⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
View-Invariant Pixelwise Anomaly Detection in Multi-object Scenes with Adaptive View Synthesis
Authors:Subin Varghese, Vedhus Hoskere
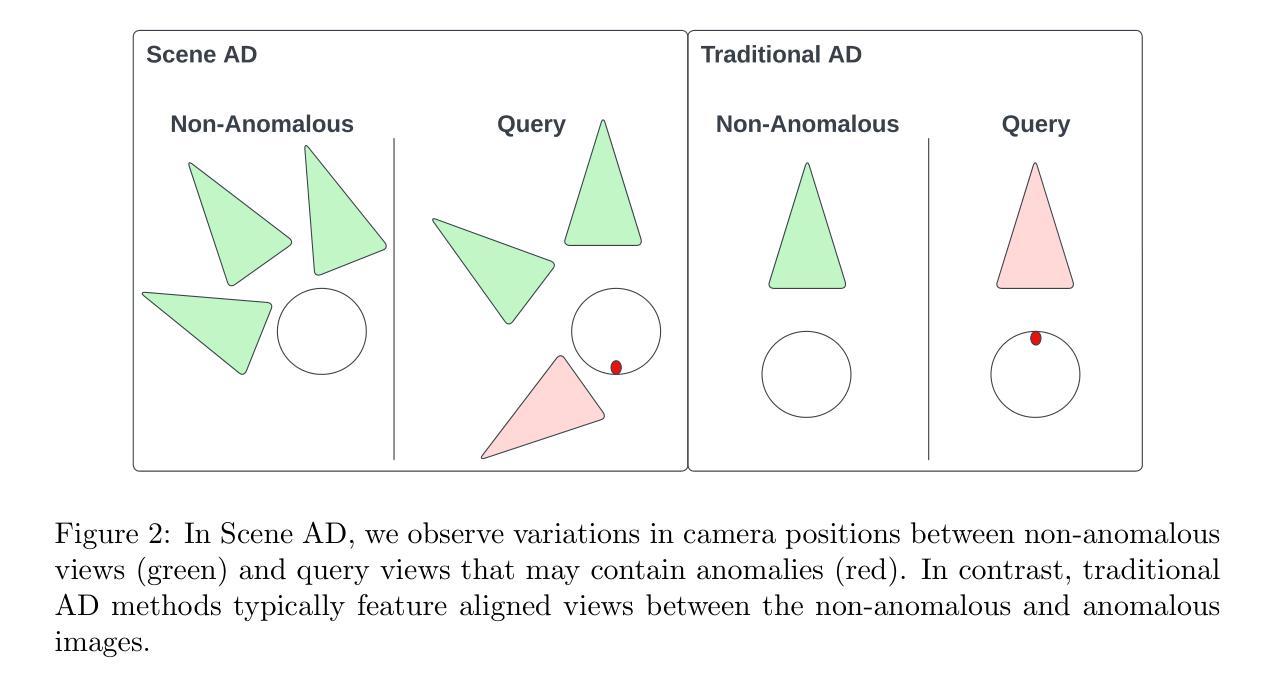
The built environment, encompassing critical infrastructure such as bridges and buildings, requires diligent monitoring of unexpected anomalies or deviations from a normal state in captured imagery. Anomaly detection methods could aid in automating this task; however, deploying anomaly detection effectively in such environments presents significant challenges that have not been evaluated before. These challenges include camera viewpoints that vary, the presence of multiple objects within a scene, and the absence of labeled anomaly data for training. To address these comprehensively, we introduce and formalize Scene Anomaly Detection (Scene AD) as the task of unsupervised, pixel-wise anomaly localization under these specific real-world conditions. Evaluating progress in Scene AD required the development of ToyCity, the first multi-object, multi-view real-image dataset, for unsupervised anomaly detection. Our initial evaluations using ToyCity revealed that established anomaly detection baselines struggle to achieve robust pixel-level localization. To address this, two data augmentation strategies were created to generate additional synthetic images of non-anomalous regions to enhance generalizability. However, the addition of these synthetic images alone only provided minor improvements. Thus, OmniAD, a refinement of the Reverse Distillation methodology, was created to establish a stronger baseline. Our experiments demonstrate that OmniAD, when used with augmented views, yields a 64.33% increase in pixel-wise (F_1) score over Reverse Distillation with no augmentation. Collectively, this work offers the Scene AD task definition, the ToyCity benchmark, the view synthesis augmentation approaches, and the OmniAD method. Project Page: https://drags99.github.io/OmniAD/
所构建的环境包括桥梁和建筑等重要基础设施,需要对捕捉的图像中的意外异常或偏离正常状态的情况进行持续监控。异常检测方法可以帮助自动化这项任务;然而,在这种环境中有效地部署异常检测却存在尚未评估过的重大挑战。这些挑战包括摄像头视角的变化、场景中多个物体的存在以及缺乏用于训练的标记异常数据。为了全面解决这些问题,我们引入并形式化场景异常检测(Scene AD)作为这些特定现实条件下进行无监督像素级异常定位的任务。为了评估Scene AD的进展,需要开发ToyCity,这是第一个用于无监督异常检测的多对象、多视角真实图像数据集。我们在ToyCity的初步评估显示,已建立的异常检测基线难以实现稳健的像素级定位。为了解决这一问题,我们创建了两种数据增强策略来生成非异常区域的附加合成图像以提高通用性。然而,仅仅添加这些合成图像只提供了轻微的改进。因此,我们创建了OmniAD,对逆向蒸馏法进行了改进,以建立更强的基线。我们的实验表明,OmniAD与增强视图结合使用时,在像素级F1分数上比没有增强的逆向蒸馏法高出64.33%。总的来说,这项工作提供了Scene AD任务定义、ToyCity基准、视图合成增强方法和OmniAD方法。项目页面:https://drags99.github.io/OmniAD/
论文及项目相关链接
Summary:
建立环境,包括桥梁和建筑物等重要基础设施,需要密切监测图像捕捉中意外异常或正常状态的偏差。异常检测方法有助于自动化此任务;然而,在现实环境中有效部署异常检测却存在诸多挑战,包括摄像头角度不同、场景内多个物体以及缺乏异常标签数据进行训练。为全面应对这些挑战,我们引入并形式化场景异常检测(Scene AD)作为在无监督条件下进行像素级异常定位的任务。为评估Scene AD的进展,开发了ToyCity数据集,这是首个用于无监督异常检测的多对象、多视角真实图像数据集。我们的初步评估显示,现有的异常检测基线难以达到稳健的像素级定位。为解决这一问题,我们创建了两种数据增强策略以生成额外的非异常区域合成图像来提高泛化能力。然而,仅添加这些合成图像只带来了微小的改进。因此,我们创建了OmniAD,对反向蒸馏法进行精细化改进。实验表明,当OmniAD与增强视图结合使用时,其像素级F1分数比无增强的反向蒸馏法高出64.33%。总之,本研究提供了场景异常检测任务定义、ToyCity基准测试、视图合成增强方法和OmniAD方法。
Key Takeaways:
- 场景异常检测(Scene AD)是现实环境中无监督条件下的像素级异常定位任务。
- ToyCity数据集是首个用于无监督异常检测的多对象、多视角真实图像数据集。
- 现有异常检测基线在像素级定位上表现欠佳。
- 数据增强策略通过生成合成图像提高模型泛化能力,但效果有限。
- OmniAD方法是对反向蒸馏法的改进,与增强视图结合使用时效果更佳。
- OmniAD方法相比反向蒸馏法提高了64.33%的像素级F1分数。
点此查看论文截图