⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-20 更新
Unifying Segment Anything in Microscopy with Multimodal Large Language Model
Authors:Manyu Li, Ruian He, Zixian Zhang, Weimin Tan, Bo Yan
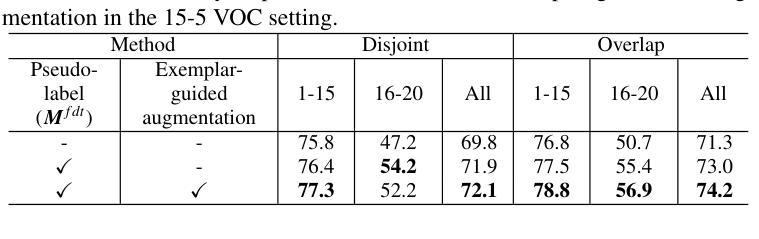
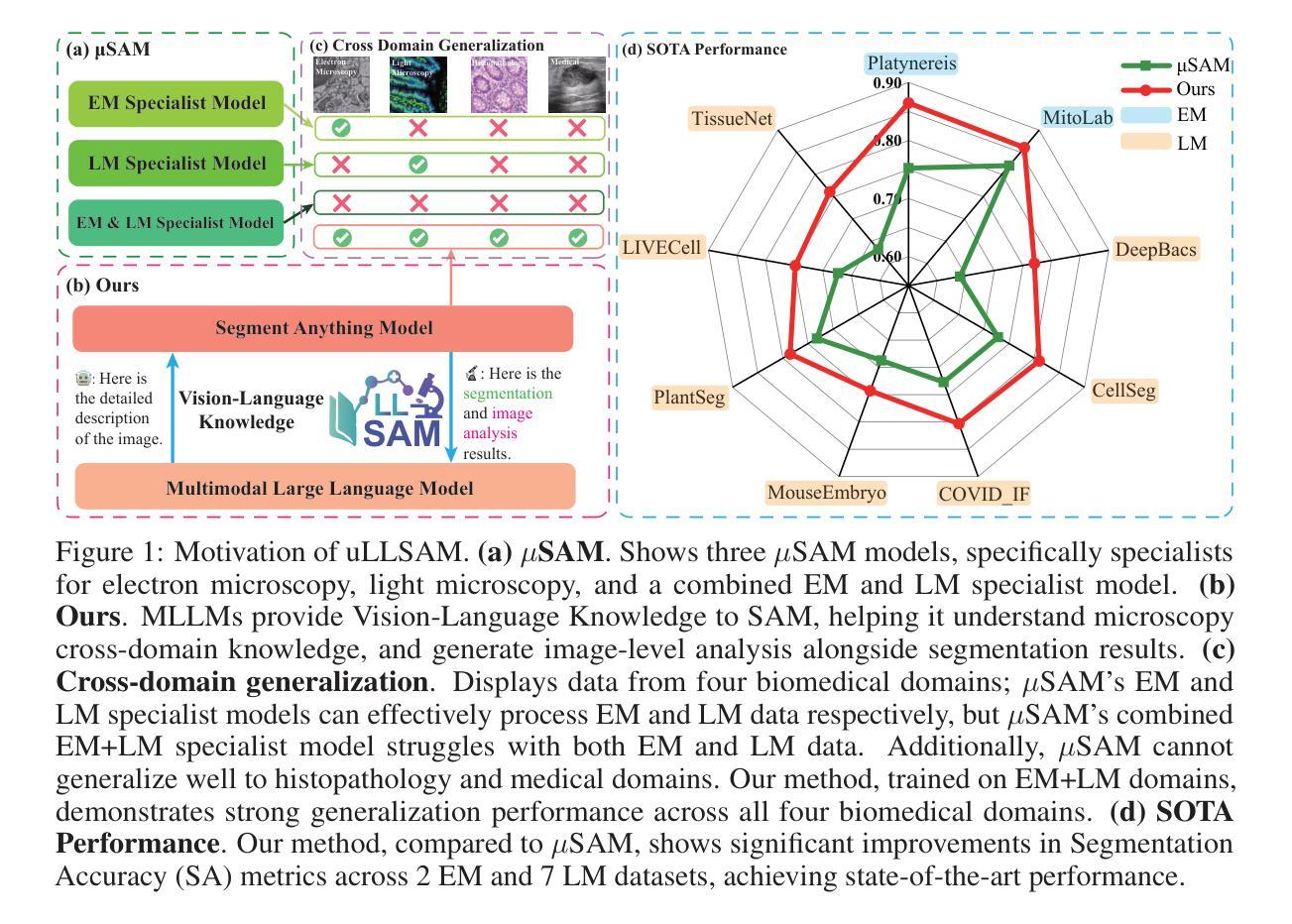
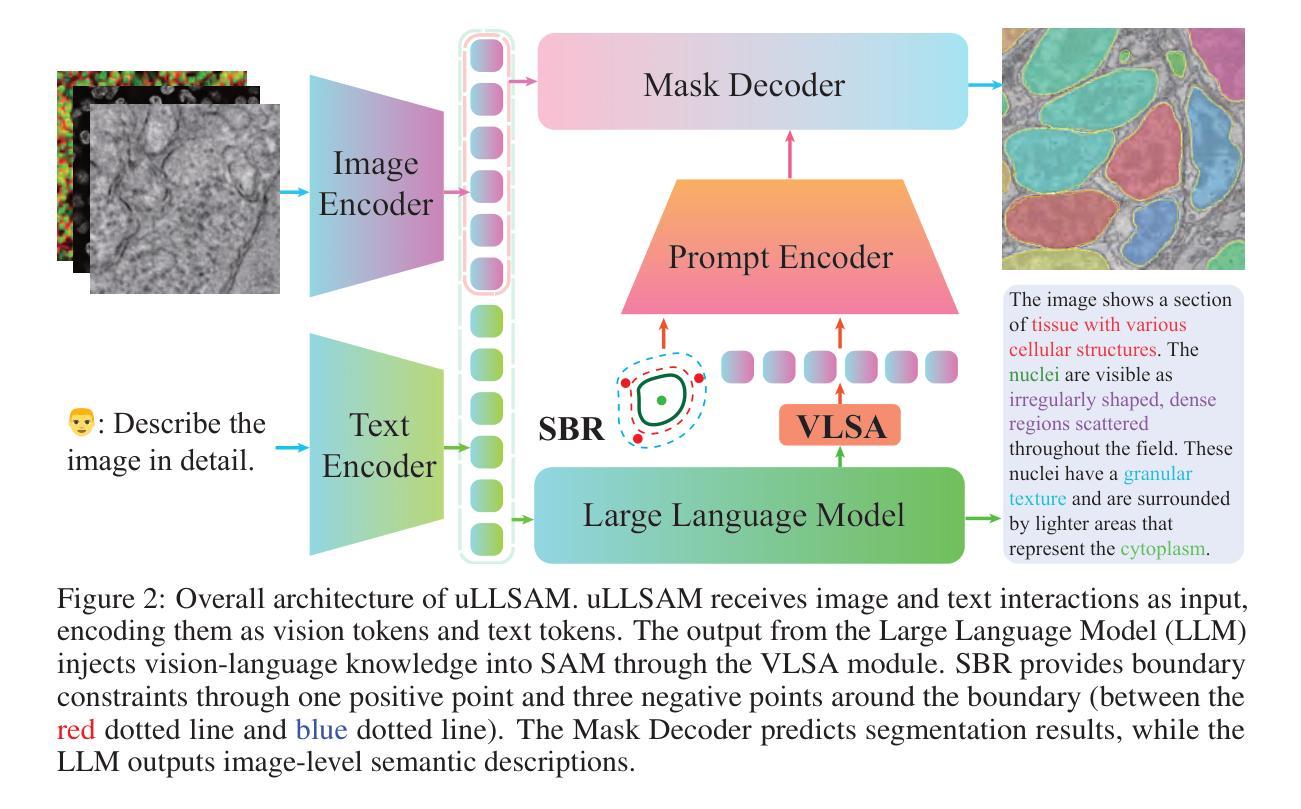
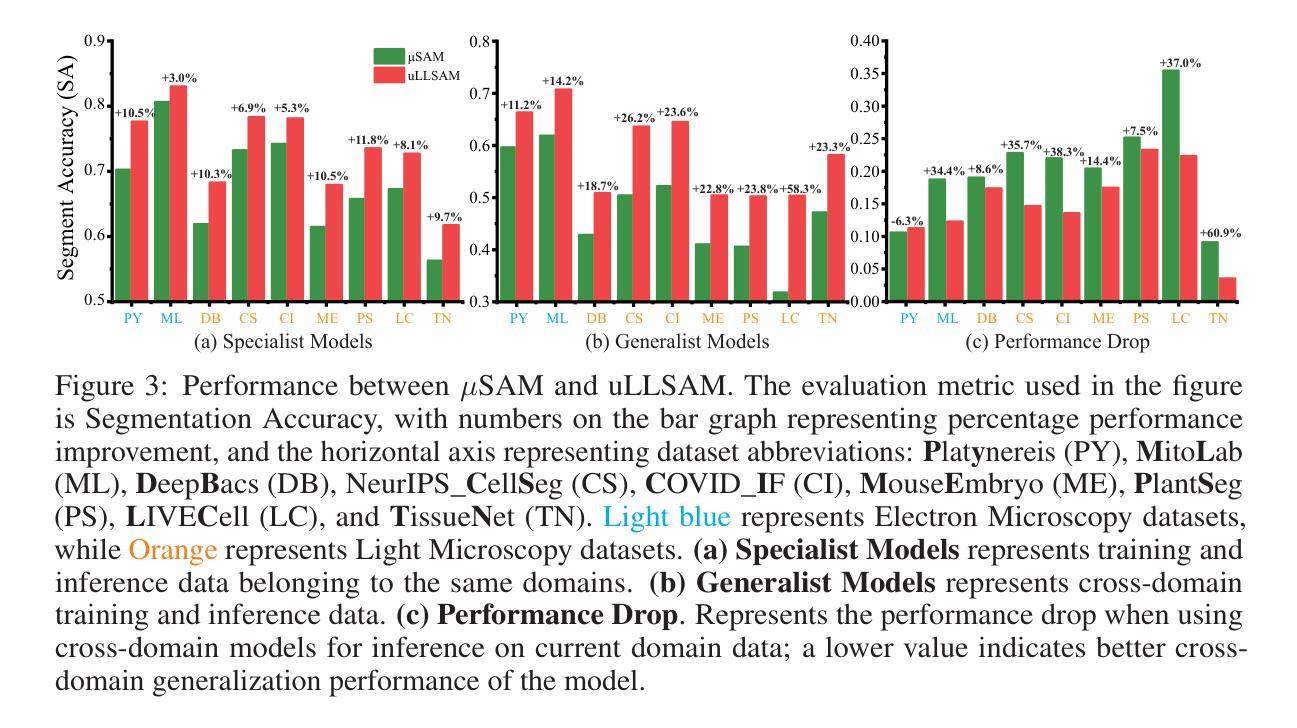
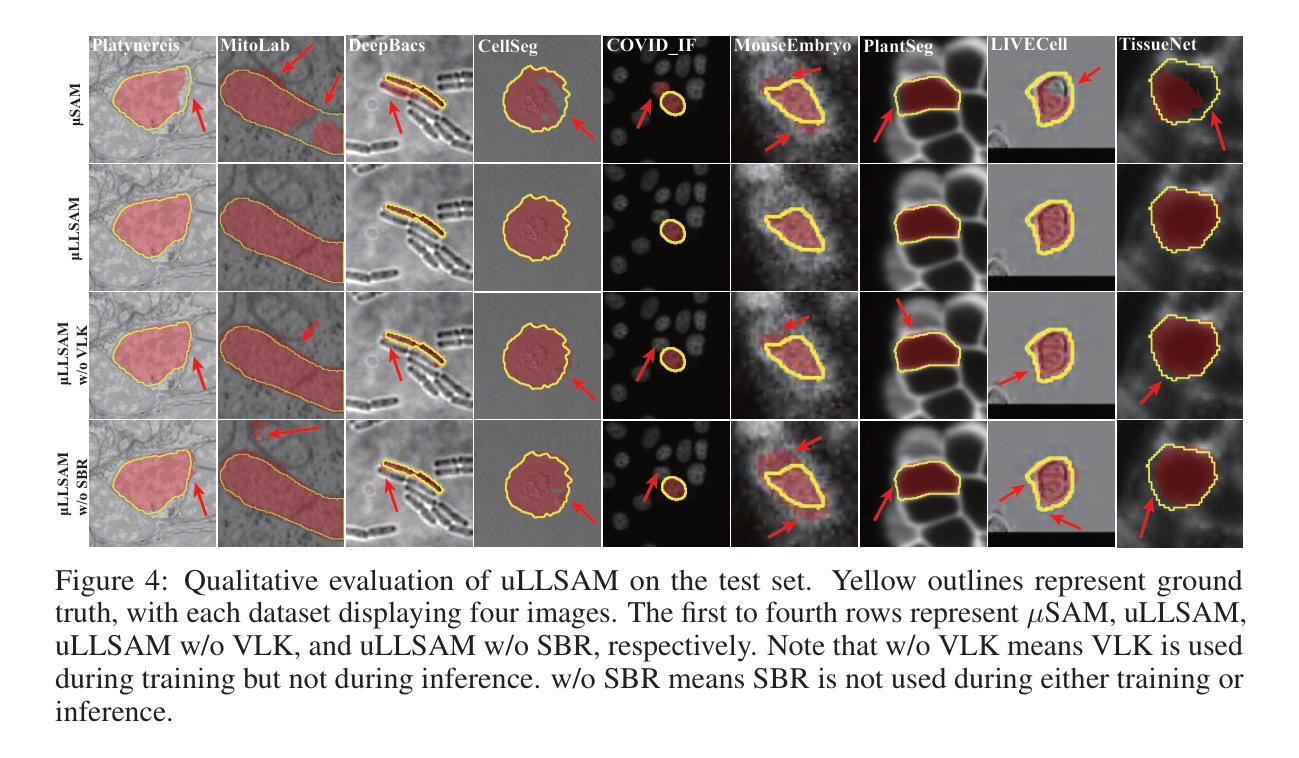
Accurate segmentation of regions of interest in biomedical images holds substantial value in image analysis. Although several foundation models for biomedical segmentation have currently achieved excellent performance on certain datasets, they typically demonstrate sub-optimal performance on unseen domain data. We owe the deficiency to lack of vision-language knowledge before segmentation. Multimodal Large Language Models (MLLMs) bring outstanding understanding and reasoning capabilities to multimodal tasks, which inspires us to leverage MLLMs to inject Vision-Language Knowledge (VLK), thereby enabling vision models to demonstrate superior generalization capabilities on cross-domain datasets. In this paper, we propose using MLLMs to guide SAM in learning microscopy crose-domain data, unifying Segment Anything in Microscopy, named uLLSAM. Specifically, we propose the Vision-Language Semantic Alignment (VLSA) module, which injects VLK into Segment Anything Model (SAM). We find that after SAM receives global VLK prompts, its performance improves significantly, but there are deficiencies in boundary contour perception. Therefore, we further propose Semantic Boundary Regularization (SBR) to prompt SAM. Our method achieves performance improvements of 7.71% in Dice and 12.10% in SA across 9 in-domain microscopy datasets, achieving state-of-the-art performance. Our method also demonstrates improvements of 6.79% in Dice and 10.08% in SA across 10 out-ofdomain datasets, exhibiting strong generalization capabilities. Code is available at https://github.com/ieellee/uLLSAM.
生物医学图像中感兴趣区域的精确分割在图像分析中具有重要意义。尽管目前一些生物医学分割的基础模型在某些数据集上取得了卓越的性能,但它们在未见域数据上的表现通常并不理想。我们认为这种不足是由于分割前的视觉语言知识缺乏所导致的。多模态大型语言模型(MLLMs)为跨模态任务带来了出色的理解和推理能力,这激励我们利用MLLMs来注入视觉语言知识(VLK),从而使视觉模型在跨域数据集上展现出更优越的泛化能力。在本文中,我们提出使用MLLMs来引导SAM学习显微镜跨域数据,并统一显微镜中的任何分段,命名为uLLSAM。具体来说,我们提出了视觉语言语义对齐(VLSA)模块,该模块将VLK注入到分段任何模型(SAM)中。我们发现,在SAM接收全局VLK提示后,其性能得到了显著提高,但在边界轮廓感知方面仍存在不足。因此,我们进一步提出了语义边界正则化(SBR)来提示SAM。我们的方法在9个域内显微镜数据集上实现了Dice系数提高7.71%,SA提高12.10%,达到最新性能水平。我们的方法还展示了在10个跨域数据集上Dice系数提高6.79%,SA提高10.08%,表现出强大的泛化能力。代码可访问https://github.com/ieellee/uLLSAM获取。
论文及项目相关链接
PDF 18 pages, 9 figures
Summary
引入多模态大型语言模型(MLLMs)注入视觉语言知识(VLK),提升医学图像分割模型的跨域泛化能力。通过VLSA模块,将VLK引入分段任何模型(SAM),提出uLLSAM方法,改进SAM的边界轮廓感知能力,并在多个数据集上实现最佳性能。
Key Takeaways
- 引入多模态大型语言模型(MLLMs)以增强医学图像分割模型的性能。
- 视觉语言知识(VLK)的注入有助于提升模型的跨域泛化能力。
- 使用VLSA模块将VLK融入分段任何模型(SAM)。
- SAM接受全局VLK提示后性能显著提升。
- 语义边界正则化(SBR)用于改进SAM的边界轮廓感知能力。
- uLLSAM方法在多个领域内的医学数据集上实现了最佳性能,与现有技术相比,Dice系数提高了7.71%,SA提高了12.1%。
点此查看论文截图

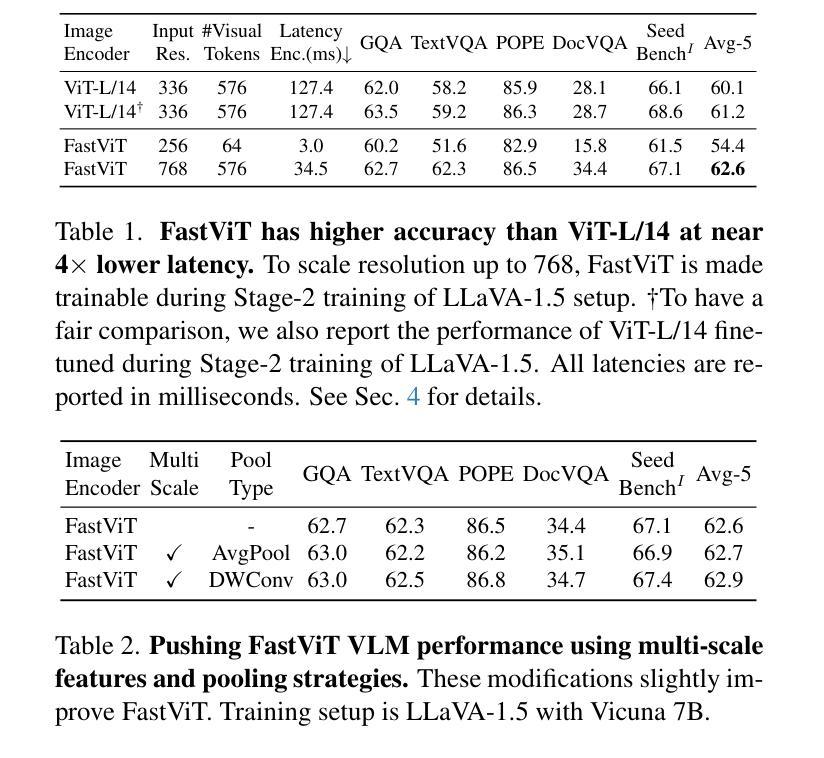
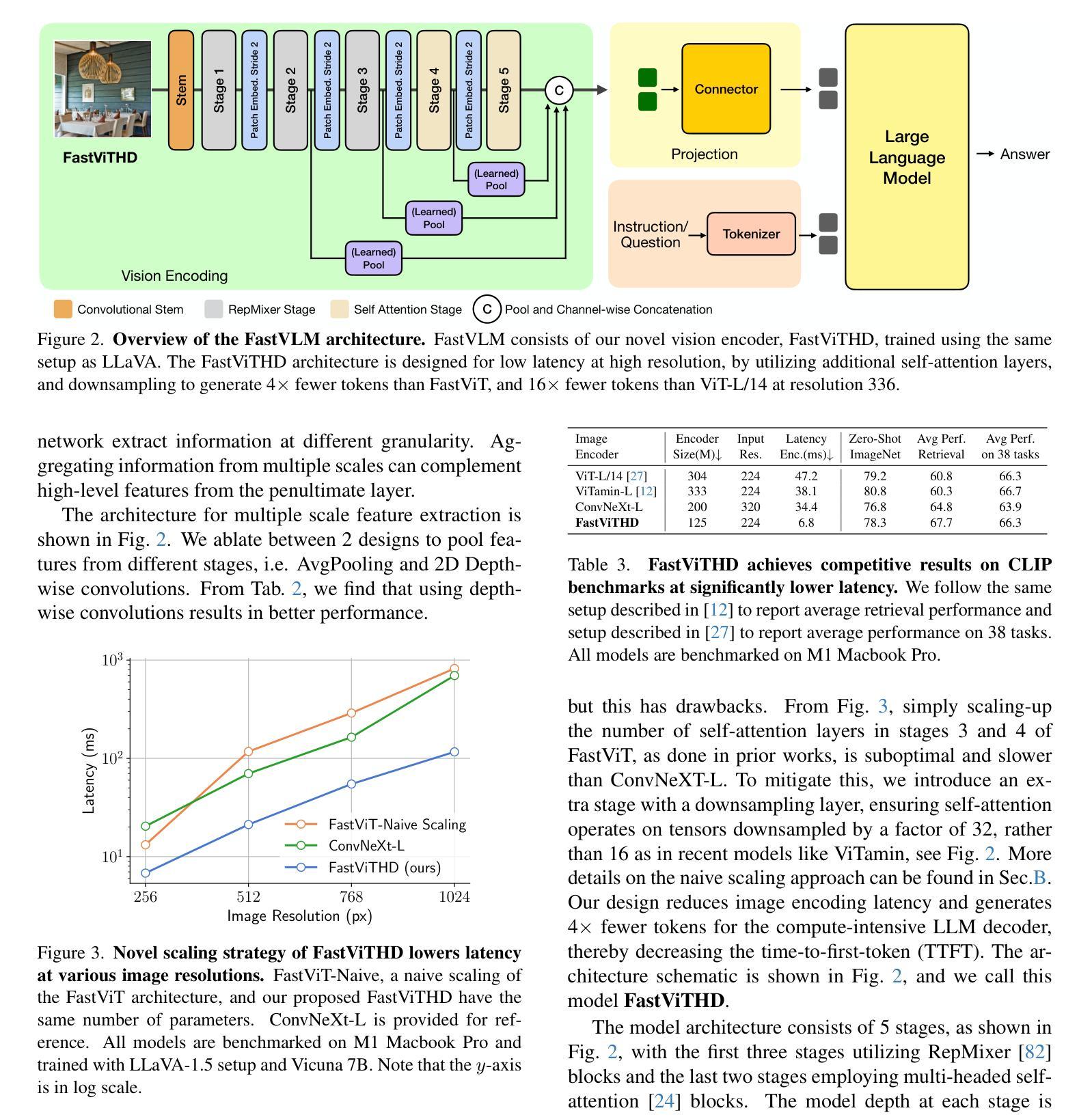
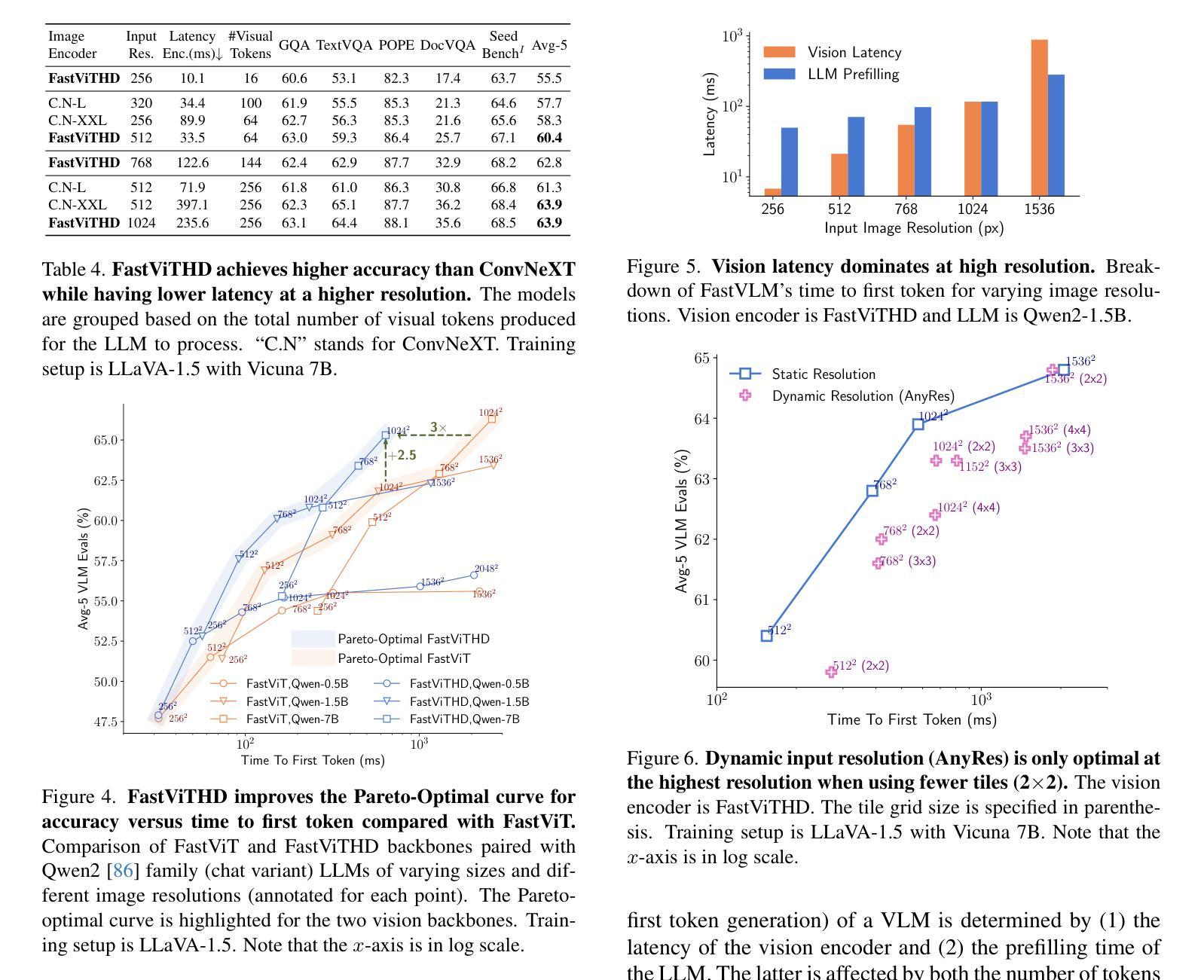
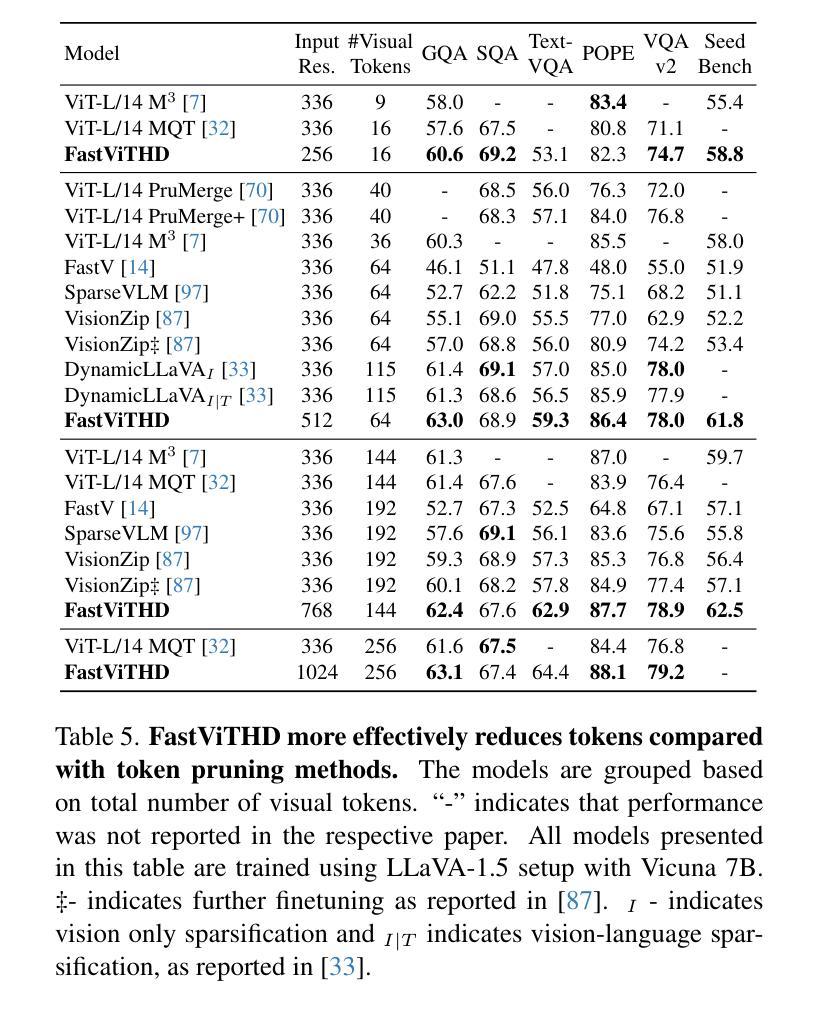
FastVLM: Efficient Vision Encoding for Vision Language Models
Authors:Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, Hadi Pouransari
Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency caused by stacked self-attention layers. At different operational resolutions, the vision encoder of a VLM can be optimized along two axes: reducing encoding latency and minimizing the number of visual tokens passed to the LLM, thereby lowering overall latency. Based on a comprehensive efficiency analysis of the interplay between image resolution, vision latency, token count, and LLM size, we introduce FastVLM, a model that achieves an optimized trade-off between latency, model size and accuracy. FastVLM incorporates FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images. Unlike previous methods, FastVLM achieves the optimal balance between visual token count and image resolution solely by scaling the input image, eliminating the need for additional token pruning and simplifying the model design. In the LLaVA-1.5 setup, FastVLM achieves 3.2$\times$ improvement in time-to-first-token (TTFT) while maintaining similar performance on VLM benchmarks compared to prior works. Compared to LLaVa-OneVision at the highest resolution (1152$\times$1152), FastVLM achieves better performance on key benchmarks like SeedBench, MMMU and DocVQA, using the same 0.5B LLM, but with 85$\times$ faster TTFT and a vision encoder that is 3.4$\times$ smaller. Code and models are available at https://github.com/apple/ml-fastvlm.
提高输入图像分辨率对提升视觉语言模型(VLMs)的性能至关重要,特别是在文本丰富的图像理解任务中。然而,流行的视觉编码器(如ViTs)在高分辨率下会变得效率低下,这是由于堆叠的自注意层导致的令牌数量众多和编码延迟高。在不同的操作分辨率下,VLM的视觉编码器可以通过两个轴进行优化:减少编码延迟并尽量减少传递给LLM的视觉令牌数量,从而降低总体延迟。基于对图像分辨率、视觉延迟、令牌计数和LLM大小之间交互的全面效率分析,我们引入了FastVLM模型,该模型在延迟、模型大小和准确性之间实现了优化折衷。FastVLM结合了FastViTHD这一新型混合视觉编码器,旨在输出较少的令牌并显著减少高分辨率图像的编码时间。与以前的方法不同,FastVLM仅通过调整输入图像大小即可在视觉令牌计数和图像分辨率之间实现最佳平衡,从而消除了对额外令牌修剪的需求并简化了模型设计。在LLaVA-1.5设置中,FastVLM在时间上首次令牌(TTFT)实现了3.2倍的改进,同时在VLM基准测试中保持与先前作品相似的性能。与最高分辨率(1152×1152)下的LLaVa-OneVision相比,FastVLM在SeedBench、MMU和DocVQA等主要基准测试上表现更好,使用相同的0.5B LLM,但TTFT更快,达到85倍,并且视觉编码器更小,为3.4倍。代码和模型可在https://github.com/apple/ml-fastvlm处获得。
论文及项目相关链接
PDF CVPR 2025
Summary
提升输入图像分辨率对提升视觉语言模型(VLMs)在文本丰富图像理解任务中的性能至关重要。针对高分辨率图像,流行视觉编码器如ViTs因堆叠的自注意力层导致的令牌数量庞大和编码延迟,效率降低。本文提出FastVLM模型,通过优化视觉编码器,在降低编码延迟和减少传递给LLM的视觉令牌数量的同时,实现了对图像分辨率的优化。FastVLM采用新颖混合视觉编码器FastViTHD,可输出较少令牌并显著降低高分辨率图像的编码时间。无需额外的令牌修剪,仅通过调整输入图像即可实现视觉令牌数量和图像分辨率之间的最佳平衡,简化了模型设计。在LLaVA-1.5设置下,FastVLM在时间至首令牌(TTFT)上实现了3.2倍改进,同时在VLM基准测试中保持与先前工作相似的性能。在相同LLM下,FastVLM在SeedBench、MMMU和DocVQA等主要基准测试上表现更佳,且TTFT更快(为LLaVa-OneVision的85倍),视觉编码器体积更小(为前者的3.4倍)。代码和模型可通过链接获取。
Key Takeaways
- 提升图像分辨率对增强视觉语言模型性能至关重要,特别是在文本丰富的图像理解任务中。
- 流行的视觉编码器在高分辨率下效率较低,因自注意力层导致的令牌数量庞大和编码延迟。
- FastVLM模型通过优化视觉编码器,在降低编码延迟和减少传递给LLM的视觉令牌数量的同时,提高了图像分辨率。
- FastVLM引入新颖混合视觉编码器FastViTHD,能高效处理高分辨率图像。
- 仅通过调整输入图像,FastVLM实现了视觉令牌数量和图像分辨率之间的平衡,无需额外的令牌修剪。
- FastVLM在多个基准测试上表现优异,同时提高了性能和效率。
点此查看论文截图