⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-21 更新
Are vision language models robust to uncertain inputs?
Authors:Xi Wang, Eric Nalisnick
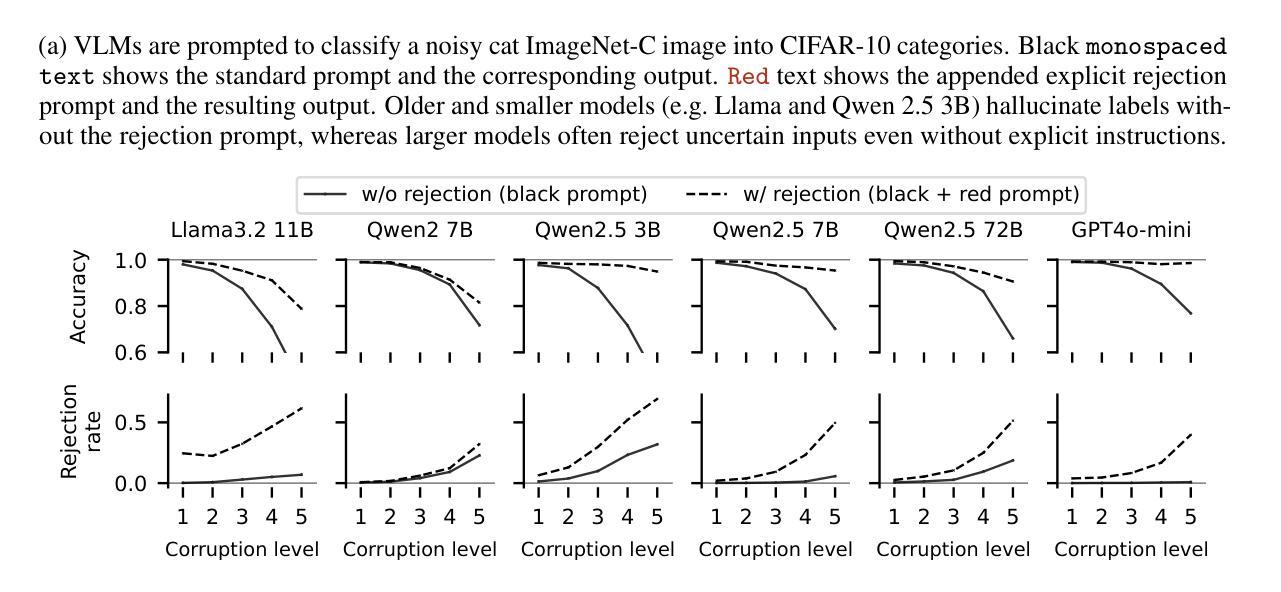
Robustness against uncertain and ambiguous inputs is a critical challenge for deep learning models. While recent advancements in large scale vision language models (VLMs, e.g. GPT4o) might suggest that increasing model and training dataset size would mitigate this issue, our empirical evaluation shows a more complicated picture. Testing models using two classic uncertainty quantification tasks, anomaly detection and classification under inherently ambiguous conditions, we find that newer and larger VLMs indeed exhibit improved robustness compared to earlier models, but still suffer from a tendency to strictly follow instructions, often causing them to hallucinate confident responses even when faced with unclear or anomalous inputs. Remarkably, for natural images such as ImageNet, this limitation can be overcome without pipeline modifications: simply prompting models to abstain from uncertain predictions enables significant reliability gains, achieving near-perfect robustness in several settings. However, for domain-specific tasks such as galaxy morphology classification, a lack of specialized knowledge prevents reliable uncertainty estimation. Finally, we propose a novel mechanism based on caption diversity to reveal a model’s internal uncertainty, enabling practitioners to predict when models will successfully abstain without relying on labeled data.
对于深度学习模型来说,对抗不确定性和模糊输入的稳健性是一个关键挑战。虽然最近大规模视觉语言模型(如GPT4o)的进展可能表明,增加模型和训练数据集的大小可以缓解这个问题,但我们的经验评估显示情况更为复杂。我们使用两个经典的不确定性量化任务(异常检测和在固有模糊条件下的分类)来测试模型,我们发现与早期模型相比,更新、更大的视觉语言模型确实表现出更好的稳健性,但它们仍然有严格遵循指令的倾向,这导致它们在面对模糊或异常输入时,即使不确定也会自信地给出答案。值得注意的是,对于像ImageNet这样的自然图像,我们可以通过提示模型避免不确定的预测来克服这一局限性,这可以在多个设置中显著提高可靠性,实现近乎完美的稳健性。然而,对于星系形态分类等特定领域的任务,由于缺乏专业知识,我们无法进行可靠的不确定性估计。最后,我们提出了一种基于字幕多样性的新机制,以揭示模型的内部不确定性,使从业者能够预测模型何时会成功避免不确定预测,而无需依赖标记数据。
论文及项目相关链接
Summary
本文探讨了深度学习模型在面对不确定和模糊输入时的稳健性问题。研究发现,虽然大规模视觉语言模型(VLMs)的近期进展显示增加模型和训练数据集的大小可能会缓解这一问题,但实际情况更为复杂。在利用两个经典的不确定性量化任务(异常检测和内在模糊条件下的分类)进行测试时,发现新型的大型VLMs确实展现出比早期模型更高的稳健性,但仍存在严格遵循指令的倾向,导致面对模糊或异常输入时产生自信的幻觉响应。对于自然图像,如ImageNet,可以通过提示模型避免不确定预测来克服这一限制,从而实现显著的可靠性增益,并在某些情况下达到近乎完美的稳健性。然而,对于特定领域的任务,如星系形态分类,由于缺乏专业知识,无法进行可靠的不确定性估计。最后,提出了一种基于字幕多样性的新机制,以揭示模型的不确定性,使从业者能够预测模型何时会成功避免依赖标签数据的预测。
Key Takeaways
- 深度学习模型在处理不确定和模糊输入时面临稳健性挑战。
- 大型视觉语言模型在异常检测和内在模糊条件下的分类任务中展现出改进,但仍存在严格遵循指令的问题。
- 面对模糊或异常输入,模型可能产生自信的幻觉响应。
- 对于自然图像,通过提示模型避免不确定预测,可以显著提高模型的稳健性。
- 在特定领域任务中,由于缺乏专业知识,模型难以进行可靠的不确定性估计。
- 提出了一种基于字幕多样性的新机制来揭示模型的不确定性。
点此查看论文截图




AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
Authors:Bin-Bin Gao, Yue Zhou, Jiangtao Yan, Yuezhi Cai, Weixi Zhang, Meng Wang, Jun Liu, Yong Liu, Lei Wang, Chengjie Wang
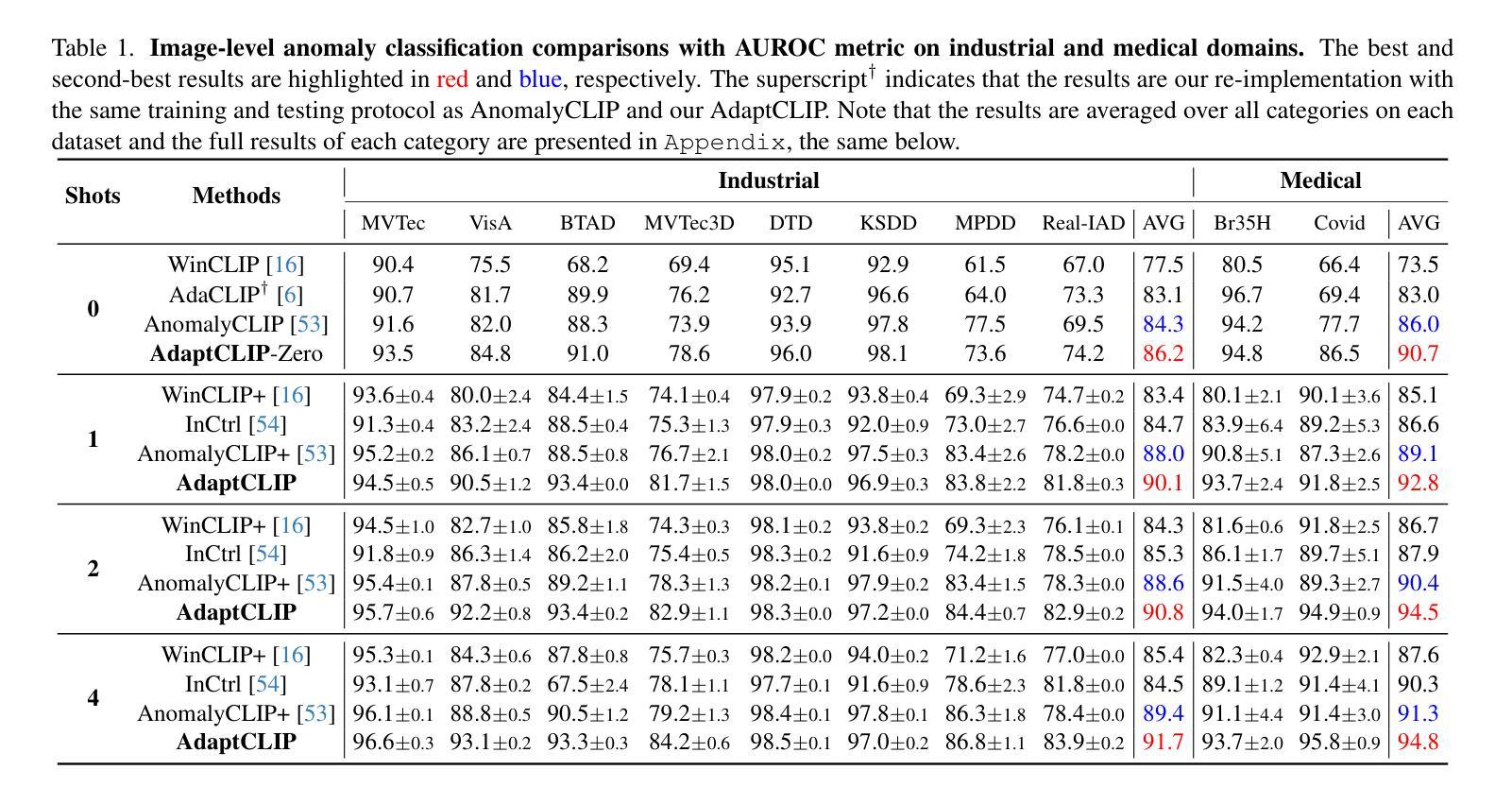
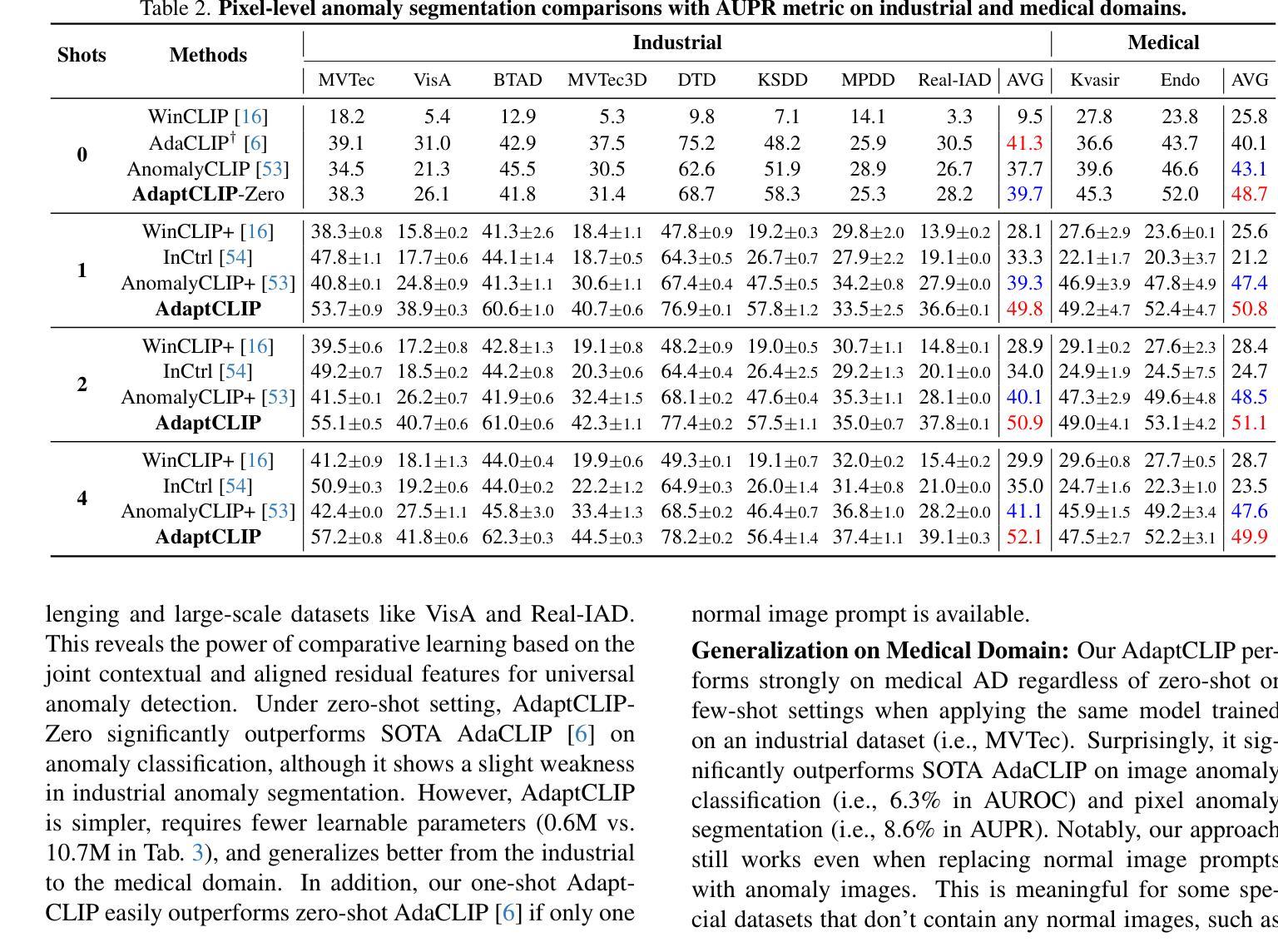
Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
通用视觉异常检测旨在从新型或未见过的视觉领域识别异常值,这在开放场景中至关重要,而无需额外的微调。最近的研究表明,仅使用零或少量正常图像,预训练的视觉语言模型(如CLIP)就能展现出强大的泛化能力。然而,现有方法在设计提示模板、处理复杂的标记交互或需要额外的微调方面遇到了困难,导致灵活性有限。在这项工作中,我们提出了一种简单有效的方法,称为基于两个关键见解的AdaptCLIP。首先,应该交替学习自适应的视觉和文本表示,而不是联合学习。其次,查询和正常图像提示之间的比较学习应融入上下文和已对齐的残差特征,而不是仅依赖残差特征。AdaptCLIP将CLIP模型作为基础服务,仅在输入或输出端添加三个简单的适配器:视觉适配器、文本适配器和提示查询适配器。AdaptCLIP支持跨领域的零/少样本泛化,并且在基于数据集进行训练后,在目标领域上采用无训练方式。AdaptCLIP在来自工业和医疗领域的12个异常检测基准测试上实现了最先进的性能,显著优于现有的竞争方法。我们将在https://github.com/gaobb/AdaptCLIP上提供AdaptCLIP的代码和模型。
论文及项目相关链接
PDF 27 pages, 15 figures, 22 tables
Summary
基于CLIP模型的AdaptCLIP方法实现了跨领域异常检测,通过交替学习视觉和文本表示,并结合比较学习来识别异常。该方法通过添加简单的适配器实现,无需额外微调,具有良好的通用性和灵活性,适用于多种领域中的零样本或少样本异常检测任务,且在工业与医疗领域的多个数据集上表现领先。代码和模型将公开于https://github.com/gaobb/AdaptCLIP。
Key Takeaways
- AdaptCLIP是一种基于CLIP模型的简单有效的通用视觉异常检测方法。
- 它实现了零样本或少样本情况下的跨领域异常检测,具有出色的泛化能力。
- 通过交替学习视觉和文本表示,并结合比较学习技术来识别异常。
- 该方法通过添加视觉适配器、文本适配器和提示查询适配器,无需对CLIP模型进行额外微调。
- AdaptCLIP适用于多种领域中的异常检测任务,包括工业和医疗领域的数据集。
- 在多个异常检测基准测试中,AdaptCLIP表现出领先的性能。
点此查看论文截图



Ultrasound Report Generation with Multimodal Large Language Models for Standardized Texts
Authors:Peixuan Ge, Tongkun Su, Faqin Lv, Baoliang Zhao, Peng Zhang, Chi Hong Wong, Liang Yao, Yu Sun, Zenan Wang, Pak Kin Wong, Ying Hu
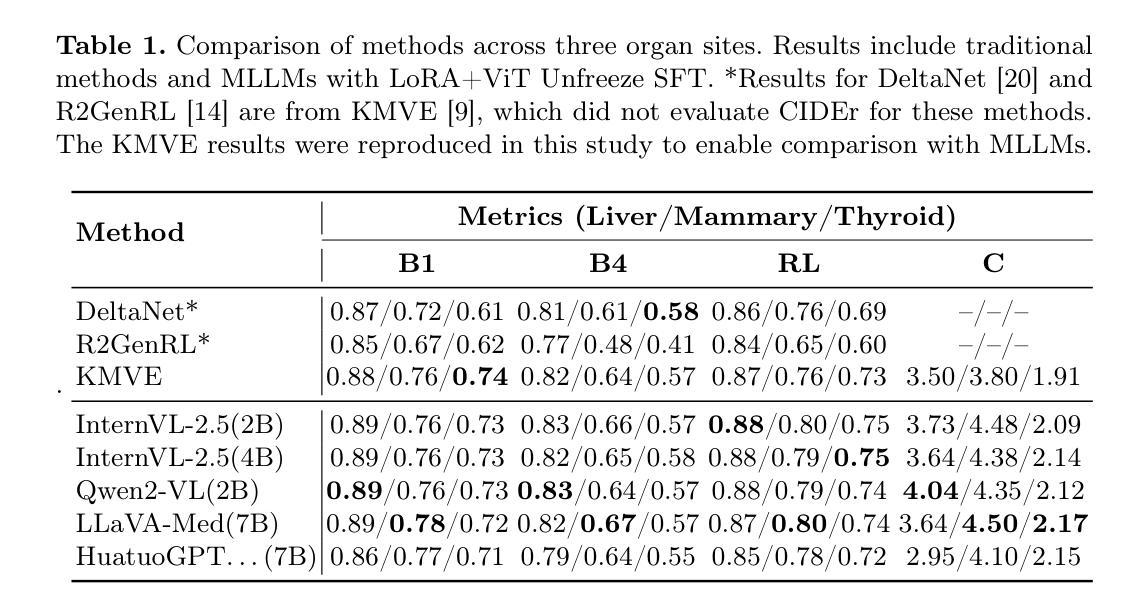
Ultrasound (US) report generation is a challenging task due to the variability of US images, operator dependence, and the need for standardized text. Unlike X-ray and CT, US imaging lacks consistent datasets, making automation difficult. In this study, we propose a unified framework for multi-organ and multilingual US report generation, integrating fragment-based multilingual training and leveraging the standardized nature of US reports. By aligning modular text fragments with diverse imaging data and curating a bilingual English-Chinese dataset, the method achieves consistent and clinically accurate text generation across organ sites and languages. Fine-tuning with selective unfreezing of the vision transformer (ViT) further improves text-image alignment. Compared to the previous state-of-the-art KMVE method, our approach achieves relative gains of about 2% in BLEU scores, approximately 3% in ROUGE-L, and about 15% in CIDEr, while significantly reducing errors such as missing or incorrect content. By unifying multi-organ and multi-language report generation into a single, scalable framework, this work demonstrates strong potential for real-world clinical workflows.
超声波(US)报告生成是一项具有挑战性的任务,因为超声波图像存在差异性、依赖于操作员,并且需要标准化文本。与X射线和计算机断层扫描不同,超声波成像缺乏一致的数据集,使得自动化变得困难。在本研究中,我们提出了一个统一的框架,用于多器官和多语言的超声波报告生成,该框架整合了基于片段的多语言训练和利用超声波报告的标准性质。通过模块化文本片段与各种成像数据的对齐,并创建一个双语英文-中文数据集,该方法可以在不同器官部位和语言之间实现一致且临床准确的文本生成。使用选择性解冻视觉变压器(ViT)进行微调进一步提高了文本与图像的对齐性。与之前的最新技术KMVE方法相比,我们的方法在BLEU得分上相对提高了约2%,在ROUGE-L上提高了约3%,在CIDEr上提高了约15%,同时显著减少了缺失或错误内容等错误。通过将多器官和多语言报告生成统一到一个可扩展的框架中,这项工作为现实世界中的临床工作流程展示了强大的潜力。
论文及项目相关链接
Summary
超声报告生成是一项具有挑战性的任务,因为超声图像具有多变性和标准化文本的需求。本研究提出了一种统一的框架,用于多器官和多语言超声报告生成,通过基于片段的多语言训练和利用超声报告的标准化性质实现文本生成的连贯性和准确性。该研究还通过微调视觉转换器(ViT)的选择解冻进一步改进了文本图像对齐,相较于之前的方法取得了相对优势。这项工作展示了一个强大的框架,适用于现实世界的临床工作流程。
Key Takeaways
- 本研究提出了一个统一的框架,用于生成多器官和多语言的超声报告。
- 通过基于片段的多语言训练,该框架实现了跨器官和语言的文本生成的连贯性和准确性。
- 利用超声报告的标准化性质是该框架的一个重要特点。
- 通过微调视觉转换器(ViT)的选择解冻,改进了文本图像对齐。
- 与之前的先进方法相比,该研究在BLEU分数、ROUGE-L和CIDEr等方面取得了相对优势。
- 该框架显著减少了缺失或错误内容等错误。
点此查看论文截图


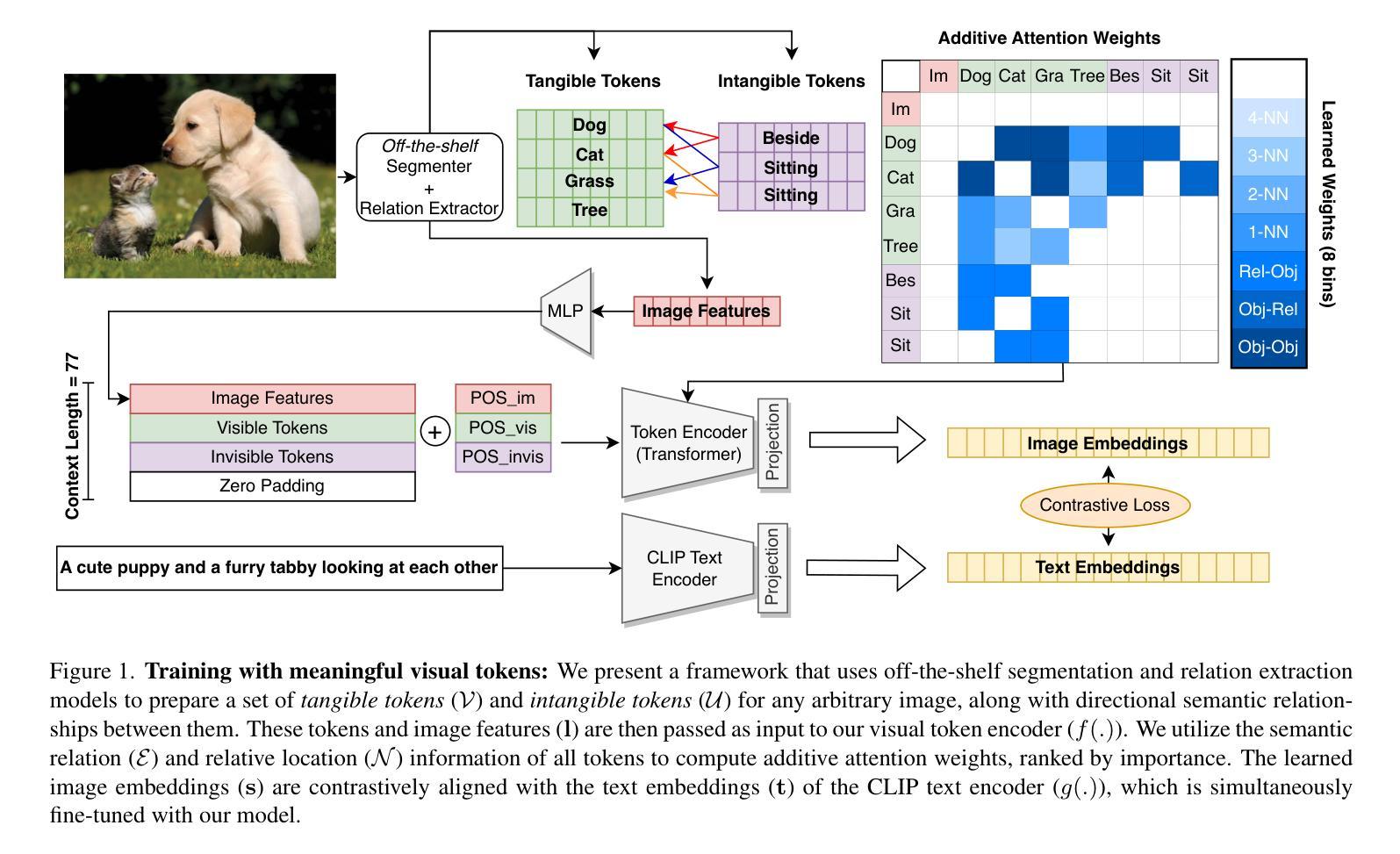
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
Authors:Neha Kalibhat, Priyatham Kattakinda, Sumit Nawathe, Arman Zarei, Nikita Seleznev, Samuel Sharpe, Senthil Kumar, Soheil Feizi
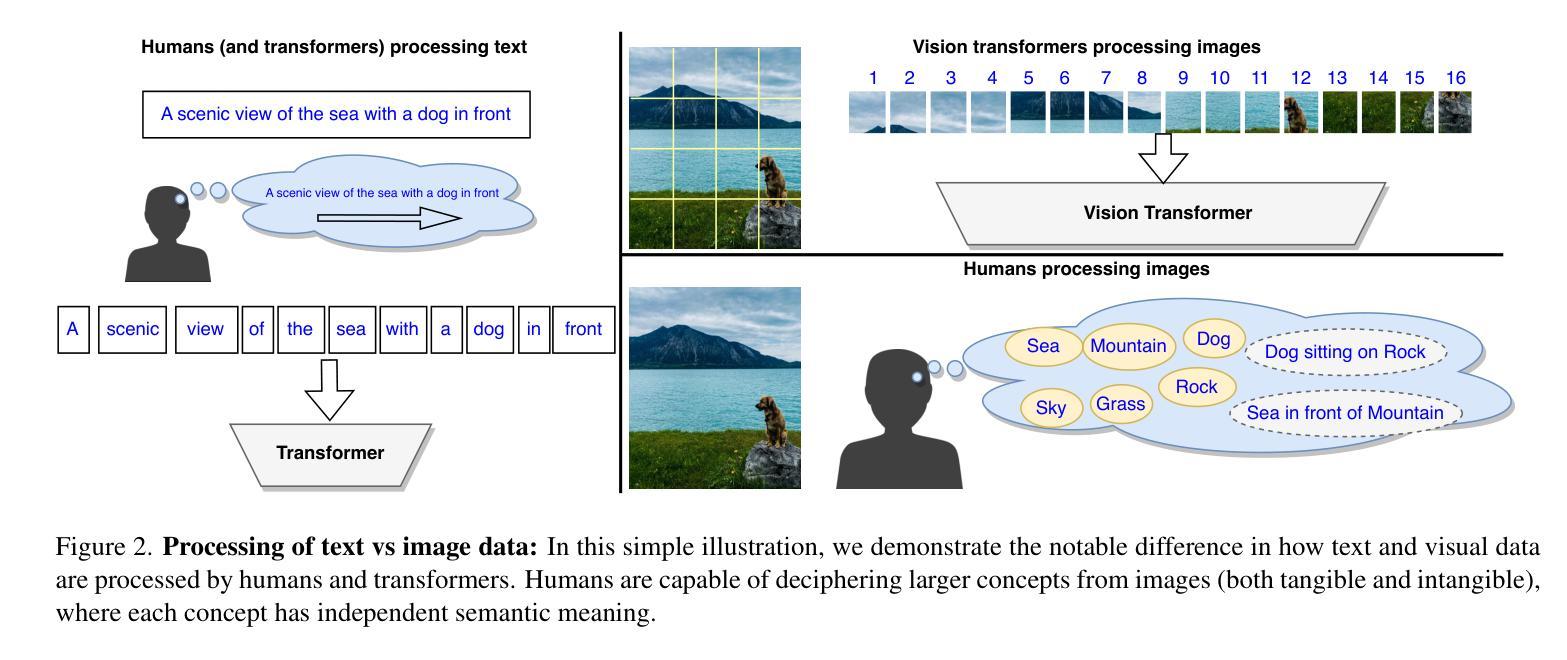
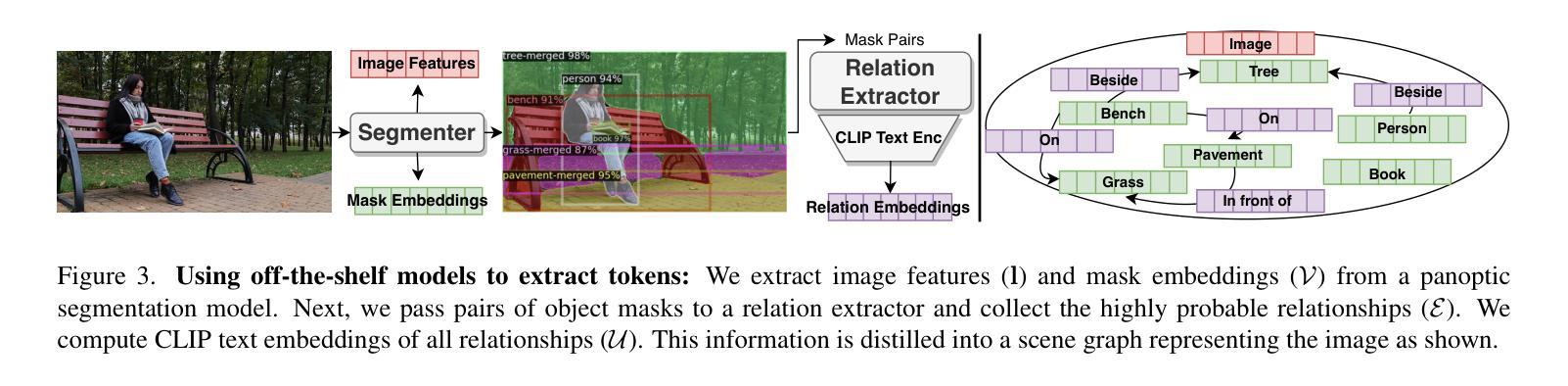
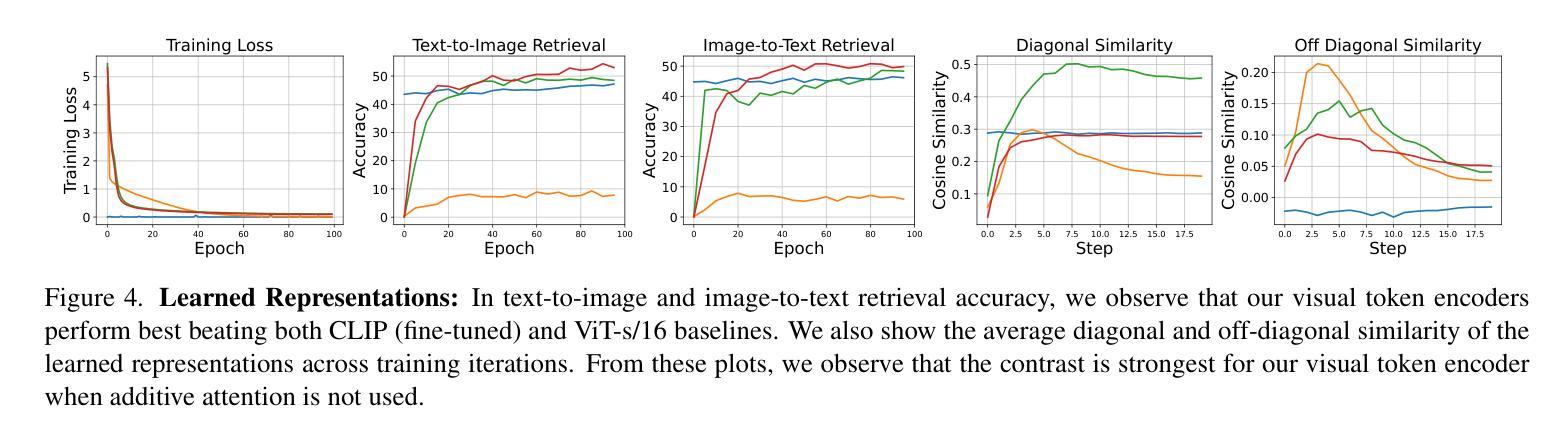
Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
视觉Transformer在处理图像之前,已经形成了将图像分割成大小统一的块状的先例。我们假设这种设计选择可能会限制模型从视觉数据中学习全面和组合式表示的能力。本文探讨了在视觉语言预训练框架内,向Transformer编码器提供语义上有意义的视觉符号的概念。我们利用现成的分割和场景图模型,提取实例分割掩模的表示(称为有形符号)以及关系和动作(称为无形符号)。随后,我们通过融入这些新提取的符号,并通过对齐产生的嵌入量与文本侧编码器的字幕嵌入量,来预训练视觉方面的Transformer。为了捕捉视觉符号之间的结构和语义关系,我们引入了附加的注意力权重,用于计算自注意力分数。我们在COCO数据集上的实验表明,与ViT相比,我们在文本到图像(+47%)和图像到文本检索(+44%)任务上的学习表示质量有了显著的提升。此外,我们在组合性基准测试(如ARO + 18%)和Winoground(+ 10%)上展示了优势。
论文及项目相关链接
PDF Published at CVPR Workshops 2025
Summary
本文探讨了将语义上有意义的视觉标记提供给视觉语言预训练框架中的转换器编码器的方法。通过利用现成的分割和场景图模型,提取实例分割掩模的表示(称为有形标记)和关系及动作(称为无形标记)。通过引入加法注意力权重来捕捉视觉标记之间的结构和语义关系,并计算自注意力得分。实验结果表明,该方法在COCO数据集上相对于ViTs在文本到图像(+47%)和图像到文本检索(+44%)任务中的表现有所提升。此外,在组合性基准测试(如ARO和Winoground)上的优势也得到了展示。
Key Takeaways
- 论文对视觉转换器中的图像分割方式提出假设,认为将图像分割成统一尺寸的块可能限制了模型从视觉数据中学习全面和组合式表示的能力。
- 提出了一种在视觉语言预训练框架中提供语义上有意义的视觉标记给转换器编码器的方法。
- 利用现成的分割模型和场景图模型提取实例分割掩模和关系及动作作为视觉标记。
- 通过引入加法注意力权重来捕捉视觉标记之间的结构和语义关系。
- 在COCO数据集上的实验结果表明,该方法在文本到图像和图像到文本检索任务上的表现优于ViTs。
- 在组合性基准测试(如ARO和Winoground)上的优势表明该方法在理解和处理复杂视觉场景方面更具优势。
点此查看论文截图