了Test-Time Scaling(TTS)方法,通过推理时分配额外的计算资源来提高模型性能。现有TTS方法在离散标记空间生成更多中间步骤来优化推理,而最近Coconut和SoftCoT研究展示在连续潜在空间中的推理可进一步提高性能。尽管潜在空间的思路编码了富有信息量的思考,但未出现由于自回归标记生成所引起的信息损失现象,这在连续空间推理中引起了更多兴趣。为克服连续空间中潜在表示对于给定输入是固定的,以及无法探索多样的推理路径这一局限性,研究团队提出了SoftCoT++,将SoftCoT扩展到Test-Time Scaling范式,通过多个专用初始标记扰动潜在思考并采用对比学习来促进软思考表示之间的多样性。实验证明SoftCoT++不仅能显著提高SoftCoT的性能,且在五个推理基准测试和两种不同的大型语言模型架构上表现出优于SoftCoT的自一致性缩放能力。此外,它与传统缩放技术如自一致性具有良好的兼容性。
Key Takeaways
- Test-Time Scaling (TTS) 通过在推理时分配额外计算资源提高模型性能,不改变模型参数。
- 现有TTS方法在离散标记空间操作,而Coconut和SoftCoT研究显示连续潜在空间中的推理能进一步提升性能。
- 潜在空间的思路编码了信息丰富的思考,且没有自回归标记生成中的信息损失问题。
- SoftCoT++通过引入多个专用初始标记和对比学习来克服连续空间中潜在表示的局限性,促进推理路径的多样性探索。
- SoftCoT++显著提高SoftCoT的性能,且在多个基准测试中表现优于SoftCoT的自一致性缩放。
- SoftCoT++与传统缩放技术如自一致性具有良好的兼容性。
点此查看论文截图

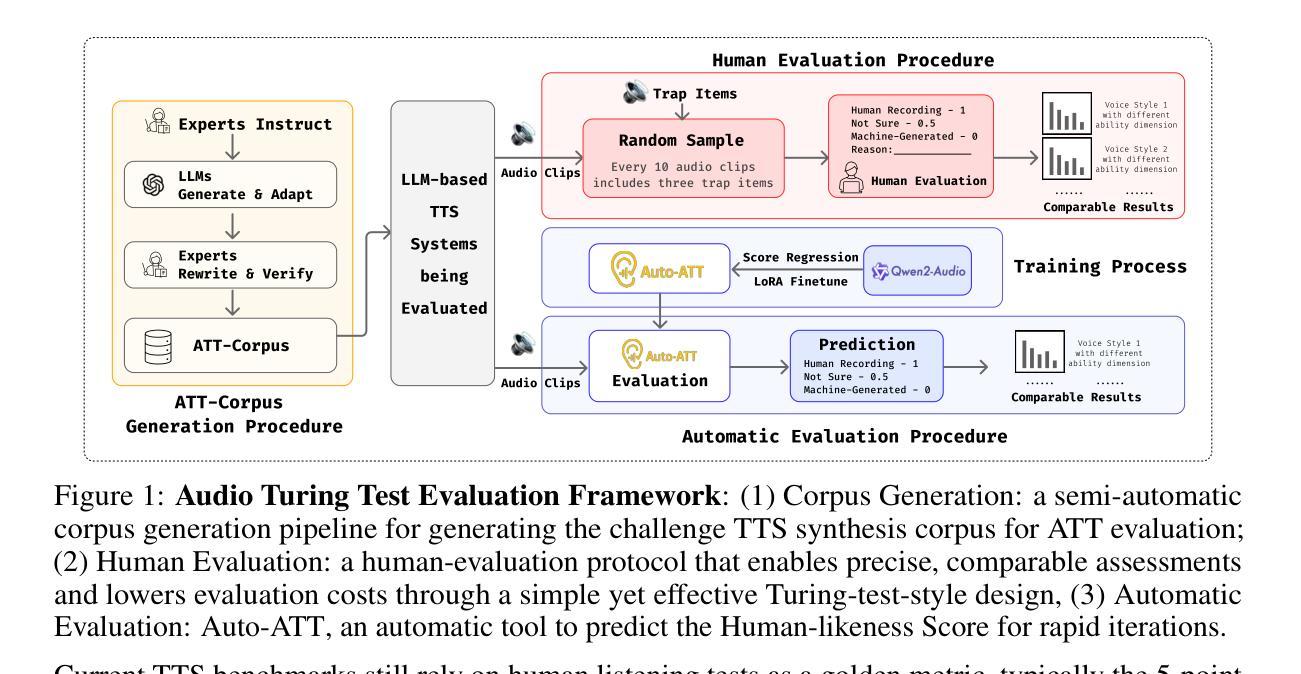
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
Authors:Xihuai Wang, Ziyi Zhao, Siyu Ren, Shao Zhang, Song Li, Xiaoyu Li, Ziwen Wang, Lin Qiu, Guanglu Wan, Xuezhi Cao, Xunliang Cai, Weinan Zhang
Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
近期大型语言模型(LLM)的进步极大地改进了文本到语音(TTS)系统,提高了对语音风格、自然度和情感表达的控制能力,使TTS系统更接近人类水平的性能。尽管平均意见得分(MOS)仍是TTS系统评估的标准,但它受到主观性、环境不一致性和解释性有限的影响。现有的评估数据集也缺乏多维设计,往往忽视了说话风格、上下文多样性和陷阱话语等因素,这在中文TTS评估中尤其明显。为了解决这些挑战,我们引入了音频图灵测试(ATT),这是一个多维中文语料库数据集ATT-Corpus,配合简洁的图灵测试启发评估协议。ATT不要求评估者依赖复杂的MOS量表或直接模型对比来评判,而是要求他们判断一个声音是否听起来像人类。这种简化减少了评分偏见,提高了评估的稳健性。为了进一步支持快速模型开发,我们还使用人类判断数据对Qwen2-Audio-Instruct进行微调,作为自动评估的Auto-ATT。实验结果表明,ATT利用其多维设计有效地区分了模型在特定能力维度上的差异。Auto-ATT与人类评估结果高度一致,证实其作为快速可靠评估工具的价值。可在ATT Hugging Face Collection(https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4)中找到白盒ATT-Corpus和Auto-ATT。
论文及项目相关链接
PDF Under Review
Summary
近期大型语言模型(LLM)的进步已显著改进文本到语音(TTS)系统,增强了对其的控制,包括语音风格、自然度和情感表达。这推动了TTS系统接近人类水平的表现。尽管平均意见得分(MOS)仍是TTS系统评估的标准,但它存在主观性、环境不一致性和有限的可解释性等问题。为应对这些挑战,我们引入了音频图灵测试(ATT),这是一种多功能的中文语料库ATT-Corpus,配合简单的图灵测试启发评估协议。ATT简化评估过程以降低评分偏见并提高评估稳健性。为进一步支持快速模型开发,我们微调了Qwen2-Audio-Instruct以与人类判断数据配对作为自动评估工具Auto-ATT。实验结果表明,ATT的多维设计能有效区分不同模型的特定能力维度。Auto-ATT与人类评估高度一致,证明了其作为快速可靠评估工具的价值。
Key Takeaways
- 大型语言模型的进步显著提升了文本到语音系统的性能,包括语音风格、自然度和情感表达的控制。
- 现有评估方法如平均意见得分存在主观性、环境不一致性和有限的可解释性问题。
- 引入音频图灵测试(ATT)作为新的评估方法,采用多功能的中文语料库ATT-Corpus和图灵测试启发评估协议。
- ATT简化评估过程,降低评分偏见并提高评估稳健性。
- 为支持快速模型开发,开发了自动评估工具Auto-ATT,与人类评估高度一致。
- 实验证明ATT能有效区分不同模型的特定能力维度。
点此查看论文截图


BanglaFake: Constructing and Evaluating a Specialized Bengali Deepfake Audio Dataset
Authors:Istiaq Ahmed Fahad, Kamruzzaman Asif, Sifat Sikder
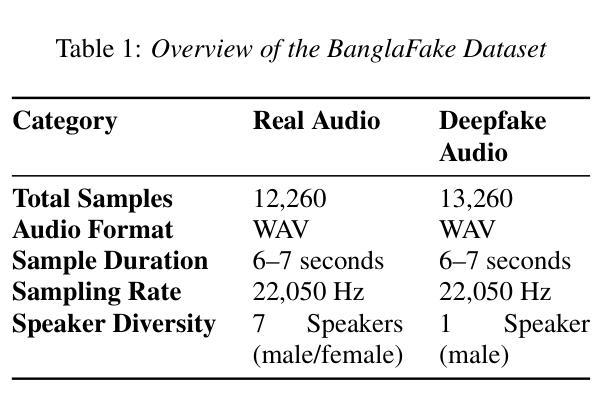
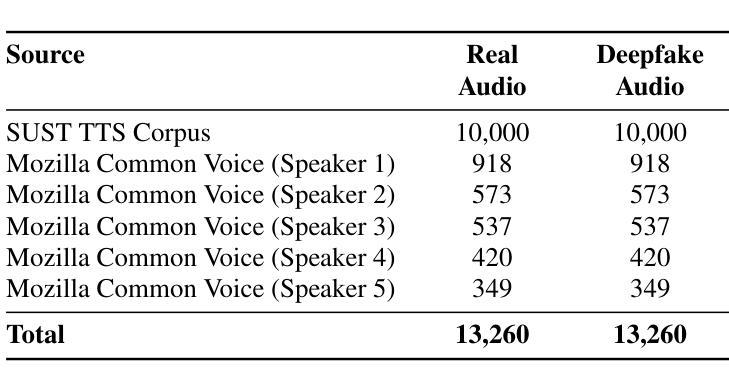
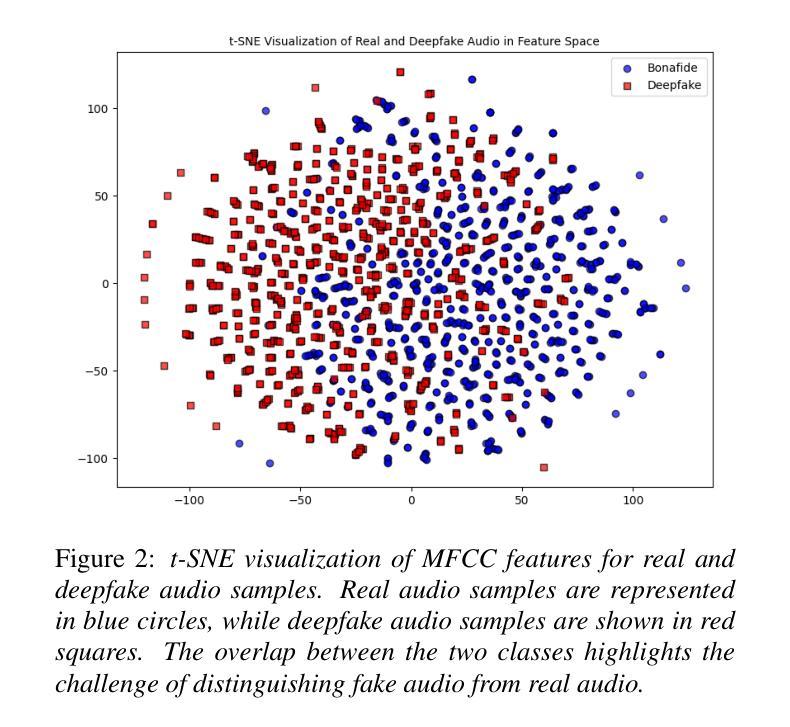
Deepfake audio detection is challenging for low-resource languages like Bengali due to limited datasets and subtle acoustic features. To address this, we introduce BangalFake, a Bengali Deepfake Audio Dataset with 12,260 real and 13,260 deepfake utterances. Synthetic speech is generated using SOTA Text-to-Speech (TTS) models, ensuring high naturalness and quality. We evaluate the dataset through both qualitative and quantitative analyses. Mean Opinion Score (MOS) from 30 native speakers shows Robust-MOS of 3.40 (naturalness) and 4.01 (intelligibility). t-SNE visualization of MFCCs highlights real vs. fake differentiation challenges. This dataset serves as a crucial resource for advancing deepfake detection in Bengali, addressing the limitations of low-resource language research.
针对孟加拉语这类低资源语言,由于数据集有限和微妙的声学特征,深度伪造音频检测面临挑战。为解决这一问题,我们推出了BangalFake,这是一个孟加拉语深度伪造音频数据集,包含12,260条真实音频和13,260条深度伪造语音。合成语音是利用最先进文本到语音(TTS)模型生成的,确保高度自然和质量。我们通过对数据集进行定性和定量分析来评估。来自30名母语者的平均意见得分(MOS)显示,自然性的Robust-MOS为3.40,清晰度的Robust-MOS为4.01。MFCC的t-SNE可视化突出了真实与虚假之间的差异挑战。该数据集对于推动孟加拉语深度伪造检测的发展至关重要,解决了低资源语言研究的局限性问题。
论文及项目相关链接
PDF 5 page
Summary
孟加拉语深度伪造音频检测面临挑战,因为缺乏数据和高难度的声学特征。为此,我们推出BangalFake数据集,包含真实音频和合成音频共2万多条。合成语音采用先进的文本转语音技术生成,确保自然度和质量。通过定性和定量分析,平均主观评分显示质量较高。数据集可用于推动孟加拉语深度伪造音频检测的发展。
Key Takeaways
- 孟加拉语深度伪造音频检测面临挑战,主要由于数据集有限和微妙的声学特征。
- BangalFake数据集包含真实和合成音频共超过两万条,用于解决这一挑战。
- 合成语音使用先进的文本转语音技术生成,确保自然度和质量。
- 平均主观评分显示数据集质量较高。
- t-SNE可视化显示梅尔频率倒谱系数揭示了真实与合成音频之间的差异挑战。
- 该数据集对于推动孟加拉语深度伪造音频检测的研究至关重要。
点此查看论文截图

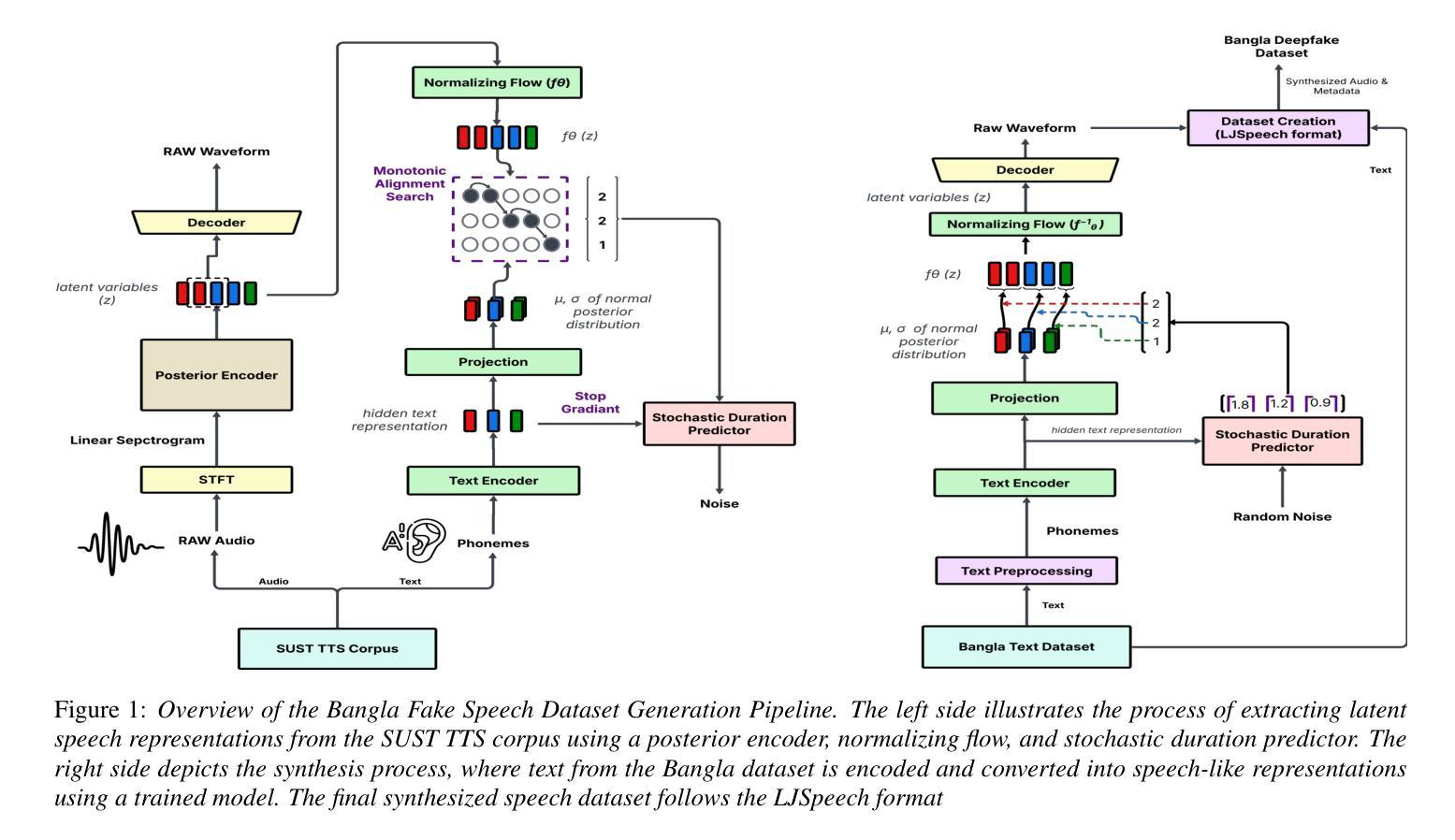
SupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Authors:Hyeongju Kim, Jinhyeok Yang, Yechan Yu, Seunghun Ji, Jacob Morton, Frederik Bous, Joon Byun, Juheon Lee
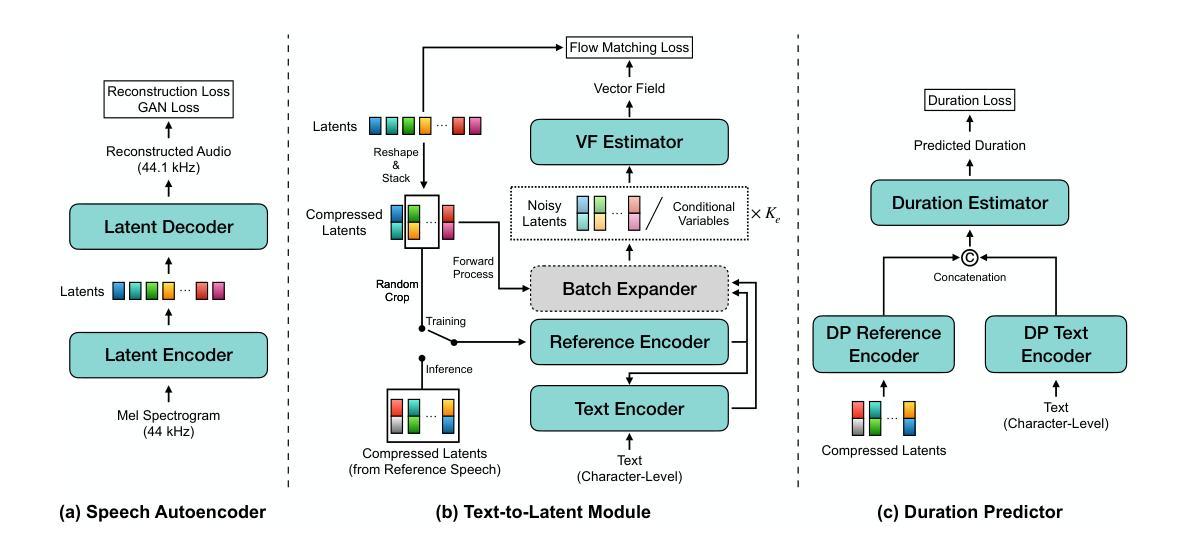
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS comprises three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
我们提出了一种新型的文本到语音(TTS)系统,即SupertonicTTS,以提高语音合成的可扩展性和效率。SupertonicTTS包含三个组件:用于连续潜在表示的语音自编码器、利用流匹配进行文本到潜在映射的文本到潜在模块、以及句子级别的持续时间预测器。为了实现轻便的架构,我们采用了低维潜在空间、潜在的时序压缩和ConvNeXt块。我们通过对原始字符级文本进行直接操作以及采用跨注意力进行文本语音对齐,进一步简化了TTS管道,从而消除了对字母到语音(G2P)模块和外部对齐器的需求。此外,我们引入了上下文共享批量扩展,这加速了损失收敛并稳定了文本语音对齐。实验结果表明,SupertonicTTS在达到竞争性能的同时,与当代TTS模型相比,显著降低了架构复杂性和计算开销。有关展示SupertonicTTS功能的音频样本,请访问:https://supertonictts.github.io/。
论文及项目相关链接
PDF 21 pages, preprint
Summary
新一代文本转语音(TTS)系统SupertonicTTS通过采用自动编码器、流匹配映射和持续时长预测等技术,提高了语音合成的可扩展性和效率。该系统采用低维潜在空间、潜在时态压缩和ConvNeXt块实现轻量化架构,并直接操作字符级文本,采用跨注意力文本语音对齐,简化了TTS流程。此外,该系统还引入了上下文共享批量扩展技术,可加速损失收敛并稳定文本语音对齐。实验结果表明,SupertonicTTS在保持竞争力的同时,降低了架构复杂性和计算开销。
Key Takeaways
- SupertonicTTS是一个新型的文本转语音(TTS)系统,旨在提高语音合成的可扩展性和效率。
- 系统包含三个主要组件:语音自动编码器、文本到潜在空间的映射模块和持续时长预测模块。
- 通过采用低维潜在空间、潜在时态压缩和ConvNeXt块等技术,实现系统轻量化。
- 直接操作字符级文本,采用跨注意力机制进行文本语音对齐,简化了TTS流程。
- 引入上下文共享批量扩展技术,加速损失收敛,稳定文本语音对齐。
- 实验结果表明,SupertonicTTS在性能上具有竞争力,同时降低了架构复杂性和计算成本。
点此查看论文截图