⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-21 更新
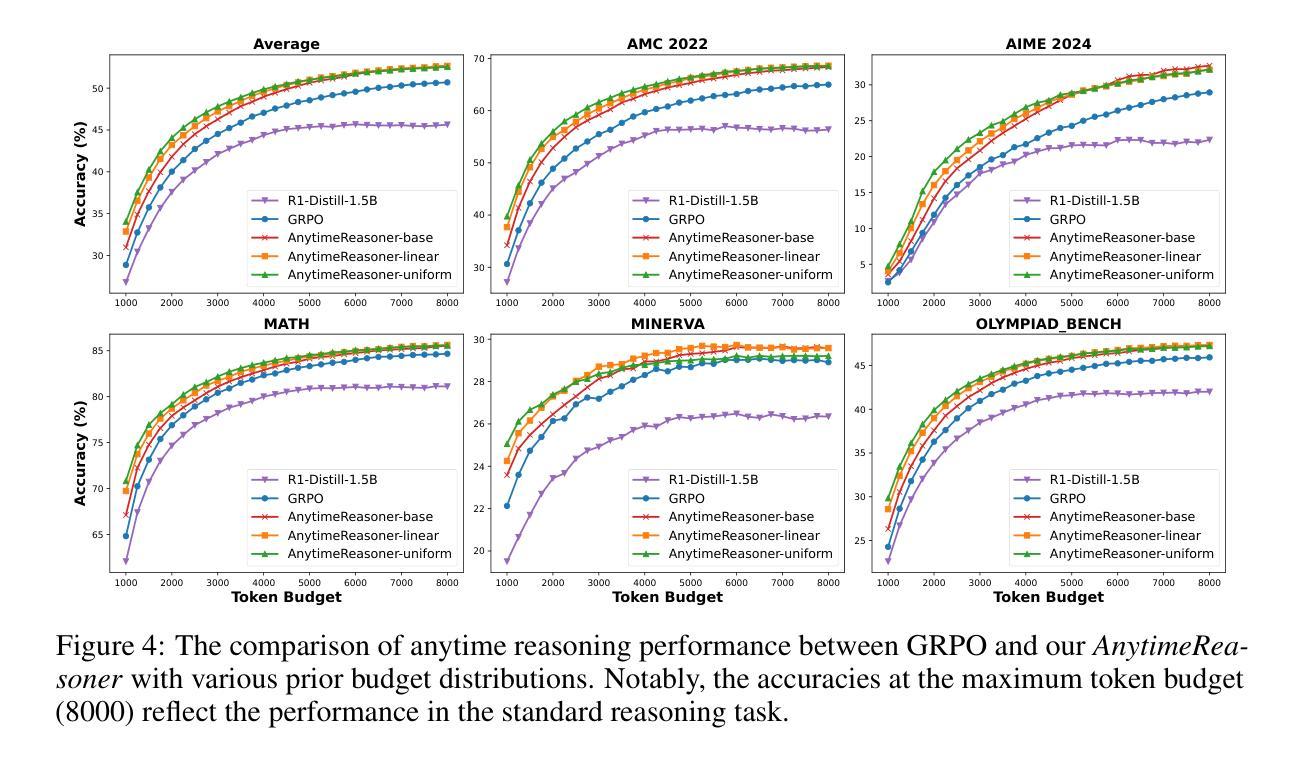
Optimizing Anytime Reasoning via Budget Relative Policy Optimization
Authors:Penghui Qi, Zichen Liu, Tianyu Pang, Chao Du, Wee Sun Lee, Min Lin
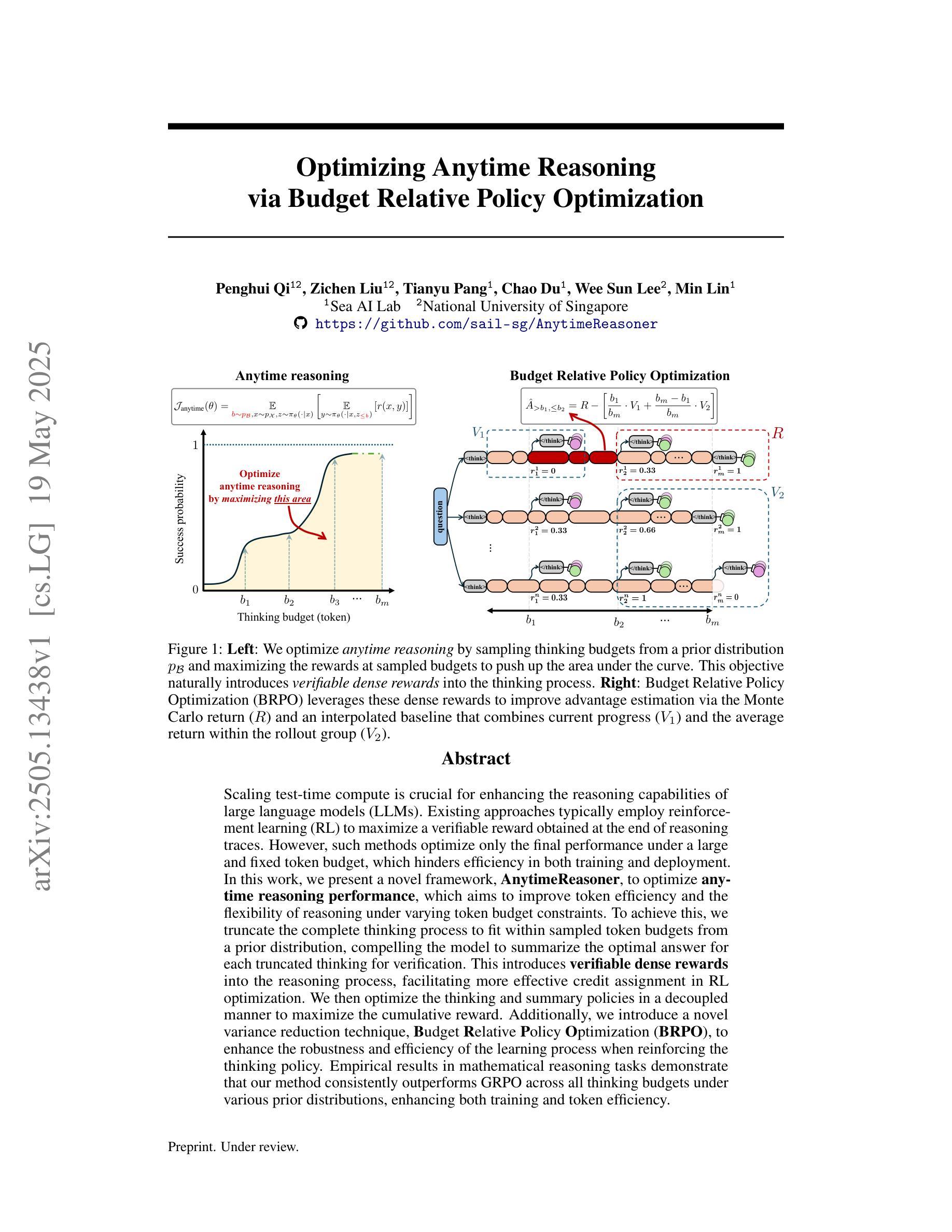
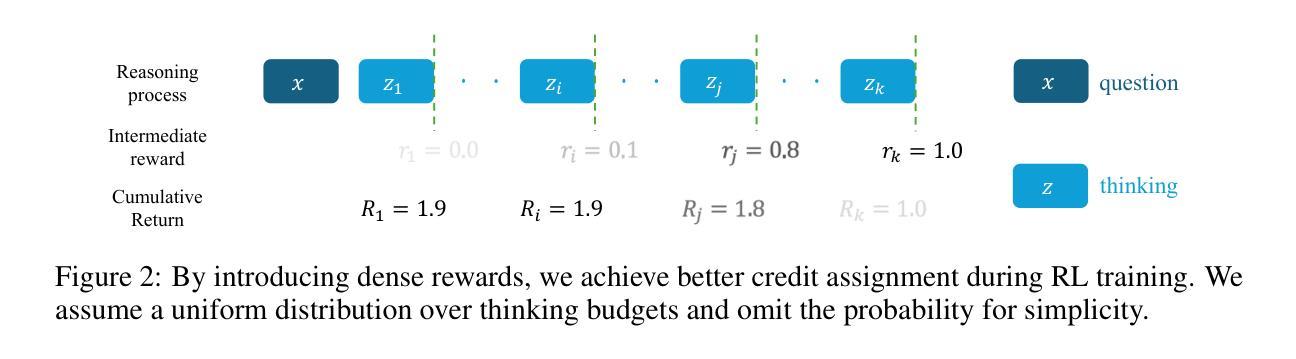
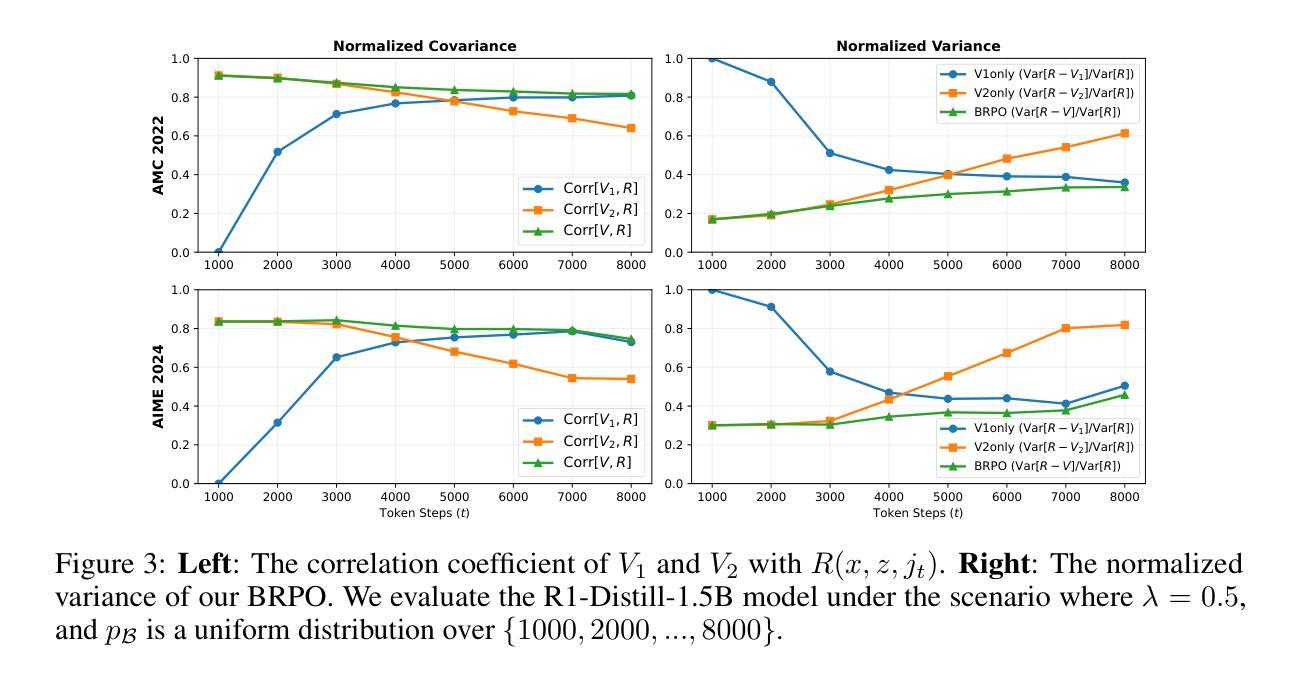
Scaling test-time compute is crucial for enhancing the reasoning capabilities of large language models (LLMs). Existing approaches typically employ reinforcement learning (RL) to maximize a verifiable reward obtained at the end of reasoning traces. However, such methods optimize only the final performance under a large and fixed token budget, which hinders efficiency in both training and deployment. In this work, we present a novel framework, AnytimeReasoner, to optimize anytime reasoning performance, which aims to improve token efficiency and the flexibility of reasoning under varying token budget constraints. To achieve this, we truncate the complete thinking process to fit within sampled token budgets from a prior distribution, compelling the model to summarize the optimal answer for each truncated thinking for verification. This introduces verifiable dense rewards into the reasoning process, facilitating more effective credit assignment in RL optimization. We then optimize the thinking and summary policies in a decoupled manner to maximize the cumulative reward. Additionally, we introduce a novel variance reduction technique, Budget Relative Policy Optimization (BRPO), to enhance the robustness and efficiency of the learning process when reinforcing the thinking policy. Empirical results in mathematical reasoning tasks demonstrate that our method consistently outperforms GRPO across all thinking budgets under various prior distributions, enhancing both training and token efficiency.
在大型语言模型(LLM)中,提升测试时间的计算能力对于增强推理能力至关重要。现有方法通常采用强化学习(RL)来最大化推理轨迹末尾的可验证奖励。然而,这些方法仅针对固定标记预算下的最终性能进行优化,这阻碍了训练和部署的效率。在本研究中,我们提出了一种新的框架AnytimeReasoner,旨在优化任意时间的推理性能,旨在提高标记效率和在不同标记预算约束下的推理灵活性。为了实现这一点,我们将完整的思考过程截断以适应从先验分布中采样的标记预算,迫使模型为每次截断的思考过程总结最佳答案以进行验证。这为推理过程引入了可验证的密集奖励,有助于更有效的强化学习优化中的奖励分配。然后,我们以解耦的方式优化思考和总结策略以最大化累积奖励。此外,我们引入了一种新的方差减少技术——预算相对策略优化(BRPO),以提高在强化思考策略时学习过程的稳健性和效率。在数学推理任务的实证结果表明,我们的方法在所有思考预算下均优于GRPO在各种先验分布的表现,提高了训练和标记的效率。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理过程中需要处理大量计算任务,为此必须扩大测试时间计算规模以提升模型推理能力。传统的强化学习(RL)方法仅在最终阶段最大化奖励得分,而这无法满足持续变化的标记需求和提高模型的灵活性及令牌效率的需求。为此,本研究提出了一种名为AnytimeReasoner的新框架,以优化任意时间的推理性能,提升模型的令牌效率和在不同令牌预算约束下的灵活性。其实现过程包括对完整推理过程的截断处理以适应特定采样令牌预算需求,要求模型必须汇总不同截断情况下的最优答案以便进行验证,引入了一种即时验证机制并产生了密集型奖励信息以增强学习的可靠性及调整任务的动态执行路径以提升执行效率和避免错过获取中间阶段正确的回答而导致失控问题。此外,本研究还提出了一种新的方差缩减技术——预算相对策略优化(BRPO),以增强策略学习过程时的稳健性和效率。在实证的数学推理任务中,该方法在多种先验分布下各思考预算均表现出优于GRPO的效果,表明此方法能够在提高推理性能和增强计算效率两方面提供稳健表现。
Key Takeaways
以下是基于文本提取的七个关键见解:
- 测试时间的计算扩展对于增强大型语言模型(LLM)的推理能力至关重要。
- 传统强化学习(RL)方法在处理大型语言模型时存在不足,因为它们主要关注最终性能的优化。
- AnytimeReasoner框架旨在优化任意时间的推理性能,提高模型的令牌效率和灵活性。
- AnytimeReasoner通过截断完整的推理过程以适应不同的令牌预算约束,并引入即时验证和奖励信息机制提升性能。
- 该框架要求对模型在不同截断思考下的最优答案进行汇总以验证输出准确性并改善动态任务路径的调整过程。
- 提出了一种新的方差缩减技术——预算相对策略优化(BRPO),以增强学习过程的稳健性和效率。
点此查看论文截图
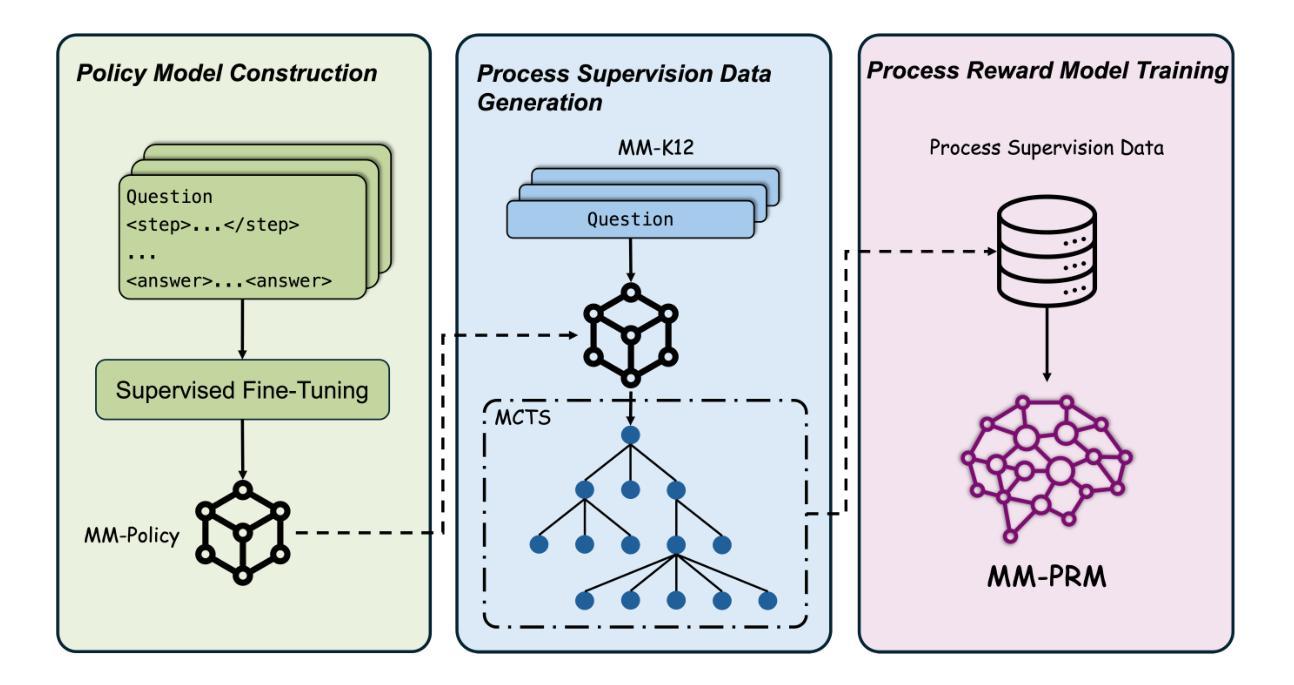
MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision
Authors:Lingxiao Du, Fanqing Meng, Zongkai Liu, Zhixiang Zhou, Ping Luo, Qiaosheng Zhang, Wenqi Shao
While Multimodal Large Language Models (MLLMs) have achieved impressive progress in vision-language understanding, they still struggle with complex multi-step reasoning, often producing logically inconsistent or partially correct solutions. A key limitation lies in the lack of fine-grained supervision over intermediate reasoning steps. To address this, we propose MM-PRM, a process reward model trained within a fully automated, scalable framework. We first build MM-Policy, a strong multimodal model trained on diverse mathematical reasoning data. Then, we construct MM-K12, a curated dataset of 10,000 multimodal math problems with verifiable answers, which serves as seed data. Leveraging a Monte Carlo Tree Search (MCTS)-based pipeline, we generate over 700k step-level annotations without human labeling. The resulting PRM is used to score candidate reasoning paths in the Best-of-N inference setup and achieves significant improvements across both in-domain (MM-K12 test set) and out-of-domain (OlympiadBench, MathVista, etc.) benchmarks. Further analysis confirms the effectiveness of soft labels, smaller learning rates, and path diversity in optimizing PRM performance. MM-PRM demonstrates that process supervision is a powerful tool for enhancing the logical robustness of multimodal reasoning systems. We release all our codes and data at https://github.com/ModalMinds/MM-PRM.
多模态大型语言模型(MLLM)在视觉语言理解方面取得了令人印象深刻的进展,但在处理复杂的多步骤推理时仍面临挑战,常常产生逻辑不一致或部分正确的解决方案。一个关键的局限性在于中间推理步骤缺乏精细的监督。为了解决这一问题,我们提出了MM-PRM,这是一个在全自动化可扩展框架中训练的流程奖励模型。我们首先建立了一个强大的多模态模型MM-Policy,该模型在多样化的数学推理数据上进行训练。然后,我们构建了MM-K12数据集,这是一个包含一万道可验证答案的多模态数学问题集,作为种子数据。通过利用基于蒙特卡洛树搜索(MCTS)的管道,我们生成了超过70万步级别的注释,无需人工标注。所得的PRM用于在Best-of-N推理设置中评分候选推理路径,并在内部领域(MM-K12测试集)和外部领域(OlympiadBench、MathVista等)的基准测试中实现了显著改进。进一步的分析证实了软标签、较小学习率和路径多样性在优化PRM性能方面的有效性。MM-PRM证明过程监督是提高多模态推理系统逻辑稳健性的有力工具。我们已将所有代码和数据发布在https://github.com/ModalMinds/MM-PRM。
论文及项目相关链接
Summary
本文介绍了针对多模态大型语言模型(MLLMs)在复杂多步骤推理方面存在的不足,提出了一种名为MM-PRM的过程奖励模型。该模型通过构建MM-Policy和MM-K12,利用蒙特卡洛树搜索(MCTS)生成超过70万步的注释数据,实现了对候选推理路径的评分,显著提高了在域内和域外基准测试上的性能。研究证实了过程监督在增强多模态推理系统的逻辑稳健性方面的强大作用。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉语言理解方面取得了显著进展,但在复杂多步骤推理方面仍存在挑战。
- 当前模型在推理过程中常产生逻辑不一致或部分正确的解决方案。
- MM-PRM模型通过构建MM-Policy和MM-K12数据集来解决这一问题。
- MM-K12数据集包含1万个多模态数学问题及其可验证的答案,作为种子数据。
- 利用蒙特卡洛树搜索(MCTS)生成了超过70万步的注释数据,实现了全自动、可扩展的过程奖励模型训练。
- PRM在Best-of-N推理设置中对候选推理路径进行评分,显著提高了在多种基准测试上的性能。
- 研究结果证实了过程监督在增强多模态推理系统的逻辑稳健性方面的有效性。
点此查看论文截图

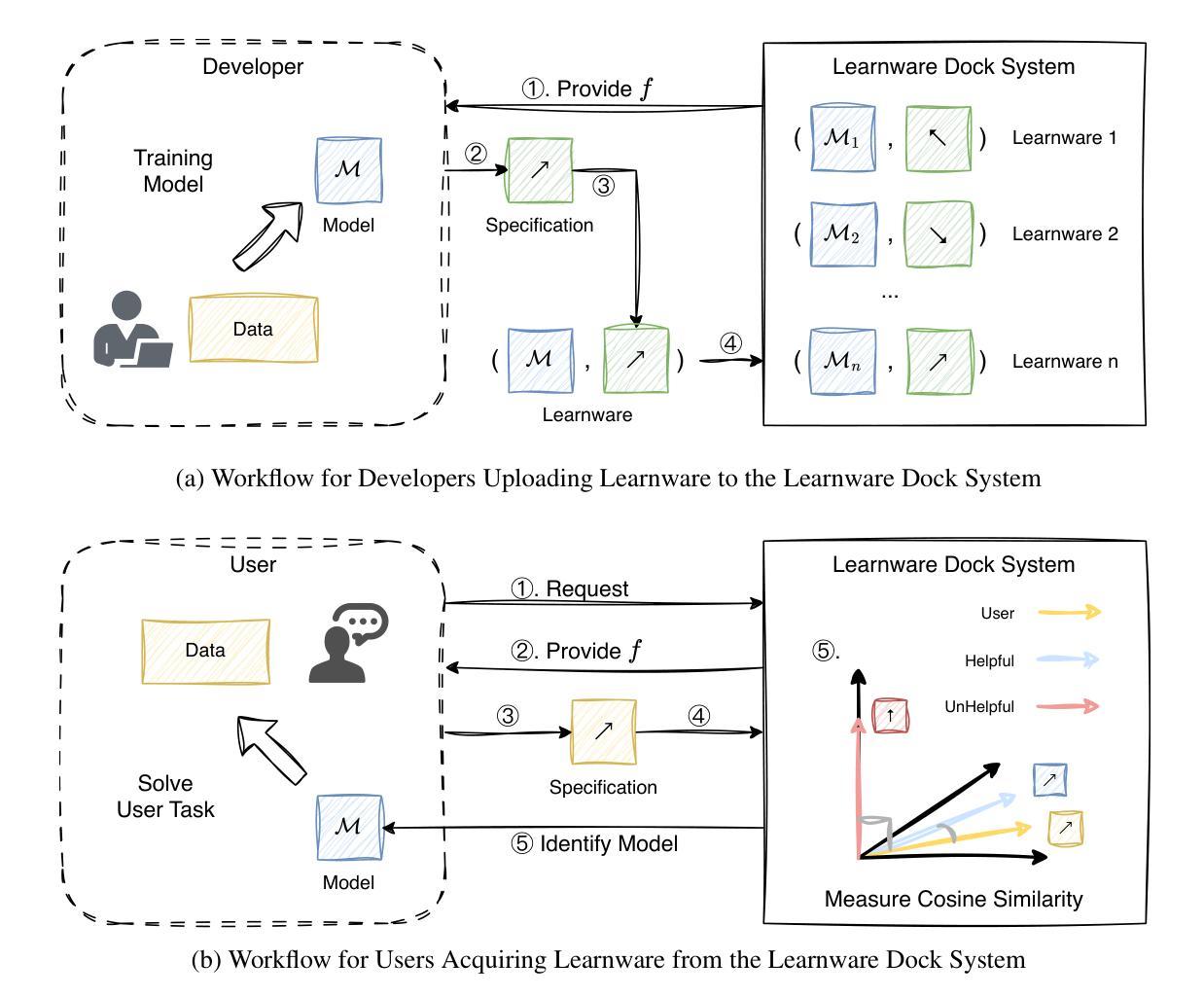
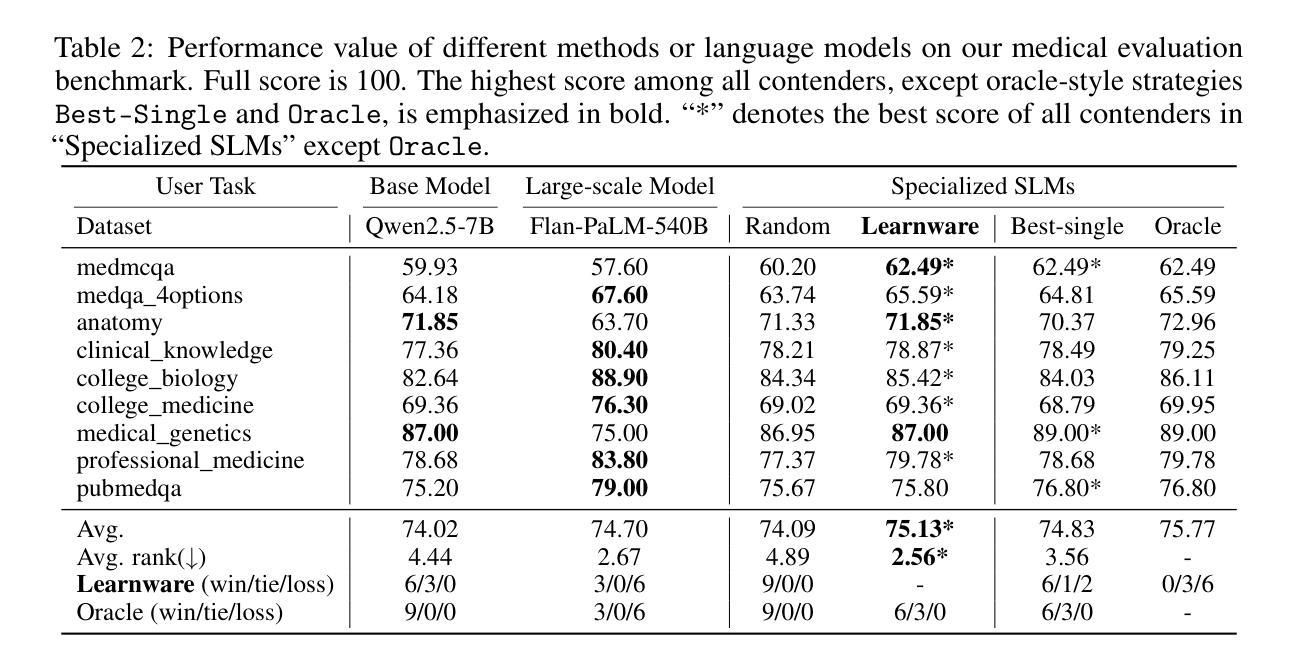
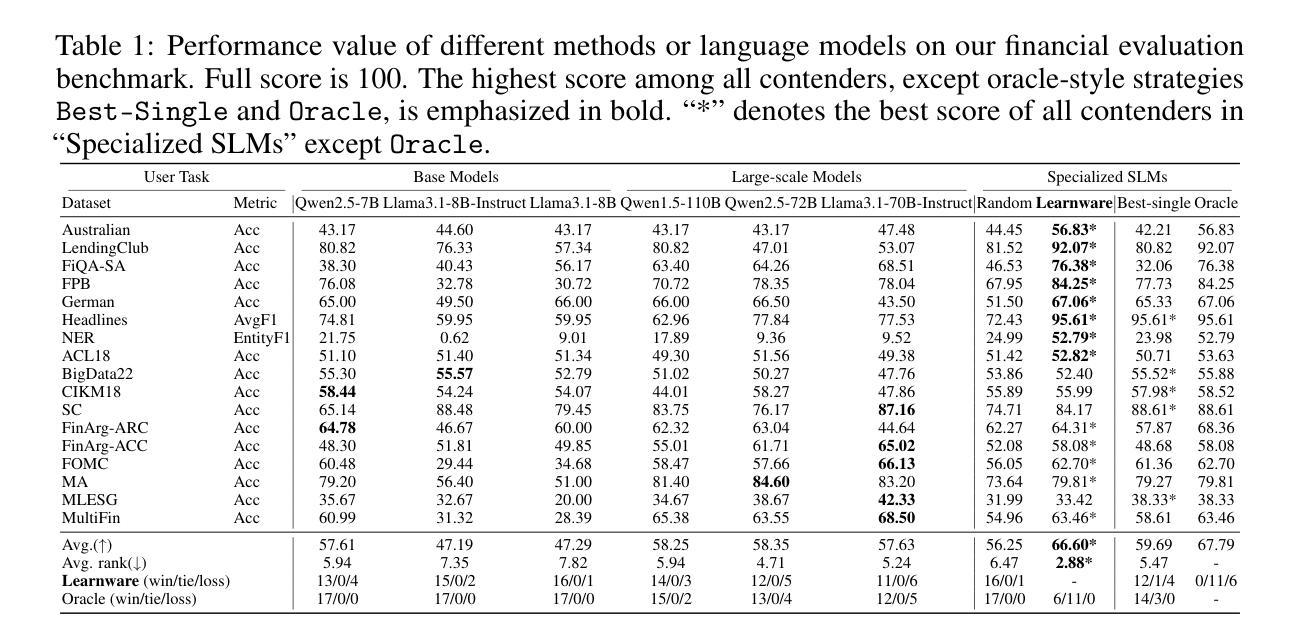
Learnware of Language Models: Specialized Small Language Models Can Do Big
Authors:Zhi-Hao Tan, Zi-Chen Zhao, Hao-Yu Shi, Xin-Yu Zhang, Peng Tan, Yang Yu, Zhi-Hua Zhou
The learnware paradigm offers a novel approach to machine learning by enabling users to reuse a set of well-trained models for tasks beyond the models’ original purposes. It eliminates the need to build models from scratch, instead relying on specifications (representations of a model’s capabilities) to identify and leverage the most suitable models for new tasks. While learnware has proven effective in many scenarios, its application to language models has remained largely unexplored. At the same time, large language models (LLMs) have demonstrated remarkable universal question-answering abilities, yet they face challenges in specialized scenarios due to data scarcity, privacy concerns, and high computational costs, thus more and more specialized small language models (SLMs) are being trained for specific domains. To address these limitations systematically, the learnware paradigm provides a promising solution by enabling maximum utilization of specialized SLMs, and allowing users to identify and reuse them in a collaborative and privacy-preserving manner. This paper presents a preliminary attempt to apply the learnware paradigm to language models. We simulated a learnware system comprising approximately 100 learnwares of specialized SLMs with 8B parameters, fine-tuned across finance, healthcare, and mathematics domains. Each learnware contains an SLM and a specification, which enables users to identify the most relevant models without exposing their own data. Experimental results demonstrate promising performance: by selecting one suitable learnware for each task-specific inference, the system outperforms the base SLMs on all benchmarks. Compared to LLMs, the system outperforms Qwen1.5-110B, Qwen2.5-72B, and Llama3.1-70B-Instruct by at least 14% in finance domain tasks, and surpasses Flan-PaLM-540B (ranked 7th on the Open Medical LLM Leaderboard) in medical domain tasks.
学习软件范式通过使用户能够重复使用一组经过良好训练的模型来完成超出模型原始目的的的任务,为机器学习提供了一种新颖的方法。它消除了从头构建模型的需求,而是依赖于规范(模型的能力的表示)来识别和利用最适合新任务的模型。虽然学习软件在许多场景中已被证明是有效的,但其对语言模型的应用却鲜有探索。与此同时,大型语言模型(LLM)已经显示出惊人的通用问答能力,但由于数据稀缺、隐私担忧和计算成本高昂等挑战,它们在特定场景中的表现受到限制。因此,越来越多的针对特定领域的小型语言模型(SLM)正在接受训练。为了系统地解决这些局限性,学习软件范式通过最大限度地利用专门的SLM并允许用户以协作和隐私保护的方式识别和重复使用它们,提供了一个有前景的解决方案。本文是尝试将学习软件范式应用于语言模型的初步尝试。我们模拟了一个学习软件系统,其中包括大约100个SLM的组件(具有跨金融、医疗和数学领域的微调参数),每个学习软件中都包含一个SLM和一个规范,使用户能够识别最相关的模型而不暴露自己的数据。实验结果表明,通过为每个特定任务选择适当的学习软件来进行推理,该系统在所有基准测试中均优于基础SLM的性能。与LLM相比,该系统在金融领域任务中至少优于Qwen 1.5-110B、Qwen 2.5-72B和Llama 3.1-70B-Instruct 14%,并在医疗领域任务中超越了在开放医学LLM排行榜上排名第七的Flan-PaLM-540B。
论文及项目相关链接
Summary
本文介绍了学习软件范式在机器学习领域的新应用,特别是在语言模型中的应用。学习软件范式允许用户重用已训练好的模型来完成超出其原始目的的任务。文章尝试将学习软件范式应用于语言模型,模拟了一个包含约100个学习软件的专业小型语言模型系统,并在金融、医疗和数学领域进行了微调。实验结果表明,该系统在选择适合每个任务的学习软件时,其性能优于基础小型语言模型和大语言模型。
Key Takeaways
- 学习软件范式允许用户重用已训练好的模型,避免了从头开始构建模型的繁琐过程。
- 该范式通过规格(模型的表示)来识别和利用最适合新任务的模型。
- 大型语言模型(LLMs)虽然在通用问答方面表现出色,但在特定领域面临数据稀缺、隐私关注和计算成本高等挑战。
- 学习软件范式为解决这些挑战提供了有希望的解决方案,通过最大化利用专业小型语言模型(SLMs)并允许用户以协作和隐私保护的方式识别和重用它们。
- 模拟系统包括大约100个学习软件的专业小型语言模型,涵盖金融、医疗和数学等领域。
- 实验结果表明,该系统在选择适合每个任务的学习软件时,性能优于基础小型语言模型和大语言模型在特定领域的任务表现。
点此查看论文截图

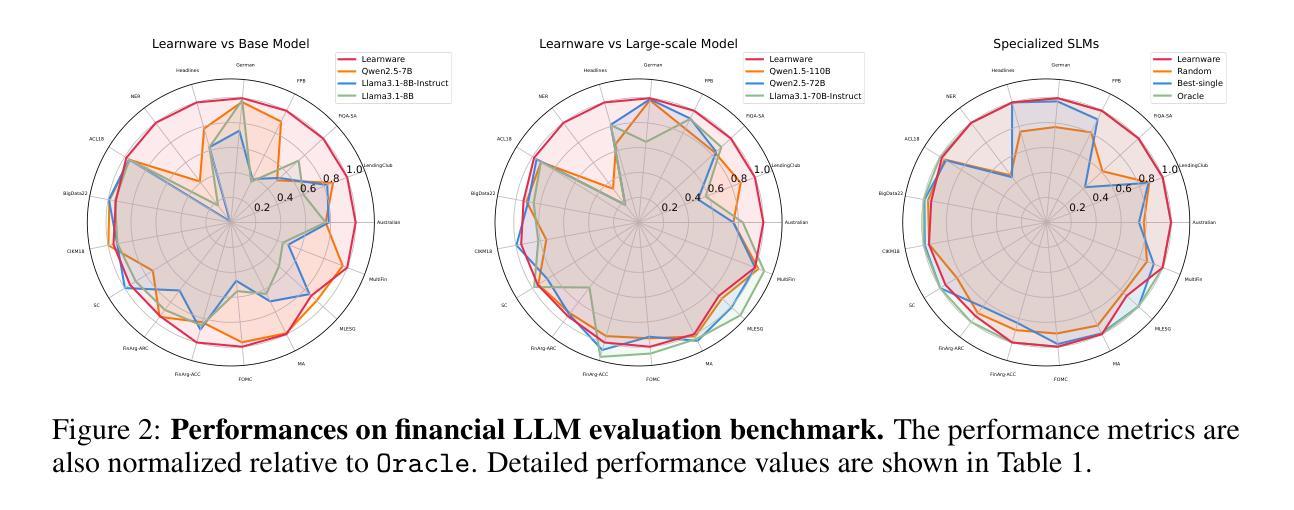
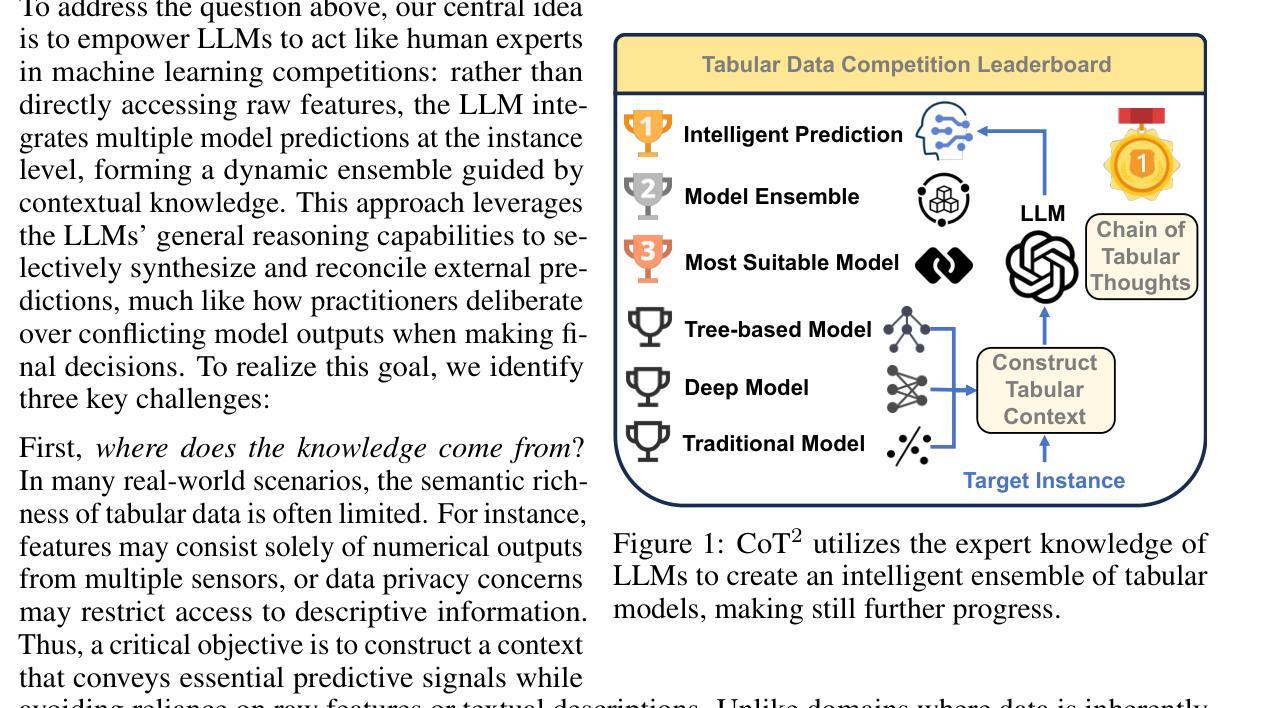
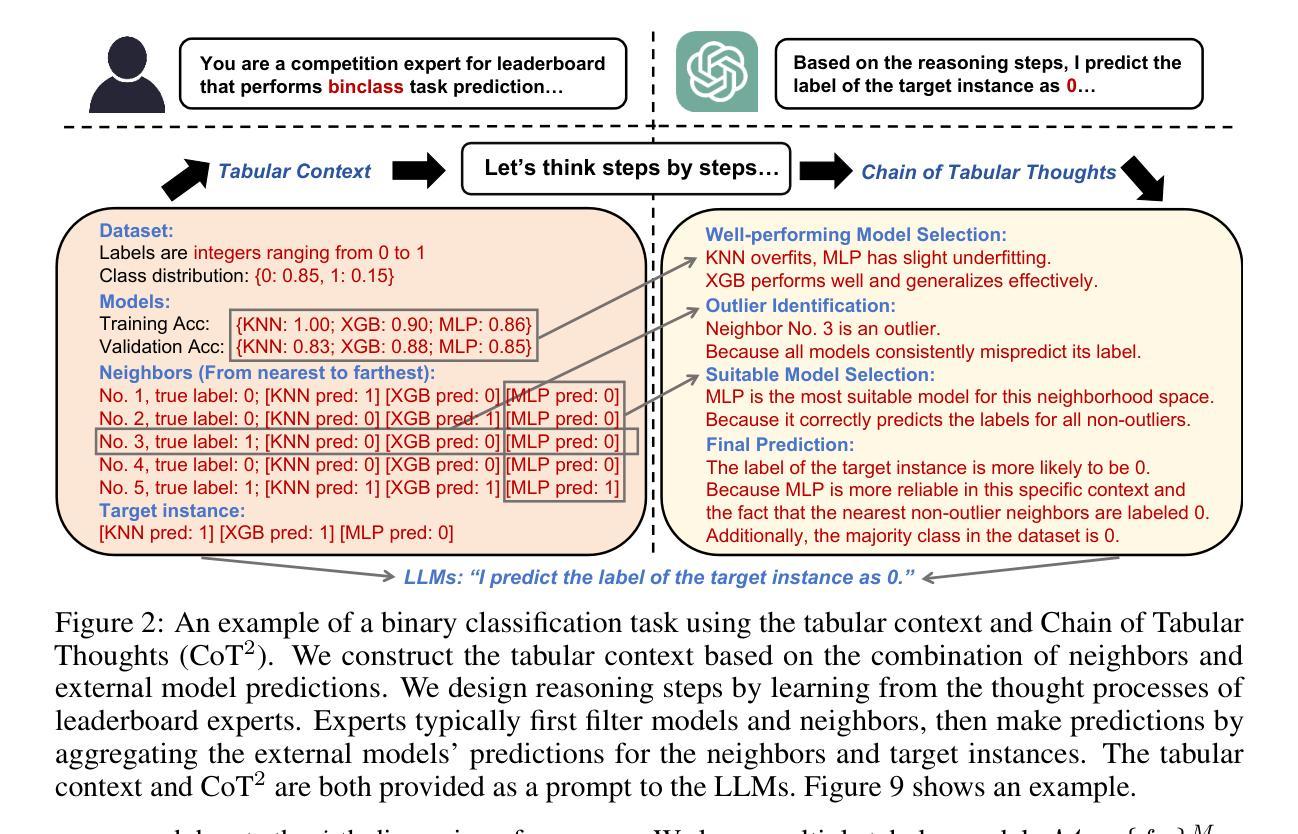
Make Still Further Progress: Chain of Thoughts for Tabular Data Leaderboard
Authors:Si-Yang Liu, Qile Zhou, Han-Jia Ye
Tabular data, a fundamental data format in machine learning, is predominantly utilized in competitions and real-world applications. The performance of tabular models–such as gradient boosted decision trees and neural networks–can vary significantly across datasets due to differences in feature distributions and task characteristics. Achieving top performance on each dataset often requires specialized expert knowledge. To address this variability, practitioners often aggregate the predictions of multiple models. However, conventional aggregation strategies typically rely on static combination rules and lack instance-level adaptability. In this work, we propose an in-context ensemble framework for tabular prediction that leverages large language models (LLMs) to perform dynamic, instance-specific integration of external model predictions. Without access to raw tabular features or semantic information, our method constructs a context around each test instance using its nearest neighbors and the predictions from a pool of external models. Within this enriched context, we introduce Chain of Tabular Thoughts (CoT$^2$), a prompting strategy that guides LLMs through multi-step, interpretable reasoning, making still further progress toward expert-level decision-making. Experimental results show that our method outperforms well-tuned baselines and standard ensemble techniques across a wide range of tabular datasets.
表格数据是机器学习中的基本数据格式,在竞赛和实际应用中得到了广泛应用。由于特征分布和任务特性的差异,梯度增强决策树和神经网络等表格模型的性能在不同数据集上可能会有很大差异。在每个数据集上实现最佳性能通常需要专业的专家知识。为了应对这种差异,从业者通常会聚合多个模型的预测结果。然而,传统的聚合策略通常依赖于静态的组合规则,缺乏实例级别的适应性。在这项工作中,我们提出了一种用于表格预测的上下文集成框架,该框架利用大型语言模型(LLM)执行动态、针对特定实例的外部模型预测集成。我们的方法无需访问原始表格特征或语义信息,而是围绕每个测试实例构建上下文环境,使用其最近邻居和来自外部模型池中的预测结果。在这个丰富的上下文环境中,我们引入了“表格思维链”(CoT$^2$),这是一种提示策略,通过多步骤的可解释推理来引导LLM,进一步推动向专家级决策制定迈进。实验结果表明,我们的方法在多种表格数据集上优于经过良好调整的基准模型和标准的集成技术。
论文及项目相关链接
Summary
文中主要探讨了表格数据在机器学习领域的重要性及其在竞赛和实际应用中的广泛应用。文章指出,由于特征分布和任务特性的差异,梯度增强决策树和神经网络等表格模型的性能在不同数据集上可能会有很大差异。为了应对这种差异并实现最佳性能,研究人员通常采用多种模型的预测聚合。然而,传统的聚合策略通常依赖于静态组合规则,缺乏实例级别的适应性。因此,本文提出了一种基于大型语言模型(LLM)的上下文集成框架,用于动态、特定实例地整合外部模型预测。该方法通过构建每个测试实例的上下文环境(使用其最近邻居和外部模型的预测),在不需要原始表格特征或语义信息的情况下,引入了一种名为Chain of Tabular Thoughts(CoT$^2$)的提示策略,通过多步骤、可解释性的推理引导LLM进行决策。实验结果表明,该方法在多种表格数据集上的性能优于精心调整的基准模型和标准的集成技术。
Key Takeaways
- 表格数据在机器学习和实际应用中广泛应用。
- 表格模型的性能在不同数据集上可能会有显著差异,需考虑特征分布和任务特性。
- 为了提高性能,研究人员常采用多模型预测聚合的方法。
- 传统聚合策略缺乏实例级别的适应性。
- 本文提出了一种基于大型语言模型的上下文集成框架,用于动态整合外部模型预测。
- 该方法通过构建测试实例的上下文环境,引入Chain of Tabular Thoughts(CoT$^2$)提示策略。
点此查看论文截图

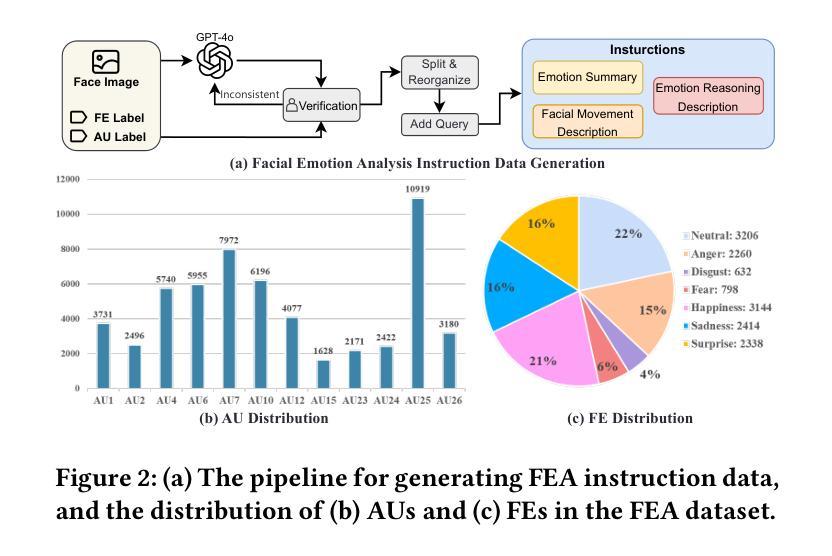
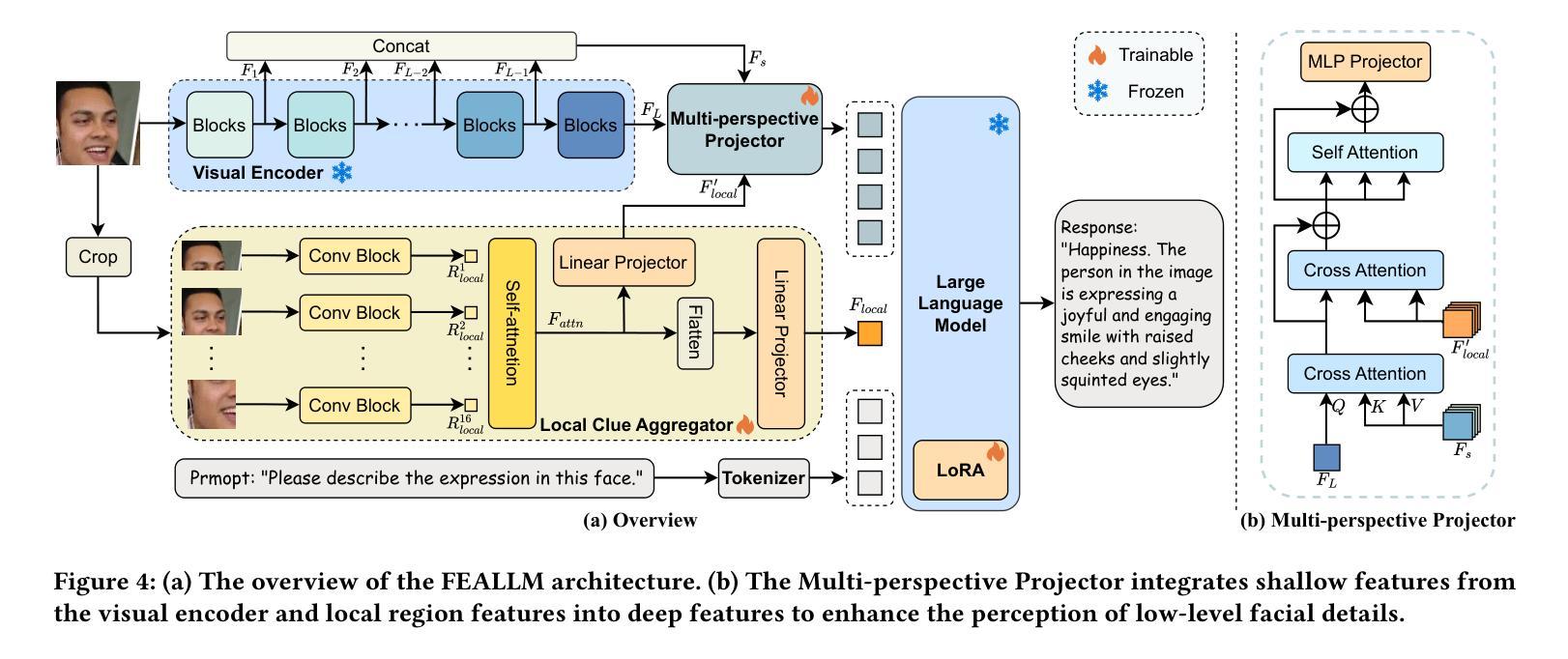
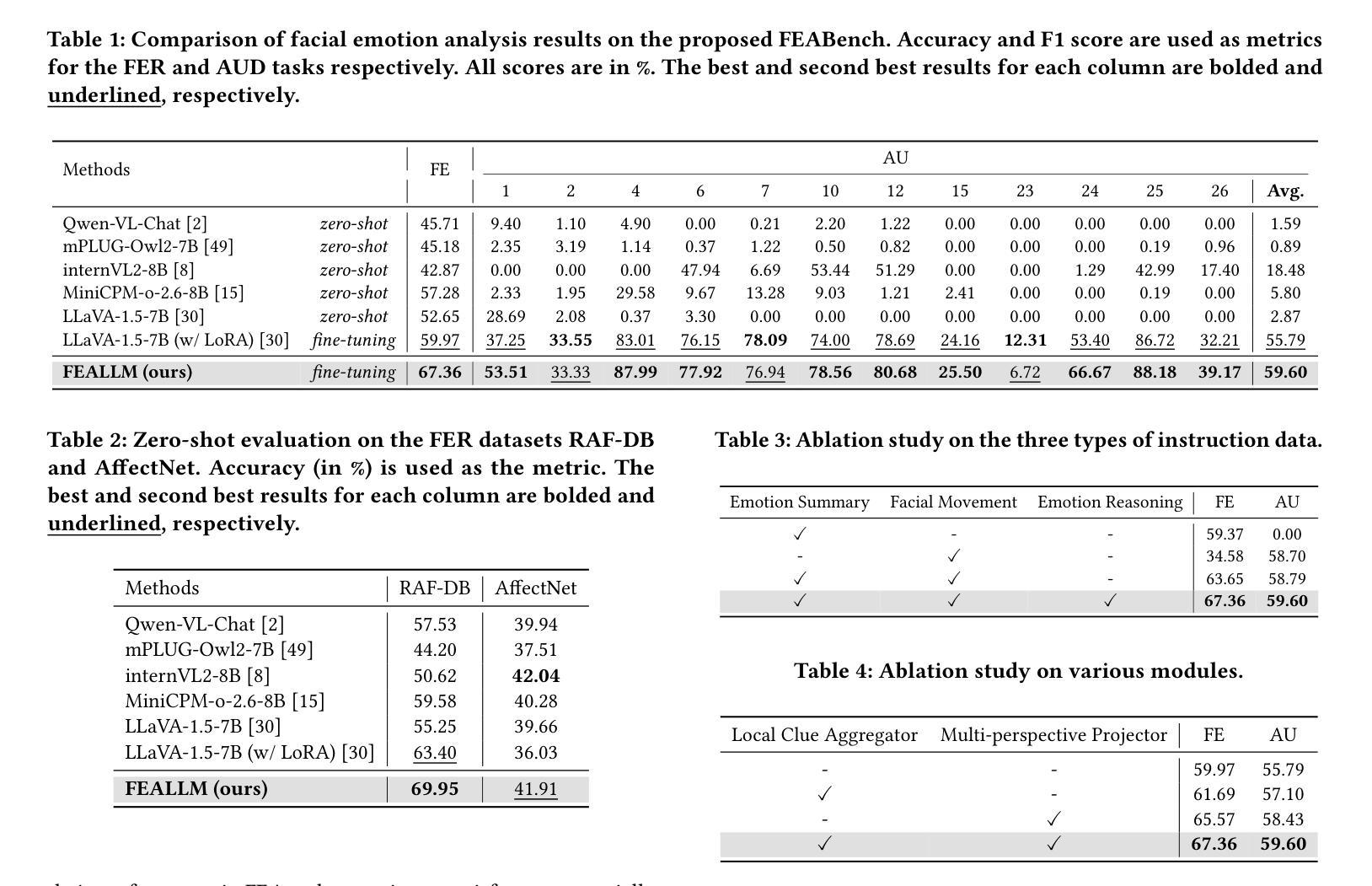
FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
Authors:Zhuozhao Hu, Kaishen Yuan, Xin Liu, Zitong Yu, Yuan Zong, Jingang Shi, Huanjing Yue, Jingyu Yang
Facial Emotion Analysis (FEA) plays a crucial role in visual affective computing, aiming to infer a person’s emotional state based on facial data. Scientifically, facial expressions (FEs) result from the coordinated movement of facial muscles, which can be decomposed into specific action units (AUs) that provide detailed emotional insights. However, traditional methods often struggle with limited interpretability, constrained generalization and reasoning abilities. Recently, Multimodal Large Language Models (MLLMs) have shown exceptional performance in various visual tasks, while they still face significant challenges in FEA due to the lack of specialized datasets and their inability to capture the intricate relationships between FEs and AUs. To address these issues, we introduce a novel FEA Instruction Dataset that provides accurate and aligned FE and AU descriptions and establishes causal reasoning relationships between them, followed by constructing a new benchmark, FEABench. Moreover, we propose FEALLM, a novel MLLM architecture designed to capture more detailed facial information, enhancing its capability in FEA tasks. Our model demonstrates strong performance on FEABench and impressive generalization capability through zero-shot evaluation on various datasets, including RAF-DB, AffectNet, BP4D, and DISFA, showcasing its robustness and effectiveness in FEA tasks. The dataset and code will be available at https://github.com/953206211/FEALLM.
面部情感分析(FEA)在视觉情感计算中扮演着至关重要的角色,其旨在基于面部数据推断一个人的情感状态。科学上,面部表情(FE)是面部肌肉协调运动的结果,可以分解为特定的动作单元(AU),从而提供详细的情感洞察。然而,传统的方法常常在解释性、通用性和推理能力方面存在局限。最近,多模态大型语言模型(MLLM)在各种视觉任务中表现出了出色的性能,而在FEA中仍然面临重大挑战,主要是由于缺乏专业数据集和无法捕捉面部表情和动作单元之间复杂的关系。为了解决这些问题,我们引入了一个新的面部情感分析指令数据集,提供准确和对齐的面部表情和动作单元描述,并建立它们之间的因果推理关系,然后构建了一个新的基准测试FEABench。此外,我们提出了FEALLM,这是一种新的MLLM架构,旨在捕捉更详细的面部信息,提高其在面部情感分析任务中的能力。我们的模型在FEABench上表现出强大的性能,在各种数据集(包括RAF-DB、AffectNet、BP4D和DISFA)上进行零样本评估时,展现出令人印象深刻的泛化能力,证明了其在面部情感分析任务中的稳健性和有效性。数据集和代码将在https://github.com/953206211/FEALLM上提供。
论文及项目相关链接
PDF 10 pages, 7 figures
Summary
面部表情分析(FEA)在视觉情感计算中起着关键作用,旨在基于面部数据推断人的情感状态。面部表达是由面部肌肉协调运动产生的,可以分解为特定的动作单元(AU)以提供详细的情感见解。然而,传统方法在解释、推广和推理方面存在局限性。最近,多模态大型语言模型(MLLM)在各种视觉任务中表现出卓越性能,但在FEA方面仍面临缺乏专用数据集和无法捕捉面部表情与动作单元之间复杂关系的挑战。为解决这些问题,我们引入了新型的FEA指令数据集,提供了准确对齐的面部表情和动作单元描述,建立了它们之间的因果关系。我们还构建了新的基准测试FEABench,并提出了FEALLM,一种新型MLLM架构,能够捕捉更详细的面部信息,增强FEA任务的能力。模型在FEABench上表现出强大的性能,并在多个数据集上通过零样本评估展示了其在FEA任务中的稳健性和有效性。
Key Takeaways
- 面部表情分析(FEA)是视觉情感计算中的关键领域,旨在通过面部数据推断人的情感状态。
- 面部表达是由面部肌肉的协调运动产生的,可以分解为动作单元(AU)以获得详细的情感理解。
- 传统方法在FEA方面存在解释性、推广和推理能力的局限性。
- 多模态大型语言模型(MLLM)在视觉任务中表现出卓越性能,但在FEA中仍面临挑战,主要由于缺乏专用数据集和捕捉复杂关系的能力不足。
- 引入新型的FEA指令数据集,提供准确对齐的面部表情和动作单元描述,并建立它们之间的因果关系。
- 构建了新的FEA基准测试FEABench以评估模型性能。
点此查看论文截图


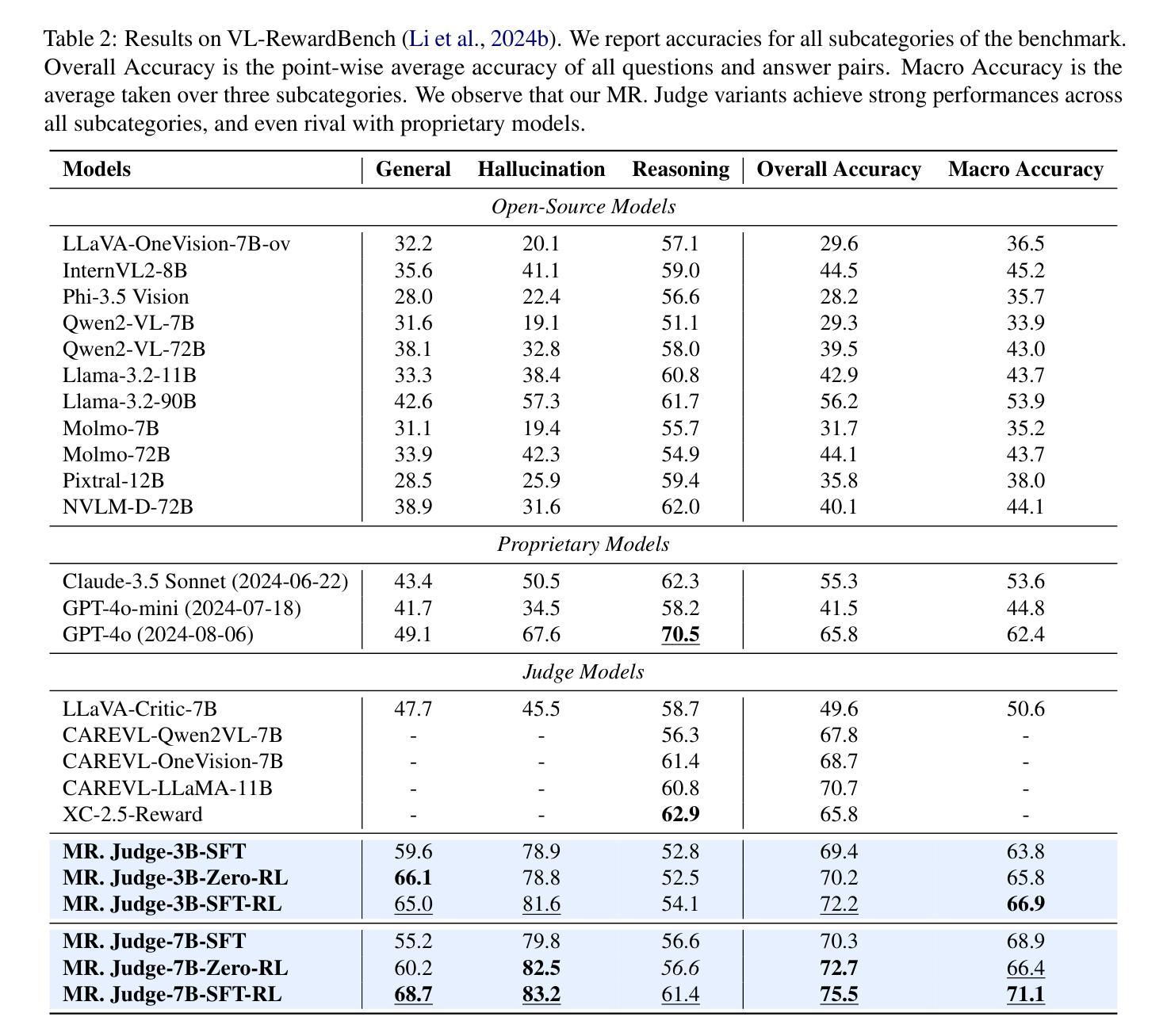
MR. Judge: Multimodal Reasoner as a Judge
Authors:Renjie Pi, Felix Bai, Qibin Chen, Simon Wang, Jiulong Shan, Kieran Liu, Meng Cao
The paradigm of using Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) as evaluative judges has emerged as an effective approach in RLHF and inference-time scaling. In this work, we propose Multimodal Reasoner as a Judge (MR. Judge), a paradigm for empowering general-purpose MLLMs judges with strong reasoning capabilities. Instead of directly assigning scores for each response, we formulate the judgement process as a reasoning-inspired multiple-choice problem. Specifically, the judge model first conducts deliberate reasoning covering different aspects of the responses and eventually selects the best response from them. This reasoning process not only improves the interpretibility of the judgement, but also greatly enhances the performance of MLLM judges. To cope with the lack of questions with scored responses, we propose the following strategy to achieve automatic annotation: 1) Reverse Response Candidates Synthesis: starting from a supervised fine-tuning (SFT) dataset, we treat the original response as the best candidate and prompt the MLLM to generate plausible but flawed negative candidates. 2) Text-based reasoning extraction: we carefully design a data synthesis pipeline for distilling the reasoning capability from a text-based reasoning model, which is adopted to enable the MLLM judges to regain complex reasoning ability via warm up supervised fine-tuning. Experiments demonstrate that our MR. Judge is effective across a wide range of tasks. Specifically, our MR. Judge-7B surpasses GPT-4o by 9.9% on VL-RewardBench, and improves performance on MM-Vet during inference-time scaling by up to 7.7%.
使用大型语言模型(LLM)和多模态大型语言模型(MLLM)作为评价者的范式,在RLHF和推理时间缩放中已成为一种有效的方法。在这项工作中,我们提出了“多模态推理者作为评判员”(MR Judge)这一范式,旨在赋予通用MLLM评判员强大的推理能力。我们并不直接为每种回应打分,而是将评判过程制定为受推理启发的多项选择题。具体来说,评判模型首先进行涵盖回应不同方面的深思熟虑的推理,并最终从中选择最佳的回应。这种推理过程不仅提高了评判的可解释性,还大大提高了MLLM评判员的表现。为了应对缺乏带评分回应的问题,我们提出以下策略来实现自动标注:1)反向回应候选合成:从监督微调(SFT)数据集开始,我们将原始回应视为最佳候选,并提示MLLM生成合理的但存在缺陷的负面候选;2)基于文本的推理提取:我们精心设计了一个数据合成管道,以从基于文本的推理模型中提炼推理能力,采用该模型使MLLM评委能够通过热身的监督微调恢复复杂的推理能力。实验表明,我们的MR Judge在多种任务上均表现出良好的效果。具体来说,我们的MR Judge-7B在VL-RewardBench上的表现优于GPT-4o,超过9.9%,并在推理时间缩放期间MM-Vet上的性能提高了高达7.7%。
论文及项目相关链接
Summary
本摘要中,提出了一种基于多模态大语言模型(MLLMs)的通用评价法官模型——多模态推理法官(MR. Judge)。该模型将评价过程形式化为一个基于推理的多选问题,提高了评估的可靠性和模型的性能。为了解决缺少带有得分的响应问题,提出通过合成逆向响应候选和基于文本的推理提取策略实现自动标注。实验表明,MR. Judge在不同任务上均表现出优异的效果,如MR. Judge-7B在VL-RewardBench上的性能优于GPT-4o达9.9%,并在推理时间尺度上在MM-Vet上的性能提升高达7.7%。
Key Takeaways
- 使用多模态大语言模型(MLLMs)作为评价法官已成为有效方法。
- 提出多模态推理法官(MR. Judge)模型,将评价过程形式化为基于推理的多选问题。
- 通过合成逆向响应候选和基于文本的推理提取策略实现自动标注。
- MR. Judge模型提高了评估的可靠性和模型的性能。
- MR. Judge在多种任务上表现优异,特别是在VL-RewardBench和MM-Vet上的性能提升显著。
- MR. Judge模型通过精细设计的合成数据管道实现复杂推理能力的提炼。
点此查看论文截图



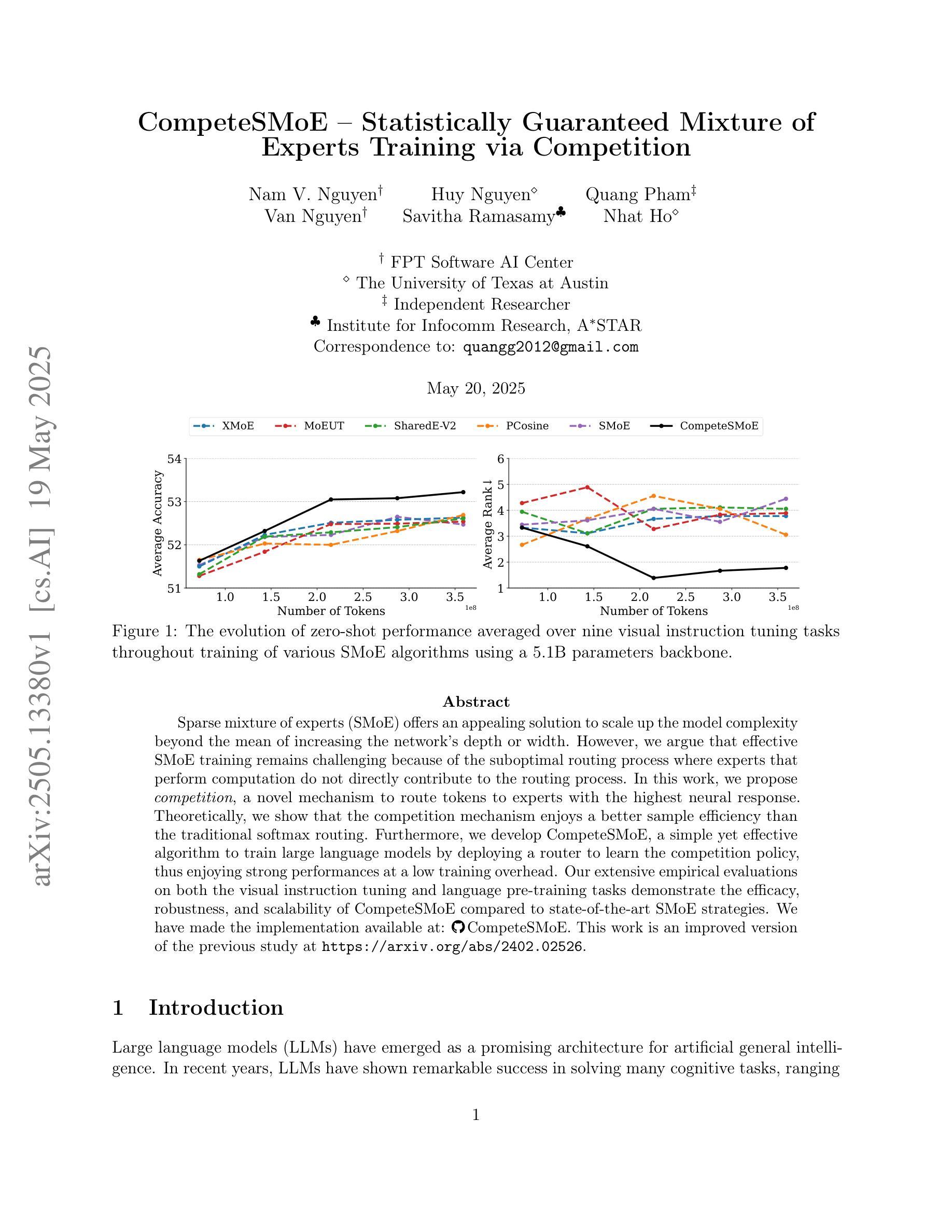
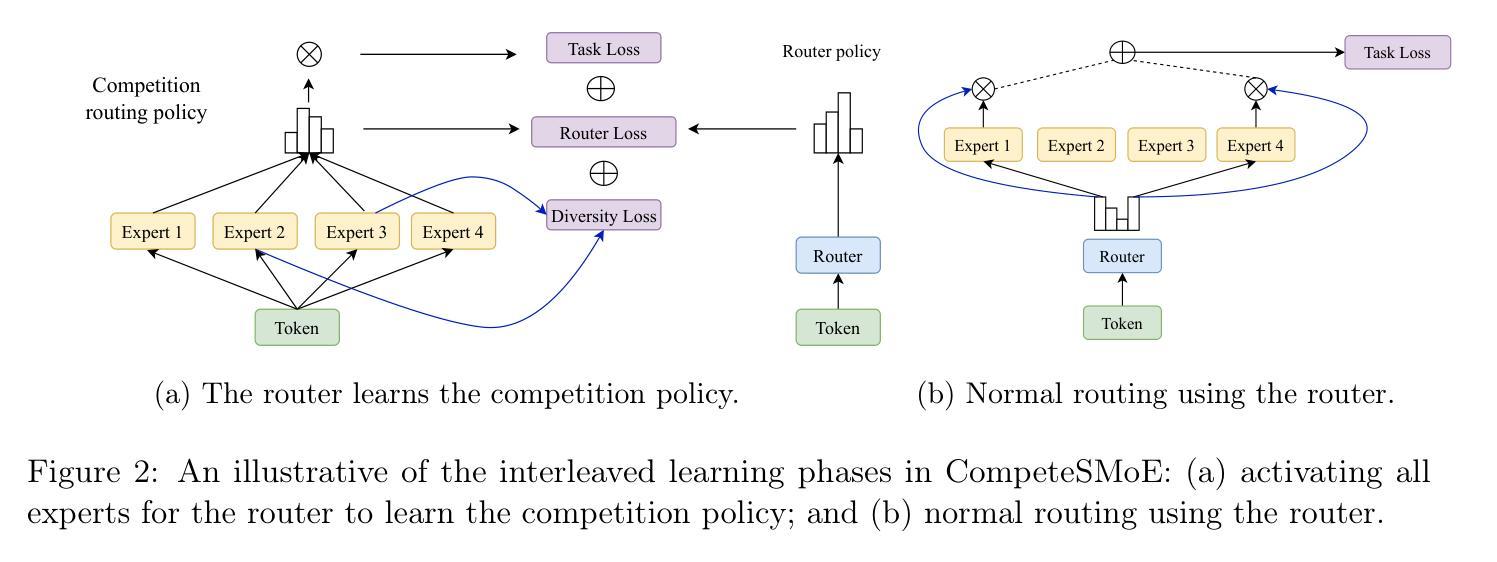
CompeteSMoE – Statistically Guaranteed Mixture of Experts Training via Competition
Authors:Nam V. Nguyen, Huy Nguyen, Quang Pham, Van Nguyen, Savitha Ramasamy, Nhat Ho
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network’s depth or width. However, we argue that effective SMoE training remains challenging because of the suboptimal routing process where experts that perform computation do not directly contribute to the routing process. In this work, we propose competition, a novel mechanism to route tokens to experts with the highest neural response. Theoretically, we show that the competition mechanism enjoys a better sample efficiency than the traditional softmax routing. Furthermore, we develop CompeteSMoE, a simple yet effective algorithm to train large language models by deploying a router to learn the competition policy, thus enjoying strong performances at a low training overhead. Our extensive empirical evaluations on both the visual instruction tuning and language pre-training tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies. We have made the implementation available at: https://github.com/Fsoft-AIC/CompeteSMoE. This work is an improved version of the previous study at arXiv:2402.02526
稀疏混合专家网络(SMoE)提供了一种吸引人的解决方案,可以扩大模型复杂度,而不仅仅是增加网络的深度或宽度。然而,我们认为有效的SMoE训练仍然具有挑战性,因为次优的路由过程并不能使执行计算的专家直接贡献于路由过程。在这项工作中,我们提出了竞争机制,这是一种将令牌路由到具有最高神经响应的专家的新机制。从理论上讲,我们证明了竞争机制的样本效率高于传统的softmax路由。此外,我们开发了CompeteSMoE,这是一种简单有效的算法,通过部署路由器来学习竞争策略,从而以较低的训练开销享受强大的性能。我们在视觉指令调整和语言预训练任务上的广泛实证评估表明,与最新的SMoE策略相比,CompeteSMoE具有高效性、稳健性和可扩展性。我们的实现可在[https://github.com/Fsoft-AIC/CompeteSMoE上获得。这项工作是arXiv:2402.02526之前研究的一个改进版本。
论文及项目相关链接
PDF 52 pages. This work is an improved version of the previous study at arXiv:2402.02526
Summary
本文介绍了Sparse Mixture of Experts (SMoE)模型面临的挑战,并提出了竞争机制来解决这一问题。竞争机制通过将令牌路由到响应最高的专家来提高样本效率。为此,文章开发了一种名为CompeteSMoE的新算法,通过部署路由器来学习竞争策略,实现了强大的性能且训练开销较低。文章在视觉指令调整和语言预训练任务上的大量实证评估表明,相较于最新SMoE策略,CompeteSMoE更有效、稳健且可扩展。
Key Takeaways
- SMoE模型面临专家路由过程的挑战,其中进行计算的专家并未直接对路由过程做出贡献。
- 竞争机制被提出作为一种解决方案,该机制能将令牌路由到响应最高的专家。
- 竞争机制的理论优势在于其样本效率高于传统的softmax路由。
- CompeteSMoE算法简单有效,通过部署路由器学习竞争策略,实现高性能和低训练开销。
- 实证评估显示CompeteSMoE在视觉指令调整和语言预训练任务上的表现优于其他最新SMoE策略。
- 该研究是对arXiv上之前研究的一种改进。
点此查看论文截图
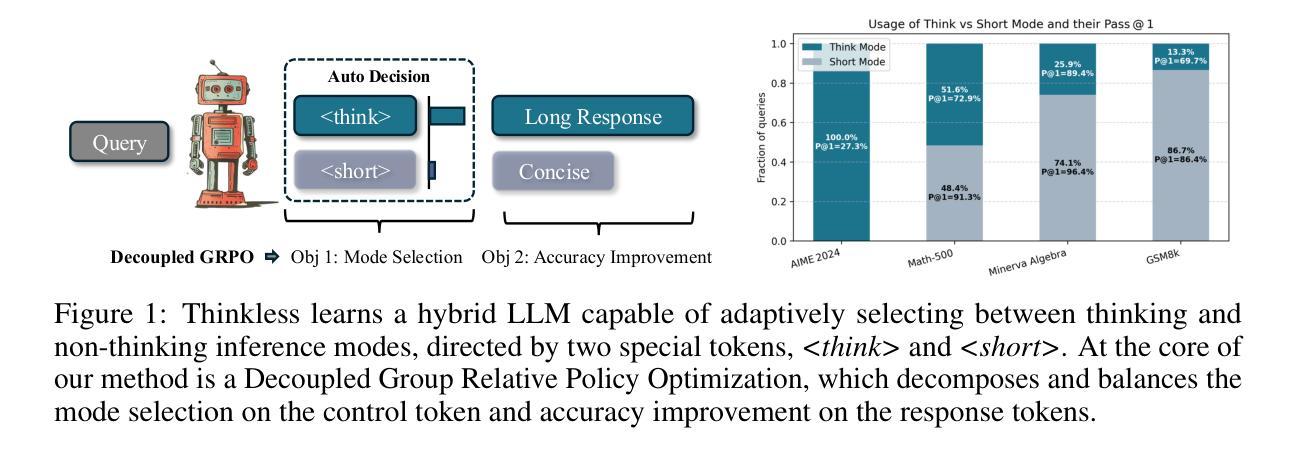
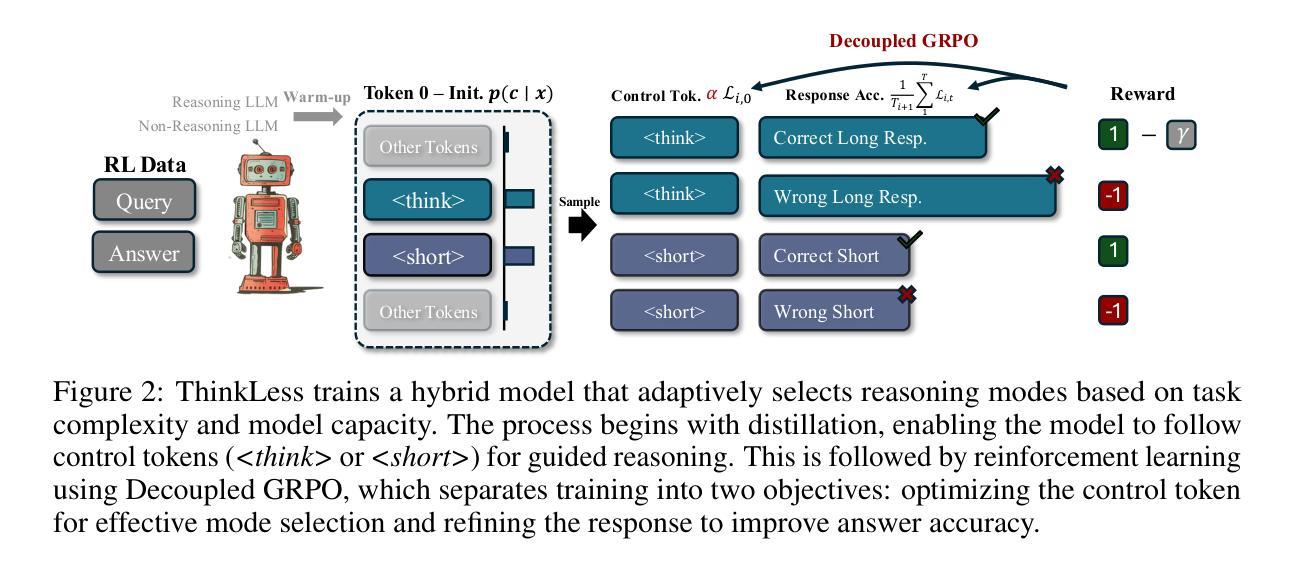
Thinkless: LLM Learns When to Think
Authors:Gongfan Fang, Xinyin Ma, Xinchao Wang
Reasoning Language Models, capable of extended chain-of-thought reasoning, have demonstrated remarkable performance on tasks requiring complex logical inference. However, applying elaborate reasoning for all queries often results in substantial computational inefficiencies, particularly when many problems admit straightforward solutions. This motivates an open question: Can LLMs learn when to think? To answer this, we propose Thinkless, a learnable framework that empowers an LLM to adaptively select between short-form and long-form reasoning, based on both task complexity and the model’s ability. Thinkless is trained under a reinforcement learning paradigm and employs two control tokens,
推理语言模型具备扩展的链式思维推理能力,在需要复杂逻辑推断的任务中表现出卓越的性能。然而,对所有查询进行精细推理通常会导致大量的计算效率低下,特别是当许多问题都有简单解决方案时。这引发了一个开放性的问题:LLM能否学会何时思考?为了回答这个问题,我们提出了Thinkless,这是一个可学习的框架,能够赋予LLM根据任务复杂度和模型能力自适应选择短形式和长形式推理。Thinkless是在强化学习模式下进行训练的,并采用两个控制令牌,
用于简洁的回答和 用于详细的推理。我们的方法的核心是解耦组相对策略优化(DeGRPO)算法,该算法将混合推理的学习目标分解为两个部分:(1)控制令牌损失,它控制推理模式的选择;(2)响应损失,它提高生成答案的准确性。这种解耦的公式化表达能够精细控制每个目标的贡献,稳定训练,并有效防止了原始GRPO中观察到的崩溃。在Minerva Algebra、MATH-500和GSM8K等多个基准测试中,Thinkless能够减少长链思考的使用率50%~90%,显著提高推理语言模型的效率。代码可用在https://github.com/VainF/Thinkless。
论文及项目相关链接
Summary
本文提出了Thinkless框架,该框架让大型语言模型(LLM)能够自适应地选择简洁回答和详细推理的模式,基于任务复杂度和模型能力。Thinkless采用强化学习模式训练,使用两个控制符号:
Key Takeaways
- Thinkless框架让LLM能够自适应选择简洁回答和详细推理的模式。
- Thinkless采用强化学习模式训练,使用控制符号来控制推理模式。
- Decoupled Group Relative Policy Optimization(DeGRPO)算法是Thinkless的核心方法,它将混合推理的学习目标分解为两个组成部分。
- 控制符号损失负责选择推理模式,响应损失则提高生成答案的准确性。
- Thinkless能够在多个基准测试中减少LLM的长链思考使用。
- Thinkless显著提高了推理效率。
点此查看论文截图

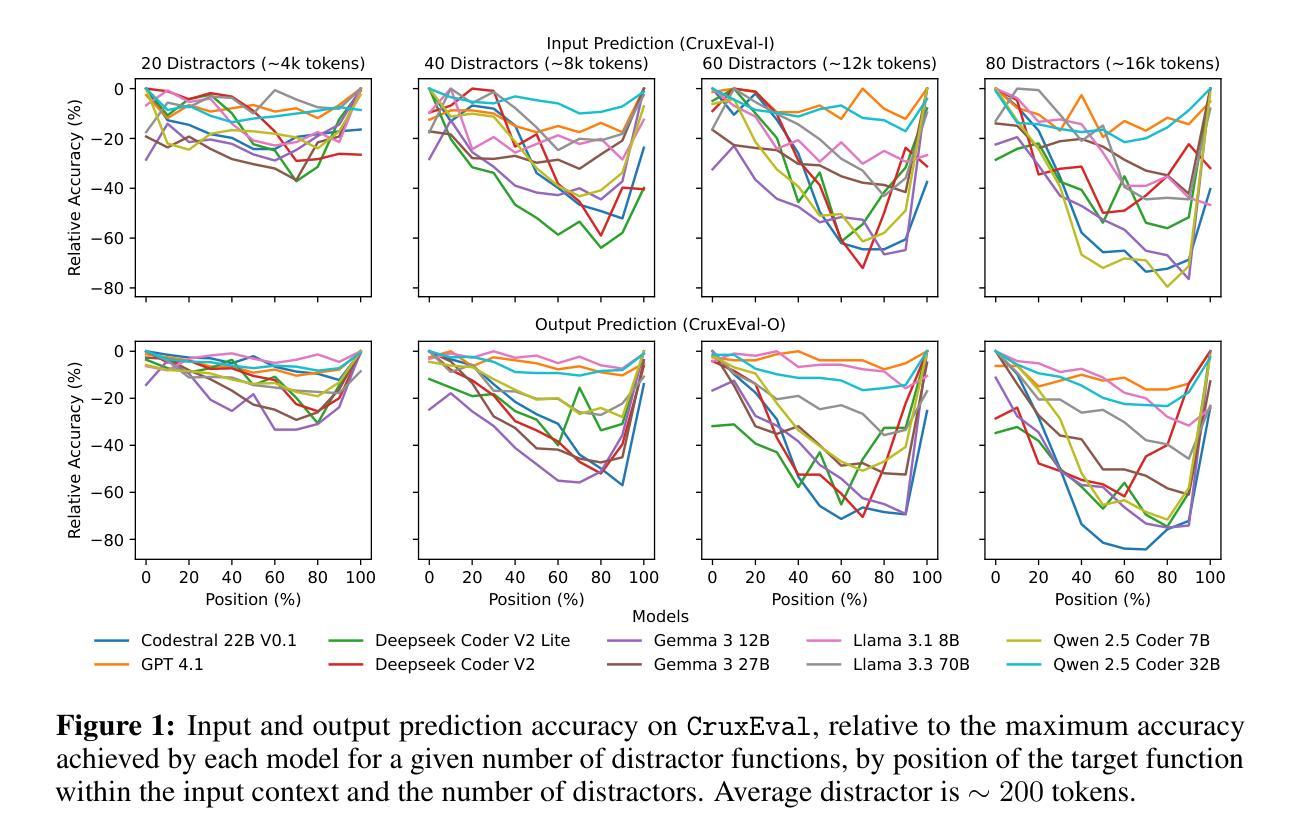
Sense and Sensitivity: Examining the Influence of Semantic Recall on Long Context Code Reasoning
Authors:Adam Štorek, Mukur Gupta, Samira Hajizadeh, Prashast Srivastava, Suman Jana
Although modern Large Language Models (LLMs) support extremely large contexts, their effectiveness in utilizing long context for code reasoning remains unclear. This paper investigates LLM reasoning ability over code snippets within large repositories and how it relates to their recall ability. Specifically, we differentiate between lexical code recall (verbatim retrieval) and semantic code recall (remembering what the code does). To measure semantic recall, we propose SemTrace, a code reasoning technique where the impact of specific statements on output is attributable and unpredictable. We also present a method to quantify semantic recall sensitivity in existing benchmarks. Our evaluation of state-of-the-art LLMs reveals a significant drop in code reasoning accuracy as a code snippet approaches the middle of the input context, particularly with techniques requiring high semantic recall like SemTrace. Moreover, we find that lexical recall varies by granularity, with models excelling at function retrieval but struggling with line-by-line recall. Notably, a disconnect exists between lexical and semantic recall, suggesting different underlying mechanisms. Finally, our findings indicate that current code reasoning benchmarks may exhibit low semantic recall sensitivity, potentially underestimating LLM challenges in leveraging in-context information.
尽管现代的大型语言模型(LLM)支持极大的上下文环境,但它们利用长上下文进行代码推理的有效性仍不明确。本文调查了LLM在大仓库中的代码片段推理能力及其与回忆能力的关系。具体来说,我们区分了词汇代码回忆(逐字检索)和语义代码回忆(记住代码的功能)。为了衡量语义回忆,我们提出了SemTrace,这是一种代码推理技术,可以追溯特定语句对输出的影响,且具有不可预测性。我们还介绍了一种在现有基准测试中量化语义回忆敏感度的方法。对最新LLM的评估显示,当代码片段接近输入上下文的中部时,特别是需要使用高语义回忆的技术(如SemTrace),代码推理的准确性会显著下降。此外,我们发现词汇回忆的粒度不同,模型在函数检索方面表现出色,但在逐行回忆方面却遇到困难。值得注意的是,词汇回忆和语义回忆之间存在断层,这表明了不同的潜在机制。最后,我们的研究结果表明,当前的代码推理基准测试可能表现出较低的语义回忆敏感性,可能会低估LLM在利用上下文信息方面的挑战。
论文及项目相关链接
Summary
本论文探讨了大型语言模型(LLM)在代码片段推理方面的能力,及其与代码召回能力的关联。研究区分了词汇代码召回(逐字检索)和语义代码召回(记住代码的功能)。为衡量语义召回能力,提出了SemTrace代码推理技术,并介绍了在现有基准测试中量化语义召回敏感度的方法。评估显示,随着代码片段位于输入上下文中的位置逐渐居中,特别是需要高度语义召回的技术如SemTrace,代码推理的准确性会显著下降。此外,还发现词汇召回能力因粒度而异,模型擅长函数检索,但在逐行召回方面遇到困难。重要的是,词汇召回和语义召回之间存在断层,说明存在不同的内在机制。最后,研究表明现有的代码推理基准测试可能表现出较低的语义召回敏感性,可能会低估LLM在利用上下文信息方面的挑战。
Key Takeaways
- LLM在代码片段推理方面的能力尚不清楚。
- 区分了词汇代码召回和语义代码召回。
- 提出了SemTrace技术来衡量语义召回能力。
- LLM在代码推理方面存在准确性下降的问题,特别是在需要高语义召回的技术上。
- 词汇召回能力因粒度而异,模型在函数检索方面表现较好,但在逐行召回方面存在困难。
- 词汇召回和语义召回之间存在断层,表明它们有不同的内在机制。
点此查看论文截图


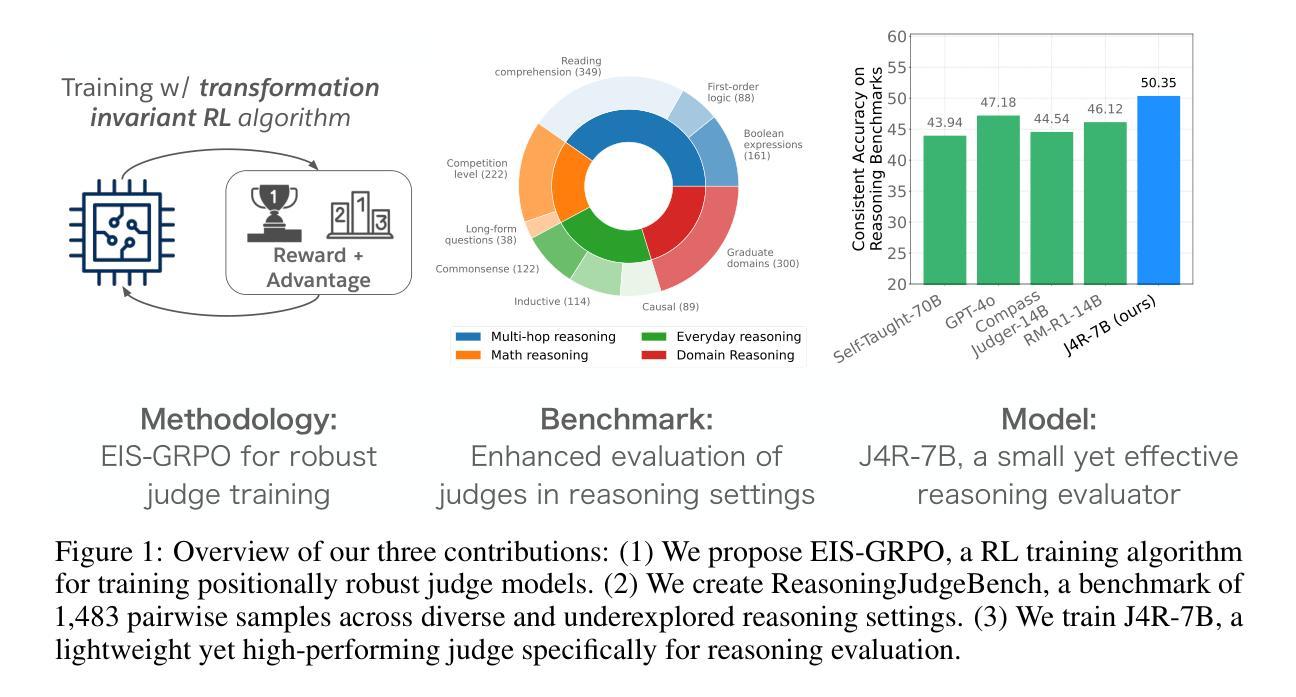
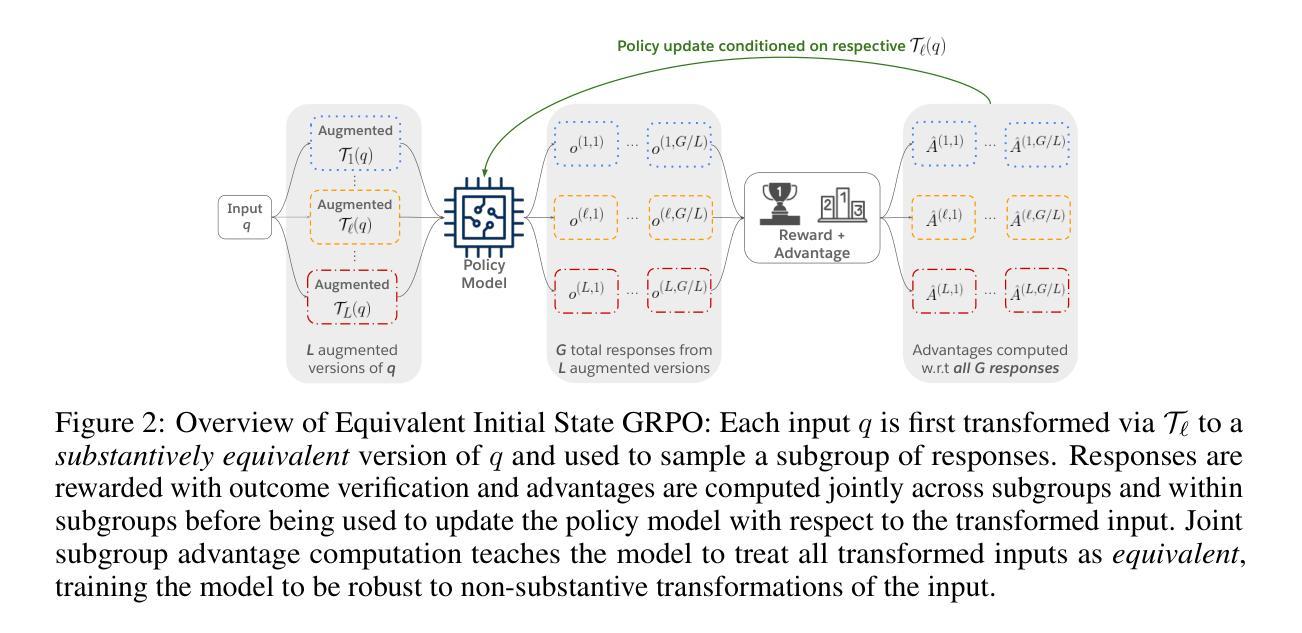
J4R: Learning to Judge with Equivalent Initial State Group Relative Preference Optimization
Authors:Austin Xu, Yilun Zhou, Xuan-Phi Nguyen, Caiming Xiong, Shafiq Joty
To keep pace with the increasing pace of large language models (LLM) development, model output evaluation has transitioned away from time-consuming human evaluation to automatic evaluation, where LLMs themselves are tasked with assessing and critiquing other model outputs. LLM-as-judge models are a class of generative evaluators that excel in evaluating relatively simple domains, like chat quality, but struggle in reasoning intensive domains where model responses contain more substantive and challenging content. To remedy existing judge shortcomings, we explore training judges with reinforcement learning (RL). We make three key contributions: (1) We propose the Equivalent Initial State Group Relative Policy Optimization (EIS-GRPO) algorithm, which allows us to train our judge to be robust to positional biases that arise in more complex evaluation settings. (2) We introduce ReasoningJudgeBench, a benchmark that evaluates judges in diverse reasoning settings not covered by prior work. (3) We train Judge for Reasoning (J4R), a 7B judge trained with EIS-GRPO that outperforms GPT-4o and the next best small judge by 6.7% and 9%, matching or exceeding the performance of larger GRPO-trained judges on both JudgeBench and ReasoningJudgeBench.
随着大型语言模型(LLM)发展步伐的加快,模型输出评估已经从耗时的人类评估转变为自动评估。在自动评估中,大型语言模型本身被用来评估和批判其他模型的输出。LLM作为评判者的模型是一类生成评估器,擅长评估相对简单的领域,如聊天质量,但在需要推理的复杂领域中表现挣扎,这些领域的模型回应包含更多实质性的挑战内容。为了弥补现有评判者的不足,我们探索使用强化学习(RL)来训练评判者。我们做出了三个关键贡献:(1)我们提出了等价初始状态组相对策略优化(EIS-GRPO)算法,该算法使我们能够训练评判者对更复杂评估环境中出现的定位偏差具有鲁棒性。(2)我们引入了ReasoningJudgeBench,这是一个评估在以前的工作中没有涵盖的各种推理环境中的评判者。(3)我们使用EIS-GRPO训练了J4R(推理评判者),这是一个7B的评判者,其性能超过了GPT-4o和下一个最佳小型评判者6.7%和9%,在JudgeBench和ReasoningJudgeBench上的表现与更大的GRPO训练过的评判者相匹配或更好。
论文及项目相关链接
PDF 25 pages, 4 figures, 6 tables. To be updated with links for code/benchmark
Summary
大型语言模型(LLM)的发展推动了模型输出评估的转变,从耗时的人力评估逐渐转向自动评估。现在,LLM自身被用于评估和批判其他模型的输出。本文探讨了利用强化学习(RL)训练评价模型的方案,提出一种名为EIS-GRPO的新算法,增强了评价模型在复杂环境下的稳健性。同时,文章引入了一个名为ReasoningJudgeBench的新基准测试,用于评估评价模型在不同推理场景下的表现。最终,通过EIS-GRPO训练的J4R模型在ReasoningJudgeBench上的表现超过了GPT-4o和其他小型评价模型,甚至与大型GRPO训练的评价模型相匹配或表现更好。
Key Takeaways
- 大型语言模型(LLM)的发展推动了模型输出评估的转变,现在更多地依赖于自动评估和LLM自身的评价。
- LLM-as-judge模型在评估相对简单的领域(如聊天质量)表现良好,但在需要大量推理的复杂领域表现欠佳。
- 为了改进现有评价模型的不足,研究者采用强化学习(RL)进行训练,并提出了一种新的算法EIS-GRPO,增强了评价模型在复杂环境下的稳健性。
- 引入了一个新的基准测试ReasoningJudgeBench,用于评估评价模型在不同推理场景下的表现。
- 通过EIS-GRPO训练的J4R模型在ReasoningJudgeBench上的表现超过了GPT-4o和其他小型评价模型。
- J4R模型的表现与大型GRPO训练的评价模型相匹配或表现更好。
点此查看论文截图

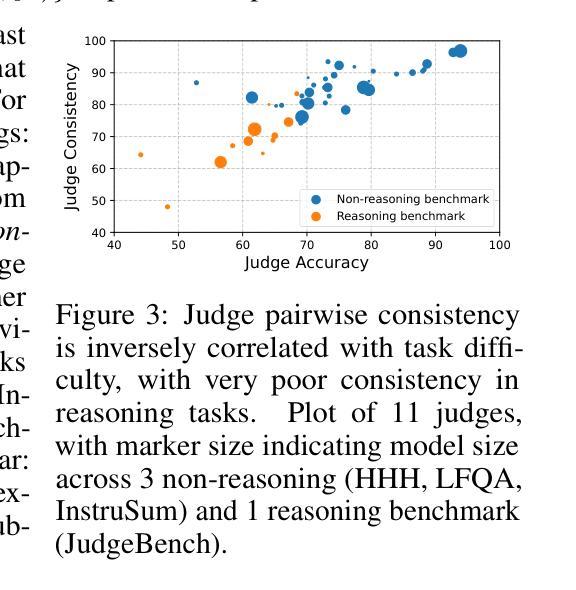
JNLP at SemEval-2025 Task 11: Cross-Lingual Multi-Label Emotion Detection Using Generative Models
Authors:Jieying Xue, Phuong Minh Nguyen, Minh Le Nguyen, Xin Liu
With the rapid advancement of global digitalization, users from different countries increasingly rely on social media for information exchange. In this context, multilingual multi-label emotion detection has emerged as a critical research area. This study addresses SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection. Our paper focuses on two sub-tracks of this task: (1) Track A: Multi-label emotion detection, and (2) Track B: Emotion intensity. To tackle multilingual challenges, we leverage pre-trained multilingual models and focus on two architectures: (1) a fine-tuned BERT-based classification model and (2) an instruction-tuned generative LLM. Additionally, we propose two methods for handling multi-label classification: the base method, which maps an input directly to all its corresponding emotion labels, and the pairwise method, which models the relationship between the input text and each emotion category individually. Experimental results demonstrate the strong generalization ability of our approach in multilingual emotion recognition. In Track A, our method achieved Top 4 performance across 10 languages, ranking 1st in Hindi. In Track B, our approach also secured Top 5 performance in 7 languages, highlighting its simplicity and effectiveness\footnote{Our code is available at https://github.com/yingjie7/mlingual_multilabel_emo_detection.
随着全球数字化的快速发展,来自不同国家的用户越来越依赖社交媒体进行信息交流。在此背景下,多语言多标签情感检测已成为一个关键研究领域。本研究旨在解决SemEval-2025任务11:文本情感检测中的鸿沟问题。我们的论文重点关注该任务中的两个子领域:(1)赛道A:多标签情感检测;(2)赛道B:情感强度。为了应对多语言挑战,我们利用预训练的多语言模型,并专注于两种架构:(1)微调后的基于BERT的分类模型;(2)经过指令训练的生成式大型语言模型。此外,我们提出了两种处理多标签分类的方法:基础方法直接将输入映射到其对应的所有情感标签上;配对方法则分别建模输入文本与每个情感类别之间的关系。实验结果表明,我们的方法在多种语言的情感识别中具有强大的泛化能力。在赛道A中,我们的方法在10种语言中取得了前4名的成绩,并在印地语中排名第1。在赛道B中,我们的方法也在7种语言中取得了前5名的成绩,突显了其简单性和有效性【我们的代码可在https://github.com/yingjie7/mlingual_multilabel_emo_detection找到】。
论文及项目相关链接
PDF Published in The 19th International Workshop on Semantic Evaluation (SemEval-2025)
Summary
随着全球数字化进程加快,不同国家用户日益依赖社交媒体进行信息交流,多语言多标签情感检测成为重要研究领域。本研究关注SemEval-2025 Task 11:文本情感检测中的鸿沟问题。针对该任务的两个子课题:(1)多标签情感检测和(2)情感强度进行深入研究。为应对多语言挑战,研究利用预训练多语言模型和两种架构,即微调BERT分类模型和指令微调生成式大型语言模型。同时提出两种处理多标签分类的方法:基础方法直接映射输入到其对应的情感标签,配对方法则独立建模输入文本与每种情感类别之间的关系。实验结果显示,该方法在多语言情感识别中具有强大的泛化能力,在A赛道10种语言中位列第4,并在印度语中排名第1;在B赛道7种语言中位列第5,凸显其简洁性和有效性^[注:代码可访问https://github.com/yingjie7/mlingual_multilabel_emo_detection]。
Key Takeaways
- 全球数字化进程中,社交媒体成为信息交流的关键渠道,多语言多标签情感检测成为研究热点。
- 本研究关注SemEval-2025 Task 11中的两个子课题:多标签情感检测和情感强度。
- 为应对多语言挑战,研究利用预训练多语言模型和两种架构:微调BERT分类模型和指令微调生成式大型语言模型。
- 提出两种处理多标签分类的方法:基础方法和配对方法。
- 实验结果显示,该方法在多语言情感识别中具有强大的泛化能力。
- 在特定赛道中取得优异成绩,如A赛道印度语排名第1,B赛道7种语言中位列第5。
点此查看论文截图



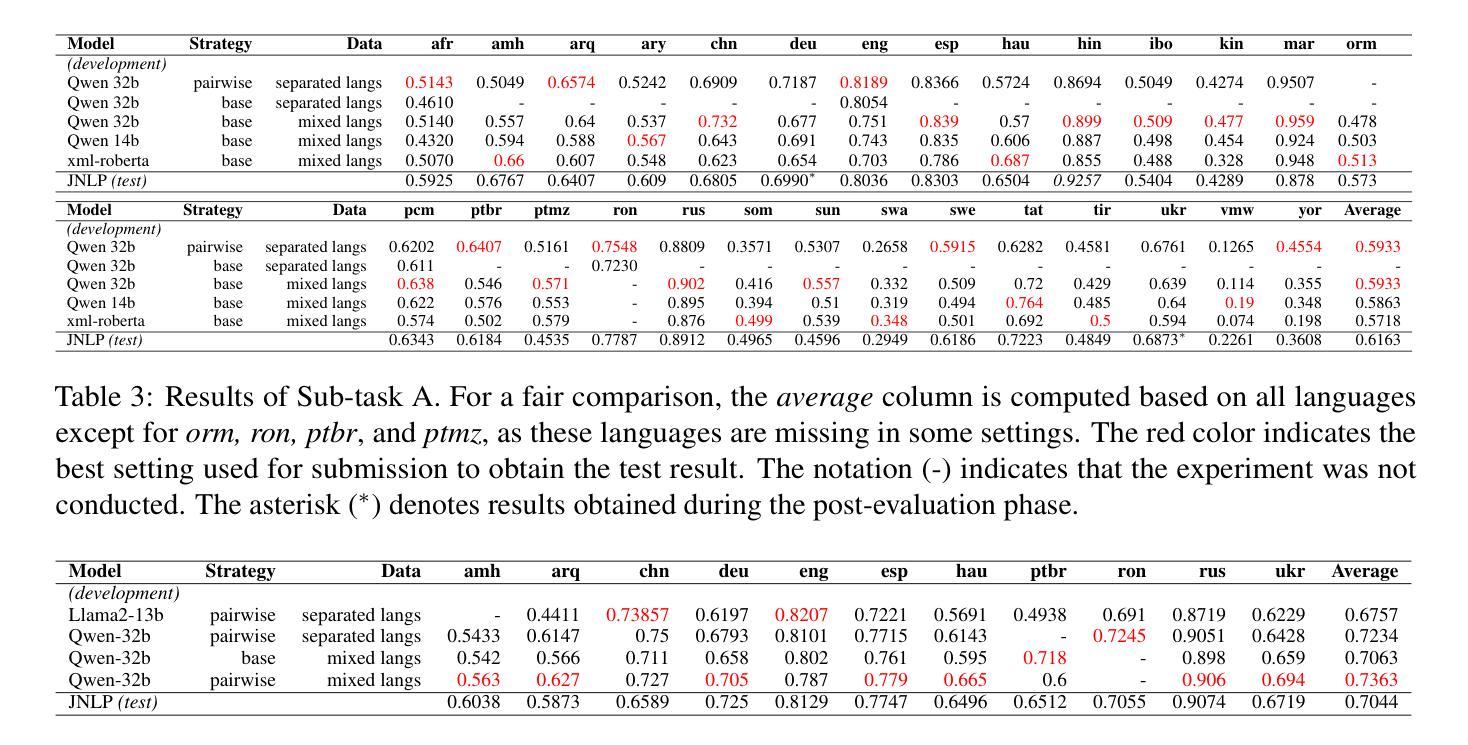
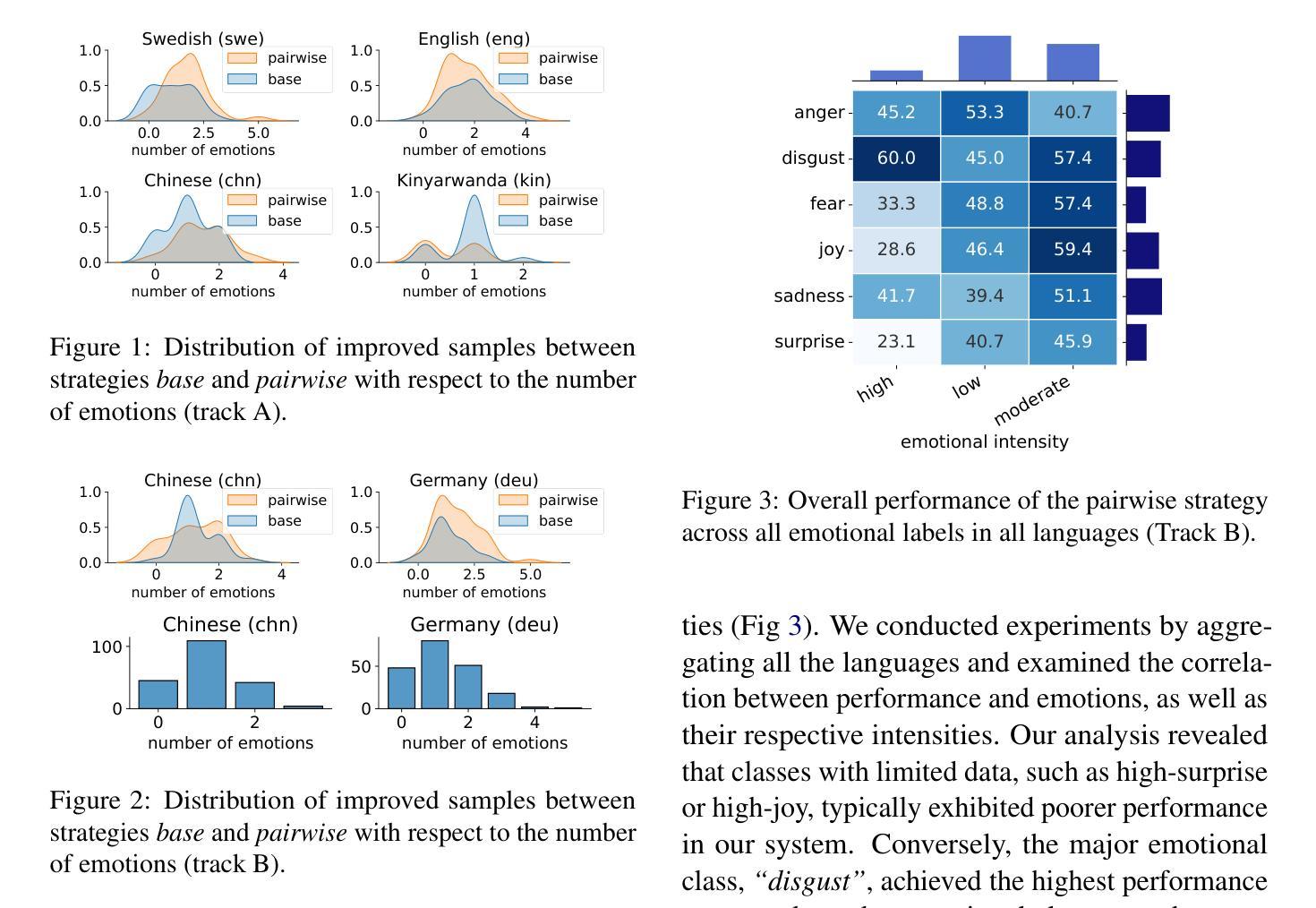
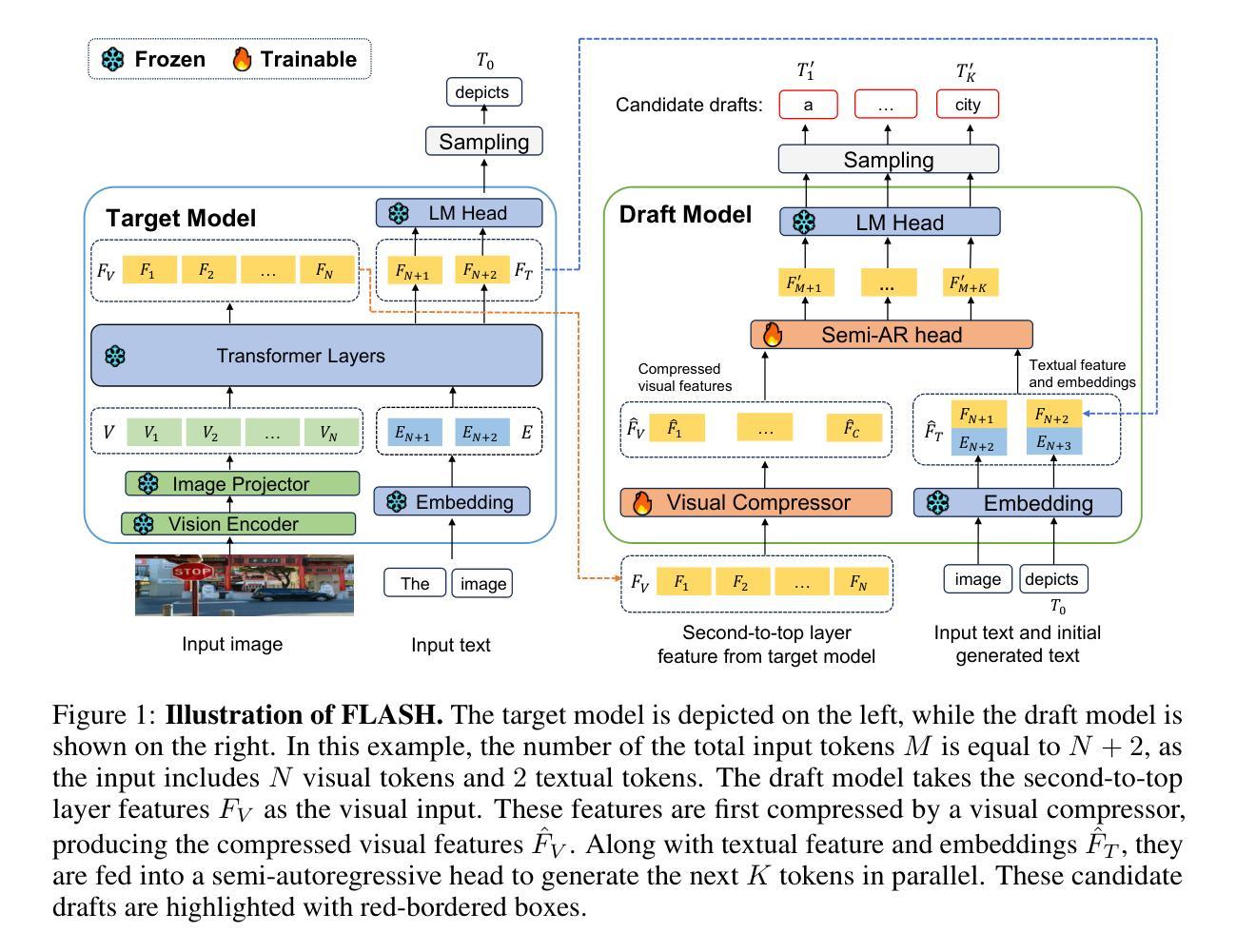
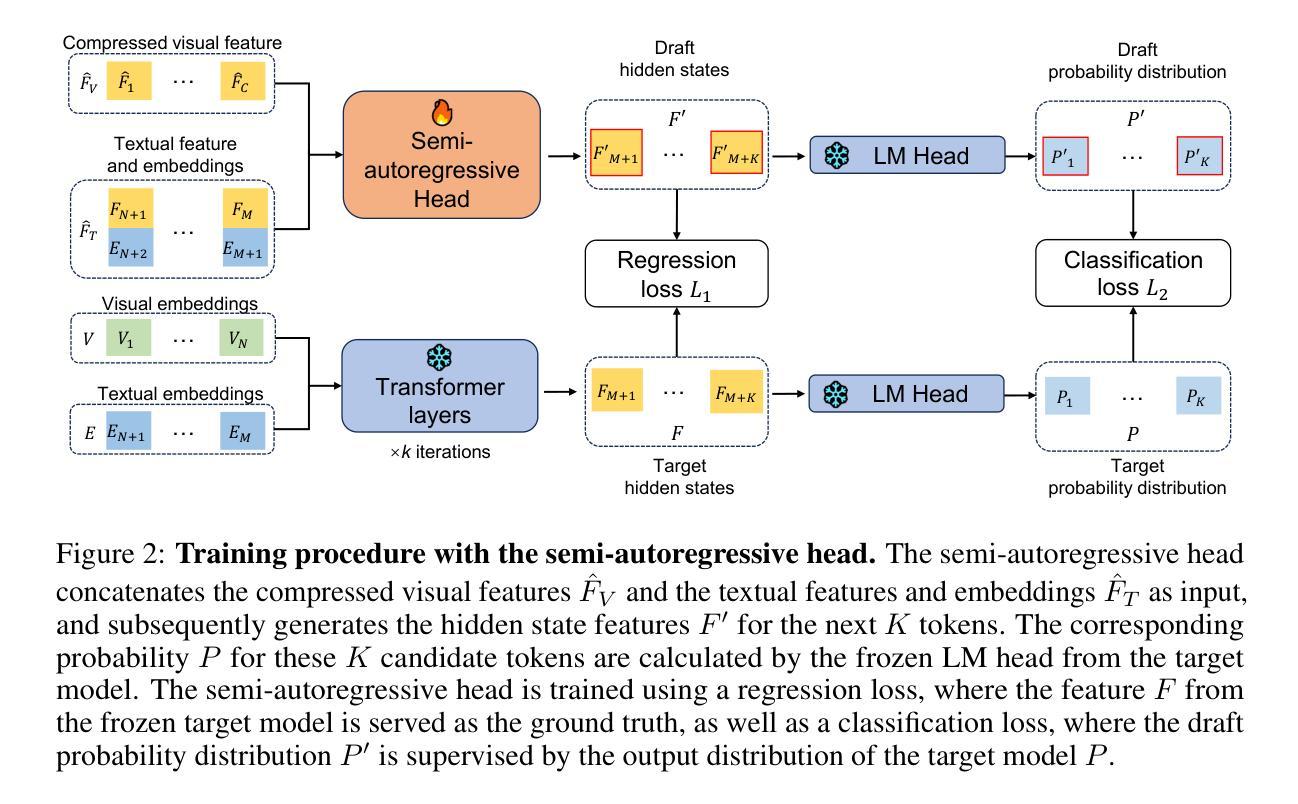
FLASH: Latent-Aware Semi-Autoregressive Speculative Decoding for Multimodal Tasks
Authors:Zihua Wang, Ruibo Li, Haozhe Du, Joey Tianyi Zhou, Yu Zhang, Xu Yang
Large language and multimodal models (LLMs and LMMs) exhibit strong inference capabilities but are often limited by slow decoding speeds. This challenge is especially acute in LMMs, where visual inputs typically comprise more tokens with lower information density than text – an issue exacerbated by recent trends toward finer-grained visual tokenizations to boost performance. Speculative decoding has been effective in accelerating LLM inference by using a smaller draft model to generate candidate tokens, which are then selectively verified by the target model, improving speed without sacrificing output quality. While this strategy has been extended to LMMs, existing methods largely overlook the unique properties of visual inputs and depend solely on text-based draft models. In this work, we propose \textbf{FLASH} (Fast Latent-Aware Semi-Autoregressive Heuristics), a speculative decoding framework designed specifically for LMMs, which leverages two key properties of multimodal data to design the draft model. First, to address redundancy in visual tokens, we propose a lightweight latent-aware token compression mechanism. Second, recognizing that visual objects often co-occur within a scene, we employ a semi-autoregressive decoding strategy to generate multiple tokens per forward pass. These innovations accelerate draft decoding while maintaining high acceptance rates, resulting in faster overall inference. Experiments show that FLASH significantly outperforms prior speculative decoding approaches in both unimodal and multimodal settings, achieving up to \textbf{2.68$\times$} speed-up on video captioning and \textbf{2.55$\times$} on visual instruction tuning tasks compared to the original LMM.
大型语言和多模态模型(LLM 和 LMM)展现出强大的推理能力,但往往受到解码速度较慢的限制。这一挑战在 LMM 中尤为突出,因为视觉输入通常包含比文本更多的标记,但信息密度较低——这一问题因近期为提升性能而出现的更精细的视觉标记化趋势而加剧。投机解码通过使用较小的草稿模型生成候选标记来加速 LLM 推理,然后目标模型会进行选择性验证,从而在提高速度的同时不牺牲输出质量。虽然这一策略已扩展到 LMM,但现有方法大多忽略了视觉输入的独特属性,仅依赖于文本草稿模型。在这项工作中,我们提出一种名为 FLASH(快速潜在感知半自回归启发式方法)的投机解码框架,它是专门针对 LMM 设计的,利用多模态数据的两个关键属性来构建草稿模型。首先,为了解决视觉标记的冗余问题,我们提出了一种轻量级的潜在感知标记压缩机制。其次,我们认识到视觉对象通常会在场景中共现,因此采用半自回归解码策略,每次前向传递生成多个标记。这些创新加速了草稿解码,同时保持了较高的接受率,从而实现了更快的整体推理。实验表明,无论是在单模态还是多模态环境中,FLASH 都显著优于之前的投机解码方法。在与原始 LMM 的比较中,FLASH 在视频描述和视觉指令调整任务上分别实现了高达 2.68 倍和 2.55 倍的加速。
论文及项目相关链接
Summary
本文介绍了针对大型语言和多媒体模型(LLMs和LMMs)的推理速度限制问题,提出了一种名为FLASH的投机解码框架。该框架针对LMMs的特性进行设计,通过利用视觉数据的冗余性和对象共现性,实现了快速解码。实验表明,FLASH在单模态和多模态场景下均显著优于传统投机解码方法,视频描述和视觉指令调整任务的速度提升最高可达2.68倍和2.55倍。
Key Takeaways
- LLMs和LMMs具有强大的推理能力,但解码速度较慢,特别是在处理视觉输入时更为明显。
- 现有投机解码方法主要面向LLMs,忽略了视觉输入的独特性。
- FLASH框架针对LMMs设计,利用视觉数据的冗余性和对象共现性来加速解码。
- FLASH采用轻量级的潜在感知令牌压缩机制和半自动递归解码策略。
- 实验表明,FLASH在单模态和多模态场景下均显著提高了解码速度。
- FLASH在视频描述和视觉指令调整任务中的速度提升最高可达2.68倍和2.55倍。
点此查看论文截图


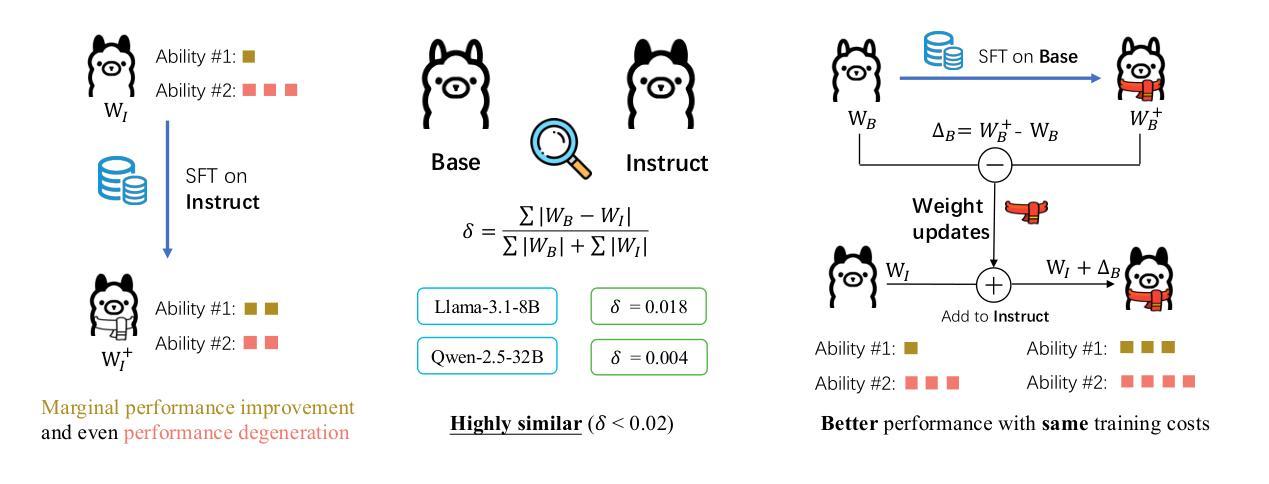
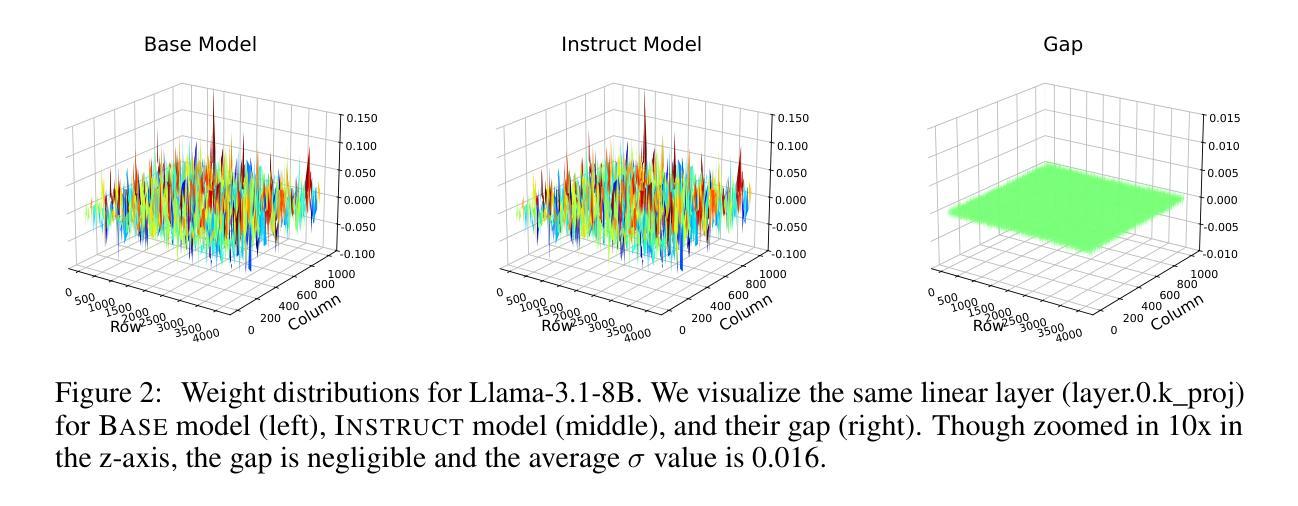
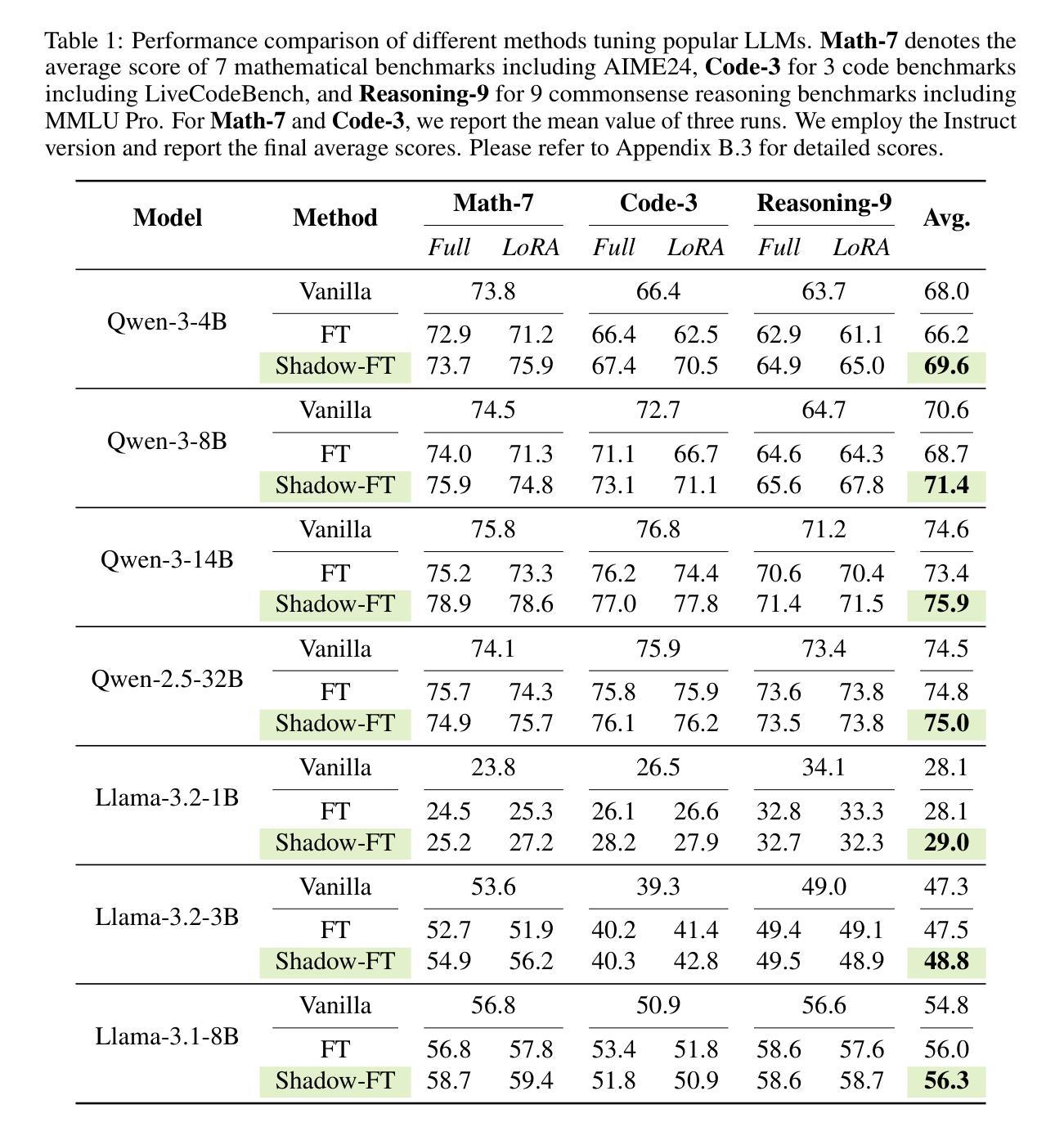
Shadow-FT: Tuning Instruct via Base
Authors:Taiqiang Wu, Runming Yang, Jiayi Li, Pengfei Hu, Ngai Wong, Yujiu Yang
Large language models (LLMs) consistently benefit from further fine-tuning on various tasks. However, we observe that directly tuning the INSTRUCT (i.e., instruction tuned) models often leads to marginal improvements and even performance degeneration. Notably, paired BASE models, the foundation for these INSTRUCT variants, contain highly similar weight values (i.e., less than 2% on average for Llama 3.1 8B). Therefore, we propose a novel Shadow-FT framework to tune the INSTRUCT models by leveraging the corresponding BASE models. The key insight is to fine-tune the BASE model, and then directly graft the learned weight updates to the INSTRUCT model. Our proposed Shadow-FT introduces no additional parameters, is easy to implement, and significantly improves performance. We conduct extensive experiments on tuning mainstream LLMs, such as Qwen 3 and Llama 3 series, and evaluate them across 19 benchmarks covering coding, reasoning, and mathematical tasks. Experimental results demonstrate that Shadow-FT consistently outperforms conventional full-parameter and parameter-efficient tuning approaches. Further analyses indicate that Shadow-FT can be applied to multimodal large language models (MLLMs) and combined with direct preference optimization (DPO). Codes and weights are available at \href{https://github.com/wutaiqiang/Shadow-FT}{Github}.
大型语言模型(LLM)在各种任务上通过进一步的微调持续受益。然而,我们观察到直接调整INSTRUCT(即指令调整)模型通常只会带来微小的改进,甚至会导致性能下降。值得注意的是,这些INSTRUCT变体的基础配套BASE模型包含高度相似的权重值(例如Llama 3.1 8B的平均值小于2%)。因此,我们提出了一种新的Shadow-FT框架,利用相应的BASE模型来调整INSTRUCT模型。关键思路是微调BASE模型,然后将学习到的权重更新直接移植到INSTRUCT模型。我们提出的Shadow-FT无需添加额外的参数,易于实现,并能显著提高性能。我们在主流的LLM上进行了广泛的实验,如Qwen 3和Llama 3系列,并在涵盖编码、推理和数学任务的19个基准测试上对其进行了评估。实验结果表明,Shadow-FT持续优于传统的全参数和参数高效的调整方法。进一步的分析表明,Shadow-FT可应用于多模态大型语言模型(MLLM),并与直接偏好优化(DPO)相结合。相关代码和权重可在Github上获取。
论文及项目相关链接
PDF Under review
摘要
大语言模型通过进一步的微调在各种任务上持续受益,但直接对INSTRUCT模型进行微调往往导致性能提升有限甚至出现退化。本文提出了Shadow-FT框架,利用相应的BASE模型对INSTRUCT模型进行微调。Shadow-FT的核心思想是先对BASE模型进行微调,然后将学习到的权重更新直接应用到INSTRUCT模型上。该方法无需添加额外的参数,易于实现,且能显著提高性能。实验结果表明,Shadow-FT在主流LLM上的性能优于传统的全参数和参数高效调整方法。同时,Shadow-FT可应用于多模态大型语言模型(MLLMs)并与直接偏好优化(DPO)结合。
关键见解
- 直接微调INSTRUCT模型常常导致性能提升有限或性能退化。
- 提出的Shadow-FT框架利用相应的BASE模型进行微调。
- Shadow-FT通过对BASE模型进行微调,然后将学习到的权重更新应用到INSTRUCT模型上。
- Shadow-FT方法无需额外的参数,易于实现。
- 实验表明,Shadow-FT在主流LLM上的性能优于传统方法。
- Shadow-FT可应用于多模态大型语言模型(MLLMs)。
- Shadow-FT可与直接偏好优化(DPO)结合使用。
点此查看论文截图

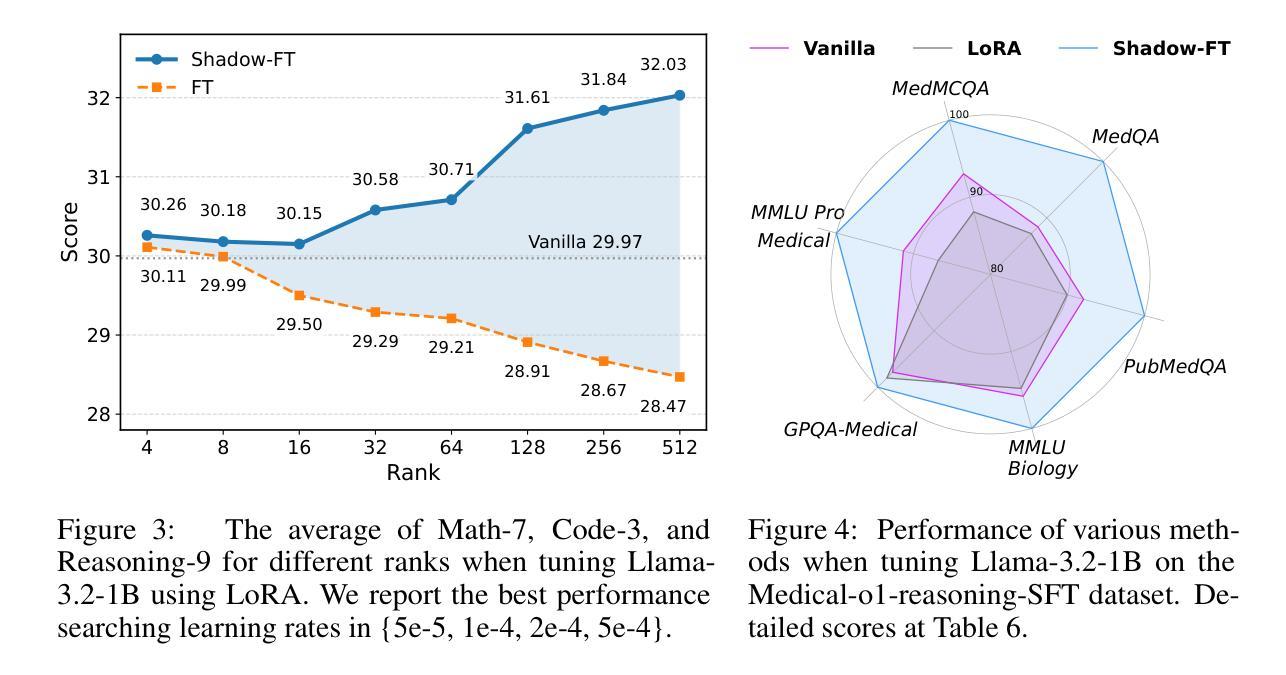
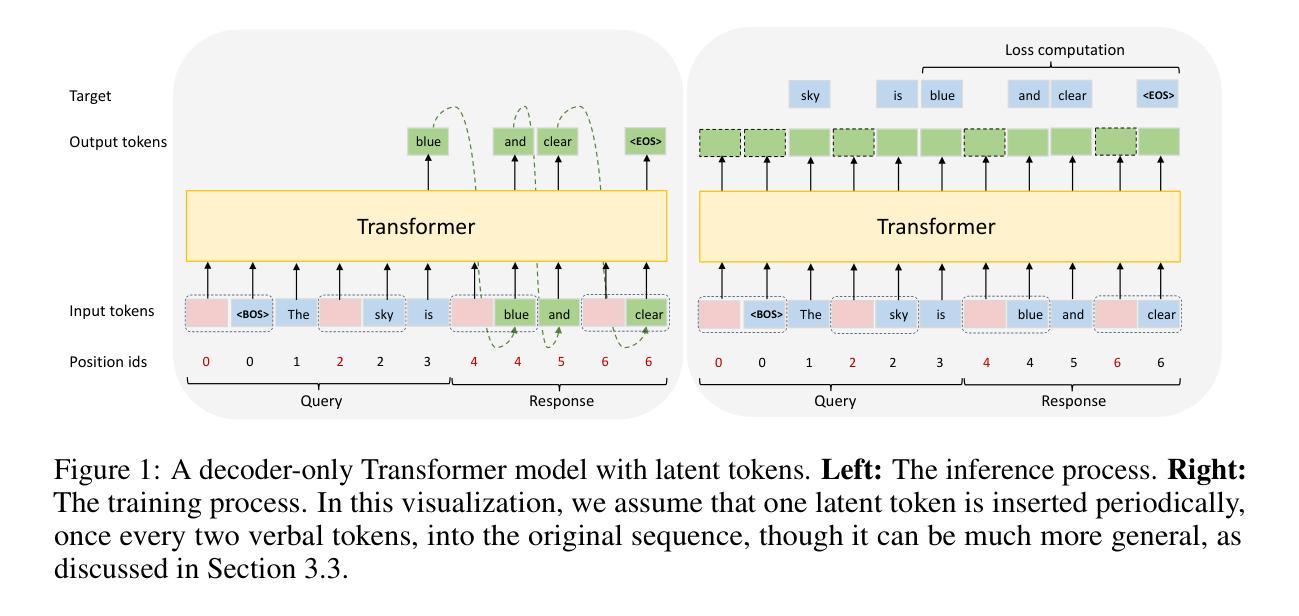
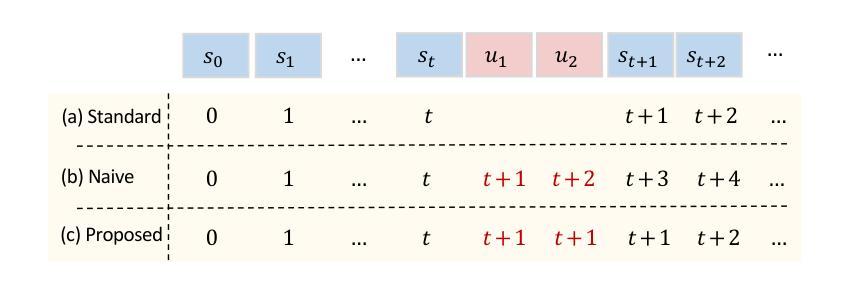
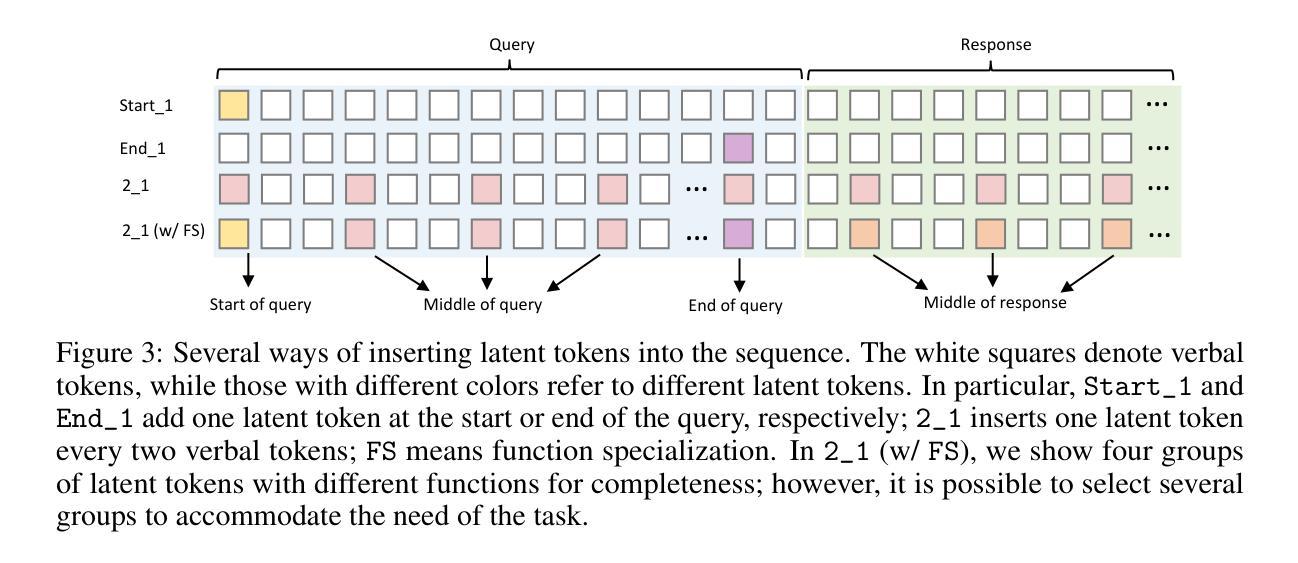
Enhancing Latent Computation in Transformers with Latent Tokens
Authors:Yuchang Sun, Yanxi Chen, Yaliang Li, Bolin Ding
Augmenting large language models (LLMs) with auxiliary tokens has emerged as a promising strategy for enhancing model performance. In this work, we introduce a lightweight method termed latent tokens; these are dummy tokens that may be non-interpretable in natural language but steer the autoregressive decoding process of a Transformer-based LLM via the attention mechanism. The proposed latent tokens can be seamlessly integrated with a pre-trained Transformer, trained in a parameter-efficient manner, and applied flexibly at inference time, while adding minimal complexity overhead to the existing infrastructure of standard Transformers. We propose several hypotheses about the underlying mechanisms of latent tokens and design synthetic tasks accordingly to verify them. Numerical results confirm that the proposed method noticeably outperforms the baselines, particularly in the out-of-distribution generalization scenarios, highlighting its potential in improving the adaptability of LLMs.
通过辅助标记增强大型语言模型(LLM)已成为提高模型性能的一种有前途的策略。在这项工作中,我们提出了一种轻量级的方法,称为潜在标记。这些是非自然语言中不可解释的虚拟标记,但通过注意力机制引导基于Transformer的LLM的自回归解码过程。所提出的潜在标记可以无缝地集成到预训练的Transformer中,以高效参数的方式进行训练,并在推理时间灵活应用,同时给现有标准Transformer基础设施增加最小的复杂性开销。我们对潜在标记的潜在机制提出了一些假设,并设计了相应的合成任务来验证它们。数值结果表明,该方法明显优于基线,特别是在超出分布范围的泛化场景中表现尤为突出,突显其在提高LLM适应性方面的潜力。
论文及项目相关链接
Summary
潜藏令牌是一种增强大型语言模型(LLM)性能的有效策略。该策略通过引入非自然语言理解的潜藏令牌,利用注意力机制引导基于Transformer的LLM的自回归解码过程。这些令牌可无缝集成到预训练的Transformer中,以高效的方式训练,并在推理时灵活应用,同时为现有的标准Transformer架构增加极低的复杂性开销。实验结果表明,该方法在特别是非分布泛化场景中显著优于基线方法,显示出提高LLM适应性的潜力。
Key Takeaways
- 潜藏令牌是一种增强LLM性能的有效策略。
- 潜藏令牌通过注意力机制引导基于Transformer的LLM的自回归解码过程。
- 潜藏令牌可以无缝集成到预训练的Transformer中,并以参数高效的方式进行训练。
- 潜藏令牌在推理时具有灵活性,并增加了极低的复杂性开销。
- 实验结果表明,潜藏令牌在特别是非分布泛化场景中显著提高了模型性能。
- 潜藏令牌提高了LLM的适应性。
点此查看论文截图

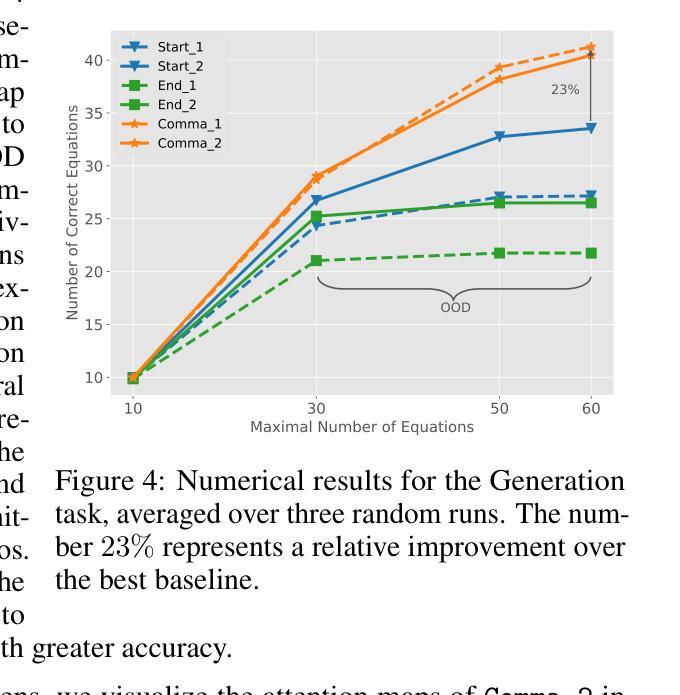
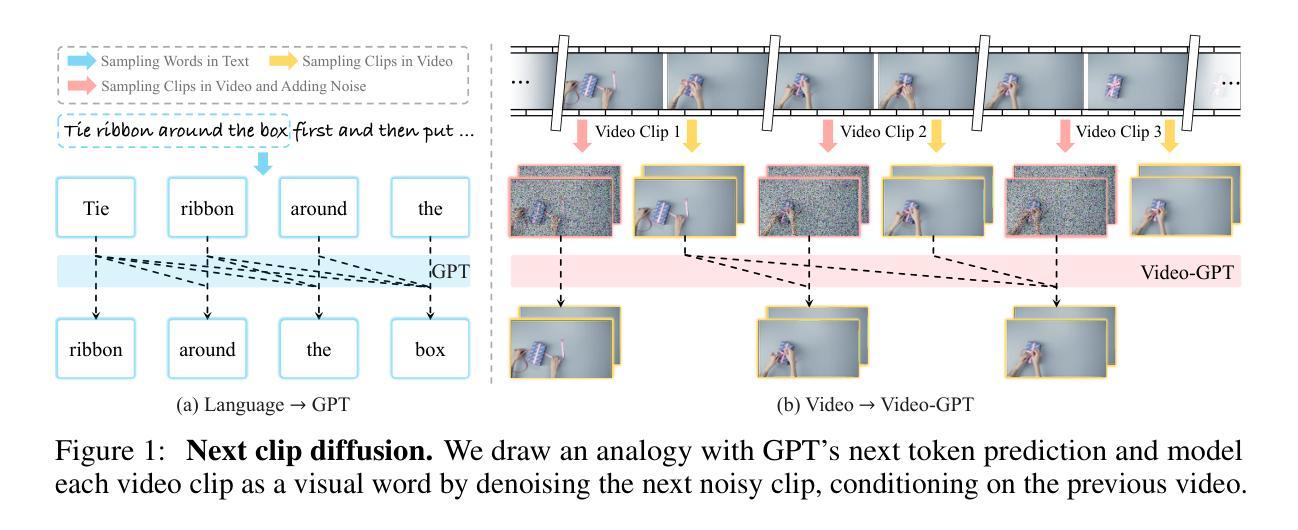
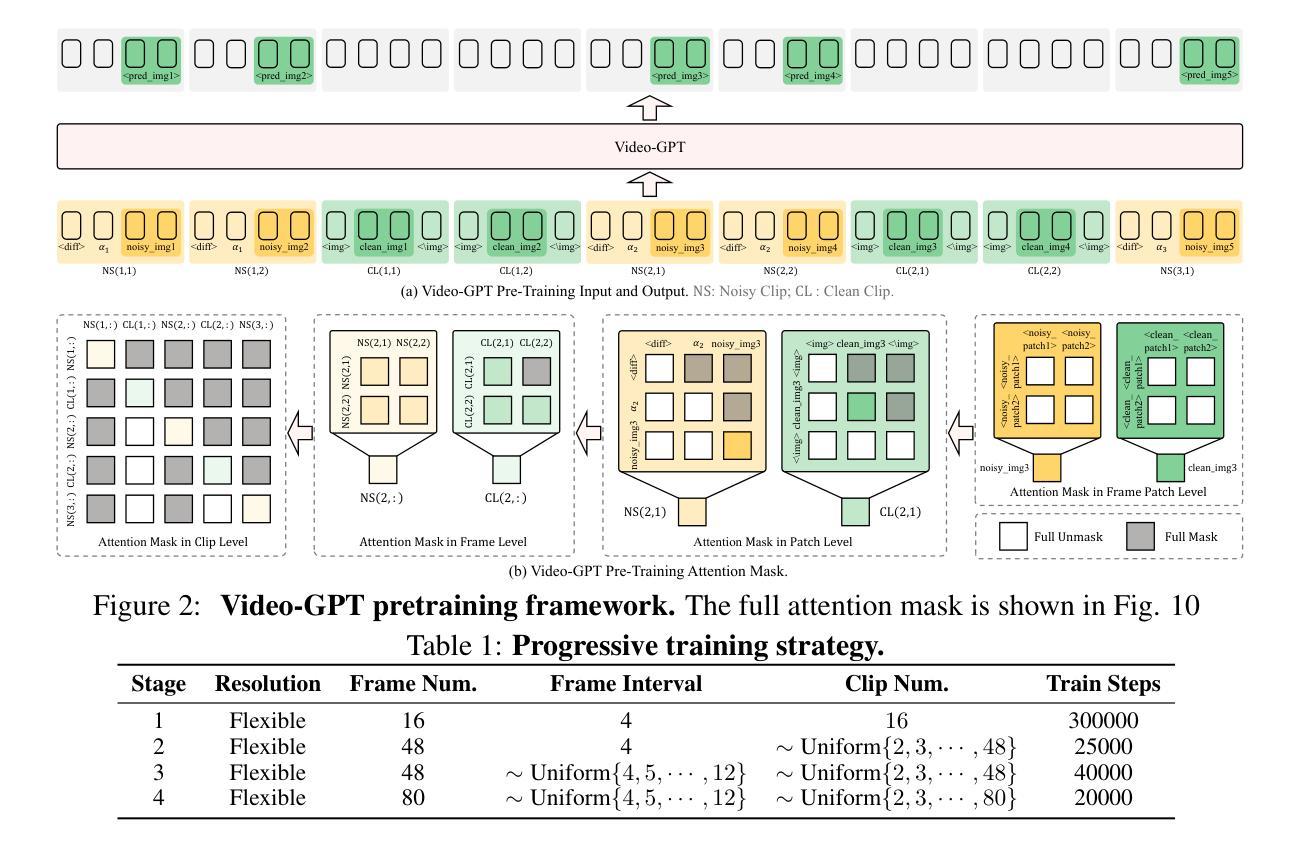
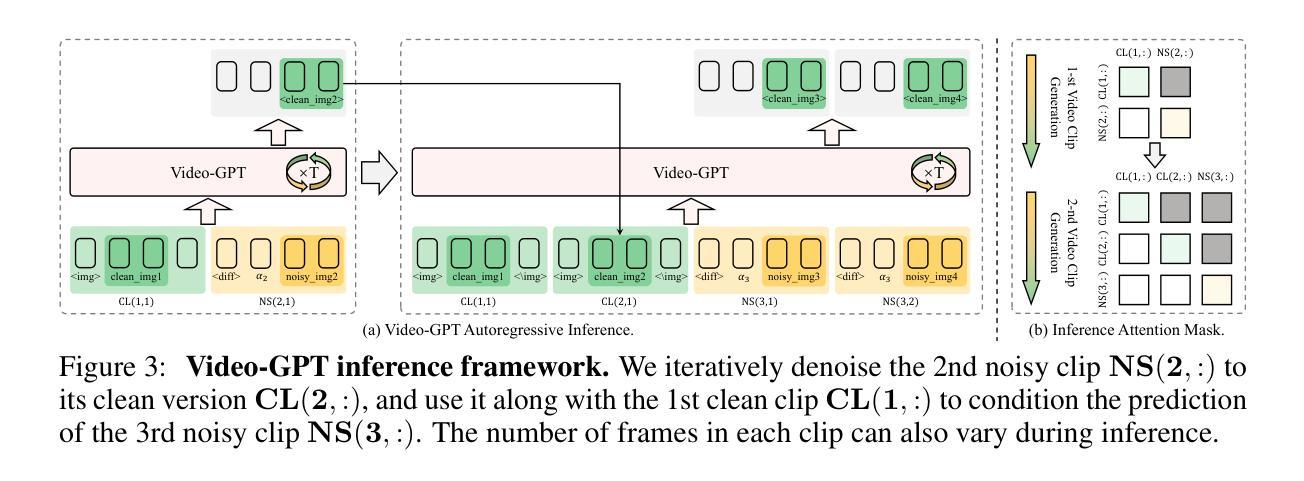
Video-GPT via Next Clip Diffusion
Authors:Shaobin Zhuang, Zhipeng Huang, Ying Zhang, Fangyikang Wang, Canmiao Fu, Binxin Yang, Chong Sun, Chen Li, Yali Wang
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://Video-GPT.github.io.
GPT在自然语言处理方面取得了显著的成功。然而,仅仅依靠语言序列不足以描述视觉世界中的时空细节。相比之下,视频序列更擅长捕捉这些细节。基于这一事实,我们在本文中提出了一种简洁的视频GPT,将视频视为视觉世界建模的新语言。通过模拟GPT中的下一个令牌预测,我们引入了一种新的下一个片段扩散模式来预训练视频GPT。与以前的工作不同,这种独特的模式允许视频GPT解决短期生成和长期预测问题,根据历史中的干净片段自回归地对嘈杂片段进行降噪。大量实验表明,我们的视频GPT在视频预测方面达到了最新水平的技术性能,这是实现世界建模的关键因素(Physics-IQ Benchmark:视频GPT 34.97对Kling 23.64对Wan 20.89)。此外,它还可以很好地适应视频生成和理解方面的6个主流任务,显示出其在下游任务中强大的泛化能力。项目页面位于https://Video-GPT.github.io。
论文及项目相关链接
PDF 22 pages, 12 figures, 18 tables
Summary
本文提出了一个新颖的Video-GPT模型,将视频视为一种新的语言来进行视觉世界建模。通过借鉴GPT中的下一个词预测,引入了下一个片段扩散范式来预训练Video-GPT。与以往的工作不同,这种独特的范式使得Video-GPT能够同时进行短期生成和长期预测。通过自适应去除噪声片段中的噪声,它达到了视频预测方面的最佳性能。此外,Video-GPT在视频生成和理解方面的六个主流任务上具有良好的适应性,显示出其出色的下游任务泛化能力。
Key Takeaways
- Video-GPT模型将视频视为一种新语言进行视觉世界建模。
- 借鉴GPT中的下一个词预测,引入了下一个片段扩散范式进行预训练。
- 这种新的范式使得Video-GPT能够同时进行短期生成和长期预测。
- Video-GPT通过自适应去除噪声片段中的噪声,实现了视频预测的最佳性能。
- Video-GPT在多个视频任务上表现优秀,具有良好的泛化能力。
- Video-GPT在Physics-IQ Benchmark上的得分远高于其他模型,体现了其优越性。
点此查看论文截图

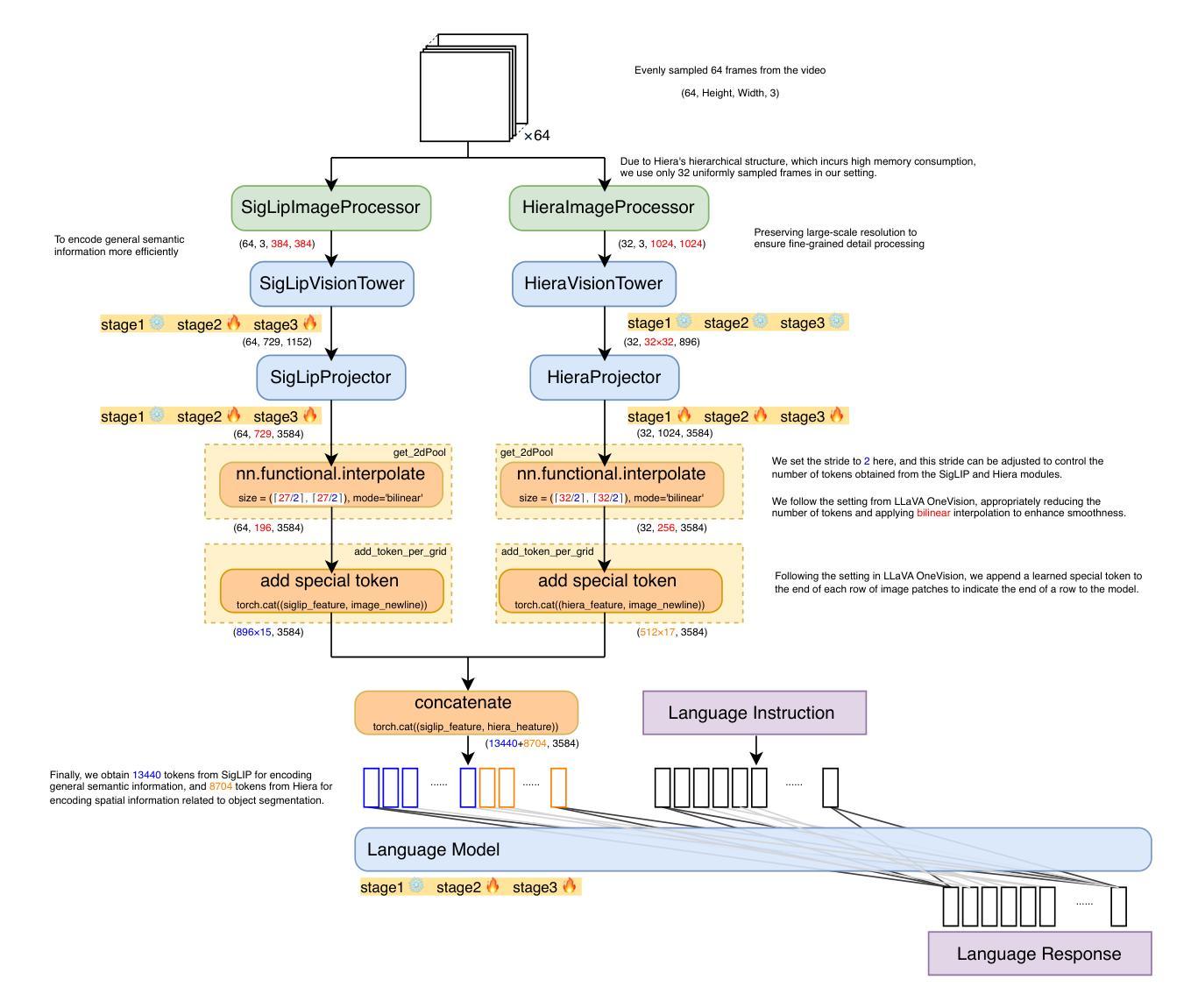
Towards Visuospatial Cognition via Hierarchical Fusion of Visual Experts
Authors:Qi Feng, Hidetoshi Shimodaira
While Multimodal Large Language Models (MLLMs) excel at general vision-language tasks, visuospatial cognition - reasoning about spatial layouts, relations, and dynamics - remains a significant challenge. Existing models often lack the necessary architectural components and specialized training data for fine-grained spatial understanding. We introduce ViCA2 (Visuospatial Cognitive Assistant 2), a novel MLLM designed to enhance spatial reasoning. ViCA2 features a dual vision encoder architecture integrating SigLIP for semantics and Hiera for spatial structure, coupled with a token ratio control mechanism for efficiency. We also developed ViCA-322K, a new large-scale dataset with over 322,000 spatially grounded question-answer pairs for targeted instruction tuning. On the challenging VSI-Bench benchmark, our ViCA2-7B model achieves a state-of-the-art average score of 56.8, significantly surpassing larger open-source models (e.g., LLaVA-NeXT-Video-72B, 40.9) and leading proprietary models (Gemini-1.5 Pro, 45.4). This demonstrates the effectiveness of our approach in achieving strong visuospatial intelligence with a compact model. We release ViCA2, its codebase, and the ViCA-322K dataset to facilitate further research.
多模态大型语言模型(MLLMs)在一般的视觉语言任务上表现出色,但对于空间布局、关系和动态的空间认知仍然是一个巨大的挑战。现有模型通常缺乏必要的架构组件和精细空间理解所需的专门训练数据。我们推出了ViCA2(视觉空间认知助手2),这是一款旨在增强空间推理能力的新型MLLM。ViCA2采用双视觉编码器架构,集成SigLIP进行语义分析,结合Hiera进行空间结构分析,同时采用令牌比率控制机制以提高效率。我们还开发了ViCA-322K,这是一个新的大规模数据集,包含超过32万对空间定位的问题和答案,用于针对性的指令调整。在具有挑战性的VSI-Bench基准测试中,我们的ViCA2-7B模型达到了平均得分56.8分的业界最佳水平,显著超过了更大的开源模型(例如LLaVA-NeXT-Video-72B的40.9分)和领先的专有模型(Gemini-1.5 Pro的45.4分)。这证明了我们的方法在实现强大空间智能时的有效性,且采用了紧凑的模型。我们发布ViCA2、其代码库和ViCA-322K数据集,以促进进一步的研究。
论文及项目相关链接
PDF 26 pages, 19 figures, 4 tables. Code, models, and dataset are available at our project page: https://github.com/nkkbr/ViCA
Summary
MLLM在一般视觉语言任务上表现出色,但在处理空间布局、关系和动态的视觉空间认知上仍面临挑战。针对这一问题,我们推出了ViCA2(视觉空间认知助手2),这是一款设计用于增强空间推理的新型Multimodal大型语言模型。ViCA2采用双视觉编码器架构,集成SigLIP进行语义分析并Hiera进行空间结构分析,同时采用令牌比率控制机制以提高效率。此外,我们还开发了大型数据集ViCA-322K,包含超过32万组空间定位问题答案对,用于针对性指导调整。在具有挑战性的VSI-Bench基准测试中,我们的ViCA2-7B模型平均得分达到56.8,显著超越了其他开源大型模型(如LLaVA-NeXT-Video-72B的40.9分)和领先的专有模型(Gemini-1.5 Pro的45.4分)。这证明了我们的方法在实现强大的视觉空间智能方面的有效性,同时模型较为紧凑。我们公开发布了ViCA2、其代码库和ViCA-322K数据集,以促进进一步研究。
Key Takeaways
- Multimodal Large Language Models (MLLMs)虽擅长一般视觉语言任务,但在视觉空间认知方面存在挑战。
- ViCA2是一款新型MLLM,旨在增强空间推理能力,具有双视觉编码器架构、语义分析、空间结构分析以及高效的令牌比率控制机制。
- 开发了大型数据集ViCA-322K,用于针对性指导调整模型。
- ViCA2在VSI-Bench基准测试中表现优异,平均得分56.8,显著超越其他模型。
- ViCA2实现了强大的视觉空间智能,同时模型较为紧凑。
- ViCA2、其代码库和ViCA-322K数据集已公开发布,以促进进一步研究。
点此查看论文截图
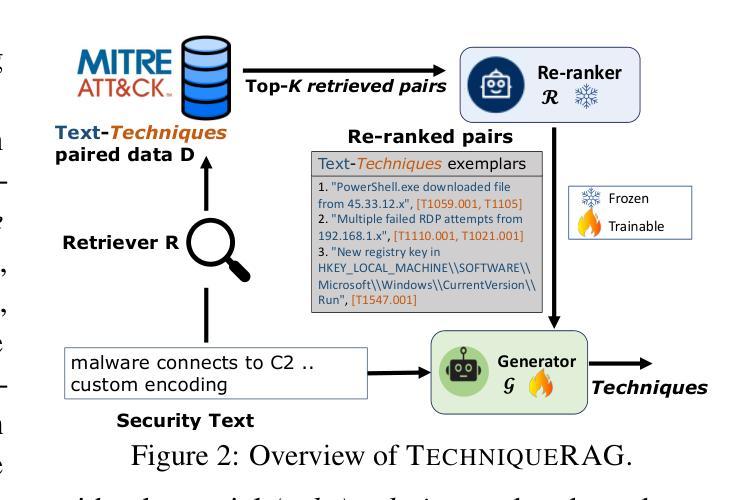
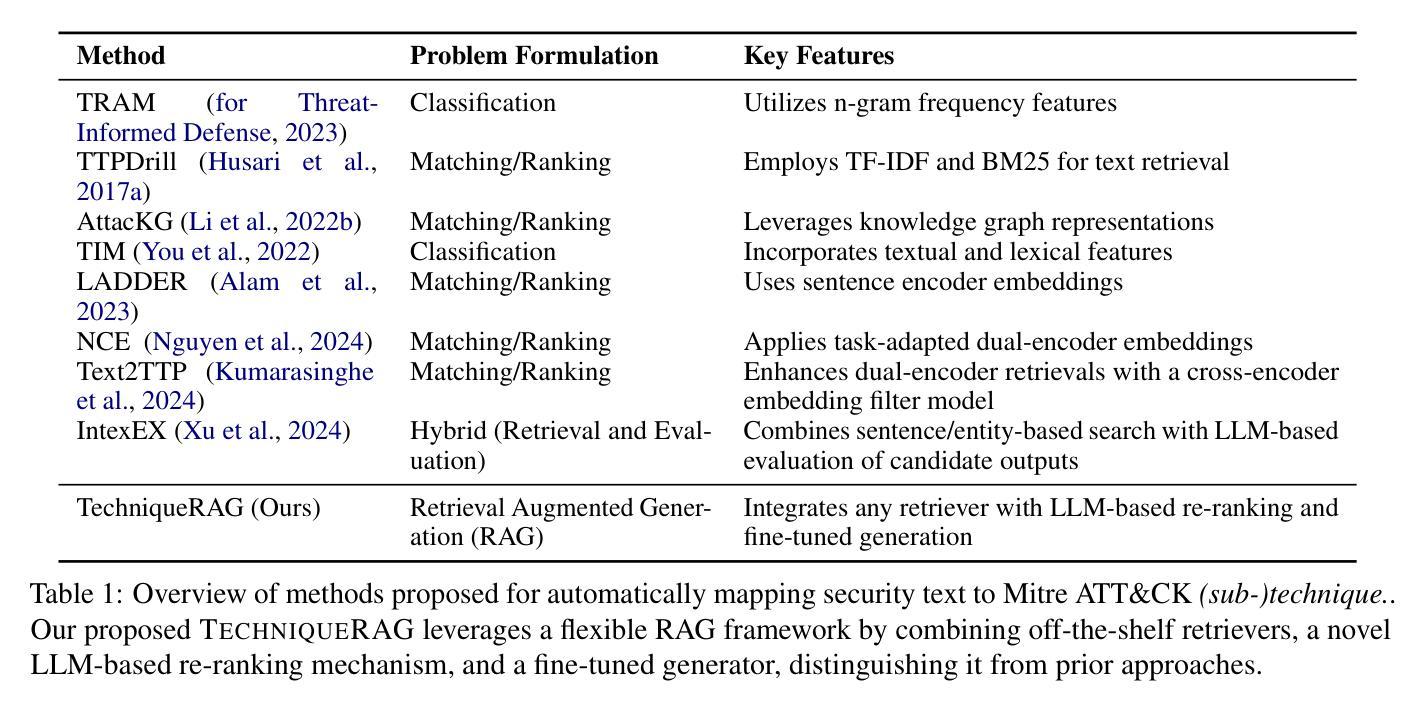
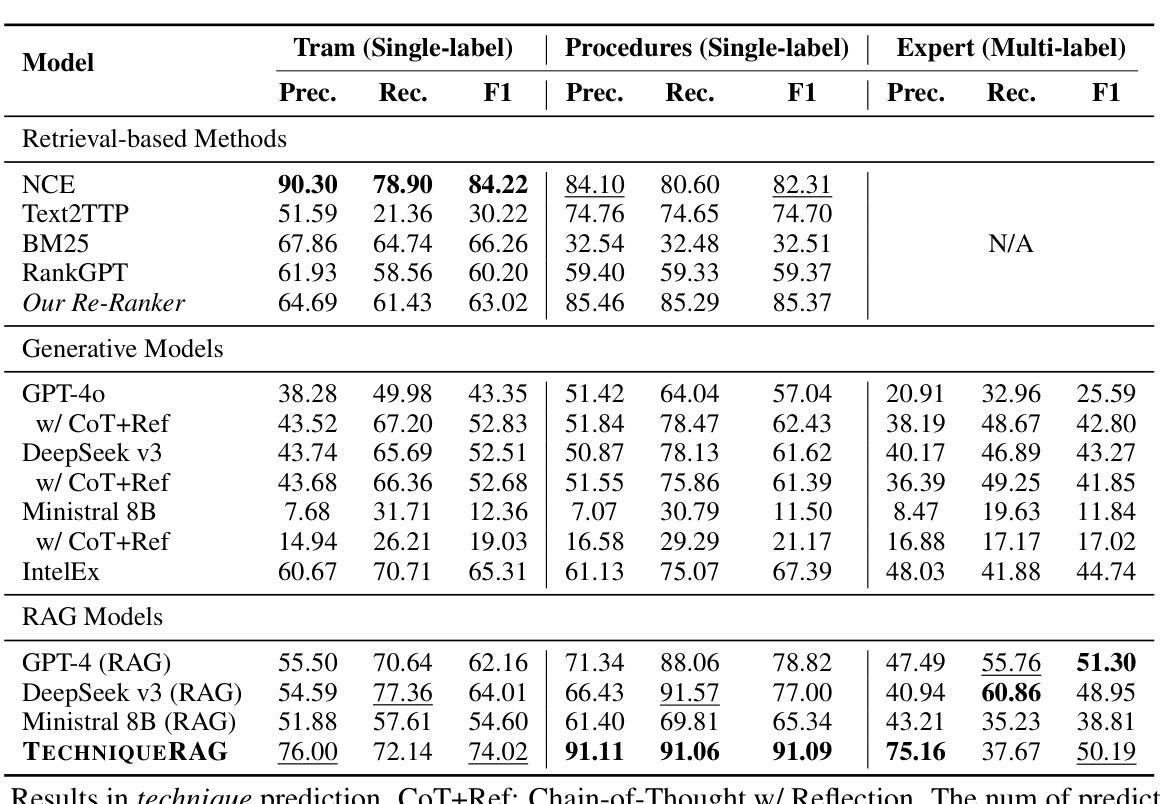
TechniqueRAG: Retrieval Augmented Generation for Adversarial Technique Annotation in Cyber Threat Intelligence Text
Authors:Ahmed Lekssays, Utsav Shukla, Husrev Taha Sencar, Md Rizwan Parvez
Accurately identifying adversarial techniques in security texts is critical for effective cyber defense. However, existing methods face a fundamental trade-off: they either rely on generic models with limited domain precision or require resource-intensive pipelines that depend on large labeled datasets and task-specific optimizations, such as custom hard-negative mining and denoising, resources rarely available in specialized domains. We propose TechniqueRAG, a domain-specific retrieval-augmented generation (RAG) framework that bridges this gap by integrating off-the-shelf retrievers, instruction-tuned LLMs, and minimal text-technique pairs. Our approach addresses data scarcity by fine-tuning only the generation component on limited in-domain examples, circumventing the need for resource-intensive retrieval training. While conventional RAG mitigates hallucination by coupling retrieval and generation, its reliance on generic retrievers often introduces noisy candidates, limiting domain-specific precision. To address this, we enhance retrieval quality and domain specificity through zero-shot LLM re-ranking, which explicitly aligns retrieved candidates with adversarial techniques. Experiments on multiple security benchmarks demonstrate that TechniqueRAG achieves state-of-the-art performance without extensive task-specific optimizations or labeled data, while comprehensive analysis provides further insights.
准确识别安全文本中的对抗技术是有效网络防御的关键。然而,现有方法面临基本权衡:它们要么依赖于具有有限领域精度的通用模型,要么需要依赖大量标记数据和特定任务优化(如自定义的硬负样本挖掘和去噪)的资源密集型管道,这些资源在特定领域很少可用。我们提出了TechniqueRAG,这是一个领域特定的检索增强生成(RAG)框架,它通过集成现成的检索器、指令调优的LLM和少量的文本技术配对来弥补这一差距。我们的方法通过仅对领域内的有限示例进行生成组件的微调来解决数据稀缺问题,从而避免了资源密集型的检索训练需求。虽然传统的RAG通过耦合检索和生成来缓解虚构问题,但它对通用检索器的依赖往往会引入嘈杂的候选对象,从而限制了领域特定的精度。为了解决这一问题,我们通过零样本LLM重新排序来提高检索质量和领域特异性,这将明确地将检索到的候选对象与对抗技术对齐。在多个安全基准测试上的实验表明,TechniqueRAG在不进行大量特定任务优化或标记数据的情况下实现了最佳性能,而综合分析提供了进一步的见解。
论文及项目相关链接
PDF Accepted at ACL (Findings) 2025
Summary
本文介绍了在安全文本中准确识别对抗技术的重要性,并指出了现有方法的局限性。为此,提出了一种基于检索增强生成(RAG)的域特定框架TechniqueRAG,通过集成现成的检索器、指令微调的大型语言模型和少量的文本技术对数据对来弥补数据稀缺的缺陷。该框架通过提高检索质量和领域特异性来解决传统RAG方法的问题,实现了在安全文本领域的卓越性能。
Key Takeaways
- 准确识别安全文本中的对抗技术是有效网络防御的关键。
- 现有方法面临通用模型与领域精度有限的权衡问题。
- TechniqueRAG是一个域特定的RAG框架,集成了现成的检索器、指令微调的大型语言模型和少量文本技术对数据对。
- TechniqueRAG解决了数据稀缺的问题,通过只对生成组件进行微调,而无需大量领域特定的数据集和任务特定优化。
- 传统RAG方法中的检索和生成耦合有助于缓解虚构问题,但依赖于通用检索器,可能导致引入噪声候选者,限制了领域特定的精度。
- TechniqueRAG通过零样本大型语言模型重新排名增强检索质量和领域特异性。
点此查看论文截图

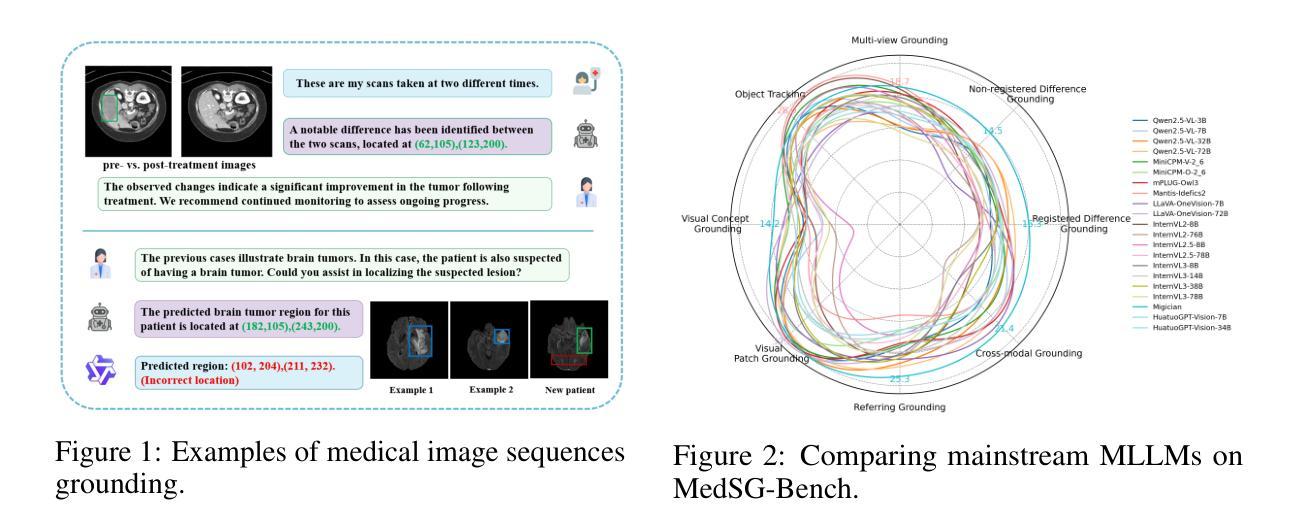
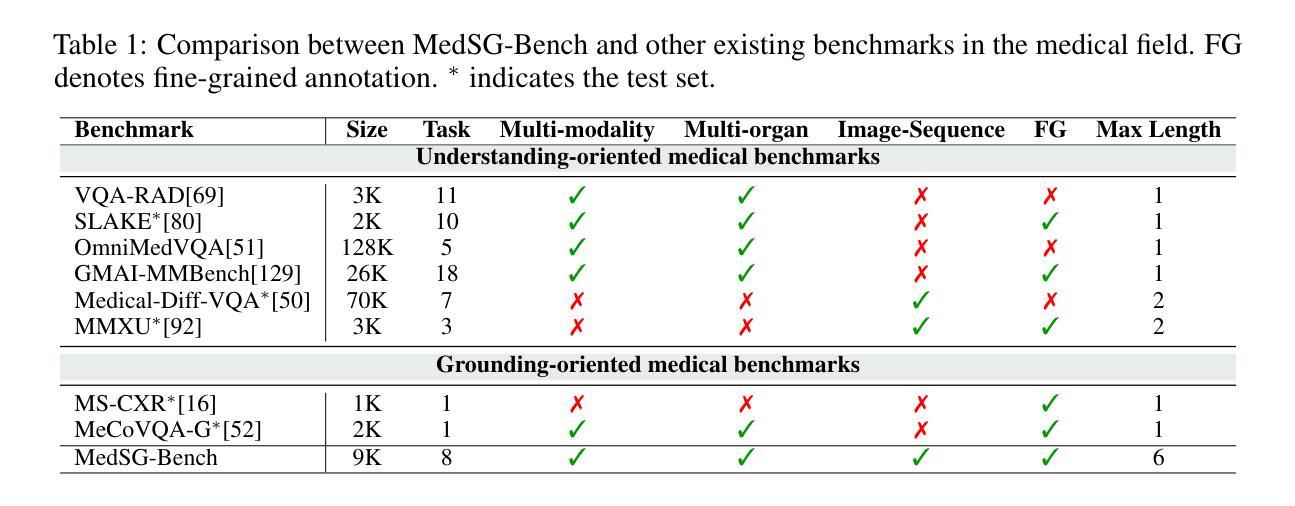
MedSG-Bench: A Benchmark for Medical Image Sequences Grounding
Authors:Jingkun Yue, Siqi Zhang, Zinan Jia, Huihuan Xu, Zongbo Han, Xiaohong Liu, Guangyu Wang
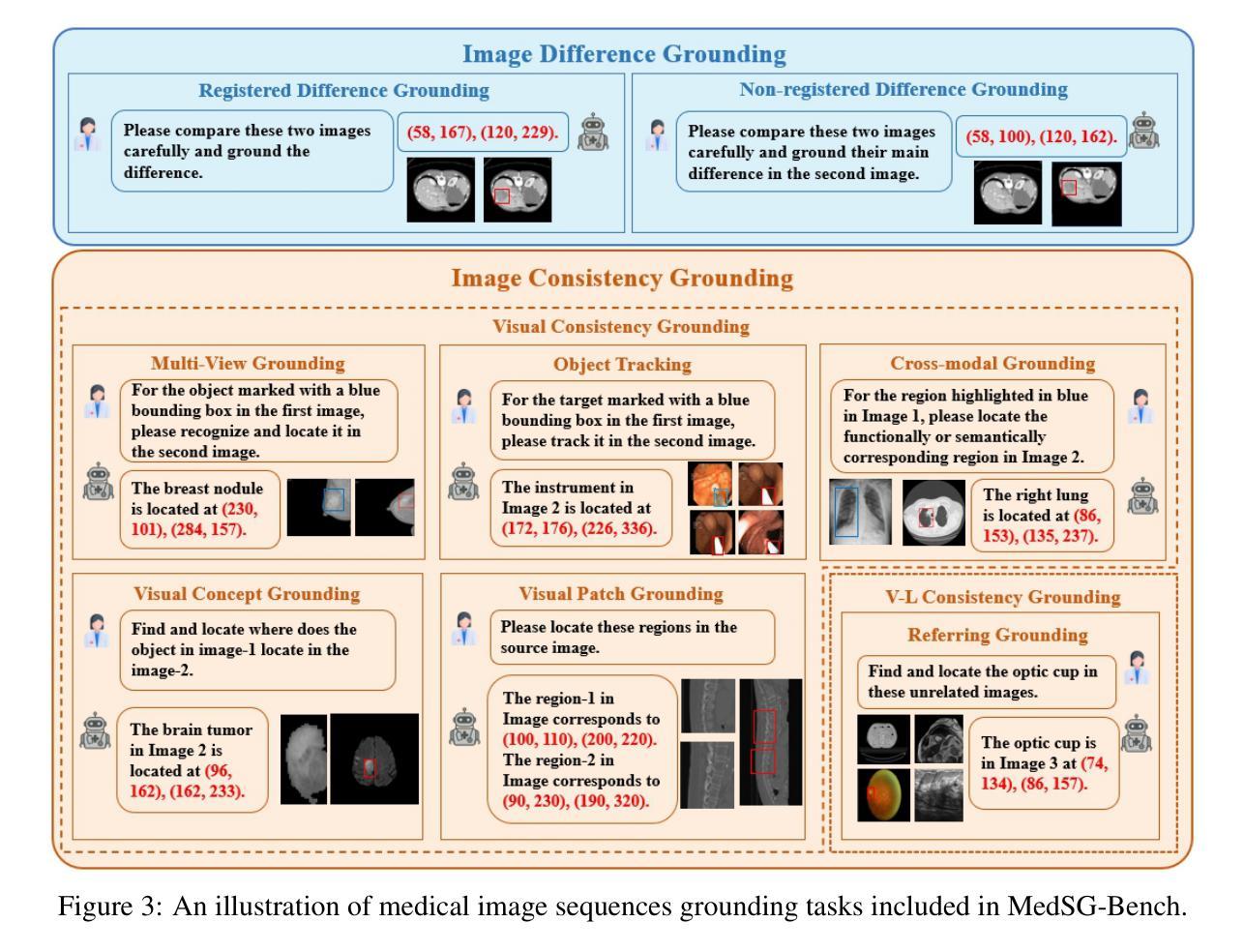
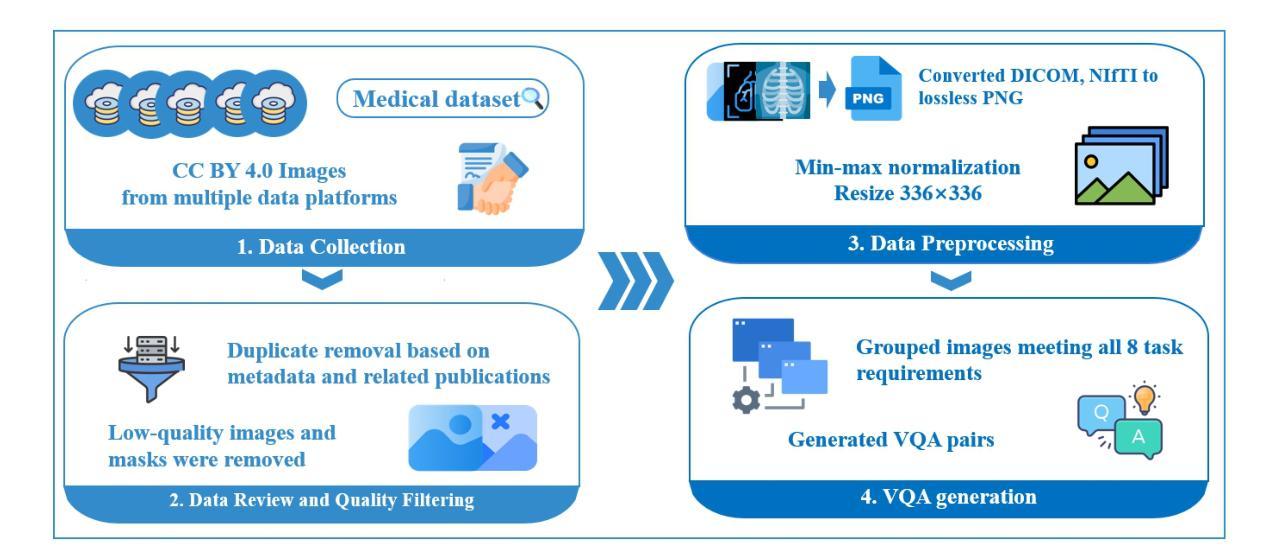
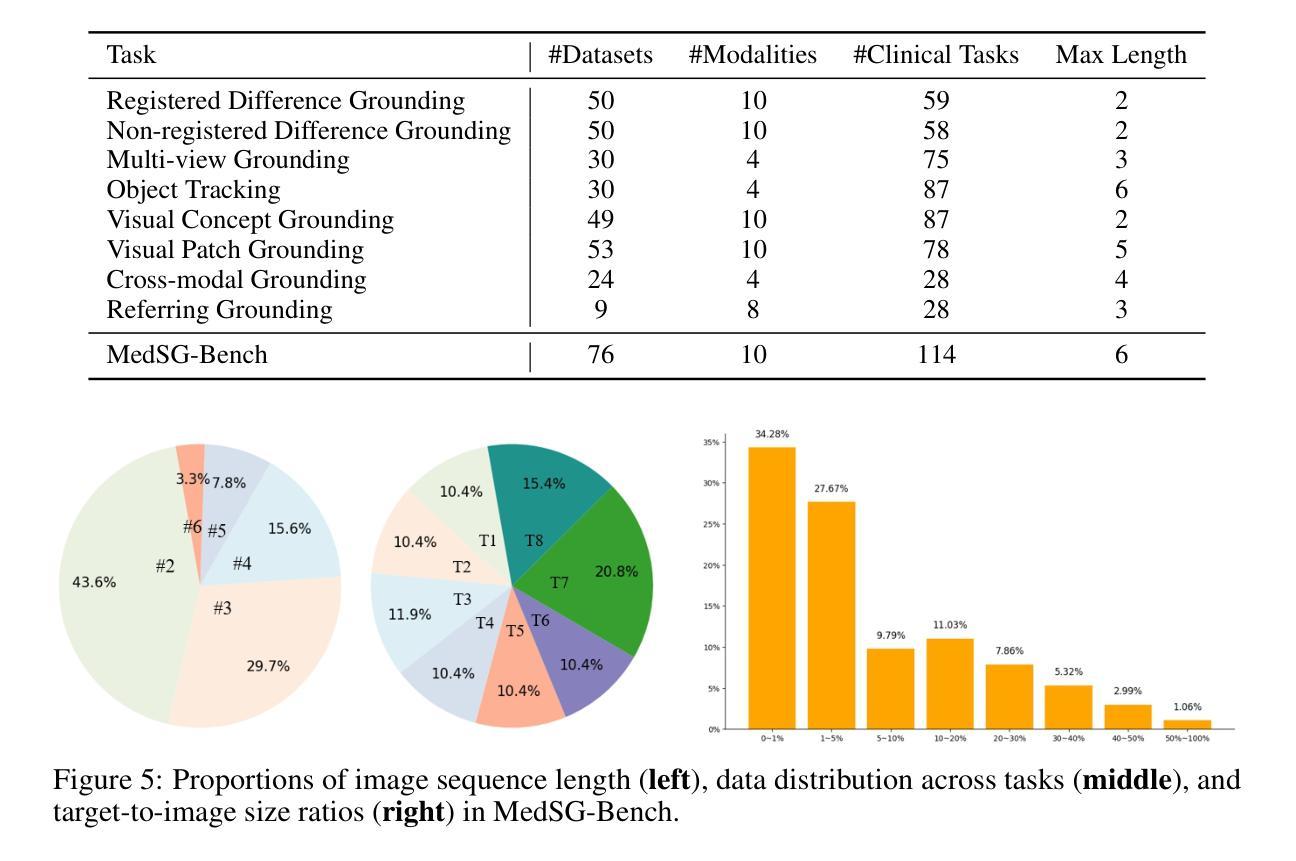
Visual grounding is essential for precise perception and reasoning in multimodal large language models (MLLMs), especially in medical imaging domains. While existing medical visual grounding benchmarks primarily focus on single-image scenarios, real-world clinical applications often involve sequential images, where accurate lesion localization across different modalities and temporal tracking of disease progression (e.g., pre- vs. post-treatment comparison) require fine-grained cross-image semantic alignment and context-aware reasoning. To remedy the underrepresentation of image sequences in existing medical visual grounding benchmarks, we propose MedSG-Bench, the first benchmark tailored for Medical Image Sequences Grounding. It comprises eight VQA-style tasks, formulated into two paradigms of the grounding tasks, including 1) Image Difference Grounding, which focuses on detecting change regions across images, and 2) Image Consistency Grounding, which emphasizes detection of consistent or shared semantics across sequential images. MedSG-Bench covers 76 public datasets, 10 medical imaging modalities, and a wide spectrum of anatomical structures and diseases, totaling 9,630 question-answer pairs. We benchmark both general-purpose MLLMs (e.g., Qwen2.5-VL) and medical-domain specialized MLLMs (e.g., HuatuoGPT-vision), observing that even the advanced models exhibit substantial limitations in medical sequential grounding tasks. To advance this field, we construct MedSG-188K, a large-scale instruction-tuning dataset tailored for sequential visual grounding, and further develop MedSeq-Grounder, an MLLM designed to facilitate future research on fine-grained understanding across medical sequential images. The benchmark, dataset, and model are available at https://huggingface.co/MedSG-Bench
视觉定位在多模态大型语言模型(MLLMs)中,特别是在医学影像领域,对于精确感知和推理至关重要。尽管现有的医学视觉定位基准测试主要关注单图像场景,但现实世界临床应用通常涉及图像序列,其中不同模态之间的精确病灶定位和疾病进展的时空追踪(例如,治疗前后的比较)需要精细的跨图像语义对齐和上下文感知推理。为了弥补现有医学视觉定位基准测试中图像序列表示不足的问题,我们提出了MedSG-Bench,这是专门为医学图像序列定位量身定制的第一个基准测试。它包含了八个VQA风格的任务,制定为两种定位任务的模式,包括1)图像差异定位,专注于检测图像之间的变化区域;2)图像一致性定位,强调检测序列图像中一致或共享的语义。MedSG-Bench涵盖了76个公共数据集、10种医学成像模态以及广泛的解剖结构和疾病,总共9630个问答对。我们对通用MLLMs(例如Qwen2.5-VL)和医疗领域专用MLLMs(例如HuatuoGPT-vision)进行了基准测试,发现即使在医学序列定位任务中,先进模型也表现出相当大的局限性。为了推动这一领域的发展,我们构建了MedSG-188K,这是一个专门用于序列视觉定位的大型指令调整数据集,并进一步发展了MedSeq-Grounder,这是一个MLLM,旨在促进未来对医学序列图像的精细理解研究。该基准测试、数据集和模型均可在https://huggingface.co/MedSG-Bench找到。
论文及项目相关链接
Summary
针对多模态大型语言模型(MLLMs)在医疗成像领域中的精确感知和推理,视觉基础至关重要。现有医疗视觉基础基准测试主要集中在单图像场景上,而现实世界中的临床应用通常涉及图像序列,要求精细的跨图像语义对齐和上下文感知推理。为此,我们提出MedSG-Bench,首个针对医疗图像序列基础的基准测试。它包括八种VQA风格的任务,分为两大基础任务范式,包括1)图像差异基础,专注于检测图像间的变化区域;2)图像一致性基础,强调检测序列图像中一致或共享语义。MedSG-Bench覆盖76个公共数据集、10种医学影像模态和广泛的结构与疾病,共包含9630个问答对。我们对通用MLLMs(如Qwen2.5-VL)和医疗领域专用MLLMs(如HuatuoGPT-vision)进行了基准测试,发现即使是高级模型在医疗序列基础任务上也存在显著局限性。为了推动这一领域的发展,我们构建了针对序列视觉基础的大规模指令调整数据集MedSG-188K,并开发了MLLM——MedSeq-Grounder,以促进对医疗序列图像的精细理解研究。
Key Takeaways
- 视觉基础在多模态大型语言模型(MLLMs)的精确感知和推理中至关重要,特别是在医疗成像领域。
- 现有医疗视觉基础基准测试主要关注单图像场景,但实际应用涉及图像序列。
- MedSG-Bench首次为医疗图像序列基础提供基准测试,涵盖多种任务和数据集。
- 基准测试显示,即使是高级MLLMs在医疗序列基础任务上仍存在局限性。
- 为了改进模型性能,构建了针对序列视觉基础的大规模指令调整数据集MedSG-188K。
- 开发了MedSeq-Grounder这一MLLM,以促进对医疗序列图像的精细理解研究。
点此查看论文截图

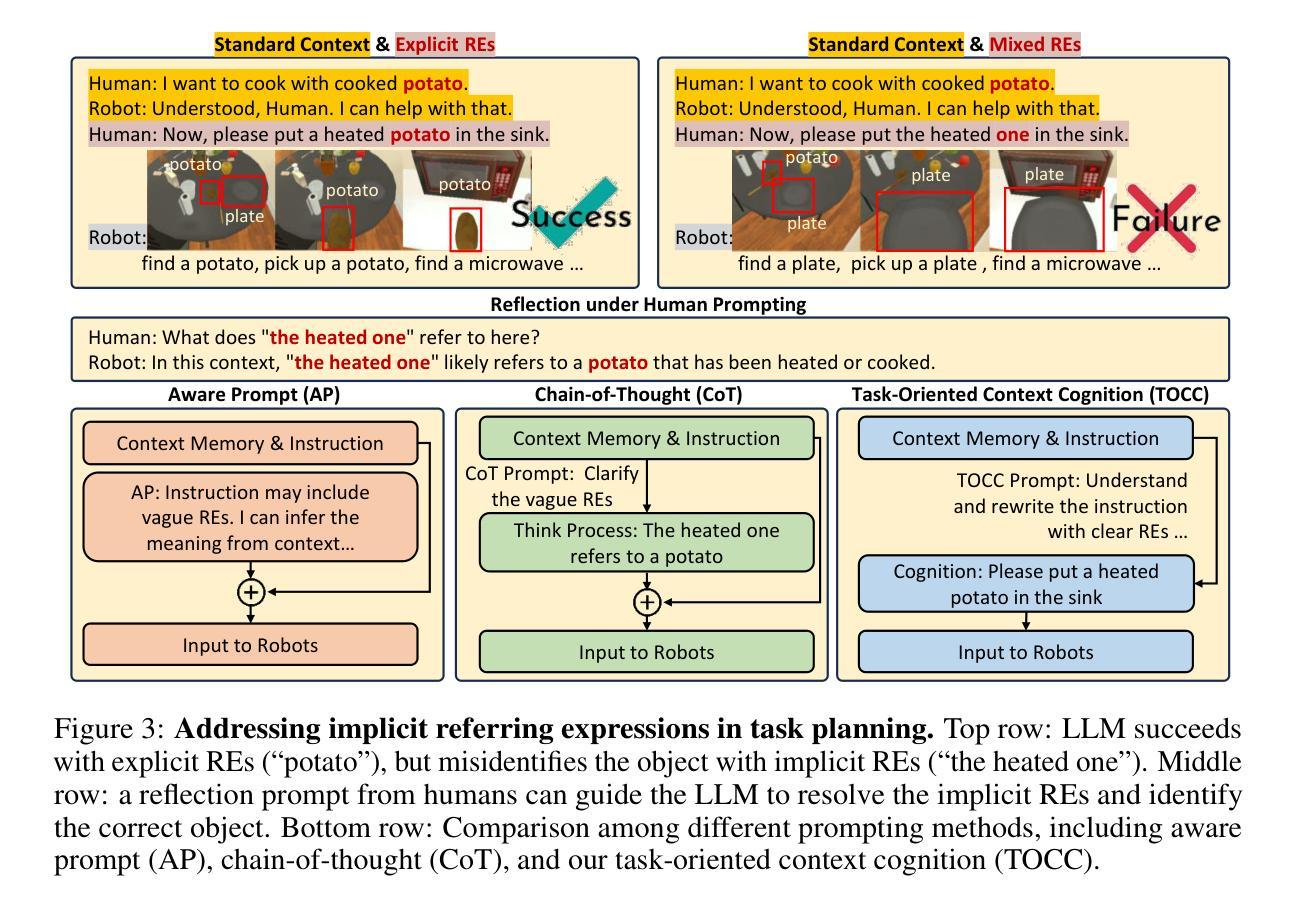
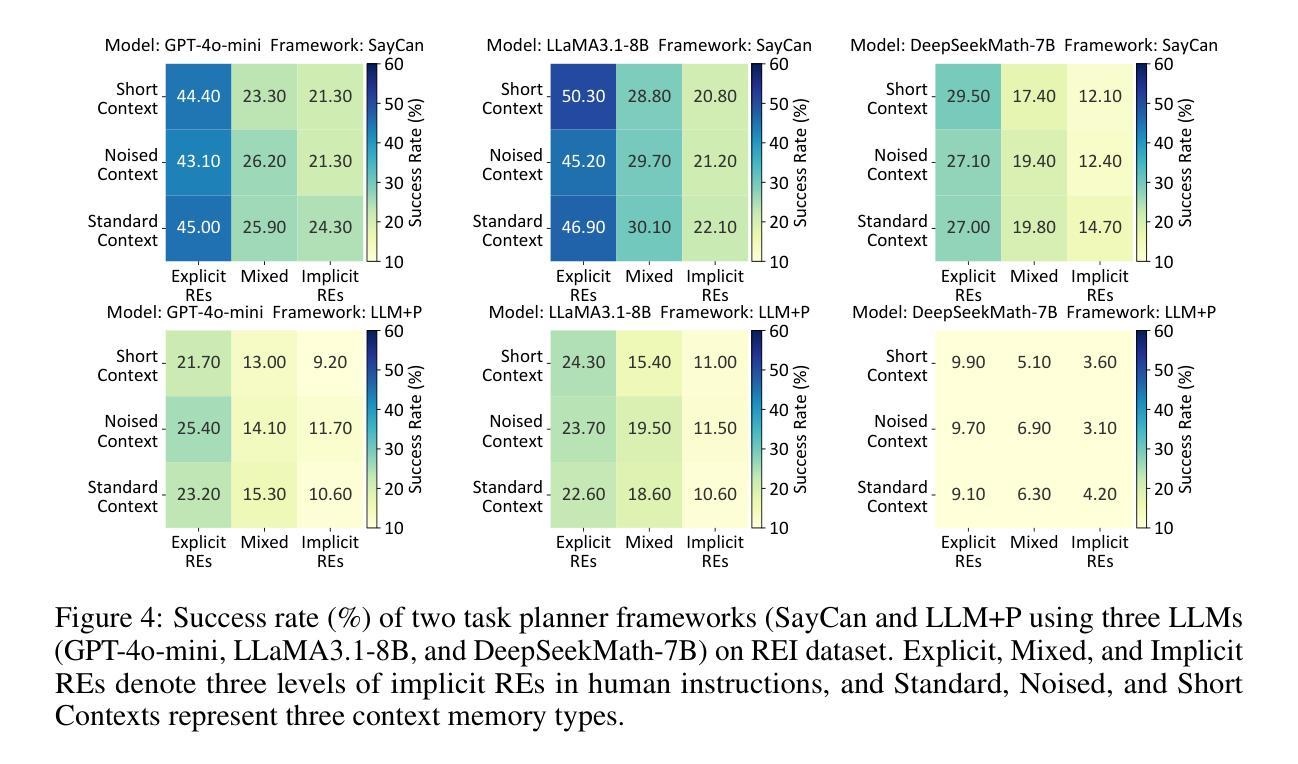
REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
Authors:Chenxi Jiang, Chuhao Zhou, Jianfei Yang
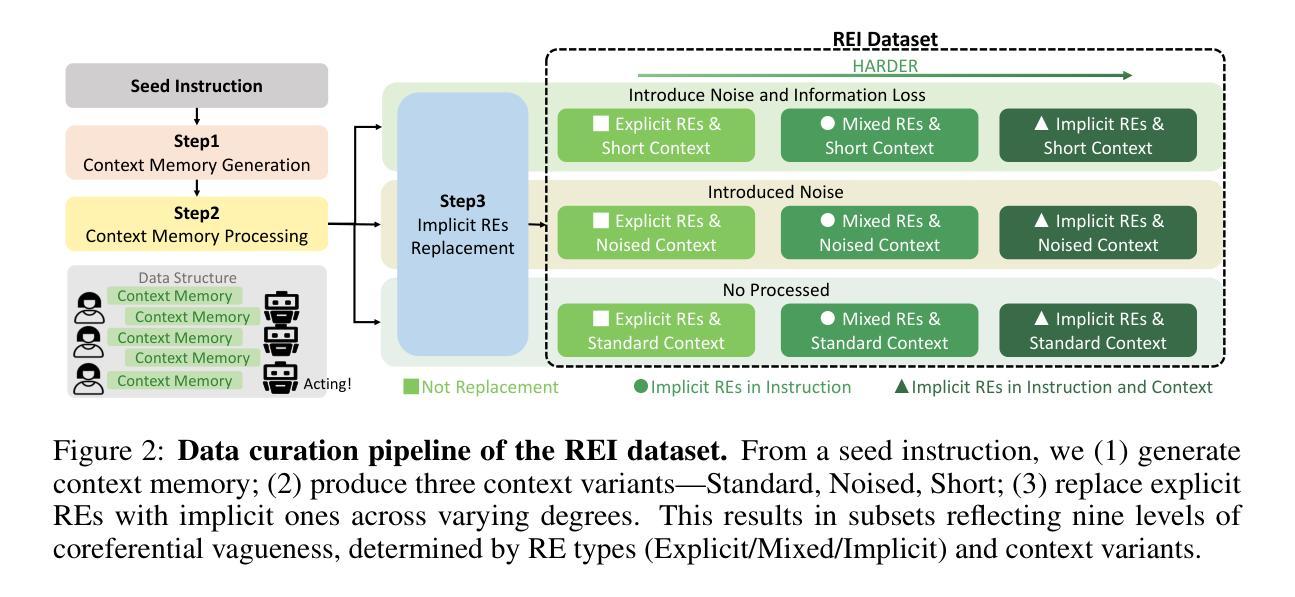
Robot task planning decomposes human instructions into executable action sequences that enable robots to complete a series of complex tasks. Although recent large language model (LLM)-based task planners achieve amazing performance, they assume that human instructions are clear and straightforward. However, real-world users are not experts, and their instructions to robots often contain significant vagueness. Linguists suggest that such vagueness frequently arises from referring expressions (REs), whose meanings depend heavily on dialogue context and environment. This vagueness is even more prevalent among the elderly and children, who robots should serve more. This paper studies how such vagueness in REs within human instructions affects LLM-based robot task planning and how to overcome this issue. To this end, we propose the first robot task planning benchmark with vague REs (REI-Bench), where we discover that the vagueness of REs can severely degrade robot planning performance, leading to success rate drops of up to 77.9%. We also observe that most failure cases stem from missing objects in planners. To mitigate the REs issue, we propose a simple yet effective approach: task-oriented context cognition, which generates clear instructions for robots, achieving state-of-the-art performance compared to aware prompt and chains of thought. This work contributes to the research community of human-robot interaction (HRI) by making robot task planning more practical, particularly for non-expert users, e.g., the elderly and children.
机器人任务规划能够将人类指令分解为可执行的行动序列,从而使机器人能够完成一系列复杂任务。尽管最近基于大型语言模型的任务规划器取得了惊人的表现,但它们假设人类指令是清晰直接的。然而,真实世界的用户并非专家,他们对机器人的指令通常包含大量的模糊性。语言学家认为,这种模糊性往往源于指代表达式(RE),其含义在很大程度上依赖于对话上下文和环境。这种模糊性在老年人和儿童中更为普遍,而机器人应该更多地为他们服务。这篇论文研究了人类指令中的指代表达式(RE)的模糊性是如何影响基于大型语言模型的机器人任务规划的,以及如何解决这一问题。为此,我们提出了首个具有模糊指代表达式的机器人任务规划基准测试(REI-Bench),在该基准测试中我们发现,指代表达式的模糊性会严重降低机器人规划的性能,导致成功率下降高达77.9%。我们还观察到,大多数失败的情况源于规划中的目标对象缺失。为了缓解指代表达式的问题,我们提出了一种简单有效的方法:面向任务的上下文认知,它为机器人生成清晰的指令,与有意识的提示和思维链相比,取得了最先进的性能。这项工作通过使机器人任务规划更加实用,特别是针对非专业用户(如老年人和儿童),为人工智能与机器人交互研究社区做出了贡献。
论文及项目相关链接
PDF Under Review
摘要
机器人任务规划将人类指令分解成可执行的动作序列,使机器人能够完成一系列复杂的任务。虽然基于大型语言模型(LLM)的任务规划器取得了令人瞩目的性能,但它们假设人类指令是清晰和直接的。然而,真实世界的用户并非专家,他们对机器人的指令通常包含大量的模糊性。本文研究了人类指令中的参照表达式(REs)的模糊性如何影响基于LLM的机器人任务规划,并探讨了如何解决这一问题。为此,我们提出了首个含有模糊参照表达式的机器人任务规划基准测试(REI-Bench),发现参照表达式的模糊性会严重降低机器人规划的性能,成功率下降高达77.9%。我们还发现大多数失败的情况是由于规划中的目标缺失。为了缓解参照表达式的问题,我们提出了一种简单有效的方法:面向任务的上下文认知,为机器人生成清晰的指令,实现了与意识提示和思考链相比的先进性能。本研究为机器人与人类互动的研究群体做出了贡献,使机器人任务规划更加实用,特别是面向非专业用户,如老年人和儿童。
关键见解
- 机器人任务规划能将复杂的人类指令转化为可执行动作序列。
- 基于LLM的机器人任务规划器在假设人类指令清晰直接时表现最佳。
- 真实世界的用户指令常包含模糊性,主要源于参照表达式的使用。
- 参照表达式的模糊性对机器人任务规划性能产生重大影响,成功率下降可高达77.9%。
- 大多数规划失败的情况是因为目标在指令中的缺失。
- 提出了一种新的方法——面向任务的上下文认知,以处理模糊的参照表达式,为机器人生成清晰指令。
- 此方法实现了卓越的性能,特别是在处理非专业用户的指令时,如老年人和儿童。
点此查看论文截图

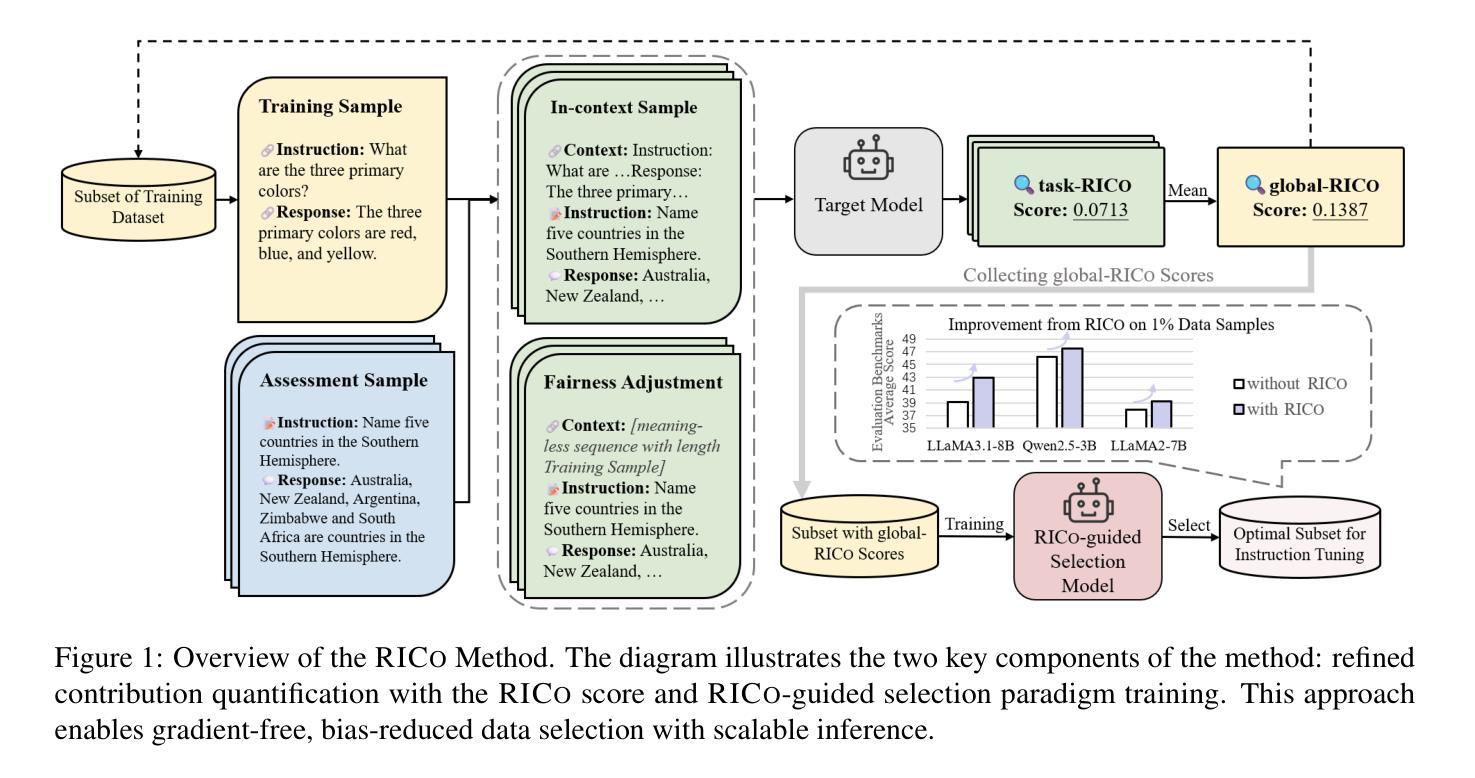
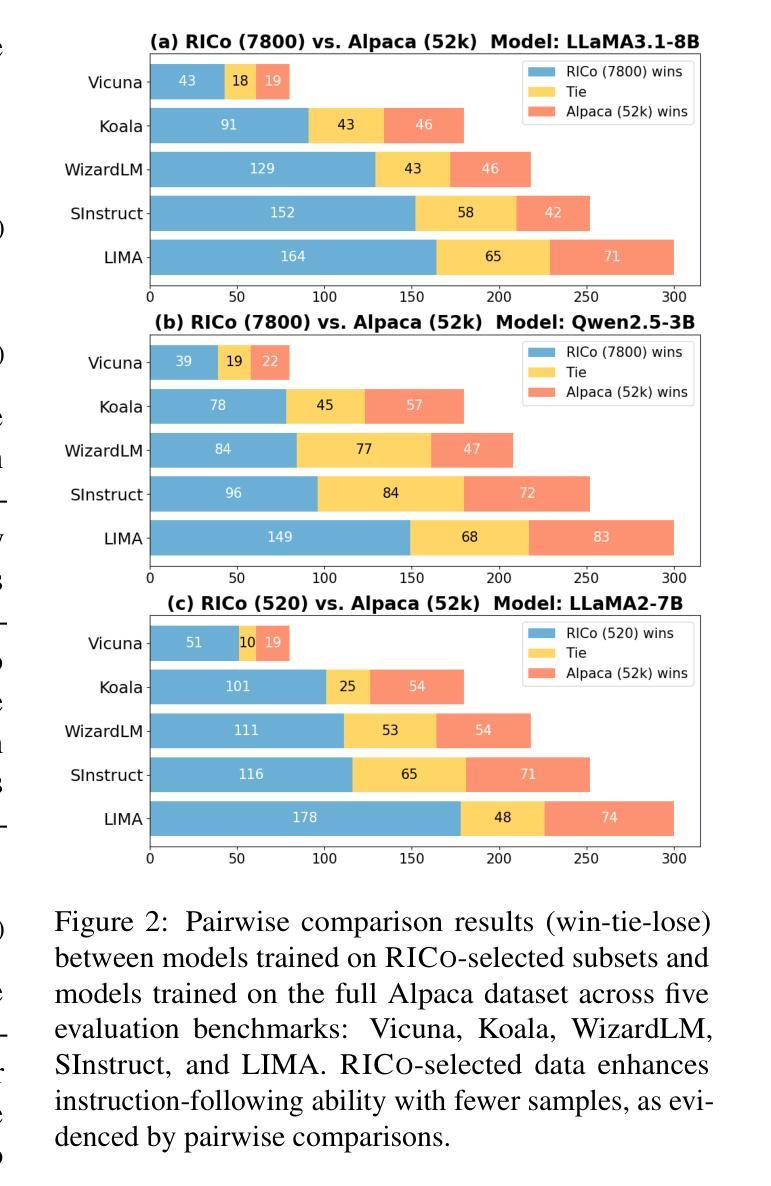
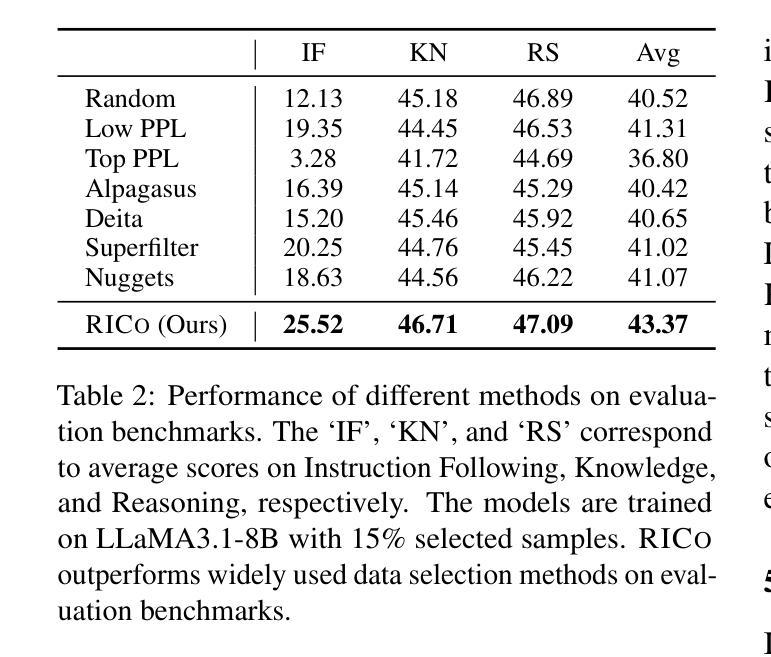
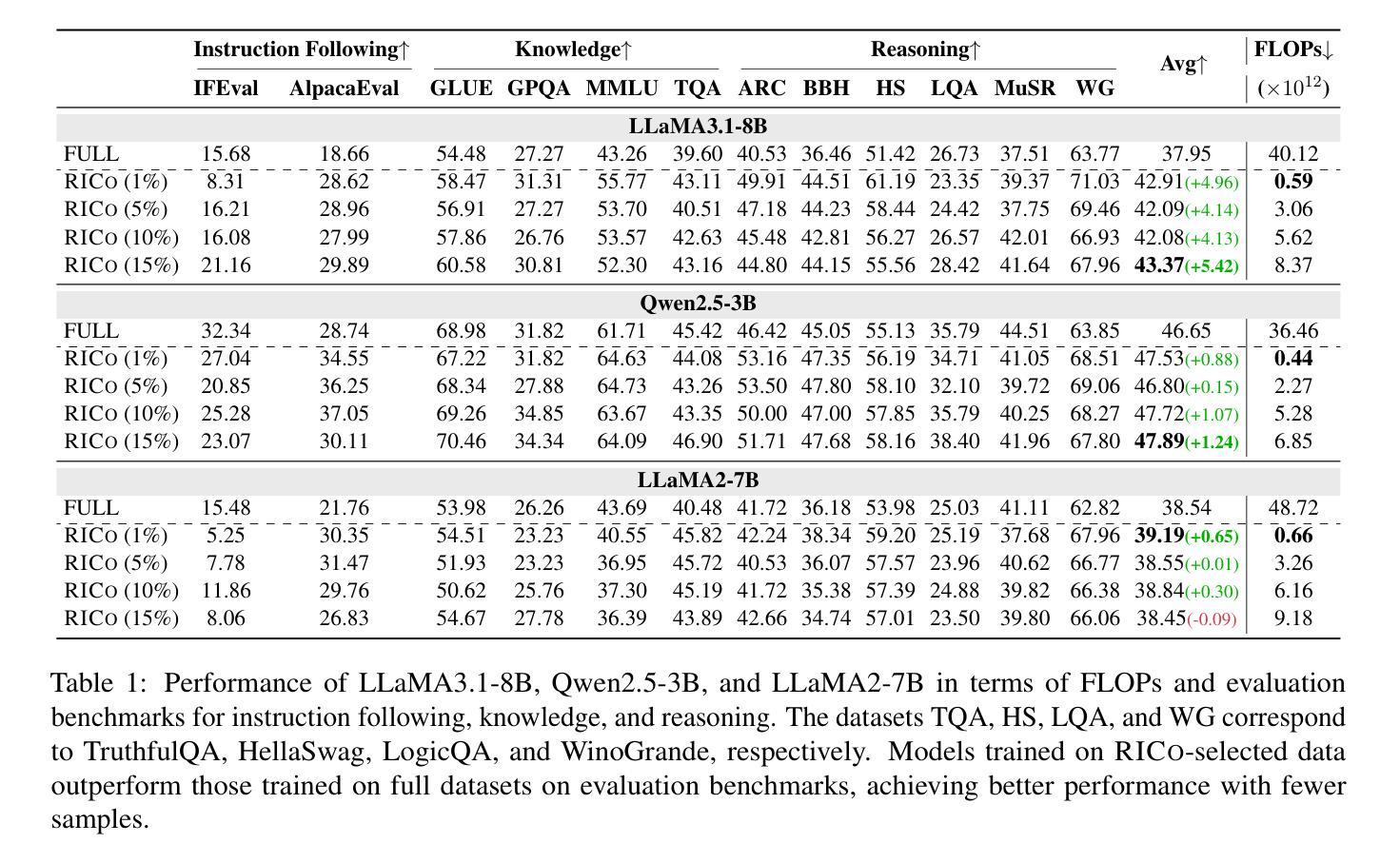
RICo: Refined In-Context Contribution for Automatic Instruction-Tuning Data Selection
Authors:Yixin Yang, Qingxiu Dong, Linli Yao, Fangwei Zhu, Zhifang Sui
Data selection for instruction tuning is crucial for improving the performance of large language models (LLMs) while reducing training costs. In this paper, we propose Refined Contribution Measurement with In-Context Learning (RICo), a novel gradient-free method that quantifies the fine-grained contribution of individual samples to both task-level and global-level model performance. RICo enables more accurate identification of high-contribution data, leading to better instruction tuning. We further introduce a lightweight selection paradigm trained on RICo scores, enabling scalable data selection with a strictly linear inference complexity. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of RICo. Remarkably, on LLaMA3.1-8B, models trained on 15% of RICo-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by RICo, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.
数据选择在指令微调中对于提高大型语言模型(LLM)的性能和降低训练成本至关重要。在本文中,我们提出了基于上下文学习的精细贡献度量(RICo),这是一种新的无需梯度的方法,可以量化单个样本对任务级别和全局级别模型性能的精细贡献。RICo能够更准确地识别高贡献数据,从而实现更好的指令微调。我们进一步引入了一种基于RICo分数的轻量级选择范式,实现了具有严格线性推理复杂度的可扩展数据选择。在三个LLM的12个基准测试和5个配对评估集上的大量实验证明了RICo的有效性。值得注意的是,在LLaMA3.1-8B上,使用RICo选择数据的15%训练的模型在全数据集上表现更优,高出5.42个百分点,并超过了广泛使用的选择方法中的最佳性能,高出2.06个百分点。我们还进一步分析了RICo选择的高贡献样本,这些样本显示了多样化的任务和适当的难度水平,而不仅仅是难度最大的任务。
论文及项目相关链接
Summary
本文提出一种名为Refined Contribution Measurement with In-Context Learning(RICo)的数据选择方法,用于改进大型语言模型(LLM)的性能并降低训练成本。RICo是一种无需梯度的全新方法,能够精确衡量每个样本对任务级别和全局级别模型性能的细微贡献。该方法可以更准确地识别高贡献数据,从而实现更优质的指令微调。此外,本文还引入了一种基于RICo得分的轻量级选择范式,可实现具有严格线性推理复杂度的可扩展数据选择。广泛实验表明,RICo在三个LLM上,跨越12个基准测试和5个配对评估集均表现出良好的效果。特别是,使用RICo选择的数据训练的LLaMA3.1-8B模型在仅使用15%数据的情况下,性能比使用全数据集高出5.42%,并超过了广泛使用的选择方法中的最佳性能2.06%。对RICo选择的高贡献样本的分析显示,这些样本具有多样化的任务和适当的难度级别,并非仅仅是难度最大的样本。
Key Takeaways
- RICo是一种新型数据选择方法,用于改进LLM的性能并降低训练成本。
- RICo通过精确衡量每个样本的贡献来实现更准确的数据识别。
- RICo可以支持更优质的指令微调。
- 引入了一种基于RICo得分的轻量级选择范式,实现数据选择的可扩展性。
- RICo在多个LLM和基准测试上表现出良好的性能提升效果。
- 使用RICo选择的数据训练的LLaMA模型性能显著提升。
点此查看论文截图