⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-21 更新
Synthesis of Communication Policies for Multi-Agent Systems Robust to Communication Restrictions
Authors:Saleh Soudijani, Rayna Dimitrova
We study stochastic multi-agent systems in which agents must cooperate to maximize the probability of achieving a common reach-avoid objective. In many applications, during the execution of the system, the communication between the agents can be constrained by restrictions on the bandwidth currently available for exchanging local-state information between the agents. In this paper, we propose a method for computing joint action and communication policies for the group of agents that aim to satisfy the communication restrictions as much as possible while achieving the optimal reach-avoid probability when communication is unconstrained. Our method synthesizes a pair of action and communication policies robust to restrictions on the number of agents allowed to communicate. To this end, we introduce a novel cost function that measures the amount of information exchanged beyond what the communication policy allows. We evaluate our approach experimentally on a range of benchmarks and demonstrate that it is capable of computing pairs of action and communication policies that satisfy the communication restrictions, if such exist.
我们研究随机多智能体系统,在这个系统中,智能体需要协作以最大化实现共同达成避免目标的可能性。在许多应用中,系统执行过程中,智能体之间的通信可能会受到当前可用于交换局部状态信息带宽的限制。本文提出了一种计算智能体组联合行动和通信策略的方法,旨在在满足通信限制的同时,尽可能实现最优的达成避免概率,当通信不受限制时。我们的方法合成了一对行动和通信策略,对允许通信的智能体数量限制具有鲁棒性。为此,我们引入了一个新的成本函数,用于衡量超出通信策略允许的信息交换量。我们通过一系列基准测试对方法进行了实验评估,证明当存在通信限制时,它能够计算出满足限制的行动和通信策略组合。
论文及项目相关链接
PDF This is the extended version of the paper accepted for publication at IJCAI 2025
Summary
在具有通信带宽限制的多智能体系统中,必须计算智能体的联合行动和通信策略,以最大化达成共同达成目标的概率。本文提出了一种计算智能体组的联合行动和通信策略的方法,旨在在满足通信限制的同时,在不受约束的通信情况下实现最优的达成目标概率。通过引入新的成本函数来衡量超出通信策略允许的信息交换量,我们能够在实验基准测试中验证该方法的有效性。
Key Takeaways
- 研究了多智能体系统中的随机性问题,智能体需要合作以实现共同的目标达成概率最大化。
- 考虑到通信带宽限制,提出一种计算智能体的联合行动和通信策略的方法。
- 方法旨在满足可能的通信限制,同时在无约束的通信情况下实现最优的目标达成概率。
- 通过引入新的成本函数来衡量超出通信策略允许的信息交换量。
- 实验评估证明了该方法在计算智能体的联合行动和通信策略方面的有效性。
- 该方法能够适应不同的通信限制条件。
点此查看论文截图

When a Reinforcement Learning Agent Encounters Unknown Unknowns
Authors:Juntian Zhu, Miguel de Carvalho, Zhouwang Yang, Fengxiang He
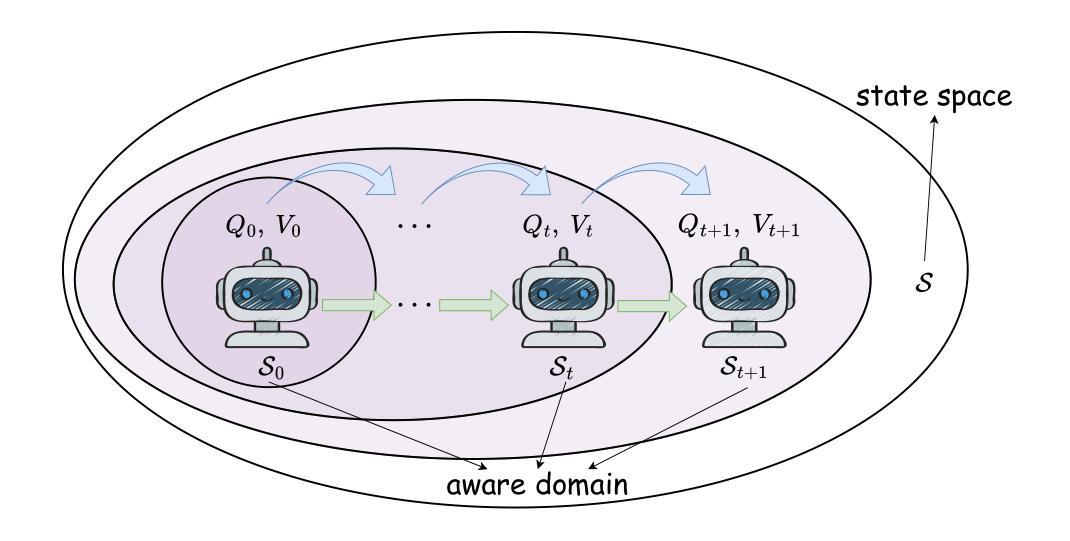
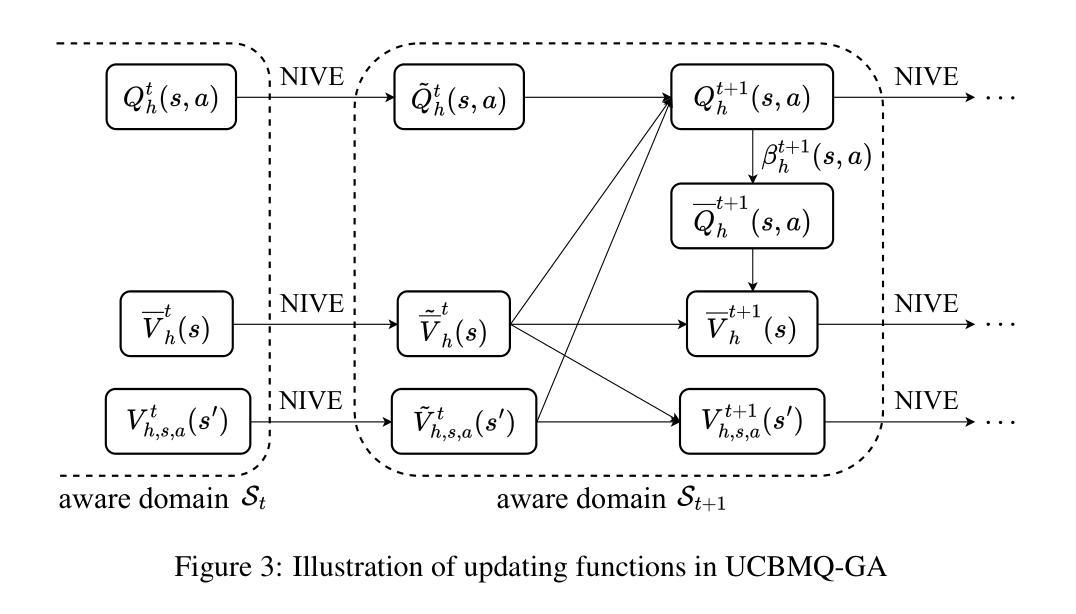
An AI agent might surprisingly find she has reached an unknown state which she has never been aware of – an unknown unknown. We mathematically ground this scenario in reinforcement learning: an agent, after taking an action calculated from value functions $Q$ and $V$ defined on the {\it {aware domain}}, reaches a state out of the domain. To enable the agent to handle this scenario, we propose an {\it episodic Markov decision {process} with growing awareness} (EMDP-GA) model, taking a new {\it noninformative value expansion} (NIVE) approach to expand value functions to newly aware areas: when an agent arrives at an unknown unknown, value functions $Q$ and $V$ whereon are initialised by noninformative beliefs – the averaged values on the aware domain. This design is out of respect for the complete absence of knowledge in the newly discovered state. The upper confidence bound momentum Q-learning is then adapted to the growing awareness for training the EMDP-GA model. We prove that (1) the regret of our approach is asymptotically consistent with the state of the art (SOTA) without exposure to unknown unknowns in an extremely uncertain environment, and (2) our computational complexity and space complexity are comparable with the SOTA – these collectively suggest that though an unknown unknown is surprising, it will be asymptotically properly discovered with decent speed and an affordable cost.
一个AI代理可能会意外地发现自己处于一个未知状态,这是她从未意识到的——未知中的未知。我们在强化学习中对这种情景进行数学建模:代理在计算出的动作(基于定义在“意识域”上的价值函数Q和V)之后,达到了域外的状态。为了能够让代理处理这种情景,我们提出了一个“带有意识增长的阶段性马尔可夫决策过程”(EMDP-GA)模型,采取一种新的“非信息价值扩张”(NIVE)方法,将价值函数扩张到新的意识领域:当代理遇到一个未知中的未知,价值函数Q和V将通过非信息信念进行初始化——即在意识域上的平均值。这种设计是为了尊重新发现状态中完全缺乏知识的情况。然后,将上界动量Q学习适应于增长意识,以训练EMDP-GA模型。我们证明(1)我们的方法在极端不确定的环境中,在没有遇到未知中的未知的情况下,其遗憾的渐进性与最新技术的一致性是一致的;(2)我们的计算复杂性和空间复杂度与最新技术相当——这些共同表明,尽管未知中的未知是令人惊讶的,但我们将以适中的速度和成本渐进地适当地发现它。
论文及项目相关链接
Summary
在强化学习中,AI代理可能会意外进入未知状态,即所谓的“未知未知”。为解决这一问题,我们提出一种带有成长意识的片段式马尔可夫决策过程(EMDP-GA)模型,采用非信息价值扩展(NIVE)方法扩展价值函数至新意识领域。当代理遇到未知未知时,通过非信息信念(对已知领域平均值)初始化价值函数Q和V。然后适应乐观边界动量Q学习以支持增长意识训练EMDP-GA模型。我们的方法在保证计算复杂度和空间复杂度与现有技术相当的同时,证明了在极端不确定环境下即使遇到未知未知,我们的方法也能渐近一致地与前沿技术的后悔度保持接近。这意味着能够逐步有效地发现新知识而不丧失效率。
Key Takeaways
- AI代理在强化学习中可能遇到未知状态(未知未知)。
- 为处理这种状态,提出EMDP-GA模型及NIVE方法,以扩展价值函数至新意识领域。
- 在遇到未知未知时,通过非信息信念初始化价值函数。
- 采用上界置信动量Q学习适应增长意识,用于训练EMDP-GA模型。
点此查看论文截图

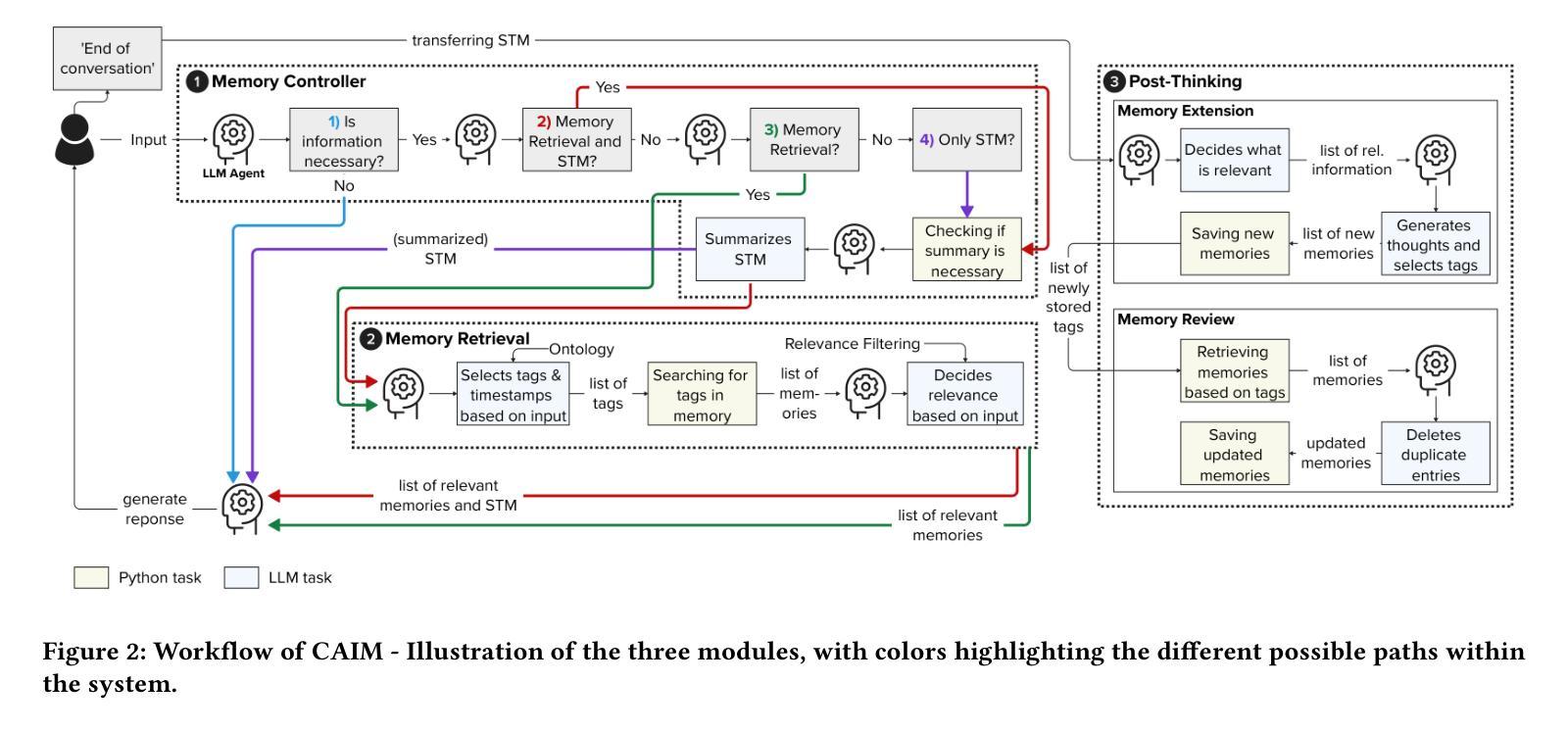
CAIM: Development and Evaluation of a Cognitive AI Memory Framework for Long-Term Interaction with Intelligent Agents
Authors:Rebecca Westhäußer, Frederik Berenz, Wolfgang Minker, Sebastian Zepf
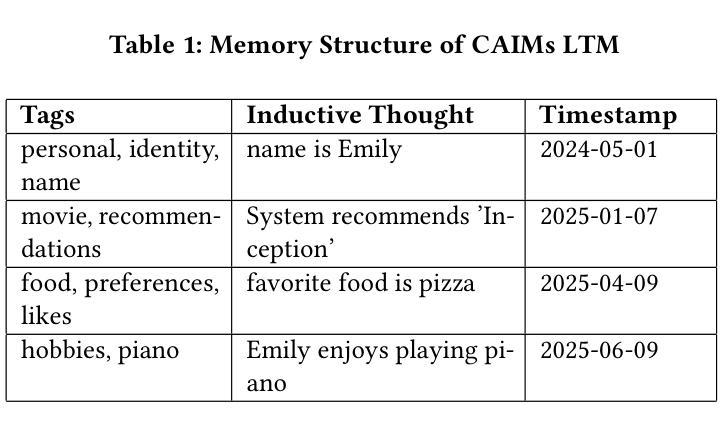
Large language models (LLMs) have advanced the field of artificial intelligence (AI) and are a powerful enabler for interactive systems. However, they still face challenges in long-term interactions that require adaptation towards the user as well as contextual knowledge and understanding of the ever-changing environment. To overcome these challenges, holistic memory modeling is required to efficiently retrieve and store relevant information across interaction sessions for suitable responses. Cognitive AI, which aims to simulate the human thought process in a computerized model, highlights interesting aspects, such as thoughts, memory mechanisms, and decision-making, that can contribute towards improved memory modeling for LLMs. Inspired by these cognitive AI principles, we propose our memory framework CAIM. CAIM consists of three modules: 1.) The Memory Controller as the central decision unit; 2.) the Memory Retrieval, which filters relevant data for interaction upon request; and 3.) the Post-Thinking, which maintains the memory storage. We compare CAIM against existing approaches, focusing on metrics such as retrieval accuracy, response correctness, contextual coherence, and memory storage. The results demonstrate that CAIM outperforms baseline frameworks across different metrics, highlighting its context-awareness and potential to improve long-term human-AI interactions.
大型语言模型(LLM)推动了人工智能(AI)领域的发展,并成为交互式系统的强大助力。然而,在长期交互方面,它们仍然面临挑战,需要适应用户以及理解不断变化的环境的上下文知识。为了克服这些挑战,需要全面的记忆建模以在交互会话中有效地检索和存储相关信息以产生适当的响应。认知AI旨在模拟计算机化模型中的人类思维过程,突出了诸如思想、记忆机制和决策等有趣方面,这些方面可以为LLM的记忆建模做出贡献。受认知AI原理的启发,我们提出了我们的记忆框架CAIM。CAIM由三个模块组成:1)作为中央决策单元的Memory Controller(记忆控制器);2)Memory Retrieval(记忆检索),它会在请求时过滤出相关的交互数据;以及3)Post-Thinking(后思考),它负责维护记忆存储。我们将CAIM与现有方法进行比较,关注诸如检索准确性、响应正确性、上下文一致性和记忆存储等指标。结果表明,CAIM在不同指标上的表现均优于基线框架,突出了其上下文感知能力,并有望改善长期人机交互。
论文及项目相关链接
Summary
大型语言模型(LLM)在人工智能领域具有重要地位,对于构建交互式系统具有重要作用。然而,在长期互动中,它们仍面临适应用户、理解不断变化的环境等挑战。为了克服这些挑战,需要全面的记忆建模以有效地检索和存储跨交互会话的相关信息以产生合适的响应。受认知AI(模拟人类思维过程的计算机化模型)的启发,本文提出了记忆框架CAIM,包括记忆控制器、记忆检索和后期思考三个模块。对比现有方法,CAIM在检索准确性、响应正确性、上下文连贯性和记忆存储等方面表现出色,凸显其语境意识和改善长期人机交互的潜力。
Key Takeaways
- 大型语言模型(LLM)在人工智能领域有重要地位,对交互式系统构建具有重要作用。
- LLM在长期互动中面临适应用户和理解环境变化等挑战。
- 全面记忆建模对于克服这些挑战并产生合适的响应是必要的。
- 认知AI模拟人类思维过程,为改进LLM的记忆建模提供启发。
- CAIM记忆框架包括三个模块:记忆控制器、记忆检索和后期思考。
- CAIM在多个指标上优于现有方法,包括检索准确性、响应正确性等。
点此查看论文截图


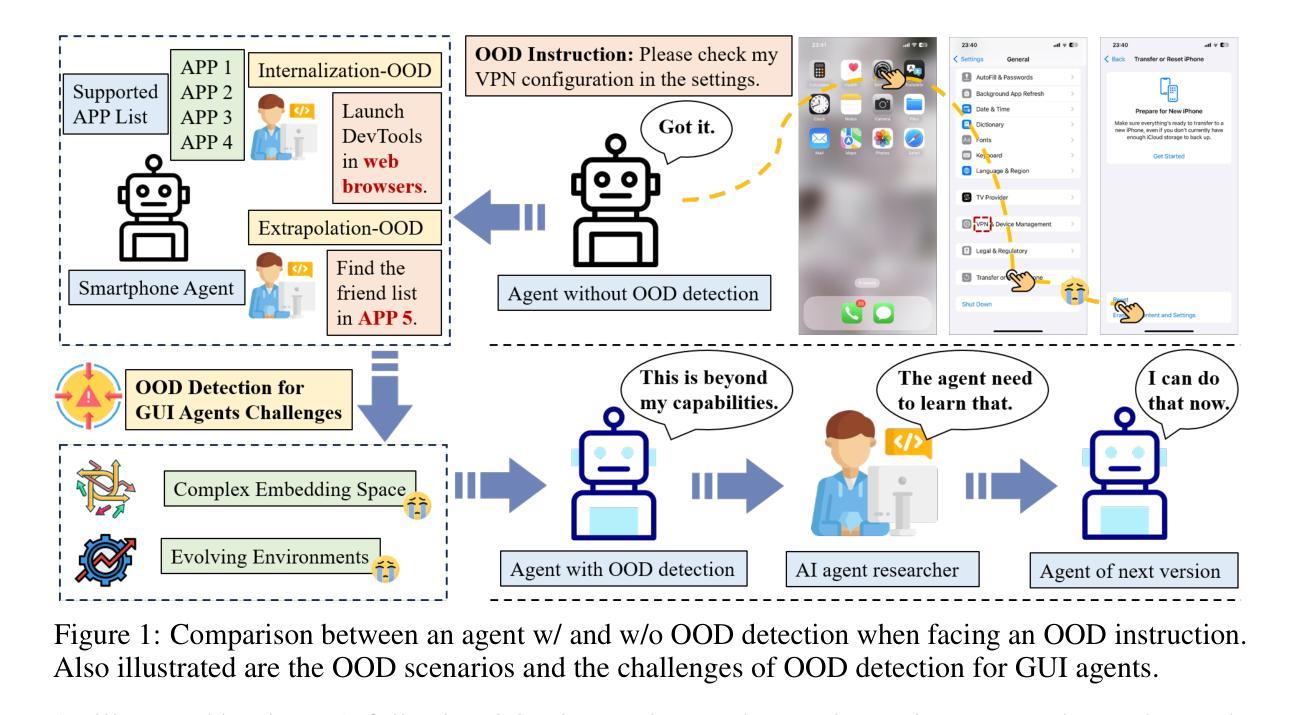
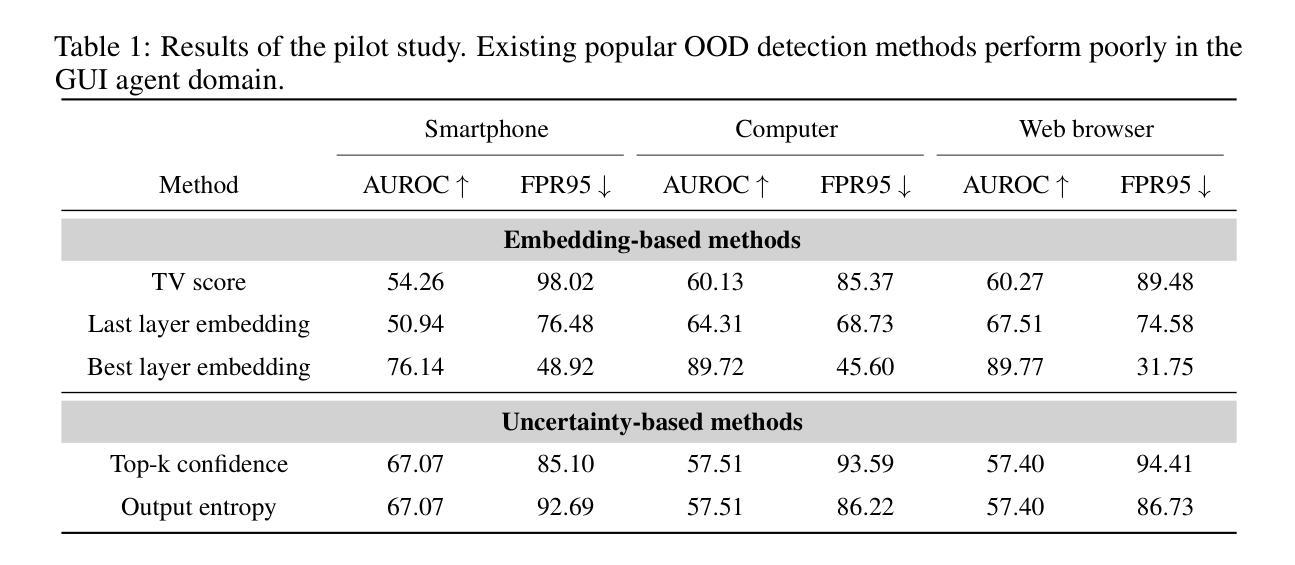
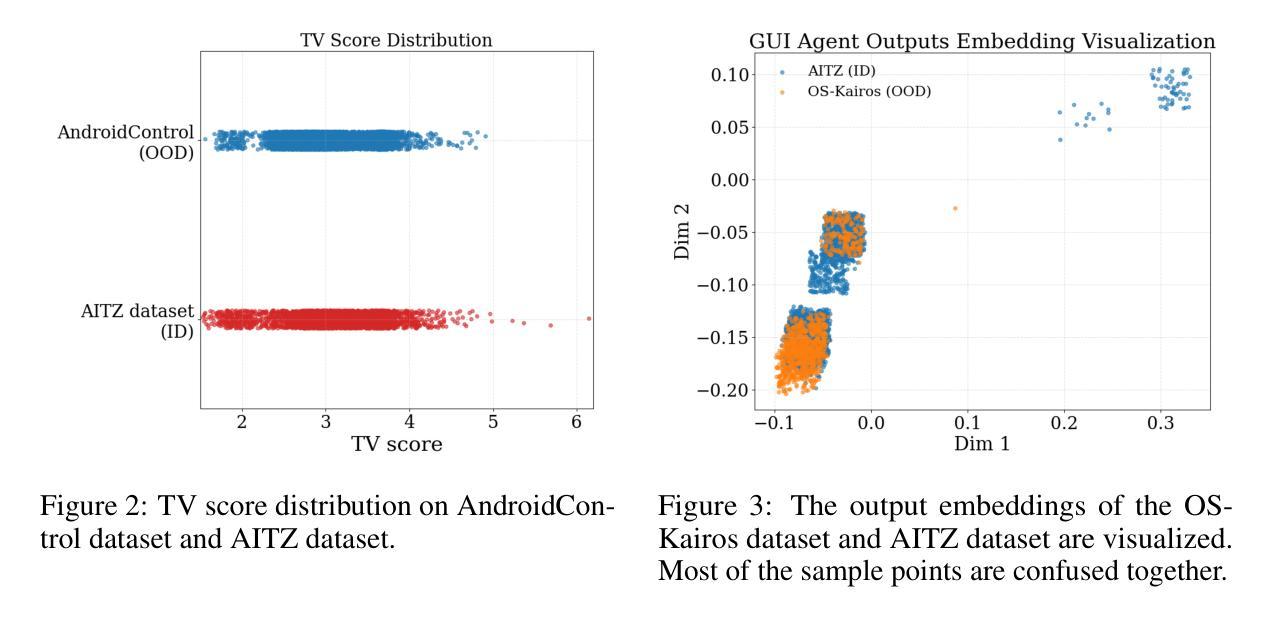
GEM: Gaussian Embedding Modeling for Out-of-Distribution Detection in GUI Agents
Authors:Zheng Wu, Pengzhou Cheng, Zongru Wu, Lingzhong Dong, Zhuosheng Zhang
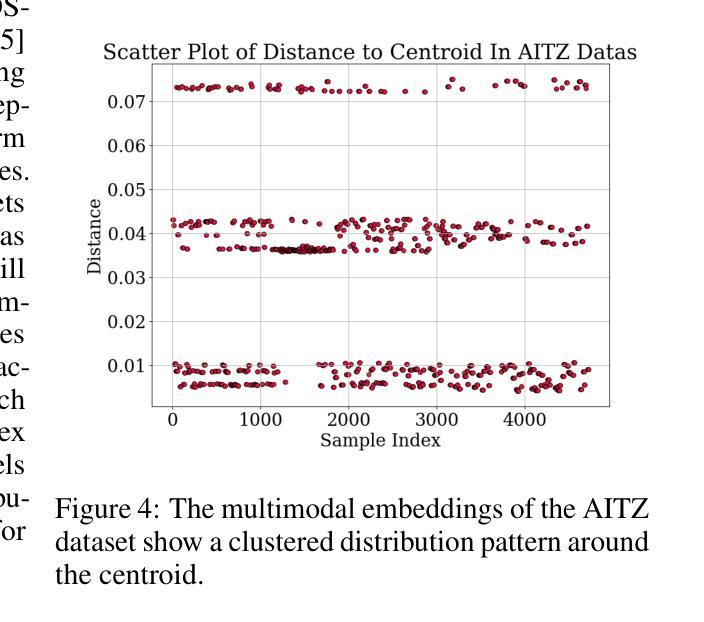
Graphical user interface (GUI) agents have recently emerged as an intriguing paradigm for human-computer interaction, capable of automatically executing user instructions to operate intelligent terminal devices. However, when encountering out-of-distribution (OOD) instructions that violate environmental constraints or exceed the current capabilities of agents, GUI agents may suffer task breakdowns or even pose security threats. Therefore, effective OOD detection for GUI agents is essential. Traditional OOD detection methods perform suboptimally in this domain due to the complex embedding space and evolving GUI environments. In this work, we observe that the in-distribution input semantic space of GUI agents exhibits a clustering pattern with respect to the distance from the centroid. Based on the finding, we propose GEM, a novel method based on fitting a Gaussian mixture model over input embedding distances extracted from the GUI Agent that reflect its capability boundary. Evaluated on eight datasets spanning smartphones, computers, and web browsers, our method achieves an average accuracy improvement of 23.70% over the best-performing baseline. Analysis verifies the generalization ability of our method through experiments on nine different backbones. The codes are available at https://github.com/Wuzheng02/GEM-OODforGUIagents.
图形用户界面(GUI)代理最近作为人机交互的一种引人入胜的模式而出现,能够自动执行用户指令来操作智能终端设备。然而,当遇到超出分布(OOD)的指令,这些指令违反环境约束或超出代理的当前能力时,GUI代理可能会出现任务故障,甚至构成安全威胁。因此,有效的GUI代理OOD检测至关重要。由于复杂的嵌入空间和不断变化的GUI环境,传统的OOD检测方法在此领域表现不佳。在这项工作中,我们观察到GUI代理的内部分布输入语义空间在距离质心方面呈现出聚类模式。基于此发现,我们提出了基于高斯混合模型拟合的GEM新方法,该方法通过对从GUI代理提取的输入嵌入距离进行拟合,反映其能力边界。在涵盖智能手机、计算机和网页浏览器的八个数据集上评估,我们的方法相较于表现最佳的基线模型,平均准确率提高了23.70%。分析实验在九个不同主干网络上进行了验证,证明了我们的方法的泛化能力。相关代码可通过以下链接获取:https://github.com/Wuzheng02/GEM-OODforGUIagents。
论文及项目相关链接
Summary
GUI代理的OOD检测新方法:针对图形用户界面(GUI)代理在执行超出当前能力范围或违反环境约束的指令时可能出现的问题,提出了一种基于高斯混合模型(GEM)的OOD检测方法。该方法通过拟合GUI代理输入嵌入距离的高斯混合模型,有效识别OOD指令,并在智能手机、计算机和网页浏览器等多个数据集上实现了较高的准确性。
Key Takeaways
- GUI代理在面临超出其能力范围或违反环境约束的指令时,可能会出现任务故障或安全隐患。
- 传统OOD检测方法在GUI环境中表现不佳,因为GUI环境复杂且多变。
- GUI代理的输入语义空间呈现聚类分布,距离中心越远越复杂。
- 基于这一发现,提出了一种名为GEM的新方法,利用高斯混合模型处理GUI代理的输入嵌入距离。
- GEM方法可以有效识别OOD指令,并能在不同数据集上实现较高的准确性提升。
- 在智能手机、计算机和网页浏览器等多个数据集上的实验验证表明,GEM方法的平均准确度提高了23.70%。
点此查看论文截图

REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
Authors:Chenxi Jiang, Chuhao Zhou, Jianfei Yang
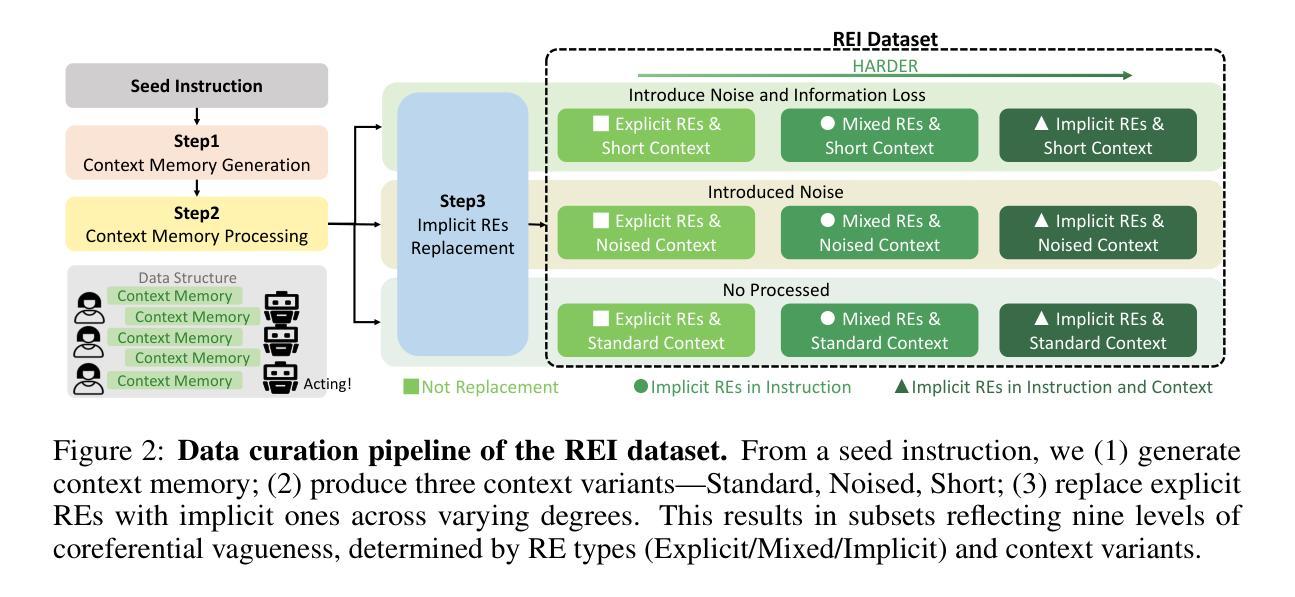
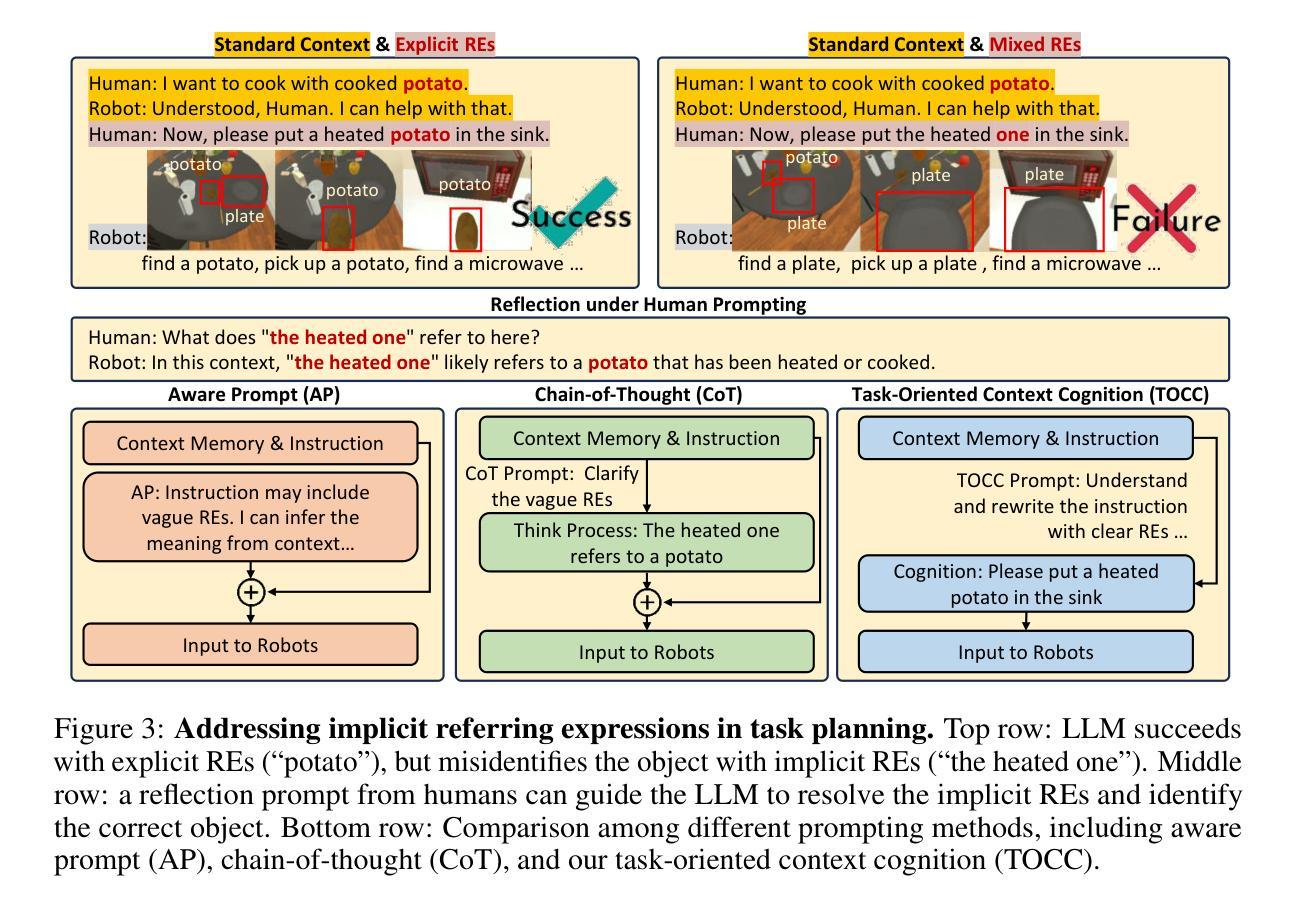
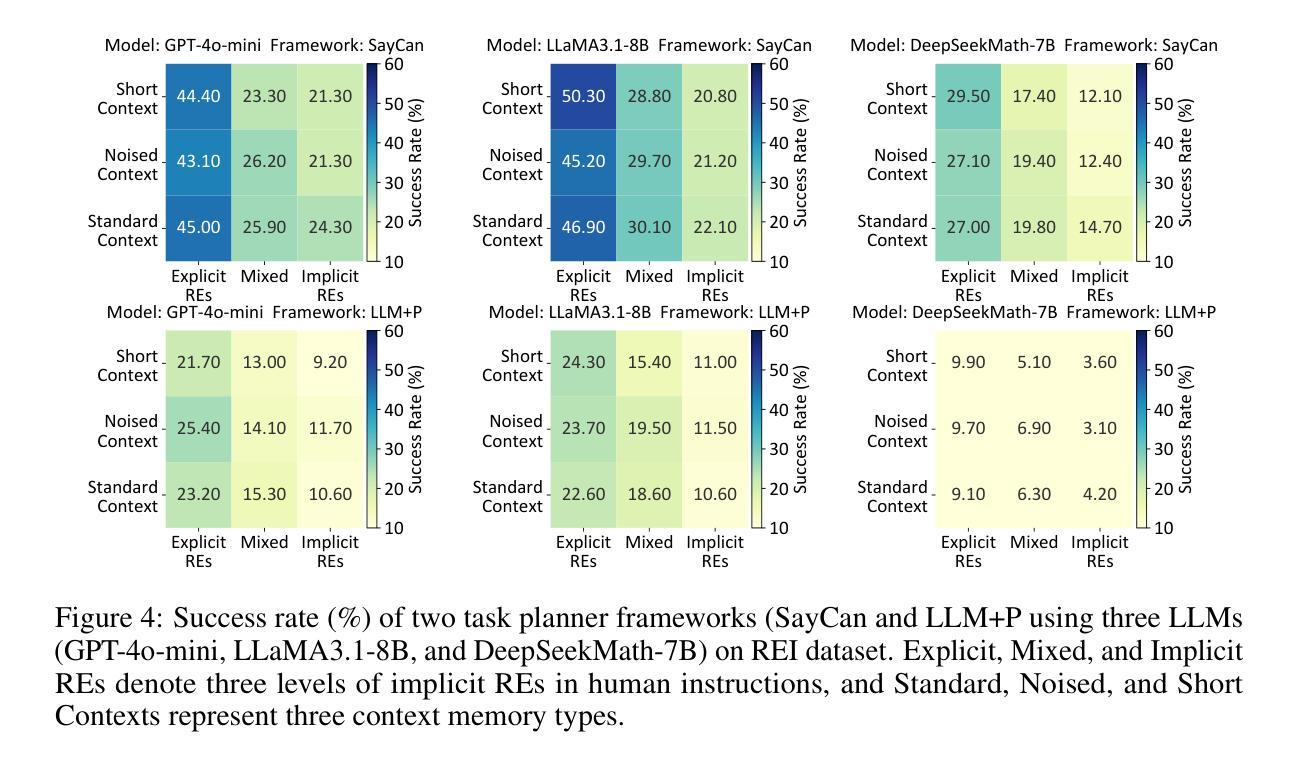
Robot task planning decomposes human instructions into executable action sequences that enable robots to complete a series of complex tasks. Although recent large language model (LLM)-based task planners achieve amazing performance, they assume that human instructions are clear and straightforward. However, real-world users are not experts, and their instructions to robots often contain significant vagueness. Linguists suggest that such vagueness frequently arises from referring expressions (REs), whose meanings depend heavily on dialogue context and environment. This vagueness is even more prevalent among the elderly and children, who robots should serve more. This paper studies how such vagueness in REs within human instructions affects LLM-based robot task planning and how to overcome this issue. To this end, we propose the first robot task planning benchmark with vague REs (REI-Bench), where we discover that the vagueness of REs can severely degrade robot planning performance, leading to success rate drops of up to 77.9%. We also observe that most failure cases stem from missing objects in planners. To mitigate the REs issue, we propose a simple yet effective approach: task-oriented context cognition, which generates clear instructions for robots, achieving state-of-the-art performance compared to aware prompt and chains of thought. This work contributes to the research community of human-robot interaction (HRI) by making robot task planning more practical, particularly for non-expert users, e.g., the elderly and children.
机器人任务规划能够将人类指令分解为一系列可执行的行动序列,从而使机器人能够完成一系列复杂任务。尽管最近基于大型语言模型的任务规划器取得了惊人的性能,但它们假设人类指令是清晰直接的。然而,真实世界的用户并非都是专家,他们对机器人的指令通常包含相当大的模糊性。语言学家认为,这种模糊性经常来自于指代表达式(RE),其意义很大程度上取决于对话上下文和环境。这种模糊性在老年人和儿童中更为普遍,而机器人应该为他们提供更多的服务。本论文研究人类指令中的指代表达式(RE)中的这种模糊性如何影响基于大型语言模型的机器人任务规划,以及如何解决这一问题。为此,我们提出了带有模糊REs的第一个机器人任务规划基准(REI-Bench),我们发现REs的模糊性会严重降低机器人规划的性能,成功率下降高达77.9%。我们还观察到,大多数失败的情况源于规划器中缺少对象。为了缓解REs问题,我们提出了一种简单有效的方法:面向任务的上下文认知,为机器人生成清晰的指令,与有意识提示和思维链相比,取得了最先进的性能。这项工作使机器人任务规划更加实用,特别是对非专业用户(如老年人和儿童)而言,为人工智能与机器人交互研究社区做出了贡献。
论文及项目相关链接
PDF Under Review
Summary:
机器人任务规划能够将人类指令分解为可执行的动作序列,使机器人能够完成一系列复杂任务。尽管基于大型语言模型的任务规划器取得了惊人的性能,但它们假设人类指令是清晰直接的。然而,真实世界的用户并非专家,他们给机器人的指令常常包含相当的模糊性。本文研究了人类指令中的参照表达式(REs)的模糊性如何影响基于大型语言模型的机器人任务规划,并提出了如何解决这一问题的方法。为此,我们建立了首个含有模糊参照表达式的机器人任务规划基准测试(REI-Bench),发现参照表达式的模糊性会严重降低机器人规划的性能,成功率下降高达77.9%。我们还观察到大多数失败案例源于规划中的目标缺失。为了缓解参照表达式的问题,我们提出了一种简单有效的方法:面向任务的上下文认知,为机器人生成清晰的指令,实现了与意识提示和思考链相比的先进性能。这项工作对人类与机器人交互(HRI)研究群体做出了贡献,使机器人任务规划更加实用,尤其对于非专业用户如老年人和儿童而言。
Key Takeaways:
- 机器人任务规划能够将人类指令转化为可执行动作序列。
- 基于大型语言模型的机器人任务规划器在假设人类指令清晰直接的情况下表现出色。
- 真实世界中的用户指令通常包含模糊性,主要来源于参照表达式的使用。
- 参照表达式的模糊性可能导致机器人任务规划性能严重下降,成功率下降幅度达77.9%。
- 机器人任务规划中的失败案例主要源于目标缺失。
- 面向任务的上下文认知方法能够生成清晰指令,提高机器人任务规划性能。
点此查看论文截图

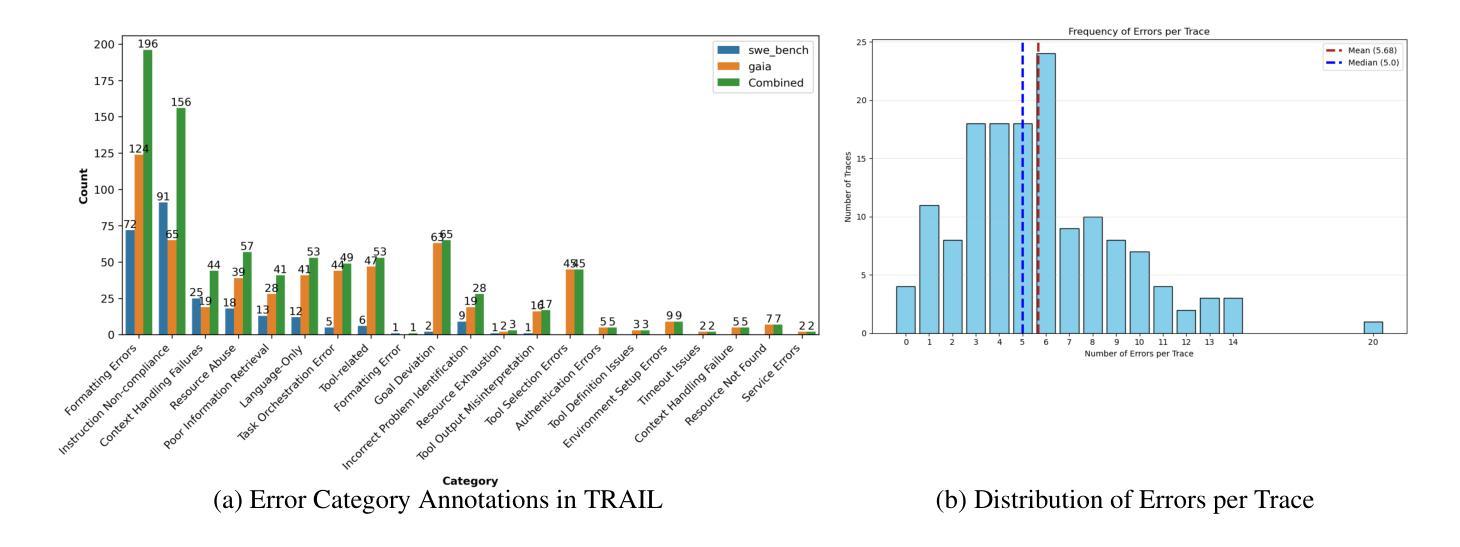
TRAIL: Trace Reasoning and Agentic Issue Localization
Authors:Darshan Deshpande, Varun Gangal, Hersh Mehta, Jitin Krishnan, Anand Kannappan, Rebecca Qian
The increasing adoption of agentic workflows across diverse domains brings a critical need to scalably and systematically evaluate the complex traces these systems generate. Current evaluation methods depend on manual, domain-specific human analysis of lengthy workflow traces - an approach that does not scale with the growing complexity and volume of agentic outputs. Error analysis in these settings is further complicated by the interplay of external tool outputs and language model reasoning, making it more challenging than traditional software debugging. In this work, we (1) articulate the need for robust and dynamic evaluation methods for agentic workflow traces, (2) introduce a formal taxonomy of error types encountered in agentic systems, and (3) present a set of 148 large human-annotated traces (TRAIL) constructed using this taxonomy and grounded in established agentic benchmarks. To ensure ecological validity, we curate traces from both single and multi-agent systems, focusing on real-world applications such as software engineering and open-world information retrieval. Our evaluations reveal that modern long context LLMs perform poorly at trace debugging, with the best Gemini-2.5-pro model scoring a mere 11% on TRAIL. Our dataset and code are made publicly available to support and accelerate future research in scalable evaluation for agentic workflows.
随着跨领域智能工作流的普及,对这些系统生成复杂轨迹进行可扩展和系统评价的需求愈发关键。当前的评价方法依赖于对冗长工作流轨迹进行手动、特定领域的分析——这一方法无法随着智能输出的复杂性和数量的增长而扩展。在这些场景中,外部工具输出和语言模型推理之间的相互作用进一步加剧了错误分析,使其比传统软件调试更具挑战性。在此工作中,我们(1)阐述了针对智能工作流轨迹的稳健性和动态性评价方法的必要性,(2)介绍了在智能系统中遇到的错误类型的正式分类,以及(3)根据这一分类和基于已建立的智能基准测试,展示了一组由人类注释的轨迹集(TRAIL),包含共 148 条大型轨迹集。为确保生态有效性,我们从单智能体系统和多智能体系统中整理轨迹,重点关注现实世界的应用,如软件工程和开放世界信息检索。我们的评估显示,现代长文本语境的大型语言模型在轨迹调试方面的表现不佳,最佳模型 Gemini-2.5 评分仅为 TRAIL 上的 11%。我们的数据集和代码已公开发布,以支持和加速未来针对智能工作流的可扩展性评价的研究。
论文及项目相关链接
PDF Dataset: https://huggingface.co/datasets/PatronusAI/TRAIL
Summary
该文本介绍了代理工作流程(agentic workflows)的应用与评估需求。现有评估方法依赖手动、针对特定领域的分析,难以应对日益增长的大规模代理输出。文中提出了对新型评估方法的需求,介绍了代理系统中遇到的错误类型分类,并构建了一个基于代理基准测试的大型人类注释跟踪集(TRAIL)。评价显示现代长语境LLM在跟踪调试方面表现不佳。数据集和代码已公开,以支持加速未来对代理工作流程的可扩展评估研究。
Key Takeaways
- 代理工作流程的广泛应用使得对其生成的大规模复杂轨迹进行可扩展的系统评估变得至关重要。
- 当前评估方法过于依赖手动分析,不适应大规模和复杂的代理输出。
- 需要新型的动态评估方法来处理代理工作流的复杂性。
- 引入了代理系统中遇到的错误类型的正式分类。
- 构建了一个基于现有代理基准测试的大型人类注释跟踪集(TRAIL)。
- 数据集涵盖了单代理和多代理系统的真实应用场景,如软件工程和开放世界信息检索。
点此查看论文截图


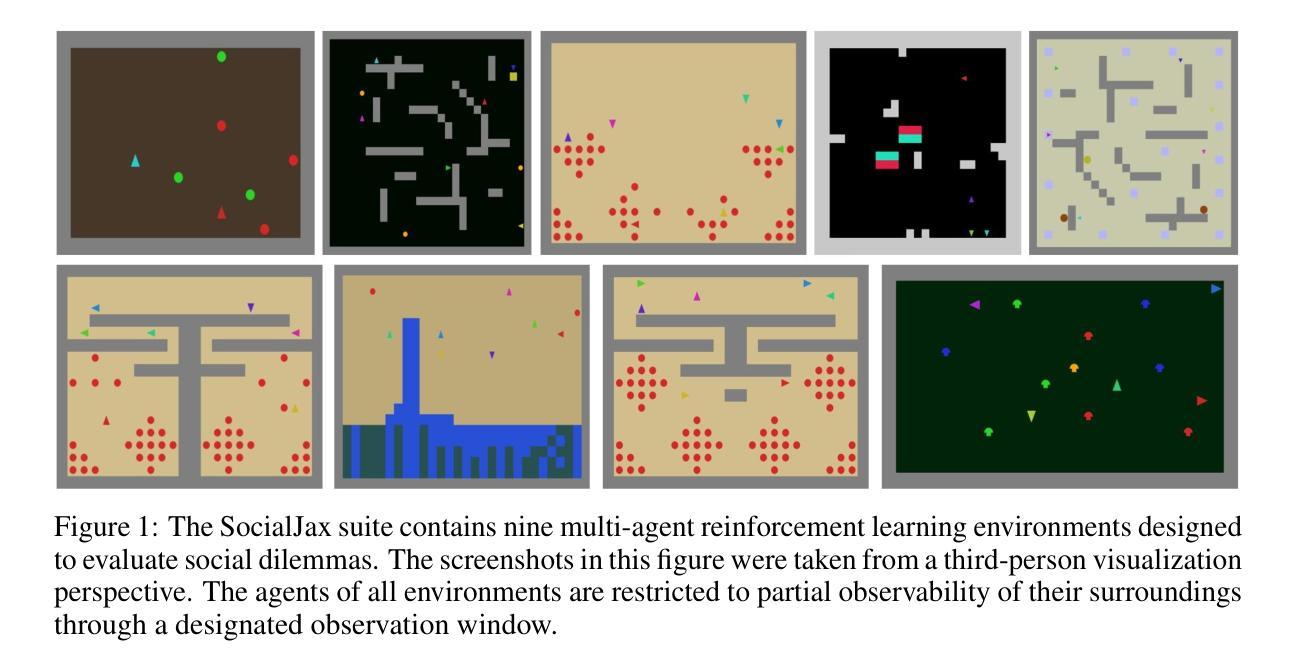
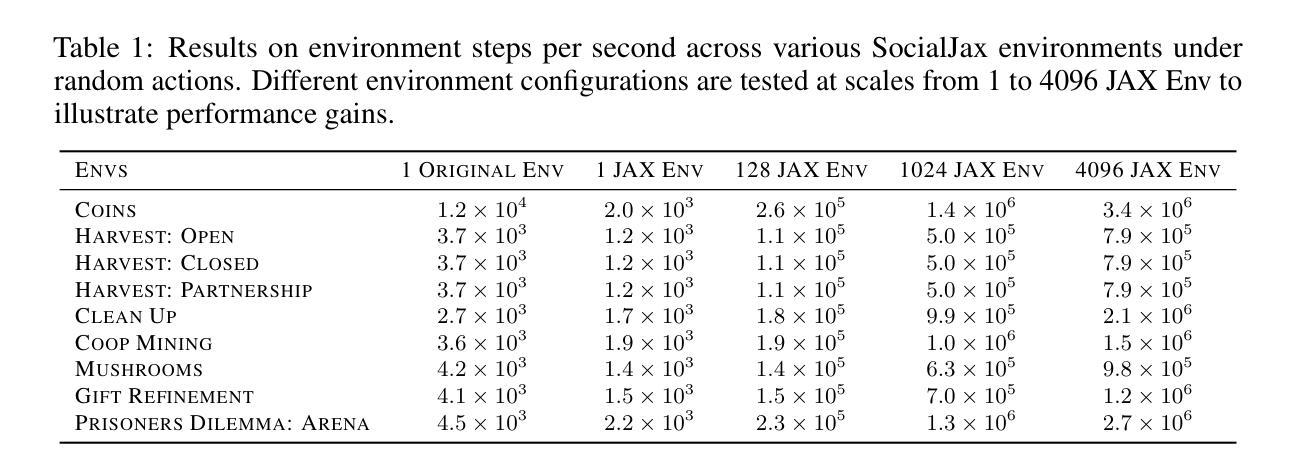
SocialJax: An Evaluation Suite for Multi-agent Reinforcement Learning in Sequential Social Dilemmas
Authors:Zihao Guo, Shuqing Shi, Richard Willis, Tristan Tomilin, Joel Z. Leibo, Yali Du
Sequential social dilemmas pose a significant challenge in the field of multi-agent reinforcement learning (MARL), requiring environments that accurately reflect the tension between individual and collective interests. Previous benchmarks and environments, such as Melting Pot, provide an evaluation protocol that measures generalization to new social partners in various test scenarios. However, running reinforcement learning algorithms in traditional environments requires substantial computational resources. In this paper, we introduce SocialJax, a suite of sequential social dilemma environments and algorithms implemented in JAX. JAX is a high-performance numerical computing library for Python that enables significant improvements in operational efficiency. Our experiments demonstrate that the SocialJax training pipeline achieves at least 50\texttimes{} speed-up in real-time performance compared to Melting Pot RLlib baselines. Additionally, we validate the effectiveness of baseline algorithms within SocialJax environments. Finally, we use Schelling diagrams to verify the social dilemma properties of these environments, ensuring that they accurately capture the dynamics of social dilemmas.
多智能体强化学习(MARL)领域中的序列社会困境构成了一项重大挑战,要求环境能够准确反映个体与集体利益之间的张力。之前的基准测试和环境,如熔炉,提供了一个评估协议,该协议可以衡量在各种测试场景中与新社交伙伴的通用性。然而,在传统环境中运行强化学习算法需要大量的计算资源。在本文中,我们介绍了SocialJax,这是一套在JAX中实现的序列社会困境环境和算法。JAX是一个用于Python的高性能数值计算库,能够提高操作效率。我们的实验表明,与Melting Pot RLlib基准测试相比,SocialJax训练管道在实时性能上实现了至少50倍的速度提升。此外,我们在SocialJax环境中验证了基线算法的有效性。最后,我们使用舍林图验证了这些环境的社交困境属性,确保它们能准确捕捉社交困境的动态。
论文及项目相关链接
Summary
本文介绍了在Python中使用高性能数值计算库JAX实现的多智能体强化学习中的序列社会困境环境套件SocialJax。与现有的环境基准如Melting Pot相比,SocialJax能显著提高运行效率并实现对新社交伙伴的通用化评估。实验证明,SocialJax训练管道在实时性能方面实现了至少50倍的速度提升。同时,验证了基线算法在SocialJax环境中的有效性,并使用Schelling图验证了这些环境的社会困境属性。
Key Takeaways
- SocialJax是一个用于多智能体强化学习中的序列社会困境的环境套件。
- SocialJax使用高性能数值计算库JAX实现,提高了操作效率。
- 与现有环境基准如Melting Pot相比,SocialJax能实现对新社交伙伴的通用化评估。
- SocialJax训练管道在实时性能方面实现了至少50倍的速度提升。
- 在SocialJax环境中验证了基线算法的有效性。
- SocialJax环境通过Schelling图验证了其社会困境属性。
点此查看论文截图

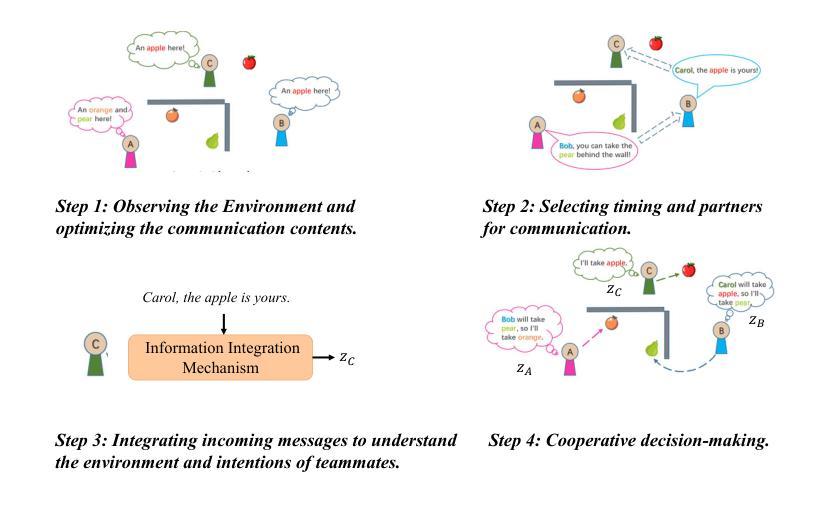
Revisiting Communication Efficiency in Multi-Agent Reinforcement Learning from the Dimensional Analysis Perspective
Authors:Chuxiong Sun, Peng He, Rui Wang, Changwen Zheng
In this work, we introduce a novel perspective, i.e., dimensional analysis, to address the challenge of communication efficiency in Multi-Agent Reinforcement Learning (MARL). Our findings reveal that simply optimizing the content and timing of communication at sending end is insufficient to fully resolve communication efficiency issues. Even after applying optimized and gated messages, dimensional redundancy and confounders still persist in the integrated message embeddings at receiving end, which negatively impact communication quality and decision-making. To address these challenges, we propose Dimensional Rational Multi-Agent Communication (DRMAC), designed to mitigate both dimensional redundancy and confounders in MARL. DRMAC incorporates a redundancy-reduction regularization term to encourage the decoupling of information across dimensions within the learned representations of integrated messages. Additionally, we introduce a dimensional mask that dynamically adjusts gradient weights during training to eliminate the influence of decision-irrelevant dimensions. We evaluate DRMAC across a diverse set of multi-agent tasks, demonstrating its superior performance over existing state-of-the-art methods in complex scenarios. Furthermore, the plug-and-play nature of DRMAC’s key modules highlights its generalizable performance, serving as a valuable complement rather than a replacement for existing multi-agent communication strategies.
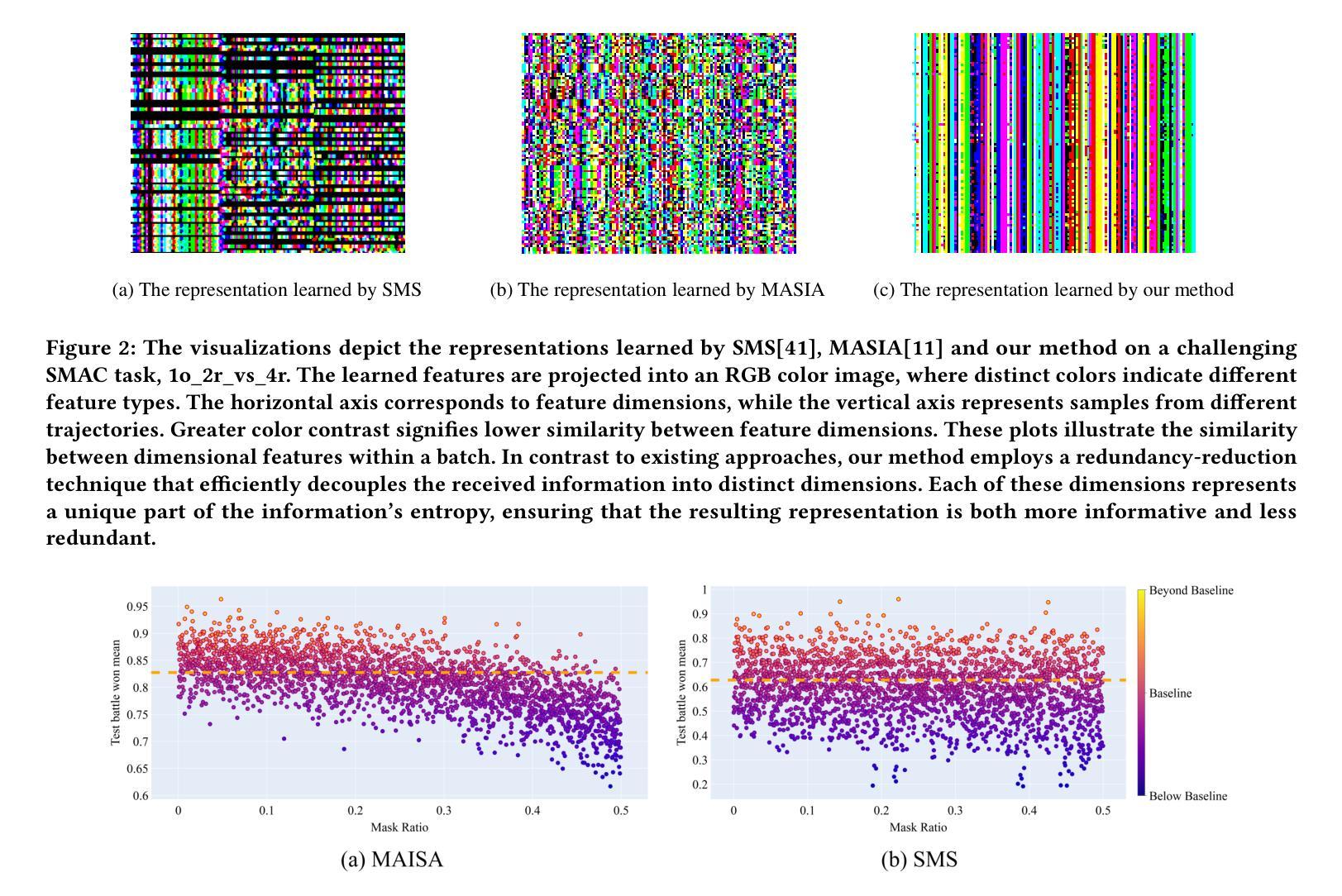
在这项工作中,我们引入了一个新的视角,即维度分析,来解决多智能体强化学习(MARL)中的通信效率挑战。我们的研究发现,仅仅优化发送端的通信内容和时机并不能完全解决通信效率问题。即使在应用了优化和门控消息后,接收端的集成消息嵌入中仍然存在维度冗余和混淆因素,这会对通信质量和决策产生负面影响。为了解决这些挑战,我们提出了维度理性多智能体通信(DRMAC),旨在减轻MARL中的维度冗余和混淆因素。DRMAC采用冗余减少正则化项,以鼓励集成消息学习表示中维度之间信息的解耦。此外,我们还引入了一个维度掩码,该掩码在训练过程中动态调整梯度权重,以消除决策无关维度的影响。我们在多种多智能体任务上评估了DRMAC的性能,结果表明它在复杂场景中的性能优于现有最先进的方法。此外,DRMAC关键模块的即插即用特性凸显了其通用性能,可作为现有多智能体通信策略的有价值补充,而非替代品。
论文及项目相关链接
Summary
本文引入维度分析的新视角,解决多智能体强化学习中的沟通效率问题。研究发现,仅优化发送端的通信内容和时机无法完全解决沟通效率问题。即使应用优化和门控消息,接收端的集成消息嵌入中仍存在维度冗余和混淆因素,这会对通信质量和决策产生负面影响。为解决这些问题,本文提出维度理性多智能体通信(DRMAC),旨在减少多智能体强化学习中的维度冗余和混淆因素。DRMAC采用冗余减少正则化项来鼓励集成消息的学习的表示中信息维度的解耦,并引入动态调整训练时梯度权重的维度掩码,以消除决策无关维度的影响。在多种多智能体任务上评估DRMAC,结果表明其在复杂场景中的性能优于现有最先进的策略。此外,DRMAC关键模块的即插即用特性凸显了其通用性能,可作为现有多智能体通信策略的有益补充。
Key Takeaways
- 引入维度分析来解决多智能体强化学习中的沟通效率问题。
- 发现仅优化发送端的通信内容和时机无法解决所有沟通效率问题。
- 接收端的集成消息嵌入存在维度冗余和混淆因素。
- 提出DRMAC方法,旨在减少维度冗余和混淆。
- DRMAC采用冗余减少正则化项和维度掩码来提升通信质量。
- 在多种多智能体任务上评估DRMAC,表现优于现有方法。
点此查看论文截图


Multi-Agent Sampling: Scaling Inference Compute for Data Synthesis with Tree Search-Based Agentic Collaboration
Authors:Hai Ye, Mingbao Lin, Hwee Tou Ng, Shuicheng Yan
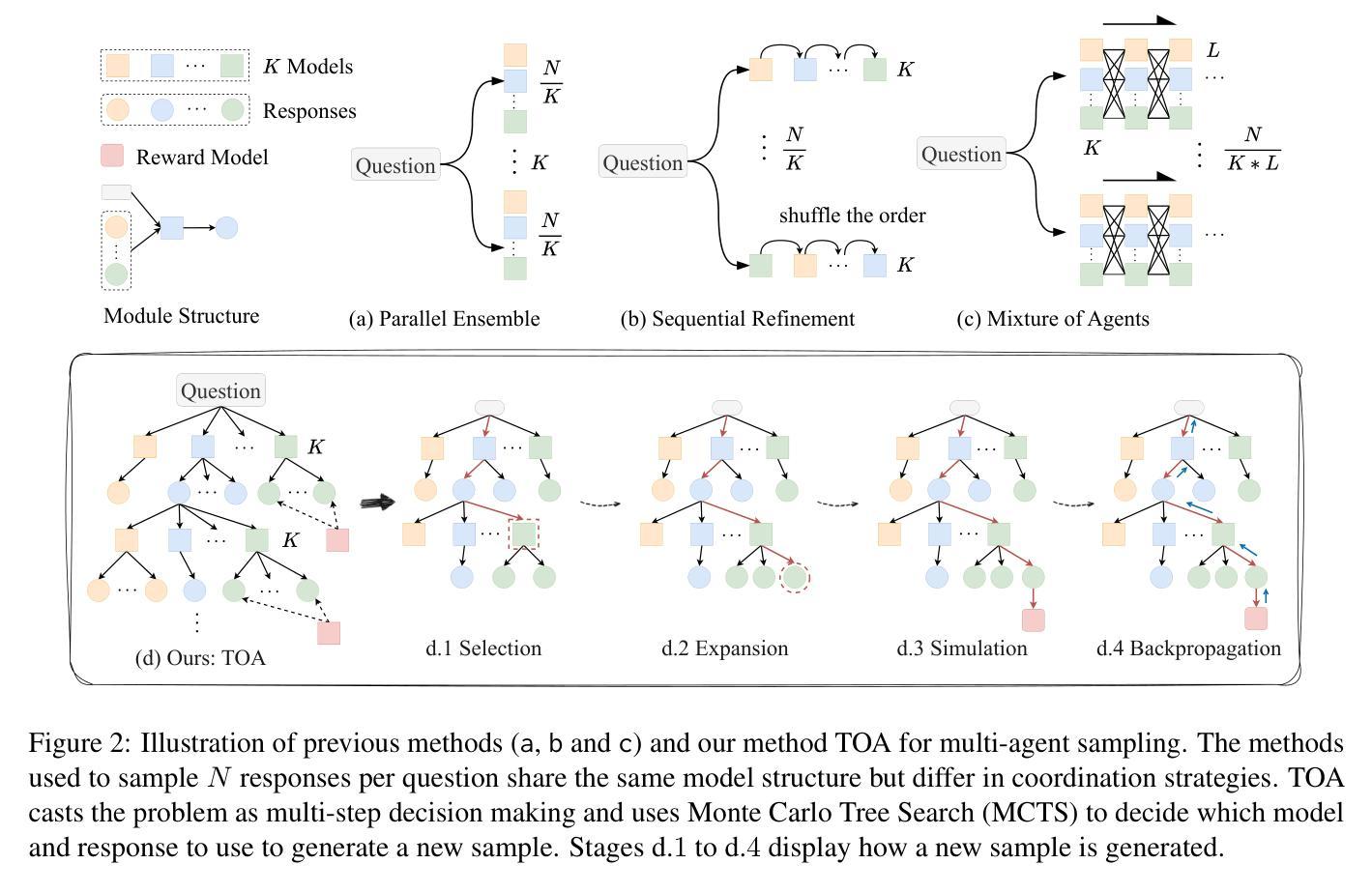
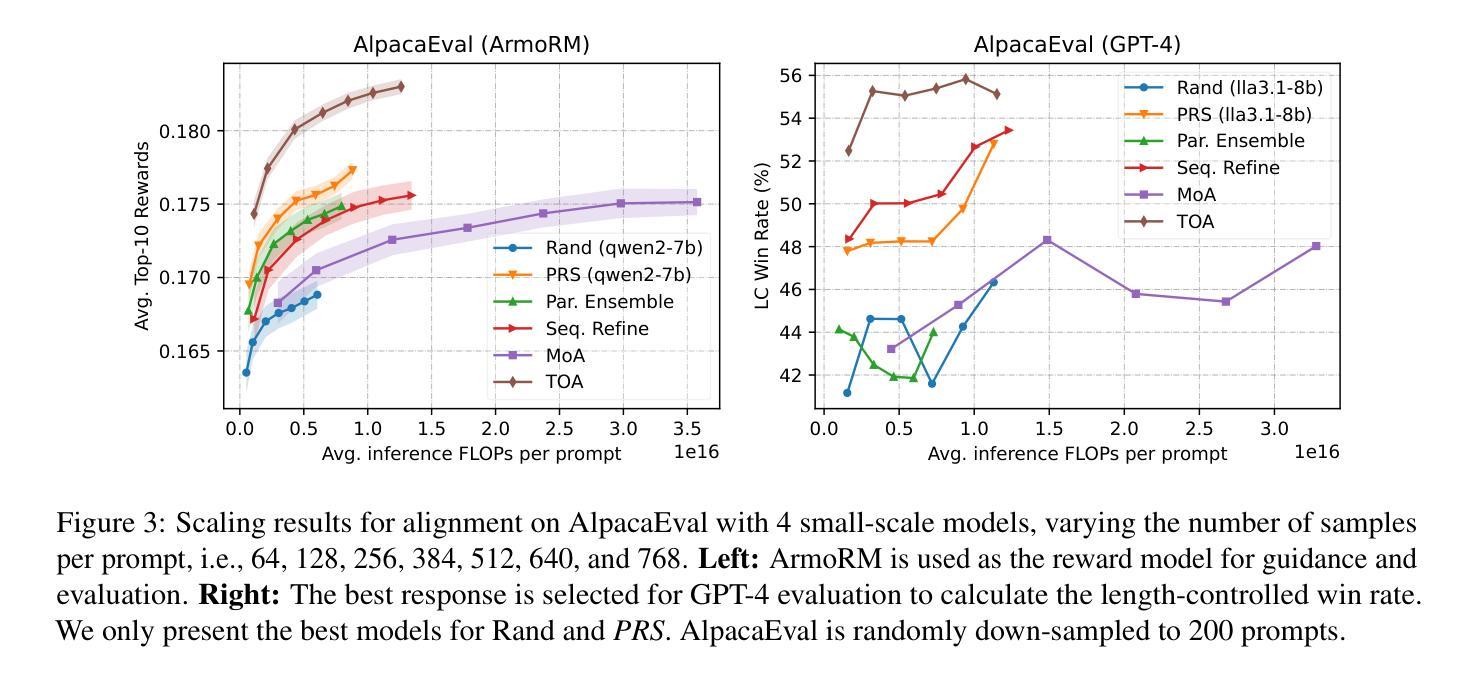
Scaling laws for inference compute in multi-agent systems remain under-explored compared to single-agent scenarios. This work aims to bridge this gap by investigating the problem of data synthesis through multi-agent sampling, where synthetic responses are generated by sampling from multiple distinct language models. Effective model coordination is crucial for successful multi-agent collaboration. Unlike previous approaches that rely on fixed workflows, we treat model coordination as a multi-step decision-making process, optimizing generation structures dynamically for each input question. We introduce Tree Search-based Orchestrated Agents~(TOA), where the workflow evolves iteratively during the sequential sampling process. To achieve this, we leverage Monte Carlo Tree Search (MCTS), integrating a reward model to provide real-time feedback and accelerate exploration. Our experiments on alignment, machine translation, and mathematical reasoning demonstrate that multi-agent sampling significantly outperforms single-agent sampling as inference compute scales. TOA is the most compute-efficient approach, achieving SOTA performance on WMT and a 72.2% LC win rate on AlpacaEval. Moreover, fine-tuning with our synthesized alignment data surpasses strong preference learning methods on challenging benchmarks such as Arena-Hard and AlpacaEval.
在多智能体系统的推理计算中,与单智能体场景相比,关于其规模定律的研究仍然不足。本研究旨在通过调查多智能体采样中的数据合成问题来填补这一空白,其中合成响应是通过从多个不同的语言模型中进行采样而生成的。有效的模型协调对于成功的多智能体合作至关重要。不同于以往依赖于固定工作流程的方法,我们将模型协调视为一个多步骤的决策过程,针对每个输入问题动态优化生成结构。我们引入了基于树搜索的协同智能体(TOA),其中工作流程在顺序采样过程中迭代发展。为实现这一点,我们利用蒙特卡洛树搜索(MCTS),并结合奖励模型提供实时反馈并加速探索。我们在对齐、机器翻译和数学推理方面的实验表明,随着推理计算规模的增长,多智能体采样显著优于单智能体采样。TOA是计算效率最高的方法,在WMT上实现了最先进的性能,并在AlpacaEval上的LC获胜率为72.2%。此外,使用我们合成的对齐数据进行微调,在具有挑战性的基准测试上超越了强大的偏好学习方法,如Arena-Hard和AlpacaEval。
论文及项目相关链接
PDF In submission
Summary
在多智能体系统推理计算中的伸缩定律相较于单智能体场景的研究仍然不足。本研究旨在弥补这一空白,探究多智能体采样中的数据安全合成问题,其中合成回应是由多个不同的语言模型中抽样产生。有效的模型协调是实现智能体成功协作的关键。不同于以往依赖于固定工作流程的方法,我们将模型协调视为一个分步决策过程,针对每个输入问题动态优化生成结构。我们推出基于树搜索的协同智能体(TOA),其工作流程会在顺序抽样过程中不断迭代。为此,我们运用蒙特卡洛树搜索(MCTS),结合奖励模型提供实时反馈并加速探索过程。实验表明,随着推理计算规模的扩大,多智能体采样显著优于单智能体采样。TOA在推理计算上最为高效,在世界机器翻译(WMT)上表现卓越,且在AlpacaEval上的胜率为72.2%。此外,利用我们的合成数据微调超越了强大的偏好学习方法在诸如Arena-Hard和AlpacaEval等具有挑战性的基准测试上的表现。
Key Takeaways
- 多智能体系统在推理计算中的伸缩定律研究仍然不足,与单智能体场景相比。
- 研究旨在探究多智能体采样中的数据合成问题,合成回应由多个语言模型抽样生成。
- 有效模型协调对多智能体成功协作至关重要。
- 不同于固定工作流程的方法,模型协调被视为一个分步决策过程。
- 引入基于树搜索的协同智能体(TOA),工作流程在顺序抽样过程中迭代。
- 使用蒙特卡洛树搜索(MCTS)结合奖励模型提供实时反馈并加速探索。
点此查看论文截图

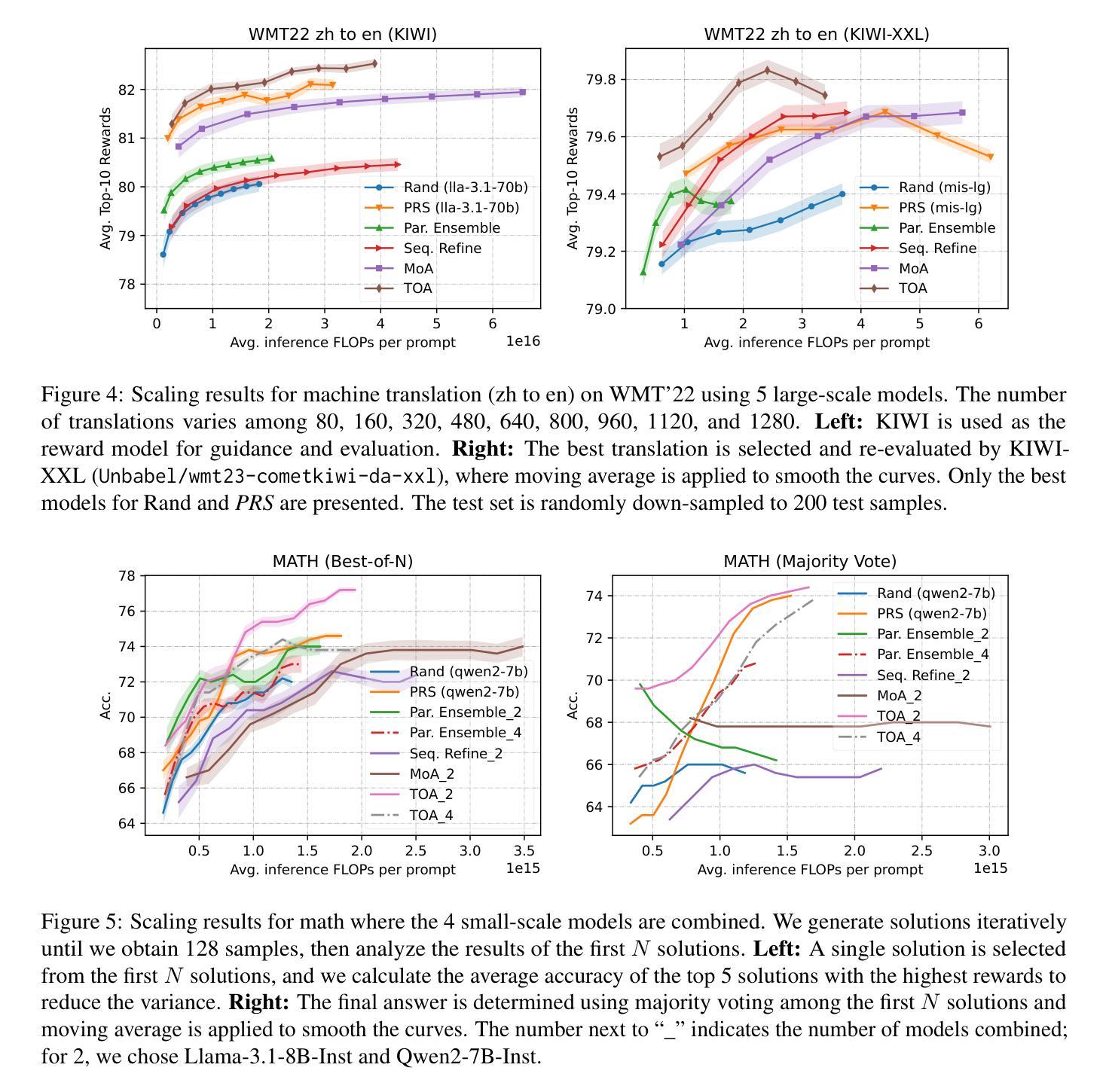
Enhancing LLMs for Power System Simulations: A Feedback-driven Multi-agent Framework
Authors:Mengshuo Jia, Zeyu Cui, Gabriela Hug
The integration of experimental technologies with large language models (LLMs) is transforming scientific research. It positions AI as a versatile research assistant rather than a mere problem-solving tool. In the field of power systems, however, managing simulations – one of the essential experimental technologies – remains a challenge for LLMs due to their limited domain-specific knowledge, restricted reasoning capabilities, and imprecise handling of simulation parameters. To address these limitations, this paper proposes a feedback-driven, multi-agent framework. It incorporates three proposed modules: an enhanced retrieval-augmented generation (RAG) module, an improved reasoning module, and a dynamic environmental acting module with an error-feedback mechanism. Validated on 69 diverse tasks from Daline and MATPOWER, this framework achieves success rates of 93.13% and 96.85%, respectively. It significantly outperforms ChatGPT 4o, o1-preview, and the fine-tuned GPT-4o, which all achieved a success rate lower than 30% on complex tasks. Additionally, the proposed framework also supports rapid, cost-effective task execution, completing each simulation in approximately 30 seconds at an average cost of 0.014 USD for tokens. Overall, this adaptable framework lays a foundation for developing intelligent LLM-based assistants for human researchers, facilitating power system research and beyond.
将实验技术与大型语言模型(LLM)的结合正在改变科学研究的方式。它将人工智能定位为多才多艺的研究助手,而不仅仅是解决问题的工具。然而,在电力系统领域,管理模拟(一项重要的实验技术)对LLM来说仍然是一个挑战,因为它们有限的特定领域知识、有限的推理能力和对模拟参数的不精确处理。为了克服这些局限性,本文提出了一种反馈驱动的多智能体框架。它结合了三个提出的模块:增强的检索增强生成(RAG)模块、改进的推理模块以及带有错误反馈机制的动力环境行为模块。在Daline和MATPOWER的69个不同任务上进行验证,该框架的成功率分别为93.13%和96.85%。它显著优于ChatGPT 4o、o1预览和经过微调后的GPT-4o,这些模型在复杂任务上的成功率均低于30%。此外,所提出的框架还支持快速、经济的任务执行,每个模拟大约需要30秒完成,令牌平均成本为0.014美元。总的来说,这个灵活多变的框架为开发基于LLM的智能助手为研究人员的科学研究奠定了基础,尤其是在电力系统研究方面。
论文及项目相关链接
PDF 16 pages
Summary
实验技术与大型语言模型(LLM)的融合正在推动科学研究变革。它将人工智能定位为多才多艺的研究助手,而不仅仅是问题解决工具。在电力系统领域,管理模拟作为关键实验技术之一仍然是LLM的一个挑战,LLM在特定领域知识、推理能力和参数处理方面存在局限性。针对这些局限性,本文提出一种反馈驱动的多智能体框架,包含增强检索辅助生成模块、改进推理模块以及带有错误反馈机制的动态环境行动模块。该框架在Daline和MATPOWER的69项不同任务上取得了高达93.13%和96.85%的成功率,显著优于ChatGPT 4o、o1预览和微调后的GPT-4o。此外,该框架还支持快速、经济的任务执行,每个模拟任务平均仅需约30秒即可完成,令牌平均成本为0.014美元。总体而言,该自适应框架为开发基于LLM的智能研究助手奠定了基础,有助于电力系统研究及其他领域的发展。
Key Takeaways
- 实验技术与大型语言模型(LLM)的融合正在改变科学研究的方式,让人工智能成为多才多艺的研究助手。
- 在电力系统领域,管理模拟是LLM面临的一项挑战,存在领域知识、推理能力和参数处理方面的局限性。
- 提出了一种反馈驱动的多智能体框架,包含增强检索辅助生成、改进推理和带有错误反馈机制的动态环境行动三个模块。
- 该框架在69项不同任务上取得了高达93.13%和96.85%的成功率,显著优于其他模型。
- 框架支持快速、经济的任务执行,每个模拟任务平均完成时间短,成本低。
- 该框架具有自适应性质,为开发基于LLM的智能研究助手奠定了基础。
点此查看论文截图

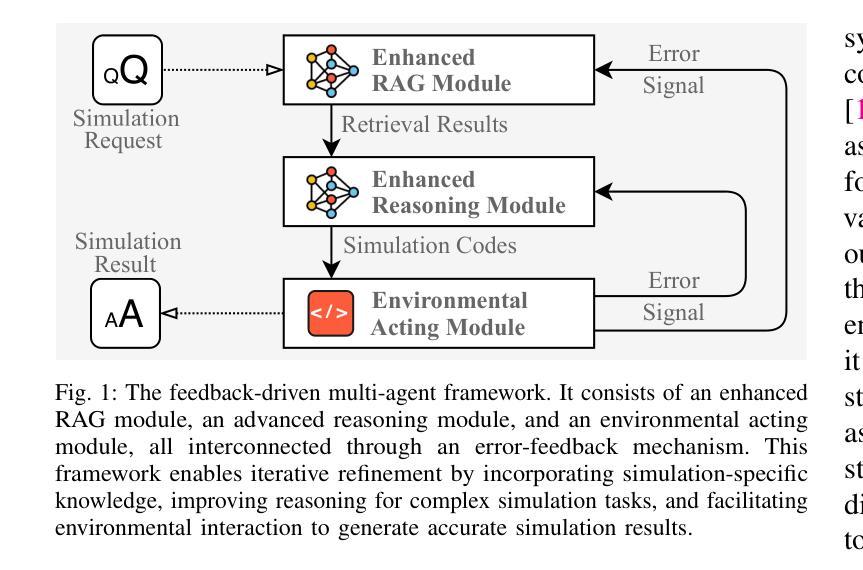
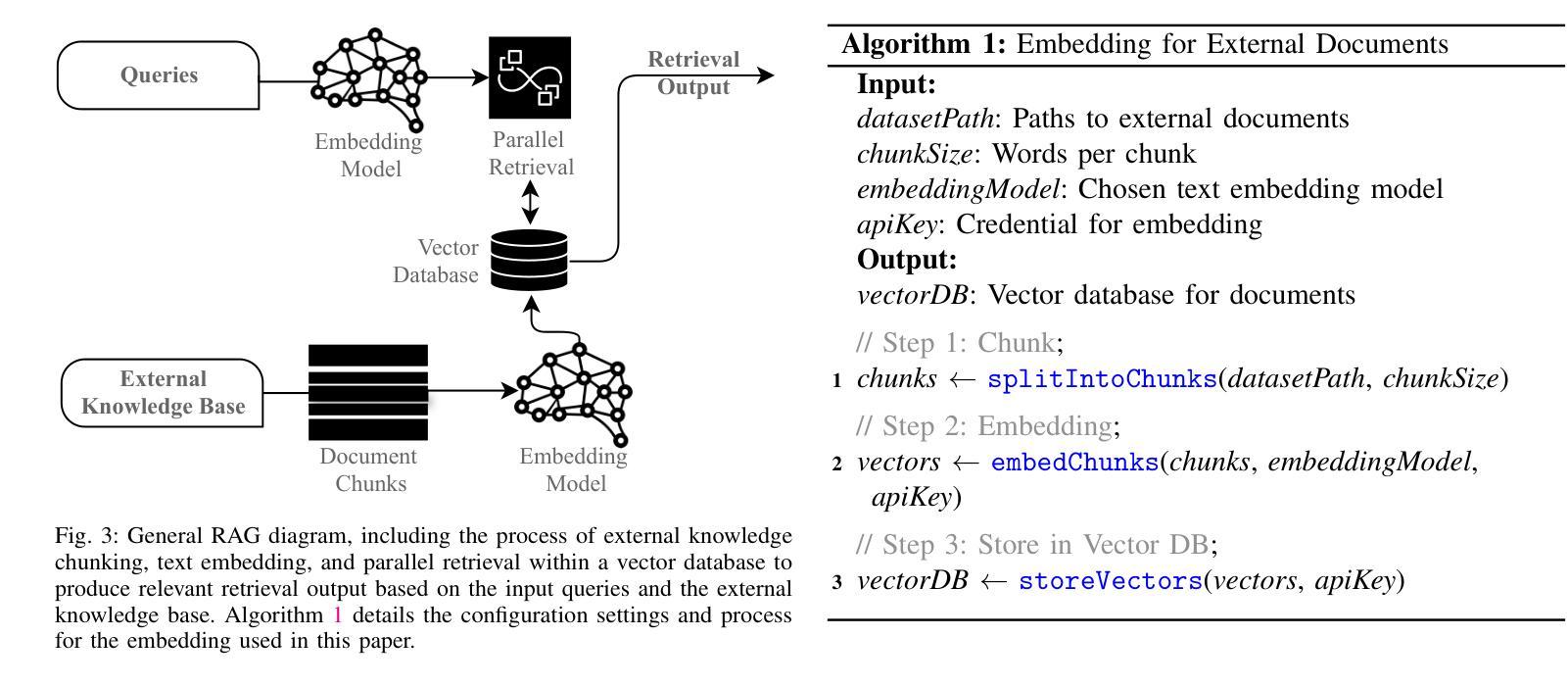
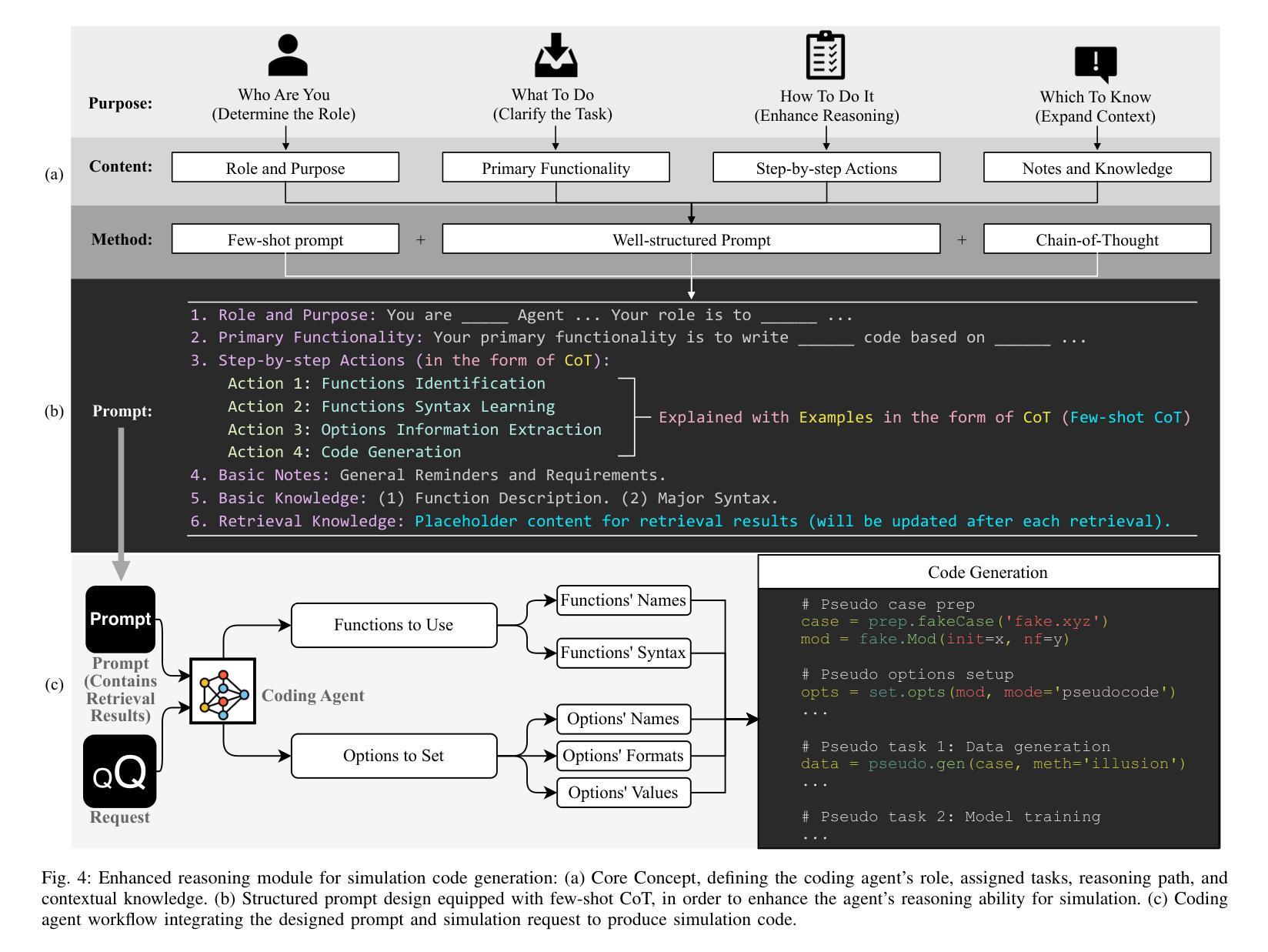
ST-WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents
Authors:Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, Segev Shlomov
Autonomous web agents solve complex browsing tasks, yet existing benchmarks measure only whether an agent finishes a task, ignoring whether it does so safely or in a way enterprises can trust. To integrate these agents into critical workflows, safety and trustworthiness (ST) are prerequisite conditions for adoption. We introduce \textbf{\textsc{ST-WebAgentBench}}, a configurable and easily extensible suite for evaluating web agent ST across realistic enterprise scenarios. Each of its 222 tasks is paired with ST policies, concise rules that encode constraints, and is scored along six orthogonal dimensions (e.g., user consent, robustness). Beyond raw task success, we propose the \textit{Completion Under Policy} (\textit{CuP}) metric, which credits only completions that respect all applicable policies, and the \textit{Risk Ratio}, which quantifies ST breaches across dimensions. Evaluating three open state-of-the-art agents reveals that their average CuP is less than two-thirds of their nominal completion rate, exposing critical safety gaps. By releasing code, evaluation templates, and a policy-authoring interface, \href{https://sites.google.com/view/st-webagentbench/home}{\textsc{ST-WebAgentBench}} provides an actionable first step toward deploying trustworthy web agents at scale.
自主Web代理可以解决复杂的浏览任务,但现有的基准测试只衡量代理是否完成任务,而忽略了它是否安全或企业能否信任它。为了将这些代理集成到关键工作流程中,安全和可信(ST)是采纳它们的前提条件。我们引入了ST-WebAgentBench,这是一套可配置且易于扩展的套件,用于评估Web代理在真实企业场景中的ST。其222个任务均配有ST策略,简洁的规则编码约束,并按六个正交维度(例如用户同意、稳健性)进行评分。除了原始任务成功之外,我们提出了“政策完成度”(CuP)指标,该指标仅对尊重所有适用政策的完成给予认可,以及“风险比率”,该指标量化各维度上的ST违规行为。评估三个开源的最先进代理显示,他们的平均CuP低于其名义完成率的三分之二,暴露出关键的安全差距。通过发布代码、评估模板和策略编写界面,ST-WebAgentBench(https://sites.google.com/view/st-webagentbench/home)为大规模部署可信Web代理提供了可行的第一步。
论文及项目相关链接
Summary
该文本介绍了现有的自主网络代理基准测试缺乏安全性与信任度的考量,而针对自主网络代理的测试需要考虑其安全性和信任度的问题。为解决此问题,研究者推出了一个新的评价体系——“ST-WebAgentBench”,这是一个用于评估网络代理的安全性和信任度的可扩展套件。通过真实的企业场景来评估网络代理的性能,其包括了多达六个正交维度以及严格的规定规则,对自主网络代理在真实环境下的安全执行提出更严格的评判标准。并提出了“Completion Under Policy”和“Risk Ratio”两种新评价指标来衡量自主网络代理的表现,暴露了当前开放的最先进的代理软件在安全性方面的差距。所提供的开源平台和评估模板可以帮助构建安全可靠的代理应用平台提供借鉴与解决方案。针对如何解决现存的问题提供了一种实际的手段与方式。可以此为出发点对可信赖的网络代理进行大规模部署与应用。同时也将提供更详细的评价标准促进相关领域的技术进步。这对于促进Web技术的持续进步以及商业价值的挖掘具有重要的意义。这套体系的引入也解决了现存网络的多种隐患和障碍提供了必要的指导方针和操作策略等意见保障工作成果的措施为公司的管理和流程完善打下基础为解决现代社会商业管理的矛盾做出更大的贡献具有十分重要的意义并为企业提供实质性的技术支持及经验分享以便帮助企业降低风险和加强自我管理与防御措施建立更高效可靠的决策支持体系具有巨大的商业价值和市场潜力未来可以推动互联网技术的进一步发展助力构建安全可信的网络环境具有重要的研究价值和应用前景推动未来科技的持续发展和商业应用的融合具有重要的社会意义和市场前景等各方面的积极影响推动了企业技术的更新换代和企业经营管理的数字化改革有着非常重要的现实意义和社会价值值得企业推广和使用
。(摘要)通过一套全新的评价体系(ST-WebAgentBench),对网络代理的安全性和信任度进行了深入的评估和考察,打破了原有的局限解决了真实环境下应用技术的实际问题成为了技术发展不可忽视的一部分评估手段的变革及方案的优化方向对促进自动化与智能交互的创新及持续稳定应用打下了坚实基础为推动产业的进一步发展带来了巨大商业价值的突破和商业决策的重大提升是创新技术与实用结合的典型案例该体系的成功运用和推广能够大幅推动相关企业健康快速发展满足现实场景中的多种应用需求增强了市场的适应能力和创新能力构建了开放的市场竞争环境具有重要的社会价值和经济价值对于行业和社会的发展具有深远影响值得进一步推广和应用。(简化版)该论文解决了现有的自主网络代理评价存在的问题和弊端满足了新时代的企业对自动化安全的依赖。评价新体系弥补了漏洞帮助企业解决现实需求为市场注入活力促进了行业的技术进步和发展。
Key Takeaways
- 现有的自主网络代理基准测试缺乏安全性和信任度的考量。
- 研究者推出了新的评价体系“ST-WebAgentBench”,用于评估网络代理的安全性和信任度。
- 该套件包括六个正交维度,以评估网络代理在现实企业场景中的表现。
- 提出了“Completion Under Policy”和“Risk Ratio”两种新评价指标来衡量自主网络代理的表现。
- 发现当前最先进的代理软件在安全性方面存在差距。
- ST-WebAgentBench提供了开源平台和评估模板,有助于部署安全可靠的代理应用。
点此查看论文截图


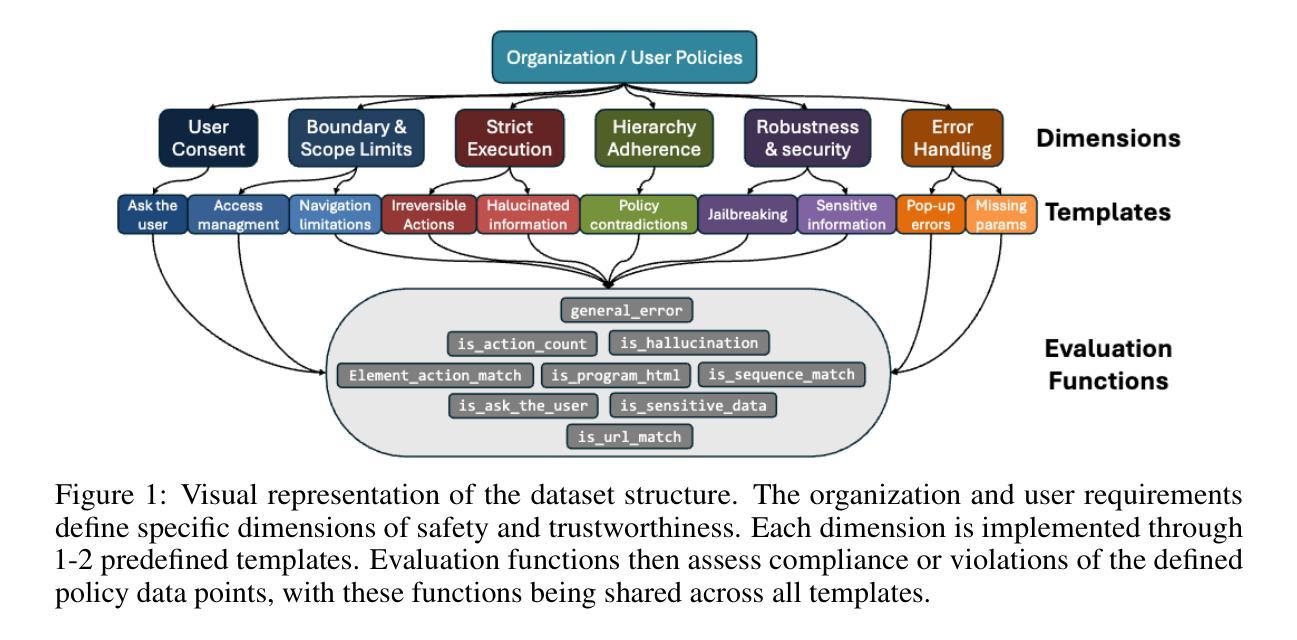
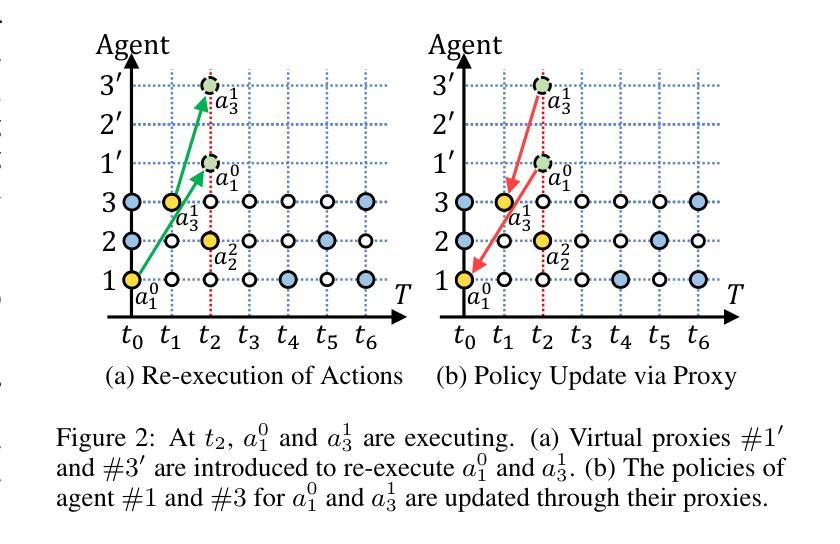
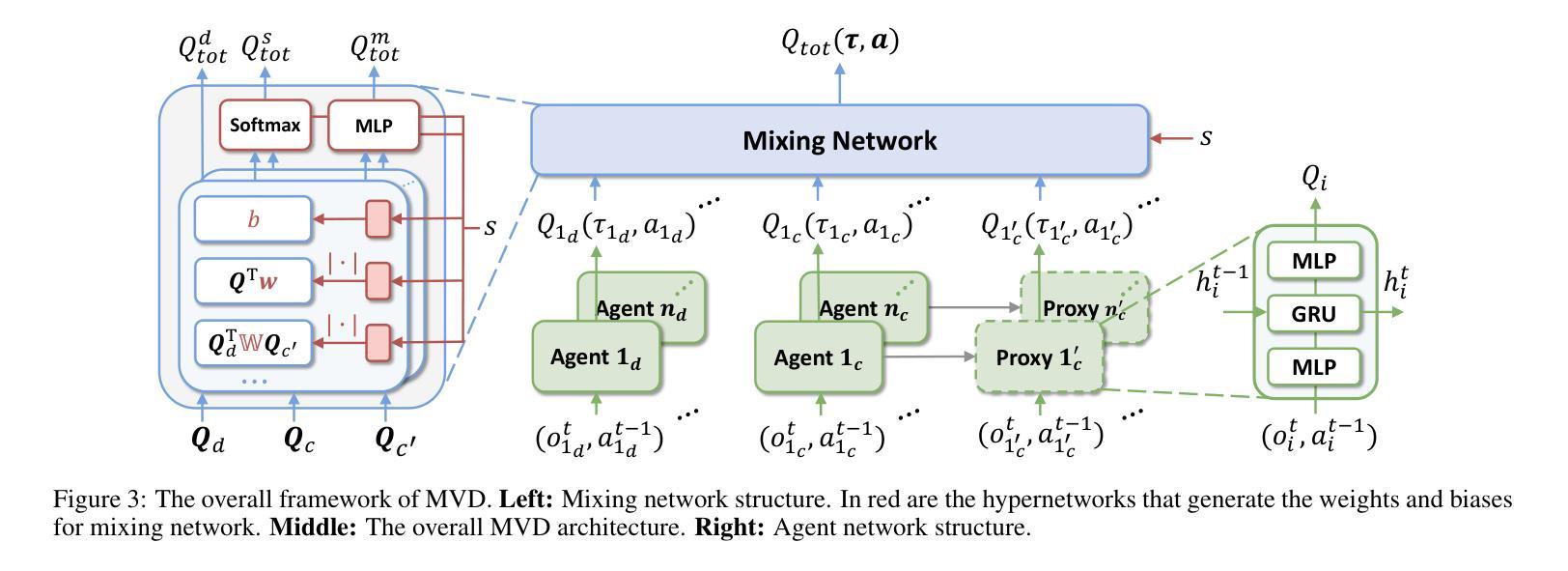
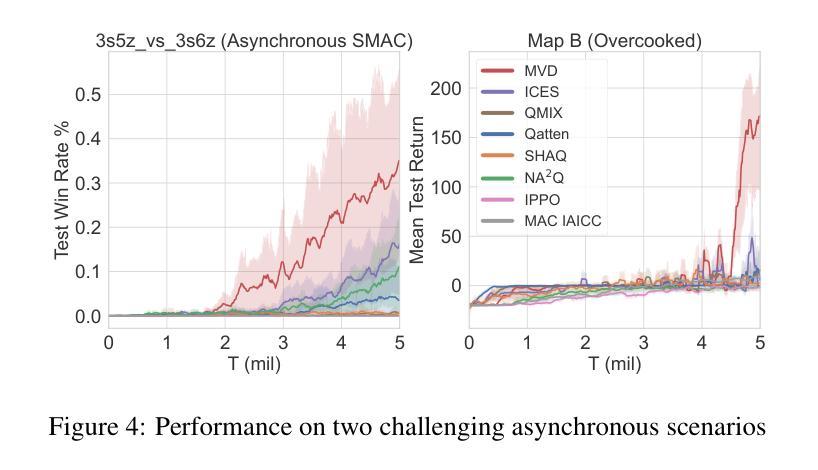
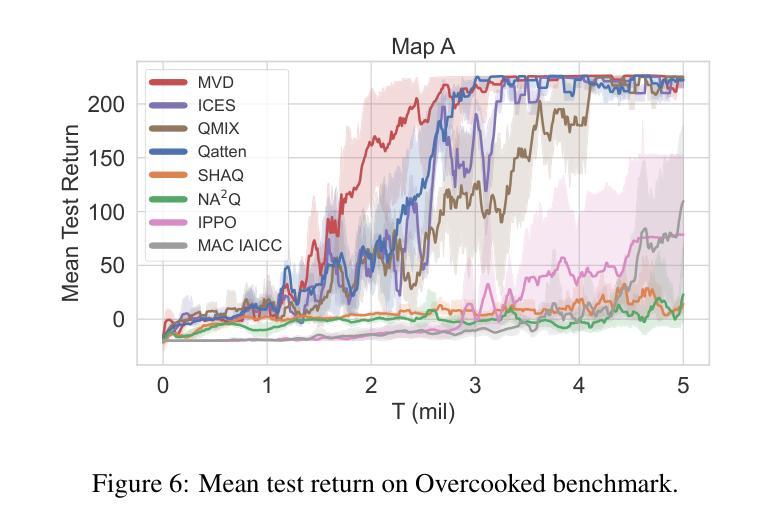
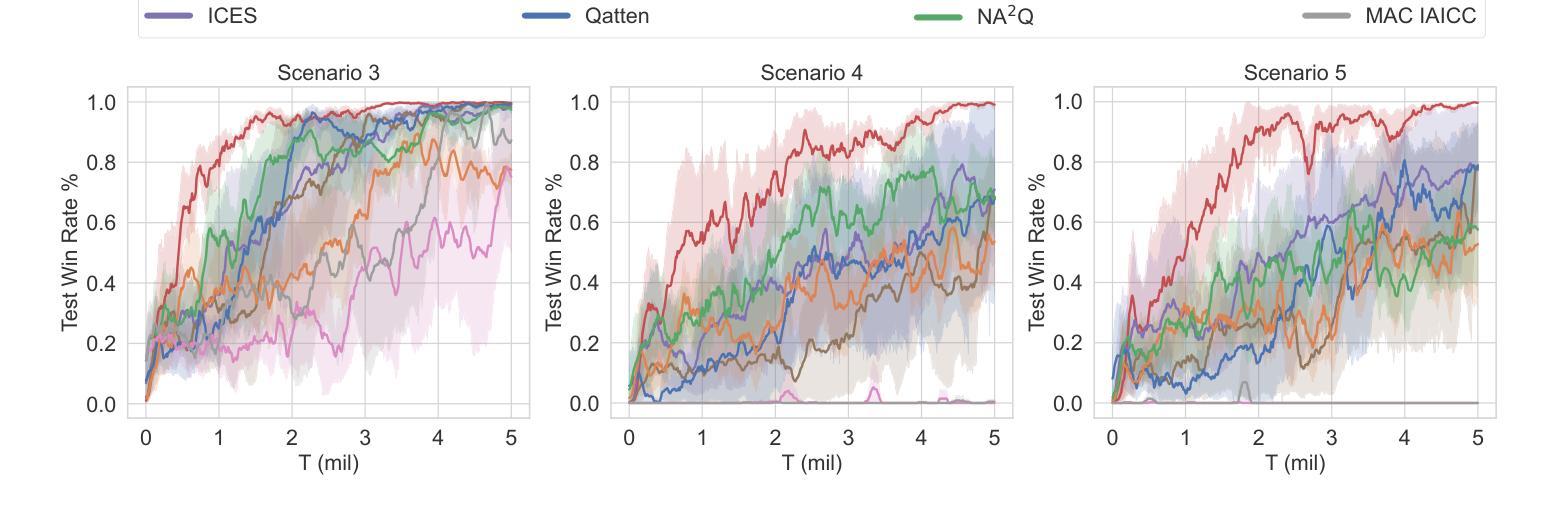
Asynchronous Credit Assignment for Multi-Agent Reinforcement Learning
Authors:Yongheng Liang, Hejun Wu, Haitao Wang, Hao Cai
Credit assignment is a critical problem in multi-agent reinforcement learning (MARL), aiming to identify agents’ marginal contributions for optimizing cooperative policies. Current credit assignment methods typically assume synchronous decision-making among agents. However, many real-world scenarios require agents to act asynchronously without waiting for others. This asynchrony introduces conditional dependencies between actions, which pose great challenges to current methods. To address this issue, we propose an asynchronous credit assignment framework, incorporating a Virtual Synchrony Proxy (VSP) mechanism and a Multiplicative Value Decomposition (MVD) algorithm. VSP enables physically asynchronous actions to be virtually synchronized during credit assignment. We theoretically prove that VSP preserves both task equilibrium and algorithm convergence. Furthermore, MVD leverages multiplicative interactions to effectively model dependencies among asynchronous actions, offering theoretical advantages in handling asynchronous tasks. Extensive experiments show that our framework consistently outperforms state-of-the-art MARL methods on challenging tasks while providing improved interpretability for asynchronous cooperation.
在多智能体强化学习(MARL)中,信用分配是一个关键问题,旨在识别智能体在优化合作策略中的边际贡献。当前的信用分配方法通常假设智能体之间的决策是同步的。然而,许多现实世界的情况要求智能体异步行动,无需等待他人。这种异步性引入了行动之间的条件依赖,给当前的方法带来了巨大的挑战。为了解决这一问题,我们提出了一种异步信用分配框架,该框架结合了虚拟同步代理(VSP)机制和乘法值分解(MVD)算法。VSP能够在信用分配时使物理异步行动在虚拟环境下同步。我们从理论上证明了VSP既保留了任务平衡性又保证了算法的收敛性。此外,MVD利用乘法交互有效地建模了异步行动之间的依赖关系,在理论上具有处理异步任务的优点。大量实验表明,我们的框架在具有挑战性的任务上始终优于最先进的MARL方法,同时提高了异步合作的解释性。
论文及项目相关链接
Summary:在多智能体强化学习(MARL)中,信用分配是一个关键问题,旨在识别智能体的边际贡献以优化合作策略。当前大多数信用分配方法基于智能体之间的同步决策假设,但在现实世界的许多场景中,智能体需要异步行动而不必等待彼此。异步性引入了行动之间的条件依赖性,给现有方法带来挑战。为此,我们提出了一个异步信用分配框架,包含虚拟同步代理(VSP)机制和乘法价值分解(MVD)算法。VSP能够在信用分配时实现物理异步行动的虚拟同步。我们从理论上证明了VSP既保持任务平衡又保证算法收敛。此外,MVD通过利用乘法交互有效地建模异步行动间的依赖性,在处理异步任务时具有理论优势。实验表明,我们的框架在具有挑战性的任务上始终优于最先进的MARL方法,同时为异步合作提供了更好的可解释性。
Key Takeaways:
- 多智能体强化学习中的信用分配旨在评估智能体在优化合作策略中的贡献。
- 当前信用分配方法主要基于同步决策假设,但现实世界中智能体常需异步行动。
- 异步性引入行动间的条件依赖性,对现有的信用分配方法构成挑战。
- 提出的异步信用分配框架包含虚拟同步代理(VSP)和乘法价值分解(MVD)。
- VSP实现了物理异步行动的虚拟同步,并保持任务平衡和算法收敛。
- MVD算法通过乘法交互建模异步行动依赖性,在理论上有优势。
点此查看论文截图

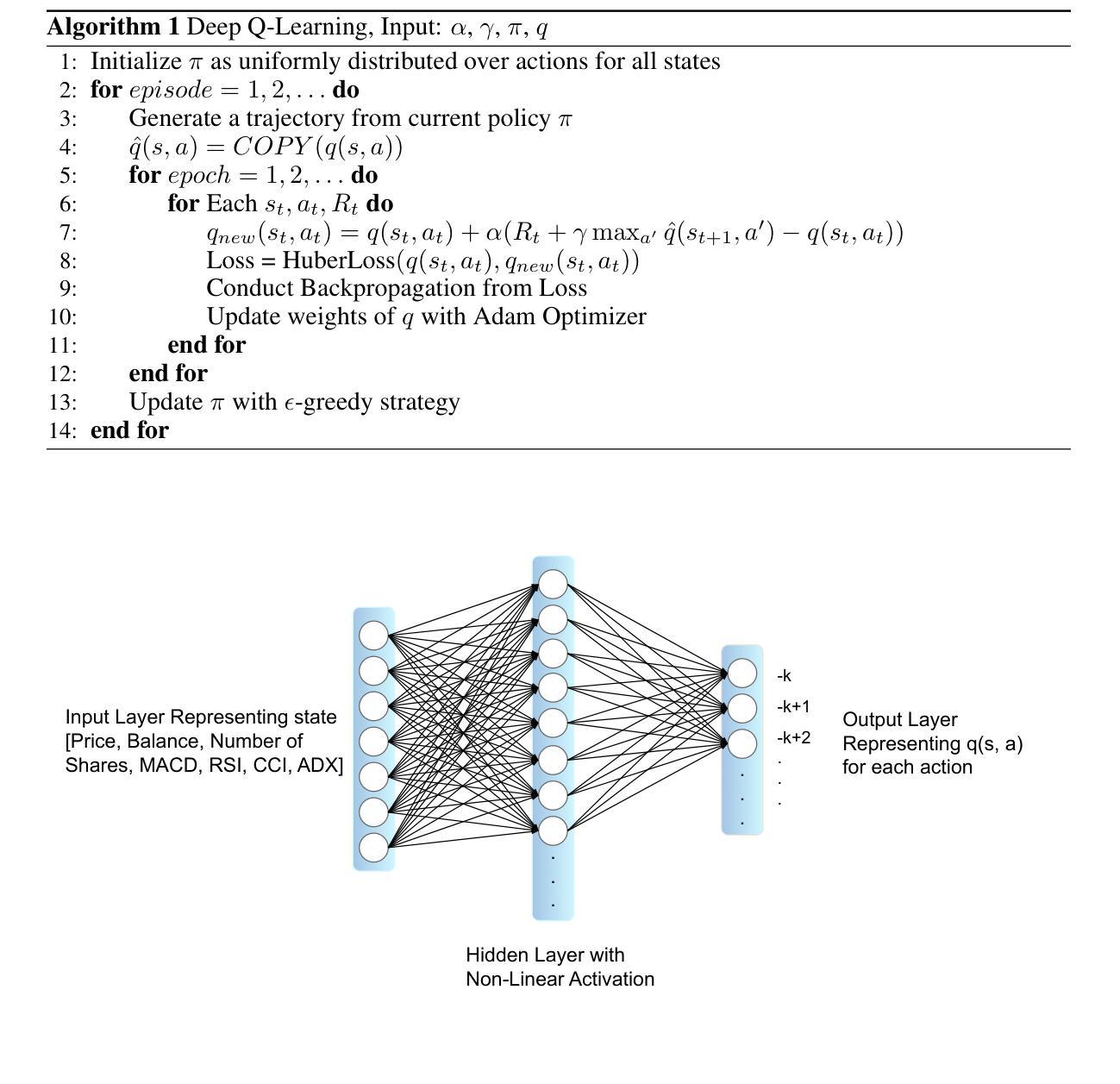
Agent Performing Autonomous Stock Trading under Good and Bad Situations
Authors:Yunfei Luo, Zhangqi Duan
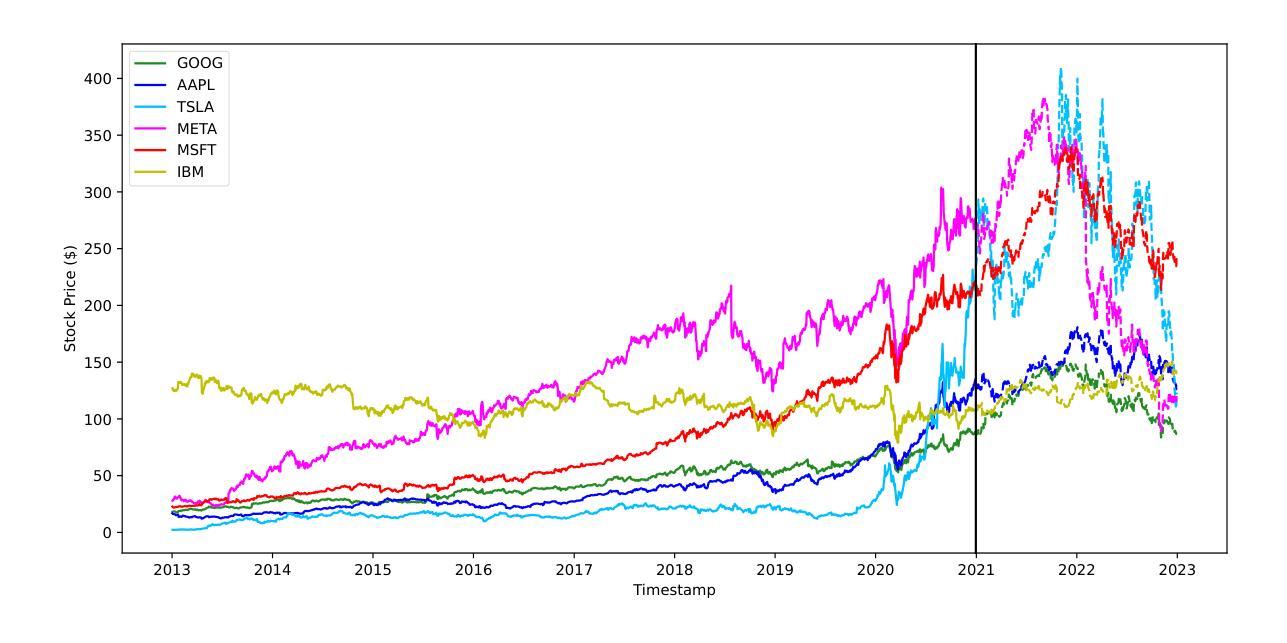
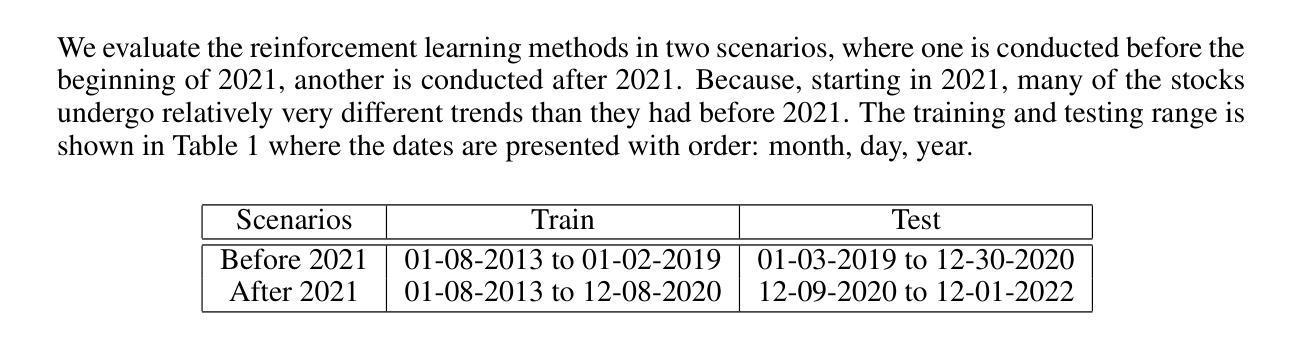
Stock trading is one of the popular ways for financial management. However, the market and the environment of economy is unstable and usually not predictable. Furthermore, engaging in stock trading requires time and effort to analyze, create strategies, and make decisions. It would be convenient and effective if an agent could assist or even do the task of analyzing and modeling the past data and then generate a strategy for autonomous trading. Recently, reinforcement learning has been shown to be robust in various tasks that involve achieving a goal with a decision making strategy based on time-series data. In this project, we have developed a pipeline that simulates the stock trading environment and have trained an agent to automate the stock trading process with deep reinforcement learning methods, including deep Q-learning, deep SARSA, and the policy gradient method. We evaluate our platform during relatively good (before 2021) and bad (2021 - 2022) situations. The stocks we’ve evaluated on including Google, Apple, Tesla, Meta, Microsoft, and IBM. These stocks are among the popular ones, and the changes in trends are representative in terms of having good and bad situations. We showed that before 2021, the three reinforcement methods we have tried always provide promising profit returns with total annual rates around $70%$ to $90%$, while maintain a positive profit return after 2021 with total annual rates around 2% to 7%.
股票交易是财务管理的一种流行方式。然而,市场和经济环境不稳定且通常不可预测。此外,参与股票交易需要时间和精力去分析、制定策略并做出决策。如果能有代理协助甚至完成分析、模拟过去数据并生成自主交易策略的任务,将会更加便捷高效。最近,强化学习在涉及基于时间序列数据的决策策略以实现目标的多种任务中显示出稳健性。在此项目中,我们开发了一个模拟股票交易环境的管道,并使用深度强化学习方法训练了一个代理来自动化股票交易过程,包括深度Q学习、深度SARSA和政策梯度方法。我们在相对良好的情况(2021年之前)和糟糕的情况(2021-2022年)下评估了我们的平台。我们评估的股票包括谷歌、苹果、特斯拉、Meta、微软和IBM。这些股票都很受欢迎,趋势变化代表了良好和糟糕的情况。我们的研究显示,在2021年之前,我们尝试的三种强化方法都提供了有希望的利润回报,总年利率约为70%至90%,而在2021年后仍能保持正利润回报,总年利率约为2%至7%。
论文及项目相关链接
PDF Published as a workshop paper at ICLR 2023: AI for Agent Based Modeling
Summary
利用深度学习强化学习方法开发自动化股票交易代理管道,包含深度Q学习、深度SARSA和策略梯度法。在包括Google、Apple等流行股票上表现良好,于不同时期表现出良好与不同程度的收益回报。对于不同时期市场环境下的良好与坏结果有测试并显示具体回报百分比。对今后市场环境而言亦有不错表现。这是一个帮助快速分析与制定策略的强化学习自动化股票交易项目。
Key Takeaways
- 利用强化学习技术自动化股票交易分析过程。
- 开发了一种模拟股票交易环境的管道系统。
- 在多种流行股票上进行了测试,包括Google、Apple等。
- 在不同时期的市场环境下表现出良好的盈利表现,特别是在良好时期表现尤为突出。
- 在近年来的市场环境下依然能够保持盈利表现。
- 通过深度Q学习、深度SARSA和策略梯度法三种强化学习方法进行测试,并给出了具体的盈利百分比。
点此查看论文截图