⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
EmoFace: Emotion-Content Disentangled Speech-Driven 3D Talking Face Animation
Authors:Yihong Lin, Liang Peng, Zhaoxin Fan, Xianjia Wu, Jianqiao Hu, Xiandong Li, Wenxiong Kang, Songju Lei
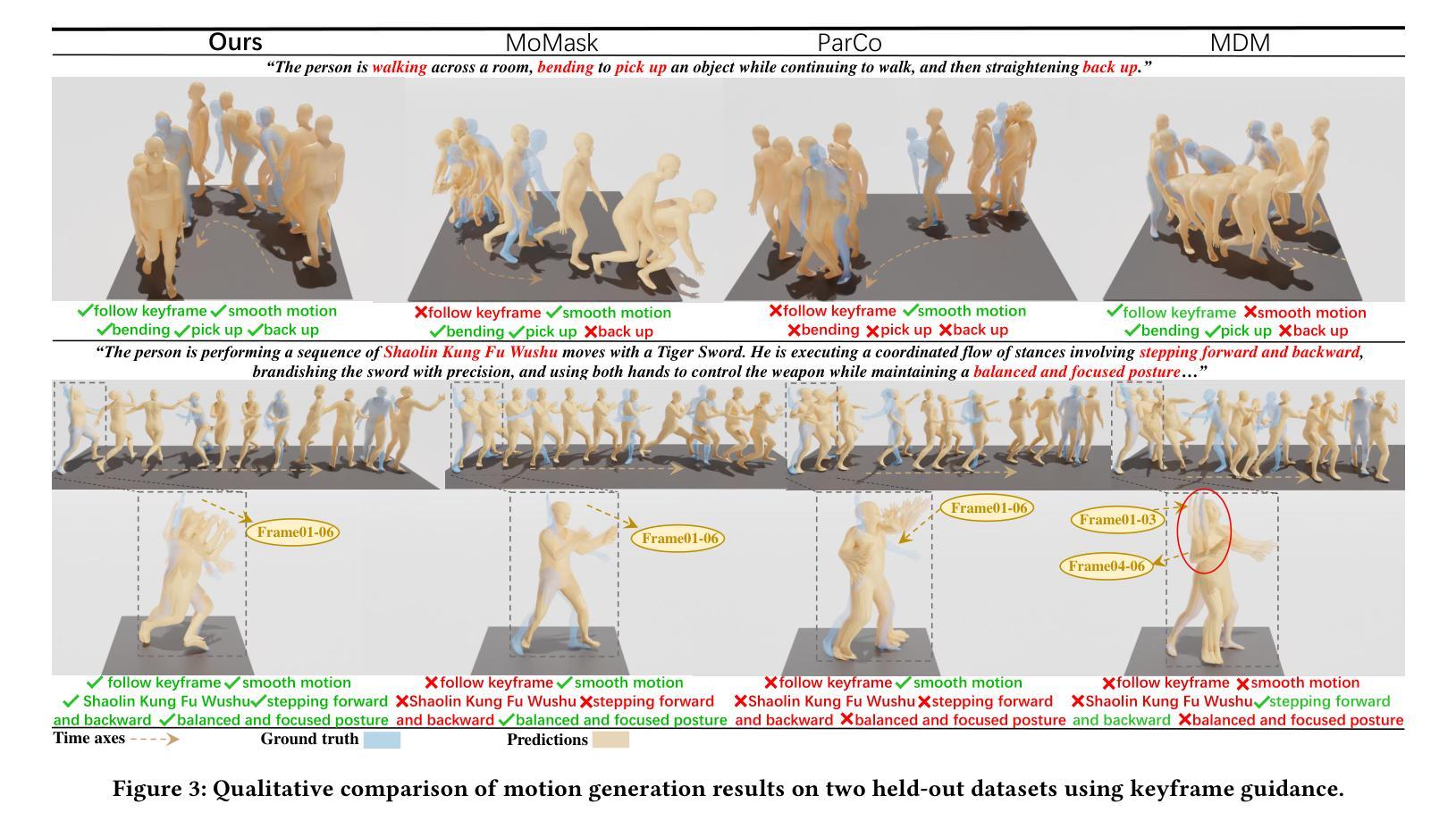
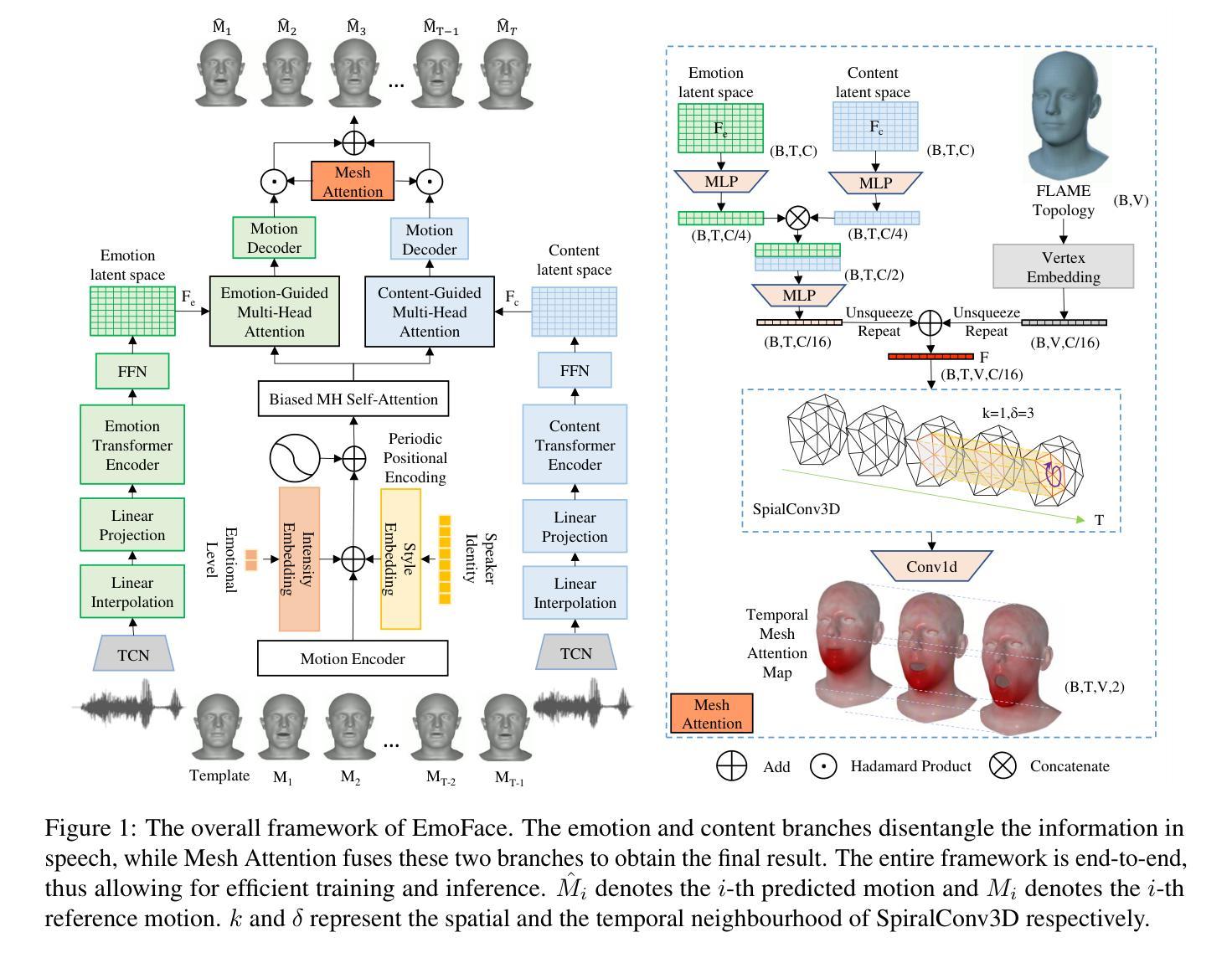
The creation of increasingly vivid 3D talking face has become a hot topic in recent years. Currently, most speech-driven works focus on lip synchronisation but neglect to effectively capture the correlations between emotions and facial motions. To address this problem, we propose a two-stream network called EmoFace, which consists of an emotion branch and a content branch. EmoFace employs a novel Mesh Attention mechanism to analyse and fuse the emotion features and content features. Particularly, a newly designed spatio-temporal graph-based convolution, SpiralConv3D, is used in Mesh Attention to learn potential temporal and spatial feature dependencies between mesh vertices. In addition, to the best of our knowledge, it is the first time to introduce a new self-growing training scheme with intermediate supervision to dynamically adjust the ratio of groundtruth adopted in the 3D face animation task. Comprehensive quantitative and qualitative evaluations on our high-quality 3D emotional facial animation dataset, 3D-RAVDESS ($4.8863\times 10^{-5}$mm for LVE and $0.9509\times 10^{-5}$mm for EVE), together with the public dataset VOCASET ($2.8669\times 10^{-5}$mm for LVE and $0.4664\times 10^{-5}$mm for EVE), demonstrate that our approach achieves state-of-the-art performance.
近年来,创建越来越生动的3D说话脸已成为热门话题。目前,大多数语音驱动的研究工作主要集中在唇同步上,但忽略了情绪和面部动作之间的关联的有效捕捉。为了解决此问题,我们提出了一种名为EmoFace的两流网络,其包括情感分支和内容分支。EmoFace采用了一种新型的Mesh Attention机制来分析并融合情感特征和内容特征。特别是,一种新设计的基于时空图的卷积,SpiralConv3D,在Mesh Attention中用于学习网格顶点之间潜在的临时和空间特征依赖性。此外,据我们所知,这是首次引入一种新的自我成长训练方案,具有中间监督,以动态调整用于三维面部动画任务的真实值比率。在我们高质量的三维情感面部动画数据集3D-RAVDESS(LVE为$ 4.8863\times 10^{-5}$毫米,EVE为$ 0.9509\times 10^{-5}$毫米)以及公共数据集VOCASET(LVE为$ 2.8669\times 10^{-5}$毫米,EVE为$ 0.4664\times 10^{-5}$毫米)上的全面定量和定性评估表明,我们的方法达到了最新性能水平。
论文及项目相关链接
Summary
本文研究了创建生动3D谈话面部的热门话题,提出了一种名为EmoFace的两流网络,包含情感分支和内容分支,并采用Mesh Attention机制和SpiralConv3D时空图卷积来分析和融合情感特征和内容特征。此外,本文首次引入了一种新的自我成长训练方案,带有中间监督,以动态调整3D面部动画任务中采用的真实比例。在高质量的情感面部表情动画数据集上的评估和公共数据集上的结果表明,该方法达到了最先进的性能。
Key Takeaways
- 3D谈话面部的创建已成为近年来的热门话题,目前的研究主要关注语音驱动的唇部同步技术。
- 提出了一种名为EmoFace的两流网络架构,包括情感分支和内容分支,以处理情感和面部动作之间的关联。
- 引入了Mesh Attention机制来分析和融合情感特征和内容特征。
- 采用SpiralConv3D时空图卷积学习网格顶点之间的潜在时空特征依赖性。
- 第一次引入了一种自我成长训练方案,带中间监督的动态调整地面真实比例对优化训练有积极作用。
点此查看论文截图

GLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Authors:Yihong Lin, Zhaoxin Fan, Xianjia Wu, Lingyu Xiong, Liang Peng, Xiandong Li, Wenxiong Kang, Songju Lei, Huang Xu
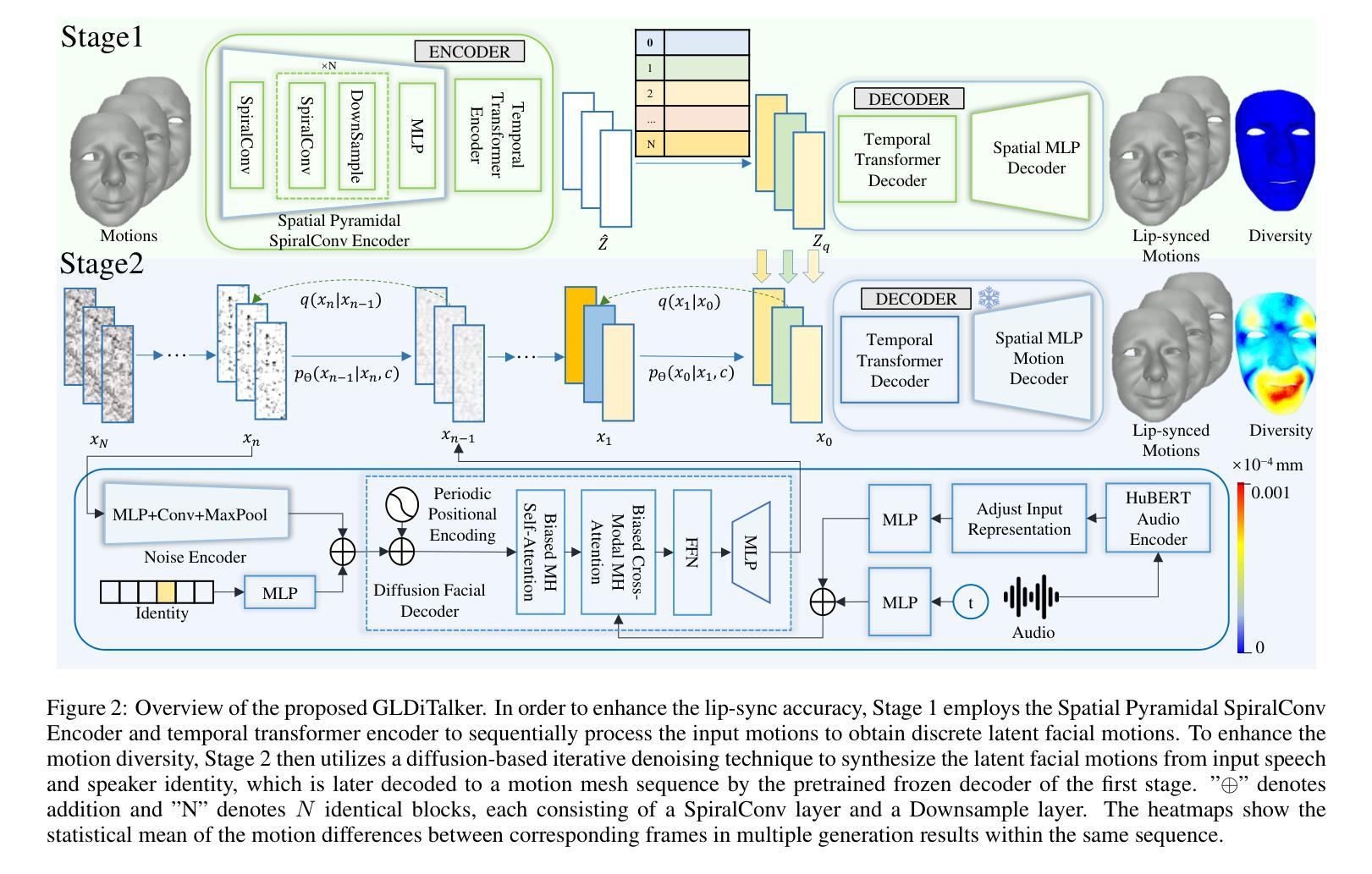
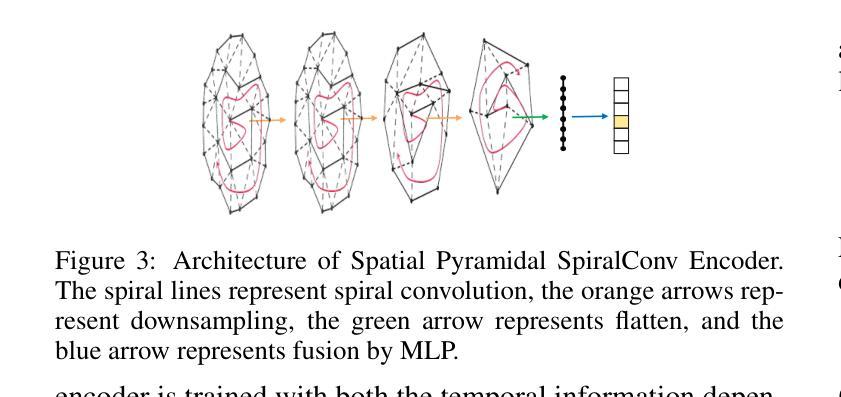
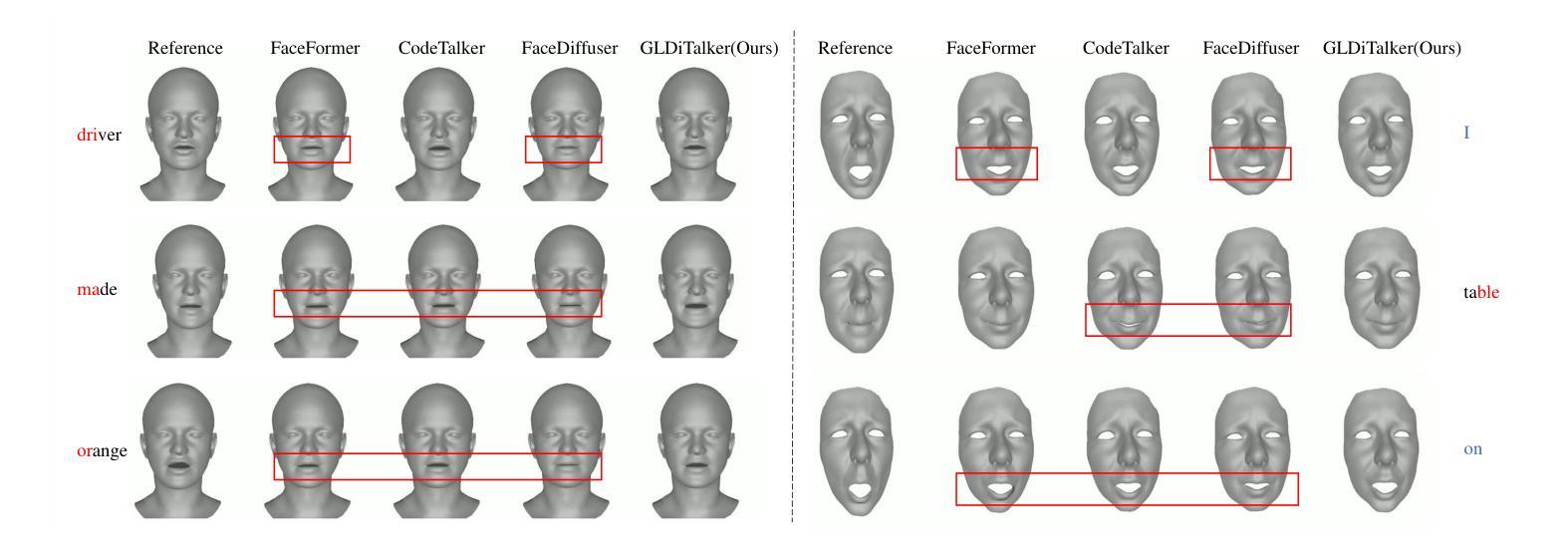
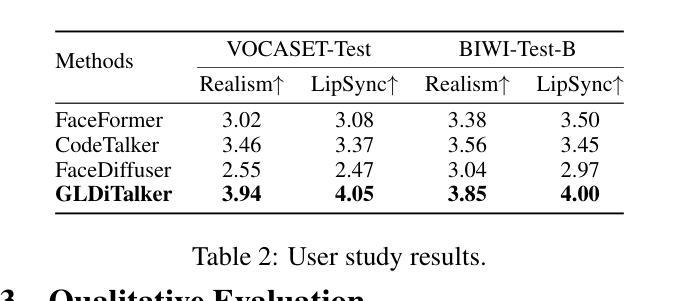
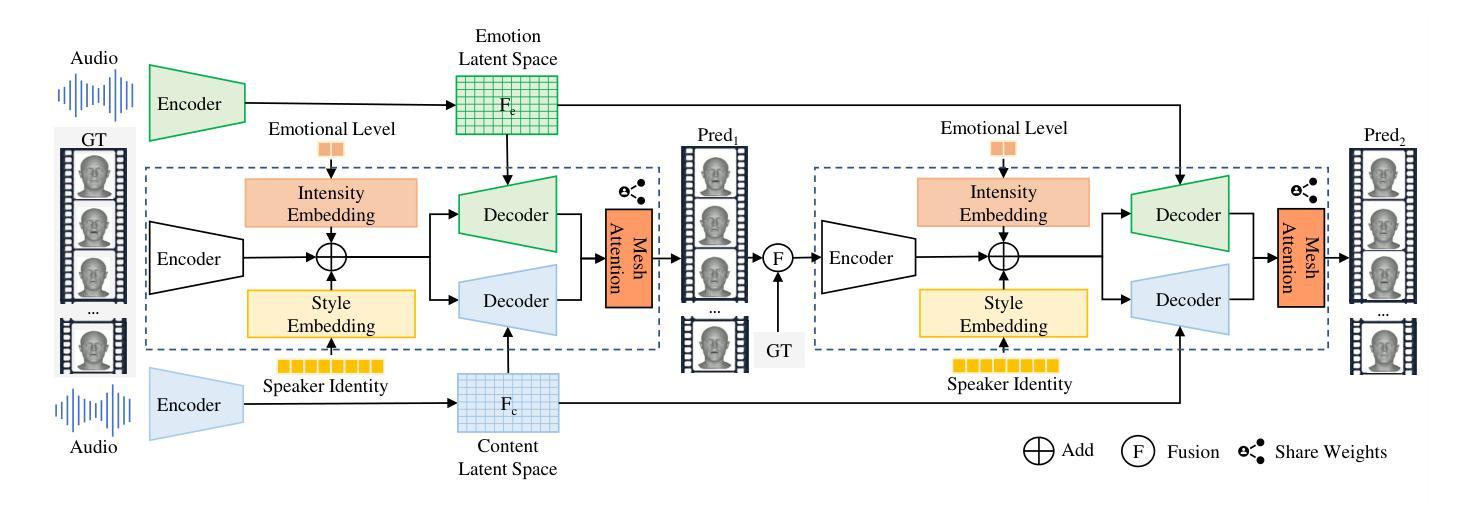
Speech-driven talking head generation is a critical yet challenging task with applications in augmented reality and virtual human modeling. While recent approaches using autoregressive and diffusion-based models have achieved notable progress, they often suffer from modality inconsistencies, particularly misalignment between audio and mesh, leading to reduced motion diversity and lip-sync accuracy. To address this, we propose GLDiTalker, a novel speech-driven 3D facial animation model based on a Graph Latent Diffusion Transformer. GLDiTalker resolves modality misalignment by diffusing signals within a quantized spatiotemporal latent space. It employs a two-stage training pipeline: the Graph-Enhanced Quantized Space Learning Stage ensures lip-sync accuracy, while the Space-Time Powered Latent Diffusion Stage enhances motion diversity. Together, these stages enable GLDiTalker to generate realistic, temporally stable 3D facial animations. Extensive evaluations on standard benchmarks demonstrate that GLDiTalker outperforms existing methods, achieving superior results in both lip-sync accuracy and motion diversity.
语音驱动的头部分离生成是一项至关重要且具有挑战性的任务,在增强现实和虚拟人类建模等领域具有广泛的应用。虽然最近采用自回归和扩散模型的方法取得了显著的进步,但它们经常遭受模态不一致的问题,特别是音频和网格之间的不匹配,导致运动多样性和唇同步准确性降低。为了解决这一问题,我们提出了GLDiTalker,这是一个基于图潜在扩散变压器的新型语音驱动3D面部动画模型。GLDiTalker通过量化时空潜在空间内的信号扩散来解决模态不匹配问题。它采用两阶段训练管道:图增强量化空间学习阶段确保唇同步准确性,而时空动力潜在扩散阶段增强运动多样性。这两个阶段共同使GLDiTalker能够生成逼真、时间稳定的3D面部动画。在标准基准测试上的广泛评估表明,GLDiTalker优于现有方法,在唇同步准确性和运动多样性方面都取得了优越的结果。
论文及项目相关链接
PDF 9 pages, 5 figures
Summary
本文介绍了基于Graph Latent Diffusion Transformer的语音驱动3D面部动画模型GLDiTalker。GLDiTalker解决了模态不一致的问题,通过量化时空潜在空间内的信号扩散来确保唇音同步准确性和运动多样性。采用两阶段训练管道,包括图形增强量化空间学习阶段和时空动力潜在扩散阶段。评估结果表明,GLDiTalker在唇音同步和运动多样性方面均优于现有方法。
Key Takeaways
- GLDiTalker是一种新型的语音驱动3D面部动画模型,基于Graph Latent Diffusion Transformer。
- 该模型解决了模态不一致的问题,特别是在音频和网格之间的不匹配,确保了唇音同步的准确性。
- GLDiTalker通过量化时空潜在空间内的信号扩散来实现运动多样性的增强。
- 模型采用两阶段训练管道,包括图形增强量化空间学习阶段和时空动力潜在扩散阶段。
- GLDiTalker能够生成逼真的、时间稳定的3D面部动画。
- 在标准基准测试上的评估表明,GLDiTalker在唇音同步和运动多样性方面均优于现有方法。
点此查看论文截图