⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-21 更新
Higher fidelity perceptual image and video compression with a latent conditioned residual denoising diffusion model
Authors:Jonas Brenig, Radu Timofte
Denoising diffusion models achieved impressive results on several image generation tasks often outperforming GAN based models. Recently, the generative capabilities of diffusion models have been employed for perceptual image compression, such as in CDC. A major drawback of these diffusion-based methods is that, while producing impressive perceptual quality images they are dropping in fidelity/increasing the distortion to the original uncompressed images when compared with other traditional or learned image compression schemes aiming for fidelity. In this paper, we propose a hybrid compression scheme optimized for perceptual quality, extending the approach of the CDC model with a decoder network in order to reduce the impact on distortion metrics such as PSNR. After using the decoder network to generate an initial image, optimized for distortion, the latent conditioned diffusion model refines the reconstruction for perceptual quality by predicting the residual. On standard benchmarks, we achieve up to +2dB PSNR fidelity improvements while maintaining comparable LPIPS and FID perceptual scores when compared with CDC. Additionally, the approach is easily extensible to video compression, where we achieve similar results.
基于去噪扩散模型(Denoising Diffusion Models)在多个图像生成任务中取得了令人印象深刻的结果,通常超越了基于生成对抗网络(GAN)的模型。最近,扩散模型的生成能力已被应用于感知图像压缩,例如在CDC中。这些基于扩散的方法的一个主要缺点是,尽管它们能够产生令人印象深刻的感知质量图像,但在与其他传统或学习图像压缩方案相比时,它们在保真度方面表现较差,或在压缩原始图像时增加了失真。在本论文中,我们提出了一种针对感知质量优化的混合压缩方案,该方案扩展了CDC模型的方法,并加入了解码器网络,以减少PSNR等失真指标的影响。使用解码器网络生成初始图像(针对失真进行优化后),潜在的条件扩散模型通过预测残差来完善重建过程以提高感知质量。在标准基准测试中,与CDC相比,我们的方案在维持相当水平的LPIPS和FID感知得分的同时,实现了高达+2dB的PSNR保真度改进。此外,该方法很容易扩展到视频压缩,并在此取得了类似的结果。
论文及项目相关链接
PDF Accepted at AIM Workshop 2024 at ECCV 2024
Summary
扩散模型在图像生成任务上取得了令人印象深刻的成果,通常超越了基于GAN的模型。最近,扩散模型的生成能力被用于感知图像压缩,如CDC。但扩散模型的一个主要缺点是它们在追求感知质量的同时,与追求保真度的传统或学习图像压缩方案相比,会降低图像保真度或增加失真。本文提出了一种针对感知质量优化的混合压缩方案,该方案扩展了CDC模型的解码器网络方法,以减少失真度量(如PSNR)的影响。解码器网络首先生成初始图像以优化失真,然后潜在条件扩散模型通过预测残差来完善重建以提高感知质量。在标准基准测试中,与CDC相比,我们的方法实现了高达+2dB的PSNR保真度提升,同时保持相当的的LPIPS和FID感知分数。此外,该方法很容易扩展到视频压缩,并实现了类似的结果。
Key Takeaways
- 扩散模型在图像生成任务上表现优异,经常超越基于GAN的模型。
- 扩散模型近期被用于感知图像压缩,如CDC方法中。
- 扩散模型在追求感知质量时容易降低图像保真度或增加失真。
- 本文提出了一种混合压缩方案,结合了解码器网络和扩散模型以优化感知质量和失真度量。
- 解码器网络生成初始图像以优化失真,而扩散模型通过预测残差提高感知质量。
- 与CDC相比,该方法在标准基准测试中实现了提高的PSNR保真度,同时保持了感知质量分数。
点此查看论文截图

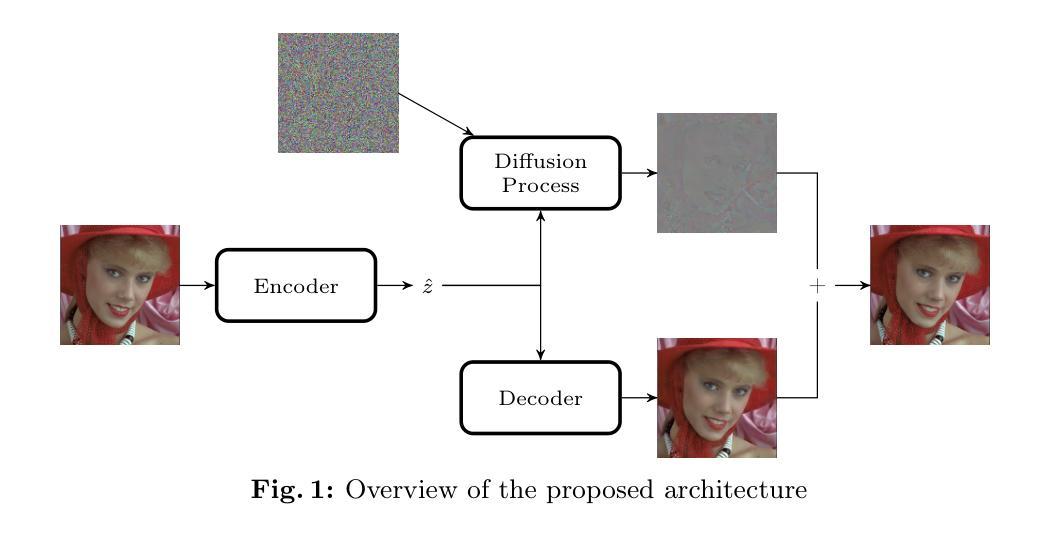


Few-Step Diffusion via Score identity Distillation
Authors:Mingyuan Zhou, Yi Gu, Zhendong Wang
Diffusion distillation has emerged as a promising strategy for accelerating text-to-image (T2I) diffusion models by distilling a pretrained score network into a one- or few-step generator. While existing methods have made notable progress, they often rely on real or teacher-synthesized images to perform well when distilling high-resolution T2I diffusion models such as Stable Diffusion XL (SDXL), and their use of classifier-free guidance (CFG) introduces a persistent trade-off between text-image alignment and generation diversity. We address these challenges by optimizing Score identity Distillation (SiD) – a data-free, one-step distillation framework – for few-step generation. Backed by theoretical analysis that justifies matching a uniform mixture of outputs from all generation steps to the data distribution, our few-step distillation algorithm avoids step-specific networks and integrates seamlessly into existing pipelines, achieving state-of-the-art performance on SDXL at 1024x1024 resolution. To mitigate the alignment-diversity trade-off when real text-image pairs are available, we introduce a Diffusion GAN-based adversarial loss applied to the uniform mixture and propose two new guidance strategies: Zero-CFG, which disables CFG in the teacher and removes text conditioning in the fake score network, and Anti-CFG, which applies negative CFG in the fake score network. This flexible setup improves diversity without sacrificing alignment. Comprehensive experiments on SD1.5 and SDXL demonstrate state-of-the-art performance in both one-step and few-step generation settings, along with robustness to the absence of real images. Our efficient PyTorch implementation, along with the resulting one- and few-step distilled generators, will be released publicly as a separate branch at https://github.com/mingyuanzhou/SiD-LSG.
扩散蒸馏已成为一种有前途的策略,通过将预训练的分数网络蒸馏到一步或几步生成器中,来加速文本到图像(T2I)的扩散模型。尽管现有方法已经取得了显著的进步,但它们在蒸馏高分辨率T2I扩散模型(如Stable Diffusion XL(SDXL))时,往往依赖于真实或教师合成的图像才能获得良好的性能,而且它们使用的无分类器引导(CFG)在文本图像对齐和生成多样性之间引入了持久的权衡。我们通过优化分数身份蒸馏(SiD)——一种无数据、一步蒸馏框架,来解决这些挑战,用于几步生成。我们的理论分析和证明了将所有生成步骤的输出均匀混合匹配到数据分布,几步蒸馏算法避免了特定步骤的网络,并无缝集成到现有管道中,在SDXL的1024x1024分辨率上达到了最先进的性能。当可用真实的文本图像对时,为了减轻对齐和多样性的权衡,我们引入了基于扩散GAN的对抗性损失,应用于均匀混合,并提出了两种新的引导策略:Zero-CFG,它在教师中禁用CFG并删除假分数网络中的文本条件,以及Anti-CFG,它在假分数网络中应用负CFG。这种灵活的设置提高了多样性,不会牺牲对齐。在SD1.5和SDXL上的综合实验证明,在一步和几步生成设置中均达到了最先进的性能,并且对缺少真实图像具有稳健性。我们高效的PyTorch实现以及得到的一步和几步蒸馏生成器将作为单独的分支在https://github.com/mingyuanzhou/SiD-LSG上公开发布。
论文及项目相关链接
Summary
本文介绍了通过无数据蒸馏优化文本到图像扩散模型的新策略。针对现有方法依赖真实或教师合成的图像进行蒸馏以及使用分类器自由引导产生的文本与图像对齐和生成多样性之间的权衡问题,本文提出了一种基于分数身份蒸馏(SiD)的一步和几步蒸馏算法。该算法通过匹配所有生成步骤的输出混合与数据分布,避免了特定步骤的网络,并实现了在SDXL上的高性能。为解决真实文本图像对可用时的对齐与多样性权衡问题,引入了基于扩散GAN的对抗损失和两种新的引导策略。该策略提高了生成多样性而不牺牲对齐性,并在SD1.5和SDXL上实现了高性能。
Key Takeaways
- 扩散蒸馏已成为加速文本到图像扩散模型的一种有前途的策略。
- 现有方法依赖真实或教师合成的图像进行高分辨率T2I扩散模型的蒸馏。
- 分类器自由引导引入文本与图像对齐和生成多样性之间的权衡。
- 分数身份蒸馏(SiD)算法通过匹配所有生成步骤的输出混合与数据分布,实现了在SDXL上的高性能,避免了特定步骤的网络。
- 引入基于扩散GAN的对抗损失来解决真实文本图像对可用时的对齐与多样性权衡问题。
- 提出了两种新的引导策略:无CFG和Anti-CFG,提高了生成多样性而不牺牲对齐性。
- 在SD1.5和SDXL上的实验证明了该策略的高性能和稳健性。
点此查看论文截图

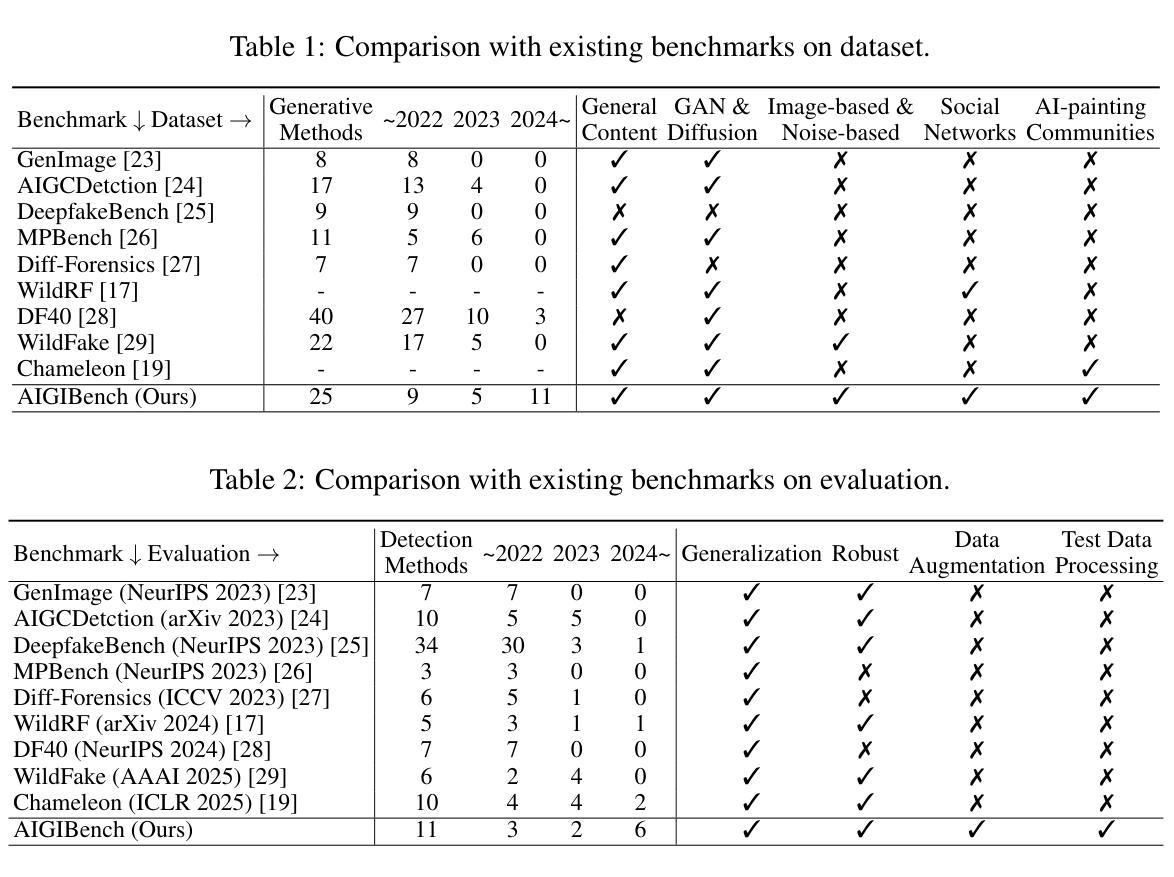
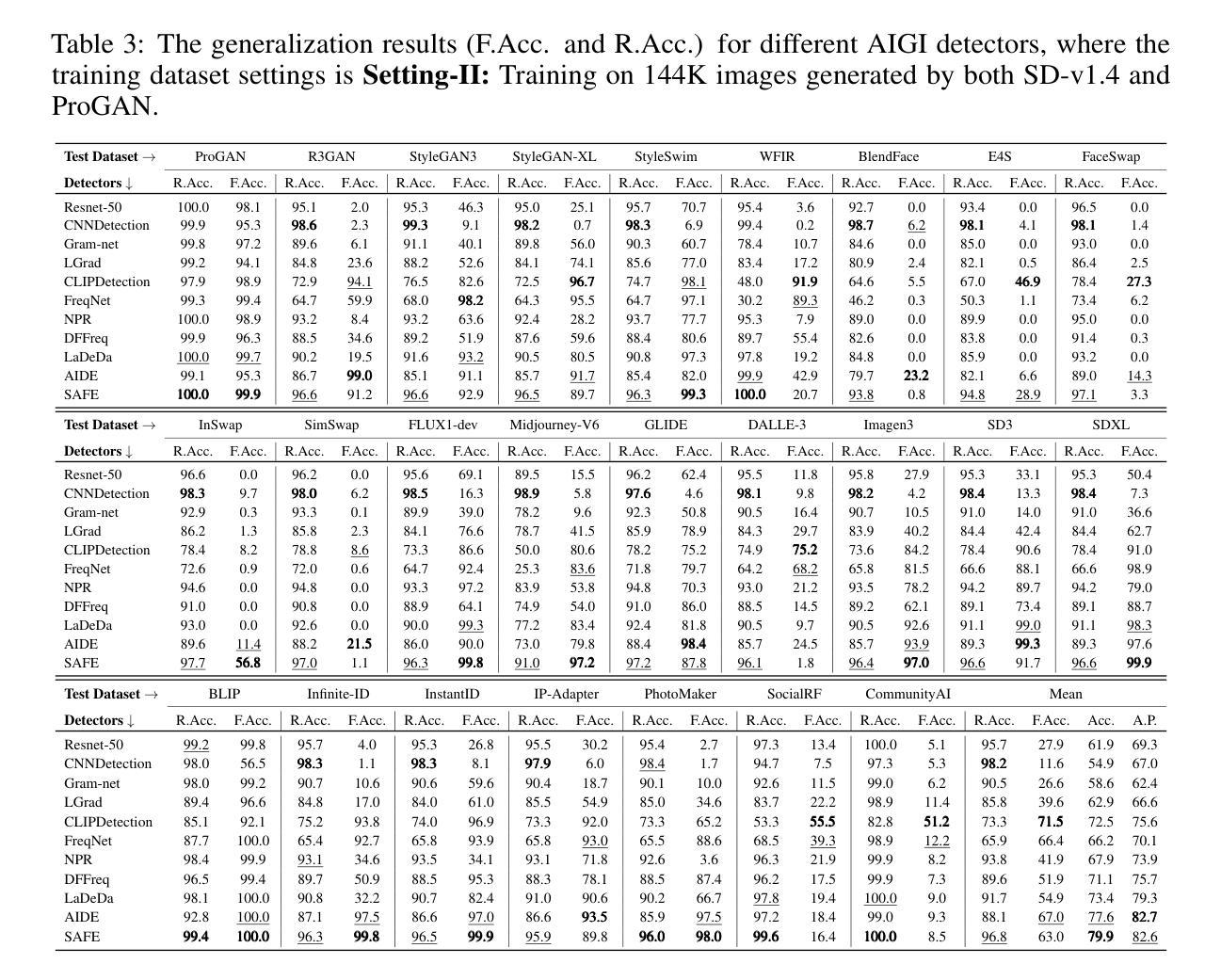
Is Artificial Intelligence Generated Image Detection a Solved Problem?
Authors:Ziqiang Li, Jiazhen Yan, Ziwen He, Kai Zeng, Weiwei Jiang, Lizhi Xiong, Zhangjie Fu
The rapid advancement of generative models, such as GANs and Diffusion models, has enabled the creation of highly realistic synthetic images, raising serious concerns about misinformation, deepfakes, and copyright infringement. Although numerous Artificial Intelligence Generated Image (AIGI) detectors have been proposed, often reporting high accuracy, their effectiveness in real-world scenarios remains questionable. To bridge this gap, we introduce AIGIBench, a comprehensive benchmark designed to rigorously evaluate the robustness and generalization capabilities of state-of-the-art AIGI detectors. AIGIBench simulates real-world challenges through four core tasks: multi-source generalization, robustness to image degradation, sensitivity to data augmentation, and impact of test-time pre-processing. It includes 23 diverse fake image subsets that span both advanced and widely adopted image generation techniques, along with real-world samples collected from social media and AI art platforms. Extensive experiments on 11 advanced detectors demonstrate that, despite their high reported accuracy in controlled settings, these detectors suffer significant performance drops on real-world data, limited benefits from common augmentations, and nuanced effects of pre-processing, highlighting the need for more robust detection strategies. By providing a unified and realistic evaluation framework, AIGIBench offers valuable insights to guide future research toward dependable and generalizable AIGI detection.
生成模型(如GAN和Diffusion模型)的快速发展使得能够创建高度逼真的合成图像,这引发了人们对虚假信息、深度伪造和版权侵犯的严重关注。尽管已经提出了许多人工智能生成图像(AIGI)检测器,并且通常报告具有较高的准确性,但它们在现实场景中的有效性仍然值得怀疑。为了弥补这一差距,我们引入了AIGIBench,这是一个综合基准测试,旨在严格评估最新AIGI检测器的鲁棒性和泛化能力。AIGIBench通过四个核心任务模拟现实世界的挑战:多源泛化、对图像退化的鲁棒性、对数据增强的敏感性以及测试时预处理的影响。它包括23个多样的虚假图像子集,涵盖了先进和广泛采用的图像生成技术,以及从社交媒体和AI艺术平台收集的真实世界样本。对11个先进检测器的广泛实验表明,尽管它们在受控环境中的报告准确率很高,但这些检测器在真实世界数据上的性能却大幅下降,从常见的数据增强中获益有限,以及预处理的影响微妙,这凸显了需要更稳健的检测策略。通过提供统一和现实的评估框架,AIGIBench为未来的研究提供了有价值的见解,以可靠和通用的AIGI检测为目标。
论文及项目相关链接
PDF Under Review
Summary
生成模型如GANs和Diffusion模型的快速发展,使得创建高度逼真的合成图像成为可能,引发了关于虚假信息、深度伪造和版权侵犯的担忧。尽管已提出许多人工智能生成图像(AIGI)检测器,并报告了高准确性,但它们在现实世界场景中的有效性仍存在疑问。为了缩小这一差距,本文引入了AIGIBench,这是一个综合基准测试,旨在严格评估最新AIGI检测器的稳健性和泛化能力。AIGIBench通过四个核心任务模拟现实世界的挑战:多源泛化、对图像退化的稳健性、对数据增强的敏感性以及测试时预处理的影响。它包括了23个多样化的虚假图像子集,涵盖了先进和广泛采用的图像生成技术,以及从社交媒体和AI艺术平台收集的真实世界样本。实验表明,尽管在受控环境中的报告准确性很高,但这些检测器在现实世界数据上的性能下降显著,从常见的数据增强中获益有限,以及预处理微妙的效应,这突显了需要更稳健的检测策略。AIGIBench提供了统一和现实的评估框架,为未来的研究提供了有价值的见解,以可靠和通用的AIGI检测为目标。
Key Takeaways
- 生成模型如GANs和Diffusion模型能快速创建逼真合成图像,引发关于虚假信息、深度伪造和版权侵犯的担忧。
- 现有的人工智能生成图像(AIGI)检测器在报告高准确性的同时,在现实世界场景中的有效性存在疑问。
- AIGIBench作为一个综合基准测试,旨在评估AIGI检测器的稳健性和泛化能力。
- AIGIBench模拟现实世界的挑战,包括多源泛化、图像退化、数据增强和测试时预处理的影响。
- 实验显示,先进的AIGI检测器在现实世界数据上的性能显著下降,需要从更广泛的现实情境和数据增强中提升其稳健性和泛化能力。
- AIGIBench为研究者提供了统一和现实的评估框架,有助于未来研究更可靠和通用的AIGI检测技术。
点此查看论文截图